1. Introduction
According to ISO 25000 [
1], one critical aspect of software development is security. Software security has gained significant attention over the last decade due to the increasing number of cybersecurity incidents resulting from poor software development practices. Consequently, industrial standards such as IEC 62443 [
2] mandate the implementation of a secure software development lifecycle to address and reduce the number of vulnerabilities in products and services. The development of secure software is not only vital for the industry, particularly in critical infrastructures, but it is also a significant subject taught in many engineering and informatics courses at various universities.
There are several established methods to improve the quality of software. These include performing secure code reviews, using static application security testing (SAST), and employing security testing techniques such as unit testing, penetration testing, and fuzzing. These methods generally rely on the principle that software should comply with secure coding guidelines, which are policies aimed at minimizing vulnerabilities and bugs in software. One way to ensure adherence to secure coding guidelines is through the use of static application security testing tools. However, not all secure coding guidelines are decidable [
3]. This means that there exist certain secure coding guidelines for which no theoretical Turing machine can be constructed to determine compliance or non-compliance with the guidelines. This theoretical limitation raises an immediate issue: the full automation of secure coding is not possible. Therefore, software developers are ultimately responsible for the security of the code they write. In a 2019 survey of more than 4000 software developers from the industry, Patel [
4] demonstrated that more than 50% of them cannot recognize vulnerabilities in source code.
To address this problem, raising awareness of secure coding among software developers is crucial. Similarly to Patel, Gasiba [
5] has shown that industrial software developers lack awareness of secure coding guidelines. He extended the work by Hänsch et al. [
6] to the field of secure coding, defining secure coding awareness in three dimensions: perception, protection, and behavior. A recent study by the Linux Foundation [
7] also highlighted the importance and need to train software developers to develop secure software.
Artificial intelligence (AI) technology has garnered significant attention and traction in recent years, with integration into various fields, including cybersecurity. However, there are growing concerns about the security, privacy, and ethical implications associated with AI applications as indicated by the standardization efforts of governments in the EU and the USA [
8,
9]. In the industrial sector, security vulnerabilities can lead to severe consequences, ranging from financial losses to threats to human life. AI has experienced several cycles of hype and disillusionment, often referred to as ‘AI winters’ and ‘AI summers’, respectively [
10]. We believe we are currently in an ‘AI summer’ due to the rampant integration experiments with generative AI (genAI). Furthermore, we believe that AI will play a major role in the field of secure software development as is already being demonstrated by several companies, products, and services emerging in this field.
However, previous studies that highlight the advantages, disadvantages, and expected performance of using AI for software development are scarce. Therefore, new techniques to assist software developers in writing secure code, along with a scientific evaluation, are a fruitful area of research. Gasiba et al. [
11] in their work demonstrated that artificial intelligence could be used to raise awareness among software developers. The authors devised an intelligent coach using an AI technique known as the laddering technique, which is commonly used in chatbots [
12]. The intelligent coach, facilitating human–machine interaction (HMi) in a controlled environment (the Sifu platform), was shown to be very effective in raising awareness of secure coding guidelines among software developers in the industry.
In this work, we extend the previous research by exploring the use of ChatGPT [
13] as a means of HMi. ChatGPT, released in November 2022, is built on the GPT-3 family of large language models and was developed by the American research laboratory OpenAI. The language model has been fine-tuned with both supervised and reinforcement learning techniques.
Given the authors’ experience, previous work, and the theoretical limitations inherent to the field of secure coding, this work aims to broaden the understanding of the extent to which ChatGPT can aid software developers in writing secure code. This research seeks to answer the following questions: RQ1. To what extent can ChatGPT recognize vulnerabilities in source code? RQ2. To what extent can ChatGPT rewrite code to eliminate present security vulnerabilities?
The authors have chosen ChatGPT for experimentation over other existing generative models, particularly those trained specifically for cybersecurity, because ChatGPT is widely available to the public and allows users to maintain a conversation with context, taking previous requests and answers into account. This study presented in this work is composed of two parts: in the first part, the authors conduct interactions with ChatGPT based on five exercises from the serious game CyberSecurity Challenges (CSC) and an analysis of the responses in terms of secure coding; in the second part, the authors extend this work through additional and more extensive interactions, and using a more recent model of ChatGPT compared to the first experiment. The first experiment has been partially reported in previous work [
14].
This work provides significant contributions to both academia and industry by offering a nuanced analysis of AI models in an industrial context and drawing on our extensive experience in teaching secure coding. For academia, our study highlights the practical advantages and limitations of AI, addressing often overlooked issues such as code maintainability and the prevention of undesired functionalities. These insights go beyond traditional statistical evaluations, presenting a comprehensive view that can inform future academic research into the role of AI in secure software development. For industry, our research facilitates a reflective assessment of AI integration, helping practitioners leverage tools like ChatGPT effectively while developing strategies to mitigate potential risks. By exploring the advantages, disadvantages, and limitations of human–machine interactions in raising secure coding awareness, we enrich the discourse on secure coding practices and AI applications. This work also highlights a new and rich field of research: using machine learning algorithms and Generative AI to enhance secure coding awareness through human–machine interactions, fostering a deeper understanding and improved implementation strategies in both domains.
The rest of this paper is organized as follows:
Section 2 discusses previous work that is either related to or served as inspiration for our study.
Section 3 briefly discusses the experiment setup followed in this work to address the research questions. In
Section 4, we provide a summary of our results, and in
Section 5, we conduct a critical discussion of these results. Finally, in
Section 6, we conclude our work and outline future research.
2. Related Work
The use of AI in secure software development is an emerging area of research that has garnered significant attention in recent years. This section reviews the relevant standards, frameworks, and practical implementations that inform our understanding of how AI can be leveraged to enhance software security. We also examine studies and case studies that highlight both the potential and the limitations of AI tools in this context and explore the role of AI in secure software development, to illustrate the current state of the field.
The industry fosters the creation and adoption of standardization efforts because they ensure quality assurance as well as the facilitation of regulatory compliance. In the following, we will mention the standards most relevant to our work, which concern themselves with information security in the context of the software development lifecycle.
The IEC 62443 standard by the International Electrotechnical Commission provides guidelines for securing industrial automation and control systems (IACSs) [
2]. It encompasses system security, risk assessment, and management, as well as secure development and lifecycle management of components. While the standard outlines processes that could benefit from AI, such as vulnerability mitigation and dynamic security measures, it is important to underscore that, at the time of writing, the standard has not yet been updated to address the fulminant advances in Generative Artificial Intelligence (GenAI). As such, AI should be considered one component of a broader, multifaceted approach to cybersecurity when considering IEC 62443 compliance.
Governmental bodies are adapting to the GenAI revolution as well. The European Union Artificial Intelligence Act focuses on regulating AI systems to align with EU values and fundamental rights, classifying AI systems into risk categories and setting requirements for high-risk categories to ensure transparency and data governance [
8]. The U.S. initiative, AI.gov, serves as a central resource for federal AI activities, promoting AI innovation and public trust through coordination across various agencies, focusing on policy, research, and education [
9]. Furthermore, The National Institute of Standards and Technology (NIST) has released four draft publications intended to help improve the safety, security and trustworthiness of AI System, together with an AI Risk Management Framework [
15,
16]. These resources aim to guide organizations in the ethical and technical considerations of AI systems.
ISO/IEC 27001 [
17] and ISO/IEC 27002 [
18] are internationally recognized standards for information security management [
17]. ISO/IEC 27001 provides a framework for establishing, implementing, maintaining, and continuously improving an information security management system (ISMS). ISO/IEC 27002 offers guidelines and best practices for initiating, implementing, and maintaining information security management. As such, these standards ensure that organizations can effectively manage and protect their information assets, which is essential when integrating AI into secure software development processes.
ISO/IEC 25000 [
1], also known as the Software Product Quality Requirements and Evaluation (SQuARE) series, focuses on software quality. It provides a comprehensive framework for evaluating the quality of software products and includes standards such as ISO/IEC 25010, which defines quality models for software and systems. These models include characteristics like security, reliability, and maintainability, which are essential for assessing the quality of code, regardless of whether they are AI generated or not. By adhering to the ISO/IEC 25000 standards, developers can ensure that AI tools contribute positively to software quality and security.
At the technical level of secure software development, several frameworks and standards guide developers toward safer software development practices. For example, the MITRE Corporation’s Common Weakness Enumeration (CWE) releases a secure coding standard containing more than 1200 secure coding guidelines for different programming languages. MITRE also releases the CWE Top 25, which highlights twenty-five guidelines out of the entire catalog which are considered very important in addressing security in software, i.e., it ranks the top 25 “most dangerous software weaknesses” that could lead to serious vulnerabilities if left unaddressed. This list helps developers prioritize their security efforts based on the potential risks and impacts of these weaknesses across different types of software development projects.
Similarly, the OWASP (Open Worldwide Application Security Project) offers various Top 10 lists, updated periodically, across different domains. With the rise in popularity of large language models (LLMs), OWASP has expanded its scope by releasing a Top 10 specifically for LLMs. This resource aims to educate developers, designers, architects, managers, and organizations on the potential security risks associated with deploying and managing LLMs [
19]. MITRE, through the ATLAS Matrix project [
20], has also adapted its ATT&CK matrix, a resource on attacker tactics and techniques that covers machine learning (ML) techniques.
Furthermore, the ISO/IEC TR 24772-1 [
21] provides a taxonomy of software vulnerabilities, offering guidance on avoiding common mistakes in a variety of programming languages. This technical report is part of a series that aids developers in understanding how to implement secure coding practices effectively. It covers vulnerabilities related to language-specific issues and provides mitigation strategies that are essential for developing robust, secure applications.
Driven by innovations in machine learning and deep learning, GenAI models are designed to generate content, such as text and images. Notable examples include generative adversarial networks (GANs) and transformer-based models like GPT (Generative Pre-trained Transformer) [
22]. The latter has demonstrated capabilities in natural language understanding and generation, facilitating tasks ranging from automated content creation to complex problem-solving. Next, we will mention the most notable models available today.
ChatGPT, part of the GPT series by OpenAI, has gained widespread attention for its conversational abilities and versatility in handling diverse queries. Its application ranges from customer service to educational tools and beyond [
23]. In the context of software development, ChatGPT’s ability to understand and generate human-like text provides a unique opportunity to assist developers. Another model that is gaining traction both in industry and also academia is
LLaMA (Large Language Model-based Automated Assistant), which its parent company, Meta, has made openly available [
24]. However, since these models are probabilistic in nature, their usage and performance in the field of secure software development still lacks understanding. In contrast, our work contributes to the understanding of using AI as a means to assist software developers in writing secure code.
Russel et al. [
25] have explored the potential of AI to revolutionize industries by enhancing efficiency, accuracy, and innovation. However, they also highlighted critical challenges such as ethical considerations, security risks, and the need for robust validation mechanisms. Shen et al. [
26] also showed that, in software development, AI tools show promise in automating repetitive tasks, improving code quality, and identifying vulnerabilities. Yet, these studies also caution about the over-reliance on AI without proper oversight, which can lead to unintended consequences, including the introduction of new security flaws.
Fu et al. [
27] introduced LineVul, a Transformer-based method for line-level vulnerability prediction, improving upon the IVDetect approach of Li et al. [
28]. In their study with over 188,000 C/C++ functions, LineVul significantly outperformed existing methods, notably achieving up to 379% better F1-measure for function-level predictions and reducing effort by up to 53% for achieving 20% recall. Notably, concerning the CWE Top-25, LineVul is very accurate (75–100%) for predicting vulnerable functions. This highlights AI tools’ potential to become more efficient and effective in vulnerability detection in real-world applications, similar to how SAST tools are integrated today in the development lifecycle.
GitHub CoPilot, developed in collaboration with OpenAI, is a developer productivity tool. It utilizes AI to provide real-time code suggestions and auto-completions within integrated development environments (IDEs). CoPilot can predict and generate code snippets, thereby accelerating the coding process [
29]. However, concerns have been raised about its potential to inadvertently propagate insecure coding practices and vulnerabilities, necessitating a closer examination of its impact on secure software development. Not only that, concerns have also been raised about privacy and intellectual property, with GitHub Copilot having been found to leak secrets in the past [
30].
Although increasingly explored as a tool to improve secure software development practices, Perry et al. [
31] conducted a comprehensive user study on how individuals use an AI Code assistant for security tasks in various programming languages. Their findings revealed that participants using the AI, specifically OpenAI’s codex-davinci-002 model, generally wrote less secure code than those who did not use the AI. Furthermore, those with AI access often overestimated the security of their code. Notably, the study found that participants who were more critical of the AI and adjusted their prompts produced code with fewer vulnerabilities. Similarly, Pearce et al. (2022) [
32] systematically investigated the prevalence and conditions that can cause GitHub Copilot, a popular AI coding assistant, to recommend insecure code. The authors analyzed code generated in Python, C, and Verilog with CodeQL [
33] and through manual inspection, focusing on the MITRE CWE Top-25 [
34]. According to their findings, roughly 40% of the programs produced in their experiments were found to be vulnerable.
In the domain of software development, AI is being explored in the Test Driven Development (TDD) style, where AI generates code based on predefined tests, improving coding efficiency and adhering to the principles of TDD [
35].
4. Results
In this section, we provide the results that were obtained during the Preliminary Study and the Extended Analysis Study as detailed in
Section 3.
4.2. Results for Extended Analysis with GPT-4
In this section, we cover the analysis of LLM responses for GPT-4, which were conducted in the Extended Analysis experiment. We provide the results on the code snippets of used in Set 1 and Set 2. Note that while the individual results from the SANS Top 25 (Set 1) also relate to individual CWEs, the Curated Code Snippet used in Set 2 relates to twenty individual CWEs.
Table 6 presents the results of the Set 1 code snippets based on the automated prompts. As detailed in
Section 3, the results are based on the fulfillment or non-fulfillment of the individual-defined evaluation criteria. Additionally, we provide an evaluation of the coverage of each prompt toward its criteria in the last row of the table.
Our results show that the LLM fulfills the criteria of code understanding (P1) with 100%. In terms of vulnerability detection (P2), our results show a coverage of 88%. The same percentage value is also obtained for code fix suggestions (P4) and comprehensive vulnerability detection (P5). In terms of the obtainment of details on the vulnerability, our results show a coverage of 56%.
Table 6.
Results for SANS Top 25 CWE (Set 1) for GPT-4 experiment.
| CWE ID | Short Description | P1 | P2 | P3 | P4 | P5 |
|---|
| CWE-787 | Out-of-bounds Write | ✔ | ✔ | ✔ | ✔ | ✔ |
| CWE-79 | Cross-site Scripting | ✔ | ✔ | ✔ | ✔ | ✔ |
| CWE-89 | SQL Injection | ✔ | ✔ | ✔ | ✔ | ✔ |
| CWE-416 | Use After Free | ✔ | ✔ | ✔ | ✔ | ✔ |
| CWE-78 | OS Command Injection | ✔ | ✔ | - | ✔ | ✔ |
| CWE-20 | Improper Input Validation | ✔ | ✔ | - | ✔ | ✔ |
| CWE-125 | Out-of-bounds Read | ✔ | ✔ | ✔ | ✔ | ✔ |
| CWE-22 | Path Traversal | ✔ | ✔ | ✔ | ✔ | ✔ |
| CWE-352 | Cross-Site Request Forgery | ✔ | ✔ | ✔ | ✔ | ✔ |
| CWE-434 | Unrestricted Dangerous File Upload | ✔ | ✔ | ✔ | ✔ | ✔ |
| CWE-862 | Missing Authorization | ✔ | - | - | - | - |
| CWE-476 | NULL Pointer Dereference | ✔ | ✔ | ✔ | ✔ | ✔ |
| CWE-287 | Improper Authentication | ✔ | ✔ | ✔ | ✔ | ✔ |
| CWE-190 | Integer Overflow or Wraparound | ✔ | ✔ | - | ✔ | ✔ |
| CWE-502 | Deserialization of Untrusted Data | ✔ | ✔ | ✔ | ✔ | ✔ |
| CWE-77 | Command Injection | ✔ | ✔ | - | ✔ | ✔ |
| CWE-119 | Buffer Overflow | ✔ | ✔ | - | ✔ | ✔ |
| CWE-798 | Use of Hard-coded Credentials | ✔ | ✔ | - | ✔ | ✔ |
| CWE-918 | Server-Side Request Forgery | ✔ | ✔ | ✔ | ✔ | ✔ |
| CWE-306 | Missing Critical Function Authentication | ✔ | - | - | - | - |
| CWE-362 | Race Condition | ✔ | - | ✔ | - | ✔ |
| CWE-269 | Improper Privilege Management | ✔ | ✔ | - | ✔ | ✔ |
| CWE-94 | Code Injection | ✔ | ✔ | - | ✔ | ✔ |
| CWE-863 | Incorrect Authorization | ✔ | ✔ | - | ✔ | ✔ |
| CWE-276 | Incorrect Default Permissions | ✔ | - | - | - | - |
| Coverage | 100% | 88% | 56% | 88% | 88% |
As described in the experiment section, we also evaluated the overall correctness of the results. In P1, GPT-4 consistently provided clear and accurate explanations of the code functionality across all 25 code snippets, demonstrating a robust understanding of diverse coding constructs. The model’s explanations were generally precise, highlighting its capability to interpret and articulate code operations effectively. For P2, which inquired about the presence of vulnerabilities, GPT-4 accurately identified vulnerabilities in 22 out of 25 cases, reflecting an 88% success rate in initial vulnerability detection. Notably, it successfully flagged critical vulnerabilities such as CWE-787 (Out-of-bounds Write), CWE-79 (Cross-site Scripting), and CWE-89 (SQL Injection). However, the model exhibited deficiencies in accurately identifying vulnerabilities in cases like CWE-862 (Missing Authorization) and CWE-276 (Incorrect Default Permissions), suggesting areas where the model’s training data might need refinement or where the inherent complexity of these vulnerabilities poses challenges (such as lack of context). For P3, which required specifying the vulnerability and providing the CWE number, GPT-4 correctly identified and described the vulnerabilities, including the correct CWE number, in 14 out of 25 cases (56%). This demonstrates a limitation in specificity and detail, as the model often struggled with assigning the correct CWE numbers, particularly for vulnerabilities such as CWE-78 (OS Command Injection) and CWE-20 (Improper Input Validation).
In terms of completeness, we observed that GPT-4’s performance in identifying multiple vulnerabilities was variable. For 56% of the code snippets, the LLM successfully detected additional vulnerabilities beyond the primary one. For instance, in cases like CWE-125 (Out-of-bounds Read) and CWE-434 (Unrestricted Dangerous File Upload), the model provided comprehensive analyses, indicating a thorough understanding of these vulnerabilities and their potential impacts. However, it often missed secondary vulnerabilities in more complex scenarios, such as CWE-862 (Missing Authorization), CWE-190 (Integer Overflow or Wraparound), and CWE-77 (Command Injection). The ability to detect multiple vulnerabilities is crucial for comprehensive code security analysis, and GPT-4’s 56% coverage rate indicates significant room for improvement in this area.
In terms of the relevance aspect, our results show that GPT-4 provided relevant and practical fixes for many identified vulnerabilities. As an example, the suggested fixes for SQL injection (CWE-89), cross-site scripting (CWE-79), and use after free (CWE-416) were appropriate and effective, directly addressing the identified issues. These suggestions were typically clear and implementable, showcasing GPT-4’s potential as a useful tool for developers. However, there were instances where the proposed fixes were less practical or introduced unnecessary complexity. In the case of CWE-78 (OS Command Injection) and CWE-20 (Improper Input Validation), the suggested fixes sometimes failed to fully address the issues or introduced new complexities, which could potentially lead to further vulnerabilities. Overall, the relevance of fixes showed coverage of 88%, indicating that while GPT-4 is generally capable of suggesting practical and effective fixes, there is still a need for improvement to ensure all proposed solutions are fully relevant and comprehensive.
Table 7 shows the results pertaining to prompts P1 through to P5 obtained for the Set 2 code snippet, i.e., the Curated Code Snippet.
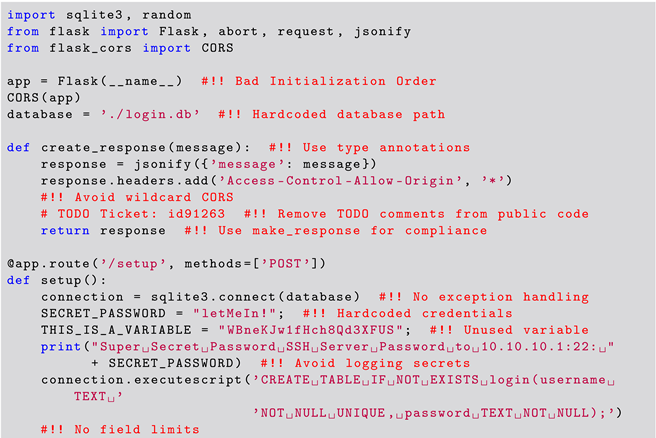
When evaluating the GPT-4 model’s response for correctness on the Curated Code Snippet, the results were less impressive compared to its performance on the SANS Top 25 snippets (Set 1). Out of the twenty issues present in the snippet, GPT-4 identified only eight issues. This result indicates that GPT-4 had issues identifying less common vulnerabilities, particularly when requiring a nuanced understanding of context and secure coding practices. When prompted about the identification of vulnerabilities (P3), the GPT-4 LLM correctly identified a single vulnerability, namely, the SQL injection vulnerability, which is present in the Curated Code Snippet. The GPT-4 LLM also failed to correctly identify issues that, according to the authors’ experience, are important to address in the industrial context in P3, namely, hardcoded credentials and relative database file paths. The LLM model also overlooked critical problems like declaring the Flask app globally, as this issue can lead to unpredictable initialization. However, when asked if there were any additional vulnerabilities (P5), the model identified 7 additional issues out of the remaining 19. Additionally, we noted that the model generated false positives in P5 by identifying vulnerabilities that did not actually exist. This problem is also known as hallucination. In this regard, our experiment also showed that the model hallucinated random CWE numbers and descriptions when prompted with P3, only giving correct CWEs 56% of the time. Furthermore, we note that the LLM failed to identify 12 out of the 20 vulnerabilities present in the script.
The completeness of GPT-4’s responses for the results obtained in Set 2 in identifying vulnerabilities was inconsistent. While the model managed to identify several critical vulnerabilities, the overall identification rate was lower than for Set 1. In particular, we again highlight that, out of the 20 issues present in the code snippet, GPT-4 identified only 8, thus having a negative impact on completeness. In particular, the GPT-4 failed to identify the risk of disabling Cross-Origin Resource Sharing (CORS) in responses, which can increase the risk of cross-site scripting (XSS) attacks and information leakage. We also observe that, although the LLM correctly identified the SQL injection vulnerability in Set 2, it missed critical issues such as declaring the Flask app globally, using hardcoded database paths. It also overlooked improper exception handling for database operations, which can lead to application crashes or inconsistent database states. Additionally, it missed identifying the use of insecure random number generation for session IDs, which can make session hijacking attacks more likely.
In terms of the relevance aspect for Set 2, the results varied considerably. Our results show that the GPT-4 model correctly suggested securing cookies by setting the httponly and secure flags, mitigating the risk of session hijacking. Upon further prompting (P5 and more), the GPT-4 also identified the need to fix hardcoded credentials and suggested removing sensitive information from console logs to prevent exposure. Additionally, we observed incomplete proposals for fixes of identified vulnerabilities, e.g., the advice on remediation for SQL injection and insecure cookie handling vulnerabilities. In this case, the LLM failed to address issues such as improper initialization and the use of hardcoded database paths. The authors’ opinion is that these fixes are crucial for ensuring the security and robustness of the application; however, they were not identified or suggested by the GPT-4 model.
5. Discussion
In this section, we provide a critical discussion of the results obtained in the Preliminary Study and the Extended Analysis study. The focus of our discussion is on the two guiding research questions of the present work, namely, the following: RQ1. To what extent can ChatGPT recognize vulnerabilities in source code? RQ2. To what extent can ChatGPT rewrite code to eliminate present security vulnerabilities?. We also draw conclusions on the practical implications of using LLMs for secure software development in an industrial context. Additionally, we provide an authors’ view on the perceived advantages and disadvantages of using LLMs for secure software development and provide practical recommendations for industrial practitioners.
5.1. Critical Discussion of the Results
In terms of the capability to recognize vulnerabilities (RQ1), our Preliminary Study of GPT-3 revealed notable potential in identifying security vulnerabilities and providing remediation, especially in smaller code snippets (under 40 lines). GPT-3 successfully pinpointed underlying issues and suggested appropriate fixes in over 60% of cases despite the inherent challenges in secure coding. This result is encouraging, particularly given the non-decidable nature of many secure coding problems.
Additionally, GPT-3 demonstrated a capacity to explain its reasoning, offering accurate descriptions of vulnerabilities in about three-fifths of the analyzed cases. This suggests that LLMs like ChatGPT could be a valuable teaching tool for secure coding, helping developers understand not only what needs to be fixed but also why it needs to be fixed.
Despite these strengths, several limitations became evident in the Preliminary Study. GPT-3 often struggled to maintain the correct context of the code, leading to unnecessary corrections or changes that altered the intended semantics (RQ2). This is particularly concerning for safety-critical systems, where even subtle changes can have serious repercussions. Additionally, GPT-3 sometimes generated unnecessarily complex code compared to the original, potentially introducing performance inefficiencies and maintainability issues.
Building upon the foundation established by GPT-3, we carried out an Extended Analysis Study with a newer LLM model, namely, GPT-4. Our results show significant improvements in terms of the usability of the tool as a means to assist the development of secure software in the industry. The ability to detect vulnerabilities by GPT-4 was better than GPT-3. In particular, we observed that our Set 2 of SANS Top 25 vulnerabilities achieved an overall accuracy of 88%, compared to 60% obtained with GPT-3. While this result shows an improvement in the detection capability, it also shows that about one in ten vulnerabilities are not identified. This means that vulnerability handling in secure software development cannot be fully covered by this tool. Nevertheless, the LLM model identified common vulnerabilities such as SQL injection (CWE-89), cross-site scripting (CWE-79), and out-of-bounds write (CWE-787). We believe that this showcases the models’ effectiveness in handling well-known and well-documented security issues. The authors believe that the results highlight the usage of LLM as a valuable tool for practitioners to detect frequently encountered vulnerability issues in code.
However, GPT-4’s performance on Set 2 (Curated Code Snippet) was less consistent in the identification of code vulnerabilities compared to Set 1 (SANS Top 25), resulting in a lower detection rate in Set 2 compared to Set 1. We attribute this discrepancy to the fact that the identification of code vulnerabilities in Set 2 requires additional contextual knowledge compared to Set 1. This result suggests that while GPT-4 excels with well-known vulnerabilities that have ample training data, it can struggle when faced with less common or context-dependent issues. This also highlights a potential critical challenge for the model and researchers alike: expanding and diversifying the models’ training data is essential to improving its generalizability and robustness across a broader range of vulnerability types.
Moreover, GPT-4, like GPT-3, showed limitations in reliably identifying and classifying vulnerabilities in the Curated Code Snippet. We observed identification mistakes, such as misidentifying issues or generating false claims about vulnerabilities that do not actually exist, a problem known as “hallucinations”. Furthermore, our results hint that the model can exhibit issues when connecting vulnerabilities to CWE numbers. We note that, due to the nature of CWEs, this result was expected. However, these issues contribute to reducing the model’s reliability for practical usage. The results also highlight the need for well-trained software developers in secure coding who can cover the gaps in the LLM, i.e., to aid in the LLM gaps in accuracy and usefulness, human experts need to be involved. Integrating GPT-4 into security workflows, where people can review, interpret, and correct their findings, has the potential to significantly enhance its reliability and effectiveness.
The differences in performance between the Set 1 vulnerabilities and those of Set 2 further underscore GPT-4’s limitations. While our engineered Curated Code Snippet contains 18 vulnerabilities and 2 security practice issues, the GPT-4 model only identified 8 issues. This result highlights that LLMs can produce less reliable results on software vulnerabilities that appear less in practice compared to higher reliable results for well-known and more frequent vulnerabilities found in practice. It is the authors’ understanding that this result can also be tied to the context-specific nature of security flaws; however, this requires further study. Our results show that the LLM failed to reliably handle vulnerabilities such as SQL injection, particularly in its recommendations on how to fix the code. These kinds of omissions are likely dependent on the models’ comprehensiveness of their training data. This result also highlights the importance of the continuous refinement of the training of the model.
Despite these challenges, we observed a notable improvement in the results offered by GPT-4 compared to those of GPT-3 in terms of accuracy and vulnerability identification. This improvement likely stems not only from the structured nature of the SANS Top 25 snippets but also their likely inclusion in the model’s training data. According to recent research results, this effect can indeed likely be tied to the quality and diversity of its training data [
37] as well as to the higher number of model parameters of GPT-4 compared to GPT-3. Nevertheless, the authors noticed reliability issues of GPT-4 in more complex and context-specific scenarios (Set 2). The authors also noticed false-positive suggestions by the LLM model. Thus, we believe that integrating GPT-4 into secure coding practices requires careful knowledge, understanding, and consideration of its limitations. In particular, we advocate for the need for human validation of its findings to avoid potential misidentifications or oversights.
Another limitation of these models is the potential reliance on outdated training data. This may prevent the model from recognizing emerging threats and vulnerabilities or provide outdated solutions for code fixes. This also highlights the essential need for continuous updates and refinement to ensure the model remains relevant in the face of evolving security challenges. Additionally, industry practice has shown that the model’s capacity to learn from user interactions introduces additional risks in industrial environments. Not only could incorrect data lead to flawed recommendations but the leakage of intellectual property could also become a serious issue. We believe that implementing safeguards to prevent the model from learning inaccurate information and leaking intellectual information is crucial, particularly in critical infrastructure settings.
Both GPT-3 and GPT-4 demonstrated potential in suggesting fixes for identified vulnerabilities, though with varying effectiveness (RQ2). Some proposed solutions were creative and well suited to the problems, such as securing cookies by setting the ‘httponly’ and ‘secure’ flags. However, the models also introduced overly complex fixes that could negatively impact code maintainability and performance—a critical aspect for industrial software. Inconsistencies in addressing security concerns such as hardcoded database paths or improper initialization highlight the need for further development to ensure that remediation suggestions are both accurate and comprehensive.
Our experiment shows that GPT-4 effectively suggested securing cookies and fixing hardcoded credentials; however, it failed to suggest the restriction of the network interface exposure. This lapse by the LLM can result in an increased risk of unauthorized system access.
Additionally, GPT-4 failed to identify the presence of hardcoded credentials, which not only are problematic due to their nature of being hardcoded but could also be easily guessed or brute-forced by an attacker. This result reveals additional gaps in the analysis of the vulnerabilities by the LLM.
Our view is that while both GPT-3 and GPT-4 show potential as tools for improving existing secure coding practices, their usage still has additional considerations that need attention. Our experience shows that the GPT-3 model excels in providing creative solutions and clear explanations for small code snippets and that it is a valuable tool to teach software developers about secure coding vulnerabilities. However, its lack of context and inability to provide consistently semantic-preserving fixes limit its practicality in industrial settings.
However, our results show inconsistencies with less common issues and the models’ susceptibility to hallucinations. While GPT-4 demonstrates considerable potential in aiding software developers with secure coding practices, its limitations in detecting multiple vulnerabilities and assigning correct CWE numbers indicate areas where further refinement is needed by the research community. Ensuring that all suggested solutions are fully comprehensive and do not introduce new complexities also remains a challenge, underscoring the importance of ongoing improvements in AI models like GPT-4 to enhance their effectiveness in supporting secure software development.
6. Conclusions
This study provides a comprehensive evaluation of ChatGPT’s capabilities in identifying and mitigating software vulnerabilities, with a particular focus on its performance with the SANS Top 25 and a Curated Code Snippet. The results demonstrate that ChatGPT version GPT-4 significantly improves upon the GPT-3 earlier model, especially in its ability to detect common vulnerabilities. Specifically, ChatGPT achieved an accuracy rate of 88% when identifying vulnerabilities from the SANS Top 25 list, effectively recognizing issues such as SQL injection, cross-site scripting, and out-of-bounds write errors. This result underscores ChatGPT’s potential as a valuable tool in automated vulnerability detection.
Software security is not only a critical aspect of software development but has also gained increasing attention in recent years due. This increase in attention is due to the observed growing number of cybersecurity incidents, which have significant consequences for society in general. Poor coding practices are often the root cause of these incidents, highlighting the importance of teaching and employing best practices in software development. Traditionally, these practices are taught in academic settings or through industry training programs. In this context, ChatGPT has the potential to play a dual role: assisting software developers in writing secure code and raising awareness of secure coding practices.
Addressing RQ1, the extent to which ChatGPT can recognize vulnerabilities in source code is substantial when dealing with well-known and frequently occurring issues. However, the study highlighted critical limitations, particularly when ChatGPT was confronted with random code snippets or more obscure and context-specific vulnerabilities. In the curated code snippet analysis, which included 18 vulnerabilities and 2 security practice issues, ChatGPT was only able to identify 8 issues. This indicates that while ChatGPT is effective in handling common vulnerabilities, it remains less reliable in detecting less frequent or complex security flaws and is prone to generating false positives or “hallucinations”.
Regarding RQ2, ChatGPT has shown potential in rewriting code to eliminate present security vulnerabilities, but its success is largely dependent on the complexity of the vulnerabilities. For well-known vulnerabilities identified in the SANS Top 25, ChatGPT was able to provide accurate and relevant fixes, improving the security of the code. However, when dealing with less common vulnerabilities or those requiring deep contextual understanding, ChatGPT’s rewrites were less effective, sometimes failing to address the root cause of the issue. Furthermore, we have identified additional issues not necessarily related to the code security but which are crucial for industrial code, such as issues with code maintainability.
The present work also investigates and reflects on the advantages and disadvantages of using generative AI for secure software development, based on the authors’ opinion rooted in their experience in the field. While ChatGPT and similar models show clear potential as aids in software development, there are practical and theoretical limitations to their use. One of the major contributions of this work is an in-depth discussion on the use of ChatGPT. Based on these discussions, we provide insights relevant to both academia and industry practitioners, highlighting not only potential future research avenues but also practical advice on the use of large language models (LLMs).
In conclusion, while ChatGPT represents a significant advancement in the use of LLMs for software security, its limitations necessitate careful application and continued refinement. The model’s strong performance with the SANS Top 25 vulnerabilities demonstrates its potential to assist in automated security processes, but the gaps in its detection and code rewriting capabilities, particularly with more complex or context-specific issues, indicate that ChatGPT should be used in conjunction with traditional security practices and expert oversight. Future research should explore the extent to which ChatGPT and similar models can be used to evaluate software quality and assist in code review, as well as addressing the validity of the advantages and disadvantages identified in this study.


 ,
, 






{kind=link}
{kind=link}

