
Toward Robust Arabic AI-Generated Text Detection: Tackling Diacritics Challenges


Abstract
1. Introduction
1.1. Arabic Diacritized Texts Background
1.2. The Impact of Diacritics on AI Detection of Arabic Texts
- Will training the classifier on diacritized texts enhance the detector’s robustness towards such texts?
- Does training the detector on diacritics-laden texts prove more effective than implementing a dediacritization filter prior to the classification step?
- Should the dataset include a diverse range of HWTs from various domains/fields to enhance recognition capabilities, or is it sufficient to focus on one domain with multiple writing styles?
- How do different transformer-based, pre-trained models (AraELECTRA, AraBERT, XLM-R, and mBERT) compare in terms of performance when trained on diacritized versus dediacritized texts?
- What is the impact of using a dediacritization filter during evaluation on the overall accuracy and robustness of the detection models across different OOD datasets?
2. Related Works
3. Methodology
3.1. Data Collection and Preparation
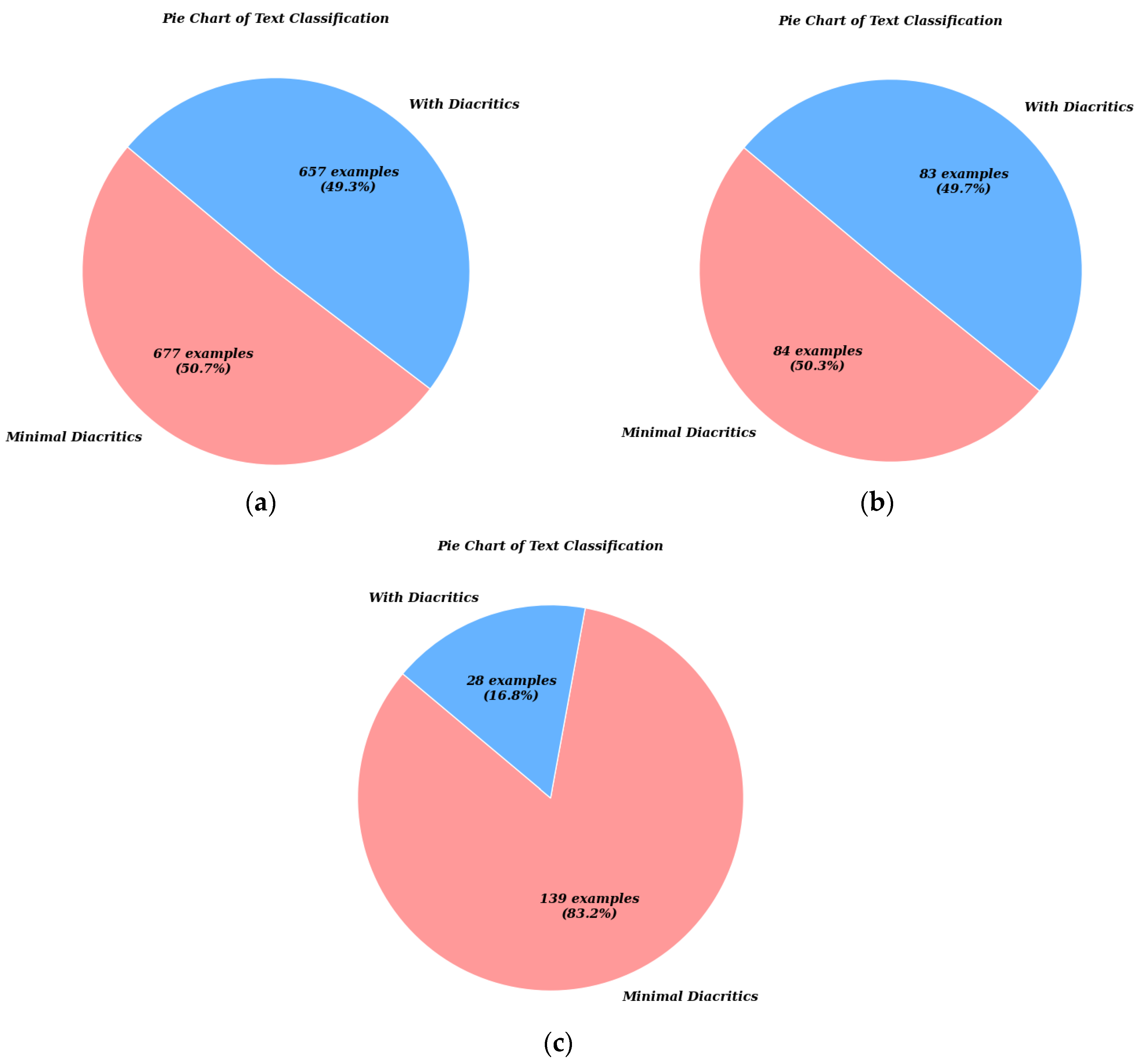
3.1.1. Diacritized Custom Dataset
3.1.2. Ejabah-Driven Datasets
- (1)
- AIGTs Samples
- Inclusion Criteria:
- ⮚
- Length: We included responses that exceeded 350 characters. This criterion was established because shorter responses often do not exhibit the distinct characteristics of AIGTs. For instance, a response to a simple query like “What is the capital city of the USA?” may yield a brief answer such as “Washington DC” (13 characters), which lacks the detailed features typical of LLM responses.
- ⮚
- Balance: We ensured that the number of AIGT examples matched the number of HWT examples for a balanced comparison.
- Exclusion Criteria:
- ⮚
- Short Responses: Responses under 350 characters were excluded as they typically fail to demonstrate the detailed and coherent characteristics of LLM outputs.
- (2)
- HWTs Samples
- Inclusion Criteria:
- ⮚
- Authenticity: Only responses that were clearly identifiable as HWTs were included. If a response did not provide the source of the reply (such as books or website links), we copied the reply and searched for it on Google. This method consistently revealed that the answers were copied from online sources written by humans.
- ⮚
- Length: Unlike AIGT samples, we accepted human responses regardless of character count because humans tend to provide shorter answers or supplement their brief answers with readily available internet text (from forums and Wikipedia), especially in community Q&A formats.
- Exclusion Criteria:
- ⮚
- Uncertain Origin: To maintain the integrity of the HWT dataset, examples that could not be definitively classified as HWT were excluded.
- ⮚
- Adversarial Texts: Human responses that showed signs of being a combination of AIGT and HWT, which might occur in adversarial attacks, were also excluded.
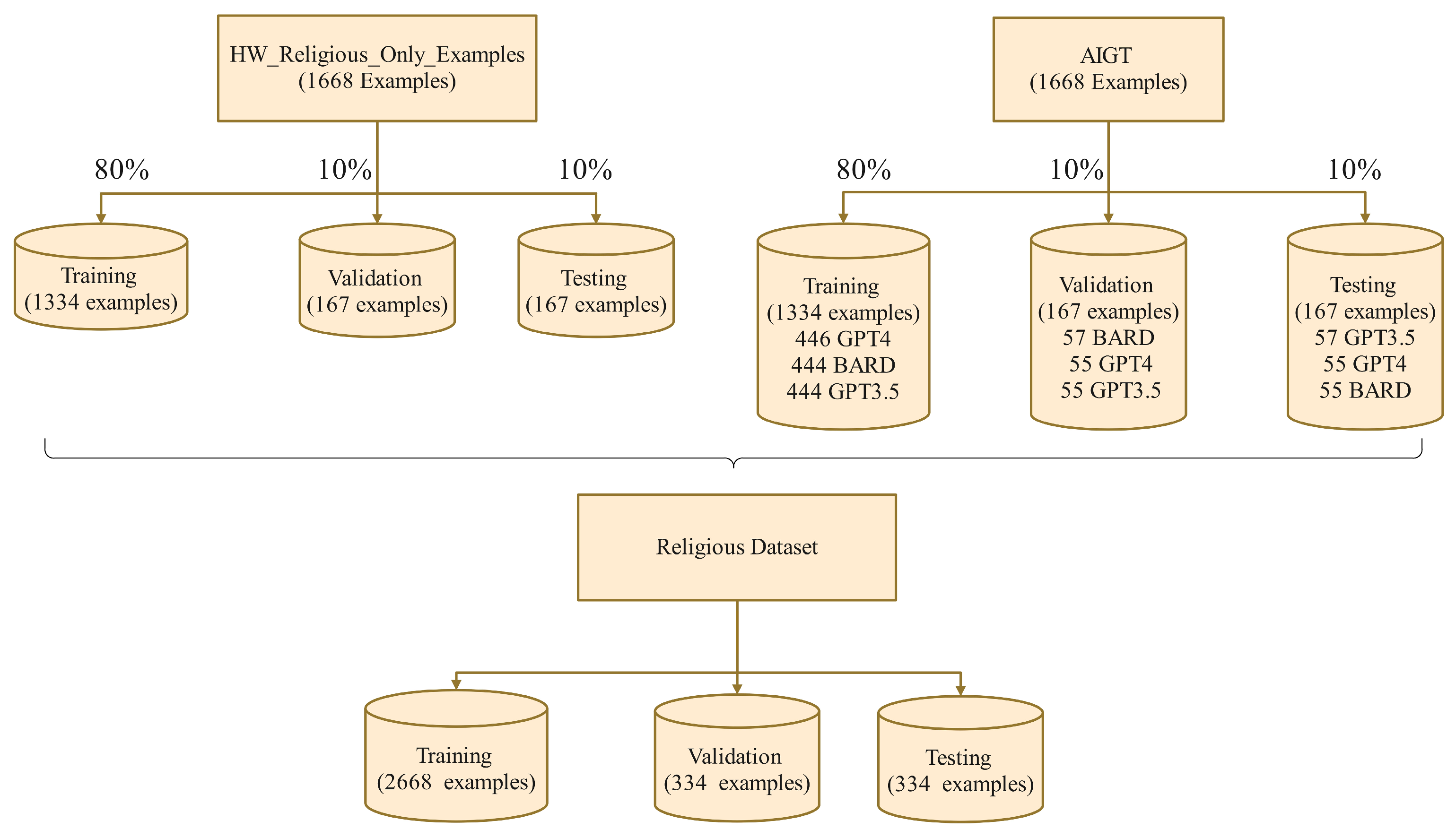
Religious Dataset
- (1)
- Generalization Capability: This assessment determines whether a model trained solely on HWTs from a single field (religious texts) can effectively generalize its recognition capabilities to HWTs from other diverse fields in real-world scenarios. This challenge challenges the model to demonstrate its broader applicability, which is important for practical deployments where the model might encounter HWTs from various subjects and styles.
- (2)
- Impact of Diacritization: We evaluated whether training the model on a proportion of diacritized Arabic texts enhanced its ability to generalize its recognition capabilities to diacritized texts. Specifically, we aimed to determine whether this training approach helped the model to distinguish diacritized HWTs from AIGT compared to a model trained on diacritic-free texts.
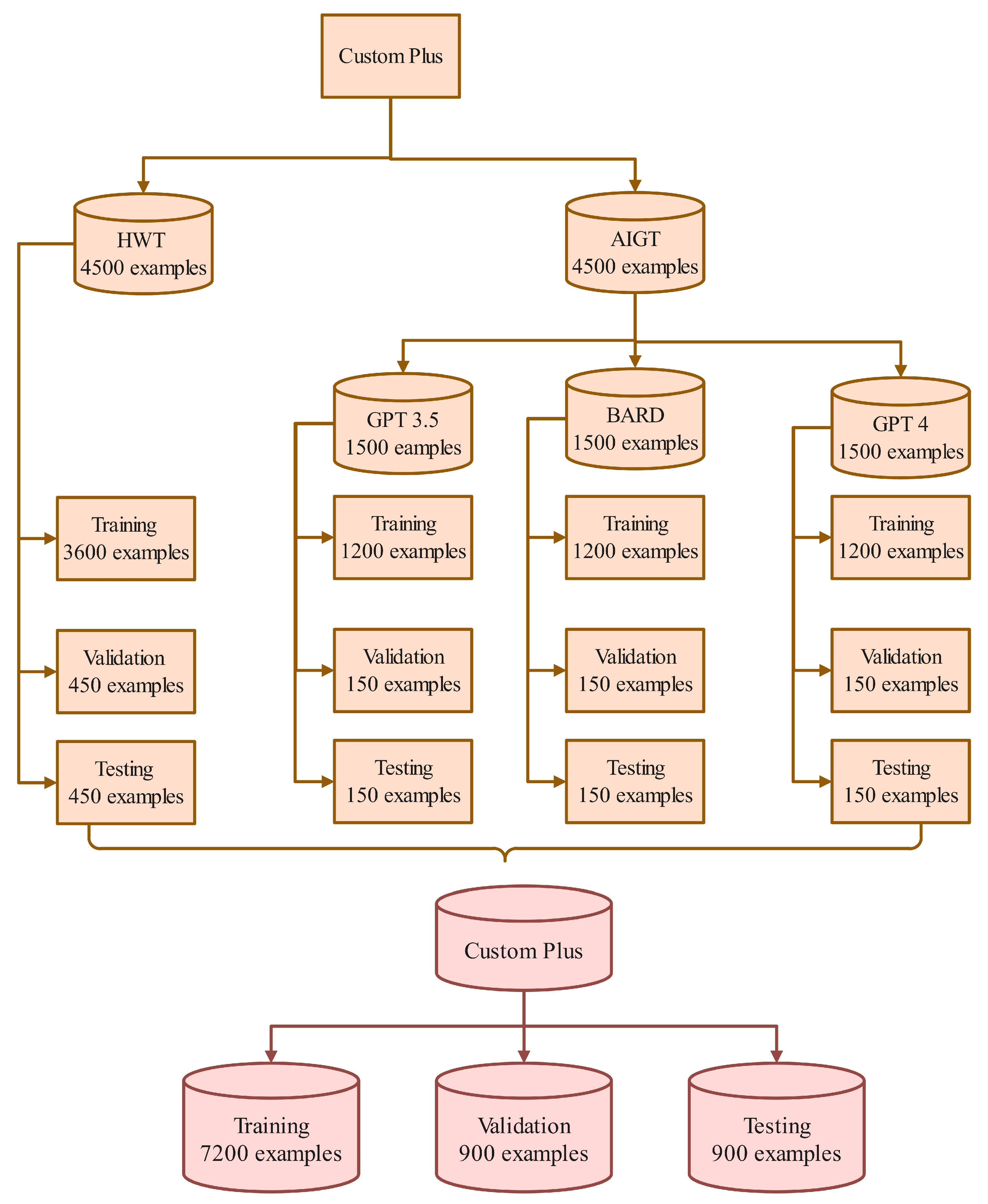
Custom Plus Dataset
Custom Max Dataset
3.2. Detector Architecture
3.2.1. Training
3.2.2. Evaluation
3.2.3. Hyperparameters
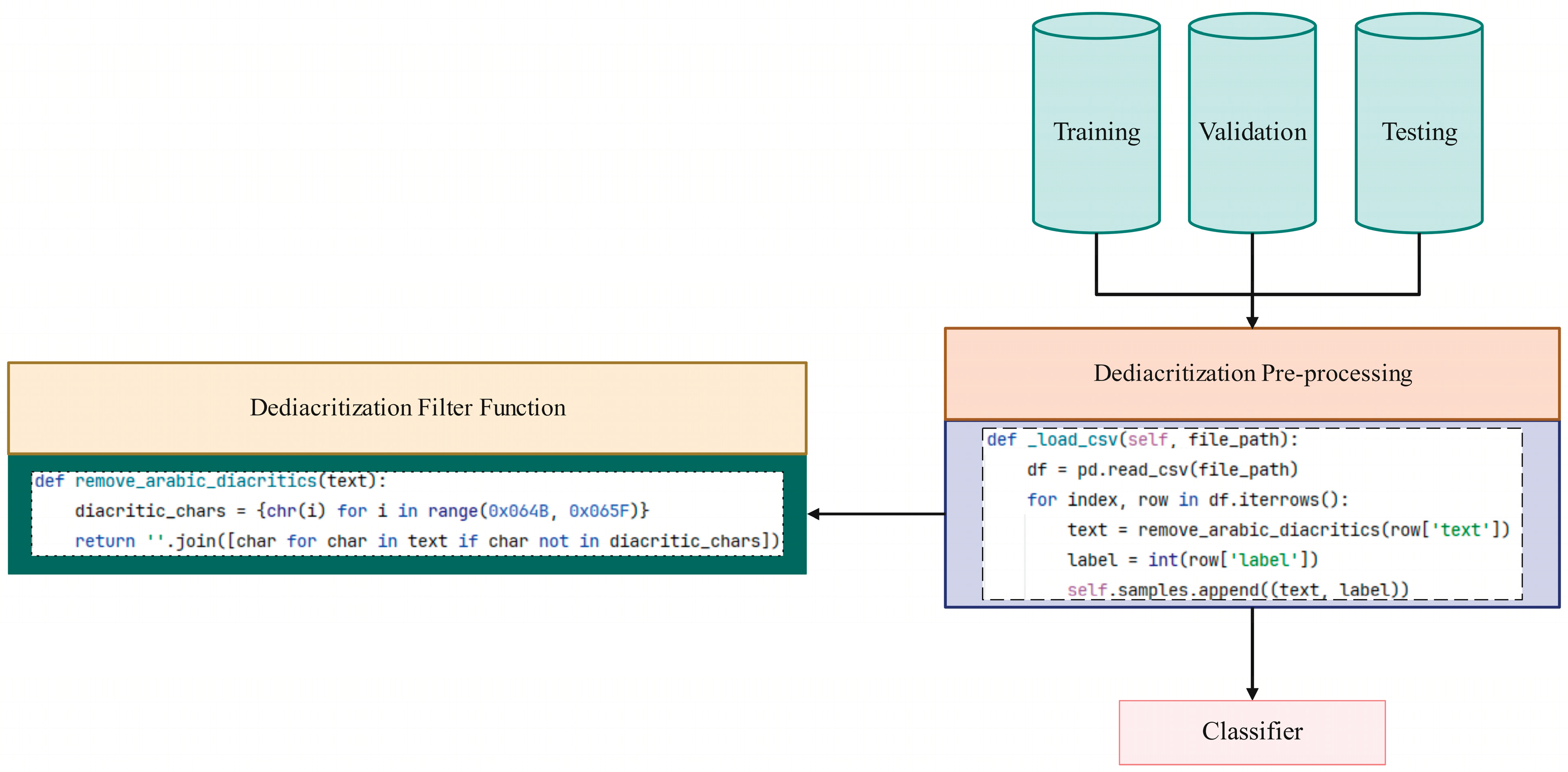
3.2.4. Dediacritization Filter Function
3.3. Evaluation Strategy and Methodology
3.3.1. Diacritization Impact Evaluation
- Diacritized Validation set: Contains 612 examples.
- Diacritized Testing set: Contains 612 examples.
- Religious Testing set: Contains 334 examples.
- AIRABIC Benchmark Testing set: Contains 1000 examples.
- Religious Validation set: Contains 334 examples.
- Religious Testing set: Contains 334 examples.
- Diacritized Custom Testing set: Contains 612 examples.
- Custom Testing dataset (diacritics-free): Contains 306 examples.
- AIRABIC Benchmark Testing set: Contains 1000 examples.
- AIRABIC Benchmark Testing set with dediacritization filter: The diacritics are removed from the testing set using a dediacritization filter.
3.3.2. Evaluation of Larger and More Diverse Training Corpus and Comparative Analysis of Preprocessing Approaches
Non-Preprocessing Approach
- Validation set: Contains 900 examples.
- Testing set: Contains 900 examples.
- Custom dataset: This contains 306 examples.
- AIRABIC Benchmark Testing set: Contains 1000 examples used to benchmark the model’s performance against the standard dataset.
- AIRABIC Benchmark Testing set with dediacritization filter: The diacritics are removed from the testing set using a dediacritization filter to assess the model’s adaptability to diacritic-free text.
Preprocessing Approach
3.3.3. Combining All Datasets for Maximizing the Corpus Size
4. Results
4.1. Diacritized Datasets Results
4.2. Evaluation of Custom Plus Results
4.2.1. Non-Preprocessing Approach
4.2.2. Preprocessing Approach
4.3. Combined Dataset Evaluation
5. Discussion
5.1. Comparison of Our Detection Models with GPTZero on the AIRABIC Benchmark Dataset
5.2. Analysis of the Diacritized Datasets Results
5.2.1. Diacritization Involvement Benefit
5.2.2. Importance of Diverse Examples
5.3. Analysis of the Results from Custom Plus and Custom Max
- (1)
- Impact of Diacritics: Including diacritics in the training data generally enhances the models’ ability toward HWTs, as evidenced by higher recall values across different datasets. This suggests that including diacritized texts during training can be beneficial, especially in scenarios where recall is important. However, the presence of diacritics can sometimes reduce precision, particularly when there is a mismatch between the training and evaluation text formats.
- (2)
- Precision vs. recall Trade-off: The dediacritization preprocessing approach typically improves precision, but at the cost of recall. This trade-off was observed across both the Custom Plus and Custom Max datasets. Applying a dediacritization filter can be advantageous in scenarios where precision is important. Conversely, if recall is more important, maintaining diacritics in the training data may be preferable.
- (3)
- Marginal Differences: While the differences in performance between the two approaches were marginal in some cases, the overall trends varied. In the Custom Plus dataset, models trained with diacritics showed higher recall, but lower precision. In contrast, the Custom Max dataset showed that models trained with dediacritization achieved higher precision, but also maintained competitive recall values. These variations highlight that the impact of diacritization versus dediacritization can depend on the dataset’s size and diversity.
5.4. Takeaway Recommendations for Handling Diacritics in Arabic Text Detection
5.5. In-Depth Analysis of Models’ Performance
5.5.1. Preliminary Investigation of Models’ Tokenization and Embeddings
- Multilingual Models (mBERT and XLM-R):
- Arabic-Specific Models (AraBERT and AraELECTRA):
5.5.2. Performance Evaluation of Fine-Tuned Models
5.6. Limitations
5.7. Ethical Considerations
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
- ○
- EdrawMax (version 13.5.0, Wondershare Technology, Shenzhen, China)—used for drawing the diagrams
- ○
- Python (version 3.9.18, Python Software Foundation, Beaverton, OR, USA)
- ○
- PyTorch (version 2.1.0+cu121, Facebook, Inc., Menlo Park, CA, USA)
- ○
- Farasa (version 1.0, QCRI, Doha, Qatar)
- ○
- NumPy (version 1.23.5, NumPy Developers)
- ○
- pandas (version 1.5.3, pandas Development Team)
- ○
- transformers (version 4.31.0, Hugging Face, Inc., New York, NY, USA)
- ○
- scikit-learn (version 1.3.2, Scikit-learn Developers)
- ○
- matplotlib (version 3.8.0, Matplotlib Development Team)
- ○
- seaborn (version 0.13.2, Seaborn Developers)
- ○
- tqdm (version 4.66.1, tqdm Developers)
- ○
- openpyxl (version 3.1.2, OpenPyXL Developers)
- ○
- farasapy (version 0.0.14, QCRI, Doha, Qatar)
- ○
- PyArabic (version 0.6.15, ArabTechies)
- ○
- NVIDIA GeForce RTX 3090 GPU (NVIDIA Corporation, Santa Clara, CA, USA)
References
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S. Palm: Scaling language modeling with pathways. arXiv 2022, arXiv:2204.02311. [Google Scholar]
- OpenAI. ChatGPT (Mar 14 Version) [Large Language Model]. Available online: https://chat.openai.com/chat (accessed on 30 March 2023).
- Bard, G.A. BARD. Available online: https://bard.google.com/ (accessed on 10 October 2023).
- Gemini. Available online: https://gemini.google.com/app (accessed on 1 February 2024).
- Weidinger, L.; Uesato, J.; Rauh, M.; Griffin, C.; Huang, P.-S.; Mellor, J.; Glaese, A.; Cheng, M.; Balle, B.; Kasirzadeh, A. Taxonomy of risks posed by language models. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, Seoul, Republic of Korea, 21–24 June 2022; pp. 214–229. [Google Scholar]
- Sheng, E.; Chang, K.-W.; Natarajan, P.; Peng, N. Societal biases in language generation: Progress and challenges. arXiv 2021, arXiv:2105.04054. [Google Scholar]
- Zhuo, T.Y.; Huang, Y.; Chen, C.; Xing, Z. Exploring ai ethics of chatgpt: A diagnostic analysis. arXiv 2023, arXiv:2301.12867. [Google Scholar]
- Cotton, D.R.; Cotton, P.A.; Shipway, J.R. Chatting and cheating: Ensuring academic integrity in the era of ChatGPT. Innov. Educ. Teach. Int. 2023, 61, 228–239. [Google Scholar] [CrossRef]
- Gao, C.A.; Howard, F.M.; Markov, N.S.; Dyer, E.C.; Ramesh, S.; Luo, Y.; Pearson, A.T. Comparing scientific abstracts generated by ChatGPT to original abstracts using an artificial intelligence output detector, plagiarism detector, and blinded human reviewers. BioRxiv 2022. [Google Scholar] [CrossRef]
- Anderson, N.; Belavy, D.L.; Perle, S.M.; Hendricks, S.; Hespanhol, L.; Verhagen, E.; Memon, A.R. AI did not write this manuscript, or did it? Can we trick the AI text detector into generated texts? The potential future of ChatGPT and AI in Sports & Exercise Medicine manuscript generation. BMJ Open Sport Exerc. Med. 2023, 9, e001568. [Google Scholar]
- Pegoraro, A.; Kumari, K.; Fereidooni, H.; Sadeghi, A.-R. To ChatGPT, or not to ChatGPT: That is the question! arXiv 2023, arXiv:2304.01487. [Google Scholar]
- Alshammari, H.; El-Sayed, A.; Elleithy, K. Ai-generated text detector for arabic language using encoder-based transformer architecture. Big Data Cogn. Comput. 2024, 8, 32. [Google Scholar] [CrossRef]
- Alshammari, H.; Ahmed, E.-S. AIRABIC: Arabic Dataset for Performance Evaluation of AI Detectors. In Proceedings of the 2023 International Conference on Machine Learning and Applications (ICMLA), Jacksonville, FL, USA, 15–17 December 2023; pp. 864–870. [Google Scholar]
- Farghaly, A.; Shaalan, K. Arabic natural language processing: Challenges and solutions. ACM Trans. Asian Lang. Inf. Process. 2009, 8, 1–22. [Google Scholar] [CrossRef]
- Obeid, O.; Zalmout, N.; Khalifa, S.; Taji, D.; Oudah, M.; Alhafni, B.; Inoue, G.; Eryani, F.; Erdmann, A.; Habash, N. CAMeL tools: An open source python toolkit for Arabic natural language processing. In Proceedings of the Twelfth Language Resources and Evaluation Conference; European Language Resources Association: Marseille, France, 2020; pp. 7022–7032. [Google Scholar]
- Darwish, K.; Habash, N.; Abbas, M.; Al-Khalifa, H.; Al-Natsheh, H.T.; Bouamor, H.; Bouzoubaa, K.; Cavalli-Sforza, V.; El-Beltagy, S.R.; El-Hajj, W. A panoramic survey of natural language processing in the Arab world. Commun. ACM 2021, 64, 72–81. [Google Scholar] [CrossRef]
- Habash, N.Y. Introduction to Arabic natural language processing. Synth. Lect. Hum. Lang. Technol. 2010, 3, 1–187. [Google Scholar]
- Abbache, M.; Abbache, A.; Xu, J.; Meziane, F.; Wen, X. The Impact of Arabic Diacritization on Word Embeddings. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2023, 22, 1–30. [Google Scholar] [CrossRef]
- Al-Khalifa, S.; Alhumaidhi, F.; Alotaibi, H.; Al-Khalifa, H.S. ChatGPT across Arabic Twitter: A Study of Topics, Sentiments, and Sarcasm. Data 2023, 8, 171. [Google Scholar] [CrossRef]
- Alshalan, R.; Al-Khalifa, H. A deep learning approach for automatic hate speech detection in the saudi twittersphere. Appl. Sci. 2020, 10, 8614. [Google Scholar] [CrossRef]
- El-Alami, F.-z.; El Alaoui, S.O.; Nahnahi, N.E. Contextual semantic embeddings based on fine-tuned AraBERT model for Arabic text multi-class categorization. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 8422–8428. [Google Scholar] [CrossRef]
- Inoue, G.; Alhafni, B.; Baimukan, N.; Bouamor, H.; Habash, N. The interplay of variant, size, and task type in Arabic pre-trained language models. arXiv 2021, arXiv:2103.06678. [Google Scholar]
- Antoun, W.; Baly, F.; Hajj, H. Arabert: Transformer-based model for arabic language understanding. arXiv 2020, arXiv:2003.00104. [Google Scholar]
- Antoun, W.; Baly, F.; Hajj, H. AraELECTRA: Pre-training text discriminators for Arabic language understanding. arXiv 2020, arXiv:2012.15516. [Google Scholar]
- Abdelali, A.; Darwish, K.; Durrani, N.; Mubarak, H. Farasa: A fast and furious segmenter for arabic. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations, San Diego, CA, USA, 12–17 June 2016. [Google Scholar]
- MADAMIRA. Available online: https://camel.abudhabi.nyu.edu/madamira/ (accessed on 7 May 2023).
- Shijaku, R.; Canhasi, E. ChatGPT Generated Text Detection. 2023; Unpublished. [Google Scholar]
- Guo, B.; Zhang, X.; Wang, Z.; Jiang, M.; Nie, J.; Ding, Y.; Yue, J.; Wu, Y. How close is chatgpt to human experts? comparison corpus, evaluation, and detection. arXiv 2023, arXiv:2301.07597. [Google Scholar]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. Squad: 100,000+ questions for machine comprehension of text. arXiv 2016, arXiv:1606.05250. [Google Scholar]
- Fan, A.; Jernite, Y.; Perez, E.; Grangier, D.; Weston, J.; Auli, M. ELI5: Long form question answering. arXiv 2019, arXiv:1907.09190. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Antoun, W.; Mouilleron, V.; Sagot, B.; Seddah, D. Towards a Robust Detection of Language Model Generated Text: Is ChatGPT that Easy to Detect? arXiv 2023, arXiv:2306.05871. [Google Scholar]
- Antoun, W.; Sagot, B.; Seddah, D. Data-Efficient French Language Modeling with CamemBERTa. arXiv 2023, arXiv:2306.01497. [Google Scholar]
- Martin, L.; Muller, B.; Suárez, P.J.O.; Dupont, Y.; Romary, L.; de La Clergerie, É.V.; Seddah, D.; Sagot, B. CamemBERT: A tasty French language model. arXiv 2019, arXiv:1911.03894. [Google Scholar]
- Clark, K.; Luong, M.-T.; Le, Q.V.; Manning, C.D. Electra: Pre-training text encoders as discriminators rather than generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised cross-lingual representation learning at scale. arXiv 2019, arXiv:1911.02116. [Google Scholar]
- Zaitsu, W.; Jin, M. Distinguishing ChatGPT (-3.5,-4)-generated and human-written papers through Japanese stylometric analysis. PLoS ONE 2023, 18, e0288453. [Google Scholar] [CrossRef]
- GPTZero. Available online: https://gptzero.me/ (accessed on 1 June 2023).
- OpenAI. Available online: https://beta.openai.com/ai-text-classifier (accessed on 1 June 2023).
- Schaaff, K.; Schlippe, T.; Mindner, L. Classification of Human-and AI-Generated Texts for English, French, German, and Spanish. arXiv 2023, arXiv:2312.04882. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Yafooz, W.M. Enhancing Arabic Dialect Detection on Social Media: A Hybrid Model with an Attention Mechanism. Information 2024, 15, 316. [Google Scholar] [CrossRef]
- Aldyaflah, I.M.; Zhao, W.; Yang, S.; Luo, X. The Impact of Input Types on Smart Contract Vulnerability Detection Performance Based on Deep Learning: A Preliminary Study. Information 2024, 15, 302. [Google Scholar] [CrossRef]
- Khalif, K.M.N.K.; Chaw Seng, W.; Gegov, A.; Bakar, A.S.A.; Shahrul, N.A. Integrated Generative Adversarial Networks and Deep Convolutional Neural Networks for Image Data Classification: A Case Study for COVID-19. Information 2024, 15, 58. [Google Scholar] [CrossRef]
- Pardede, H.F.; Adhi, P.; Zilvan, V.; Yuliani, A.R.; Arisal, A. A generalization of sigmoid loss function using tsallis statistics for binary classification. Neural Process. Lett. 2023, 55, 5193–5214. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Text Type | Text | GPTZero Classification |
|---|---|---|
| Diacritized Text | تَعْرِيفُ الإِشْعاعِ الشَمْسِيِّ وَنَصِيبُ الأَرْضِ منه: الإِشْعاعُ الشَمْسِيُّ بِمَعْناِهِ العامِّ هُوَ الطاقَةُ الإِشْعاعِيَّةُ الَّتِي تُطْلِقها الشَمْسُ فِي كُلِّ الاتجاهات، وَالَّتِي تَسْتَمِدّ مِنها كُلُّ الكَواكِبِ التابِعَةِ لَها وَأَقْمارِها كُلَّ حَرارَةِ أَسْطُحِها وَاجوائها، وَهِيَ طاقَةٌ ضَخْمَةٌ جِدّاً يُقَدِّرها البَعْضُ بنحو170 إِلْفِ حِصانٍ لِكُلِّ مِتْرٍ مُرَبَّعٍ مِن سَطْحِ الشمس | AI-Generated Text |
| Non-Diacritized Text | تعريف الإشعاع الشمسي ونصيب الأرض منه: الإشعاع الشمسي بمعناه العام هو الطاقة الإشعاعية التي تطلقها الشمس في كل الاتجاهات، والتي تستمد منها كل الكواكب التابعة لها وأقمارها كل حرارة أسطحها وأجوائها، وهي طاقة ضخمة جدًّا يقدرها البعض بنحو170 ألف حصان لكل متر مربع من سطح الشمس | Human-Written Text |
| English Translation | Definition of Solar Radiation and Earth’s Share of It: Solar radiation, in its general sense, is the radiant energy that the sun emits in all directions, which all the planets and their moons derive all the heat of their surfaces and atmospheres from. It is an enormous amount of energy that some estimate to be about 170 thousand horsepower per square meter of the sun’s surface. | - |
| Parameter | Value 1 | Description |
|---|---|---|
| Model Name | xlm-roberta-base bert-base-multilingual-cased aubmindlab/araelectra-base-discriminator aubmindlab/bert-base-arabertv2 | Names of the models used |
| Initial Learning Rate | Initial learning rate before warmup | |
| Learning Rate | The learning rate for training | |
| Warmup Epochs | 2 to 4 | Number of epochs for learning rate warmup that followed linear schedule |
| Epochs | 6 to 10 | Total number of training epochs |
| Batch Size | 32 to 64 | Batch size for training, validation, and testing |
| OOD Testing/Inference Batch Size | 64 | Batch size for out-of-domain (OOD) testing |
| Seed | 1–10 | Random seed for reproducibility |
| Model | Trained on | Evaluated on | Precision | Recall | F1 Score | AUC-ROC | Loss |
|---|---|---|---|---|---|---|---|
| AraELECTRA | Diacritized Custom Dataset | Validation set | 0.9965 | 0.9444 | 0.9697 | 0.9978 | 0.0981 |
| Testing set | 1.0 | 0.9803 | 0.9900 | 0.9997 | 0.0311 | ||
| Religious testing set | 0.9871 | 0.4610 | 0.6285 | 0.8795 | 1.2046 | ||
| AIRABIC | 0.9014 | 0.97 | 0.9344 | 0.9895 | 0.2296 | ||
| Religious Dataset | Validation set | 0.9940 | 1.0 | 0.9970 | 0.9999 | 0.0144 | |
| Testing set | 1.0 | 0.9520 | 0.9754 | 0.9995 | 0.0737 | ||
| Custom dataset | 0.9491 | 0.7320 | 0.8265 | 0.9410 | 0.5754 | ||
| Diacritized Custom dataset | 0.6264 | 0.8660 | 0.7270 | 0.6366 | 1.9190 | ||
| AIRABIC | 0.6488 | 0.924 | 0.7623 | 0.6447 | 1.5706 | ||
| AIRABIC using dediacritization filter | 1.0 | 0.846 | 0.9165 | 0.9937 | 0.3009 | ||
| AraBERT | Diacritized Custom Dataset | Validation set | 0.9931 | 0.9477 | 0.9698 | 0.9976 | 0.0865 |
| Testing set | 1.0 | 0.9803 | 0.9900 | 0.9993 | 0.0357 | ||
| Religious testing set | 0.972 | 0.8383 | 0.9003 | 0.9719 | 0.2558 | ||
| AIRABIC | 0.9535 | 0.986 | 0.9695 | 0.9965 | 0.0833 | ||
| Religious Dataset | Validation set | 0.9940 | 1.0 | 0.9970 | 0.9996 | 0.0189 | |
| Testing set | 0.9877 | 0.9640 | 0.9757 | 0.9983 | 0.0925 | ||
| Custom dataset | 0.6298 | 0.8954 | 0.7395 | 0.5786 | 2.1242 | ||
| Diacritized Custom dataset | 0.9379 | 0.7908 | 0.8581 | 0.9337 | 0.5864 | ||
| AIRABIC | 0.6498 | 0.928 | 0.7644 | 0.5654 | 1.7418 | ||
| AIRABIC using dediacritization filter | 0.9976 | 0.864 | 0.9260 | 0.9956 | 0.2985 | ||
| XLM-R | Diacritized Custom Dataset | Validation set | 1.0 | 0.9836 | 0.9917 | 0.9999 | 0.0414 |
| Testing set | 1.0 | 0.9967 | 0.9983 | 1.0 | 0.0067 | ||
| Religious testing set | 1.0 | 0.6886 | 0.8156 | 0.9624 | 0.8342 | ||
| AIRABIC | 0.9801 | 0.988 | 0.9840 | 0.9982 | 0.0827 | ||
| Religious Dataset | Validation set | 0.9940 | 1.0 | 0.9970 | 0.9994 | 0.0222 | |
| Testing set | 0.9937 | 0.9520 | 0.9724 | 0.9991 | 0.1246 | ||
| Custom dataset | 0.6244 | 0.9019 | 0.7379 | 0.5992 | 2.8667 | ||
| Diacritized Custom dataset | 0.9044 | 0.8039 | 0.8512 | 0.8970 | 0.8676 | ||
| AIRABIC | 0.6492 | 0.944 | 0.7693 | 0.5949 | 2.296 | ||
| AIRABIC using dediacritization filter | 0.9694 | 0.888 | 0.9269 | 0.9708 | 0.4012 | ||
| mBERT | Diacritized Custom Dataset | Validation set | 0.9965 | 0.9313 | 0.9628 | 0.9994 | 0.0984 |
| Testing set | 1.0 | 0.9901 | 0.9950 | 1.0 | 0.0156 | ||
| Religious testing set | 0.9074 | 0.8802 | 0.8936 | 0.9453 | 0.5468 | ||
| AIRABIC | 0.9377 | 0.994 | 0.9650 | 0.9983 | 0.1687 | ||
| Religious Dataset | Validation set | 0.9940 | 1.0 | 0.9970 | 0.9988 | 0.0234 | |
| Testing set | 1.0 | 0.8682 | 0.9294 | 0.9972 | 0.2687 | ||
| Custom dataset | 0.6104 | 0.8398 | 0.7070 | 0.6419 | 2.601 | ||
| Diacritized Custom dataset | 0.9043 | 0.6797 | 0.7761 | 0.8893 | 0.8409 | ||
| AIRABIC | 0.6323 | 0.898 | 0.7421 | 0.7519 | 2.148 | ||
| AIRABIC using dediacritization filter | 0.9482 | 0.806 | 0.8713 | 0.9432 | 0.5416 |
| Model | Trained on | Evaluated on | Precision | Recall | F1 Score | AUC-ROC | Loss |
|---|---|---|---|---|---|---|---|
| AraELECTRA | Custom Plus Dataset | Validation | 0.9928 | 0.9311 | 0.9610 | 0.9978 | 0.1312 |
| Testing | 0.9975 | 0.9177 | 0.9560 | 0.9981 | 0.1437 | ||
| Custom dataset | 0.9589 | 0.9150 | 0.9364 | 0.9814 | 0.2230 | ||
| AIRABIC | 0.6639 | 0.988 | 0.7942 | 0.7528 | 1.5129 | ||
| AIRABIC using dediacritization filter | 1.0 | 0.978 | 0.9888 | 1.0 | 0.0232 | ||
| AraBERT | Custom Plus Dataset | Validation | 0.9931 | 0.9622 | 0.9774 | 0.9976 | 0.0814 |
| Testing | 0.9976 | 0.9488 | 0.9726 | 0.9984 | 0.0968 | ||
| Custom dataset | 0.94 | 0.9215 | 0.9306 | 0.9821 | 0.2633 | ||
| AIRABIC | 0.6590 | 0.986 | 0.7900 | 0.7076 | 1.7246 | ||
| AIRABIC using dediacritization filter | 0.9858 | 0.974 | 0.9798 | 0.9992 | 0.0516 | ||
| XLM-R | Custom Plus Dataset | Validation | 0.9802 | 0.9911 | 0.9856 | 0.9988 | 0.0756 |
| Testing | 0.9801 | 0.9866 | 0.9833 | 0.9992 | 0.0957 | ||
| Custom dataset | 0.8571 | 0.9803 | 0.9146 | 0.9911 | 0.5848 | ||
| AIRABIC | 0.6635 | 0.994 | 0.7958 | 0.8082 | 2.0532 | ||
| AIRABIC using dediacritization filter | 0.9919 | 0.99 | 0.9909 | 0.9996 | 0.0423 | ||
| mBERT | Custom Plus Dataset | Validation | 0.9954 | 0.9644 | 0.9796 | 0.9989 | 0.0928 |
| Testing | 0.9953 | 0.9444 | 0.9692 | 0.9981 | 0.1591 | ||
| Custom dataset | 0.9483 | 0.9607 | 0.9545 | 0.9850 | 0.2832 | ||
| AIRABIC | 0.6618 | 0.998 | 0.7958 | 0.8392 | 2.2670 | ||
| AIRABIC using dediacritization filter | 0.9632 | 0.996 | 0.9793 | 0.9992 | 0.0843 |
| Model | Training Using the Dediacritization Filter | Evaluation Using the Dediacritization Filter | Precision | Recall | F1 Score | AUC-ROC | Loss |
|---|---|---|---|---|---|---|---|
| AraELECTRA | Custom Plus Dataset | Validation | 0.9951 | 0.9066 | 0.9488 | 0.9924 | 0.1740 |
| Testing | 0.9949 | 0.88 | 0.9339 | 0.9980 | 0.1780 | ||
| Custom dataset | 1.0 | 0.9640 | 0.9817 | 1.0 | 0.0508 | ||
| AIRABIC | 0.996 | 0.996 | 0.996 | 0.9996 | 0.0192 | ||
| AraBERT | Custom Plus Dataset | Validation | 0.9953 | 0.9555 | 0.9750 | 0.9988 | 0.0865 |
| Testing | 0.9976 | 0.9311 | 0.9632 | 0.9972 | 0.1519 | ||
| Custom dataset | 0.9788 | 0.9084 | 0.9423 | 0.9936 | 0.2058 | ||
| AIRABIC | 1.0 | 0.984 | 0.9919 | 0.9999 | 0.0219 | ||
| XLM-R | Custom Plus Dataset | Validation | 0.9975 | 0.8933 | 0.9425 | 0.9984 | 0.2015 |
| Testing | 1.0 | 0.8755 | 0.9336 | 0.9954 | 0.2648 | ||
| Custom dataset | 1.0 | 0.9281 | 0.9627 | 0.9979 | 0.1282 | ||
| AIRABIC | 1.0 | 0.976 | 0.9878 | 0.9998 | 0.0462 | ||
| mBERT | Custom Plus Dataset | Validation | 1.0 | 0.9155 | 0.9559 | 0.9985 | 0.1713 |
| Testing | 1.0 | 0.8733 | 0.9323 | 0.9957 | 0.3161 | ||
| Custom dataset | 0.9542 | 0.9542 | 0.9542 | 0.9847 | 0.2067 | ||
| AIRABIC | 0.9536 | 0.988 | 0.9705 | 0.9983 | 0.1139 |
| Model | Training on | Evaluation on | Precision | Recall | F1 Score | AUC-ROC | Loss |
|---|---|---|---|---|---|---|---|
| AraELECTRA | Custom Max | Validation | 0.9915 | 0.9784 | 0.9849 | 0.9981 | 0.0954 |
| Testing | 0.9982 | 0.9618 | 0.9797 | 0.9990 | 0.1133 | ||
| AIRABIC | 0.6666 | 1.0 | 0.8 | 0.8986 | 2.2833 | ||
| AIRABIC using the dediacritization filter | 1.0 | 1.0 | 1.0 | 1.0 | 0.0005 | ||
| AraBERT | Custom Max | Validation | 0.99488 | 0.9668 | 0.9806 | 0.9986 | 0.0729 |
| Testing | 0.9947 | 0.9485 | 0.9711 | 0.9976 | 0.1195 | ||
| AIRABIC | 0.6662 | 0.998 | 0.7990 | 0.7236 | 1.7459 | ||
| AIRABIC using the dediacritization filter | 1.0 | 0.996 | 0.9979 | 1.0 | 0.0052 | ||
| XLM-R | Custom Max | Validation | 0.9982 | 0.9585 | 0.9780 | 0.9997 | 0.1093 |
| Testing | 1.0 | 0.9502 | 0.9744 | 0.9989 | 0.1897 | ||
| AIRABIC | 0.6657 | 0.996 | 0.7980 | 0.8323 | 2.5058 | ||
| AIRABIC using the dediacritization filter | 1.0 | 0.998 | 0.9989 | 1.0 | 0.0048 | ||
| mBERT | Custom Max | Validation | 0.9982 | 0.9585 | 0.9780 | 0.9985 | 0.0317 |
| Testing | 0.9982 | 0.9303 | 0.9630 | 0.9960 | 0.1629 | ||
| AIRABIC | 0.6662 | 0.994 | 0.7977 | 0.8740 | 1.6262 | ||
| AIRABIC using the dediacritization filter | 0.9979 | 0.99 | 0.9939 | 0.9997 | 0.0278 |
| Model | Training Using the Dediacritization Filter | Evaluation Using the Dediacritization Filter | Precision | Recall | F1 Score | AUC-ROC | Loss |
|---|---|---|---|---|---|---|---|
| AraELECTRA | Custom Max | Validation | 0.9982 | 0.9369 | 0.9666 | 0.9993 | 0.1412 |
| Testing | 1.0 | 0.9203 | 0.9585 | 0.9993 | 0.1755 | ||
| AIRABIC | 1.0 | 0.994 | 0.9969 | 0.9999 | 0.0148 | ||
| AraBERT | Custom Max | Validation | 0.9866 | 0.9834 | 0.9850 | 0.9985 | 0.0578 |
| Testing | 0.9931 | 0.9651 | 0.9789 | 0.9982 | 0.0916 | ||
| AIRABIC | 0.9979 | 0.996 | 0.9969 | 0.9999 | 0.0112 | ||
| XLM-R | Custom Max | Validation | 0.9982 | 0.9651 | 0.9814 | 0.9996 | 0.0991 |
| Testing | 1.0 | 0.9568 | 0.9779 | 0.9987 | 0.1461 | ||
| AIRABIC | 1.0 | 0.998 | 0.9989 | 0.9999 | 0.0065 | ||
| mBERT | Custom Max | Validation | 0.9947 | 0.9452 | 0.9693 | 0.9984 | 0.1244 |
| Testing | 0.9965 | 0.9485 | 0.9719 | 0.9976 | 0.1199 | ||
| AIRABIC | 0.9900 | 0.996 | 0.9930 | 0.9999 | 0.0218 |
| Detection Model | - | Predicted: HWT | Predicted: AIGT | Performance Metrics | Value |
|---|---|---|---|---|---|
| GPTZero | Actual: HWT | 150 (TP) | 350 (FN) | Sensitivity | 30% |
| Specificity | 95% | ||||
| Precision | 86.7% | ||||
| Actual: AIGT | 23 (FP) | 477 (TN) | Accuracy | 62.7% | |
| F1-Score | 44.5% | ||||
| AraELECTRA | Actual: HWT | 485 (TP) | 15 (FN) | Sensitivity | 97% |
| Specificity | 89% | ||||
| Precision | 90.15% | ||||
| Actual: AIGT | 53 (FP) | 447 (TN) | Accuracy | 93.2% | |
| F1-Score | 93.45% | ||||
| AraBERT | Actual: HWT | 493 (TP) | 7 (FN) | Sensitivity | 99% |
| Specificity | 95% | ||||
| Precision | 95.36% | ||||
| Actual: AIGT | 24 (FP) | 476 (TN) | Accuracy | 96.9% | |
| F1-Score | 96.95% | ||||
| XLM-R | Actual: HWT | 494 (TP) | 6 (FN) | Sensitivity | 99% |
| Specificity | 98% | ||||
| Precision | 98.02% | ||||
| Actual: AIGT | 10 (FP) | 490 (TN) | Accuracy | 98.4% | |
| F1-Score | 98.41% | ||||
| mBERT | Actual: HWT | 497 (TP) | 3 (FN) | Sensitivity | 99% |
| Specificity | 93% | ||||
| Precision | 93.77% | ||||
| Actual: AIGT | 33 (FP) | 467 (TN) | Accuracy | 96.4% | |
| F1-Score | 96.50% |
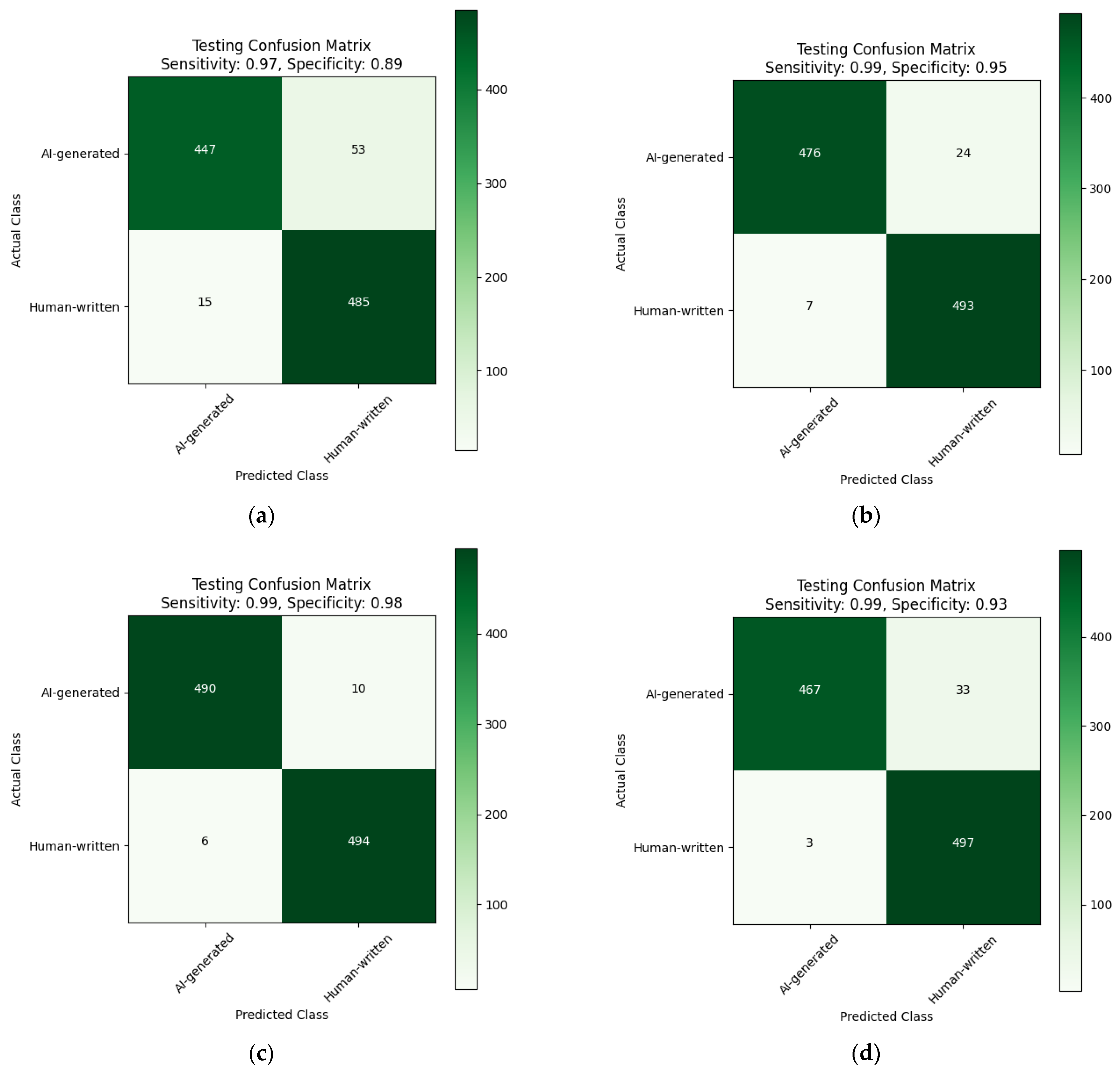
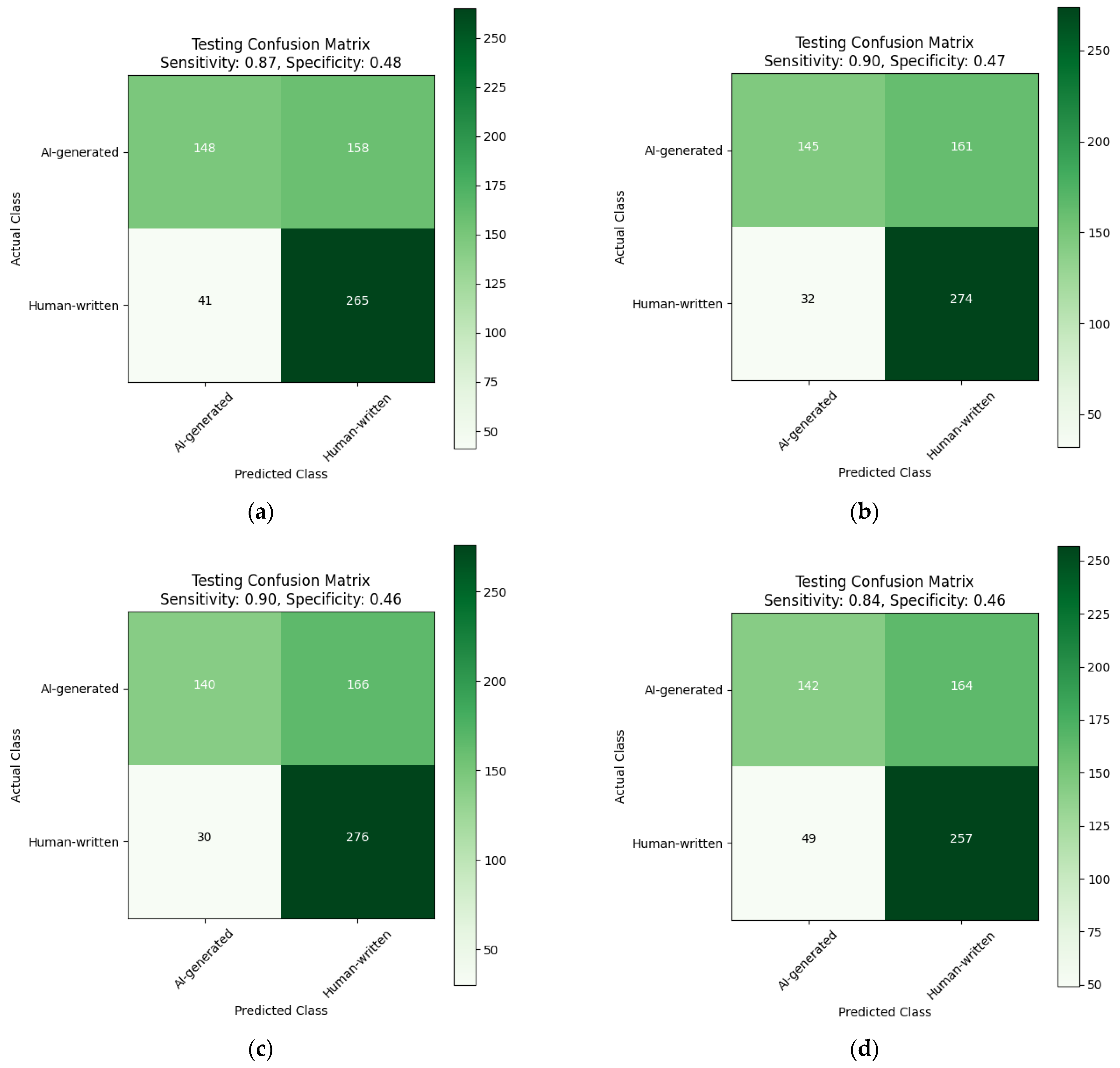
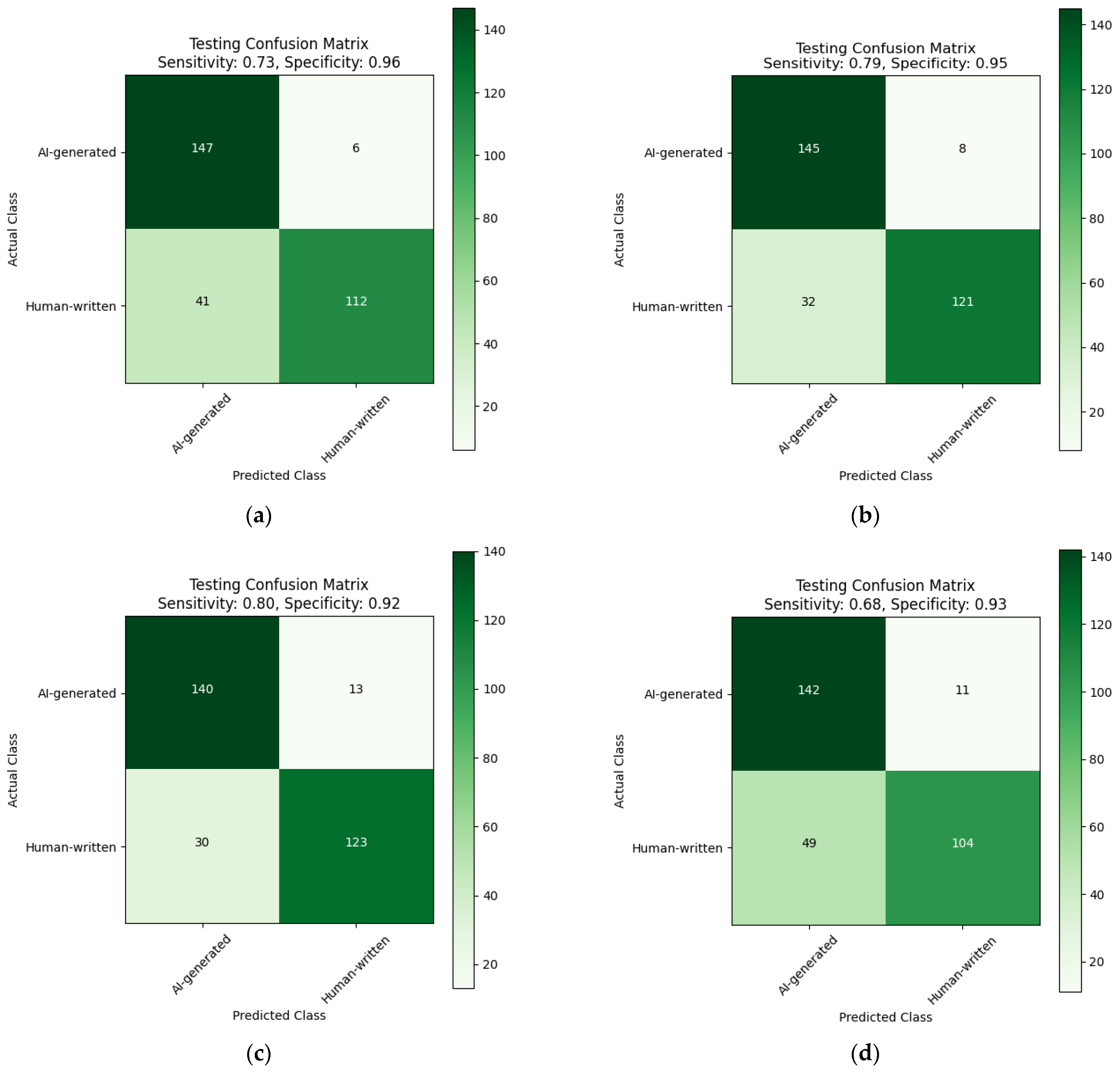
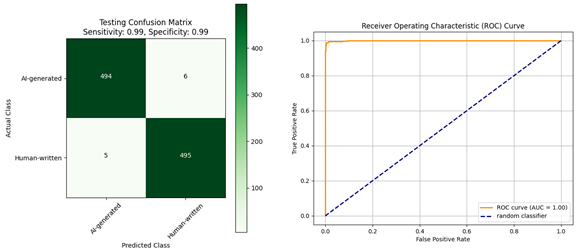
| Trained on Diacritized Custom Dataset | Trained on Custom Dataset and Evaluated Using a Dediacritization Filter |
|---|---|
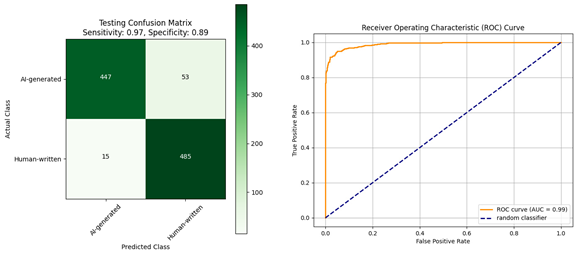 |  |
| (a) | (b) |
| Confusion matrix and ROC curve for the evaluation of the AraELECTRA model: (a) trained using the Diacritized Custom dataset; (b) trained using the Custom dataset and evaluated with a dediacritization filter. | |
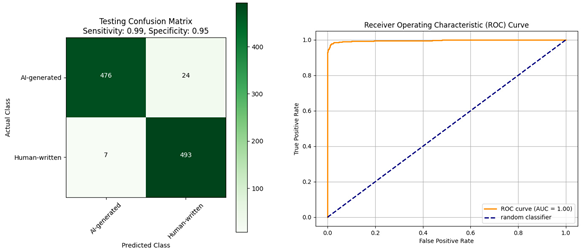 |  |
| (a) | (b) |
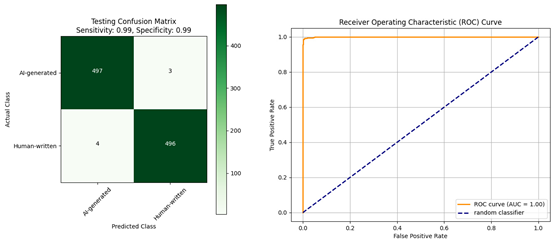
| Confusion matrix and ROC curve for the evaluation of the AraBERT model: (a) trained using the Diacritized Custom dataset; (b) trained using the Custom dataset and evaluated with a dediacritization filter. | |
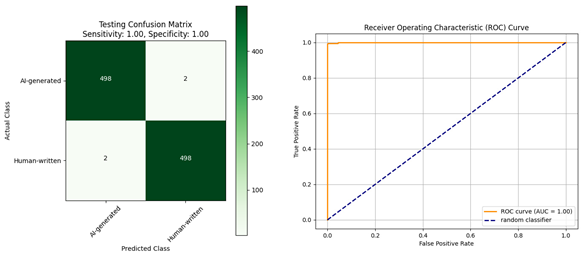
 |  |
| (a) | (b) |
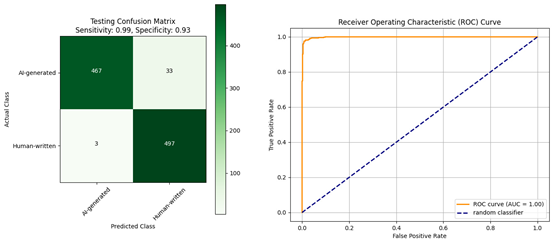
| Confusion matrix and ROC curve for the evaluation of the XLM-R model: (a) trained using the Diacritized Custom dataset; (b) trained using the Custom dataset and evaluated with a dediacritization filter. | |
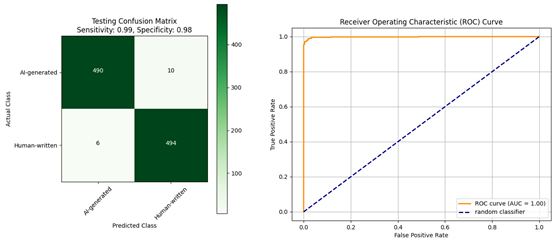
 |  |
| (a) | (b) |
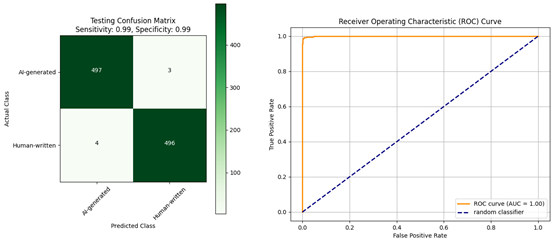
| Confusion matrix and ROC curve for the evaluation of the mBERT model: (a) trained using the Diacritized Custom dataset; (b) trained using the Custom dataset and evaluated with a dediacritization filter. | |
| Model | Tokens |
|---|---|
| mBERT | [CLS], ع, ##ُ, ##ل, ##ِ, ##م, [SEP] |
| XLM-R | <s>, ▁ع, ُ, ل, ِ, م, </s> |
| AraBERT | [CLS], [UNK], [SEP] |
| AraELECTRA | [CLS], [UNK], [SEP] |
| Model | Cosine Similarity |
|---|---|
| mBERT | 0.9853 |
| XLM-R | 0.9988 |
| AraBERT | 0.6100 |
| AraELECTRA | 0.6280 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alshammari, H.; Elleithy, K. Toward Robust Arabic AI-Generated Text Detection: Tackling Diacritics Challenges. Information 2024, 15, 419. https://doi.org/10.3390/info15070419
Alshammari H, Elleithy K. Toward Robust Arabic AI-Generated Text Detection: Tackling Diacritics Challenges. Information. 2024; 15(7):419. https://doi.org/10.3390/info15070419
Chicago/Turabian StyleAlshammari, Hamed, and Khaled Elleithy. 2024. "Toward Robust Arabic AI-Generated Text Detection: Tackling Diacritics Challenges" Information 15, no. 7: 419. https://doi.org/10.3390/info15070419
APA StyleAlshammari, H., & Elleithy, K. (2024). Toward Robust Arabic AI-Generated Text Detection: Tackling Diacritics Challenges. Information, 15(7), 419. https://doi.org/10.3390/info15070419