
CCNN-SVM: Automated Model for Emotion Recognition Based on Custom Convolutional Neural Networks with SVM

 ,
,  , and
, and
Abstract
1. Introduction
- Propose CCNN-SVM as an automated model for emotion recognition. A fusion of a deep neural network that include many convolution layers and an SVM classifier to improve the efficiency of facial emotion recognition.
- Investigate the impact of image preprocessing operations on facial recognition tasks.
2. Related Works
2.1. Facial Expression Recognition Methodologies Based on Machine Learning
2.2. Facial Expression Recognition Methodologies Based on Deep Learning
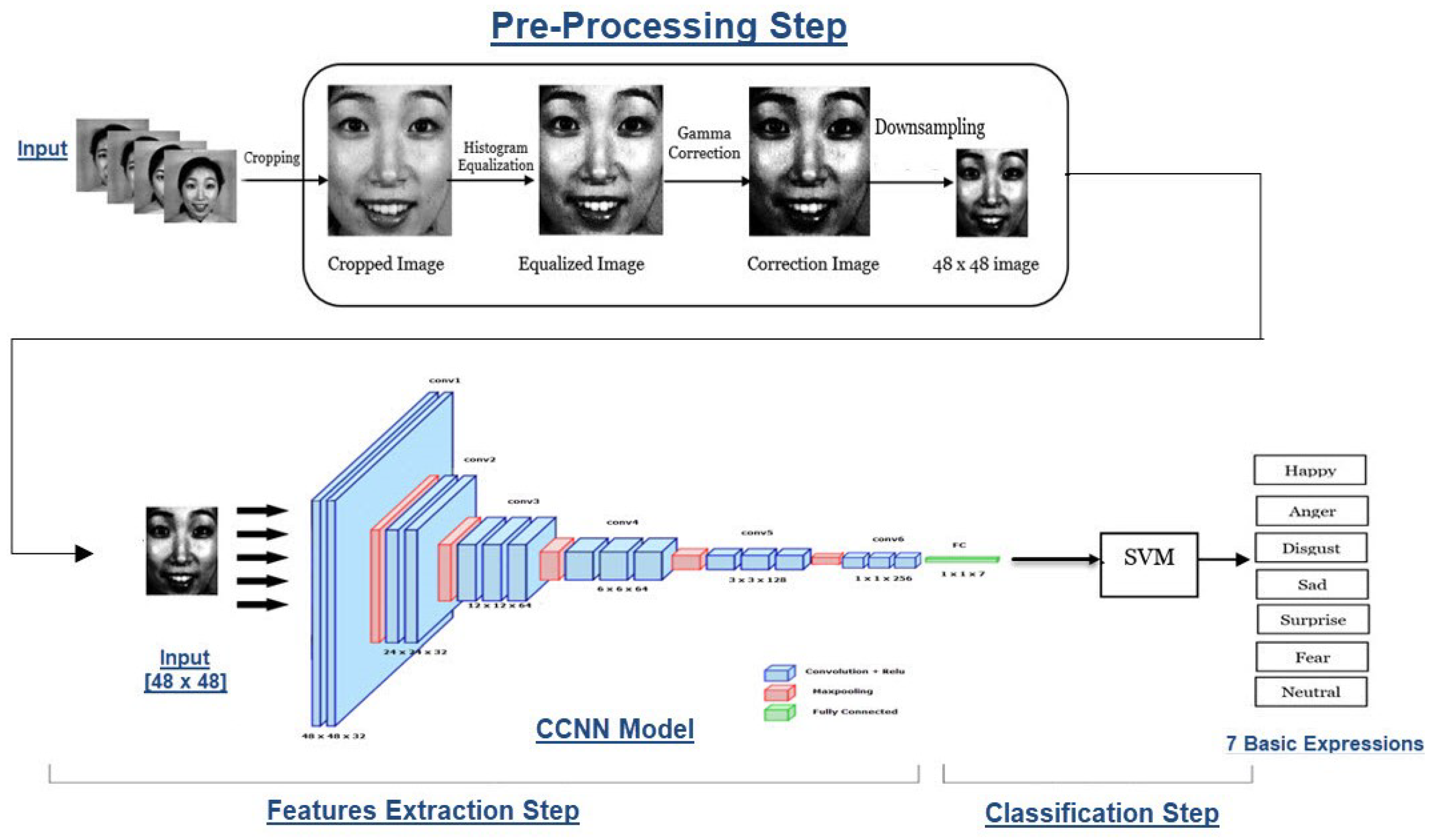
3. The Proposed Model
3.1. The Preprocessing Step
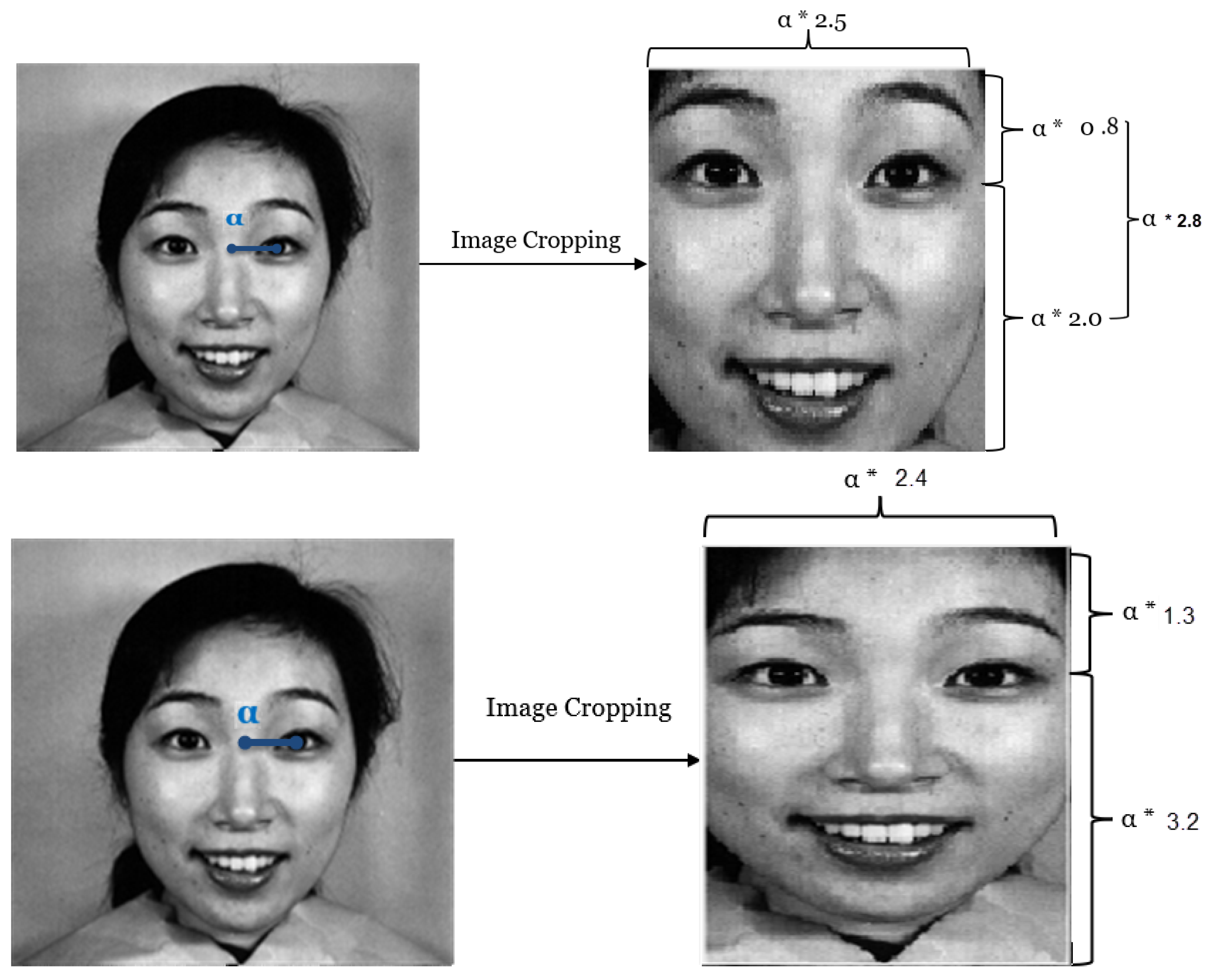
3.1.1. Image Cropping Stage
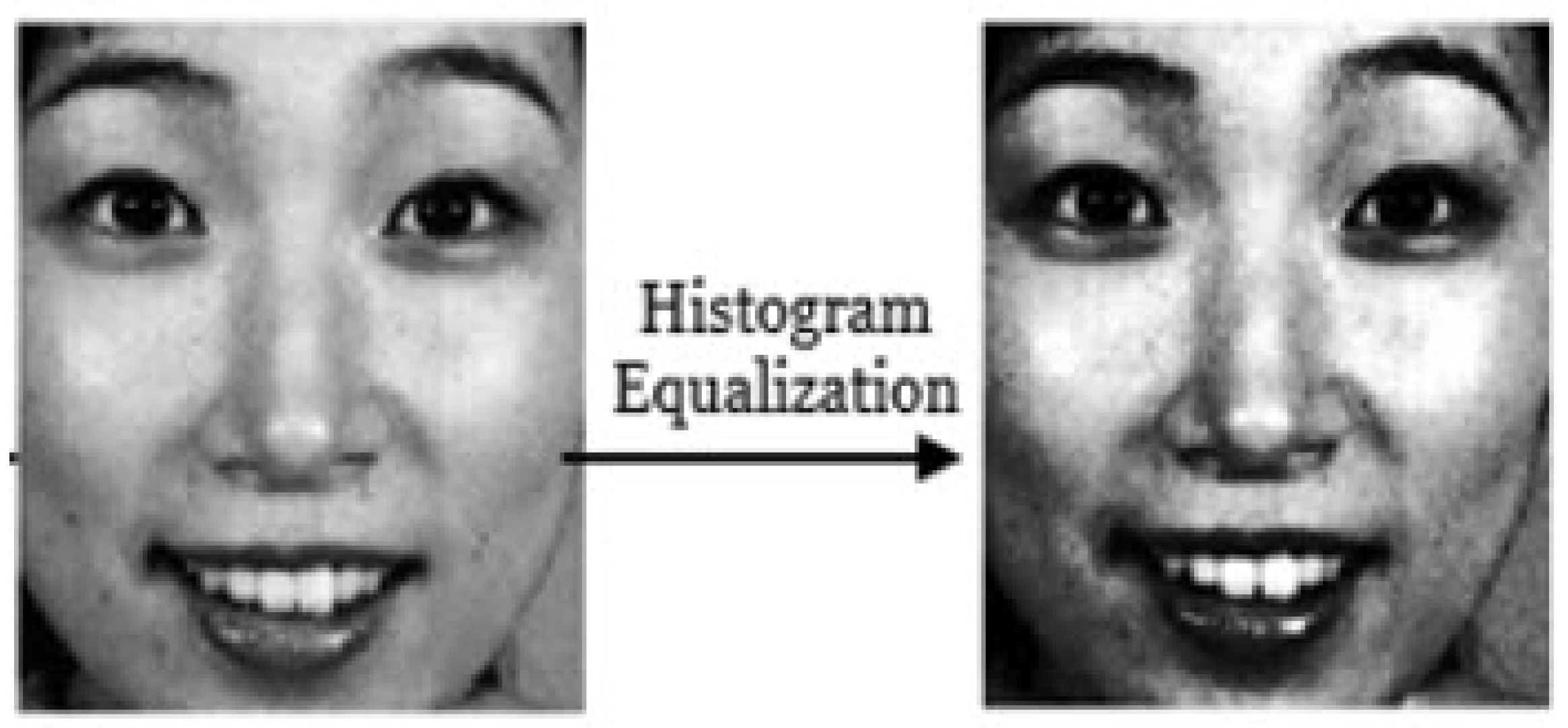
3.1.2. Histogram Equalization Stage
3.1.3. Gamma Correction Stage
3.1.4. Downsampling Stage
3.2. The Feature Extraction Step
3.3. The Classification Step
4. Experimental Results
4.1. Datasets
4.2. Experiments
4.2.1. Accuracy with Different Preprocessing Stages
- (a)
- Without preprocessingThe initial experiment was conducted using the dataset without any modifications or image preprocessing. The suggested CNN is trained using a gradient descendant method. The order of the provided samples is used by gradient descendant methods to find the local minimum.Every experimental setup is repeated ten times, both during training and testing, with diverse image presentations to avoid fluctuations. This adjustment enables the descending gradient algorithm to explore more pathways and adjust the recognition rate by either decreasing or increasing it. The accuracy is presented as the highest value achieved among all ten runs, along with the average performance. We demonstrate that the approach still produces good accuracy rates even when the presentation order is not optimal by using the accuracy as an average.In this experiment, the highest accuracy obtained across all ten runs on the JAFFE dataset was , and the average accuracy for all ten runs was . The highest accuracy obtained across all ten runs on the CK+ dataset was , and the average accuracy for all ten runs was . When compared to most recent models, the recognition rate achieved using only CNN without any image preprocessing is significantly lower.
- (b)
- Image CroppingTo enhance the accuracy of the suggested model, the image is automatically cropped to eliminate areas that are not related to a facial regions as shown in Section 3. In this experiment, the highest accuracy obtained across all ten runs on the JAFFE dataset was , and the average was . The highest accuracy obtained across all ten runs on the CK+ dataset was , and the average accuracy for all ten runs was . Because the input of the suggested network is a fixed pixels image, downsampling is also performed here.By merely adding the cropping procedure, we can observe a considerable improvement in the recognition rate when compared to the results previously displayed. The primary factor contributing to the improvement in accuracy is the removal of a significant amount of irrelevant data that the classifier would otherwise have to process to find out the subject expression and make better use of the image space present in the network input.
- (c)
- Image Cropping and EqualizationThe cropping and equalization results provide the erroneous impression that the model’s accuracy might be reduced. The highest accuracy obtained across all ten runs on the JAFFE dataset was , and the average accuracy for all ten runs was . The highest accuracy obtained across all ten runs on the CK+ dataset was , and the average accuracy for all ten runs was .
- (d)
- Image Cropping and Gamma CorrectionThe result of the cropping and gamma correction also gives a false impression that the gamma correction might make the technique less accurate. The highest accuracy obtained across all ten runs on the JAFFE dataset was , and the average accuracy for all ten runs was . The highest accuracy obtained across all ten runs on the CK+ dataset was , and the average accuracy for all ten runs was .
- (e)
- Image Cropping, Equalization and Gamma CorrectionThe best results achieved in the proposed model apply the three image preprocessing steps: image cropping, equalization, and gamma correction. The highest accuracy obtained across all ten runs on the JAFFE dataset was , and the average accuracy for all ten runs was . The highest accuracy obtained across all ten runs on the CK+ dataset was , and the average accuracy for all ten runs was .
4.2.2. Accuracy with a Five-Fold Cross-Validation Method
4.2.3. Comparisons with the State of the Art
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jain, A.K.; Li, S.Z. Handbook of Face Recognition; Springer: New York, NY, USA, 2011; Volume 1. [Google Scholar]
- Liu, M.; Li, S.; Shan, S.; Chen, X. Au-inspired deep networks for facial expression feature learning. Neurocomputing 2015, 159, 126–136. [Google Scholar] [CrossRef]
- Ali, G.; Iqbal, M.A.; Choi, T.S. Boosted NNE collections for multicultural facial expression recognition. Pattern Recognit. 2016, 55, 14–27. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, Y.; Ma, L.; Guan, J.; Gong, S. Multimodal learning for facial expression recognition. Pattern Recognit. 2015, 48, 3191–3202. [Google Scholar] [CrossRef]
- Fan, X.; Tjahjadi, T. A spatial-temporal framework based on histogram of gradients and optical flow for facial expression recognition in video sequences. Pattern Recognit. 2015, 48, 3407–3416. [Google Scholar] [CrossRef]
- Demirkus, M.; Precup, D.; Clark, J.J.; Arbel, T. Multi-layer temporal graphical model for head pose estimation in real-world videos. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 3392–3396. [Google Scholar]
- Liu, P.; Reale, M.; Yin, L. 3d head pose estimation based on scene flow and generic head model. In Proceedings of the 2012 IEEE International Conference on Multimedia and Expo, Melbourne, Australia, 9–13 July 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 794–799. [Google Scholar]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef]
- Bynagari, N.B. The difficulty of learning long-term dependencies with gradient flow in recurrent nets. Eng. Int. 2020, 8, 127–138. [Google Scholar] [CrossRef]
- Jain, D.K.; Shamsolmoali, P.; Sehdev, P. Extended deep neural network for facial emotion recognition. Pattern Recognit. Lett. 2019, 120, 69–74. [Google Scholar] [CrossRef]
- Sadeghi, H.; Raie, A.A. Suitable models for face geometry normalization in facial expression recognition. J. Electron. Imaging 2015, 24, 013005. [Google Scholar] [CrossRef]
- Farajzadeh, N.; Hashemzadeh, M. Exemplar-based facial expression recognition. Inf. Sci. 2018, 460, 318–330. [Google Scholar] [CrossRef]
- Sadeghi, H.; Raie, A.A. Human vision inspired feature extraction for facial expression recognition. Multimed. Tools Appl. 2019, 78, 30335–30353. [Google Scholar] [CrossRef]
- Makhmudkhujaev, F.; Abdullah-Al-Wadud, M.; Iqbal, M.T.B.; Ryu, B.; Chae, O. Facial expression recognition with local prominent directional pattern. Signal Process. Image Commun. 2019, 74, 1–12. [Google Scholar] [CrossRef]
- Avola, D.; Cinque, L.; Foresti, G.L.; Pannone, D. Automatic deception detection in rgb videos using facial action units. In Proceedings of the 13th International Conference on Distributed Smart Cameras, Trento, Italy, 9–11 September 2019; pp. 1–6. [Google Scholar]
- Leo, M.; Carcagnì, P.; Distante, C.; Mazzeo, P.L.; Spagnolo, P.; Levante, A.; Petrocchi, S.; Lecciso, F. Computational analysis of deep visual data for quantifying facial expression production. Appl. Sci. 2019, 9, 4542. [Google Scholar] [CrossRef]
- Dong, J.; Zheng, H.; Lian, L. Dynamic facial expression recognition based on convolutional neural networks with dense connections. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 3433–3438. [Google Scholar]
- Tsai, H.H.; Chang, Y.C. Facial expression recognition using a combination of multiple facial features and support vector machine. Soft Comput. 2018, 22, 4389–4405. [Google Scholar] [CrossRef]
- Wang, C.; Zeng, J.; Shan, S.; Chen, X. Multi-task learning of emotion recognition and facial action unit detection with adaptively weights sharing network. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 56–60. [Google Scholar]
- Li, J.; Jin, K.; Zhou, D.; Kubota, N.; Ju, Z. Attention mechanism-based CNN for facial expression recognition. Neurocomputing 2020, 411, 340–350. [Google Scholar] [CrossRef]
- Fu, Y.; Wu, X.; Li, X.; Pan, Z.; Luo, D. Semantic neighborhood-aware deep facial expression recognition. IEEE Trans. Image Process. 2020, 29, 6535–6548. [Google Scholar] [CrossRef] [PubMed]
- Chirra, V.R.R.; Uyyala, S.R.; Kolli, V.K.K. Virtual facial expression recognition using deep CNN with ensemble learning. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 10581–10599. [Google Scholar] [CrossRef]
- Gera, D.; Balasubramanian, S. Landmark guidance independent spatio-channel attention and complementary context information based facial expression recognition. Pattern Recognit. Lett. 2021, 145, 58–66. [Google Scholar] [CrossRef]
- Behzad, M.; Vo, N.; Li, X.; Zhao, G. Towards reading beyond faces for sparsity-aware 3d/4d affect recognition. Neurocomputing 2021, 458, 297–307. [Google Scholar] [CrossRef]
- Hernández-Luquin, F.; Escalante, H.J. Multi-branch deep radial basis function networks for facial emotion recognition. Neural Comput. Appl. 2023, 35, 18131–18145. [Google Scholar] [CrossRef]
- Kar, N.B.; Nayak, D.R.; Babu, K.S.; Zhang, Y.D. A hybrid feature descriptor with Jaya optimised least squares SVM for facial expression recognition. IET Image Process. 2021, 15, 1471–1483. [Google Scholar] [CrossRef]
- Kim, J.C.; Kim, M.H.; Suh, H.E.; Naseem, M.T.; Lee, C.S. Hybrid approach for facial expression recognition using convolutional neural networks and SVM. Appl. Sci. 2022, 12, 5493. [Google Scholar] [CrossRef]
- Shaik, N.S.; Cherukuri, T.K. Visual attention based composite dense neural network for facial expression recognition. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 16229–16242. [Google Scholar] [CrossRef]
- Saurav, S.; Saini, R.; Singh, S. Fast facial expression recognition using Boosted Histogram of Oriented Gradient (BHOG) features. Pattern Anal. Appl. 2022, 26, 381–402. [Google Scholar] [CrossRef]
- Jabbooree, A.I.; Khanli, L.M.; Salehpour, P.; Pourbahrami, S. A novel facial expression recognition algorithm using geometry β–skeleton in fusion based on deep CNN. Image Vis. Comput. 2023, 134, 104677. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Liew, C.F.; Yairi, T. Facial expression recognition and analysis: A comparison study of feature descriptors. IPSJ Trans. Comput. Vis. Appl. 2015, 7, 104–120. [Google Scholar] [CrossRef]
- Shima, Y.; Omori, Y. Image augmentation for classifying facial expression images by using deep neural network pre-trained with object image database. In Proceedings of the 3rd International Conference on Robotics, Control and Automation, Chengdu, China, 11–13 August 2018; pp. 140–146. [Google Scholar]
- Akhand, M.A.H.; Roy, S.; Siddique, N.; Kamal, M.A.S.; Shimamura, T. Facial Emotion Recognition Using Transfer Learning in the Deep CNN. Electronics 2021, 10, 1036. [Google Scholar] [CrossRef]
- Minaee, S.; Minaei, M.; Abdolrashidi, A. Deep-emotion: Facial expression recognition using attentional convolutional network. Sensors 2021, 21, 3046. [Google Scholar] [CrossRef] [PubMed]
- Niu, B.; Gao, Z.; Guo, B. Facial expression recognition with LBP and ORB features. Comput. Intell. Neurosci. 2021, 2021, 8828245. [Google Scholar] [CrossRef] [PubMed]
- Gowda, S.M.; Suresh, H. Facial Expression Analysis and Estimation Based on Facial Salient Points and Action Unit (AUs). IJEER 2022, 10, 7–17. [Google Scholar] [CrossRef]
- Borgalli, M.R.A.; Surve, S. Deep learning for facial emotion recognition using custom CNN architecture. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2022; Volume 2236, p. 012004. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Facial Expression Recognition Methodologies Based on Machine Learning | ||||
|---|---|---|---|---|
| Publications | Method | Database | Accuracy | Year |
| [11] | local binary patterns and local phase quantization + SVM | CK+, JAFFE | 95.07, 91.8 | 2015 |
| [12] | local binary patterns and HOG+ SVM | CK, CK+, JAFFE, TFEID, and MMI. | 97.14, 97.94, 92.53, 98.90 and 83.12 | 2018 |
| [13] | Gabor filters and a new coding scheme + SVM | CK+, SFEW, MMI, and RAF-DB | 95.72, 36.92, 71.88 and 76.23 | 2019 |
| [14] | Local Prominent Directional Pattern(LPDP) + SVM | CK+, MMI, BU-3DFE, ISED, GEMEP-FERA and FACES | 94.50, 70.63, 73.4, 78.32, 94.72, 94.72 | 2019 |
| [15] | Extracts facial Action Units (AU) using SVM-RBF | Real trial court data | 76.84 | 2019 |
| Facial Expression Recognition Methodologies based on Deep Learning | ||||
| Publications | Method | Database | Accuracy | Year |
| [18] | Combined (ART), (DCT) and (GF) | CKFI, FG-NET, and JAFFE | 99.25, 98.5, and 98.46 | 2018 |
| [17] | Deep Temporal Geometry Network (DTGN) | CK+ and Oulu-CASIA | 97.25, and 83.33 | 2018 |
| [16] | CECLM | ASD Children | 93.11 | 2019 |
| [19] | Adaptively Weights Sharing Network (AWS-Net) | RAF | 84.55 | 2019 |
| [20] | LBP, attention mechanism | CK+, JAFFE, FER2013 and Oulu-CASIA | 98.9, 98.5, 75.8, 94.6 | 2020 |
| [21] | Neighborhood Semantic Transformation | CK+ | 98.5 | 2020 |
| [22] | multi-block DCNN-SVM | UIBVFED, FERG, CK+, JAFFE, and TFEID | 98.45, 99.95, 98.09, 99.29, and 99.3 | 2021 |
| [23] | Spatio-Channel Attention Net(SCAN) | CK+, JAFFE | 91.4, 58.49 | 2021 |
| [24] | sparsity-aware deep network, a long short-term memory (LSTM) network | BU-3DFE, BU-4DFE and BP4D-Spontaneous | 85.11, 86.97, 89.91 | 2021 |
| [25] | Multi-Branch Deep Radial Basis Function | CK+, JAFFE | 98.58, 95.83 | 2021 |
| [27] | CNN with SVM | CK+ and BU4D | 99.69, 94.69 | 2022 |
| [28] | Visual attention based composite dense neural network | CK+, JAFFE | 97.46, 97.67 | 2022 |
| [29] | Enhanced Histogram of Oriented Gradient + Kernel extreme machine learning | CK+, JAFFE | 99.84, 98.63 | 2022 |
| [30] | Fusion-CNN | CK+, JAFFE, KDEF, and Oulu-CASIA | 98.22, 93.07, 90.3, and 90.13 | 2023 |
| Input Image Size | CK+ | JAFFE | KDEF |
|---|---|---|---|
| 130 × 114 | 95.9 | 96.8 | 73.5 |
| 48 × 48 | 99.5 | 90.0 | 77.6 |
| 32 × 32 | 94.8 | 85.1 | 71.4 |
| Parameter | Value |
|---|---|
| Optimizer | Adam |
| Learning Rate | 0.01 |
| Epochs | 100 |
| Batch Size | 128 |
| Type | Filter Size/Stride | Output Size |
|---|---|---|
| Conv1 + batchN + relu | 5 × 5/1 | 48 × 48 × 32 |
| Maxpool1 | 2 × 2/2 | 24 × 24 × 32 |
| Conv2 + batchN + relu | 3 × 3/1 | 24 × 24 × 32 |
| Maxpool2 | 2 × 2/2 | 12 × 12 × 32 |
| Conv3 + batchN + relu | 3 × 3/1 | 12 × 12 × 64 |
| Maxpool3 | 2 × 2/2 | 6 × 6 × 64 |
| Conv4 + batchN + relu | 3 × 3/1 | 6 × 6 × 64 |
| Maxpool4 | 2 × 2/2 | 3 × 3 × 64 |
| Conv5 + batchN + relu | 3 × 3/1 | 3 × 3 × 128 |
| Maxpool5 | 2 × 2/2 | 1 × 1 × 128 |
| Conv6 + batchN + relu | 3 × 3 / 1 | 1 × 1 × 256 |
| FC | 7 | 7 |
| CK+ | JAFFE | KDEF | FER | |
|---|---|---|---|---|
| Label | 7 classes | 7 classes | 7 classes | 7 classes |
| Total Number of Images | 974 | 213 | 4900 | 35,736 |
| Individuals | 123 | 10 | 70 | - |
| Resolution | ||||
| Format | .png | .tiff | .jpeg | .jpg |
| Facial Expressions | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Preprocessing Step | Sad | Angery | Disgust | Fear | Happy | Surprise | Contempt | Average Accuracy for 10 Runs | Best Accuracy for 10 Runs |
| (a) | 100 | 87 | 100 | 91.7 | 100 | 100 | 93.3 | 96.9 | 97.5 |
| (b) | 100 | 86 | 100 | 100 | 100 | 92.5 | 100 | 95.9 | 96.9 |
| (c) | 83.3 | 100 | 100 | 91.7 | 100 | 100 | 100 | 97.6 | 98 |
| (d) | 100 | 100 | 100 | 95.5 | 98.4 | 100 | 84.2 | 98.3 | 99 |
| (e) | 92 | 100 | 100 | 100 | 100 | 100 | 100 | 99.3 | 100 |
| Facial Expressions | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Preprocessing Step | Sad | Anger | Disgust | Fear | Happy | Surprise | Neutral | Average Accuracy for 10 Runs | Best Accuracy for 10 Runs |
| (a) | 77.8 | 75 | 60 | 100 | 100 | 100 | 90 | 85.8 | 89.5 |
| (b) | 100 | 100 | 100 | 80 | 66.7 | 100 | 100 | 90 | 93.3 |
| (c) | 100 | 90 | 71.4 | 72.7 | 85.7 | 100 | 80 | 85.5 | 90.6 |
| (d) | 80 | 87.5 | 87.5 | 62.5 | 85.7 | 66.7 | 88.9 | 79 | 85.2 |
| (e) | 100 | 88.9 | 100 | 100 | 100 | 100 | 100 | 98.4 | 98.7 |
| Fold | CK+ | Jaffe | FER | KDEF |
|---|---|---|---|---|
| 1 | 99 | 92.9 | 82.3 | 85.6 |
| 2 | 99 | 95.1 | 90.2 | 83.5 |
| 3 | 99.5 | 95.1 | 90.2 | 84.4 |
| 4 | 99.5 | 100 | 90.3 | 87.6 |
| 5 | 99.5 | 100 | 90.5 | 94.8 |
| Average Accuracy | 99.3 | 96.62 | 88.7 | 87.18 |
| Facial Expression | Predicted | Classification Accuracy (%) | ||||||
|---|---|---|---|---|---|---|---|---|
| Sad | Anger | Disgust | Fear | Happiness | Contempt | Surprise | ||
| Sad | 23 | 0 | 0 | 0 | 0 | 0 | 0 | 100 |
| Anger | 2 | 40 | 0 | 0 | 0 | 0 | 0 | 95.2 |
| Disgust | 0 | 0 | 53 | 0 | 0 | 0 | 0 | 100 |
| Fear | 0 | 0 | 0 | 22 | 0 | 0 | 0 | 100 |
| Happiness | 0 | 0 | 0 | 0 | 62 | 0 | 0 | 100 |
| Contempt | 0 | 0 | 0 | 0 | 0 | 16 | 0 | 100 |
| Surprise | 0 | 0 | 0 | 0 | 0 | 0 | 74 | 100 |
| Overall Accuracy | 99.3 | |||||||
| Facial Expression | Predicted | Classification Accuracy (%) | ||||||
|---|---|---|---|---|---|---|---|---|
| Sad | Anger | Disgust | Fear | Happiness | Neutral | Surprise | ||
| Sad | 9 | 0 | 0 | 0 | 0 | 0 | 0 | 100 |
| Anger | 0 | 9 | 0 | 0 | 0 | 0 | 0 | 100 |
| Disgust | 0 | 0 | 8 | 0 | 0 | 0 | 0 | 100 |
| Fear | 0 | 0 | 0 | 9 | 1 | 0 | 0 | 90 |
| Happiness | 0 | 0 | 0 | 0 | 8 | 0 | 0 | 100 |
| Neutral | 0 | 0 | 0 | 0 | 0 | 9 | 0 | 100 |
| Surprise | 0 | 0 | 0 | 0 | 0 | 0 | 9 | 100 |
| Overall Accuracy | 98.4 | |||||||
| Facial Expression | Predicted | Classification Accuracy (%) | ||||||
|---|---|---|---|---|---|---|---|---|
| Sad | Anger | Disgust | Fear | Happiness | Neutral | Surprise | ||
| Sad | 19 | 0 | 0 | 0 | 0 | 2 | 0 | 95.5 |
| Anger | 0 | 20 | 1 | 0 | 0 | 0 | 0 | 90.5 |
| Disgust | 0 | 1 | 19 | 1 | 0 | 0 | 0 | 85.7 |
| Fear | 2 | 0 | 0 | 18 | 0 | 0 | 1 | 90.5 |
| Happiness | 0 | 0 | 0 | 2 | 19 | 0 | 0 | 95.2 |
| Neutral | 0 | 0 | 0 | 1 | 20 | 0 | 0 | 90.5 |
| Surprise | 1 | 0 | 0 | 1 | 0 | 1 | 18 | 85.7 |
| Overall Accuracy | 90.5 | |||||||
| Facial Expression | Predicted | Classification Accuracy (%) | ||||||
|---|---|---|---|---|---|---|---|---|
| Sad | Anger | Disgust | Fear | Happiness | Neutral | Surprise | ||
| Sad | 520 | 29 | 6 | 31 | 25 | 20 | 17 | 80.2 |
| Anger | 27 | 289 | 12 | 27 | 42 | 20 | 19 | 66.2 |
| Disgust | 0 | 1 | 26 | 2 | 1 | 2 | 0 | 81.3 |
| Fear | 56 | 35 | 10 | 289 | 16 | 41 | 33 | 60.2 |
| Happiness | 48 | 51 | 5 | 39 | 678 | 74 | 42 | 72.4 |
| Neutral | 50 | 71 | 6 | 35 | 55 | 402 | 24 | 62.5 |
| Surprise | 17 | 20 | 1 | 57 | 26 | 19 | 255 | 64.6 |
| Overall Accuracy | 69.6 | |||||||
| Model | Year | Model Name | JAFFE | CK+ | KDEF | FER | Validation Patterns Selection |
|---|---|---|---|---|---|---|---|
| [32] | 2015 | Gabor, Haar, LBP and SVM, KNN, LDA | 89.50 | - | 82.40 | - | Split dataset into train and test |
| [33] | 2018 | CNN+SVM | 95.31 | - | - | - | K-fold Cross Validation |
| [20] | 2020 | Attention mechanism-based CNN | 98.52 | 98.68 | - | 75.82 | K-fold Cross Validation |
| [25] | 2021 | Multi-Branch Deep Radial Basis Function | 97.96 | 99.64 | - | 68.15 | Split dataset into train and test |
| [34] | 2021 | pretrained Deep CNN | 99.52 | - | 96.51 | - | K-fold Cross Validation |
| [23] | 2021 | Spatio-Channel Attention Net(SCAN) | 58.49 | 91.4 | - | - | Split dataset into train and test |
| [35] | 2021 | Attentional convolutional network | 92.8 | 98 | - | - | Split dataset into train and test |
| [36] | 2021 | ORB (oriented FAST and rotated BRIEF) and LBP | 90.5 | 96.2 | - | - | Split dataset into train and test |
| [28] | 2022 | Visual attention based composite dense neural network | 97.67 | 97.46 | - | - | K-fold Cross Validation |
| [37] | 2022 | Active Learning and SVM | 88.31 | - | - | - | K-fold Cross Validation |
| [38] | 2022 | Custom CNN | 95 | 83 | - | 86.78 | K-fold Cross Validation |
| [30] | 2023 | Fusion-CNN | 93.07 | 98.22 | 90.30 | - | K-fold Cross Validation |
| Proposed Model CCNN-SVM | 98.4 | 99.3 | 90.43 | 91.2 | Split dataset into for train and for test | ||
| 96.92 | 99.3 | 87.18 | 88.77 | Five-fold cross validation | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rashad, M.; Alebiary, D.M.; Aldawsari, M.; El-Sawy, A.A.; AbuEl-Atta, A.H. CCNN-SVM: Automated Model for Emotion Recognition Based on Custom Convolutional Neural Networks with SVM. Information 2024, 15, 384. https://doi.org/10.3390/info15070384
Rashad M, Alebiary DM, Aldawsari M, El-Sawy AA, AbuEl-Atta AH. CCNN-SVM: Automated Model for Emotion Recognition Based on Custom Convolutional Neural Networks with SVM. Information. 2024; 15(7):384. https://doi.org/10.3390/info15070384
Chicago/Turabian StyleRashad, Metwally, Doaa M. Alebiary, Mohammed Aldawsari, Ahmed A. El-Sawy, and Ahmed H. AbuEl-Atta. 2024. "CCNN-SVM: Automated Model for Emotion Recognition Based on Custom Convolutional Neural Networks with SVM" Information 15, no. 7: 384. https://doi.org/10.3390/info15070384
APA StyleRashad, M., Alebiary, D. M., Aldawsari, M., El-Sawy, A. A., & AbuEl-Atta, A. H. (2024). CCNN-SVM: Automated Model for Emotion Recognition Based on Custom Convolutional Neural Networks with SVM. Information, 15(7), 384. https://doi.org/10.3390/info15070384