2. Material and Methods
The materials selected for this analysis were debitage artifacts, specifically blades and bladelets. The selection was made using a random-stratified methodology, which allowed the selection of any technological subcategories in which these laminar blanks are divided [
14,
15]. These artifacts are known in archaeology to be the most regular artifacts in terms of the dimensional proportion and technology. The realization of these elements is indeed obtainable through a pre-determined reduction process of the raw material (in this case, flint), mostly based on bidirectional and secondarily unidirectional technology [
16,
17]. These artifacts belong to the technological category of laminar blanks, which can be further divided into two sub-categories: blades and bladelets. Both represent elongated artifacts with a length of at least twice their width. Bladelets are artifacts with a length smaller than 50 mm and a width narrower or equal to 12 mm, while blades are artifacts with a length longer than 50 mm and a width larger than 12 mm.
The measuring method used for obtaining dimensional information on each artifact was based on measuring the maximum technological length, width, and thickness, and if it was possible due to the state of conservation, the thickness and width were measured in specific positions according to the technological characteristics of any lithic artifacts, which are represented by the localization of the proximal and distal ends. The width and thickness were indeed also measured on the line that separates the proximal end and mesial part, and on the line that separates the mesial part and the distal end (
Figure 1). This methodology allowed us to obtain all the possible information, not only on undamaged artifacts but also on fragmented ones (
Figure 2).
Due to the state of conservation of the artifacts and the most suitable amount for a proper neural network, we decided to focus the comparative analysis on the metrics prediction of artifacts of which the distal end has not been preserved, either due to use wear, re-shaping, or ritual processes. For this study, a total of 291 artifacts were used. Out of these, 181 laminar artifacts that were undamaged were used as input. These 181 artifacts were further sub-divided into 149 blades and 32 bladelets. The remaining 110 laminar artifacts that had a missing distal end were used as output. These 110 artifacts were further sub-divided into 85 blades and 35 bladelets.
Concerning the application of AI to the materials, an ML method was chosen as the most relevant method available for this analysis. Both the Bayesian regularization backpropagation (BRBP) and Levenberg–Marquardt training algorithms were chosen to obtain the most performant results on a small set of data [
18,
19].
In Bayesian regularization backpropagation learning algorithms, the objective function is the mean square error. The mean square error (
MSE) measures the average squared difference between the predictions and the actual targets:
where:
is the number of elements in the dataset.
is the neural network output.
is the target output corresponding to .
In the BRBP algorithm, the objective function is as follows:
where:
represent two regularization coefficients.
ω represents the neural network weights.
= represents the sum of the squared network weight and is the data error term.
Including Eω in the objective function alongside the data error term allows the algorithm to find a balance between fitting the training data well (minimizing ) and keeping the model’s complexity in check (minimizing Eω).
The objective function used in the BRBP algorithm is responsible for guiding the training of the neural network. This function is comprised of two main components. The first component minimizes the sum of the squares of the network weights, while the second component (e) represents the error between the model’s predictions and the actual data or targets. The objective of this function is to ensure that the model is making accurate predictions on the training data, thus resulting in a well-trained neural network.
The coefficients α and β control the influence of each term on the overall objective.
The process of finding the optimum values for α and β in the context of Bayesian regularization can indeed be challenging. These parameters play a crucial role in balancing the trade-off between fitting the training data well and controlling the complexity of the model.
The statement suggests that the relative values of α and influence the training error differently. Specifically:
If , smaller values of α compared to lead to smaller errors related to the regularization term on the sum of the squared network weights Eω. This means that the algorithm may prioritize fitting the training data more closely, potentially risking overfitting if not properly controlled.
If , larger values of compared to emphasize the importance of reducing the size of the network weights. This encourages the algorithm to prefer simpler models with smaller weights, even if it comes at the cost of slightly higher errors in the training data.
To determine the optimal values for
and
, we used a Bayesian regularization method. Bayesian methods usually involve introducing prior distributions of the parameters (in this case,
ω), updating these distributions with observed data, and then making probabilistic inferences. In the regularization system, this approach allows for a principled way of incorporating uncertainty and making informed decisions about the balance between fitting the data and controlling the model complexity. The Bayesian regularization method is based on Bayes’ theorem in the following way:
where:
is the posterior probability of event A, given B.
is the prior probability of event B, given A.
is the prior probability of event A.
is the non-zero prior probability of event B, serving as a normalizing constant.
Bayes’ theorem provides a mathematical framework for updating our prior beliefs in light of new evidence. It enables us to refine our initial assumptions by incorporating observed data, resulting in a more accurate and reliable estimate of the underlying probability distribution. By applying Bayes’ theorem, we can determine the posterior probability of a hypothesis, given our prior belief and the likelihood of observing the available evidence.
In order to find the optimal weight space in the Bayesian framework, the objective function
F(
ω) needs to be minimized to make it equivalent to maximizing the posterior probability function as follows:
where:
D stands for the dataset.
M is the specific neural network model being used.
is the vector of the network weights.
P(ω|α,M) is the prior density. It encapsulates our prior knowledge about the weights ω before we have observed any data.
This is a fundamental concept in Bayesian statistics, where our prior beliefs are updated as far as new data are added. In a neural network model M, the prior knowledge could be either based on previous studies, expert knowledge, or other relevant information.
is the likelihood function. It represents the observation probability of data D, given the weights ω, under the specific model M. It quantifies how well the selected model is, while the specific set of weights explains the observed data. In other words, if you were to use the model M with weights ω to generate data, the likelihood function tells you the probability that the model would generate the observed data D. It is a fundamental concept in machine learning and statistics that helps us understand how well our model represents the data we have.
P(D|α,β,M) represents a normalization factor in this context. In Bayesian inference, the posterior distribution of the parameters is often a priority, because it is proportional to the likelihood and the prior product. However, to ensure that the posterior distribution is a valid probability distribution, it is necessary to ensure that it integrates (or sums) to 1 over all the possible values of the parameters. This is the exact step where the function P(D|α,β,M) comes in. It essentially represents the integral (or sum) of the product of the likelihood and the prior overall possible values of the parameters. By using this system, the posterior distribution is guaranteed to be a valid probability distribution that adds up to 1. This term is often difficult to calculate directly, especially for complex models and large datasets, but various computational techniques, such as Markov chain Monte Carlo (MCMC), are often used to handle this.
Bayesian regularization in backpropagation algorithms typically involves incorporating prior distributions over the model parameters and updating them using techniques such as variational inference or Markov Chain Monte Carlo (MCMC) methods. The steps in a Bayesian regularization backpropagation algorithm would generally involve the following:
Initialization: Initialization of the weights and biases of the neural network.
Forward Pass: Performance of a forward pass through the network to compute the predicted output for a given input.
Compute Loss: Calculation of the loss function, which is typically a combination of a data term (e.g., mean squared error) and a regularization term based on the prior distribution over the model parameters.
Backward Pass (Backpropagation): A backpropagation approach to compute the gradients of the loss function in relation to the model parameters.
Update Parameters: Update the model parameters using both the gradients achieved in the previous step and an optimization algorithm such as the stochastic gradient descent (SGD) or its variants.
Incorporate Bayesian regularization as follows:
Prior Specification: Definition of prior distributions over the model parameters, which may include Gaussian priors, Laplace priors, etc.
Variational Inference or MCMC Sampling: Performance of variational inference or MCMC sampling to approximate the posterior distribution over the model parameters, given the observed data and the prior distributions.
Update Parameters with Regularization: Update the model parameters using the gradients achieved from the posterior distribution, incorporating the Bayesian regularization term into the update rule.
Repetition: Repetition of steps 2–6 for a specified number of iterations or until the convergence criteria are met.
Prediction: After training, the trained model must be used for making predictions on new data by performing a forward pass through the network.
Evaluation: Evaluation of the performance of the trained model on a separate validation or test dataset using appropriate metrics. The specifics of the implementation of this algorithm may vary depending on the choice of prior distributions and inference techniques.
The Levenberg–Marquardt training algorithm is instead aimed at minimizing a cost function, defined as the residual sum of squares (RSS). This cost function is used in nonlinear regression problems and the optimization of models. Furthermore, the model parameters are iteratively updated using a combination of descending gradient methods and Newton methods, exemplified by the following formula:
where:
wk+1 = wk − αgkrepresents the EPB algorithm
wk+1 = wk − Hk−1gk is the Newton algorithm
wk+1 = wk− (JkTJk)−1Jkek is the Newton–Gauss algorithm
The EPB algorithm, the Newton–Gauss algorithm, and the Newton algorithm are methods used to optimize the parameters in different types of problems.
The EPB algorithm is commonly used in machine learning to optimize the parameters in learning classifiers or regressors. It works by iteratively minimizing an objective function (or loss) with a gradient descent-based approach. The learning rate may vary during optimization, and an exponential term may be included to boost or penalize the objective function based on its current value.
The Newton–Gauss algorithm, also known as Gauss–Newton, is used in nonlinear regression problems to optimize the parameters. It updates the parameters using an approximate version of the Hessian matrix, which is the matrix of second derivatives of the objective function with respect to the parameters. The Newton–Gauss algorithm is particularly useful when the objective function is approximately quadratic near the minimum.
The Newton algorithm is an optimization method commonly used to solve nonlinear optimization problems. It uses the second derivative of the objective function to guide the parameter updates and can converge more quickly than other optimization methods, especially when the objective function is convex and well-behaved. However, it may require computationally expensive calculations of the Hessian matrix and may not be stable in all situations.
During each iteration, the algorithm balances between Newton’s steps and the gradient steps, using an “amortization” parameter to control the step size, which helps to avoid divergence or slowness issues. The algorithm iteratively continues to update the parameters until convergence is reached or until a stop criterion is fulfilled.
During the training process of the neural network, several parameters were custom-made and set in MATLAB. Each parameter has a specific role in the neural network training process. Here is an explanation of each parameter:
net.trainParam.epochs: This parameter specifies the number of epochs, which is the number of times the entire training set is presented to the neural network for training. A complete era is when the network has seen and learned from all the training data once.
net.trainParam.lr: This parameter represents the learning rate (LR). It indicates how many times the neural network should update the weights based on the error during each iteration of the optimization algorithm. A higher learning rate may accelerate the training, but it may also cause oscillations or converging difficulties.
net.trainParam.max_fail: This parameter represents the maximum number of consecutive failures allowed during training. If the network error stops decreasing for several epochs specified by this parameter, the training may stop before reaching the maximum number of epochs to avoid overfitting problems.
net.trainParam.min_grad: This parameter specifies the minimum gradient threshold. During training, if the weight gradient of the neural network becomes lower than this value, the optimization algorithm may consider that the network has reached a convergence condition.
net.trainParam.goal: This parameter is the training performance goal. It represents the average error that you want to achieve during training. Once the average neural network error reaches or approaches this value, the training ends.
The parameters chosen are heavily dependent on the specific problem confronted, the complexity of the dataset, and the structure of the neural network. However, there are some suggested best practices to be considered, such as the following:
The learning rate (LR) should be initially set to small values and then adjusted as the training proceeds to avoid oscillations and divergence.
The number of epochs (epochs) should be sufficient to allow the network to learn from the data, but not too large to avoid overfitting.
max_fail can be adjusted according to the training stability and overfitting measurement.
min_grad and goal are often set according to the desired accuracy and tolerance for convergence.
In both cases, the neural network was built on two hidden layers: 1 composed of 80 perceptrons and 1 composed of 40 perceptrons. This specific architecture was chosen after several tests set on different amounts of perceptrons in order, first, to avoid underfitting problems due to the low number of artifacts (small dataset), and secondly, to achieve the best results and to avoid overfitting problems.
The input layer therefore consisted of four perceptrons, as many as the known variables for every single artifact, such as the length, mesial width, and mesial thickness; two hidden layers; and one output layer represented by three perceptrons, as many as the number of unknown variables, comprising the missing metric information to be predicted by the neural network (
Figure 3).
where:
represents the output of the j-th node located on the K-layer;
is the output of the i-th node on the K-1-layer;
is the connection weight between nodes and j.
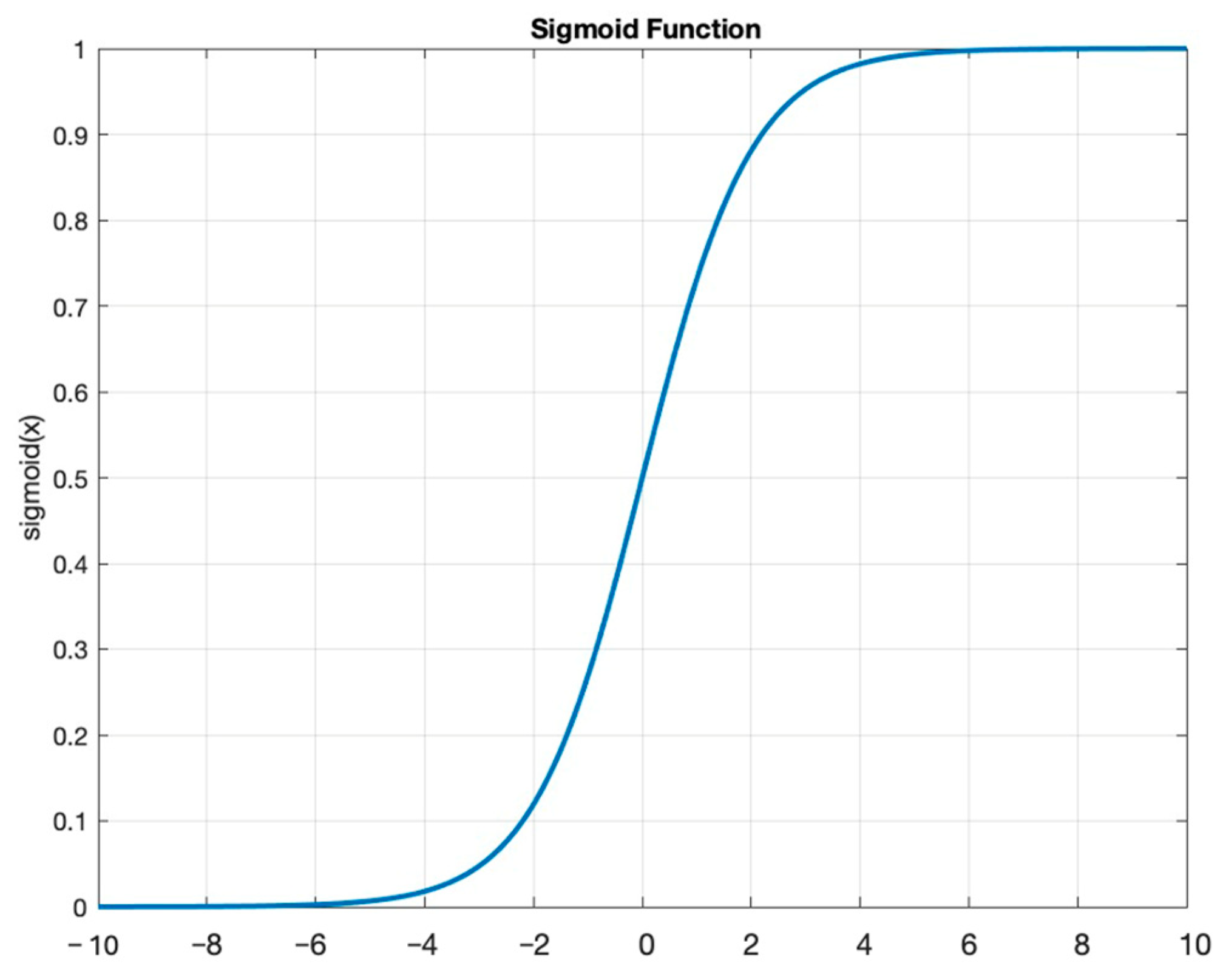
The node activation function (perceptron) is as follows (
Figure 4):
Taking Equation (1) as the node activation function (perceptron), it can be formulated in the following way:
Concerning the activation function of the perceptrons, two different functions were selected. One activation function corresponded to the sigmoid not-tangent hyperbolic and was meant to be used for the hidden layers, and the other activation function corresponded to a linear function and was meant to be used for the last output layer. The choice of activation functions for the neural network layers is crucial because it affects the network’s ability to learn and represent complex data relationships. We ultimately settled on this specific activation function, which produced the desired outcomes. The hidden layer activation function was the sigmoid not-tangent hyperbolic function (
Figure 5), which is commonly used in neural network studies to introduce non-linearities and represents the best solution for the purpose of this study. A linear function was instead used for the output layer.
In neural networks, the error
E is defined by the difference between the expected vector and the real value.
where:
dj defines the expected error;
represents the real output value at node j;
defines the number of nodes in the K-th layer.
The aim is to achieve an approach between the output values’ vector and the expected values’ vector. Therefore, it is possible to minimize Equation (3) by adjusting the values of weights
among the serval nodes, allowing us to consider the derivative of (3) as follows:
By choosing
R(s) as the function achieved in Equation (1), its derivative will be:
Applying (6) to (5), the following function is obtained:
Substituting (7) into (4), the following function is achieved:
The following equation shows that changing the weights
is sufficient to minimize the error by starting from random values for the various weights at time
t = 0,
w_(
i,
j):
where:
η defines the learning rate that assumes a value range from 0.1 to 0.9. It represents the value that adjusts the algorithm learning rate.
Starting from the iteration at instant t = 0 in the next one t + 1, it is necessary to adjust the weights until (9) converges.
Substituting (8) into (9), the following function is achieved:
In conclusion, rewriting the function (10):
Based on these considerations, a feedforward backpropagation learning algorithm can be implemented by applying the following operations:
Random initialization of weights ; the network input vector is set to “target” samples with which a vector of the output values is necessary to classify the model correctly.
The function needs to be calculated for each layer from the input to the output as follows:
For each node, calculate the following function starting from the output layer:
For hidden layers ranging from (
k − 1) to 1, the calculation is as follows:
Update of weight values as follows:
Repetition of the previous steps is performed until the convergence is achieved.
If the mean square error increases as the weights increase 0, the algorithm predicts a decrease in the weights ; otherwise, if the error decreases as the weights increase, the backpropagation learning algorithm then has high convergence times and may stop at a local minimum. It is possible, therefore, to analyze other algorithms that provide solutions to these problems and that are part of the backpropagation group but differ from the classical algorithm by the method used to update the weights.
Taking into account the Newton’s algorithm, the weights are updated according to the following law:
where:
is the matrix of the weights;
H is the Hessian matrix of the error;
g is the gradient of the error.
To improve the accuracy of a model, it is necessary to update the weights and biases of the model through multiple iterations. However, this process involves the computation of the Hessian matrix, which is the matrix of the second derivatives of the error with respect to the weights. This computation can be quite onerous.
Luckily, there is a class of algorithms called quasi-Newton algorithms that can make this process much simpler. One such algorithm is the Levenberg–Marquardt algorithm. This algorithm does not require the computation of the Hessian matrix. Instead, it approximates the Hessian matrix and error gradient using equations that are much easier to compute, as shown in (14) and (15):
where:
J is the Jacobian matrix whose elements are the prime derivatives of the error with respect to the weights;
E is the error vector.
If functions (14) and (15) are merged into (13), then the update matrix of the weights becomes as follows:
The latter algorithm (16) was chosen to perform the neural network learning ability. The generalization of the network is the ability to recognize data that are slightly different from the data it was trained with. Too much data in the learning phase might affect the network on the training set, causing overfitting problems, and thus it might limit the ability to generalize. A few data may instead not be enough to reduce the overall error; therefore, it is indispensable to understand when it is necessary to stop training the network in order not to incur learning data overfitting. A method to optimize the generalization ability is the “early stopping” method.
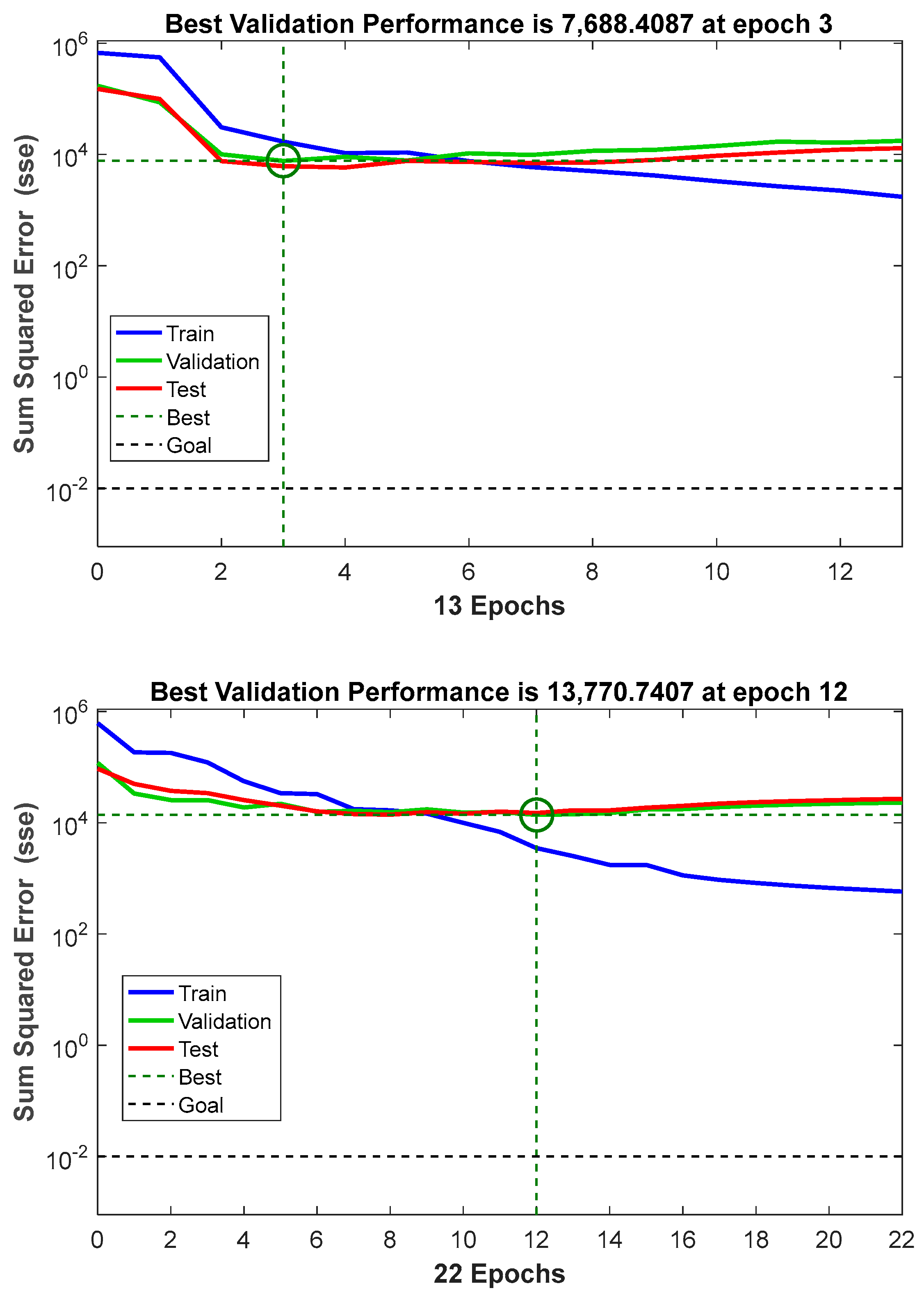
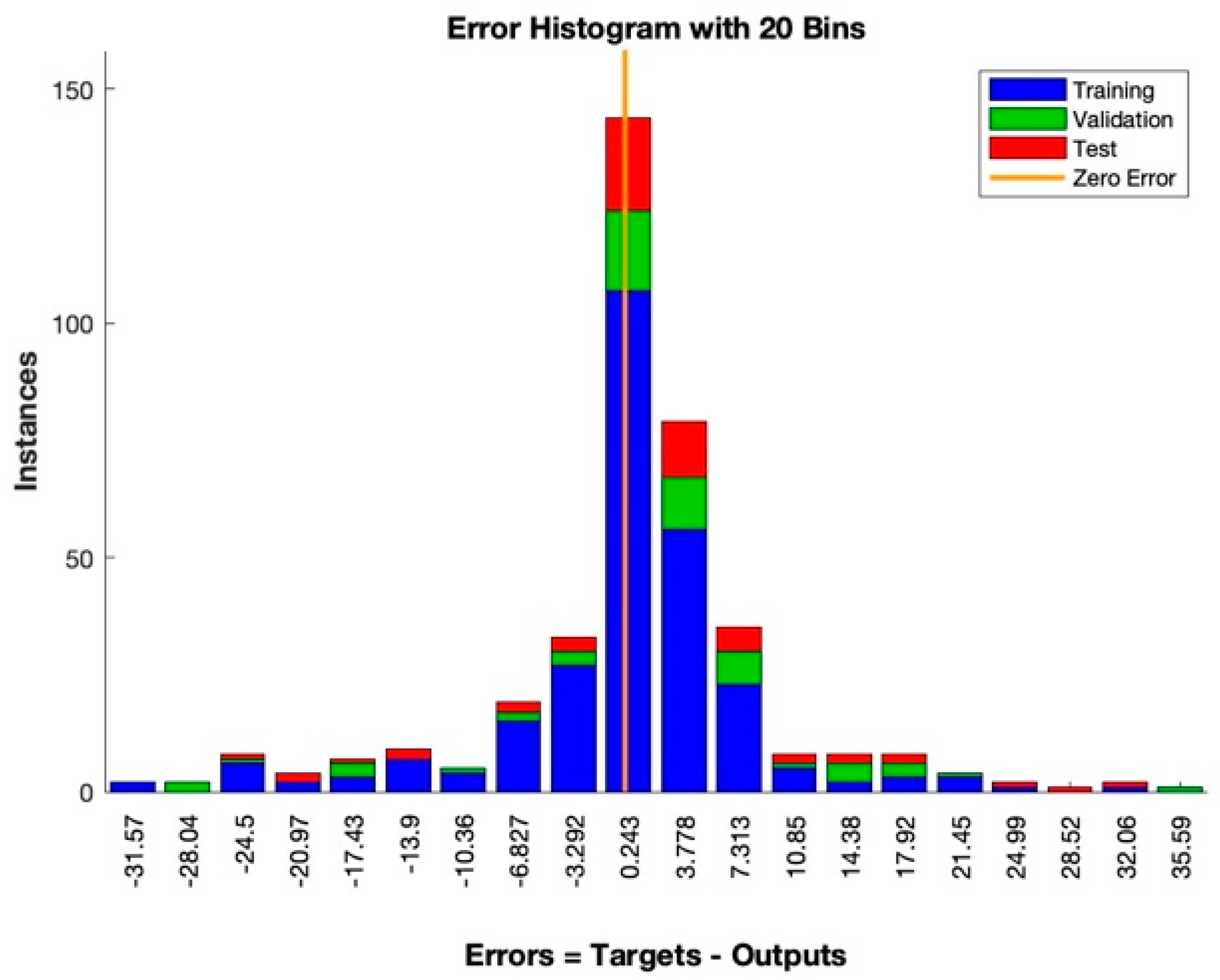
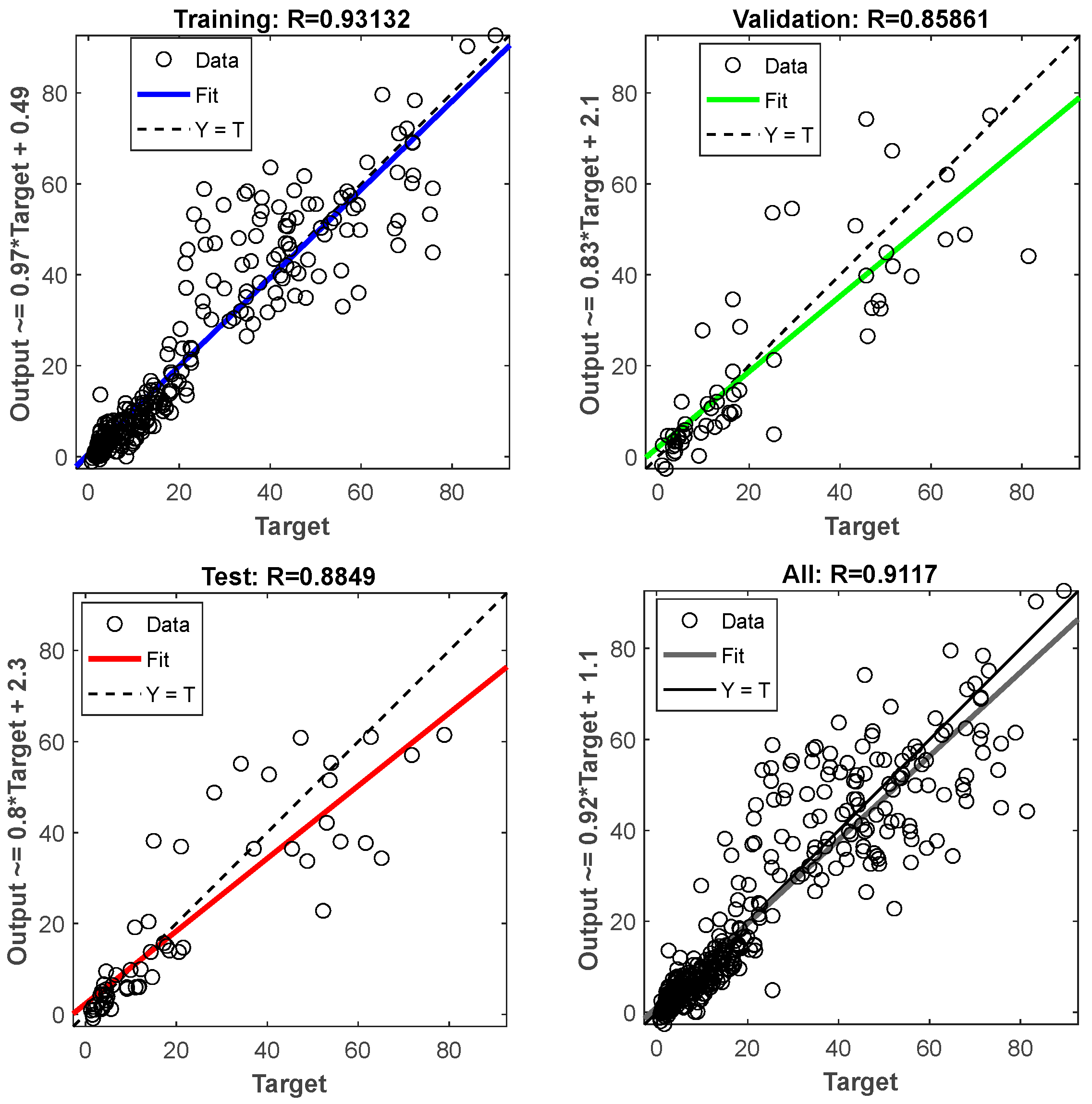
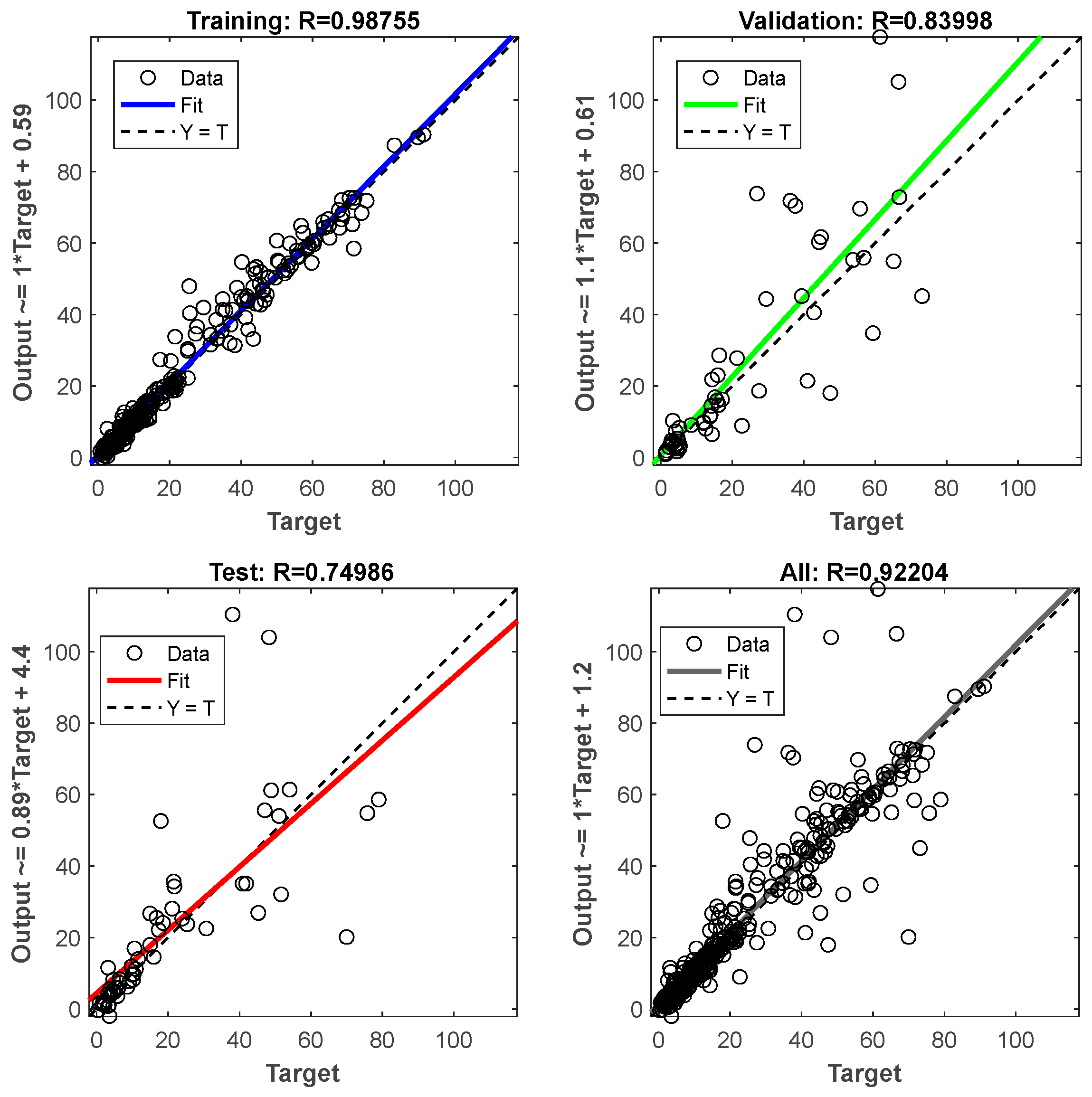
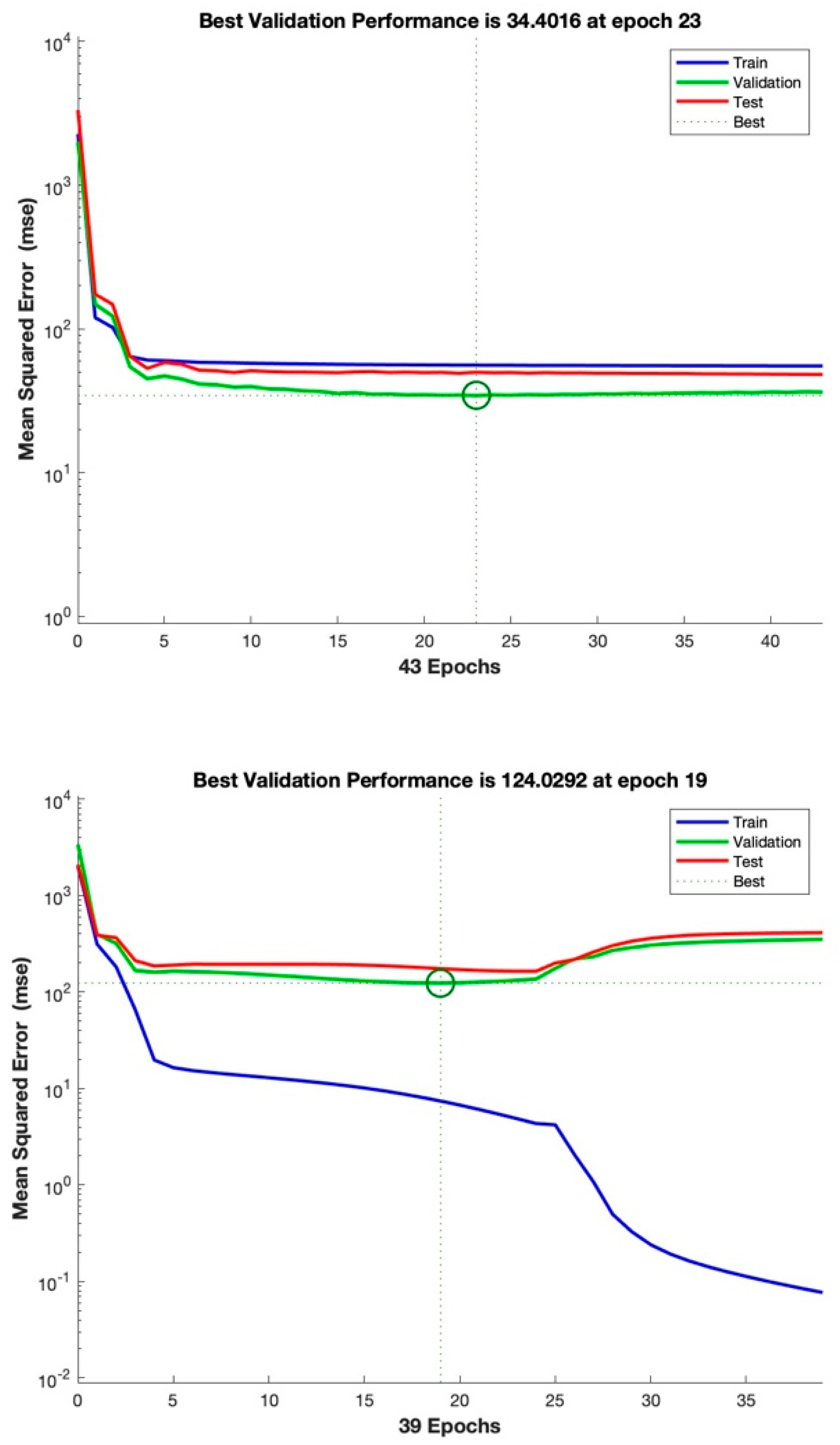
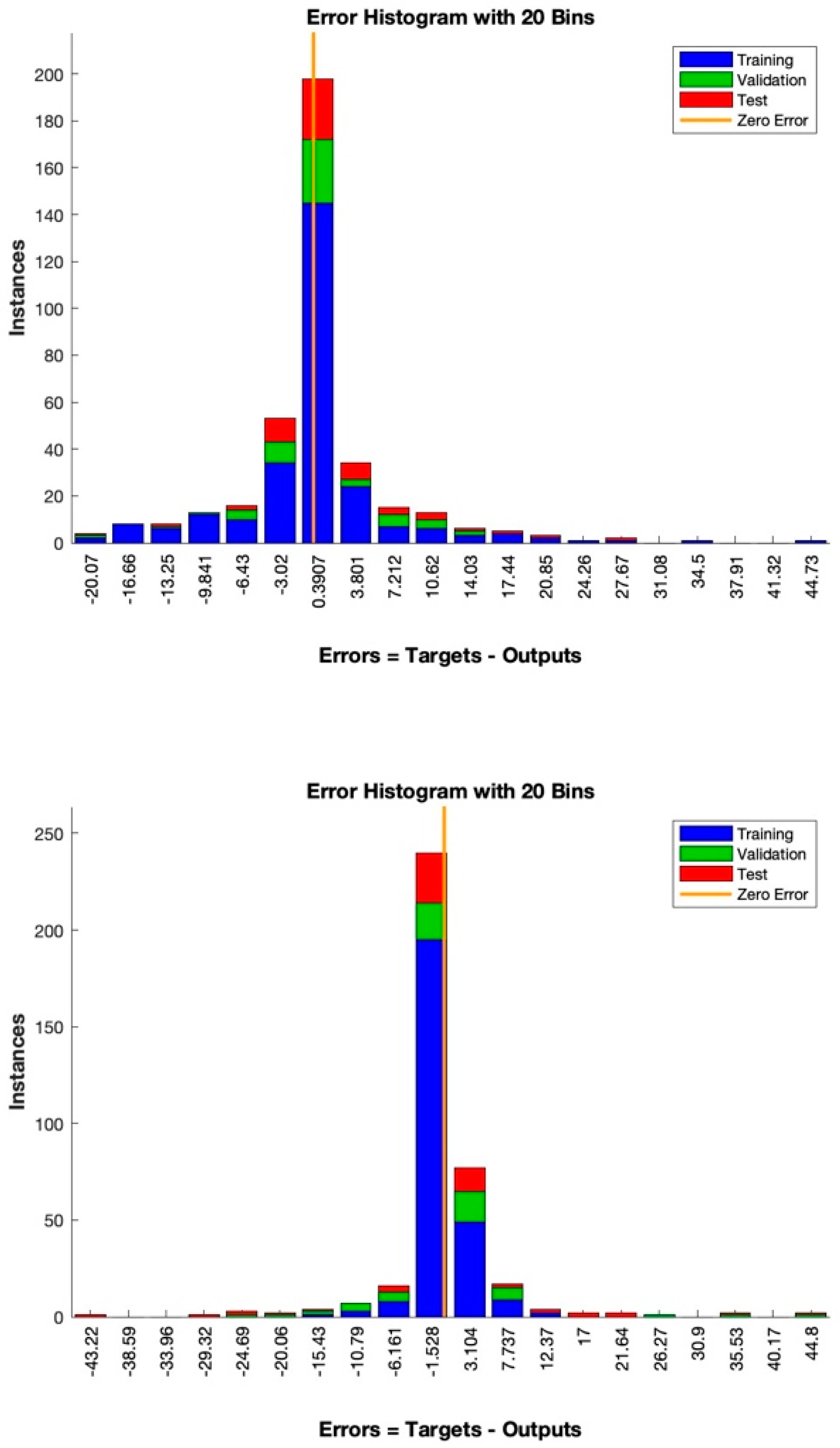
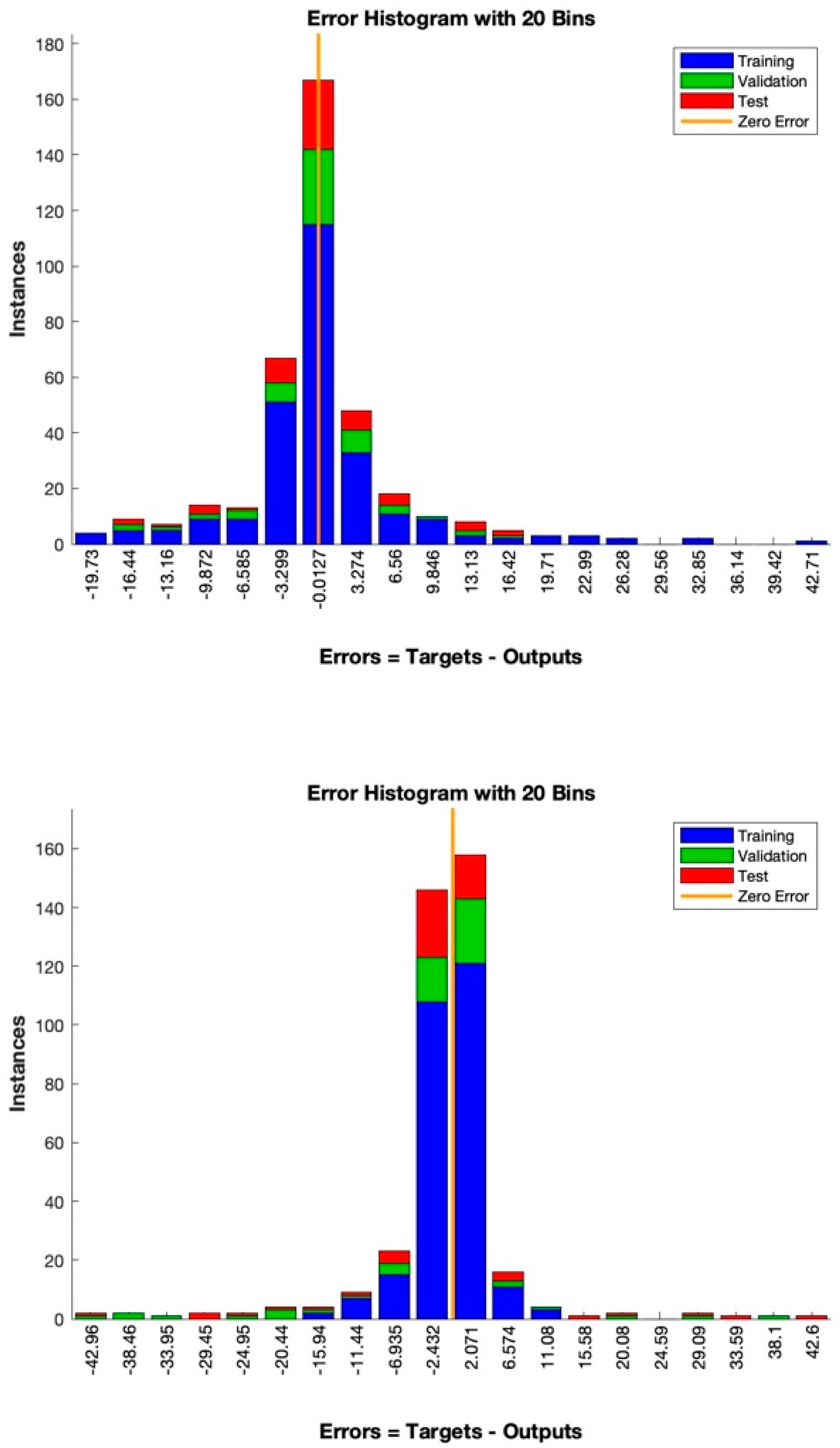
The training data were randomly divided into two subsets. The larger subset was used for the training, where the network’s weights must be necessarily adjusted, while the smaller subset was reserved for testing. The validation test was performed by selecting from the training dataset a subset called “validation set”. During the training algorithm, the error trend was periodically tested with the validation set. When it started increasing, the training was stopped. Subsequently, it was fundamental to verify the final accuracy in terms of correct answers (expressed in percentages) compared to the test set data. It might be plausible to think, observing the error trend, that it could decrease proportionally to the increase in the weights’ update. It is essential to avoid continuing the training process beyond the point where the validation error is as low as possible, as this can cause the network to only learn the “noise” present in the training set. A good network is considered to generate an error of less than 20% of the input/output pairs on the final test.
Finally, for neural network learning, a database of exclusively complete and undamaged artifacts was used. A total of 70% of the undamaged artifacts in each prediction were used for the training process, and the remaining 30% were used for the error calculation. Furthermore, both the algorithms divided the 70% into three sets: one for the proper training process, one for the data validation, and one for the final test. In both the training and validation processes, the selection was random, with no experimenter decisions or interference that might have affected the results (
Supplementary Material S1).
The neural networks were tested with different LRs for both the Bayesian (LRBa) and Levenberg–Marquardt (LRLM) regularization training algorithms, respectively, set as LRBa_1 = 0.1; LRBa_2 = 0.3; LRBa_3 = 0.4; LRLM_! = 0.1; LRLM_2 = 0.3; LRLM_3 = 0.4.
Therefore, a comparative analysis was conducted for each test at the same rate.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}