
A Scalable and Automated Framework for Tracking the Likely Adoption of Emerging Technologies


Abstract
1. Introduction
- The extraction of aspects relating to a range of emerging technologies from social media discourse over a period of time.
- The classification of the sentiments expressed towards such technologies, indicating the positive and negative outlooks of users towards adopting them.
- A ground truth analysis to validate the hypothesis that the sentiments captured by the text mining approach are comparable to the results provided by human annotators when asked to label whether such texts positively or negatively impact their outlook towards adopting an emerging technology.
- A scalable and automated framework for tracking the likely adoption and/or rejection of new technologies. This information serves as an important decisionmaking component when, for example, recognising shifts in user behaviours, new demands, and emerging uncertainties.
- Resources that can further support research, such as a large corpus of social media discourse covering five years worth of data that provide recent organic expressions of sentiment towards emerging technologies. This distinguishes our work from prior research that often relies on smaller manually curated datasets or datasets generated under controlled experimental conditions.
2. Related Work
3. Data Collection and Preparation
- Converting text to lowercase.
- Removing mentioned usernames, hashtags, and URLs using Python’s regular expression package, RegEx (version 2020.9.27).
- To remove bias from the analysis, the keywords (i.e., “IoT” and “Internet of Things”) used to scrape tweets were also removed.
4. Aspect-Based Sentiment Analysis
- Aspect extraction—aims to automatically identify and extract the specific entities and/or properties of entities in text [31].
4.1. Aspect Extraction
4.2. Sentiment Analysis
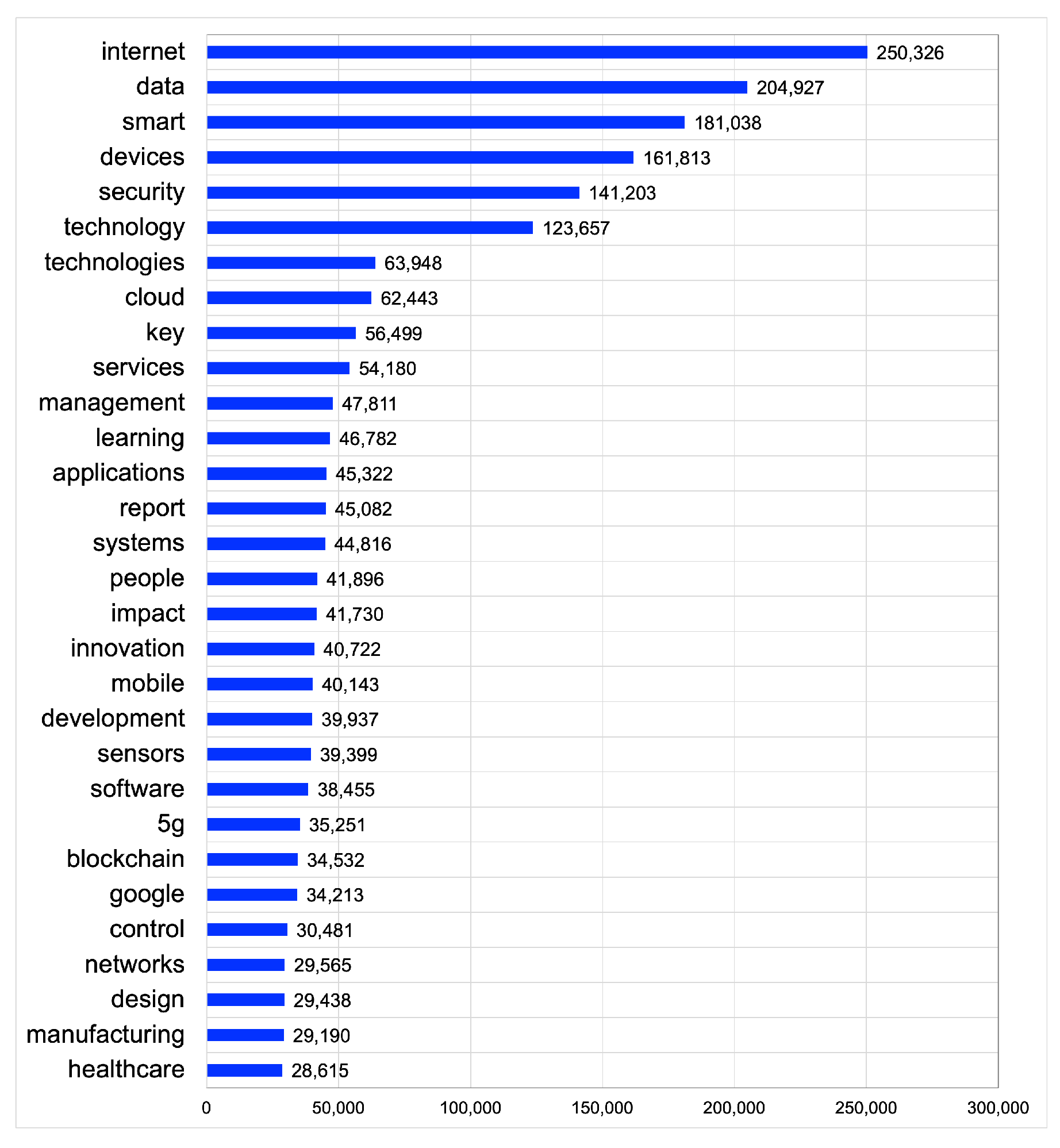
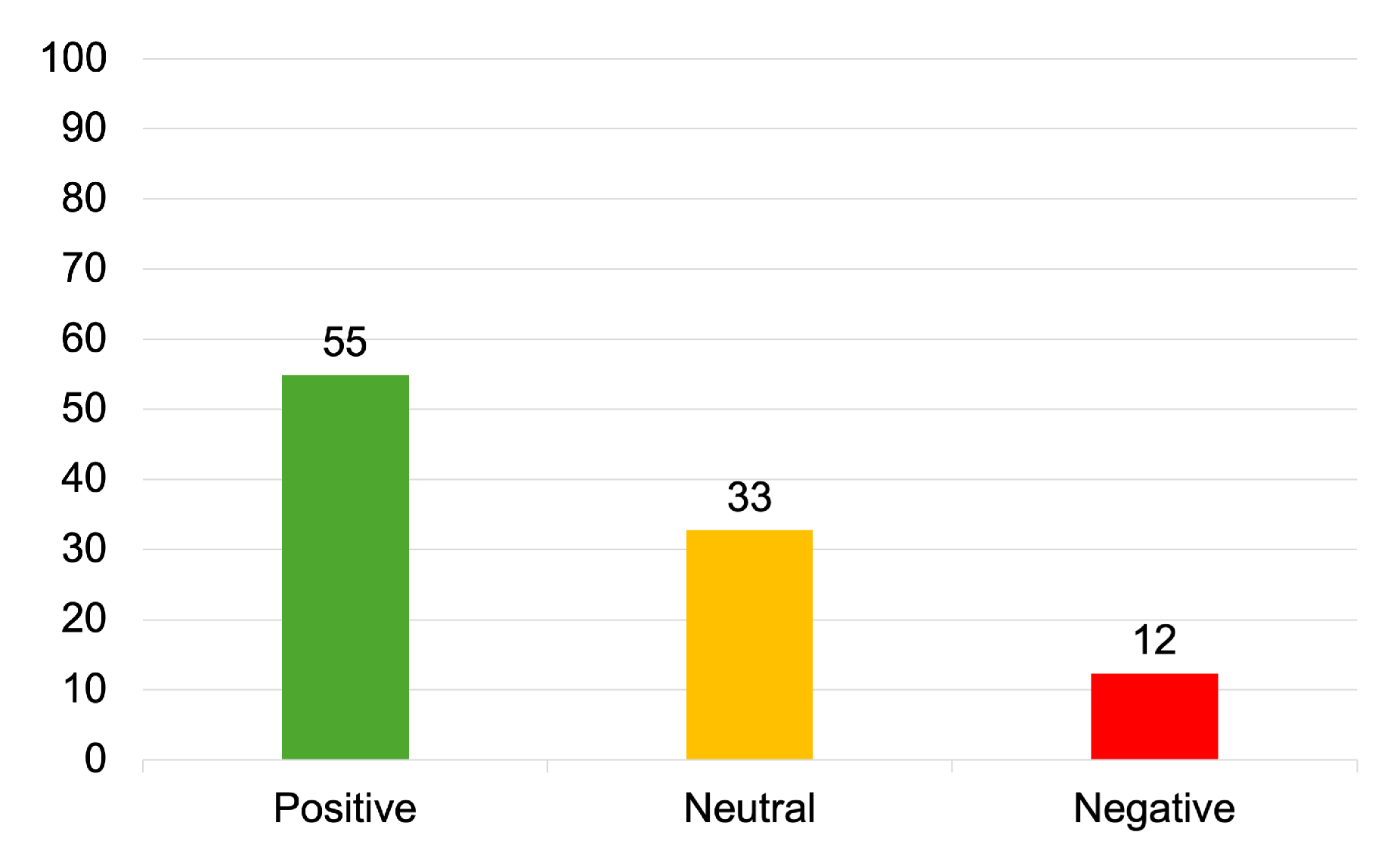
5. Results and Discussion
6. Evaluation
- Positive—The text has a positive impact on the reader. Given this information, they are now more likely to accept, integrate, and/or use the technology in their business or personal life.
- Negative—The text has a negative impact on the reader. Given this information, they now feel against integrating and using the technology in their business or personal life.
- Neutral—The text has no impact on the reader and they feel indifferent about the technology.
7. Conclusions
8. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jackson, D.; Allen, C.; Michelson, G.; Munir, R. Strategies for Managing Barriers and Challenges to Adopting New Technologies; CPA Australia: Southbank, MEL, Australia, 2022. [Google Scholar]
- Rogers, P.L. Barriers to adopting emerging technologies in education. J. Educ. Comput. Res. 2000, 22, 455–472. [Google Scholar] [CrossRef]
- Kucharavy, D.; De Guio, R. Technological forecasting and assessment of barriers for emerging technologies. In Proceedings of the 17th International Conference on Management of Technology (IAMOT 2008), Dubai, United Arab Emirates, 6–10 April 2008; p. 14.2. [Google Scholar]
- Bacow, L.S.; Bowen, W.G.; Guthrie, K.M.; Long, M.P.; Lack, K.A. Barriers to Adoption of Online Learning Systems in US Higher Education; Ithaka: New York, NY, USA, 2012. [Google Scholar]
- Christodoulakis, C.; Asgarian, A.; Easterbrook, S. Barriers to adoption of information technology in healthcare. In Proceedings of the 27th Annual International Conference on Computer Science and Software Engineering, Markham, ON, Canada, 6–8 November 2017; pp. 66–75. [Google Scholar]
- Kapurubandara, M.; Lawson, R. Barriers to Adopting ICT and E-Commerce with SMEs in Developing Countries: An Exploratory Study in Sri Lanka; University of Western Sydney: Sydney, Australia, 2006; Volume 82, pp. 2005–2016. [Google Scholar]
- Yusif, S.; Soar, J.; Hafeez-Baig, A. Older people, assistive technologies, and the barriers to adoption: A systematic review. Int. J. Med. Inform. 2016, 94, 112–116. [Google Scholar] [CrossRef]
- Burnap, P.; Williams, M.L. Us and them: Identifying cyber hate on Twitter across multiple protected characteristics. EPJ Data Sci. 2016, 5, 1–15. [Google Scholar] [CrossRef]
- Williams, L.; Bannister, C.; Arribas-Ayllon, M.; Preece, A.; Spasić, I. The role of idioms in sentiment analysis. Expert Syst. Appl. 2015, 42, 7375–7385. [Google Scholar] [CrossRef]
- Liu, B. Sentiment Analysis and Subjectivity. In Handbook of Natural Language Processing; Department of Computer Science, University of Illinois at Chicago: Chicago, IL, USA, 2010; Volume 2, pp. 627–666. [Google Scholar]
- Munezero, M.; Montero, C.S.; Sutinen, E.; Pajunen, J. Are they different? Affect, feeling, emotion, sentiment, and opinion detection in text. IEEE Trans. Affect. Comput. 2014, 5, 101–111. [Google Scholar] [CrossRef]
- Davis, F.D. Perceived usefulness, perceived ease of use, and user acceptance of information technology. MIS Q. 1989, 13, 319–340. [Google Scholar] [CrossRef]
- Venkatesh, V.; Morris, M.G.; Davis, G.B.; Davis, F.D. User acceptance of information technology: Toward a unified view. MIS Q. 2003, 27, 425–478. [Google Scholar] [CrossRef]
- Alalwan, A.A.; Dwivedi, Y.K.; Rana, N.P. Factors influencing adoption of mobile banking by Jordanian bank customers: Extending UTAUT2 with trust. Int. J. Inf. Manag. 2017, 37, 99–110. [Google Scholar] [CrossRef]
- Oliveira, T.; Thomas, M.; Baptista, G.; Campos, F. Mobile payment: Understanding the determinants of customer adoption and intention to recommend the technology. Comput. Hum. Behav. 2016, 61, 404–414. [Google Scholar] [CrossRef]
- Bhattacherjee, A.; Park, S.C. Why end-users move to the cloud: A migration-theoretic analysis. Eur. J. Inf. Syst. 2014, 23, 357–372. [Google Scholar] [CrossRef]
- Sun, T.Q.; Medaglia, R. Mapping the challenges of Artificial Intelligence in the public sector: Evidence from public healthcare. Gov. Inf. Q. 2019, 36, 368–383. [Google Scholar] [CrossRef]
- AL-Hadban, W.; Yusof, S.A.M.; Hashim, K.F. The barriers and facilitators to the adoption of new technologies in public healthcare sector: A qualitative investigation. Int. J. Bus. Manag. 2017, 12, 159–168. [Google Scholar] [CrossRef]
- Poon, E.G.; Jha, A.K.; Christino, M.; Honour, M.M.; Fernandopulle, R.; Middleton, B.; Newhouse, J.; Leape, L.; Bates, D.W.; Blumenthal, D.; et al. Assessing the level of healthcare information technology adoption in the United States: A snapshot. BMC Med. Inform. Decis. Mak. 2006, 6, 1–9. [Google Scholar] [CrossRef]
- Jin, Q.; Liu, Y.; Yarosh, S.; Han, B.; Qian, F. How Will VR Enter University Classrooms? Multi-stakeholders Investigation of VR in Higher Education. In Proceedings of the CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 30 April–5 May 2022; pp. 1–17. [Google Scholar]
- Dequanter, S.; Fobelets, M.; Steenhout, I.; Gagnon, M.P.; Bourbonnais, A.; Rahimi, S.; Buyl, R.; Gorus, E. Determinants of technology adoption and continued use among cognitively impaired older adults: A qualitative study. BMC Geriatr. 2022, 22, 1–16. [Google Scholar] [CrossRef]
- Kwarteng, M.A.; Ntsiful, A.; Botchway, R.K.; Pilik, M.; Oplatková, Z.K. Consumer Insight on Driverless Automobile Technology Adoption via Twitter Data: A Sentiment Analytic Approach. In Proceedings of the Re-imagining Diffusion and Adoption of Information Technology and Systems: A Continuing Conversation: IFIP WG 8.6 International Conference on Transfer and Diffusion of IT, TDIT 2020, Tiruchirappalli, India, 18–19 December 2020; Springer: Berlin/Heidelberg, Germany, 2020. Part I. pp. 463–473. [Google Scholar]
- Efuwape, T.O.; Abioye, T.E.; Abdullah, A.K. Text Analytics of Opinion-Poll On Adoption of Digital Collaborative Tools for Academic Planning using Vader-Based Lexicon Sentiment Analysis. FUDMA J. Sci. 2022, 6, 152–159. [Google Scholar] [CrossRef]
- Hizam, S.M.; Ahmed, W.; Akter, H.; Sentosa, I.; Masrek, M.N. Web 3.0 Adoption Behavior: PLS-SEM and Sentiment Analysis. arXiv 2022, arXiv:2209.04900. [Google Scholar]
- Mardjo, A.; Choksuchat, C. HyVADRF: Hybrid VADER–Random Forest and GWO for Bitcoin Tweet Sentiment Analysis. IEEE Access 2022, 10, 101889–101897. [Google Scholar] [CrossRef]
- Caviggioli, F.; Lamberti, L.; Landoni, P.; Meola, P. Technology adoption news and corporate reputation: Sentiment analysis about the introduction of Bitcoin. J. Prod. Brand Manag. 2020, 29, 877–897. [Google Scholar] [CrossRef]
- Ikram, M.T.; Butt, N.A.; Afzal, M.T. Open source software adoption evaluation through feature level sentiment analysis using Twitter data. Turk. J. Electr. Eng. Comput. Sci. 2016, 24, 4481–4496. [Google Scholar] [CrossRef]
- Lueth, K.L. IoT 2016 in Review: The 8 Most Relevant IoT Developments of the Year. Available online: https://iot-analytics.com/iot-2016-in-review-10-most-relevant-developments/. (accessed on 13 July 2022).
- Anthi, E.; Williams, L.; Słowińska, M.; Theodorakopoulos, G.; Burnap, P. A supervised intrusion detection system for smart home IoT devices. IEEE Internet Things J. 2019, 6, 9042–9053. [Google Scholar] [CrossRef]
- The Essential Eight Technologies Board Byte: The internet of Things. Available online: https://www.pwc.com.au/pdf/essential-8-emerging-technologies-internet-of-things.pdf. (accessed on 2 June 2022).
- Thet, T.T.; Na, J.C.; Khoo, C.S. Aspect-based sentiment analysis of movie reviews on discussion boards. J. Inf. Sci. 2010, 36, 823–848. [Google Scholar] [CrossRef]
- Kang, H.J.; Kim, C.; Kang, K. Analysis of the trends in biochemical research using Latent Dirichlet Allocation (LDA). Processes 2019, 7, 379. [Google Scholar] [CrossRef]
- Jacobi, C.; Van Atteveldt, W.; Welbers, K. Quantitative analysis of large amounts of journalistic texts using topic modelling. Digit. J. 2016, 4, 89–106. [Google Scholar] [CrossRef]
- Greene, D.; O’Callaghan, D.; Cunningham, P. How many topics? Stability analysis for topic models. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Turin, Italy, 18–22 September 2023; Springer: Berlin/Heidelberg, Germany, 2014; pp. 498–513. [Google Scholar]
- spaCy: Industrial-Strength NLP. Available online: https://spacy.io/ (accessed on 5 March 2021).
- Gensim: Topic Modelling for Human. Available online: https://radimrehurek.com/gensim/ (accessed on 5 March 2021).
- The Cybersecurity Body of Knowledge (CyBOK)—CyBOK Mapping Reference Version 1.1. Available online: https://www.cybok.org/media/downloads/CyBOk-mapping-reference-v1.1.pdf (accessed on 10 April 2022).
- Hutto, C.; Gilbert, E. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; Volume 8, pp. 216–225. [Google Scholar]
- Rogers, E.M. Diffusion of Innovations; Simon and Schuster: New York, NY, USA, 2003; p. 576. [Google Scholar]
- Moore, G. Crossing the Chasm: Marketing and Selling High-Tech Products to Mainstream Customers; Harper Business Essentials; Harper Business: New York, NY, USA, 1991. [Google Scholar]
- Gallagher, S. Siemens, DHS Warn of “Low Skill” Exploits against Medical Scanners. Available online: https://arstechnica.com/gadgets/2017/08/siemens-dhs-warn-of-low-skill-exploits-against-ct-and-pet-scanners/ (accessed on 12 July 2022).
- Tarasov, A.; Delany, S.J.; Cullen, C. Using crowdsourcing for labelling emotional speech assets. In Proceedings of the W3C Workshop on Emotion ML, Paris, France, 5–6 October 2010. [Google Scholar]
- Passonneau, R.J.; Yano, T.; Lippincott, T.; Klavans, J. Relation between agreement measures on human labeling and machine learning performance: Results from an art history image indexing domain. In Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC), Marrakech, Morocco, 28–30 May 2008; pp. 2841–2848. [Google Scholar]
- Snow, R.; O’connor, B.; Jurafsky, D.; Ng, A.Y. Cheap and fast–but is it good? Evaluating non-expert annotations for natural language tasks. In Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing, Honolulu, HI, USA, 25–27 October 2008; pp. 254–263. [Google Scholar]
- Krippendorff, K. Content Analysis: An Introduction to Its Methodology; Sage Publications: Thousand Oaks, CA, USA, 2018. [Google Scholar]
- A Python Computation of the Krippendorff’s Alpha Measure. Available online: https://pypi.org/project/krippendorff/ (accessed on 5 March 2021).
- Krippendorff, K. Reliability in Content Analysis: Some Common Misconceptions and Recommendations. Hum. Commun. Res. 2004, 30, 411–433. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tweet | Extracted Aspect |
|---|---|
| One of our engineers was at the Google Cloud On-Board roadshow this morning. It’s great to hear we’re being described as an industry leader in cloud native platform delivery! | [‘google’, ‘cloud’, ‘cloud native’] |
| 5 of the best Alexa-enabled devices for automation. | [‘devices’, ‘automation’] |
| How the growth of IoT is changing data management. | [‘data management’] |
| Challenge in talent part of implementing: marrying domain knowledge of software and hardware engineers; finding people who can wear many hats; competitiveness of the data science space; realize what’s possible is changing all the time. | [‘software’, ‘hardware’, ‘data science’] |
| Mobile re-emerges as revolutionizing tech behind virtual reality, machine learning. | [‘mobile’, ‘machine learning’] |
| Tweet | Sentiment | Sentiment Score |
|---|---|---|
| My Home Assistant has 11,498 lines of YAML code tested. | Neutral | 0 |
| Bear Stone Smart home currently runs on 11,409 lines of YAML code. Check it all out. | Positive | 0.4019 |
| vCloudInfo—Simple Example of using YAML Node Anchors in Home Assistant. | Neutral | 0 |
| instead of writing automations for #HomeAssistant in Yaml, you can create them visually using NodeRed. | Positive | 0.2732 |
| Human Annotations | ||||
| Positive | Negative | Neutral | ||
| Positive | 37 | 0 | 13 | |
| Text Mining | Negative | 2 | 45 | 3 |
| Neutral | 8 | 1 | 41 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Williams, L.; Anthi, E.; Burnap, P. A Scalable and Automated Framework for Tracking the Likely Adoption of Emerging Technologies. Information 2024, 15, 237. https://doi.org/10.3390/info15040237
Williams L, Anthi E, Burnap P. A Scalable and Automated Framework for Tracking the Likely Adoption of Emerging Technologies. Information. 2024; 15(4):237. https://doi.org/10.3390/info15040237
Chicago/Turabian StyleWilliams, Lowri, Eirini Anthi, and Pete Burnap. 2024. "A Scalable and Automated Framework for Tracking the Likely Adoption of Emerging Technologies" Information 15, no. 4: 237. https://doi.org/10.3390/info15040237
APA StyleWilliams, L., Anthi, E., & Burnap, P. (2024). A Scalable and Automated Framework for Tracking the Likely Adoption of Emerging Technologies. Information, 15(4), 237. https://doi.org/10.3390/info15040237