
Ensemble Modeling with a Bayesian Maximal Information Coefficient-Based Model of Bayesian Predictions on Uncertainty Data



Abstract
1. Introduction
2. Related Works
2.1. Uncertainty in Machine Learning Prediction
- Measurement errors occur during the measurement process in equipment, sensors, or human observation.
- Human subjectivity relates to the judgment or interpretation of any situation, such as survey responses or subjective assessments.
- Expert judgement refers to opinions or estimations which typically serve as inputs for models or influence decision-making outcomes.
- Sampling variability can be found in a large sample dataset.
- Environment variability may be affected by external factors or environmental conditions during data collection.
- Incomplete or missing data presents the unavailability of data or values, which provides insufficient information to process.
- Modeling assumptions can happen during the development of statistical or machine learning models which can lead to errors in predictions.
- Model complexity may occur due to many parameters in modeling and this tends to affect the overfit model.
- Stochastic processes occur with random phenomena that are uncontrollable.
- Evolving systems emphasize changes over time, such as time-series data.
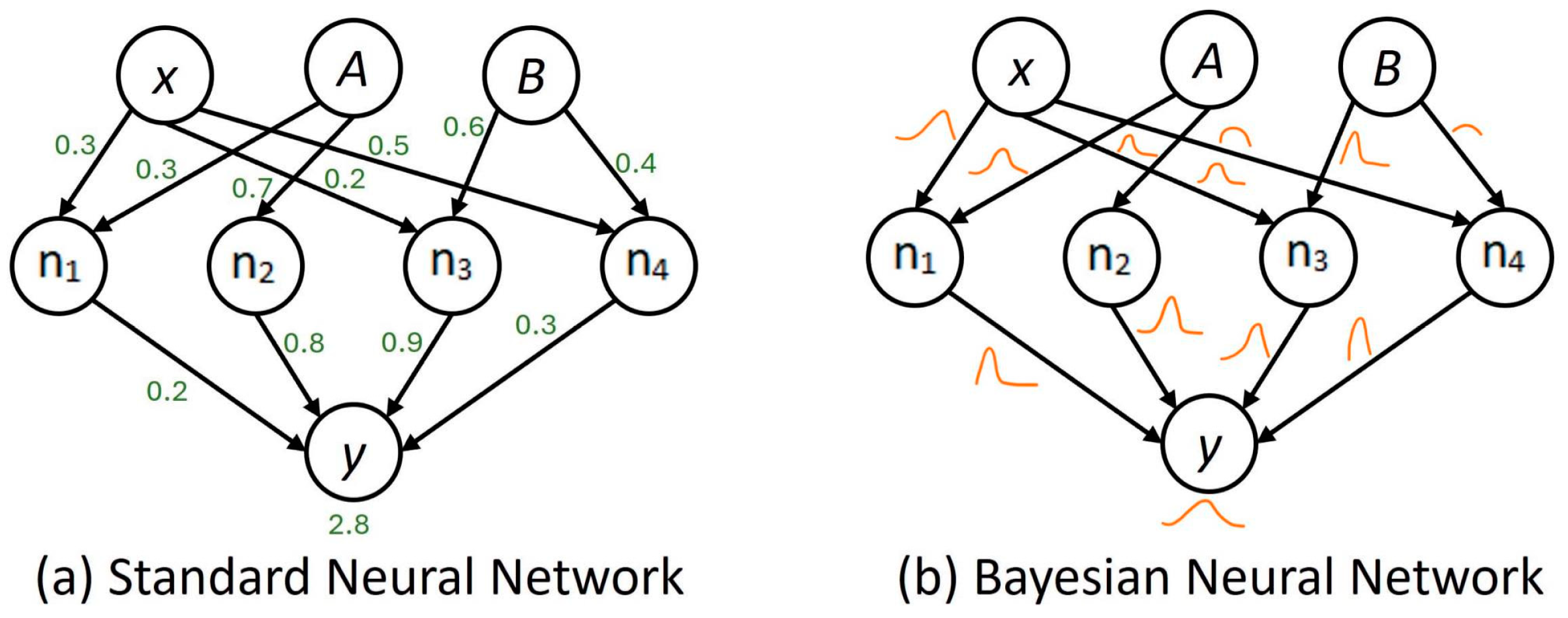
2.2. Bayesian Neural Network (BNN)
- for to do
- Draw ;
- ;
- end for
- return , ; where is a sample set of and is a collection sample of .
2.3. Ensemble Model
- Homogeneous ensemble involves using multiple models of the same type or family to create an ensemble. In this approach, identical base learners, often sharing the same algorithm, are trained on different subsets of the data or with variations in training parameters. The individual models work collectively to provide a more robust and accurate prediction. Bagging, where multiple decision trees are trained independently, is an example of a homogeneous ensemble approach.
- Heterogeneous ensemble employs diverse types of base learners within the ensemble. This approach combines models that may belong to different algorithm families, utilizing their unique strengths and characteristics. Heterogeneous ensembles aim to enhance predictive performance by leveraging the complementary nature of different algorithms. Stacking, where models with distinct architectures or learning algorithms are combined, exemplifies a heterogeneous ensemble strategy.
- Bagging (bootstrap aggregating) involves training several instances of the same base learning algorithm on diverse subsets of the dataset. These subsets are often created through bootstrap sampling, and the predictions from individual models are then aggregated, commonly through averaging or voting. The goal of bagging is to mitigate overfitting and improve overall model robustness.
- Boosting focuses on sequential training models, with each subsequent model assigning higher weights to instances misclassified by previous models. This adaptive approach aims to correct errors and improve the model’s performance, particularly in challenging instances. AdaBoost and gradient boosting are popular boosting algorithms used to create strong predictive models.
- Stacking (stacked generalization) involves training diverse base models, often of different types or families, and combining their predictions through a meta-model. Instead of directly aggregating predictions, a meta-model is trained to learn how to combine the outputs of the individual models best. Stacking is a more sophisticated ensemble method that aims to capture complex relationships within the data.
- Blending is an ensemble technique whereby different models are trained independently on the dataset and their predictions are combined through a weighted average or a simple linear model. Unlike stacking, blending typically involves using a holdout validation set to create the ensemble model.
- Voting is also known as majority voting and is a straightforward ensemble method where multiple models make predictions, and the final prediction is determined based on a majority vote. In the case of classification, the class that receives the most votes is chosen as the overall prediction. This approach is commonly used in both binary and multiclass classification scenarios.
3. Methods
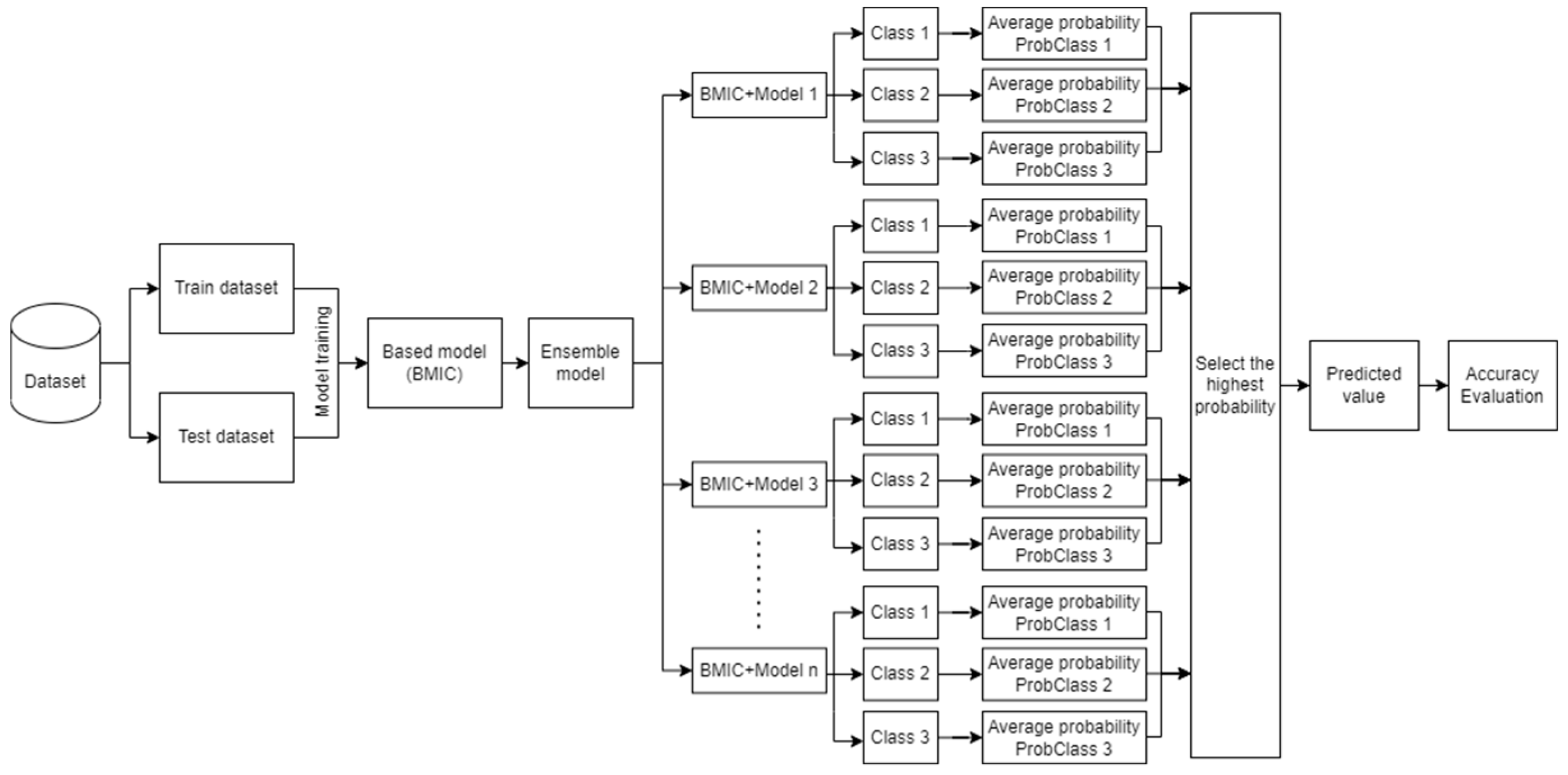
3.1. Methodology
| Algorithm 1 Ensemble learning of the BMIC and traditional classification model algorithms |
| Input: dataset from csv file Read data from Split into features(X)80% and target variable(y)20% Procedure BMIC prediction Define the structure of the Bayesian Network: Define the nodes and their dependencies Initialize the BMIC on the structure of the Bayesian Network Fit the BMIC on the training data Predict probabilities of three distinct labels for testing data Store predicted probability results in PredProb_BMIC Procedure traditional classification models prediction Define a list of classification models to loop through: models = [LogisticRegression(), K-nearestNeighbors(), DecisionTree(), RandomForest(), SVM(), NeuralNetwork(), NaiveBayes(), XGBoost()] Define a list to store model performance metrics: model_acc = [] Loop each model in the list of classification models: For each model in models: Initialize the model Fit the model on the training data Predict probabilities of three distinct labels for testing data Store predicted probability results in PredProb_model Procedure ensemble model of BMIC and each traditional classification model Calculate the average probabilities of BMIC and each traditional classification model avg_PredProb = (PredProb_BMIC + PredProb_model)/2 Select the maximum value of predicted probability among three distinct labels If label1.value is greater than label2.value and label1.value is greater than label3.value: PredMaxLable = label1.value Else if num2 is greater than num1 and num2 is greater than num3: PredMaxLable = label2.value Else: PredMaxLable = label3.value Calculate the accuracy score true labels of y test and PredMaxLable Store in testing_acc Print PredMaxLable Print testing_acc |
3.2. Data Preparation
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Siddique, T.; Mahmud, S.; Keesee, A.M.; Ngwira, C.M.; Connor, H. A Survey of Uncertainty Quantification in Machine Learning for Space Weather Prediction. Geosciences 2022, 12, 27. [Google Scholar] [CrossRef]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [PubMed]
- Aworka, R.; Cedric, L.S.; Adoni, W.Y.H.; Zoueu, J.T.; Mutombo, F.K.; Kimpolo, C.L.M.; Nahhal, T.; Krichen, M. Agricultural decision system based on advanced machine learning models for yield prediction: Case of East African countries. Smart Agric. Technol. 2022, 2, 100048. [Google Scholar] [CrossRef]
- Shuliang, W.; Surapunt, T. Bayesian Maximal Information Coefficient (BMIC) to reason novel trends in large datasets. Appl. Intell. 2022, 52, 10202–10219. [Google Scholar] [CrossRef]
- Kendall, A.; Gal, Y. What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Der Kiureghian, A.; Ditlevsen, O. Aleatory or epistemic? Does it matter? Struct. Saf. 2009, 31, 105–112. [Google Scholar] [CrossRef]
- Hariri, R.H.; Fredericks, E.M.; Bowers, K.M. Uncertainty in big data analytics: Survey, opportunities, and challenges. J. Big Data 2019, 6, 44. [Google Scholar] [CrossRef]
- Jang, H.; Lee, J. An empirical study on modeling and prediction of bitcoin prices with Bayesian neural networks based on blockchain information. IEEE Access 2017, 6, 5427–5437. [Google Scholar] [CrossRef]
- Jospin, L.V.; Laga, H.; Boussaid, F.; Buntine, W.; Bennamoun, M. Hands-On Bayesian Neural Networks—A Tutorial for Deep Learning Users. IEEE Comput. Intell. Mag. 2022, 17, 29–48. [Google Scholar] [CrossRef]
- Semenova, E.; Williams, D.P.; Afzal, A.M.; Lazic, S.E. A Bayesian neural network for toxicity prediction. Comput. Toxicol. 2020, 16, 100133. [Google Scholar] [CrossRef]
- Chandra, R.; He, Y. Bayesian neural networks for stock price forecasting before and during COVID-19 pandemic. PLoS ONE 2021, 16, e0253217. [Google Scholar] [CrossRef] [PubMed]
- Kocadağlı, O.; Aşıkgil, B. Nonlinear time series forecasting with Bayesian neural networks. Expert Syst. Appl. 2014, 41, 6596–6610. [Google Scholar] [CrossRef]
- Magris, M.; Iosifidis, A. Bayesian learning for neural networks: An algorithmic survey. Artif. Intell. Rev. 2023, 56, 11773–11823. [Google Scholar] [CrossRef]
- Chang, D.T. Bayesian neural networks: Essentials. arXiv 2021, arXiv:2106.13594. [Google Scholar]
- Xiao, F.; Chen, X.; Cheng, J.; Yang, S.; Ma, Y. Establishment of probabilistic prediction models for pavement deterioration based on Bayesian neural network. Int. J. Pavement Eng. 2023, 24, 2076854. [Google Scholar] [CrossRef]
- Rojarath, A.; Songpan, W. Cost-sensitive probability for weighted voting in an ensemble model for multi-class classification problems. Appl. Intell. 2021, 51, 4908–4932. [Google Scholar] [CrossRef]
- Saha, S.; Arabameri, A.; Saha, A.; Blaschke, T.; Ngo, P.T.T.; Nhu, V.H.; Band, S.S. Prediction of landslide susceptibility in Rudraprayag, India using novel ensemble of conditional probability and boosted regression tree-based on cross-validation method. Sci. Total Environ. 2020, 764, 142928. [Google Scholar] [CrossRef] [PubMed]
- Pisula, T. An Ensemble Classifier-Based Scoring Model for Predicting Bankruptcy of Polish Companies in the Podkarpackie Voivodeship. J. Risk Financ. Manag. 2020, 13, 37. [Google Scholar] [CrossRef]
- Lahmiri, S.; Bekiros, S.; Giakoumelou, A.; Bezzina, F. Performance assessment of ensemble learning systems in financial data classification. Intell. Syst. Account. Financ. Manag. 2020, 27, 3–9. [Google Scholar] [CrossRef]
- Xiong, H.; Berkovsky, S.; Romano, M.; Sharan, R.V.; Liu, S.; Coiera, E.; McLellan, L.F. Prediction of anxiety disorders using a feature ensemble based Bayesian neural network. J. Biomed. Inform. 2021, 123, 103921. [Google Scholar] [CrossRef] [PubMed]
- Chang, J.-F.; Dong, N.; Ip, W.H.; Yung, K.L. An ensemble learning model based on Bayesian model combination for solar energy prediction. J. Renew. Sustain. Energy 2019, 11, 043702. [Google Scholar] [CrossRef]
- Sreedharan, M.; Khedr, A.M.; El Bannany, M. A Comparative Analysis of Machine Learning Classifiers and Ensemble Techniques in Financial Distress Prediction. In Proceedings of the 2020 17th International Multi-Conference on Systems, Signals & Devices (SSD), Monastir, Tunisia, 20–23 July 2020; pp. 653–657. [Google Scholar] [CrossRef]
- The Office of Agricultural Economics. Available online: https://www.oae.go.th (accessed on 15 January 2021).
- The Thai Rice Exporter Association. Available online: http://www.thairiceexporters.or.th (accessed on 15 January 2021).
- Thai Customs. Available online: https://www.customs.go.th (accessed on 15 January 2021).
- The Thai Meteorological Department. Available online: https://www.tmd.go.th (accessed on 15 January 2021).

{kind=link}
{kind=link}
{kind=link}
| Cause Features | Effect Feature |
|---|---|
| Export Vietnamese white rice price | Export Pakistani white rice price |
| Export Pakistani white rice price | Export Thai white rice price |
| Export Thai white rice price | Gold price in Thailand |
| Export Thai jasmine rice price | Jasmine rice price in Thailand |
| Export Thai jasmine rice price | Paddy price in Thailand |
| Export Thai jasmine rice price | Exchange rate of US Dollar with Thai Baht |
| Paddy price in Thailand | Jasmine rice price in Thailand |
| Jasmine rice price in Thailand | Exchange rate of US Dollar with Thai Baht |
| Exchange rate of US Dollar with Thai Baht | Gasoline price in Thailand |
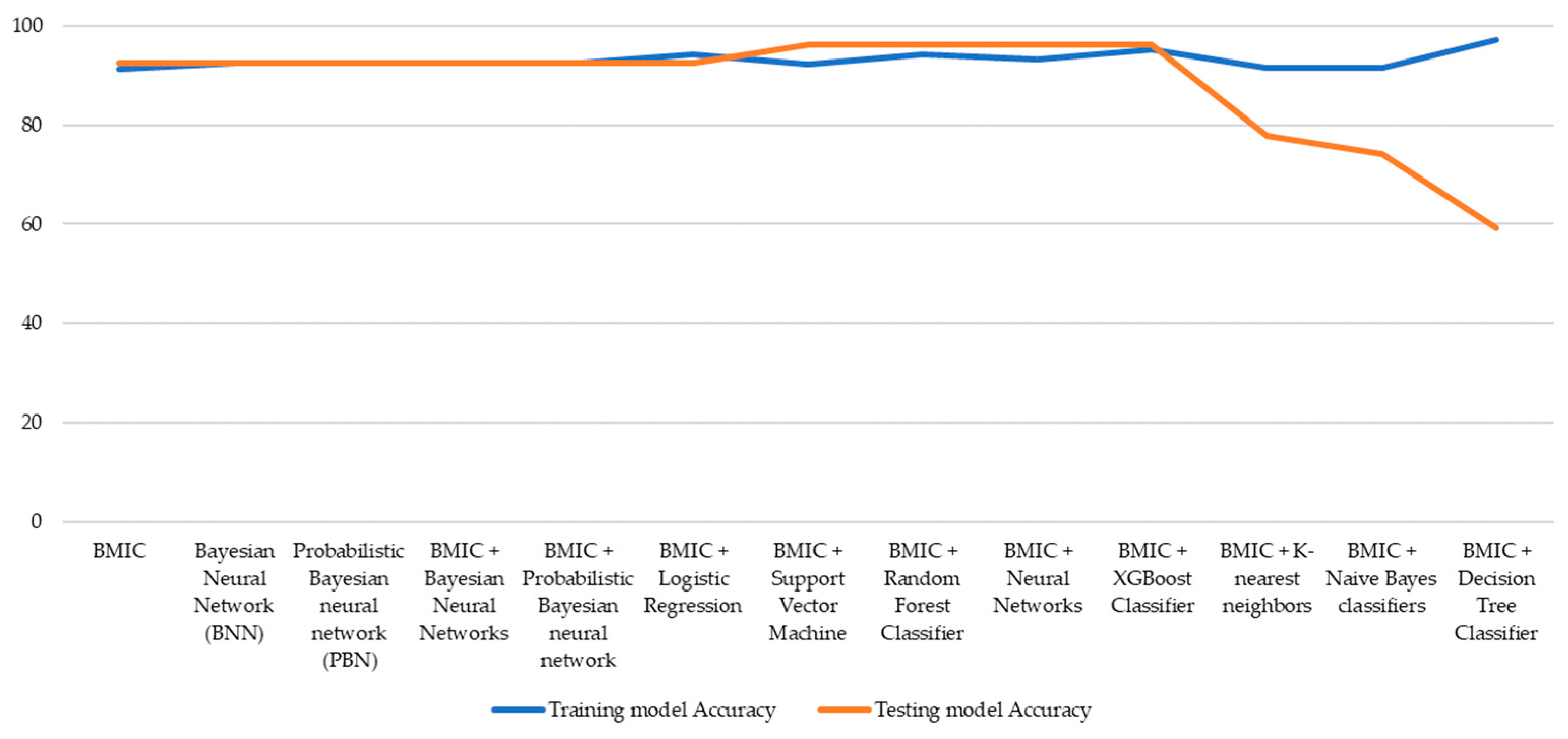
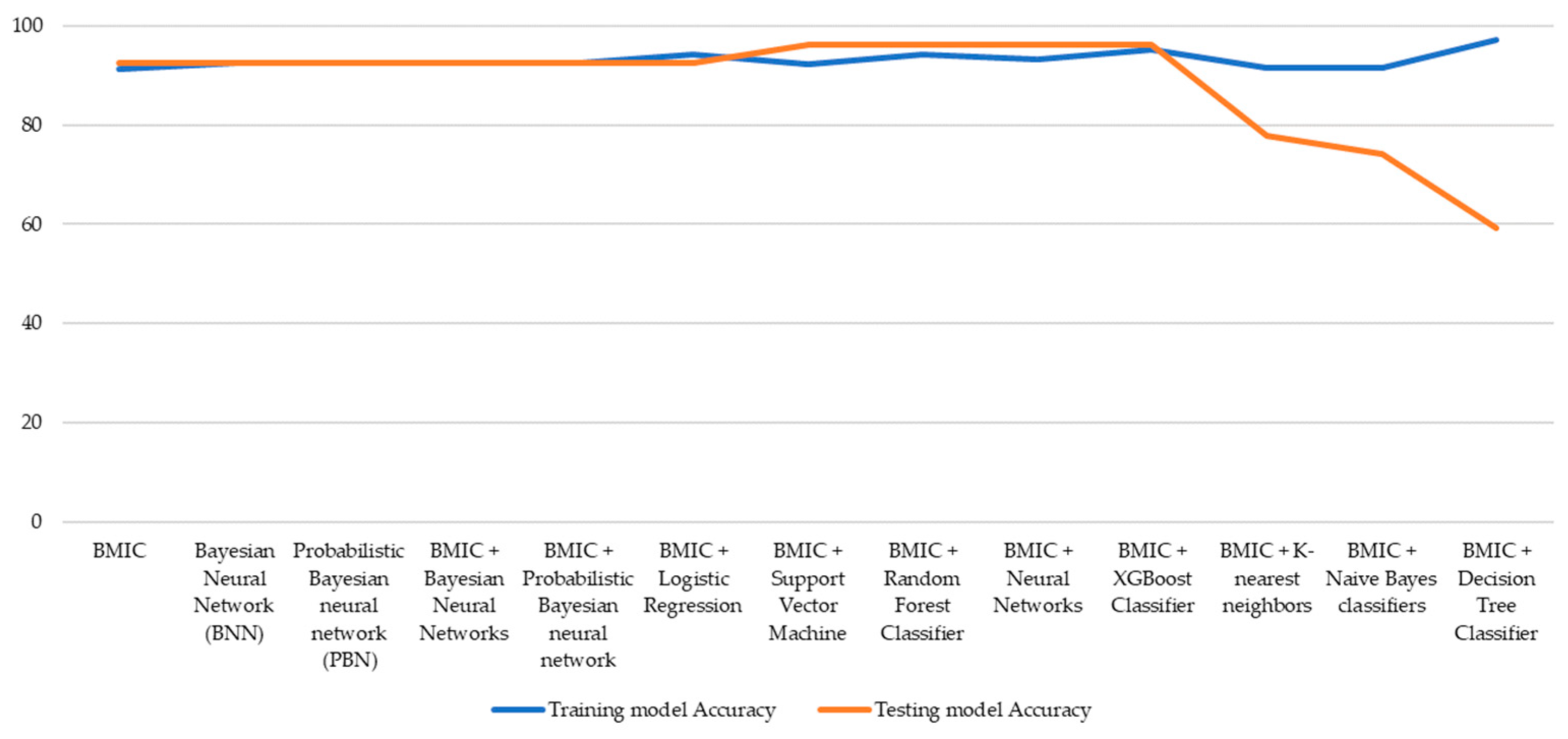
| Models | Training Model Accuracy |
|---|---|
| BMIC | 91.42 |
| Bayesian Neural Network (BNN) | 92.59 |
| Probabilistic Bayesian neural network (PBN) | 92.59 |
| BMIC + Bayesian Neural Networks | 92.59 |
| BMIC + Probabilistic Bayesian neural network | 92.59 |
| BMIC + Logistic Regression | 94.29 |
| BMIC + Support Vector Machine | 92.38 |
| BMIC + Random Forest Classifier | 94.29 |
| BMIC + Neural Networks | 93.33 |
| BMIC + XGBoost Classifier | 95.24 |
| BMIC + K-Nearest Neighbors | 91.43 |
| BMIC + Naive Bayes Classifiers | 91.43 |
| BMIC + Decision Tree Classifier | 97.14 |
| Model | Testing Model Accuracy |
|---|---|
| BMIC | 92.58 |
| Bayesian Neural Network (BNN) | 92.58 |
| Probabilistic Bayesian neural network (PBN) | 92.58 |
| BMIC + Bayesian Neural Networks | 92.59 |
| BMIC + Probabilistic Bayesian neural network | 92.59 |
| BMIC + Logistic Regression | 92.59 |
| BMIC + Support Vector Machine | 96.3 |
| BMIC + Random Forest Classifier | 96.3 |
| BMIC + Neural Networks | 96.3 |
| BMIC + XGBoost Classifier | 96.3 |
| BMIC + K-Nearest Neighbors | 77.77 |
| BMIC + Naive Bayes classifiers | 74.1 |
| BMIC + Decision Tree Classifier | 59.26 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Surapunt, T.; Wang, S. Ensemble Modeling with a Bayesian Maximal Information Coefficient-Based Model of Bayesian Predictions on Uncertainty Data. Information 2024, 15, 228. https://doi.org/10.3390/info15040228
Surapunt T, Wang S. Ensemble Modeling with a Bayesian Maximal Information Coefficient-Based Model of Bayesian Predictions on Uncertainty Data. Information. 2024; 15(4):228. https://doi.org/10.3390/info15040228
Chicago/Turabian StyleSurapunt, Tisinee, and Shuliang Wang. 2024. "Ensemble Modeling with a Bayesian Maximal Information Coefficient-Based Model of Bayesian Predictions on Uncertainty Data" Information 15, no. 4: 228. https://doi.org/10.3390/info15040228
APA StyleSurapunt, T., & Wang, S. (2024). Ensemble Modeling with a Bayesian Maximal Information Coefficient-Based Model of Bayesian Predictions on Uncertainty Data. Information, 15(4), 228. https://doi.org/10.3390/info15040228