1. Introduction
Whether we are talking about the everyday lives of individuals or the daily activities of any organization, digital technology has become a core element of modern society. As the scale of software systems has dramatically grown, the attack surface for cybercriminals has also significantly extended, thus making cybersecurity a top priority.
One approach to defending against such attacks involves determining if a given action is legitimate or malicious, also known as intrusion detection, which often incorporates Machine Learning (ML) techniques. Various methodologies exist for this purpose: one focuses on real-time defense by analyzing data such as networking traffic or system calls from the time the attack is attempted or even ongoing; alternatively, another approach involves analyzing different sources of data left after the attack (e.g., syslog records) [
1]. In our current investigation, we focus on building a tool for security auditing purposes, which anticipates the potential impacts that a vulnerability or series of vulnerabilities may have upon a system, even in the absence of an actual attack. A strong understanding of vulnerabilities is crucial in creating an efficient defense against such threats.
Many large-scale security assessments involve a direct or indirect mapping of vulnerabilities to how they can be exploited. This is needed to understand how to defend against attacks or how exploiting a series of vulnerabilities on different nodes of a wider infrastructure can form a kill chain and what the effects of such an event are. Of course, a team of cybersecurity specialists can perform all these activities manually. However, time is essential in this field, and a delayed response can sometimes be as bad as a total lack of action. This aspect, coupled with the time delay between the moment when a vulnerability is discovered and when the corresponding information is published, results in a critical requirement for a fast and automated manner to better understand vulnerabilities.
To address the challenges of handling the increasingly large number of security flaws, the MITRE Corporation set up two powerful sources of cyber threat and vulnerability information, namely the CVEs list and the MITRE ATT&CK Enterprise Matrix. The CVEs list publicly disclosed computer security flaws. When someone refers to a CVE, they mean a security flaw assigned a CVE ID number [
2]. Each CVE record includes an ID number, a brief description of the security vulnerability, and other references, like vulnerability reports and advisories. ATT&CK stands for MITRE Adversarial Tactics, Techniques, and Common Knowledge. The MITRE ATT&CK framework is a knowledge base and model for cyber adversary behavior. It reflects the various phases of an adversary’s attack life cycle and the platforms they are known to target [
3]. It is a free tool widely adopted by private and public sector organizations of all sizes and industries. Users include security defenders, penetration testers, red teams, cyber threat intelligence teams, and any internal teams interested in building secure systems, applications, and services [
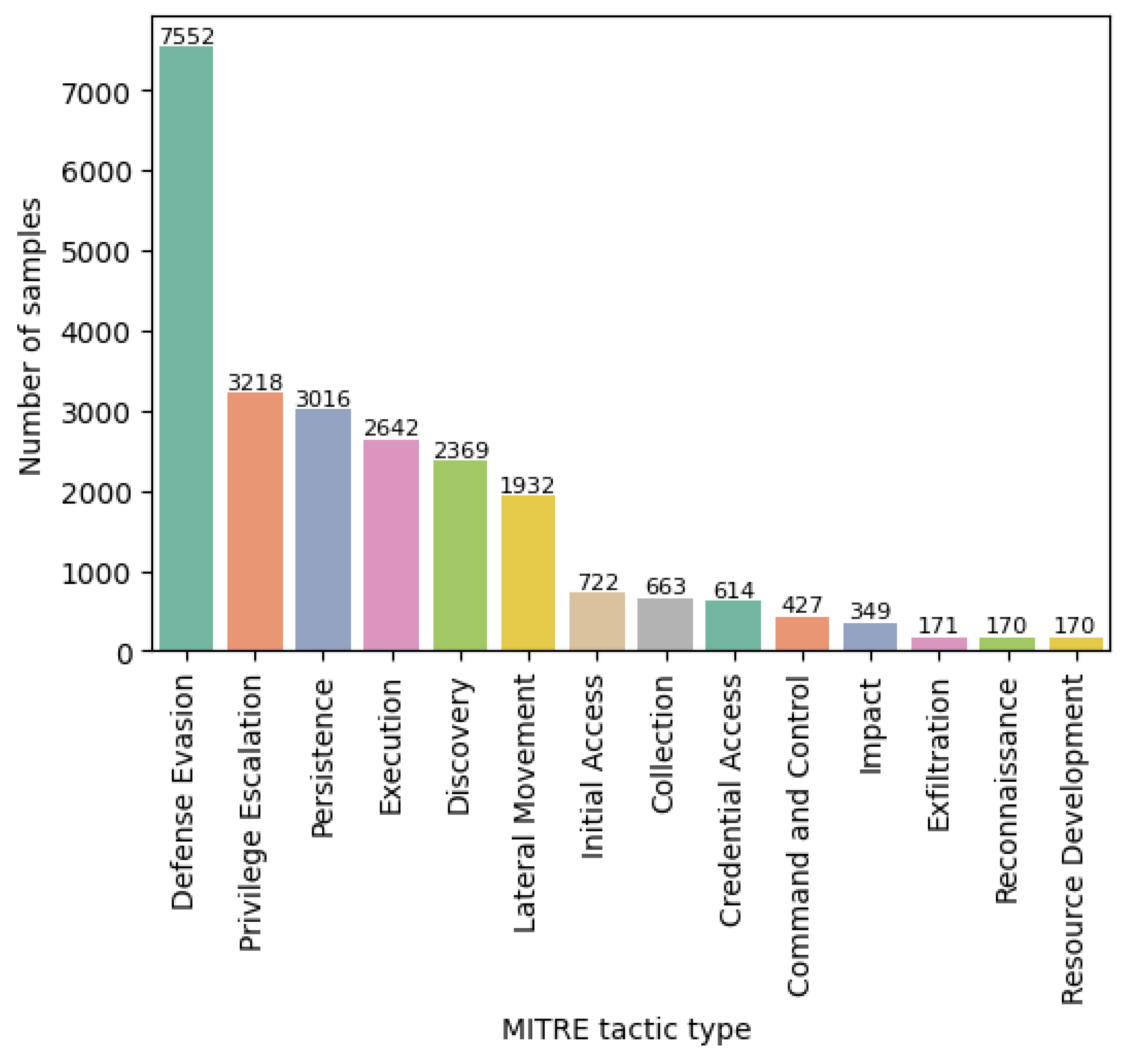
4]. The ATT&CK Enterprise Matrix includes 14 tactics (i.e., Reconnaissance, Resource Development, Initial Access, Execution, Persistence, Privilege Escalation, Defense Evasion, Credential Access, Discovery, Lateral Movement, Collection, Command and Control, Exfiltration, and Impact) listed in a logical sequence, thereby indicating the possible phases of an attack [
3].
Currently, CVEs and the MITRE ATT&CK Matrix are separate entities, even if they are conceptually strongly connected. Linking them leads to a better understanding of the potential risks associated with given vulnerabilities and to the further adoption of better responses and defensive strategies. This mapping facilitates a more systematic and standardized approach to vulnerability management and helps organizations prioritize their mitigation efforts based on known adversary techniques and tactics. One of the main reasons such a link does not exist for now is that building it manually would require a lot of effort and specialized human resources. However, due to the recent progress in ML, mapping the two entities using artificial intelligence became promising.
This study builds on the work of Grigorescu et al. [
5] and aims to automatically map CVEs to the corresponding list of 14 MITRE ATT&CK tactics using state-of-the-art transformer-based models. Instead of addressing the entire collection of 201 possible techniques, we focus on the higher-level task, which is more suitable for practice and provides an overarching view of potential exposure. The initial dataset had several shortcomings regarding a high imbalance and the lack of examples for certain techniques. As such, we now focus on the 14 tactics that have better coverage and a more balanced distribution instead of focusing only on the 31 considered techniques after applying a minimum threshold [
5]. Additionally, Grigorescu et al. [
5] used classical ML models (naïve Bayes classifiers and/or support vector machines) and convolutional neural networks, coupled with older techniques for word embeddings like word2vec, while the current study brings improvements by focusing on newer models and architectures, such as T5 or GPT-4.
The main contributions of this paper are as follows:
We introduce and release a new, extended dataset of 9985 entries (starting from the previous work of Grigorescu et al. [
5] with 1718 entries), with each tactic now having at least 170 samples.
We establish a strong baseline involving various transformer-based architectures ranging from encoder models (e.g., CyBERT and SecBERT) and encoder–decoder models (e.g., TARS and T5) to zero-shot learning, with GPT-4 having been used for solving the multilabel tactic classification task;
We perform an in-depth results analysis to better understand the models’ performance and limitations.
The paper is structured as follows:
Section 2 presents the related work regarding vulnerability classification based on the MITRE matrix. Further on, we present our method, including our dataset and the employed models. We used three types of transformer architectures, namely encoder (represented by SecBERT, CyBERT, and SecRoBERTa), encoder–decoder (represented by TARS and T5), and decoder only (GPT-4). We then present and discuss our results and, in the end, show our conclusion and our directions for future work.
4. Results
All the previously described architectures that involved training (i.e., CyBERT, SecBERT, SecRoBERTa, TARS, and T5) were evaluated on both validation (
Table 4) and testing datasets (
Table 5). The GPT-4 experiments performed in a zero-shot setting were only conducted once for the static testing dataset (20% of the available data). More precisely, based on the initial splits computed with respect to the constant tactic distribution, the validation results were computed after crossvalidation experiments on the train and validation common set, thereby representing 80% of all the available data. During the validation experiments, the best parameters (e.g., learning rate) were established. Each model was trained four times on 60% of the available data and also evaluated each time on 20% of the available data, with the reported data from
Table 4 being the average of the four results and the standard deviation being computed for each metric. The validation results (
Table 4) have highlighted the stability and consistency of the models while being trained and validated on different data subsets. The standard deviation (SD) for all the computed metrics was less than 4.5%, thereby indicating a small variability among the models and therefore arguing for their reliability.
Next, the models trained on the four variable training subsets from the previously described validation experiments were tested on the static testing set. Moreover, in order to take advantage of as much data as possible, with the perspective of deploying the models in the future, a fifth experiment was executed, with training on the whole training and validation set (i.e., 80% of available data) and testing on the static test set. The reported results from
Table 5 represent the average of these five experiments and the standard deviation for each metric.
The best weighted F1 score for both validation (77.65%) and testing experiments (78.88%) was achieved by SecRoBERTa, by a very close margin, which was closely followed by SecBERT and CyBERT. Both TARS experiments exhibited a slightly smaller weighted F1 score but a better F1 macro score on the validation experiments, thus indicating that, given the information of what a tactic means, TARS may be less influenced by the strong dataset imbalance. Another interesting aspect is that, in multiple validation runs, the short-label TARS experiment showed better results than the long-label experiments, which is counterintuitive, as the former offered the model more context about what each tactic means. T5, on the other hand, showed lower performance on all metrics.
Table 6 highlights the per-tactic results for our best-performing model, SecRoBERTa. The reported results were computed after training the model on the whole training and validation dataset and testing on the fixed test dataset.
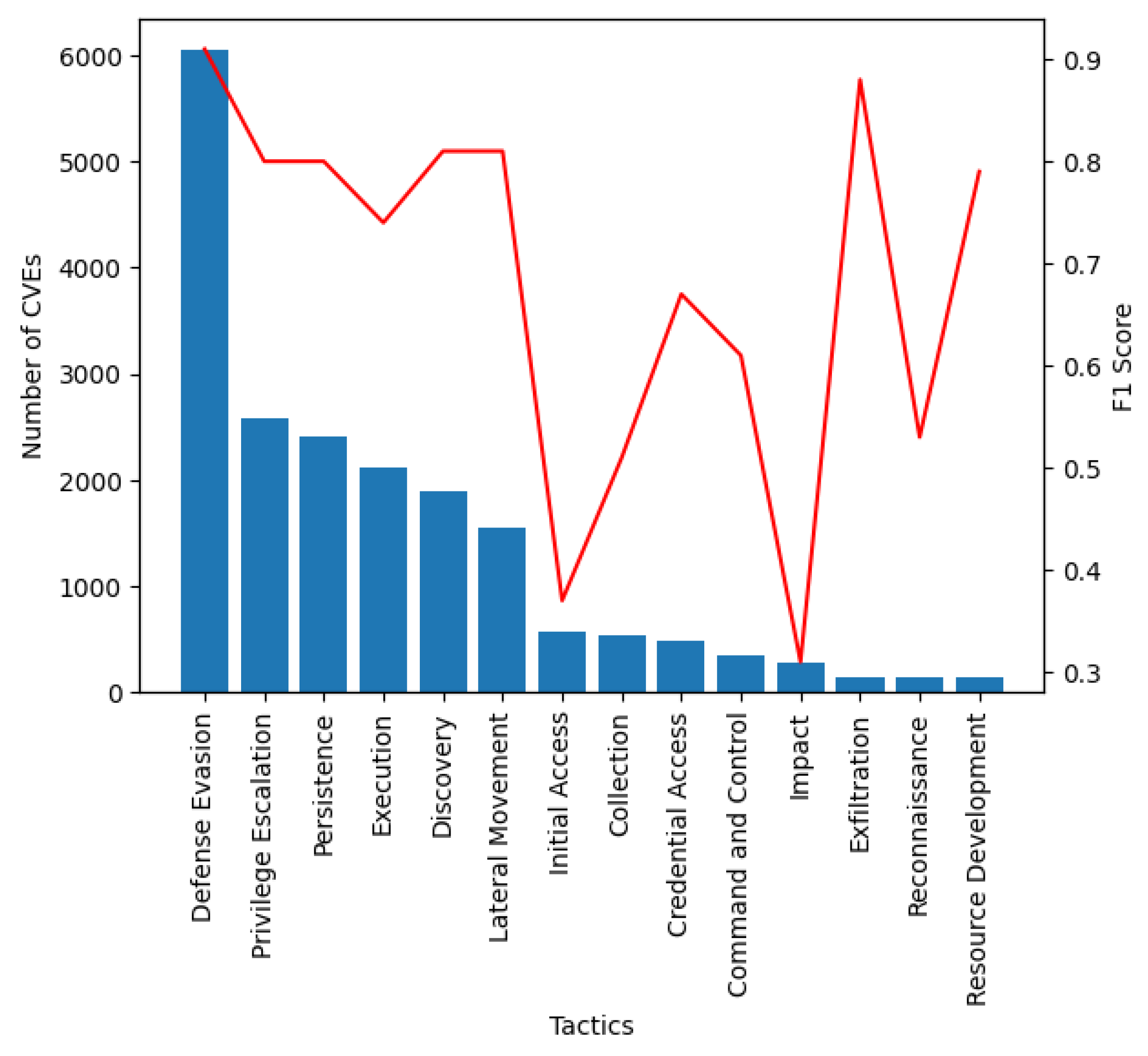
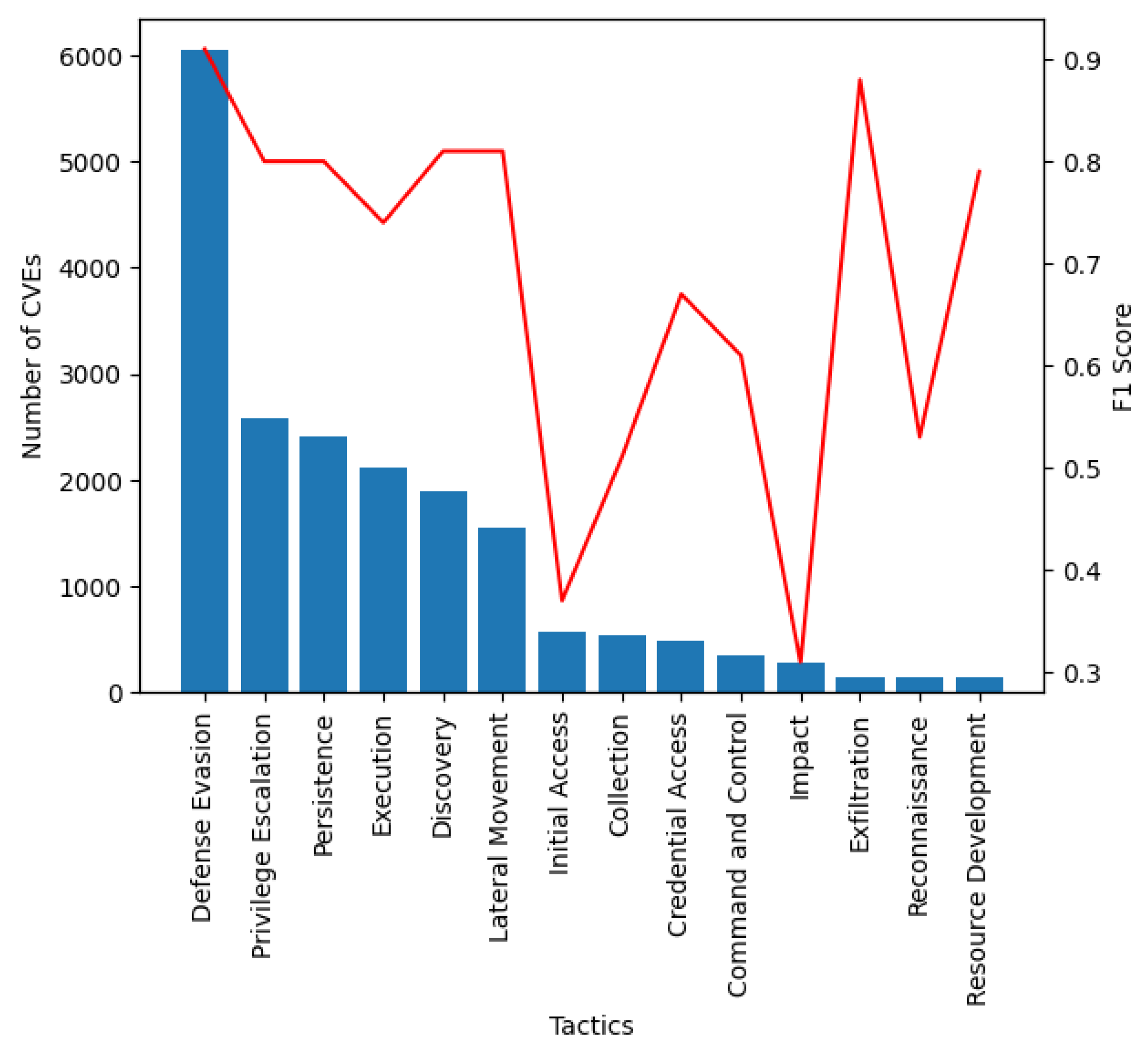
Figure 4 highlights the correlation between the per-class F1 score and the number of samples from the training dataset. As expected from the imbalance in the dataset, the best F1 score was obtained for the dominating class, namely Defense Evasion (F1 score of 91.66%). However, the next most frequent classes (Privilege Escalation, Persistence, Execution, Discovery, and Lateral Movement) also showed promising results, with F1 scores of over 74%. Despite being less-frequent classes, Exfiltration and Resource Development showed good F1 scores of 88.88% and 79.13%. Weaker results were registered for Initial Access and Impact, with F1 score slightly over 30%. For the best experiment, we have also computed the weighted accuracy having a value of 89.52% and the accuracy score (computed using the subsets accuracy) having a value of 65.34%. The reason why these two metrics have different values is that in multilabel classification, the subset accuracy takes into account that the set of labels predicted for a sample must exactly match the corresponding set of labels [
31].
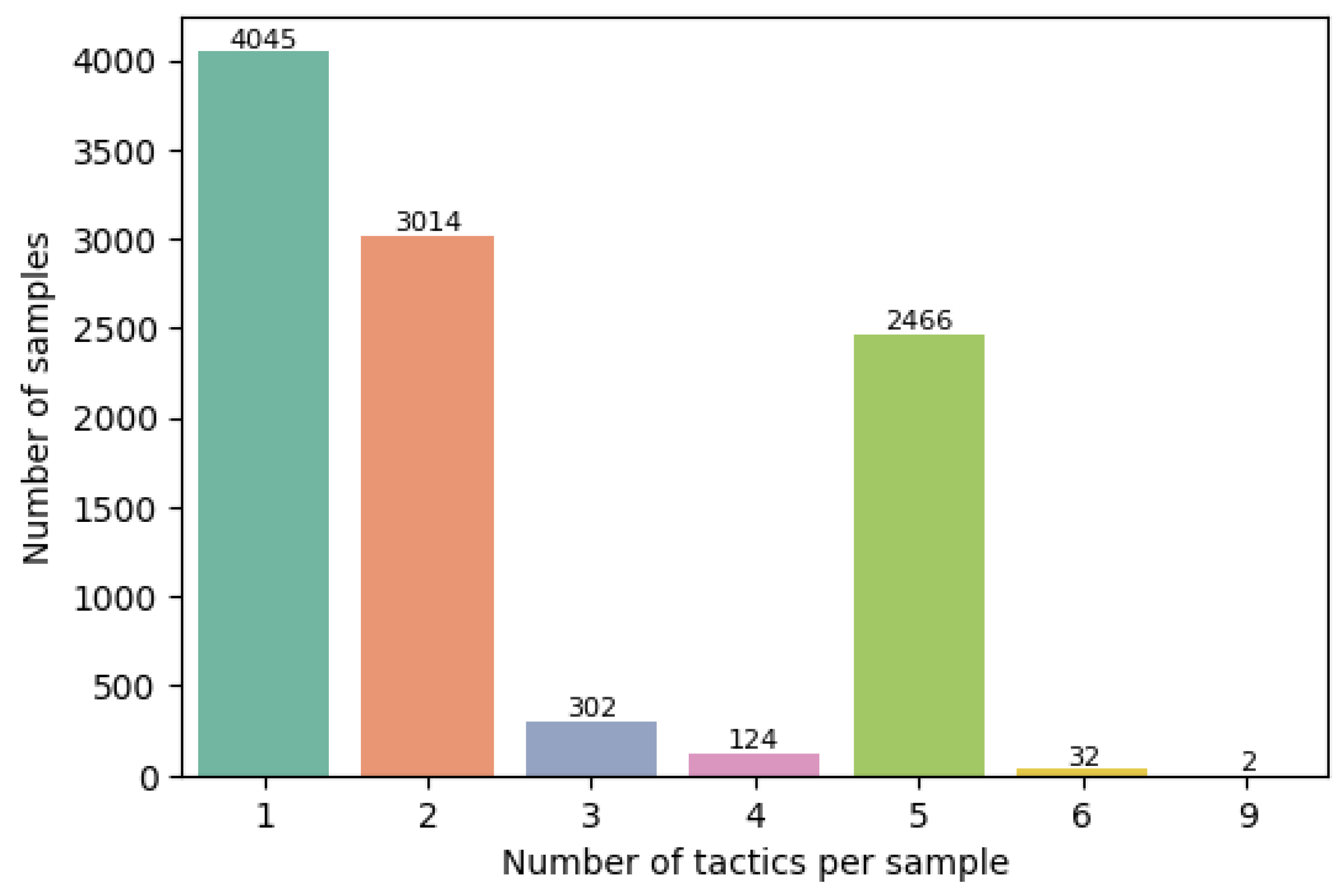
Given the relatively large number of classes for the current multilabel classification task (14), the macro F1 score of 68.67%, which gives equal value to each class, shows that even if the model naturally has the tendency to better classify the class with the largest number of samples, it still differentiates between the rest of the classes, thus extracting relevant linguistic features from the CVE’s description.
As shown in
Table 5, GPT-4 exhibited weak performance in a zero-shot setup compared to the fine-tuned models. Adding a short description of each tactic in the prompt did not improve the results, thereby leading to slightly worse performance. The imbalanced dataset did not influence GPT-4’s performance; nevertheless, its F1 macro score was much lower than those from the prior experiments, thereby confirming that the current task is a difficult one even for such large language models as GPT-4.
5. Discussion
The top performance models were SecRoBERTa (F1 weighed: 78.88%), SecBERT (F1 weighed: 78.77%), and TARS (F1 weighed: 78.10%). For the well- and medium-represented classes, the per-class F1 score had satisfactory values, with some variations depending on the model. However, it is visible that the models were extracting valuable information from training and learning in some measure to map those tactics, thereby indicating significant potential regarding the information that can be extracted from a CVE’s textual description.
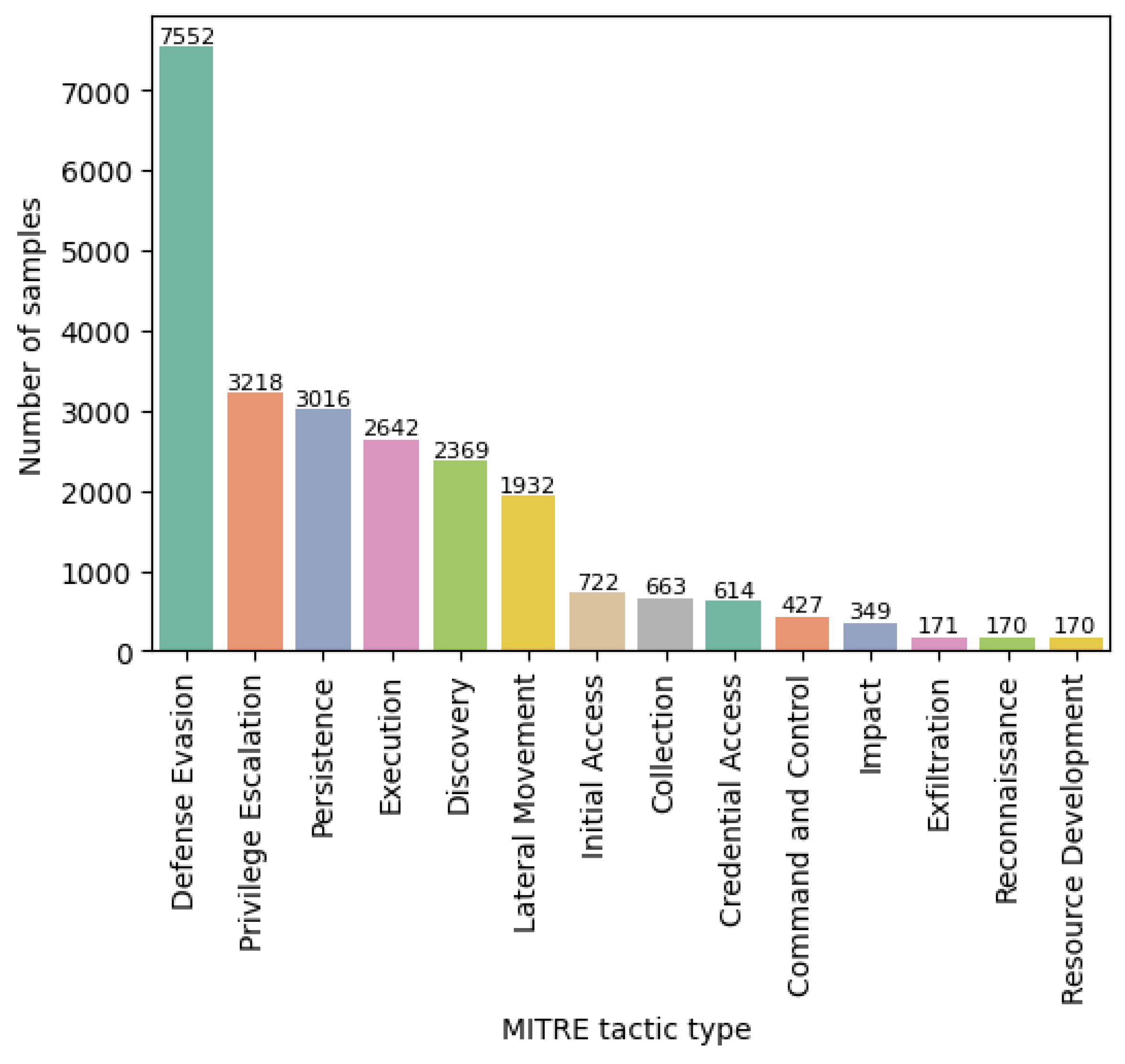
The fine-tuned models still had minor problems when tackling the high off-balance between the classes (i.e., 171 samples compared to 7552 samples for the most frequent one). Also, the results obtained for the Defense Evasion tactic were influenced by the very large amount of data for this class, as the models inherently tended to have a bias toward predicting the majority tactic. For the confusion with Defense Evasion, a more balanced dataset would be necessary, because Defense Evasion tended to dominate, and the class appeared even when it was not applicable. Adding synthetic data by augmenting the existing data (e.g., using TextAttack [
32] or state-of-the-art LLMs like GPT-4) from the under-represented classes was considered, but given the specialized cybersecurity terms and the relatively fixed structure of a CVE, this technique would not have provided realistic additional information for the models.
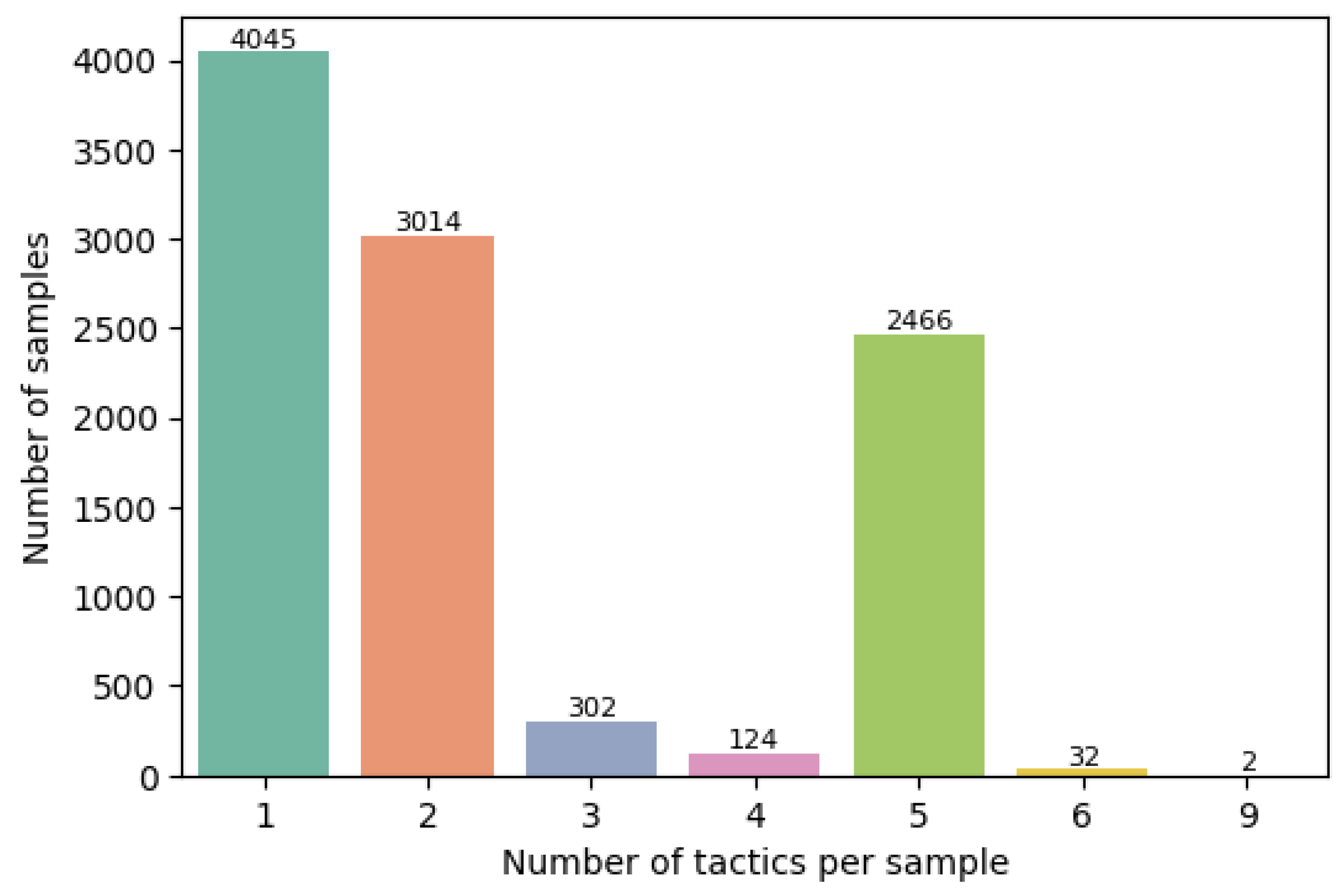
Our best model had problems identifying two classes (i.e., Initial Access and Impact), for which its F1 scores were below 50%. The precision score was over 65%; thus, when the model predicted these tactics, it was usually right, but these classes had a low recall score under 25%, thereby reflecting that the model frequently missed them. Given the multilabel task, sometimes the model predicted a smaller number of tactics for those entries with multiple associated tactics, thereby ignoring tactics like Initial Access or Impact. Other times, it confused the previously two mentioned tactics with other tactics. Upon closer inspection, the model had problems discriminating between Initial Access and Defense Evasion, as well as between Impact and Credential Access. The first confusion might come from the fact that both tactics usually take advantage of public-facing services, with Initial Access being an intermediary step needed for the attacker to enter a context where avoiding detection is actually needed. The second confusion can also be explained by the conceptual link between tactics like Impact, which involves compromising the integrity of a system, and Credential Access, which involves obtaining sensitive data that leads to the system’s compromise.
MITRE states that the Impact tactic consists of techniques that adversaries use to disrupt availability or compromise integrity by manipulating business and operational processes. As such, we infer that reaching Impact can occur following the malicious acquisition of credentials, thereby suggesting a causal relationship between the two tactics. Providing more examples of Impact, especially ones not related to credentials since it is one of the rarer classes, would be beneficial in avoiding this confusion.
Given our multilabel class, computing a single 14 × 14 confusion matrix was not possible; instead, 142 × 2 confusion matrixes containing the number of true positive, true negative, false positive, and false negative samples for the best model were computed using multilabel_confusion_matrix from sklearn [
33] (additional tables are presented in
Appendix A).
Furthermore, it is interesting to note that GPT-4 only had F1 scores of over 50% for Discovery, Privilege Escalation, and Exfiltration. This shows that for a specific classification task such as ours, a very large, generative model might have, in zero-shot settings, a surprisingly poor performance, being much lower than significantly smaller, fine-tuned models.
Error Analysis
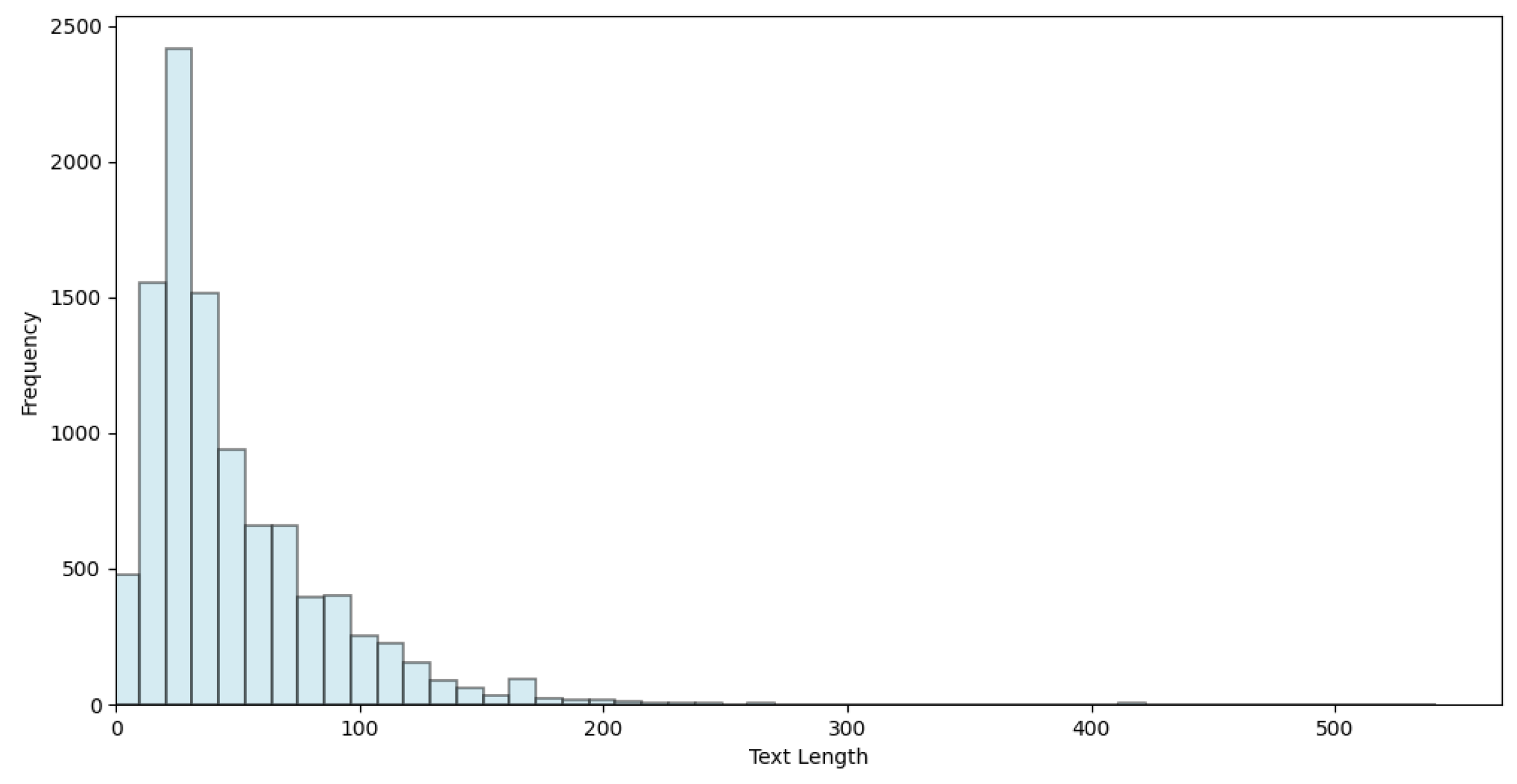
Table 7 shows different predictions of the best model, from fully correct classifications to only partially correct classifications and, finally, completely wrong classifications. As illustrated, some CVEs contain much more information than others, thereby making the classification difficult for those with very short text. Especially for these cases, adding more data beyond the sole CVE textual description would be helpful. We have extended the initial dataset and integrated data from ENISA (details in
Section 3.1). We have observed that, in time, other organizations (e.g., ENISA) have publicly released precisely the required data. Hence, it is possible that this could occur again in the future, thus allowing us to incorporate new data from such sources. Another envisioned approach is to explore semisupervised learning, as proposed in the future work section, which leverages the abundance of unlabeled CVEs.
Moreover, the model tended to correctly classify some tactics based on more semantically obvious keywords, like ‘execute’. In many CVE descriptions, the word ‘execute’ appears, thus making it easier for the model to classify the respective CVE as Execution. The same happens for CVEs containing the words ‘authenticated’ (which tend to be classified as Privilege Escalation) and ‘credentials’ (which tend to be classified as Credentials Access) without considering the actual deeper meanings of the CVE. This aspect, coupled with the fact that some vulnerabilities have similar texts with similar affected software (e.g., ‘Oracle Java SE ’ and ‘Cisco Web Security ’), makes it easier to confuse the model based on non-necessarily relevant text sequences.
However, many vulnerabilities are indeed interpretable, as their correct labels are highly influenced by the labeling methodology. This happens because many tactics are also conceptually linked, thereby making it difficult to derive a tactic sequence only from the textual description. The most direct manner to solve this issue is to manually label more data to focus on the classes with low performance. Unfortunately, this is not a trivial task, as such CVEs are less frequent in the wild and are likely coupled with a more popular tactic.
Author Contributions
Conceptualization, O.G., I.B. and M.D.; methodology, O.G. and M.D.; software, I.B.; validation, O.G., I.B. and M.D.; formal analysis, O.G., I.B. and M.D.; investigation, I.B., O.G. and M.D.; resources, O.G. and I.B.; data curation, I.B.; writing original draft, I.B. and O.G.; writing—review and editing, M.D.; visualization, I.B.; supervision, M.D.; project administration, M.D.; funding acquisition, M.D. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by a grant from the Romanian National Authority for Scientific Research and Innovation, CNCS—UEFISCDI, project number 2PTE/2020, YGGDRASIL—“Automated System for Early Detection of Cyber Security Vulnerabilities”.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Acknowledgments
We would like to show our gratitude to Ioana Nedelcu, Ciprian Stanila, and Andreea Nica for their contributions to building the labeled CVE corpus. We would also like to show our gratitude to Ioana Raluca Zaman for her suggestions and final improvements.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ATT&CK | Adversarial Tactics, Techniques, and Common Knowledge |
| BiLSTM | Bidirectional Long Short-Term Memory |
| BERT | Bidirectional Encoder Representations from Transformers |
| CVE | Common Vulnerabilities and Exposures |
| CVET | Common Vulnerabilities and Exposures Transformer |
| CyBERT | Cybersecurity BERT |
| GPT | Generative Pretrained Transformer |
| LSTM | Long-Short Term Memory |
| ML | Machine Learning |
| MLM | Masked Language Modeling |
| NIST | National Institute of Standards and Technology |
| NLP | Natural Language Processing |
| FN | False Negative |
| FP | False Positive |
| RNN | Recurrent Neural Network |
| RoBERTa | Robustly Optimized Bidirectional Encoder Representations from
Transformers Approach |
| SD | Standard Deviation |
| SecBERT | Security BERT |
| SecRoBERTa | Security RoBERTa |
| SVM | Support Vector Machine |
| TARS | Task-Aware Representation of Sentences |
| TN | True Negative |
| TP | True Positive |
| T5 | Text-to-Text Transfer Transformer |
References
- Ishaque, M.; Gapar, M.; Johar, M.; Khatibi, A.; Yamin, M. Hybrid deep learning based intrusion detection system using Modified Chicken Swarm Optimization algorithm. ARPN J. Eng. Appl. Sci. 2023, 18, 1707–1718. [Google Scholar] [CrossRef]
- MITRE. 2023. Available online: https://www.mitre.org/ (accessed on 20 June 2023).
- What Is the MITRE ATT&CK Framework. 2021. Available online: https://www.trellix.com/security-awareness/cybersecurity/what-is-mitre-attack-framework/ (accessed on 20 June 2023).
- Walkowski, D. MITRE ATT&CK: What It Is, How it Works, Who Uses It and Why. Available online: https://www.f5.com/labs/learning-center/mitre-attack-what-it-is-how-it-works-who-uses-it-and-why (accessed on 20 June 2023).
- Grigorescu, O.; Nica, A.; Dascalu, M.; Rughinis, R. CVE2ATT&CK: BERT-Based Mapping of CVEs to MITRE ATT&CK Techniques. Algorithms 2022, 15, 314. [Google Scholar] [CrossRef]
- MITRE-Engenuity. Mapping ATT&CK to CVE for Impact. 2021. Available online: https://mitre-engenuity.org/blog/2021/10/21/mapping-attck-to-cve-for-impact/ (accessed on 20 June 2023).
- Baker, J. CVE + MITRE ATT&CK® to Understand Vulnerability Impact. 2021. Available online: https://medium.com/mitre-engenuity/cve-mitre-att-ck-to-understand-vulnerability-impact-c40165111bf7 (accessed on 20 June 2023).
- Baker, J. Mapping MITRE ATT&CK® to CVEs for Impact. 2021. Available online: https://github.com/center-for-threat-informed-defense/attack_to_cve (accessed on 20 June 2023).
- Kuppa, A.; Aouad, L.M.; Le-Khac, N. Linking CVE’s to MITRE ATT&CK Techniques. In Proceedings of the ARES 2021: The 16th International Conference on Availability, Reliability and Security, Vienna, Austria, 17–20 August 2021; Reinhardt, D., Müller, T., Eds.; ACM: New York, NY, USA, 2021; pp. 21:1–21:12. [Google Scholar] [CrossRef]
- Ampel, B.; Samtani, S.; Ullman, S.; Chen, H. Linking Common Vulnerabilities and Exposures to the MITRE ATT&CK Framework: A Self-Distillation Approach. arXiv 2021, arXiv:2108.01696. [Google Scholar] [CrossRef]
- Haddad, A.; Aaraj, N.; Nakov, P.; Mare, S.F. Automated Mapping of CVE Vulnerability Records to MITRE CWE Weaknesses. arXiv 2023, arXiv:2304.11130. [Google Scholar] [CrossRef]
- ENISA State of Vulnerabilities 2018 2019 Report. 2019. Available online: https://www.enisa.europa.eu/publications/technical-reports-on-cybersecurity-situation-the-state-of-cyber-security-vulnerabilities/ (accessed on 23 February 2023).
- ENISA State of Vulnerabilities 2018 2019 Report GitHub. 2019. Available online: https://github.com/enisaeu/vuln-report?tab=readme-ov-file/ (accessed on 18 February 2023).
- Iterative-Stratification. 2023. Available online: https://pypi.org/project/iterative-stratification/ (accessed on 25 October 2023).
- Sechidis, K.; Tsoumakas, G.; Vlahavas, I.P. On the Stratification of Multi-label Data. In Proceedings of the ECML/PKDD, Athens, Greece, 5–9 September 2011. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.U.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186, Long and Short Papers. [Google Scholar]
- OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv 2019, arXiv:1910.10683. [Google Scholar] [CrossRef]
- SecBERT. 2023. Available online: https://huggingface.co/jackaduma/SecBERT (accessed on 24 October 2023).
- SecRoBERTa. 2023. Available online: https://huggingface.co/jackaduma/SecRoBERTa (accessed on 24 October 2023).
- CyBERT. 2023. Available online: https://huggingface.co/jenfung/CyBERT-Base-MLM-v1.1 (accessed on 24 October 2023).
- Aghaei, E.; Niu, X.; Shadid, W.; Al-Shaer, E. SecureBERT: A Domain-Specific Language Model for Cybersecurity. arXiv 2022, arXiv:2204.02685. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arxiv 2019, arXiv:1907.11692. [Google Scholar]
- Ranade, P.; Piplai, A.; Joshi, A.; Finin, T. CyBERT: Contextualized Embeddings for the Cybersecurity Domain. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; Chen, Y., Ludwig, H., Tu, Y., Fayyad, U.M., Zhu, X., Hu, X., Byna, S., Liu, X., Zhang, J., Pan, S., et al., Eds.; IEEE: Piscataway, NJ, USA, 2021; pp. 3334–3342. [Google Scholar] [CrossRef]
- Pytorch. BCE with Logit Loss. 2023. Available online: https://pytorch.org/docs/stable/generated/torch.nn.BCEWithLogitsLoss.html (accessed on 25 October 2023).
- Halder, K.; Akbik, A.; Krapac, J.; Vollgraf, R. Task-Aware Representation of Sentences for Generic Text Classification. In Proceedings of the 28th International Conference on Computational Linguistics, COLING 2020, Barcelona, Spain, 8–13 December 2020; Scott, D., Bel, N., Zong, C., Eds.; International Committee on Computational Linguistics: New York, NY, USA, 2020; pp. 3202–3213. [Google Scholar] [CrossRef]
- OpenAI API. 2023. Available online: https://openai.com/blog/openai-api (accessed on 20 June 2023).
- Flair Framework. 2023. Available online: https://github.com/flairNLP/flair (accessed on 25 October 2023).
- T5. 2023. Available online: https://huggingface.co/transformers/v3.0.2/model_doc/t5.html (accessed on 28 October 2023).
- Accuracy Classification Score. 2024. Available online: https://scikit-learn.org (accessed on 5 April 2023).
- Morris, J.X.; Lifland, E.; Yoo, J.Y.; Grigsby, J.; Jin, D.; Qi, Y. TextAttack: A Framework for Adversarial Attacks, Data Augmentation, and Adversarial Training in NLP. arXiv 2020, arXiv:2005.05909. [Google Scholar]
- Multilabel Confusion Matrix. 2023. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.multilabel_confusion_matrix.html (accessed on 23 February 2023).
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




{kind=link}
{kind=link}
{kind=link}
{kind=link}