
LighterFace Model for Community Face Detection and Recognition

 ,
,
Abstract
1. Introduction
2. Materials and Methods
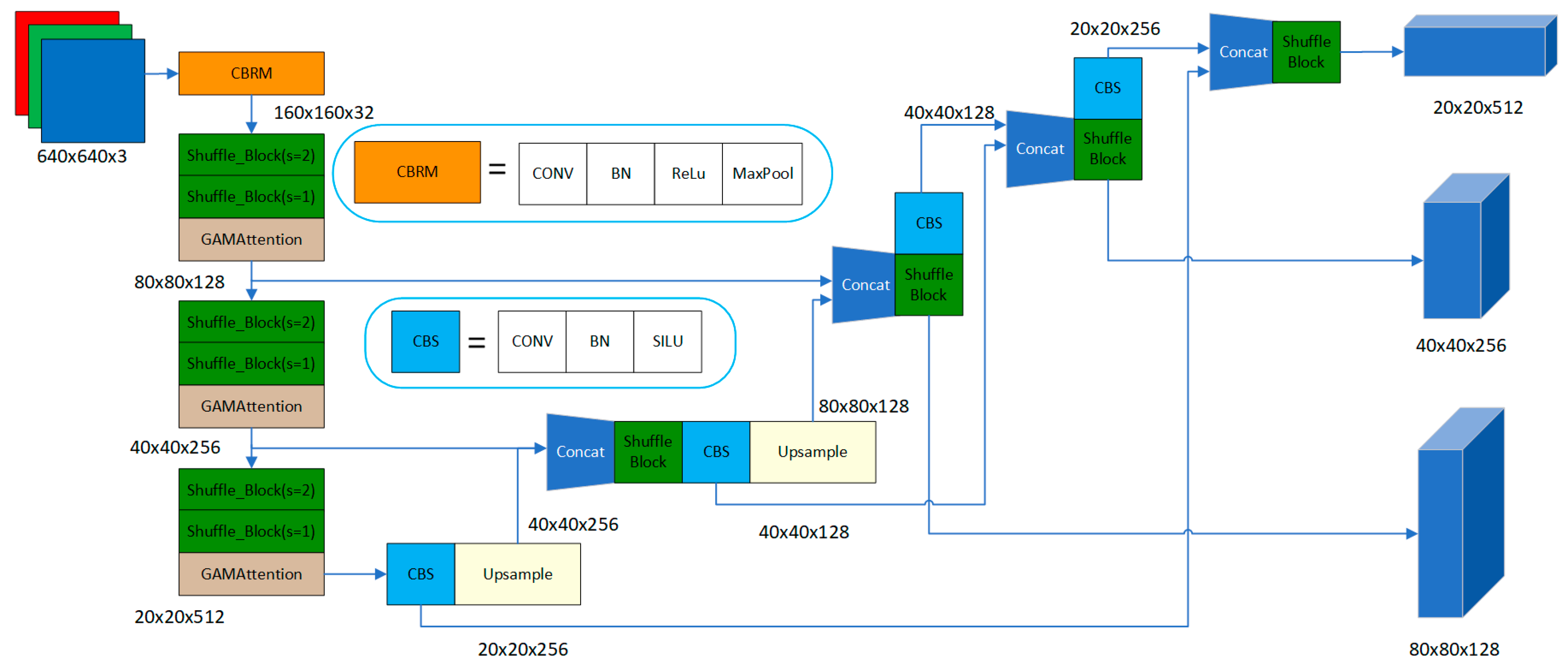
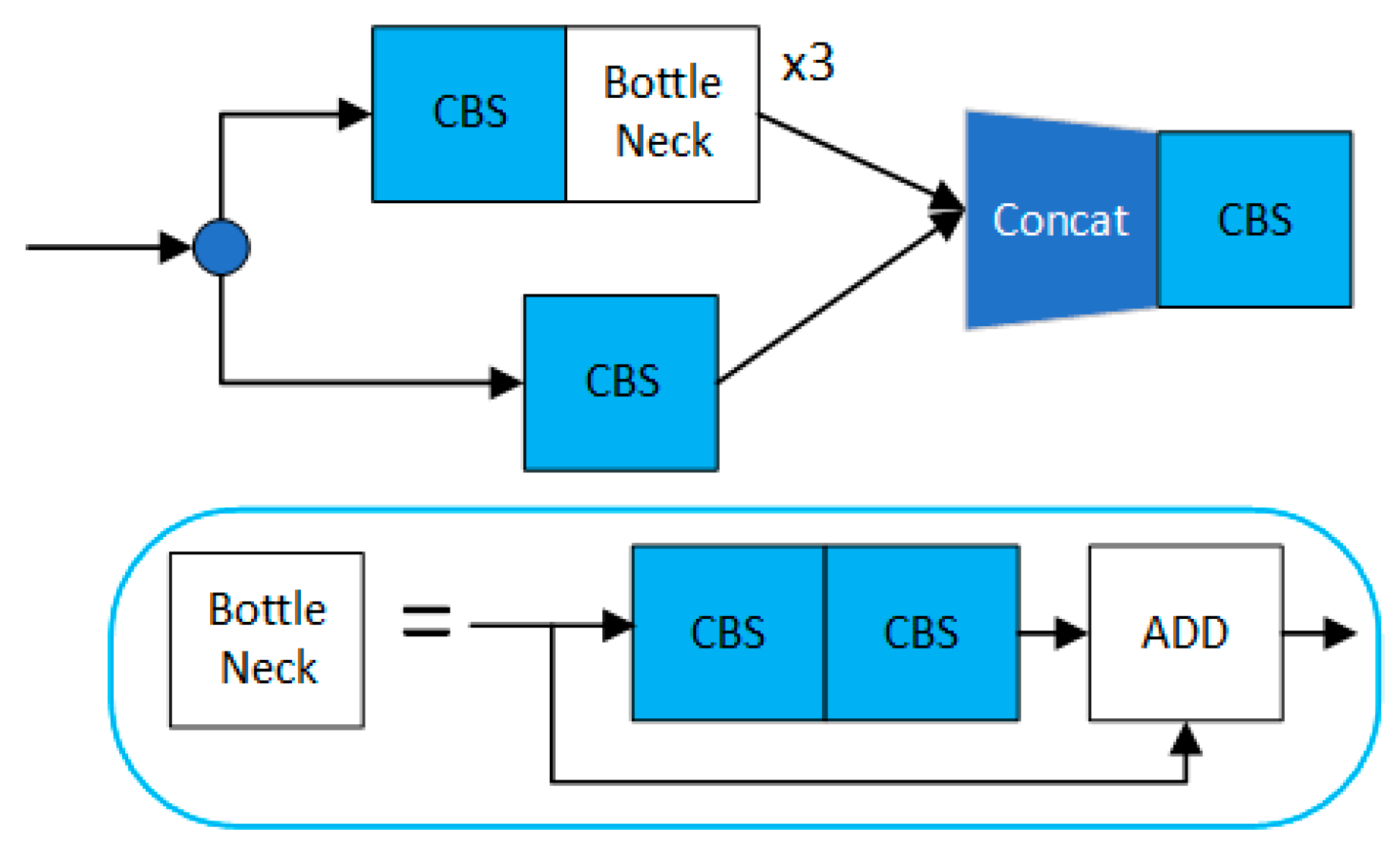
2.1. Face Detection Model
2.1.1. CBRM Module Structure
- i.
- Equal channel width minimizes Memory Access Cost (MAC);
- ii.
- Excessive group convolution increases MAC;
- iii.
- Network fragmentation reduces the degree of parallelism;
- iv.
- Element-wise operations are non-negligible.
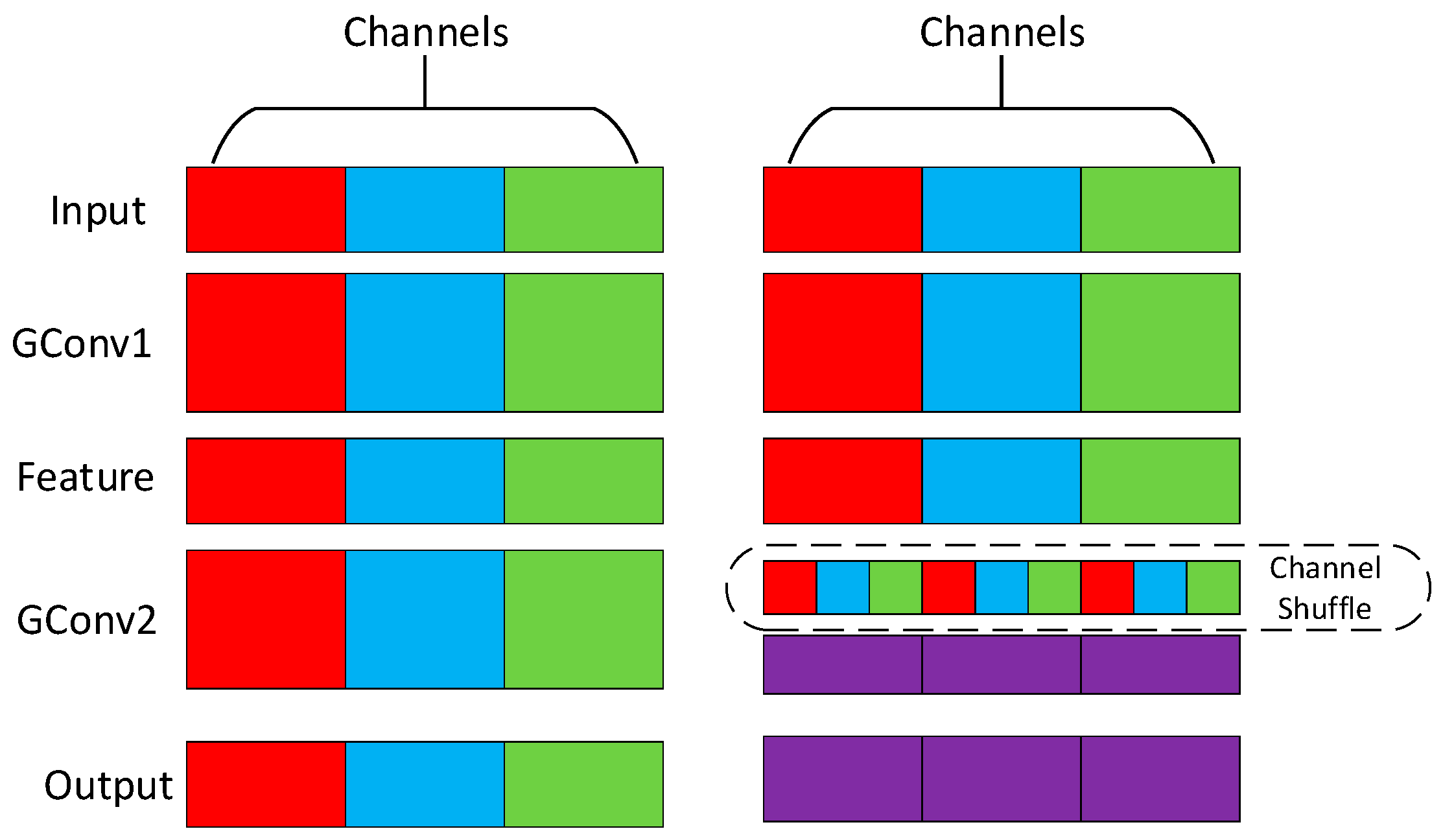
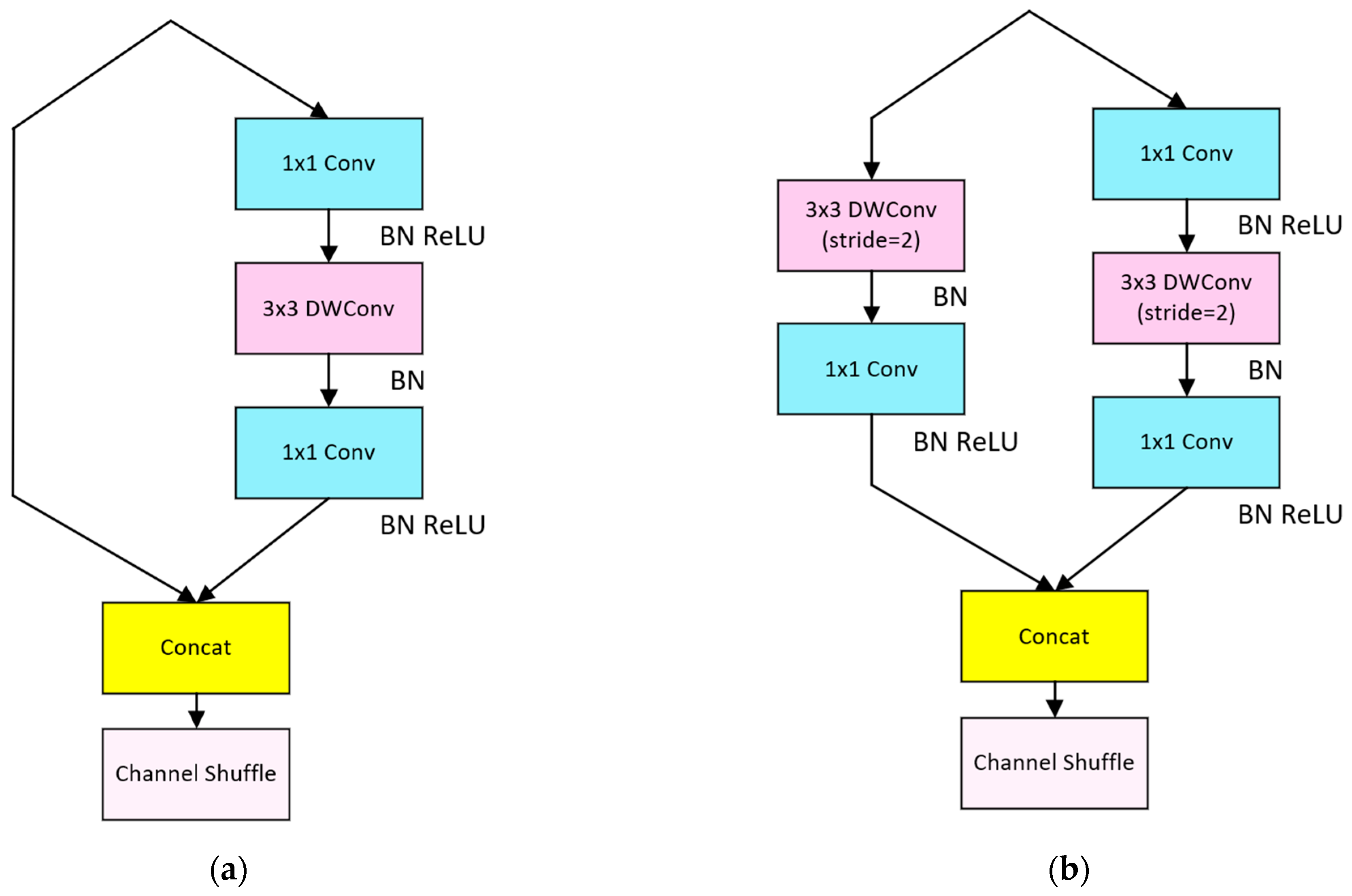
2.1.2. ShuffleBlock
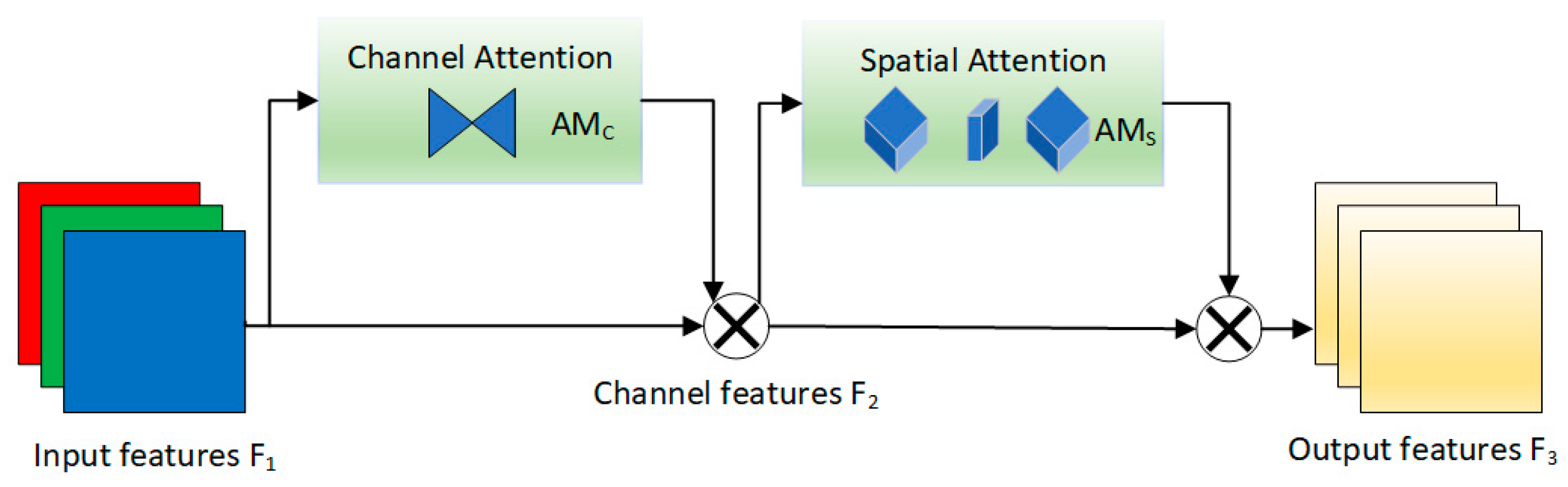
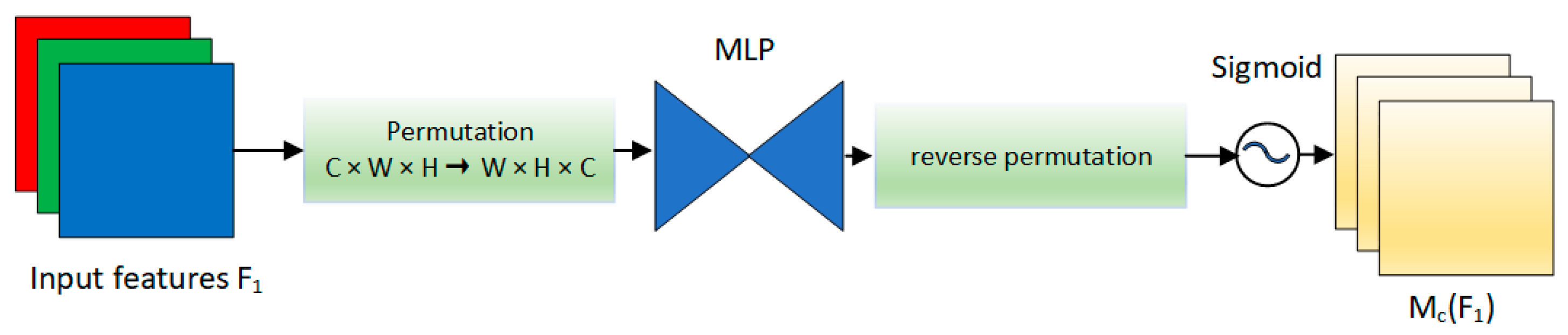
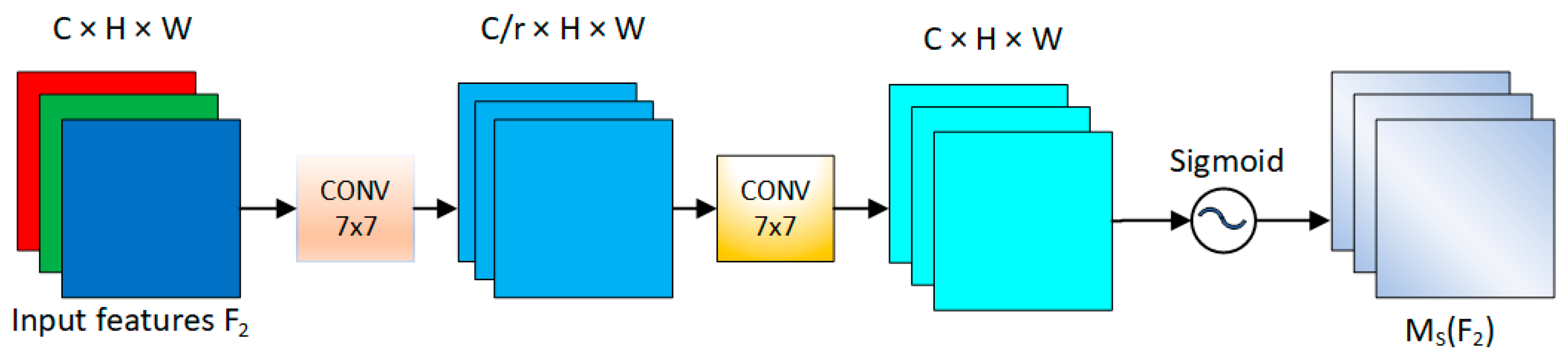
2.1.3. GAMAttention
2.1.4. Loss Function
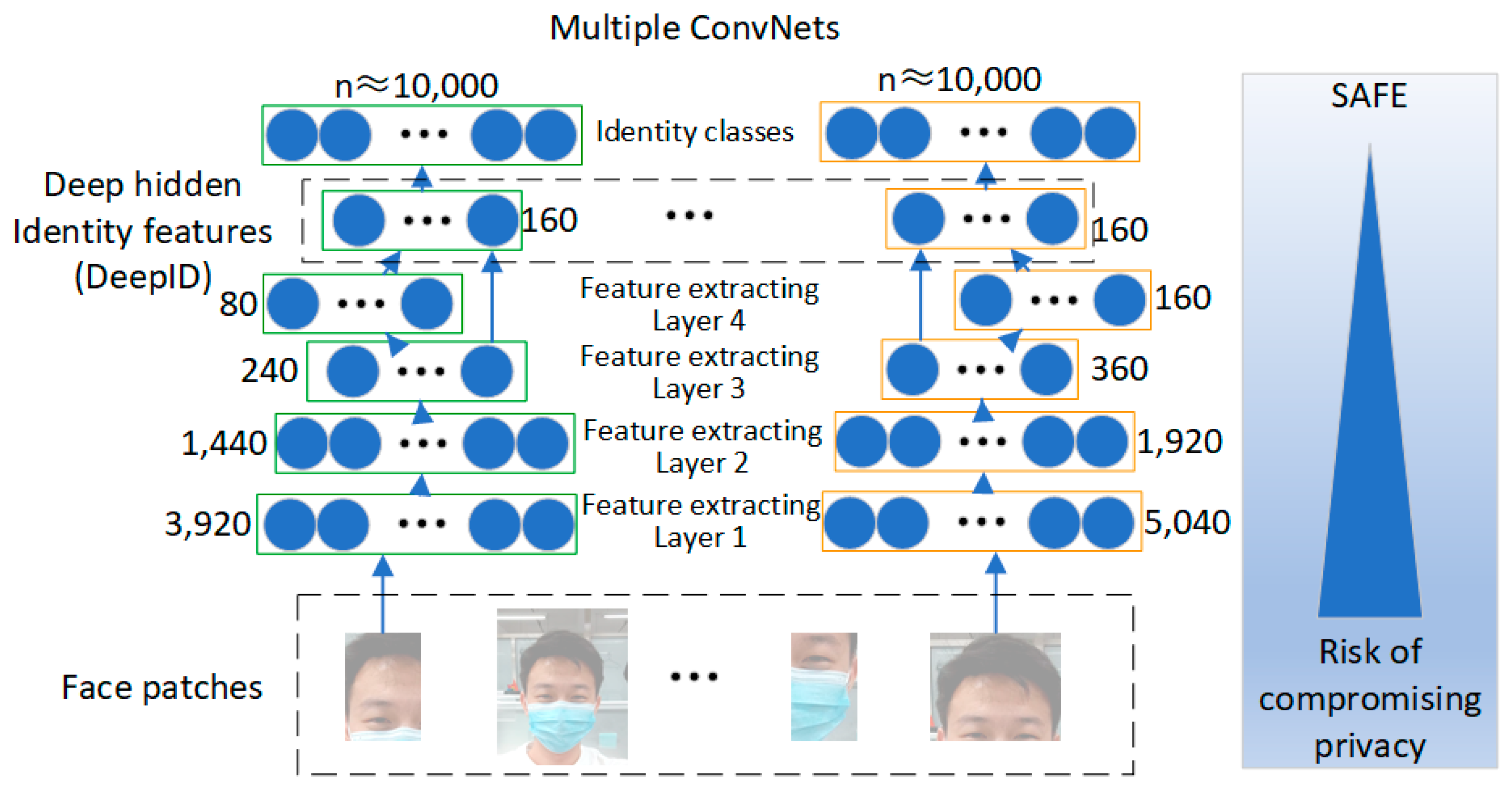
2.2. Face Feature Extraction DeepID
2.2.1. Network Infrastructure
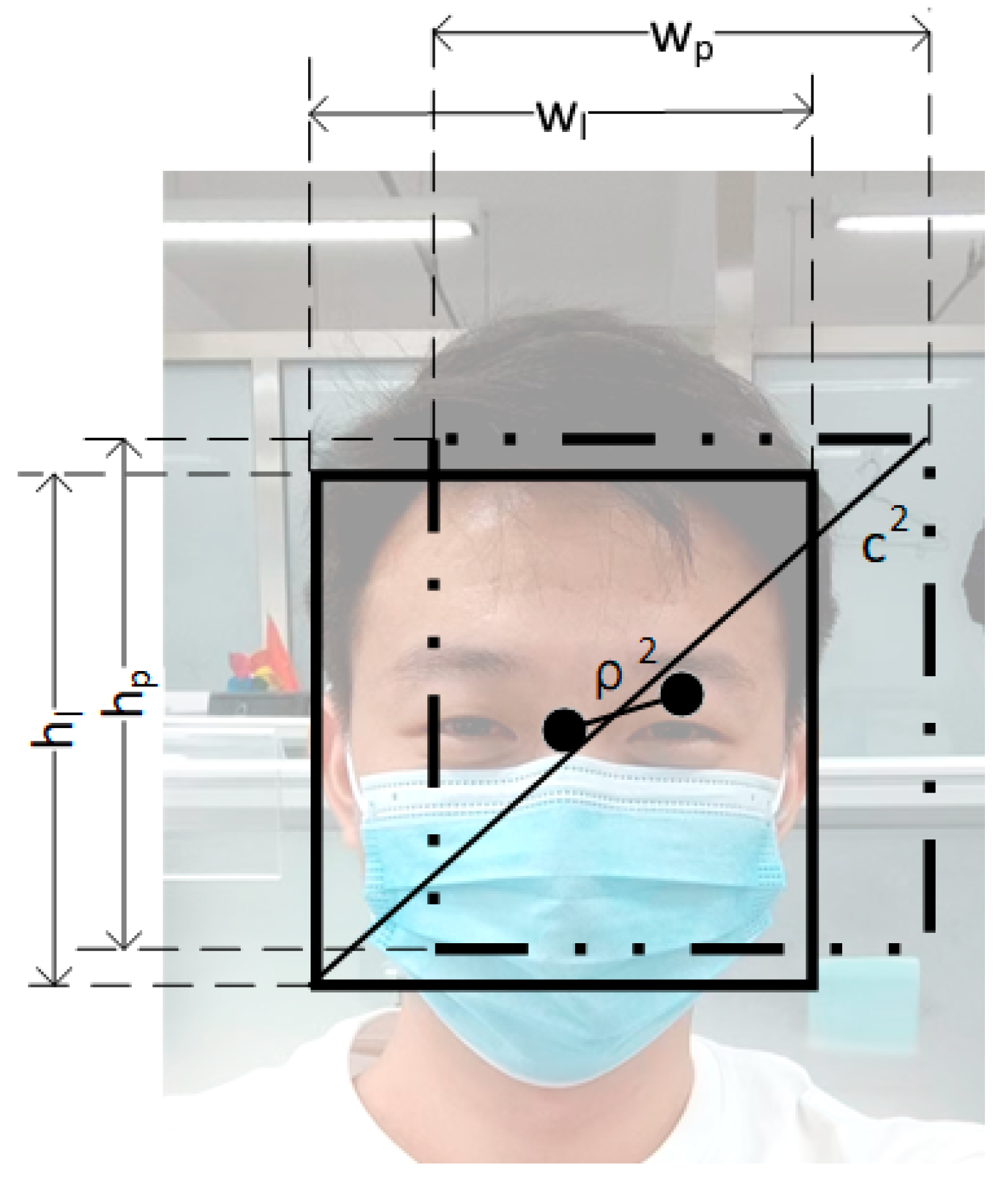
2.2.2. Face Privacy Protection
3. Experiment and Discussion
3.1. Datasets
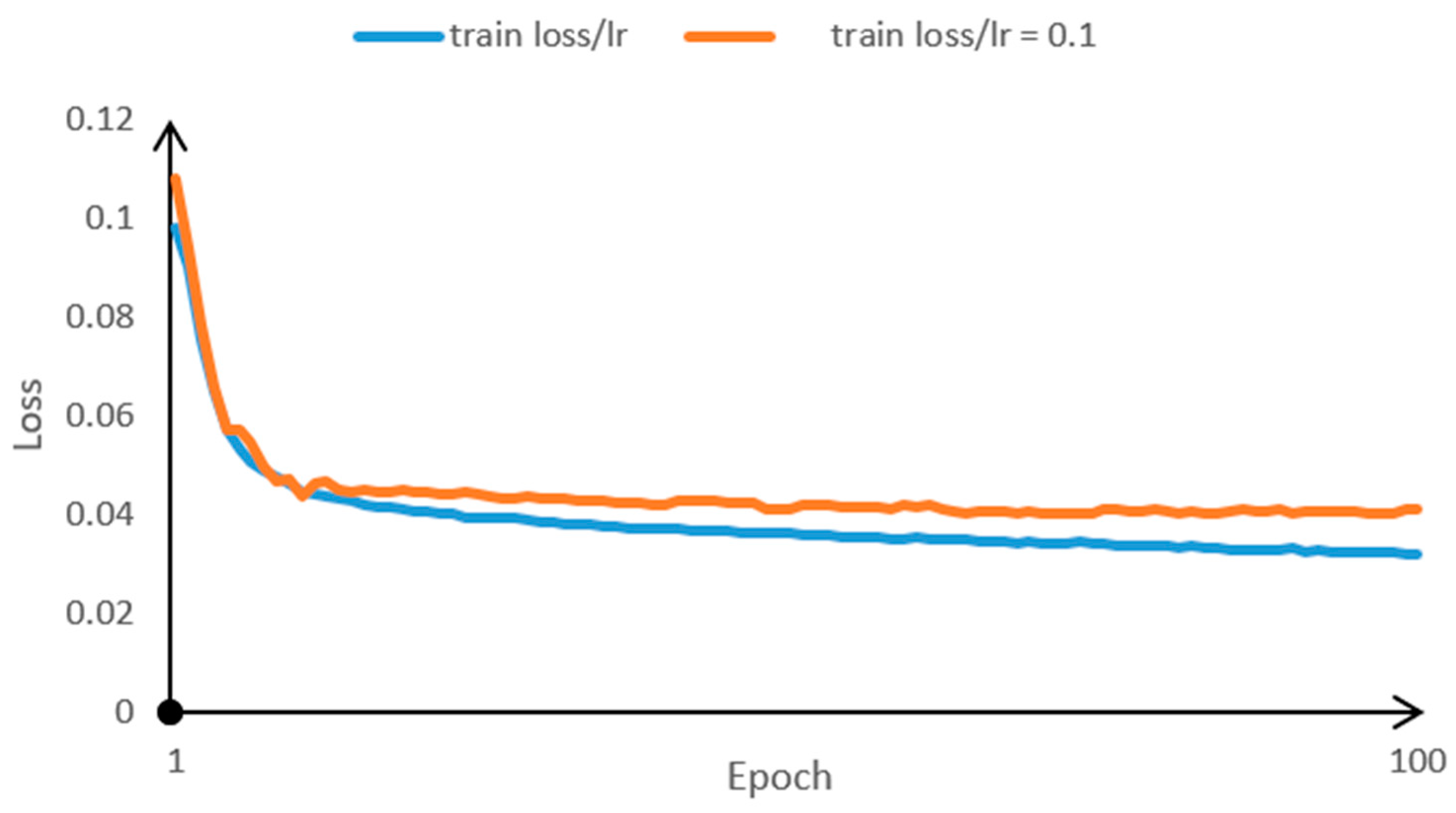
3.2. Experimental Setup and Technical Details
3.3. Face Detection Accuracy and Speed
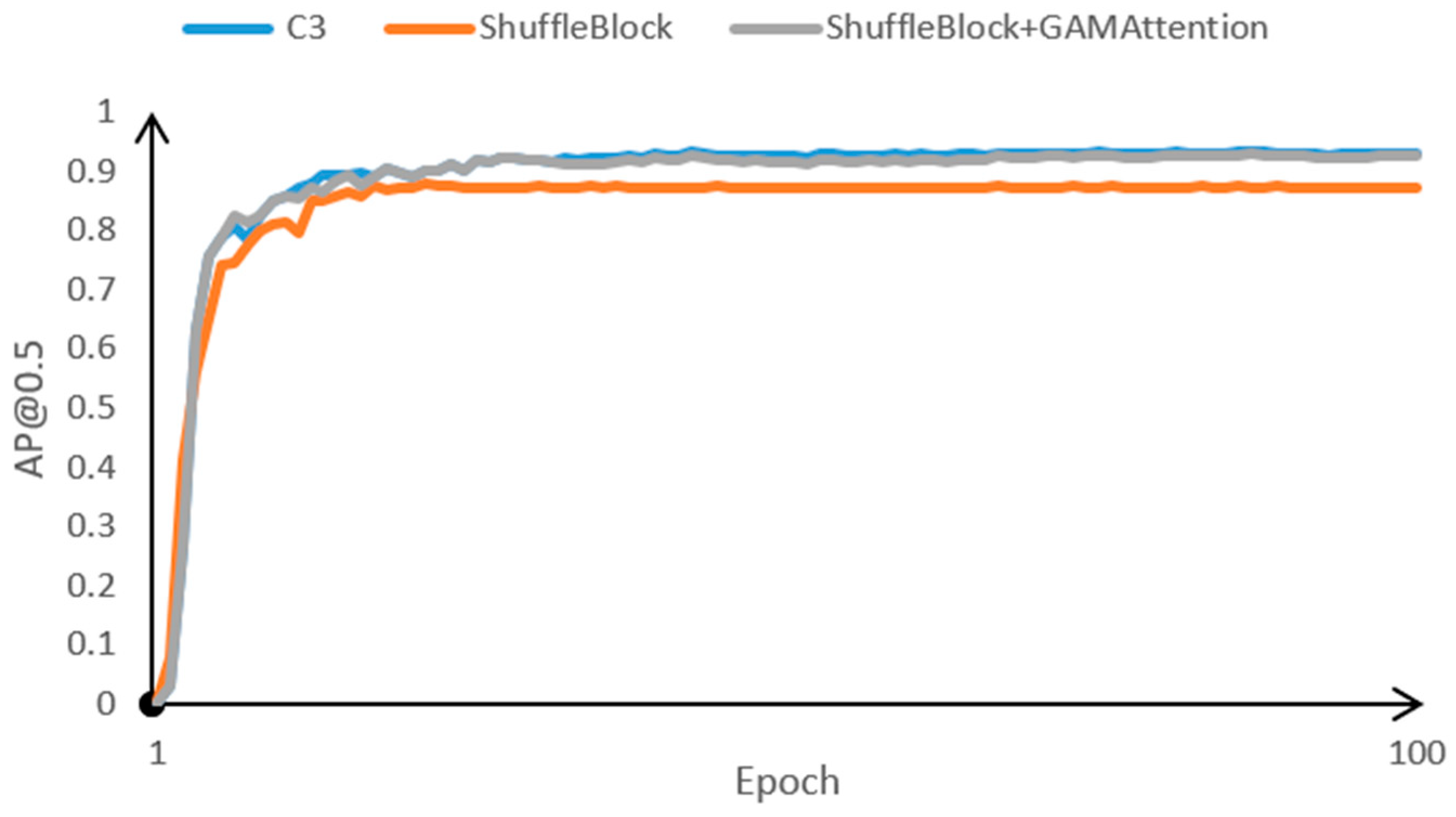
3.4. Ablation Experiment
3.5. Community Detection Scenarios
3.6. LighterFace in the Monitoring Area
4. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nakamura, K.; Koike, Y.; Sato, Y.; Yanagitani, T. Giga-hertz ultrasonic reflectometry for fingerprint imaging using epitaxial PbTiO3 transducers. Appl. Phys. Lett. 2022, 121, 172903. [Google Scholar] [CrossRef]
- Saguy, M.; Almog, J.; Cohn, D.; Champod, C. Proactive forensic science in biometrics: Novel materials for fingerprint spoofing. J. Forensic Sci. 2022, 67, 534–542. [Google Scholar] [CrossRef] [PubMed]
- Bayoudh, K.; Knani, R.; Hamdaoui, F.; Mtibaa, A. A survey on deep multimodal learning for computer vision: Advances, trends, applications, and datasets. Vis. Comput. 2022, 38, 2939–2970. [Google Scholar] [CrossRef] [PubMed]
- Marasinghe, R.; Yigitcanlar, T.; Mayere, S.; Washington, T.; Limb, M. Computer vision applications for urban planning: A systematic review of opportunities and constraints. Sustain. Cities Soc. 2023, 100, 105047. [Google Scholar] [CrossRef]
- Yang, S.; Luo, P.; Loy, C.C.; Tang, X.O. Wider Face: A Face Detection Benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vegas, NV, USA, 27–30 June 2016; pp. 5525–5533. [Google Scholar]
- Albiero, V.; Chen, X.; Yin, X.; Pang, G.; Hassner, T. Img2pose: Face Alignment and Detection Via 6dof, Face Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7617–7627. [Google Scholar]
- Xu, D.; Wu, L.; He, Y.; Zhao, Q. OS-LFFD: A Light and Fast Face Detector with Ommateum Structure. Multimed Tools Appl. 2021, 80, 34153–34172. [Google Scholar] [CrossRef]
- Deng, J.; Guo, J.; Ververas, E.; Kotsia, I.; Zafeiriou, S. Retinaface: Single-Shot Multi-Level Face Localisation in The Wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Srattle, WA, USA, 13–19 June 2020; pp. 5203–5212. [Google Scholar]
- Zhu, Y.; Cai, H.; Zhang, S.H.; Wang, C.H.; Xiong, Y.C. Tinaface: Strong but Simple Baseline for Face Detection. arXiv 2022, arXiv:2011.13183. [Google Scholar]
- Najibi, M.; Samangouei, P.; Chellappa, R.; Davis, L.S. SSH: Single Stage Headless Face Detector. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4875–4884. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Zhang, C.; Xu, X.; Tu, D. Face Detection Using Improved Faster RCNN. Neurocomputing 2018, 299, 42–50. [Google Scholar]
- Wang, J.; Yuan, Y.; Yu, G. Face Attention Network: An Effective Face Detector for The Occluded Faces. arXiv 2017, arXiv:1711.07246. [Google Scholar]
- Tang, X.; Du, D.K.; He, Z.; Liu, J. Pyramidbox: A Context-Assisted Single Shot Face Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 812–828. [Google Scholar]
- Liu, Z.; Li, J.G.; Shen, Z.Q.; Huang, G.; Yan, S.M.; Zhang, C.S. Learning Efficient Convolutional Networks through Network Slimming. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2736–2744. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in A Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (CVPR), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2018, 13, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 640–651. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 386–397. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. Yolov4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Liu, Y.C.; Shao, Z.R.; Hoffmann, N. Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions. arXiv 2021, arXiv:2112.05561. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | BackBones | AP@0.5WF | Detection Speed (CPU)/ms | Detection Speed (ARM)/ms |
|---|---|---|---|---|
| YoloV5s | CSPNet | 92.6% | 69.66 | 4578 |
| TinaFace | ResNet50 | 96.3% | 92.24 | ---- |
| LFFD | LFFDNet | 88.1% | 64.70 | 4114 |
| RetinaFace | ResNet50 | 96.1% | 91.45 | ---- |
| YoloV5n | CSPNet | 89.2% | 39.08 | 1934 |
| LighterFace | CSPNet | 90.6% | 36.16 | 1543 |
| Name | Average Speed (CPU)/ms | Average Speed (ARM)/ms |
|---|---|---|
| CSPNet-C3 | 69.66 | 4578 |
| CSPNet-ShuffleBlock | 37.16 | 1423 |
| CSPNet-ShuffleBlock + GAMAttention | 39.50 | 1543 |
| Name | AP@0.5WF | AP@0.5:0.95WF | AP@0.5CF | AP@0.5:0.95CF | Parameters | FLOPs |
|---|---|---|---|---|---|---|
| CSPNet-C3 | 92.8% | 60.9% | 95.2% | 64.3% | 7.02M | 15.8 |
| CSPNet-ShuffleBlock | 86.4% | 58.1% | 89.3% | 61.2% | 0.843M | 1.8 |
| CSPNet-ShuffleBlock + GAMAttention | 90.6% | 59.5% | 92.8% | 62.9% | 1.32M | 2.3 |
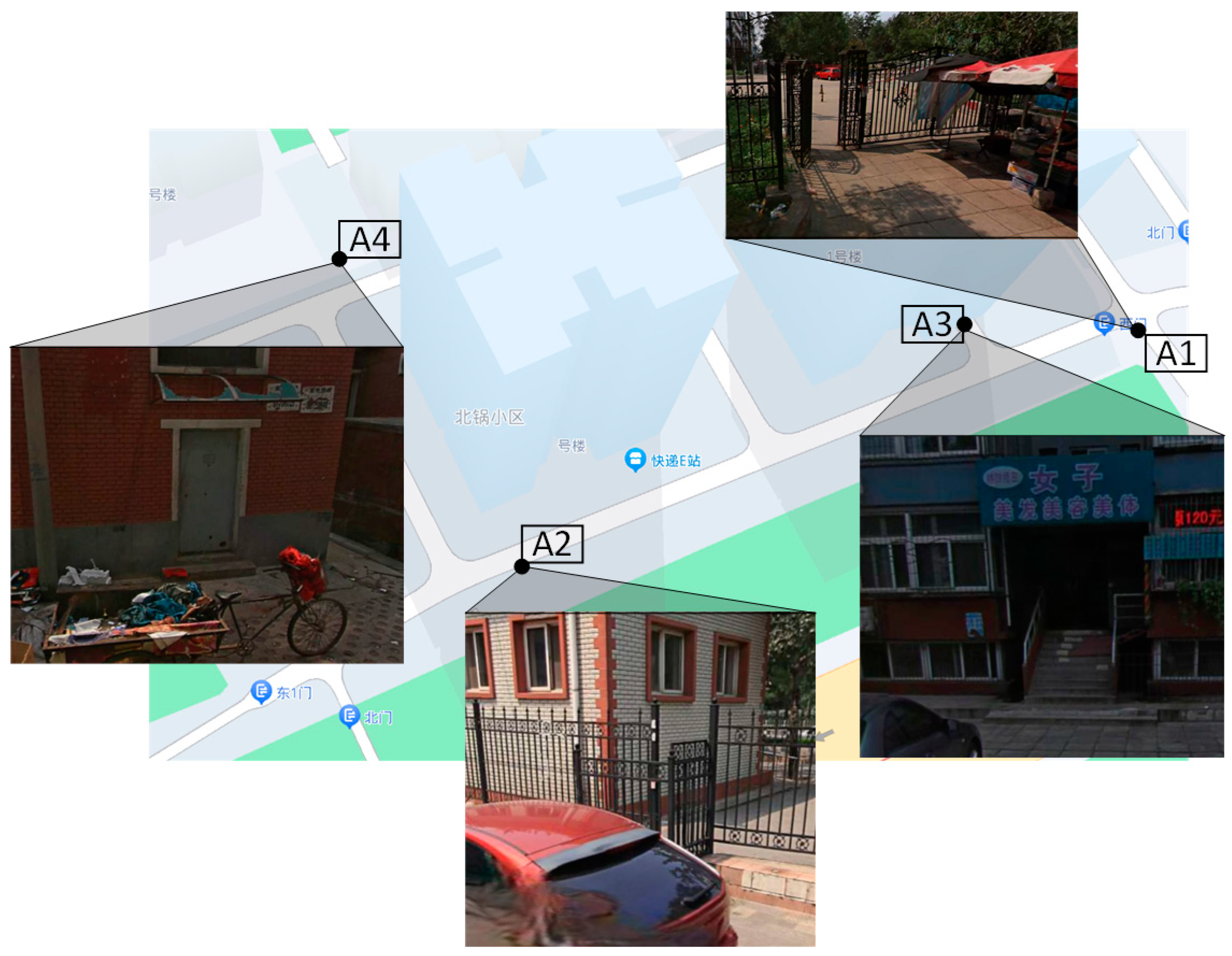
| Activity ID | Descriptions |
|---|---|
| A1 | Appeared near the entrance to the complex |
| A2 | Appeared near the neighborhood exit |
| A3 | Appeared near the entrance to a residential building |
| A4 | Appeared near the powerhouse |
| Name | Activity ID | AP@0.5 | Recognition Accuracy | Average Speed (ARM)/ms |
|---|---|---|---|---|
| YoloV5s | A1 | 92.5% | 94% | 4461 |
| A2 | 92.3% | 96% | 4301 | |
| A3 | 93.8% | 82% | 4256 | |
| A4 | 91.5% | 93% | 4513 | |
| LFFD | A1 | 88.6% | 87% | 4186 |
| A2 | 87.5% | 85% | 4026 | |
| A3 | 88.3% | 79% | 3956 | |
| A4 | 89.3% | 81% | 4235 | |
| YoloV5n | A1 | 89.6% | 91% | 1645 |
| A2 | 87.4% | 88% | 1546 | |
| A3 | 91.3% | 81% | 1456 | |
| A4 | 88.7% | 87% | 1734 | |
| LighterFace | A1 | 90.3% | 93% | 1532 |
| A2 | 89.6% | 92% | 1486 | |
| A3 | 91.5% | 87% | 1396 | |
| A4 | 89.6% | 91% | 1685 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, Y.; Zhang, H.; Guo, W.; Zhou, M.; Li, S.; Li, J.; Ding, Y. LighterFace Model for Community Face Detection and Recognition. Information 2024, 15, 215. https://doi.org/10.3390/info15040215
Shi Y, Zhang H, Guo W, Zhou M, Li S, Li J, Ding Y. LighterFace Model for Community Face Detection and Recognition. Information. 2024; 15(4):215. https://doi.org/10.3390/info15040215
Chicago/Turabian StyleShi, Yuntao, Hongfei Zhang, Wei Guo, Meng Zhou, Shuqin Li, Jie Li, and Yu Ding. 2024. "LighterFace Model for Community Face Detection and Recognition" Information 15, no. 4: 215. https://doi.org/10.3390/info15040215
APA StyleShi, Y., Zhang, H., Guo, W., Zhou, M., Li, S., Li, J., & Ding, Y. (2024). LighterFace Model for Community Face Detection and Recognition. Information, 15(4), 215. https://doi.org/10.3390/info15040215