3. Previous Work
Peer-to-peer ride matching offers shared journeys to the participants while maximising some global objective (usually savings in travel time) subject to the participants’ spatiotemporal constraints [
2]. There are multiple variants of this problem; some classifications are based on cardinality of matching (one-to-one, one-to-many, many-to-many), while others are based on the roles the participants play (riders, drivers). These roles can be either fixed or flexible [
3].
One-to-one ride matching can be represented as a graph matching problem [
3] in which each participant is a node, potential matches are edges, and the edge weight indicates the savings from the match. When roles are fixed, it becomes a maximum weighted bipartite matching problem, while if the roles are flexible it can be formulated as a maximum weight matching problem in general graphs. In the past, many polynomial-time algorithms have been proposed to solve these problems optimally [
4,
5,
6,
7]. Recent studies with exact solutions [
8,
9] have attempted the matching problem at a very small scale with up to few hundred participants and a small number of locations.
Unlike in the above studies, real-world ride sharing problems are large-scale and dynamic in nature [
2] and require solutions in close to real time. In their landmark survey of a decade ago, Agatz et al. [
10] noted the lack of fast optimal solutions for large metropolitan areas; since then, a substantial body of work has focused on developing fast solutions for real-time large-scale ride sharing systems, especially for the one-to-one version. Catering to the assumption of continuous travel requests, most studies are dynamic and use a rolling time window approach [
11]. To reduce complexity, previous studies have tended to publish methods dividing the problem into smaller subproblems. Shen et al. [
12] partitioned the road network into grids, with every participant only being matched within their grid. Xu et al. [
13] made use of ellipses to bound possible locations for matches in order to avoid removing the optimal solution during pruning; however, this approach requires equal speed limits. A similar approach was taken by Masoud and Jayakrishnan [
8]. A number of approaches have used graph partitioning techniques [
11,
14]. The ride sharing problem has been formulated as a linear program; at times this has been applied to a reduced search space [
11], while in other cases authors have used a time-out period to provide answers within the specified time [
15].
In other examples of heuristic approaches, Najmi et al. [
16] used a clustering approach to investigate potential matches for riders in two sets of clusters: one based on the riders’ origins, and the other on their destinations. Ketabi et al. [
17] also employed a clustering method to find matches for one-to-one matching. In their study, Ta et al. [
18] exclusively examined matches where the intersection of the driver and riders’ journeys surpassed a predetermined threshold, typically set at 80%. However, they did not provide a rationale for the selection of this specific percentage. They chose matches using an approximate method focused on maximising the shared route percentage. Li et al. [
19] approached the ridesharing problem by framing it as a vehicle routing problem, exploring both one-to-one and many-to-one variations. Stressing the NP-hard nature of the problem, they opted for a hybrid heuristic algorithm combining an insertion algorithm with tabu search for quick solution generation. Additionally, they incorporated clustering to pair participants within their respective clusters. Kleiner et al. [
20] proposed an auction-based mechanism for matching drivers and riders. Their approach prioritised either maximising cost savings through reduced travel distance or achieving a high matching rate, but not both simultaneously. Nourinejad and Roorda [
21] presented an auction-based model in which driver agents bid on riders and only willing riders accept the bids. Aissat and Oulamara [
22] solved the fixed roles matching problem heuristically, and introduced the concept of intermediate meeting points to minimise detours for drivers.
Thus far, no published approach has solved dynamic one-to-one matching for large-scale demand in time for an operating service. Tafreshian and Masoud [
11] have come the closest; however, their solution takes an impractically long time to compute an optimal match. For example, when working with another instance of similar size from the same dataset that we have utilised here, it takes roughly six minutes to solve for one-to-one matching with flexible roles for a demand contained in a one-minute time window. To address this shortcoming, they resorted to using a graph-partitioning heuristic to achieve real-time solutions. Another issue with their approach is that, to reduce the computational complexity, they introduce the concept of stations instead of providing door-to-door service, thereby reducing the number of graph nodes to be considered. Thus, passengers are expected to walk from their origin to the nearest station and board/disembark vehicles there. Similar approaches include Fiedler et al. [
23], Fielbaum [
24], and Wang et al. [
25]. While computationally advantageous, station-based approaches present limitations in real-world scenarios. Notably, they might disadvantage individuals with mobility limitations, elderly individuals, and those who are unable or unwilling to walk to designated stations. Therefore, these methods represent a trade-off between computational efficiency and inclusivity.
Lu et al. [
26] is the most recent work in pursuit of optimality that we have come across. They have proposed an exact methodology for addressing one-to-one matching with flexible roles; however, it is crucial to highlight that their approach achieves optimality only for very small instances. For problem instances involving ten participants their algorithm required only a few minutes for completion, whereas experiments with 35 participants required hours to solve. Consequently, it is evident that an optimal approach to one-to-one matching that can provide solutions within practical time frames is absent from the literature.
Furuhata et al. [
27] have postulated that an optimal approach to solving one-to-one matching at large scale in an authentic setting would be a major breakthrough. In this paper, we propose and empirically test such an approach.
Contributions
In this paper, we publish the following contributions:
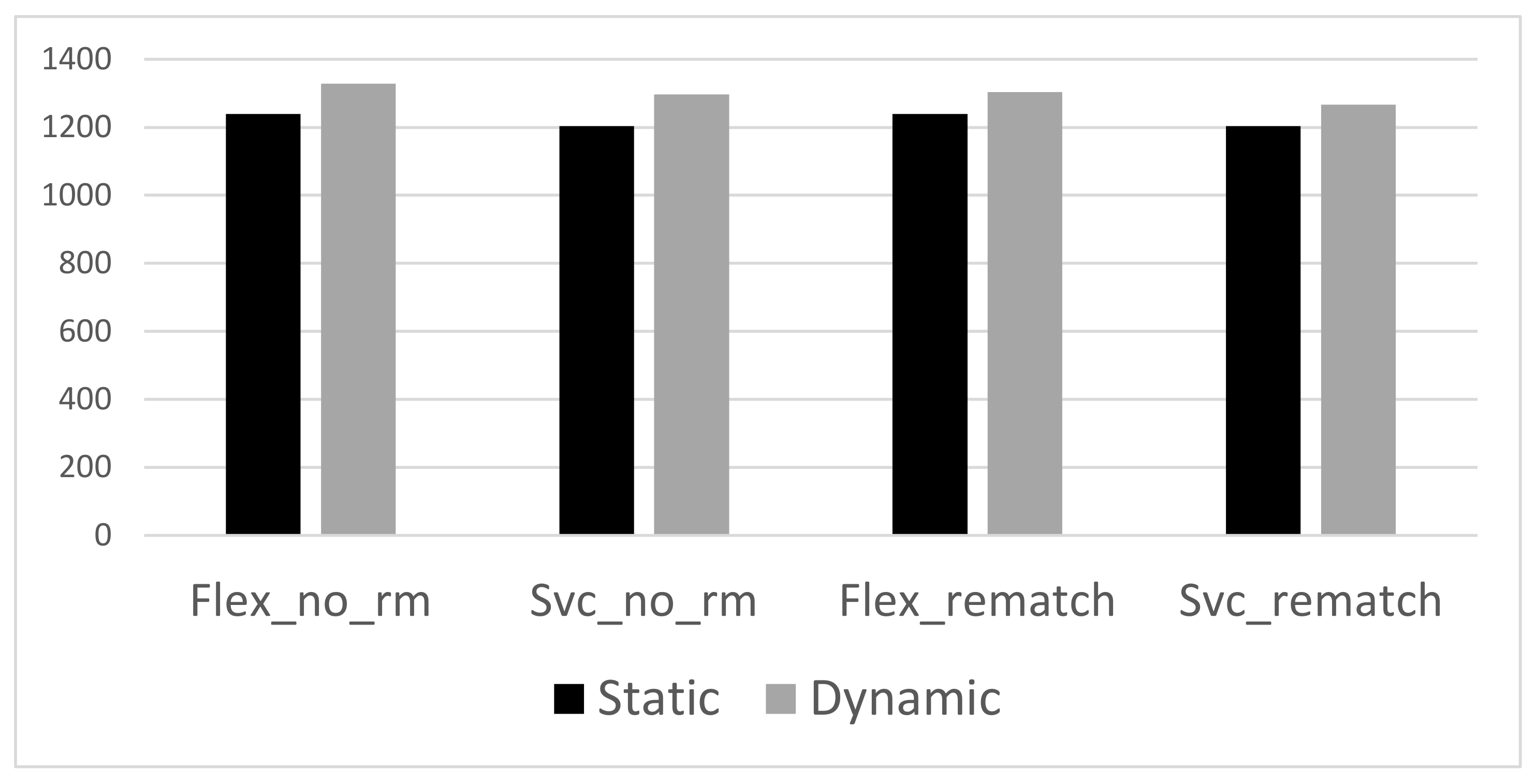
A fully implemented and tested new algorithm, SnapPair, that guarantees a snapshot-optimal solution at each time point in a dynamic one-to-one matching problem. SnapPair is more than two orders of magnitude faster than the current state-of-the-art.
A novel formulation of the dynamic one-to-one matching problem in which riders and vehicles are independent.
This new formulation is more complex due to the increased number of possible matches. We call this formulation FreeMatch. We consider this formulation timely and significant, particularly in light of research indicating that a higher number of individuals have reported issues with crowded vehicles since the COVID-19 pandemic compared to the prepandemic period [
28,
29,
30]. With FreeMatch, our objective is to establish a framework that optimally utilises standard commonplace vehicles with a maximum capacity capped at two, enhancing the appeal of ridesharing in accordance with travelers’ altered preferences following the COVID-19 pandemic.
An extended algorithm, including a rematching procedure that pairs both new riders and riders whose previous match has been dropped off, with the objective of optimising the use of vehicles available in the system.
Experiments successfully applying the proposed algorithms to a problem size that is relevant to fleet operators.
4. Methodology
4.2. Parameters and Variables
The road network is represented as a graph
, where
and where each edge
has an associated and positive edge cost
indicating the travel time. Based on these times, the system uses Dijkstra’s algorithm [
32] to compute the shortest paths between all pairs of nodes
in the graph, then records the time
. In our experiments, we show that this can either be done once in advance or repeatedly for all relevant pairs at the beginning of every iteration, with the choice based on the current congestion-dependent edge costs.
Here, R is the set of riders; each rider has an origin , destination , earliest possible departure time , and latest possible arrival time .
For each rider r, the system computes the earliest possible arrival time .
A match
, where
j and
k are riders, is feasible if
j can pick up
k and if both riders depart after their earliest departure time and reach their destinations before their latest arrival time. If
j is on the way to picking up
k, then either
j or
k may have to wait at
until the other party is ready. Waiting times are permitted as long as both riders arrive at their destinations in time. For the sake of simplicity, pickup and dropoff are instantaneous and do not incur any delay. Formally, the route
is feasible for riders
j and
k if
and
The cost of this match is
if
is feasible and infinity otherwise.
The route
is feasible for riders
j and
k if
and
Its cost is if is feasible and infinity otherwise.
Based on this,
is a feasible match if
or
is feasible, and its cost is
For an unmatched rider, the cost is
We write F for the set of all feasible matches.
To minimise VHT (vehicle hours travelled), the model can be formulated in terms of the variables
M (the set of matched pairs) and
U (the set of unmatched riders) as follows:
where the objective function minimises the cost of all paired and solo journeys. Constraint 1 stipulates that all matched pairs are selected from feasible pairs, while the unmatched riders must belong to the set of riders. Constraint 2 stipulates that every rider in set
R must be included in either a matched pair or the set of unmatched riders. Constraint 3 ensures that the matched pairs and unmatched riders are mutually exclusive sets, meaning that their intersection is empty. Constraint 4 stipulates that each rider can appear in at most one matched pair.
This model corresponds to both flexible roles and FreeMatch problems, where matched riders are picked up by a dedicated vehicle at their origin and taken to their destination using the shortest path. In FreeMatch, a vehicle is assumed to materialise instantly at the origin of its first rider and disappear when no longer needed, while in the version with flexible roles the vehicle is provided by one of the participants and stays with them.
The model is modified below to handle both driver and passenger roles. With fixed-role ride matching, the driver is responsible for initiating the trip and providing the vehicle for the passenger. In this variant, riders are divided into a set of drivers D and a set of passengers P. A match is now feasible only if and . Consequently, it is computationally easier to generate the set F of feasible matches.
The model (
1) for minimising VHT can be be modified as follows in order to cater to the scenario with fixed roles:
Constraint 4 enforces the exclusivity of rider-driver pairings, implying that a driver assigned to a matched pair cannot be paired with another rider and vice versa.
4.6. Dynamic Optimisation and Rematching
Dynamic optimisation handles new demands within a rolling time horizon. When a new demand is introduced at time t, the system simulates the situation up to t and determines which existing riders can be considered for the optimisation iteration.
We introduce the notion of
slack for riders, which is the difference between the latest and earliest possible arrival times. The
slack for an unmatched rider is
For each unmatched rider r, reoptimisation is possible if . In this case, is updated to t.
A vehicle currently in transit with matched riders may be eligible for multiple matches if the remaining rider is matched again after dropping off the first rider. Thus, the departure location and earliest departure time for matched riders in transit are updated according to the current trip leg and position, as follows:
If the current leg ends with arriving there at time , then is updated to and is updated to ; rider k is added to the set of drivers D and rider j is dropped from R.
If the current leg ends with arriving there at time , then is updated to and is updated to ; rider j is added to the set of drivers D and rider k is dropped from R.
Riders may request a ride with advance notice of minutes, where denotes the time before their earliest departure time of a rider r becomes known to the system.
Newly arrived riders are added to
R. The earliest departure time and origin for in-transit riders is updated to the current time
t and the rider’s current location. When the participants in the iteration have been determined, the reachability and match graphs are reconstructed while enforcing the constraint that
where
denotes the riders in transit.
This implies that a modification of the match graph construction outlined in Algorithm 2 is implemented for riders already in transit. These riders are exempt from the need to seek potential candidates who can pick them up, as they are already in transit; thus, they are only considered for such matches where they will be performing the pickup.
For matching variants in which the participants provide vehicles, i.e., fixed roles and flexible roles, an additional constraint is enforced when constructing the match graph:
This ensures that the vehicle stays with the participant who provided it. The constraint disallows routes such as
, where the last person to be dropped off was not the one who brought the vehicle. Accordingly, the optimal pairing of riders that minimises the total cost, as in the model (
1), results in a snapshot optimal solution.






{kind=link}