
Vehicle Target Recognition in SAR Images with Complex Scenes Based on Mixed Attention Mechanism



Abstract
1. Introduction
2. The Proposed Method
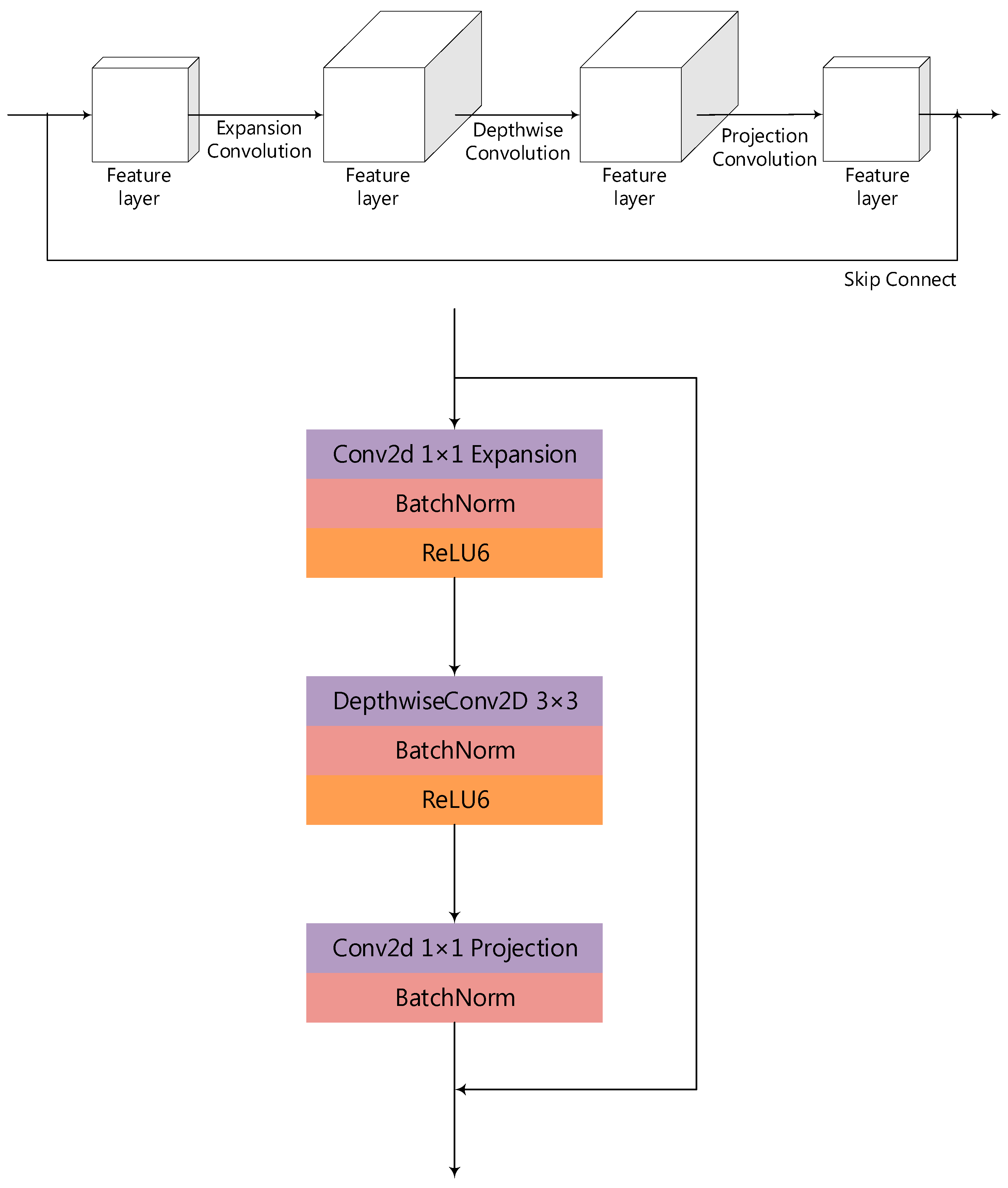
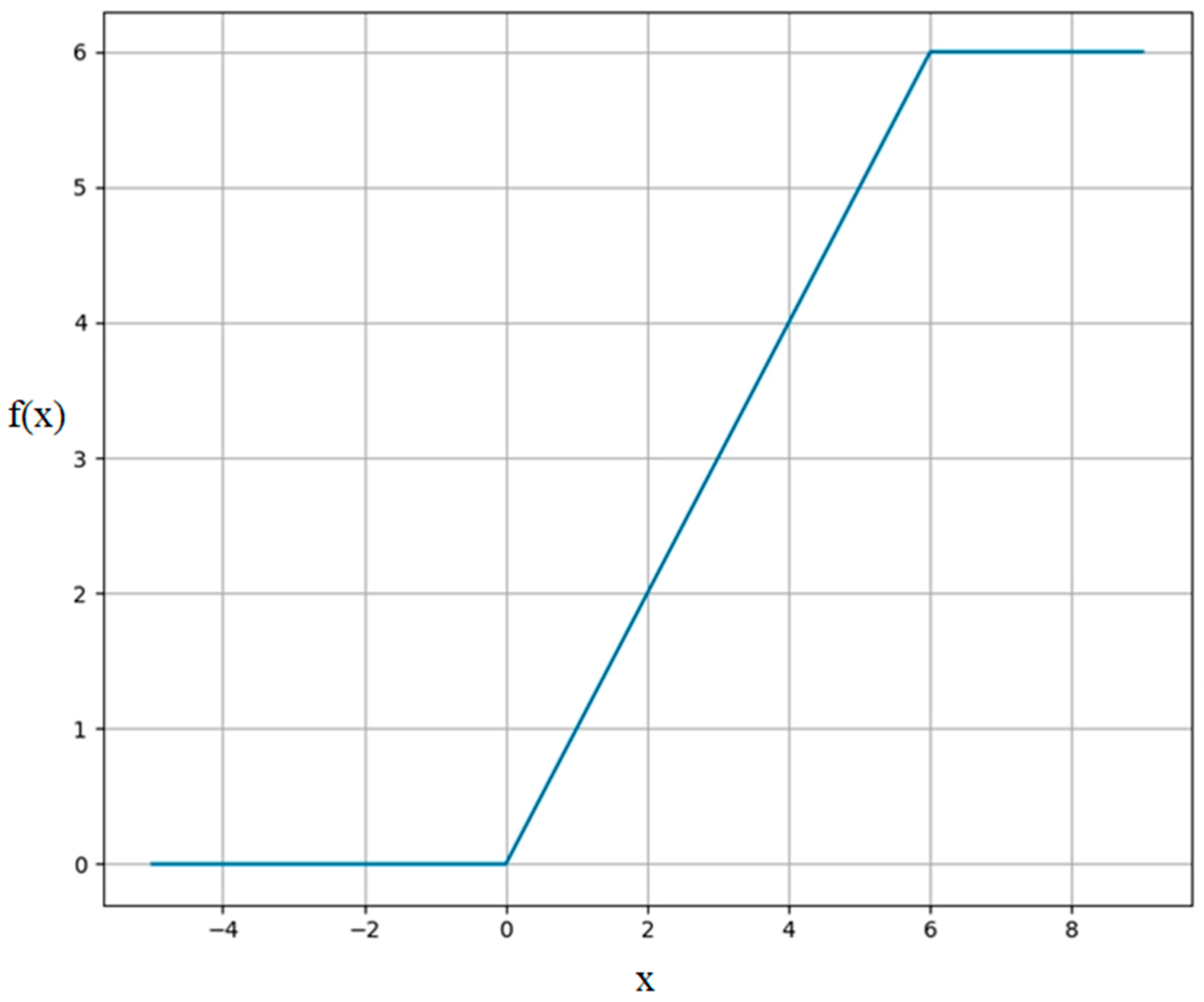
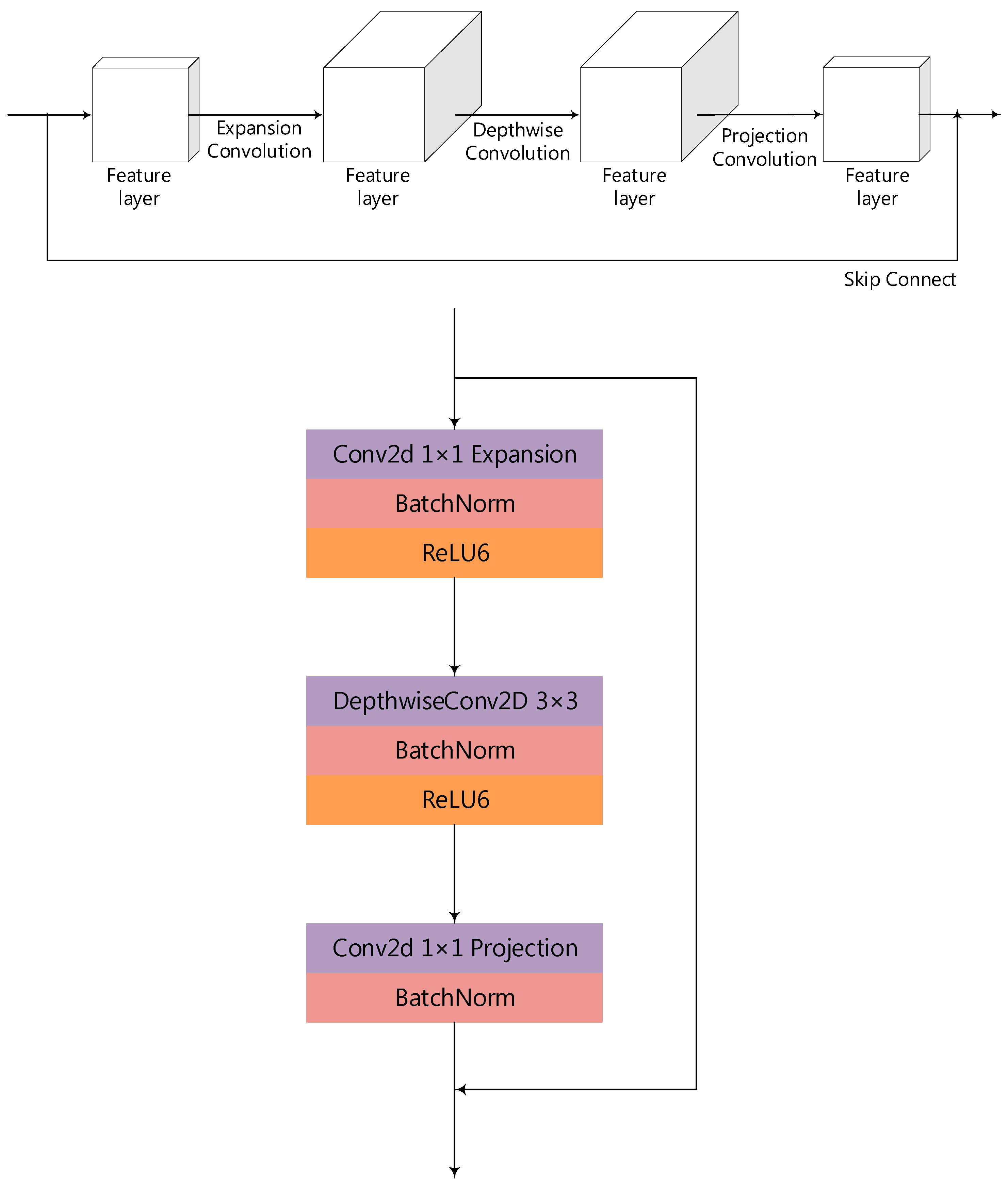
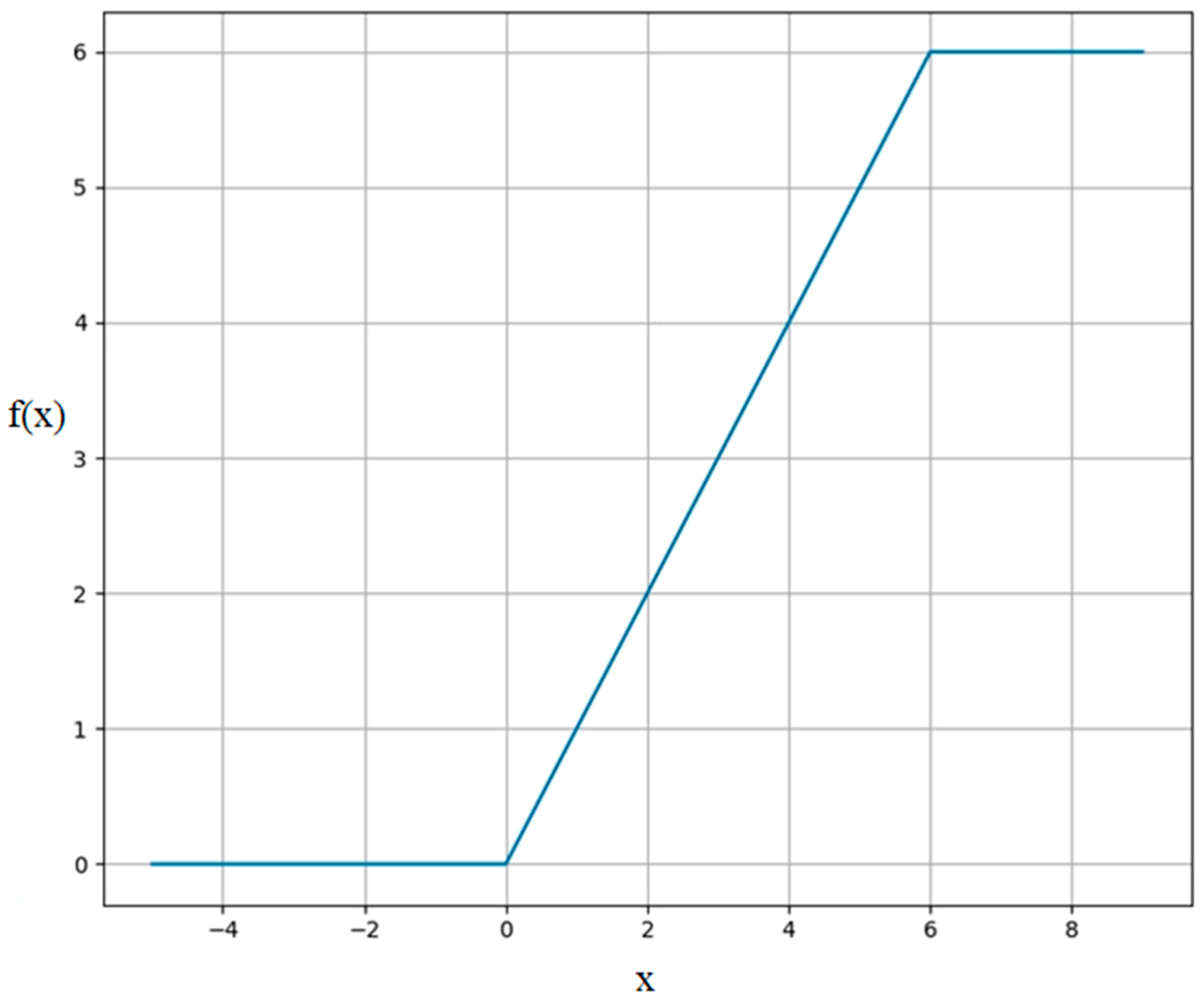
2.1. The MobileNetV2 Model
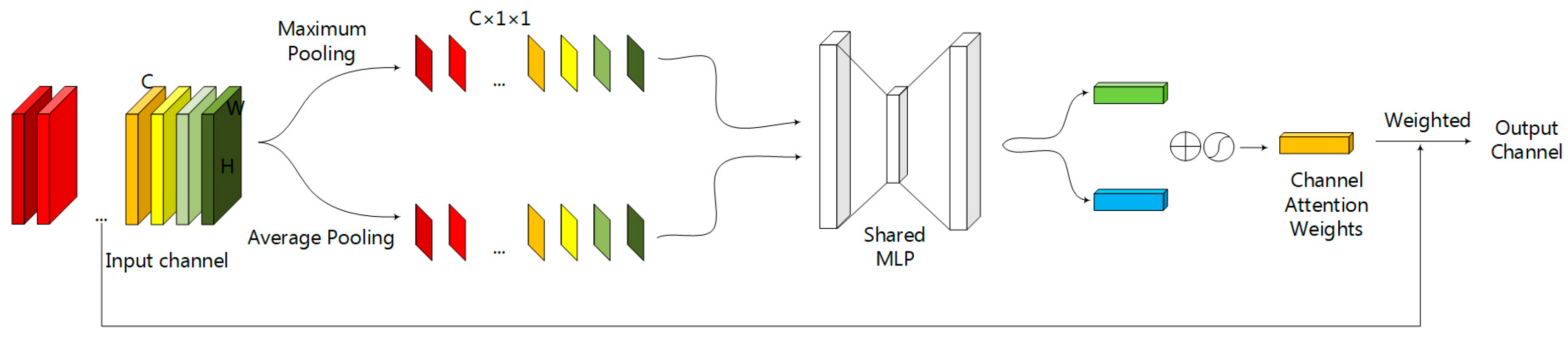
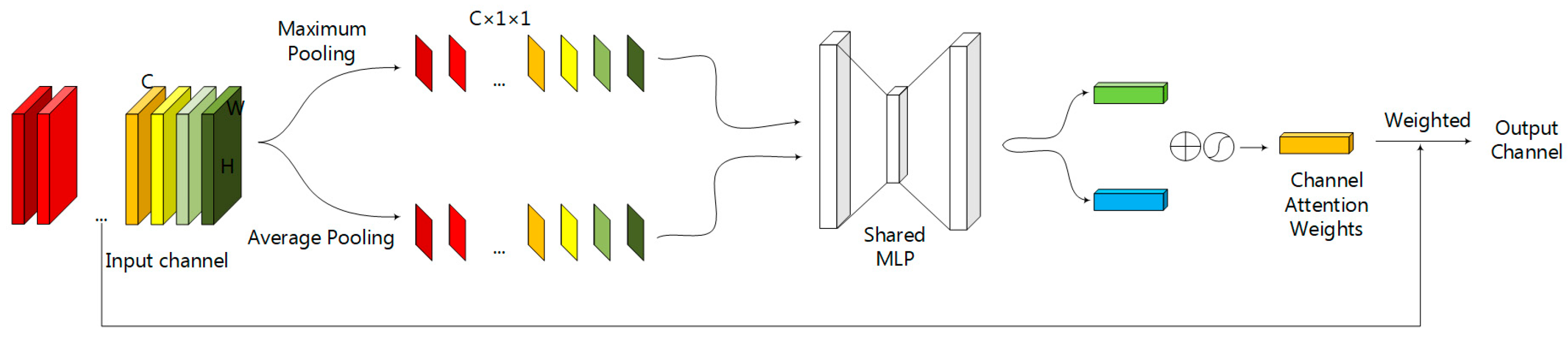
2.2. The Channel Attention Module
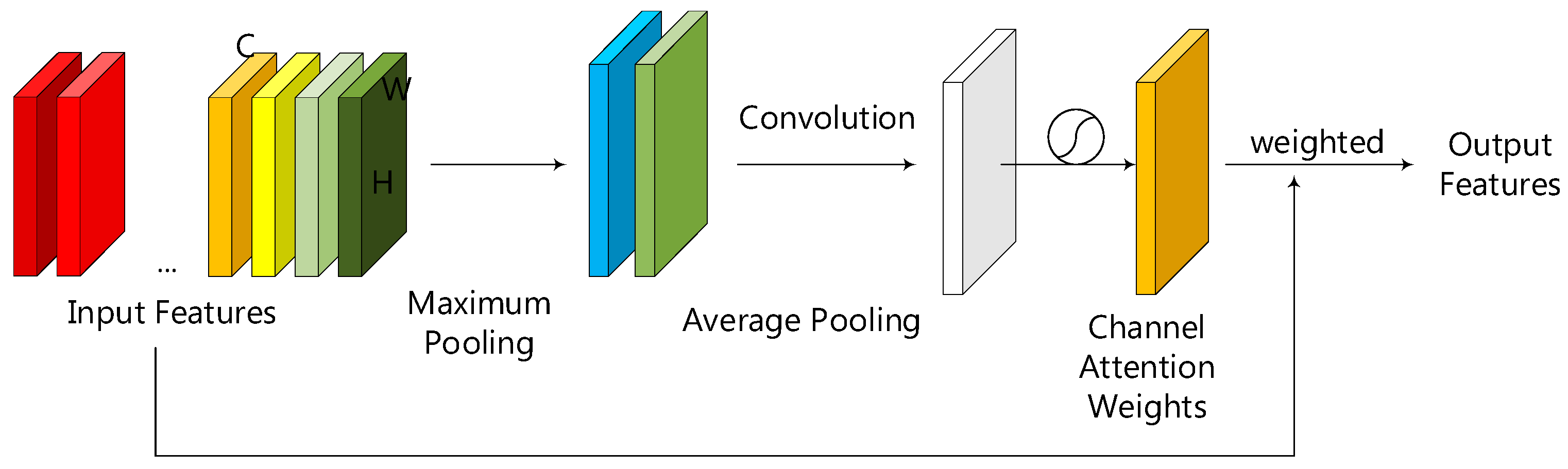
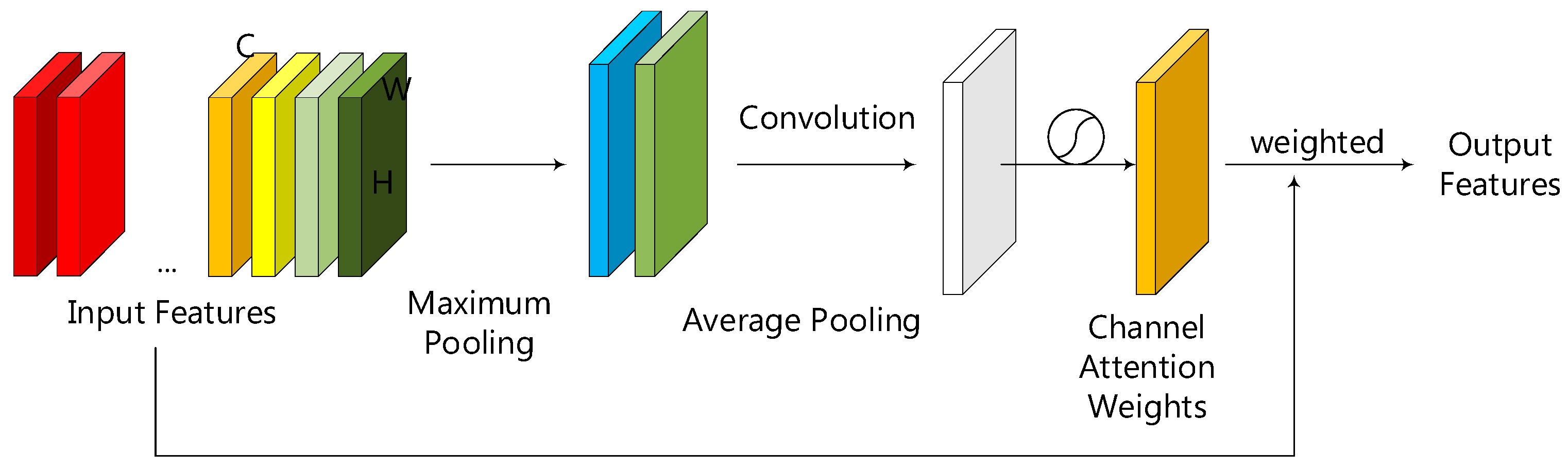
2.3. The Spatial Attention Module
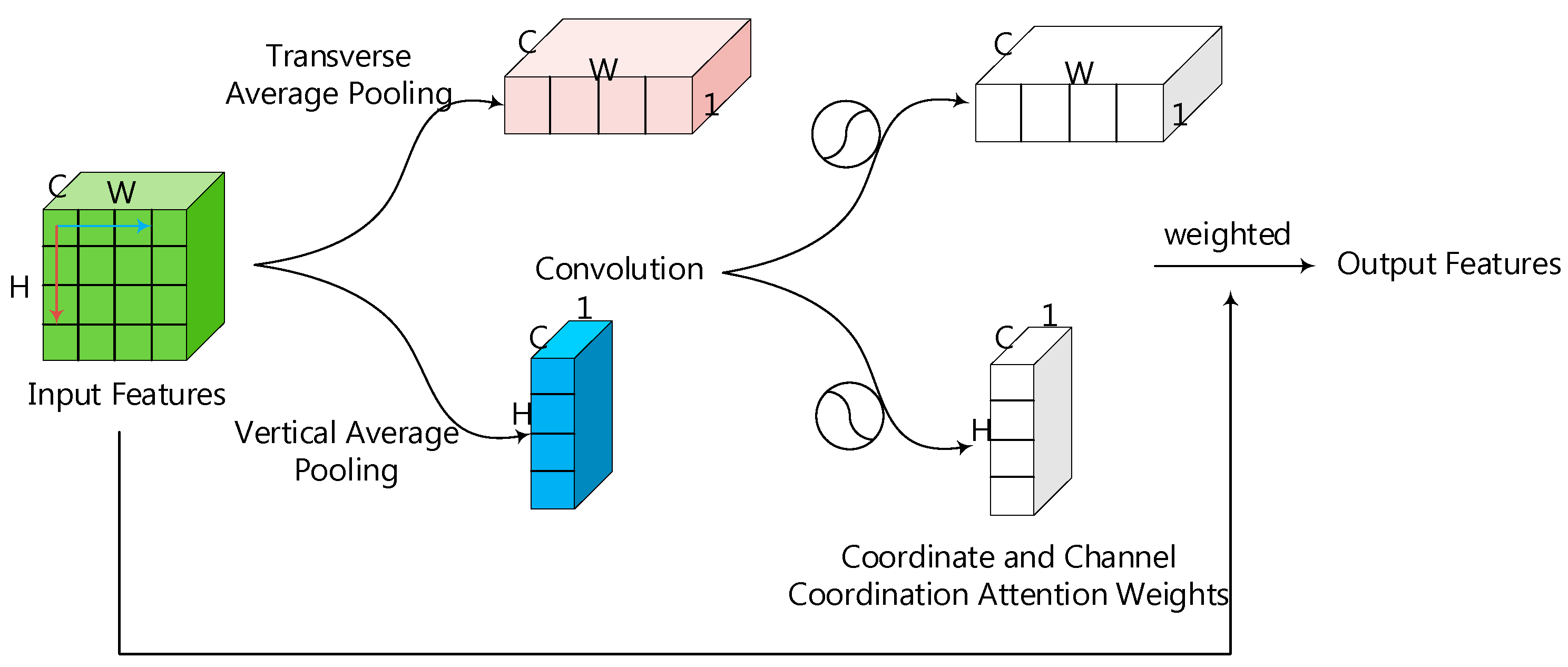
2.4. The Spatial and Channel Coordinated Attention Module
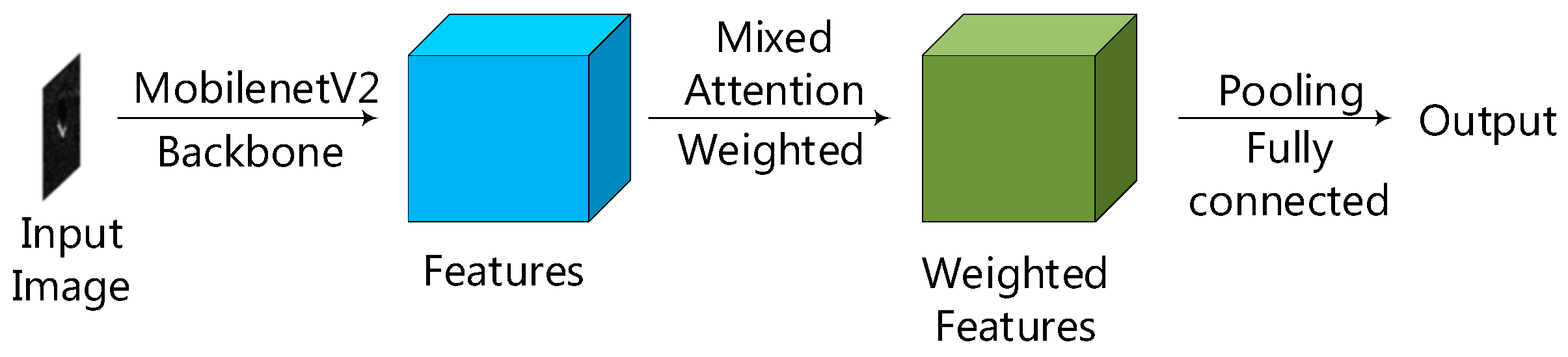
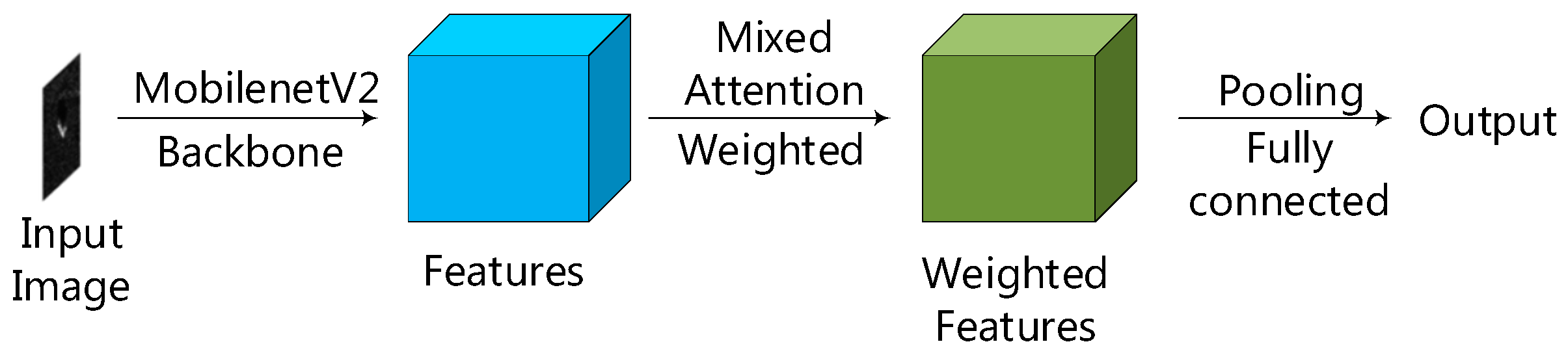
2.5. The Mixed Attention Convolutional Neural Network (MA-MobileNetV2)
3. Results and Analysis
3.1. Experimental Data and Parameter Settings
- The model parameters in the experiment are initialized using optical pre-trained recognition model parameters.
- The features extracted by the backbone network of the model are universal. Freezing the training of the backbone network can speed up training efficiency and prevent weight destruction. Therefore, for the first 5% of epochs in all experiments, the backbone network is frozen to adjust the parameters of the hybrid attention module and fully connected layers. At this stage, the feature extraction network remains unchanged, ensuring the stability of network training. The freezing is then lifted for the remaining 95% of epochs to adjust the overall parameters of the network. The batch size for the first 5% of epochs is set to 32, and the batch size for the remaining 95% of epochs is also set to 32.
- The optimizer used for all models in the experiment is Stochastic Gradient Descent (SGD) optimizer. The learning rate is adjusted using the cosine annealing function. The initial learning rate is set to 0.01, and the minimum learning rate is set to 0.0001.
- The computer configuration during the experiment is as follows: (1) CPU: AMD Ryzen 7 5800H with Radeon Graphics 3.20 GHz. (2) RAM: 16 GB. (3) GPU: NVIDIA Geforce RTX 3060 Laptop. (4) Operating System: Windows 11.
3.2. Performance Evaluation Metrics
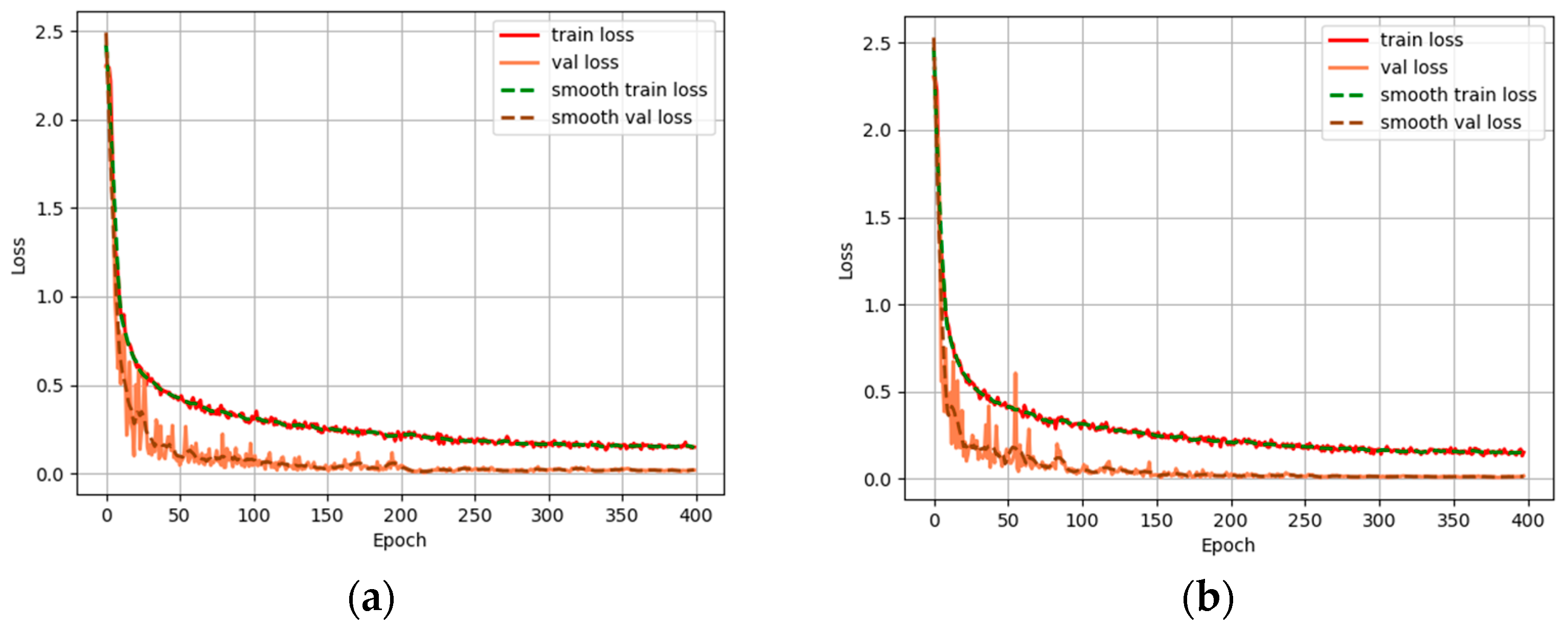
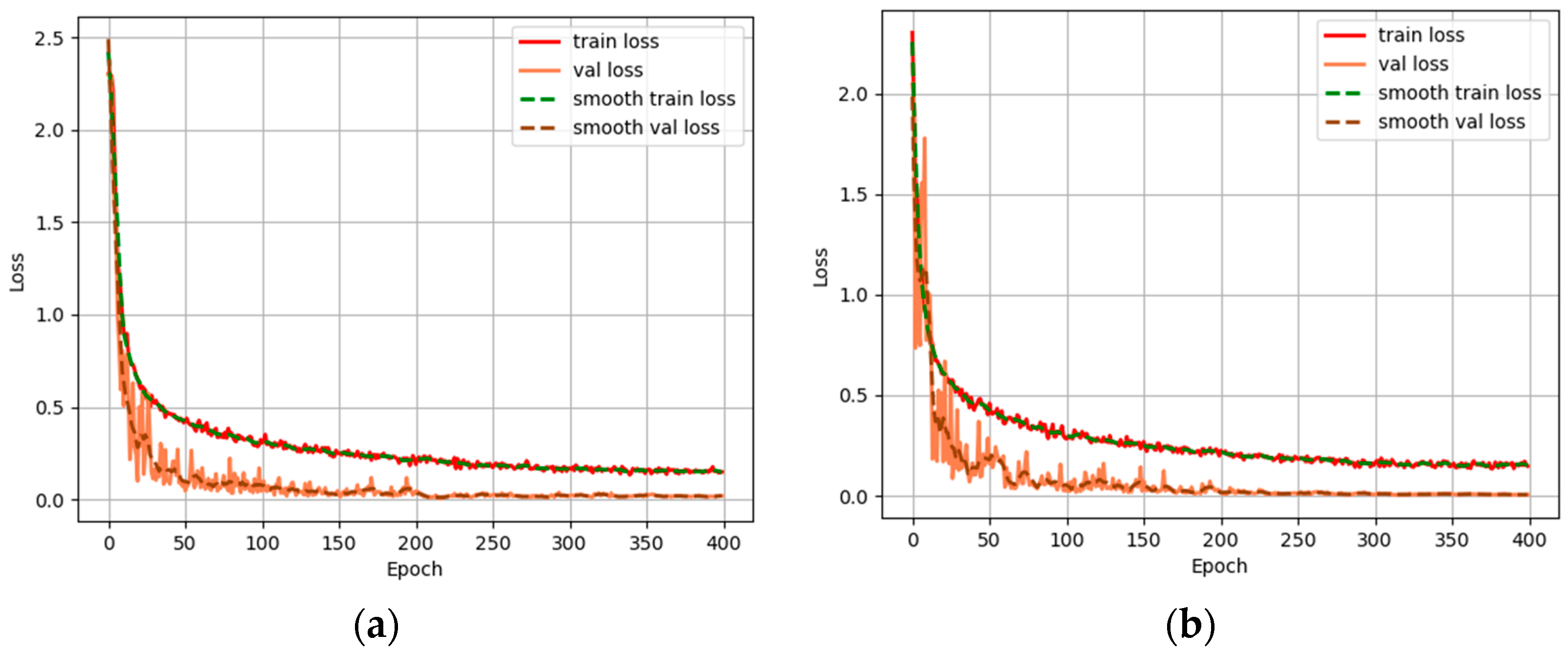
3.3. Performance Comparison between the MA-MobileNetV2 Network and the MobileNetV2 Network
3.4. Performance Comparison between the MA-MobileNetV2 Network and State-of-the-Art Algorithms
4. Discussion
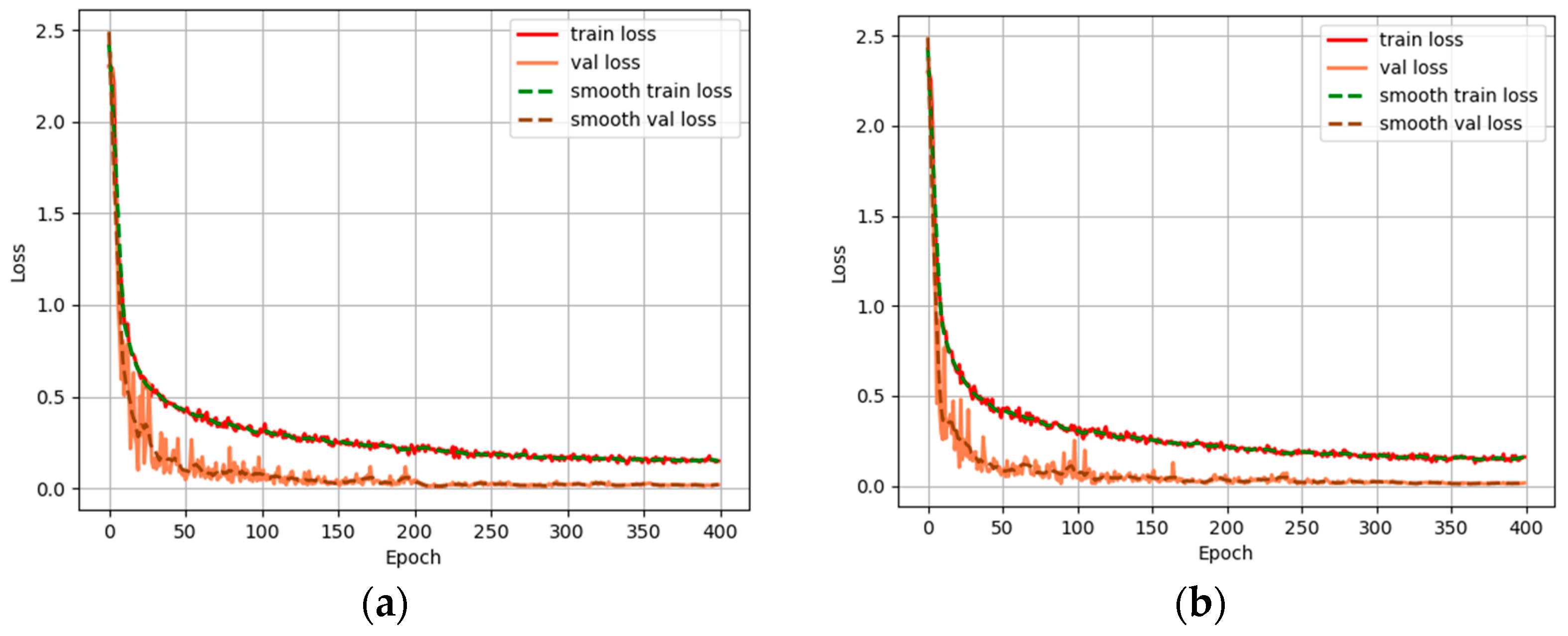
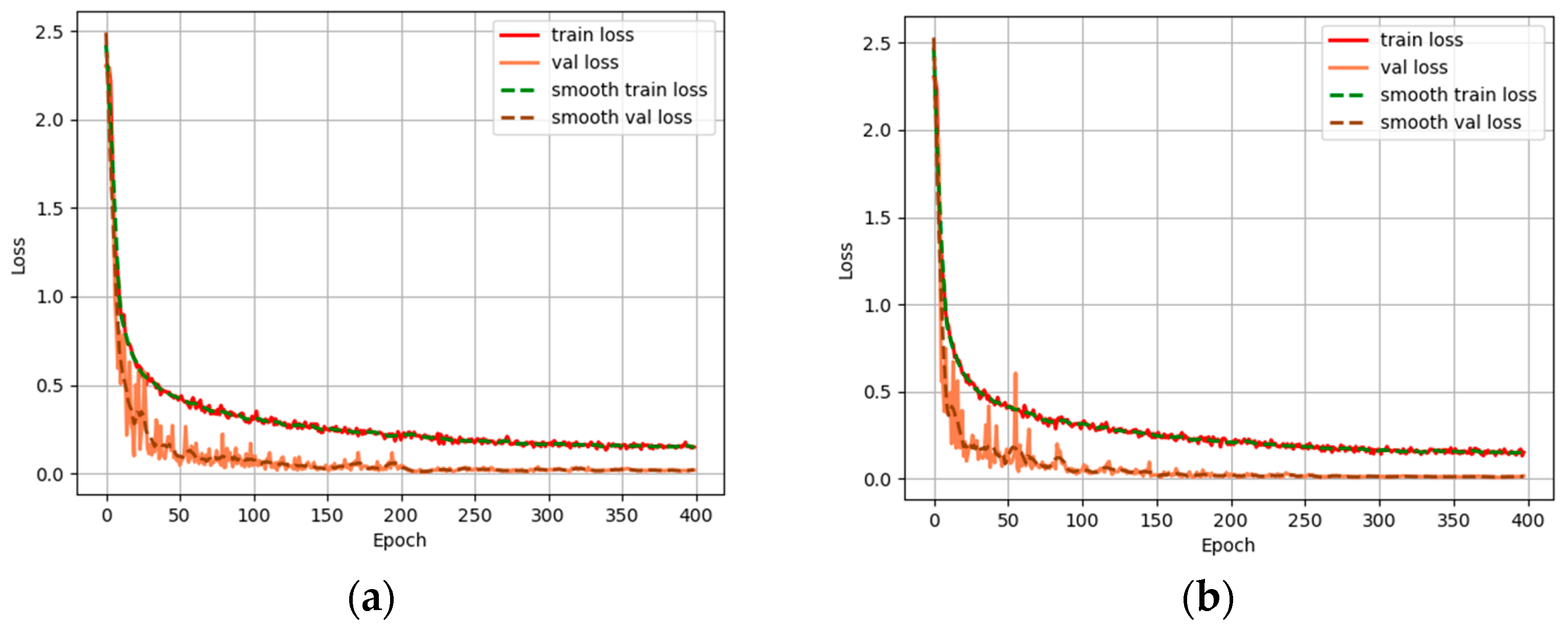
4.1. Ablation Experiments on CHA Module
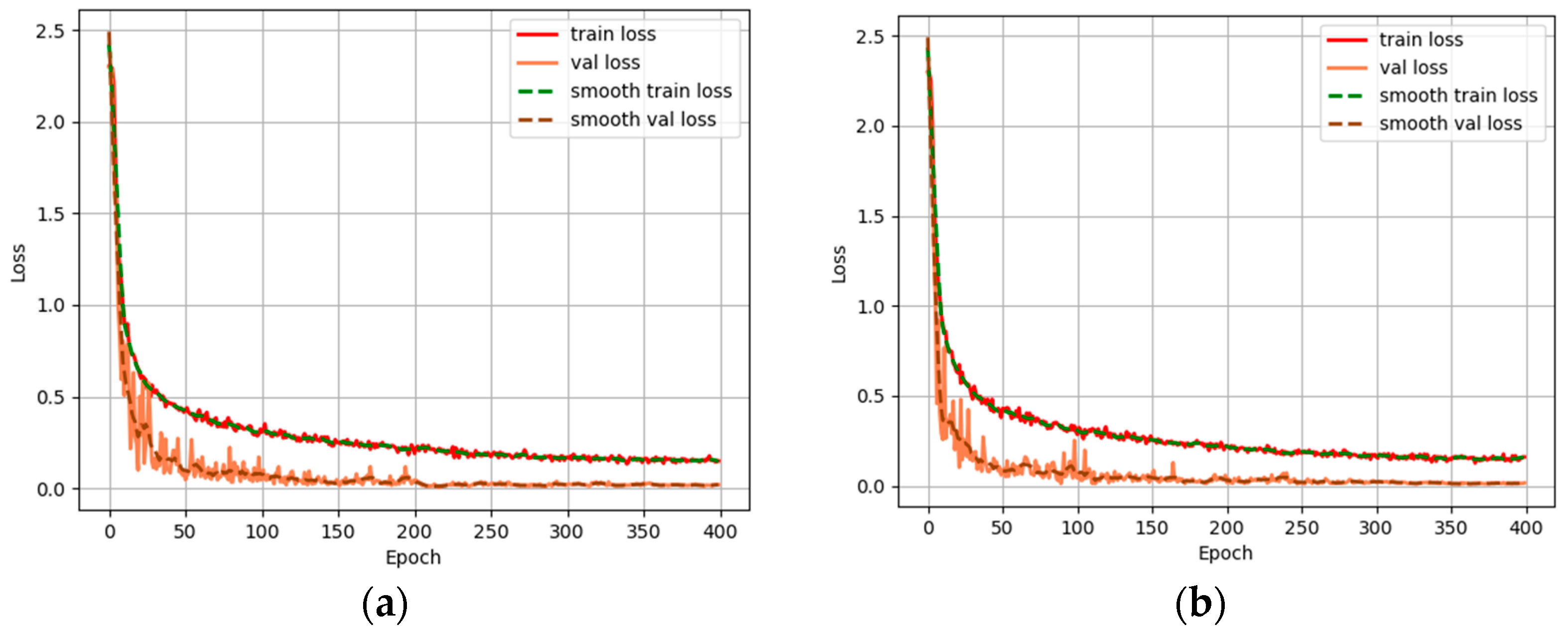
4.2. Ablation Experiments on SPA Module
4.3. Ablation Experiments on CA Module
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dong, G.; Kuang, G.; Wang, N.; Zhao, L.; Lu, J. SAR Target Recognition via Joint Sparse Representation of Monogenic Signal. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3316–3328. [Google Scholar] [CrossRef]
- Huang, X.; Qiao, H.; Zhang, B. SAR Target Configuration Recognition Using Tensor Global and Local Discriminant Embedding. IEEE Geosci. Remote Sens. Lett. 2016, 13, 222–226. [Google Scholar] [CrossRef]
- El-Darymli, K.; Gill, E.W.; Mcguire, P.; Power, D.; Moloney, C. Automatic Target Recognition in Synthetic Aperture Radar Imagery: A State-of-the-Art Review. IEEE Access 2016, 4, 6014–6058. [Google Scholar] [CrossRef]
- Yang, N.; Zhang, Y. A Gaussian Process Classification and Target Recognition Algorithm for SAR Images. Sci. Program. 2022, 2022, 9212856. [Google Scholar] [CrossRef]
- Ding, B. Model-driven Automatic Target Recognition of SAR Images with Part-level Reasoning. Optik 2022, 252, 168561. [Google Scholar] [CrossRef]
- Hu, J. Automatic Target Recognition of SAR Images Using Collaborative Representation. Comput. Intell. Neurosci. 2022, 2022, 3100028. [Google Scholar] [CrossRef]
- Du, L.; Wang, Z.; Wang, Y.; Di, W.; Lu, L.I. Survey of research progress on target detection and discrimination of single-channel SAR images for complex scenes. J. Radars 2020, 9, 34–54. [Google Scholar] [CrossRef]
- Xu, F.; Wang, H.; Jin, Y. Deep Learning as Applied in SAR Target Recognition and Terrain Classification. J. Radars 2017, 6, 136–148. [Google Scholar] [CrossRef]
- Ding, J.; Chen, B.; Liu, H.; Huang, M. Convolutional Neural Network With Data Augmentation for SAR Target Recognition. IEEE Geosci. Remote Sens. Lett. 2016, 13, 364–368. [Google Scholar] [CrossRef]
- Chen, S.; Wang, H.; Xu, F.; Jin, Y.-Q. Target Classification Using the Deep Convolutional Networks for SAR Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4806–4817. [Google Scholar] [CrossRef]
- Shao, J.; Qu, C.; Li, J.; Peng, S. A Lightweight Convolutional Neural Network Based on Visual Attention for SAR Image Target Classification. Sensors 2018, 18, 3039. [Google Scholar] [CrossRef]
- Chen, H.; Zhang, F.; Tang, B.; Yin, Q.; Sun, X. Slim and Efficient Neural Network Design for Resource-constrained SAR Target Recognition. Remote Sens. 2018, 10, 1618. [Google Scholar] [CrossRef]
- Min, R.; Lan, H.; Cao, Z.; Cui, Z. A Gradually Distilled CNN for SAR Target Recognition. IEEE Access 2019, 7, 42190–42200. [Google Scholar] [CrossRef]
- Zhang, F.; Liu, Y.; Zhou, Y.; Yin, Q.; Li, H.-C. A lossless lightweight CNN design for SAR target recognition. Remote Sens. Lett. 2020, 11, 485–494. [Google Scholar] [CrossRef]
- Pei, J.; Huang, Y.; Sun, Z.; Zhang, Y.; Yang, J.; Yeo, T.-S. Multiview Synthetic Aperture Radar Automatic Target Recognition Optimization: Modeling and Implementation. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6425–6439. [Google Scholar] [CrossRef]
- Zhao, P.; Liu, K.; Zou, H.; Zhen, X. Multi-Stream Convolutional Neural Network for SAR Automatic Target Recognition. Remote Sens. 2018, 10, 1473. [Google Scholar] [CrossRef]
- Wang, N.; Wang, Y.; Liu, H.; Zuo, Q.; He, J. Feature-Fused SAR Target Discrimination Using Multiple Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1695–1699. [Google Scholar] [CrossRef]
- Cho, J.H.; Park, C.G. Multiple Feature Aggregation Using Convolutional Neural Networks for SAR Image-Based Automatic Target Recognition. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1882–1886. [Google Scholar] [CrossRef]
- Tian, Z.; Wang, L.; Zhan, R.; Hu, J.; Zhang, J. Classification via weighted kernel CNN: Application to SAR target recognition. Int. J. Remote Sens. 2018, 39, 9249–9268. [Google Scholar] [CrossRef]
- Kwak, Y.; Song, W.J.; Kim, S.E. Speckle-Noise-Invariant Convolutional Neural Network for SAR Target Recognition. IEEE Geosci. Remote Sens. Lett. 2019, 16, 549–553. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]
- Zhang, M.; An, J.; Yang, L.D.; Wu, L.; Lu, X.Q. Convolutional Neural Network with Attention Mechanism for SAR Automatic Target Recognition. IEEE Geosci. Remote Sens. Lett. 2020, 19, 1–5. [Google Scholar]
- Wang, D.; Song, Y.; Huang, J.; An, D.; Chen, L. SAR Target Classification Based on Multiscale Attention Super-Class Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 9004–9019. [Google Scholar] [CrossRef]
- Lang, P.; Fu, X.; Feng, C.; Dong, J.; Qin, R.; Martorella, M. LW-CMDANet: A Novel Attention Network for SAR Automatic Target Recognition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 6615–6630. [Google Scholar] [CrossRef]
- Li, R.; Wang, X.; Wang, J.; Song, Y.; Lei, L. SAR Target Recognition Based on Efficient Fully Convolutional Attention Block CNN. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Wang, Z.; Xin, Z.; Liao, G.; Huang, P.; Xuan, J.; Sun, Y.; Tai, Y. Land-Sea Target Detection and Recognition in SAR Image Based on Non-Local Channel Attention Network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Xu, H.; Xu, F. Multi-Scale Capsule Network with Coordinate Attention for SAR Automatic Target Recognition. In Proceedings of the 2021 7th Asia-Pacific Conference on Synthetic Aperture Radar (APSAR), Virtual Conference, 1–3 November 2021; pp. 1–5. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Operator | Expansion | Output Channels | Operator Repeat Times | Stride |
|---|---|---|---|---|---|
| 128 × 128 × 3 | Conv2d | - | 32 | 1 | 2 |
| 64 × 64 × 32 | Bottleneck | 1 | 16 | 1 | 1 |
| 64 × 64 × 16 | Bottleneck | 6 | 24 | 2 | 2 |
| 32 × 32 × 24 | Bottleneck | 6 | 32 | 3 | 2 |
| 16 × 16 × 32 | Bottleneck | 6 | 64 | 4 | 2 |
| 8 × 8 × 64 | Bottleneck | 6 | 96 | 3 | 1 |
| 8 × 8 × 96 | Bottleneck | 6 | 160 | 3 | 2 |
| 4 × 4 × 160 | Bottleneck | 6 | 320 | 1 | 1 |
| 4 × 4 × 320 | Conv2d | - | 1280 | 1 | 1 |
| 4 × 4 × 1280 | Avgpool | - | - | 1 | - |
| 1 × 1 × 1280 | Conv2d | - | k | - | - |
| Input | Operator | Expansion | Output Channels | Operator Repeat Times | Stride |
|---|---|---|---|---|---|
| 128 × 128 × 3 | Conv2d | - | 32 | 1 | 2 |
| 64 × 64 × 32 | Bottleneck | 1 | 16 | 1 | 1 |
| 64 × 64 × 16 | Bottleneck | 6 | 24 | 2 | 2 |
| 32 × 32 × 24 | Bottleneck | 6 | 32 | 3 | 2 |
| 16 × 16 × 32 | Bottleneck | 6 | 64 | 4 | 2 |
| 8 × 8 × 64 | Bottleneck | 6 | 96 | 3 | 1 |
| 8 × 8 × 96 | Bottleneck | 6 | 160 | 3 | 2 |
| 4 × 4 × 160 | Bottleneck | 6 | 320 | 1 | 1 |
| 4 × 4 × 320 | Conv2d | - | 1280 | 1 | 1 |
| 4 × 4 × 1280 | CHA | - | 1280 | 1 | - |
| 4 × 4 × 1280 | SPA | - | 1280 | 1 | - |
| 4 × 4 × 1280 | CA | - | 1280 | 1 | - |
| 4 × 4 × 1280 | Avgpool | - | - | 1 | - |
| 1 × 1 × 1280 | Conv2d | - | k | - | - |
| Class | Number of Targets (17) | Number of Targets (15) | Sum. of Targets (17 and 15) |
|---|---|---|---|
| 2S1 | 299 | 274 | 573 |
| BMP2 | 233 | 195 | 428 |
| BRDM_2 | 298 | 274 | 572 |
| BTR60 | 256 | 195 | 451 |
| BTR70 | 233 | 196 | 429 |
| D7 | 299 | 274 | 573 |
| T62 | 298 | 273 | 571 |
| T72 | 232 | 196 | 428 |
| ZIL131 | 299 | 274 | 573 |
| ZSU_23_4 | 299 | 274 | 573 |
| Sum | 2746 | 2425 | 5171 |
| 2S1 | BMP2 | BRDM_2 | BTR60 | BTR70 | D7 | T62 | T72 | ZIL131 | ZSU_23_4 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 2S1 | 274 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| BMP2 | 0 | 194 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| BRDM_2 | 0 | 0 | 274 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| BTR60 | 0 | 0 | 0 | 195 | 0 | 0 | 0 | 0 | 0 | 0 |
| BTR70 | 0 | 0 | 0 | 2 | 194 | 0 | 0 | 0 | 0 | 0 |
| D7 | 0 | 0 | 0 | 0 | 0 | 274 | 0 | 0 | 0 | 0 |
| T62 | 0 | 0 | 0 | 0 | 0 | 0 | 273 | 0 | 0 | 0 |
| T72 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 196 | 0 | 0 |
| ZIL131 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 274 | 0 |
| ZSU_23_4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 274 |
| 2S1 | BMP2 | BRDM_2 | BTR60 | BTR70 | D7 | T62 | T72 | ZIL131 | ZSU_23_4 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 2S1 | 252 | 6 | 0 | 3 | 3 | 0 | 0 | 8 | 2 | 0 |
| BMP2 | 0 | 184 | 0 | 2 | 0 | 0 | 0 | 9 | 0 | 0 |
| BRDM_2 | 0 | 0 | 265 | 0 | 0 | 3 | 0 | 1 | 4 | 1 |
| BTR60 | 0 | 0 | 0 | 193 | 1 | 0 | 0 | 1 | 0 | 0 |
| BTR70 | 0 | 2 | 0 | 6 | 187 | 0 | 0 | 1 | 0 | 0 |
| D7 | 0 | 0 | 0 | 0 | 0 | 273 | 0 | 0 | 1 | 0 |
| T62 | 0 | 0 | 0 | 0 | 0 | 1 | 267 | 2 | 0 | 3 |
| T72 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 195 | 0 | 0 |
| ZIL131 | 0 | 0 | 0 | 0 | 0 | 13 | 0 | 0 | 261 | 0 |
| ZSU_23_4 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 273 |
| MA-MobileNetV2 Network | MobileNetV2 Network | |
|---|---|---|
| Recognition accuracy | 99.85% | 96.75% |
| Recall | 99.85% | 96.92% |
| Accuracy | The Proposed Method | AM-CNN [25] | FCAB-CNN [28] | GoogleNet-APNB-ISEB [29] | CA-MCN [30] |
|---|---|---|---|---|---|
| 2S1 | 100% | 98.90% | 100% | 99.80% | 99.27% |
| BMP2 | 100% | 100% | 98.46% | 99.50% | 100% |
| BRDM_2 | 100% | 99.64% | 99.27% | 99.80% | 99.64% |
| BTR60 | 98.98% | 96.41% | 98.98% | 99.20% | 99.49% |
| BTR70 | 100% | 100% | 100% | 100% | 100% |
| D7 | 100% | 99.27% | 100% | 99.30% | 99.27% |
| T62 | 100% | 99.63% | 99.27% | 100% | 99.63% |
| T72 | 99.49% | 100% | 100% | 99.80% | 100% |
| ZIL131 | 100% | 99.64% | 100% | 99.80% | 99.64% |
| ZSU_23_4 | 100% | 100% | 98.17 | 99.40% | 100% |
| Average accuracy | 99.85% | 99.35% | 99.51% | 99.72% | 99.59% |
| Input | Operator | Expansion | Output Channels | Operator Repeat Times | Stride |
|---|---|---|---|---|---|
| 128 × 128 × 3 | Conv2d | - | 32 | 1 | 2 |
| 64 × 64 × 32 | Bottleneck | 1 | 16 | 1 | 1 |
| 64 × 64 × 16 | Bottleneck | 6 | 24 | 2 | 2 |
| 32 × 32 × 24 | Bottleneck | 6 | 32 | 3 | 2 |
| 16 × 16 × 32 | Bottleneck | 6 | 64 | 4 | 2 |
| 8 × 8 × 64 | Bottleneck | 6 | 96 | 3 | 1 |
| 8 × 8 × 96 | Bottleneck | 6 | 160 | 3 | 2 |
| 4 × 4 × 160 | Bottleneck | 6 | 320 | 1 | 1 |
| 4 × 4 × 320 | Conv2d | - | 1280 | 1 | 1 |
| 4 × 4 × 1280 | SPA | - | 1280 | 1 | - |
| 4 × 4 × 1280 | CA | - | 1280 | 1 | - |
| 4 × 4 × 1280 | Avgpool | - | - | 1 | - |
| 1 × 1 × 1280 | Conv2d | - | k | - | - |
| 2S1 | BMP2 | BRDM_2 | BTR60 | BTR70 | D7 | T62 | T72 | ZIL131 | ZSU_23_4 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 2S1 | 271 | 0 | 0 | 1 | 2 | 0 | 0 | 0 | 0 | 0 |
| BMP2 | 0 | 191 | 0 | 1 | 2 | 0 | 0 | 1 | 0 | 0 |
| BRDM_2 | 0 | 0 | 274 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| BTR60 | 0 | 0 | 0 | 195 | 0 | 0 | 0 | 0 | 0 | 0 |
| BTR70 | 0 | 0 | 0 | 1 | 195 | 0 | 0 | 0 | 0 | 0 |
| D7 | 0 | 0 | 0 | 0 | 0 | 273 | 0 | 0 | 1 | 0 |
| T62 | 0 | 0 | 0 | 0 | 0 | 0 | 273 | 0 | 0 | 0 |
| T72 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 196 | 0 | 0 |
| ZIL131 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 274 | 0 |
| ZSU_23_4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 274 |
| MA-MobileNetV2 Network | CHA Module Network | |
|---|---|---|
| Recognition accuracy | 99.85% | 99.56% |
| Recall | 99.85% | 99.60% |
| Input | Operator | Expansion | Output Channels | Operator Repeat Times | Stride |
|---|---|---|---|---|---|
| 128 × 128 × 3 | Conv2d | - | 32 | 1 | 2 |
| 64 × 64 × 32 | Bottleneck | 1 | 16 | 1 | 1 |
| 64 × 64 × 16 | Bottleneck | 6 | 24 | 2 | 2 |
| 32 × 32 × 24 | Bottleneck | 6 | 32 | 3 | 2 |
| 16 × 16 × 32 | Bottleneck | 6 | 64 | 4 | 2 |
| 8 × 8 × 64 | Bottleneck | 6 | 96 | 3 | 1 |
| 8 × 8 × 96 | Bottleneck | 6 | 160 | 3 | 2 |
| 4 × 4 × 160 | Bottleneck | 6 | 320 | 1 | 1 |
| 4 × 4 × 320 | Conv2d | - | 1280 | 1 | 1 |
| 4 × 4 × 1280 | CHA | - | 1280 | 1 | - |
| 4 × 4 × 1280 | CA | - | 1280 | 1 | - |
| 4 × 4 × 1280 | Avgpool | - | - | 1 | - |
| 1 × 1 × 1280 | Conv2d | - | k | - | - |
| 2S1 | BMP2 | BRDM_2 | BTR60 | BTR70 | D7 | T62 | T72 | ZIL131 | ZSU_23_4 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 2S1 | 268 | 0 | 0 | 5 | 0 | 0 | 0 | 0 | 1 | 0 |
| BMP2 | 0 | 194 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| BRDM_2 | 0 | 0 | 273 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| BTR60 | 0 | 0 | 0 | 195 | 0 | 0 | 0 | 0 | 0 | 0 |
| BTR70 | 0 | 0 | 0 | 3 | 193 | 0 | 0 | 0 | 0 | 0 |
| D7 | 0 | 0 | 0 | 0 | 0 | 274 | 0 | 0 | 0 | 0 |
| T62 | 0 | 0 | 0 | 0 | 0 | 0 | 273 | 0 | 0 | 0 |
| T72 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 196 | 0 | 0 |
| ZIL131 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 274 | 0 |
| ZSU_23_4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 274 |
| MA-MobileNetV2 Network | SPA Module Network | |
|---|---|---|
| Recognition accuracy | 99.85% | 99.49% |
| Recall | 99.85% | 99.54% |
| Input | Operator | Expansion | Output Channels | Operator Repeat Times | Stride |
|---|---|---|---|---|---|
| 128 × 128 × 3 | Conv2d | - | 32 | 1 | 2 |
| 64 × 64 × 32 | Bottleneck | 1 | 16 | 1 | 1 |
| 64 × 64 × 16 | Bottleneck | 6 | 24 | 2 | 2 |
| 32 × 32 × 24 | Bottleneck | 6 | 32 | 3 | 2 |
| 16 × 16 × 32 | Bottleneck | 6 | 64 | 4 | 2 |
| 8 × 8 × 64 | Bottleneck | 6 | 96 | 3 | 1 |
| 8 × 8 × 96 | Bottleneck | 6 | 160 | 3 | 2 |
| 4 × 4 × 160 | Bottleneck | 6 | 320 | 1 | 1 |
| 4 × 4 × 320 | Conv2d | - | 1280 | 1 | 1 |
| 4 × 4 × 1280 | CHA | - | 1280 | 1 | - |
| 4 × 4 × 1280 | SPA | - | 1280 | 1 | - |
| 4 × 4 × 1280 | Avgpool | - | - | 1 | - |
| 1 × 1 × 1280 | Conv2d | - | k | - | - |
| 2S1 | BMP2 | BRDM_2 | BTR60 | BTR70 | D7 | T62 | T72 | ZIL131 | ZSU_23_4 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 2S1 | 272 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| BMP2 | 0 | 195 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| BRDM_2 | 0 | 0 | 274 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| BTR60 | 0 | 1 | 0 | 194 | 0 | 0 | 0 | 0 | 0 | 0 |
| BTR70 | 0 | 0 | 0 | 1 | 195 | 0 | 0 | 0 | 0 | 0 |
| D7 | 0 | 0 | 0 | 0 | 0 | 271 | 0 | 0 | 3 | 0 |
| T62 | 0 | 0 | 0 | 0 | 0 | 0 | 269 | 0 | 0 | 4 |
| T72 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 194 | 0 | 0 |
| ZIL131 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 274 | 0 |
| ZSU_23_4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 274 |
| MA-MobileNetV2 Network | CA Module Network | |
|---|---|---|
| Recognition accuracy | 99.85% | 99.44% |
| Recall | 99.85% | 99.47% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, T.; Cui, Y.; Feng, R.; Xiang, D. Vehicle Target Recognition in SAR Images with Complex Scenes Based on Mixed Attention Mechanism. Information 2024, 15, 159. https://doi.org/10.3390/info15030159
Tang T, Cui Y, Feng R, Xiang D. Vehicle Target Recognition in SAR Images with Complex Scenes Based on Mixed Attention Mechanism. Information. 2024; 15(3):159. https://doi.org/10.3390/info15030159
Chicago/Turabian StyleTang, Tao, Yuting Cui, Rui Feng, and Deliang Xiang. 2024. "Vehicle Target Recognition in SAR Images with Complex Scenes Based on Mixed Attention Mechanism" Information 15, no. 3: 159. https://doi.org/10.3390/info15030159
APA StyleTang, T., Cui, Y., Feng, R., & Xiang, D. (2024). Vehicle Target Recognition in SAR Images with Complex Scenes Based on Mixed Attention Mechanism. Information, 15(3), 159. https://doi.org/10.3390/info15030159