

Drowning in the Information Flood: Machine-Learning-Based Relevance Classification of Flood-Related Tweets for Disaster Management



Abstract
1. Introduction
2. Related Work
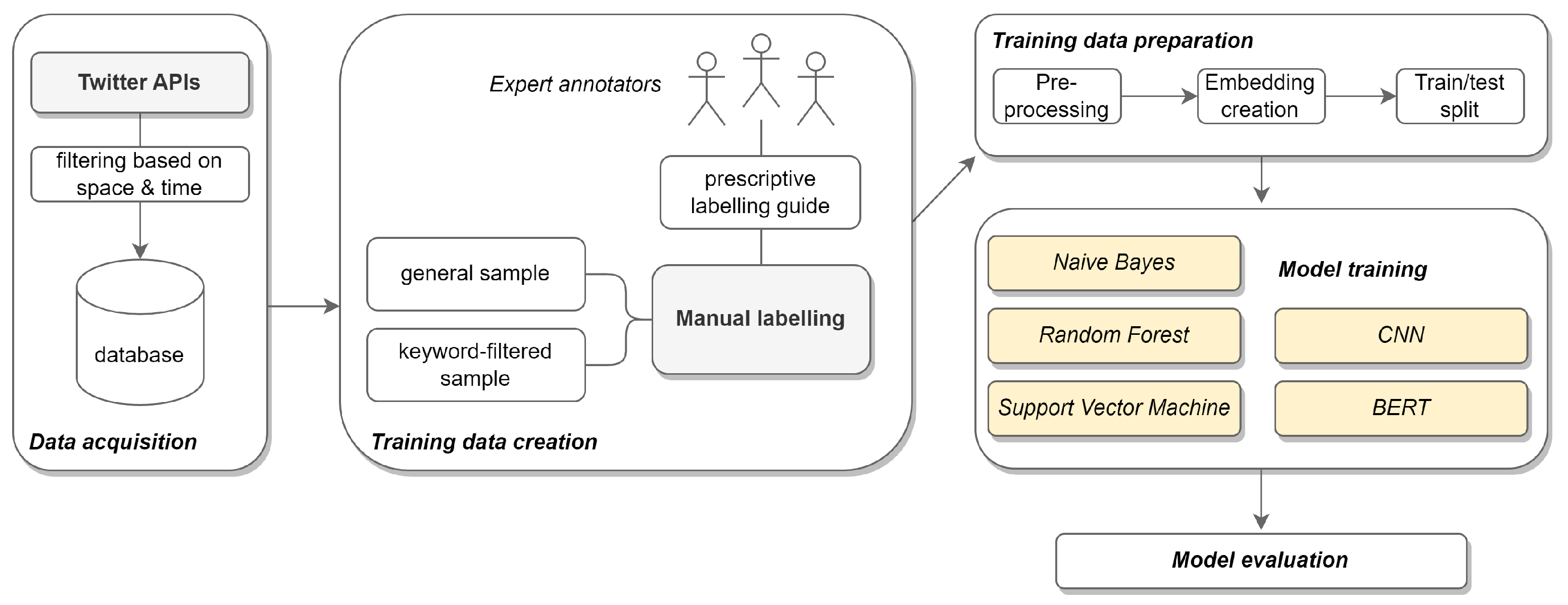
3. Materials and Methods
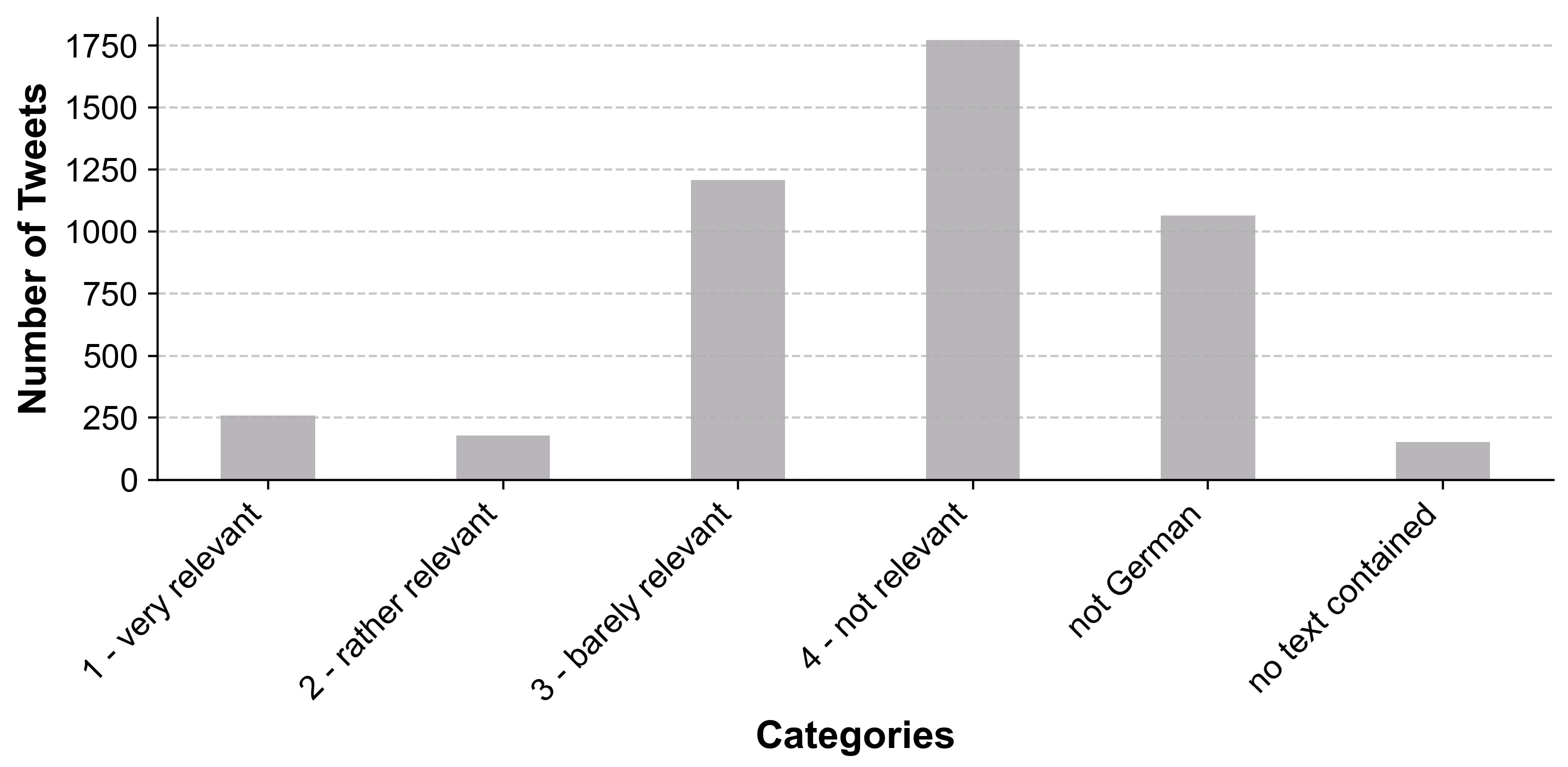
3.1. Data Collection and Labelling
3.2. Naïve Bayes
3.3. Support Vector Machine
3.4. Random Forest
3.5. Convolutional Neural Networks
3.6. BERT
3.7. Evaluation Metrics
4. Results
| Algorithm 1: Inference by relevance classification model |
 |
5. Discussion
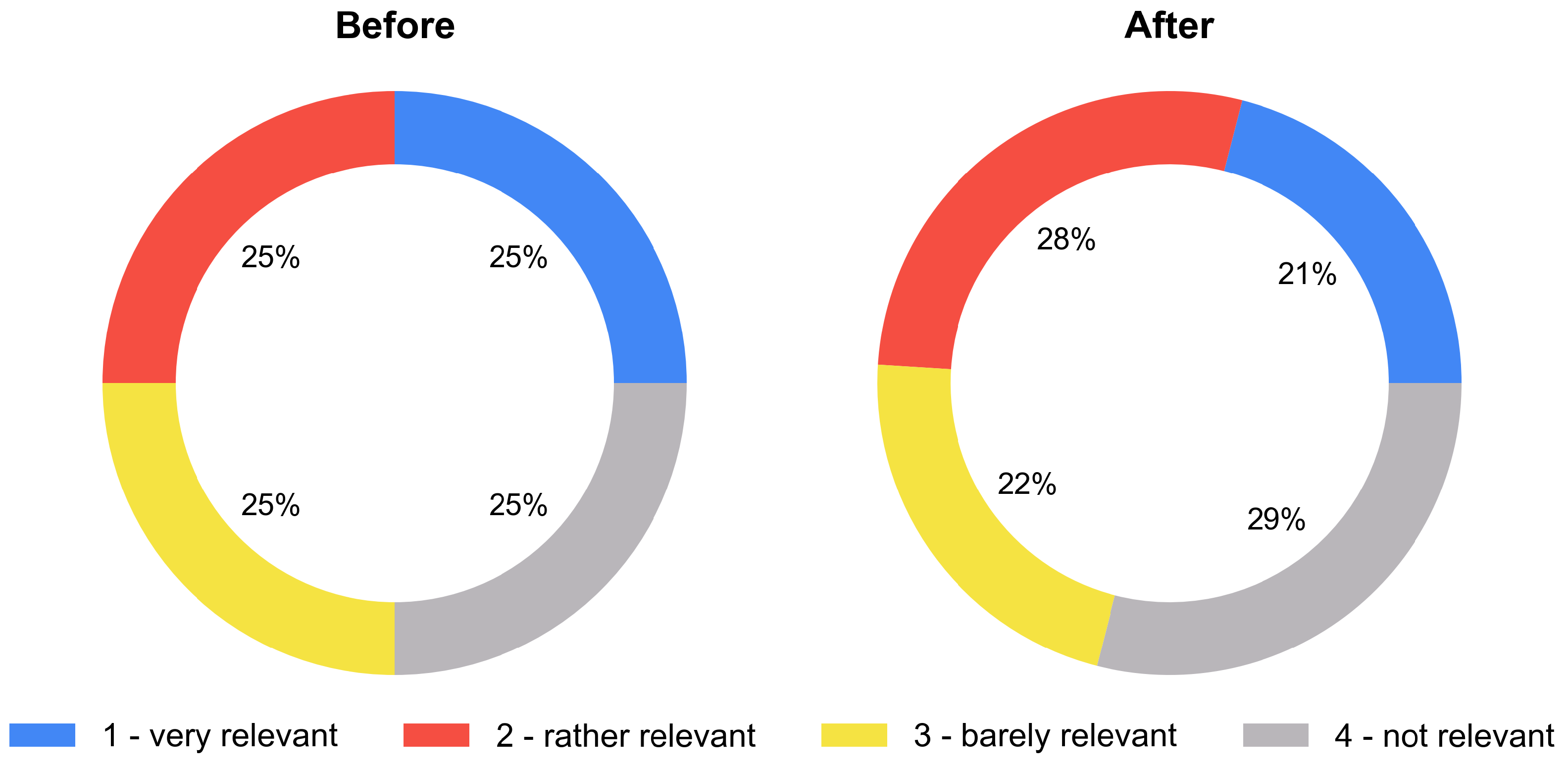
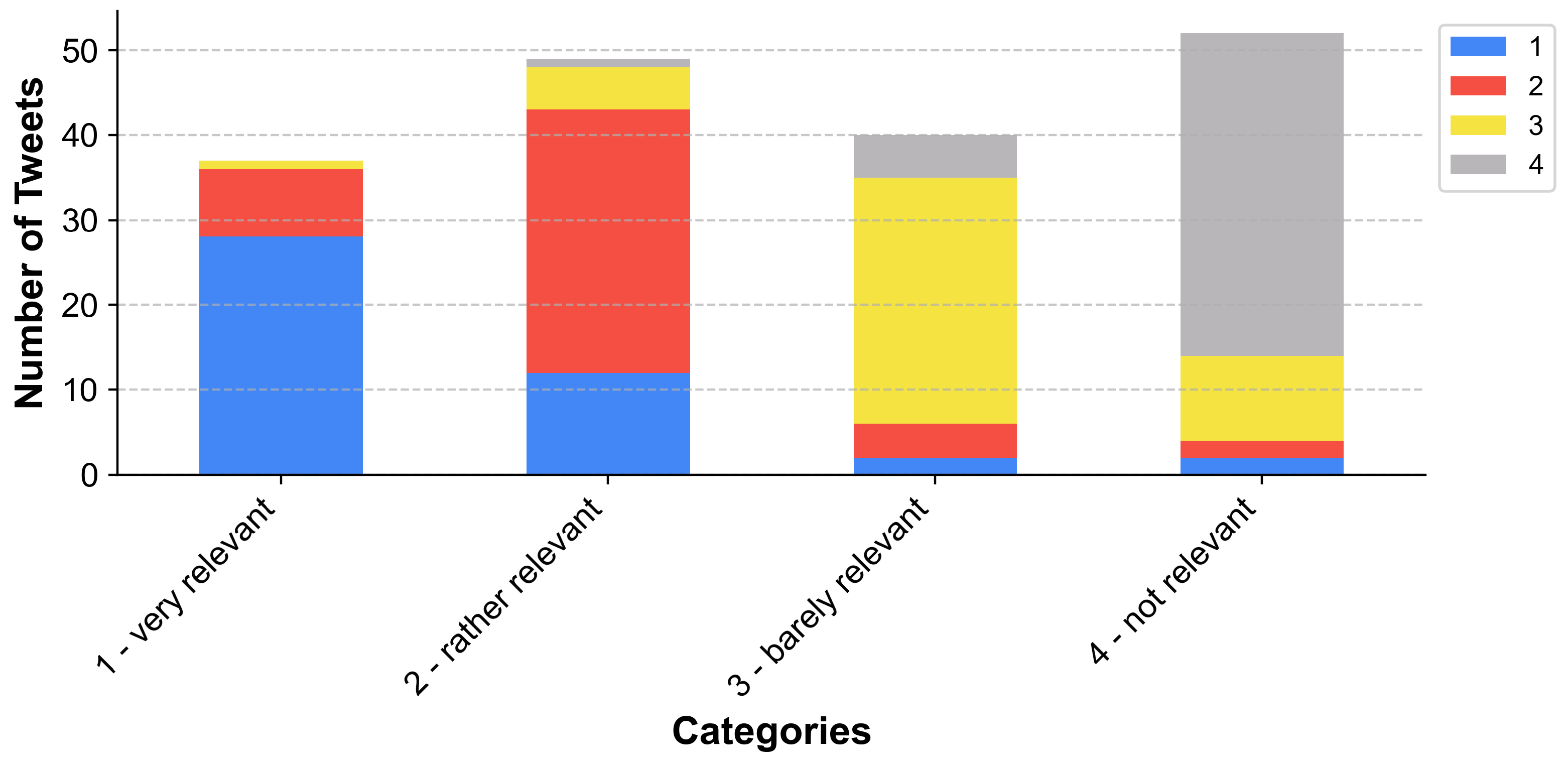
5.1. Training Data
5.2. Results
5.3. Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Network |
| API | Application Programming Interface |
| BERT | Bidirectional Encoder Representations from Transformers |
| CAMM | Cross-Attention Multi-Modal |
| CNN | Convolutional Neural Network |
| GNN | Graph Neural Network |
| kNN | k-nearest neighbour |
| LDA | Latent Dirichlet Allocation |
| NB | Naïve Bayes |
| NLP | Natural Language Processing |
| RF | Random Forest |
| SVM | Support Vector Machine |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| German Keyword | Translation |
|---|---|
| Aufräumarbeiten | cleanup work |
| Bergung | salvage |
| Dammbruch | dam breach |
| Dammschäden | damage to dams |
| Dauerregen | continuous rain |
| Deichbruch | levee breach |
| Deichschäden | damages to levees |
| Einsturz | collapse |
| Erdrutsch | landslide |
| Evakuierung | evacuation |
| Extremwetterlage | extreme weather situation |
| Freiwillige Helfer | volunteers |
| Geröll | rubble |
| Gewitter | thunderstorm |
| Großeinsatz | major operation |
| Hangrutschung | landslide |
| Hilfsaktion | relief operation |
| Höchststand | peak/peak level |
| Hochwasser | flood |
| Katastrophe | disaster |
| Krisenstab | crisis management team |
| Luftrettung | air rescue |
| Murgang | mudflow |
| Niederschlag | precipitation |
| Notunterkunft | emergency shelter |
| Orkan | hurricane (European windstorm) |
| Pegel | water level/gauge |
| Platzregen | torrential rain |
| Retentionsfläche | retention area |
| Rettungskräfte | rescue forces |
| Sandsäcke | sandbags |
| Schneeschmelze | snow melting |
| Schlammlawine | mudslide |
| Schutt | debris |
| Starkregen | heavy rain |
| Stromausfall | power outage |
| Sturm | storm |
| Sturzflut | flash flood |
| Tornado | tornado |
| Trümmer | ruins |
| Überflutung | flooding |
| Überschwemmung | inundation |
| Unwetter | severe weather |
| Wasserrettung | water rescue |
| Wiederaufbau | reconstruction |
| Zerstörung | destruction |
| Category | Translated Tweet | Reasoning |
|---|---|---|
| 1—very relevant | Within one day, the flood water has risen so high that the road is no longer passable. The ferry has stopped operating. #rhine #walsum | flooding/high water level |
| Despite rising water levels on the Saale and Weißer Elster rivers, there is no danger of flooding in Halle. The Landesbetrieb für Hochwasserschutz (LHW) has not yet issued a flood warning for Halle. | flood warning | |
| Here in Rheinbach too. Traffic is flowing through the main street again, while the mud is being cleared away there at the same time. | affected infrastructure/damage | |
| 2—rather relevant | We are lucky that our cellar was not flooded. | non-affected people |
| Watch out #FakeNews Share @user report. #flood disaster #disasterarea #weareVOST #VOST #SMEM | reference to emergency forces | |
| 3—barely relevant | I feel very sorry for the people in NRW. Keep your fingers crossed for all of them. The only thing it can be about now is helping. #Floods | declarations of solidarity |
| @user Seriously? While the rescue measures are still underway and the #FederalPresident flies from Berlin to the Rhineland, they stand in the background and smile? That is disrespectful to the victims and their families and also politically disrespectful… | political or religious statements | |
| Please all join the campaign stop of the @user and concentrate all forces on the essentials and who can, donate! #Flood | fundraising appeals | |
| 4—not relevant | I decided to turn up the music excessively loud today, before the neighbour’s child, who can only ride a bike if he squeals, starts doing his rounds. | not related to flood event |
| @user Good morning at now 16.1 ℃, overcast/thunderstorm, wind N 2 bft, air pressure 1022 mbar, precipitation risk 26% from 55,599 Siefersheim in Rheinhessen. |
References
- Kron, W.; Löw, P.; Kundzewicz, Z.W. Changes in Risk of Extreme Weather Events in Europe. Environ. Sci. Policy 2019, 100, 74–83. [Google Scholar] [CrossRef]
- Crooks, A.; Croitoru, A.; Stefanidis, A.; Radzikowski, J. #Earthquake: Twitter as a Distributed Sensor System: #Earthquake: Twitter as a Distributed Sensor System. Trans. GIS 2013, 17, 124–147. [Google Scholar] [CrossRef]
- Doan, S.; Vo, B.K.H.; Collier, N. An Analysis of Twitter Messages in the 2011 Tohoku Earthquake. In Proceedings of the Electronic Healthcare: 4th International Conference, eHealth 2011, Málaga, Spain, 21–23 November 2011; Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering; LNICST. Volume 91, pp. 58–66. [Google Scholar] [CrossRef]
- Earle, P.S.; Bowden, D.C.; Guy, M. Twitter Earthquake Detection: Earthquake Monitoring in a Social World. Ann. Geophys. 2012, 54, 708–715. [Google Scholar] [CrossRef]
- Resch, B.; Usländer, F.; Havas, C. Combining Machine-Learning Topic Models and Spatiotemporal Analysis of Social Media Data for Disaster Footprint and Damage Assessment. Cartogr. Geogr. Inf. Sci. 2018, 45, 362–376. [Google Scholar] [CrossRef]
- Niles, M.T.; Emery, B.F.; Reagan, A.J.; Dodds, P.S.; Danforth, C.M. Social Media Usage Patterns during Natural Hazards. PLoS ONE 2019, 14, e0210484. [Google Scholar] [CrossRef]
- Kaufhold, M.A.; Bayer, M.; Reuter, C. Rapid Relevance Classification of Social Media Posts in Disasters and Emergencies: A System and Evaluation Featuring Active, Incremental and Online Learning. Inf. Process. Manag. 2020, 57, 102132. [Google Scholar] [CrossRef]
- Li, L.; Ma, Z.; Cao, T. Data-Driven Investigations of Using Social Media to Aid Evacuations amid Western United States Wildfire Season. Fire Saf. J. 2021, 126, 103480. [Google Scholar] [CrossRef]
- Luna, S.; Pennock, M.J. Social Media Applications and Emergency Management: A Literature Review and Research Agenda. Int. J. Disaster Risk Reduct. 2018, 28, 565–577. [Google Scholar] [CrossRef]
- Saracevic, T. RELEVANCE: A Review of and a Framework for the Thinking on the Notion in Information Science. J. Am. Soc. Inf. Sci. 1975, 26, 321–343. [Google Scholar] [CrossRef]
- Schamber, L.; Eisenberg, M.B.; Nilan, M.S. A Re-Examination of Relevance: Toward a Dynamic, Situational Definition*. Inf. Process. Manag. 1990, 26, 755–776. [Google Scholar] [CrossRef]
- Cooper, W. A Definition of Relevance for Information Retrieval. Inf. Storage Retr. 1971, 7, 19–37. [Google Scholar] [CrossRef]
- Cuadra, C.A.; Katter, R. Experimental Studies of Relevance Judgments; Technical Report 1; System Development Corporation: Santa Monica, CA, USA, 1967. [Google Scholar]
- Rohweder, J.P.; Kasten, G.; Malzahn, D.; Piro, A.; Schmid, J. Informationsqualität–Definitionen, Dimensionen und Begriffe. In Daten- und Informationsqualität; Hildebrand, K., Gebauer, M., Hinrichs, H., Mielke, M., Eds.; Vieweg+Teubner: Wiesbaden, Germany, 2011; pp. 25–45. [Google Scholar] [CrossRef]
- Jensen, G.E.; Cranefield, J. Key Criteria for Information Quality in the Use of Online Social Media for Emergency Management in New Zealand. Master Thesis, Victoria University of Wellington, Wellington, New Zealand, 2012. [Google Scholar] [CrossRef]
- Eisenberg, M.B. Measuring Relevance Judgments. Inf. Process. Manag. 1988, 24, 373–389. [Google Scholar] [CrossRef]
- Havas, C.; Resch, B. Portability of Semantic and Spatial-Temporal Machine Learning Methods to Analyse Social Media for near-Real-Time Disaster Monitoring. Nat. Hazards 2021, 108, 2939–2969. [Google Scholar] [CrossRef] [PubMed]
- Havas, C.; Wendlinger, L.; Stier, J.; Julka, S.; Krieger, V.; Ferner, C.; Petutschnig, A.; Granitzer, M.; Wegenkittl, S.; Resch, B. Spatio-Temporal Machine Learning Analysis of Social Media Data and Refugee Movement Statistics. ISPRS Int. J. Geo-Inf. 2021, 10, 498. [Google Scholar] [CrossRef]
- Petutschnig, A.; Havas, C.R.; Resch, B.; Krieger, V.; Ferner, C. Exploratory Spatiotemporal Language Analysis of Geo-Social Network Data for Identifying Movements of Refugees. GI_Forum 2020, 1, 137–152. [Google Scholar] [CrossRef]
- Kogan, N.E.; Clemente, L.; Liautaud, P.; Kaashoek, J.; Link, N.B.; Nguyen, A.T.; Lu, F.S.; Huybers, P.; Resch, B.; Havas, C.; et al. An Early Warning Approach to Monitor COVID-19 Activity with Multiple Digital Traces in near Real Time. Sci. Adv. 2021, 7, eabd6989. [Google Scholar] [CrossRef]
- Arifi, D.; Resch, B.; Kinne, J.; Lenz, D. Innovation in Hyperlink and Social Media Networks: Comparing Connection Strategies of Innovative Companies in Hyperlink and Social Media Networks. PLoS ONE 2023, 18, e0283372. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.; Li, Z.; Wang, C.; Ning, H. Identifying Disaster Related Social Media for Rapid Response: A Visual-Textual Fused CNN Architecture. Int. J. Digit. Earth 2020, 13, 1017–1039. [Google Scholar] [CrossRef]
- Madichetty, S.; Muthukumarasamy, S.; Jayadev, P. Multi-Modal Classification of Twitter Data during Disasters for Humanitarian Response. J. Ambient Intell. Humaniz. Comput. 2021, 12, 10223–10237. [Google Scholar] [CrossRef]
- Adwaith, D.; Abishake, A.K.; Raghul, S.V.; Sivasankar, E. Enhancing Multimodal Disaster Tweet Classification Using State-of-the-Art Deep Learning Networks. Multimed. Tools Appl. 2022, 81, 18483–18501. [Google Scholar] [CrossRef]
- Li, J.; Wang, Y.; Li, W. MGMP: Multimodal Graph Message Propagation Network for Event Detection. In MultiMedia Modeling; Þór Jónsson, B., Gurrin, C., Tran, M.T., Dang-Nguyen, D.T., Hu, A.M.C., Huynh Thi Thanh, B., Huet, B., Eds.; Springer International Publishing: Cham, Switerland, 2022; Volume 13141, pp. 141–153. [Google Scholar] [CrossRef]
- Barz, B.; Schröter, K.; Kra, A.C.; Denzler, J. Finding Relevant Flood Images on Twitter Using Content-Based Filters. In ICPR International Workshops and Challenges. ICPR 2021. Lecture Notes in Computer Science; Springer: Cham, Switerland, 2021; Volume 12666. [Google Scholar] [CrossRef]
- de Albuquerque, J.P.; Herfort, B.; Brenning, A.; Zipf, A. A Geographic Approach for Combining Social Media and Authoritative Data towards Identifying Useful Information for Disaster Management. Int. J. Geogr. Inf. Sci. 2015, 29, 667–689. [Google Scholar] [CrossRef]
- Vieweg, S.E. Situational Awareness in Mass Emergency: A Behavioral and Linguistic Analysis of Microblogged Communications. Ph.D. Thesis, University of Colorado at Boulder, Boulder, CO, USA, 2012. [Google Scholar]
- Starbird, K.; Palen, L. Pass It on?: Retweeting in Mass Emergency. In Proceedings of the 7th International International Conference on Information Systems for Crisis Response and Management, Seattle, WA, USA, 2–5 May 2010. [Google Scholar]
- Derczynski, L.; Bontcheva, K.; Meesters, K.; Maynard, D. Helping Crisis Responders Find the Informative Needle in the Tweet Haystack. In Proceedings of the 15th International Conference on Information Systems for Crisis Response and Management, Rochester, NY, USA, 20–23 May 2018. WiPe Paper—Social Media Studies. [Google Scholar]
- Ghosh, S.; Srijith, P.K.; Desarkar, M.S. Using Social Media for Classifying Actionable Insights in Disaster Scenario. Int. J. Adv. Eng. Sci. Appl. Math. 2017, 9, 224–237. [Google Scholar] [CrossRef]
- Ragini, J.R.; Anand, P.M.; Bhaskar, V. Big Data Analytics for Disaster Response and Recovery through Sentiment Analysis. Int. J. Inf. Manag. 2018, 42, 13–24. [Google Scholar] [CrossRef]
- Madichetty, S.; Muthukumarasamy, S. Detecting Informative Tweets during Disaster Using Deep Neural Networks. In Proceedings of the 2019 11th International Conference on Communication Systems & Networks (COMSNETS), Bengaluru, India, 7–11 January 2019; pp. 709–713. [Google Scholar] [CrossRef]
- Pekar, V.; Binner, J.; Najafi, H.; Hale, C.; Schmidt, V. Early Detection of Heterogeneous Disaster Events Using Social Media. J. Assoc. Inf. Sci. Technol. 2020, 71, 43–54. [Google Scholar] [CrossRef]
- Maharani, W. Sentiment Analysis during Jakarta Flood for Emergency Responses and Situational Awareness in Disaster Management Using BERT. In Proceedings of the 2020 8th International Conference on Information and Communication Technology (ICoICT), Yogyakarta, Indonesia, 24–26 June 2020. [Google Scholar] [CrossRef]
- Khattar, A.; Quadri, S.M.K. CAMM: Cross-Attention Multimodal Classification of Disaster-Related Tweets. IEEE Access 2022, 10, 92889–92902. [Google Scholar] [CrossRef]
- Powers, C.J.; Devaraj, A.; Ashqeen, K.; Dontula, A.; Joshi, A.; Shenoy, J.; Murthy, D. Using Artificial Intelligence to Identify Emergency Messages on Social Media during a Natural Disaster: A Deep Learning Approach. Int. J. Inf. Manag. Data Insights 2023, 3, 100164. [Google Scholar] [CrossRef]
- Koshy, R.; Elango, S. Multimodal Tweet Classification in Disaster Response Systems Using Transformer-Based Bidirectional Attention Model. Neural Comput. Appl. 2023, 35, 1607–1627. [Google Scholar] [CrossRef]
- Papadimos, T.; Andreadis, S.; Gialampoukidis, I.; Vrochidis, S.; Kompatsiaris, I. Flood-Related Multimedia Benchmark Evaluation: Challenges, Results and a Novel GNN Approach. Sensors 2023, 23, 3767. [Google Scholar] [CrossRef]
- Hovy, D.; Prabhumoye, S. Five Sources of Bias in Natural Language Processing. Lang. Linguist. Compass 2021, 15, e12432. [Google Scholar] [CrossRef]
- Aly, M. Survey on Multiclass Classification Methods. Int. J. Comput. Sci. Inf. Technol. 2005, 4, 572–576. [Google Scholar]
- Perera, P.; Oza, P.; Member, S.; Patel, V.M.; Member, S. One-Class Classification: A Survey. arXiv 2021, arXiv:2101.03064. [Google Scholar]
- Schmidt, S.; Zorenböhmer, C.; Arifi, D.; Resch, B. Polarity-Based Sentiment Analysis of Georeferenced Tweets Related to the 2022 Twitter Acquisition. Information 2023, 14, 71. [Google Scholar] [CrossRef]
- Röttger, P.; Vidgen, B.; Hovy, D.; Pierrehumbert, J.B. Two Contrasting Data Annotation Paradigms for Subjective NLP Tasks. arXiv 2022, arXiv:2112.07475. [Google Scholar]
- Lin, W.C.; Tsai, C.F.; Hu, Y.H.; Jhang, J.S. Clustering-Based Undersampling in Class-Imbalanced Data. Inf. Sci. 2017, 409–410, 17–26. [Google Scholar] [CrossRef]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach. In Pearson Series, 4th ed.; Pearson: Bloomington, MN, USA, 2021. [Google Scholar]
- Witten, I.H.; Bell, T.C. The Zero-Frequency Problem: Estimating the Probabilities of Novel Events in Adaptive Text Compression. IEEE Trans. Inf. Theory 1991, 37, 1085–1094. [Google Scholar] [CrossRef]
- Rennie, J.D.M.; Shih, L.; Teevan, J.; Karger, D.R. Tackling the Poor Assumptions of Naive Bayes Text Classifiers. Int. Conf. Mach. Learn. 2003, 3, 616–623. [Google Scholar]
- Mammone, A.; Turchi, M.; Cristianini, N. Support Vector Machines. Wiley Interdiscip. Rev. Comput. Stat. 2009, 1, 283–289. [Google Scholar] [CrossRef]
- Noble, W.S. What Is a Support Vector Machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Kotsiantis, S.B. Decision Trees: A Recent Overview. Artif. Intell. Rev. 2013, 39, 261–283. [Google Scholar] [CrossRef]
- Jasmine, P.H.; Arun, S. Machine Learning Applications in Structural Engineering—A Review. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1114, 012012. [Google Scholar] [CrossRef]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a Convolutional Neural Network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar] [CrossRef]
- O’Shea, K.; Nash, R. An Introduction to Convolutional Neural Networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT 2019—2019 Conference of the North 548 American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Adhikari, A.; Ram, A.; Tang, R.; Lin, J.; Cheriton, D.R. DocBERT: BERT for Document Classification. arXiv 2019, arXiv:1904.08398. [Google Scholar]
- Chan, B.; Schweter, S.; Möller, T. German’s Next Language Model. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain (Online), 8–13 December 2020; pp. 6788–6796. [Google Scholar] [CrossRef]
- Verma, S.; Vieweg, S.; Corvey, W.; Palen, L.; Martin, J.; Palmer, M.; Schram, A.; Anderson, K.M. Natural Language Processing to the Rescue? Extracting “Situational Awareness” Tweets during Mass Emergency. In Proceedings of the International AAAI Conference on Web and Social Media, Barcelona, Spain, 17–21 July 2011. [Google Scholar]
- Krawczyk, B. Learning from Imbalanced Data: Open Challenges and Future Directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef]

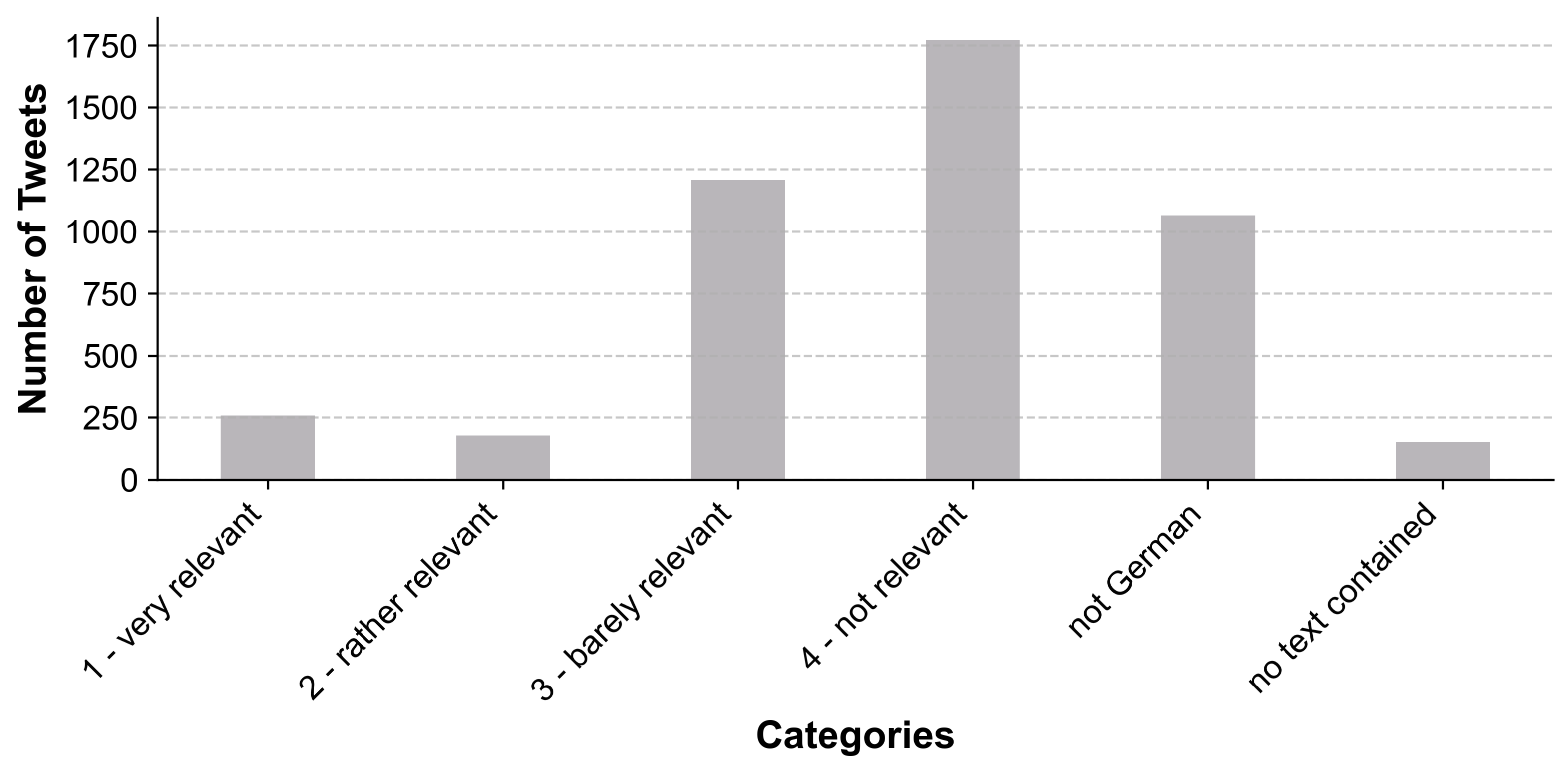
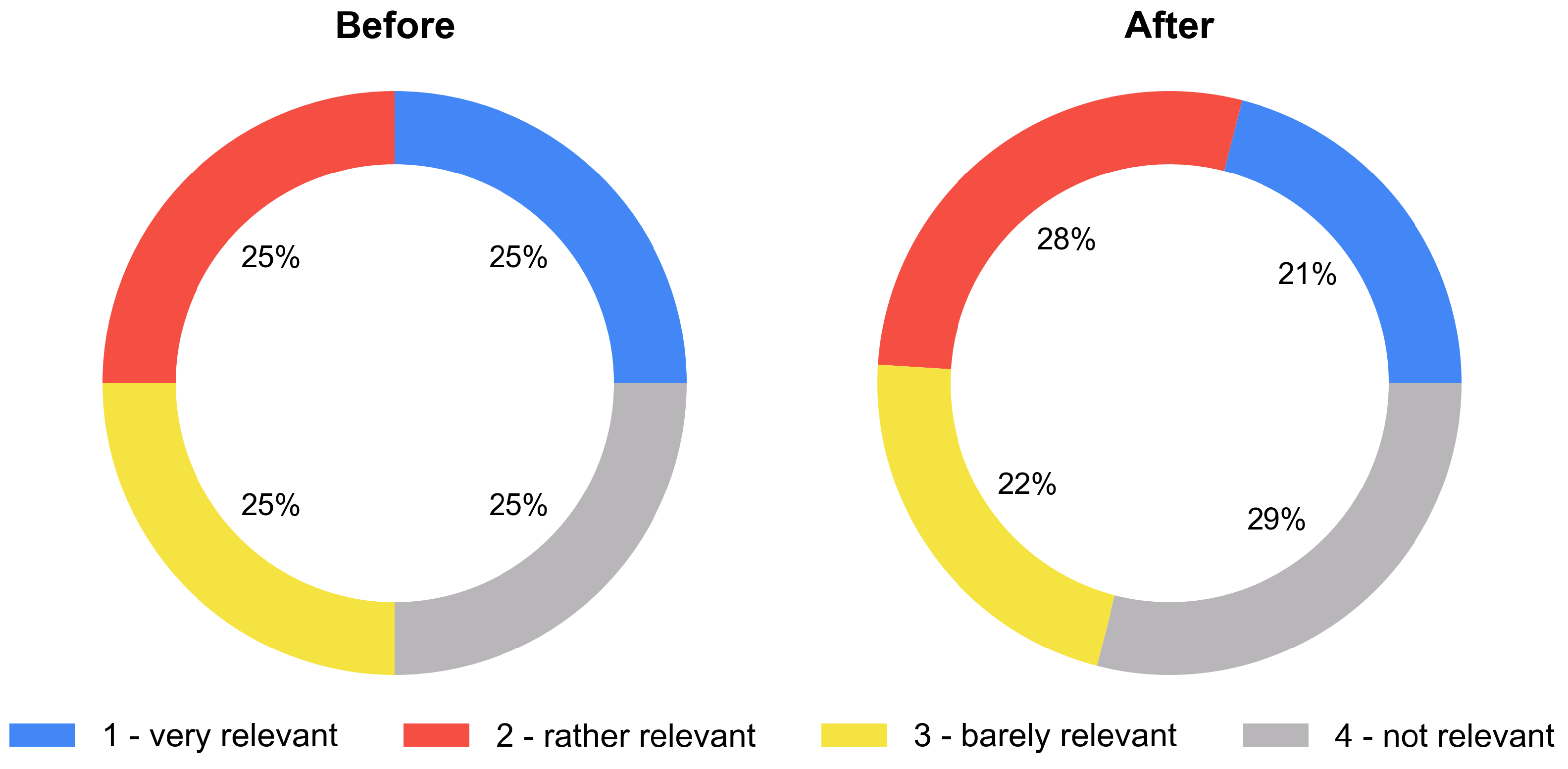
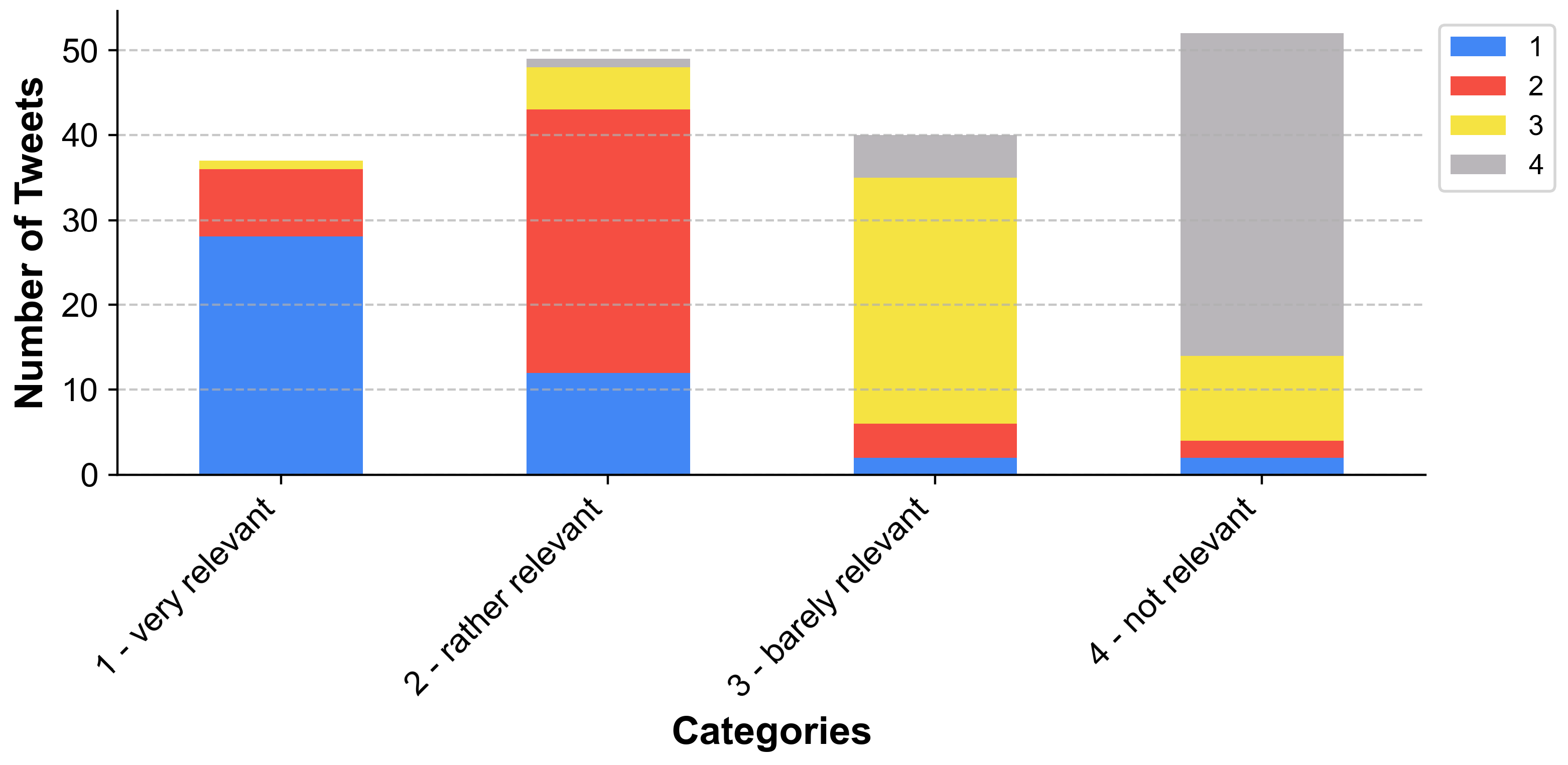
| Category | Explanation |
|---|---|
| 1—very relevant | A Tweet that is very helpful in supporting crisis management in case of a flood (e.g., Tweets referring to destructions, critical infrastructure). |
| 2—rather relevant | A Tweet that is somewhat helpful in supporting crisis management in case of a flood (e.g., Tweets mentioning efforts by first aid organisations, people that are not affected). |
| 3—barely relevant | A Tweet that is not really relevant but refers to a flood event (e.g., declarations of solidarity, appeals for donations, political or religious statements). |
| 4—not relevant | A Tweet that has no relation to a flood event. |
| not German | A Tweet that is not written in German language. |
| no text contained | A Tweet that contains no text, e.g., only emojis, links or user handles. |
| Model | Accuracy | Precision | Recall | F1 Score | GS |
|---|---|---|---|---|---|
| NB | 0.40 | 0.40 | 0.40 | 0.40 | 0.70 |
| RF | 0.44 | 0.45 | 0.44 | 0.45 | 0.73 |
| SVM | 0.28 | 0.28 | 0.28 | 0.28 | 0.65 |
| CNN | 0.51 | 0.54 | 0.51 | 0.52 | 0.84 |
| BERT | 0.71 | 0.71 | 0.71 | 0.71 | 0.90 |
| Relevance Categories | ||||||||
|---|---|---|---|---|---|---|---|---|
| 1—Very Relevant | 2— Rather Relevant | |||||||
| Model | P | R | F1 | GS | P | R | F1 | GS |
| NB | 0.39 | 0.32 | 0.35 | 0.58 | 0.38 | 0.47 | 0.42 | 0.74 |
| RF | 0.44 | 0.40 | 0.42 | 0.59 | 0.44 | 0.50 | 0.47 | 0.79 |
| SVM | 0.38 | 0.41 | 0.40 | 0.56 | 0.26 | 0.22 | 0.24 | 0.68 |
| CNN | 0.62 | 0.45 | 0.53 | 0.83 | 0.38 | 0.44 | 0.41 | 0.80 |
| BERT | 0.76 | 0.64 | 0.69 | 0.89 | 0.63 | 0.69 | 0.66 | 0.89 |
| 3—Barely Relevant | 4—Not Relevant | |||||||
| Model | P | R | F1 | GS | P | R | F1 | GS |
| NB | 0.38 | 0.32 | 0.35 | 0.73 | 0.44 | 0.49 | 0.46 | 0.74 |
| RF | 0.35 | 0.36 | 0.36 | 0.74 | 0.56 | 0.51 | 0.53 | 0.78 |
| SVM | 0.17 | 0.18 | 0.18 | 0.69 | 0.30 | 0.31 | 0.31 | 0.67 |
| CNN | 0.50 | 0.68 | 0.58 | 0.84 | 0.64 | 0.47 | 0.54 | 0.87 |
| BERT | 0.72 | 0.64 | 0.68 | 0.90 | 0.73 | 0.86 | 0.79 | 0.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Blomeier, E.; Schmidt, S.; Resch, B. Drowning in the Information Flood: Machine-Learning-Based Relevance Classification of Flood-Related Tweets for Disaster Management. Information 2024, 15, 149. https://doi.org/10.3390/info15030149
Blomeier E, Schmidt S, Resch B. Drowning in the Information Flood: Machine-Learning-Based Relevance Classification of Flood-Related Tweets for Disaster Management. Information. 2024; 15(3):149. https://doi.org/10.3390/info15030149
Chicago/Turabian StyleBlomeier, Eike, Sebastian Schmidt, and Bernd Resch. 2024. "Drowning in the Information Flood: Machine-Learning-Based Relevance Classification of Flood-Related Tweets for Disaster Management" Information 15, no. 3: 149. https://doi.org/10.3390/info15030149
APA StyleBlomeier, E., Schmidt, S., & Resch, B. (2024). Drowning in the Information Flood: Machine-Learning-Based Relevance Classification of Flood-Related Tweets for Disaster Management. Information, 15(3), 149. https://doi.org/10.3390/info15030149