
Predicting Conversion from Mild Cognitive Impairment to Alzheimer’s Disease Using K-Means Clustering on MRI Data


Abstract
1. Introduction
1.1. Backgrounds and Motivations
1.2. Study Design
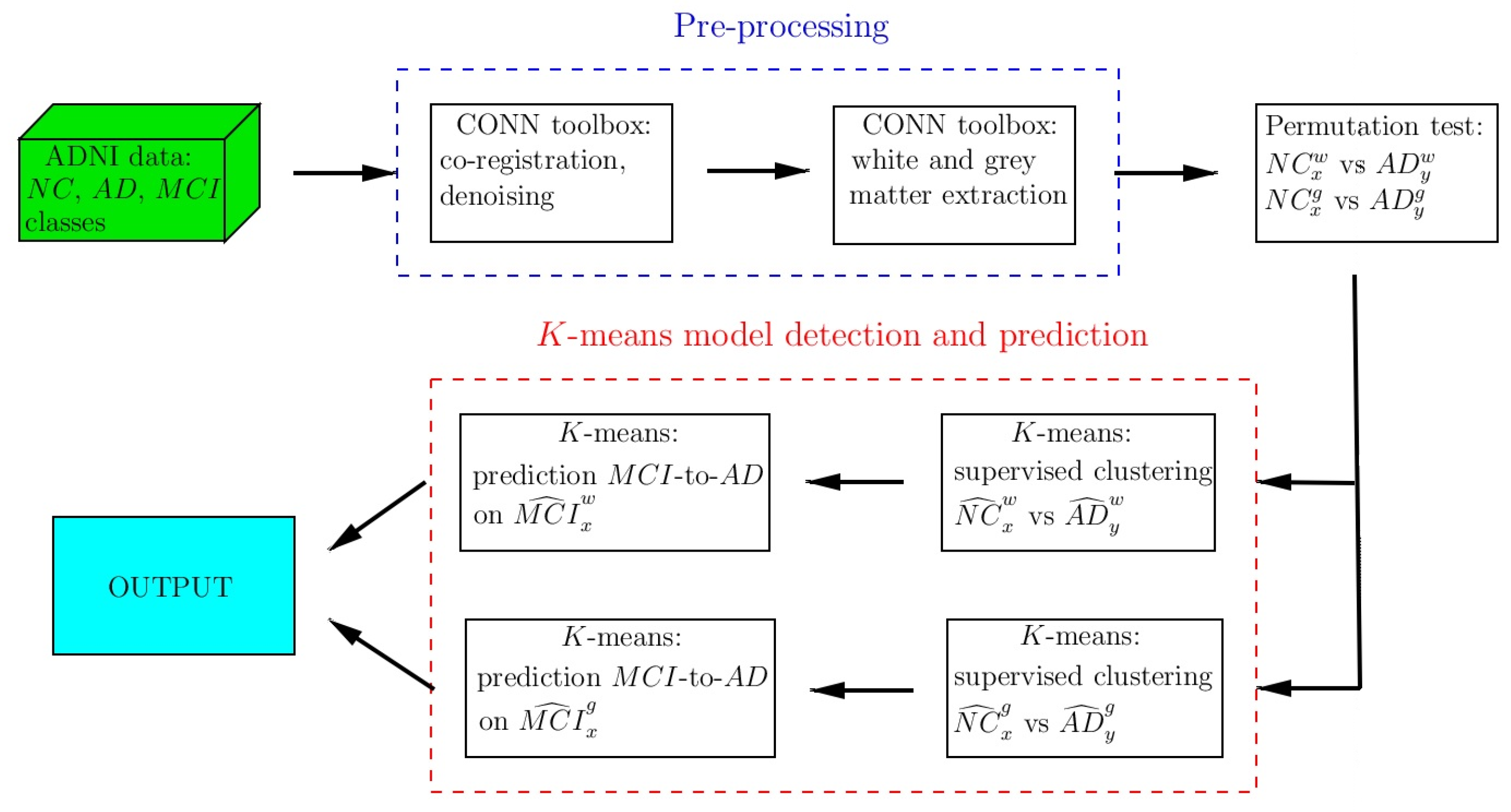
2. Materials and Methods
2.1. Subjects
2.2. Clinical Evaluation
2.3. MRI Acquisition
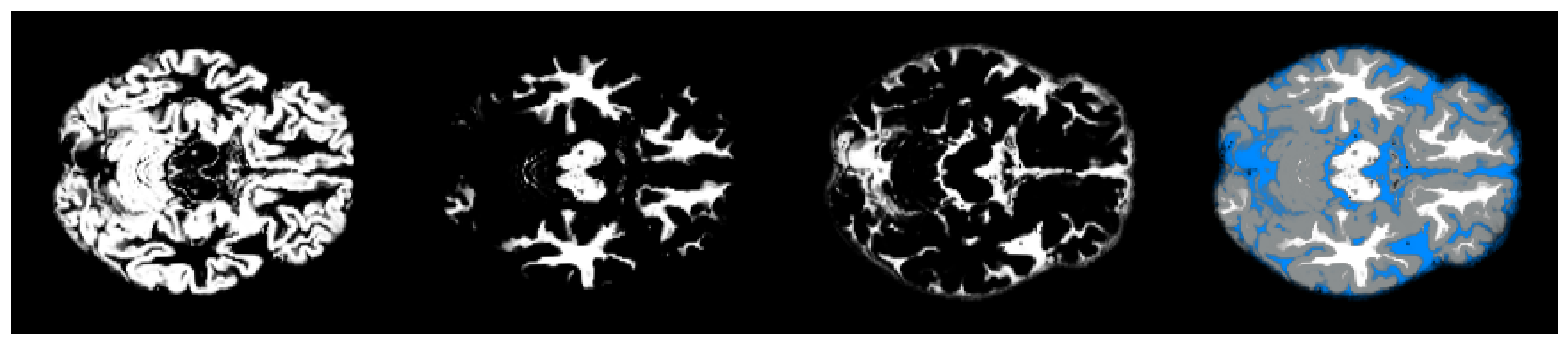
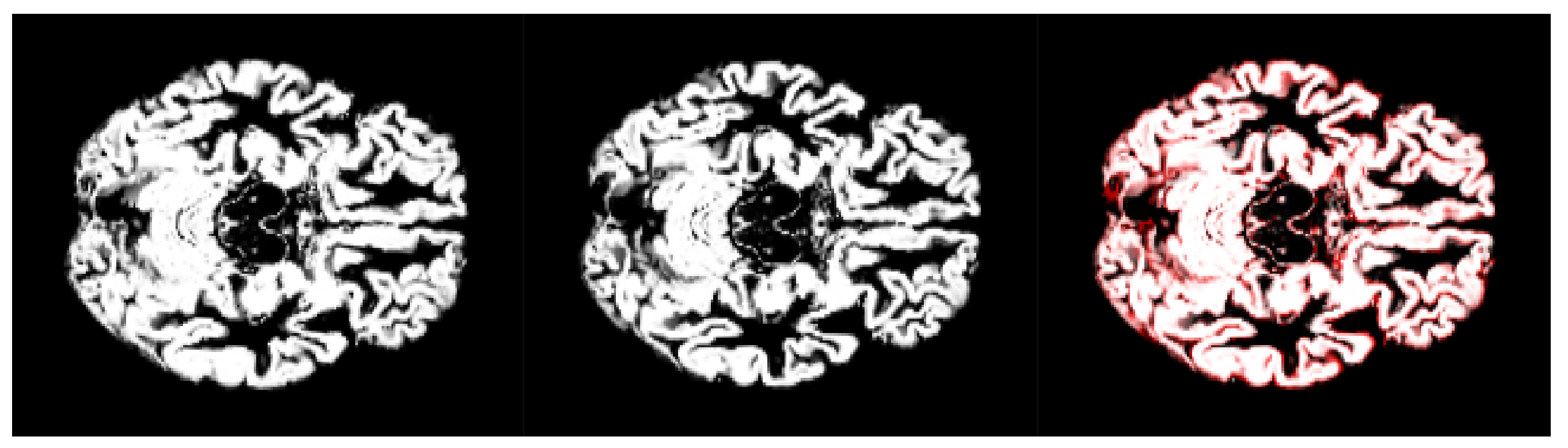
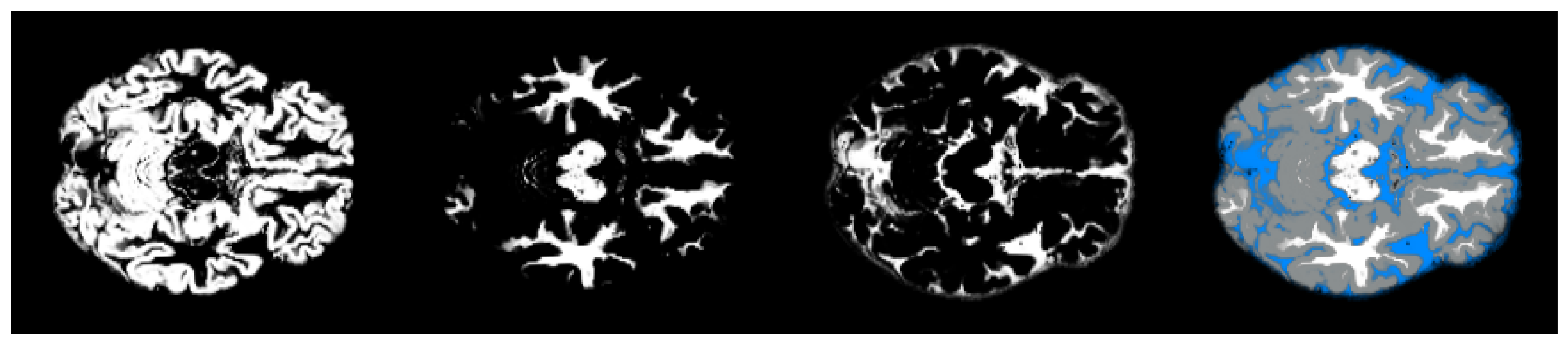
2.4. Pre-Processing
2.5. Matrix Differences and Statistical Analysis
2.5.1. Permutation Test
2.5.2. Slice Interval Choice
2.6. K-Means Clustering
| Algorithm 1 K-means(subjects, centroids) |
|
2.7. Dunn Index for K-Means Clustering
3. Results
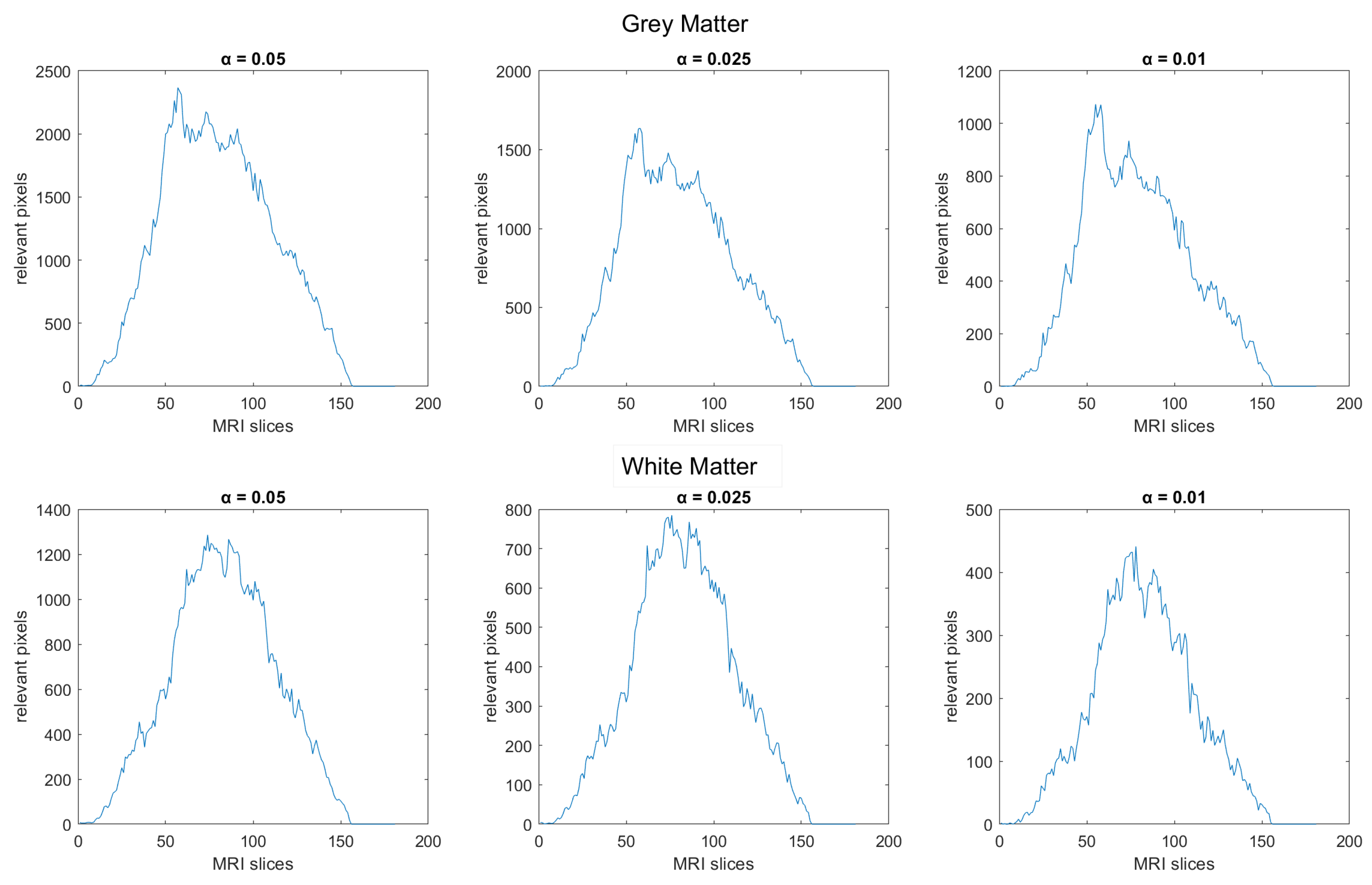
3.1. Permutation Test Analysis and Slice Interval Choice
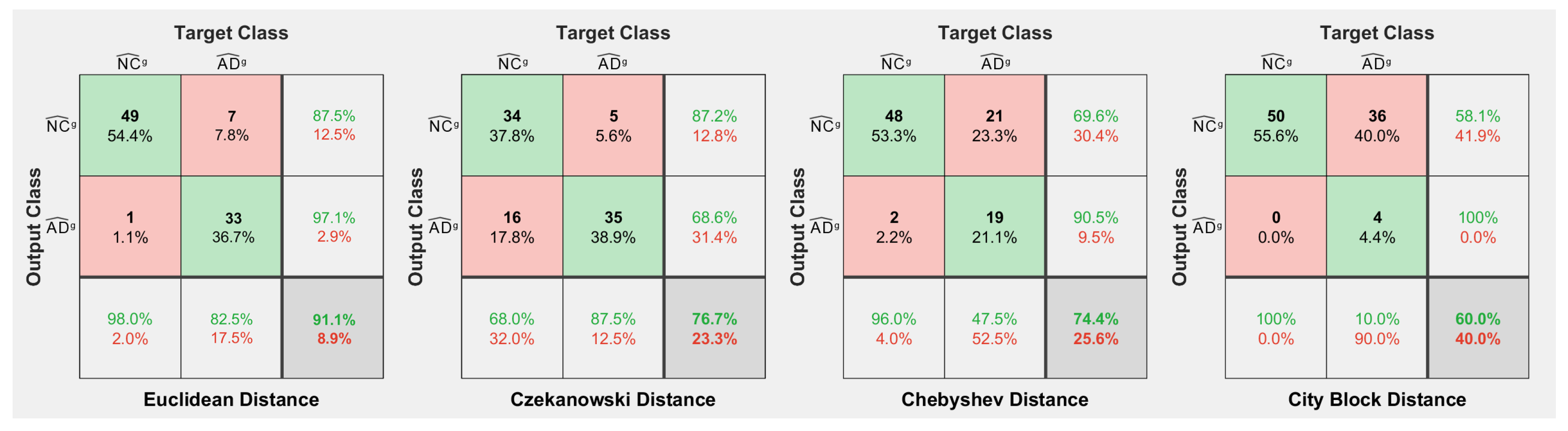
3.2. K-Means Clustering and Centroid Detection: Classes AD and NC
3.3. MCI-to-AD Predictions Based on Centroid Distances
4. Discussion
- We have introduced the notion of significant pixels, i.e., the pixels of the MRI images where the white (resp. gray) matter decays in the considered two-year time span, significantly differ between and subjects. The number of significant pixels, in the brain slices where the phenomenon mostly appeared, according to the different values obtained after performing a permutation test on all the pixels of the images, i.e., , , and , was about 4%, 2%, and 1.5% of the totality of the white matter and slightly more, i.e., 6%, 4%, and 2.5%, of the totality of the gray matter. Such a small number of significant pixels is sufficient to discriminate between and , as reported in Table 2 and Table 3, using the K-means clustering technique. Not surprisingly, when considering the white matter, all the and subjects were correctly clustered, i.e., the white matter decay of subjects significantly differed from that of ones. On the other hand, when considering gray matter, the subjects were correctly classified, while 6 of the 40 subjects were assigned to the class, with a percentage of error of 15%. This can be ascribed to the fact that Alzheimer’s disease strongly impacts on the white matter first, and later leads to the decay of the gray matter.We also underline that, according to the wide and consolidated literature, the most involved areas of the brain affected by Alzheimer’s decay are the medial portion of the temporal lobe, where the hippocampus, amygdala, entoryl cortex, and parahippocampal cortex reside. These areas are located inside the selected slice intervals where most of the significant pixels were detected. As an example, Figure 7 shows the significant pixels of slice 58, where a peak in the white and gray matter occurred, with the involved brain areas highlighted.
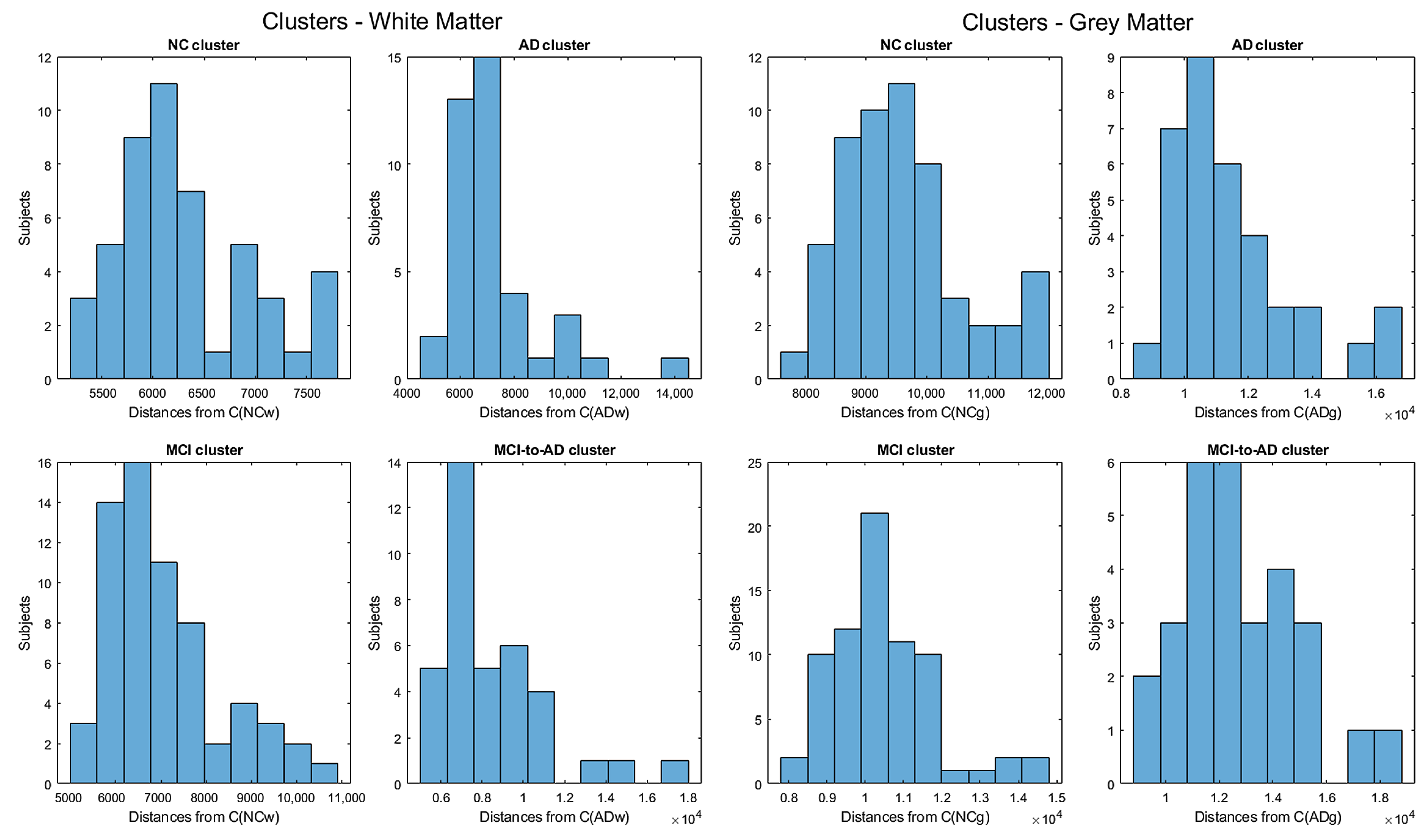
- Moving to the -to- predictive capability of the K-means model restricted to significant pixels, again we found different percentages according to the considered white or gray matter in the considered two-year time span. As expected, analyzing the white matter a high percentage of , namely, (Table 2), showed an pattern-like decay, similar to what was detected in [16,17,18] on the same dataset. So, our result, with a time span of two years, was slightly below the results presented in [20], where after one year only 8 of 37 patients with converted to (22%), verifying the reduction in the regional glucose metabolic rate, a truthful signal of early-onset .This high percentage of pattern in could be attributed to the similarly located decay of white matter in the two classes of subjects, as reported in [43]. This study involved 23 , 15 , and 15 subjects that underwent diffusion tensor magnetic resonance imaging (DTI), an advanced MRI technique extremely sensitive to white matter alterations. The authors found that patients with had an increase in mean diffusivity in the limbic, interhemispheric, cortico-cortical, and corticospinal tracts and, similarly, patients with showed an increase in axial diffusivity only in tracts projecting to the frontal cortex and splenium of the corpus callosum.On the other hand, time passing caused a milder effect on the gray matter of subjects, whose analysis revealed only 29% of -to- cases (see Table 3),, in accordance with the more optimistic studies in the work of [8], obtained through using machine learning techniques on fMRI images.Table 2 and Table 3 report the obtained statistics on the classification performance of subjects, together with the related indexes. In Figure 6, the distributions of subjects’ distances within the clusters show smaller distances between the subjects and the related centroids when white matter is considered with respect to gray matter. This implies that the classification using white matter produces tighter clusters and, consequently, a stronger accuracy than gray matter. All the clusters show some borderline subjects that produce small local maxima while moving away from the centroids. However, the computation of the Dunn indexes showed the high reliability of the obtained clustering. Again, we underline that the small diameter of the cluster may also be due to the smaller variability in the age range of the subjects. However, this does not constitute an issue in the final results of the research.
- A crucial aspect of our research, related to point 1, concerns the possibility of using exclusively the significant pixels instead of the whole MRI images to significantly lower the computational costs (in time and resources) when performing statistics on the Alzheimer’s disease course. One can realize the benefits of shrinking the data size by about when nonlinear statistical analysis has to be performed or, even more, when machine learning predictive studies or feature detection are required. As a matter of fact, the step with the highest resource consumption in our research was the detection of the significant pixels, carried out by performing a permutation test on all the MRI image pixels, which lasted some days.Furthermore, lowering the computational costs of the classification task set the path for a real-time process to aid specialists’ examinations (and predictions) of the Alzheimer’s status and development.
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gómez-Isla, T.; Price, J.L.; McKeel, D.W., Jr.; Morris, J.C.; Growdon, J.H.; Hyman, B.T. Profound Loss of Layer II Entorhinal Cortex Neurons Occurs in Very Mild Alzheimer’s Disease. J. Neurosci. 1996, 16, 4491–4500. [Google Scholar] [CrossRef]
- Laakso, M.P.; Soininen, H.; Partanen, K.; Lehtovirta, M.; Hallikainen, M.; Hänninen, T.; Helkala, E.-L.; Vainio, P.; Riekkinen, P.J. MRI of the Hippocampus in Alzheimer’s Disease: Sensitivity, Specificity, and Analysis of the Incorrectly Classified Subjects. Neurobiol. Aging 1998, 19, 23–31. [Google Scholar] [CrossRef]
- Arnold, S.E.; Hyman, B.T.; Flory, J.; Damasio, A.R.; Van Hoesen, G.W. The Topographical and Neuroanatomical Distribution of Neurofibrillary Tangles and Neuritic Plaques in the Cerebral Cortex of Patients with Alzheimer’s Disease. Cereb. Cortex 1991, 1, 103–116. [Google Scholar] [CrossRef] [PubMed]
- Oppenheim, G. The earliest signs of Alzheimer’s disease. J. Geriatr. Psychiatry Neurol. 1994, 7, 116–120. [Google Scholar] [CrossRef] [PubMed]
- Morris, J.C.; Cummings, J. Mild cognitive impairment (MCI) represents early-stage Alzheimer’s disease. J. Alzheimers Dis. 2005, 7, 235–239. [Google Scholar] [CrossRef] [PubMed]
- Hojjati, S.H.; Ebrahimzadeh, A.; Khazaee, A.; Babajani-Feremi, A. Predicting conversion from MCI to AD by integrating rs-fMRI and structural MRI. Comput. Biol. Med. 2018, 102, 30–39. [Google Scholar] [CrossRef] [PubMed]
- Feldman, H.; Scheltens, P.; Scarpini, E.; Hermann, N.; Mesenbrink, P.; Mancione, L.; Tekin, S.; Lane, R.; Ferris, S. Behavioral symptoms in mild cognitive impairment. Neurology 2004, 62, 1199–1201. [Google Scholar] [CrossRef]
- Hojjati, S.H.; Ebrahimzadeha, A.; Khazaee, A.; Babajani-Feremi, A. Predicting conversion from MCI to AD using resting-state fMRI, graph theoretical approach and SVM. J. Neurosci. Meth. 2017, 282, 69–80. [Google Scholar] [CrossRef] [PubMed]
- Ghafoori, S.; Shalbaf, A. Predicting conversion from MCI to AD by integration of rs-fMRI and clinical information using 3D-convolutional neural network. Int. J. Comput. Assist. Radiol. Surg. 2022, 17, 1245–1255. [Google Scholar] [CrossRef] [PubMed]
- Petersen, R.C.; Smith, G.E.; Waring, S.C.; Ivnik, R.J.; Tangalos, E.G.; Kokmen, E. Mild cognitive impairment: Ten years later. Arch. Neurol. 2009, 66, 1447–1455. [Google Scholar] [CrossRef]
- Rye, I.; Vik, A.; Kocinski, M.; Lundervold, A.; Lundervold, A. Predicting conversion to Alzheimer’s disease in individuals with Mild Cognitive Impairment using clinically transferable features. Sci. Rep. 2022, 12, 15566. [Google Scholar] [CrossRef]
- Adams, H.H.H.; de Bruijn, R.F.A.G.; Hofman, A.; Uitterlinden, A.G.; van Duijn, C.M.; Vernooij, M.W.; Koudstaal, P.J.; Ikram, M.A. Genetic risk of neurodegenerative diseases is associated with mild cognitive impairment and conversion to dementia. Alzheimers Dement. 2015, 11, 1277–1285. [Google Scholar] [CrossRef]
- Nicastro, N.; Malpetti, M.; Cope, T.E.; Bevan-Jones, W.R.; Mak, E.; Passamonti, L.; Rowe, J.B.; O’Brien, J.T. Cortical Complexity Analyses Their Cognitive Correlate in Alzheimer’s Disease Frontotemporal Dementia. J. Alzheimers Dis. 2020, 76, 331–340. [Google Scholar] [CrossRef] [PubMed]
- Rodríguez-Rodríguez, E.; Sánchez-Juan, P.; Vázquez-Higuera, J.L.; Mateo, I.; Pozueta, A.; Berciano, J.; Cervantes, S.; Alcolea, D.; Martínez-Lage, P.; Clarimón, J.; et al. Genetic risk score predicting accelerated progression from mild cognitive impairment to Alzheimer’s disease. J. Neural. Trans. 2013, 120, 807–812. [Google Scholar] [CrossRef] [PubMed]
- Afgin, A.E.; Massarwa, M.; Schechtman, E.; Israeli-Korn, S.D.; Strugatsky, R.; Abuful, A.; Farrer, L.A.; Friedl, R.P.; Inzelberget, R. High Prevalence of Mild Cognitive Impairment and Alzheimer’s Disease in Arabic Villages in Northern Israel: Impact of Gender and Education. J. Alzheimers Dis. 2012, 29, 431–439. [Google Scholar] [CrossRef] [PubMed]
- Davatzikos, C.; Bhatt, P.; Shaw, L.M.; Batmanghelich, K.N.; Trojanowski, J.Q. Prediction of MCI to AD conversion, via MRI, CSF biomarkers, and pattern classification. Neurobiol. Aging 2011, 32, 2322.e19–2322.e27. [Google Scholar] [CrossRef] [PubMed]
- Fan, Y.; Batmanghelich, N.; Clark, C.M.; Davatzikos, C. Spatial patterns of brain atrophy in MCI patients, identified via high-dimensional pattern classification, predict subsequent cognitive decline. NeuroImage 2008, 39, 1731–1743. [Google Scholar] [CrossRef] [PubMed]
- Misra, C.; Fan, Y.; Davatzikos, C. Baseline and longitudinal patterns of brain atrophy in MCI patients, and their use in prediction of short-term conversion to AD: Results from ADNI. NeuroImage 1999, 44, 1415–1422. [Google Scholar] [CrossRef] [PubMed]
- Moradi, E.; Pepe, A.; Gaser, C.; Huttunen, H.; Tohka, J. Machine learning framework for early MRI-based Alzheimer’s conversion prediction in MCI subjects. NeuroImage 2015, 104, 398–412. [Google Scholar] [CrossRef] [PubMed]
- Mosconi, L.; Perani, D.; Sorbi, S.; Herholz, K.; Nacmias, B.; Holthoff, V.; Salmon, E.; Baron, J.-C.; De Cristofaro, M.T.R.; Padovani, A.; et al. MCI conversion to dementia and the APOE genotype, Wolters Kluwer Health. Neurology 2004, 63, 2332–2340. [Google Scholar] [CrossRef]
- Lin, W.; Gao, Q.; Yuan, J.; Chen, Z.; Feng, C.; Chen, W.; Du, M.; Tong, T. Predicting Alzheimer’s disease conversion from mild cognitive impairment using an extreme learning machine-based grading method with multimodal data. Front. Aging Neurosci. 2020, 12, 77. [Google Scholar] [CrossRef]
- Liu, S.; Cao, Y.; Liu, J.; Ding, X.; Coyle, D. A novelty detection approach to effectively predict conversion from mild cognitive impairment to Alzheimer’s disease. Int. J. Mach. Learn. Cybern. 2023, 14, 213–228. [Google Scholar] [CrossRef]
- Alashwal, H.; El Halaby, M.; Crouse, J.J.; Abdalla, A.; Moustafa, A.A. The Application of Unsupervised Clustering Methods to Alzheimer’s Disease. Front. Comput. Neurosci. 2019, 13, 31. [Google Scholar] [CrossRef]
- Kishore, P.; Usha Kumari, C.; Kumar, M.N.V.S.S.; Pavani, T. Detection and analysis of Alzheimer’s disease using various machine learning algorithms. Mater. Today Proc. 2021, 45, 1502–1508. [Google Scholar] [CrossRef]
- Li, H.; Habes, M.; Wolk, D.A.; Fan, Y. A deep learning model for early prediction of Alzheimer’s disease dementia based on hippocampal magnetic resonance imaging data. Alzheimers Dement. 2019, 15, 1059–1070. [Google Scholar] [CrossRef]
- Nijana, V.; Rajendran, P.S. Alzheimer’s Disease Prediction with K-means Clustering and Reinforcement Learning Approach. In Proceedings of the 2023 International Conference on Distributed Computing and Electrical Circuits and Electronics (ICDCECE), Ballar, India, 29–30 April 2023; pp. 1–6. [Google Scholar]
- Gao, F.; Yoon, H.; Xu, Y.; Goradia, D.; Luo, J.; Wu, T.; Su, Y. Age-adjust neural network for improved MCI to AD conversion prediction. NeuroImage Clin. 2020, 27, 102290. [Google Scholar] [CrossRef] [PubMed]
- Jack, C.R., Jr.; Bernstein, M.A.; Fox, N.C.; Thompson, P.; Alexander, G.; Harvey, D.; Borowski, B.; Britson, P.J.; Whitwell, J.L.; Ward, C.; et al. The Alzheimer’s Disease Neuroimaging Initiative (ADNI): MRI methods. JMRI-J. Magn. Reson. Imaging 2008, 27, 685–691. [Google Scholar] [CrossRef] [PubMed]
- Tohka, J.; Minhas, S.; Khanum, A.; Alvi, A.; Riaz, F.; Khan, S.A.; Alsolami, F.; Khan, M.A. Early MCI-to-AD Conversion Prediction Using Future Value Forecasting of Multimodal Features. Comput. Intell. Neurosci. 2021, 2021, 6628036. [Google Scholar]
- Kaufman, A.S.; Lichtenberger, E. Assessing Adolescent and Adult Intelligence, 3rd ed.; Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
- Folstein, M.F.; Folstein, S.E.; McHugh, P.R. Mini-mental state. A practical method for grading the cognitive state of patients for the clinician. J. Psychiatr. Res. 1975, 12, 189–198. [Google Scholar] [CrossRef]
- Hughes, C.P.; Berg, L.; Danziger, W.L.; Coben, L.A.; Martin, R.L. A new clinical scale for the staging of dementia. Br. J. Psychiatry 1982, 140, 566–572. [Google Scholar] [CrossRef]
- Hachinski, V.C.; Iliff, L.D.; Zilhka, E.; Du Boulay, G.H.; McAllister, V.L.; Marshall, J.; Russell, R.W.R.; Symon, L. Cerebral blood flow in dementia. Arch. Neurol. 1975, 32, 632–637. [Google Scholar] [CrossRef] [PubMed]
- Sheikh, J.I.; Yesavage, J.A.; Brooks, J.O.; Friedman, L.; Gratzinger, P.; Hill, R.D.; Zadeik, A.; Crook, T. Proposed factor structure of the Geriatric Depression Scale. Int. Psychogeriatr. 1991, 3, 23–28. [Google Scholar] [CrossRef]
- ADNI. MRI Analysis. Available online: https://adni.loni.usc.edu/methods/mri-tool/mri-analysis/ (accessed on 20 March 2023).
- Whitfield-Gabrieli, S.; Nieto-Castanon, A. Conn: A functional connectivity toolbox for correlated and anticorrelated brain networks. Brain Connect. 2012, 2, 125–141. [Google Scholar] [CrossRef] [PubMed]
- Nieto-Castanon, A. Handbook of Functional Connectivity Magnetic Resonance Imaging Methods in CONN; Hilbert Press: Boston, MA, USA, 2020. [Google Scholar]
- Fonov, V.S.; Evans, A.C.; Botteron, K.; Almli, C.R.; McKinstry, R.C.; Collins, D.L.; Brain Development Cooperative Group. Unbiased average age-appropriate atlases for pediatric studies. NeuroImage 2011, 54, 313–327. [Google Scholar] [CrossRef] [PubMed]
- Ashburner, J.; Friston, K.J. Unified segmentation. NeuroImage 2005, 26, 839–851. [Google Scholar] [CrossRef] [PubMed]
- Moore, J.H. Bootstrapping, permutation testing and the method of surrogate data. Phys. Med. Biol. 1999, 44, L11. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A K-Means Clustering Algorithm. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Dunn, J.C. Well-Separated Clusters and Optimal Fuzzy Partitions. J. Cybern. 1974, 4, 95–104. [Google Scholar] [CrossRef]
- Agosta, F.; Pievani, M.; Sala, S.; Geroldi, C.; Galluzzi, S.; Frisoni, G.B.; Filippi, M. White Matter Damage in Alzheimer Disease and Its Relationship to Gray Matter Atrophy. Radiology 2011, 258, 853–863. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Full MRI Images | Selected MRI Slice Intervals | |||
|---|---|---|---|---|
| All Pixels | Significant Pixels | All Pixels | Significant Pixels | |
| White matter | 29.362 s | 0.823 s | 18.403 s | 0.569 s |
| Gray matter | 70.584 s | 1.501 s | 19.462 s | 0.709 s |
| Subjects | Cl.D. | W.c.d. | Std. Dev. | DI | |
|---|---|---|---|---|---|
| NC | 50 | 11,261.55 | 6313.38 | 662.79 | 0.56 |
| AD | 40 | 19,933.77 | 7236.79 | 1746.69 | 0.36 |
| MCI-to-AD | 37 | 20,832.19 | 8452.98 | 2677.15 | 0.40 |
| MCI | 64 | 14,954.89 | 7030.72 | 1271.85 | 0.47 |
| Subjects | Cl.D. | W.c.d. | Std. Dev. | DI | |
|---|---|---|---|---|---|
| NC | 56 | 17,447.07 | 9581.68 | 1008.61 | 0.55 |
| AD | 34 | 24,415.07 | 11,426.67 | 1909.34 | 0.47 |
| MCI-to-AD | 29 | 24,291.55 | 12,768.19 | 2106.07 | 0.53 |
| MCI | 72 | 20,219.51 | 10,482.42 | 1360.34 | 0.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bellezza, M.; di Palma, A.; Frosini, A. Predicting Conversion from Mild Cognitive Impairment to Alzheimer’s Disease Using K-Means Clustering on MRI Data. Information 2024, 15, 96. https://doi.org/10.3390/info15020096
Bellezza M, di Palma A, Frosini A. Predicting Conversion from Mild Cognitive Impairment to Alzheimer’s Disease Using K-Means Clustering on MRI Data. Information. 2024; 15(2):96. https://doi.org/10.3390/info15020096
Chicago/Turabian StyleBellezza, Miranda, Azzurra di Palma, and Andrea Frosini. 2024. "Predicting Conversion from Mild Cognitive Impairment to Alzheimer’s Disease Using K-Means Clustering on MRI Data" Information 15, no. 2: 96. https://doi.org/10.3390/info15020096
APA StyleBellezza, M., di Palma, A., & Frosini, A. (2024). Predicting Conversion from Mild Cognitive Impairment to Alzheimer’s Disease Using K-Means Clustering on MRI Data. Information, 15(2), 96. https://doi.org/10.3390/info15020096