

HaCk: Hand Gesture Classification Using a Convolutional Neural Network and Generative Adversarial Network-Based Data Generation Model

 , , , , , and
, , , , , and
Abstract
1. Introduction
1.1. Research Gap
- Limited Diversity in Generated Data: Many GAN-based data generation models tend to produce synthetic data that closely resemble the training data. However, these data need to enhance the diversity of generated hand gestures, ensuring that the CNN classifier is robust in recognizing a more comprehensive range of gestures and variations.
- Small Imbalanced Dataset: Hand gesture datasets are often limited in size, leading to challenges in effectively training a CNN classifier. Addressing this gap may involve investigating techniques for data augmentation and class imbalances in generated datasets.
- Generalization to Real-World Conditions: GAN-generated data may only partially capture the complexity of real-world scenarios, such as lighting, background, and noise variations.
- Optimal Architectures and Hyperparameters: Identifying the most suitable CNN architectures and hyperparameters for hand gesture recognition tasks using GAN-generated data is an ongoing challenge.
- Efficiency and Real-Time Processing: Real-time hand gesture recognition applications, such as sign language interpretation and gesture-based interfaces, require efficient CNN models. One research gap involves developing CNN architectures that balance accuracy and computational efficiency with real-time processing.
1.2. Motivation
- This study proposes an unsupervised learning model focused on data efficiency to augment skeleton-based data, HaCk. HaCk can adapt to novel data containing previously unseen classes once trained.
- As it does not necessitate prior knowledge and examination of input data during training, HaCk facilitates an automated cross-domain data augmentation procedure, requiring minimal hyperparameter adjustment.
- HaCk utilizes real data for training customized gesture classifiers, allowing users to significantly reduce the effort needed to gather individualized training data.
2. Literature Survey
2.1. The Application of DL Techniques in GR and Human Activity Recognition
- DL models obviate the requirement for manual feature extraction, eliminating the dependence on domain-specific knowledge.
- DL models can learn more complex and profound features compared to ML-based heuristic approaches.
- DL models can utilize unlabeled data during training, whereas traditional ML methods rely heavily on a significant amount of labeled data.
2.2. Customized Classifiers
2.3. Domain Adaptation and STNs
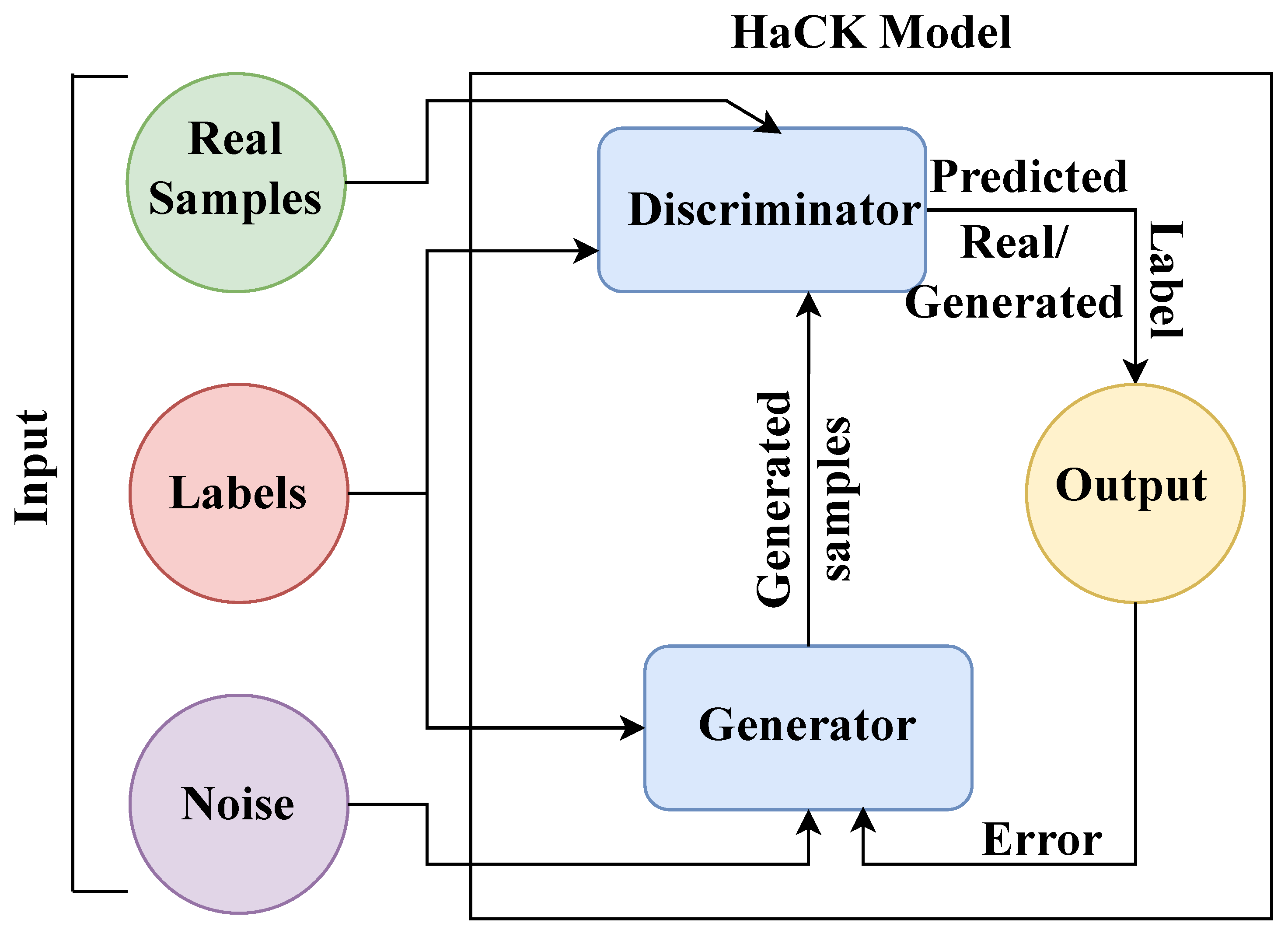
3. System Architecture and Problem Formulation
3.1. System Architecture
3.2. Problem Formulation
3.2.1. CNN Formulation
- is the linear output of layer l;
- is the activation of layer l;
- is the activation function;
- is the CNN loss function;
- is the predicted output;
- m is the number of samples;
- n is the number of classes.
3.2.2. GAN and Data Generation Formulation
- is the latent vector;
- is the augmented dataset;
- is the GAN loss function.
4. Dataset
Dataset Description
5. Proposed HaCk System
- Feature Extraction: CNNs are known for their ability to automatically learn and extract relevant features from image data. Also, CNNs are used for image classification tasks due to their hierarchical feature extraction capabilities.
- Spatial Hierarchies: CNNs are designed to capture spatial hierarchies in images, recognizing patterns at different scales. This architecture aligns with the hierarchical nature of hand gesture recognition, where specific hand shapes and movements may be composed of more minor, recognizable elements.
- Computational Efficiency: CNNs are known for their computational efficiency in processing image data, which can be important in real-time or resource-constrained applications.
5.1. Phase I: Data Generation Phase
5.1.1. Discriminator
5.1.2. Generator
| Algorithm 1 Discriminator Algorithm |
|
| Algorithm 2 Generator Algorithm |
|
5.2. Phase II: Training Phase
- 1.
- Hyperparameters for CNN:
- (a)
- Number of Layers: This includes the number of convolutional layers, pooling layers, and fully connected layers. The architecture of the CNN dramatically impacts its ability to learn complex features from the data.
- (b)
- Filter Size and Stride: The size of convolutional filters (kernels) and the stride at which they move over the input data determine the spatial characteristics that the network can capture.
- (c)
- Number of Filters: The number of filters in each convolutional layer affects the depth of the network and its capacity to learn features at different levels of abstraction.
- (d)
- Activation Functions: Choices like the use of Rectified Linear Units (ReLUs) are standard, but other activation functions like Leaky ReLU or Sigmoid can also be used. The chosen activation functions affect the network’s non-linearity.
- (e)
- Dropout Rate: Dropout is a regularization technique that helps prevent overfitting by randomly dropping a fraction of neurons during training. The dropout rate is a hyperparameter determining the number of neurons to drop.
- (f)
- Batch Size: The number of data samples used in each training iteration (mini batch) can impact training speed and generalization. It is important to find a balance between computational efficiency and convergence.
- (g)
- Learning Rate: The learning rate determines the step size during gradient descent optimization. It must be carefully tuned to ensure convergence without overshooting or becoming stuck in local minima.
- (h)
- Weight Initialization: How the network weights are initialized can affect training. Standard methods include random initialization and techniques like Xavier/Glorot initialization.
- (i)
- Optimizer: The choice of optimization algorithms, such as Stochastic Gradient Descent (SGD), Adam, or RMSProp, can influence the convergence speed and final performance.
- (j)
- Padding: Padding can be valid (no padding) or the same (zero-padding), and this affects the spatial dimensions of the output feature maps after convolution.
- 2.
- Hyperparameters for GAN:
- (a)
- lGenerator Architecture: Similar to CNN, the architecture of the generator network is crucial. This includes the number of layers, filter sizes, and activation functions.
- (b)
- Discriminator Architecture: The discriminator must also be designed appropriately. It should be capable of distinguishing between real and generated data effectively.
- (c)
- Learning Rate: The learning rates for both the generator and discriminator are essential. They can impact the stability of GAN training. Sometimes, different learning rates are used for each network.
- (d)
- Loss Functions: GANs use two loss functions—generator loss (often a form of binary cross-entropy) and the discriminator loss. The choice of these loss functions can influence the quality of generated samples.
- (e)
- Noise Dimension: GANs often take random noise as inputs to generate data. The dimensionality and distribution of this noise can impact the diversity and quality of generated samples.
- (f)
- Batch Size: Similar to CNNs, the batch size used during GAN training can affect the stability and convergence of the model.
- (g)
- Training Duration: Deciding when to stop training is essential. Training GANs can be tricky, and setting the number of epochs or other stopping criteria is a hyperparameter choice.
- (h)
- Regularization Techniques: Techniques like weight clipping (for Wasserstein GANs), gradient penalties, and feature matching can stabilize training and improve sample quality.
- (i)
- Architecture Variants: There are various GAN variants, such as Deep Convolutional GAN (DHaCk), Wasserstein GAN (WGAN), and more. The choice of GAN architecture should align with the specific task and data.
- (j)
- Data Preprocessing: Data preprocessing, including normalization and scaling, can also be considered part of the hyperparameter selection process.
5.3. Phase III: Testing Phase
5.4. Algorithm and Flow Chart of the HaCk System
5.4.1. CNN Integration
5.4.2. GAN Integration
5.4.3. Integration and Training Procedure
- Pretraining the CNN: The CNN is initially pretrained using available labeled data for hand gestures. This step provides the CNN with a foundation for recognizing real hand gestures accurately.
- Adversarial Training: GAN training involves a two-step process. First, the discriminator is trained on both real and synthetic hand gesture images, which are optimized for accurate discrimination. Subsequently, the generator is trained to produce synthetic images that can effectively deceive the discriminator. This adversarial training loop is iterated to refine both the generator and discriminator.
- Fine-Tuning the CNN: The CNN is then fine-tuned using the combined dataset of real and synthetic hand gesture images generated by the GAN. This step helps the CNN adapt to the augmented dataset, potentially improving its generalization to unseen gestures.
5.4.4. Parameter Selection Rationale
| Algorithm 3 Hand Gesture Classification Using a Convolutional Neural Network and Generative Adversarial Network-Based Data Generation Model (HaCk) |
|
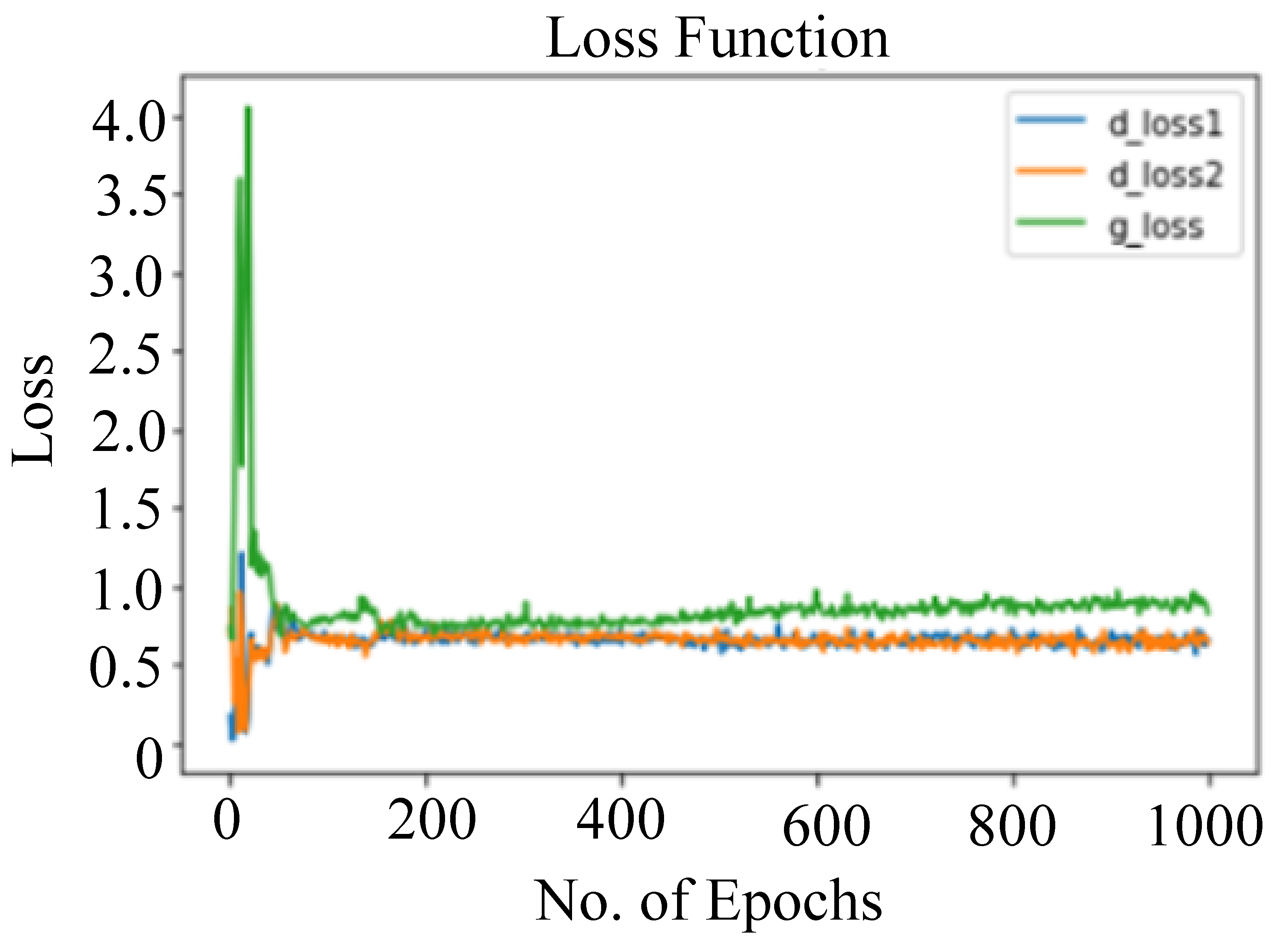
6. Experimental Results and Discussion
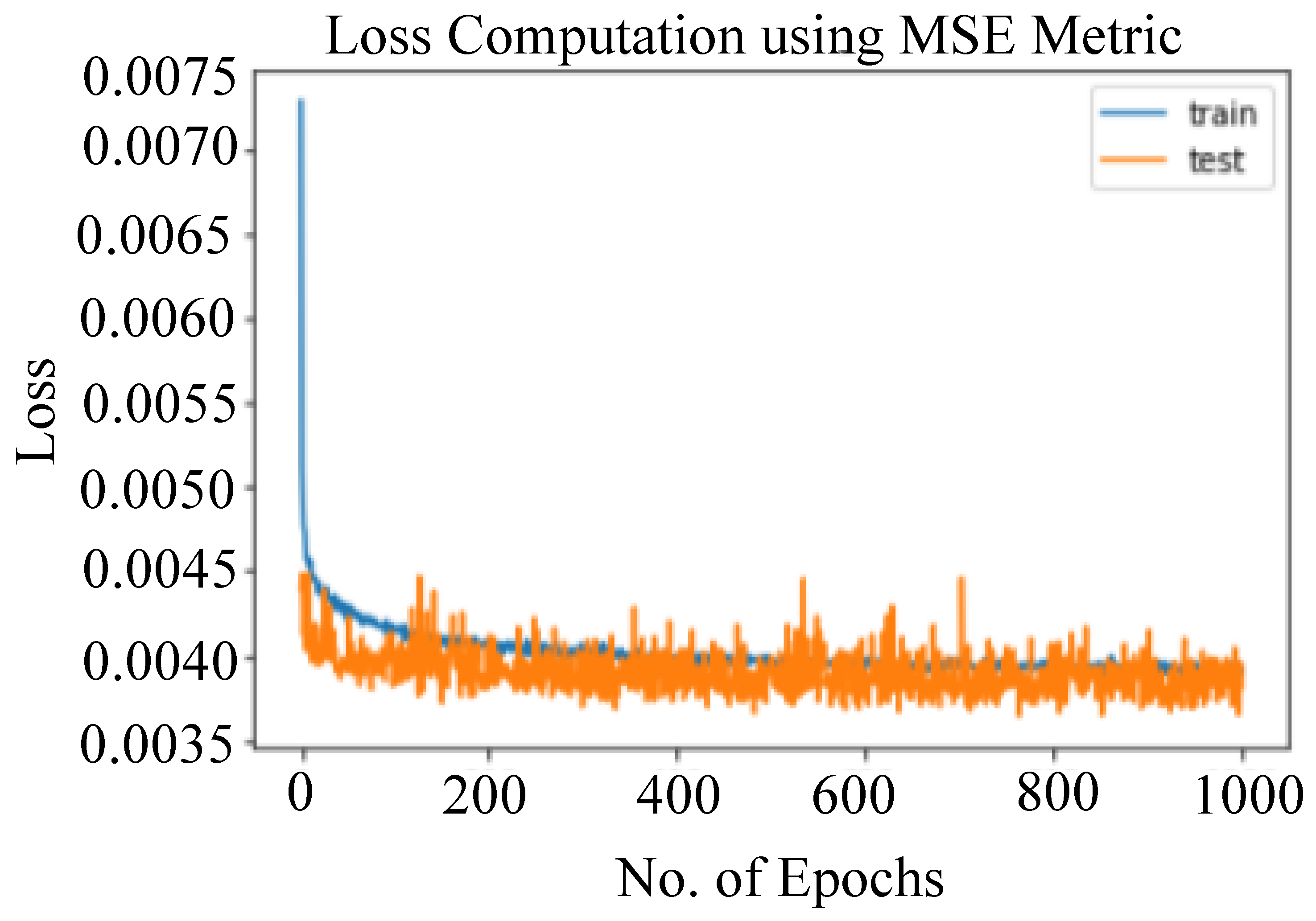
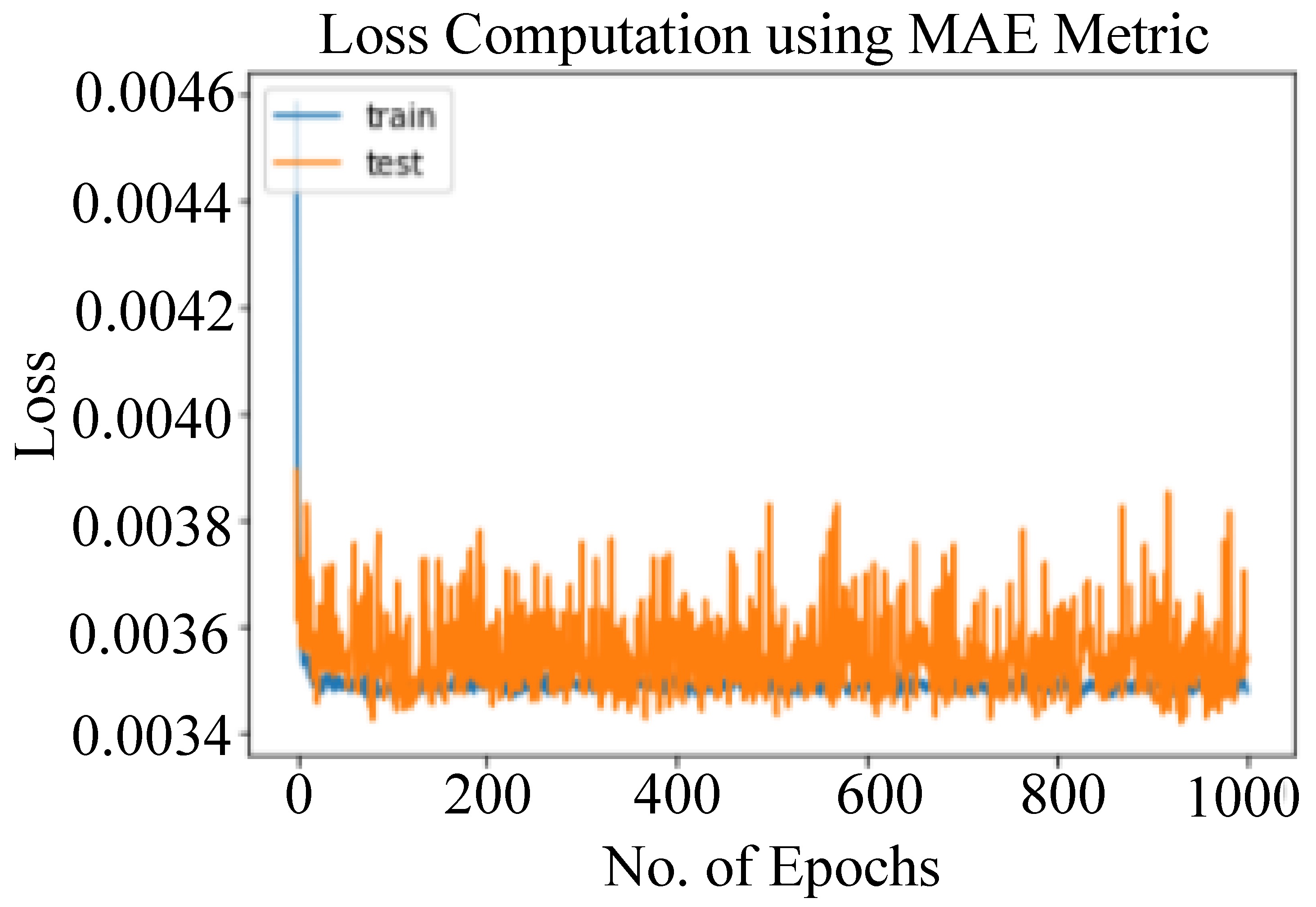
6.1. Model Evaluation
- For each data point in the dataset used, subtract the actual observed value (the ground truth) from the predicted value obtained from HaCk.
- Square the result of each subtraction to ensure that all differences are positive and emphasize larger errors.
- Calculate the average (mean) of all these squared differences.
- For each data point in the dataset used, subtract the actual observed value from the predicted value, taking the absolute value of the difference.
- Calculate the average (mean) of all these absolute differences.
6.2. Hand GR
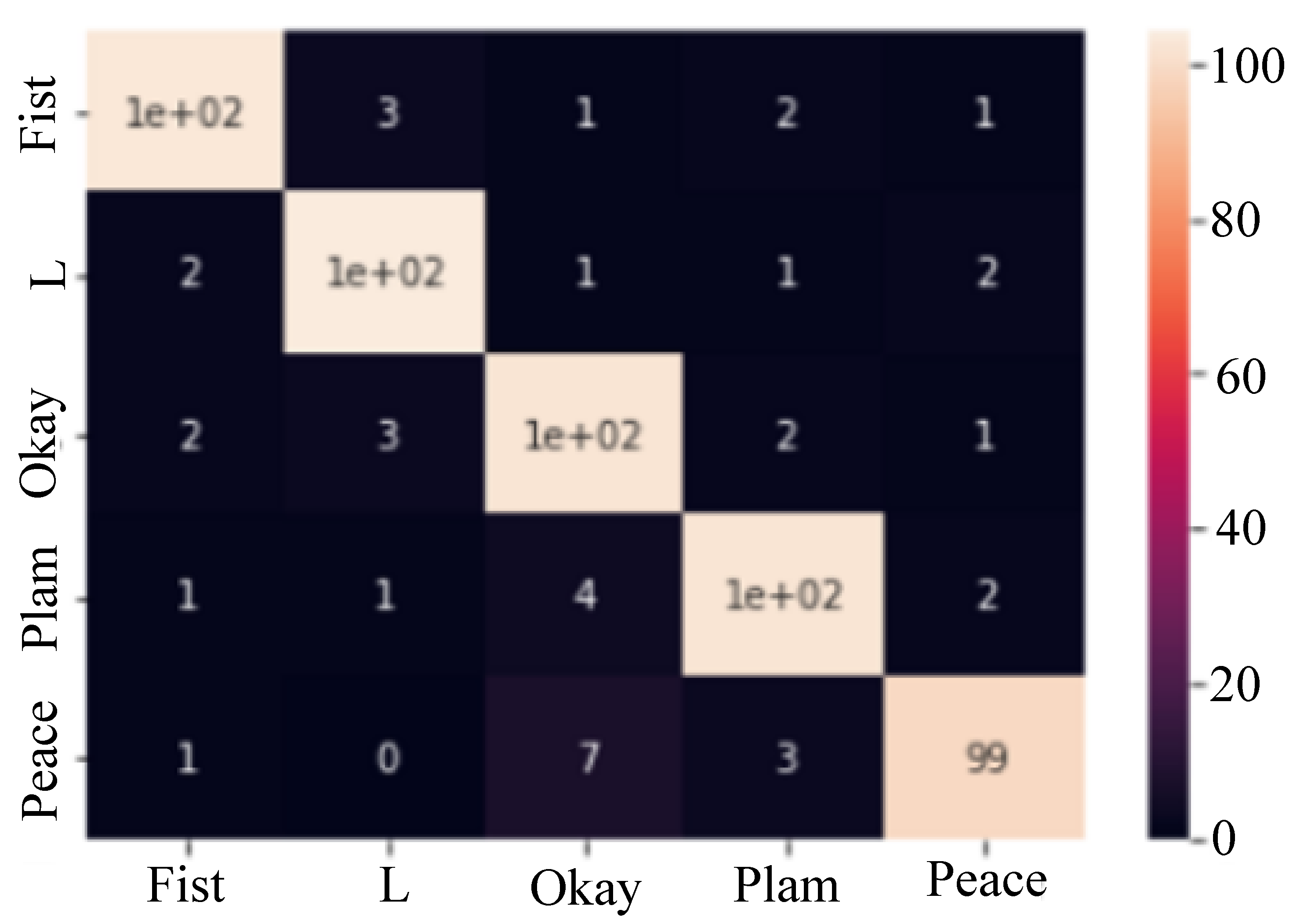
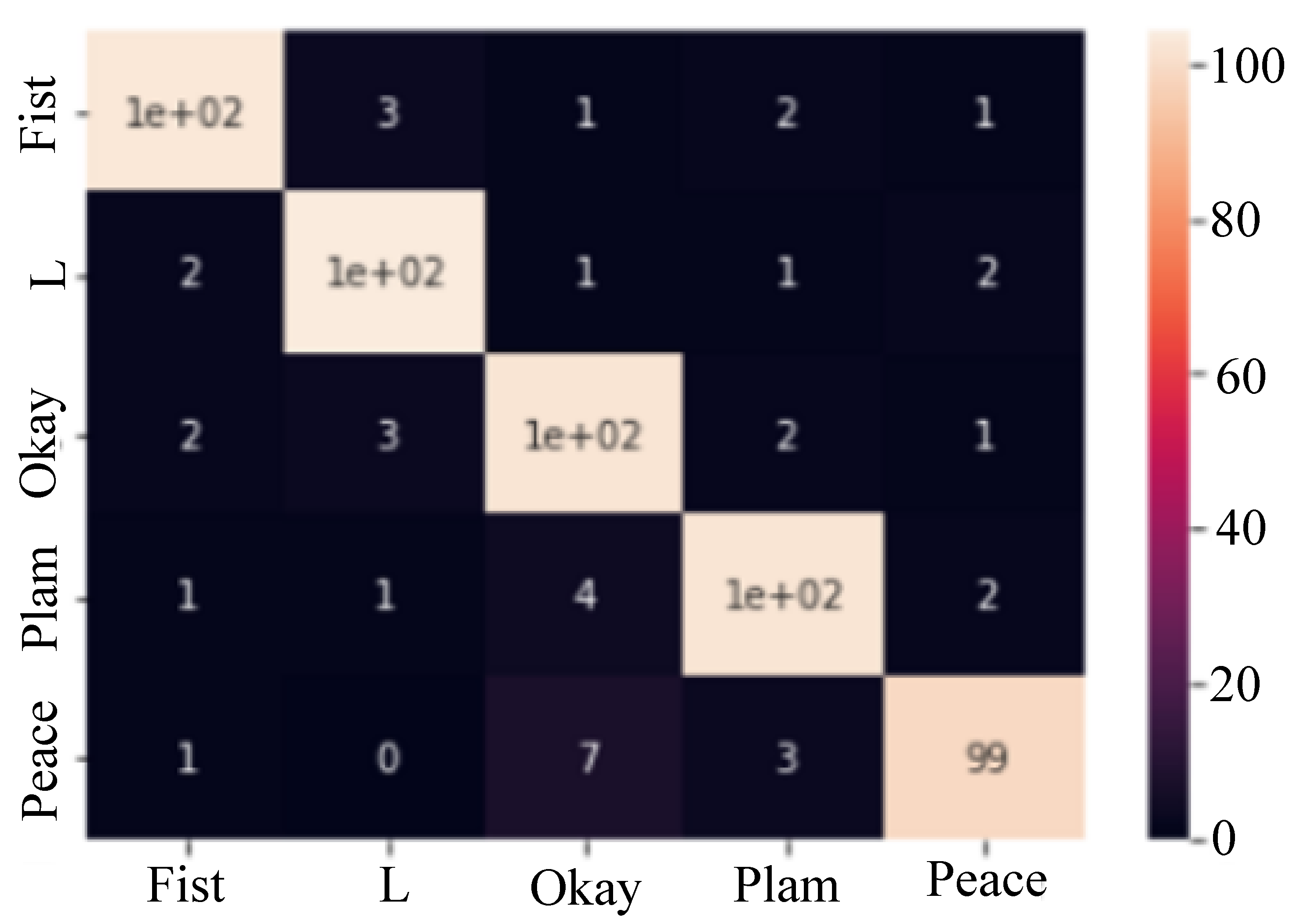
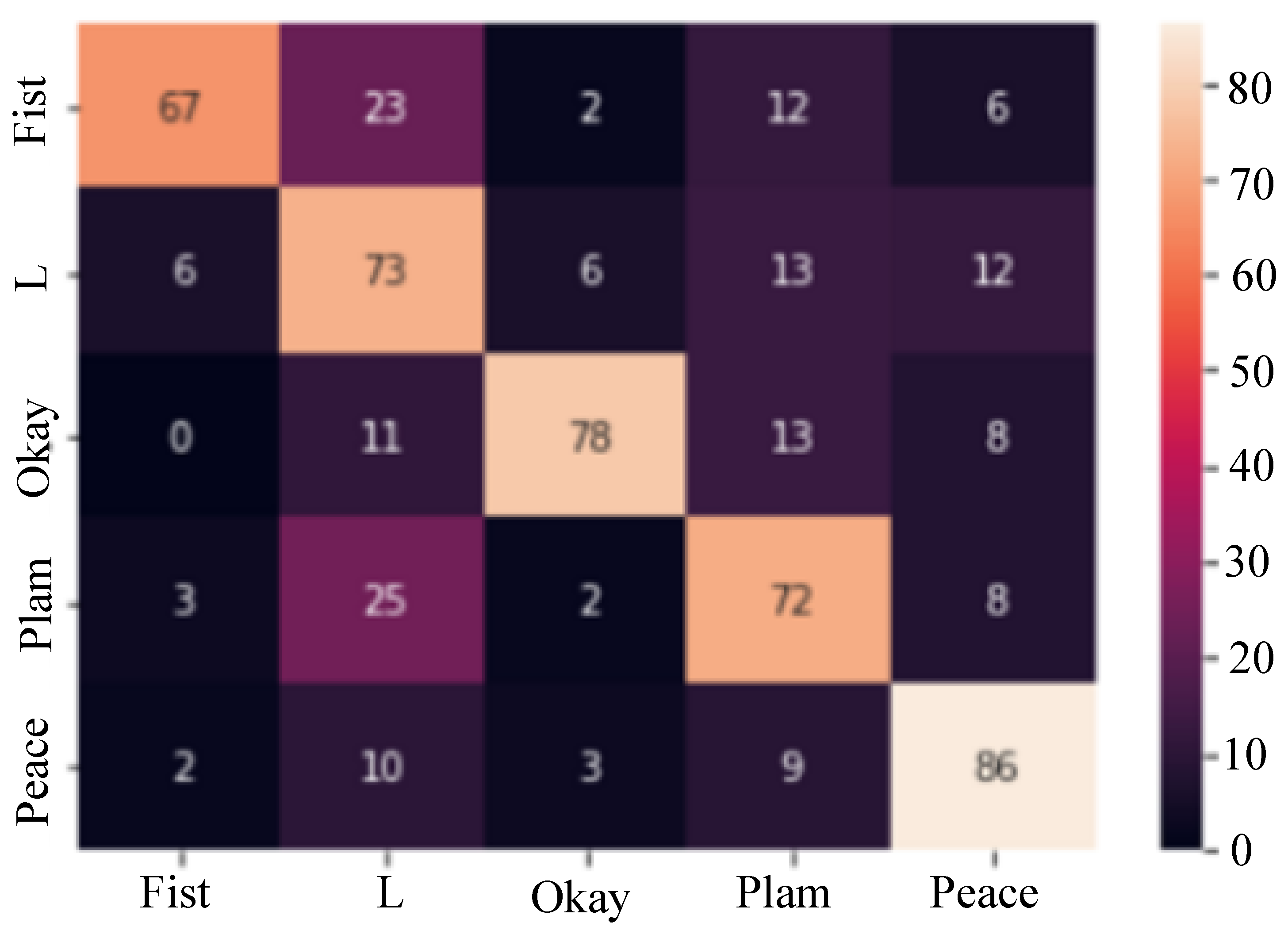
- The CNN model, trained using real data samples, achieved an accuracy of 93% in predicting the class of the testing hand gestures, as described in Figure 9.
- HaCk, trained using generated data samples, achieved an accuracy of 68% in predicting the class of the testing hand gestures, as depicted in Figure 10.
6.3. Comparison of Hand GR with Other Existing Models
6.4. Computational Complexity
- Model Architecture: The number of layers, neurons, and connections in the CNN classifier, GAN generator, and discriminator networks significantly determine computational complexity. Deeper and larger networks generally require more computational resources.
- Training: Training deep neural networks like CNNs and GANs involves forward and backward passes through the network, including matrix multiplications and gradient calculations. The number of training iterations and the mini batch size can affect the training time and memory usage.
- Data Augmentation: If extensive data augmentation techniques are used to expand the dataset, this can increase computational complexity during training and inference, as additional transformations must be applied to the data.
- GAN Training: Training a GAN involves multiple iterations of generator and discriminator updates, which can be computationally intensive, especially for more extensive networks.
- Real-Time Inference: When using the system for real-time hand gesture recognition with a webcam feed, the computational complexity depends on the inference speed of the CNN model and the rate at which new frames are processed.
- Hyperparameter Search: If hyperparameter tuning is performed, it adds an extra computational burden as the system evaluates multiple combinations of hyperparameters.
- Memory Usage: The size of the neural network parameters and the dataset size can impact memory requirements. Large models and datasets may require more memory, potentially leading to memory limitations on some hardware.
- Optimization Techniques: Optimization techniques, such as weight quantization, can influence the computational complexity and efficiency of the system.
- Hardware Resources: The computational complexity depends on the available hardware resources. High-performance GPUs or TPUs can handle more complex models and larger datasets more efficiently than CPUs.
6.5. Methodological Approaches
- Addressing Visual Impairment Challenges: HaCk is explicitly designed to address visual impairment challenges, making it a suitable choice for applications where accessibility for individuals with visual impairments is a priority.
- Non-Contact Interaction for Accessibility: The HaCk system’s emphasis on non-contact interaction aligns with scenarios where hands-free or touchless interaction is essential for user accessibility.
- Diverse Set of Hand Gestures: HaCk’s ability to generate a diverse set of hand gestures suggests its versatility in accommodating a wide range of gestures. This could be advantageous in applications requiring a comprehensive set of recognizable hand movements.
- Two-Step Recognition Approach: The integration of CNN and GAN in a two-step recognition approach enhances the model’s adaptability and performance.
- Rigorous Evaluation through Cross-Validation: HaCk undergoes rigorous evaluation through cross-validation tests, indicating a focus on generalization, robustness, and practical suitability. This makes it a favorable choice for applications where reliability and performance validation are critical.
- Versatility in Cross-Validation Tests: HaCk’s versatility, as demonstrated by its success in both Leave-One-Out and Holdout Cross-Validation tests, suggests its potential applicability across different datasets and scenarios.
- Ethical Considerations: Ethical considerations related to the generation of synthetic data are acknowledged in relation to HaCk.
6.6. Real-World Application
- 1.
- Data Collection:
- (a)
- Gather a diverse dataset of sign language gestures representing various signs and expressions.
- (b)
- Annotate the dataset with corresponding labels or translations.
- 2.
- Model Training:
- (a)
- Train HaCk based on a CNN and GAN architecture.
- (b)
- Train the CNN to recognize hand gestures from visual inputs. At the same time, employ the GAN for data augmentation or generating additional synthetic data to improve HaCk system’s performance.
- 3.
- Gesture Recognition:
- (a)
- Deploy the trained HaCk to recognize hand gestures in real-time or from recorded video inputs.
- (b)
- Process the visual information using the CNN component so that the corresponding sign can be predicted.
- 4.
- Translation:
- (a)
- Translate the recognized sign language gestures into textual or spoken form.
- (b)
- Associate each recognized gesture with its corresponding meaning.
- 5.
- Output Display:
- (a)
- Display the translated output, making it accessible to users who may not be proficient in sign language.
- (b)
- Options include displaying the translation as text or using a speech synthesis system for spoken outputs.
- 6.
- User Interaction:
- (a)
- Design the system to facilitate user interaction, allowing individuals to input sign language gestures through a camera or other input devices.
- (b)
- Consider providing feedback to users, such as highlighting the recognized gestures on display.
- 7.
- Adaptability and Robustness:
- (a)
- Ensure HaCk’s adaptability to different signing styles and variations in hand movements.
- (b)
- Implement robustness features for lighting conditions, background noise, and occlusion variations.
- 8.
- User Feedback and Iterative Refinement:
- (a)
- Encourage user feedback to improve HaCk’s accuracy and user experience.
- (b)
- Consider implementing an iterative refinement process, updating HaCk based on observed limitations and user suggestions.
- 9.
- Accessibility Features:
- (a)
- Implement accessibility features within HaCk, like options for adjusting the model’s sensitivity, adapting to different signing speeds, and accommodating users with varying proficiency levels in sign language.
- 10.
- Integration with Assistive Technologies:
- (a)
- Explore integration with assistive technologies to enhance accessibility for individuals with differing abilities.
- (b)
- Consider compatibility with smart glasses and wearable technology for seamless interaction.
- 11.
- Ethical Considerations:
- (a)
- Address all ethical considerations related to user privacy, informed consent, and the responsible use of AI technology in sign language interpretation.
- 12.
- Continuous Improvement:
- (a)
- Implement feedback mechanisms for the continuous improvement of the HaCk system based on advancements in AI and user feedback.
6.7. Discussion
6.7.1. Choice of Background Subtraction
- Noise Reduction: Hand gesture recognition relies heavily on accurately detecting the hand and its movements. A cluttered or dynamic background can introduce noise into the input data, making it challenging for the CNN-based classifier to focus on the hand itself. By subtracting the background, we isolate the region of interest (ROI), which is the hand, and reduce noise from the surrounding environment.
- Feature Extraction: Background subtraction simplifies feature extraction. The CNN can then focus on extracting meaningful features from the hand region without being distracted by irrelevant information in the background. This can lead to more robust and accurate recognition of hand gestures.
- Consistency: Lighting conditions and backgrounds can vary significantly in real-world scenarios. Using background subtraction helps achieve consistency in the input data, making it easier for the CNN model to generalize across different environments.
- Real-Time Processing: For applications that require real-time processing, such as gesture recognition for interactive systems, background subtraction can be computationally efficient compared to more complex methods like background modeling and subtraction. This allows for faster inference times, which is critical for interactive applications.
6.7.2. Scalability, User Adaptability, and Computational Efficiency of the HaCk System
- Scalability:
- –
- Scenario: The system is deployed in a public space, such as a transportation hub, where a diverse group of users may need to utilize a sign language interpretation service.
- –
- Scalability Measures:
- ∗
- The system is designed to handle a growing number of users, ensuring that the model’s performance remains consistent even during peak usage times.
- ∗
- Training the model on a large and diverse sign language dataset allows it to recognize a broad range of gestures, accommodating various signing styles.
- User Adaptability:
- –
- Scenario: The system caters to users with different signing proficiency levels and physical characteristics.
- –
- User Adaptability Measures:
- ∗
- HaCk includes adaptive features that adjust its recognition sensitivity based on individual user preferences, allowing both beginners and advanced signers to use the system effectively.
- ∗
- Robustness in recognizing gestures from users with different hand shapes or sizes is ensured through extensive training on diverse datasets.
- Computational Efficiency:
- –
- Scenario: The system is integrated into a portable device that enables real-time sign language interpretation on the go.
- –
- Computational Efficiency Measures:
- ∗
- HaCk is optimized for efficient inference on the device, ensuring minimal latency in recognizing and interpreting gestures.
- ∗
- Quantization techniques are applied to reduce HaCk’s size, making it suitable for deployment on resource-constrained devices without compromising performance.
- Operational Environments:
- –
- Scenario: The system is used in various operational environments, including well-lit indoor spaces and outdoor environments with dynamic lighting conditions.
- –
- Operational Environment Measures:
- ∗
- HaCk is trained to be robust to different lighting conditions, and it undergoes thorough testing in diverse environments to ensure accurate gesture recognition.
- ∗
- Adaptive algorithms dynamically adjust recognition parameters based on environmental factors, maintaining their performance in challenging conditions.
6.7.3. Ethical Considerations
- Inclusive Dataset Representation:
- –
- Ethical Concern: Bias in training data that does not adequately represent individuals with differing abilities can lead to discriminatory outcomes.
- –
- Mitigation: Ensure diverse representation in training datasets, encompassing individuals with varying abilities, ages, genders, and cultural backgrounds.
- Privacy and Informed Consent:
- –
- Ethical Concern: Gesture recognition systems may capture sensitive information; obtaining informed consent is crucial to respect individuals’ privacy.
- –
- Mitigation: Clearly communicate data collection purposes, offer opt-in/opt-out choices, and provide transparent explanations about how data will be used, stored, and shared.
- Accessibility in Design:
- –
- Ethical Concern: Excluding individuals with certain disabilities due to design limitations hinders inclusivity.
- –
- Mitigation: Prioritize universal design principles, ensuring that the gesture recognition system is accessible to individuals with diverse abilities and adaptable to assistive technologies.
- Avoiding Reinforcement of Stereotypes:
- –
- Ethical Concern: Biased algorithms can perpetuate stereotypes, affecting the fair treatment of individuals with varying abilities.
- –
- Mitigation: Regularly audit and test algorithms for bias, and implement strategies to minimize and rectify biases that may arise during training.
- Interpretable and Explainable AI:
- –
- Ethical Concern: Lack of interpretability in AI models may result in decisions that are difficult to explain or understand.
- –
- Mitigation: Prioritize the development of interpretable AI models to enhance transparency, accountability, and user trust.
- Ensuring Fair Access:
- –
- Ethical Concern: Limited accessibility to gesture recognition technology may widen existing disparities for individuals with differing abilities.
- –
- Mitigation: Strive to make the technology affordable, considerate of resource constraints, and compatible with a variety of devices to ensure widespread accessibility.
- Continuous User Feedback and Adaptability:
- –
- Ethical Concern: A lack of continuous feedback mechanisms may result in systems that do not adequately adapt to the needs of individuals with varying abilities.
- –
- Mitigation: Establish channels for ongoing user feedback, incorporate user perspectives in system refinement, and ensure adaptability to evolving accessibility requirements.
- Guarding Against Unintended Consequences:
- –
- Ethical Concern: Unintended consequences, such as misinterpretation of gestures or inadvertent exclusion, may occur.
- –
- Mitigation: Regularly assess the real-world impact of the gesture recognition system, conduct usability testing with individuals with differing abilities, and promptly address any issues identified.
- Education and Awareness:
- –
- Ethical Concern: Lack of awareness about the capabilities and limitations of gesture recognition systems can lead to unrealistic expectations.
- –
- Mitigation: Provide transparent information to users about the system’s capabilities, potential errors, and ongoing efforts to enhance inclusivity.
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, W.; Shi, P.; Yu, H. Gesture recognition using surface electromyography and deep learning for prostheses hand: State-of-the-art, challenges, and future. Front. Neurosci. 2021, 15, 621885. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef]
- Dahou, A.; Al-qaness, M.A.; Abd Elaziz, M.; Helmi, A.M. MLCNNwav: Multi-level Convolutional Neural Network with Wavelet Transformations for Sensor-based Human Activity Recognition. IEEE Internet Things J. 2023, 11, 820–828. [Google Scholar] [CrossRef]
- Verma, K.K.; Singh, B.M. Deep multi-model fusion for human activity recognition using evolutionary algorithms. Int. J. Interact. Multimed. Artif. Intell. 2021, 7, 44–58. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Jitpattanakul, A. Deep convolutional neural network with rnns for complex activity recognition using wrist-worn wearable sensor data. Electronics 2021, 10, 1685. [Google Scholar] [CrossRef]
- Alessandrini, M.; Biagetti, G.; Crippa, P.; Falaschetti, L.; Turchetti, C. Recurrent neural network for human activity recognition in embedded systems using ppg and accelerometer data. Electronics 2021, 10, 1715. [Google Scholar] [CrossRef]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef]
- Fang, W.; Ding, Y.; Zhang, F.; Sheng, J. Gesture recognition based on CNN and DCGAN for calculation and text output. IEEE Access 2019, 7, 28230–28237. [Google Scholar] [CrossRef]
- Tang, H.; Wang, W.; Xu, D.; Yan, Y.; Sebe, N. Gesturegan for hand gesture-to-gesture translation in the wild. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 774–782. [Google Scholar]
- Zhu, W.; Yang, Y.; Chen, L.; Xu, J.; Zhang, C.; Guo, H. Application of Generative Adversarial Networks in Gesture Recognition. In Proceedings of the 2022 WRC Symposium on Advanced Robotics and Automation (WRC SARA), Beijing, China, 20 August 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Garg, M.; Ghosh, D.; Pradhan, P.M. Generating multiview hand gestures with conditional adversarial network. In Proceedings of the 2021 IEEE 18th India Council International Conference (INDICON), Guwahati, India, 19–21 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Barbhuiya, A.A.; Karsh, R.K.; Jain, R. ASL hand gesture classification and localization using deep ensemble neural network. Arab. J. Sci. Eng. 2023, 48, 6689–6702. [Google Scholar] [CrossRef]
- Javed, A.R.; Faheem, R.; Asim, M.; Baker, T.; Beg, M.O. A smartphone sensors-based personalized human activity recognition system for sustainable smart cities. Sustain. Cities Soc. 2021, 71, 102970. [Google Scholar] [CrossRef]
- Fallahzadeh, R.; Ghasemzadeh, H. Personalization without user interruption: Boosting activity recognition in new subjects using unlabeled data. In Proceedings of the 8th International Conference on Cyber-Physical Systems, Pittsburgh, PA, USA, 18–20 April 2017; pp. 293–302. [Google Scholar]
- Siirtola, P.; Röning, J. Context-aware incremental learning-based method for personalized human activity recognition. J. Ambient. Intell. Humaniz. Comput. 2021, 10499–10513. [Google Scholar] [CrossRef]
- Boroujeni, S.P.H.; Razi, A. IC-GAN: An Improved Conditional Generative Adversarial Network for RGB-to-IR image translation with applications to forest fire monitoring. Expert Syst. Appl. 2024, 238, 121962. [Google Scholar] [CrossRef]
- Wang, G.; Shi, H.; Chen, Y.; Wu, B. Unsupervised image-to-image translation via long-short cycle-consistent adversarial networks. Appl. Intell. 2023, 53, 17243–17259. [Google Scholar] [CrossRef]
- Almahairi, A.; Rajeshwar, S.; Sordoni, A.; Bachman, P.; Courville, A. Augmented cyclegan: Learning many-to-many mappings from unpaired data. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 195–204. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Wu, B.; Ding, Y.; Dong, Q. Fast continuous structural similarity patch based arbitrary style transfer. Appl. Sci. 2019, 9, 3304. [Google Scholar] [CrossRef]
- Ruta, D.S. Learned Representations of Artistic Style for Image Retrieval, Description, and Stylization. Ph.D. Thesis, University of Surrey, Guildford, UK, 2023. [Google Scholar]
- Gupta, V.; Sadana, R.; Moudgil, S. Image style transfer using convolutional neural networks based on transfer learning. Int. J. Comput. Syst. Eng. 2019, 5, 53–60. [Google Scholar] [CrossRef]
- Gu, S.; Chen, C.; Liao, J.; Yuan, L. Arbitrary style transfer with deep feature reshuffle. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8222–8231. [Google Scholar]
- Jung, D.; Yang, S.; Choi, J.; Kim, C. Arbitrary style transfer using graph instance normalization. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1596–1600. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Wang, Z.; Zhao, L.; Chen, H.; Qiu, L.; Mo, Q.; Lin, S.; Xing, W.; Lu, D. Diversified arbitrary style transfer via deep feature perturbation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7789–7798. [Google Scholar]
- Sheng, L.; Lin, Z.; Shao, J.; Wang, X. Avatar-net: Multi-scale zero-shot style transfer by feature decoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8242–8250. [Google Scholar]
- Suzuki, N.; Watanabe, Y.; Nakazawa, A. Gan-based style transformation to improve gesture-recognition accuracy. In Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies; Association for Computing Machinery: New York, NY, USA, 2020; Volume 4, pp. 1–20. [Google Scholar]
- Holden, D.; Saito, J.; Komura, T. A deep learning framework for character motion synthesis and editing. Acm Trans. Graph. (Tog) 2016, 35, 1–11. [Google Scholar] [CrossRef]
- Banerjee, T.; Srikar, K.P.; Reddy, S.A.; Biradar, K.S.; Koripally, R.R.; Varshith, G. Hand Sign Recognition using Infrared Imagery Provided by Leap Motion Controller and Computer Vision. In Proceedings of the 2021 International Conference on Innovative Practices in Technology and Management (ICIPTM), Noida, India, 17–19 February 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 20–25. [Google Scholar]
- Chevtchenko, S.F.; Vale, R.F.; Macario, V.; Cordeiro, F.R. A convolutional neural network with feature fusion for real-time hand posture recognition. Appl. Soft Comput. 2018, 73, 748–766. [Google Scholar] [CrossRef]
- Sahoo, J.P.; Prakash, A.J.; Pławiak, P.; Samantray, S. Real-time hand gesture recognition using fine-tuned convolutional neural network. Sensors 2022, 22, 706. [Google Scholar] [CrossRef] [PubMed]
- Sahoo, J.P.; Sahoo, S.P.; Ari, S.; Patra, S.K. RBI-2RCNN: Residual block intensity feature using a two-stage residual convolutional neural network for static hand gesture recognition. Signal Image Video Process. 2022, 16, 2019–2027. [Google Scholar] [CrossRef]
- Qi, W.; Ovur, S.E.; Li, Z.; Marzullo, A.; Song, R. Multi-Sensor Guided Hand Gesture Recognition for a Teleoperated Robot Using a Recurrent Neural Network. IEEE Robot. Autom. Lett. 2021, 6, 6039–6045. [Google Scholar] [CrossRef]
- Qi, W.; Aliverti, A. A Multimodal Wearable System for Continuous and Real-Time Breathing Pattern Monitoring during Daily Activity. IEEE J. Biomed. Health Inform. 2020, 24, 2199–2207. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value |
|---|---|
| Loss | Validation MSE |
| Optimizer | Softmax |
| Metrics | MSE, and MAE |
| Batch size | 68 |
| Time step | 1 |
| Epochs | 500 |
| Number of CNN layers | 300 |
| Learning rate | 0.211 |
| Dropout | 0.2 |
| Activation function | ReLU |
| Dataset | Metric | Real-World Data | GAN-Generated Data | Combined Data (Real + GAN) |
|---|---|---|---|---|
| Test Set | Accuracy | 0.85 | 0.78 | 0.87 |
| Precision | 0.88 | 0.76 | 0.89 | |
| Recall | 0.82 | 0.80 | 0.85 | |
| F1 score | 0.85 | 0.78 | 0.87 | |
| Robustness Testing | Success rate | - | 0.75 | 0.80 |
| Models | Accuracy (%) |
|---|---|
| CNN [31] | 78.93% |
| FTCNN [32] | 75.69% |
| CDCGAN [8] | 80.20% |
| GestureGAN [9] | 82.20% |
| GGAN [10] | 85.80% |
| MHG-CAN [11] | 89.98% |
| ASL [12] | 90.05% |
| HaCk (proposed) | 95.96% |
| Models | Accuracy (%) |
|---|---|
| HU [33] | 41.05% |
| ZM [33] | 82.01% |
| GB [33] | 83.95% |
| GB-ZM [33] | 73.11% |
| GB-HU [33] | 74.40% |
| CDCGAN [8] | 80.20% |
| GestureGAN [9] | 82.20% |
| GGAN [10] | 85.80% |
| MHG-CAN [11] | 89.98% |
| ASL [12] | 90.10% |
| HaCk (proposed) | 97.92% |
| Models | Network Architecture | Training Strategy | Data Preprocessing | Advantages | Limitations |
|---|---|---|---|---|---|
| MGHGRS [34] | A multi-sensor data fusion model comprising a multilayer RNN. The multilayer RNN consists of an LSTM module and a dropout layer. | Multiple label classification. | Signal processing and modeling approaches. | (i) Improved accuracy, (ii) real-time responsiveness, (iii) effective management of depth data challenges, (iv) occlusion handling, (v) adaptability to dynamic conditions, (vi) versatility in collaboration tasks, and (vii) a comparative edge over traditional ML algorithms. | (i) Hardware complexity, (ii) cost implications, (iii) adaptability to novel gestures, (iv) sensitivity to environmental changes, (v) dependency on real-time processing, and (vi) interference in dynamic environments. |
| WRAM system [35] | A fusion architecture incorporating multiple modalities is formed by amalgamating a hybrid hierarchical classification (HHC) algorithm that combines both deep learning and threshold-based methods. | Multiple users breathing in real-time. | Signal denoising and DL. | The WRAM system [35] offers significant advantages, ranging from accurate activity recognition and in-depth breathing pattern analysis to real-time monitoring capabilities, demonstrating its potential impact on healthcare and precision medicine. | (i) Limited generalization to diverse populations, (ii) dependency on participant compliance, (iii) sensitivity to device placement, (iv) challenges in handling unseen activities, (v) potential interference in real-world environments, (vi) data privacy and ethical considerations, and (vii) limited exploration of health conditions. |
| HaCk (proposed) | Integration of CNN and GAN. | Multiple label classification based on DL. | Data normalization and scaling. | (i) Addressing visual impairment challenges, (ii) non-contact interaction for accessibility, (iii) diverse set of hand gestures, (iv) two-step recognition approach, (v) evaluation through rigorous cross-validation, (vi) versatility in cross-validation tests, and (vii) contributing to accessibility technology and potential for real-time applications. | (i) Limited representativeness of visual impairment, (ii) dependency on non-contact interaction, (iii) synthetic gesture generalization challenges, and (iv) potential ethical considerations in synthetic data generation. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chatterjee, K.; Raju, M.; Selvamuthukumaran, N.; Pramod, M.; Krishna Kumar, B.; Bandyopadhyay, A.; Mallik, S. HaCk: Hand Gesture Classification Using a Convolutional Neural Network and Generative Adversarial Network-Based Data Generation Model. Information 2024, 15, 85. https://doi.org/10.3390/info15020085
Chatterjee K, Raju M, Selvamuthukumaran N, Pramod M, Krishna Kumar B, Bandyopadhyay A, Mallik S. HaCk: Hand Gesture Classification Using a Convolutional Neural Network and Generative Adversarial Network-Based Data Generation Model. Information. 2024; 15(2):85. https://doi.org/10.3390/info15020085
Chicago/Turabian StyleChatterjee, Kalyan, M. Raju, N. Selvamuthukumaran, M. Pramod, B. Krishna Kumar, Anjan Bandyopadhyay, and Saurav Mallik. 2024. "HaCk: Hand Gesture Classification Using a Convolutional Neural Network and Generative Adversarial Network-Based Data Generation Model" Information 15, no. 2: 85. https://doi.org/10.3390/info15020085
APA StyleChatterjee, K., Raju, M., Selvamuthukumaran, N., Pramod, M., Krishna Kumar, B., Bandyopadhyay, A., & Mallik, S. (2024). HaCk: Hand Gesture Classification Using a Convolutional Neural Network and Generative Adversarial Network-Based Data Generation Model. Information, 15(2), 85. https://doi.org/10.3390/info15020085