2. Literature Review
According to Wikipedia, reinforcement learning (RL) is an area of machine learning to study how an agent takes actions in a dynamic environment to maximize the cumulative reward [
6]. Recently, incorporating neural networks in RL agents has received lots of attention [
7,
8,
9,
10]. There are several types of RL algorithms based on different optimality criteria. One type is the value-based algorithms, such as Q learning [
11], deep Q-learning (DQN) algorithm [
12], and double deep Q-learning (DDQN) [
13]. The Q-learning and DQN approaches have been widely used in production scheduling problems [
14,
15,
16,
17,
18,
19,
20,
21,
22], as discussed below. Another type of RL algorithms is the actor–critic type and its variants, such as proximal policy optimization (PPO) [
23]. The PPO algorithm has also been used in production scheduling problems [
5,
24,
25,
26].
Conventional Q-learning has been applied to production scheduling problems with success. Fonseca-Reyna et al. [
14] used it for solving job-shop scheduling problems. They achieved better results in a shorter computing time. Shahrabi et al. [
15] applied it to update the parameters of the variable neighborhood search algorithm, which is used as the scheduling algorithm for the studied dynamic job-shop scheduling problems with random job arrivals. Wang et al. [
16] proposed a multi-agent approach for solving JSSP. They used a weighted Q-learning algorithm to determine the most suitable operation with better performance. Wang et al. [
17] used two Q-learning agents for assembly job-shop scheduling, which consists of job-shop scheduling and an additional stage to assemble parts to jobs according to a bill of material. Their results showed that better results could be obtained than the single Q-learning and other scheduling rule approaches.
For applications of DQN to DFJSPs, Luo [
18] showed promising results for random job arrivals by letting the DQN agent select dispatching rules. Luo et al. [
19] subsequently used a two-hierarchy deep Q network to handle online multi-objective rescheduling for DFJSPs, such as new job arrivals and machine breakdowns. In their approach, the higher-level DQN determines the optimization goals, and the lower one selects the dispatching rules. Heger et al. [
20] used Q-learning to handle DFJSPs with varying job arrival times and product flows, and they demonstrated the feasibility of their method in unseen scenarios. Turgut et al. [
21] used the deep Q-network (DQN) to solve DFJSP with dynamic job arrivals, where the agent has to select and assign one of the waiting tasks to the first available machine. Their method outperformed the shortest processing time (SPT) and earliest due date (EDD), two conventional PDR methods. Chang et al. [
22] used DDQN to solve a DFJSP with stochastic job arrivals and showed that their method outperformed existing RL and heuristic methods in dynamic scheduling problems.
Graph neural networks (GNNs) are a type of artificial neural networks that can process data that have a graph structure [
27]. GNNs can learn from the graph data by using a message passing mechanism and update internal representations based on the local and global structures of the graph. A variant of the GNN is the graph isomorphism network (GIN), which is suitable for graph classification tasks [
28]. Several studies have combined GIN and PPO to solve DFJSPs with a dynamic job arrival [
5,
24,
25]. Zhang et al. introduced the L2D framework [
5], which combines the graph neural network (GNN) and proximal policy optimization (PPO) to solve JSSP. They proposed a novel idea of using jobs and machines as the state space and letting the reinforcement-learning agent assign tasks based on the state representation. L2D learns the policy in an end-to-end manner without relying on predefined rules. A modified version of L2D open-source software can be found in [
29]. Lei et al. [
24,
25] extended the L2D framework to handle dynamic job arrival problems. Their approach incorporated a high-level agent, based on double deep Q-networks (DDQN), to cache and dispatch the newly arrived jobs. Thus, a DFJSP can be transformed into static FJSPs and solved by the low-level L2D agent. Zhang et al. [
26] introduced a multi-agent-based distributed scheduling architecture, which reduces the workload on the central server. They used a scheduling model based on the PPO algorithm, which can handle unpredictable events, such as new job arrivals and machine breakdowns.
From the above review, we know that most of the existing studies use reinforcement learning algorithms to select dispatch functions based on designed features [
14,
15,
16,
17,
18,
19,
20,
21,
22]. However, this is not the ultimate goal that neural-network researchers are aiming for: an end-to-end architecture that can solve a problem [
30]. By using an end-to-end architecture, the learning algorithm can adjust its internal representations to better fit the problem.
The end-to-end L2D model was originally proposed for solving the JSPP. Although it was later extended to solve the DFJSP with a stochastic job arrival, it did not address the dynamic change in the number of machines. In fact, only a few papers have ever considered the breakdown of a machine, let alone the dynamic number of machines. We believe that this problem has not been adequately investigated in the literature.
3. Proposed Approach
This section describes the proposed approach and all necessary materials. This section starts with the mathematical description of the DFJSP. It is followed by a Markov decision process, the graph representation of the states, the node features, the calculation of rewards, and the proposed approach.
3.1. Dynamic Flexible Job-Shop Scheduling Problem
Before we formally define the studied problem, we first describe the JSSP. A JSSP instance consists of a set of jobs and a set of machines . Each job contains multiple tasks , , where indicates the number of machines that needs to visit to complete the job. The size of a JSSP instance is expressed as |J| × |M|, where denotes the cardinality (i.e., the number of elements) of the set. The JSSP has three constraints: (i) each task needs to be processed by a specified machine . (ii) Tasks must be processed in order, expressed as which is known as “precedence constraint”. (iii) Each machine can only process one task at a time, and the processing is non-preemptive.
For a specific task , its makespan is , where is the staring time of the task, and is the processing time. The optimal solution of a JSSP instance is to minimize .
The flexible job-shop scheduling problem (FJSP) allows for more than one machine for each task type. Let be the set machine types, where each type has identical machines, i.e., . Unlike the JSSP, can now be processed by any machine in , instead of one dedicated machine.
In this paper, we study the problem of dynamic machine numbers in the FJSP. We assume that the number of machines of each type follows a Poisson distribution and changes randomly over time. Therefore, the value
will vary over time with an upper bound of
, i.e.,
. The details of the Poisson distribution and the formula for increasing and decreasing the number of machines are given in
Section 4.1.
3.2. Markov Decision Process for Scheduling JSSP
Before we describe the proposed approach, we first explain how to solve a JSSP by using a Markov decision process (MDP), which contains states and actions.
States. Let be the set of nodes containing tasks, let C be the set of directed arcs (conjunction) that connect two tasks based on the precedence constraints, and let D be the set of nondirectional edges (disjunctions) that connect two tasks that need the same machine for processing. We define the state of an MDP at step t as a graph that represents the solution up to t, where is the set of edges that have been assigned a direction up to t, is the set of the remaining , and , where T is the maximum number of decision steps. Each node has two features: the first feature is the lower bound of the makespan of the task, and the second feature is a binary indicator , which is 1 if has been scheduled before , and 0 otherwise.
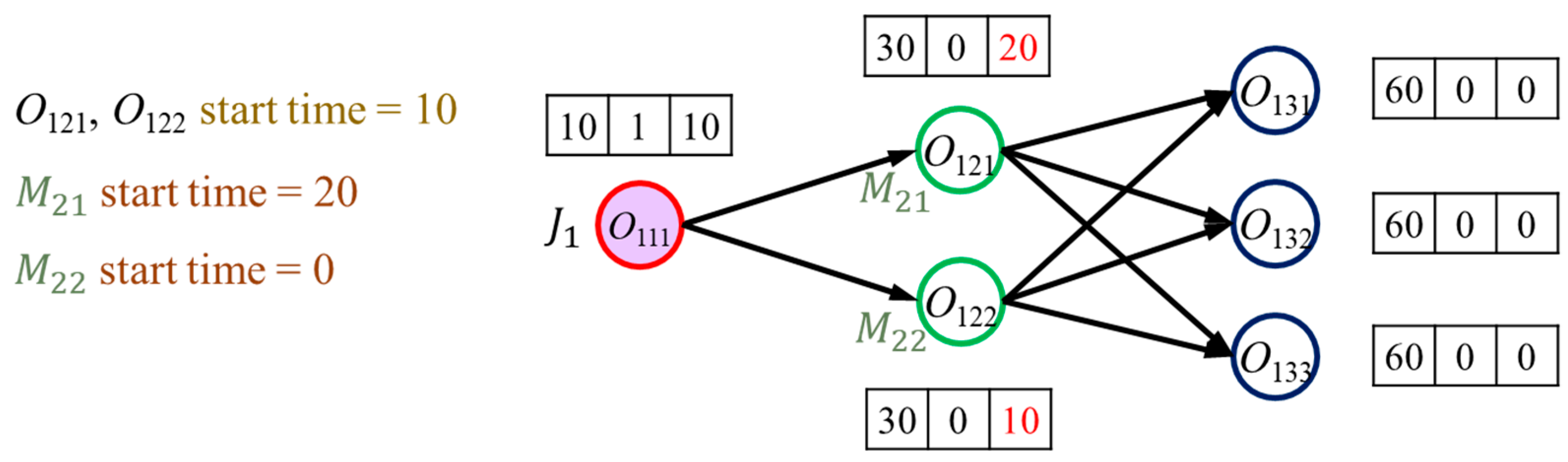
As an example, we use a simple JSSP instance, shown in
Figure 1. The dummy nodes (begin and end) are omitted for simplicity. The instance has three jobs, each with three tasks. Each task is represented by a circle, and the color of the circle indicates the machine type (A, B, or C) required for the task. The solid arrows indicate the precedence constraints of the jobs. The two numbers above each node (task) are the features explained earlier. As shown in
Figure 1, the first feature is the lower bound of its makespan of the task, which depends only on the precedence constraints, since no task has been scheduled yet.
Action. An action
is a task that can be scheduled at step
t. The action space
is a set whose elements are feasible tasks in the current state
. Feasible tasks are determined by the precedence constraints and the availability of the required machine.
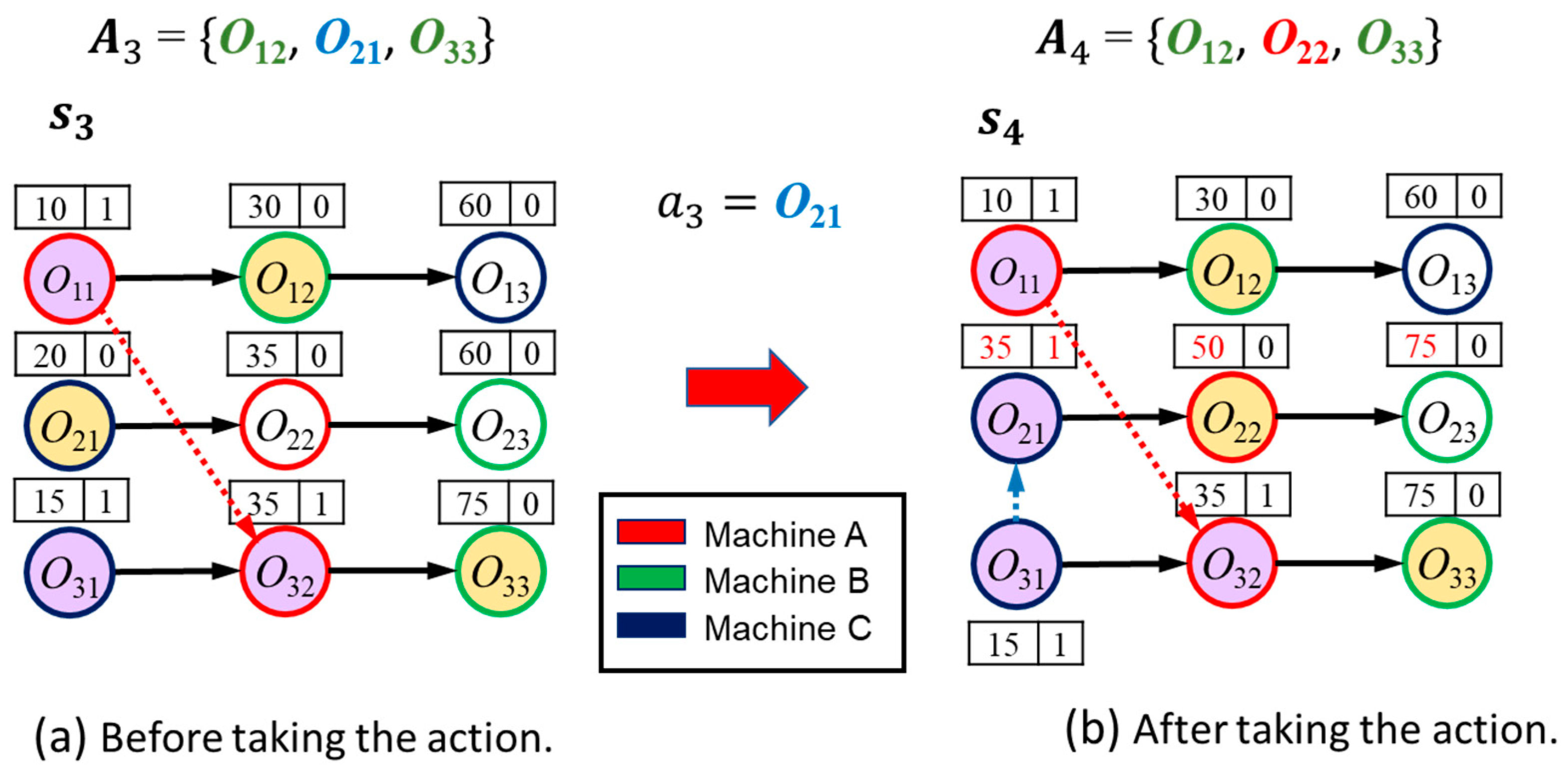
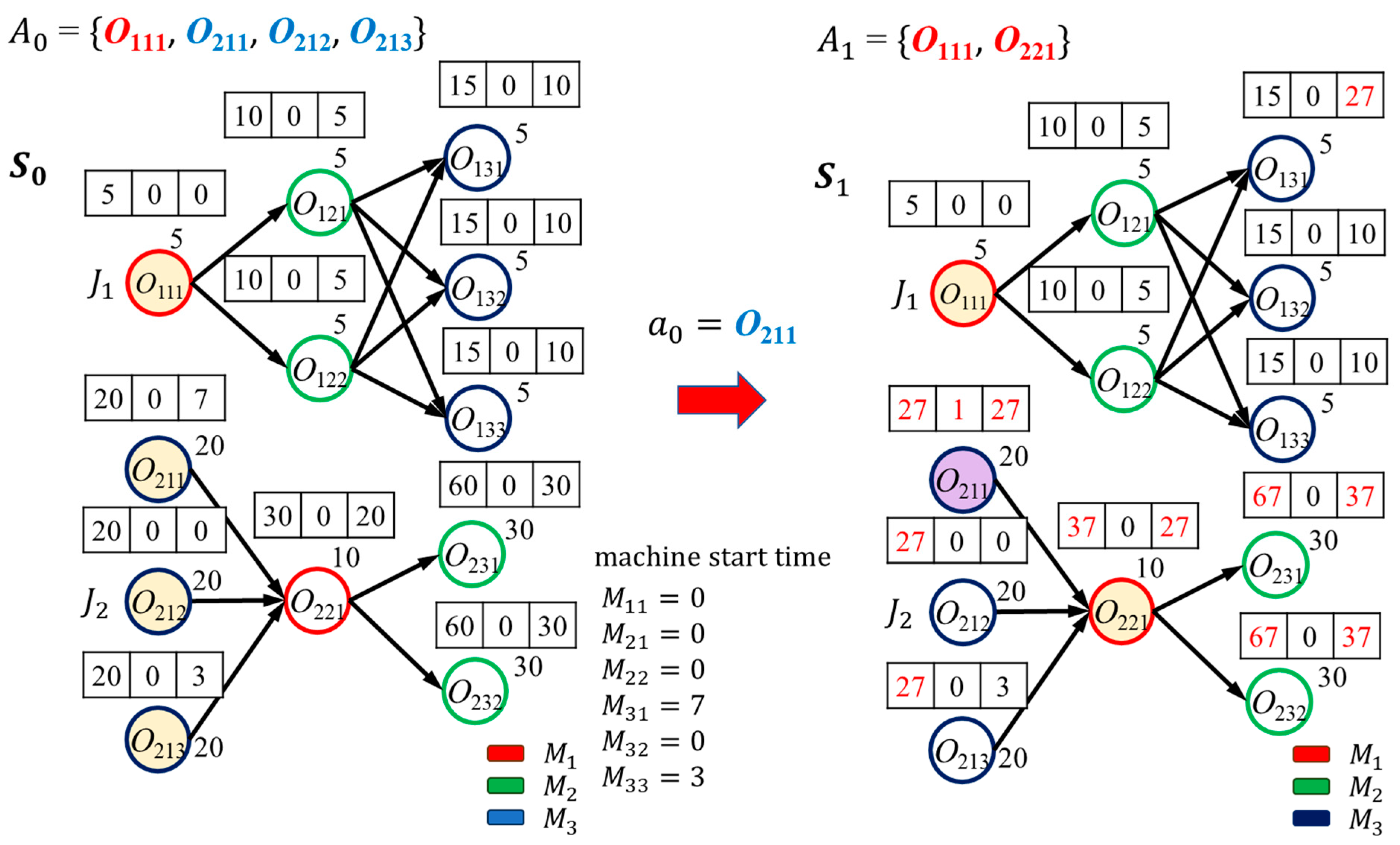
Figure 2a illustrates the action space of a JSSP in a specific state,
. Note that
are filled with purple color to indicate that they have been scheduled (as indicated by the
indicators in these nodes). Therefore, they will not be in the action space anymore. Feasible tasks are the ones that are ready to be processed for each job. For instance,
is not a feasible task because
has not been scheduled yet. All feasible tasks are filled with yellow color in
Figure 2a, i.e.,
.
State Transition. When an action
is selected in state
, the state transitions to
. This changes
in the graph
and some node features accordingly.
Figure 2b shows an example after the transition. When
. is chosen, machine C moves from
to
to start processing, so an edge is directed from
to
in
. The dashed lines in
Figure 2b show the assignments of machines A (in red circles) and C (in blue circles) to tasks. Then, task
and its successors
,
(under precedence constraints) update their first features, as
. If
, then
, the start time of the task based on the machine availability. Otherwise,
is set as
of
The second feature of
is also set to 1. Note that
may be updated only based on
; therefore, it is not the actual makespan of task
.
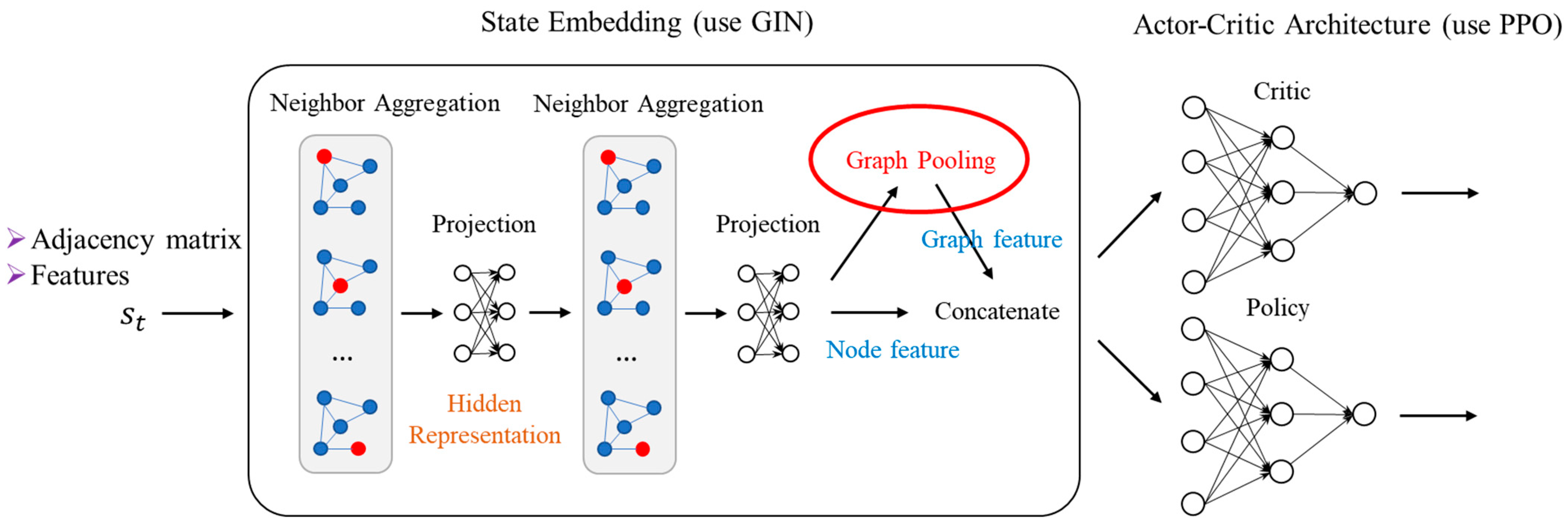
3.7. Network Model of the Proposed Approach
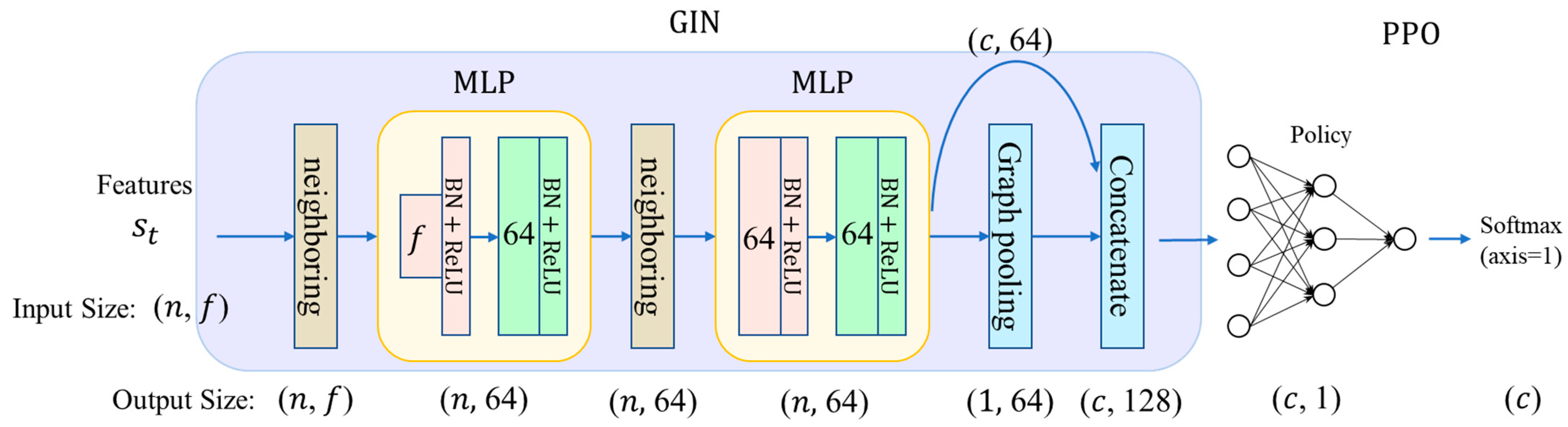
L2D architecture. Our method follows the same overall architecture as L2D [
5], which has two components: state embedding and learning policy, as shown in
Figure 7. State embedding maps the graph
G at
to an internal representation using a graph isomorphism network (GIN). The GIN can handle graphs with varying numbers of nodes and edges, but each node must have the same number of features. L2D uses a PPO algorithm as the learning policy to evaluate and select the best action. For brevity, we skip the details of the L2D method. Please see [
5] for more information.
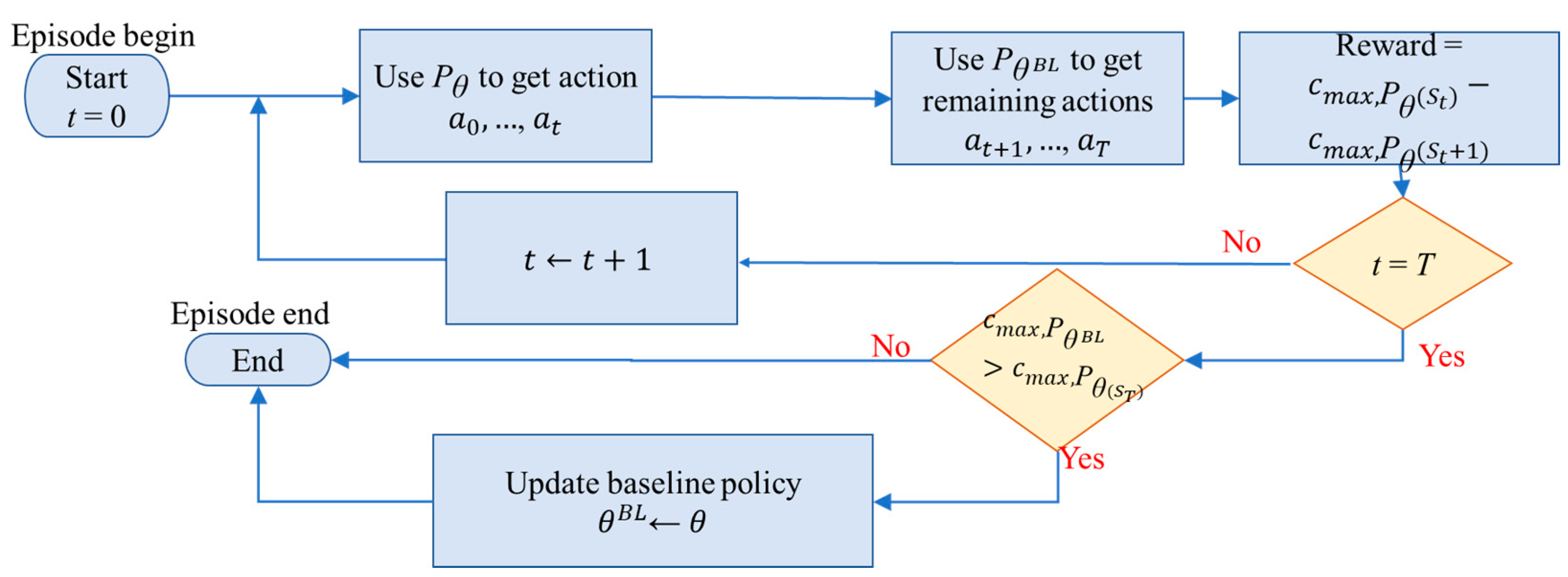
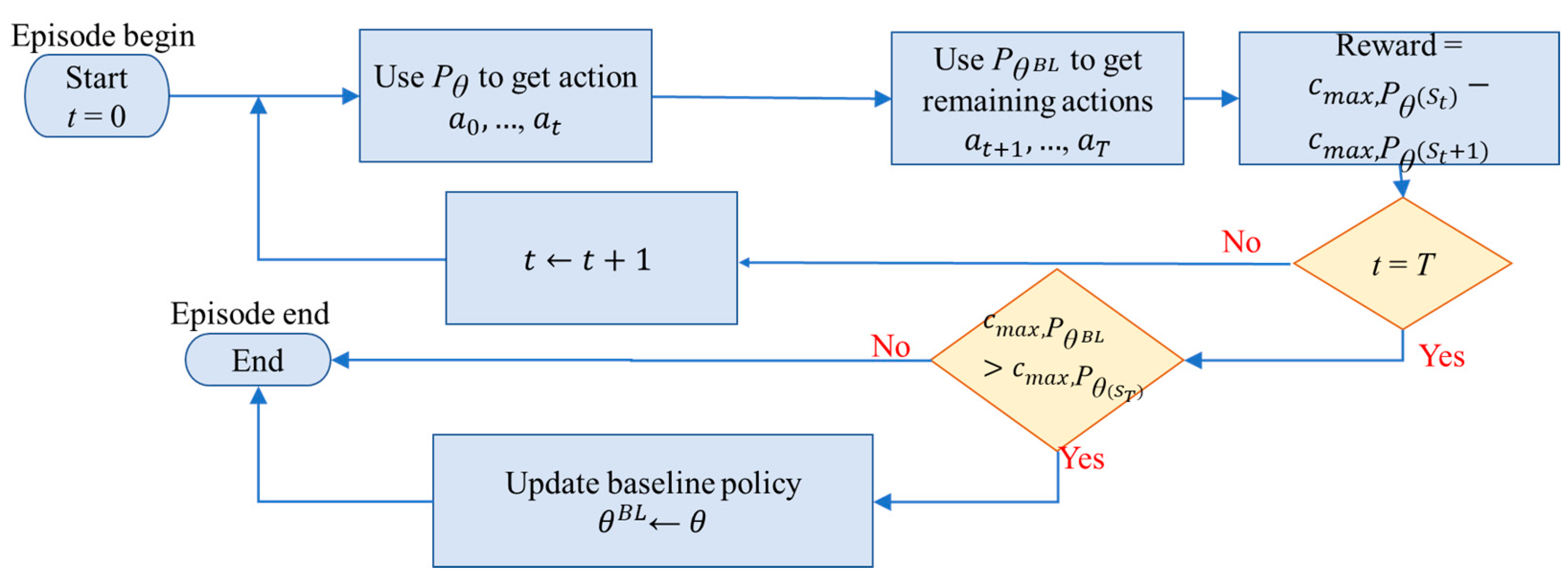
The proposed approach. The L2D framework was initially developed for JSSP, which does not contain any dynamic events. Hence, it uses only two features per node, and its reward function was merely the difference in the makespan in two successive steps. To adapt the L2D framework to our problem, we need to tackle the dynamic problem with a better reward design.
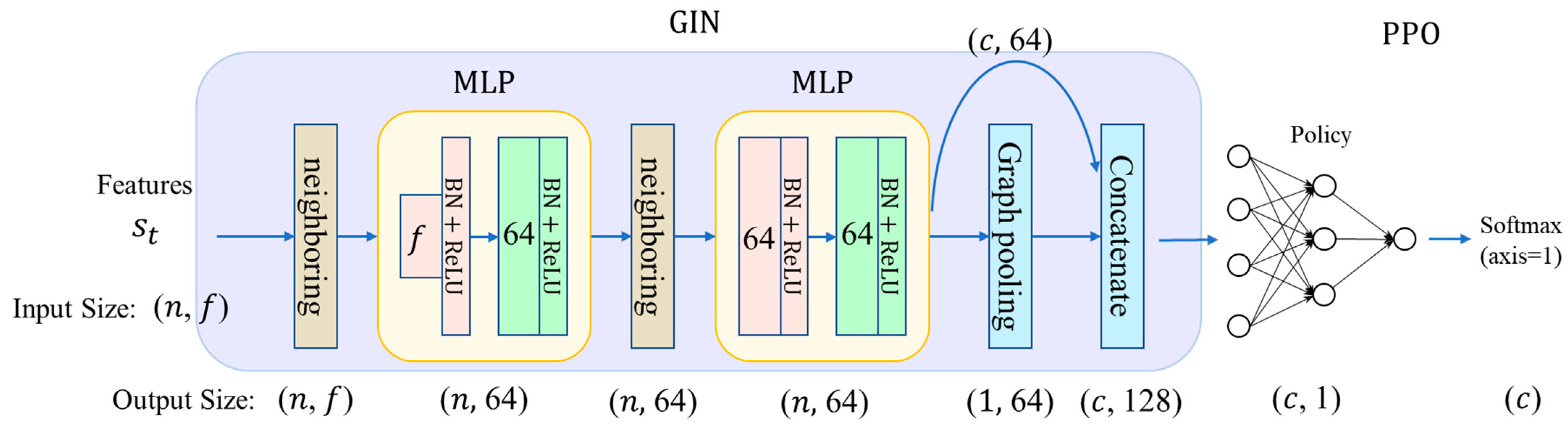
Figure 8 illustrates our proposed approach. We focus on the implementation details of our model, rather than the theoretical background, for brevity. The source code of our model is given in the
Supplementary Materials section of this paper. As
Figure 8 shows, the first step, neighboring, performs a matrix multiplication of the adjacency matrix and the feature matrix. The feature matrix has a size of
, where
is the number of nodes in the graph and
is the number of features in one node. The graph itself is represented by an adjacency matrix of size
with the rows indicating the end nodes and the columns indicating the start nodes. Then, we divide each row of the product matrix of size
by the degree of the node to achieve average pooling.
We use two multi-layer perceptrons (MLPs) to implement the GIN. Each MLP is a fully connected feedforward network with a rectified-linear-unit (ReLU) activation function and 64 hidden units. The first MLP takes inputs of size , so we need to collect the outputs n times to get the full output of size . This enables the network to handle graphs with varying sizes, such as those with a dynamic number of machines. The second neighboring layer performs the same operations mentioned previously.
The second neighboring layer repeats the same steps as the input neighboring layer, except that it uses the output of the first MLP as the feature matrix. The graph pooling performs average pooling to aggregate information from multiple nodes into one. However, it only averages the nodes in the action list (). This layer has an output size of . The concatenating layer concatenates the average-pooled outputs and the unaveraged outputs. To be able to concatenate, the outputs of the average pooling is copied times to form a matrix.
The PPO network is also a multi-layer feedforward network. It takes 128 input values, has 64 hidden units, and produces one output value at a time, corresponding to the current node in the action list
. Suppose that we feed the first row of the concatenated outputs to the PPO network and get
. Then, we feed the second row and get
. We repeat this process until we get
. Next, we apply a softmax function to all
. Since the PPO network only computes softmax for valid actions, this is equivalent to using an action mask to exclude invalid actions [
32].
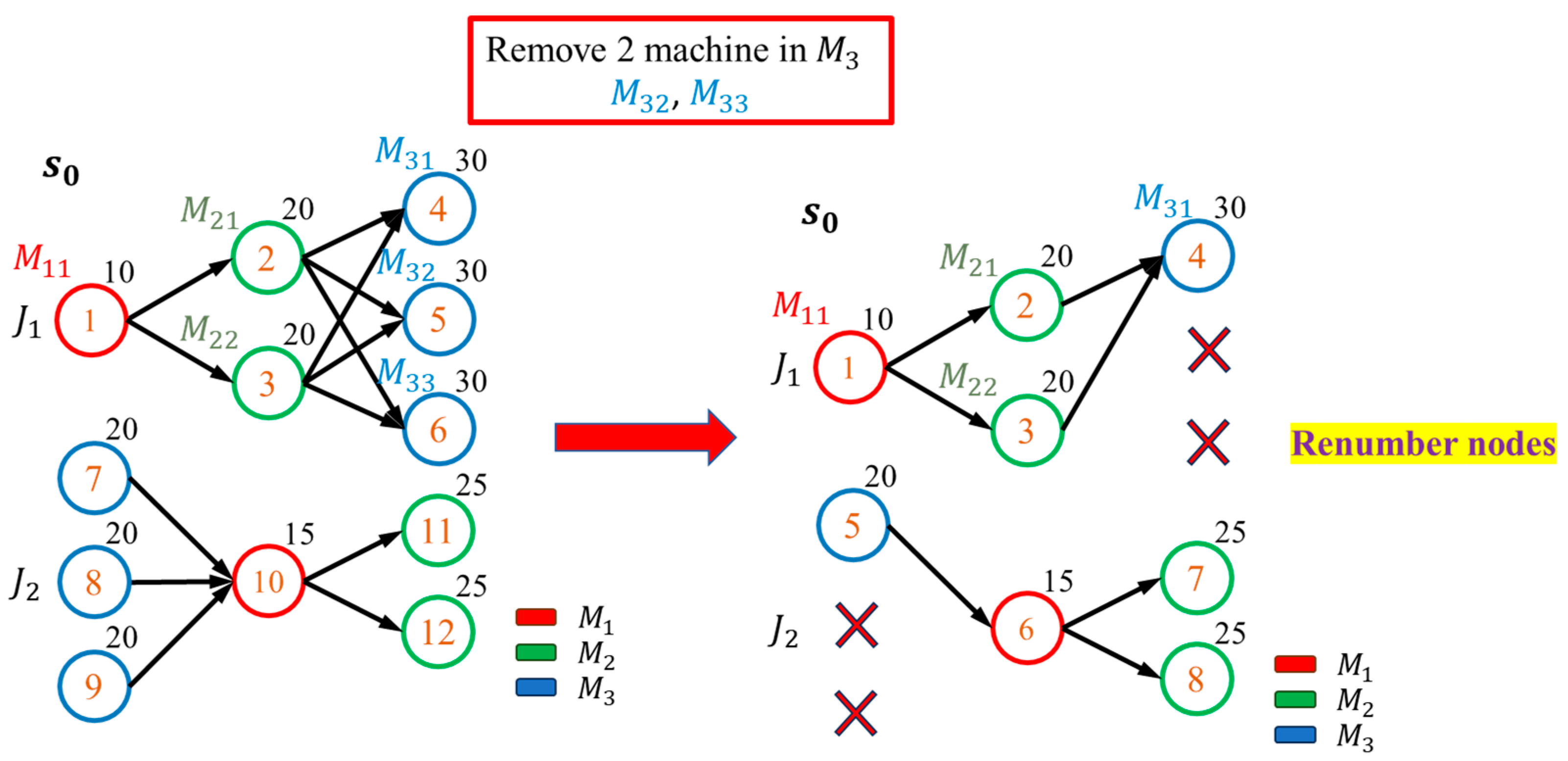
To handle the dynamic change of machine number, we have to reconstruct the graph and the node features whenever a machine goes online or offline at time . We also have to recalculate from , using the previously chosen actions for . To train the PPO with a variable number of machines, we first collect the values of the surrogate objective, the advantage estimator, and the entropy over the entire episode, and then apply backpropagation with the collected values.
Author Contributions
Conceptualization, C.-H.L. and S.D.Y.; methodology, Y.-H.C., C.-H.L. and S.D.Y.; software, Y.-H.C.; validation, Y.-H.C., C.-H.L. and S.D.Y.; formal analysis, Y.-H.C., C.-H.L. and S.D.Y.; investigation, Y.-H.C., C.-H.L. and S.D.Y.; resources, S.D.Y.; data curation, Y.-H.C.; writing—original draft preparation, S.D.Y.; writing—review and editing, C.-H.L.; visualization, Y.-H.C.; supervision, C.-H.L. and S.D.Y.; project administration, C.-H.L. and S.D.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The source code randomly generated test data for simulations.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
List of acronyms used in this paper.
| Acronym | Full name |
| DDQN | Double deep Q learning |
| DQN | Deep Q learning |
| DRL | Deep reinforcement learning |
| EDD | Earliest due date |
| FDD/MWKR | Flow Due Date per Most Work Remaining |
| FJSP | Flexible job-shop scheduling problem |
| FDJSP | Dynamic flexible job-shop scheduling problem |
| GIN | Graph isomorphism network |
| GNN | Graph neural network |
| JSSP | Job-shop scheduling problem |
| L2D | Learning to dispatch |
| MDP | Markov decision process |
| MLP | Multi-layer perceptron |
| MOPNR | Most operations remaining |
| PDR | Priority dispatching rules |
| PPO | Proximal policy optimization |
| ReLU | Rectified linear unit |
| RL | Reinforcement learning |
| SPT | Shortest Processing Time |
References
- Rinnooy Kan, A.H.G. Machine Scheduling Problems: Classification, Complexity and Computations; Springer: New York, NY, USA, 1976. [Google Scholar]
- Allahverdi, A. The third comprehensive survey on scheduling problems with setup times/costs. Eur. J. Oper. Res. 2015, 246, 345–378. [Google Scholar] [CrossRef]
- Job-Shop Scheduling. Available online: https://en.wikipedia.org/wiki/Job-shop_scheduling#NP-hardness (accessed on 18 December 2023).
- Sels, V.; Gheysen, N.; Vanhoucke, M. A comparison of priority rules for the job shop scheduling problem under different flow time-and tardiness-related objective functions. Int. J. Prod. Res. 2012, 50, 4255–4270. [Google Scholar] [CrossRef]
- Zhang, C.; Song, W.; Cao, Z.; Zhang, J.; Tan, P.S.; Chi, X. Learning to Dispatch for Job Shop Scheduling via Deep Reinforcement Learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep Reinforcement Learning: A Brief Survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep Learning in Neural Networks: An Overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Sierla, S.; Ihasalo, H.; Vyatkin, V. A Review of Reinforcement Learning Applications to Control of Heating, Ventilation and Air Conditioning Systems. Energies 2022, 15, 3526. [Google Scholar] [CrossRef]
- Watkins, C.J.C.H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level Control through Deep Reinforcement Learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- van Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Fonseca-Reyna, Y.C.; Martinez, Y.; Rodríguez-Sánchez, E.; Méndez-Hernández, B.; Coto-Palacio, L.J. An Improvement of Reinforcement Learning Approach to Permutational Flow Shop Scheduling Problem. In Proceedings of the 13th International Conference on Operations Research (ICOR 2018), Beijing, China, 7–9 July 2018. [Google Scholar]
- Shahrabi, J.; Adibi, M.A.; Mahootchi, M. A reinforcement learning approach to parameter estimation in dynamic job shop scheduling. Comput. Ind. Eng. 2017, 110, 75–82. [Google Scholar] [CrossRef]
- Wang, Y.-F. Adaptive job shop scheduling strategy based on weighted Q-learning algorithm. J. Intell. Manuf. 2018, 31, 417–432. [Google Scholar] [CrossRef]
- Wang, H.; Sarker, B.R.; Li, J.; Li, J. Adaptive scheduling for assembly job shop with uncertain assembly times based on dual Q-learning. Int. J. Prod. Res. 2020, 59, 5867–5883. [Google Scholar] [CrossRef]
- Luo, S. Dynamic scheduling for flexible job shop with new job insertions by deep reinforcement learning. Appl. Soft Comput. 2020, 91, 106208. [Google Scholar] [CrossRef]
- Luo, S.; Zhang, L.; Fan, Y. Dynamic multi-objective scheduling for flexible job shop by deep reinforcement learning. Comput. Ind. Eng. 2021, 159, 107489. [Google Scholar] [CrossRef]
- Heger, J.; Voss, T. Dynamically Changing Sequencing Rules with Reinforcement Learning in a Job Shop System with Stochastic Influences. In Proceedings of the 2020 Winter Simulation Conference, Orlando, FL, USA, 14–18 December 2020. [Google Scholar]
- Turgut, Y.; Bozdag, C.E. Deep Q-network Model for Dynamic Job Shop Scheduling Problem Based on Discrete Event Simulation. In Proceedings of the 2020 Winter Simulation Conference, Orlando, FL, USA, 14–18 December 2020. [Google Scholar]
- Chang, J.; Yu, D.; Hu, Y.; He, W.; Yu, H. Deep reinforcement learning for dynamic flexible job shop scheduling with random job arrival. Processes 2022, 10, 760. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347v2. [Google Scholar]
- Lei, K.; Guo, P.; Wang, Y.; Xiong, J.; Zhao, W. An End-to-end Hierarchical Reinforcement Learning Framework for Large-scale Dynamic Flexible Job-shop Scheduling Problem. In Proceedings of the 2022 International Joint Conference on Neural Networks, Padua, Italy, 18–23 July 2022. [Google Scholar]
- Lei, K.; Guo, P.; Wang, Y.; Zhang, J.; Meng, X.; Qian, L. Large-scale dynamic scheduling for flexible job-shop with random arrivals of new jobs by hierarchical reinforcement learning. IEEE Trans. Ind. Inform. 2024, 20, 1007–1018. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhu, H.; Tang, D.; Zhou, T.; Gui, Y. Dynamic job shop scheduling based on deep reinforcement learning for multi-agent manufacturing systems. Robot. Comput. Integr. Manuf. 2022, 78, 102412. [Google Scholar] [CrossRef]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef] [PubMed]
- Kim, B.H.; Ye, J.C. Understanding graph isomorphism network for rs-fMRI functional connectivity analysis. Front. Neurosci. 2020, 14, 630. [Google Scholar] [CrossRef] [PubMed]
- A Job-Shop Scheduling Problem (JSSP) Solver Based on Reinforcement Learning. Available online: https://github.com/jolibrain/wheatley (accessed on 18 December 2023).
- Humphrey, E.J.; Bello, J.P.; Lecun, Y. Moving Beyond Feature Design: Deep Architectures and Automatic Feature Learning in Music Informatics. In Proceedings of the 13th International Society for Music Information Retrieval Conference, Porto, Portugal, 8–12 October 2012. [Google Scholar]
- Duan, L.; Zhan, Y.; Hu, H.; Gong, Y.; Wei, J.; Zhang, X.; Xu, Y. (Efficiently Solving the Practical Vehicle Routing Problem: A Novel Joint Learning Approach. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, San Diego, CA, USA, 6–10 July 2020. [Google Scholar]
- Tang, C.Y.; Liu, C.H.; Chen, W.K.; You, S.D. Implementing action mask in proximal policy optimization (PPO) Algorithm. ICT Express 2020, 6, 200–203. [Google Scholar] [CrossRef]
- OR-Tools. Available online: https://developers.google.com/optimization (accessed on 18 December 2023).
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}