
Reimagining Literary Analysis: Utilizing Artificial Intelligence to Classify Modernist French Poetry

Abstract
1. Introduction
- Innovative AI in Literary Research: This study introduces AI, particularly SVM and advanced feature extraction like TF-IDF and Doc2Vec, into modern French poetry analysis. This approach not only brings new analytical tools to literary research but also enriches education and cross-cultural understanding.
- Enhancing Literary Comprehension: Our work advances literary understanding through AI, dissecting stylistic elements of modern French poetry. This enriches educational methodologies and opens new avenues for cross-cultural studies, deepening the appreciation of literary diversity.
- Technical Enrichment: We focus on efficient SVM deployment and diverse feature extraction methods, ensuring data integrity for machine learning classification. Our research employs various classifiers, enhancing the accuracy and applicability of AI in a literary analysis.
2. Related Works
2.1. Challenges of Text Classification in Poetry
2.2. Categorizing Existing Works Based on Approaches and Contributions
2.3. Critically Evaluating Strengths and Weaknesses of Each Work
2.4. Beyond Boundaries: Recent AI Advancements Illuminate Modernist French Poetry Analysis
2.5. Positioning the Present Work within the Broader Context
3. Methodology
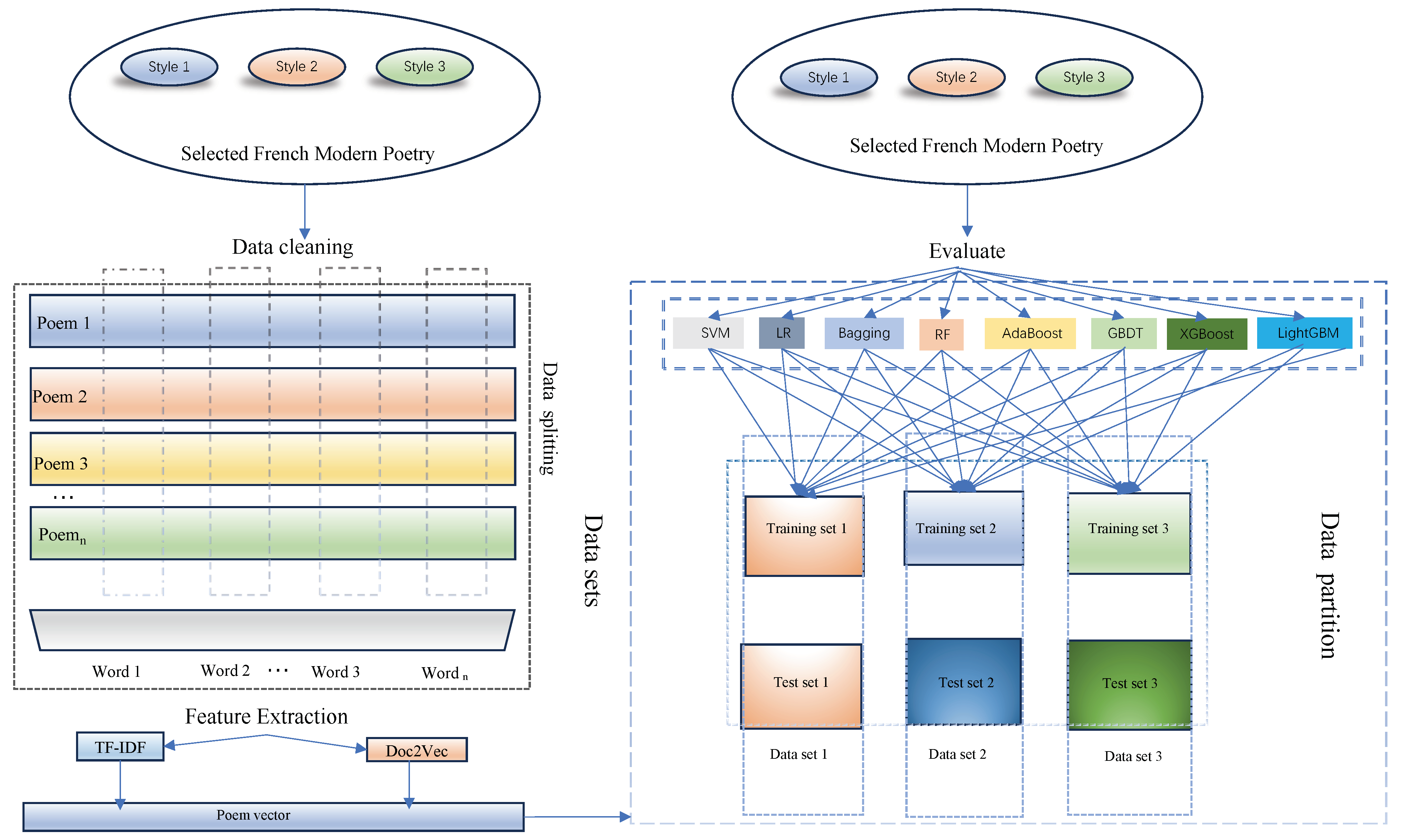
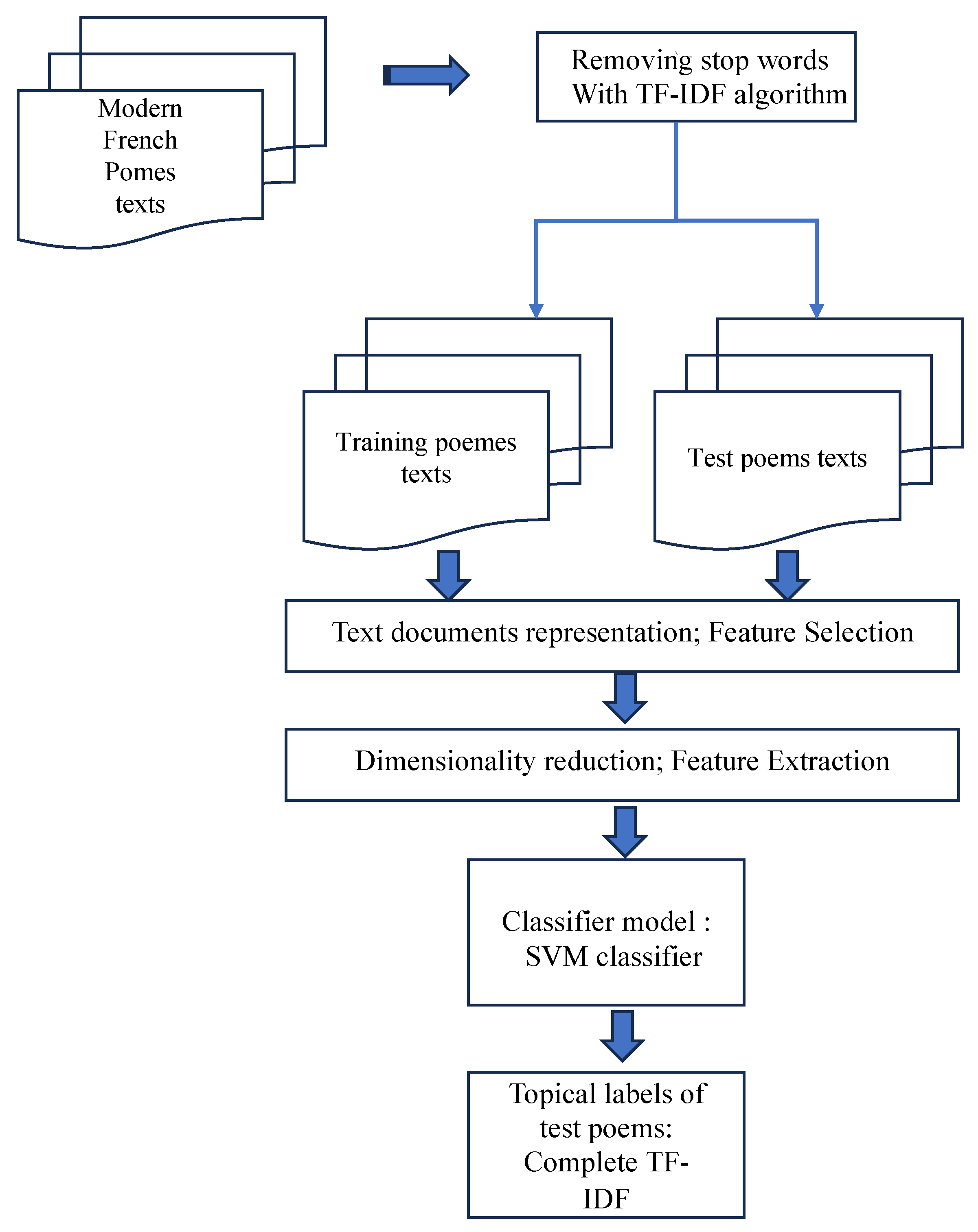
3.1. Text Preprocessing for Categorization
3.1.1. Text Processing and Vector Construction
3.1.2. Text Preprocessing: Laying the Foundation
- Normalization: Normalization ensures uniformity in the text representation by converting all characters to lowercase, eliminating punctuation marks and special characters, and handling inconsistencies in whitespace and encoding. This standardization helps in reducing the vocabulary size and unifying the text representation, making it easier for machine learning algorithms to process and analyze.
- Tokenization: Tokenization breaks down the text into individual tokens, which can be words, phrases, punctuation marks, or any other meaningful units of language. This step is essential for identifying and extracting relevant features from the text. The choice of tokenization strategy depends on the specific task and language, and in the context of poetry classification, it is crucial to consider the unique characteristics of poetic language, such as wordplay, neologisms, and unconventional syntax.
- Stop Word Removal: Stop words are common words that carry little or no meaning in a given context, such as “le”, “un”, “une”, and “à”. Removing stop words can reduce the dimensionality of the vector space and improve classification performance by eliminating noise and focusing on more meaningful terms. However, the decision of whether or not to remove stop words requires careful consideration, as some stop words may carry contextual significance in poetry, especially in cases where they contribute to the rhythm, rhyme, or overall structure of the poem.
3.2. Feature Extraction Methods: TF-IDF and Doc2Vec
3.2.1. TF-IDF
- Term Frequency (TF): This quantifies the frequency of a term within a document, signifying its role in encapsulating the document’s essence. A term’s elevated TF value denotes its recurrent presence, suggesting its pertinence to the theme or genre of the document.
- Inverse Document Frequency (IDF): This assesses a term’s rarity across a document collection, granting higher significance to rarer terms. This methodology accentuates the value of distinctive terms that contribute to differentiating documents.
- Lemmatization and Stemming: Preserving Linguistic Integrity: Lemmatization and stemming are essential in maintaining the integrity of poetic language for classification. Lemmatization is particularly valuable in poetry for preserving grammatical structure and meaning, while stemming reduces words to their root forms. The choice between these methods hinges on balancing grammatical accuracy with computational simplicity.
- Balancing Simplicity and Effectiveness: Striking the Right Chord: This involves finding a balance in text processing techniques for poetry classification. The combination of TF-IDF vectorization, Doc2Vec, and lemmatization optimizes this balance, capturing essential linguistic features while preserving the unique characteristics of poetry. This balance is crucial for maintaining the richness of poetic language without oversimplification, ensuring effective classification through machine learning.
- Enhancing Poetic Language Analysis in Machine Learning-Driven Classification: The future of poetry classification in AI hinges on addressing challenges like subjective language and poetic diversity. The research should focus on developing methods to handle these complexities, incorporating comprehensive poetic knowledge, and leveraging advancements in NLP and machine learning. This will foster a deeper understanding and appreciation of poetic language, which contributes significantly to the field’s advancement.
3.2.2. Doc2Vec
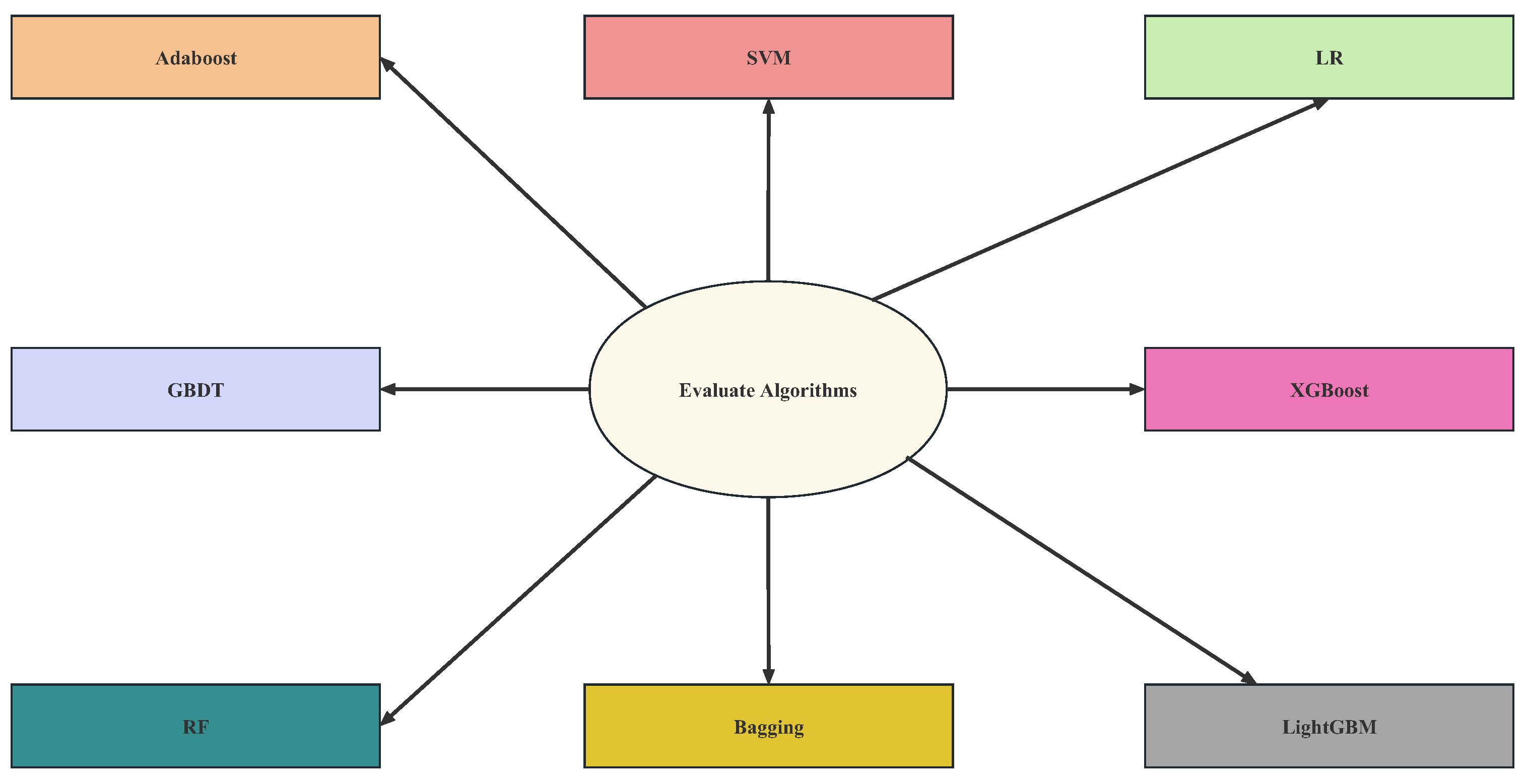
3.3. Comparison of Classification Algorithms
3.4. Significance of Automated Poetry Classification
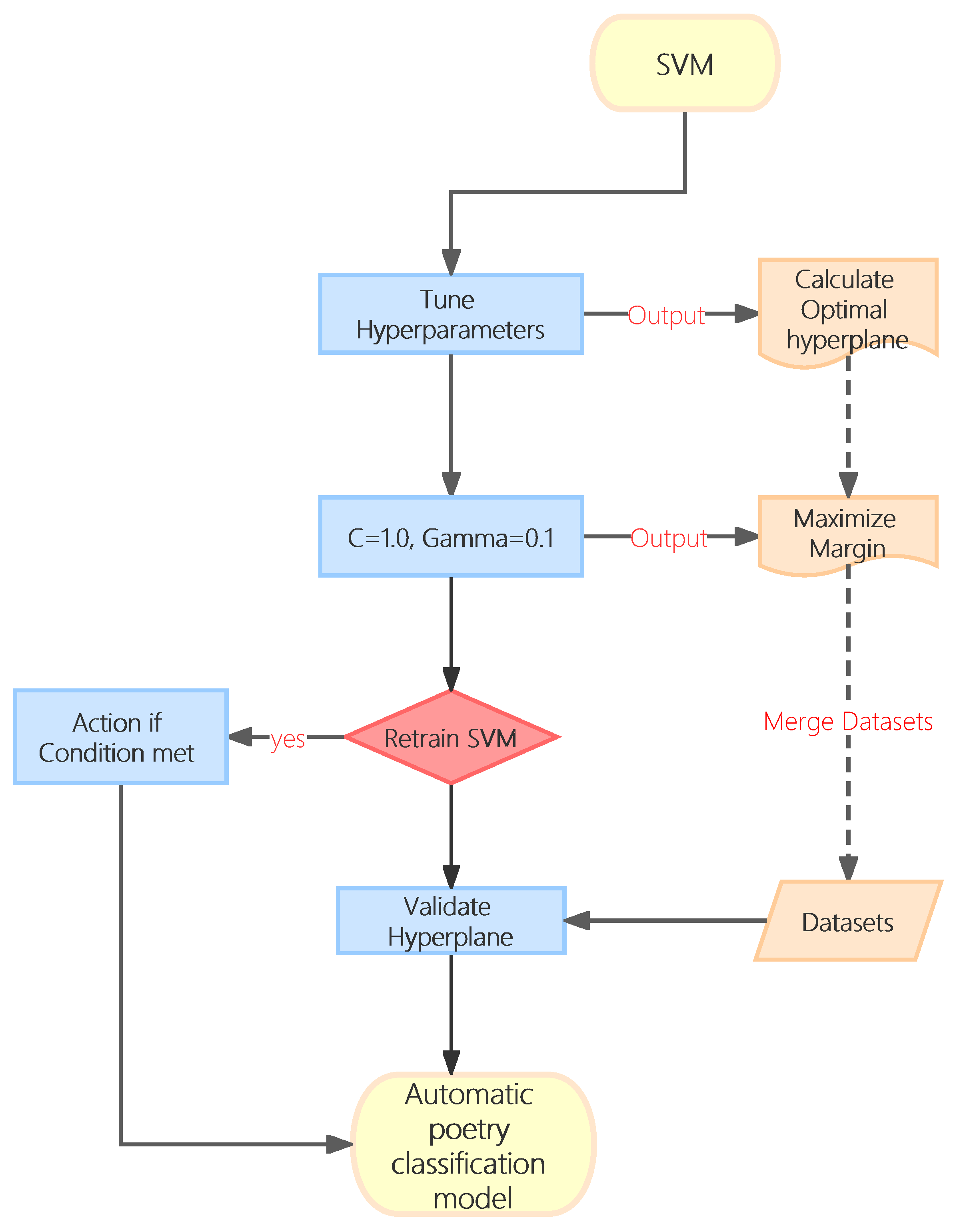
3.5. Pseudo Code for AI-Driven Poetry Classification Model
| Algorithm 1 AI-Based Poetry Classification Algorithm |
 |
4. Experiment
4.1. Source and Background of Dataset
4.2. Training and Test Sets
4.3. Training and Testing Design
4.4. Hyperparameter Optimization for Classifiers
- SVM: Adapted for high-dimensional poetry data, with rbf kernel. Parameters: , penalty = ’l2’, max_iter = 1000.
- LR: Applied for probabilistic categorization. Parameters: penalty = ’l2’, , max_iter = 1000, solver = ’lbfgs’.
- Bagging: To capture stylistic nuances. Parameters: n_estimators = 60, max_samples = 1.0.
- RF: Ensemble method suitable for diverse poetry styles. Parameters: n_estimators = 10, criterion = ’gini’, max_features = ’sqrt’.
- AdaBoost: For iterative correction and detection of stylistic elements. Parameters: n_estimators = 50.
- GBDT: Iterative model capturing stylistic intricacies. Parameters: n_estimators = 100, max_depth = 3.
- XGBoost: Efficient for sparse stylistic data. Parameters: max_depth = 6, n_estimators = 100.
- LightGBM: Effective in capturing hierarchical poetic styles. Parameters: num_leaves = 31, n_estimators = 250.
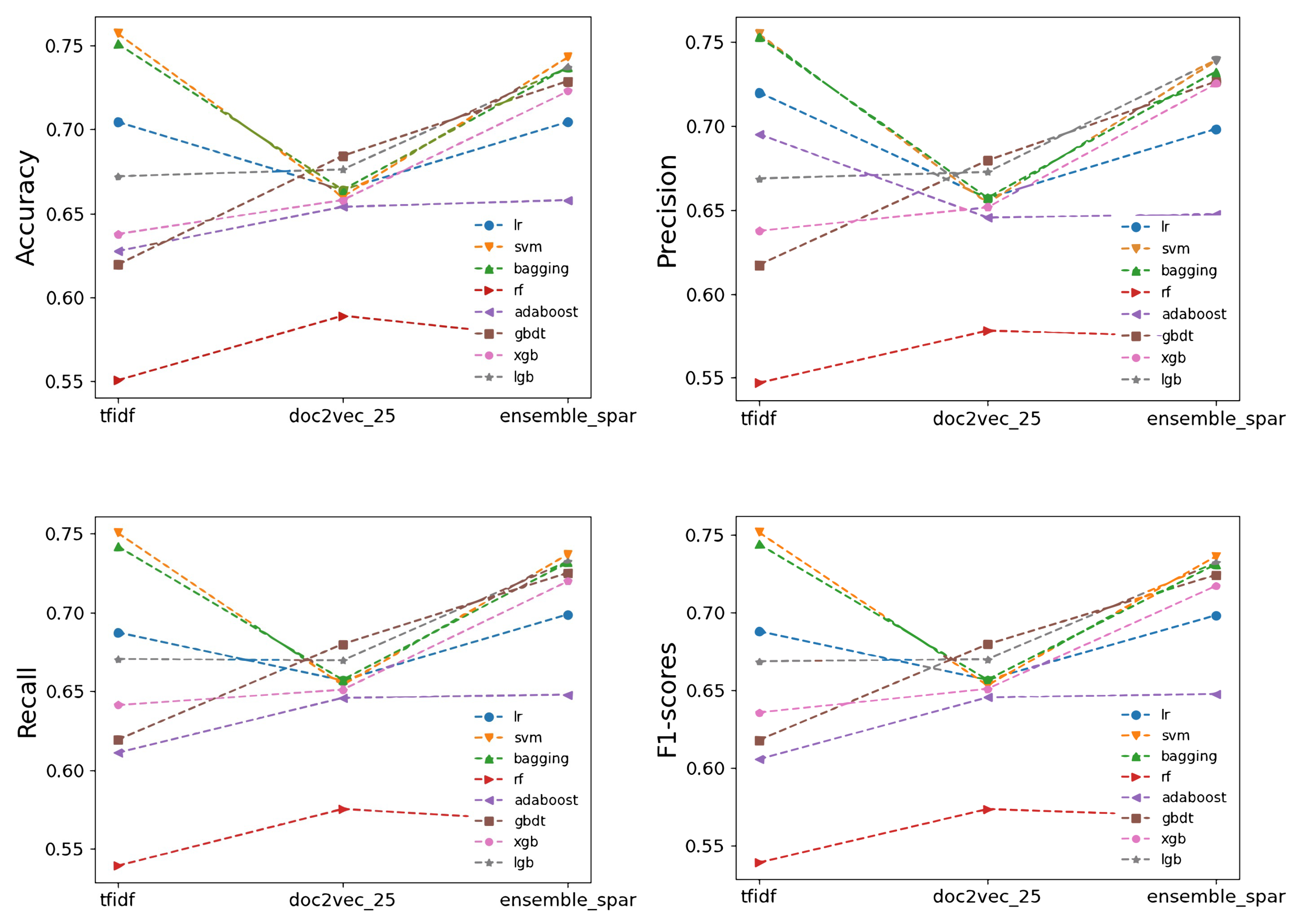
4.5. Analysis of the Results
4.5.1. Performance Using TF-IDF Features
4.5.2. Performance Using Doc2Vec Features
4.5.3. Ensemble Technique
5. Discussion
5.1. In-Depth Comparative Analysis of AI-Driven Poetry Classification Model
5.2. Summary of Findings and Future Directions
- The SVM-based model effectively classified poetry with an accuracy of 0.743, demonstrating machine learning’s potential in capturing poetic styles.
- Limitations in current feature representations (TF-IDF and Doc2Vec) were observed. Advanced methods like word embeddings could better capture poetic nuances.
- The dataset’s size limits the model’s ability to generalize. A larger dataset would offer a more robust evaluation of its performance.
- Enhancing generalization across diverse poetic styles requires a more extensive dataset.
- Investigating sophisticated feature representations like latent semantic analysis could improve style discrimination.
- Exploring other machine learning techniques, such as CNNs and RNNs, might capture poetic nuances more effectively.
- Integrating the model into educational platforms demands careful consideration of effectiveness and personalization. Further research should focus on ensuring these technologies augment educational outcomes and democratize learning.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Middleton, P.; Marsh, N. Teaching Modernist Poetry; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar] [CrossRef]
- Camilleri, M.; Camilleri, A. The Sustainable Development Goal on Quality Education. In The Future of the UN Sustainable Development Goals; United Nations: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Gallagher, M. Ethics in the Absence of Reference: Levinas and the (Aesthetic) Value of Diversity. Levinas Stud. 2012, 7, 125–195. [Google Scholar] [CrossRef]
- Röhnert, J. Vom Spleen de Paris zum spleenigen Paris. Z. Für Lit. Und Linguist. 2010, 40, 168–179. [Google Scholar] [CrossRef]
- Sherry, V. The Great War and the Language of Modernism; Oxford University Press: Oxford, UK, 2003. [Google Scholar] [CrossRef]
- Fetzer, G.W. Linguistique et analyse de la poésie: Apports actuels. Contemp. Fr. Francoph. Stud. 2016, 20, 470–477. [Google Scholar] [CrossRef]
- Gardner, W.O. Advertising Tower: Japanese Modernism and Modernity in the 1920s. Comp. Crit. Stud. 2007, 4, 455–459. [Google Scholar] [CrossRef]
- Tanasescu, C.; Paget, B.; Inkpen, D. Automatic Classification of Poetry by Meter and Rhyme. In Proceedings of the 29th International Florida Artificial Intelligence Research Society Conference (FLAIRS), Key Largo, FL, USA, 16–18 May 2016; pp. 823–828. [Google Scholar]
- Prieto, J.C.S.; Gamazo, A.; Cruz-Benito, J.; Therón, R.; García-Peñalvo, F. AI-Driven Assessment of Students: Current Uses and Research Trends. In Proceedings of the International Conference on Human-Computer Interaction, Virtual, 19–24 July 2020; Springer International Publishing: Cham, Germany, 2020; pp. 292–302. [Google Scholar] [CrossRef]
- Huang, M.H.; Rust, R. Artificial Intelligence in Service. J. Serv. Res. 2018, 21, 155–172. [Google Scholar] [CrossRef]
- Yang, S.J.H.; Ogata, H.; Matsui, T.; Chen, N. Human-centered artificial intelligence in education: Seeing the invisible through the visible. Comput. Educ. Artif. Intell. 2021, 2, 100008. [Google Scholar] [CrossRef]
- Hosseini, M.; Nasrabadi, M.; Mollanoroozy, E.; Khani, F.; Mohammadi, Z.; Barzanoni, F.; Amini, A.; Gholami, A. Relationship of sleep duration and sleep quality with health-related quality of life in patients on hemodialysis in Neyshabur. Sleep Med. 2023, 5, 100064. [Google Scholar] [CrossRef] [PubMed]
- Wei, H.; Geng, H. The Revival of Classical Chinese Poetry Composition: A Perspective from the New Liberal Arts. Int. J. Comp. Lit. Transl. Stud. 2022, 10, 18–22. [Google Scholar] [CrossRef]
- Kempton, H.M.; School of Psychology. Holy be the Lay: A Way to Mindfulness Through Christian Poetry. OBM Integr. Complement. Med. 2021, 7, 011. [Google Scholar] [CrossRef]
- Yusifov, T. Methods of Analysis of Lyrical Texts in Foreign Literature Classes in Higher Educational Institutions (Based on the Works of Nazim Hikmet). Sci. Bull. Mukachevo State Univ. Ser. Pedagogy Psychol. 2022, 8, 81–88. [Google Scholar] [CrossRef]
- Alsharif, O.; Alshamaa, D.; Ghneim, N. Emotion Classification in Arabic Poetry using Machine Learning. Int. J. Comput. Appl. 2013, 65, 10–15. [Google Scholar]
- Ahmed, M.A. A Classification of Al-hur Arabic Poetry and Classical Arabic Poetry by Using Support Vector Machine, Naïve Bayes, and Linear Support Vector Classification. Iraqi J. Comput. Sci. Math. 2022, 3, 128–137. [Google Scholar] [CrossRef]
- Rostampour, S. Word Order of Noun and Verb Phrases in Contemporary Persian and English Poems. J. Adv. Linguist. 2017, 8, 1229–1235. [Google Scholar] [CrossRef]
- Tangirova, D. Variety Of Forms And Genres In Modern Poetry. Am. J. Interdiscip. Innov. Res. 2020, 2, 32–41. [Google Scholar] [CrossRef]
- Dadhich, A.; Thankachan, B. Opinion Classification of Product Reviews Using Naïve Bayes, Logistic Regression and Sentiwordnet: Challenges and Survey. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1099, 012071. [Google Scholar] [CrossRef]
- Puri, S.; Singh, S. Text recognition in bilingual machine printed image documents—Challenges and survey: A review on principal and crucial concerns of text extraction in bilingual printed images. In Proceedings of the 2016 10th International Conference on Intelligent Systems and Control (ISCO), Coimbatore, India, 7–8 January 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Li, Q.; Peng, H.; Li, J.; Xia, C.; Yang, R.; Sun, L.; Yu, P.S.; He, L. A Survey on Text Classification: From Shallow to Deep Learning. arXiv 2020, arXiv:2008.00364. [Google Scholar] [CrossRef]
- Kowsari, K.; Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.E.; Brown, D.E. Text Classification Algorithms: A Survey. Information 2019, 10, 150. [Google Scholar] [CrossRef]
- Li, Z.; Qian, S.; Cao, J.; Fang, Q.; Xu, C. Adaptive Transformer-Based Conditioned Variational Autoencoder for Incomplete Social Event Classification. In Proceedings of the 30th ACM International Conference on Multimedia, New York, NY, USA, 10–14 October 2022. [Google Scholar] [CrossRef]
- Wu, M.; Pan, S.; Zhu, X.; Zhou, C.; Pan, L. Domain-Adversarial Graph Neural Networks for Text Classification. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019. [Google Scholar] [CrossRef]
- Rafeeque, P.C.; Sendhilkumar, S. A survey on Short text analysis in Web. In Proceedings of the 2011 Third International Conference on Advanced Computing, Chennai, India, 14–16 December 2011; pp. 365–371. [Google Scholar] [CrossRef]
- Xia, C.; Yin, W.; Feng, Y.; Yu, P. Incremental Few-shot Text Classification with Multi-round New Classes: Formulation, Dataset and System. arXiv 2021, arXiv:2104.11882. pp. 1351–1360. [Google Scholar] [CrossRef]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent Convolutional Neural Networks for Text Classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2267–2273. [Google Scholar] [CrossRef]
- Wang, P.; Hu, J.; Zeng, H.J.; Chen, Z. Using Wikipedia knowledge to improve text classification. Knowl. Inf. Syst. 2009, 19, 265–281. [Google Scholar] [CrossRef]
- Abel, J.; Lantow, B. A Methodological Framework for Dictionary and Rule-based Text Classification. In Proceedings of the KDIR, Vienna, Austria, 16–18 September 2019; pp. 330–337. [Google Scholar]
- Wang, H.; Hong, M. Supervised Hebb rule based feature selection for text classification. Inf. Process. Manag. 2019, 56, 167–191. [Google Scholar] [CrossRef]
- Hadi, W.; Al-Radaideh, Q.A.; Alhawari, S. Integrating associative rule-based classification with Naïve Bayes for text classification. Appl. Soft Comput. 2018, 69, 344–356. [Google Scholar] [CrossRef]
- Mishra, M.; Vishwakarma, S.K. Text Classification based on Association Rule Mining Technique. Int. J. Comput. Appl. 2017, 169, 46–50. [Google Scholar] [CrossRef]
- Liu, J.; Bai, R.; Lu, Z.; Ge, P.; Aickelin, U.; Liu, D. Data-driven regular expressions evolution for medical text classification using genetic programming. In Proceedings of the 2020 IEEE Congress on Evolutionary Computation (CEC), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Faguo, Z.; Fan, Z.; Bingru, Y.; Xingang, Y. Research on Short Text Classification Algorithm Based on Statistics and Rules. In Proceedings of the 2010 Third International Symposium on Electronic Commerce and Security, Nanchang, China, 29–31 July 2010; pp. 3–7. [Google Scholar] [CrossRef]
- Choi, J.; Kilmer, D.; Mueller-Smith, M.; Taheri, S.A. Hierarchical Approaches to Text-based Offense Classification. Sci. Adv. 2023, 9, eabq8123. [Google Scholar] [CrossRef] [PubMed]
- Elmahdy, A.; Inan, H.A.; Sim, R. Privacy Leakage in Text Classification: A Data Extraction Approach. arXiv 2022, arXiv:2206.04591. [Google Scholar] [CrossRef]
- Guo, Z.; Zhang, R.; Huan, H. Text Classification Method Based on PEGCN. Online Resource. 2024. Available online: https://www.authorea.com/doi/full/10.22541/au.168210369.91223406/v1 (accessed on 14 January 2024).
- Wang, H.; Tian, K.; Wu, Z.; Wang, L. A Short Text Classification Method Based on Convolutional Neural Network and Semantic Extension. Int. J. Comput. Intell. Syst. 2020, 14, 367. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, J.; Zhao, L.; Wang, X. Research on Text Classification Technology Integrating Contrastive Learning and Adversarial Training. In Proceedings of the 2023 IEEE 3rd International Conference on Electronic Technology, Communication and Information (ICETCI), Changchun, China, 26–28 May 2023; pp. 860–865. [Google Scholar]
- Zhang, R.; Guo, Z.; Huan, H. Text Classification Based on an Improved Graph Neural Network. Online Resource. 2022. Available online: https://www.researchsquare.com/article/rs-2385115/v1 (accessed on 21 December 2022).
- Kargupta, P.; Komarlu, T.; Yoon, S.; Wang, X.; Han, J. MEGClass: Extremely Weakly Supervised Text Classification via Mutually-Enhancing Text Granularities. arXiv 2023, arXiv:2304.01969. [Google Scholar] [CrossRef]
- Li, Y.; Li, W. Data Distillation for Text Classification. arXiv 2021, arXiv:2104.08448. [Google Scholar] [CrossRef]
- Shingala, A. Three Phase Synthesizing of Nlp and Text Classification for Query Generation. Int. J. Res. Appl. Sci. Eng. Technol. 2017, 5, 39–42. [Google Scholar] [CrossRef]
- Abdulla, H.H.H.A.; Awad, W.S. Text Classification of English News Articles using Graph Mining Techniques. In Proceedings of the 14th International Conference on Agents and Artificial Intelligence (ICAART 2022), Virtual, 3–5 February 2022; pp. 926–937. [Google Scholar]
- Zhang, S.; Li, H.; Zhang, S. Job opportunity finding by text classification. Procedia Eng. 2012, 29, 1528–1532. [Google Scholar] [CrossRef]
- Liu, X.; Mou, L.; Cui, H.; Lu, Z.; Song, S. Finding decision jumps in text classification. Neurocomputing 2020, 371, 177–187. [Google Scholar] [CrossRef]
- Wang, Y.; Hei, C.; Liu, H.; Zhang, S.; Wang, J. Prognostics of Remaining Useful Life for Lithium-Ion Batteries Based on Hybrid Approach of Linear Pattern Extraction and Nonlinear Relationship Mining. IEEE Trans. Power Electron. 2023, 38, 1054–1063. [Google Scholar] [CrossRef]
- Forman, G. An extensive empirical study of feature selection metrics for text classification. J. Mach. Learn. Res. 2003, 3, 1289–1305. [Google Scholar]
- Ameer, I.; Sidorov, G.; Gómez-Adorno, H.; Nawab, R.M.A. Multi-Label Emotion Classification on Code-Mixed Text: Data and Methods. IEEE Access 2022, 10, 8779–8789. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar] [CrossRef]
- Bilski, J.; Smoląg, J.; Kowalczyk, B.; Grzanek, K.; Izonin, I. Fast Computational Approach to the Levenberg-Marquardt Algorithm for Training Feedforward Neural Networks. J. Artif. Intell. Soft Comput. Res. 2023, 13, 45–61. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Poetry Category | Training Sets | Test Sets |
|---|---|---|
| Romanticism | 453 | 183 |
| Parnasse | 390 | 171 |
| Symbolism | 309 | 140 |
| Feature | Classification | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| tfidf | lr | 0.7045 | 0.7202 | 0.6872 | 0.6879 |
| tfidf | svm | 0.7571 | 0.7549 | 0.7504 | 0.7518 |
| tfidf | bagging | 0.7510 | 0.7533 | 0.7418 | 0.7442 |
| tfidf | rf | 0.5506 | 0.5469 | 0.5391 | 0.5387 |
| tfidf | adaboost | 0.6275 | 0.6952 | 0.6108 | 0.6054 |
| tfidf | gbdt | 0.6194 | 0.6172 | 0.6190 | 0.6177 |
| tfidf | xgb | 0.6377 | 0.6375 | 0.6410 | 0.6355 |
| tfidf | lgb | 0.6721 | 0.6688 | 0.6703 | 0.6685 |
| doc2vec_25 | lr | 0.6640 | 0.6570 | 0.6567 | 0.6566 |
| doc2vec_25 | svm | 0.6599 | 0.6542 | 0.6538 | 0.6531 |
| doc2vec_25 | bagging | 0.6640 | 0.6572 | 0.6571 | 0.6566 |
| doc2vec_25 | rf | 0.5891 | 0.5781 | 0.5752 | 0.5733 |
| doc2vec_25 | adaboost | 0.6538 | 0.6455 | 0.6457 | 0.6453 |
| doc2vec_25 | gbdt | 0.6842 | 0.6795 | 0.6798 | 0.6795 |
| doc2vec_25 | xgb | 0.6579 | 0.6515 | 0.6509 | 0.6508 |
| doc2vec_25 | lgb | 0.6761 | 0.6726 | 0.6694 | 0.6699 |
| ensemble_spar | lr | 0.7045 | 0.6983 | 0.6986 | 0.6982 |
| ensemble_spar | svm | 0.7429 | 0.7389 | 0.7367 | 0.7363 |
| ensemble_spar | bagging | 0.7368 | 0.7326 | 0.7315 | 0.7312 |
| ensemble_spar | rf | 0.5749 | 0.5742 | 0.5669 | 0.5683 |
| ensemble_spar | adaboost | 0.6579 | 0.6475 | 0.6477 | 0.6475 |
| ensemble_spar | gbdt | 0.7287 | 0.7266 | 0.7250 | 0.7242 |
| ensemble_spar | xgb | 0.7227 | 0.7252 | 0.7196 | 0.7172 |
| ensemble_spar | lgb | 0.7368 | 0.7394 | 0.7323 | 0.7322 |
| Classifier | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| LR | ||||
| SVM | ||||
| Bagging | ||||
| RF | ||||
| AdaBoost | ||||
| GBDT | ||||
| XGBoost | ||||
| LightGBM |
| Classifier | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| SVM | 0.7571 | 0.755 | 0.750 | 0.7518 |
| LR | ||||
| Bagging | ||||
| RF | ||||
| AdaBoost | ||||
| GBDT | ||||
| XGBoost | ||||
| LightGBM |
| Classifier | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| GBDT | 0.684 | 0.679 | 0.680 | 0.679 |
| LR | 0.664 | 0.657 | 0.657 | 0.657 |
| Bagging | 0.664 | 0.657 | 0.657 | 0.657 |
| LightGBM | 0.676 | 0.673 | 0.669 | 0.670 |
| SVM | 0.660 | 0.654 | 0.654 | 0.653 |
| XGBoost | 0.658 | 0.652 | 0.651 | 0.651 |
| AdaBoost | 0.654 | 0.645 | 0.646 | 0.645 |
| RF | 0.589 | 0.578 | 0.575 | 0.573 |
| Classifier | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| SVM | ||||
| LightGBM | ||||
| GBDT | ||||
| XGBoost | ||||
| Bagging | ||||
| LR | ||||
| AdaBoost | ||||
| RF |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, L.; Wang, G.; Wang, H. Reimagining Literary Analysis: Utilizing Artificial Intelligence to Classify Modernist French Poetry. Information 2024, 15, 70. https://doi.org/10.3390/info15020070
Yang L, Wang G, Wang H. Reimagining Literary Analysis: Utilizing Artificial Intelligence to Classify Modernist French Poetry. Information. 2024; 15(2):70. https://doi.org/10.3390/info15020070
Chicago/Turabian StyleYang, Liu, Gang Wang, and Hongjun Wang. 2024. "Reimagining Literary Analysis: Utilizing Artificial Intelligence to Classify Modernist French Poetry" Information 15, no. 2: 70. https://doi.org/10.3390/info15020070
APA StyleYang, L., Wang, G., & Wang, H. (2024). Reimagining Literary Analysis: Utilizing Artificial Intelligence to Classify Modernist French Poetry. Information, 15(2), 70. https://doi.org/10.3390/info15020070