
CGFTNet: Content-Guided Frequency Domain Transform Network for Face Super-Resolution


Abstract
1. Introduction
- We introduce the FDRFEM, which includes a frequency domain transformation branch and reparameterized focus convolution. This module enhances feature detail while preserving global structures.
- We present a novel module CGCAF that dynamically integrates rich features from both the encoder and decoder, facilitating the reconstruction of high-quality images.
- We develop the CGFTNet, a synergistic CNN-transformer network that achieves competitive performance on various FSR metrics.
2. Related Work
2.1. Super Resolution
2.2. Face Super Resolution
2.3. Face Super Resolution Under Specific Conditions
2.4. Transformer
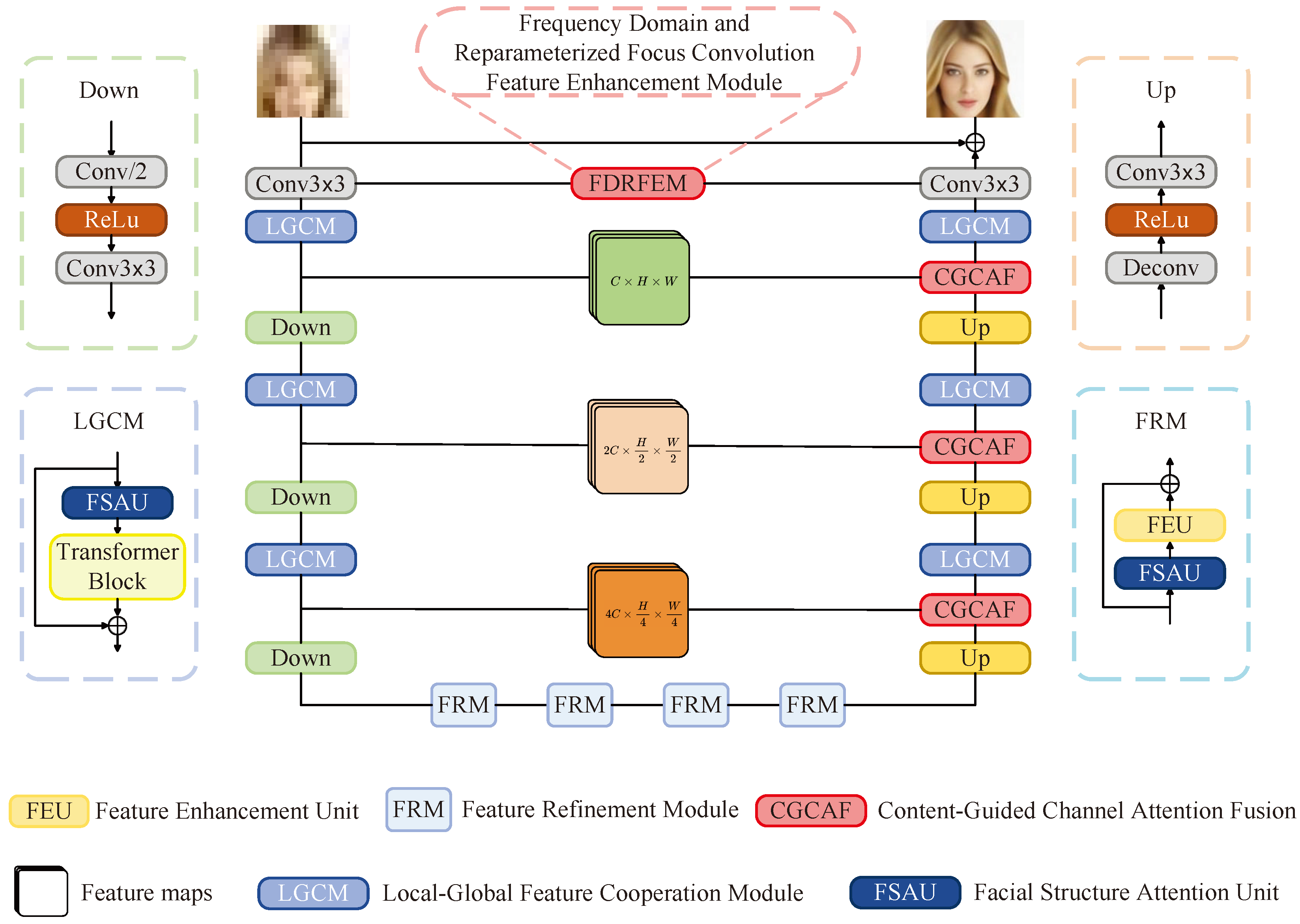
3. Architectural Details
3.1. Overview of CGFTNet
- (1)
- Encoding Stage: As outlined earlier, our objective in the feature extraction phase is to capture the inherent structure of the image. Beginning with a low-resolution input image , we initially employ a convolutional kernel for basic feature extraction. These features are then processed through three consecutive stages of feature extraction. Each stage incorporates a Local-Global Coherence module (LGCM), which consists of a facial structure awareness unit (FSAU) and a transformer unit. For more details about LGCM, FSAU, and FRM, please refer to [8]. Following this, the features are subjected to a downsampling process, involving a convolutional layer with a stride of 2 designed to reduce the dimensions of the feature maps while retaining essential information. This is coupled with a LeakyReLU activation function and another convolutional layer. As a result, each feature extraction stage halves the size of the output feature maps and doubles the channel count. For example, given an initial feature map , then at the feature extraction stage, the encoder will produce a feature map: .
- (2)
- Bottleneck: Situated between the feature extraction and reconstruction phases is a critical bottleneck stage. In this stage, all features accumulated during the encoding process are consolidated. To ensure these features are effectively leveraged in the subsequent reconstruction phase, a Feature Refinement module (FRM) is employed. The FRM is designed to optimize and amplify the encoded features, enhancing the delineation of facial structure details. The intervention of the FRM allows for a more focused processing of facial features, thereby enhancing information expression across different facial regions.
- (3)
- Decoding Stage: The objective of the decoding stage is to restore high-quality facial images. We introduce an innovative module, CGCAF. The decoder receives deep features from the low-resolution image and integrates these features progressively via the CGCAF to construct a super-resolution image. As illustrated in Figure 1, the decoder comprises an upsampling module, the CGCAF, and the Local-Global Coherence module (LGCM). The upsampling module includes a transposed convolution layer with a stride of 2, followed by a LeakyReLU activation function and a convolution layer. This transposed convolution layer expands the feature map dimensions and facilitates information extraction. Consequently, the decoder reduces the number of output feature channels while doubling the feature map dimensions with each step. The CGCAF fuses features extracted during the encoding phase, ensuring comprehensive utilization of both local and global features from the encoding and decoding stages to produce high-quality facial images. The decoding phase culminates with a convolution layer that maps the integrated features to the final super-resolution output .
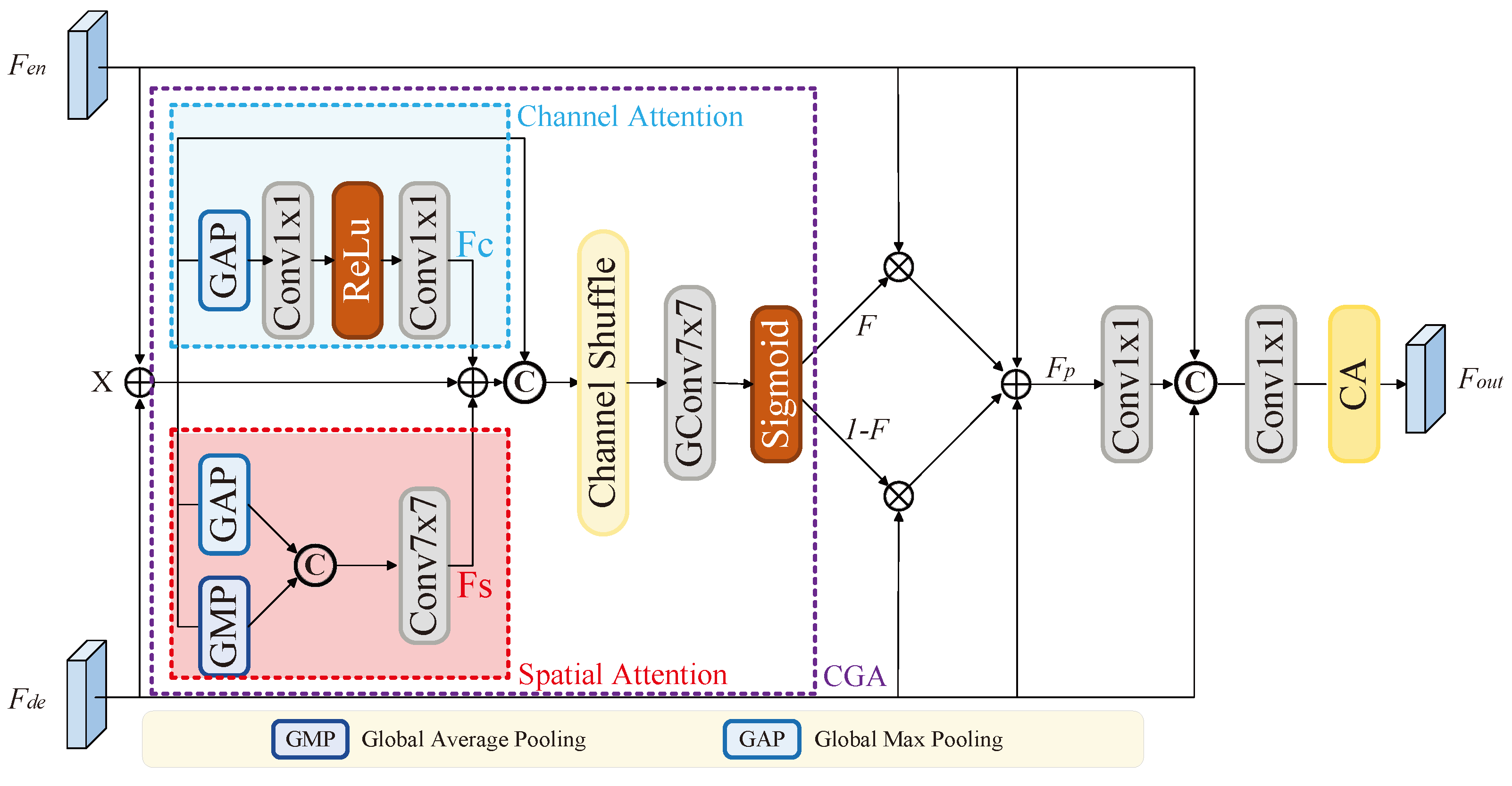
3.2. Content-Guided Channel Attention Fusion
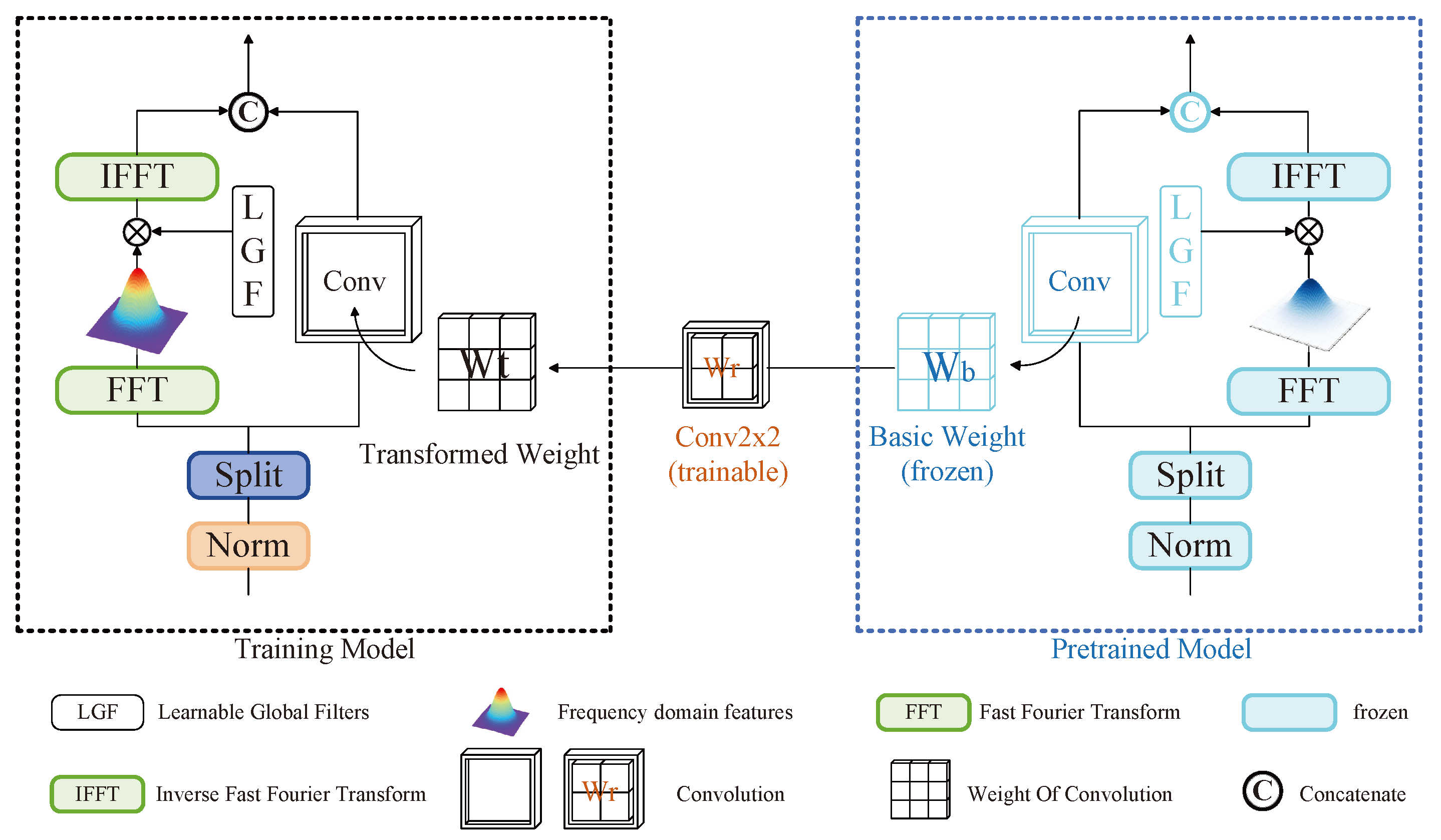
3.3. Focus Convolution Feature Enhancement Module
- (1)
- Frequency-Domain Branch: In the context of FSR, a major challenge lies in effectively extracting key facial features (such as eyes, eyebrows, and mouth) while simultaneously guiding the network to focus on these features. To address this, we leverage Fourier transform to enable the model to extract critical information for improved detail recovery. As depicted in Figure 4, the frequency-domain branch first transforms the input features into the frequency domain via a 2D real-valued fast Fourier transform (FFT). In the frequency domain, the feature maps are modulated by a set of learnable complex filters, which selectively adjust the frequency components of the feature maps, enhancing or suppressing specific frequencies. This process allows the model to capture the global frequency characteristics of the input data. Subsequently, an inverse fast Fourier transform (iFFT) is applied to convert the features back into the spatial domain, allowing the model to exploit these frequency-enhanced feature maps for improved performance.
- (2)
- Reparameterized Focused Convolution: As mentioned earlier, the frequency-domain branch simulates a convolution operation in the spatial domain, utilizing kernels of global size and circular padding, thereby capturing spatial information across the entire feature map and facilitating the modeling of long-range dependencies. The reparameterized focused convolution is designed to capture local information and enhance the model’s representational capacity through reparameterization without incurring additional inference costs. For a pre-trained model, RefConv applies a learnable refocusing transformation to the base convolution kernels inherited from the pre-trained model, establishing parameter correlations. For instance, in depth-wise convolution, RefConv allows the convolution kernel parameters of one channel to be linked with those of other channels, enabling a broader refocus beyond the input features alone. In the case of depth-wise convolution, RefConv utilizes the pre-trained convolution kernel as a base weight and applies the refocusing transformation to generate new convolution kernels. This transformation incorporates trainable refocusing weights that are combined with the base weights to produce transformed weights for processing the input features. The objective of the refocusing transformation is to learn incremental adjustments to the base weights, analogous to residual learning, where residual blocks capture incremental changes to the base feature maps. In doing so, RefConv enables each convolution channel to establish connections with other channels, facilitating the learning of novel feature representations.
4. Experiment
4.1. Datasets
4.2. Implementation Details
4.3. Ablation Studies
- (1)
- Effectiveness of FDRFEM: The FDRFEM is a key component of CGFTNet, designed to achieve global spatial interactions. To evaluate the effectiveness of FDRFEM and the feasibility of this integration, we conducted a set of ablation studies. FDRFEM comprises a frequency-domain branch and a reparameterized focused convolution. Thus, we designed three modified models for comparison. The first model removes all FDRFEM from the encoder and decoder, labeled as “w/o FDRFEM”. The second model removes all frequency-domain branches while retaining the reparameterized focused convolutions, labeled as “FDRFEM w/o Fourier”. The third model removes all reparameterized focused convolutions while keeping the frequency-domain branches in FDRFEM, labeled as “FDRFEM w/o Refconv”. The results of these modified networks are shown in Table 1. Based on these results, we can draw the following observations:
- (a)
- By comparing the first and last rows of Table 1, we observe that the introduction of FDRFEM significantly improves model performance, confirming its effectiveness.
- (b)
- Comparing the first three rows, it becomes clear that either the frequency-domain branch or the reparameterized focused convolution independently improves model performance, as both global relationships and local features contribute to image reconstruction.
- (c)
- The comparison of the last three rows further demonstrates that both the frequency-domain branch and reparameterized focused convolution serve distinct roles in the FSR task. The frequency-domain branch helps the network capture long-range dependencies, while the reparameterized focused convolution captures local details, providing complementary information for the final SR image reconstruction. Relying on only one of these components leads to suboptimal performance, further validating the effectiveness of FDRFEM and the viability of combining CNN and transformer architectures.
- (2)
- Effectiveness of CGCAF: The CGCAF module is specifically designed for feature fusion between the encoding and decoding stages. In this section, we conduct a series of experiments to demonstrate the efficacy of this connection. The first two experiments verify the necessity of content-guided attention (CGA), which refers to the part of the CGCAF module that precedes the acquisition of the feature map, as shown in the Figure 2. The third and fourth experiments retain CGA but apply only concatenation or addition operations for feature fusion. The fifth and sixth experiments explore the necessity of the final channel attention mechanism. The last two experiments, where neither CGA nor channel attention is used, serve as baselines. Each set of experiments includes a comparison between the Concat and Add operations to explain our final choice of Concat. From the results in Table 2, we can observe the following:
- (a)
- Employing feature fusion strategies between the encoding and decoding stages can significantly impact model performance, which underscores the importance of investigating strategies that leverage encoding-stage features during decoding for image reconstruction.
- (b)
- By comparing the third row with the fifth, we can find that the channel attention (CA) mechanism also positively impacts model performance.
- (c)
- By comparing the third row with the others, we can observe that the combination of the Concat operation and CA yields the best results.
- (d)
- By comparing each pair of experiments that includes CGA with those that do not, such as the first row with the third row, the second row with the fourth row, we can observe that models incorporating CGA demonstrate superior performance metrics compared to those without.
- (3)
- Effectiveness of two key modules: Based on the results presented in the Table 3, several observations can be made. We adopt CTCNet [8] as our baseline model. The term “Threelines” refers to a pruned variant of CTCNet, wherein the number of feature lines interconnecting the encoder and decoder has been reduced, retaining only three lines. Comparing the first and second rows, it is evident that the pruned model performs better than the baseline. The comparison between the second and third rows indicates that introducing the FDRFEM module alone improves the model’s performance. Analyzing the last four rows shows that simultaneously incorporating both FDRFEM and CGCAF yields higher performance than introducing each module individually.
4.4. Comparison with Other Methods
- (1)
- Comparison on the CelebA: Quantitative comparisons on the CelebA test set with other SOTA methods are presented in Table 4. The results clearly demonstrate that CGFTNet outperforms competing methods in terms of PSNR, VIP, LPIPS, and SSIM. These findings highlight the superior performance and effectiveness of CGFTNet. Additionally, as shown in the visual comparisons in Figure 6, most previous methods struggle to accurately restore facial features, such as the eyes and nose, whereas our CGFTNet reconstructs facial structures with greater precision, producing results that more closely resemble the original high-resolution (HR) images. This further substantiates the advantages of CGFTNet in facial restoration tasks.
- (2)
- Comparison on the Helen dataset: To assess the generalization capability of CGFTNet, we directly tested the model, trained on the CelebA, on the Helen test set. The quantitative results for ×8 SR experiments on the Helen test set are provided in Table 4. As shown in Table 4, CGFTNet consistently achieves the best performance on the Helen dataset as well. Furthermore, the visual comparisons in Figure 7 reveal that the performance of many competing methods significantly degrades on this dataset, failing to accurately restore facial details. In contrast, CGFTNet maintains its ability to recover realistic facial contours and details, further affirming its robustness and generalizability.
- (3)
- Comparison of real-world facial images: Recovering facial images in real-world scenarios remains a formidable challenge. While the previously mentioned experiments were conducted in simulated environments, these settings do not fully capture the complexity of real-world conditions. To further validate the effectiveness of CGFTNet, we performed experiments on low-quality facial images from the WiderFace dataset [37], which were captured in natural scenes, representing real-world diversity and complexity. These images are inherently low-resolution, requiring no additional downsampling. In this context, we aim to recover facial images with finer texture details and well-preserved facial structures. Figure 7 illustrates a visual comparison of the reconstruction performance on real-world images. Thanks to the collaborative CNN-Transformer mechanism and the specifically designed modules of CGFTNet, our method effectively restores cleaner facial details and more accurate facial structures. Furthermore, we evaluated the performance of CGFTNet in downstream tasks, such as facial matching. For this experiment, high-resolution frontal facial images of the candidates were used as source samples, while the corresponding low-resolution facial images from real-world conditions served as target samples. To ensure the robustness of our results, we conducted 8 separate trials, randomly selecting five pairs of candidate samples in each trial and calculating the average similarity. The quantitative results, presented in Table 5, demonstrate that our method consistently achieves higher similarity scores across all trials. This further demonstrates that CGFTNet can generate more realistic high-resolution facial images in real-world surveillance applications, showcasing its high practicality and adaptability.
4.5. Model Complexity Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dogan, B.; Gu, S.; Timofte, R. Exemplar Guided Face Image Super-Resolution Without Facial Landmarks. In Proceedings of the IEEE CVPR, Long Beach, CA, USA, 16–20 June 2019; pp. 1814–1823. [Google Scholar]
- Jiang, J.; Yu, Y.; Hu, J.; Tang, S.; Ma, J. Deep CNN Denoiser and Multi-layer Neighbor Component Embedding for Face Hallucination. In Proceedings of the IJCAI 2018, Stockholm, Sweden, 13–19 July 2018; pp. 771–778. [Google Scholar]
- Grm, K.; Scheirer, W.J.; Struc, V. Face Hallucination Using Cascaded Super-Resolution and Identity Priors. IEEE Trans. Image Process. 2020, 29, 2150–2165. [Google Scholar] [CrossRef] [PubMed]
- Yu, X.; Fernando, B.; Ghanem, B.; Porikli, F.; Hartley, R. Face Super-Resolution Guided by Facial Component Heatmaps. In Proceedings of the Computer Vision—ECCV 2018—15th European Conference, Munich, Germany, 8–14 September 2018; Proceedings, Part IX; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2018; Volume 11213, pp. 219–235. [Google Scholar]
- Bulat, A.; Tzimiropoulos, G. Super-FAN: Integrated Facial Landmark Localization and Super-Resolution of Real-World Low Resolution Faces in Arbitrary Poses with GANs. In Proceedings of the IEEE CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 109–117. [Google Scholar]
- Bao, Q.; Liu, Y.; Gang, B.; Yang, W.; Liao, Q. SCTANet: A spatial attention-guided CNN-transformer aggregation network for deep face image super-resolution. IEEE Trans. Multimed. 2023, 25, 8554–8565. [Google Scholar] [CrossRef]
- Qi, H.; Qiu, Y.; Luo, X.; Jin, Z. An Efficient Latent Style Guided Transformer-CNN Framework for Face Super-Resolution. IEEE Trans. Multimed. 2024, 26, 1589–1599. [Google Scholar] [CrossRef]
- Gao, G.; Xu, Z.; Li, J.; Yang, J.; Zeng, T.; Qi, G. CTCNet: A CNN-Transformer Cooperation Network for Face Image Super-Resolution. IEEE Trans. Image Process. 2023, 32, 1978–1991. [Google Scholar] [CrossRef] [PubMed]
- Shi, J.; Wang, Y.; Yu, Z.; Li, G.; Hong, X.; Wang, F.; Gong, Y. Exploiting Multi-Scale Parallel Self-Attention and Local Variation via Dual-Branch Transformer-CNN Structure for Face Super-Resolution. IEEE Trans. Multimed. 2024, 26, 2608–2620. [Google Scholar] [CrossRef]
- Srivastava, A.; Chanda, S.; Pal, U. Aga-gan: Attribute guided attention generative adversarial network with u-net for face hallucination. Image Vis. Comput. 2022, 126, 104534. [Google Scholar] [CrossRef]
- Li, W.; Guo, H.; Liu, X.; Liang, K.; Hu, J.; Ma, Z.; Guo, J. Efficient Face Super-Resolution via Wavelet-based Feature Enhancement Network. arXiv 2024, arXiv:2407.19768. [Google Scholar]
- Peng, Q.; Jiang, Z.; Huang, Y.; Peng, J. A Unified Framework to Super-Resolve Face Images of Varied Low Resolutions. arXiv 2023, arXiv:2306.03380. [Google Scholar]
- Wang, Z.; Chen, J.; Hoi, S.C.H. Deep Learning for Image Super-Resolution: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3365–3387. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Pei, Z.; Zeng, T. From Beginner to Master: A Survey for Deep Learning-based Single-Image Super-Resolution. arXiv 2021, arXiv:2109.14335. [Google Scholar]
- Gao, G.; Wang, Z.; Li, J.; Li, W.; Yu, Y.; Zeng, T. Lightweight Bimodal Network for Single-Image Super-Resolution via Symmetric CNN and Recursive Transformer. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI, Vienna, Austria, 23–29 July 2022; pp. 913–919. [Google Scholar]
- Li, J.; Fang, F.; Mei, K.; Zhang, G. Multi-scale Residual Network for Image Super-Resolution. In Proceedings of the ECCV 15th European Conference, Munich, Germany, 8–14 September 2018; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2018; Volume 11212, pp. 527–542. [Google Scholar]
- Wang, H.; Cheng, S.; Li, Y.; Du, A. Lightweight Remote-Sensing Image Super-Resolution via Attention-Based Multilevel Feature Fusion Network. IEEE Trans. Geosci. Remote Sens. 2023, 61, 2005715. [Google Scholar]
- Guo, Y.; Chen, J.; Wang, J.; Chen, Q.; Cao, J.; Deng, Z.; Xu, Y.; Tan, M. Closed-Loop Matters: Dual Regression Networks for Single Image Super-Resolution. In Proceedings of the IEEE/CVF CVPR, Seattle, WA, USA, 13–19 June 2020; pp. 5406–5415. [Google Scholar]
- Zhang, X.; Gao, P.; Liu, S.; Zhao, K.; Li, G.; Yin, L.; Chen, C.W. Accurate and Efficient Image Super-Resolution via Global-Local Adjusting Dense Network. IEEE Trans. Multimed. 2021, 23, 1924–1937. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Z.; Cheng, C.; Hsu, W.H.; Qiao, Y.; Liu, W.; Zhang, T. Super-Identity Convolutional Neural Network for Face Hallucination. In Proceedings of the ECCV 15th European Conference, Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11215, pp. 196–211. [Google Scholar]
- Chen, Y.; Tai, Y.; Liu, X.; Shen, C.; Yang, J. FSRNet: End-to-End Learning Face Super-Resolution With Facial Priors. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2492–2501. [Google Scholar]
- Kim, D.; Kim, M.; Kwon, G.; Kim, D. Progressive Face Super-Resolution via Attention to Facial Landmark. In Proceedings of the 30th British Machine Vision Conference, BMVC, Cardiff, UK, 9–12 September 2019; p. 192. [Google Scholar]
- Cheng, S.; Chan, R.; Du, A. CACFTNet: A Hybrid Cov-Attention and Cross-Layer Fusion Transformer Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–17. [Google Scholar] [CrossRef]
- Rai, D.; Rajput, S.S. Low-light robust face image super-resolution via neuro-fuzzy inferencing-based locality constrained representation. IEEE Trans. Instrum. Meas. 2023, 72, 5015911. [Google Scholar] [CrossRef]
- Yin, Z.; Liu, M.; Li, X.; Yang, H.; Xiao, L.; Zuo, W. MetaF2N: Blind Image Super-Resolution by Learning Efficient Model Adaptation from Faces. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 12987–12998. [Google Scholar]
- Zhang, H.; Cheng, S.; Du, A. Multi-Stage Auxiliary Learning for Visible-Infrared Person Re-identification. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 12032–12047. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Le, V.; Brandt, J.; Lin, Z.; Bourdev, L.D.; Huang, T.S. Interactive Facial Feature Localization. In Proceedings of the ECCV 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Proceedings, Part III. Springer: Berlin/Heidelberg, Germany, 2012; Volume 7574, pp. 679–692. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 586–595. [Google Scholar]
- Sheikh, H.R.; Bovik, A.C. Image information and visual quality. IEEE Trans. Image Process. 2006, 15, 430–444. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Gong, D.; Wang, H.; Li, Z.; Wong, K.K. Learning Spatial Attention for Face Super-Resolution. IEEE Trans. Image Process. 2021, 30, 1219–1231. [Google Scholar] [CrossRef] [PubMed]
- Lu, T.; Wang, Y.; Zhang, Y.; Wang, Y.; Wei, L.; Wang, Z.; Jiang, J. Face hallucination via split-attention in split-attention network. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 5501–5509. [Google Scholar]
- Hou, H.; Xu, J.; Hou, Y.; Hu, X.; Wei, B.; Shen, D. Semi-cycled generative adversarial networks for real-world face super-resolution. IEEE Trans. Image Process. 2023, 32, 1184–1199. [Google Scholar]
- Wang, C.; Jiang, J.; Zhong, Z.; Liu, X. Spatial-Frequency Mutual Learning for Face Super-Resolution. In Proceedings of the IEEE/CVF CVPR, Vancouver, BC, Canada, 17–24 June 2023; pp. 22356–22366. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Gool, L.V.; Timofte, R. SwinIR: Image Restoration Using Swin Transformer. In Proceedings of the IEEE/CVF ICCVW 2021, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Yang, S.; Luo, P.; Loy, C.C.; Tang, X. WIDER FACE: A Face Detection Benchmark. In Proceedings of the CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 5525–5533. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | PSNR | SSIM | VIF | LPIPS |
|---|---|---|---|---|
| w/o FDRFEM | 28.062 | 0.8049 | 0.5364 | 0.1514 |
| FDRFEM w/o Fourier | 28.065 | 0.8067 | 0.5363 | 0.1487 |
| FDRFEM w/o Refconv | 28.120 | 0.8071 | 0.5369 | 0.1513 |
| FDRFEM | 28.125 | 0.8059 | 0.5374 | 0.1481 |
| CGA | Concat | Add | CA | PSNR | SSIM |
|---|---|---|---|---|---|
| × | ✓ | × | ✓ | 28.125 | 0.8059 |
| × | × | ✓ | ✓ | 27.991 | 0.8039 |
| ✓ | ✓ | × | ✓ | 28.161 | 0.8075 |
| ✓ | × | ✓ | ✓ | 28.159 | 0.8074 |
| ✓ | ✓ | × | × | 28.153 | 0.8069 |
| ✓ | × | ✓ | × | 28.047 | 0.8047 |
| × | ✓ | × | × | 28.121 | 0.8050 |
| × | × | ✓ | × | 27.977 | 0.8028 |
| Baseline | Threelines | FDRFEM | CGCAF | PSNR | SSIM |
|---|---|---|---|---|---|
| ✓ | × | × | × | 27.990 | 0.8036 |
| ✓ | ✓ | × | × | 28.062 | 0.8049 |
| ✓ | ✓ | ✓ | × | 28.125 | 0.8059 |
| ✓ | ✓ | × | ✓ | 28.034 | 0.8039 |
| ✓ | ✓ | ✓ | ✓ | 28.161 | 0.8075 |
| Methods | CelebA | Helen | ||||||
|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | VIF | LPIPS | PSNR | SSIM | VIF | LPIPS | |
| Bicubic | 24.05 | 0.6449 | 0.4019 | 0.5697 | 23.79 | 0.6739 | 0.4353 | 0.5436 |
| SwinIR | 27.88 | 0.7967 | 0.4590 | 0.2001 | 26.53 | 0.7856 | 0.4398 | 0.2644 |
| SISN | 27.91 | 0.7971 | 0.4785 | 0.2005 | 26.64 | 0.7908 | 0.4623 | 0.2571 |
| ELSFace | 28.02 | 0.8018 | 0.5232 | 0.1526 | 26.90 | 0.8013 | 0.4931 | 0.1874 |
| SCGAN | 28.03 | 0.8013 | 0.5236 | 0.1511 | 27.04 | 0.8115 | 0.5056 | 0.1809 |
| SCTANet | 28.03 | 0.8017 | 0.5240 | 0.1520 | 26.85 | 0.8074 | 0.5041 | 0.1911 |
| SFMNet | 28.04 | 0.8024 | 0.5245 | 0.1496 | 27.09 | 0.8094 | 0.4989 | 0.1788 |
| SPARNet | 27.73 | 0.7949 | 0.4505 | 0.1995 | 26.43 | 0.7839 | 0.4262 | 0.2674 |
| CTCNet | 27.99 | 0.8036 | 0.5348 | 0.1559 | 26.96 | 0.8048 | 0.5245 | 0.1797 |
| Ours | 28.16 | 0.8075 | 0.5369 | 0.1455 | 27.18 | 0.8129 | 0.5294 | 0.1748 |
| Methods | Average Similarity | |||||||
|---|---|---|---|---|---|---|---|---|
| Case1 | Case2 | Case3 | Case4 | Case5 | Case6 | Case7 | Case8 | |
| SwinIR | 0.8942 | 0.8980 | 0.9031 | 0.8958 | 0.8958 | 0.9096 | 0.9019 | 0.8827 |
| SISN | 0.8930 | 0.9125 | 0.8960 | 0.9085 | 0.8888 | 0.9041 | 0.9075 | 0.8731 |
| ELSFace | 0.9111 | 0.9196 | 0.8963 | 0.9056 | 0.9084 | 0.9047 | 0.9139 | 0.8940 |
| SCGAN | 0.8984 | 0.8836 | 0.9038 | 0.8979 | 0.8917 | 0.9043 | 0.8911 | 0.8964 |
| SCTANet | 0.8855 | 0.8786 | 0.8699 | 0.8777 | 0.8760 | 0.8775 | 0.8840 | 0.8741 |
| SFMNet | 0.9032 | 0.8996 | 0.9055 | 0.9037 | 0.9051 | 0.8956 | 0.8966 | 0.8887 |
| SPARNet | 0.9076 | 0.9186 | 0.9013 | 0.9007 | 0.9054 | 0.9004 | 0.9080 | 0.9043 |
| CTCNet | 0.9138 | 0.9191 | 0.9108 | 0.9026 | 0.9066 | 0.9018 | 0.9145 | 0.9069 |
| Ours | 0.9278 | 0.9237 | 0.9109 | 0.9184 | 0.9242 | 0.9216 | 0.9202 | 0.9138 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yekeben, Y.; Cheng, S.; Du, A. CGFTNet: Content-Guided Frequency Domain Transform Network for Face Super-Resolution. Information 2024, 15, 765. https://doi.org/10.3390/info15120765
Yekeben Y, Cheng S, Du A. CGFTNet: Content-Guided Frequency Domain Transform Network for Face Super-Resolution. Information. 2024; 15(12):765. https://doi.org/10.3390/info15120765
Chicago/Turabian StyleYekeben, Yeerlan, Shuli Cheng, and Anyu Du. 2024. "CGFTNet: Content-Guided Frequency Domain Transform Network for Face Super-Resolution" Information 15, no. 12: 765. https://doi.org/10.3390/info15120765
APA StyleYekeben, Y., Cheng, S., & Du, A. (2024). CGFTNet: Content-Guided Frequency Domain Transform Network for Face Super-Resolution. Information, 15(12), 765. https://doi.org/10.3390/info15120765