

An Intelligent Approach to Automated Operating Systems Log Analysis for Enhanced Security





Abstract

1. Introduction
- System Administrators: They frequently review system logs to ensure that servers and other infrastructure components are functioning correctly.
- Security Analysts: These professionals analyse logs to identify signs of security breaches or other malicious activities, often as part of a Security Operations Centre (SOC).
- Network Engineers: Network logs are essential for troubleshooting network issues, and network engineers often delve into these logs to diagnose problems.
- DevOps Engineers: In continuous integration and continuous deployment (CI/CD) environments, DevOps engineers review logs to identify issues with deployments and application performance.
- IT Support Teams: When addressing user-reported issues, IT support staff may manually review logs to trace the root cause of a problem.
- Compliance Auditors: They sometimes review logs to ensure that systems comply with various regulations and standards.
- Developers: Developers may perform log analysis during debugging or when analysing the behaviour of their applications in production.
- A novel approach to classify multiple OS logs for self-healing systems using Multinomial Naive Bayes and CountVectorizer.
- An in-depth analysis of the effectiveness of Multinomial Naive Bayes and CountVectorizer on OS logs from real-world systems.
- An evaluation of the proposed approach on a dataset consisting of OS logs from Mac, Linux, Windows, and Android systems.
2. Related Work
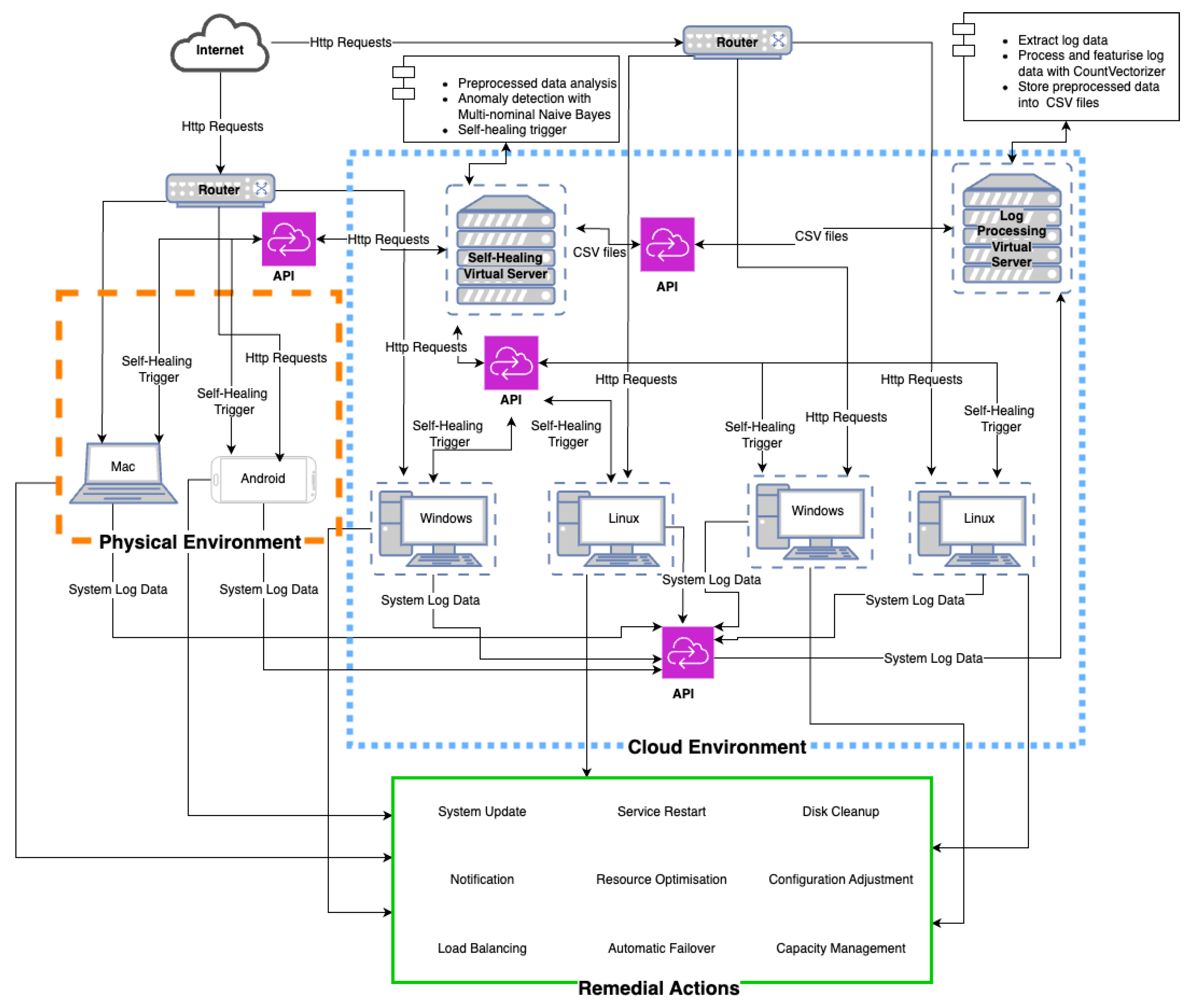
3. Overview of Proposed Method
3.1. Green Box (Remedial Actions)
- System Update: Applying updates to software or firmware to keep systems up to date and secure.
- Service Restart: Restarting services that are experiencing issues or have become unresponsive.
- Disk Clean-up: Removing unnecessary files to free up disk space and improve system performance.
- Notification: Alerting administrators or relevant stakeholders about detected issues to enable timely intervention.
- Resource Optimisation: Adjusting system resources to optimise performance and avoid potential bottlenecks.
- Configuration Adjustment: Modifying system configurations to rectify issues or optimise performance settings.
- Load Balancing: Distributing workloads evenly across servers to prevent overload and ensure efficient resource usage.
- Automatic Failover: Automatically switching to a backup system in the event of a failure, ensuring continuous operation.
- Capacity Management: Managing system resources to ensure there is sufficient capacity for current and future operations.
3.2. Blue-Dotted Box (Cloud Environment)
- Self-Healing Virtual Server: Handles core processing, including anomaly detection and the triggering of self-healing actions based on the analysed log data.
- Log Processing Virtual Server: Responsible for extracting, processing, and storing log data in a structured format (such as CSV files), preparing them for further analysis.
3.3. Orange-Dotted Box (Physical Environment)
3.4. Data Collection
3.4.1. Description of the Dataset Used
3.4.2. Sources of the Data
- Zenodo repository: Project titled “Loghub: A Large Collection of System Log Datasets for AI-driven Log Analytics” (Published on 1 September 2021, Version v7)—https://zenodo.org/records/3227177#.ZE5-FuzMJhF (accessed on 20 March 2024).
3.4.3. Data Size and Format
- Android: 192.3 MB (.log).
- Linux: 2.3 MB (.log).
- Mac: 16.9 MB (.log).
- Windows: 28.01 GB (.log).
3.4.4. Preprocessing Applied to the Data
- Data Cleaning:
- Rows with missing timestamps or tokens were removed from each DataFrame to ensure data integrity and consistency.
- Data Type Conversion:
- The “tokens” column in each DataFrame was converted to string type to facilitate further processing.
- Missing Value Imputation:
- Missing values in the “error” and “warning” columns were filled using the forward fill method to maintain temporal continuity in the log entries.
- Feature Selection:
- Only the necessary columns (“timestamp”, “tokens”, “error”, “warning”) were retained in each DataFrame, discarding any extraneous information.
- Label Assignment:
- A “Label” column was added to each DataFrame, derived from the filename of the corresponding log files, to facilitate identification and categorisation during analysis.
- Data Export:
- The preprocessed data for each operating system was saved into separate CSV files under the “preprocessed-data” directory for ease of access and further experimentation.
3.5. Modelling
3.5.1. Explanation of Multinomial Naive Bayes
- Log 1 (ERROR): “Disk failure on drive C”.
- Log 2 (WARNING): “Memory usage exceeds 90%”.
- Log 3 (INFO): “System backup completed”.
- Prior Probability:The “prior probability” represents the likelihood that a randomly selected log belongs to a particular class before we look at the content. For example, if 30% of the logs in our dataset are “ERROR” logs, the prior probability of “ERROR” is
- Likelihood:The “likelihood” represents the probability of observing specific words in a log, given that it belongs to a particular class. For example, how likely is it to observe the word “disk” in an “ERROR” log? If the word “disk” appears in 50 out of 300 “ERROR” logs, the likelihood isIf the log contains multiple words, such as “disk failure”, the overall likelihood is the product of the individual word probabilities, assuming independence:
- Posterior Probability:The “posterior probability” represents the probability that a given log belongs to a specific class, based on the words in the log. Using Bayes’ theorem,The log entry is classified into the category with the highest posterior probability.
- Word Probability and Smoothing:In cases where certain words are missing from a class during training, Laplace smoothing is applied. This prevents any word from having a probability of zero, which would otherwise cause issues during classification. The probability of a word given a class C is computed as follows:where
- is the smoothing parameter, typically set to 1 to avoid zero probabilities.
- d is the number of unique words across all logs.
- Example of Classification:Suppose we have a new log entry, “disk failure on drive C”, and we want to classify it as either “ERROR” or “INFO”. The MNB model computes the likelihood of the words appearing in each class and combines it with the prior probabilities. If the posterior probability for “ERROR” is higher than for “INFO”, the log is classified as an “ERROR”.
- Processing Logs in Practice:In our experiments, the logs are preprocessed and tokenised into their respective words. For each system (e.g., Android, Linux, Windows, Mac), the tokens are evaluated, and summary statistics such as the number of errors, warnings, and the frequency of tokens are calculated. The summary is then used to trigger self-healing actions if thresholds are exceeded. For instance, if the number of “ERROR” logs for Linux exceeds the defined threshold of 100, a self-healing mechanism would be activated to mitigate potential issues:
- How Classification Relates to Log Types:The classification process involves categorising each log entry into one of the predefined classes (INFO, WARNING, ERROR) based on the content of the logs. By analysing the words within the logs and applying the Naive Bayes algorithm, the system assigns a probability to each class. The class with the highest probability is then selected as the predicted class for that log entry. For example, if a log entry contains multiple instances of the word “error”, the system might classify it as an ERROR log with a high probability. Similarly, logs containing terms typically associated with warnings or informational messages would be classified accordingly. The classification is vital for system monitoring and self-healing processes, as it allows the system to prioritise actions based on the severity of the log entries.
3.5.2. Explanation of CountVectorizer
- Tokenisation: This step involves splitting the string into individual words or terms based on the delimiter, which is whitespace by default.
- Vocabulary Building: In this step, a vocabulary is constructed using the unique words found in the given corpus of text documents.
- Encoding: During this step, the occurrences of words from the vocabulary are counted for each document, and each unique word becomes a feature (or column).
- Log File: A log file is a collection of log entries recorded by a system over a period. Each log file typically corresponds to a specific system, application, or service and is stored as a text file on disk.
- Log Entry: A log entry is a single record within a log file. It contains specific details about an event that occurred within the system, such as timestamps, error codes, warnings, or informational messages. Each log entry can be considered analogous to a “document” in text processing.
- Document: In text processing, a “document” refers to any piece of text that we want to analyse or classify. When applying the Bag-of-Words (BoW) model to log analysis, each log entry within a log file is treated as a document. This allows us to convert the log entry into a numerical vector based on the words (tokens) it contains.
- The log file is a collection of log entries.
- Each log entry is treated as a document in the Bag-of-Words model.
- Let us consider a corpus D containing m documents (log entries): .
- The unique words from all documents will form our vocabulary V: .
- For each document (log entry), its vector representation in the BoW model will be
- Where represents the count of word in document (log entry).
- stop_words: This allows for the specification of “stop words”, which are typically common words such as “and”, “the”, “is”, etc. When set, these words are not counted. Some words, often referred to as stop words, are so common that they might not carry significant meaning in certain tasks. Let S be the set of stop words. The modified vocabulary after removing stop words will be .
- ngram_range: This is used to specify the range of n-values for the different n-grams to be extracted. For example, an ngram_range of (1,2) would include both individual words and bi-grams (combinations of adjacent two words). Instead of single words, we also consider sequences of words of length k. Such sequences are termed n-grams. For a given ngram_range , the will include n-grams where .
- max_df and min_df: These parameters can be used to set a threshold for words to be included in the vocabulary based on their document frequency. The parameters help to filter out vocabulary based on document frequency. Let be the number of documents containing the word w. Then, words with or are excluded from the vocabulary.
- max_features: This can be used to limit the number of top-occurring words to be considered. It limits the number of features to consider based on their frequency. If set to F, only the top F terms ordered by term frequency across the corpus will be kept.
- binary: If set to True, it encodes whether a word is present or not, rather than its count.
- tokeniser: It allows the setting of a custom function or tokeniser for breaking up the text.
3.5.3. Description of the Classification Model and Feature Extraction Method
- Multinomial Naive Bayes: It is a predictive model which, given input data such as word counts from extraction methods, makes predictions based on the probabilistic relationships it has learned from the training data. It is used for classification tasks and is particularly suitable for features that represent counts, making it apt for text data, especially when processing with techniques such as CountVectorizer.
- CountVectorizer: It is a processing step that transforms raw text data into a structured, numerical format suitable for machine learning models. It is a feature extraction method whose purpose is to convert a collection of text documents to a matrix of token counts. It tokenises the text documents and builds a vocabulary of known words. For each document, it creates a vector representation of the count of each word or token.
3.5.4. Feature Extraction Process from Raw System Log Files
- (a)
- Log File Access: Log files are accessed using the Python “open” function, ensuring correct encoding and handling of potential errors.
- (b)
- Log Entry Segmentation: Each log file is read line by line. Lines without “ERROR” or “WARNING” indications are promptly ignored, focusing solely on relevant entries.
- (c)
- Timestamp Extraction: Regular expressions are employed to extract timestamps from log entries, capturing each event’s exact time and date.
- (d)
- Log Message Isolation: The log message itself is obtained by removing any metadata and timestamps, providing a clear and unobstructed text for analysis.
- (e)
- Tokenisation: The log message is then tokenised, breaking it down into individual words. This dissection paves the way for more in-depth content analysis.
- (a)
- Timestamp: The timestamp extracted from each log entry, reflects the precise occurrence time.
- (b)
- Tokens: The tokenised version of the log message facilitates granular content analysis.
- (c)
- Severity Flags: Binary flags indicating the presence of certain severity levels, like “error” and “warning”, within the log message. These flags hold significant importance for later classification tasks.
4. Challenges and Limitations Encountered During Preprocessing and Model Analysis
4.1. Preprocessing Challenges
4.2. Memory Issues and Model Analysis
- Log Entry Retrieval: Log entries are retrieved from the multiple OS log files using regular expressions. Regular expressions (regex) are utilised to search for and extract specific patterns within the log files. For instance, a regex pattern might be employed to identify the start of a new log entry, typically indicated by a timestamp or a particular log level (e.g., “INFO”, “ERROR”, “WARNING”). These patterns assist in isolating individual log entries from the continuous stream of text in a log file. Commenting on the regular expressions would involve explaining the purpose of each pattern, such as matching timestamps in different formats, extracting log levels, or identifying key phrases indicative of specific events.
- Individual Entry Processing: Each log entry undergoes processing to extract relevant information, including the timestamp, tokens (the individual words or terms), and severity flags (such as “ERROR” or “WARNING”). Regular expressions might also be used in this step to precisely extract timestamps and other critical data. For example, a regex could be designed to capture timestamps in formats like “YYYY-MM-DD HH:MM:SS” or to isolate specific tokens that indicate an error or warning. Commenting on these regular expressions would clarify how they are constructed to match various timestamp formats or extract specific tokens.
- Enrichment with “ALERT” Warnings: An additional step involves identifying “ALERT” tokens within the log entries and flagging them accordingly for warning indications. Regular expressions are likely employed here to search for occurrences of the term “ALERT” (or similar terms) within the log entries. If an “ALERT” is detected, the log entry is flagged to indicate a higher severity level. Comments on the regular expressions used in this context would describe how the patterns are designed to detect variations of the word “ALERT” and differentiate between different levels of severity.
4.2.1. Analysis and Self-Healing Trigger Based on Extracted Log Data
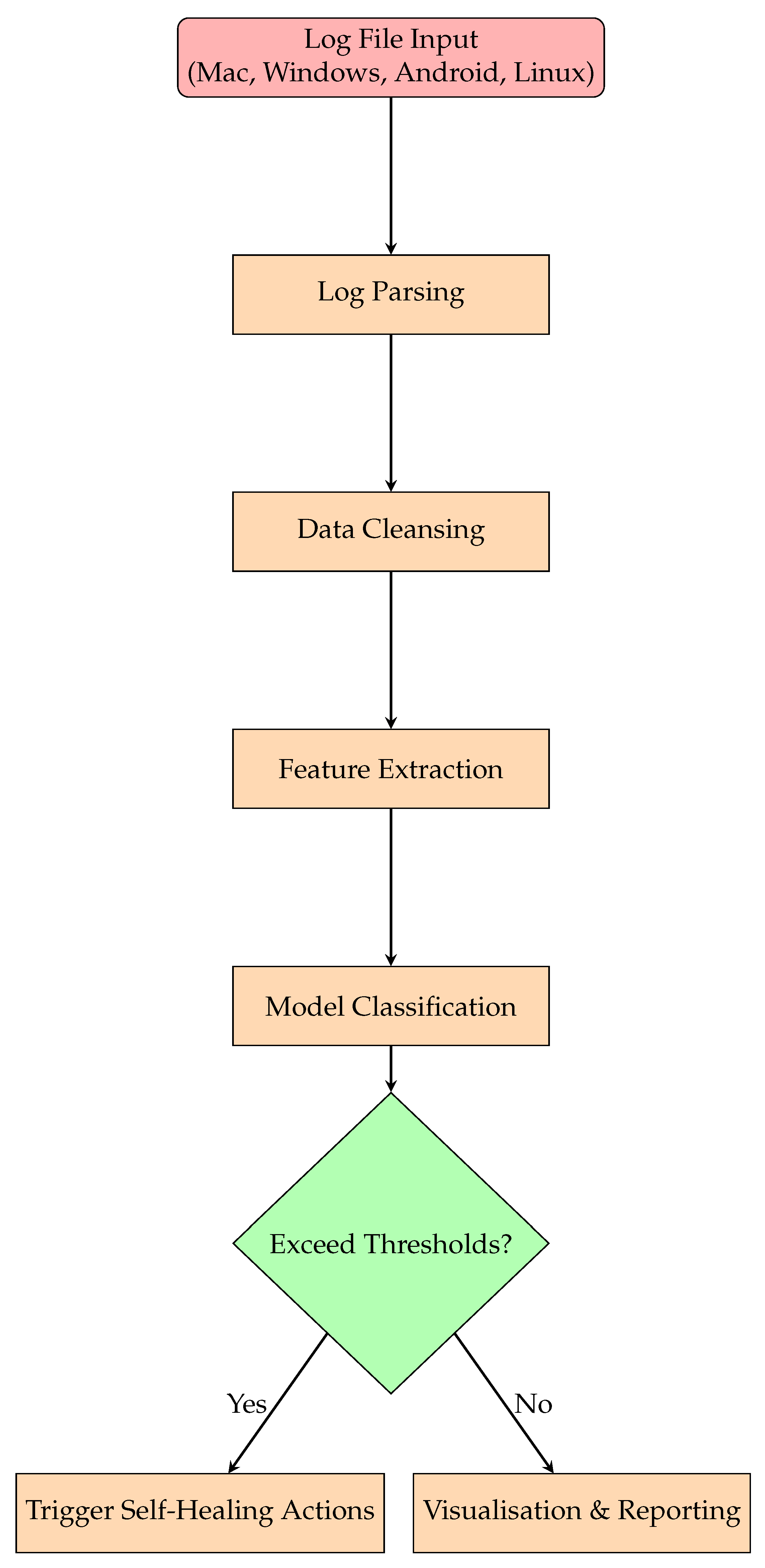
4.2.2. Explanation of Our Log Preprocessing Workflow
- Workflow Steps:
- Log Extraction: The system starts by ingesting logs from various systems.
- Log Parsing: This step extracts relevant data (such as timestamps, errors, and warnings) from the logs.
- Data Cleansing: The logs are cleaned to remove incomplete or irrelevant data.
- Feature Extraction: Key features such as error counts and log tokens are identified for further processing.
- Model Classification: The data are classified using a machine learning model to predict the occurrence of issues or events.
- Self-Healing Classification: Based on thresholds for errors and warnings, the system decides whether a self-healing action is required.
- Visualisation and Reporting: The system generates reports and visualisations to summarise the health of the monitored systems.
- Reading the Log Files: We read log files for each system (Mac_extracted.csv, Windows_extracted.csv, Android_extracted.csv, and Linux_extracted.csv) using the Pandas library’s pd.read_csv() function. Each CSV file contains logs with various columns like timestamp, tokens, error, and warning.
- Dropping Rows with Missing Values: For each system’s DataFrame (df_mac, df_win, df_android, df_linux), we dropped rows with missing values in the timestamp or tokens columns using the dropna() function. This ensures that only complete records are used in the analysis.
- Converting Tokens to String Type: For each system’s DataFrame, we converted the tokens column to a string type using the astype() function, ensuring a consistent data type for subsequent processing steps.
- Filling Missing Error and Warning Values: We filled missing values in the error and warning columns using forward fill (ffill). This ensures that missing values are replaced with the most recent non-missing value, maintaining temporal continuity in the data.
- Extracting Relevant Columns: For each system’s DataFrame, we extracted only the relevant columns (timestamp, tokens, error, warning) using indexing. This step focuses the dataset on the most important features for further analysis.
- Adding a Label Column: We added a Label column to each system’s DataFrame. The label is derived from the filename by splitting the filename to extract the required portion, aiding in the identification and categorisation of the logs during analysis.
- Saving Preprocessed Data: The preprocessed data for each system are saved to separate CSV files using the to_csv() function. The index is set to False to avoid saving the default index column. The resulting CSV files generated are as follows:
5. Threshold Determination and Impact on System Performance
5.1. Thresholds Determination
5.2. Impact on System Performance
5.2.1. Analysis of the Extracted and Preprocessed Data
- Data Loading and Preprocessing:
- (a)
- The code starts by reading the extracted log files for each system and concatenates them into a single dataframe.
- (b)
- Rows with missing or incomplete timestamp or tokens information are dropped, and the “tokens” column is converted to a string type.
- (c)
- Missing error and warning values are filled using forward fill, ensuring that missing values are replaced with the most recent non-null value.
- (d)
- The dataframe is then narrowed down to include only the relevant columns (“timestamp”, “tokens”, “error”, “warning”).
- Saving Preprocessed Data:
- (a)
- The preprocessed data for each system are saved into separate CSV files in the specified directory.
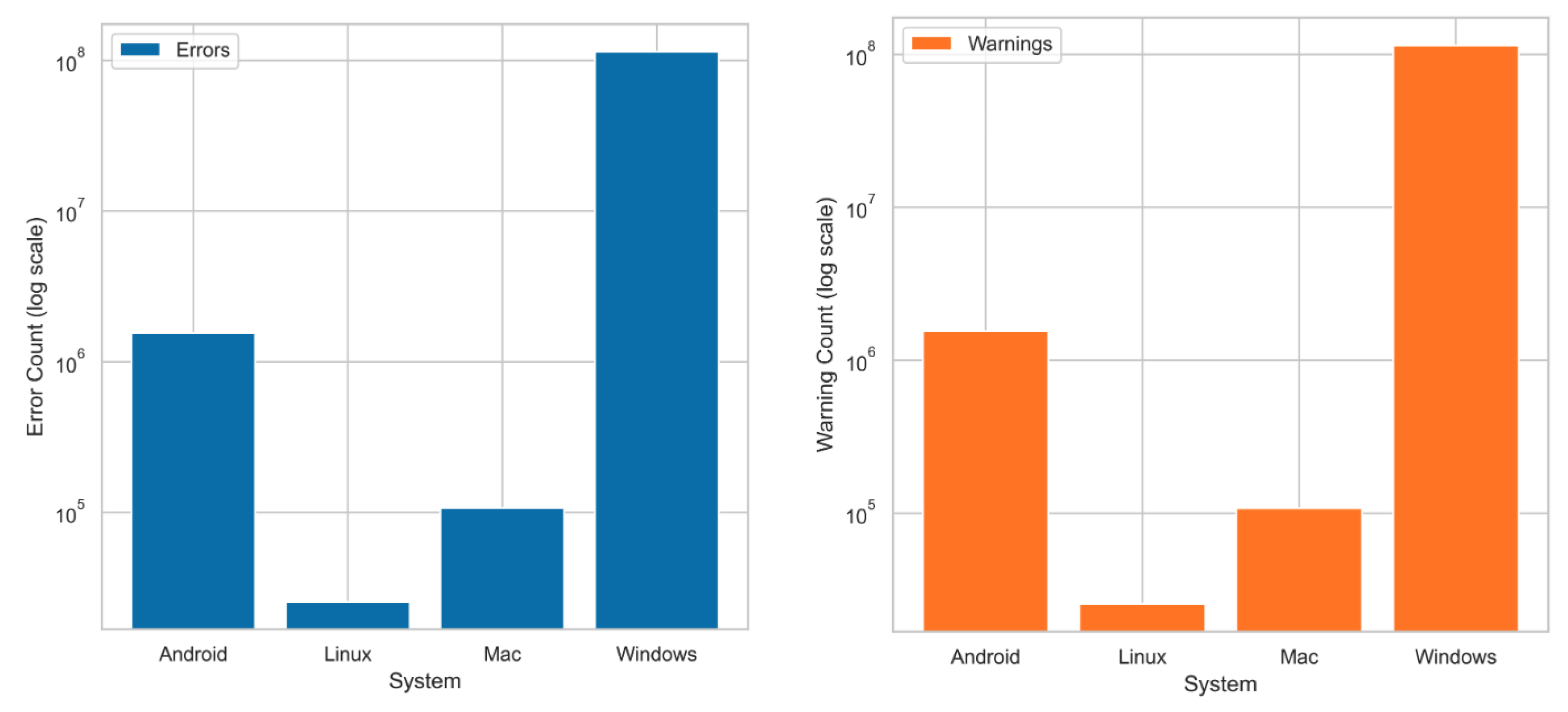
- Bar Chart Creation (Extracted Data):
- (a)
- The code calculates the number of errors and warnings for each system in the extracted data and stores them in the num_errors_extracted and num_warnings_extracted lists.
- (b)
- A bar chart is created using Matplotlib, displaying the number of errors and warnings for each system in the extracted data. Errors and warnings are represented with stacked bars for each system.
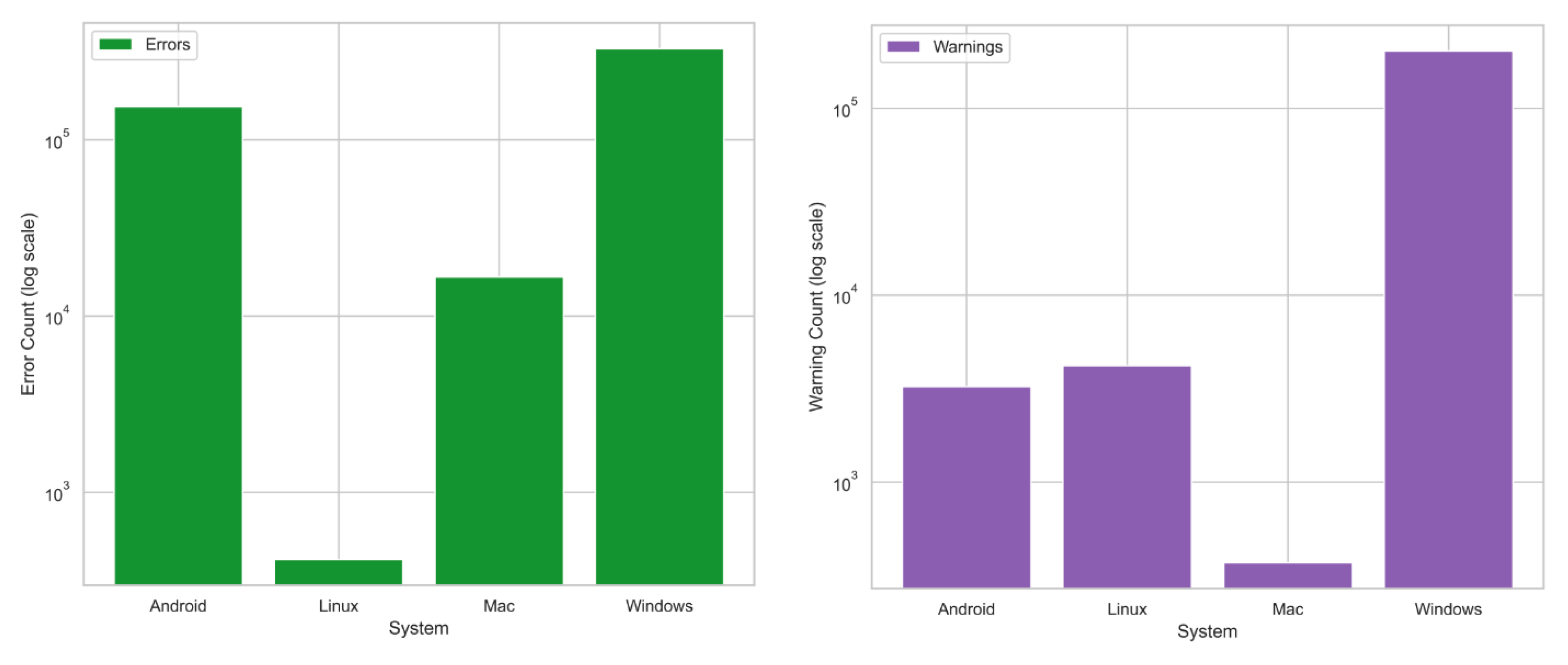
- Bar Chart Creation (Preprocessed Data):
- (a)
- The preprocessed data for each system are read from the saved CSV files.
- (b)
- The code calculates the total number of errors and warnings for each system in the preprocessed data and stores the results in the num_errors_preprocessed and num_warnings_preprocessed lists.
- (c)
- Another bar chart is created to visualise the number of errors and warnings for each system in the preprocessed data, with stacked bars for errors and warnings.
- Displaying Plots:
- (a)
- Both bar charts are displayed using plt.show().
5.2.2. Analysis of Extracted and Preprocessed Data Counts
- Extracted Data Error Count and Warning Count:
- -
- Lists the total number of errors and warnings identified during the initial extraction of log data from each operating system.
- -
- The datasets analysed include Android, Linux, Mac, and Windows.
- -
- The initial extracted logs contain raw, unstructured data directly sourced from system log files, which often include redundant, irrelevant, or incomplete entries.
- Preprocessed Data Error Count and Warning Count:
- -
- Shows the error and warning counts after preprocessing, which involves cleaning and structuring the data. The reduction in the number of errors and warnings in the preprocessed data reflects the removal of irrelevant entries and consolidation of the log entries, ensuring that the dataset is more focused and ready for subsequent analysis. Preprocessing steps include:Removal of irrelevant entries: Log entries that do not provide meaningful information for error or warning detection, such as routine informational logs (e.g., “System initialisation completed”), are removed. These logs are often verbose but do not contribute to the identification of system faults.Handling missing data: Missing values in crucial fields such as “timestamp” and “tokens” are dropped. This ensures that only complete entries, which provide sufficient context for the analysis, are retained. Incomplete records, which may hinder the accuracy of predictions, are eliminated.Forward-filling: Missing values in the “error” and “warning” columns are filled using a forward-fill method. This assumes that the last known error or warning persists until it is explicitly resolved in the logs. This technique is particularly useful when logs do not consistently document the resolution of an issue.Consolidation of repetitive log entries: Frequently repeated logs, such as those generated by regular status updates or background processes, are consolidated. This reduces redundancy, focusing the dataset on significant events rather than routine, non-critical messages.Tokenisation and standardisation of format: The “tokens” column, which holds the main log message, is processed by converting it to a consistent format (e.g., standardising case or removing special characters) to prepare the data for further analysis and classification.
5.2.3. Analysis of the Extracted and Preprocessed Data
- Count: The count represents the total number of log entries considered in the analysis for each operating system. For instance, in the Windows system, over 114 million log entries were analysed.
- Mean: The mean value is the average number of errors observed per log entry across all log entries for each operating system. For example, the mean error rate for Android logs is approximately 0.0992, indicating that errors are relatively less frequent.
- Standard Deviation (std): This value measures the variability or spread of the error counts around the mean. A higher standard deviation indicates greater variability in the error rates across log entries. For example, Mac has a standard deviation of approximately 0.362, suggesting more variability in error occurrences compared to the other systems.
- Minimum and Maximum Values: These indicate the range of error counts observed across log entries. The minimum value is 0 for all systems, showing that there are log entries without any errors, while the maximum is 1, indicating that errors are binary (either present or absent).
- Count: Similar to Table 5, the count reflects the total number of log entries analysed for warnings in each operating system.
- Mean: The mean value represents the average frequency of warnings per log entry. For instance, the mean warning rate for Linux logs is 0.164, indicating that warnings are more frequently logged in Linux compared to other systems.
- Standard Deviation (std): This measures the dispersion of warning counts around the mean. A higher standard deviation, as seen in Linux (0.370), suggests that the warning frequencies vary significantly across different log entries.
- Minimum and Maximum Values: These values highlight the range of warnings across log entries. The minimum value of 0 indicates the presence of entries without any warnings, while the maximum value of 1 shows that warnings, like errors, are binary in nature.
- For the Android system, neither errors nor warnings exceeded the thresholds. No self-healing action is triggered.
- For the Linux system, both errors and warnings exceeded the thresholds. A self-healing action is triggered to address the high error and warning counts.
- For the Mac system, errors exceeded the threshold, but warnings did not. A self-healing action is triggered for the Mac system to address the high error count.
- For the Windows system, warnings exceeded the threshold, but errors did not. A self-healing action is triggered for the Windows system to address the high warning count.
5.2.4. Libraries and Software Used
- Pandas: A powerful data manipulation and analysis library for Python, used for handling and preprocessing the dataset [28].
- NumPy: Essential for numerical computations, providing support for arrays and mathematical functions [29].
- Scikit-learn: A machine learning library used for implementing the Multinomial Naive Bayes, Logistic Regression, Linear Discriminant Analysis, and Gradient Boosting classifiers, as well as for data preprocessing and evaluating model accuracy [32].
- PyCaret: An open-source, low-code machine learning library that significantly expedited the model selection process by automating the comparison of different algorithms [33].
- Tabulate: Facilitated the presentation of results in tabular format, enhancing the readability of our findings [34].
5.2.5. Hardware Specification
- Processor: Apple M3 Pro.
- Memory: 18 GB.
- Operating System: macOS 14.5 (23F79).
- Chunk-Based Processing: The parse_log_file_in_chunks function processes the log file in manageable chunks (e.g., 10,000 lines), allowing for efficient handling and processing of large datasets.
- Incremental Data Processing: Processed chunks are saved incrementally to the output CSV file, mitigating memory overload.
- Proactive Garbage Collection: Explicit calls to gc.collect() are made to reclaim memory.
5.3. Model Selection and Training Using Multinomial Naive Bayes
5.3.1. Data Preprocessing
- Data Extraction: Importing log data from CSV files, each representing a distinct system.
- Cleaning: Dropping rows with missing values and converting the “tokens" column to a string type to ensure data consistency.
- Feature Engineering: Calculating summary statistics such as the total number of errors and warnings, and the average number of tokens per log entry.
5.3.2. Model Training
- Vectorisation: Applying TF-IDF vectorisation to convert the tokenised log messages into numerical features, enabling the MNB algorithm to process and learn from the text data.
- Model Fitting: Utilising the sci-kit-learn library’s Multinomial Naive Bayes class to fit the model on the training dataset, which comprises a subset of the preprocessed log data.
- Hyperparameter Tuning: Although MNB requires minimal hyperparameter tuning, we explored different configurations of the model’s parameters to optimise performance.
6. Model Performance Analysis Results
- 1.
- Android Dataset Results
- 2.
- Linux Dataset Results
- 3.
- Mac Dataset Results
- 4.
- Windows Dataset Results
6.1. Arguments for Multinomial Naive Bayes
- Accuracy and Recall: MNB exhibits high accuracy and recall rates, especially in critical cases where identifying all positive instances is crucial. For instance, in the Android dataset (Table 8), MNB achieved an accuracy of 98.87% and a recall of 56.21%. This indicates that MNB is highly effective in correctly identifying positive instances.
- Training Time: MNB consistently shows the lowest training times across all datasets. This efficiency is crucial for the self-healing system, which requires rapid model updates and retraining. For example, in the Windows dataset (Table 11), MNB’s training time was significantly lower than other classifiers, making it an ideal choice for real-time applications.
- Stability and Consistency: MNB maintains stable performance across different datasets, demonstrating its robustness and generalisability. The classifier consistently shows competitive precision and F1-scores, ensuring a balanced trade-off between precision and recall.
6.2. Best Four Performing Models
6.2.1. Android Dataset Results
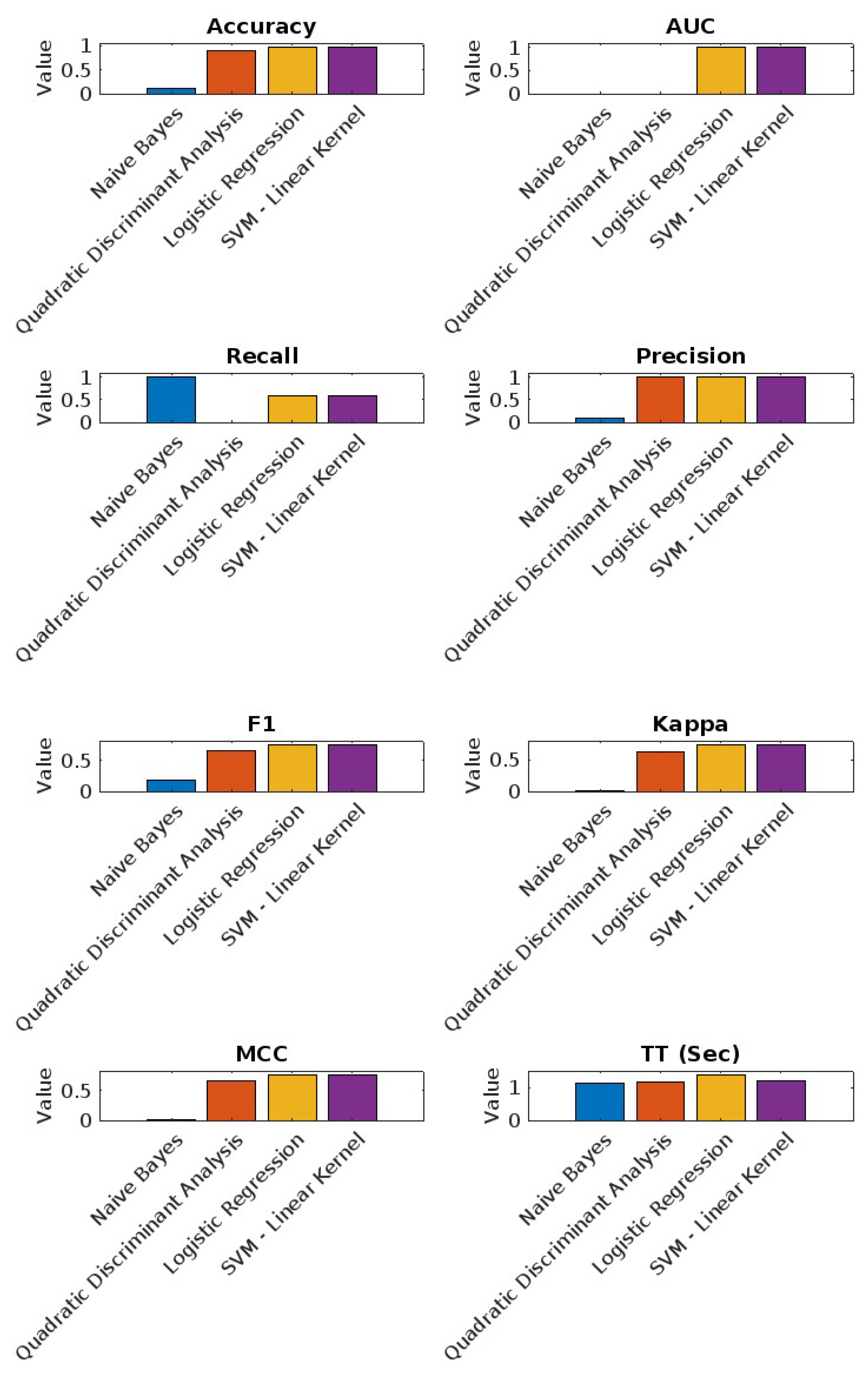
- Naive Bayes: Exhibits perfect recall (100%) but has the lowest precision (9.94%) and accuracy (10.13%), indicating a tendency to over-predict positive instances.
- Quadratic Discriminant Analysis: Shows the highest precision (99.99%) and accuracy (90.08%) but has no recall (0.00%), failing to identify positive instances.
- Logistic Regression: Achieves a balanced performance with an accuracy of 96.03% and a recall of 60.07%, complemented by a high precision of 99.87%.
- SVM—Linear Kernel: Delivers a strong AUC of 99.03%, with good overall accuracy (96.04%) and balanced recall (60.07%) and precision (100%).
6.2.2. Linux Dataset Results
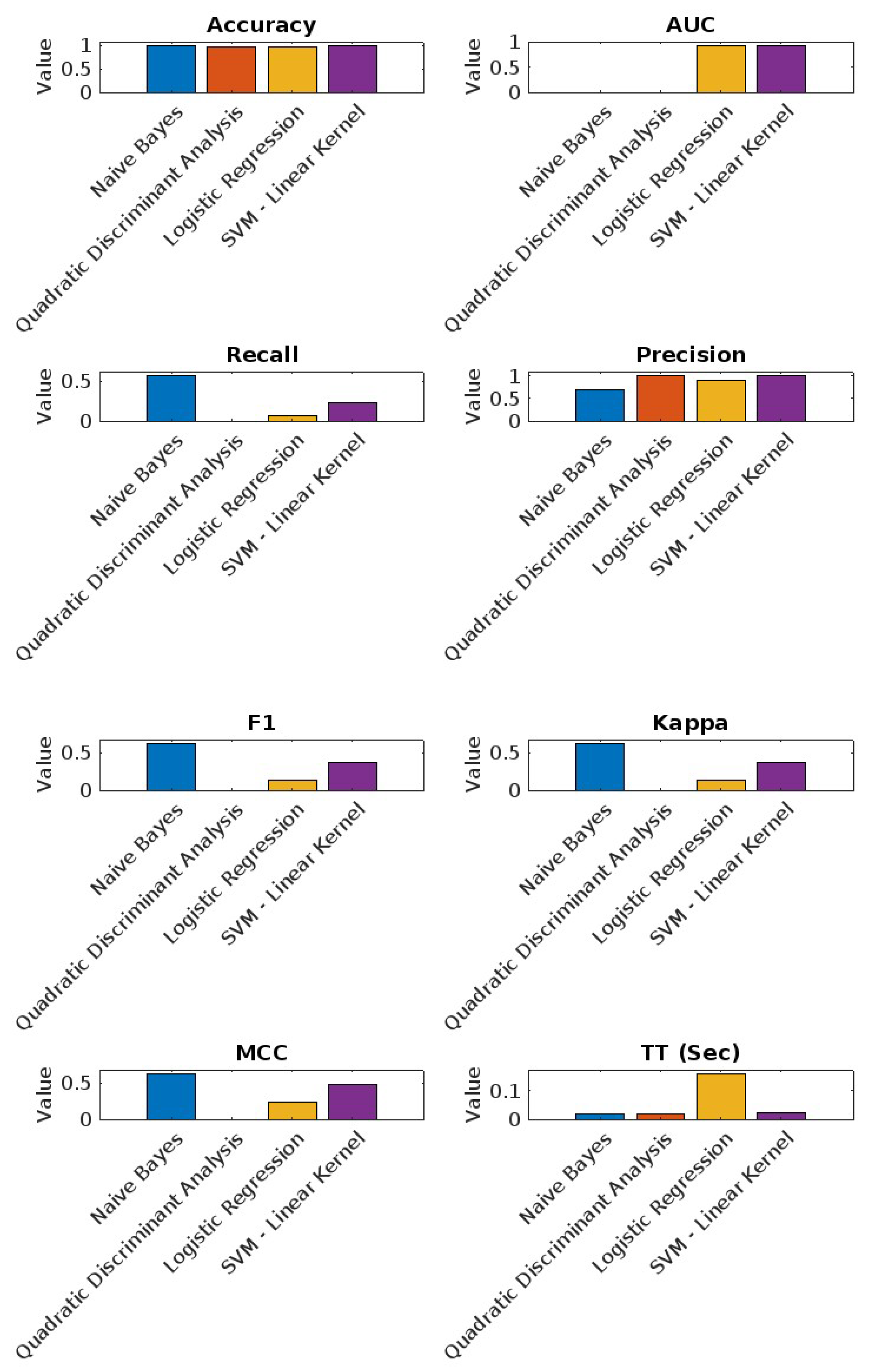
- Naive Bayes: Highest accuracy (98.87%) and a recall of 56.21%, showing strong performance in identifying positive instances.
- Quadratic Discriminant Analysis: Consistently high metrics with the lowest recall (0.00%).
- Logistic Regression: Good balance between accuracy (98.49%) and precision (90.00%).
- SVM—Linear Kernel: Shows solid performance with high AUC (91.07%).
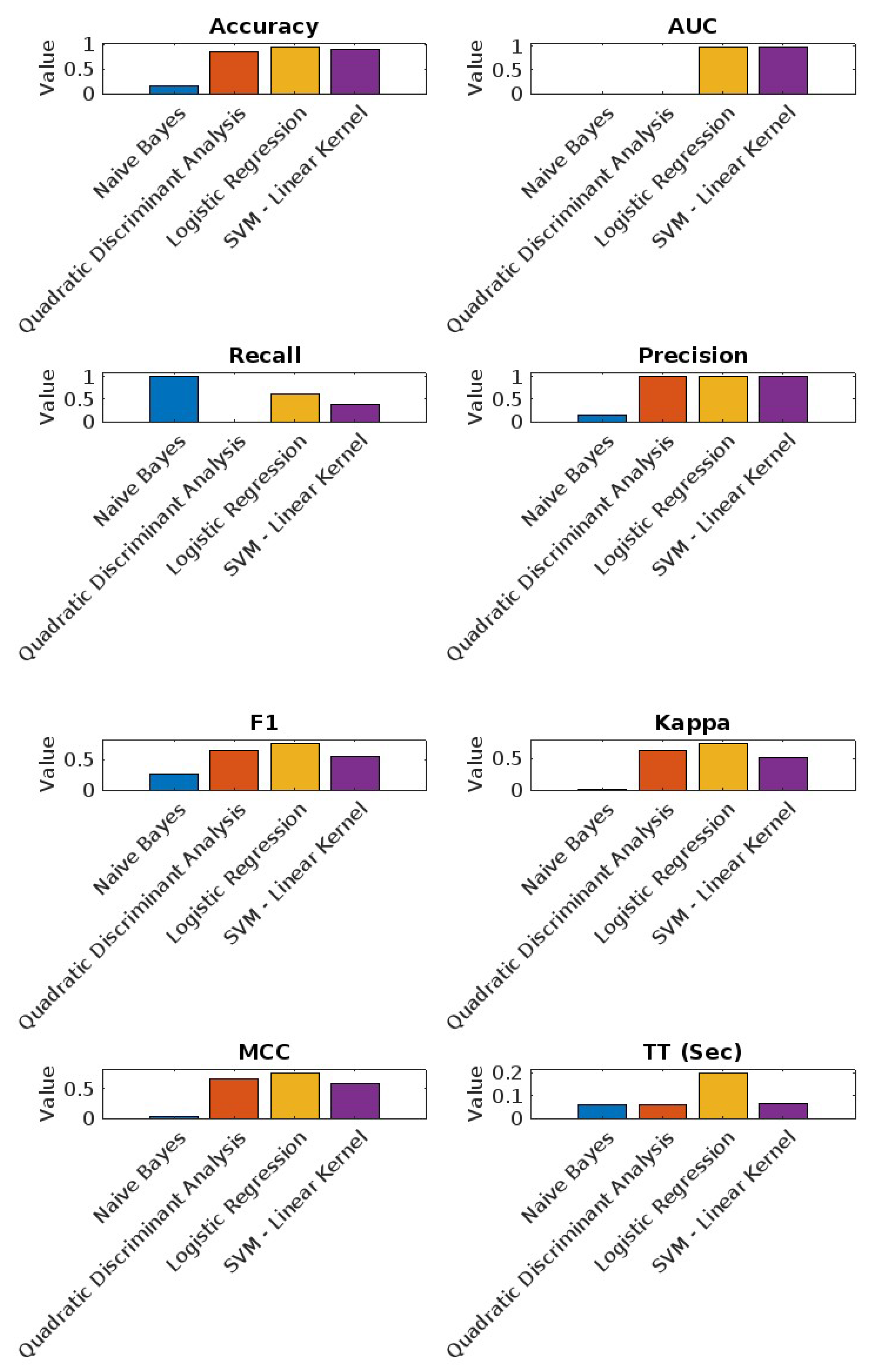
6.2.3. Mac Dataset Results
- Logistic Regression: Achieved the highest accuracy (94.00%) and AUC (97.14%) with a recall of 61.47%.
- SVM—Linear Kernel: Showed strong performance with high AUC (97.31%) and precision (100%).
- Quadratic Discriminant Analysis: Balanced performance but with lower recall (0.00%).
- Naive Bayes: Perfect recall (100%) but lower accuracy (15.88%).
6.2.4. Windows Dataset Results
- Naive Bayes: Demonstrated high accuracy (97.25%) with a recall of 55.67%, indicating robust performance in identifying positive instances.
- Quadratic Discriminant Analysis: Consistently high performance but with lower recall (0.00%).
- Logistic Regression: Balanced accuracy (96.80%) and precision (89.50%).
- SVM—Linear Kernel: Strong overall performance with high AUC (90.83%).
7. Comparison with Existing Methods
7.1. Comparison with ReLoop2
- Key Comparison Points with ReLoop2
- Model Objective:
- Our MNB model is designed for log-based error detection and self-healing in cyber-physical systems, prioritising high recall and quick training time to identify and correct system faults in real time.
- ReLoop2 focuses on self-adaptive recommendation systems by integrating error compensation loops to quickly adapt to shifting data distributions in large-scale recommendation datasets like AmazonElectronics and production systems (e.g., Huawei’s news feed).
- Datasets:
- Our study uses system logs (e.g., Android, Linux, Mac, and Windows logs) for error detection, evaluating performance through metrics like accuracy, recall, and precision.
- ReLoop2 uses recommendation datasets (AmazonElectronics, MicroVideo, KuaiVideo) and a production dataset, which are much larger and involve user–item interactions, making the task more focused on recommendations.
- Performance Metrics:
- Our Model: MNB achieved high recall (56.21%) and balanced accuracy with fast training times, making it suitable for real-time error detection in dynamic environments.
- ReLoop2: Integrating ReLoop2 with baseline models outperformed state-of-the-art methods (e.g., DeepFM, AutoInt+), achieving up to a 5.6% improvement in AUC on the AmazonElectronics dataset. ReLoop2 rapidly compensates for data distribution shifts without requiring additional model training, essential for real-time recommendation systems.
- Error Handling:
- MNB: Focuses on identifying system errors through log analysis, excelling in high recall for detecting system warnings and errors.
- ReLoop2: Incorporates an error memory module that compensates for prediction errors and adapts to changes in data distribution in recommendation tasks, outperforming incremental training techniques in many cases.
- Training Time:
- MNB demonstrated significantly lower training times (e.g., 0.019 s for Linux), critical for real-time, self-healing systems.
- ReLoop2 outperformed incremental training methods without requiring retraining, making it highly efficient for adaptive recommendations in real-time systems.
7.2. Comparison of Machine Learning Models
- Support Vector Machine (SVM): Known for its effectiveness in high-dimensional spaces, SVM can be particularly useful for text classification tasks, such as log analysis.
- Random Forest (RF): This ensemble learning method combines multiple decision trees to improve classification accuracy and robustness, making it suitable for complex datasets like OS logs.
- Gradient Boosting Classifier (GBC): GBC is another ensemble technique that sequentially builds models, optimising for classification tasks by focusing on errors made by previous models.
- AdaBoost (ADA): A boosting algorithm that combines weak learners to form a strong classifier, which can enhance classification accuracy in various scenarios.
- LightGBM: A gradient boosting framework that is optimised for efficiency and speed, particularly when dealing with large datasets.
- Logistic Regression (LR): A baseline model often used for binary and multiclass classification, providing a point of comparison for more complex models.
- Deep Learning Models: While not included in the current comparison due to the scope of our research, we recognise their importance and plan to explore these in future work.
7.3. Experimental Results
7.4. Discussion of Model Performance
- Accuracy and Precision: The Naive Bayes model excels in maintaining high accuracy and precision across the datasets, which is crucial for real-time self-healing systems that require immediate and reliable log classification.
- Training Time: The Naive Bayes algorithm also outperforms others in terms of training time, making it a preferred choice for systems where quick model updates are necessary.
- Recall and F1-Score: While some models like SVM and GBC show higher recall, indicating a better ability to detect anomalies, they may require more computational resources and longer training times.
7.5. Performance Across Operating Systems
- Windows Dataset: The Naive Bayes algorithm achieved a recall of 0.9755, which is among the highest across the models tested. This suggests that the Naive Bayes model is highly effective at identifying nearly all instances of errors and warnings in the Windows logs. This high recall is particularly advantageous in a self-healing system where missing even a small percentage of errors could lead to system vulnerabilities or downtime.
- Linux Dataset: On the Linux dataset, the recall drops significantly to 0.5621. This indicates that while the model is still capturing over half of the relevant instances, it may be missing a considerable portion of the anomalies. This decrease in recall could be due to the nature of the Linux logs, which may present a more diverse set of features that are not as well captured by the Naive Bayes model. The complexity and variability in Linux system logs might require additional feature engineering or the integration of more complex models to improve recall.
- Mac Dataset: For the Mac dataset, the Naive Bayes model’s recall is 0.6147. While this is better than its performance on the Linux dataset, it still indicates room for improvement. The recall score suggests that the model is moderately successful in identifying relevant log entries but may still miss some critical cases. Given the Mac OS’s unique structure and log generation patterns, additional preprocessing or model adjustments could be necessary to enhance recall further.
- Android Dataset: On the Android dataset, the recall achieved by Naive Bayes is 1.0000, which is perfect. This exceptional performance indicates that the Naive Bayes model was able to correctly identify every relevant instance in the Android logs. This level of recall is particularly beneficial in mobile environments where resources are limited, and the cost of errors can be high. A perfect recall means that the model did not miss any errors or warnings, ensuring comprehensive monitoring and quick corrective actions in a self-healing context.
7.6. Interpretation and Implications
- Variability Across Datasets: The Naive Bayes model’s recall performance varies significantly across different operating systems. This variability highlights the model’s sensitivity to the nature of the data it is applied to. The perfect recall in the Android dataset demonstrates the model’s potential when the features are well aligned with the model’s assumptions. In contrast, the lower recall on the Linux and Mac datasets suggests that these environments may have more complex log patterns that Naive Bayes alone may not capture fully.
- Advantages in Specific Contexts: The high recall in Windows and perfect recall in Android logs make Naive Bayes a strong candidate for environments where complete anomaly detection is critical, and missing an error could lead to significant consequences. However, in more complex environments like Linux, where the logs may exhibit a wider range of behaviours, relying solely on Naive Bayes may not be sufficient, and combining it with other models or enhancing feature extraction could be necessary.
- Balancing Precision and Recall: It is also important to note the trade-off between precision and recall. While Naive Bayes achieves high recall in certain datasets, precision, particularly in the Windows dataset, is also strong. This balance suggests that Naive Bayes is not only good at catching most of the anomalies but also at ensuring that the identified instances are indeed relevant, reducing the rate of false positives.
7.7. Comparing Different Variants of Naive Bayesian Algorithms
- Multinomial Naive Bayes (MNB): This variant is particularly advantageous for text classification tasks and datasets with discrete features, such as word counts or frequencies. It is highly effective when features represent categorical data.
- Gaussian Naive Bayes (GNB): GNB is suited for continuous features and assumes that the data follow a normal (Gaussian) distribution, making it ideal for datasets with real-valued features.
- Bernoulli Naive Bayes (BNB): This variant is best suited for binary/boolean features and is particularly useful when the dataset is composed of binary variables, making it effective in scenarios like text classification where the presence or absence of a feature (e.g., a word) is important.
7.8. Challenges of Manual System Log Analysis
- Legacy Systems: Organisations that continue to rely on older or legacy systems may not have fully integrated automated log analysis tools. In such environments, system administrators and IT support staff often perform manual log analysis to diagnose issues, identify security threats, or troubleshoot system performance.
- Small and Medium-Sized Enterprises (SMEs): Many SMEs may lack the budget to invest in advanced automated log analysis tools. Consequently, IT personnel in these organisations often resort to manual log analysis, particularly during critical incidents or when automated tools fail to provide clear insights.
- Compliance and Auditing: In certain industries, manual log analysis remains a requirement as part of compliance and auditing processes. IT auditors may manually review logs to ensure systems comply with regulatory standards, particularly in sectors such as finance, healthcare, and government.
- Security Operations Centres (SOCs): While SOCs increasingly use sophisticated Security Information and Event Management (SIEM) systems, there are still instances where security analysts perform manual log analysis. This typically occurs when investigating complex or nuanced security incidents that automated tools may not fully capture or interpret.
- Incident Response: During the incident response process, particularly in real-time scenarios, security professionals and incident responders might manually analyse logs to quickly understand and contain an issue before escalating to automated processes.
7.9. Comparison Between DA-Parser and CountVectorizer
8. Conclusions
9. Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Adeniyi, O.; Sadiq, A.S.; Pillai, P.; Taheir, M.A.; Kaiwartya, O. Proactive Self-Healing Approaches in Mobile Edge Computing: A Systematic Literature Review. Computers 2023, 12, 63. [Google Scholar] [CrossRef]
- Sarker, I.H. Deep learning: A comprehensive overview on techniques, taxonomy, applications and research directions. SN Comput. Sci. 2021, 2, 420. [Google Scholar] [CrossRef] [PubMed]
- Singh, P.; Saman Azari, M.; Vitale, F.; Flammini, F.; Mazzocca, N.; Caporuscio, M.; Thornadtsson, J. Using log analytics and process mining to enable self-healing in the Internet of Things. Environ. Syst. Decis. 2022, 42, 234–250. [Google Scholar] [CrossRef]
- Shahzad, K.; Iqbal, S.; Fraz, M.M. Automated Solution Development for Smart Grids: Tapping the Power of Large Language Models. In Proceedings of the 2023 17th International Conference on Engineering of Modern Electric Systems (EMES), Oradea, Romania, 9–10 June 2023; pp. 1–4. [Google Scholar]
- Hassan, S.U.; Ahamed, J.; Ahmad, K. Analytics of machine learning-based algorithms for text classification. Sustain. Oper. Comput. 2022, 3, 238–248. [Google Scholar] [CrossRef]
- Gan, S.; Shao, S.; Chen, L.; Yu, L.; Jiang, L. Adapting hidden naive Bayes for text classification. Mathematics 2021, 9, 2378. [Google Scholar] [CrossRef]
- Ahmed, T.; Mukta, S.F.; Al Mahmud, T.; Al Hasan, S.; Hussain, M.G. Bangla Text Emotion Classification using LR, MNB and MLP with TF-IDF & CountVectorizer. In Proceedings of the 2022 26th International Computer Science and Engineering Conference (ICSEC), Sakon Nakhon, Thailand, 21–23 December 2022; pp. 275–280. [Google Scholar]
- Siddiqui, T.; Mustaqeem, M. Performance evaluation of software defect prediction with NASA dataset using machine learning techniques. Int. J. Inf. Technol. 2023, 15, 4131–4139. [Google Scholar] [CrossRef]
- Coronado, E.; Behravesh, R.; Subramanya, T.; Fernández-Fernández, A.; Siddiqui, S.; Costa-Pérez, X.; Riggio, R. Zero touch management: A survey of network automation solutions for 5G and 6G networks. IEEE Commun. Surv. Tutor. 2022, 24, 2535–2578. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, X.; Cao, X.; Huang, C.; Liu, E.; Qian, S.; Liu, X.; Wu, Y.; Dong, F.; Qiu, C.-W.; et al. Artificial intelligence: A powerful paradigm for scientific research. Innovation 2021, 2, 100179. [Google Scholar] [CrossRef] [PubMed]
- Ghosh, D.; Sharman, R.; Rao, H.R.; Upadhyaya, S. Self-healing systems—Survey and synthesis. Decis. Support Syst. 2007, 42, 2164–2185. [Google Scholar] [CrossRef]
- Donta, P.K.; Sedlak, B.; Casamayor Pujol, V.; Dustdar, S. Governance and sustainability of distributed continuum systems: A big data approach. J. Big Data 2023, 10, 1–31. [Google Scholar] [CrossRef]
- Bhanage, D.A.; Pawar, A.V.; Kotecha, K. IT infrastructure anomaly detection and failure handling: A systematic literature review focusing on datasets, log preprocessing, machine & deep learning approaches and automated tool. IEEE Access 2021, 9, 156392–156421. [Google Scholar]
- Dash, S.; Shakyawar, S.K.; Sharma, M.; Kaushik, S. Big data in healthcare: Management, analysis and future prospects. J. Big Data 2019, 6, 1–25. [Google Scholar] [CrossRef]
- Odeh, A.H.; Odeh, M.; Odeh, N. Using Multinomial Naive Bayes Machine Learning Method To Classify, Detect, And Recognize Programming Language Source Code. In Proceedings of the 2022 International Arab Conference on Information Technology (ACIT), Abu Dhabi, United Arab Emirates, 22–24 November 2022; pp. 1–5. [Google Scholar]
- Alvi, N.; Talukder, K.H. Sentiment analysis of Bengali text using CountVectorizer with logistic regression. In Proceedings of the 2021 12th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 6–8 July 2021; pp. 1–5. [Google Scholar]
- Hafeez, S.; Kathirisetty, N. Effects and comparison of different data pre-processing techniques and ML and deep learning models for sentiment analysis: SVM, KNN, PCA with SVM and CNN. In Proceedings of the 2022 First International Conference on Artificial Intelligence Trends and Pattern Recognition (ICAITPR), Hyderabad, India, 10–12 March 2022; pp. 1–6. [Google Scholar]
- Vijay, V.; Verma, P. Variants of Naïve Bayes Algorithm for Hate Speech Detection in Text Documents. In Proceedings of the 2023 International Conference on Artificial Intelligence and Smart Communication (AISC), Greater Noida, India, 27–29 January 2023; pp. 18–21. [Google Scholar]
- Patel, A.; Meehan, K. Fake news detection on Reddit utilizing CountVectorizer and term frequency-inverse document frequency with logistic regression, MultinomialNB, and support vector machine. In Proceedings of the 2021 32nd Irish Signals and Systems Conference (ISSC), Athlone, Ireland, 10–11 June 2021; pp. 1–6. [Google Scholar]
- Wang, P.; Poovendran, P.; Manokaran, K.B. Fault detection and control in integrated energy system using machine learning. Sustain. Energy Technol. Assess. 2021, 47, 101366. [Google Scholar] [CrossRef]
- Kane, K. Finding The Available Website Name By Using Naive Bayes Classification. In Proceedings of the 2022 International Conference on Decision Aid Sciences and Applications (DASA), Chiangrai, Thailand, 23–25 March 2022; pp. 624–629. [Google Scholar]
- Singla, T.; Gaur, V.; Misra, D.K. Comparison between Multinomial Naive Bayes and Multi-Layer Perceptron for Product Review In Real Time. In Proceedings of the 2022 International Conference on Machine Learning, Big Data, Cloud and Parallel Computing (COM-IT-CON), Online, 26–27 May 2022; Volume 1, pp. 374–379. [Google Scholar]
- Singh, G.; Kumar, B.; Gaur, L.; Tyagi, A. Comparison between multinomial and Bernoulli naïve Bayes for text classification. In Proceedings of the 2019 International Conference on Automation, Computational and Technology Management (ICACTM), London, UK, 24–26 April 2019; pp. 593–596. [Google Scholar]
- McCallum, A.; Nigam, K. A comparison of event models for naive bayes text classification. In Proceedings of the AAAI-98 Workshop on Learning for Text Categorization, Madison, WI, USA, 26–27 July 1998; Volume 752, pp. 41–48. [Google Scholar]
- Joachims, T. A probabilistic analysis of the Rocchio algorithm with TFIDF for text categorization. In Proceedings of the Fourteenth International Conference on Machine Learning, Nashville, TN, USA, 8–12 July 1997; Volume 97, pp. 143–151. [Google Scholar]
- Manning, C.D.; Raghavan, P.; Schütze, H. Xml retrieval. In Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Jurafsky, D.; Martin, J.H. Spelling Correction and the Noisy Channel. In Speech and Language Processing, 2nd ed.; Prentice-Hall: Upper Saddle River, NJ, USA, 2009. [Google Scholar]
- Panda. Available online: https://pandas.pydata.org/ (accessed on 28 September 2023).
- NumPy. Available online: https://numpy.org/ (accessed on 28 September 2023).
- Seaborn. Available online: https://seaborn.pydata.org/ (accessed on 28 September 2023).
- Scikit-learn. Available online: https://scikit-learn.org/stable/ (accessed on 25 September 2023).
- PyCaret. Available online: https://pycaret.org/ (accessed on 29 September 2023).
- Tabulate. Available online: https://pypi.org/project/tabulate/ (accessed on 27 September 2023).
- Soldani, J.; Brogi, A. Anomaly detection and failure root cause analysis in (micro) service-based cloud applications: A survey. ACM Comput. Surv. (CSUR) 2022, 55, 1–39. [Google Scholar] [CrossRef]
- MathWorks. MATLAB—MathWorks. Available online: https://matlab.mathworks.com/ (accessed on 28 May 2024).
- Jieming, Z.; Guohao, C.; Junjie, H.; Zhenhua, D.; Ruiming, T.; Weinan, Z. ReLoop2: Building Self-Adaptive Recommendation Models via Responsive Error Compensation Loop. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Long Beach, CA, USA, 6–10 August 2023; pp. 5728–5738. [Google Scholar]
- Ige, T.; Kiekintveld, C. Performance Comparison and Implementation of Bayesian Variants for Network Intrusion Detection. In Proceedings of the IEEE International Conference on Artificial Intelligence, Blockchain, and Internet of Things (AIDThings), Mount Pleasant, MI, USA, 16–17 September 2023. [Google Scholar]
- Zhou, J.; Qian, Y.; Zou, Q.; Liu, P.; Xiang, J. Deepsyslog: Deep Anomaly Detection on Syslog Using Sentence Embedding and Metadata. IEEE Trans. Inf. Forensics Secur. 2022, 17, 3051–3061. [Google Scholar] [CrossRef]
- Liu, Y.; Tao, S.; Meng, W.; Wang, J.; Hao, Y.; Jiang, Y. Multi-Source Log Parsing with Pre-Trained Domain Classifier. IEEE Trans. Netw. Serv. Manag. 2024, 21, 2651–2663. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Log Entry | Probability of “ERROR” | Probability of “INFO” |
|---|---|---|
| “Disk failure on drive C” | 0.85 | 0.15 |
| “System backup completed” | 0.10 | 0.90 |
| File Name | Number of Entries |
|---|---|
| Linux_extracted.csv | 25,567 |
| Mac_extracted.csv | 107,201 |
| Windows_extracted.csv | 114,422,305 |
| Android_extracted.csv | 1,555,005 |
| System | Error | Warning | Tokens | Label |
|---|---|---|---|---|
| Android | 1431.0 | 3.0 | 9.357741 | |
| Linux | 146.0 | 250.0 | 9.048304 | |
| Mac | 356.0 | 381.0 | 11.383989 | |
| Windows | 142,113.0 | 0.0 | 6.015923 |
| Extracted Data Error Count | Extracted Data Warning Count | ||
| Dataset | Error Count | Dataset | Warning Count |
| Android | 1.555 × 106 | Android | 1.555 × 106 |
| Linux | 25,567 | Linux | 25,567 |
| Mac | 107,201 | Mac | 107,201 |
| Windows | 1.14422 × 108 | Windows | 1.14422 × 108 |
| Preprocessed Data Error Count | Preprocessed Data Warning Count | ||
| Dataset | Error Count | Dataset | Warning Count |
| Android | 154,232 | Android | 3237 |
| Linux | 415 | Linux | 4198 |
| Mac | 16,661 | Mac | 370 |
| Windows | 329,807 | Windows | 202,860 |
| Statistic | Android | Linux | Mac | Windows |
|---|---|---|---|---|
| count | 1.555005 × 106 | 25,567.000000 | 107,201.000000 | 1.144223 × 108 |
| mean | 9.918425 × 10−2 | 0.016232 | 0.155418 | 2.882366× 10−3 |
| std | 2.989093 × 10−1 | 0.126369 | 0.362305 | 5.361024 × 10−1 |
| min | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 50% | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 75% | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| max | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
| Statistic | Android | Linux | Mac | Windows |
|---|---|---|---|---|
| count | 1.555005 × 106 | 25,567.000000 | 107,201.000000 | 1.144223 × 108 |
| mean | 2.081665 × 10−3 | 0.164196 | 0.003451 | 1.772906 × 10−3 |
| std | 4.557777 × 10−2 | 0.370461 | 0.058648 | 4.206855 × 10−2 |
| min | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 50% | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 75% | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| max | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
| Operating System | Errors | Warnings |
|---|---|---|
| Android | 0.0 | 0.0 |
| Linux | 1.0 | 1.0 |
| Mac | 1.0 | 0.0 |
| Windows | 0.0 | 1.0 |
| Model | Accuracy | AUC | Recall | Prec. | F1 | Kappa | MCC | TT (s) |
|---|---|---|---|---|---|---|---|---|
| knn | 0.9604 | 0.0000 | 0.6007 | 1.0000 | 0.7506 | 0.7305 | 0.7586 | 7.1660 |
| dt | 0.9604 | 0.0000 | 0.6007 | 1.0000 | 0.7506 | 0.7305 | 0.7586 | 1.1400 |
| svm | 0.9604 | 0.9903 | 0.6007 | 1.0000 | 0.7506 | 0.7305 | 0.7586 | 1.2020 |
| rf | 0.9604 | 0.0000 | 0.6007 | 1.0000 | 0.7506 | 0.7305 | 0.7586 | 2.5570 |
| ada | 0.9604 | 0.8004 | 0.6007 | 1.0000 | 0.7506 | 0.7305 | 0.7586 | 1.1710 |
| gbc | 0.9604 | 0.8262 | 0.6007 | 1.0000 | 0.7506 | 0.7305 | 0.7586 | 3.3610 |
| et | 0.9604 | 0.0000 | 0.6007 | 1.0000 | 0.7506 | 0.7305 | 0.7586 | 1.1460 |
| lightgbm | 0.9604 | 0.0000 | 0.6007 | 1.0000 | 0.7506 | 0.7305 | 0.7586 | 1.1710 |
| lr | 0.9603 | 0.9991 | 0.6010 | 0.9987 | 0.7504 | 0.7303 | 0.7582 | 1.3720 |
| lda | 0.9562 | 0.9847 | 0.5634 | 0.9918 | 0.7186 | 0.6960 | 0.7297 | 1.1680 |
| ridge | 0.9559 | 0.9847 | 0.5588 | 0.9936 | 0.7153 | 0.6934 | 0.7273 | 1.1380 |
| qda | 0.9008 | 0.0000 | 0.4892 | 0.9000 | 0.6118 | 0.6960 | 0.7297 | 1.2390 |
| dummy | 0.9008 | 0.0000 | 0.4892 | 0.9000 | 0.6118 | 0.6960 | 0.7297 | 1.1710 |
| nb | 0.1013 | 0.0000 | 1.0000 | 0.0994 | 0.1808 | 0.0005 | 0.0152 | 1.1190 |
| Model | Accuracy | AUC | Recall | Prec. | F1 | Kappa | MCC | TT (s) |
|---|---|---|---|---|---|---|---|---|
| nb | 0.9887 | 0.0000 | 0.5621 | 0.7041 | 0.6173 | 0.6117 | 0.6196 | 0.0190 |
| knn | 0.9877 | 0.0000 | 0.2414 | 1.0000 | 0.3847 | 0.3809 | 0.4839 | 0.0910 |
| dt | 0.9875 | 0.0000 | 0.2310 | 1.0000 | 0.3703 | 0.3666 | 0.4722 | 0.0210 |
| svm | 0.9875 | 0.9107 | 0.2310 | 1.0000 | 0.3703 | 0.3666 | 0.4722 | 0.0510 |
| ridge | 0.9875 | 0.9104 | 0.2310 | 1.0000 | 0.3703 | 0.3666 | 0.4722 | 0.0190 |
| rf | 0.9875 | 0.0000 | 0.2310 | 1.0000 | 0.3703 | 0.3666 | 0.4722 | 0.0370 |
| ada | 0.9875 | 0.6155 | 0.2310 | 1.0000 | 0.3703 | 0.3666 | 0.4722 | 0.0330 |
| gbc | 0.9875 | 0.6155 | 0.2310 | 1.0000 | 0.3703 | 0.3666 | 0.4722 | 0.0390 |
| lda | 0.9875 | 0.8940 | 0.2310 | 1.0000 | 0.3703 | 0.3666 | 0.4722 | 0.0220 |
| et | 0.9875 | 0.0000 | 0.2310 | 1.0000 | 0.3703 | 0.3666 | 0.4722 | 0.0330 |
| lightgbm | 0.9875 | 0.0000 | 0.2310 | 1.0000 | 0.3703 | 0.3666 | 0.4722 | 0.0260 |
| lr | 0.9849 | 0.9035 | 0.0690 | 0.9000 | 0.1270 | 0.1253 | 0.2427 | 0.1590 |
| qda | 0.9838 | 0.0000 | 0.0690 | 0.9000 | 0.1270 | 0.1253 | 0.2427 | 0.0190 |
| dummy | 0.9838 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0180 |
| Model | Accuracy | AUC | Recall | Prec. | F1 | Kappa | MCC | TT (s) |
|---|---|---|---|---|---|---|---|---|
| lr | 0.9400 | 0.9714 | 0.6147 | 0.9993 | 0.7611 | 0.7291 | 0.7573 | 0.1980 |
| knn | 0.9398 | 0.0000 | 0.6126 | 0.9999 | 0.7597 | 0.7275 | 0.7561 | 0.1410 |
| et | 0.9216 | 0.0000 | 0.4956 | 0.9999 | 0.6549 | 0.6177 | 0.6697 | 0.1210 |
| lda | 0.9211 | 0.9626 | 0.4975 | 0.9957 | 0.6622 | 0.6230 | 0.6705 | 0.0620 |
| ridge | 0.9195 | 0.9716 | 0.4876 | 0.9904 | 0.6611 | 0.6202 | 0.6705 | 0.0620 |
| dt | 0.9033 | 0.0000 | 0.3775 | 1.0000 | 0.5480 | 0.5060 | 0.5819 | 0.0630 |
| svm | 0.9033 | 0.9731 | 0.3775 | 1.0000 | 0.5480 | 0.5060 | 0.5819 | 0.0630 |
| rf | 0.9033 | 0.0000 | 0.3775 | 1.0000 | 0.5480 | 0.5060 | 0.5819 | 0.0630 |
| ada | 0.9033 | 0.6888 | 0.3775 | 1.0000 | 0.5480 | 0.5060 | 0.5819 | 0.0660 |
| gbc | 0.9033 | 0.7341 | 0.3775 | 1.0000 | 0.5480 | 0.5060 | 0.5819 | 0.1590 |
| lightgbm | 0.9033 | 0.0000 | 0.3775 | 1.0000 | 0.5480 | 0.5060 | 0.5819 | 0.1560 |
| qda | 0.8446 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0620 |
| dummy | 0.8446 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0610 |
| nb | 0.1588 | 0.0000 | 1.0000 | 0.1560 | 0.2698 | 0.0012 | 0.0249 | 0.0610 |
| Model | Accuracy | AUC | Recall | Prec. | F1 | Kappa | MCC | TT (s) |
|---|---|---|---|---|---|---|---|---|
| knn | 0.9999 | 0.0000 | 0.9732 | 1.0000 | 0.9864 | 0.9864 | 0.9865 | 24.9233 |
| dt | 0.9999 | 0.0000 | 0.9732 | 1.0000 | 0.9864 | 0.9864 | 0.9865 | 3.5067 |
| rf | 0.9999 | 0.0000 | 0.9732 | 1.0000 | 0.9864 | 0.9864 | 0.9865 | 8.2633 |
| ada | 0.9999 | 0.9866 | 0.9732 | 1.0000 | 0.9864 | 0.9864 | 0.9865 | 4.3900 |
| gbc | 0.9999 | 0.9793 | 0.9732 | 1.0000 | 0.9864 | 0.9864 | 0.9865 | 34.6100 |
| et | 0.9999 | 0.0000 | 0.9732 | 1.0000 | 0.9864 | 0.9864 | 0.9865 | 5.7700 |
| lightgbm | 0.9999 | 0.0000 | 0.9732 | 1.0000 | 0.9864 | 0.9864 | 0.9865 | 4.8600 |
| lr | 0.9998 | 0.9993 | 0.9305 | 0.9938 | 0.9639 | 0.9634 | 0.9661 | 3.9967 |
| svm | 0.9989 | 0.9996 | 0.6156 | 1.0000 | 0.7620 | 0.7615 | 0.7842 | 3.6500 |
| lda | 0.9989 | 0.9967 | 0.6209 | 1.0000 | 0.7661 | 0.7655 | 0.7875 | 3.7233 |
| ridge | 0.9988 | 0.9968 | 0.5933 | 1.0000 | 0.7447 | 0.7442 | 0.7698 | 3.5067 |
| qda | 0.9971 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 3.6733 |
| dummy | 0.9971 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 3.1667 |
| nb | 0.9892 | 0.0000 | 0.9755 | 0.2072 | 0.3417 | 0.3386 | 0.4470 | 3.5767 |
| Model | Dataset | Key Metric | Performance | Key Feature |
|---|---|---|---|---|
| MNB (Our Work) | Android/Linux | Recall | 56.21% | High recall, fast training time (0.019 s). |
| ReLoop2 | AmazonElectronics | AUC improvement | +5.6% | Error memory for adaptive compensation. |
| MicroVideo | AUC improvement | +3.1% | Model-agnostic adaptation to changing data. | |
| Production (Huawei) | AUC | 75.0% | Combines error memory and incremental learning. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Johnphill, O.; Sadiq, A.S.; Kaiwartya, O.; Aljaidi, M. An Intelligent Approach to Automated Operating Systems Log Analysis for Enhanced Security. Information 2024, 15, 657. https://doi.org/10.3390/info15100657
Johnphill O, Sadiq AS, Kaiwartya O, Aljaidi M. An Intelligent Approach to Automated Operating Systems Log Analysis for Enhanced Security. Information. 2024; 15(10):657. https://doi.org/10.3390/info15100657
Chicago/Turabian StyleJohnphill, Obinna, Ali Safaa Sadiq, Omprakash Kaiwartya, and Mohammad Aljaidi. 2024. "An Intelligent Approach to Automated Operating Systems Log Analysis for Enhanced Security" Information 15, no. 10: 657. https://doi.org/10.3390/info15100657
APA StyleJohnphill, O., Sadiq, A. S., Kaiwartya, O., & Aljaidi, M. (2024). An Intelligent Approach to Automated Operating Systems Log Analysis for Enhanced Security. Information, 15(10), 657. https://doi.org/10.3390/info15100657