
A Comparative Analysis of Automated Machine Learning Tools: A Use Case for Autism Spectrum Disorder Detection


Abstract
1. Introduction
- This study conducted a comprehensive data collection effort by gathering ASD data from multiple rehabilitation centers across Pakistan, employing the Autism Spectrum Quotient in Toddlers-10 (Q-CHAT-10) questionnaire. This approach ensured the inclusion of a diverse population and captured critical features essential for early and accurate ASD detection.
- Leveraging cutting-edge AutoML tools, specifically TPOT and KNIME, the entire model selection and hyperparameter tuning process for ASD detection was automated. This automation not only streamlined the workflow but also facilitated the identification of the most significant ASD features, leading to the development of robust ASD feature signatures.
- This work conducted a thorough comparative analysis of the performance and feature signatures generated by TPOT and KNIME, providing valuable insights into the strengths and limitations of each AutoML tool in the context of ASD detection. This comparison underscores the potential of AutoML tools to enhance predictive accuracy and feature interpretability in clinical diagnostics.
2. Literature Review
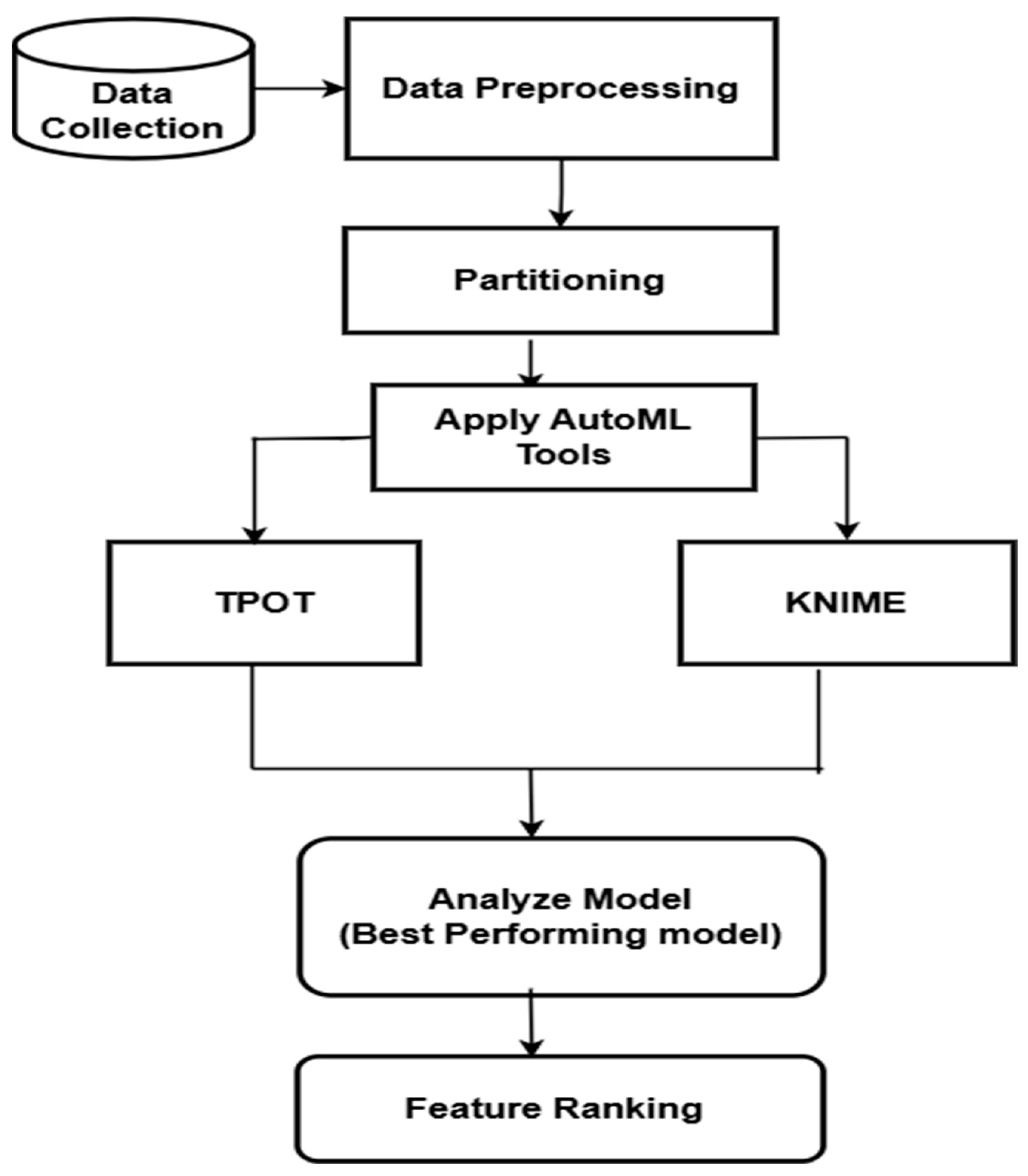
3. Proposed System Architecture
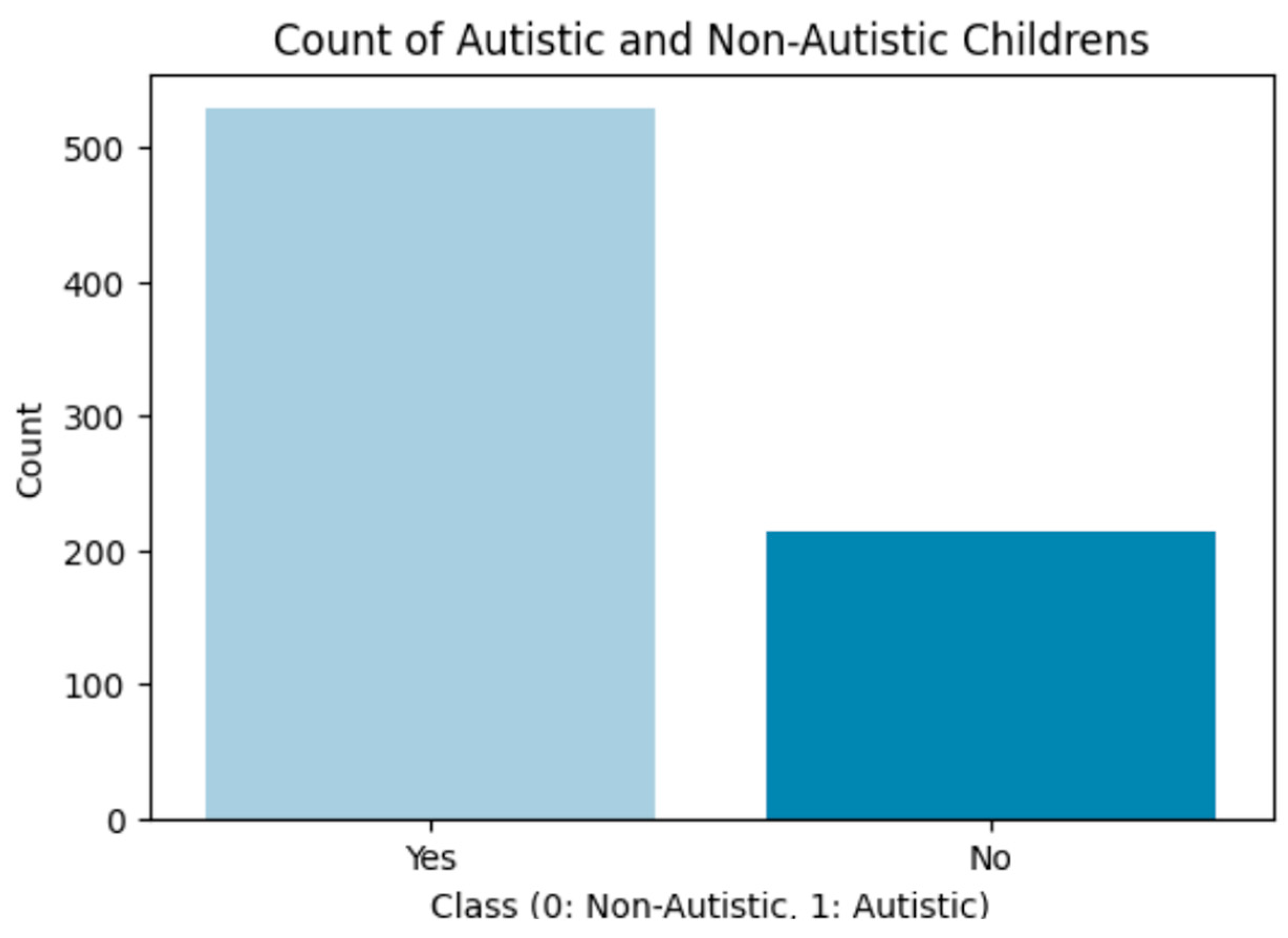
3.1. Data Collection Method
3.2. Data Preprocessing
3.3. Data Partitioning
3.4. Applying AutoML Tools
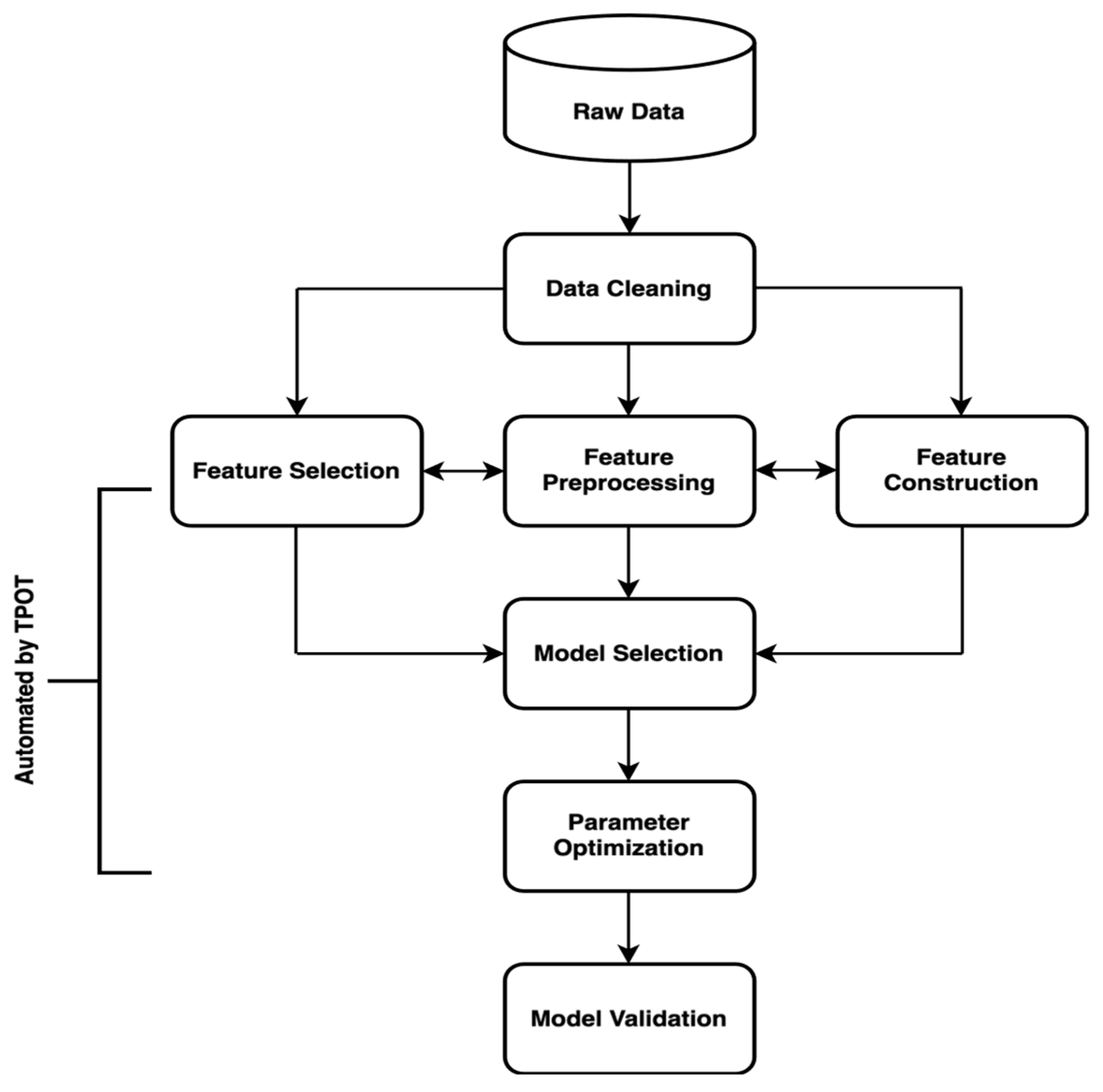
3.4.1. TPOT: Tree-Based Pipeline Optimization Tool
3.4.2. KNIME: Konstanz Information Miner
3.5. Model Selection
3.6. Feature Signature Discovery
- Prioritizing high-ranking characteristics to increase accuracy and decrease overfitting.
- Knowing which features matter most allows for targeted data collection efforts and optimized use of computational resources in training the model.
- Streamlining preprocessing and modeling processes by selecting relevant features.
4. Results and Experimentation
4.1. Results and Evaluations
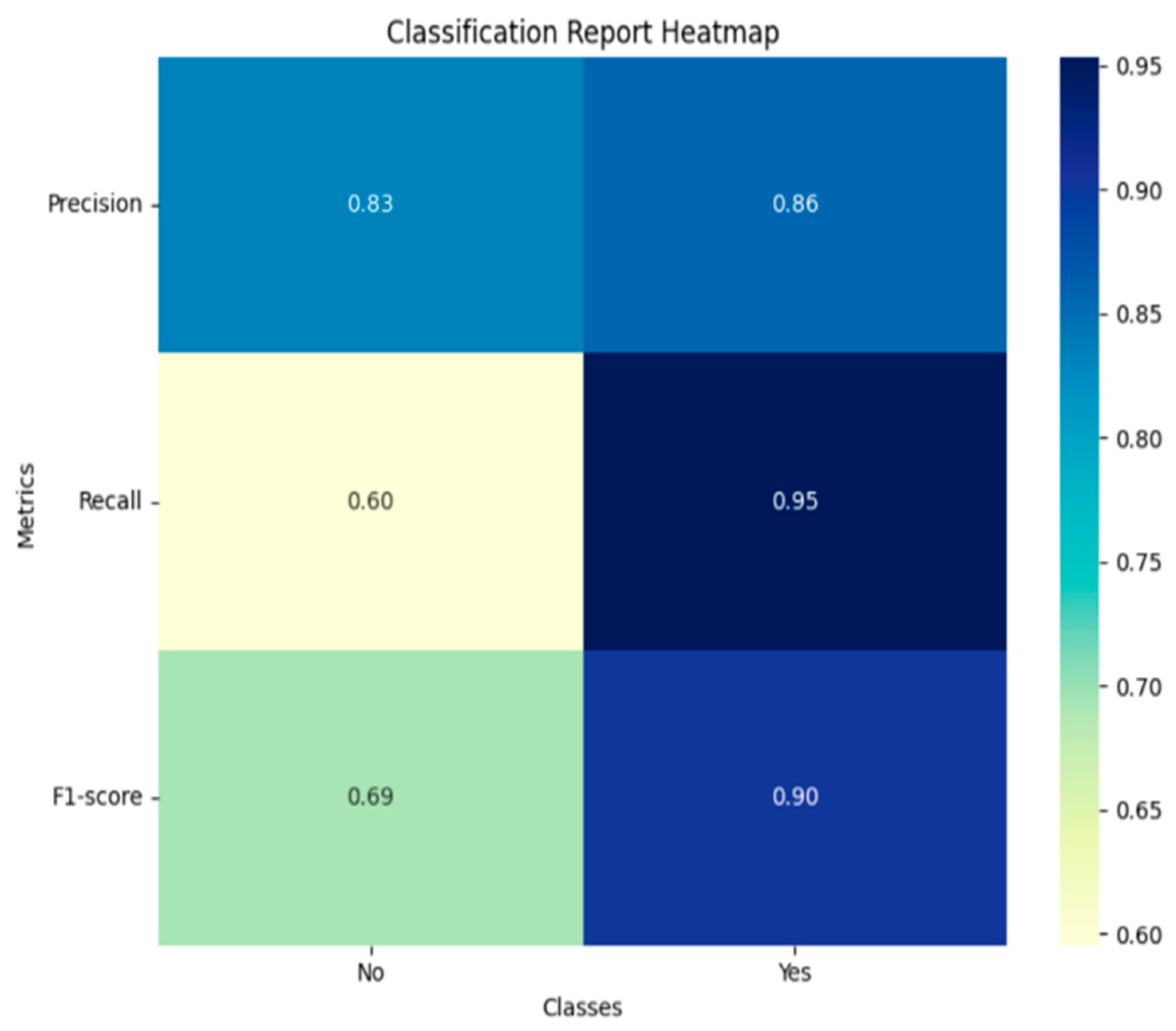
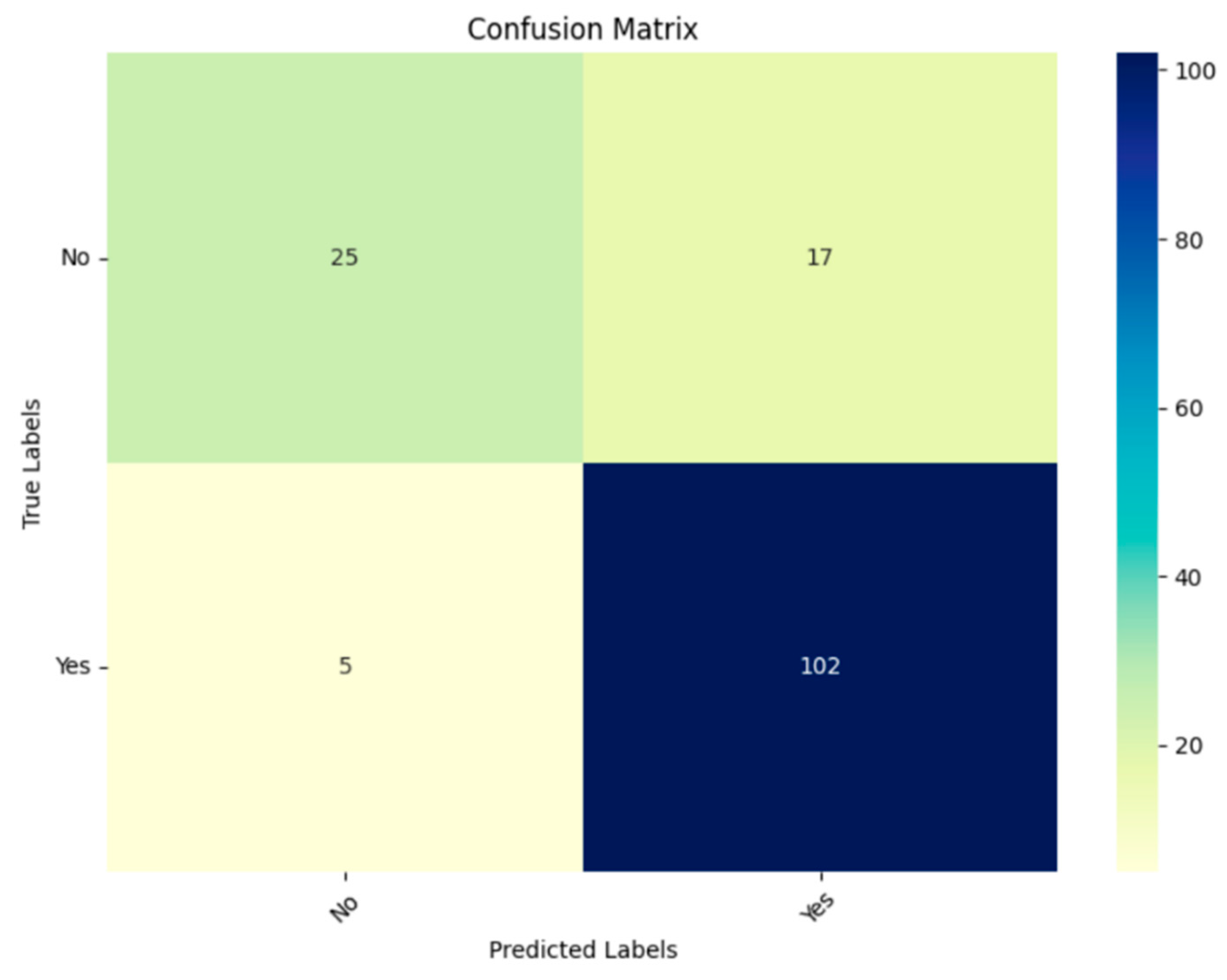
4.1.1. Experiment 1 (Applying TPOT)
- Generations: 10;
- Population size: 200;
- Scoring metric: accuracy;
- Verbosity: 2 (to provide detailed logs);
- Random state: 42 (for reproducibility).
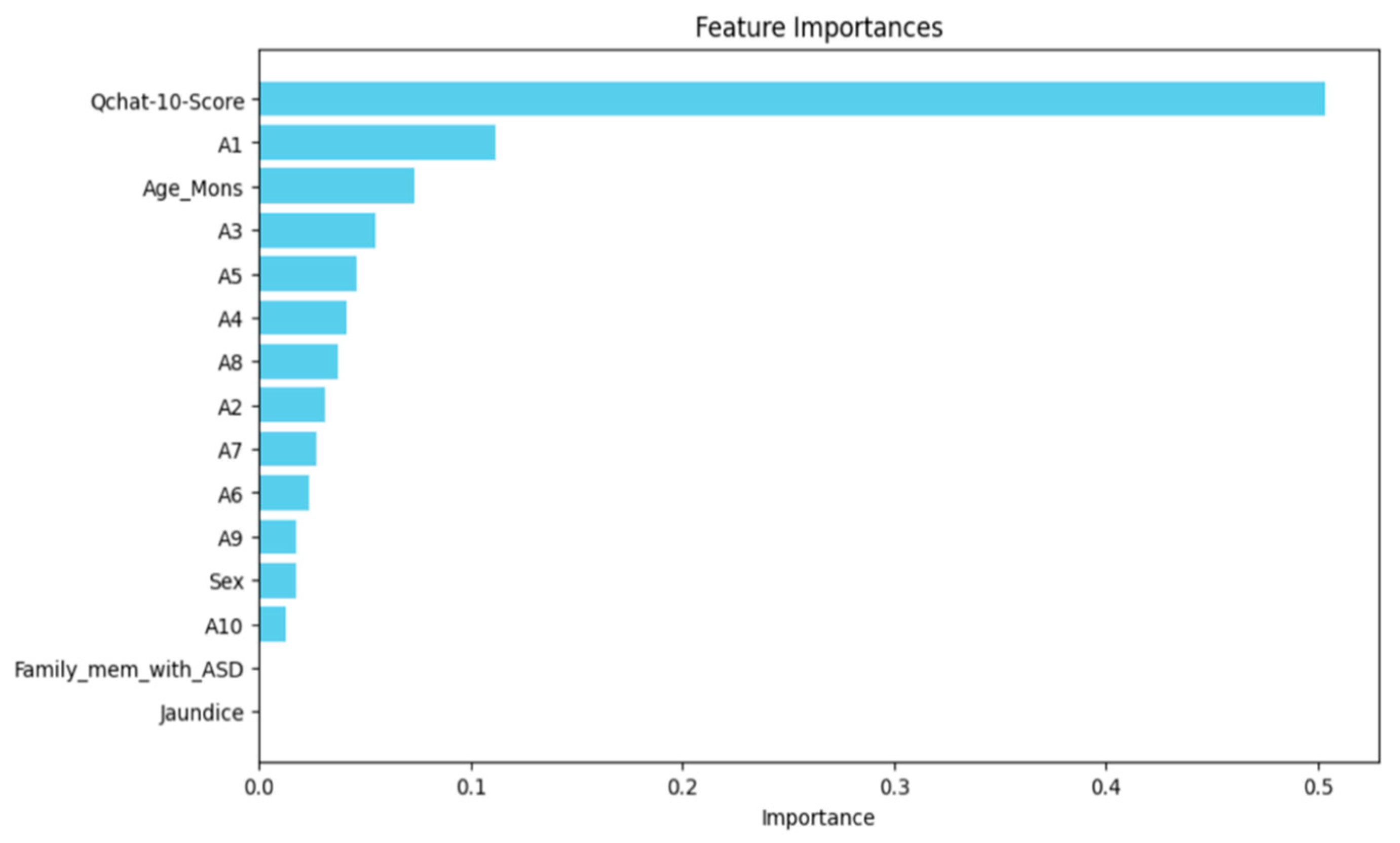
Feature Ranking
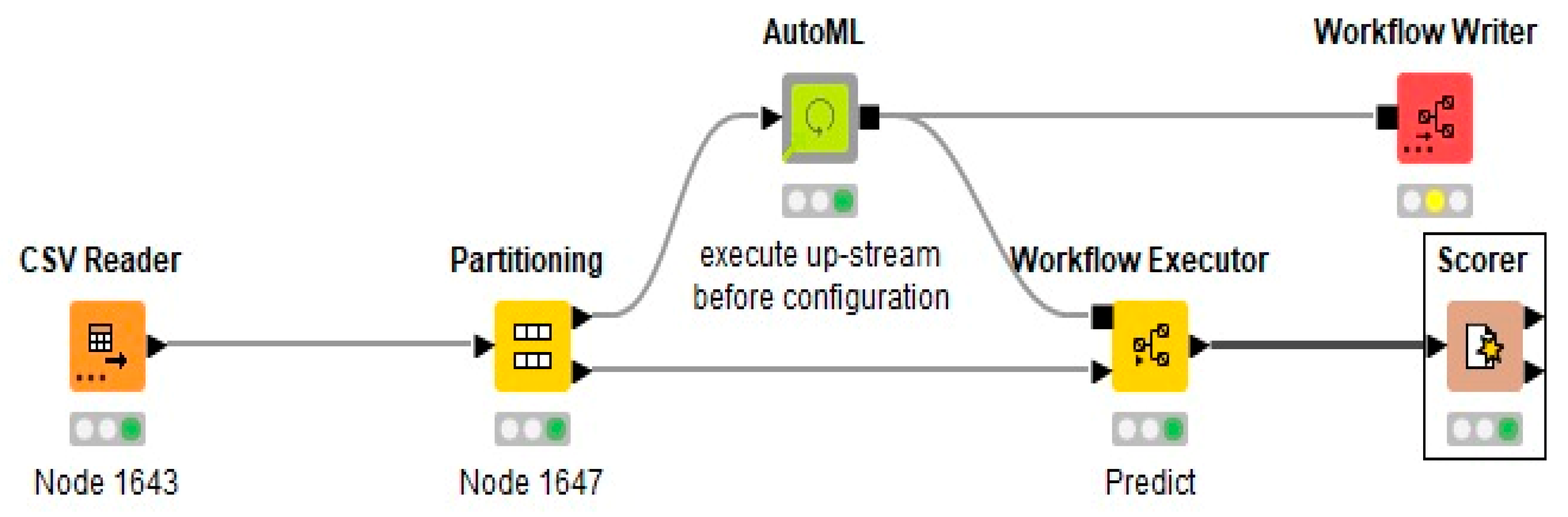
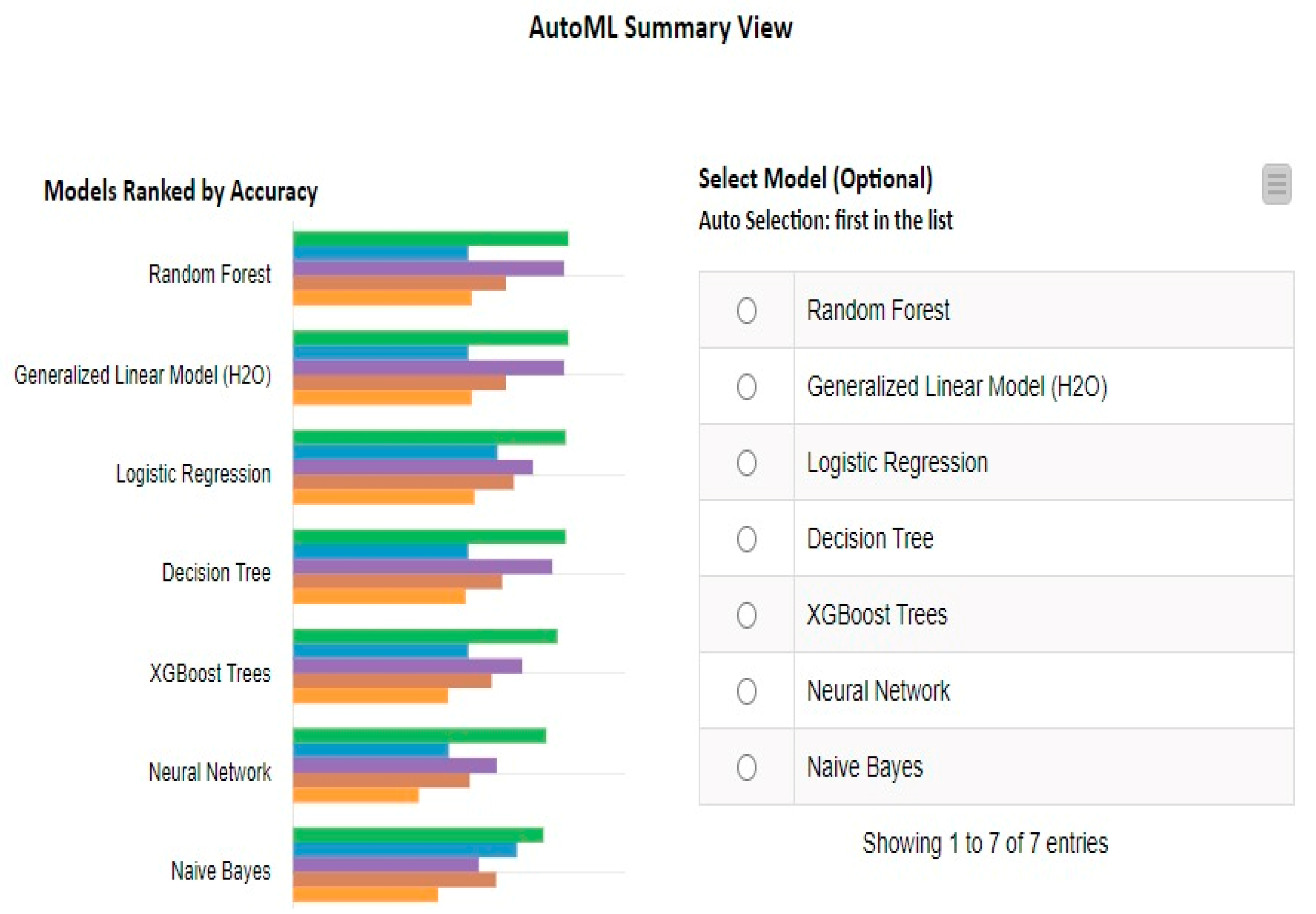
4.1.2. Experiment 2 (Applying KNIME)
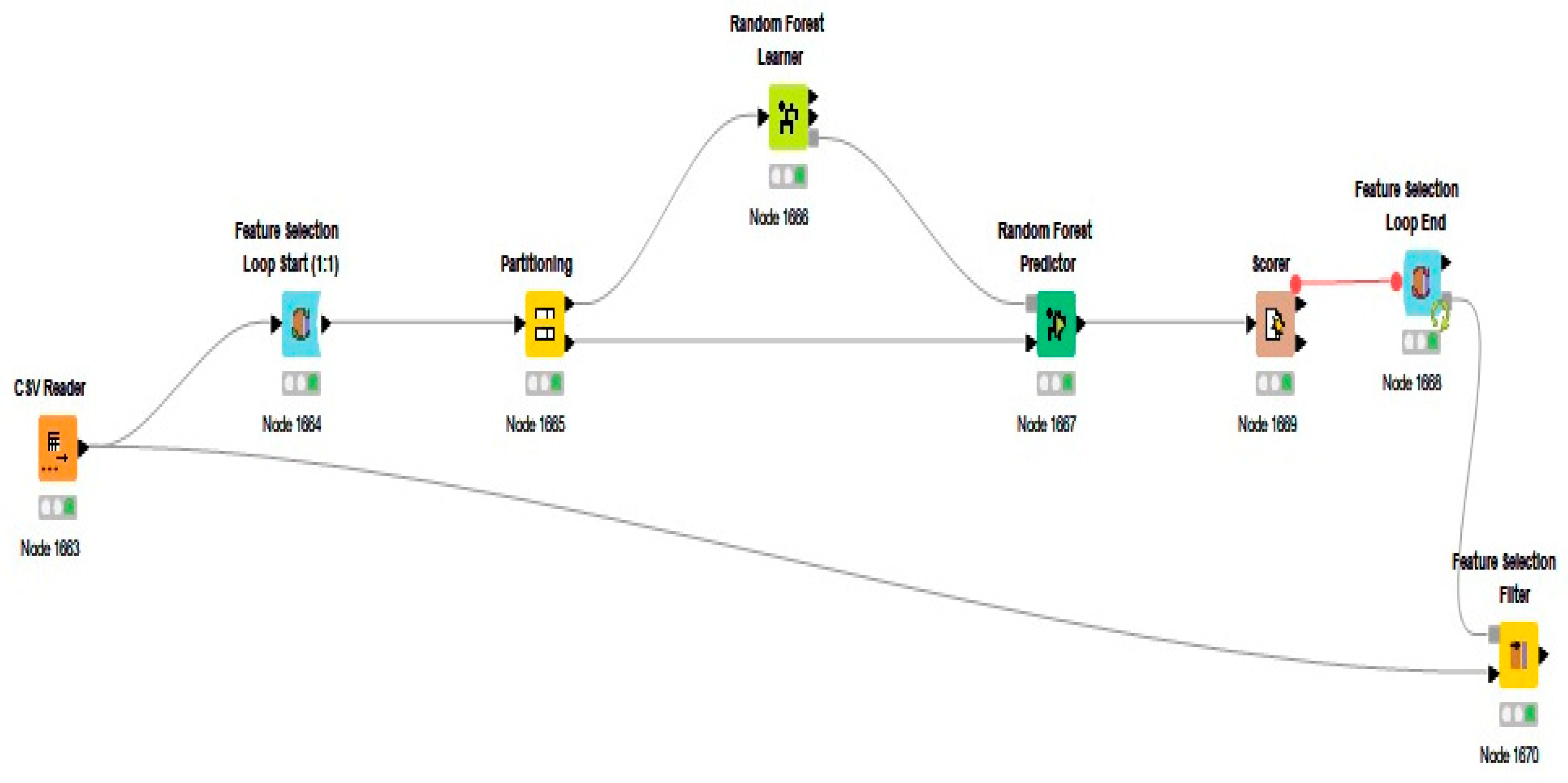
Feature Ranking Using KNIME
- CSV Reader: The dataset is initially loaded into the workflow using the CSV Reader node. This node reads the data from a CSV file, making it available for subsequent processing and analysis.
- Feature selection loop start (1:1): A feature selection loop is initiated with the given feature selection method. This node systematically iterates over different subsets of features, allowing the model to be trained and evaluated with varying feature combinations.
- Partitioning: Within each iteration of the feature selection loop, the dataset is partitioned into training and test sets using the partitioning node. This ensures that the model is trained on one subset of data and tested on another, facilitating an unbiased evaluation of its performance.
- Random Forest Learner: A Random Forest model is trained on the training set for each subset of features using the Random Forest Learner node. This node constructs the model based on the selected features, learning patterns, and relationships within the training data.
- Random Forest Predictor: The trained Random Forest model is then applied to the test set using the Random Forest Predictor node. This node generates predictions for the test instances based on the model built in the previous step.
- Scorer: The performance of the Random Forest model is evaluated using the Scorer node. This node compares the predicted labels with the actual labels in the test set, calculating various performance metrics to assess the model’s effectiveness for each subset of features.
- Feature Selection Loop End: The loop is concluded with the Feature Selection Loop End node. This node aggregates the scores from each iteration, providing a comprehensive evaluation of different feature subsets’ performance.
- Feature Selection Filter: Finally, the Feature Selection Filter node selects the best subset of features based on the aggregated performance scores. This node identifies the feature combination that yields the highest model performance, optimizing the feature set for the Random Forest classifier.
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jomthanachai, S.; Wong, W.P.; Khaw, K.W. An application of machine learning regression to feature selection: A study of logistics performance and economic attribute. Neural Comput. Appl. 2022, 34, 15781–15805. [Google Scholar] [CrossRef]
- Abdallah, T.A.; de La Iglesia, B. Survey on Feature Selection. arXiv 2015, arXiv:1510.02892. [Google Scholar]
- Cai, J.; Luo, J.; Wang, S.; Yang, S. Feature selection in machine learning: A new perspective. Neurocomputing 2018, 300, 70–79. [Google Scholar] [CrossRef]
- Roffo, G. Feature selection library (MATLAB toolbox). arXiv 2016, arXiv:1607.01327. [Google Scholar]
- Jacob, S.G.; Sulaiman, M.M.B.A.; Bennet, B. Feature signature discovery for autism detection: An automated machine learning based feature ranking framework. Comput. Intell. Neurosci. 2023, 2023, 6330002. [Google Scholar] [CrossRef] [PubMed]
- Sharma, A.A.; Dey, S. A comparative study of feature selection and machine learning techniques for sentiment analysis. In Proceedings of the 2012 ACM Research in Applied Computation Symposium, San Antonio, TX, USA, 23–26 October 2012; pp. 1–7. [Google Scholar]
- Aksu, D.D.; Üstebay, S.; Aydin, M.A.; Atmaca, T. Intrusion detection with comparative analysis of supervised learning techniques and fisher score feature selection algorithm. In Computer and Information Sciences, Proceedings of the 32nd International Symposium, ISCIS 2018, the 24th IFIP World Computer Congress, WCC 2018, Poznan, Poland, 20–21 September 2018; Proceedings 32; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 141–149. [Google Scholar]
- Kuzhippallil, M.A.; Joseph, C.; Kannan, A. Comparative analysis of machine learning techniques for indian liver disease patients. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 778–782. [Google Scholar]
- Khagi, B.; Kwon, G.R.; Lama, R. Comparative analysis of Alzheimer’s disease classification by CDR level using CNN, feature selection, and machine-learning techniques. Int. J. Imaging Syst. Technol. 2019, 29, 297–310. [Google Scholar] [CrossRef]
- Mafarja, M.; Thaher, T.; Al-Betar, M.A.; Too, J.; Awadallah, M.A.; Abu Doush, I.; Turabieh, H. Classification framework for faulty-software using enhanced exploratory whale optimizer-based feature selection scheme and random forest ensemble learning. Appl. Intell. 2023, 53, 18715–18757. [Google Scholar] [CrossRef] [PubMed]
- Li, K.Y.; Sampaio de Lima, R.; Burnside, N.G.; Vahtmäe, E.; Kutser, T.; Sepp, K.; Sepp, K. Toward automated machine learning-based hyperspectral image analysis in crop yield and biomass estimation. Remote Sens. 2022, 14, 1114. [Google Scholar] [CrossRef]
- Adla, Y.A.A.; Raydan, D.G.; Charaf, M.Z.J.; Saad, R.A.; Nasreddine, J.; Diab, M.O. Automated detection of polycystic ovary syndrome using machine learning techniques. In Proceedings of the 2021 Sixth International Conference on Advances in Biomedical Engineering (ICABME), Werdanyeh, Lebanon, 7–9 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 208–212. [Google Scholar]
- Raj, S.; Masood, S. Analysis and detection of autism spectrum disorder using machine learning techniques. Procedia Comput. Sci. 2020, 167, 994–1004. [Google Scholar] [CrossRef]
- Romero-García, R.; Martínez-Tomás, R.; Pozo, P.; de la Paz, F.; Sarriá, E. Q-CHAT-NAO: A robotic approach to autism screening in toddlers. J. Biomed. Inform. 2021, 118, 103797. [Google Scholar] [CrossRef]
- Thabtah, F. An accessible and efficient autism screening method for behavioural data and predictive analyses. Health Inform. J. 2019, 25, 1739–1755. [Google Scholar] [CrossRef]
- Allison, C.; Auyeung, B.; Baron-Cohen, S. Toward brief “red flags” for autism screening: The short autism spectrum quotient and the short quantitative checklist in 1,000 cases and 3,000 controls. J. Am. Acad. Child Adolesc. Psychiatry 2012, 51, 202–212. [Google Scholar] [CrossRef] [PubMed]
- Allison, C.; Baron-Cohen, S.; Wheelwright, S.; Charman, T.; Richler, J.; Pasco, G.; Brayne, C. The Q-CHAT (Quantitative CHecklist for Autism in Toddlers): A normally distributed quantitative measure of autistic traits at 18–24 months of age: Preliminary report. J. Autism Dev. Disord. 2008, 38, 1414–1425. [Google Scholar] [CrossRef]
- Ruta, L.; Chiarotti, F.; Arduino, G.M.; Apicella, F.; Leonardi, E.; Maggio, R.; Carrozza, C.; Chericoni, N.; Costanzo, V.; Turco, N.; et al. Validation of the quantitative checklist for autism in toddlers in an Italian clinical sample of young children with autism and other developmental disorders. Front. Psychiatry 2019, 10, 488. [Google Scholar] [CrossRef] [PubMed]
- Eldridge, J.; Lane, A.E.; Belkin, M.; Dennis, S. Robust features for the automatic identification of autism spectrum disorder in children. J. Neurodev. Disord. 2014, 6, 12. [Google Scholar] [CrossRef] [PubMed]
- Stevanović, D. Quantitative Checklist for Autism in Toddlers (Q-CHAT): A psychometric study with Serbian Toddlers. Res. Autism Spectr. Disord. 2021, 83, 101760. [Google Scholar] [CrossRef]
- Islam, S.; Akter, T.; Zakir, S.; Sabreen, S.; Hossain, M.I. Autism spectrum disorder detection in toddlers for early diagnosis using machine learning. In Proceedings of the 2020 IEEE Asia-Pacific Conference on Computer Science and Data Engineering (CSDE), Gold Coast, Australia, 16–18 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Marlow, M.; Servili, C.; Tomlinson, M. A review of screening tools for the identification of autism spectrum disorders and developmental delay in infants and young children: Recommendations for use in low-and middle-income countries. Autism Res. 2019, 12, 176–199. [Google Scholar] [CrossRef]
- Farooqi, N.; Bukhari, F.; Iqbal, W. Predictive analysis of autism spectrum disorder (ASD) using machine learning. In Proceedings of the 2021 International Conference on Frontiers of Information Technology (FIT), Islamabad, Pakistan, 13–14 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 305–310. [Google Scholar]
- Cerrada, M.; Trujillo, L.; Hernández, D.E.; Correa Zevallos, H.A.; Macancela, J.C.; Cabrera, D.; Vinicio Sánchez, R. AutoML for feature selection and model tuning applied to fault severity diagnosis in spur gearboxes. Math. Comput. Appl. 2022, 27, 6. [Google Scholar] [CrossRef]
- Baron-Cohen, S.; Allen, J.; Gillberg, C. Can autism be detected at 18 months?: The needle, the haystack, and the CHAT. Br. J. Psychiatry 1992, 161, 839–843. [Google Scholar] [CrossRef]
- Available online: https://epistasislab.github.io/tpot/ (accessed on 1 January 2020).
- Olson, R.S.; Moore, J.H. TPOT: A tree-based pipeline optimization tool for automating machine learning. In Proceedings of the Workshop on Automatic Machine Learning, New York, NY, USA, 24 June 2016; pp. 66–74. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Variables | Data Type | Attribute Description |
|---|---|---|
| a1 | Binary (0,1) | Does the child respond when their name is called by looking at the caller? |
| a2 | Binary (0,1) | How easy is it for the caregiver to establish eye contact with the child? |
| a3 | Binary (0,1) | Does the child use pointing gestures to communicate needs or desires, such as indicating a toy out of reach? |
| a4 | Binary (0,1) | Does the child use pointing gestures to share interest or excitement with others, such as pointing at something interesting? |
| a5 | Binary (0,1) | Does the child engage in pretend play, such as caring for dolls or talking on a toy phone? |
| a6 | Binary (0,1) | Does the child follow the direction of someone else’s gaze? |
| a7 | Binary (0,1) | When a family member displays visible distress, does the child exhibit signs of wanting to comfort them, such as by stroking their hair or offering a hug? |
| a8 | Binary (0,1) | How would you describe the child’s initial spoken words? |
| a9 | Binary (0,1) | Does the child use simple gestures, such as waving goodbye? |
| a10 | Binary (0,1) | Does the child engage in prolonged periods of staring with no apparent purpose? |
| Age_Mons | Number | Child’s age in months |
| Sex | String | Male/Female |
| Jaundice | Boolean (Yes/No) | Whether the child was born with Jaundice |
| Family_mem_with_ASD | Boolean (Yes/No) | Any family member diagnosed with ASD |
| Who completed the test | String | Parent, caregiver, medical staff, clinician |
| Class/ASD Traits | Boolean | The class label shows the presence of ASD traits, a score of “0” indicates the absence of such traits, and a score of “1” indicates their presence. |
| TPOT | KNIME | Explanation | |
|---|---|---|---|
| Model Accuracy | 85.23% | 83.89% | TPOT genetic programming approach gives better accuracy as it explores a broader range of model configurations pipelines and feature combinations, optimizing them iteratively as compared to KNIME’s rule-based workflow. |
| Important Key Feature | Q-CHAT 10 score | Q-CHAT 10 score | Both techniques identified the most significant feature as having high predictive value for ASD identification. |
| Feature Signature Discovery | Q-CHAT 10 score,A1 Age_mons A3,A5,A4,A8,A2,A7 A6,A9 Gender,A10 Jaundice | Q-Chat 10- score Age_mons,A3,A6 A4,A1 A2,A10 Jaundice A7,A5 A8,A9 Gender | The features differ since each tool utilizes different algorithms and techniques for feature selection. TPOT’s genetic programming approach uses iterative evolution and selection, whereas KNIME’s randomized process approaches feature selection in a different way. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abbas, R.T.; Sultan, K.; Sheraz, M.; Chuah, T.C. A Comparative Analysis of Automated Machine Learning Tools: A Use Case for Autism Spectrum Disorder Detection. Information 2024, 15, 625. https://doi.org/10.3390/info15100625
Abbas RT, Sultan K, Sheraz M, Chuah TC. A Comparative Analysis of Automated Machine Learning Tools: A Use Case for Autism Spectrum Disorder Detection. Information. 2024; 15(10):625. https://doi.org/10.3390/info15100625
Chicago/Turabian StyleAbbas, Rana Tuqeer, Kashif Sultan, Muhammad Sheraz, and Teong Chee Chuah. 2024. "A Comparative Analysis of Automated Machine Learning Tools: A Use Case for Autism Spectrum Disorder Detection" Information 15, no. 10: 625. https://doi.org/10.3390/info15100625
APA StyleAbbas, R. T., Sultan, K., Sheraz, M., & Chuah, T. C. (2024). A Comparative Analysis of Automated Machine Learning Tools: A Use Case for Autism Spectrum Disorder Detection. Information, 15(10), 625. https://doi.org/10.3390/info15100625