

Machine Learning Ensemble Methodologies for the Prediction of the Failure Mode of Reinforced Concrete Beam–Column Joints

 , ,
, ,  ,
,  and
and
Abstract
1. Introduction
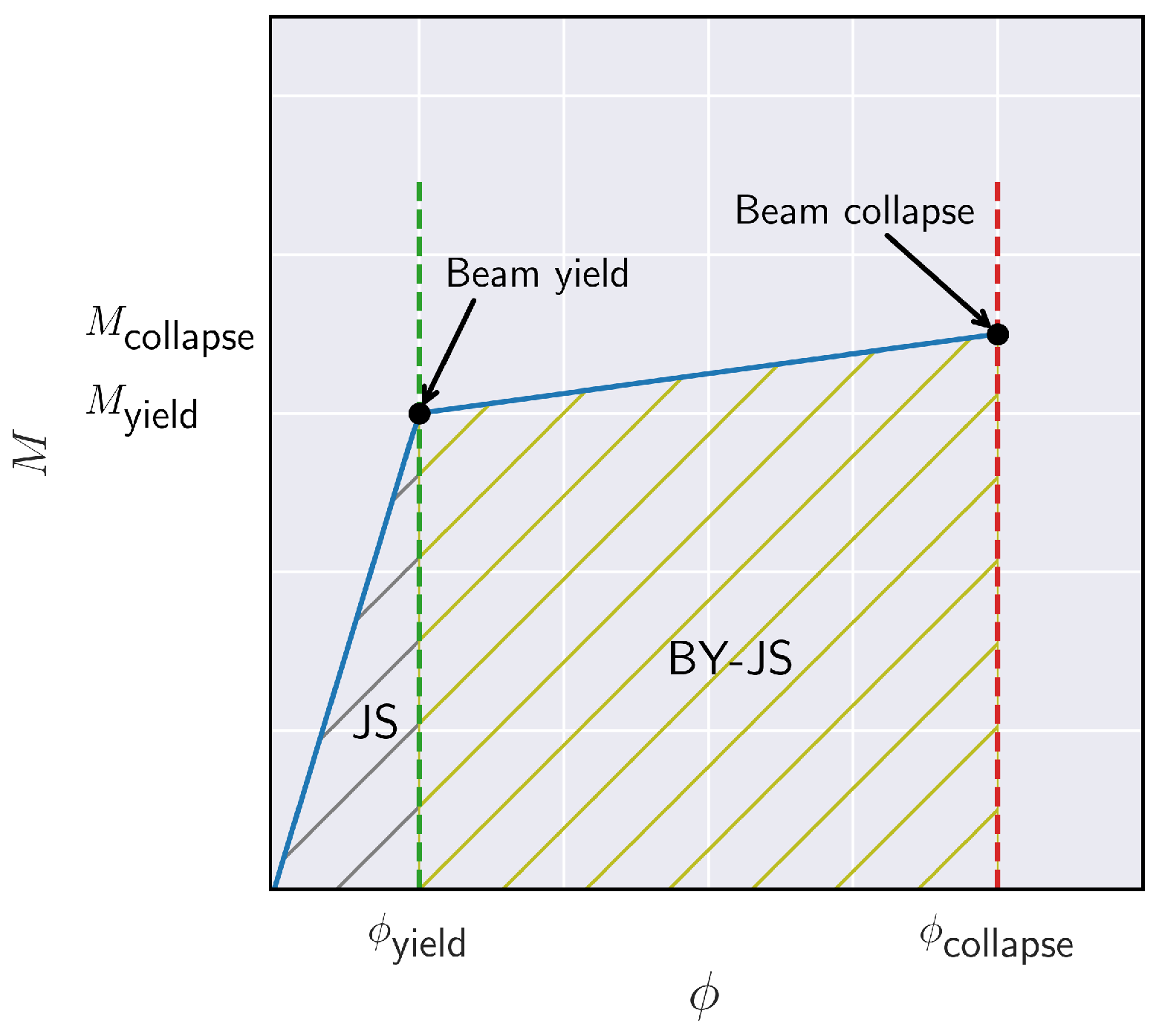
2. Dataset
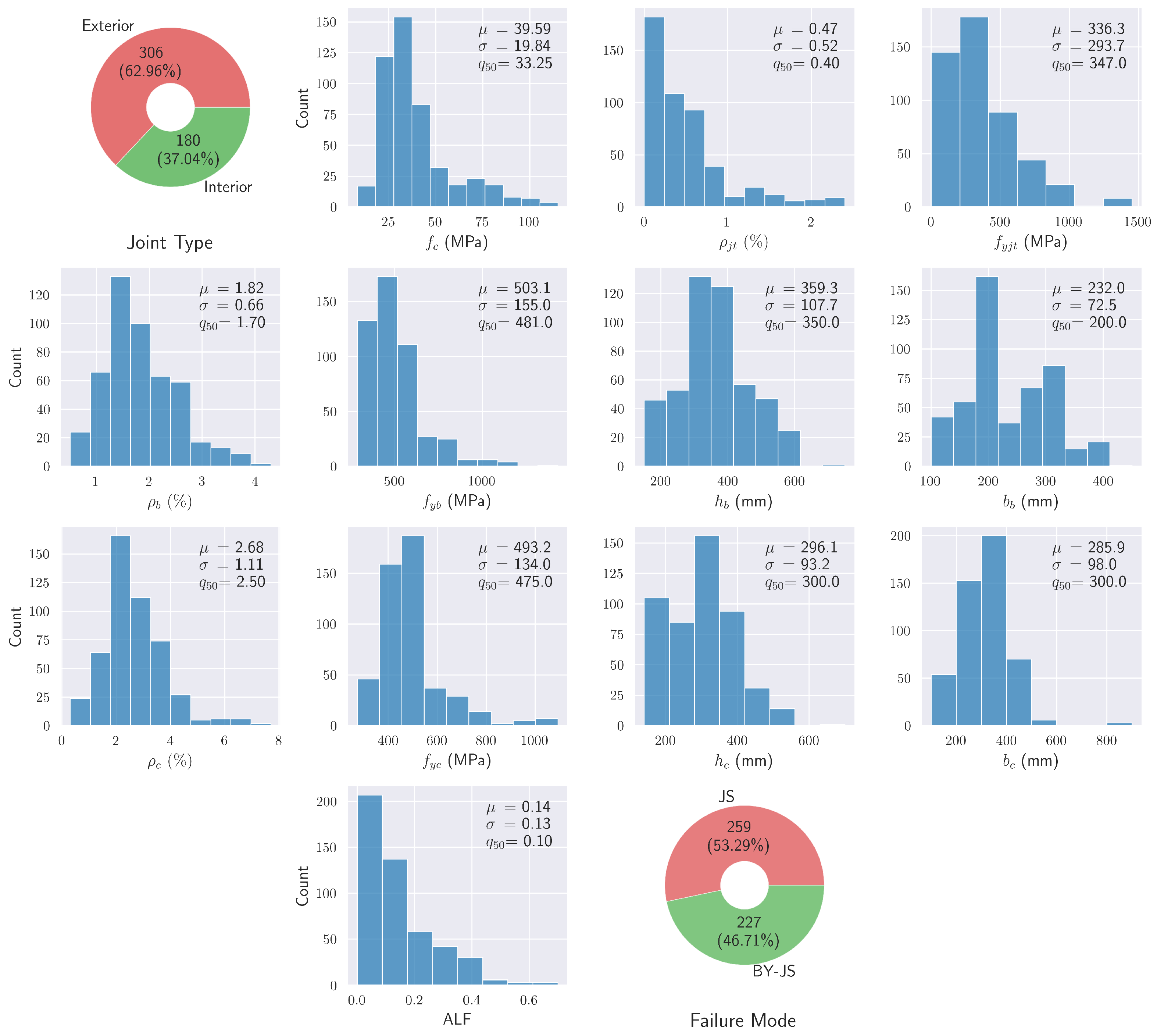
2.1. Exploratory Data Analysis (EDA)
2.2. Dataset Preprocessing
3. Machine Learning Algorithms
3.1. Individual Learners
- Logistic Regression (LR): In a binary classification setting, as is the case in the present paper, LR works by solving a linear regression problem on the so-called logit or log-odds [34]. Thus, logistic regression is a linear classifier, as the classification surface it learns corresponds to a hyperplane.
- k-Nearest Neighbors (k-NN): The fundamental idea behind the k-NN classifier is to assign each input data point to the majority class of the k “closest” vectors in the training set [35]. These “nearest neighbors” are selected based on a user-defined metric function. The majority can be obtained by simple voting or by weighting the contribution from each individual neighbor.
- Decision Tree (DT): A Decision Tree generally comprises three parts [36]. The top part is known as the root and corresponds to the initial training dataset. The bottom part comprises the leaves. Between the root and the leaves, the DT contains the branches and the branching nodes. Each node is associated with a single feature/attribute and learns a binary decision rule based on this feature. It is important to note that there is a single path from the root to each leaf [17]. Thus, to classify each data point , the decision path is followed and is assigned to the (weighted) majority class of the samples in the corresponding leaf.
- Artificial Neural Network (ANN): An Artificial Neural Network also generally comprises 3 parts. Each part consists of one or more layers of processing nodes called neurons. The first layer is called the input layer, where the input data points are inserted into the network. The last layer is called the output layer, which produces the final results of the network. In a binary classification setting, this layer consists of a single node, which outputs the probability that the given input vector belongs to the positive class. Between the input and output layers are the so-called hidden layers. Each node in the hidden layers receives as input the output of the nodes in the previous layer and combines them in a weighted sum. Subsequently, this is passed through a so-called activation function, which introduces non-linearities that allow for the model to learn complex patterns in the data.
3.2. Ensemble Methodologies
- 1.
- Bagging: Bagging, which stands for “bootstrap aggregating”, is an ensemble methodology initially introduced by Breiman in 1996 [37]. The fundamental idea behind this algorithm is to use the original training dataset, , to produce k new sets, , by sampling with replacement from . These “bootstrapped” datasets are then used to train k corresponding individual learners. Due to the fact that these base models are trained on different datasets, they tend to produce different errors. By aggregating their predictions, these errors tend to cancel each other out, thus improving the overall performance of the ensemble model [37]. Any ML model can be employed as a base model. In fact, in the present study, all the individual learners presented in the previous section were employed as base learners for our bagging ensembles.
- 2.
- Boosting: The individual learners in a boosting ensemble are trained iteratively and sequentially. Each iteration employs a transformed dataset to train the corresponding base learner. The transformed dataset’s target variables are based on the errors of the model up to that iteration. Thus, each successive model iteratively “boosts” the performance of the ensemble [38]. Some widely established boosting algorithms, which were also employed in the present study, include AdaBoost (Adaptive Boosting) [39], Gradient Boosting [38], and XGBoost (eXtreme Gradient Boosting) [40].
- 3.
- Stacking: This ensemble methodology is also known as meta-learning because the predictions of the base models are used to generate the so-called meta-features on which the final ensemble is trained. Optionally, the original features can also be passed as inputs to the ensemble, or they can be combined to create additional meta-features. In order to avoid overfitting, a procedure known as k-fold cross-validation is employed [32,41]. Thus, the training dataset is split into k parts. Iteratively, the algorithm uses parts to train the base models and the last part is used to generate the predictions, i.e., the meta-features.
- 4.
- Voting: This is arguably the simplest methodology of ensembling. It consists of training a group of models and averaging the predictions. The models are trained independently on the original training dataset and not one of its variations, as in the previously examined methodologies. However, this can still offer the advantages of ensembling, as it can provide models that perform better than the individual components [42].
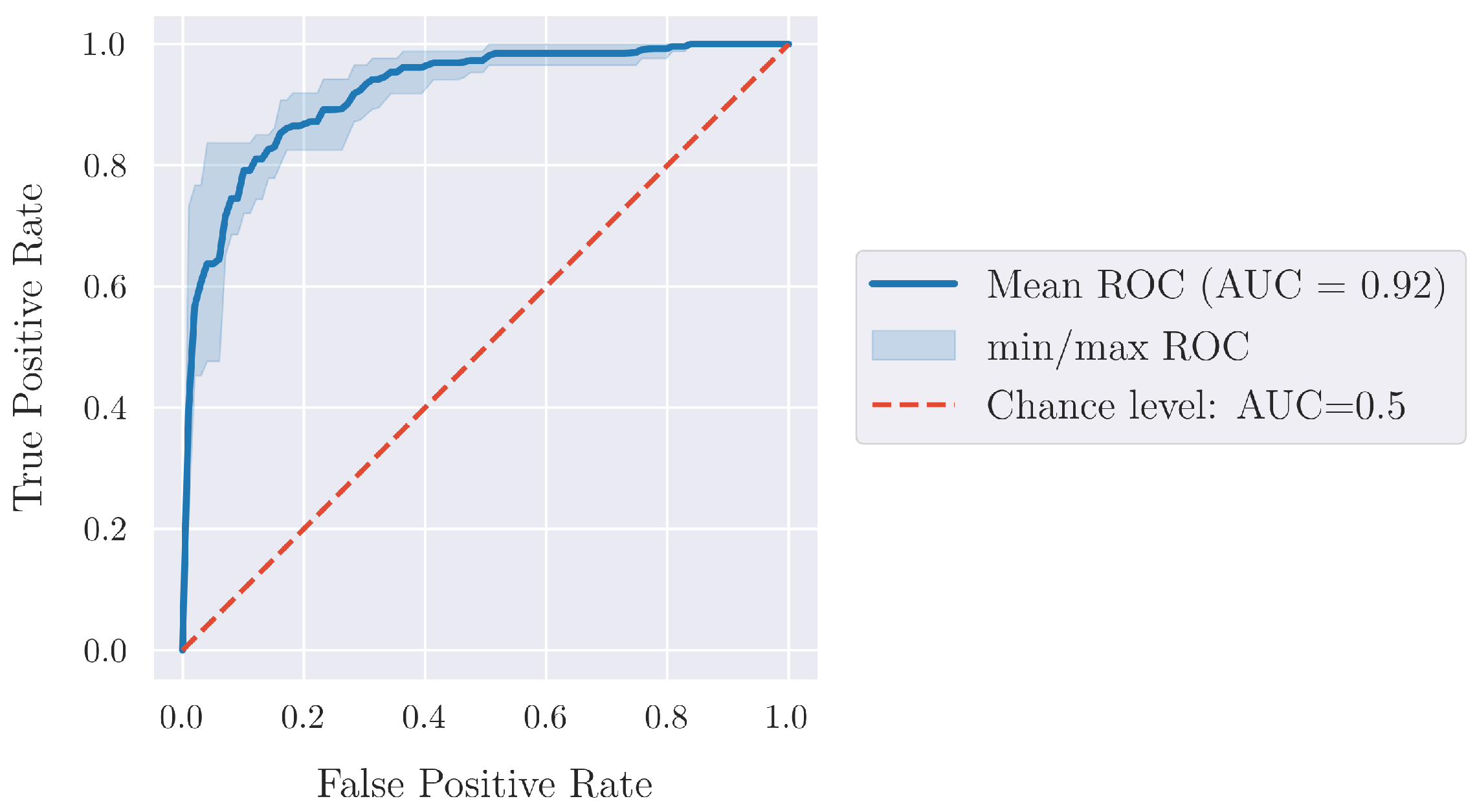
4. Results
5. Summary and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| RC | Reinforced Concrete |
| ML | Machine Learning |
| ANN | Artificial Neural Network |
| OLS | Ordinary Least Squares |
| SVM | Support Vector Machine |
| MARS | Multivariate Adaptive Regression Splines |
| ELM | Extreme Learning Machine |
| DT | Decision Tree |
| XGBoost | eXtreme Gradient Boosting |
References
- Palermo, V.; Tsionis, G.; Sousa, M.L. Building Stock Inventory to Assess Seismic Vulnerability Across Europe; Technical Report; Publications Office of the European Union: Luxembourg, 2018. [Google Scholar]
- Pantelides, C.P.; Hansen, J.; Ameli, M.; Reaveley, L.D. Seismic performance of reinforced concrete building exterior joints with substandard details. J. Struct. Integr. Maint. 2017, 2, 1–11. [Google Scholar] [CrossRef]
- Najafgholipour, M.; Dehghan, S.; Dooshabi, A.; Niroomandi, A. Finite element analysis of reinforced concrete beam-column connections with governing joint shear failure mode. Lat. Am. J. Solids Struct. 2017, 14, 1200–1225. [Google Scholar] [CrossRef]
- Kuang, J.; Wong, H. Behaviour of Non-seismically Detailed Beam-column Joints under Simulated Seismic Loading: A Critical Review. In Proceedings of the fib Symposium on Concrete Structures: The Challenge of Creativity, Avignon, France, 26–28 May 2004. [Google Scholar]
- Karayannis, C.G.; Sirkelis, G.M. Strengthening and rehabilitation of RC beam–column joints using carbon-FRP jacketing and epoxy resin injection. Earthq. Eng. Struct. Dyn. 2008, 37, 769–790. [Google Scholar] [CrossRef]
- Karabinis, A.; Rousakis, T. Concrete confined by FRP material: A plasticity approach. Eng. Struct. 2002, 24, 923–932. [Google Scholar] [CrossRef]
- Tsonos, A.; Stylianidis, K. Pre-seismic and post-seismic strengthening of reinforced concrete structural subassemblages using composite materials (FRP). In Proceedings of the 13th Hellenic Concrete Conference, Rethymno, Greece, 25 October 1999; Volume 1, pp. 455–466. [Google Scholar]
- Park, R.; Paulay, T. Reinforced Concrete Structures; John Wiley & Sons: Hoboken, NJ, USA, 1991. [Google Scholar]
- Tsonos, A.G. Cyclic load behaviour of reinforced concrete beam-column subassemblages of modern structures. WIT Trans. Built Environ. 2005, 81, 439–449. [Google Scholar]
- Antonopoulos, C.P.; Triantafillou, T.C. Experimental investigation of FRP-strengthened RC beam-column joints. J. Compos. Constr. 2003, 7, 39–49. [Google Scholar] [CrossRef]
- Karayannis, C.; Golias, E.; Kalogeropoulos, G.I. Influence of carbon fiber-reinforced ropes applied as external diagonal reinforcement on the shear deformation of RC joints. Fibers 2022, 10, 28. [Google Scholar] [CrossRef]
- Karabini, M.; Rousakis, T.; Golias, E.; Karayannis, C. Seismic tests of full scale reinforced concrete T joints with light external continuous composite rope strengthening—Joint deterioration and failure assessment. Materials 2023, 16, 2718. [Google Scholar] [CrossRef]
- Nikolić, Ž.; Živaljić, N.; Smoljanović, H.; Balić, I. Numerical modelling of reinforced-concrete structures under seismic loading based on the finite element method with discrete inter-element cracks. Earthq. Eng. Struct. Dyn. 2017, 46, 159–178. [Google Scholar] [CrossRef]
- Ghobarah, A.; Biddah, A. Dynamic analysis of reinforced concrete frames including joint shear deformation. Eng. Struct. 1999, 21, 971–987. [Google Scholar] [CrossRef]
- Thai, H.T. Machine learning for structural engineering: A state-of-the-art review. Structures 2022, 38, 448–491. [Google Scholar] [CrossRef]
- Karampinis, I.; Iliadis, L. Seismic vulnerability of reinforced concrete structures using machine learning. Earthquakes Struct. 2024, 27, 83. [Google Scholar]
- Karampinis, I.; Bantilas, K.E.; Kavvadias, I.E.; Iliadis, L.; Elenas, A. Machine Learning Algorithms for the Prediction of the Seismic Response of Rigid Rocking Blocks. Appl. Sci. 2023, 14, 341. [Google Scholar] [CrossRef]
- Kotsovou, G.M.; Cotsovos, D.M.; Lagaros, N.D. Assessment of RC exterior beam-column Joints based on artificial neural networks and other methods. Eng. Struct. 2017, 144, 1–18. [Google Scholar] [CrossRef]
- Suwal, N.; Guner, S. Plastic hinge modeling of reinforced concrete Beam-Column joints using artificial neural networks. Eng. Struct. 2024, 298, 117012. [Google Scholar] [CrossRef]
- Marie, H.S.; Abu El-hassan, K.; Almetwally, E.M.; El-Mandouh, M.A. Joint shear strength prediction of beam-column connections using machine learning via experimental results. Case Stud. Constr. Mater. 2022, 17, e01463. [Google Scholar] [CrossRef]
- Mangalathu, S.; Jeon, J.S. Classification of failure mode and prediction of shear strength for reinforced concrete beam-column joints using machine learning techniques. Eng. Struct. 2018, 160, 85–94. [Google Scholar] [CrossRef]
- Gao, X.; Lin, C. Prediction model of the failure mode of beam-column joints using machine learning methods. Eng. Fail. Anal. 2021, 120, 105072. [Google Scholar] [CrossRef]
- Rincy, T.N.; Gupta, R. Ensemble learning techniques and its efficiency in machine learning: A survey. In Proceedings of the 2nd International Conference on Data, Engineering and Applications (IDEA), Bhopal, India, 28–29 February 2020; pp. 1–6. [Google Scholar]
- Scheda, R.; Diciotti, S. Explanations of machine learning models in repeated nested cross-validation: An application in age prediction using brain complexity features. Appl. Sci. 2022, 12, 6681. [Google Scholar] [CrossRef]
- Ma, C.; Chi, J.w.; Kong, F.c.; Zhou, S.h.; Lu, D.c.; Liao, W.z. Prediction on the seismic performance limits of reinforced concrete columns based on machine learning method. Soil Dyn. Earthq. Eng. 2024, 177, 108423. [Google Scholar] [CrossRef]
- Al-Shehari, T.; Alsowail, R.A. An insider data leakage detection using one-hot encoding, synthetic minority oversampling and machine learning techniques. Entropy 2021, 23, 1258. [Google Scholar] [CrossRef] [PubMed]
- Ahsan, M.M.; Mahmud, M.P.; Saha, P.K.; Gupta, K.D.; Siddique, Z. Effect of data scaling methods on machine learning algorithms and model performance. Technologies 2021, 9, 52. [Google Scholar] [CrossRef]
- Abd Elrahman, S.M.; Abraham, A. A review of class imbalance problem. J. Netw. Innov. Comput. 2013, 1, 9. [Google Scholar]
- Longadge, R.; Dongre, S. Class imbalance problem in data mining review. arXiv 2013, arXiv:1305.1707. [Google Scholar]
- Kotsiantis, S.B.; Zaharakis, I.; Pintelas, P. Supervised machine learning: A review of classification techniques. Emerg. Artif. Intell. Appl. Comput. Eng. 2007, 160, 3–24. [Google Scholar]
- Aloisio, A.; Rosso, M.M.; Di Battista, L.; Quaranta, G. Machine-learning-aided regional post-seismic usability prediction of buildings: 2016–2017 Central Italy earthquakes. J. Build. Eng. 2024, 91, 109526. [Google Scholar] [CrossRef]
- Ganaie, M.A.; Hu, M.; Malik, A.K.; Tanveer, M.; Suganthan, P.N. Ensemble deep learning: A review. Eng. Appl. Artif. Intell. 2022, 115, 105151. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble methods in machine learning. In International Workshop on Multiple Classifier Systems; Springer: Berlin/Heidelberg, Germany, 2000; pp. 1–15. [Google Scholar]
- Algamal, Z.Y.; Lee, M.H. Regularized logistic regression with adjusted adaptive elastic net for gene selection in high dimensional cancer classification. Comput. Biol. Med. 2015, 67, 136–145. [Google Scholar] [CrossRef]
- Steinbach, M.; Tan, P.N. kNN: k-nearest neighbors. In The Top Ten Algorithms in Data Mining; Chapman and Hall/CRC: London, UK, 2009; pp. 165–176. [Google Scholar]
- Loh, W.Y. Classification and regression trees. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 14–23. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Leon, F.; Floria, S.A.; Bădică, C. Evaluating the effect of voting methods on ensemble-based classification. In Proceedings of the 2017 IEEE International Conference on Innovations in Intelligent Systems and Applications (INISTA), Gdynia, Poland, 3–5 July 2017; pp. 1–6. [Google Scholar]
- Karampinis, I. Mathematical Structure of Fuzzy Connectives with Applications in Artificial Intelligence. PhD Thesis, Democritus University of Thrace, Komotini, Greece, 2024. [Google Scholar]
- Yang, L.; Shami, A. On hyperparameter optimization of machine learning algorithms: Theory and practice. Neurocomputing 2020, 415, 295–316. [Google Scholar] [CrossRef]
- Raschka, S. An overview of general performance metrics of binary classifier systems. arXiv 2014, arXiv:1410.5330. [Google Scholar]
- Fan, J.; Upadhye, S.; Worster, A. Understanding receiver operating characteristic (ROC) curves. Can. J. Emerg. Med. 2006, 8, 19–20. [Google Scholar] [CrossRef]
- Recommendations for Design of Beam-Column Connections in Monolithic Reinforced Concrete Structures (ACI 352R-02); Technical Report; Amercian Concrete Institute: Indianapolis, IN, USA, 2002.
- Liu, A.; Park, R. Seismic behavior and retrofit of pre-1970’s as-built exterior beam-column joints reinforced by plain round bars. Bull. N. Z. Soc. Earthq. Eng. 2001, 34, 68–81. [Google Scholar] [CrossRef]
- Retrofitting of Concrete Structures by Externally Bonded FRPs with Emphasis on Seismic Applications (FIB-35); Technical Report; The International Federation for Structural Concrete: Lausanne, Switzerland, 2002.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Description |
|---|---|
| (MPa) | The compressive strength of the concrete. |
| The percentage of transverse reinforcement (stirrups) in the joint. | |
| (MPa) | The yield stress of the stirrups in the joint. |
| (%) | The percentage of longitudinal reinforcement in the beam. |
| (MPa) | The yield stress of the longitudinal reinforcement in the beam. |
| (mm), (mm) | The height and width of the beam, respectively. |
| (%) | The percentage of longitudinal reinforcement in the column. |
| (MPa) | The yield stress of the longitudinal reinforcement in the column. |
| (mm), (mm) | The height and width of the column, respectively. |
| ALF (%) | The axial load factor. |
| Ensemble | Architecture Description |
|---|---|
| Bagging | Each of the Logistic Regression, k-Nearest Neighbors, Decision Tree, and ANN was independently employed as a base model for the bagging ensemble. |
| Boosting | AdaBoost, XGBoost, and Gradient Boosting were implemented separately. |
| Stacking | Logistic Regression, k-Nearest Neighbors, and Decision Tree were used as base learners. ANN was used as the final meta-model. |
| Voting | Logistic Regression, k-Nearest Neighbors, Decision Tree, and ANN were employed as base learners. |
| Training Set | Testing Set | |||
|---|---|---|---|---|
| BY-JS | JS | BY-JS | JS | |
| Precision | 0.92086 | 0.93046 | 0.83578 | 0.86361 |
| Recall | 0.92072 | 0.93049 | 0.84578 | 0.85311 |
| F1-Score | 0.92076 | 0.93045 | 0.84036 | 0.85801 |
| Accuracy | 0.92593 | 0.84979 | ||
| Park and Paulay | XGBoost | |||
|---|---|---|---|---|
| BY-JS | JS | BY-JS | JS | |
| Precision | 0.70701 | 0.64742 | 0.83578 | 0.86361 |
| Recall | 0.48898 | 0.82239 | 0.84578 | 0.85311 |
| F1-Score | 0.57813 | 0.72449 | 0.84036 | 0.85801 |
| Accuracy | 0.66667 | 0.84979 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karabini, M.; Karampinis, I.; Rousakis, T.; Iliadis, L.; Karabinis, A. Machine Learning Ensemble Methodologies for the Prediction of the Failure Mode of Reinforced Concrete Beam–Column Joints. Information 2024, 15, 647. https://doi.org/10.3390/info15100647
Karabini M, Karampinis I, Rousakis T, Iliadis L, Karabinis A. Machine Learning Ensemble Methodologies for the Prediction of the Failure Mode of Reinforced Concrete Beam–Column Joints. Information. 2024; 15(10):647. https://doi.org/10.3390/info15100647
Chicago/Turabian StyleKarabini, Martha, Ioannis Karampinis, Theodoros Rousakis, Lazaros Iliadis, and Athanasios Karabinis. 2024. "Machine Learning Ensemble Methodologies for the Prediction of the Failure Mode of Reinforced Concrete Beam–Column Joints" Information 15, no. 10: 647. https://doi.org/10.3390/info15100647
APA StyleKarabini, M., Karampinis, I., Rousakis, T., Iliadis, L., & Karabinis, A. (2024). Machine Learning Ensemble Methodologies for the Prediction of the Failure Mode of Reinforced Concrete Beam–Column Joints. Information, 15(10), 647. https://doi.org/10.3390/info15100647