1. Introduction
Attribute-based access control (ABAC) is a relatively recent model for access control where rules are declared through attributes. The ABAC reference guide was launched by the National Institute of Standards and Technology (NIST) in 2014 [
1]. The main characteristic of ABAC is its fine granularity, which allows a security administrator to create very specific rules; in contrast, writing detailed rules based on roles is a cumbersome task. Moreover, the current technological trends (e.g., Industry 4.0, smart homes, and smart cities [
2,
3,
4]) make it necessary to define rules beyond roles. The ABAC rules are defined by combining the values of three types of attributes: user, resource, and session attributes.
Policy mining is an automated procedure for generating access rules by means of mining attribute–value patterns (a-v patterns, for short) from permissions of already exercised systems [
5]. Since individual permissions are usually embedded in complex access mechanisms, the data to be mined are collected from access logs. Each log entry records useful information about the requester, the requested resource, and the environmental conditions.
Despite the benefits and the existing ABAC solutions in the market, ABAC requires meticulous planning, and establishing attribute-based rules from scratch is only workable in small scenarios, since it is imperative to analyze all the valid and invalid value combinations in the system [
6]. Therefore, policy mining has been identified as the key for achieving widespread adoption of the attribute-based approach [
7].
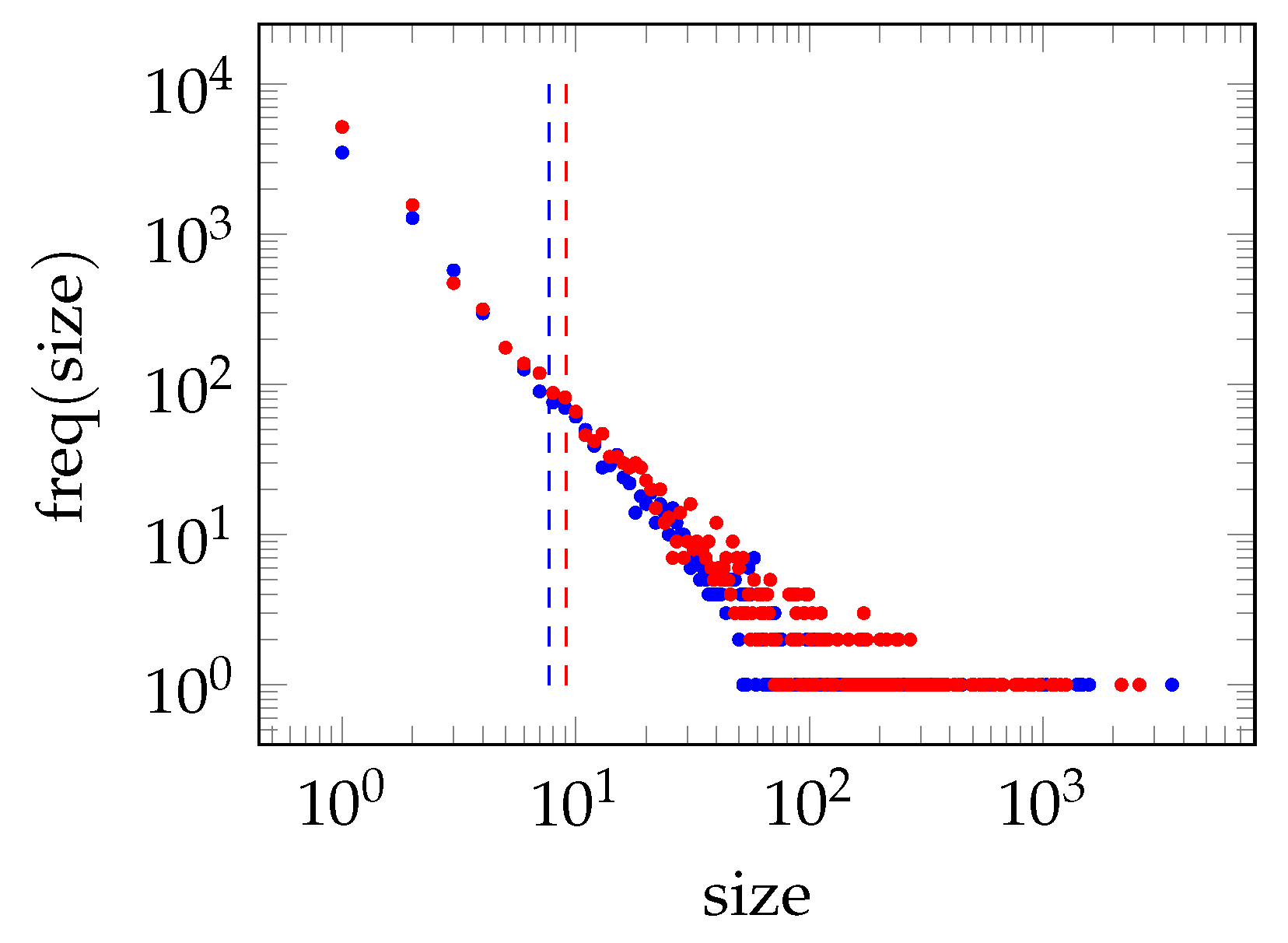
The policy mining approaches that offer convergence on large access logs (i.e., with thousand of users, resources and attribute–values, and even millions of entries), support the a-v patterns associated with rules through frequency [
8,
9,
10]. Thus, a pattern is a good candidate for creating rules when its frequency in the log is greater than a frequency threshold. However, the problem with this strategy is that selecting a high support leaves many resources without rules (especially those with few requesters), and a low support leads to the rule explosion of unreliable rules. Therefore, the first challenge is to design an extraction algorithm that guarantees high coverage of the resources with a manageable number of rules.
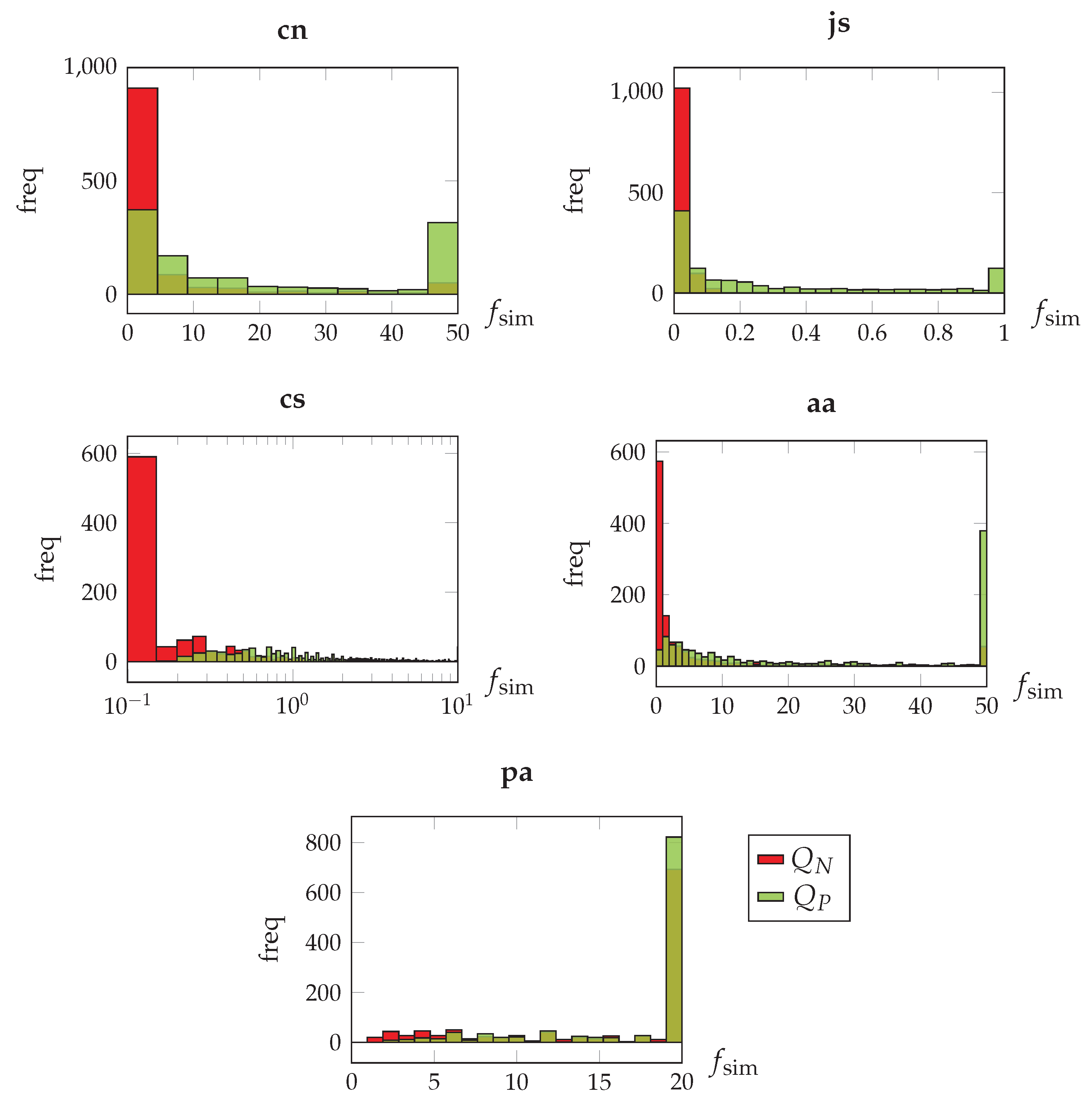
A second challenge in ABAC policy mining is the difficulty of collecting examples for correctness evaluation. These examples are user–resource pairs which represent new access requests; examples labeled as
permit are positive examples, and those labeled as
deny are negative examples. The easiest way to obtain these pairs is to split the access log into training and test sets; however, positive pairs outnumber negatives in real access logs. To counteract class imbalance, it is possible to uniformly sample negative pairs from the set of pairs not registered in the log [
11]; however, more sophisticated synthetics are required to confirm results or to reduce evaluation biases.
Due to the scarcity of negatives in access logs, alternative evaluation criteria to correctness are desirable. Two unexplored criteria for policy mining are peculiarity and diversity [
12]. A pattern is peculiar when it is significantly different from other discovered patterns. A set of patterns is diverse if its elements differ significantly from each other. The advantage of peculiarity and diversity measures is that they do not depend on frequency and they do not need negative test examples to be computed. However, since the number of attribute–values can have the same order of magnitude as the number of users and resources in real access logs, many of the detected patterns can be discriminated as very peculiar, and the set of rules is very diverse. Therefore, a third challenge is the design of non-biased measures.
Our contribution is to model access logs as affiliation networks and to apply network and biclique analysis techniques in order to address the previously mentioned policy mining challenges. This new data representation is suitable (1) to extract ABAC rules supported by graph patterns without a frequency threshold, (2) to generate synthetic examples for correctness evaluation, and (3) to create alternative evaluation measures to correctness. We discovered that the rules extracted through our graph-based strategy can cover more resources than the frequency-based strategy and perform this without rule explosion; moreover, our synthetics are useful to increment the certainty level of correctness results; finally, our alternative measures offer a wider evaluation profile for policy mining.
Section 2 presents the background and preliminaries on ABAC, policy mining, its corresponding notation, and challenges.
Section 3 describes the related work.
Section 4 explains our graph-based proposal to solve three challenges of policy mining.
Section 5 describes the datasets employed in our experiments.
Section 6,
Section 7 and
Section 8 describe each of our solutions to the three identified challenges and present their corresponding experiments. Finally,
Section 9 presents the conclusion and the future work.
4. Our Proposal
We propose to model access logs as affiliation networks, analyze such networks, and process their biclique formations in order to achieve the following objectives:
Increase the policy coverage and deal with rule explosion.
Generate synthetic examples for correctness evaluation of rules.
Design alternative evaluation measures to correctness measures.
An affiliation network is a graph that consists of two sets of disjoint vertices, which are known as the top set and bottom set, and the edges between these sets of vertices. A biclique is a fully connected subgraph of an affiliation network. We model access logs through affiliation networks the following way:
Definition 6 (Access control graph (ACG)). Given an access log L, an access control graph is an affiliation network that represents L, where is the top set of vertices, is the bottom set of vertices and is the set of edges. There is an edge if and only if there exists an entry in the log .
Notice that our definition only takes into account positive entries for creating an ACG because we only consider the extraction of positive access rules in this work. Additionally, we define two functions for such networks: (i) , which returns the set of adjacent vertices (known as neighbors) of vertex , and (ii) function , which returns the number of neighbors of v, which is known as the degree of v.
In a previous work [
32], we observed that logs modeled through ACGs exhibit two important properties of complex networks [
33], so it is possible to apply these network analysis techniques to discover useful access patterns for ABAC policy mining:
Small-world property: ACGs are structured in small fully connected subgraphs known as
bicliques (which can be interpreted as collaboration groups of users through specific resources), and the average hop distance of ACGs is much shorter than the total vertices [
34,
35].
Homophily property: members of each biclique tend to share attribute–values, close bicliques are similar, and distant bicliques are dissimilar [
36].
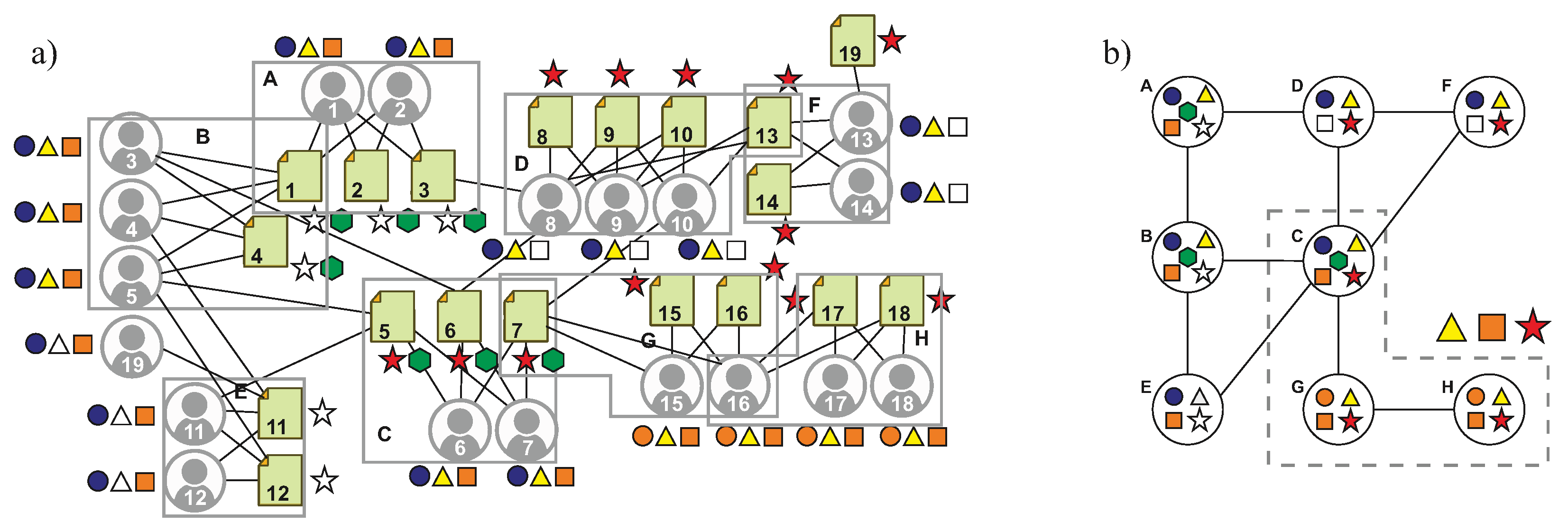
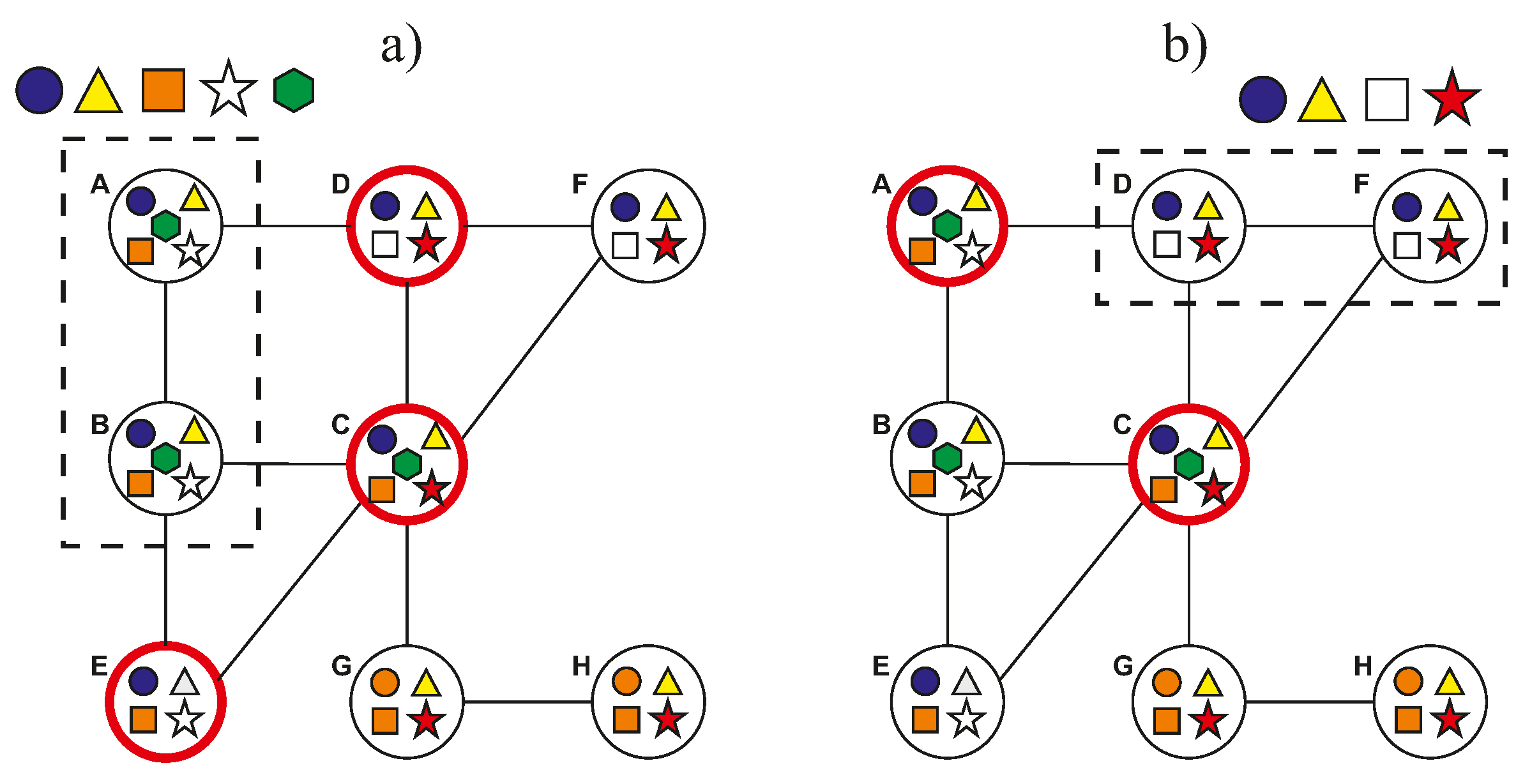
Figure 1a shows an example of a small access control graph, which has small-worldness and exhibits the homophily property. Observe that it has biclique formations, and users of biclique A share three attribute–values: the resources of A share one value, values of biclique A are similar to those of biclique B and D and values of biclique A are dissimilar to those of biclique H. We explain below the analysis techniques applied to the access control graph to achieve the stated objectives.
4.1. Our Solution for Objective 1
In order to increase the policy coverage and to deal with rule explosion, it is required to reformulate the attribute–value patterns associated with access rules and therefore to apply a different procedure to extract such patterns.
First, let K be the set of maximal bicliques of , such that each element in K is a fully connected induced subgraph (i.e., biclique) denoted by , where and . The term ‘maximal’ means that no biclique in K is a subgraph of another biclique in K; in this document, when we mention the term ‘bicliques’, we refer always to maximal bicliques. We also define the function , which returns the longest pattern from biclique , such that the frequency of in is equal to (similarly, for resources). From bicliques, we can define the following type of pattern:
Definition 7 (Biclique graph pattern (BGP))
. A biclique graph pattern is a 3-tuple , where is a subset of connected bicliques of such that: where is the subset of user attribute–values shared by all users of biclique κ (similarly, for resources). For example, a biclique graph pattern in
Figure 1a is
such that
contains the connected bicliques C, G, and H;
corresponds to triangle–yellow and square–orange and
corresponds to star–red. Therefore, a candidate ABAC positive rule can be inferred which states that resources with star–red are authorized for users fulfilling triangle–yellow and square–orange.
In order to extract our patterns, it is required to modify the implementation of pre-processing and rule extraction phases of policy mining because conventional mining is based on frequent patterns (FPs). First, instead of directly extracting BGPs from the ACG, we transform this network into a suitable representation for our extraction algorithm:
Definition 8 (Graph of bicliques). The graph of bicliques of an access control graph is a graph , where is its set of vertices which corresponds to a set of maximal bicliques of , and is its set of edges. An edge means the biclique κ and relate structurally to each other.
Figure 1b shows the resulting graph of bicliques of the ACG of
Figure 1a, and the BGP
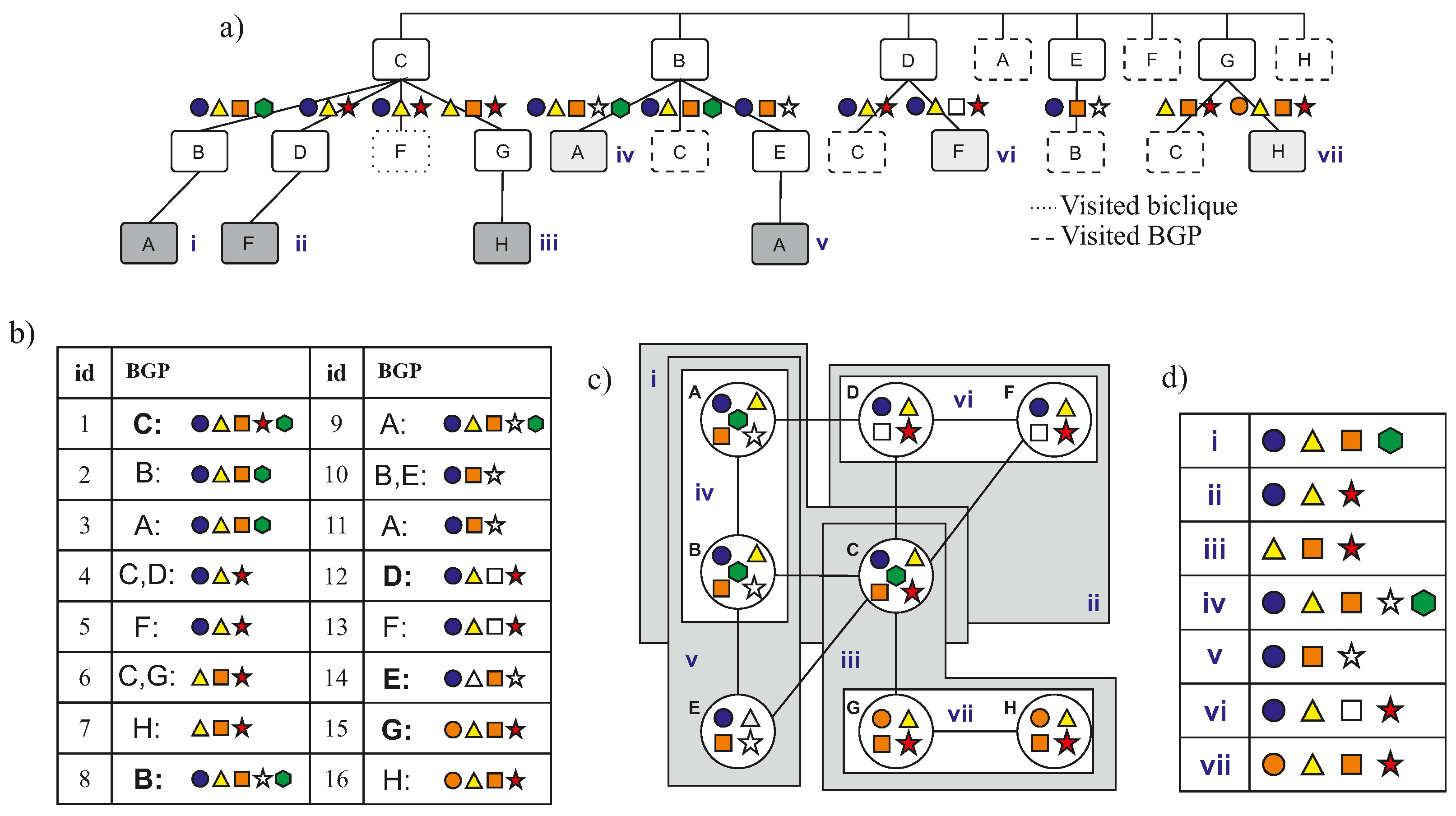
of our previous example. Secondly, we designed a bottom-up algorithm to detect BGPs starting from bicliques as building blocks, and agglomerating adjacent similar bicliques in a depth-first search fashion to create larger substructures. The procedure is summarized as follows:
For each biclique in the graph :
The resulting set of biclique graph patterns after applying our procedure is
(where
and
), such that
:
and corresponding ABAC rules are:
For Objective 1 of our research, the resulting rules must achieve the following requirements:
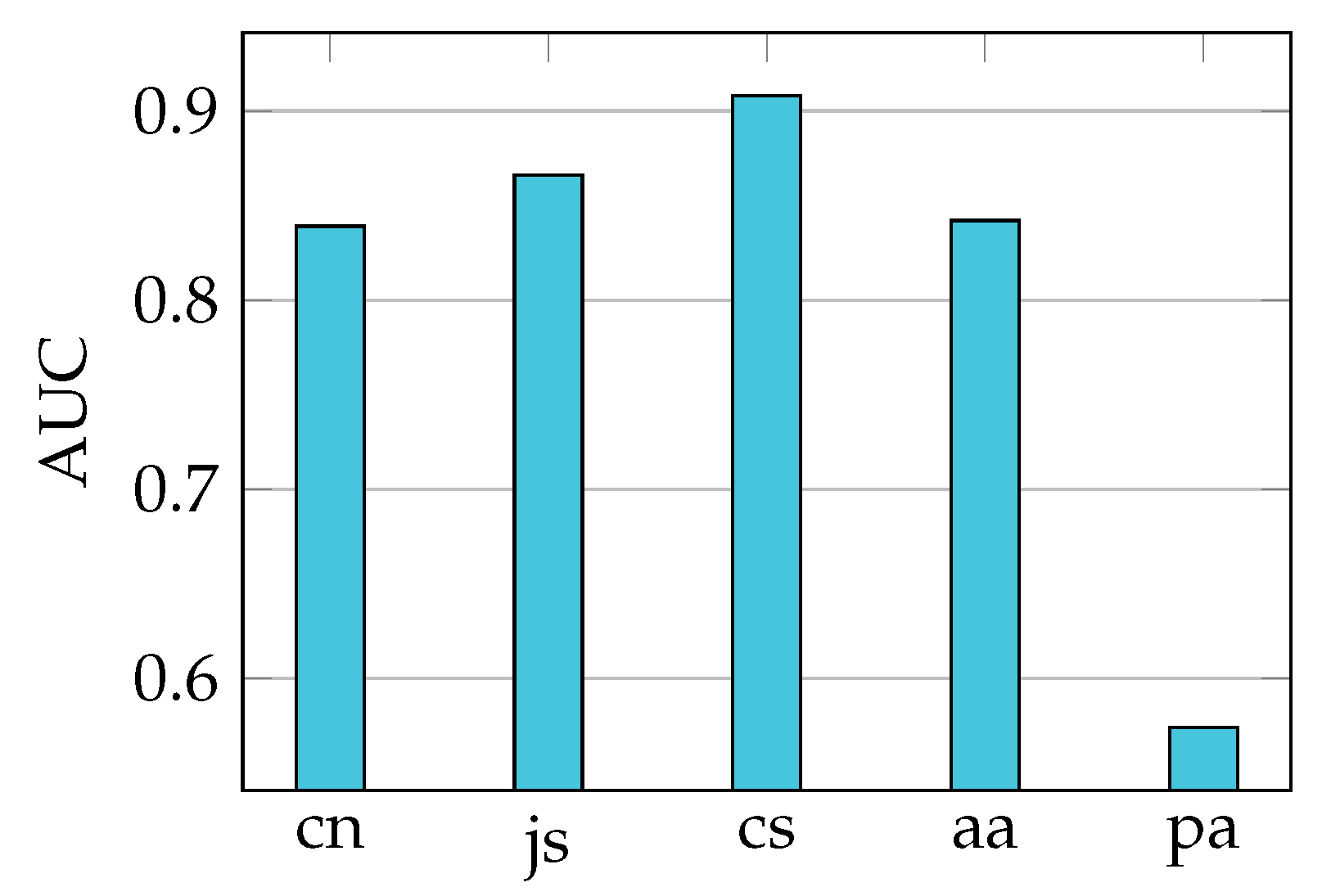
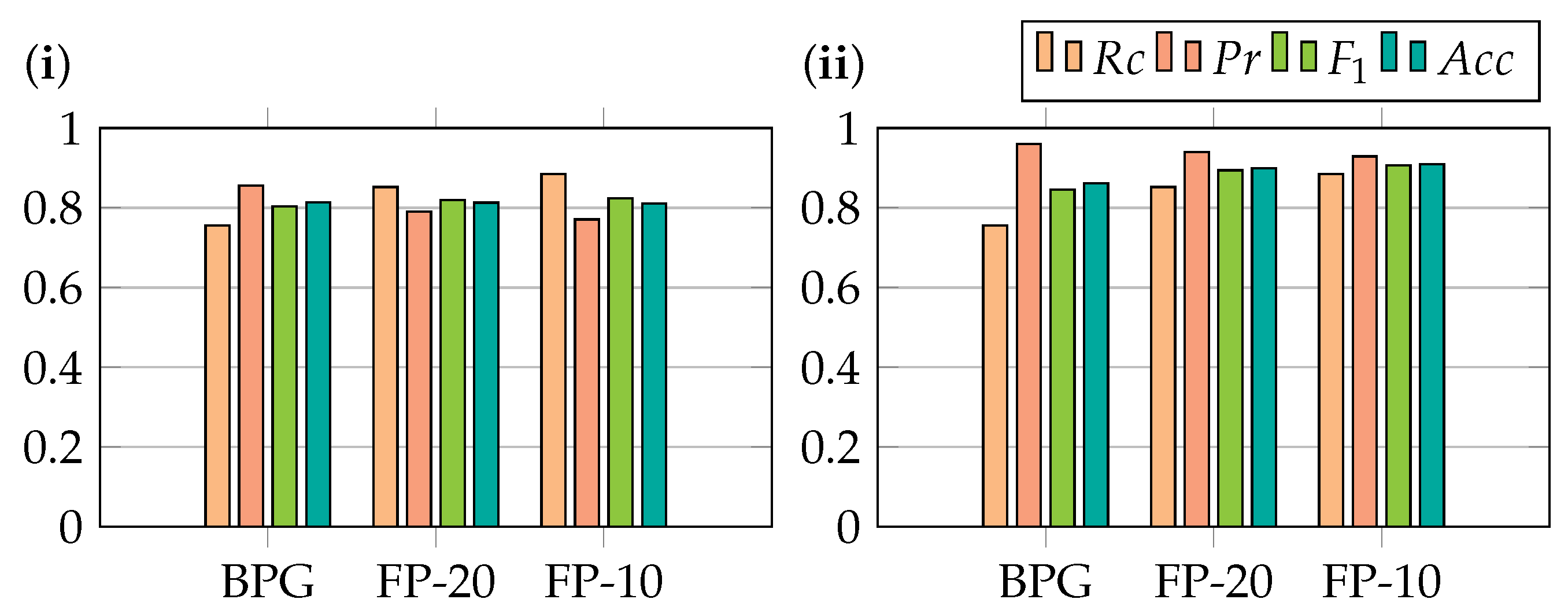
High coverage: the set of rules must cover most of the log entries and many of the resources (especially those with few requesters).
Manageable rule explosion: the total number of rules must be much lower than the number of log entries.
For measuring the first requirement, we used the log coverage of Equation (
4), and we defined the following measure:
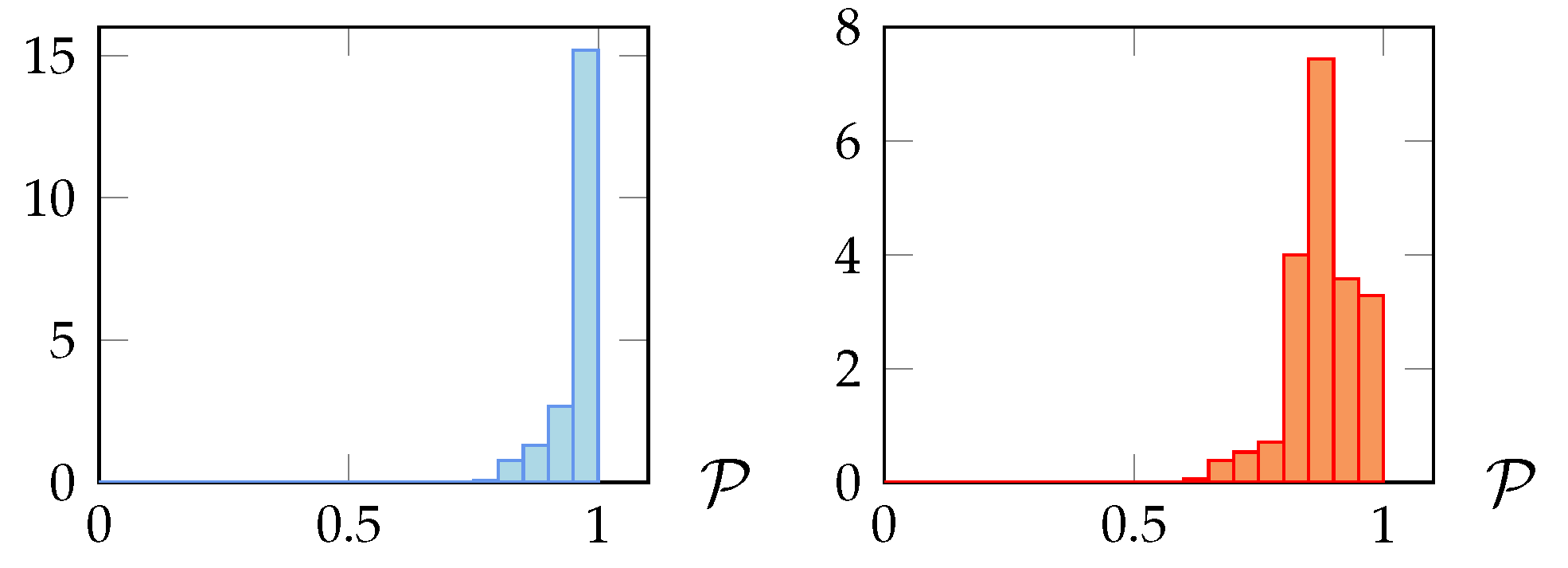
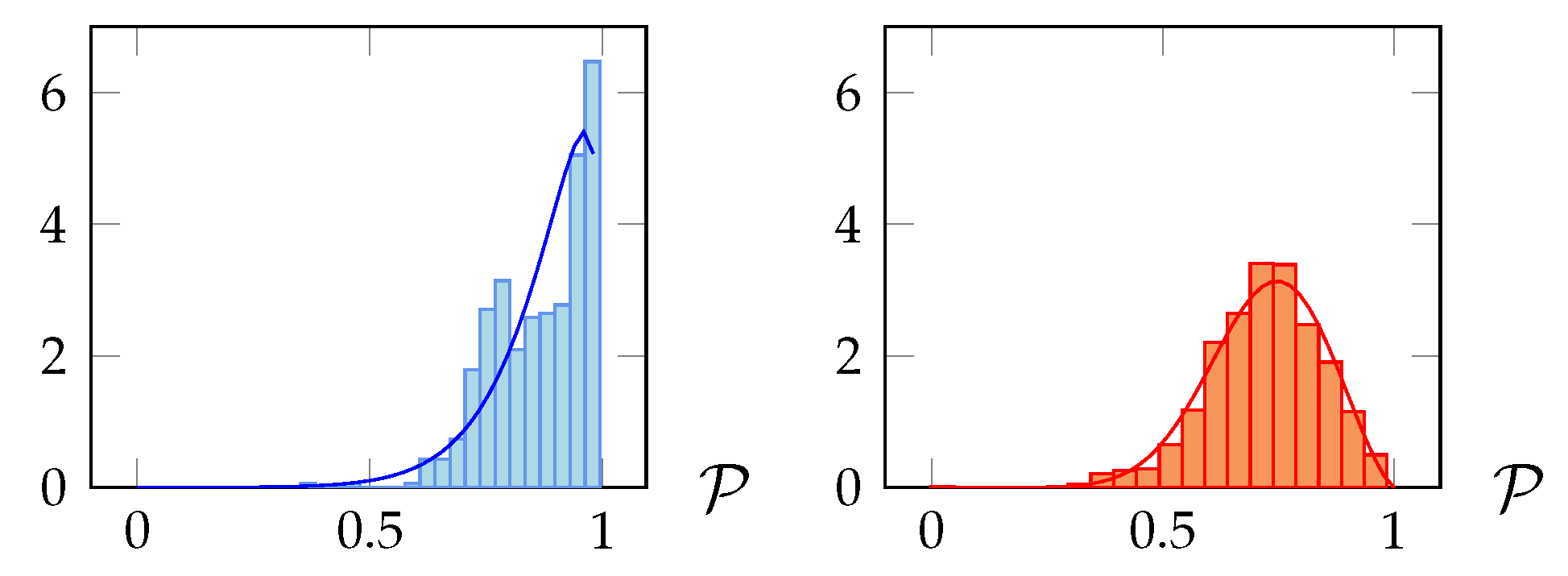
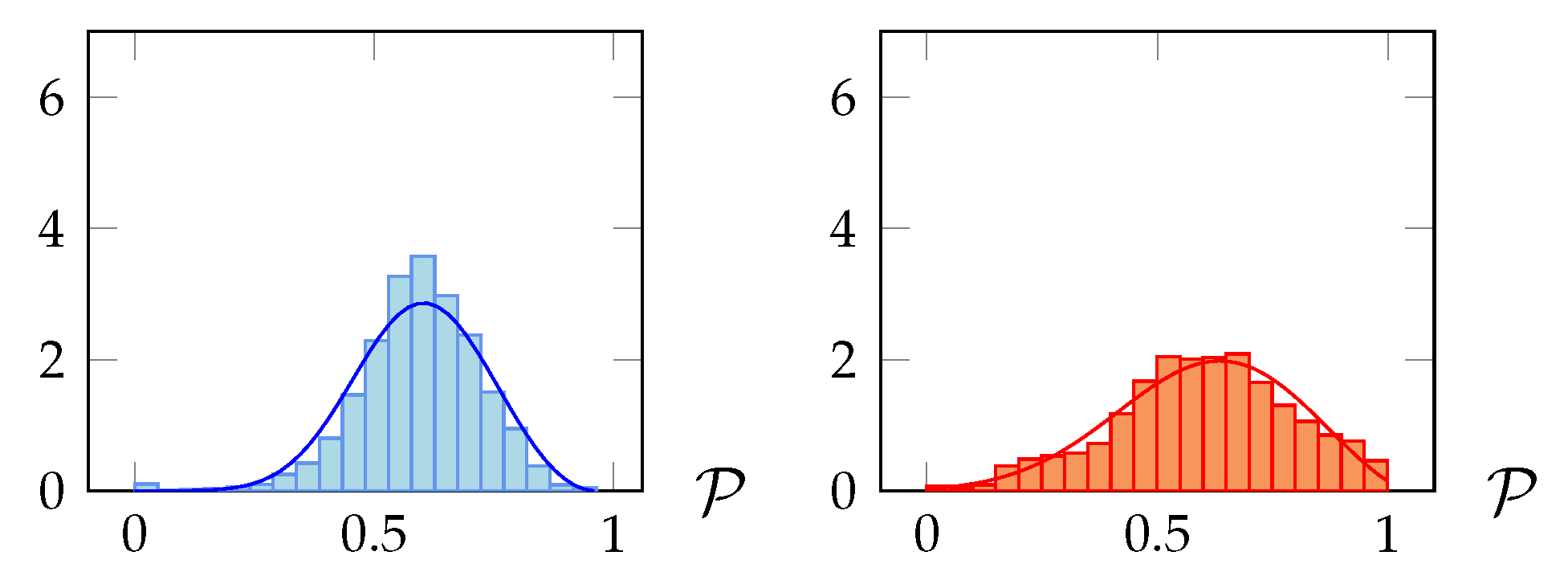
Definition 9 (Resource coverage)
. The resource coverage of the rule set π in the resource subset (denoted by ) is the ratio , where corresponds to the resources in covered by π:







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}