

Secure Genomic String Search with Parallel Homomorphic Encryption

Abstract
1. Introduction
Contributions
- We primarily expand Boolean gates (i.e., XOR, AND, etc.) from an existing FHE framework [12] to secure algebraic circuits comprising addition and multiplication.
- Taking full advantage of the latest enhancements in GPU architecture, we introduce parallel FHE operations. We further propose several enhancement methods, like bit coalescing, compound gates, and tree-based additions, for the execution of the secure algebraic circuits.
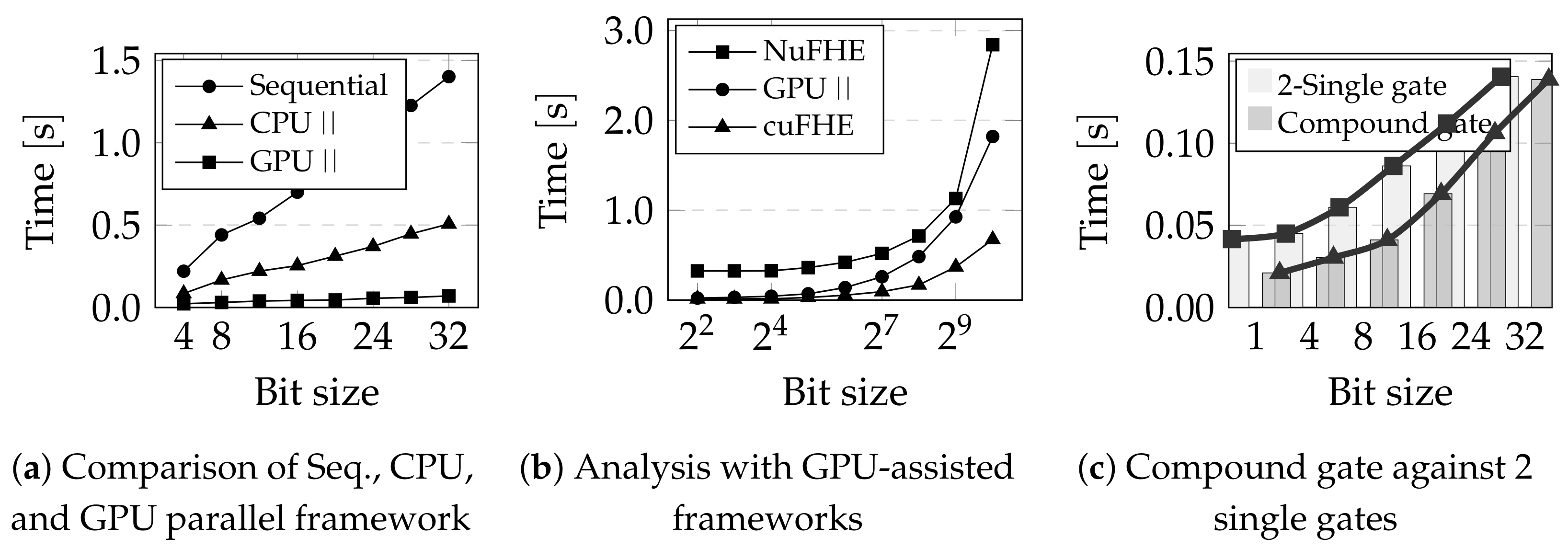
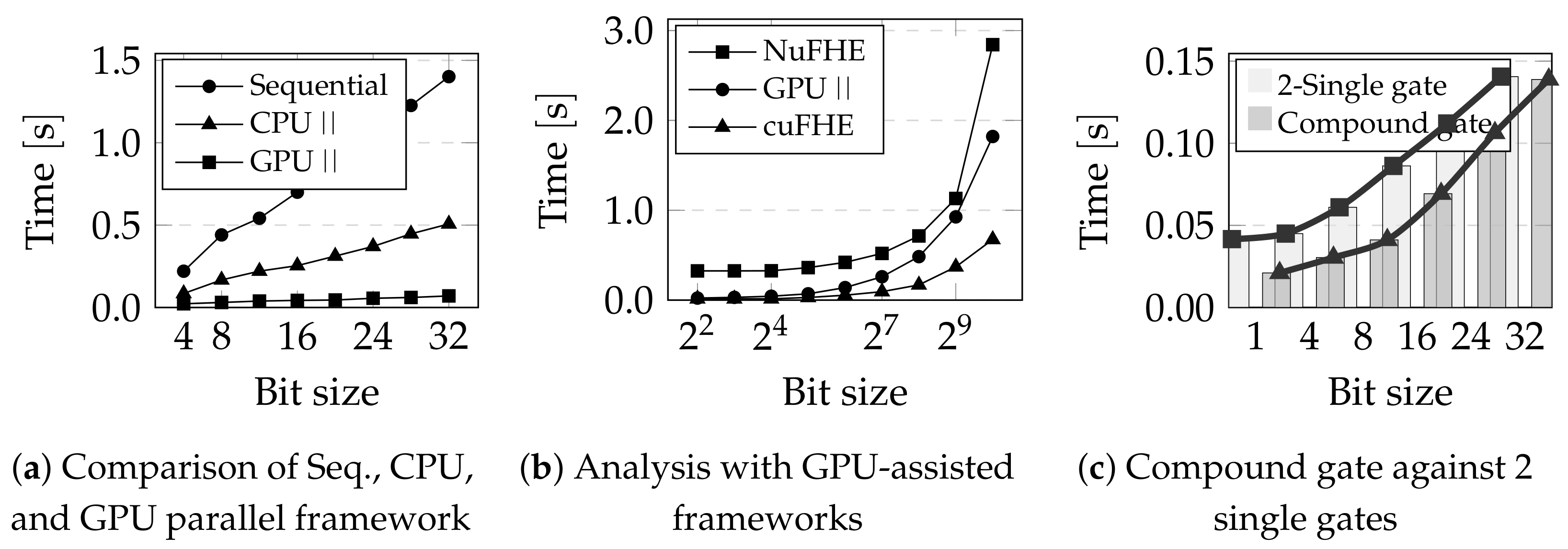
- We conducted a series of experiments to contrast the execution time of the sequential TFHE [12] with our proposed GPU parallel framework. Data from Table 1 demonstrate that our proposed GPU parallel method is 14.4 and 46.81 times quicker than the existing technique for standard and matrix multiplications, respectively. We also compared our performance with existing GPU-based TFHE frameworks, such as cuFHE [13], NuFHE [14], and Cingulata [15].
- Lastly, we focused on different string search operations in the genomic dataset (hamming distance, edit distance, and set-maximal matches) and executed them under encryption. Experimental outcomes reveal that the framework requires approximately 12 min to execute hamming distance and set-maximal matching on two genomic sequences with 128 genomes. In addition, for 8 genomes, the framework takes 11 min for an edit distance operation, significantly improving from the previous 5 h attempt by Cheon et al. [16].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gate Op. | Addition | Multiplication | |||
|---|---|---|---|---|---|
| Regular | Vector | Regular | Matrix (min) | ||
| GPU-parallel | 0.07 | 1.99 | 11.22 | 33.93 | 186.23 |
| CPU-parallel | 0.50 | 7.04 | 77.18 | 174.54 | 2514.34 |
| TFHE [12] | 1.40 | 7.04 | 224.31 | 489.93 | 8717.89 |
| cuFHE [13] | - | 2.03 | - | 132.23 | - |
| NuFHE [14] | - | 4.16 | - | 186 | - |
| Cingulata [15] | - | 2.16 | - | 50.69 | - |
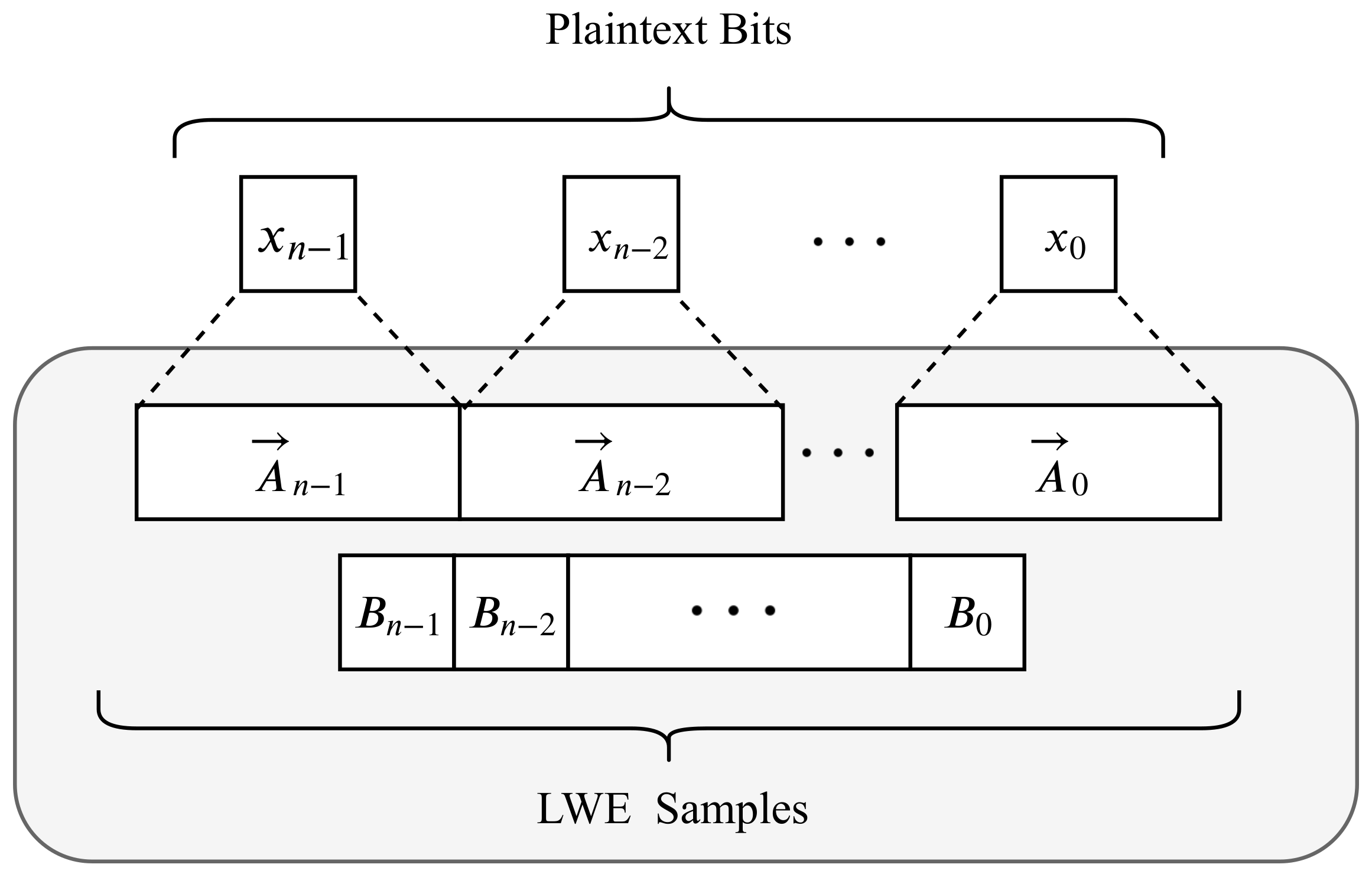
2. Background
2.1. Torus FHE (TFHE)
- Fast and Exact Bootstrapping: TFHE provides the fastest exact bootstrapping requiring around s. Some recent encryption schemes [20,21] also propose faster bootstrapping and homomorphic computations in general. However, they do not perform exact bootstrapping and are erroneous after successive computations on the same ciphertexts.
- Ciphertext Size: Compared with the other HE schemes, TFHE offers a smaller ciphertext size as it operates on binary plaintexts (only 32 kb compared to 8mb for one 32-bit number). Nevertheless, this minimal storage advantage allows us to utilize the limited and fixed memory of GPU when we optimize the gate structures.
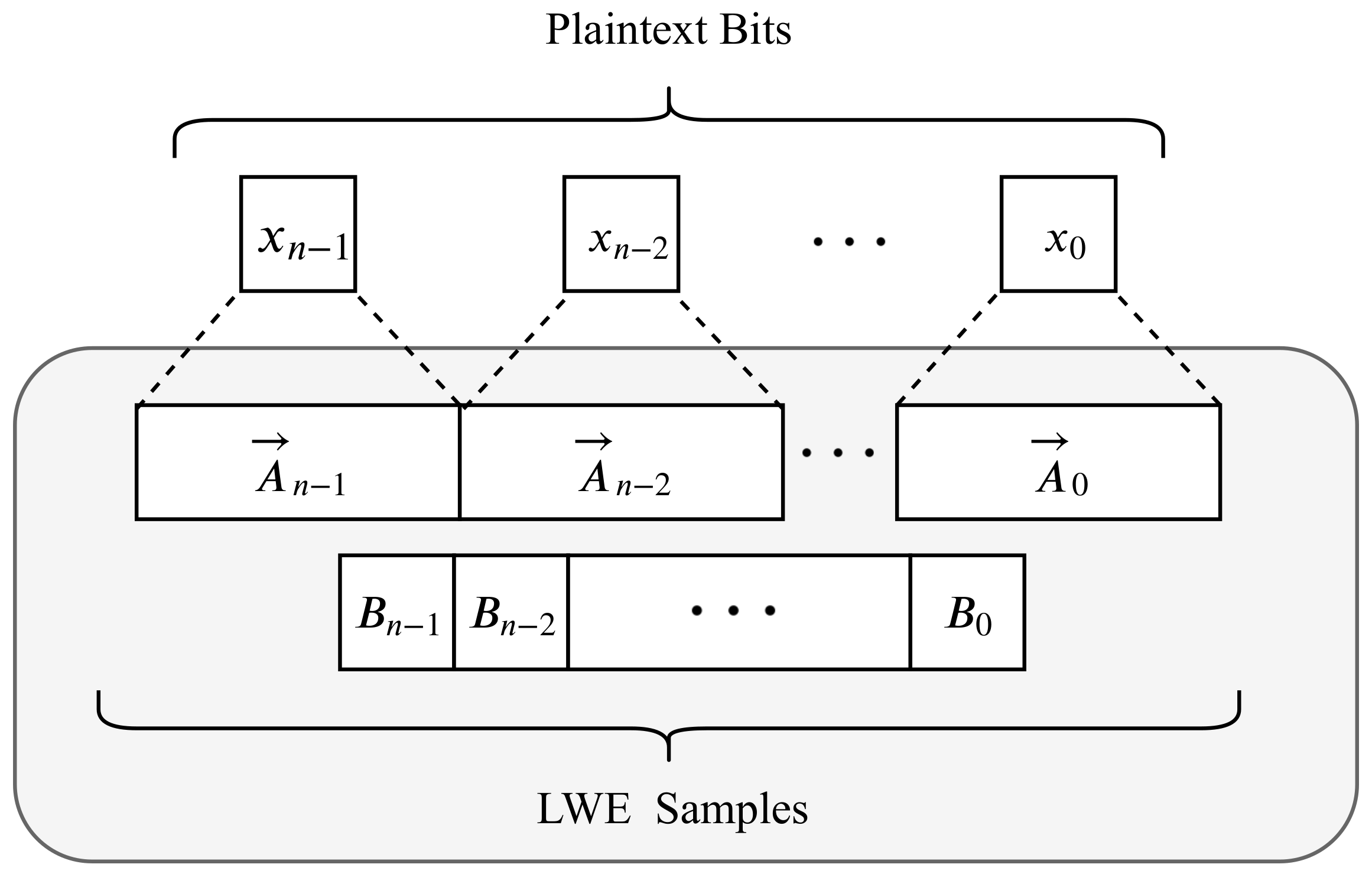
- Boolean Operations: TFHE also supports Boolean operations that can be extended to construct arbitrary functions. These binary bits can then be operated in parallel if their computations are independent of each other.
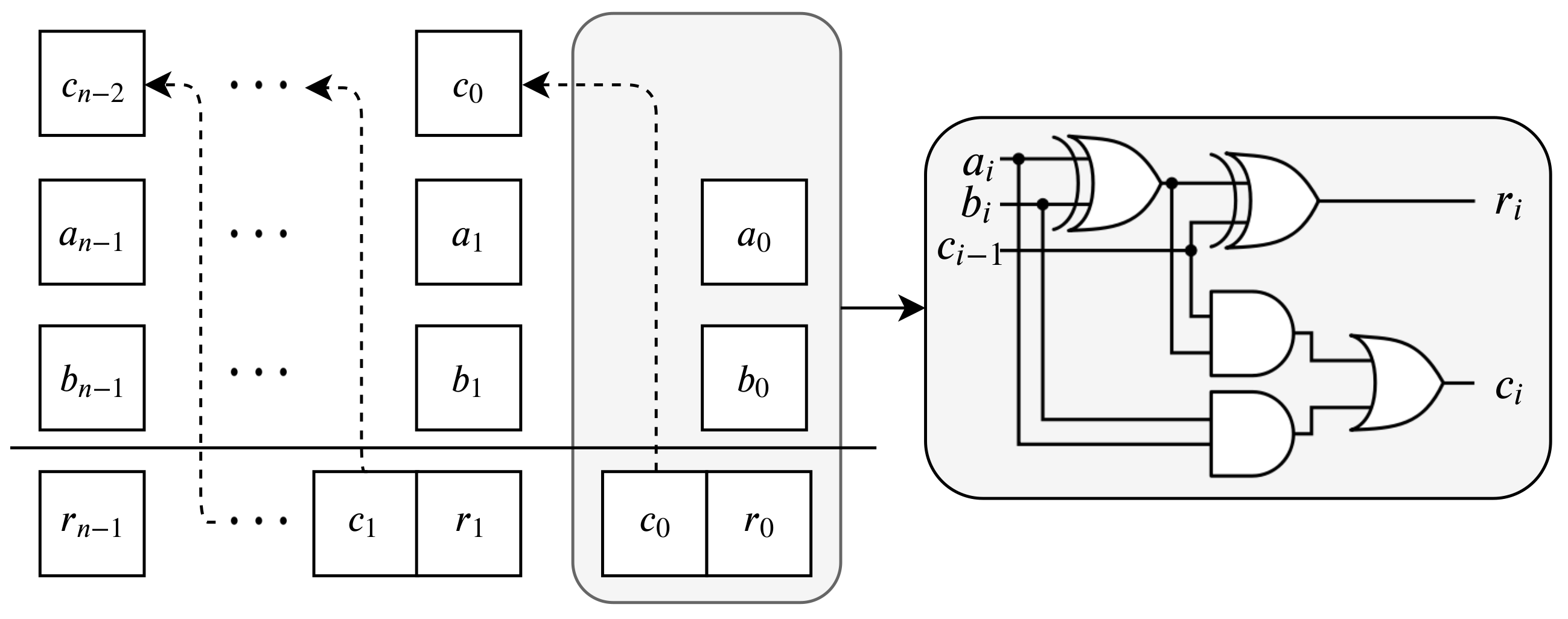
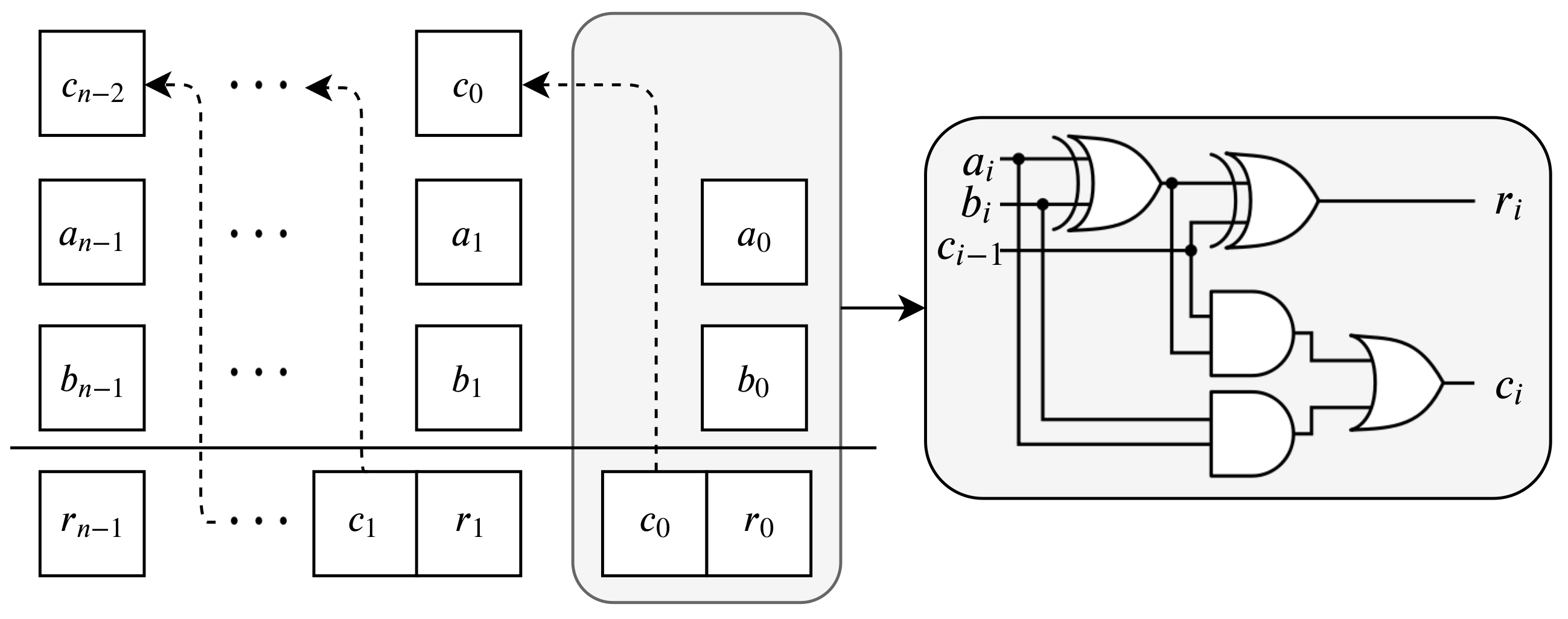
2.2. Sequential Framework
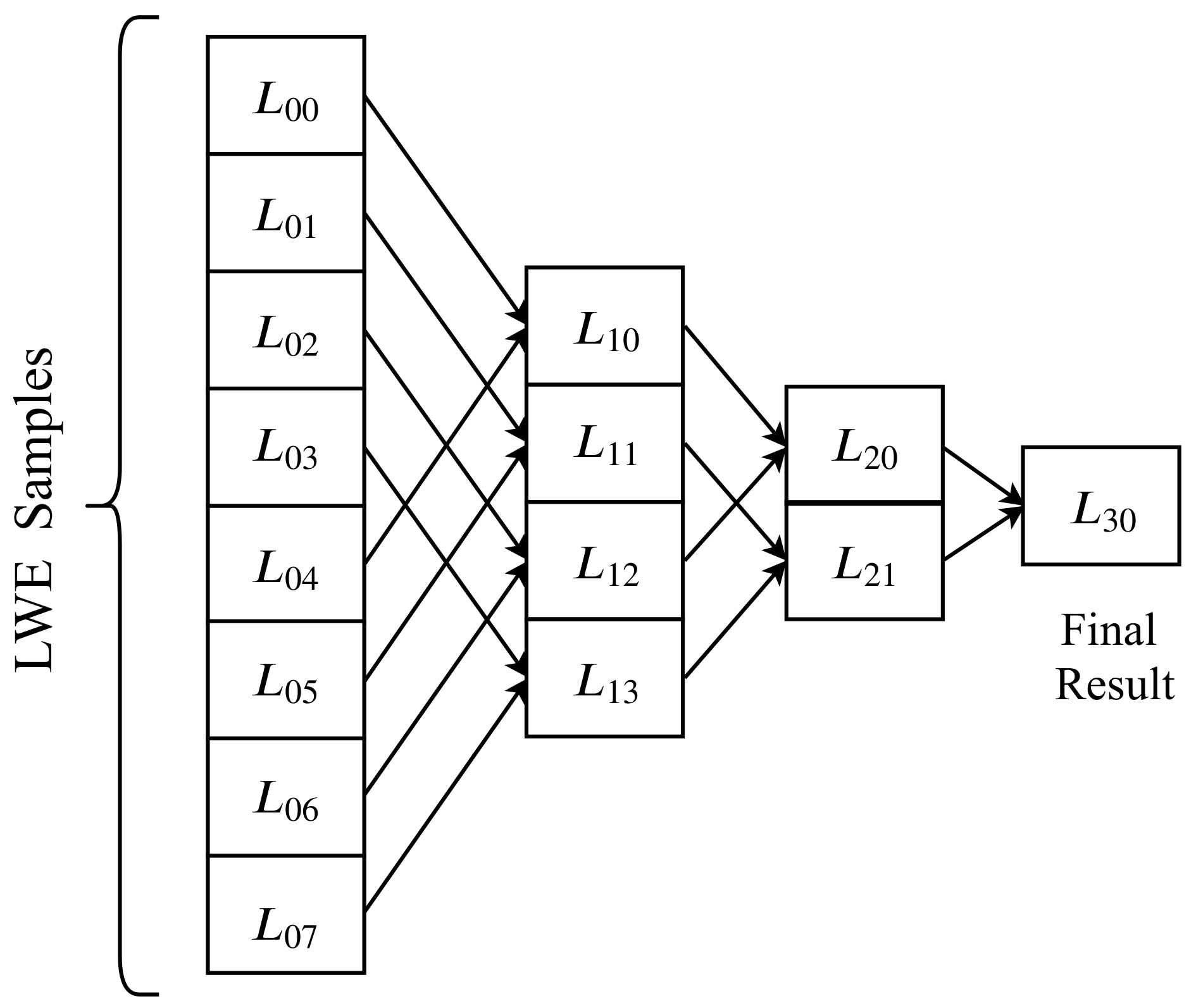
2.2.1. Addition
2.2.2. Multiplication
Naive Approach
Karatsuba Algorithm
| Algorithm 1: Karatsuba Multiplication [28]. |
 |
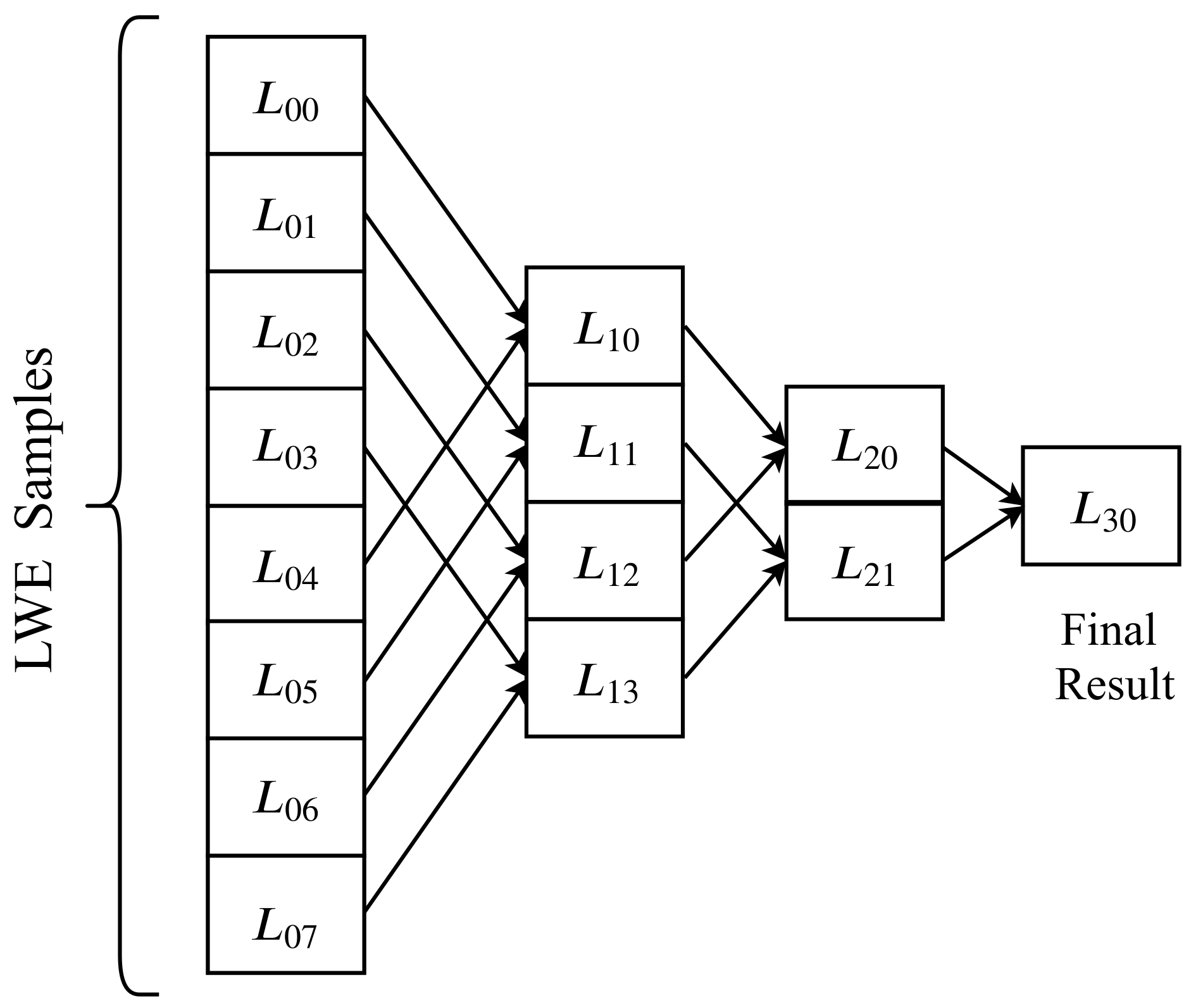
2.3. CPU-Based Parallel Framework
2.3.1. Addition
2.3.2. Multiplication
2.4. String Search: Problem Definition
- 1.
- There exists some index such that (same substring);
- 2.
- and ; and
- 3.
- For all other genes, and , if there exist then it must be .
3. Methods
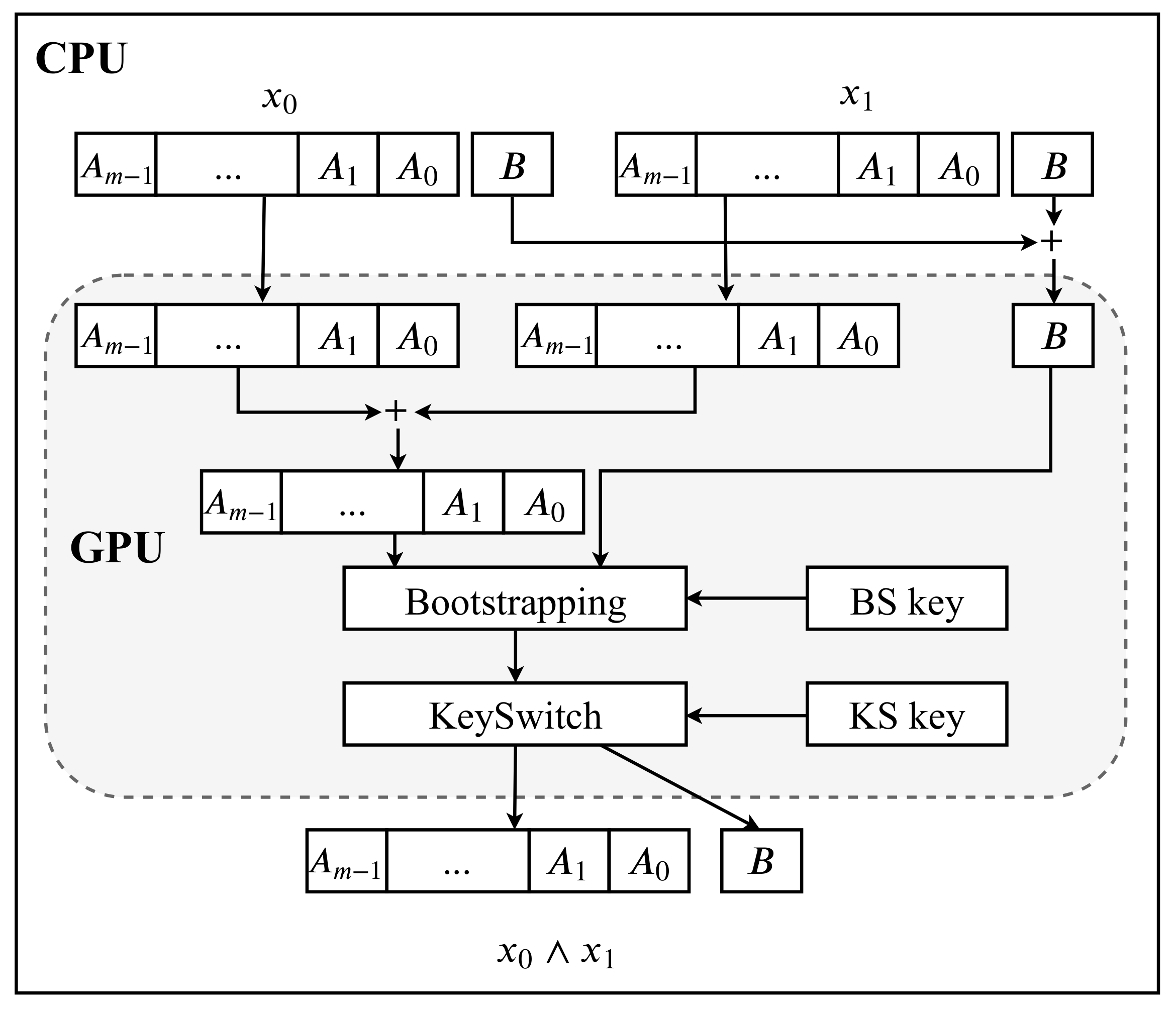
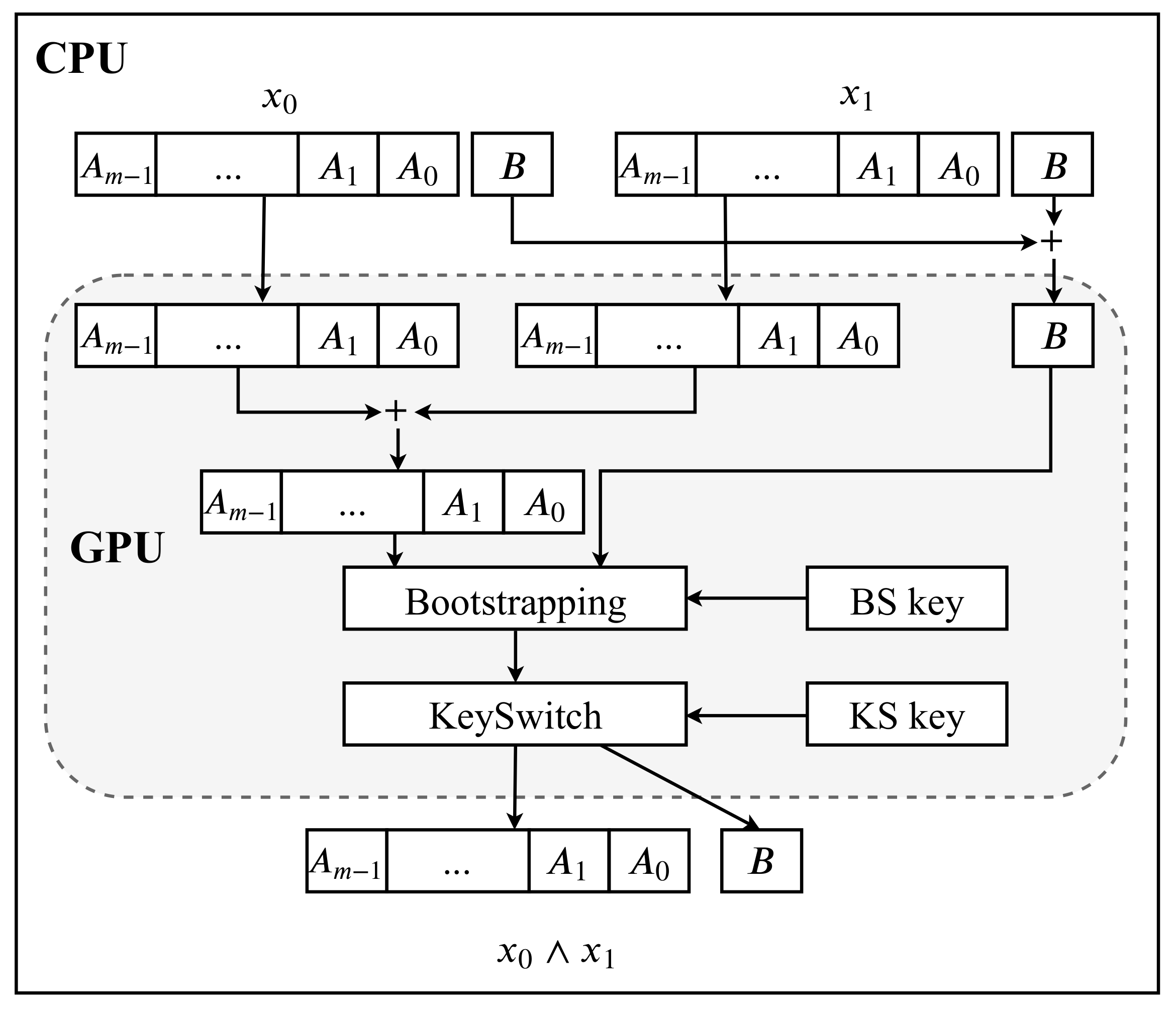
3.1. GPU-Based Parallel Framework
3.1.1. Proposed Techniques for Parallel HE Operations
Parallel TFHE Construction
Bit Coalescing (BC)
Compound Gate
3.1.2. Algebraic Circuits on GPU
| Algorithm 2: Determine if input number is greater than zero. |
 |
3.1.3. Bitwise Operations
Greater Than Zero
Longest Consecutive Ones
| Algorithm 3: Find longest consecutive ones. |
 |
Finding Minimum and Maximum Number
| Algorithm 4: Get minimum number among encrypted positive numbers (). |
 |
| Algorithm 5: Get maximum number among encrypted positive numbers . |
 |
Alternative Approach
3.2. Secure String Search Operations
3.2.1. Hamming Distance
| Algorithm 6: Hamming distances between a query and encrypted sequences. |
 |
3.2.2. Edit Distance Approximation
| Algorithm 7: Banded edit distance on encrypted sequence. |
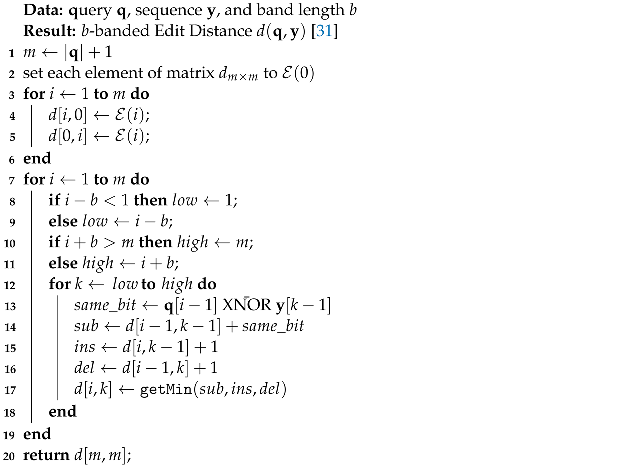 |
3.2.3. Set-Maximal Distance
Threshold SMM
| Algorithm 8: Thresholded set-maximal matching. |
 |
4. Experimental Analysis
4.1. GPU-Accelerated TFHE
4.2. Compound Gate Analysis
4.3. Addition
4.4. Multiplication
4.5. Karatsuba Multiplication
4.6. String Search Operations
5. Discussion
6. Related Works
6.1. Parallel Frameworks for FHE
- Bitwise;
- modular; and
- approximate.
| Year | Homomorphism | Bootstrapping | Parallelism | Bit security | Size (kb) | Add. (ms) | Mult. (ms) | |
|---|---|---|---|---|---|---|---|---|
| RSA [38] | 1978 | Partial | × | × | 128 | 0.9 | × | 5 |
| Paillier [39] | 1999 | Partial | × | × | 128 | 0.3 | 4 | × |
| TFHE [12] | 2016 | Fully | Exact | AVX [22] | 110 | 31.5 | 7044 | 489,938 |
| HEEAN [20] | 2018 | Somewhat | Approximate | CPU | 157 | 7168 | 11.37 | 1215 |
| SEAL (BFV) [40] | 2019 | Somewhat | × | × | 157 | 8806 | 4237 | 23,954 |
| cuFHE [13] | 2018 | Fully | Exact | GPU | 110 | 31.5 | 2032 | 132,231 |
| NuFHE [14] | 2018 | Fully | Exact | GPU | 110 | 31.5 | 4162 | 186,011 |
| Cigulata [15] | 2018 | Fully | Exact | × | 110 | 31.5 | 2160 | 50,690 |
| Our Method | - | Fully | Exact | GPU | 110 | 31.5 | 1991 | 33,930 |
6.2. Secure String Distances in Genomic Data
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
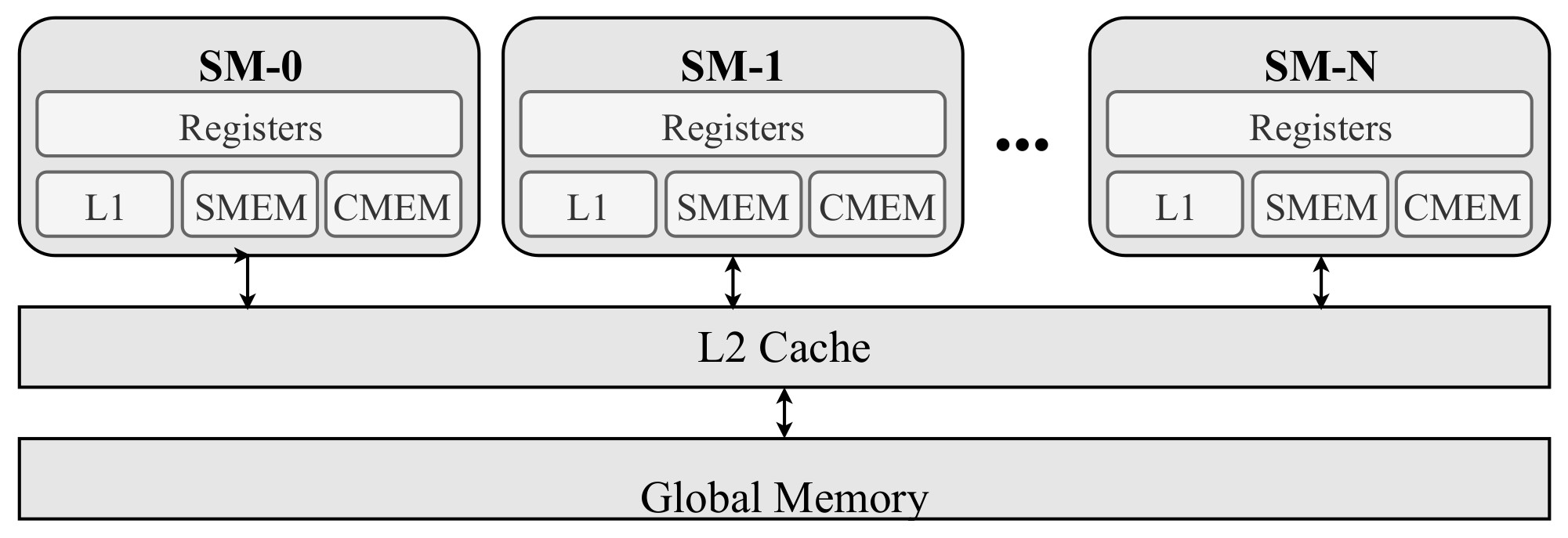
Appendix A. GPU Computational Hierarchy
Appendix A.1. Memory Hierarchy in GPU
- (a)
- Register;
- (b)
- Cache;
- (c)
- Shared;
- (d)
- Constant; and
- (e)
- Global.
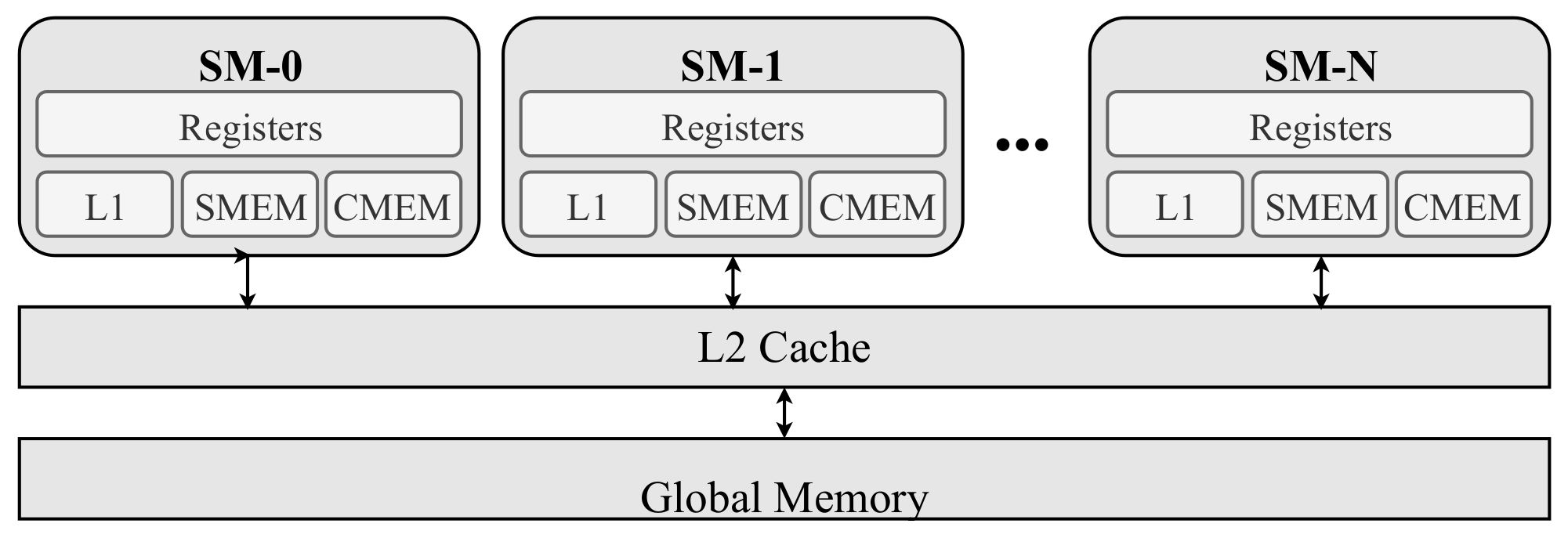
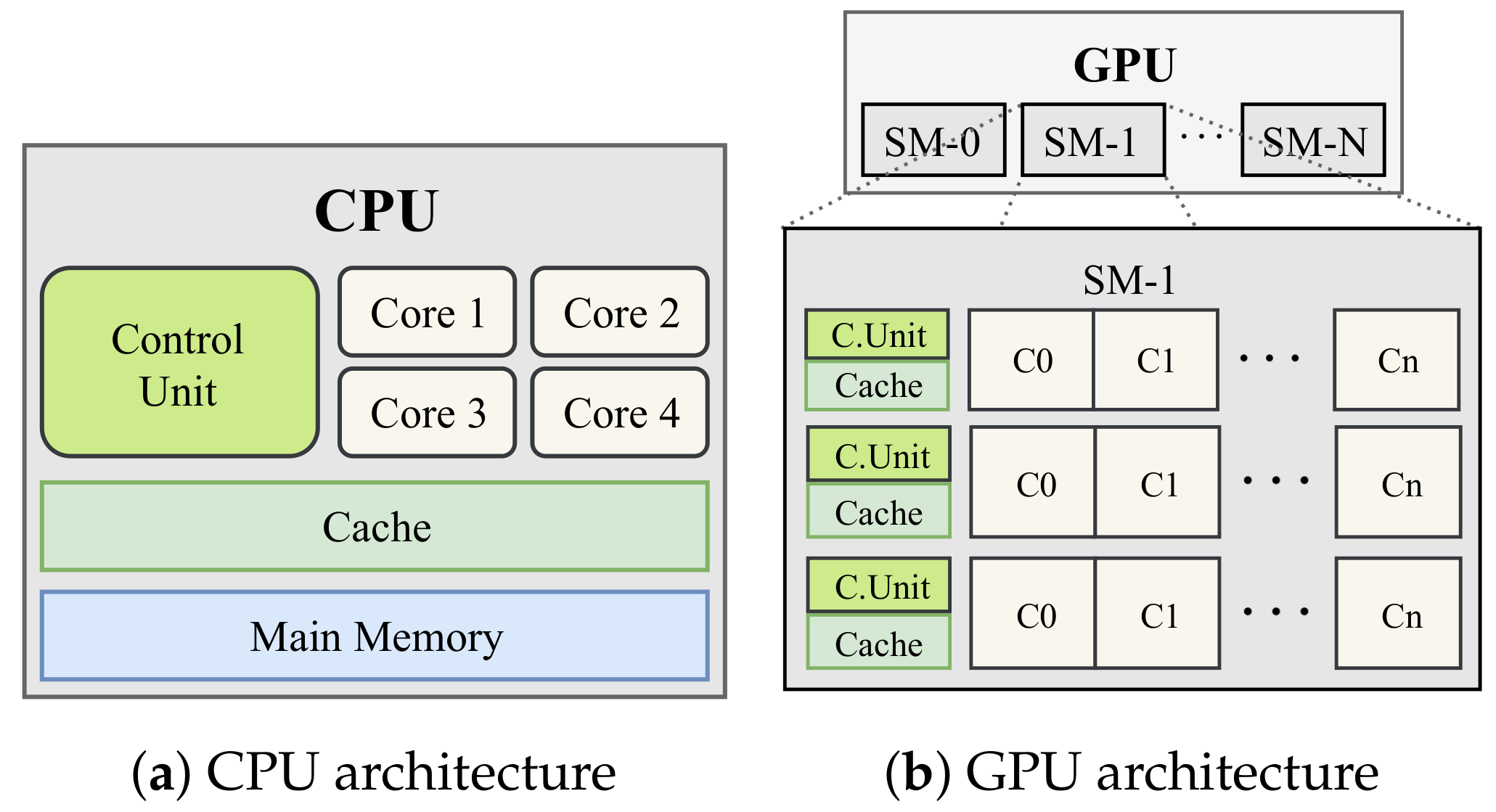
| CPU | GPU | |
|---|---|---|
| Clock speed | 3.40 GHz | 1734 MHz |
| Main memory | 16 GB | 8 GB |
| L1 cache | 256 KB | 48 KB |
| L2 cache | 256 KB | 2048 KB |
| L3 cache | 8192 KB | × |
| Physical threads | 8 | 40,960 |
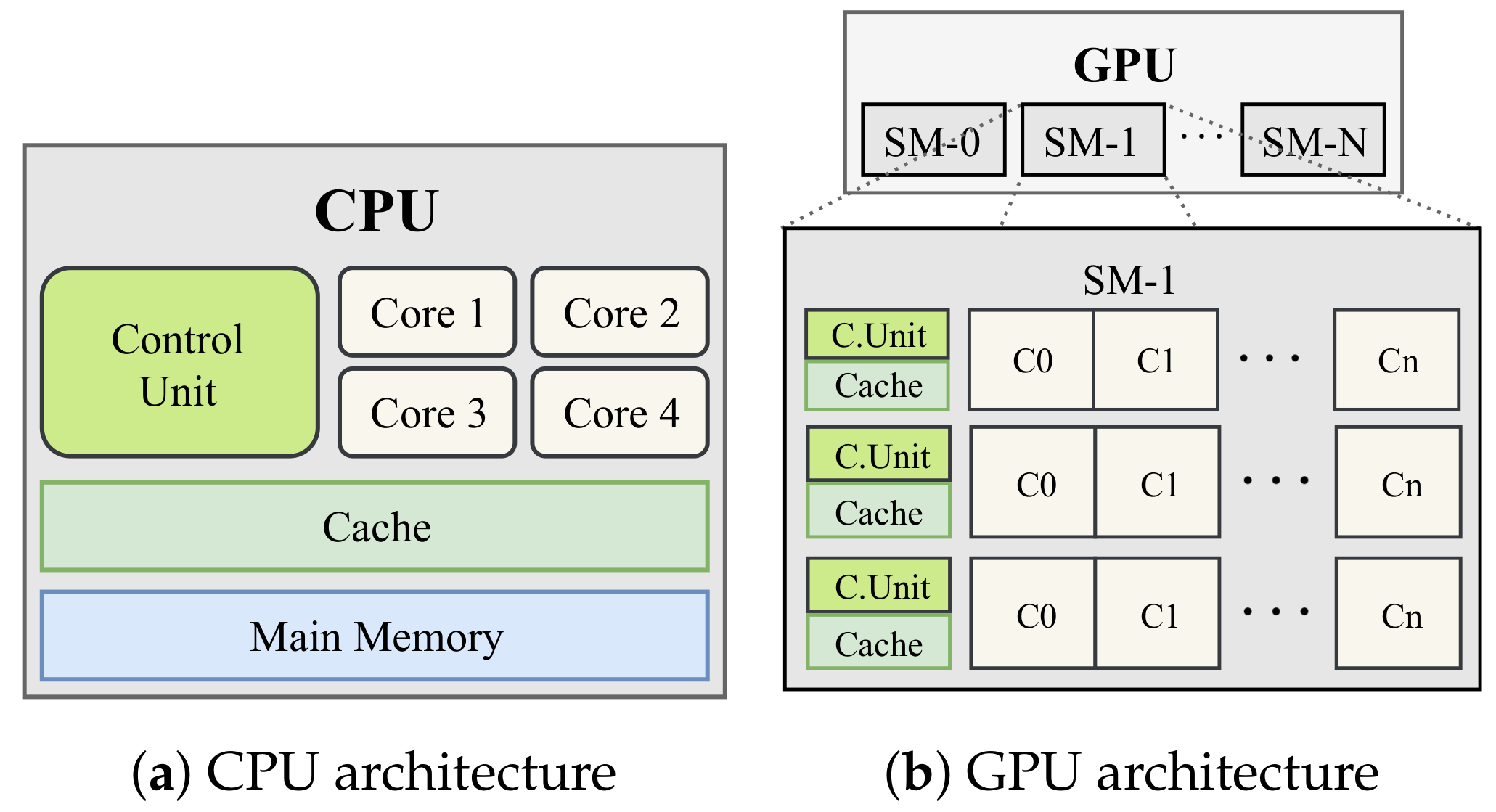
Appendix A.2. Computational and Memory Hierarchy Coordination
Appendix A.3. Architectural Differences with CPU
References
- Gentry, C. Fully homomorphic encryption using ideal lattices. In Proceedings of the STOC, Bethesda, MD, USA, 31 May 31–2 June 2009; Volume 9, pp. 169–178. [Google Scholar]
- Pham, A.; Dacosta, I.; Endignoux, G.; Pastoriza, J.R.T.; Huguenin, K.; Hubaux, J.P. ORide: A Privacy-Preserving yet Accountable Ride-Hailing Service. In Proceedings of the 26th USENIX Security Symposium (USENIX Security 17), Vancouver, BC, Canada, 16–18 August 2017; pp. 1235–1252. [Google Scholar]
- Kim, M.; Song, Y.; Cheon, J.H. Secure searching of biomarkers through hybrid homomorphic encryption scheme. BMC Med. Genom. 2017, 10, 42. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Gilad-Bachrach, R.; Han, K.; Huang, Z.; Jalali, A.; Laine, K.; Lauter, K. Logistic regression over encrypted data from fully homomorphic encryption. BMC Med. Genom. 2018, 11, 81. [Google Scholar] [CrossRef] [PubMed]
- Morshed, T.; Alhadidi, D.; Mohammed, N. Parallel Linear Regression on Encrypted Data. In Proceedings of the 16th Annual Conference on Privacy, Security and Trust (PST), Belfast, Ireland, 28–30 August 2018; pp. 1–5. [Google Scholar]
- Naveed, M.; Ayday, E.; Clayton, E.W.; Fellay, J.; Gunter, C.A.; Hubaux, J.P.; Malin, B.A.; Wang, X. Privacy in the genomic era. ACM Comput. Surv. (CSUR) 2015, 48, 6. [Google Scholar] [CrossRef] [PubMed]
- Aziz, M.M.A.; Sadat, M.N.; Alhadidi, D.; Wang, S.; Jiang, X.; Brown, C.L.; Mohammed, N. Privacy-preserving techniques of genomic data: A survey. Briefings Bioinform. 2017, 20, 887–895. [Google Scholar] [CrossRef] [PubMed]
- 23AndMe.com. Our Health + Ancestry DNA Service—23AndMe Canada. Available online: https://www.23andme.com/en-ca/dna-health-ancestry (accessed on 20 November 2020).
- Wang, X.S.; Huang, Y.; Zhao, Y.; Tang, H.; Wang, X.; Bu, D. Efficient genome-wide, privacy-preserving similar patient query based on private edit distance. In Proceedings of the 22Nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; ACM: New York, NY, USA, 2015; pp. 492–503. [Google Scholar]
- Al Aziz, M.M.; Alhadidi, D.; Mohammed, N. Secure approximation of edit distance on genomic data. BMC Med. Genom. 2017, 10, 41. [Google Scholar] [CrossRef] [PubMed]
- Guerrini, C.J.; Robinson, J.O.; Petersen, D.; McGuire, A.L. Should police have access to genetic genealogy databases? Capturing the Golden State Killer and other criminals using a controversial new forensic technique. PLoS Biol. 2018, 16, e2006906. [Google Scholar] [CrossRef] [PubMed]
- Chillotti, I.; Gama, N.; Georgieva, M.; Izabachène, M. Faster fully homomorphic encryption: Bootstrapping in less than 0.1 seconds. In Proceedings of the Advances in Cryptology—ASIACRYPT 2016: 22nd International Conference on the Theory and Application of Cryptology and Information Security, Hanoi, Vietnam, 4–8 December 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 3–33. [Google Scholar]
- CUDA-Accelerated Fully Homomorphic Encryption Library. 2019. Available online: https://github.com/vernamlab/cuFHE (accessed on 15 December 2023).
- NuFHE, a GPU-Powered Torus FHE Implementation. 2019. Available online: https://github.com/nucypher/nufhe (accessed on 15 December 2023).
- Cingulata. 2019. Available online: https://github.com/CEA-LIST/Cingulata (accessed on 15 December 2023).
- Cheon, J.H.; Kim, M.; Lauter, K. Homomorphic computation of edit distance. In Proceedings of the International Conference on Financial Cryptography and Data Security, San Juan, Puerto Rico, 26–30 January 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 194–212. [Google Scholar]
- Chillotti, I.; Gama, N.; Georgieva, M.; Izabachène, M. Faster packed homomorphic operations and efficient circuit bootstrapping for TFHE. In Proceedings of the International Conference on the Theory and Application of Cryptology and Information Security, Hong Kong, China, 3–7 December 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 377–408. [Google Scholar]
- Morshed, T.; Aziz, M.; Mohammed, N. CPU and GPU Accelerated Fully Homomorphic Encryption. In Proceedings of the 2020 IEEE International Symposium on Hardware Oriented Security and Trust (HOST), Los Alamitos, CA, USA, 7–11 December 2020; pp. 142–153. [Google Scholar] [CrossRef]
- Regev, O. On lattices, learning with errors, random linear codes, and cryptography. J. ACM 2009, 56, 34. [Google Scholar] [CrossRef]
- Cheon, J.H.; Han, K.; Kim, A.; Kim, M.; Song, Y. Bootstrapping for approximate homomorphic encryption. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Tel Aviv, Israel, 29 April–3 May 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 360–384. [Google Scholar]
- Boura, C.; Gama, N.; Georgieva, M. Chimera: A Unified Framework for B/FV, TFHE and HEAAN Fully Homomorphic Encryption and Predictions for Deep Learning. IACR Cryptol. ePrint Arch. 2018, 2018, 758. [Google Scholar]
- Lomont, C. Introduction to Intel Advanced Vector Extensions. Intel White Paper 2011, pp. 1–21. Available online: https://hpc.llnl.gov/sites/default/files/intelAVXintro.pdf (accessed on 16 December 2023).
- Frigo, M.; Johnson, S.G. FFTW: An adaptive software architecture for the FFT. In Proceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP’98 (Cat. No. 98CH36181), Seattle, WA, USA, 12–15 May 1998; Volume 3, pp. 1381–1384. [Google Scholar]
- Brakerski, Z.; Gentry, C.; Halevi, S. Packed ciphertexts in LWE-based homomorphic encryption. In Proceedings of the International Workshop on Public Key Cryptography, Nara, Japan, 26 February–1 March 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 1–13. [Google Scholar]
- Ducas, L.; Micciancio, D. FHEW: Bootstrapping Homomorphic Encryption in Less Than a Second. Cryptology ePrint Archive, Report 2014/816, 2014. Available online: https://eprint.iacr.org/2014/816 (accessed on 20 December 2023).
- Fan, J.; Vercauteren, F. Somewhat Practical Fully Homomorphic Encryption. IACR Cryptol. Eprint Arch. 2012, 2012, 144. [Google Scholar]
- McGeoch, C.C. Parallel Addition. Am. Math. Mon. 1993, 100, 867–871. [Google Scholar] [CrossRef]
- Karatsuba, A.A.; Ofman, Y.P. Multiplication of many-digital numbers by automatic computers. In Proceedings of the Doklady Akademii Nauk; Russian Academy of Sciences: Moskva, Russia, 1962; Volume 145, pp. 293–294. [Google Scholar]
- Chandra, R.; Dagum, L.; Kohr, D.; Menon, R.; Maydan, D.; McDonald, J. Parallel Programming in OpenMP; Morgan Kaufmann: Cambridge, MA, USA, 2001. [Google Scholar]
- NVIDIA. GeForce GTX 1080 Graphics Cards from NVIDIA GeForce. Available online: https://www.nvidia.com/en-us/geforce/products/10series/geforce-gtx-1080/ (accessed on 20 December 2023).
- Fickett, J.W. Fast optimal alignment. Nucleic Acids Res. 1984, 12, 175–179. [Google Scholar] [CrossRef] [PubMed]
- Sotiraki, K.; Ghosh, E.; Chen, H. Privately computing set-maximal matches in genomic data. BMC Med. Genom. 2020, 13, 72. [Google Scholar] [CrossRef] [PubMed]
- Shimizu, K.; Nuida, K.; Rätsch, G. Efficient Privacy-Preserving String Search and an Application in Genomics. Bioinformatics 2016, 32, 1652–1661. [Google Scholar] [CrossRef] [PubMed]
- Durbin, R. Efficient haplotype matching and storage using the positional Burrows–Wheeler transform (PBWT). Bioinformatics 2014, 30, 1266–1272. [Google Scholar] [CrossRef] [PubMed]
- Xie, P.; Bilenko, M.; Finley, T.; Gilad-Bachrach, R.; Lauter, K.; Naehrig, M. Crypto-nets: Neural networks over encrypted data. arXiv 2014, arXiv:1412.6181. [Google Scholar]
- Takabi, H.; Hesamifard, E.; Ghasemi, M. Privacy preserving multi-party machine learning with homomorphic encryption. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Chillotti, I.; Gama, N.; Georgieva, M.; Izabachène, M. TFHE: Fast Fully Homomorphic Encryption Library. August 2016. Available online: https://tfhe.github.io/tfhe/ (accessed on 20 December 2023).
- Rivest, R.L.; Shamir, A.; Adleman, L. A method for obtaining digital signatures and public-key cryptosystems. Commun. ACM 1978, 21, 120–126. [Google Scholar] [CrossRef]
- Paillier, P. Public-key cryptosystems based on composite degree residuosity classes. In Proceedings of the Advances in cryptology, EUROCRYPT, Prague, Czech Republic, 2–6 May 1999; Springer: Berlin/Heidelberg, Germany, 1999; pp. 223–238. [Google Scholar]
- Microsoft SEAL (Release 3.2). 2019. Microsoft Research, Redmond, WA. Available online: https://github.com/Microsoft/SEAL (accessed on 20 December 2023).
- Gentry, C.; Sahai, A.; Waters, B. Homomorphic encryption from learning with errors: Conceptually-simpler, asymptotically-faster, attribute-based. In Advances in Cryptology–CRYPTO 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 75–92. [Google Scholar]
- Brakerski, Z.; Vaikuntanathan, V. Efficient fully homomorphic encryption from (standard) LWE. SIAM J. Comput. 2014, 43, 831–871. [Google Scholar] [CrossRef]
- Brakerski, Z.; Gentry, C.; Vaikuntanathan, V. (Leveled) fully homomorphic encryption without bootstrapping. ACM Trans. Comput. Theory 2014, 6, 13. [Google Scholar] [CrossRef]
- Cheon, J.H.; Kim, A.; Kim, M.; Song, Y. Homomorphic encryption for arithmetic of approximate numbers. In Proceedings of the International Conference on the Theory and Application of Cryptology and Information Security, Hong Kong, China, 3–7 December 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 409–437. [Google Scholar]
- Flynn, M.J. Some computer organizations and their effectiveness. IEEE Trans. Comput. 1972, 100, 948–960. [Google Scholar] [CrossRef]
- Halevi, S.; Shoup, V. Algorithms in helib. In Proceedings of the Annual Cryptology Conference, Santa Barbara, CA, USA, 17–21 August 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 554–571. [Google Scholar]
- Doröz, Y.; Öztürk, E.; Savaş, E.; Sunar, B. Accelerating LTV based homomorphic encryption in reconfigurable hardware. In Proceedings of the International Workshop on Cryptographic Hardware and Embedded Systems, Saint-Malo, France, 13–16 September 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 185–204. [Google Scholar]
- López-Alt, A.; Tromer, E.; Vaikuntanathan, V. On-the-fly multiparty computation on the cloud via multikey fully homomorphic encryption. In Proceedings of the forty-fourth annual ACM symposium on Theory of computing, New York, NY, USA, 20–22 May 2012; ACM: New York, NY, USA, 2012; pp. 1219–1234. [Google Scholar]
- Dai, W.; Sunar, B. cuHE: A homomorphic encryption accelerator library. In Proceedings of the International Conference on Cryptography and Information Security in the Balkans, Koper, Slovenia, 3–4 September 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 169–186. [Google Scholar]
- Dai, W.; Doröz, Y.; Sunar, B. Accelerating swhe based pirs using gpus. In Proceedings of the International Conference on Financial Cryptography and Data Security, San Juan, Puerto Rico, 26–30 January 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 160–171. [Google Scholar]
- Lei, X.; Guo, R.; Zhang, F.; Wang, L.; Xu, R.; Qu, G. Accelerating Homomorphic Full Adder based on FHEW Using Multicore CPU and GPUs. In Proceedings of the 2019 IEEE 21st International Conference on High Performance Computing and Communications; IEEE 17th International Conference on Smart City; IEEE 5th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Zhangjiajie, China, 10–12 August 2019. [Google Scholar]
- Yang, H.; Yao, W.; Liu, W.; Wei, B. Efficiency Analysis of TFHE Fully Homomorphic Encryption Software Library Based on GPU. In Proceedings of the Workshops of the International Conference on Advanced Information Networking and Applications, Matsue, Japan, 27–29 March 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 93–102. [Google Scholar]
- Zhou, T.; Yang, X.; Liu, L.; Zhang, W.; Li, N. Faster bootstrapping with multiple addends. IEEE Access 2018, 6, 49868–49876. [Google Scholar] [CrossRef]
- Zama. Concrete: TFHE Compiler that Converts Python Programs into FHE Equivalent. 2022. Available online: https://github.com/zama-ai/concrete (accessed on 20 December 2023).
- Jha, S.; Kruger, L.; Shmatikov, V. Towards practical privacy for genomic computation. In Proceedings of the 2008 IEEE Symposium on Security and Privacy (sp 2008), Oakland, CA, USA, 18–21 May 2008; pp. 216–230. [Google Scholar]
- NVidia, F. Nvidia’s Next Generation Cuda Compute Architecture; NVidia: Santa Clara, CA, USA, 2009. [Google Scholar]

| Bit Size | Sequential | GPU | ||||||
|---|---|---|---|---|---|---|---|---|
| n | Bootstrapping | Key Switch | Misc. | Total | Bootstrapping | Key Switch | Misc. | Total |
| 2 | 68.89 | 17.13 | 27.04 | 113.05 | 19.64 | 2.65 | 0.45 | 22.74 |
| 4 | 138.02 | 34.18 | 47.97 | 220.17 | 18.86 | 2.69 | 0.08 | 21.63 |
| 8 | 275.67 | 68.31 | 96.48 | 440.46 | 27.83 | 2.69 | 0.06 | 30.58 |
| 16 | 137.25 | 137.25 | 425.22 | 699.72 | 40.70 | 2.91 | 0.44 | 44.06 |
| 32 | 274.3 | 274.30 | 852.51 | 1401.10 | 66.74 | 3.34 | 0.42 | 70.50 |
| Frameworks | 16-Bit | 24-Bit | 32-Bit |
|---|---|---|---|
| Sequential | 3.51 | 5.23 | 7.04 |
| cuFHE [13] | 1.00 | 1.51 | 2.03 |
| NuFHE [14] | 2.92 | 3.56 | 4.16 |
| Cingulata [15] | 1.10 | 1.63 | 2.16 |
| Our Methods | |||
| CPU ‖ | 3.51 | 5.23 | 7.04 |
| GPUn ‖ | 0.94 | 2.55 | 4.44 |
| GPU1 ‖ | 0.98 | 1.47 | 1.99 |
| Length | 16-Bit | 32-Bit | ||||
|---|---|---|---|---|---|---|
| ℓ | Seq. | CPU ‖ | GPU ‖ | Seq. | CPU ‖ | GPU ‖ |
| 4 | 13.98 | 5.07 | 1.27 | 28.05 | 10.02 | 2.56 |
| 8 | 27.86 | 9.96 | 1.78 | 56.01 | 19.29 | 3.58 |
| 16 | 55.66 | 19.65 | 2.82 | 111.3 | 38.77 | 5.70 |
| 32 | 111.32 | 38.99 | 5.41 | 224.31 | 77.18 | 11.22 |
| Frameworks | 16-Bit | 24-Bit | 32-Bit |
|---|---|---|---|
| Naive | |||
| Sequential | 120.64 | 273.82 | 489.94 |
| CPU ‖ | 52.77 | 101.22 | 174.54 |
| GPU ‖ | 11.16 | 22.08 | 33.99 |
| cuFHE [13] | 32.75 | 74.21 | 132.23 |
| NuFHE [14] | 47.72 | 105.48 | 186.00 |
| Cingulata [15] | 11.50 | 27.04 | 50.69 |
| Karatsuba | |||
| CPU ‖ | 54.76 | - | 177.04 |
| GPU ‖ | 7.6708 | - | 24.62 |
| Length | 16-Bit | 32-Bit | ||||
|---|---|---|---|---|---|---|
| ℓ | Seq. | CPU ‖ | GPU ‖ | Seq. | CPU ‖ | GPU ‖ |
| 4 | 8.13 | 3.25 | 0.41 | 32.56 | 12.15 | 1.61 |
| 8 | 16.29 | 6.17 | 0.75 | 65.12 | 23.48 | 2.96 |
| 16 | 32.62 | 11.93 | 1.40 | 130.31 | 46.39 | 5.62 |
| 32 | 65.15 | 23.58 | 2.68 | 260.52 | 92.44 | 10.79 |
| Method | m | |||||
|---|---|---|---|---|---|---|
| 8 | 16 | 32 | 64 | 128 | 256 | |
| Hamming distance | 2.89 | 11.84 | 47.95 | 189.81 | 758.73 | 3035.0 |
| Set-maximal | 3.76 | 13.3 | 51.24 | 195.72 | 771.08 | 3061.48 |
| Set-maximal (with t) | 7.15 | 20.67 | 64.43 | 223.14 | 827.76 | 3173.34 |
| Edit distance | 662 | 2577 | 9989 | 39,022 | 154,194 | 612,435 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aziz, M.M.A.; Tamal, M.T.M.; Mohammed, N. Secure Genomic String Search with Parallel Homomorphic Encryption. Information 2024, 15, 40. https://doi.org/10.3390/info15010040
Aziz MMA, Tamal MTM, Mohammed N. Secure Genomic String Search with Parallel Homomorphic Encryption. Information. 2024; 15(1):40. https://doi.org/10.3390/info15010040
Chicago/Turabian StyleAziz, Md Momin Al, Md Toufique Morshed Tamal, and Noman Mohammed. 2024. "Secure Genomic String Search with Parallel Homomorphic Encryption" Information 15, no. 1: 40. https://doi.org/10.3390/info15010040
APA StyleAziz, M. M. A., Tamal, M. T. M., & Mohammed, N. (2024). Secure Genomic String Search with Parallel Homomorphic Encryption. Information, 15(1), 40. https://doi.org/10.3390/info15010040