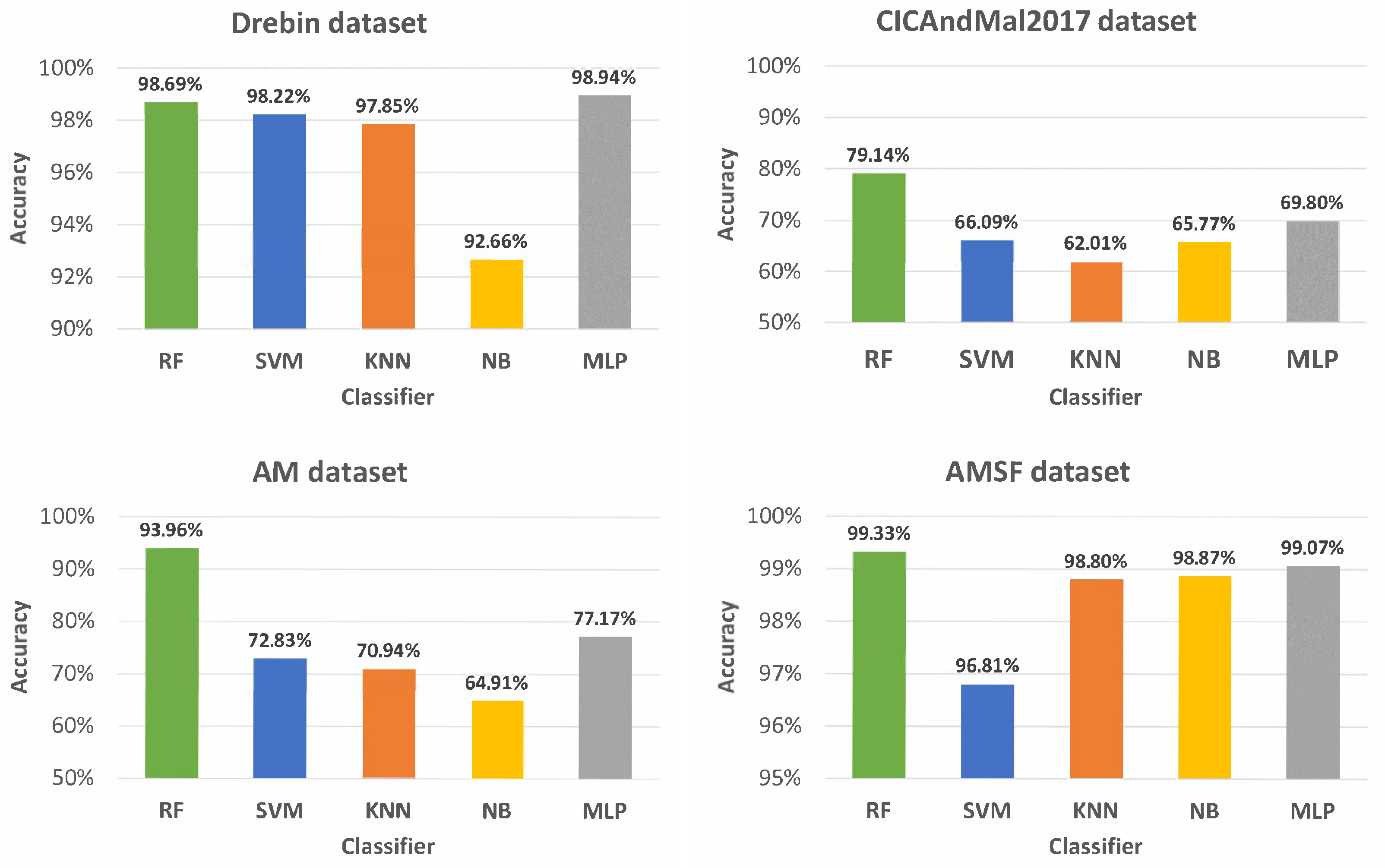
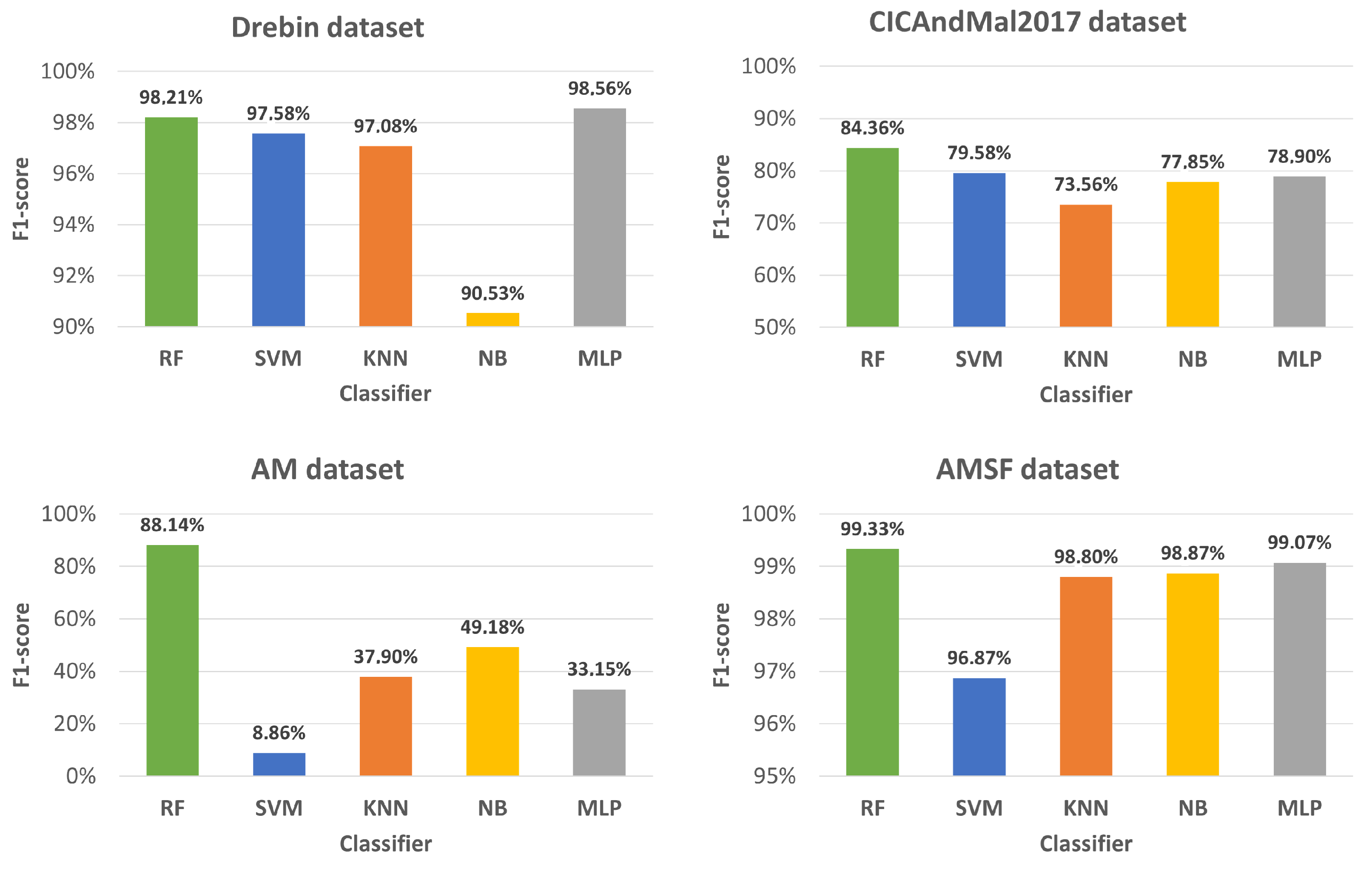
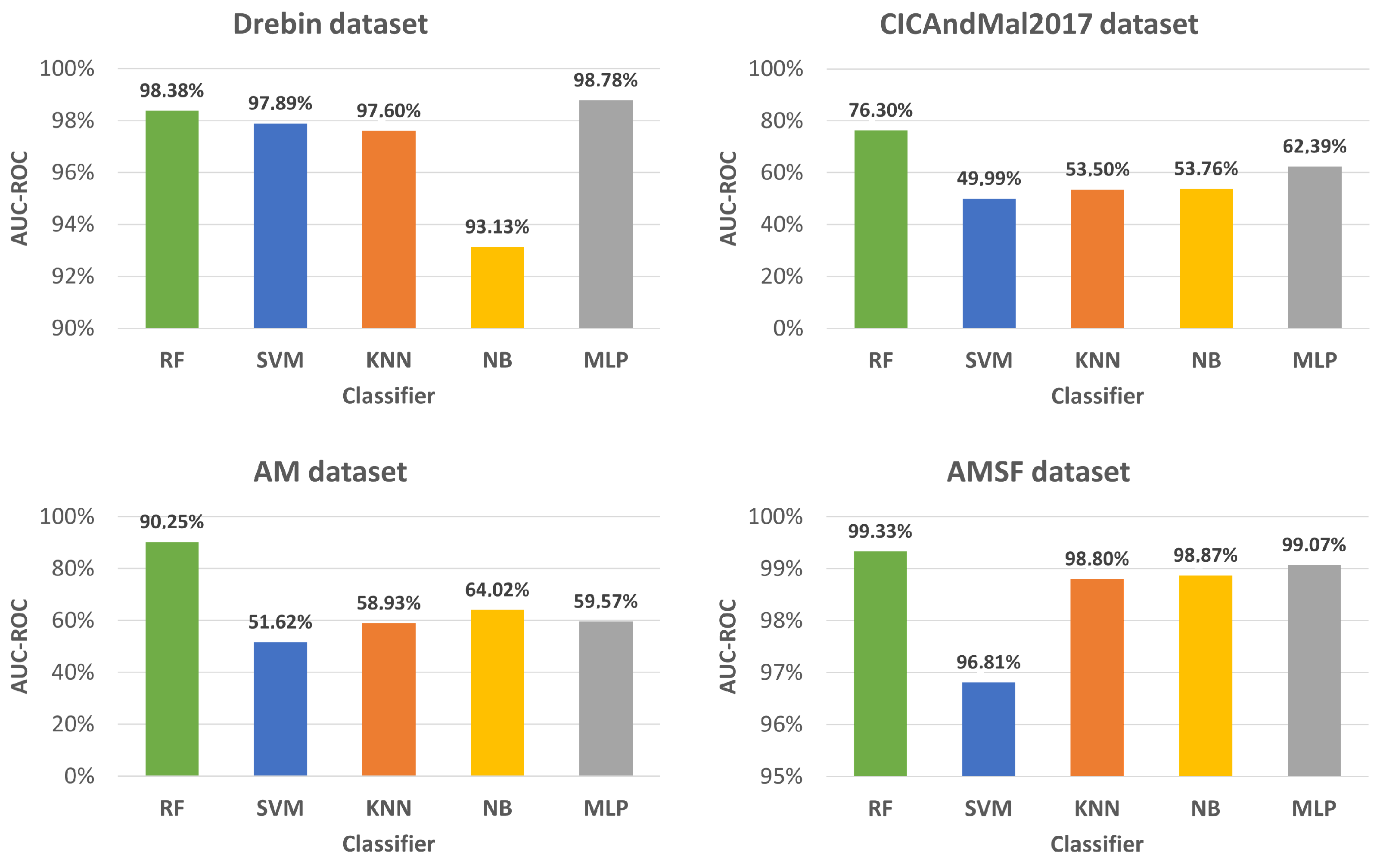
4. Experimental Evaluation
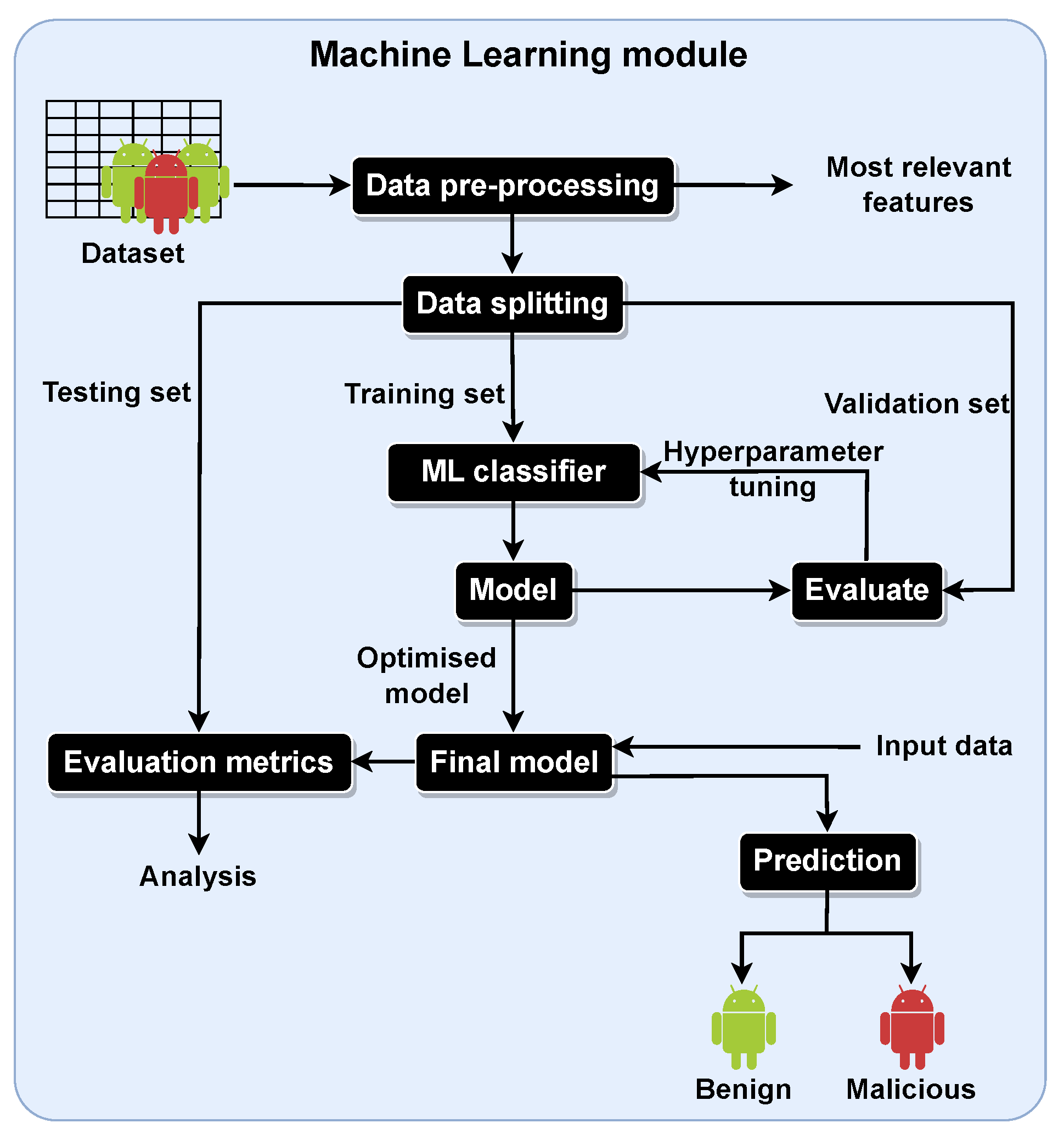
We now report the experimental evaluation process, conducted using Python and the ML library ‘scikit-learn’. We have considered the classifiers mentioned in
Section 2.5 and the evaluation metrics described in
Section 2.6.
This section is organized as follows.
Section 4.1 performs dataset analysis. Baseline experimental results are presented in
Section 4.2.
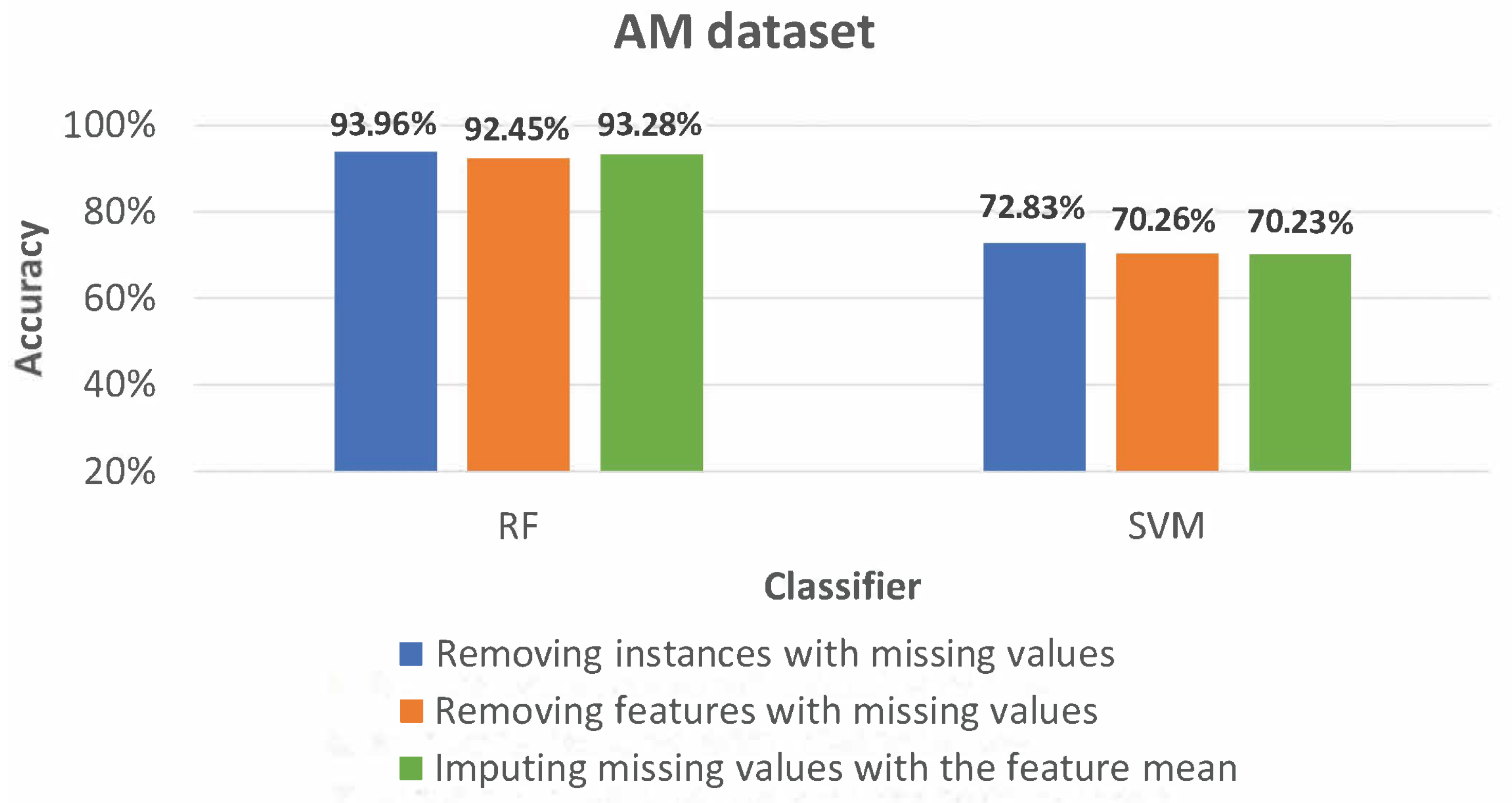
Section 4.3 reports experimental results after applying some data pre-processing techniques.
Section 4.4 presents the outcomes of applying FS.
Section 4.5 displays the results obtained via CV and by performing hyperparameter tuning.
Section 4.6 compares some of the obtained experimental results with those from existing studies. In
Section 4.7, real-world Android applications are used to assess the prototype of the proposed approach. Finally,
Section 4.8 provides an overall assessment of the experimental evaluation and a comparison with existing approaches.
4.4. Experimental Results—Feature Selection
This section reports the experimental results obtained in the FS experiments, namely, with the RRFS algorithm by Ferreira and Figueiredo [
19]. Different relevance measures were tested, namely, the supervised relevance measure FR and the unsupervised relevance measure MM. The redundancy measure used was the AC, with an allowed maximum similarity (
) between consecutive pairs of features of 0.3.
Table 8 reports the accuracy (Acc) values for the SVM classifier on each dataset in the following settings: baseline (without FS), using RRFS with MM relevance, and using RRFS with the FR metric.
Overall, the results worsen slightly after applying RRFS, and the same applies to the RF classifier. However, these slight drops in accuracy in some of the results are arguably compensated for by the reduction in the number of features. The original number of features versus the number of features after applying the RRFS approach with different relevance measures for each dataset are presented in
Figure 11.
Regardless of the relevance metric, the RRFS approach significantly reduced the number of features in each dataset. The supervised relevance measure FR led to a more considerable reduction in dimensionality than the unsupervised relevance measure MM. The number of reduced features combined with the evaluation metrics results indicate that the FR relevance measure presents overall better results. Thus, the use of the class label improves on the results for this task.
With the FR measure, a subset of the most relevant features is obtained. The RRFS approach continues by removing redundant features from this subset to obtain the best feature subset [
19], consisting of the most relevant and non-redundant features.
The redundancy measure applied was the AC. The value can define the maximum allowed similarity between pairs of features. Different values of were tested (0.2, 0.3, and 0.4) to balance better the number of reduced features while maintaining good results in the evaluation metrics. The results obtained with different were similar. However, a pattern could be seen where, typically, would provide the best results, closely followed by and then . The higher the value, the less strict the selection is regarding redundancy between features; thus, more features are kept. Based on the results, to better accommodate both reducing features and maintaining good results, seems to be the best choice.
Overall, the results with the SVM classifier seem to vary more with the use of FS than the results obtained with the RF classifier, with the latter being more robust to irrelevant features. The results with the SVM classifier suffered more influence of FS, with a tendency to get slightly worse. This could be because of the removal of too many features, which may oversimplify the model (underfitting), or the dimensionality reduction was too aggressive, leading to SVM struggling to find a reasonable decision boundary. However, the slightly worse results in terms of evaluation metrics are the cost of being able to reduce the dataset’s dimensionality, with a reduction of 56% for the Drebin dataset, 76% for the CICAndMal2017 dataset, 92% for the AM dataset and 87% for the AMSF dataset.
Besides dimensionality reduction, RRFS enables the identification of the most relevant features for malware detection in Android apps, which is a key factor for the proposed approach. To better understand if the most relevant features follow a pattern or are the same among the different datasets, the five most decisive features are enumerated next.
For the Drebin dataset, RRFS (FR) selects:
- 1.
transact
- 2.
SEND_SMS
- 3.
Ljava.lang.Class.getCanonicalName
- 4.
android.telephony.SmsManager
- 5.
Ljava.lang.Class.getField
For the CICAndMal2017 dataset, RRFS (FR) selects:
- 1.
Category
- 2.
Price
- 3.
Network communication : view network state (S)
- 4.
Your location : access extra location provider commands (S)
- 5.
System tools : set wallpaper (S)
For the AM dataset, RRFS (FR) selects:
- 1.
com.android.launcher.permission.UNINSTALL_SHORTCUT
- 2.
android.permission.VIBRATE
- 3.
android.permission.ACCESS_FINE_LOCATION
- 4.
name
- 5.
android.permission.BLUETOOTH_ADMIN
- 6.
android.permission.WAKE_LOCK
For the AMSF dataset, RRFS (FR) selects:
- 1.
androidpermissionSEND_SMS
- 2.
android.telephony.SmsManager.sendTextMessage
- 3.
float-to-int
- 4.
android.telephony.SmsManager
- 5.
android.support.v4.widget
The most relevant features in the Drebin and AMSF datasets are permissions and classes or methods. Permissions are the most relevant features in the AM dataset. In the CICAndMAl2017 dataset, the most relevant features are permissions and meta information. Summarizing, across the different datasets, we have that some of the most relevant features for Android malware detection are android.permission.SEND_SMS and android.telephony.SmsManager. Overall, we found that the most indicative features regarding the presence of malware in Android apps are permissions and typically SMS-related.
4.5. Experimental Results—CV and Hyperparameter Tuning
This section reports the experimental results obtained after performing the hyperparameter tuning of the RF and SVM classifiers and the use of CV. Initially, a random stratified split was applied to the datasets with a 70–30 ratio for training and testing, respectively, with no validation set considered and no hyperparameter tuning performed.
To perform the hyperparameter tuning of the RF and SVM classifiers, the function GridSearchCV [
65] of the scikit-learn library was applied. This function performs an exhaustive search over specified parameter values for an estimator. The parameters of the estimator are optimized by CV. The training set is provided to the function, which splits it into training and validation sets. By default, the CV splitting strategy is stratified five-fold CV. This function also enables the specification of the hyperparameters to be optimized and their range of values.
The parameters we deemed more relevant and, thus, the parameters set during hyperparameter tuning were as follows. For the RF classifier, we considered:
the number of trees in the range [100, 1000] with steps of 100.
the maximum tree depth with the values 3, 5, 7, and None. The latter means the nodes are expanded until all leaves are pure or until all leaves contain less than the minimum number of samples required to split an internal node.
the split quality measure as Gini, Entropy, or Log Loss.
For the SVM classifier, we considered:
the regularization parameter (C) in the range [1, 20] with steps of 1.
the kernel type to be used in the algorithm: the radial basis function (RBF) kernel, the polynomial kernel, the linear kernel, and the Sigmoid kernel.
the kernel coefficient (gamma) for the previous kernel types (except the linear kernel).
Overall, the results improved across all evaluation metrics. However, this improvement did not surpass 2%, thus only slightly improving the performance.
To also perform CV with the training and testing sets, an outer loop for CV was added. In this case, we have a nested CV considering the CV performed in the GridSearchCV function with the training and validation sets. For the outer loop, 10-fold CV and LOOCV were applied. Here, the training time for the ML models frequently led to a “training time bottleneck” due to the limited computational resources, the number of iterations, and the number of hyperparameter combinations being tested. This was an even more significant issue with LOOCV, where the number of iterations matches the number of instances of the dataset used. As an attempt to sidestep this issue, the number of hyperparameter combinations in the GridSearchCV function was reduced by considering the values more often chosen in the optimization for each of the used datasets. However, some results still could not be obtained, namely, with LOOCV, which is much slower than 10-fold CV. Although it takes longer, its results are more stable and reliable than 10-fold CV since it uses more training samples and iterations. With 10-fold CV, some results were obtained, namely, in the form of the mean and standard deviation measures for each evaluation metric. Overall, the results were satisfying, with the mean values not differing substantially from those obtained after performing hyperparameter tuning, and the standard deviation obtained throughout the different evaluation metrics was low, indicating that the results are clustered around the mean, thus being more stable and reliable.
5. Conclusions and Future Work
Malware in Android applications affects millions of users worldwide and is constantly evolving. Thus, its detection is a current and relevant problem. In the past few years, ML approaches have been proposed to mitigate malware in mobile applications. In this study, a prototype that resorts to ML techniques to detect malware in Android applications was developed. This task was formulated as a binary classification problem, and public domain datasets (Drebin, CICAndMal2017, AM, and AMSF) were used. Experiments were performed with RF, SVM, KNN, NB, and MLP classifiers, showing that the RF and SVM classifiers are the most suited for this problem.
Data pre-processing techniques were also explored to improve the results. Emphasis was given to FS by applying the RRFS approach to obtain the most relevant and non-redundant subset of features. Although RRFS provided slightly worse results regarding the evaluation metrics, these were arguably compensated for by the dimensionality reduction achieved in each of the used datasets. A reduction of 56% was achieved for the Drebin dataset, 76% for the CICAndMal2017 dataset, 92% for the AM dataset, and 87% for the AMSF dataset. Aside from the dimensionality reduction, RRFS selected the most relevant subset of features to identify the presence of malware. Overall, permissions have a prevalent presence among the most relevant features for Android malware detection.
A nested CV was used to evaluate the trained model better and to tune the ML algorithms hyperparameters, improving the final ML model. As for evaluation metrics, accuracy was used, but, since it can be misleading, other metrics were also applied.
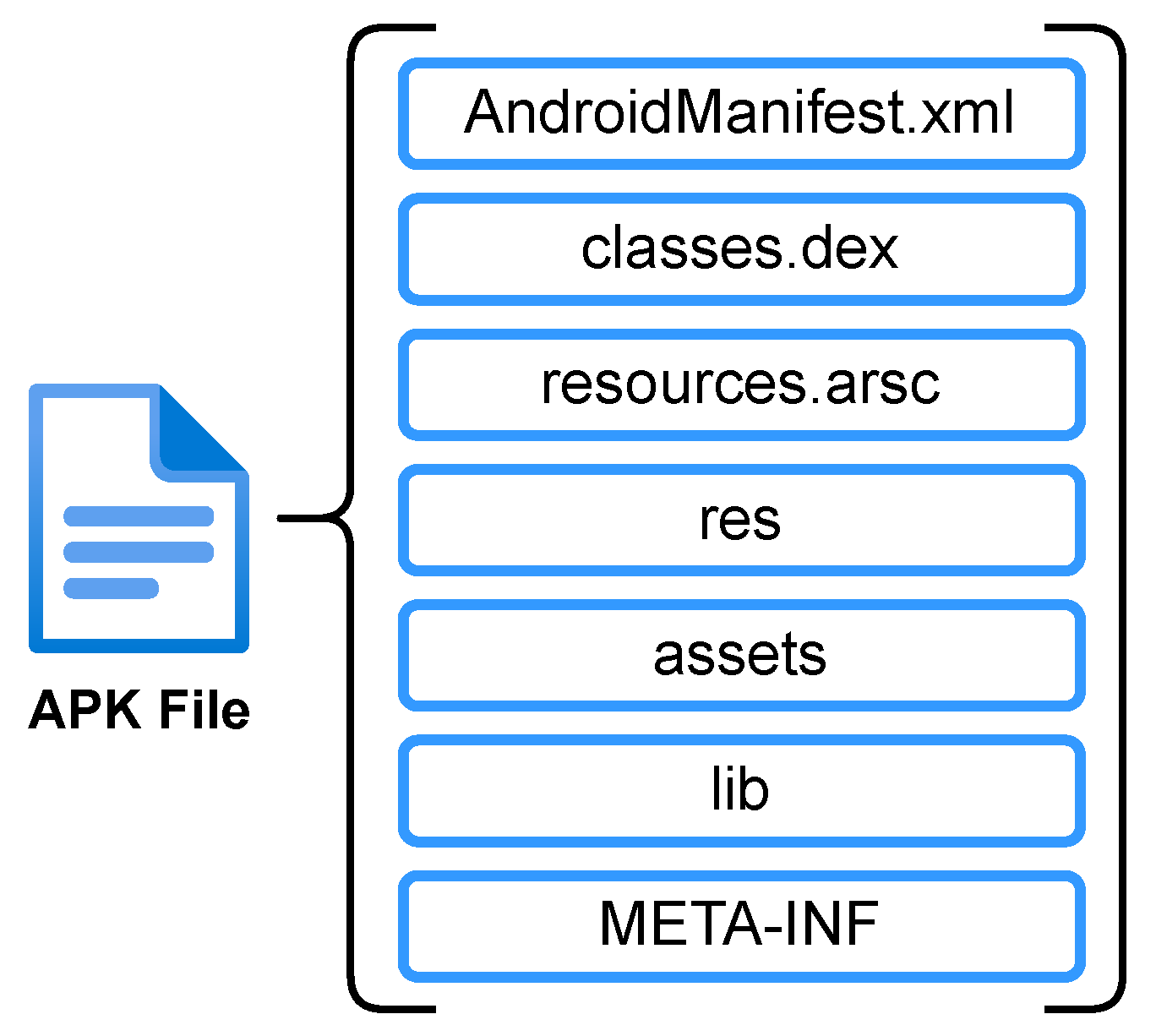
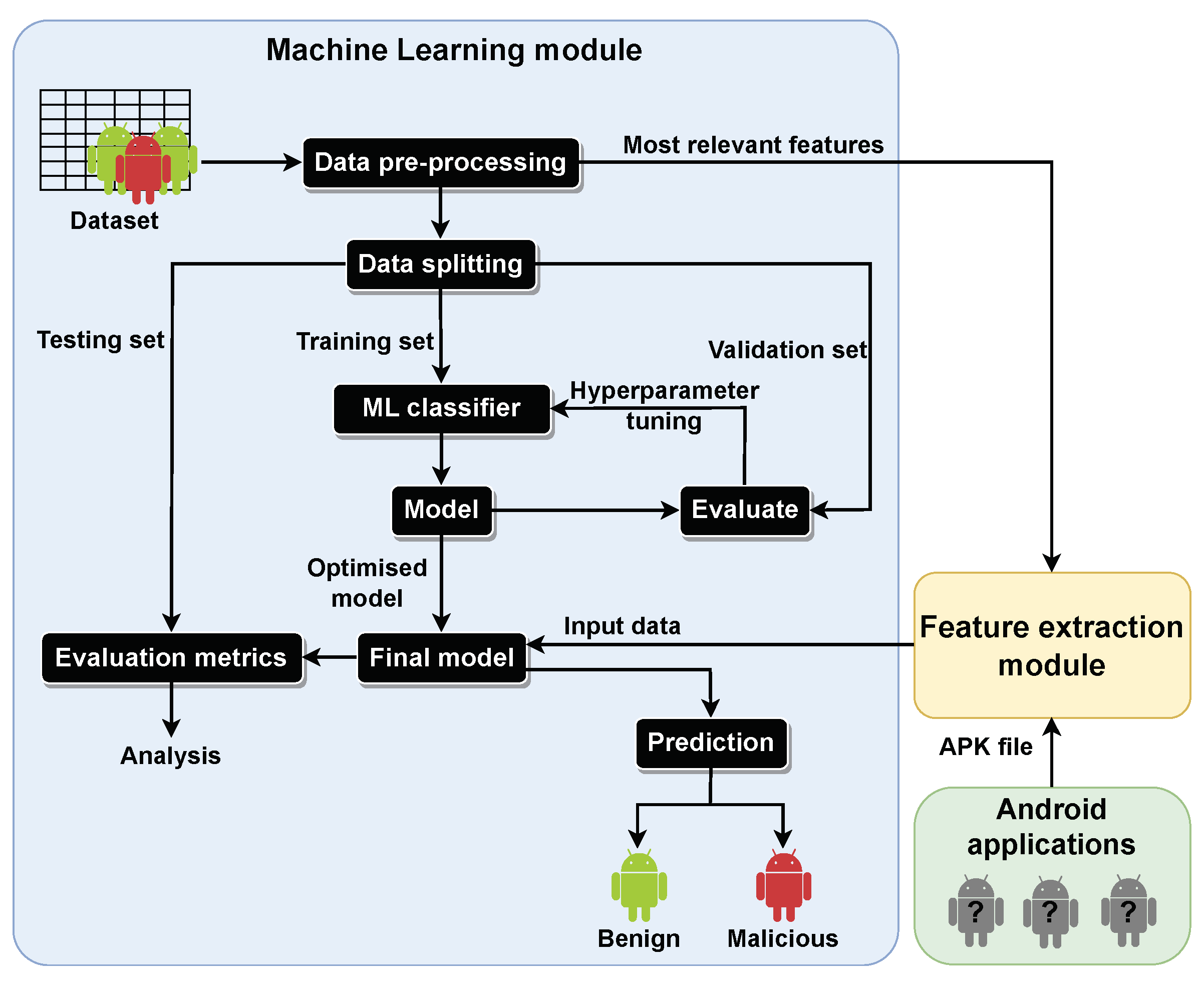
The prototype of the proposed approach was assessed using real-world applications. Overall, the results were negatively impacted by the non-standardization of the dataset’s feature names, which prevented accurate mapping between the extracted features and the most relevant subset of features.
The proposed approach can identify the most decisive features to classify an app as malware and greatly reduce the data dimensionality while achieving good results in identifying malware in Android applications across the various evaluation metrics.
In future work, more up-to-date datasets should be made available and used, and DL approaches and others should be further explored. Furthermore, the proposed approach could be extended to hybrid analysis and/or addressing this problem with a multiclass approach instead of a binary one. Lastly, the feature names across the datasets should have a more uniform designation and be aligned with the names of the features extracted from APK files.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}