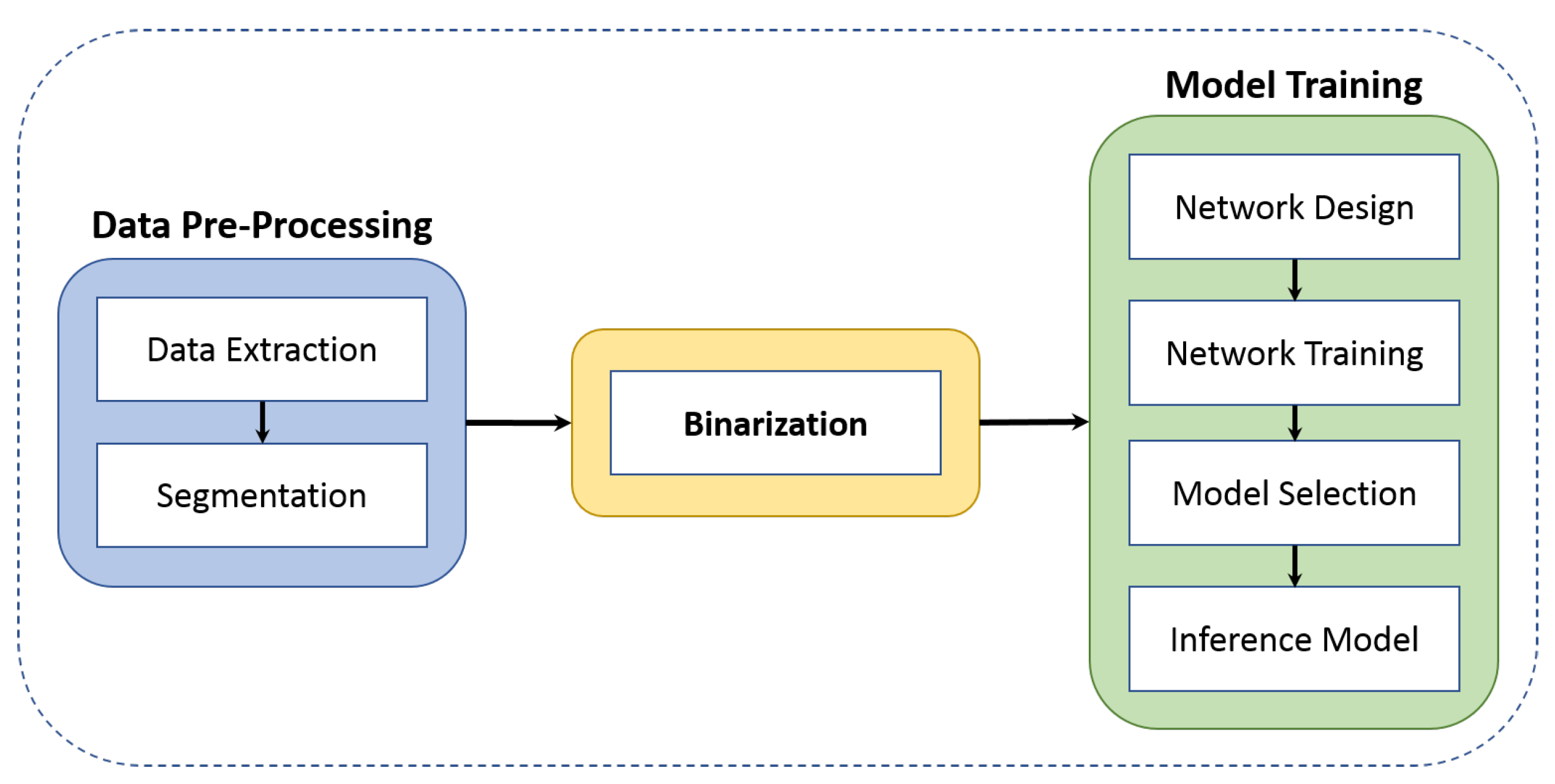
The business processes that derived the event logs were generated in different hospitals or, in the case of the healthcare collaboration process, simulated the relationship established in the clinic for the care of a sick patient. The four healthcare processes used in our approach coexist in the operation of a hospital, starting with patient care through the healthcare collaboration process, from which the sepsis process or the patient transfer process to a second or third-level hospital can be derived. In other cases, the patient transfer process can occur after sepsis. For its part, the hospital billing process can be performed after each previous process. An event log typically contains attributes related to the identifier and name of the executed process, the name of the activities executed, resources responsible for the execution of the activity (human, system, or equipment), date and time of the execution of the activity, and the events that triggered the activity. A case contains a sequence of traces representing the behavior identified in an instance of a process.
3.1. Experiment 1
The event log contains historical information (from 2012 to 2018) about patient transfer orders and medical referral management processes. The event log basis is a project for collaborating healthcare services between a primary care provider (PCP) and a specialist care provider (SCP) located in northern Mexico, presented in [
31]. The procedure of a patient referral assumes negotiating a patient transfer order and managing the medical referral. The social work department of each hospital operates the patient transfer order process. A social worker executes a patient transfer upon request from a specialist doctor. The social work department coordinates all activities related to patient transfer, including equipment, care facilities, personnel, and transportation. The patients are referred from a PCP to an SCP when requiring medical care for cancer, heart, vascular, and neurological diseases. Both hospitals have defined a set of inter-organizational business processes at design time executed by the HIS of each hospital in a coordinated way while respecting the institutions’ autonomy involved in the collaboration.
The dataset was extracted from the test environment of the PCP information system by information technology personnel authorized by the hospital. This environment contains the real behavior of the healthcare processes executed between hospitals with n instances of all possible behaviors defined in each healthcare process. The data was extracted automatically, assigning a Case-ID for each instance of the logged process, generating an XML file with the required structure in the XES schema. It is essential to mention that this data set does not include sensitive data about the patient’s identity, disease, or diagnosis, the doctors’ or specialists’ identification, or the hospital’s administrative staff.
In this experimentation, the event log exclusively contains instances generated by the patient transfer order process’s execution through the HIS of the PCP (see
Table 1), composed of 2500 traces, 25 unique activities, and 76,948 events. The event log contains traces from a patient transfer order process (including medical referral management), with attributes of Case-ID, activity name, resource, and timestamp.
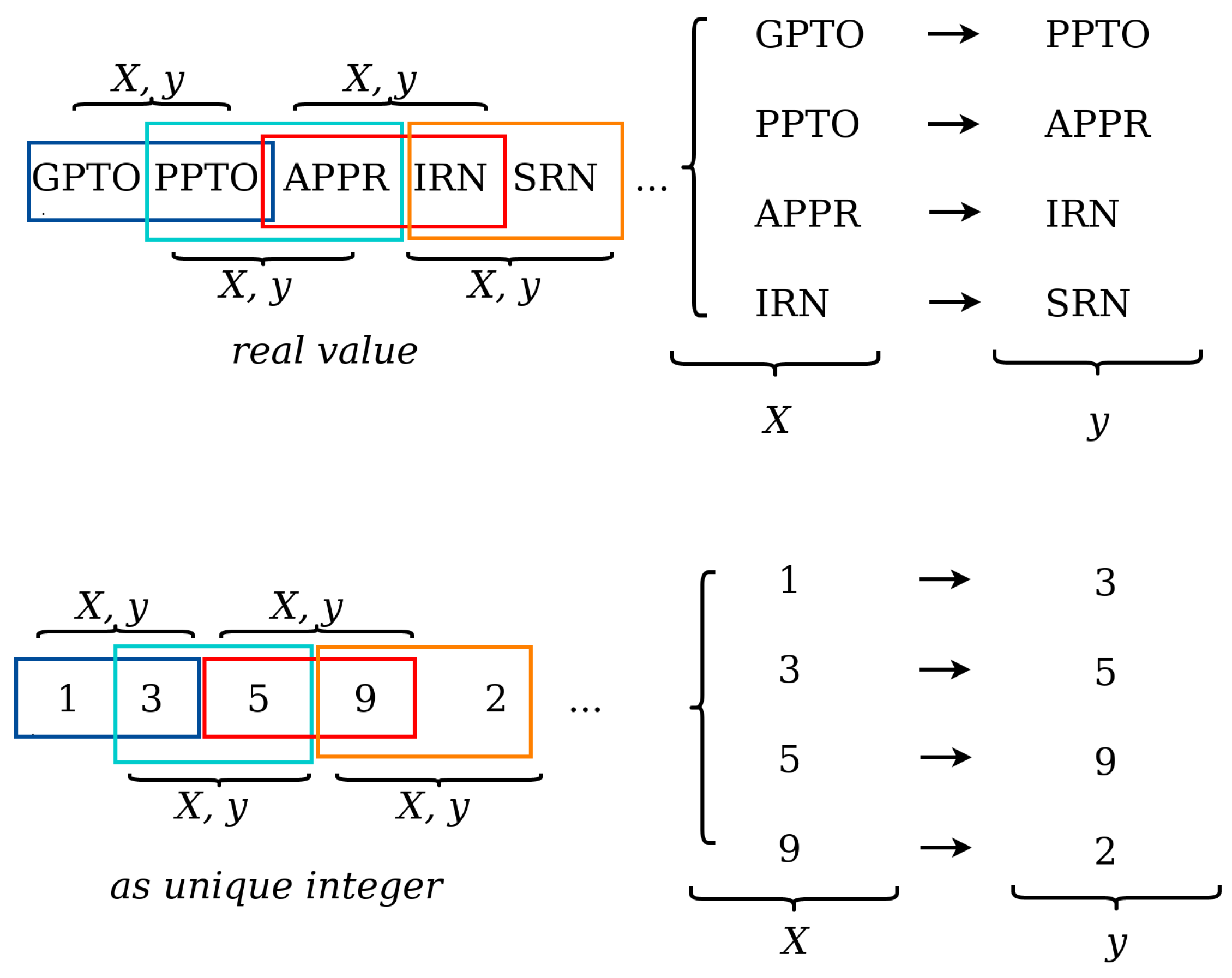
Table 2 shows an excerpt of the results obtained. The “input activity” column represents the activity or set of activities introduced at the input gate of the LSTM network. The “target event” column contains the events that can be predicted according to the behavior pattern identified in the event log traces. A target event value is an event with the highest prediction probability, estimated according to the weight of the event tag value. The prediction of the event generated by the LSTM method is presented in the “output event” column. In instances 1 and 4, the LSTM model has correctly predicted the next event according to the expected event in the process model, e.g., when the new input activity is START. The output event is GPTO (see
Table 2). In instances 2 and 3, it can be seen that the neural network has not correctly predicted the next event in the process model. In instance 3, the target event has two prediction possibilities (APPR∣ PPR), but the model did not predict the next event correctly. In the “Target Event” column of
Table 2, we present instances (3 and 5) with two expected events (APPR∣RPPR, CPR∣IRLC) because the activities are potentially found in the output paths at a decision point or path division gateway of the process flow. Also, in instances 5–7 (see
Table 2), a sequence of two input activities is shown in the “Input Activity” column; i.e., the LSTM network receives a sequence of input activities to predict the next event. Additionally, in instances 8–10, three input activities are entered into the LSTM model, which correctly predicts the next event in all cases.
Table 3 shows the accuracy and precision metrics achieved by the LSTM neural network model in the validation stage. The precision measure allows us to know the number of correct positive predictions. This way, the LSTM model can predict the next event with 0.98 precision. This model achieves the highest precision confirming the ability to predict the next event in the patient referral healthcare process. Similarly, the accuracy measure achieved by the LSTM model is highly acceptable (0.94), supporting the precision measure obtained. The value obtained by the inference model for the recall metric was 0.94 (see
Table 3). The recall metric indicates how much the model captures the behavior present in the event log. The recall is close to the precision value, which is desirable when training a model. This means the LSTM model detects the most positive examples, providing higher reliability. Similarly, high reliability is observed when calculating the F1-score, with a value of 0.95 (see
Table 3). Furthermore, our experiment was evaluated using 10-fold cross-validation, achieving an accuracy of 94.62% (±0.09%), which demonstrates that the model can predict the next event correctly, regardless of the partitioning of the dataset used for training and validation (see
Table 3). The aforementioned confirms that the selected LSTM model parameters do not operate only on a particular dataset partition; on the contrary, they function correctly for data not seen within a dataset partition.
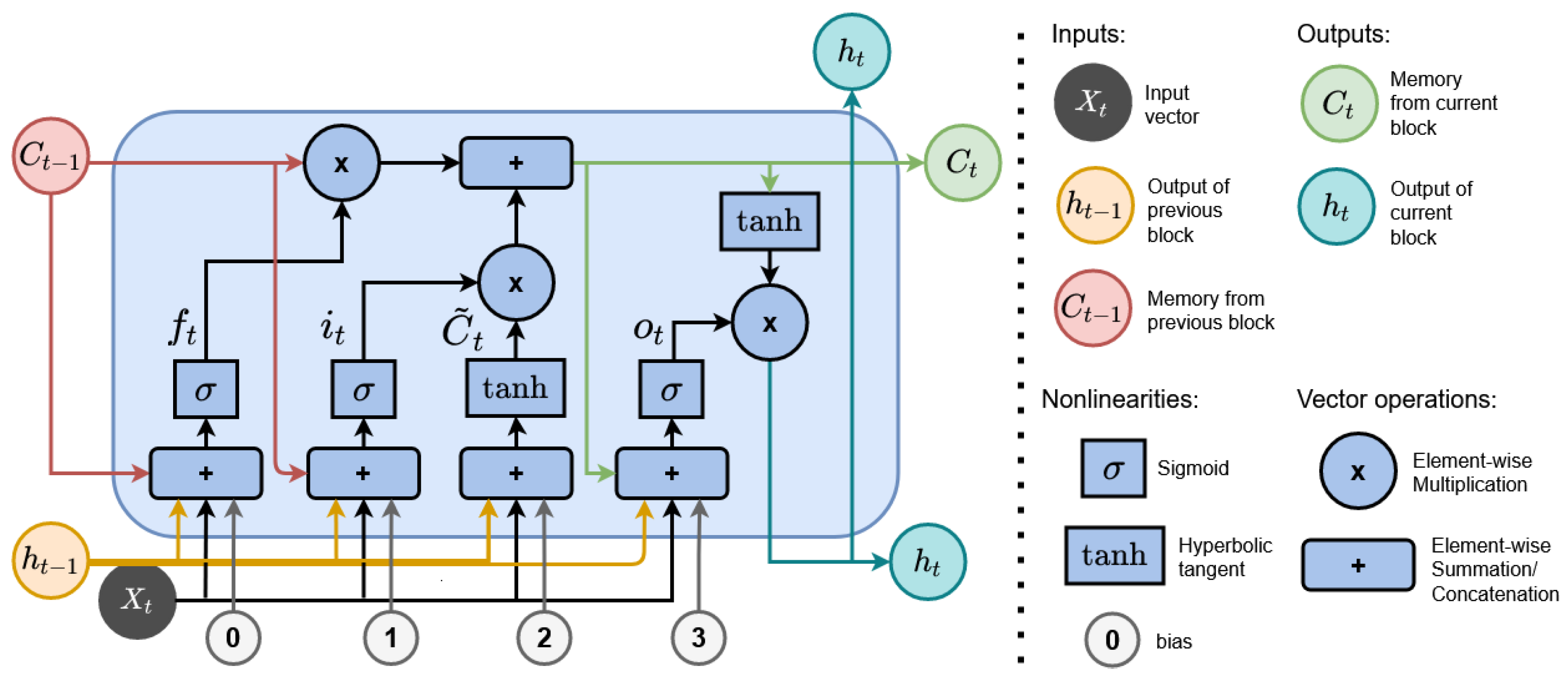
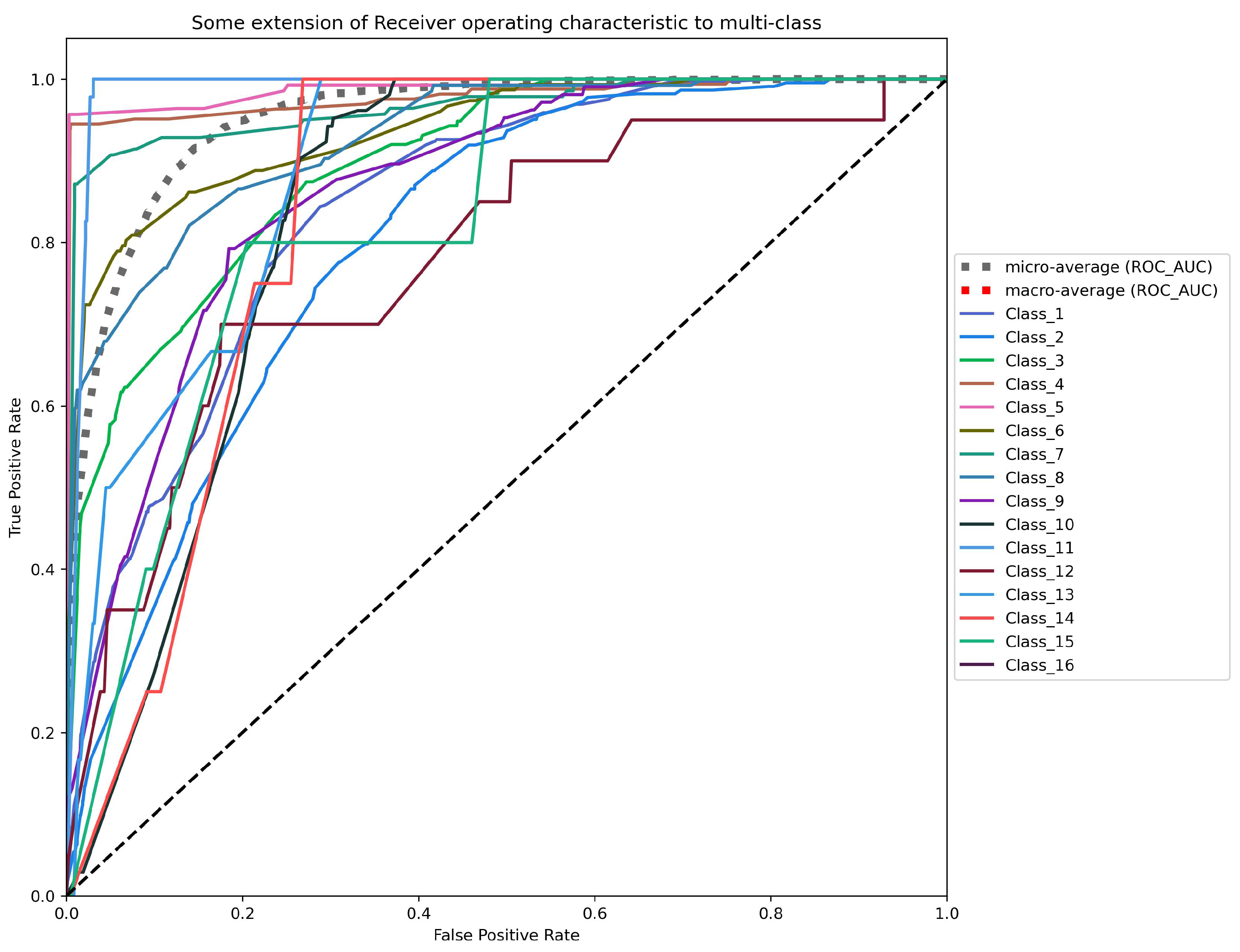
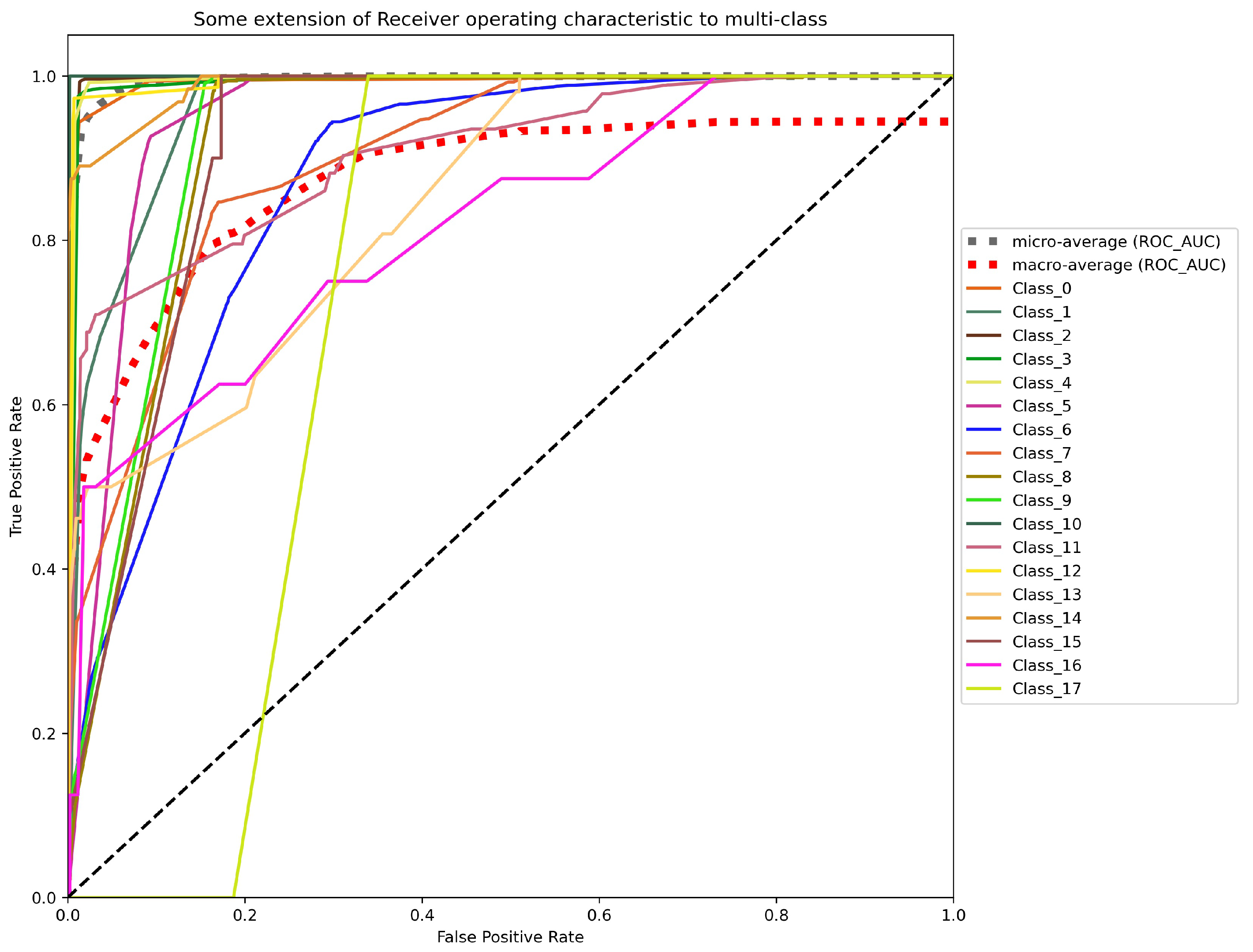
Moreover, we report the receiver operating characteristic (ROC) curves computed from the output probabilities provided by the LSTM inference model. The area under the ROC curve (AUC) represents the degree of class separability that the model achieves. This measure quantifies the ability of a model to distinguish between classes. The higher the AUC value is, the greater the model’s ability to distinguish one class from another. This metric is generally used with binary classifiers; to be used with multi-class classifiers, it is necessary to binarize the output. This condition is satisfied by using one-hot encoding. A ROC curve can be plotted for each class, taking a one-vs-all approach for each class. The scenario used in our experimentation consists of 25 classes.
ROC-AUC quantifies the continuous relation between true and false positives, given the ROC curve plots the true positive rate (TPR) against the false positive rate (FPR), as defined in Equations (
1) and (
2). TPR is also termed sensitivity or recall. It is important to mention that a good classification model should have an AUC value close to 1.
where
represents the number of identified positive instances in the positive set,
means the number of classification negative instances in the negative set,
refers to the number of identified positive instances in the negative set, and
represents the number of identified negative instances in the positive set.
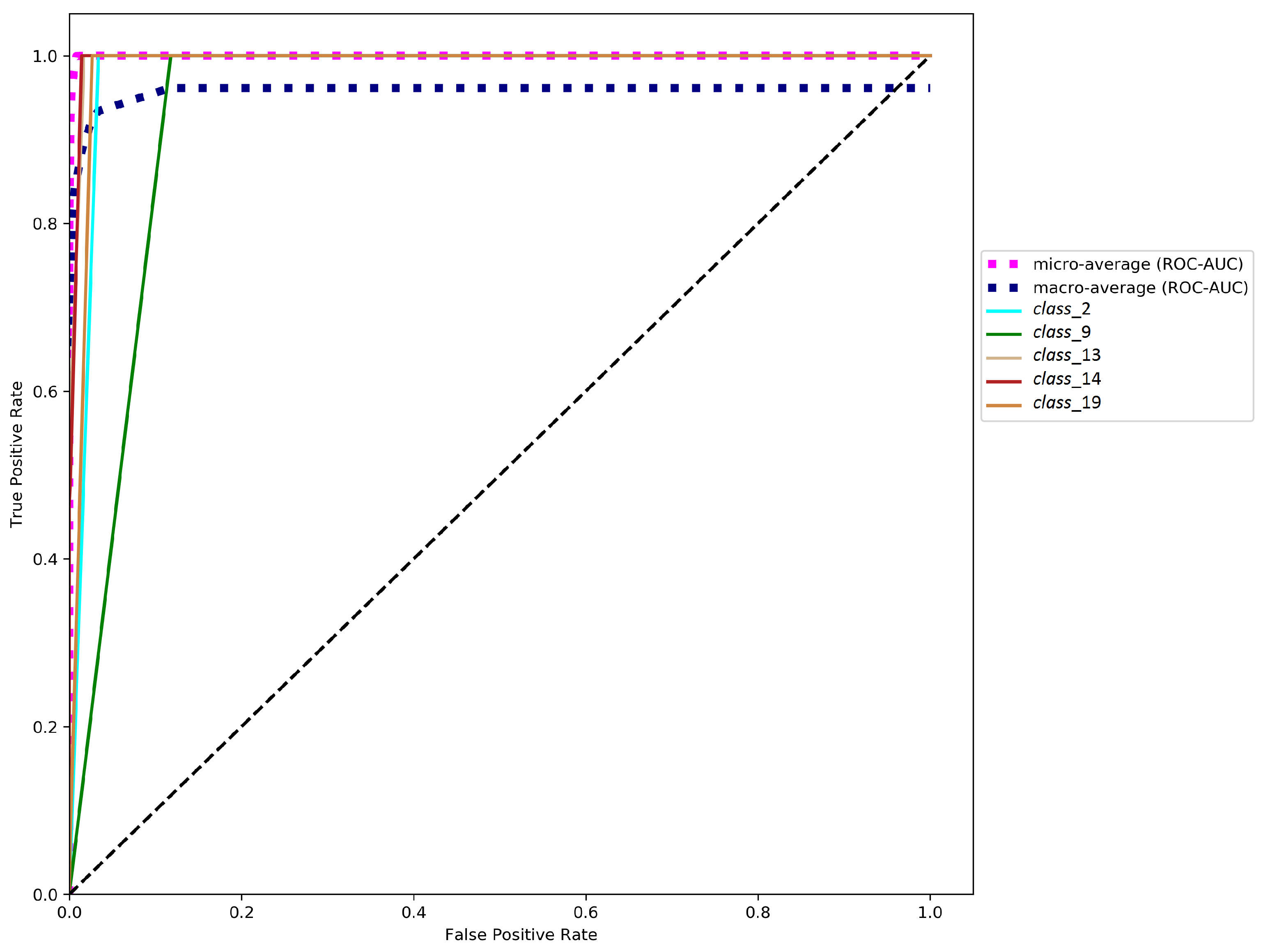
Figure 5 shows an analysis of the area under ROC curves using the TPR on the Y-axis (Equation (
1)) and the FPR on the X-axis (Equation (
2)). Also,
Figure 5 presents the micro-average and the macro-average ROC-AUC values. The former consists of adding each class’s contribution to calculate its average. The latter is calculated independently for each class to calculate all the classes’ averages (managing each class equally).
Figure 5 displays the five worst ROC curves according to the AUC values obtained with the one-vs-all approach (illustrated by continuous lines). The ROC-AUC values for these five classes are
,
,
,
, and
. Most of the remaining classes of the experiment obtained a ROC-AUC value between
and
. On the other hand, a magenta dotted line represents the micro-average ROC-AUC, and a blue dotted line represents the macro-average ROC-AUC, calculated for all the classes (
Figure 5). The micro-average and macro-average ROC-AUC of the LSTM method are 1.000 and 0.958, respectively.
In addition, an equal error rate (EER) was checked for all of the given classes to evaluate the results. EER is defined as the error rate at a point on the ROC curve where FPR (Equation (
2)) is equal to FNR (Equation (
3)). EER gives a good overview of a classifier’s strength in deep learning approaches as it provides a comparable and reproducible compromise between acceptance and rejection rates. Then, EER can serve as a quantitative measure of the classifier quality assessment. An EER equal to 0.00% corresponds to the inference model’s error-free work, meaning the correct classification at the point on the ROC curve. EER is the value of the FPR (Equation (
2)) and the false negative rate (FNR) for a given matching process when the FPR = FNR. The FNR measure is defined by Equation (
3).
In this case, the value furthest from 0 within the experiment is an EER of 11.78% achieved in , corresponding to the value obtained by the same class in the ROC-AUC metric. The other four worst EER values reached are 3.38%, 1.65%, 1.43%, and 2.65% for the classes , , , and , respectively. The EER value for the remaining 20 classes is between and . The results listed show that the LSTM method attains a significantly low EER in most classes.
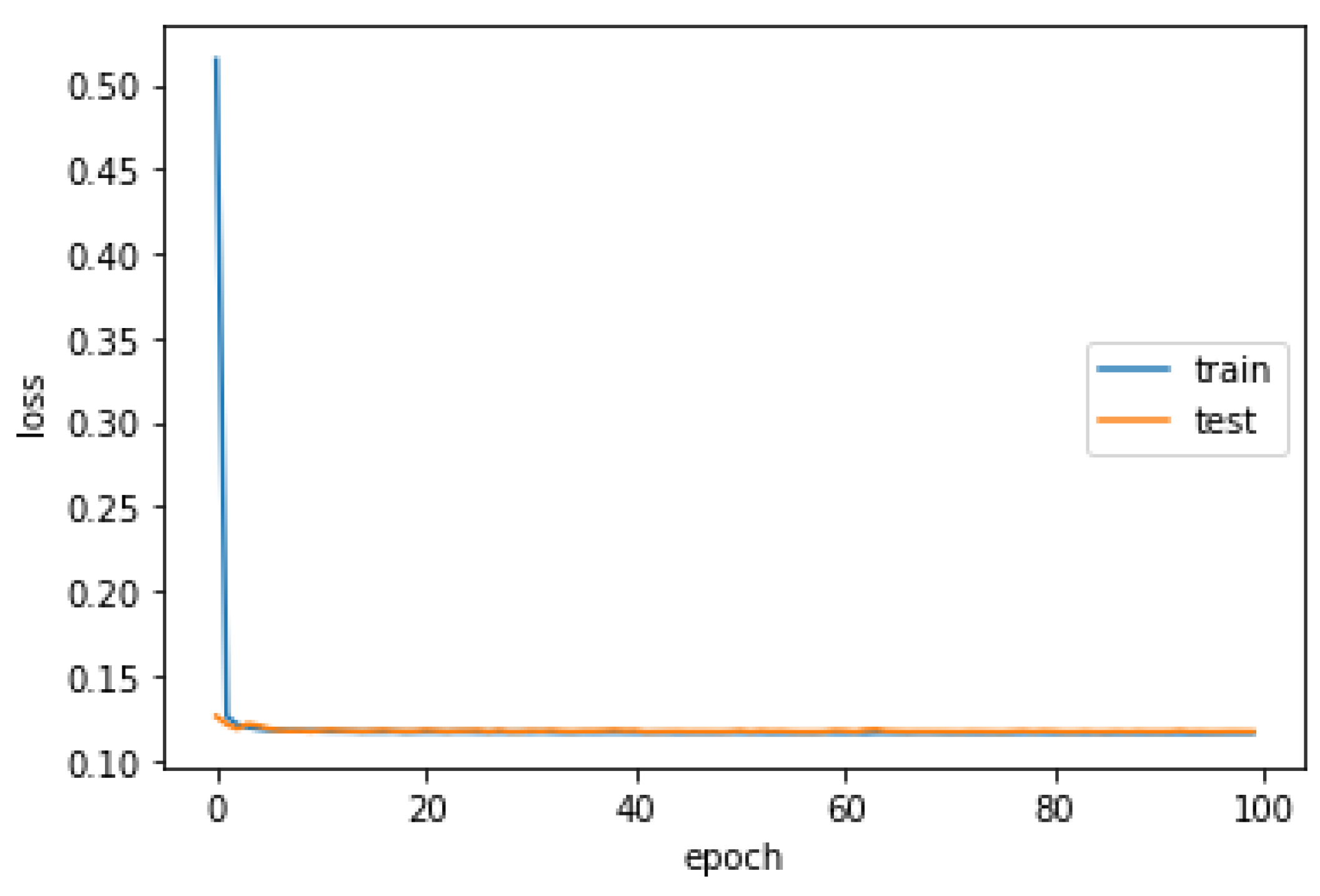
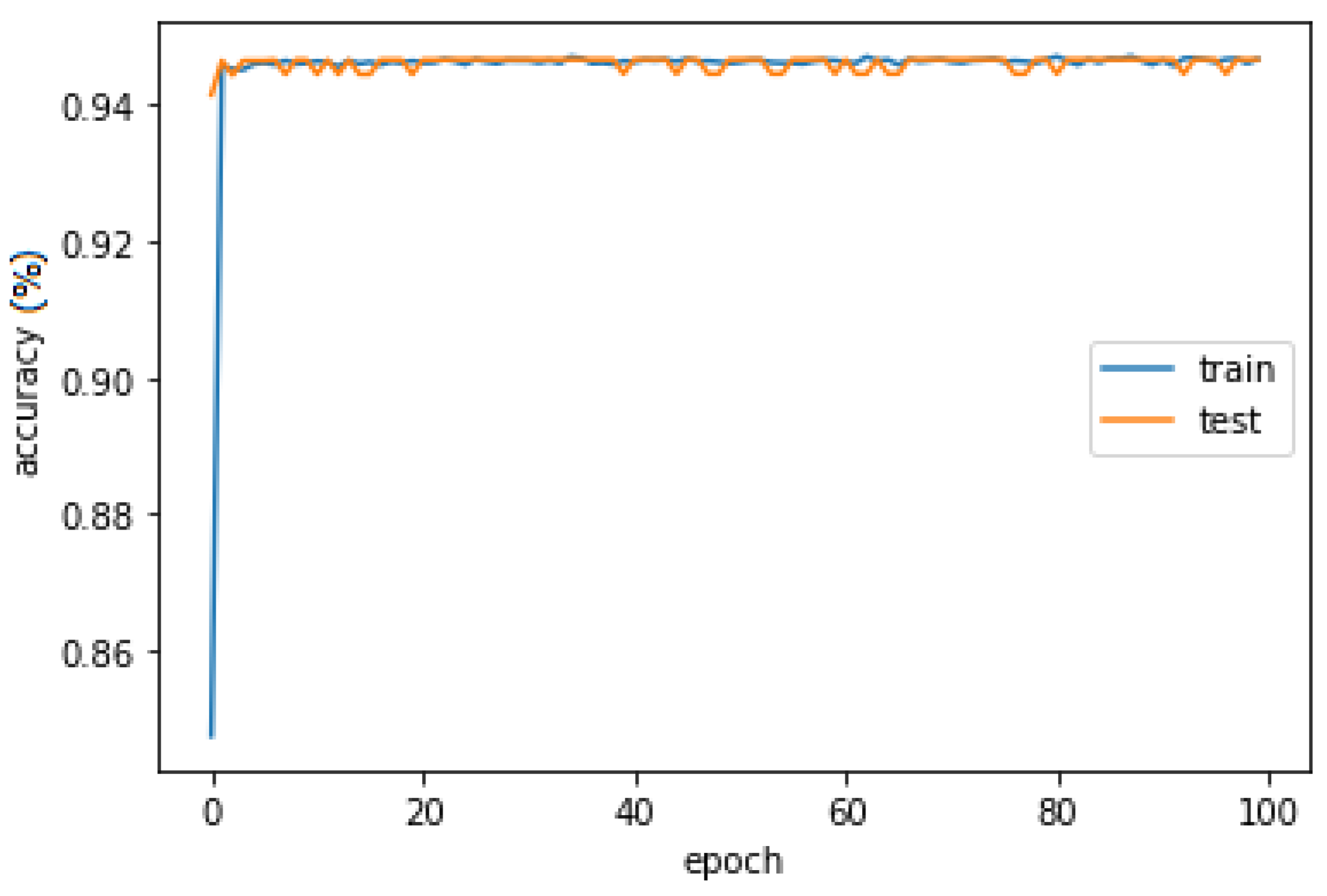
Finally, the LSTM was trained with an optimization procedure that requires a loss function to calculate the model error, allowing a precise summary to be generated through an indicator considering all the assessable aspects of the model. On the one hand, the LSTM model obtains 0.1160 and 0.9465 of the average loss function and accuracy in the training stage, respectively (
Figure 6). On the other hand, the inference LSTM model reaches 0.1172 and 0.9466 of the average loss function and prediction accuracy in the validation stage, respectively (
Figure 7).


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}