
BGP Dataset-Based Malicious User Activity Detection Using Machine Learning





Abstract
:1. Introduction
2. Related Work
2.1. Border Gateway Protocol (BGP) Data
2.2. Research on Cyber Anomaly Detection
2.3. Anomaly Detection with Machine Learning
2.3.1. Random Forest (RF)
2.3.2. Convolutional Neural Network–Long Short-Term Memory (CNN–LSTM)
2.3.3. One-Class Support Vector Machine (One-SVM)
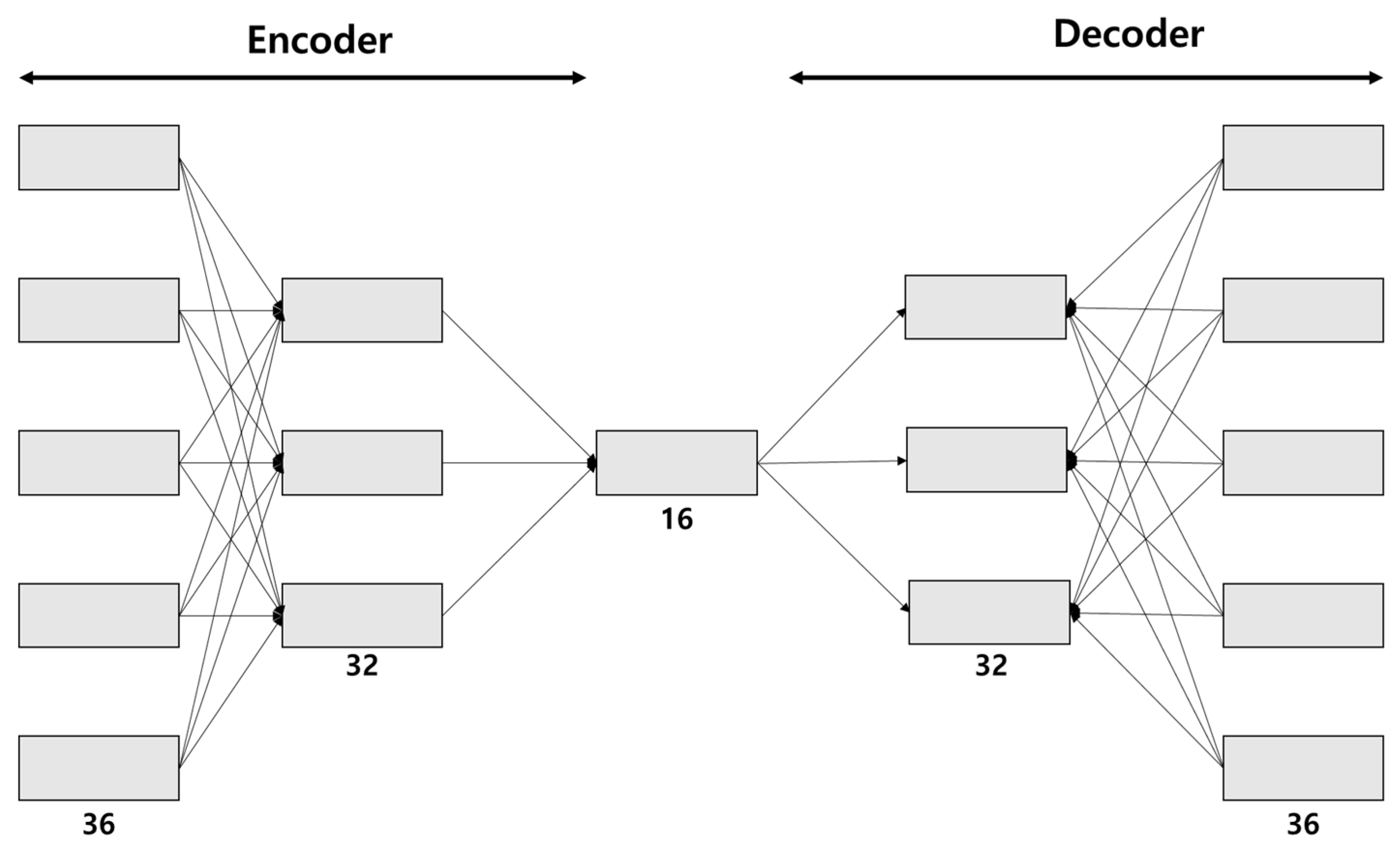
2.3.4. AutoEncoder (AE)
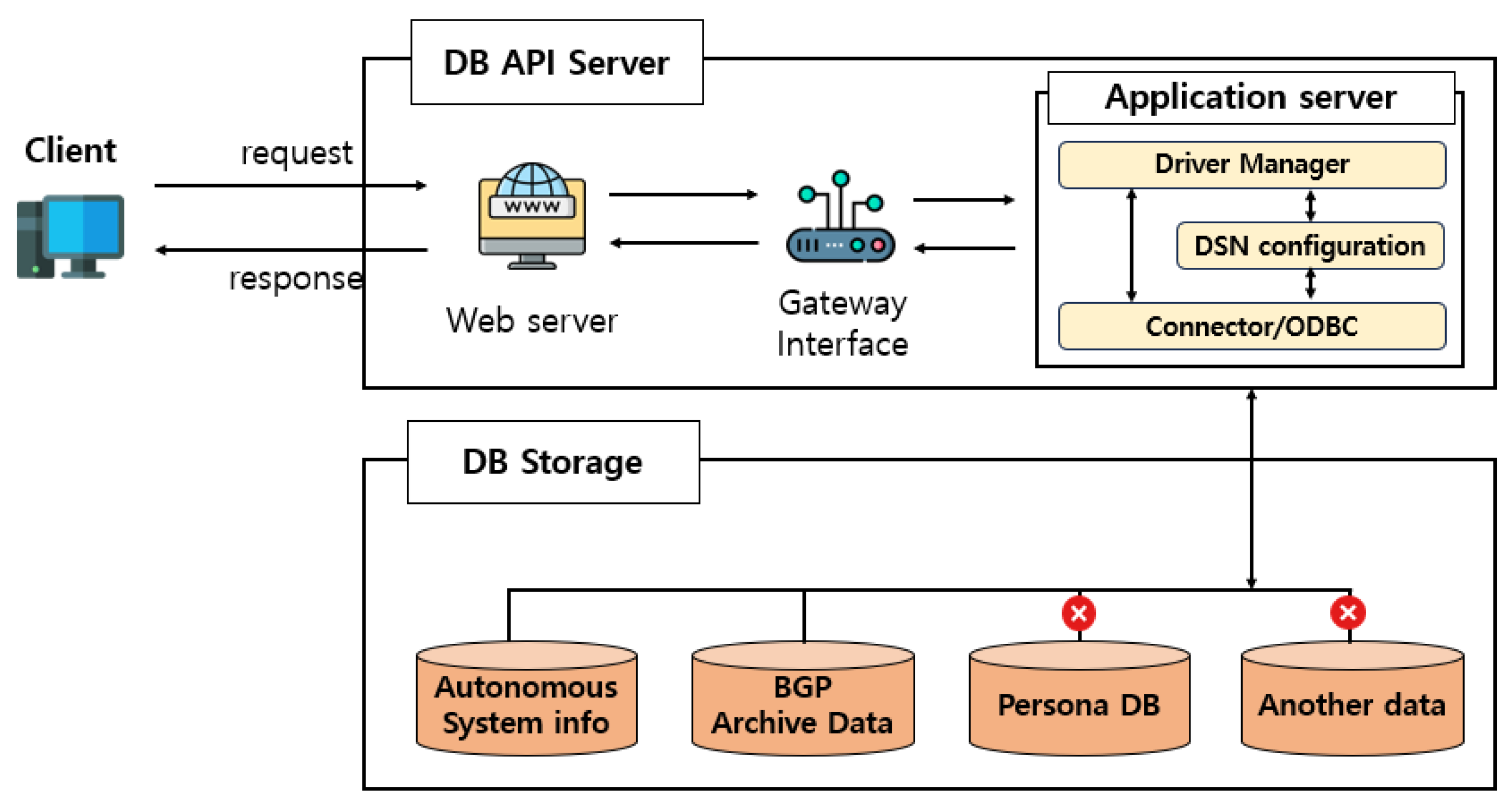
3. BGP Dataset Description and Anomaly Detection Environment
4. Experiments
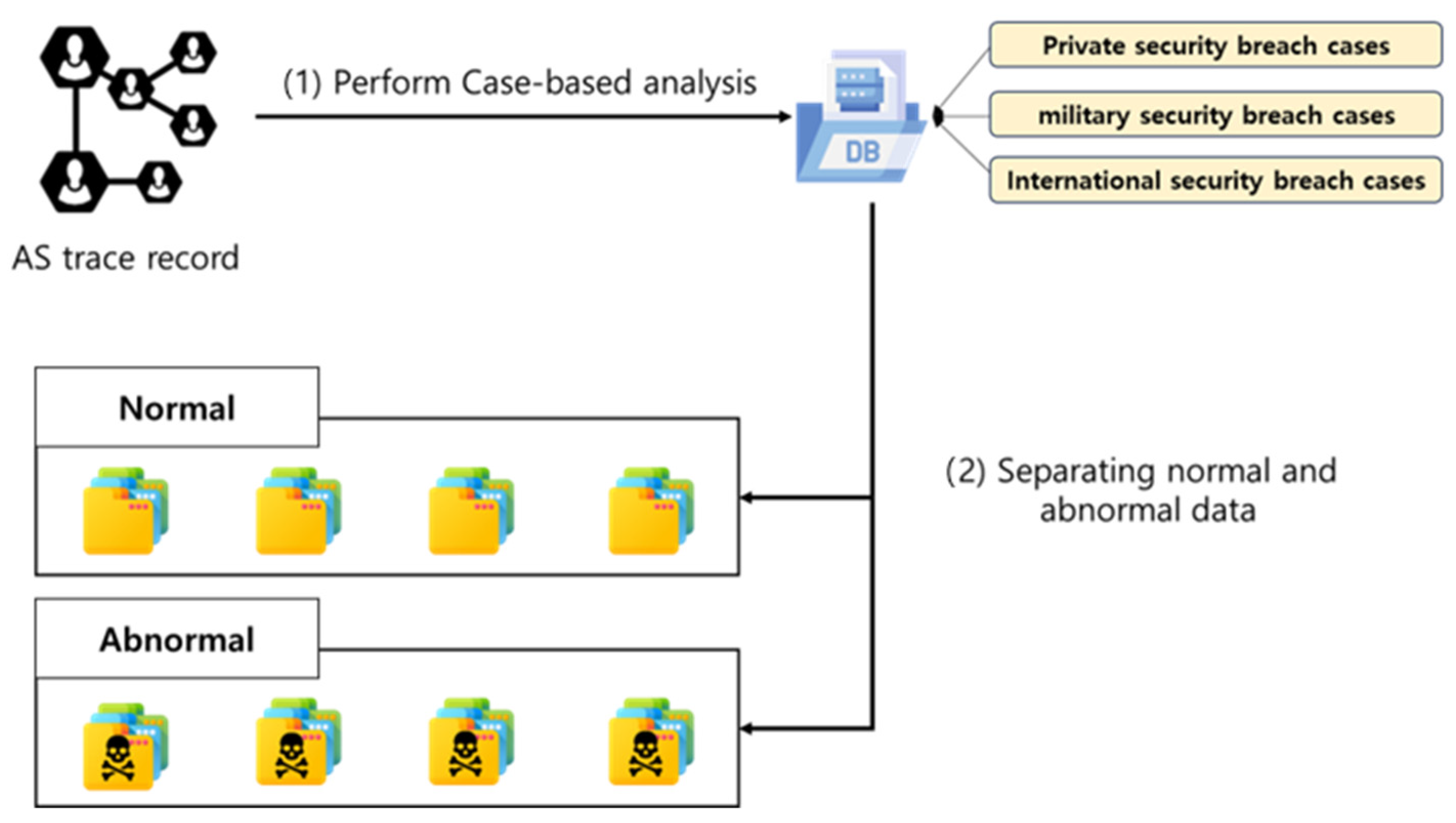
4.1. BGP Dataset Preprocessing with Tokenizer
4.2. Parameters and Performance Evaluation of Models
- Precision: The percentage of data in the experiment that correctly identified the abnormal AS path as an abnormal AS path. This metric assesses the accuracy of the model’s classification of anomaly data.
- Recall: It, also known as “sensitivity” or “true positive rate”, represents how well the model correctly identifies true abnormal AS paths. For example, if the recall is 0.9, it means that the model misses 10% of the true abnormal AS paths.
- F1-Score: It is computed as the harmonic mean of precision and recall, providing a balanced measure in datasets with class imbalances where one class is dominant. This metric comprehensively assesses the model’s performance by considering false positives and false negatives. A high F1 score indicates a well-balanced trade-off between precision and recall, signifying the model’s ability to accurately classify both positive and negative samples.
- Receiver Operation Characteristic (ROC) Curve: One of the methods used to visualize the performance of binary classification models. This curve represents the relationship between the False Positive Rate (FPR) and True Positive Rate (TPR) as the threshold of the classification model is adjusted. The ROC curve plots the FPR on the x-axis and the TPR on the y-axis, showing the model’s performance at different thresholds. The TPR is equivalent to the recall and represents the proportion of true positive samples correctly classified as positive. On the other hand, the FPR represents the proportion of false–positive samples incorrectly classified as positive.
- True Positive (TP): A metric that represents the number of correctly classified positive samples in a binary classification model. These are the samples that the model correctly identified as positive when they were positive, meaning the model made accurate positive predictions. TP is a crucial indicator of the model’s performance, helping to assess its ability to correctly detect positive instances in the dataset.
- True Negative (TN): A metric used in binary classification to represent the number of correctly classified negative samples by the model. These are the samples that the model accurately identified as negative when they were indeed negative, indicating that the model made correct negative predictions. TN is an important measure of the model’s performance, assessing its ability to correctly identify and exclude negative instances in the dataset.
- False Positive (FP): Measures the frequency of the anomaly detection model incorrectly predicting normal data as anomalies, i.e., the model incorrectly categorizes normal instances as anomalies.
- False Negative (FN): Indicates the number of times the anomaly detection model incorrectly predicted abnormal data as normal.
- TPR: The percentage of abnormal data that the model correctly classified as anomalous out of the actual abnormal data.
- FPR: The percentage of normal data that the model misclassifies as abnormal data.
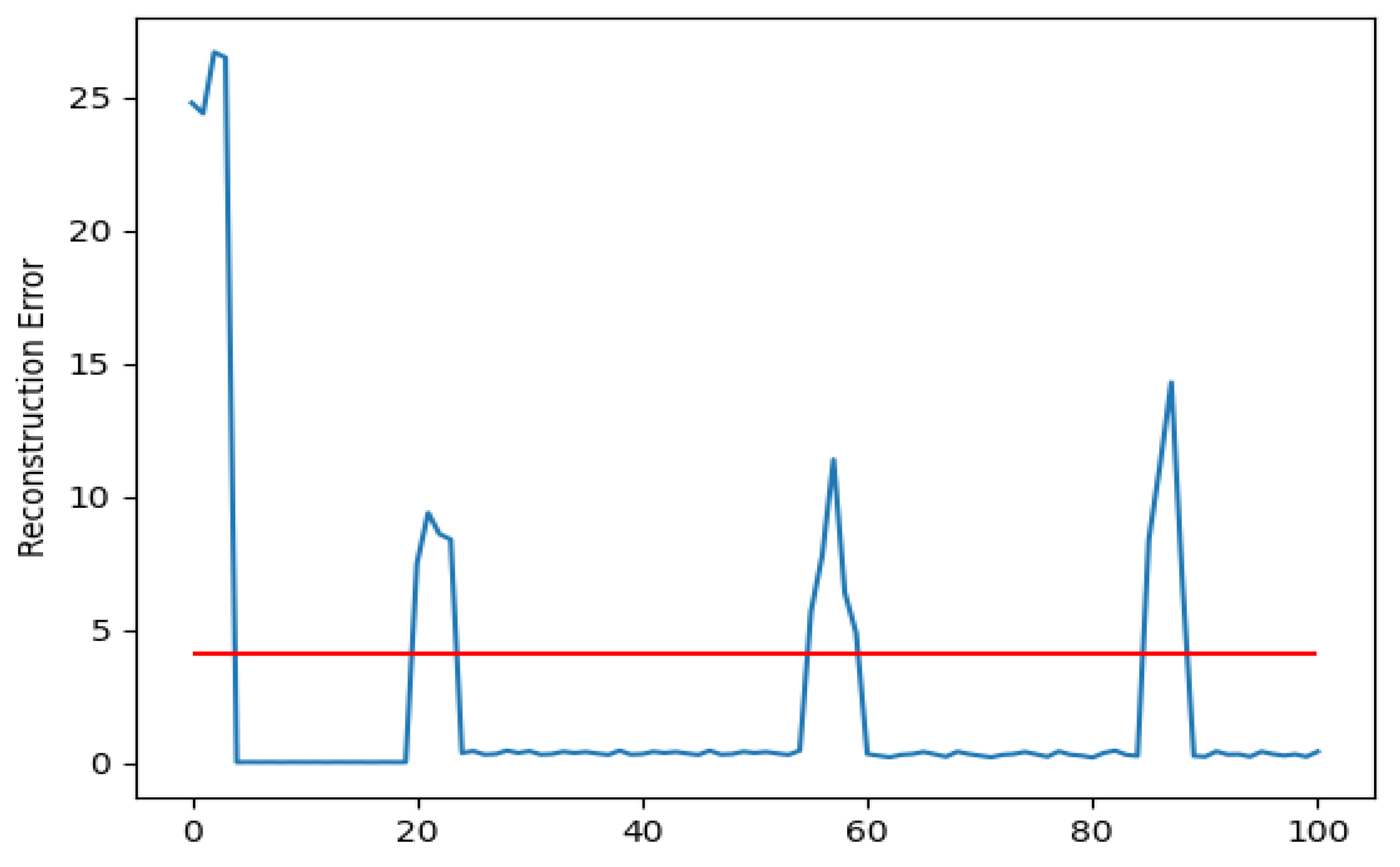
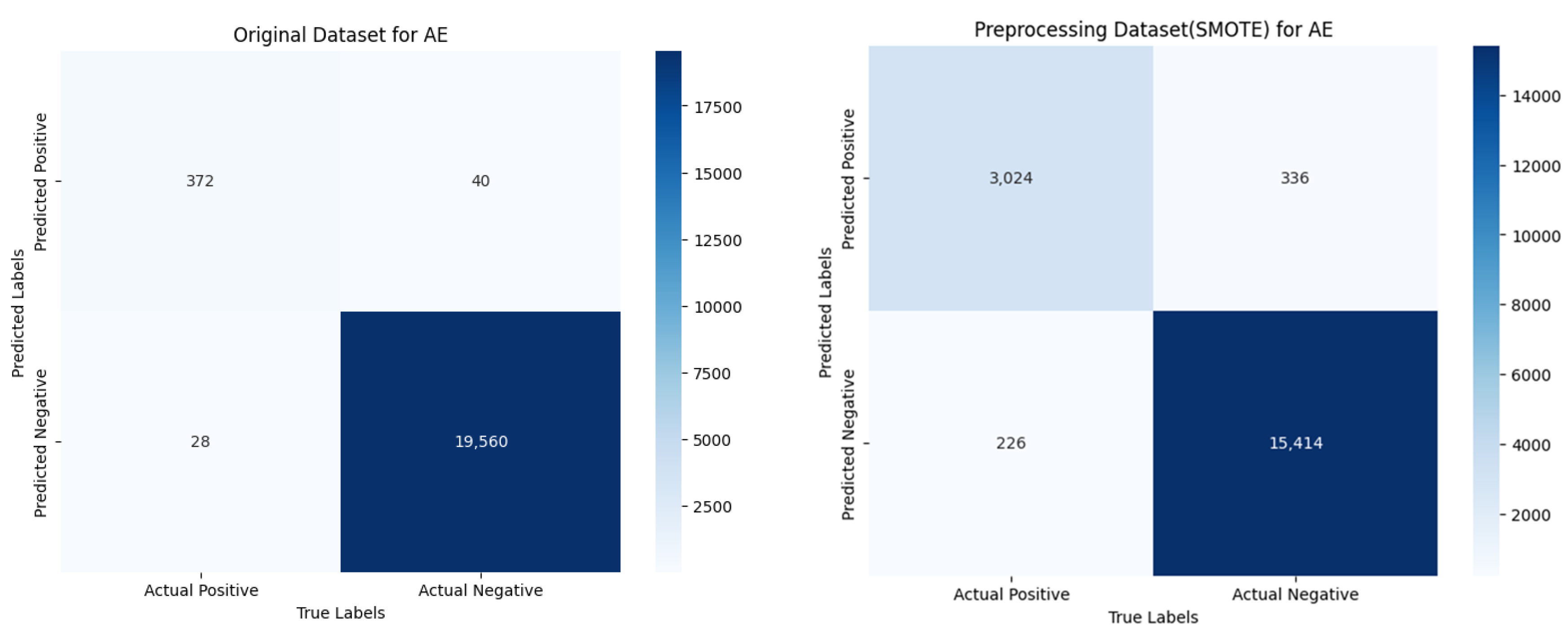
4.3. Experiments Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| BGP | Border Gateway Protocol |
| AS | Autonomous System |
| AE | Autoencoder |
| NB | Naïve Bayes |
| DNN | Deep Neural Network |
| One-SVM | One-Class Support Vector Machine |
| CNN–LSTM | Convolutional Neural Network–Long Short-Term Memory |
| LR | Logistic Regression |
| DT | Decision Tree |
| RF | Random Forest |
| SVM | Support Vector Machine |
| ReLU | Rectified Linear Unit |
| BGP | Border Gateway Protocol |
| SMOTE | Synthetic Minority Oversampling Technique |
| PCA | Principal Component Analysis |
| t-SNE | t-distributed Stochastic Neighbor Embedding |
| AUROC | Area Under the Receiver Operating Characteristic |
References
- Check Point: Third Quarter of 2022 Reveals Increase in Cyberattacks and Unexpected Developments in Global Trends. Available online: https://blog.checkpoint.com/2022/10/26/third-quarter-of-2022-reveals-increase-in-cyberattacks/ (accessed on 26 April 2023).
- Scott, K.D. Joint Publication (JP) 3–12 Cyberspace Operation; The Joint Staff: Washington, DC, USA, 2018. [Google Scholar]
- Ahn, G.; Kim, K.; Park, W.; Shin, D. Malicious file detection method using machine learning and interworking with MITRE ATT&CK framework. Appl. Sci. 2022, 21, 10761. [Google Scholar]
- Rekhter, Y.; Li, T.; Hares, S. A Border Gateway Protocol 4 (BGP-4); No. rfc4271; Internet Engineering Task Force: Fremont, CA, USA, 2006. [Google Scholar]
- Lad, M.; Massey, D.; Pei, D.; Wu, Y.; Zhang, B.; Zhang, L. PHAS: A Prefix Hijack Alert System. In Proceedings of the 15th USENIX Security Symposium, Vancouver, BC, Canada, 31 July–4 August 2006; p. 3. [Google Scholar]
- Comarela, G.; Crovella, M. Identifying and analyzing high impact routing events with PathMiner. In Proceedings of the 2014 Conference on Internet Measurement Conference, Vancouver, BC, Canada, 5–7 November 2014; pp. 421–434. [Google Scholar]
- McGlynn, K.; Acharya, H.B.; Kwon, M. Detecting BGP route anomalies with deep learning. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Paris, France, 29 April–2 May 2019; pp. 1039–1040. [Google Scholar]
- Chen, Z.; Yeo, C.K.; Lee, B.S.; Lau, C.T. Autoencoder-based network anomaly detection. In Proceedings of the 2018 Wireless Telecommunications Symposium (WTS), Phoenix, AZ, USA, 17–20 April 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Copstein, R.; Zincir-Heywood, N. Temporal representations for detecting BGP blackjack attacks. In Proceedings of the 2020 16th International Conference on Network and Service Management (CNSM), Izmir, Turkey, 2–6 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–7. [Google Scholar]
- Choudhary, S.; Kesswani, N. Analysis of KDD-Cup’99, NSL-KDD and UNSW-NB15 datasets using deep learning in IoT. Procedia Comput. Sci. 2020, 167, 1561–1573. [Google Scholar] [CrossRef]
- Zhang, J.; Zheng, Y.; Qi, D.; Li, R.; Yi, X. DNN-based prediction model for spatio-temporal data. In Proceedings of the ACM Sigspatial International Conference on Advances in Geographic Information Systems, San Francisco, CA, USA, 31 October–3 November 2016. [Google Scholar]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar]
- Dhanabal, L.; Shantharajah, S. A study on NSL-KDD dataset for intrusion detection system based on classification algorithms. Int. J. Adv. Res. Comput. Commun. Eng. 2015, 4, 446–452. [Google Scholar]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the IEEE Symposium on Computational Intelligence for Security and Defense Applications (CISDA), Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar]
- Ji, Y.; Lee, H. Event-Based Anomaly Detection Using a One-Class SVM for a Hybrid Electric Vehicle. IEEE Trans. Vehic. Technol. 2022, 71, 6032–6043. [Google Scholar] [CrossRef]
- Sarah, M.E.; Rajasegarar, S.; Karunasekera, S.; Leckie, C. High-dimensional and large-scale anomaly detection using a linear one-class SVM with deep learning. Pattern Recognit. 2016, 58, 121–134. [Google Scholar]
- Halbouni, A.; Gunawan, T.; Habaebi, M. CNN-LSTM: Hybrid Deep Neural Network for Network Intrusion Detection System. IEEE Access 2022, 10, 99837–99849. [Google Scholar] [CrossRef]
- Yulianto, A.; Sukarno, P.; Suwastika, N.A. Improving Adaboost-Based Intrusion Detection System (IDS) Performance on CIC IDS 2017 Dataset. In Proceedings of the 2nd International Conference on Data and Information Science, Bandung, Indonesia, 15–16 November 2018; Volume 1192, p. 012018. [Google Scholar]
- Almomani, I.; Al-Kasasbeh, B.; Al-Akhras, M. WSN-DS: A Dataset for Intrusion Detection Systems in Wireless Sensor Networks. J. Sens. 2016, 2016, 4731953. [Google Scholar] [CrossRef]
- Kim, T.Y.; Cho, S.B. Web Traffic Anomaly Detection Using C-LSTM Neural Networks. Expert Syst. Appl. 2018, 106, 66–76. [Google Scholar] [CrossRef]
- Wright, R.E. Logistic regression. In Reading and Understanding Multivariate Statistics; American Psychological Association: Washington, DC, USA, 1995. [Google Scholar]
- Muniyandi, A.P.; Rajeswari, R.; Rajaram, R. Network anomaly detection by cascading k-Means clustering and C4. 5 decision tree algorithms. Procedia Eng. 2012, 30, 174–182. [Google Scholar] [CrossRef]
- Anton, S.D.D.; Sinha, S.; Schotten, H.D. Anomaly-based intrusion detection in industrial data with SVM and random forests. In Proceedings of the 2019 International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, Croatia, 19–21 September 2019; pp. 1–6. [Google Scholar]
- Morris, T.H.; Thornton, Z.; Turnipseed, I. Industrial control system simulation and data logging for intrusion detection system research. In Proceedings of the 7th Annual Southeastern Cyber Security Summit, Huntsville, AL, USA, 3–4 June 2015; pp. 3–4. [Google Scholar]
- Anton, S.D.; Gundall, M.; Fraunholz, D.; Schotten, H.D. Implementing scada scenarios and introducing attacks to obtain training data for intrusion detection methods. In Proceedings of the ICCWS 2019 14th International Conference on Cyber Warfare and Security: ICCWS 2019, Stellenbosch, South Africa, 28 February–1 March 2019; Academic Conferences and Publishing Limited: Berkshire, UK, 2019; p. 56. [Google Scholar]
- Zhang, X.; Gu, C.; Lin, J. Support vector machines for anomaly detection. In Proceedings of the 2006 6th World Congress on Intelligent Control and Automation, Dalian, China, 21–23 June 2006. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Yassin, W.; Udzir, N.I.; Muda, Z.; Sulaiman, M.N. Anomaly-based intrusion detection through k-means clustering and naives Bayes classification. In Proceedings of the 4th International Conference on Computing and Informatics, ICOCI, Kuching, Malaysia, 28–30 August 2013; Volume 49, pp. 298–303. [Google Scholar]
- Zhang, J.; Zulkernine, M.; Haque, A. Random-forests-based network intrusion detection systems. IEEE Trans. Syst. Man Cybern. 2008, 38, 649–659. [Google Scholar] [CrossRef]
- Sun, H.; Chen, M.; Weng, J.; Liu, Z.; Geng, G. Anomaly Detection for In-Vehicle Network Using CNN-LSTM with Attention Mechanism. IEEE Trans. Veh. Technol. 2021, 70, 10880–10893. [Google Scholar] [CrossRef]
- Liu, Y.; Kumar, N.; Xiong, Z.; Lim, W.Y.B.; Kang, J.; Niyato, D. Communication-Efficient Federated Learning for Anomaly Detection in Industrial Internet of Things. In Proceedings of the 2020 IEEE Global Communications Conference, Taipei City, Taiwan, 7–10 December 2020; Volume 2020, pp. 1–6. [Google Scholar]
- Li, K.L.; Huang, H.K.; Tian, S.F.; Xu, W. Improving one-class SVM for anomaly detection. In Proceedings of the 2003 International Conference on Machine Learning and Cybernetics (IEEE Cat. No. 03EX693), Xi’an, China, 5 November 2003; Volume 5, pp. 3077–3081. [Google Scholar]
- Perdisci, R.; Gu, G.; Lee, W. Using an Ensemble of One-Class SVM Classifiers to Harden Payload-based Anomaly Detection Systems. In Proceedings of the Sixth International Conference on Data Mining (ICDM’06), Hong Kong, China, 18–22 December 2006; pp. 488–498. [Google Scholar]
- Tschannen, M.; Bachem, O.; Lucic, M. Recent advances in autoencoder-based representation learning. In Proceedings of the Third Workshop on Bayesian Deep Learning (NeurIPS 2018), Montréal, QC, Canada, 7 December 2018. [Google Scholar]
- Liu, X.-Y.; Wu, J.; Zhou, Z.-H. Exploratory undersampling for class-imbalance learning. IEEE Trans. Syst. Man Cybern. 2009, 39, 539–550. [Google Scholar]
- Good, P.I. Resampling Methods; Springer: Boston, MA, USA, 2006. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Fernández, A.; Garcia, S.; Herrera, F.; Chawla, N.V. SMOTE for learning from imbalanced data: Progress and challenges, marking the 15-year anniversary. J. Artif. Intell. Res. 2018, 61, 863–905. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]


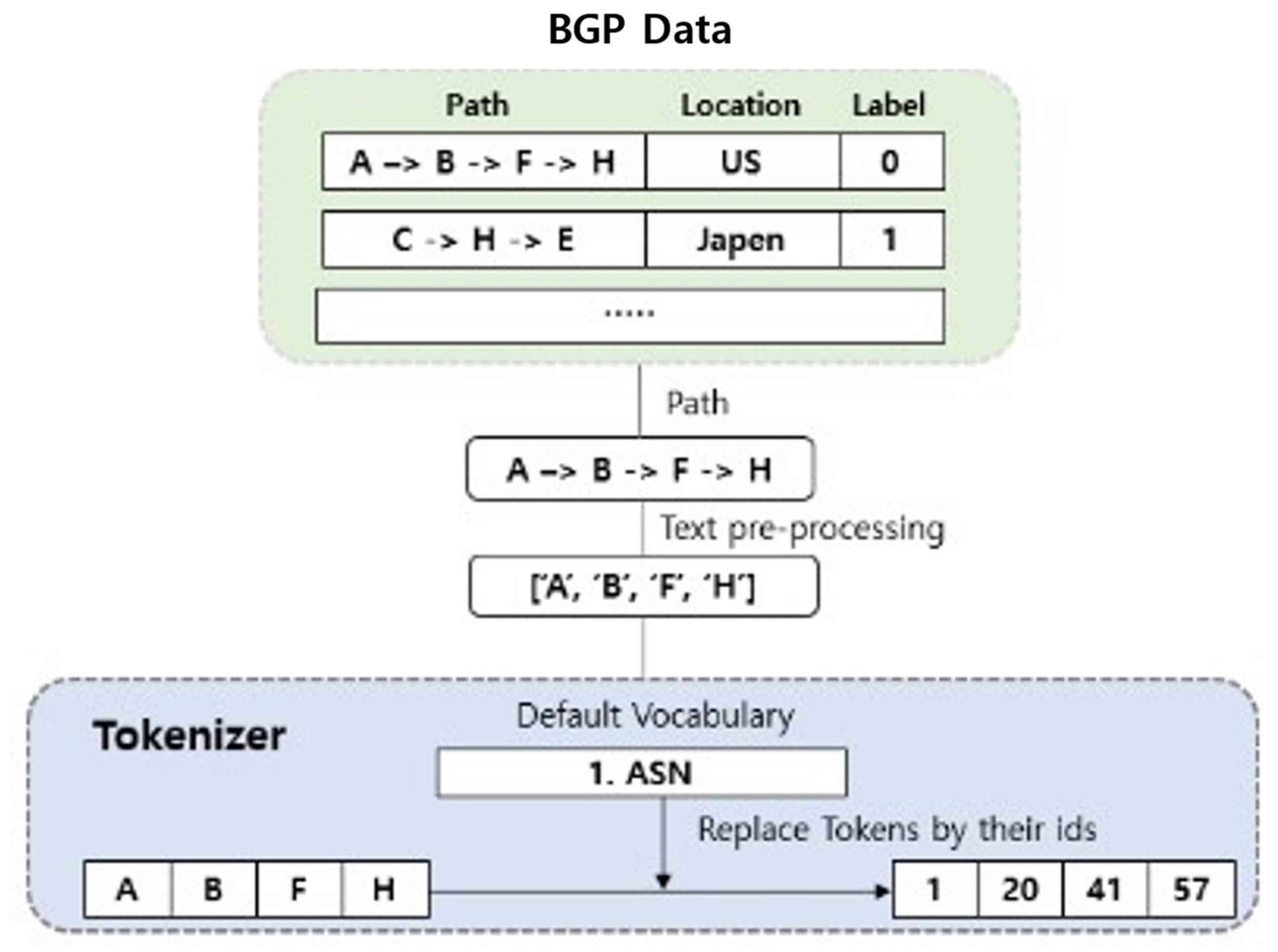
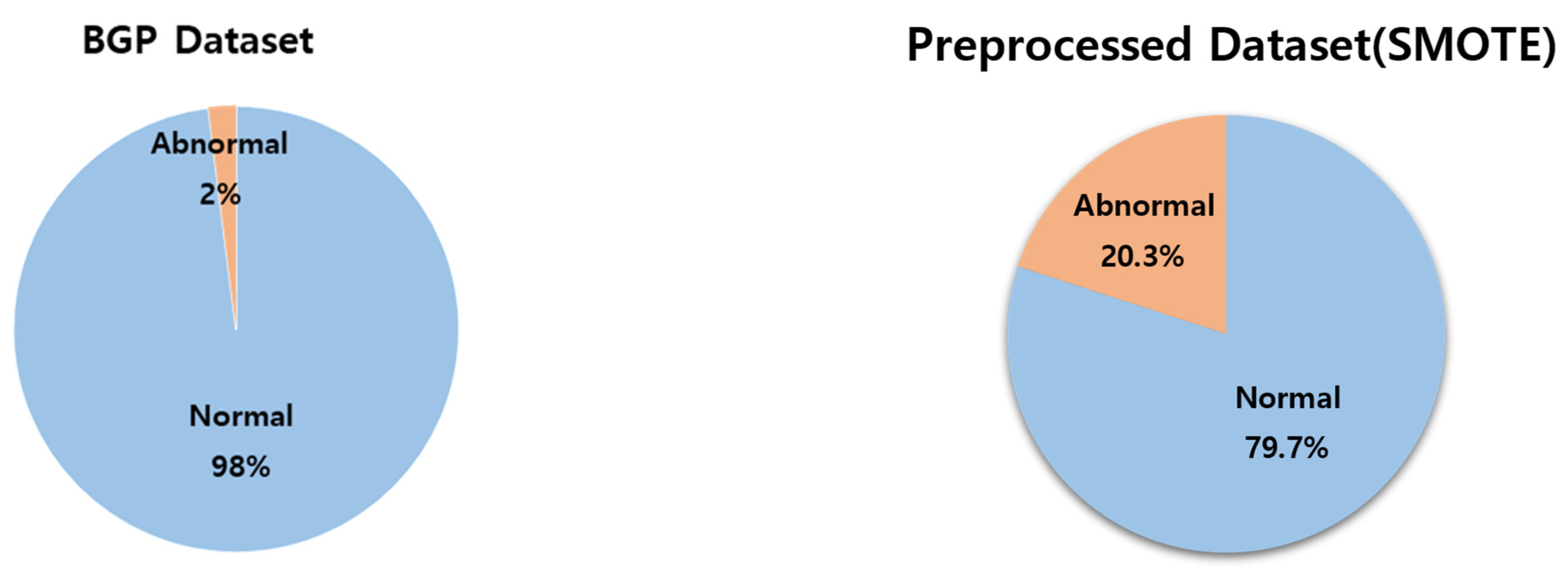
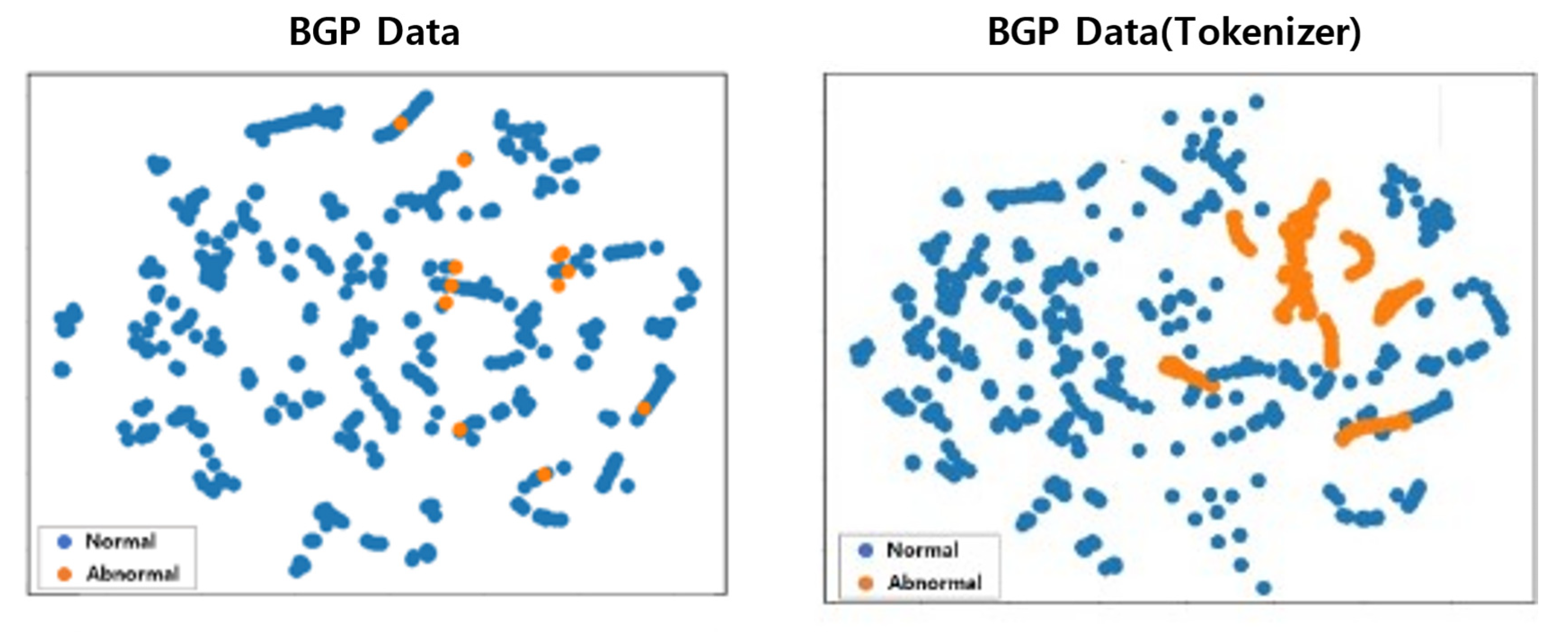
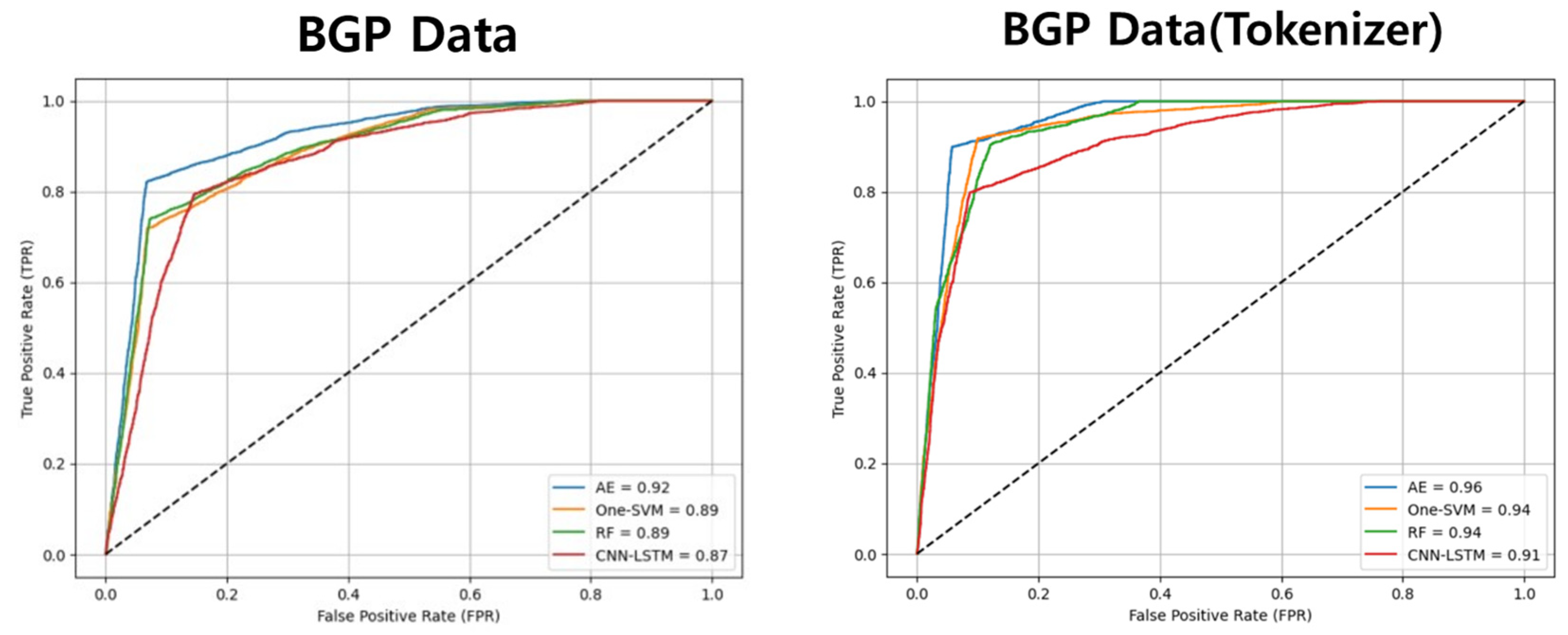

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Study | Data | Detection Technique | Performance |
|---|---|---|---|---|
| 2006 | Lad M. et al. [5] | BGP Data [4] | No technique | No Performance |
| 2014 | Comarela G. et al. [6] | BGP Data [4] | No technique | No Performance |
| 2019 | McGlynn K. et al. [7] | BGP Data [4] | AE [8] | F1-Score: 0.82 |
| 2020 | Copstein R. et al. [9] | BGP Data [4] | NB [28] | Accuracy: 0.84 Recall: 0 |
| 2020 | Choudhary S. et al. [11] | UNSW-NB15 [13], NSL-KDD [14], KDD-Cup’99 [15] | DNN [12], | Accuracy: 0.96 AUROC: 0.96 |
| 2022 | Jl Y. et al. [16] | Sensor Data [16] | One-SVM [17] | TRP: 0.81 TNR: 1.0 |
| 2022 | Halbouni A. et al. [18] | UNSW-NB15 [13], CIC-IDS2017 [19], WSN-DS [20] | CNN–LSTM [21], NB [10], LR [22], DT [23] | Accuracy: 0.98 |
| 2019 | Anton S.D.D et al. [24] | DS1 [25], DS2 [26] | RF [27], SVM [29] | SVM Accuracy: 0.92, RF Accuracy: 0.99 |
| Timestamp | Peer IP | Peer AS | Path | Location | Label |
|---|---|---|---|---|---|
| 16 September 2022 | 212.66.96.212 | 20,912 | A -> C -> D | Italy | 1 |
| 16 September 2022 | 12.0.1.63 | 7018 | U -> F -> E | US | 0 |
| 16 September 2022 | 37.139.139.17 | 57,866 | H -> U -> A | Netherland | 1 |
| 17 September 2022 | 194.153.0.2 | 5413 | L -> C -> A | Australia | 0 |
| 17 September 2022 | 198.129.33.85 | 293 | U -> A -> D | US | 0 |
| … | … | … | … | … | … |
| Column | Definition |
|---|---|
| Timestamp | Time information that indicates when routing data were sent or received. It is usually combined with date and time information to show the exact time an event occurred. |
| Peer Ip | An IP address between two devices or systems that communicate back and forth in a network environment. Each device has a unique IP address, which allows it to identify its owner. |
| Peer AS | When sending and receiving communications in a network environment, it refers to the number of the AS that sent the communication. Like IPs and carriage numbers, AS numbers have a unique identification number that identifies the owner. |
| Path | Information about which AS a dataset packet traversed to reach its destination. |
| Location | Information about the country of ownership of the peer AS. |
| Label | Distinguish between normal and abnormal data. 0: Normal data 1: abnormal data |
| Parameters | AE Value |
|---|---|
| Epoch | 100 |
| Batch size | 32 |
| Activation Function | LeaklyReLu, Linear |
| Optimizer | Adam |
| Loss Function | MSE |
| Parameters | RF Value |
|---|---|
| N_estimaotors | 100 |
| Max_depth | None |
| Min_sample_split | 3 |
| Min_sample_leaf | 2 |
| Max_features | ‘auto’ |
| bootstrap | True |
| Parameters | One-SVM Value |
|---|---|
| kernel | ‘rbf’ |
| nu | 0.05 |
| gamma | 1.0 |
| degree | 4 |
| Shrinking | True |
| Cache size | 500 |
| Random state | None |
| Parameters | One-SVM Value |
|---|---|
| Convolutional Filters | 64 |
| Convolutional Kernel | 3 × 3 |
| Convolutional Activation | ReLU |
| Max Pooling Size | 2 |
| LSTM Units | 100 |
| LSTM Activation | tanh |
| Dropout Rate | 0.2 |
| Dense Activation | ReLU |
| Output Activation | sigmoid |
| Loss Function | Binary Crossentropy |
| Optimizer | Adam |
| Equipment | Name |
|---|---|
| OS | Window 11 pro |
| CPU | Intel(R) Core 19-13900K |
| RAM | 32 GB |
| GPU | NVIDIA GeForce RTX 4080 SUPER 16 GB |
| Language | Python 3. 6. 4 |
| Libraries | TensorFlow, scikit-learn, Pandas |
| Actual Values | |||
| Positive | Negative | ||
| Predicted Values | Positive | TP | FP |
| Negative | FN | TN | |
| Models | BGP Data | BGP Data (Tokenizer) |
|---|---|---|
| RF | 0.893 | 0.944 |
| One-SVM | 0.892 | 0.946 |
| CNN–LSTM | 0.873 | 0.914 |
| AE | 0.927 | 0.961 |
| Models | Precision | Recall | F1-Score |
|---|---|---|---|
| CNN–LSTM | 0.82 | 0.84 | 0.83 |
| One-SVM | 0.8 | 0.85 | 0.83 |
| RF | 0.86 | 0.89 | 0.87 |
| AE | 0.9 | 0.93 | 0.9 |
| Models | Precision | Recall | F1-Score |
|---|---|---|---|
| CNN–LSTM | 0.90 | 0.92 | 0.92 |
| NB | 0.93 | 0.94 | 0.93 |
| RF | 0.95 | 0.93 | 0.97 |
| AE | 0.98 | 0.99 | 0.99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, H.; Kim, K.; Shin, D.; Shin, D. BGP Dataset-Based Malicious User Activity Detection Using Machine Learning. Information 2023, 14, 501. https://doi.org/10.3390/info14090501
Park H, Kim K, Shin D, Shin D. BGP Dataset-Based Malicious User Activity Detection Using Machine Learning. Information. 2023; 14(9):501. https://doi.org/10.3390/info14090501
Chicago/Turabian StylePark, Hansol, Kookjin Kim, Dongil Shin, and Dongkyoo Shin. 2023. "BGP Dataset-Based Malicious User Activity Detection Using Machine Learning" Information 14, no. 9: 501. https://doi.org/10.3390/info14090501
APA StylePark, H., Kim, K., Shin, D., & Shin, D. (2023). BGP Dataset-Based Malicious User Activity Detection Using Machine Learning. Information, 14(9), 501. https://doi.org/10.3390/info14090501