
FinChain-BERT: A High-Accuracy Automatic Fraud Detection Model Based on NLP Methods for Financial Scenarios


Abstract
:1. Introduction
- 1.
- FinChain-BERT: An avant-garde model uniquely positioned to recognize financial fraud terms, underscoring our commitment to advancing the precision in the realm of fraud detection.
- 2.
- Advanced Optimization: By integrating the Stable-Momentum Adam Optimizer, we have significantly accelerated the convergence of the loss function, enhancing the model’s learning efficiency.
- 3.
- Fraud Focus Filter: This specially curated filter zeroes in on vital financial terms, ensuring that the model’s attention is consistently directed towards potentially deceptive indicators.
- 4.
- Keywords Loss Function: A novel loss calculation approach that attributes heightened significance to essential financial terms, ensuring the model is finely attuned to subtleties that might otherwise be overlooked.
- 5.
- Efficient Model Lightening with Int-Distillation: Through meticulous integer computation and strategic pruning of network layers, we have streamlined the model, bolstering its adaptability and scalability without compromising on performance.
- 6.
- Custom-Built Dataset Contribution: Drawing from our meticulous data collection methodology, we have supplemented our research with a high-quality, self-curated dataset, reinforcing the model’s understanding of real-world financial intricacies and scenarios.
2. Related Work
- 1.
- RNNs offered the first glimpse into processing sequences in data, an essential feature for understanding time-bound financial transactions. By retaining memory from previous inputs, RNNs provided a way to establish continuity in data, a crucial aspect for tracking fraudulent activities over a period.
- 2.
- LSTMs, an evolution over RNNs, tackled some of the RNN’s inherent limitations, specifically their struggle with long-term dependencies. In the vast temporal landscapes of financial transactions, the ability to remember events from the distant past (such as a suspicious transaction from months ago) can be critical in spotting fraudulent activities.
- 3.
- Transformer models, on the other hand, introduced a paradigm shift by eliminating the sequential nature of processing data. Their emphasis on attention mechanisms enabled them to capture relationships in data irrespective of the distance between elements, offering a robust model for detecting intricate fraud patterns spread across vast datasets.
2.1. Recurrent Neural Network and Its Relevance in Financial Fraud Detection
2.2. Relevance of Long Short-Term Memory in Financial Fraud Detection
2.3. Relevance of Transformer in Financial Fraud Detection
2.4. Evaluative Summary of Neural Models in Financial Fraud Detection
3. Materials
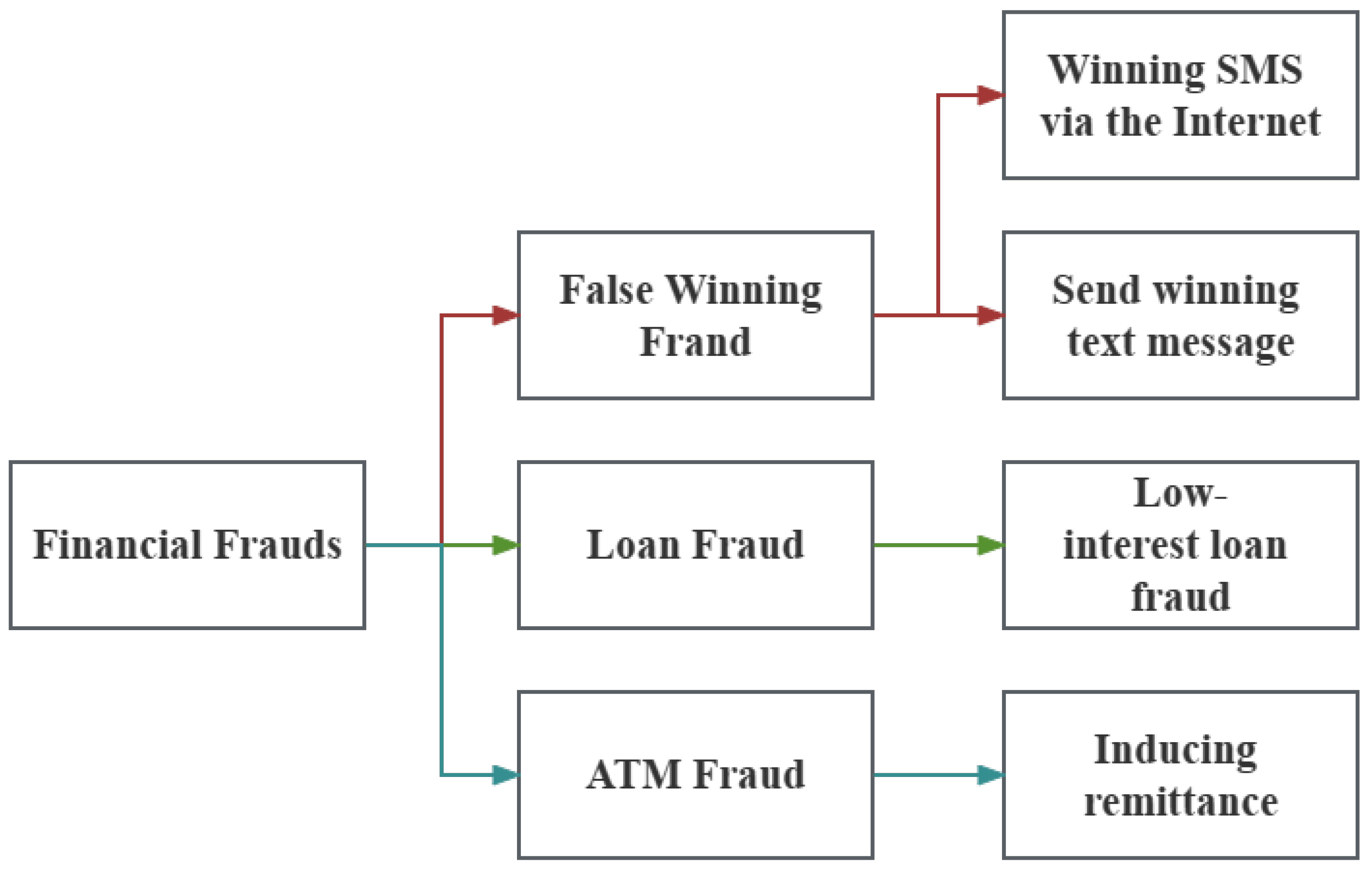
3.1. Data Collection
- 1.
- Negative Information Determination: Given a piece of financial text and a list of financial entities appearing in the text, the first task is to ascertain whether the text contains negative information regarding the financial entities. If the text does not encapsulate any negative details, or although containing negativity it does not pertain to any financial entities, the outcome is determined as 0.
- 2.
- Entity Determination: Upon the detection of negative financial information concerning an entity in the first subtask, this task further discerns which entities from the list are the subjects of the negative information.
3.2. Data Annotation
3.3. Data Preprocessing
3.4. Dataset Augmentation and Rebalancing
4. Proposed Method
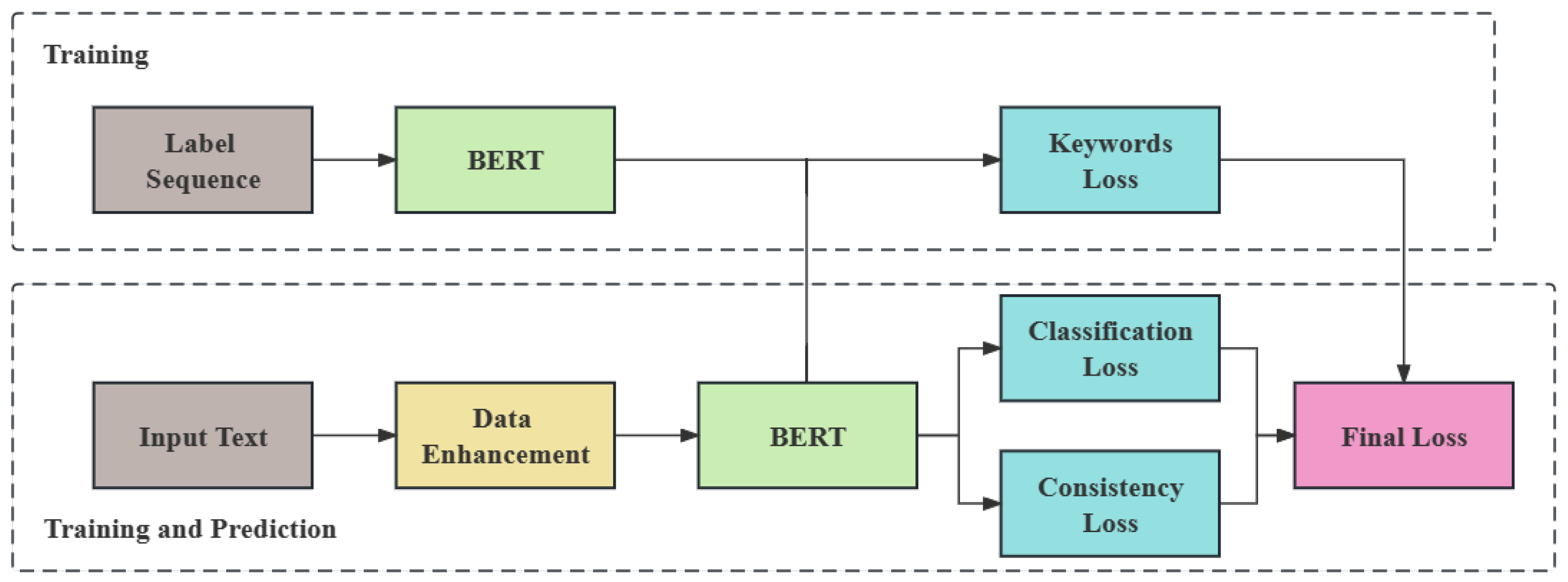
4.1. Overall
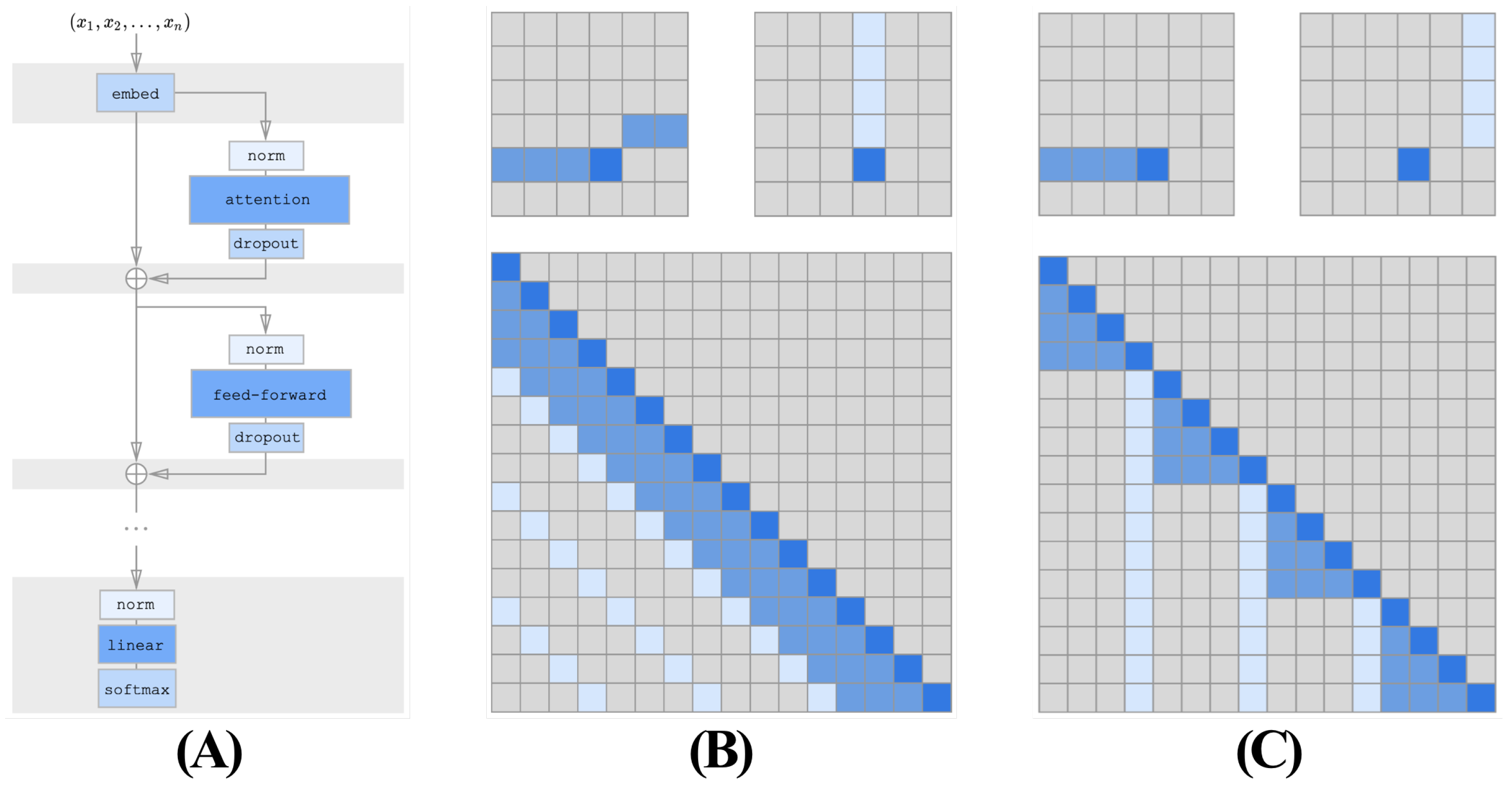
4.2. The FinChain-BERT Model
4.3. Stable-Momentum Adam Optimizer
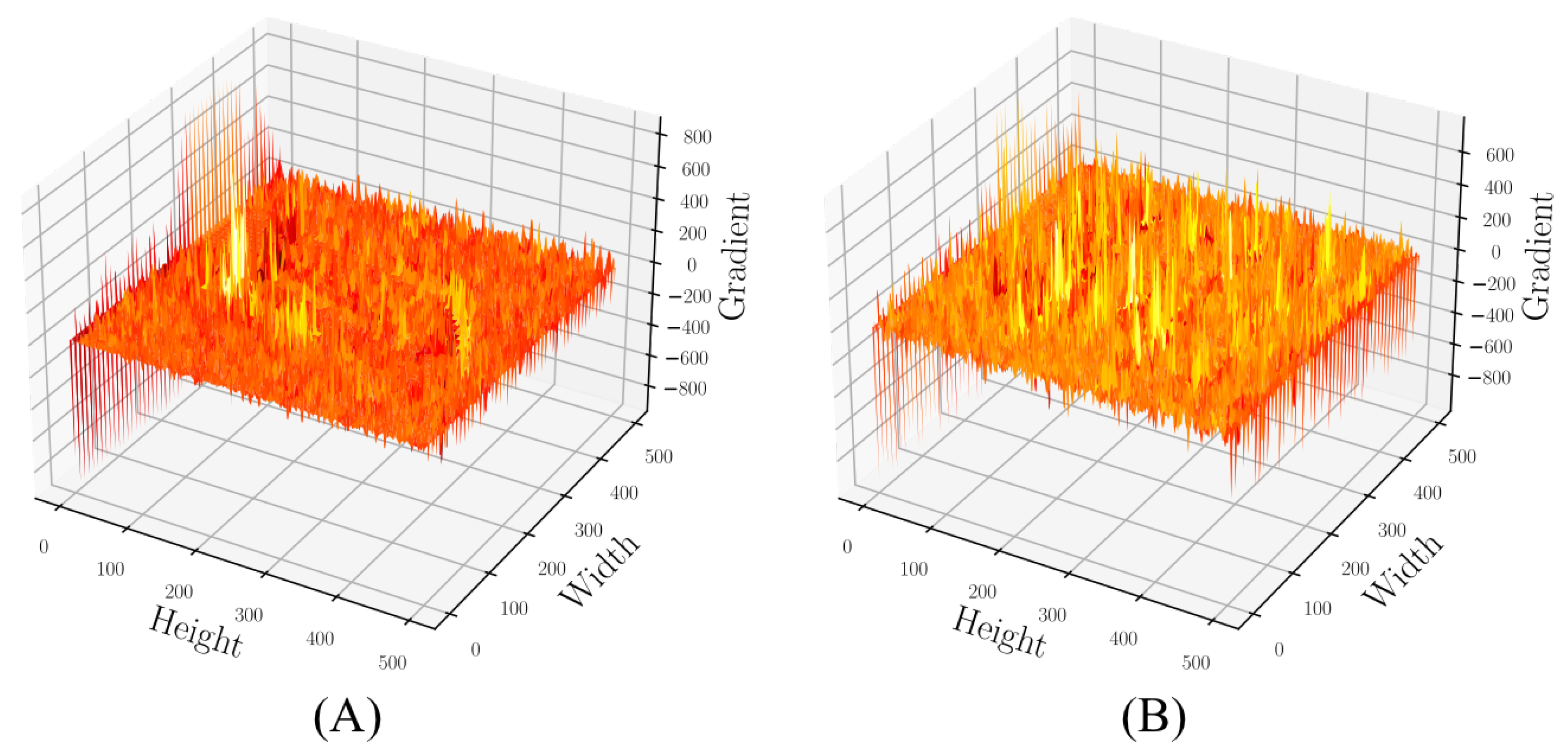
4.4. Fraud Focus Filter
4.5. Keywords Loss
4.6. Int-Distillation
4.6.1. Integer Quantization
4.6.2. Knowledge Distillation
4.6.3. Combination
4.7. Experimental Settings
4.7.1. Platform and Testbed
4.7.2. Evaluation Metric
- 1.
- Precision. For each class c, precision is defined as the number of samples correctly classified as class c divided by the total number of samples predicted as class c:where represents the count of samples that are both truly and predicted as class c, while is the number of samples that are predicted as class c but truly belong to a different class.
- 2.
- Recall. For each class c, recall is defined as the number of samples correctly classified as class c divided by all actual instances of class c:where remains consistent with the previous definition and denotes the count of samples that truly belong to class c but are predicted differently.
- 3.
- Accuracy. Generally, the accuracy in multi-class problems is the proportion of all samples that are correctly classified across all classes. However, for per-class accuracy for each class c, it is given as the sum of samples correctly classified for class c and those correctly classified for all other classes, divided by the total sample count:where represents the samples that are neither truly nor predicted as class c and is the overall number of samples.
4.7.3. Experiment Design
5. Results and Discussion
5.1. Fraud Detection Results
5.2. Ablation Studies
5.2.1. Ablation Experiment on Different Optimizers
5.2.2. Ablation Experiment on Different Loss Functions
5.2.3. Ablation Experiment on Int-Distillation
5.3. Test on Model Robustness
5.4. Limits and Future Work
6. Conclusions
- 1.
- Model Overhead: While we optimized the model, its deep architecture may still demand substantial computational resources, which might be challenging to provide in real-time detection scenarios.
- 2.
- Adaptability: Our study’s focus was primarily on financial fraud detection. The adaptability of the FinChain-BERT model to other forms of fraud or malicious activities remains to be examined.
- 1.
- Expanding Datasets: Enriching the training datasets with more diverse real-world financial fraud scenarios would be beneficial. This would enhance the model’s capability to generalize and detect new fraud patterns.
- 2.
- Model Transferability: Investigating the model’s transferability to other domains, such as insurance fraud or e-commerce fraud, can provide insights into its versatility and applicability.
- 3.
- Hybrid Approaches: Combining the FinChain-BERT model with other machine learning techniques or fraud detection algorithms could yield more robust and comprehensive fraud detection systems.
Author Contributions
Funding
Conflicts of Interest
References
- Syed, A.A.; Ahmed, F.; Kamal, M.A.; Trinidad Segovia, J.E. Assessing the role of digital finance on shadow economy and financial instability: An empirical analysis of selected South Asian countries. Mathematics 2021, 9, 3018. [Google Scholar] [CrossRef]
- Hashim, H.A.; Salleh, Z.; Shuhaimi, I.; Ismail, N.A.N. The risk of financial fraud: A management perspective. J. Financ. Crime 2020, 27, 1143–1159. [Google Scholar] [CrossRef]
- Craja, P.; Kim, A.; Lessmann, S. Deep learning for detecting financial statement fraud. Decis. Support Syst. 2020, 139, 113421. [Google Scholar] [CrossRef]
- Zhu, X.; Ao, X.; Qin, Z.; Chang, Y.; Liu, Y.; He, Q.; Li, J. Intelligent financial fraud detection practices in post-pandemic era. Innovation 2021, 2, 100176. [Google Scholar] [CrossRef] [PubMed]
- Singh, N.; Lai, K.h.; Vejvar, M.; Cheng, T.E. Data-driven auditing: A predictive modeling approach to fraud detection and classification. J. Corp. Account. Financ. 2019, 30, 64–82. [Google Scholar] [CrossRef]
- Jan, C.L. Detection of financial statement fraud using deep learning for sustainable development of capital markets under information asymmetry. Sustainability 2021, 13, 9879. [Google Scholar] [CrossRef]
- Xiuguo, W.; Shengyong, D. An analysis on financial statement fraud detection for Chinese listed companies using deep learning. IEEE Access 2022, 10, 22516–22532. [Google Scholar] [CrossRef]
- Lokanan, M.E.; Sharma, K. Fraud prediction using machine learning: The case of investment advisors in Canada. Mach. Learn. Appl. 2022, 8, 100269. [Google Scholar] [CrossRef]
- De Oliveira, N.R.; Pisa, P.S.; Lopez, M.A.; de Medeiros, D.S.V.; Mattos, D.M. Identifying fake news on social networks based on natural language processing: Trends and challenges. Information 2021, 12, 38. [Google Scholar] [CrossRef]
- Nanomi Arachchige, I.A.; Sandanapitchai, P.; Weerasinghe, R. Investigating machine learning & natural language processing techniques applied for predicting depression disorder from online support forums: A systematic literature review. Information 2021, 12, 444. [Google Scholar]
- Kanakogi, K.; Washizaki, H.; Fukazawa, Y.; Ogata, S.; Okubo, T.; Kato, T.; Kanuka, H.; Hazeyama, A.; Yoshioka, N. Tracing cve vulnerability information to capec attack patterns using natural language processing techniques. Information 2021, 12, 298. [Google Scholar] [CrossRef]
- Zhang, Y.; He, S.; Wa, S.; Zong, Z.; Lin, J.; Fan, D.; Fu, J.; Lv, C. Symmetry GAN Detection Network: An Automatic One-Stage High-Accuracy Detection Network for Various Types of Lesions on CT Images. Symmetry 2022, 14, 234. [Google Scholar] [CrossRef]
- Taherdoost, H.; Madanchian, M. Artificial intelligence and sentiment analysis: A review in competitive research. Computers 2023, 12, 37. [Google Scholar] [CrossRef]
- Dang, N.C.; Moreno-García, M.N.; De la Prieta, F. Sentiment analysis based on deep learning: A comparative study. Electronics 2020, 9, 483. [Google Scholar] [CrossRef]
- Villavicencio, C.; Macrohon, J.J.; Inbaraj, X.A.; Jeng, J.H.; Hsieh, J.G. Twitter sentiment analysis towards COVID-19 vaccines in the Philippines using naïve bayes. Information 2021, 12, 204. [Google Scholar] [CrossRef]
- Kwon, H.J.; Ban, H.J.; Jun, J.K.; Kim, H.S. Topic modeling and sentiment analysis of online review for airlines. Information 2021, 12, 78. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, D.; Wang, Y.; Fang, Y.; Xiao, W. Abstract text summarization with a convolutional seq2seq model. Appl. Sci. 2019, 9, 1665. [Google Scholar] [CrossRef]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent neural network regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Graves, A.; Graves, A. Long short-term memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–45. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Federation, C.C. Negative Financial Information and Subject Determination. Available online: https://www.datafountain.cn/competitions/353 (accessed on 17 August 2019).
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input () | Output () |
|---|---|
| register petty cash | Fabrication |
| transfer 30 RMB | Remittance |
| pull me into the blacklist | Realization |
| Model | Precision | Recall | Accuracy |
|---|---|---|---|
| FinChain-BERT | 0.97 | 0.96 | 0.97 |
| RNN [18] | 0.75 | 0.72 | 0.84 |
| LSTM [19] | 0.86 | 0.83 | 0.87 |
| BERT [25] | 0.92 | 0.89 | 0.91 |
| RoBERTa [22] | 0.94 | 0.95 | 0.95 |
| ALBERT [23] | 0.90 | 0.86 | 0.89 |
| DistillBERT [24] | 0.93 | 0.91 | 0.92 |
| Optimizer | Precision | Recall | Accuracy |
|---|---|---|---|
| SGD [26] | 0.93 | 0.89 | 0.91 |
| Adam [27] | 0.95 | 0.92 | 0.94 |
| Stable-Momentum Adam | 0.97 | 0.96 | 0.97 |
| Loss Functions | Precision | Recall | Accuracy |
|---|---|---|---|
| Negative Log-Likelihood Loss Function | 0.91 | 0.88 | 0.89 |
| Keywords Loss Function | 0.97 | 0.96 | 0.97 |
| Loss Functions | Precision | Recall | Accuracy | Model Size |
|---|---|---|---|---|
| Original FinChain-BERT | 0.97 | 0.96 | 0.97 | 140 MB |
| Distilled FinChain-BERT | 0.93 | 0.94 | 0.94 | 110 MB |
| Integer Quantization FinChain-BERT | 0.94 | 0.96 | 0.95 | 89 MB |
| Int-Distillation FinChain-BERT | 0.92 | 0.91 | 0.92 | 43 MB |
| Batch Size | Precision | Recall | Accuracy |
|---|---|---|---|
| 128 | 0.91 | 0.92 | 0.92 |
| 256 | 0.94 | 0.95 | 0.95 |
| 384 | 0.95 | 0.96 | 0.95 |
| Maximum (480) | 0.97 | 0.96 | 0.97 |
| Noise Level | Precision | Recall | Accuracy |
| 0 | 0.97 | 0.96 | 0.97 |
| 5 | 0.97 | 0.94 | 0.95 |
| 10 | 0.93 | 0.91 | 0.92 |
| 25 | 0.90 | 0.92 | 0.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Zhang, C.; Sun, Y.; Pang, K.; Jing, L.; Wa, S.; Lv, C. FinChain-BERT: A High-Accuracy Automatic Fraud Detection Model Based on NLP Methods for Financial Scenarios. Information 2023, 14, 499. https://doi.org/10.3390/info14090499
Yang X, Zhang C, Sun Y, Pang K, Jing L, Wa S, Lv C. FinChain-BERT: A High-Accuracy Automatic Fraud Detection Model Based on NLP Methods for Financial Scenarios. Information. 2023; 14(9):499. https://doi.org/10.3390/info14090499
Chicago/Turabian StyleYang, Xinze, Chunkai Zhang, Yizhi Sun, Kairui Pang, Luru Jing, Shiyun Wa, and Chunli Lv. 2023. "FinChain-BERT: A High-Accuracy Automatic Fraud Detection Model Based on NLP Methods for Financial Scenarios" Information 14, no. 9: 499. https://doi.org/10.3390/info14090499
APA StyleYang, X., Zhang, C., Sun, Y., Pang, K., Jing, L., Wa, S., & Lv, C. (2023). FinChain-BERT: A High-Accuracy Automatic Fraud Detection Model Based on NLP Methods for Financial Scenarios. Information, 14(9), 499. https://doi.org/10.3390/info14090499