
Job Vacancy Ranking with Sentence Embeddings, Keywords, and Named Entities



Abstract
:1. Introduction
- RQ1: does text enhancement with keywords or named entities improve ranking results?
- RQ2: does a summarization of either resumes or vacancies improve ranking results?
- RQ3: what text representation produces the best results?
- RQ4: can our method distinguish between vacancies relevant and irrelevant for an applicant?
2. Method
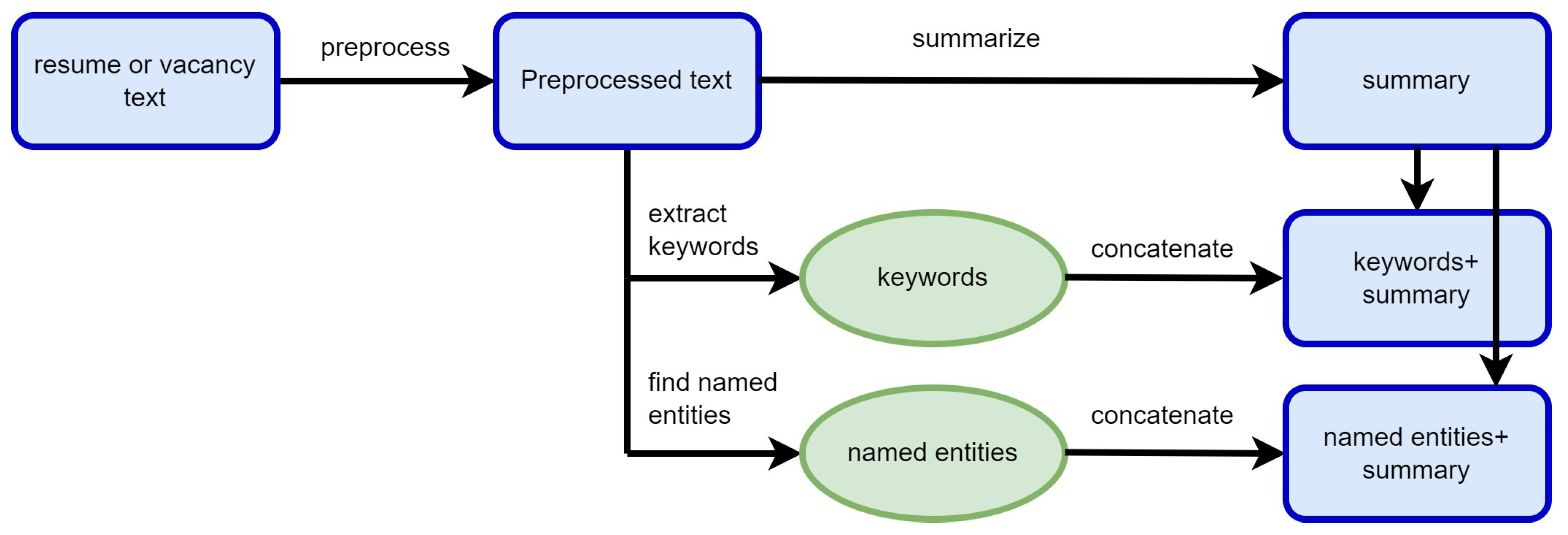
2.1. The Outline
- Full texts;
- Summarized texts (summaries);
- Summaries enhanced by keywords;
- Summaries enhanced by named entities.
2.2. Text Types
2.2.1. Full Texts
2.2.2. Extractive Summaries
2.2.3. Keyword-Enhanced Summaries
2.2.4. Named-Entity-Enhanced Summaries
2.3. Text Representation
- Word n-grams with . A word n-gram is a contiguous sequence of n words within a text or a sentence.
- Character n-grams with . A character n-gram is a contiguous sequence of n characters within a text.
- BOW vectors with TF-IDF weights, where every resume and vacancy is treated as a separate document. A BOW vector is a numerical representation of a text document that captures the occurrence or frequency of words in the document.
- Bidirectional encoder representations from transformers (BERT) sentence embeddings obtained from a pre-trained English BERT model “bert-base-uncased” [52]; this model was selected because all the resumes are written in English.
3. Baselines
3.1. The OKAPI Algorithm
3.2. BERT-Based Ranking
4. The Data
4.1. Vacancies Dataset
4.2. Resume Dataset
- Exclusion of duplicate records from the dataset.
- 2.
- Exclusion of resumes not written in English.
- 3.
- Exclusion of resumes of non-developers.
- 4.
- Anonymization.
4.3. Human Annotation
- First, we selected a subset of the resume dataset containing 30 resumes (vacancy rankings are time-consuming, and the availability of our annotators was limited).
- Then, we selected a random subset of the vacancies dataset containing five relevant vacancies.
- Two annotators with a computer science background were asked to rank the vacancies from the most relevant (rank 1) to the least relevant (rank 5) for every one of the 30 resumes.Our annotators received detailed guidelines from a manager of recruitment, organizational development, and welfare in an HR department of a large academic institution. Mrs. Yaarit Katzav (https://en.sce.ac.il/administration/human-resources1/staff (accessed on 1 June 2023)) is a senior HR manager with over 13 years of experience who is responsible, among other things, for recruiting information systems engineers at SCE Academic College. The full vacancy–resume matching guidelines provided by her appear in Table 7.
- Finally, we received 30 rank arrays of length 5 from both of our annotators and computed an average rank array of length 5 for every resume. (The resume dataset and annotations are freely available at https://github.com/NataliaVanetik/vacancy-resume-matching-dataset).
5. Metrics
6. Experimental Evaluation
6.1. Hardware and Software Setup
6.2. Methods
6.3. Metrics
6.4. Human-Annotated Data Evaluation
6.5. Automatically Annotated Data Evaluation
6.6. Extended Human-Annotated Data Evaluation
7. Limitations
7.1. Resume Type
7.2. Resume Structure
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BERT | Bidirectional Encoder Representations from Transformers |
| BOW | Bag-of-Words |
| CV | Curriculum Vitae |
| HR | Human Resources |
| IR | Information Retrieval |
| IT | Information Technology |
| NE | Named Entity or Entities |
| NER | Named Entity Recognition |
| NLP | Natural Language Processing |
| RQ | Research Question |
| TF-IDF | Term Frequency-Inverse Document Frequency |
| VM | Vector Matching |
Appendix A
Appendix A.1. Named Entity Recognition Details

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NE | Description |
|---|---|
| PERSON | Individuals, including names of people, fictional characters, or groups of people. |
| ORG | Organizations, institutions, companies, or agencies. |
| GPE | Geo-political entity that includes countries, cities, states, provinces, etc. |
| LOC | Non-GPE locations, such as mountains, bodies of water, or specific landmarks. |
| PRODUCT | Named products, including goods or commercial items. |
| EVENT | Named events, such as sports events, festivals, or conferences. |
| WORK_OF_ART | Artistic works, including books, paintings, songs, or movies. |
| LAW | Named laws, legislations, or regulations. |
| LANGUAGE | Named languages or language-related terms. |
| DATE | Dates or periods of time. |
| TIME | Specific times or time intervals. |
| PERCENT | Percentages or numerical ratios. |
| MONEY | Monetary values, including currencies, amounts, or symbols. |
| QUANTITY | Measurements or quantities. |
| ORDINAL | Ordinal numbers. |
| CARDINAL | Cardinal numbers or numerical values. |
| Data Type | Named Entity | Type |
|---|---|---|
| Resume | Arlington | GPE |
| mdm | ORG | |
| Over | CARDINAL | |
| 500 | CARDINAL | |
| The | DATE | |
| First | DATE | |
| Thirty | DATE | |
| Days | DATE | |
| The | DATE | |
| First | DATE | |
| Vacancy | 1990 | DATE |
| Israel | GPE | |
| Years | DATE | |
| Hebrew | LANGUAGE | |
| Masa | ORG | |
| English | NORP |
Appendix A.2. Keyword Analysis for Developer and Non-Developer Vacancies
| Developer Vacancies | ||
|---|---|---|
| Keywords | Count | |
| Software developer | 25 | |
| Software development | 6 | |
| Seeking software developer | 6 | |
| Software developers | 5 | |
| Senior software developer | 4 | |
| Participate in scrum | 4 | |
| Developer in Windsor | 4 | |
| Development environment candidates | 4 | |
| Agile development environment | 4 | |
| Lead software developer | 3 | |
| Data Science Vacancies | ||
| Keywords | Count | |
| Data scientist | 35 | |
| Data scientist with | 7 | |
| Data scientists | 6 | |
| The data scientist | 5 | |
| Seeking data scientist | 4 | |
| Data analyst | 3 | |
| Data scientist for | 3 | |
| Senior data scientist | 3 | |
| Data scientist role | 3 | |
| Data engineers | 3 | |
| Responsibilities kforce | 1 | |
| Responsibilities kforce has | 1 | |
| Software development engineer | 1 | |
| Talented software development | 1 |
Appendix A.3. The Effect of Different Sentence Embeddings
| Resume Text Data | Vacancy Text Data | Sentence Embedding Model | Krippendorff’s Alpha | Spearman’s Correlation |
|---|---|---|---|---|
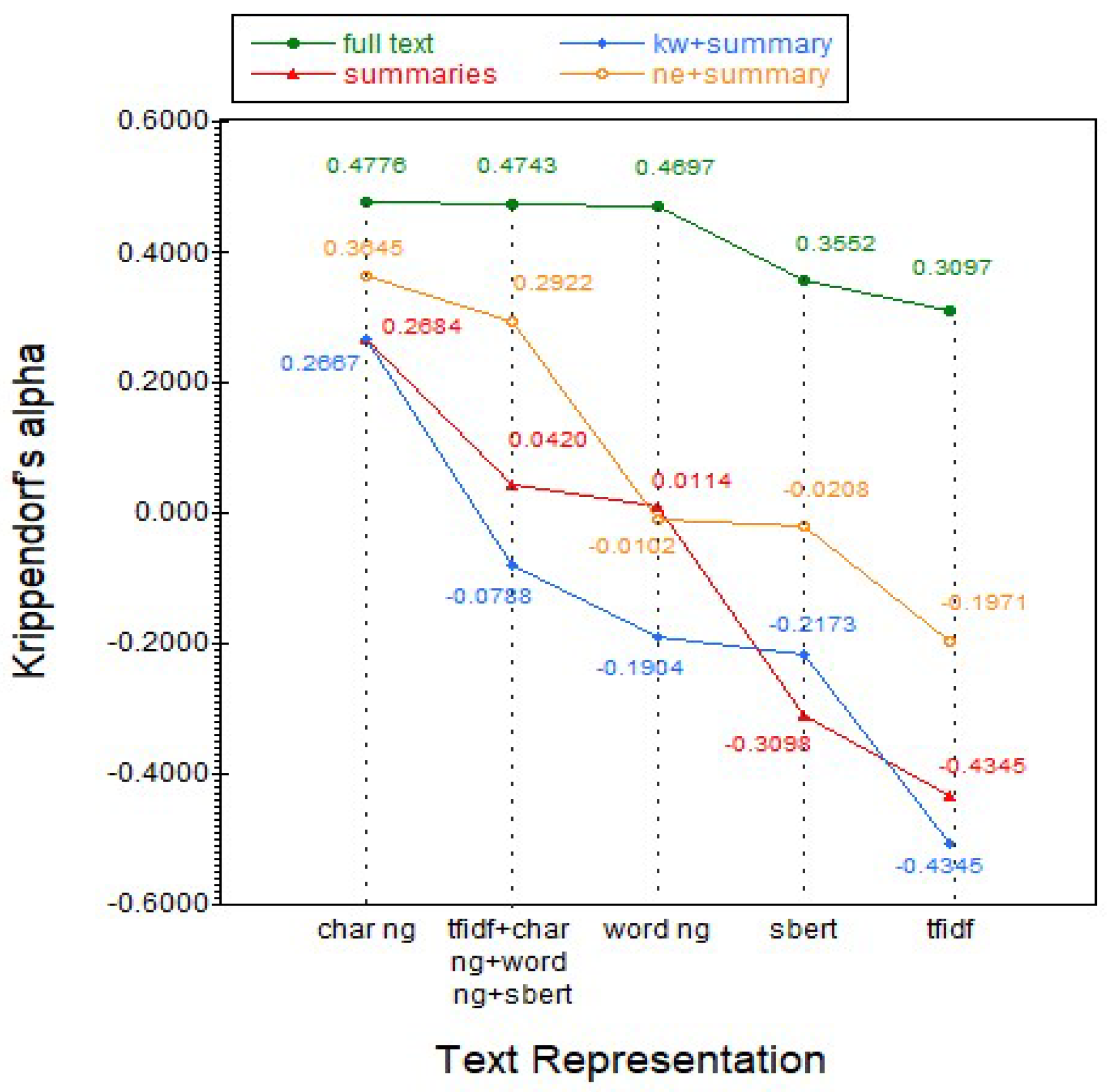
| kw + summary | Summary | bert-base-uncased | 0.3695 | 0.3003 |
| ne + summary | Full text | bert-base-uncased | 0.3466 | 0.2773 |
| ne + summary | Summary | bert-base-uncased | 0.3155 | 0.2403 |
| Full text | Full text | bert-base-uncased | 0.3097 | 0.2340 |
| Full text | Summary | bert-base-uncased | 0.2917 | 0.2140 |
| Keywords + summary | Summary | nli-bert-large-max-pooling | 0.6211 | 0.5816 |
| Keywords + summary | ner + summary | nli-bert-large-max-pooling | 0.6151 | 0.5749 |
| ner + summary | Keywords + summary | nli-bert-large-max-pooling | 0.6139 | 0.5779 |
| Full text | Summary | nli-bert-large-max-pooling | 0.6070 | 0.5680 |
| Full text | Keywords + summary | nli-bert-large-max-pooling | 0.6040 | 0.5646 |
| ner + summary | Summary | Longformer | 0.5872 | 0.5467 |
| Keywords + summary | Summary | Longformer | 0.5806 | 0.5406 |
| Full text | Full text | Longformer | 0.5564 | 0.5138 |
| ner + summary | Keywords + summary | Longformer | 0.5517 | 0.5007 |
| Full text | Summary | Longformer | 0.5362 | 0.4900 |
| Full text | Keywords + summary | all-distilroberta-v1 | 0.5403 | 0.4867 |
| Keywords + summary | Summary | all-distilroberta-v1 | 0.5282 | 0.4808 |
| Keywords + summary | Keywords + summary | all-distilroberta-v1 | 0.4922 | 0.4408 |
| ner + summary | Keywords + summary | all-distilroberta-v1 | 0.4787 | 0.4198 |
| Full text | Summary | all-distilroberta-v1 | 0.4245 | 0.3672 |
Appendix A.4. Extended Automatic Evaluation
Appendix A.5. Rankings Produced by ChatGPT API
| Baseline | Krippendorff’s Alpha | Spearman’s Correlation | Acc | ||
|---|---|---|---|---|---|
| OKAPI-BM25 BERT-rank | −0.0455 −0.2045 | −0.3939 −0.6061 | 0.3030 0.1970 | ||
| VM | |||||
| Resume text data | Vacancy text data | Text representation | Krippendorff’s | Spearman’s | acc |
| Keywords + summary | ner + summary | tfidf | 1 | 1 | 1 |
| Keywords + summary | Job + description | tfidf + char ng + word ng + sbert | 1 | 1 | 1 |
| Keywords + summary | Job + description | tfidf | 1 | 1 | 1 |
| Keywords + summary | Job + description | Char ng | 1 | 1 | 1 |
| Keywords + summary | Job + description | Word ng | 1 | 1 | 1 |
| ner + summary | ner + summary | tfidf | 1 | 1 | 1 |
| ner + summary | Job + description | tfidf + char ng + word ng + sbert | 1 | 1 | 1 |
| ner + summary | Job + description | tfidf | 1 | 1 | 1 |
| ner + summary | Job + description | Char ng | 1 | 1 | 1 |
| ner + summary | Job + description | Word ng | 1 | 1 | 1 |
| Summary | ner + summary | tfidf | 1 | 1 | 1 |
| Summary | Job + description | tfidf + char ng + word ng + sbert | 1 | 1 | 1 |
| Summary | Job + description | tfidf | 1 | 1 | 1 |
| Summary | Job + description | Char ng | 1 | 1 | 1 |
| Summary | Job + description | Word ng | 1 | 1 | 1 |
| Doc | ner + summary | tfidf | 1 | 1 | 1 |
| Doc | Job + description | tfidf | 1 | 1 | 1 |
| Doc | Job + description | Word ng | 1 | 1 | 1 |
| ner + summary | Summary | tfidf | 0.9773 | 0.9697 | 0.9848 |
| Baseline | Krippendorff’s Alpha | Spearman Correlation |
|---|---|---|
| ChatGPT | 0.1422 | 0.0430 |
References
- Do, D.Q.; Tran, H.T.; Ha, P.T. Job Vacancy and Résumé Analysis for Efficient Matching of Job Offers and Applicants. In Proceedings of the IEEE International Conference on Data Science and Advanced Analytics, Montreal, QC, Canada, 17–19 October 2016. [Google Scholar]
- Nocker, M.; Sena, V. Big data and human resources management: The rise of talent analytics. Soc. Sci. 2019, 8, 273. [Google Scholar] [CrossRef]
- Chala, S.A.; Ansari, F.; Fathi, M.; Tijdens, K. Semantic matching of job seeker to vacancy: A bidirectional approach. Int. J. Manpow. 2018, 39, 1047–1063. [Google Scholar]
- McKinney, A. Real Resumix & Other Resumes for Federal Government Jobs: Including Samples of Real Resumes Used to Apply for Federal Government Jobs; Prep Publishing: Fayetteville, NC, USA, 2003. [Google Scholar]
- Riabchenko, A. Taxonomy-Based Vacancy: CV Matching. Master’s Thesis, LUT University, Lappeenranta, Finland, 2022. [Google Scholar]
- Senthil Kumaran, V.; Sankar, A. Towards an automated system for intelligent screening of candidates for recruitment using ontology mapping (EXPERT). Int. J. Metadata Semant. Ontol. 2013, 8, 56–64. [Google Scholar] [CrossRef]
- Pudasaini, S.; Shakya, S.; Lamichhane, S.; Adhikari, S.; Tamang, A.; Adhikari, S. Scoring of Resume and Job Description Using Word2vec and Matching Them Using Gale-Shapley Algorithm. In Proceedings of the ICOECA 2021, Bangalore, India, 18–19 February 2021. [Google Scholar] [CrossRef]
- Tejaswini, K.; Umadevi, V.; Kadiwal, S.; Revanna, S. Design and Development of Machine Learning based Resume Ranking System. Glob. Transit. Proc. 2022, 3, 371–375. [Google Scholar] [CrossRef]
- Kawan, S.; Mohanty, M.N. Multiclass Resume Categorization Using Data Mining. Int. J. Electr. Eng. Technol. 2020, 11, 267–274. [Google Scholar]
- Sammut, C.; Webb, G.I. Encyclopedia of Machine Learning; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Stefanovič, P.; Kurasova, O.; Štrimaitis, R. The N-Grams Based Text Similarity Detection Approach Using Self-Organizing Maps and Similarity Measures. Appl. Sci. 2019, 9, 1870. [Google Scholar] [CrossRef]
- Brown, P.F.; Della Pietra, V.J.; Desouza, P.V.; Lai, J.C.; Mercer, R.L. Class-based n-gram models of natural language. Comput. Linguist. 1992, 18, 467–480. [Google Scholar]
- Dice, L.R. Measures of the amount of ecologic association between species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 27th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Volume 26. [Google Scholar]
- Qin, C.; Zhu, H.; Xu, T.; Zhu, C.; Jiang, L. Enhancing person-job fit for talent recruitment: An ability-aware neural network approach. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 25–34. [Google Scholar]
- Zhu, C.; Zhu, H.; Xiong, H.; Ma, C.; Xie, F.; Ding, P.; Li, P. Person-job fit: Adapting the right talent for the right job with joint representation learning. ACM Trans. Manag. Inf. Syst. 2018, 9, 12.1–12.17. [Google Scholar] [CrossRef]
- Yuan, Z.; Lu, S. Application in person-job fit evaluation of BP neural network in knowledge workers. J. Wuhan Univ. Technol. 2010, 32, 515–518. [Google Scholar]
- Bing, Y.; Fei, J. Application in person-job fit evaluation of support vector machine. J. Cent. South Univ. For. Fechnology (Soc. Sci.) 2011, 5, 92–94. [Google Scholar]
- Alsaif, S.A.; Sassi Hidri, M.; Eleraky, H.A.; Ferjani, I.; Amami, R. Learning-Based Matched Representation System for Job Recommendation. Computers 2022, 11, 161. [Google Scholar] [CrossRef]
- Koh, M.F.; Chew, Y.C. Intelligent job matching with self-learning recommendation engine. Procedia Manuf. 2015, 3, 1959–1965. [Google Scholar] [CrossRef]
- Lu, Y.; Ingram, S.; Gillet, D. A recommender system for job seeking and recruiting website. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 963–966. [Google Scholar]
- Gionis, A.; Gunopulos, D.; Koudas, N. Machine learned job recommendation. In Proceedings of the Fifth ACM Conference on Recommender Systems, Chicago, IL, USA, 23–27 October 2011; pp. 325–328. [Google Scholar]
- Wu, D.; Zhou, L.; Lin, H. Design and implementation of job recommendation system for graduates based on random walk. J. Guangxi Norm. Univ. 2011, 29, 179–185. [Google Scholar]
- Robertson, S.; Walker, S.; Jones, S.; Hancock-Beaulieu, M.; Gatford, M. Okapi at TREC-3; Nist Special Publication, Diane Publishing Co.: Darby, PA, USA, 1995; Volume 109, p. 109. [Google Scholar]
- Espenakk, E.; Knalstad, M.J.; Kofod-Petersen, A. Lazy learned screening for efficient recruitment. In Proceedings of the Case-Based Reasoning Research and Development: 27th International Conference, ICCBR 2019, Otzenhausen, Germany, 8–12 September 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 64–78. [Google Scholar]
- Martinez-Gil, J.; Paoletti, A.; Pichler, M. A Novel Approach for Learning How to Automatically Match Job Offers and Candidate Profiles. Inf. Syst. Front. 2020, 22, 1265–1274. [Google Scholar] [CrossRef]
- Moratanch, N.; Chitrakala, S. A survey on extractive text summarization. In Proceedings of the 2017 International Conference on Computer, Communication and Signal Processing (ICCCSP), Chennai, India, 10–11 January 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Widyassari, A.P.; Rustad, S.; Shidik, G.F.; Noersasongko, E.; Syukur, A.; Affandy, A. Review of automatic text summarization techniques & methods. J. King Saud Univ.—Comput. Inf. Sci. 2022, 34, 1029–1046. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Abdel-Salam, S.; Rafea, A. Performance study on extractive text summarization using BERT models. Information 2022, 13, 67. [Google Scholar] [CrossRef]
- Salton, G. Introduction to Modern Information Retrieval; McGraw-Hill: New York, NY, USA, 1983. [Google Scholar]
- Li, J.; Fan, Q.; Zhang, K. Keyword extraction based on tf/idf for Chinese news document. Wuhan Univ. J. Nat. Sci. 2007, 12, 917–921. [Google Scholar] [CrossRef]
- Mihalcea, R.; Tarau, P. Textrank: Bringing order into text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; pp. 404–411. [Google Scholar]
- Rose, S.; Engel, D.; Cramer, N.; Cowley, W. Automatic keyword extraction from individual documents. In Text Mining: Applications and Theory; John Wiley & Sons: Hoboken, NJ, USA, 2010; pp. 1–20. [Google Scholar]
- Campos, R.; Mangaravite, V.; Pasquali, A.; Jorge, A.; Nunes, C.; Jatowt, A. YAKE! Keyword extraction from single documents using multiple local features. Inf. Sci. 2020, 509, 257–289. [Google Scholar] [CrossRef]
- Hu, J.; Li, S.; Yao, Y.; Yu, L.; Yang, G.; Hu, J. Patent keyword extraction algorithm based on distributed representation for patent classification. Entropy 2018, 20, 104. [Google Scholar] [CrossRef]
- Huh, J.H. Big data analysis for personalized health activities: Machine learning processing for automatic keyword extraction approach. Symmetry 2018, 10, 93. [Google Scholar] [CrossRef]
- Sordoni, A.; Galley, M.; Auli, M.; Brockett, C.; Ji, Y.; Mitchell, M.; Nie, J.Y.; Gao, J.; Dolan, B. A neural network approach to context-sensitive generation of conversational responses. arXiv 2015, arXiv:1506.06714. [Google Scholar]
- Grootendorst, M. KeyBERT: Minimal Keyword Extraction with BERT. 2020. Available online: https://github.com/MaartenGr/KeyBERT (accessed on 1 June 2023). [CrossRef]
- Lafferty, J.; McCallum, A.; Pereira, F.C. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data; University of Pennsylvania: Philadelphia, PA, USA, 2001. [Google Scholar]
- Das, A.; Garain, U. CRF-based named entity recognition@ icon 2013. arXiv 2014, arXiv:1409.8008. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. arXiv 2016, arXiv:1603.01360. [Google Scholar]
- Syed, M.H.; Chung, S.T. MenuNER: Domain-adapted BERT based NER approach for a domain with limited dataset and its application to food menu domain. Appl. Sci. 2021, 11, 6007. [Google Scholar] [CrossRef]
- Luoma, J.; Pyysalo, S. Exploring cross-sentence contexts for named entity recognition with BERT. arXiv 2020, arXiv:2006.01563. [Google Scholar]
- Cetoli, A.; Bragaglia, S.; O’Harney, A.D.; Sloan, M. Graph convolutional networks for named entity recognition. arXiv 2017, arXiv:1709.10053. [Google Scholar]
- Zhou, R.; Xie, Z.; Wan, J.; Zhang, J.; Liao, Y.; Liu, Q. Attention and Edge-Label Guided Graph Convolutional Networks for Named Entity Recognition. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 6499–6510. [Google Scholar]
- Francis, S.; Van Landeghem, J.; Moens, M.F. Transfer learning for named entity recognition in financial and biomedical documents. Information 2019, 10, 248. [Google Scholar] [CrossRef]
- Miller, D. Bert-Extractive-Summarizer PyPI. 2019. Available online: https://pypi.org/project/bert-extractive-summarizer (accessed on 1 June 2023).
- Novoresume. Resume Keywords: How to Use Them. Novoresume. Available online: https://novoresume.com/?noRedirect=true (accessed on 12 June 2023).
- Honnibal, M.; Montani, I. spaCy: Industrial-Strength Natural Language Processing in Python. 2020. Available online: https://spacy.io (accessed on 4 June 2023).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT; Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Amati, G. BM25. In Encyclopedia of Database Systems; Liu, L., Özsu, M., Eds.; Springer: Boston, MA, USA, 2009; pp. 59–61. [Google Scholar] [CrossRef]
- Hofstätter, S.; Althammer, S.; Schröder, M.; Sertkan, M.; Hanbury, A. Improving Efficient Neural Ranking Models with Cross-Architecture Knowledge Distillation. In Proceedings of the 2021 Conference on Human Information Interaction and Retrieval, Canberra, Australia, 14–19 March 2021; ACM: New York, NY, USA, 2021; pp. 84–93. [Google Scholar]
- Jha, A.; Kumar, P. JobsPikr Datasets. 2017. Available online: https://data.world/jobspikr/software-developer-job-listings-from-usa (accessed on 20 February 2023).
- Jha, A.; Kumar, P. JobsPikr. 2017. Available online: https://www.jobspikr.com/ (accessed on 20 February 2023).
- Job Feed API. 2017. Available online: https://www.jobspikr.com/job-feed-api/ (accessed on 22 October 2022).
- Ahlmann, J. Find_Job_Titles Python SW Package. 2017. Available online: https://pypi.org/project/find-job-titles (accessed on 1 June 2023).
- Telegram FZ LLC; Telegram Messenger Inc. Telegram. Available online: https://telegram.org (accessed on 1 June 2023).
- Telegram FZ LLC; Telegram Messenger Inc. HighTech Israel Jobs Telegram Channel. Available online: https://tgstat.ru/en/channel/@israjobs (accessed on 5 September 2019).
- Docs.Python.Org. Hashlib—Secure Hashes and Message Digests. 2022. Available online: https://docs.python.org/3/library/hashlib.html (accessed on 22 October 2022).
- Danilak, M.M. Langdetect PyPI. 2022. Available online: https://pypi.org/project/langdetect/ (accessed on 22 October 2022).
- Singh, V. Flashtext PyPI. 2020. Available online: https://pypi.org/project/flashtext (accessed on 22 October 2022).
- Krippendorff, K. Computing Krippendorff’s Alpha-Reliability; University of Pennsylvania: Philadelphia, PA, USA, 2011. [Google Scholar]
- Myers, L.; Sirois, M.J. Spearman correlation coefficients, differences between. Encycl. Stat. Sci. 2004, 12. [Google Scholar] [CrossRef]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- de Raadt, A.; Warrens, M.J.; Bosker, R.J.; Kiers, H.A. A comparison of reliability coefficients for ordinal rating scales. J. Classif. 2021, 38, 519–543. [Google Scholar] [CrossRef]
- Kim, D.; Chai, K.; Kim, J.; Lee, H.; Lee, J.; Kim, J. Colaboratory: An educational research environment for machine learning using Jupyter Notebooks. J. Educ. Resour. Comput. (JERC) 2017, 16, 1–10. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. scikit-learn: Machine Learning in Python. 2011. Available online: https://scikit-learn.org (accessed on 4 June 2023).
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef]
- Freelon, D. ReCal: Intercoder reliability calculation as a web service. Int. J. Internet Sci. 2010, 5, 20–33. [Google Scholar]
- Woolson, R.F.; Wilcoxon signed-rank test. Wiley Encyclopedia of Clinical Trials; John Wiley & Sons: Hoboken, NJ, USA, 2007; pp. 1–3. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 11. [Google Scholar]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The Long-Document Transformer. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3642–3652. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- OpenAI. OpenAI. 2023. Available online: https://openai.com/ (accessed on 30 July 2023).

| Data Type | Keywords | Score |
|---|---|---|
| Vacancy | Software development | 0.5359 |
| Using software development | 0.529 | |
| Purpose development and | 0.5233 | |
| Purpose development | 0.5101 | |
| Maintenance of software | 0.5049 | |
| Resume | Java backend development | 0.6156 |
| Backend java developer | 0.6135 | |
| Java backend | 0.6066 | |
| Backend java | 0.5917 | |
| Now backend java | 0.58 |
| Field Name | Type | Non-Empty Count | Min Length | Max Length | Avg Length |
|---|---|---|---|---|---|
| Crawl_timestamp | String | 10,000 | 25 | 25 | 25 |
| URL | URL | 10,000 | - | - | - |
| Job_title | String | 10,000 | 18 | 14,230.102 | |
| Category | String | 9161 | 2 | 38 | 18.828 |
| Company_name | String | 10,000 | 2 | 277 | 27.285 |
| City string | 9869 | 1 | 41 | 10.141 | |
| Country | String | 10,000 | 2 | 3 | 2.559 |
| Inferred_city | String | 7829 | 3 | 22 | 8.649 |
| Inferred_state | String | 9207 | 4 | 20 | 8.325 |
| Inferred_country | String | 9229 | 3 | 13 | 8.602 |
| Post_date | Date | 10,000 | - | - | - |
| Job_description | String | 10,000 | 64 | 27,576 | 3966.576 |
| Job_type | String | 10,000 | 8 | 10 | 8.938 |
| Salary_offered | String | 0 | - | - | - |
| Job_board | String | 10,000 | 4 | 13 | 7.551 |
| Geo string | 9999 | 3 | 3 | 3 | |
| Cursor | Integer | 10,000 | - | - | - |
| Contact_email | String | 0 | - | - | - |
| Contact_phone_number | String | 819 | 1 | 60 | 12.009 |
| Uniq_id | String | 10,000 | 32 | 32 | 32 |
| Column Name | Content |
|---|---|
| Crawl_timestamp | 6 February 2019 05:53:38 +0000 |
| URL | https://www.dice.com/jobs/detail/C%252B%252B-Software-Developer-SigmaWay-San-Jose-CA-95101/90994229/801699 |
| Job_title | C++ Software Developer |
| Category | Computer-or-internet |
| Company_name | SigmaWay |
| City | San Jose |
| State | CA |
| Country | USA |
| Inferred_city | San Jose |
| Inferred_state | California |
| Inferred_country | USA |
| Post_date | 5 February 2019 |
| Job_description | Apply by Email/Direct Application at udit.sharma@sigmaway.org C++ Software Developer Duration: 12+ Months Location: Sunnyvale, CA Top 3 Must Haves 1. C++ Software Experience (5+ years) 2. Education in information technology, computer science, or related field. Masters is preferred. 3. Knowledge of Software Development and Design across multiple platforms Preferred but not required Having experience with robotics projects or systems is a plus Required Qualifications Bachelors degree in information technology, computer science, or related field. Masters is preferred. At least 5 years experience in C++ development Excellent knowledge in algorithms and data structures Experienced in professional software development using versioning systems (git), reviewing systems Experience in agile development projects Excellent teaming and communication skills Ability to work in cross-functional teams |
| Job_type | Undefined |
| Salary_offered | |
| Job_board | Dice |
| Geo | USA |
| Cursor | 1,549,436,429,136,812 |
| Contact_email | Empty 100% |
| Contact_phone_number | (408) 627-7905 |
| Uniq_id | 3b22ba3aa471681a909f878d8cec1b58 |
| Field | Content |
|---|---|
| Job_description | Data Scientist EnvoyIT is looking for a Data Scientist for a Full-time position with one of our Healthcare clients in Reston, VA You will be joining a new initiative. This is an outstanding employer with plenty of growth opportunity. Base plus bonus and benefits. PURPOSE: As a Data Scientist, you will: Join a brand new team of machine learning researchers with an extensive track record in both academia and industry. Bring a combination of mathematical rigor and innovative algorithm design to create recipes that extract relevant insights from billions of rows of data to effectively & efficiently improve health outcomes. Create thoughtful solutions that engage and empower members to make more informed decisions about their health Develop statistical applications that can be reproduced and deployed on enterprise platforms. Develop functional means for measuring the quality of healthcare members receive annually. Interact with and report to an audience that includes Directors, Vice-Presidents and the C-level executives. Build tools and support structures needed to analyze data, perform elements of data cleaning, feature selection and feature engineering and organize experiments in conjunction with best practices. Assess the effectiveness and accuracy of new data sources and data gathering techniques. |
| Job_title | Data Scientist |
| Uniq_id | eda91b88eb3096ed98bc1a5f6b5568df |
| Keyword | Score | Named Entity | Type |
|---|---|---|---|
| Synergy software design | 0.6431 | 3d | CARDINAL |
| Development team synergy | 0.5812 | 2004 | DATE |
| Synergy software | 0.5392 | Each | DATE |
| Com synergy software | 0.5264 | Year | DATE |
| Team synergy software | 0.5223 | Maritime | FAC |
| Plaza | FAC |
| Job Title |
|---|
| Oracle ADF Developer, Oracle Apex Developer, Oracle Applications Developer, Oracle BPM Developer, Oracle BRM Developer, Oracle Business Intelligence Developer, Oracle Data Warehouse Developer, Oracle Database Developer, Oracle Developer, Oracle E Business Developer, Oracle EBS Developer, Oracle ERP Developer, Oracle ETL Developer, Oracle Financial Application Developer, Oracle Financials Developer, Oracle Forms Developer, Oracle Fusion Developer, Oracle Fusion Middleware Developer, Oracle HRMS Developer, Oracle OBIEE Developer, Oracle PL SQL Developer, Oracle R12 Developer, Oracle Reports Developer, Oracle SOA Developer, Oracle SQL Developer, Oracle Technical Developer |
| Parameter | Explanation |
|---|---|
| Work experience | Candidates should ensure that their work experience matches the level required for the job postings they are applying for. |
| Qualifications | Educational and professional qualifications are also important considerations. Candidates should make sure that they have the necessary qualifications required for the job. |
| Clarity | Candidates should look for job postings with clear and specific job requirements and job culture descriptions, and avoid applying for roles with vague or generic requirements. They should tailor their applications to the specific job posting, highlighting the most important requirements that match their skills and qualifications. |
| Conciseness | Some job postings might have a long list of requirements. Try to focus on the most important requirements that match your skills and qualifications. |
| Keywords | Candidates should focus on the most relevant keywords and requirements that match their skills and qualifications, and avoid irrelevant information. |
| Industry trends | Candidates should stay up to date with the latest industry trends and developments in the IT field. This can help them identify new job opportunities and position themselves as experts in their field. |
| Baseline | Krippendorff’s Alpha | Spearman’s Correlation | |||
|---|---|---|---|---|---|
| OKAPI-BM25 BERT-rank | 0.3055 −0.1779 | 0.2262 −0.3071 | |||
| Method | Resume text data | Vacancy text data | Text representation | ||
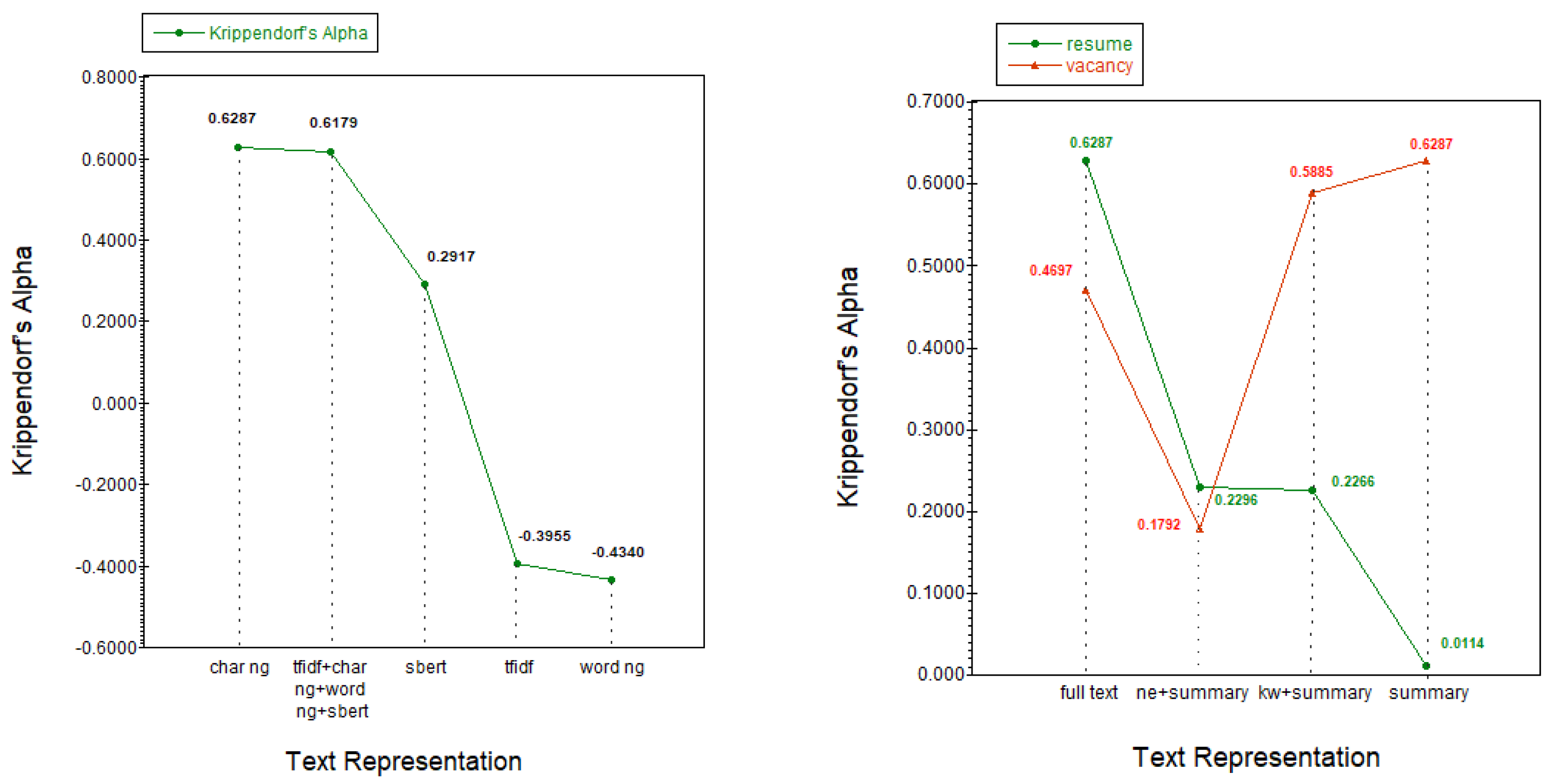
| VM | Full text | Summary | Char ng | 0.6287 | 0.5908 |
| VM | Full text | Summary | tfidf + char ng + word ng + sbert | 0.6179 | 0.5794 |
| VM | Full text | kw + summary | Char ng | 0.5885 | 0.5455 |
| VM | Full text | kw + summary | tfidf + char ng + word ng + sbert | 0.5075 | 0.4555 |
| VM | kw + summary | Full text | tfidf + char ng + word ng + sbert | 0.4918 | 0.4444 |
| VM | kw + summary | Full text | Char ng | 0.4918 | 0.4444 |
| VM | ne + summary | Full text | tfidf + char ng + word ng + sbert | 0.4918 | 0.4444 |
| VM | ne + summary | Full text | Char ng | 0.4918 | 0.4444 |
| VM | Summary | Full text | tfidf + char ng + word ng + sbert | 0.4918 | 0.4444 |
| VM | Summary | Full text | Char ng | 0.4918 | 0.4444 |
| VM | ne + summary | Full text | tfidf | 0.4858 | 0.4377 |
| VM | Full text | Full text | tfidf | 0.4776 | 0.4273 |
| VM | Full text | Full text | tfidf + char ng + word ng + sbert | 0.4743 | 0.4210 |
| VM | kw + summary | Full text | tfidf | 0.4716 | 0.4206 |
| VM | Summary | Full text | tfidf | 0.4716 | 0.4206 |
| VM | Full text | Full text | Char ng | 0.4697 | 0.4192 |
| VM | kw + summary | Summary | sbert | 0.3695 | 0.3003 |
| VM | ne + summary | ne + summary | Char ng | 0.3645 | 0.2972 |
| VM | kw + summary | ne + summary | tfidf + char ng + word ng + sbert | 0.3623 | 0.2892 |
| VM | kw + summary | Full text | Word ng | 0.3552 | 0.2900 |
| VM | ne + summary | Full text | Word ng | 0.3552 | 0.2900 |
| VM | Summary | Full text | Word ng | 0.3552 | 0.2900 |
| VM | Full text | Full text | Word ng | 0.3552 | 0.2900 |
| VM | ne + summary | Full text | sbert | 0.3466 | 0.2773 |
| VM | Summary | ne + summary | Char ng | 0.3383 | 0.2625 |
| VM | Summary | ne + summary | tfidf + char ng + word ng + sbert | 0.3312 | 0.2556 |
| VM | ne + summary | Summary | sbert | 0.3155 | 0.2403 |
| VM | kw + summary | ne + summary | Char ng | 0.3154 | 0.2377 |
| VM | Full text | Full text | sbert | 0.3097 | 0.2340 |
| Method | Resume Text Data | Vacancy Text Data | Text Representation | Krippendorff’s Alpha | Spearman’s Correlation |
|---|---|---|---|---|---|
| VM cosine | Full text | Full text | Char ng | 0.5186 | 0.4708 |
| VM cosine | Full text | Full text | tfidf + char ng + word ng + sbert | 0.5006 | 0.4508 |
| VM cosine | Summary | Full text | tfidf + char ng + word ng + sbert | 0.4473 | 0.3894 |
| VM cosine | Summary | Full text | Char ng | 0.3993 | 0.3361 |
| VM cosine | ne + summary | Full text | tfidf + char ng + word ng + sbert | 0.3741 | 0.3021 |
| VM cosine | ner + summary | Full text | Char ng | 0.3681 | 0.2955 |
| VM cosine | kw + summary | Full text | tfidf + char ng + word ng + sbert | 0.3216 | 0.2516 |
| VM cosine | kw + summary | Full text | Char ng | 0.3216 | 0.2516 |
| VM cosine | ner + summary | ner + summary | sbert | 0.2612 | 0.1867 |
| VM cosine | Full text | ner + summary | sbert | 0.1892 | 0.1067 |
| VM cosine | Summary | ner + summary | sbert | 0.1719 | 0.0861 |
| Method | Average Relevance |
|---|---|
| OKAPI-BM-25 | 2.0227 |
| VM CV full text + vacancy summary + char ng | 2.1894 |
| Baseline | Krippendorff’s Alpha | Spearman’s Correlation | Acc | |||
|---|---|---|---|---|---|---|
| OKAPI-BM25 BERT-rank | 0.7000 0.2700 | 0.6000 0.0300 | 0.8000 0.5200 | |||
| Method | Resume text data | Vacancy text data | Text representation | |||
| VM | Full text | ne + summary | Char ng | 0.9091 | 0.8788 | 0.9394 |
| VM | Full text | ne + summary | tfidf + char ng + word ng + sbert | 0.8636 | 0.8182 | 0.9091 |
| VM | Summary | Summary | Word ng | 0.8409 | 0.7879 | 0.8939 |
| VM | ne + summary | Summary | Word ng | 0.7955 | 0.7273 | 0.8636 |
| VM | kw + summary | Summary | Word ng | 0.7727 | 0.6970 | 0.8485 |
| VM | Full text | kw + Summary | Char ng | 0.6591 | 0.5455 | 0.7727 |
| VM | Full text | Summary | Char ng | 0.5455 | 0.3939 | 0.6970 |
| VM | Full text | kw + summary | tfidf + char ng + word ng + sbert | 0.5227 | 0.3636 | 0.6818 |
| VM | Full text | Summary | Word ng | 0.4091 | 0.2121 | 0.6061 |
| VM | Full text | Summary | tfidf + char ng + word ng + sbert | 0.3864 | 0.1818 | 0.5909 |
| VM | Summary | kw + summary | Word ng | 0.3636 | 0.1515 | 0.5758 |
| VM | ne + summary | kw + summary | Word ng | 0.3182 | 0.0909 | 0.5455 |
| VM | ne + summary | ne + summary | Word ng | 0.2500 | 0.0000 | 0.5000 |
| VM | ne + summary | ne + summary | sbert | 0.1818 | −0.0909 | 0.4545 |
| VM | Summary | ne + summary | sbert | 0.1818 | −0.0909 | 0.4545 |
| VM | Summary | ne + summary | Word ng | 0.1591 | −0.1212 | 0.4394 |
| VM | kw + summary | kw + summary | Word ng | 0.0909 | −0.2121 | 0.3939 |
| VM | Full text | ne + summary | sbert | 0.0227 | −0.3030 | 0.3485 |
| Baseline | Krippendorff’s Alpha | Spearman’s Correlation | |||
|---|---|---|---|---|---|
| OKAPI-BM25 BERT-rank | 0.5350 −0.2905 | 0.4908 −0.4070 | |||
| Method | Resume text data | Vacancy text data | Text representation | ||
| VM | Full text | Summary | Char ng | 0.7630 | 0.7435 |
| VM | Full text | Summary | tfidf + char ng + word ng + sbert | 0.7411 | 0.7198 |
| VM | Full text | kw + summary | Char ng | 0.7378 | 0.7158 |
| VM | kw + summary | Full text | tfidf + char ng + word ng + sbert | 0.7045 | 0.6827 |
| VM | kw + summary | Full text | Char ng | 0.7045 | 0.6827 |
| VM | ne + summary | Full text | tfidf + char ng + word ng + sbert | 0.7045 | 0.6827 |
| VM | ne + summary | Full text | Char ng | 0.7045 | 0.6827 |
| VM | Summary | Full text | tfidf + char ng + word ng + sbert | 0.7045 | 0.6827 |
| VM | Summary | Full text | Char ng | 0.7045 | 0.6827 |
| VM | Full text | kw + summary | tfidf + char ng + word ng + sbert | 0.6877 | 0.6605 |
| VM | kw + summary | Full text | Word ng | 0.6252 | 0.5947 |
| VM | ne + summary | Full text | Word ng | 0.6252 | 0.5947 |
| VM | Summary | Full text | Word ng | 0.6252 | 0.5947 |
| VM | Full text | Full text | Word ng | 0.6252 | 0.5947 |
| VM | Full text | Full text | tfidf + char ng + word ng + sbert | 0.5976 | 0.5643 |
| VM | Full text | Full text | Char ng | 0.5648 | 0.5298 |
| VM | kw + summary | Summary | sbert | 0.5587 | 0.5185 |
| VM | Full text | Summary | sbert | 0.5375 | 0.4958 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vanetik, N.; Kogan, G. Job Vacancy Ranking with Sentence Embeddings, Keywords, and Named Entities. Information 2023, 14, 468. https://doi.org/10.3390/info14080468
Vanetik N, Kogan G. Job Vacancy Ranking with Sentence Embeddings, Keywords, and Named Entities. Information. 2023; 14(8):468. https://doi.org/10.3390/info14080468
Chicago/Turabian StyleVanetik, Natalia, and Genady Kogan. 2023. "Job Vacancy Ranking with Sentence Embeddings, Keywords, and Named Entities" Information 14, no. 8: 468. https://doi.org/10.3390/info14080468
APA StyleVanetik, N., & Kogan, G. (2023). Job Vacancy Ranking with Sentence Embeddings, Keywords, and Named Entities. Information, 14(8), 468. https://doi.org/10.3390/info14080468