
Cyberbullying Detection on Social Media Using Stacking Ensemble Learning and Enhanced BERT




Abstract
:1. Introduction
- We have proposed a new stacking ensemble learning model for cyberbullying detection based on a continuous bag of words feature extractor.
- We have introduced a modified BERT model and investigated and evaluated its performance with the standard BERT model and the proposed ensemble learning model performance.
- We analyzed the performance of two standard BERT models and proposed stacked model with two benchmark datasets from Twitter and Facebook for cyberbullying detection on SM.
- We conducted and reported an empirical analysis to determine the effectiveness and performance of three methods with different feature extraction methods.
2. Related Works
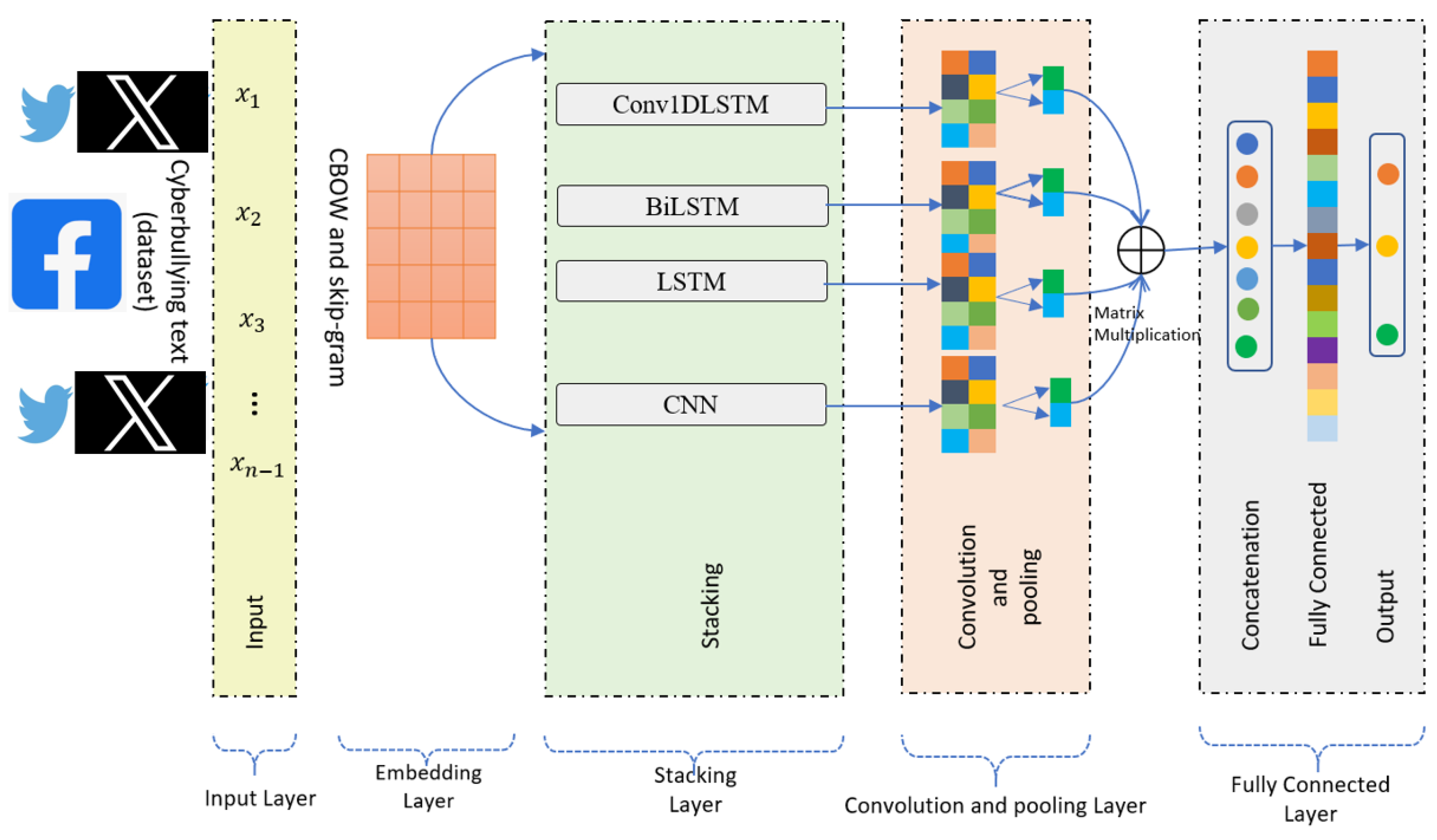
3. Materials and Methods
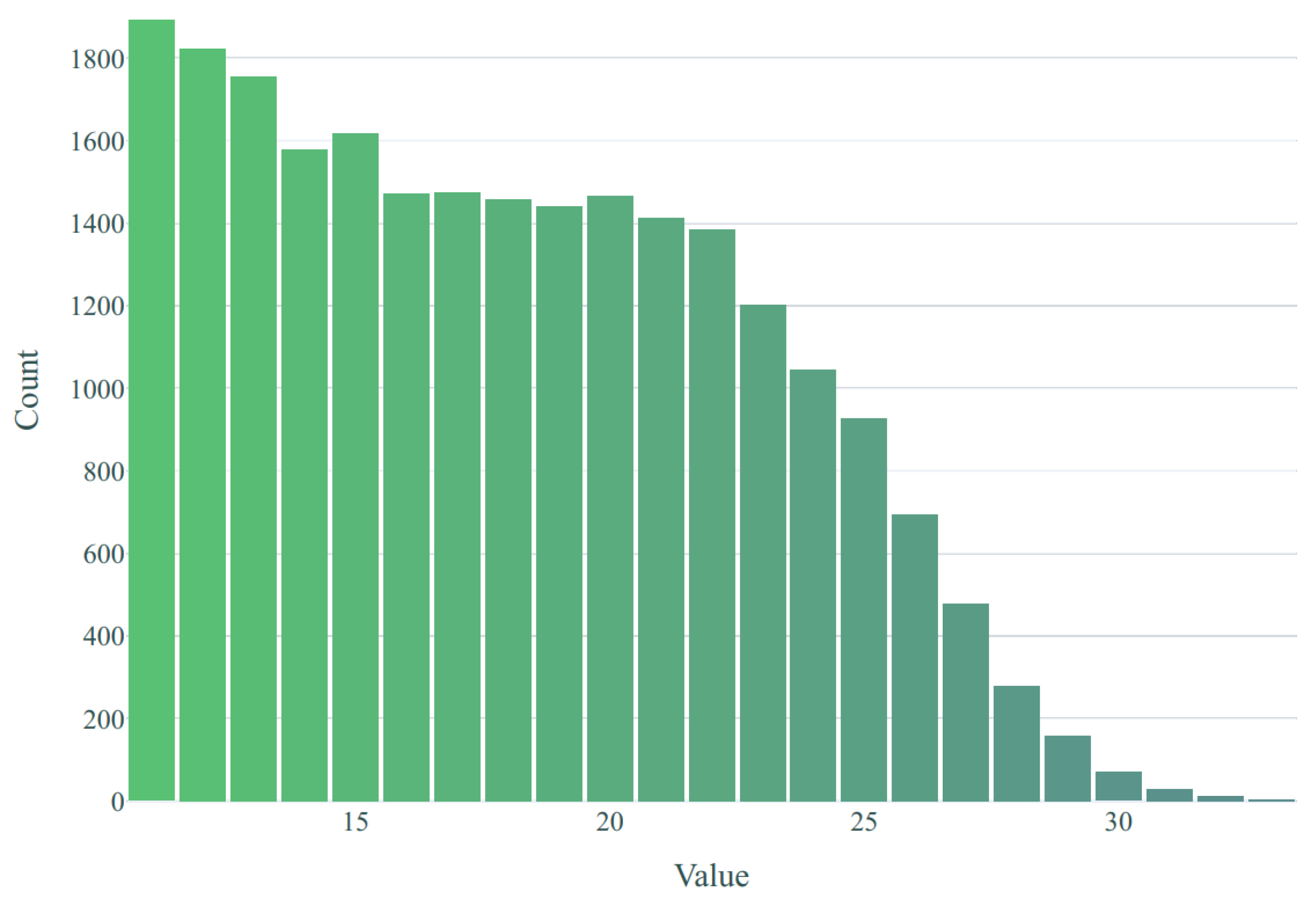
3.1. Datasets and Input Layer
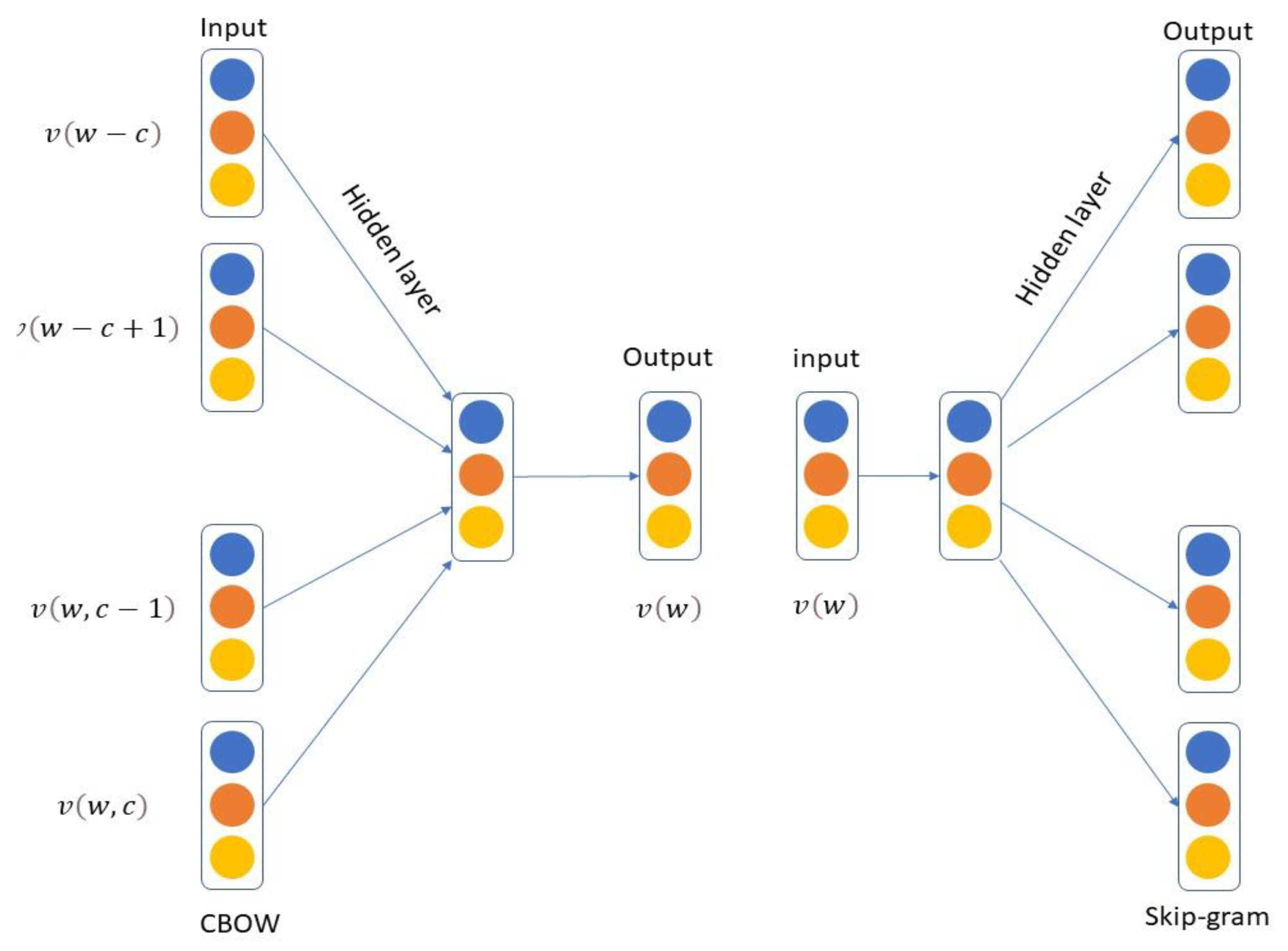
3.2. Embedding Layer
3.3. Deep Neural Networks (DNN) Baseline Models
3.3.1. Long Short-Term Memory and Bidirectional Long Short-Term Memory
- Standard LSTM units lack the utilization of an importance gate, specifically denoted as .
- LSTM units employ the output gate and the update gate as substitutes for the missing importance gate . The output gate determines the value of the hidden state in the memory cell, allowing activation outputs to be processed by additional hidden network components.
- The output gate determines the value of the hidden state in the memory cell, allowing activation outputs to be processed by additional hidden network components. The update gate governs the extent to which the previous hidden state Ht−1 is overwritten to achieve the current hidden state . For example, how much memory cell information could be ignored in order for memory cells to work properly.
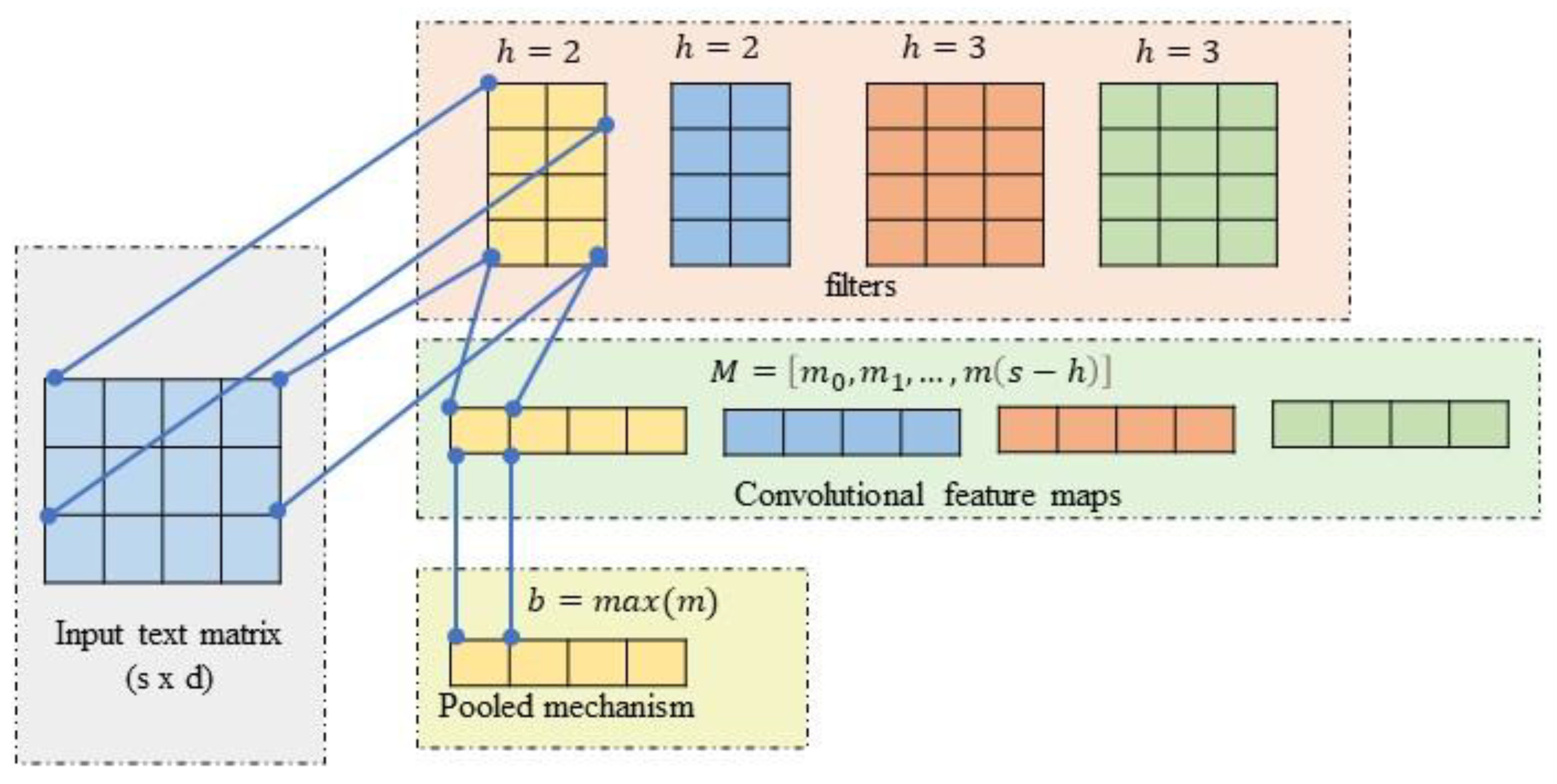
3.3.2. Convolutional Neural Network
3.3.3. Fully Connected Layer (FCL)
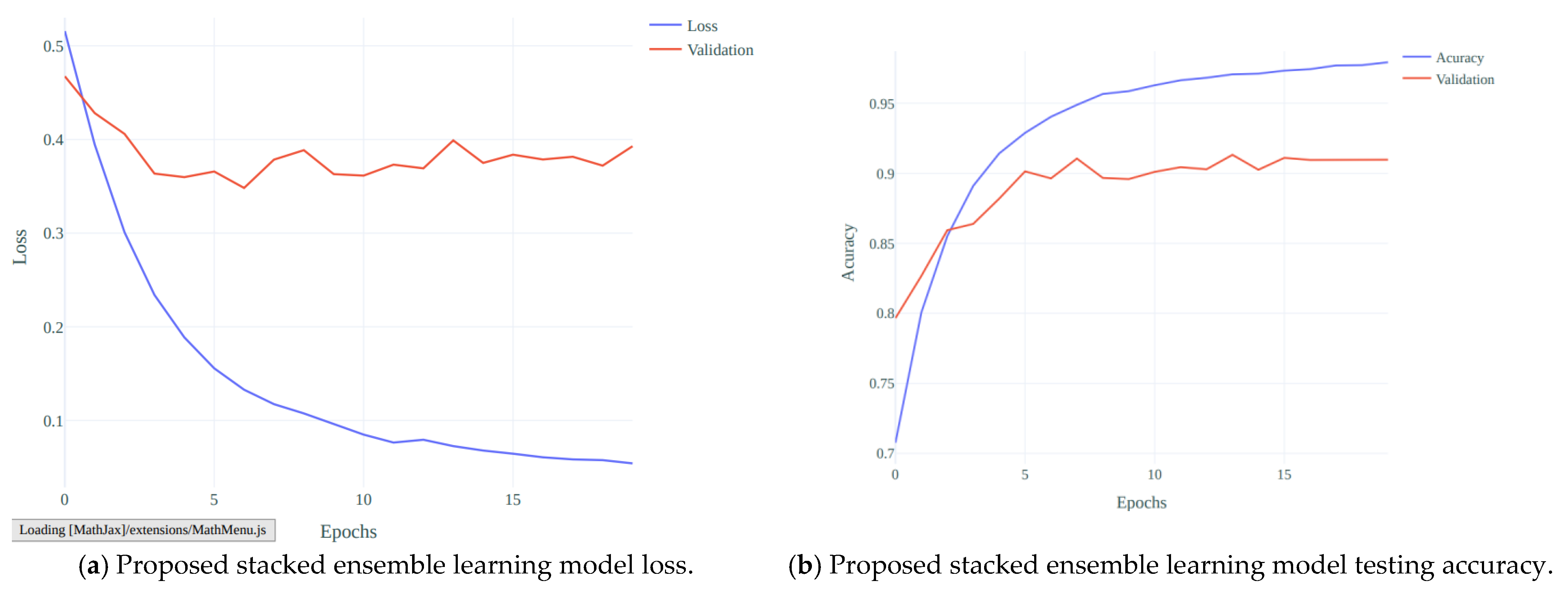
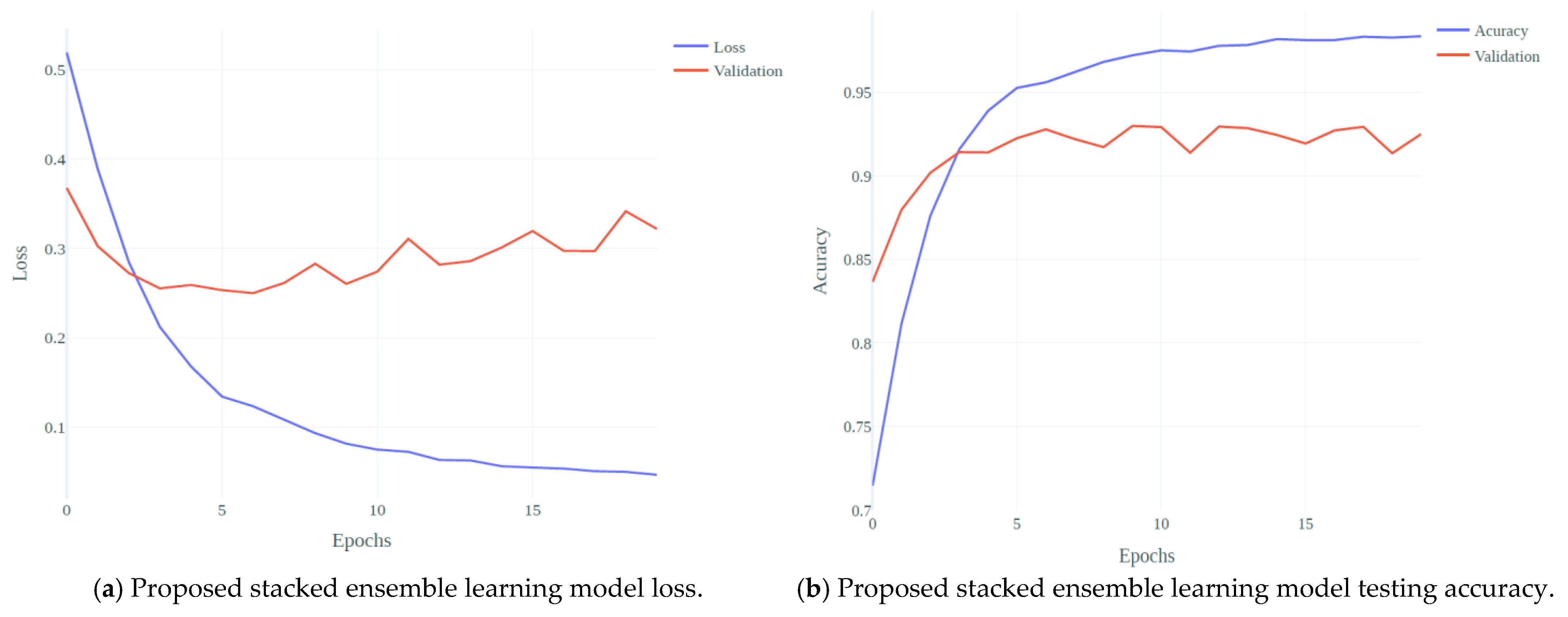
4. Results
4.1. Experimental Setting
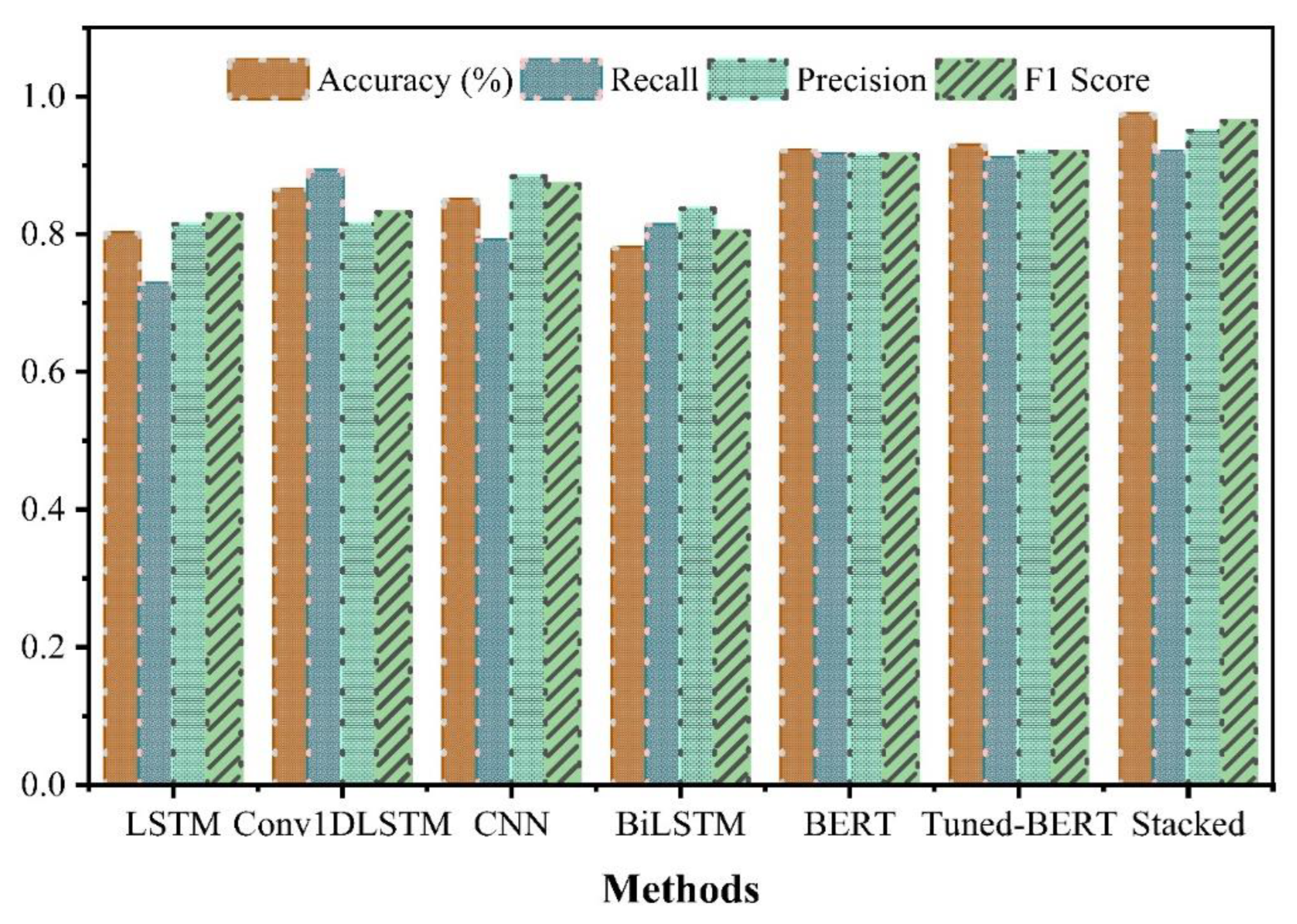
4.2. Accuracy, Precision, Recall and F1-Score
- Accuracy measures the proportion of correctly classified tweets compared to the total number of tweets for cyberbullying prediction models. Accordingly, the following calculation may be used.
- Accuracy =where fp stands for false positive, fn for false negative, tp for true positive, and tn for true negative.
- Precision measures the proportion of correctly identified positive samples out of all positive predictions.
- Recall is a metric that quantifies the proportion of relevant tweets that were successfully retrieved among all the relevant tweets in a given dataset or search.
- F1-score indicates the harmonic means of precision and recall, representing the balance between these two metrics.
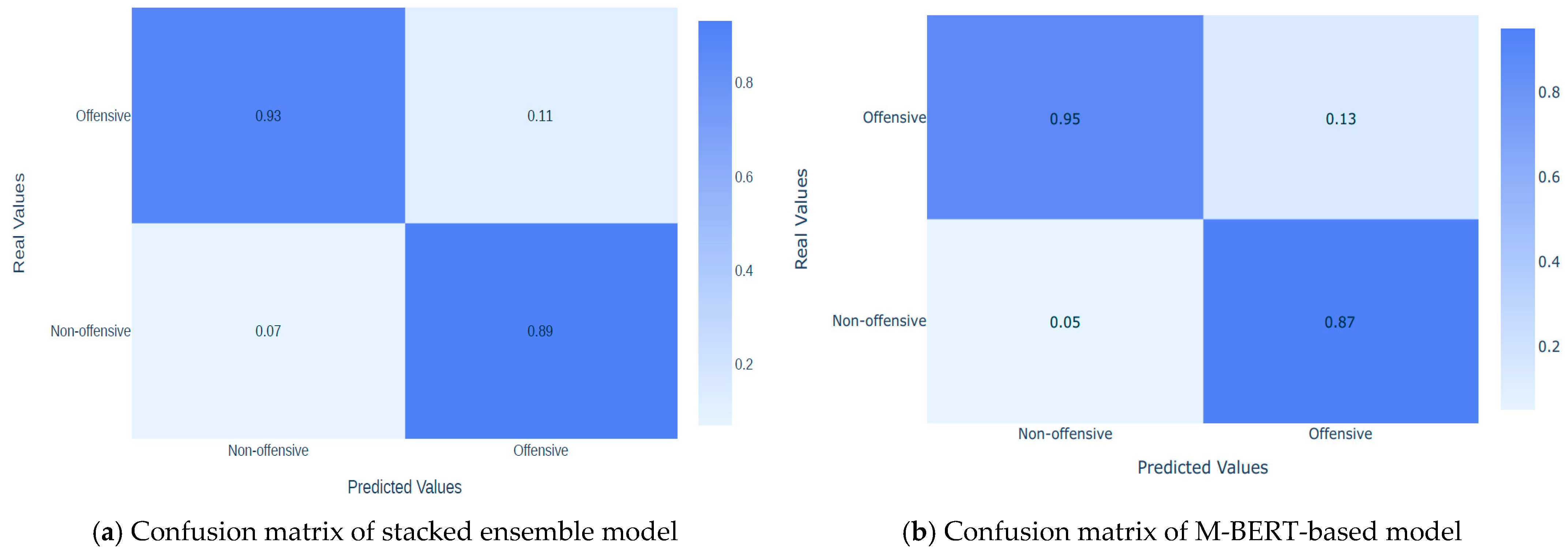
4.3. Performance Result of Baseline Models
4.4. Precision-Recall Curve
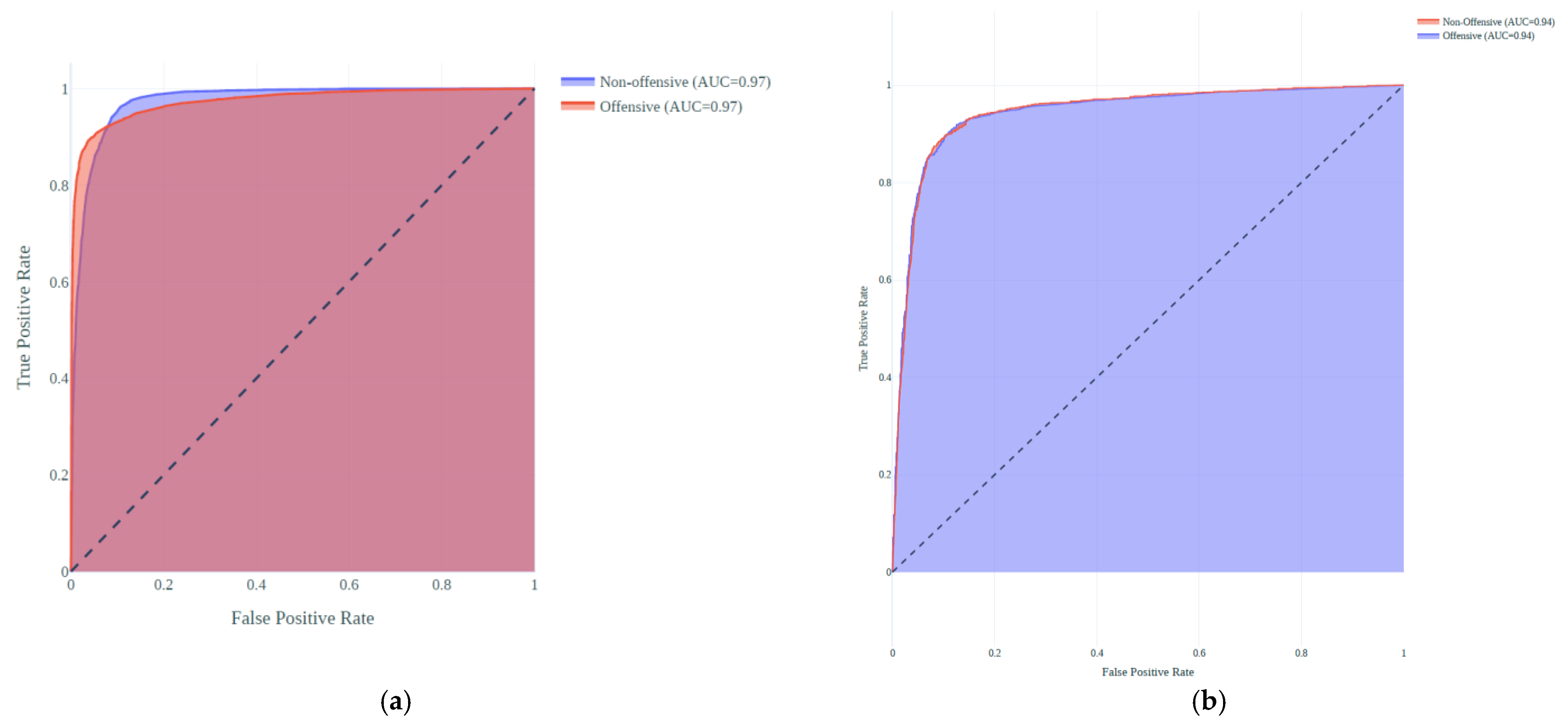
4.5. Area under the Curve (AUC)
4.6. Comparison of Proposed Models’ Complexity and Statistical Analysis
4.7. Comparison with Literature
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Balakrishnan, V. Cyberbull ying among young adults in Malaysia: The roles of gender, age and Internet frequency. Comput. Hum. Behav. 2015, 46, 149–157. [Google Scholar] [CrossRef]
- Bozzola, E.; Spina, G.; Agostiniani, R.; Barni, S.; Russo, R.; Scarpato, E.; Di Mauro, A.; Di Stefano, A.V.; Caruso, C.; Corsello, G. The use of social media in children and adolescents: Scoping review on the potential risks. Int. J. Environ. Res. Public Health 2022, 19, 9960. [Google Scholar] [CrossRef] [PubMed]
- Junke, X. Legal Regulation of Cyberbullying—From a Chinese perspective. In Proceedings of the 2020 IEEE International Conference on Dependable, Autonomic and Secure Computing, International Conference on Pervasive Intelligence and Computing, International Conference on Cloud and Big Data Computing, International Conference on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech), Calgary, AB, Canada, 17–22 August 2020; pp. 322–327. [Google Scholar]
- Vismara, M.; Girone, N.; Conti, D.; Nicolini, G.; Dell’Osso, B. The current status of Cyberbullying research: A short review of the literature. Curr. Opin. Behav. Sci. 2022, 46, 101152. [Google Scholar] [CrossRef]
- Subaramaniam, K.; Kolandaisamy, R.; Jalil, A.B.; Kolandaisamy, I. Cyberbullying challenges on society: A review. J. Posit. Sch. Psychol. 2022, 6, 2174–2184. [Google Scholar]
- Kee, D.M.H.; Al-Anesi, M.A.L.; Al-Anesi, S.A.L. Cyberbullying on Social Media under the Influence of COVID-19. Glob. Bus. Organ. Excell. 2022, 41, 11–22. [Google Scholar] [CrossRef]
- Arisanty, M.; Wiradharma, G. The motivation of flaming perpetrators as cyberbullying behavior in social media. J. Kaji. Komun. 2022, 10, 215–227. [Google Scholar] [CrossRef]
- Hair, J.F., Jr.; Sarstedt, M. Data, measurement, and causal inferences in machine learning: Opportunities and challenges for marketing. J. Mark. Theory Pract. 2021, 29, 65–77. [Google Scholar] [CrossRef]
- Bozyiğit, A.; Utku, S.; Nasibov, E. Cyberbullying detection: Utilizing social media features. Expert Syst. Appl. 2021, 179, 115001. [Google Scholar] [CrossRef]
- Cheng, L.; Guo, R.; Silva, Y.N.; Hall, D.; Liu, H. Modeling temporal patterns of cyberbullying detection with hierarchical attention networks. ACM/IMS Trans. Data Sci. 2021, 2, 1–23. [Google Scholar] [CrossRef]
- Mazari, A.C.; Boudoukhani, N.; Djeffal, A. BERT-based ensemble learning for multi-aspect hate speech detection. Clust. Comput. 2023, 1–15. [Google Scholar] [CrossRef]
- Singh, A.; Kaur, M. Cuckoo inspired stacking ensemble framework for content-based cybercrime detection in online social networks. Trans. Emerg. Telecommun. Technol. 2021, 32, e4074. [Google Scholar] [CrossRef]
- Dong, X.; Yu, Z.; Cao, W.; Shi, Y.; Ma, Q. A survey on ensemble learning. Front. Comput. Sci. 2020, 14, 241–258. [Google Scholar] [CrossRef]
- Baradaran, R.; Amirkhani, H. Ensemble learning-based approach for improving generalization capability of machine reading comprehension systems. Neurocomputing 2021, 466, 229–242. [Google Scholar] [CrossRef]
- Guo, X.; Gao, Y.; Zheng, D.; Ning, Y.; Zhao, Q. Study on short-term photovoltaic power prediction model based on the Stacking ensemble learning. Energy Rep. 2020, 6, 1424–1431. [Google Scholar] [CrossRef]
- Muneer, A.; Fati, S.M. A comparative analysis of machine learning techniques for cyberbullying detection on twitter. Future Internet 2020, 12, 187. [Google Scholar] [CrossRef]
- Koroteev, M. BERT: A review of applications in natural language processing and understanding. arXiv 2021, arXiv:2103.11943. [Google Scholar]
- Roshanzamir, A.; Aghajan, H.; Soleymani Baghshah, M. Transformer-based deep neural network language models for Alzheimer’s disease risk assessment from targeted speech. BMC Med. Inform. Decis. Mak. 2021, 21, 92. [Google Scholar] [CrossRef] [PubMed]
- Acheampong, F.A.; Nunoo-Mensah, H.; Chen, W. Transformer models for text-based emotion detection: A review of BERT-based approaches. Artif. Intell. Rev. 2021, 54, 5789–5829. [Google Scholar] [CrossRef]
- Gillioz, A.; Casas, J.; Mugellini, E.; Abou Khaled, O. Overview of the Transformer-based Models for NLP Tasks. In Proceedings of the 2020 15th Conference on Computer Science and Information Systems (FedCSIS), Sofia, Bulgaria, 6–9 September 2020; pp. 179–183. [Google Scholar]
- Van Hee, C.; Jacobs, G.; Emmery, C.; Desmet, B.; Lefever, E.; Verhoeven, B.; De Pauw, G.; Daelemans, W.; Hoste, V. Automatic detection of cyberbullying in social media text. PLoS ONE 2018, 13, e0203794. [Google Scholar] [CrossRef]
- Paul, S.; Saha, S.; Singh, J.P. COVID-19 and cyberbullying: Deep ensemble model to identify cyberbullying from code-switched languages during the pandemic. Multimed. Tools Appl. 2023, 82, 8773–8789. [Google Scholar] [CrossRef]
- Haidar, B.; Chamoun, M.; Serhrouchni, A. Multilingual cyberbullying detection system: Detecting cyberbullying in Arabic content. In Proceedings of the 2017 1st Cyber Security in Networking Conference (CSNet), Rio de Janeiro, Brazil, 18–20 October 2017; pp. 1–8. [Google Scholar]
- Yadav, J.; Kumar, D.; Chauhan, D. Cyberbullying detection using pre-trained bert model. In Proceedings of the 2020 International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 2–4 July 2020; pp. 1096–1100. [Google Scholar]
- Al-Ajlan, M.A.; Ykhlef, M. Optimized twitter cyberbullying detection based on deep learning. In Proceedings of the 2018 21st Saudi Computer Society National Computer Conference (NCC), Riyadh, Saudi Arabia, 25–26 April 2018; pp. 1–5. [Google Scholar]
- Banerjee, V.; Telavane, J.; Gaikwad, P.; Vartak, P. Detection of cyberbullying using deep neural network. In Proceedings of the 2019 5th International Conference on Advanced Computing & Communication Systems (ICACCS), Coimbatore, India, 15–16 March 2019; pp. 604–607. [Google Scholar]
- Wulczyn, E.; Thain, N.; Dixon, L. Ex machina: Personal attacks seen at scale. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 1391–1399. [Google Scholar]
- Malpe, V.; Vaikole, S. A comprehensive study on cyberbullying detection using machine learning approach. Int. J. Futur. Gener. Commun. Netw. 2020, 13, 342–351. [Google Scholar]
- Aind, A.T.; Ramnaney, A.; Sethia, D. Q-bully: A reinforcement learning based cyberbullying detection framework. In Proceedings of the 2020 International Conference for Emerging Technology (INCET), Belgaum, India, 5–7 June 2020; pp. 1–6. [Google Scholar]
- Mahat, M. Detecting cyberbullying across multiple social media platforms using deep learning. In Proceedings of the 2021 International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), Greater Noida, India, 4–5 March 2021; pp. 299–301. [Google Scholar]
- Yadav, Y.; Bajaj, P.; Gupta, R.K.; Sinha, R. A comparative study of deep learning methods for hate speech and offensive language detection in textual data. In Proceedings of the 2021 IEEE 18th India Council International Conference (INDICON), Guwahati, India, 19–21 December 2021; pp. 1–6. [Google Scholar]
- Zaidi, S.A.R. Suspicious Communication on Social Platforms. Available online: https://www.kaggle.com/datasets/syedabbasraza/suspicious-communication-on-social-platforms (accessed on 20 November 2022).
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Wang, Q.; Xu, J.; Chen, H.; He, B. Two improved continuous bag-of-word models. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 2851–2856. [Google Scholar]
- White, L. On the Surprising Capacity of Linear Combinations of Embeddings for Natural Language Processing. Ph.D. Thesis, The University of Western Australia, Perth, Australia, 2019. [Google Scholar]
- Muneer, A.; Taib, S.M.; Naseer, S.; Ali, R.F.; Aziz, I.A. Data-driven deep learning-based attention mechanism for remaining useful life prediction: Case study application to turbofan engine analysis. Electronics 2021, 10, 2453. [Google Scholar] [CrossRef]
- Naseer, S.; Fati, S.M.; Muneer, A.; Ali, R.F. iAceS-Deep: Sequence-based identification of acetyl serine sites in proteins using PseAAC and deep neural representations. IEEE Access 2022, 10, 12953–12965. [Google Scholar] [CrossRef]
- Graves, A. Long Short-Term Memory. Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–45. [Google Scholar]
- Alqushaibi, A.; Abdulkadir, S.J.; Rais, H.M.; Al-Tashi, Q.; Ragab, M.G.; Alhussian, H. Enhanced weight-optimized recurrent neural networks based on sine cosine algorithm for wave height prediction. J. Mar. Sci. Eng. 2021, 9, 524. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Durairajah, V.; Gobee, S.; Muneer, A. Automatic vision based classification system using DNN and SVM classifiers. In Proceedings of the 2018 3rd International Conference on Control, Robotics and Cybernetics (CRC), Penang, Malaysia, 18–20 December 2018; pp. 6–14. [Google Scholar]
- Muneer, A.; Fati, S.M. Efficient and automated herbs classification approach based on shape and texture features using deep learning. IEEE Access 2020, 8, 196747–196764. [Google Scholar] [CrossRef]
- Ragab, M.G.; Abdulkadir, S.J.; Aziz, N.; Al-Tashi, Q.; Alyousifi, Y.; Alhussian, H.; Alqushaibi, A. A novel one-dimensional cnn with exponential adaptive gradients for air pollution index prediction. Sustainability 2020, 12, 10090. [Google Scholar] [CrossRef]
- Naseer, S.; Ali, R.F.; Fati, S.M.; Muneer, A. iNitroY-Deep: Computational identification of Nitrotyrosine sites to supplement Carcinogenesis studies using Deep Learning. IEEE Access 2021, 9, 73624–73640. [Google Scholar] [CrossRef]
- Muneer, A.; Fati, S.M.; Akbar, N.A.; Agustriawan, D.; Wahyudi, S.T. iVaccine-Deep: Prediction of COVID-19 mRNA vaccine degradation using deep learning. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 7419–7432. [Google Scholar] [CrossRef]
- Zaheer, R.; Shaziya, H. A study of the optimization algorithms in deep learning. In Proceedings of the 2019 Third International Conference on Inventive Systems and Control (ICISC), Coimbatore, India, 10–11 January 2019; pp. 536–539. [Google Scholar]
- Fati, S.M.; Muneer, A.; Alwadain, A.; Balogun, A.O. Cyberbullying Detection on Twitter Using Deep Learning-Based Attention Mechanisms and Continuous Bag of Words Feature Extraction. Mathematics 2023, 11, 3567. [Google Scholar] [CrossRef]
- Sinha, A.; Gunwal, S.; Kumar, S. A Globally Convergent Gradient-based Bilevel Hyperparameter Optimization Method. arXiv 2022, arXiv:2208.12118. [Google Scholar]
- Saito, T.; Rehmsmeier, M. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef]
- Narkhede, S. Understanding auc-roc curve. Towards Data Sci. 2018, 26, 220–227. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Id | Cyberbullying Tweet Samples | Pred | Label |
|---|---|---|---|
| 1 | Fat people are dump | Offensive (cyberbullying) | 1 |
| 2 | WTF are you talking about Men? No men thats not a menage that’s just gay. | Offensive (cyberbullying) | 1 |
| 3 | Fake friends are no different than shadows, they stick around during your brightest moments, but disappear during your darkest. | Non-offensive (non-bullying) | 0 |
| 4 | You are big black s**t. | Offensive (cyberbullying) | 1 |
| 5 | Today something is dope. Tomorrow that same thing is trash. Next month it is irrelevant. Next year it’s classic. | Non-offensive (non-bullying) | 0 |
| Layers | Layer Name | Kernel × Unit | Other Parameters |
|---|---|---|---|
| 1 | Conv1D | 72 × 128 | Activation = ReLU, Strides = 3 |
| 2 | Batch Norm | - | - |
| 3 | Global Max Pool | - | Stride = 3 |
| 4 | Conv1D | Activation = ReLU, Strides = 3 | |
| 5 | Batch Norm | - | |
| 6 | Max Pool | Pool Size = 2, Stride = 2 | |
| 7 | Conv1D | 3 × 512 | Activation = ReLU, Stride = 1 |
| 8 | Conv1D | 3 × 128 | Activation = ReLU, Stride = 1 |
| 9 | Flatten | - | - |
| 10 | Dense | 1 × 512 | |
| 11 | Dense | 2 | Activation = SoftMax |
| No. | Algorithm | Accuracy (%) | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| 1 | LSTM | 0.8011 | 0.8142 | 0.7281 | 0.8281 |
| 2 | Conv1DLSTM | 0.8649 | 0.8146 | 0.8919 | 0.8317 |
| 3 | CNN | 0.8496 | 0.8836 | 0.7908 | 0.8720 |
| 4 | BiLSTM | 0.7795 | 0.8373 | 0.8130 | 0.8041 |
| 5 | BERT | 0.921 | 0.915 | 0.915 | 0.9149 |
| 6 | Tuned-BERT | 0.9384 | 0.92 | 0.91 | 0.92 |
| 7 | Stacked | 0.974 | 0.950 | 0.92 | 0.964 |
| No. | Algorithm | Accuracy (%) | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| 1 | BERT | 0.9042 | 0.9051 | 0.9034 | 0.9043 |
| 2 | Tuned-BERT | 0.9198 | 0.9262 | 0.9123 | 0.9191 |
| 3 | Stacked | 0.9097 | 0.9122 | 0.9082 | 0.9102 |
| No | Model | Accuracy | Time Complexity |
|---|---|---|---|
| 1 | BERT baseline | 92.1% | 1 h 6 min |
| 2 | Modified-BERT | 93.84% | 1 h 2 min |
| 3 | Proposed stacked | 97.4% | 3 min 9 s |
| No | Model | Accuracy | Time Complexity |
|---|---|---|---|
| 1 | BERT baseline | 90.42 | 44 min 25 s |
| 2 | Modified-BERT | 91.98% | 41 min 23 s |
| 3 | Proposed stacked | 90.97% | 2 min 45 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Muneer, A.; Alwadain, A.; Ragab, M.G.; Alqushaibi, A. Cyberbullying Detection on Social Media Using Stacking Ensemble Learning and Enhanced BERT. Information 2023, 14, 467. https://doi.org/10.3390/info14080467
Muneer A, Alwadain A, Ragab MG, Alqushaibi A. Cyberbullying Detection on Social Media Using Stacking Ensemble Learning and Enhanced BERT. Information. 2023; 14(8):467. https://doi.org/10.3390/info14080467
Chicago/Turabian StyleMuneer, Amgad, Ayed Alwadain, Mohammed Gamal Ragab, and Alawi Alqushaibi. 2023. "Cyberbullying Detection on Social Media Using Stacking Ensemble Learning and Enhanced BERT" Information 14, no. 8: 467. https://doi.org/10.3390/info14080467
APA StyleMuneer, A., Alwadain, A., Ragab, M. G., & Alqushaibi, A. (2023). Cyberbullying Detection on Social Media Using Stacking Ensemble Learning and Enhanced BERT. Information, 14(8), 467. https://doi.org/10.3390/info14080467