


The Application of Z-Numbers in Fuzzy Decision Making: The State of the Art
 ,
, 
Abstract
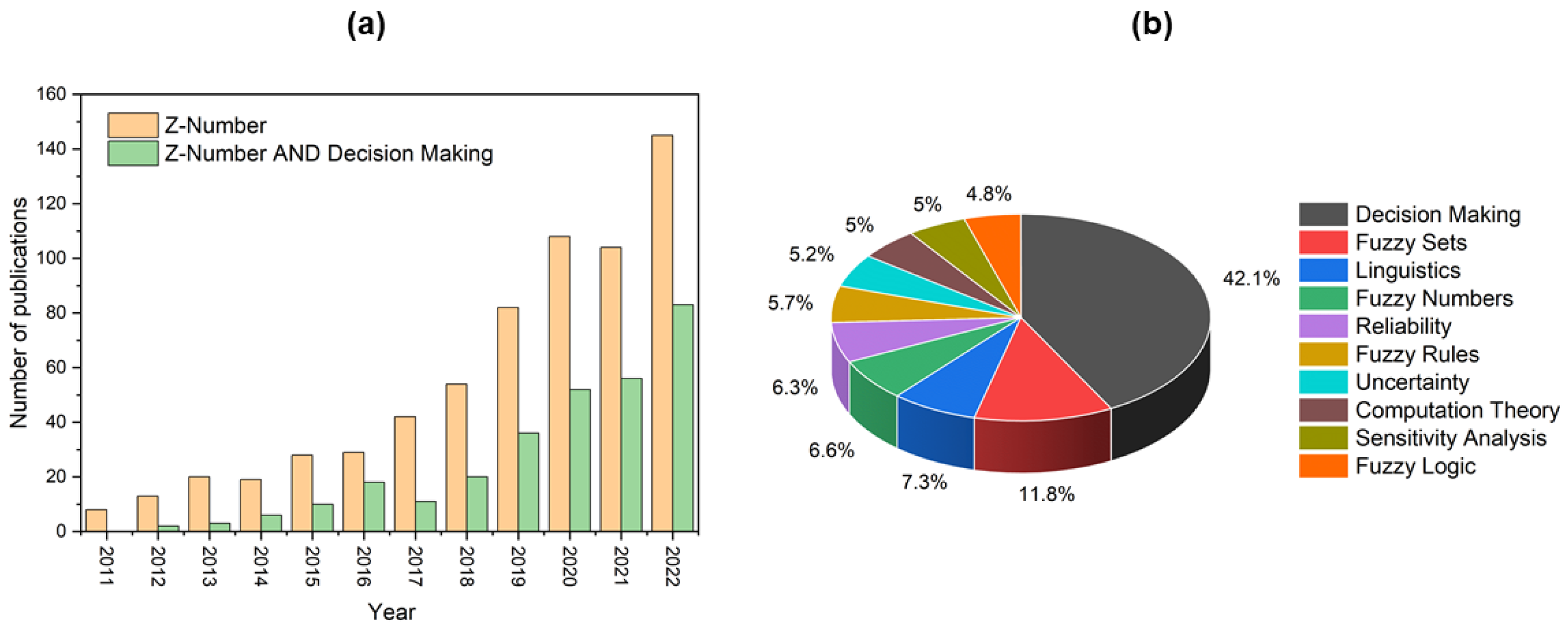
1. Introduction
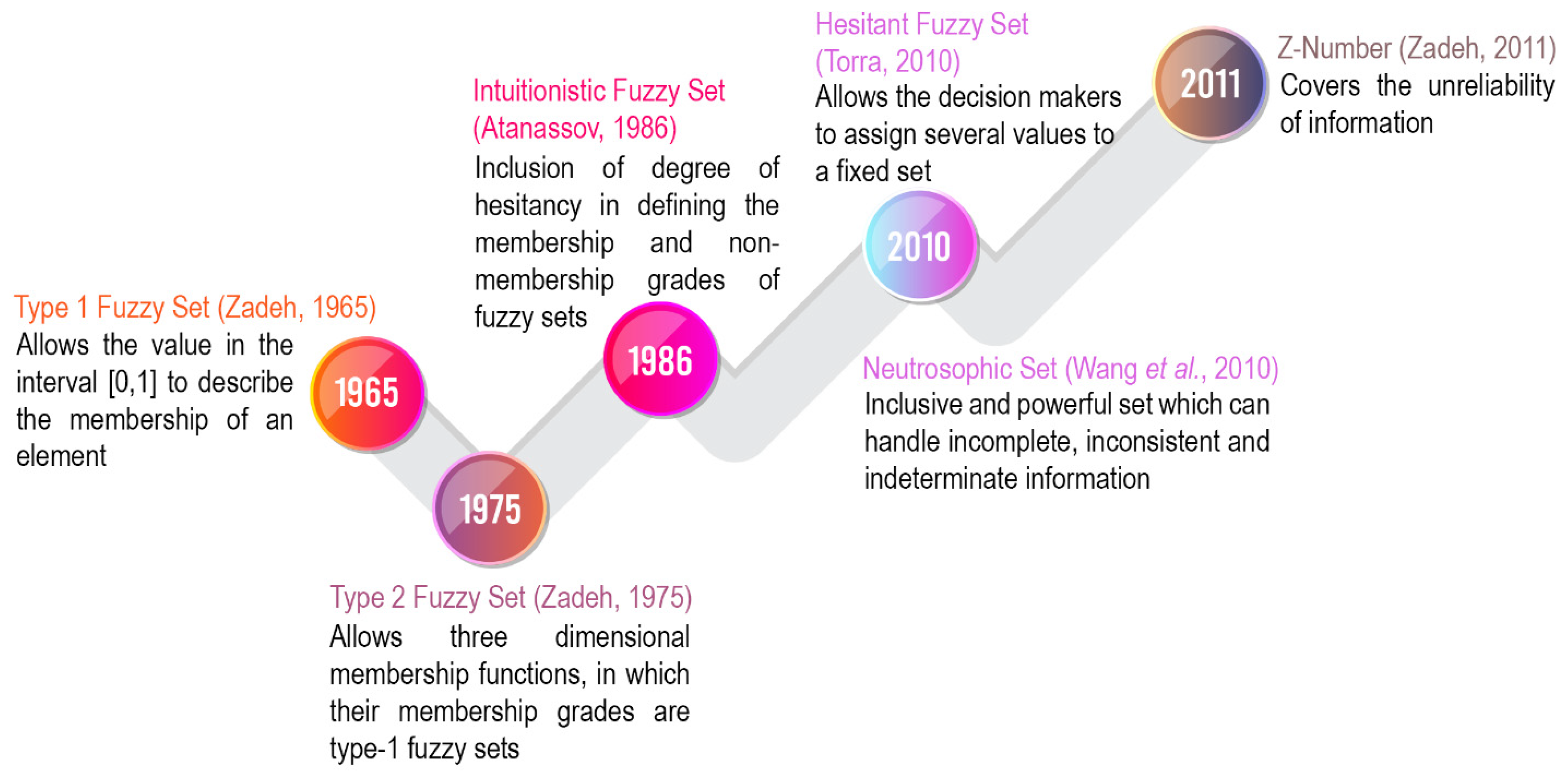
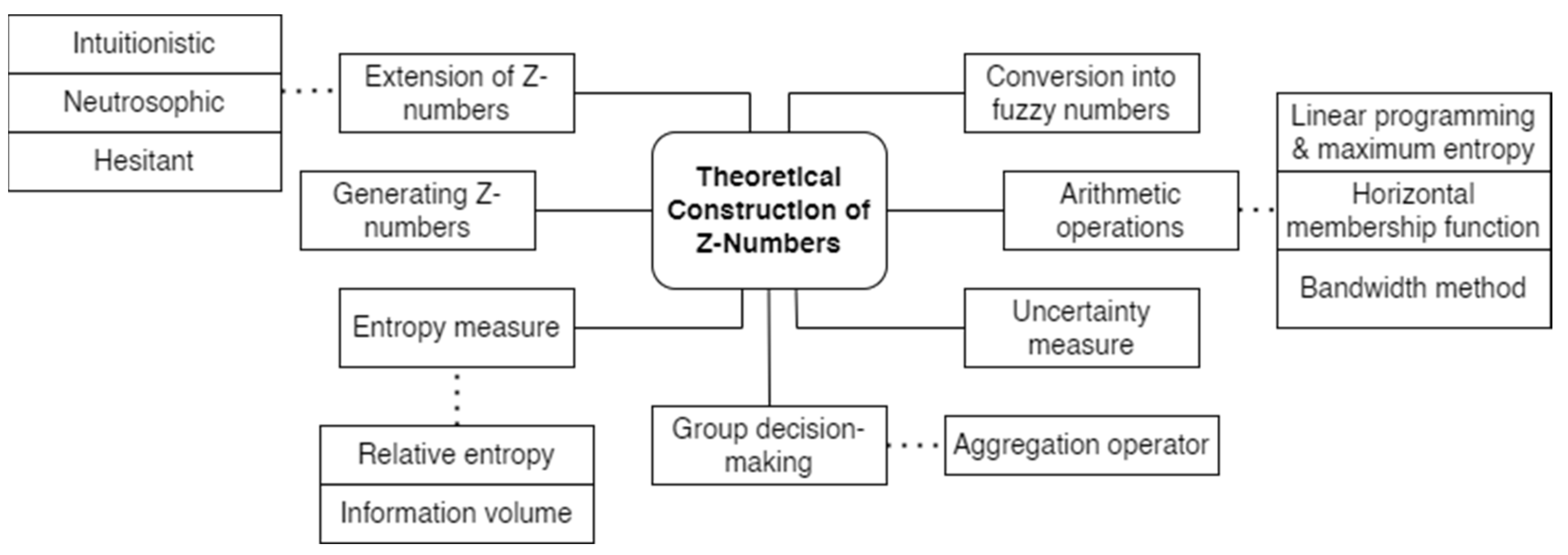
2. Theoretical Preliminaries
3. Decision-Making Methods and Approaches
4. Ranking Methods
4.1. Multiplication of Graded Mean Integration
4.2. Centroid Point and Spread
4.3. Centroid, Height, and Spread
4.4. Hyperbolic Tangent Function and Convex Combination
4.5. Sigmoid Function and Convex Combination
4.6. Value and Ambiguity
4.7. Magnitude Value
4.8. Momentum Ranking Function
4.9. Comparison of Ranking Methods
5. Evaluative Analysis
- The hybridization of more than one MCDM method using Z-numbers produced a better result [59]. When applied to MCDM models, the selection of alternatives is much better than the single MCDM model based on Z-numbers. In fact, the hybrid MCDM methods are designed to cancel out the drawbacks of their respective methods when used alone [103].
- The invention of software that can process decision information in the form of Z-numbers is vital to simplify mathematical calculation [14]. The availability of such software helps experts from other fields such as business, economy, finance, psychology, and education solve their problems that involve various attributes and alternatives.
- It is important to note that Z-numbers are not only composed of the restriction and reliability components, but the hidden probability distribution is another important concept regarding Z-numbers since it connects the restriction component to the reliability component [36].
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AHP | Analytic hierarchy process |
| CFPR | Consistent fuzzy preference relations |
| CODAS | Combinative distance-based assessment |
| COPRAS | Complex proportional assessment |
| CWW | Computing With Words |
| DE | Differential evolution |
| DEMATEL | Decision making trial and evaluation laboratory |
| DST | Dempster–Shafer theory |
| ELECTRE | Élimination et choix traduisant la realité |
| GA | Genetic algorithm |
| HEART | Human error assessment and reduction technique |
| IZN | Intuitionistic Z-number |
| MCDM | Multi-criteria decision making |
| MILP | Mixed integer linear programming |
| NL | Natural language |
| NZN | Neutrosophic Z-number |
| OWA | Ordered weighted averaging |
| PCA | Principle component analysis |
| PROMETHEE | Preference ranking for organization method for enrichment evaluation |
| SWOT | Strength, weakness, opportunity, and threat |
| TODIM | Tomada de decisao interativa multicriterio |
| TOPSIS | Technique for order of preferences by similarity to ideal solutions |
| VIKOR | Visekriterijumska optimizacija I kompromisno resenje |
| WASPAS | Weighted aggregated sum product assessment |
References
- Zadeh, L.A. Fuzzy Sets. Inf. Control. 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Zadeh, L.A. The Concept of a Linguistic Variable and Its Application to Approximate Reasoning-III. Inf. Sci. 1975, 9, 43–80. [Google Scholar] [CrossRef]
- Atanassov, K.T. Intuitionistic Fuzzy Sets. Fuzzy Sets Syst. 1986, 20, 87–96. [Google Scholar] [CrossRef]
- Torra, V. Hesitant Fuzzy Sets. Int. J. Intell. Syst. 2010, 29, 529–539. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, Y.; Sunderraman, R. Single Valued Neutrosophic Sets. Fuzzy Sets Rough Sets Multivalued Oper. Appl. 2011, 3, 33–39. [Google Scholar]
- Smarandache, F. A Unifying Field in Logics: Neutrosophic Logic, Neutrosophy, Neutrosophic Set, Neutrosophic Probability. Am. Res. Press 1999, 1–141. [Google Scholar]
- Aliev, R.A. Fundamentals of the Fuzzy Logic-Based Generalized Theory of Decisions; Springer: Berlin/Heidelberg, Germany, 2013; ISBN 9783642348945. [Google Scholar]
- Zadeh, L.A. Computing with Words and Perceptions-A Paradigm Shift. In Proceedings of the 2009 IEEE International Conference on Information Reuse & Integration, Las Vegas, CA, USA, 10–12 August 2009; IEEE: Piscataway, NJ, USA, 2009; pp. viii–x. [Google Scholar]
- Smets, P. Imperfect Information: Imprecision and Uncertainty. In Uncertainty Management in Information Systems; Springer: Boston, MA, USA, 1997; Volume 17, pp. 225–254. [Google Scholar]
- Aliev, R.A.; Guirimov, B.G.; Huseynov, O.H.; Aliyev, R.R. A Consistency-Driven Approach to Construction of Z-Number-Valued Pairwise Comparison Matrices. Iran. J. Fuzzy Syst. 2021, 18, 37–49. [Google Scholar]
- Liu, D.; Hu, C.; Guo, S.; Yu, J. Z-Number-Based Quantitative Expression of Activity Information in Uncertain Project Scheduling. J. Constr. Eng. Manag. 2022, 148, 1–10. [Google Scholar] [CrossRef]
- Zadeh, L.A. A Note on Z-Numbers. Inf. Sci. 2011, 181, 2923–2932. [Google Scholar] [CrossRef]
- Abdullahi, M.; Ahmad, T.; Ramachandran, V. A Review on Some Arithmetic Concepts of Z-Number and Its Application to Real-World Problems. Int. J. Inf. Technol. Decis. Mak. 2020, 19, 1091–1122. [Google Scholar] [CrossRef]
- Nuriyev, A.M. Fuzzy MCDM Models for Selection of the Tourism Development Site: The Case of Azerbaijan. F1000Research 2022, 11, 310. [Google Scholar] [CrossRef] [PubMed]
- Xu, B.; Deng, Y. Information Volume of Z-Number. Inf. Sci. 2022, 608, 1617–1631. [Google Scholar] [CrossRef]
- Banerjee, R.; Pal, S.K.; Pal, J.K. A Decade of the Z-Numbers. IEEE Trans. Fuzzy Syst. 2022, 30, 1. [Google Scholar] [CrossRef]
- Bilgin, F.; Alci, M. A Review on Ranking of Z-Numbers. J. Comput. Sci. Res. 2022, 4, 1–12. [Google Scholar] [CrossRef]
- Kang, B.; Wei, D.; Li, Y.; Deng, Y. A Method of Converting Z-Number to Classical Fuzzy Number. J. Inf. Comput. Sci. 2012, 9, 703–709. [Google Scholar]
- Shen, K.W.; Wang, J.Q. Z-VIKOR Method Based on a New Comprehensive Weighted Distance Measure of Z-Number and Its Application. IEEE Trans. Fuzzy Syst. 2018, 26, 3232–3245. [Google Scholar] [CrossRef]
- Gardashova, L.A. Z-Number Based TOPSIS Method in Multi-Criteria Decision Making; Springer International Publishing: Cham, Switzerland, 2019; Volume 896, ISBN 9783030041632. [Google Scholar]
- Aliev, R.A.; Huseynov, O.H.; Aliyev, R.R.; Alizadeh, A.A. The Arithmetic of Z-Numbers; World Scientific Publishing: Singapore, 2015; ISBN 9789814675284. [Google Scholar]
- Aliev, R.A.; Alizadeh, A.V.; Huseynov, O.H. An Introduction to the Arithmetic of Z-Numbers by Using Horizontal Membership Functions. Procedia Comput. Sci. 2017, 120, 349–356. [Google Scholar] [CrossRef]
- Aliev, R.A.; Huseynov, O.H.; Aliyev, R.R. A Sum of a Large Number of Z-Numbers. Procedia Comput. Sci. 2017, 120, 16–22. [Google Scholar] [CrossRef]
- Piegat, A.; Landowski, M. Is the Conventional Interval Arithmetic Correct ? J. Theor. Appl. Comput. Sci. 2012, 6, 27–44. [Google Scholar]
- Dubois, D.; Prade, H. A Fresh Look at Z-Numbers–Relationships with Belief Functions and p-Boxes. Fuzzy Inf. Eng. 2018, 10, 5–18. [Google Scholar] [CrossRef]
- Li, Y.; Garg, H.; Deng, Y. A New Uncertainty Measure of Discrete Z-Numbers. Int. J. Fuzzy Syst. 2020, 22, 760–776. [Google Scholar] [CrossRef]
- Li, Y.; Cabrerizo, F.J.; Herrera-Viedma, E.; Morente-Molinera, J.A. A Modified Uncertainty Measure of Z-Numbers. Int. J. Comput. Commun. Control. 2022, 17, 1–12. [Google Scholar] [CrossRef]
- Li, Y.; Pelusi, D.; Deng, Y.; Cheong, K.H. Relative Entropy of Z-Numbers. Inf. Sci. 2021, 581, 1–17. [Google Scholar] [CrossRef]
- Kang, B.; Deng, Y.; Hewage, K.; Sadiq, R. Generating Z-Number Based on OWA Weights Using Maximum Entropy. Int. J. Intell. Syst. 2018, 33, 1745–1755. [Google Scholar] [CrossRef]
- Yager, R.R.; Kacprzyk, J. The Ordered Weighted Averaging Operators: Theory and Applications; Springer Science & Business Media: New York, NY, USA, 1997; ISBN 978-0792399346. [Google Scholar]
- Tian, Y.; Kang, B. A Modified Method of Generating Z-Number Based on OWA Weights and Maximum Entropy. Soft Comput. 2020, 24, 15841–15852. [Google Scholar] [CrossRef]
- Aliev, R.R.; Huseynov, O.H.; Aliyeva, K.R. Z-Valued T-Norm and T-Conorm Operators-Based Aggregation of Partially Reliable Information. Procedia Comput. Sci. 2016, 102, 12–17. [Google Scholar] [CrossRef]
- Wang, F.; Mao, J. Approach to Multicriteria Group Decision Making with Z-Numbers Based on TOPSIS and Power Aggregation Operators. Math. Probl. Eng. 2019, 2019, 3014387. [Google Scholar] [CrossRef]
- Yager, R.R. The Power Average Operator. IEEE Trans. Syst. Man, Cybern. Part ASystems Humans. 2001, 31, 724–731. [Google Scholar] [CrossRef]
- Peng, H.G.; Wang, X.K.; Zhang, H.Y.; Wang, J.Q. Group Decision-Making Based on the Aggregation of Z-Numbers with Archimedean t-Norms and t-Conorms. Inf. Sci. 2021, 569, 264–286. [Google Scholar] [CrossRef]
- Cheng, R.; Zhu, R.; Tian, Y.; Kang, B.; Zhang, J. A Multi-Criteria Group Decision-Making Method Based on OWA Aggregation Operator and Z-Numbers. Soft Comput. 2022, 27, 1439–1455. [Google Scholar] [CrossRef]
- Yager, R.R. On the Fusion of Multiple Multi-Criteria Aggregation Functions with Focus on the Fusion of OWA Aggregations. Knowl. Based Syst. 2020, 191, 105216. [Google Scholar] [CrossRef]
- Qi, G.; Li, J.; Kang, B.; Yang, B. The Aggregation of Z-Numbers Based on Overlap Functions and Grouping Functions and Its Application on Group Decision-Making. Inf. Sci. 2022, 623, 857–899. [Google Scholar] [CrossRef]
- Abdullahi, M.; Ahmad, T.; Ramachandran, V. Ordered Discrete and Continuous Z-Numbers. Malays. J. Fundam. Appl. Sci. 2020, 16, 403–407. [Google Scholar] [CrossRef]
- Sari, I.U.; Kahraman, C. Intuitionistic Fuzzy Z-Numbers. In Intelligent and Fuzzy Techniques: Smart and Innovative Solutions, Proceedings of the INFUS 2020. Advances in Intelligent Systems and Computing, Istanbul, Turkey, 21–23 July 2020; Springer: Cham, Switzerland, 2021; pp. 1316–1324. ISBN 9783030511562. [Google Scholar]
- Du, S.; Ye, J.; Yong, R.; Zhang, F. Some Aggregation Operators of Neutrosophic Z-Numbers and Their Multicriteria Decision Making Method. Complex Intell. Syst. 2021, 7, 429–438. [Google Scholar] [CrossRef]
- Ye, J. Similarity Measures Based on the Generalized Distance of Neutrosophic Z-Number Sets and Their Multi-Attribute Decision Making Method. Soft Comput. 2021, 25, 13975–13985. [Google Scholar] [CrossRef]
- Roy, B. La Methode ELECTRE. Rev. d’Informatique et. Rech. Oper. 1968, 8, 57–75. [Google Scholar]
- Gabus, A.; Fontela, E. World Problems, An Invitation to Further Thought within The Framework of DEMATEL; Battelle Geneva Research Centre: Geneva, Switzerland, 1972. [Google Scholar]
- Saaty, T.L. The Analytic Hierarchy Process; McGraw-Hill: New York, NY, USA, 1980. [Google Scholar]
- Hwang, C.-L.; Yoon, K. Methods for Multiple Attribute Decision Making. In Multiple Attribute Decision Making; Springer: Berlin/Heidelberg, Germany, 1981; pp. 58–191. [Google Scholar]
- Brans, J.P.; Mareschal, B. Promethee V: Mcdm Problems with Segmentation Constraints. INFOR Inf. Syst. Oper. Res. 1992, 30, 85–96. [Google Scholar] [CrossRef]
- Opricovic, S. Multicriteria Optimization of Civil Engineering Systems. Ph.D. Thesis, Faculty of Civil Engineering, University of Belgrade, Belgrade, Serbia, 1998. [Google Scholar]
- Gomes, L.F.A.M.; Rangel, L.A.D. An Application of the TODIM Method to the Multicriteria Rental Evaluation of Residential Properties. Eur. J. Oper. Res. 2009, 193, 204–211. [Google Scholar] [CrossRef]
- Zavadskas, E.K.; Turskis, Z.; Antucheviciene, J.; Zakarevicius, A. Optimization of Weighted Aggregated Sum Product Assessment. Elektron. Elektrotechnika 2012, 122, 3–6. [Google Scholar] [CrossRef]
- Ghorabaee, M.K.; Zavadkas, E.K.; Turskis, Z.; Antucheviciene, J. A New Combinative Distance-Based Assessment (CODAS) Method for Multi-Criteria Decision-Making. Econ. Comput. Econ. Cybern. Stud. Res. 2016, 50, 25–44. [Google Scholar]
- Bellman, R.E.; Zadeh, L.A. Decision-Making in a Fuzzy Environment. Manage. Sci. 1970, 17, B-141. [Google Scholar] [CrossRef]
- Kang, B.; Wei, D.; Li, Y.; Deng, Y. Decision Making Using Z-Numbers under Uncertain Environment. J. Comput. Inf. Syst. 2012, 8, 2807–2814. [Google Scholar]
- Zeinalova, L.M. Expected Utility Based Decision Making Under Z-Information. Intell. Autom. Soft Comput. 2014, 20, 419–431. [Google Scholar] [CrossRef]
- Aliev, R.R.; Mraiziq, D.A.T.; Huseynov, O.H. Expected Utility Based Decision Making under Z-Information and Its Application. Comput. Intell. Neurosci. 2015, 2015, 364512. [Google Scholar] [CrossRef] [PubMed]
- Yaakob, A.M.; Gegov, A. Interactive TOPSIS Based Group Decision Making Methodology Using Z-Numbers. Int. J. Comput. Intell. Syst. 2016, 9, 311–324. [Google Scholar] [CrossRef]
- Babanli, M.B.; Huseynov, V.M. Z-Number-Based Alloy Selection Problem. Procedia Comput. Sci. 2016, 102, 183–189. [Google Scholar] [CrossRef]
- Aliev, R.A.; Alizadeh, A.V.; Huseynov, O.H. The Arithmetic of Discrete Z-Numbers. Inf. Sci. 2015, 290, 134–155. [Google Scholar] [CrossRef]
- Ku Khalif, K.M.N.; Gegov, A.; Abu Bakar, A.S. Hybrid Fuzzy MCDM Model for Z-Numbers Using Intuitive Vectorial Cntroid. J. Intell. Fuzzy Syst. 2017, 33, 791–805. [Google Scholar] [CrossRef]
- Forghani, A.; Sadjadi, S.J.; Moghadam, B.F. A Supplier Selection Model in Pharmaceutical Supply Chain Using PCA, Z-TOPSIS and MILP: A Case Study. PLoS ONE 2018, 13, e0201604. [Google Scholar] [CrossRef]
- Chatterjee, K.; Kar, S. A Multi-Criteria Decision Making for Renewable Energy Selection Using Z-Numbers in Uncertain Environment. Technol. Econ. Dev. Econ. 2018, 24, 739–764. [Google Scholar] [CrossRef]
- Wang, Y.M.; Yang, J.B.; Xu, D.L.; Chin, K.S. On the Centroids of Fuzzy Numbers. Fuzzy Sets Syst. 2006, 157, 919–926. [Google Scholar] [CrossRef]
- Zeinalova, L.M. A Z-Number Valued Analytical Hierarchy Process. Chem. Technol. Control Manag. 2018, 2018, 88–94. [Google Scholar] [CrossRef]
- Krohling, R.A.; Pacheco, A.G.C.; dos Santos, G.A. TODIM and TOPSIS with Z-Numbers. Front. Inf. Technol. Electron. Eng. 2019, 20, 283–291. [Google Scholar] [CrossRef]
- Aliev, R.A.; Pedrycz, W.; Huseynov, O.H.; Eyupoglu, S.Z. Approximate Reasoning on a Basis of Z-Number-Valued If-Then Rules. IEEE Trans. Fuzzy Syst. 2017, 25, 1589–1600. [Google Scholar] [CrossRef]
- Tüysüz, N.; Kahraman, C. CODAS Method Using Z-Fuzzy Numbers. J. Intell. Fuzzy Syst. 2020, 38, 1649–1662. [Google Scholar] [CrossRef]
- Kang, B.; Zhang, P.; Gao, Z.; Chhipi-Shrestha, G.; Hewage, K.; Sadiq, R. Environmental Assessment under Uncertainty Using Dempster–Shafer Theory and Z-Numbers. J. Ambient Intell. Humaniz. Comput. 2020, 11, 2041–2060. [Google Scholar] [CrossRef]
- Qiao, D.; Shen, K.W.; Wang, J.Q.; Wang, T. li Multi-Criteria PROMETHEE Method Based on Possibility Degree with Z-Numbers under Uncertain Linguistic Environment. J. Ambient Intell. Humaniz. Comput. 2020, 11, 2187–2201. [Google Scholar] [CrossRef]
- Jiang, W.; Xie, C.; Luo, Y.; Tang, Y. Ranking Z-Numbers with an Improved Ranking Method for Generalized Fuzzy Numbers. J. Intell. Fuzzy Syst. 2017, 32, 1931–1943. [Google Scholar] [CrossRef]
- Mahmoodi, A.H.; Sadjadi, S.J.; Sadi-Nezhad, S.; Soltani, R.; Sobhani, F.M. Linguistic Z-Number Weighted Averaging Operators and Their Application to Portfolio Selection Problem. PLoS ONE 2020, 15, e0227307. [Google Scholar] [CrossRef] [PubMed]
- Aliyev, R.R.; Adilova, N.E. Solution of Zadeh’s “Fast Way” Problem under z-Information. Adv. Intell. Syst. Comput. 2020, 1095 AISC, 86–92. [Google Scholar] [CrossRef]
- Jabbarova, K.; Alizadeh, A.V. Z-Decision Making in Human Resources Department. In Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2021; pp. 498–507. [Google Scholar]
- Aliev, R.A.; Guirimov, B.G.; Huseynov, O.H.; Aliyev, R.R. Country Selection Problem for Business Venturing in Z-Information Environment. Inf. Sci. 2022, 597, 230–243. [Google Scholar] [CrossRef]
- Ahmadov, S.A. Z+ − Number Based Alternatives Selection in Investment Problem. Lect. Notes Netw. Syst. 2022, 362 LNNS, 43–50. [Google Scholar] [CrossRef]
- Gardashova, L.A.; Salmanov, S. Using Z-Number-Based Information in Personnel Selection Problem. In Lecture Notes in Networks and Systems; Springer: Cham, Switzerland, 2022; Volume 362 LNNS, pp. 302–307. ISBN 9783030921262. [Google Scholar]
- Sergi, D.; Sari, U.I. Prioritization of Public Services for Digitalization Using Fuzzy Z-AHP and Fuzzy Z-WASPAS. Complex Intell. Syst. 2021, 7, 841–856. [Google Scholar] [CrossRef]
- Liu, Q.; Chen, J.; Wang, W.; Qin, Q. Conceptual Design Evaluation Considering Confidence Based on Z-AHP-TOPSIS Method. Appl. Sci. 2021, 11, 7400. [Google Scholar] [CrossRef]
- Wang, W.; Liu, X.; Liu, S. A Hybrid Evaluation Method for Human Error Probability by Using Extended DEMATEL with Z-Numbers: A Case of Cargo Loading Operation. Int. J. Ind. Ergon. 2021, 84, 103158. [Google Scholar] [CrossRef]
- Hu, Z.; Lin, J. An Integrated Multicriteria Group Decision Making Methodology for Property Concealment Risk Assessment under Z-Number Environment. Expert Syst. Appl. 2022, 205, 117369. [Google Scholar] [CrossRef]
- Peng, H.G.; Xiao, Z.; Wang, X.; Wang, J.; Li, J. Z-Number Dominance, Support and Opposition Relations for Multi-Criteria Decision-Making. Inf. Sci. 2022, 621, 437–457. [Google Scholar] [CrossRef]
- Azman, W.N.A.W.; Zamri, N.; Abas, S.S. A Hybrid Method with Fuzzy VIKOR and Z-Numbers for Decision Making Problems. In Lecture Notes in Networks and Systems; Springer: Cham, Switzerland, 2022; pp. 35–45. ISBN 9783031008283. [Google Scholar]
- Li, Y.; Rao, C.; Goh, M.; Xiao, X. Novel Multi-Attribute Decision-Making Method Based on Z-Number Grey Relational Degree. Soft Comput. 2022, 26, 13333–13347. [Google Scholar] [CrossRef]
- Nourani, V.; Najafi, H. A Z-Number Based Multi-Attribute Decision-Making Algorithm for Hydro-Environmental System Management. Neural Comput. Appl. 2022, 3, 6405–6421. [Google Scholar] [CrossRef]
- Jia, Q.; Herrera-Viedma, E. Pythagorean Fuzzy Sets to Solve Z-Numbers in Decision-Making Model. IEEE Trans. Fuzzy Syst. 2022, 31, 890–904. [Google Scholar] [CrossRef]
- Zamri, N.; Ahmad, F.; Rose, A.N.M.; Makhtar, M. A Fuzzy TOPSIS with Z-Numbers Approach for Evaluation on Accident at the Construction Site. In Recent Advances on Soft Computing and Data Mining, Proceedings of the International Conference on Soft Computing and Data Mining, Bandung, Indonesia, 18–20 August 2016; Springer: Cham, Switzerland, 2017; pp. 41–50. [Google Scholar]
- Awajan, K.Y.; Zamri, N. A Fuzzy TOPSIS with Z-Numbers Method for Assessment on Memorandum of Understanding at University. Int. J. Eng. Technol. 2018, 7, 149–152. [Google Scholar]
- Khalif, K.M.N.K.; Bakar, A.S.A.; Gegov, A. Z-Numbers Based TOPSIS Similarity Methodology for Company Performance Assessment in Malaysia. In Applying Fuzzy Logic for the Digital Economy and Society; Springer: Cham, Switzerland, 2019; pp. 97–113. [Google Scholar]
- Xiao, Z.Q. Application of Z-Numbers in Multi-Criteria Decision Making. In Proceedings of the 2014 International Conference on Informative and Cybernetics for Computational Social Systems (ICCSS), Qingdao, China, 9–10 October 2014; pp. 91–95. [Google Scholar] [CrossRef]
- Ahmad, N.; Yaakob, A.M.; Gegov, A.; Kasim, M.M. Integrating Fuzzy AHP and Z-TOPSIS for Supplier Selection in an Automotive Manufacturing Company. AIP Conf. Proc. 2019, 2138, 030003. [Google Scholar] [CrossRef]
- Zamri, N.; Ibrahim, A.K.Y. A Combined of Fuzzy TOPSIS with Z-Number and Alpha-Cut for Decision Making Problems. Advances in Visual Informatics. In Proceedings of the 6th International Visual Informatics Conference, IVIC 2019, Bangi, Malaysia, 19–21 November 2019; Volume 11870 LNCS, pp. 245–256. [Google Scholar] [CrossRef]
- Tao, R.; Xiao, F. A GMCDM Approach with Linguistic Z-Numbers Based on TOPSIS and Choquet Integral Considering Risk Preference. J. Intell. Fuzzy Syst. 2020, 39, 4285–4298. [Google Scholar] [CrossRef]
- Abu Bakar, A.S.; Gegov, A. Multi-Layer Decision Methodology for Ranking Z-Numbers. Int. J. Comput. Intell. Syst. 2015, 8, 395–406. [Google Scholar] [CrossRef]
- Mohamad, D.; Shaharani, S.A.; Kamis, N.H. Ordering of Z-Numbers. AIP Conf. Proc. 2017, 1870, 040049. [Google Scholar] [CrossRef]
- Kang, B.; Deng, Y.; Sadiq, R. Total Utility of Z-Number. Appl. Intell. 2018, 48, 703–729. [Google Scholar] [CrossRef]
- Ezadi, S.; Allahviranloo, T. New Multi-Layer Method for z-Number Ranking Using Hyperbolic Tangent Function and Convex Combination. Intell. Autom. Soft Comput. 2018, 24, 217–221. [Google Scholar] [CrossRef]
- Ezadi, S.; Allahviranloo, T.; Mohammadi, S. Two New Methods for Ranking of Z-Numbers Based on Sigmoid Function and Sign Method. Int. J. Intell. Syst. 2018, 33, 1476–1487. [Google Scholar] [CrossRef]
- Chutia, R. Ranking of Z-Numbers Based on Value and Ambiguity at Levels of Decision Making. Int. J. Intell. Syst. 2020, 36, 313–331. [Google Scholar] [CrossRef]
- Delgado, M.; Vila, M.A.; Voxman, W. On a Canonical Representation of Fuzzy Numbers. Fuzzy Sets Syst. 1998, 93, 125–135. [Google Scholar] [CrossRef]
- Chutia, R.; Chutia, B. A New Method of Ranking Parametric Form of Fuzzy Numbers Using Value and Ambiguity. Appl. Soft Comput. J. 2017, 52, 1154–1168. [Google Scholar] [CrossRef]
- Farzam, M.; Kermani, M.A.; Allahviranloo, T.; Belaghi, M.J.S. A New Method for Ranking of Z-Numbers Based on Magnitude Value. In Progress in Intelligent Decision Science. IDS 2020. Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2021; pp. 841–850. [Google Scholar]
- Parameswari, K.; Velammal, G. Momentum Ranking Function of Z-Numbers and Its Application to Game Theory. Baghdad Sci. J. 2023, 20, 305–310. [Google Scholar] [CrossRef]
- Lee, E.S.; Li, R.-J. Comparison of Fuzzy Numbers Based on the Probability Measure of Fuzzy Events. Comput. Math. Appl. 1988, 15, 887–896. [Google Scholar] [CrossRef]
- Ng, P.S.; Ignatius, J.; Goh, M.; Rahman, A.; Zhang, F. The State of the Art in FAHP in Risk Assessment. In Fuzzy Analytic Hierarchy Process; Taylor & Francis: Boca Raton, FL, USA, 2018; pp. 11–44. ISBN 9781498732482. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Method | Contribution |
|---|---|---|
| [43] | ELECTRE | The ranking of alternatives is done by selecting the best one in which the low-attractive alternatives are eliminated. |
| [44] | DEMATEL | Describes the interrelations among the attributes that can be partitioned into a cause group and an effect group. |
| [45] | AHP | The evaluation of decision-makers is performed using a pairwise comparison matrix. |
| [46] | TOPSIS | The prioritization of alternatives is based on the distance measure from the positive and negative ideal solutions. |
| [47] | PROMETHEE | An outranking method that allows the pairwise comparison of alternatives, in which they are being evaluated according to different criteria, which have to be maximized or minimized. |
| [48] | VIKOR | The ranking and selection from a set of alternatives that allows for the determining of the compromise solutions when there are conflicting criteria. |
| [49] | TODIM | The evaluation of alternatives is based on the dominance degree of each alternative over other alternatives using the overall value. |
| [50] | WASPAS | The ranking of alternatives is determined based on the utility value using the additive and multiplicative relative importance. |
| [51] | CODAS | The best alternative is determined based on the maximum distances from the negative ideal solution. |
| Reference | Method | Processing of Z-Numbers | Ranking of Alternatives | Application | Advantage | Disadvantage |
|---|---|---|---|---|---|---|
| [56] | TOPSIS | Conversion using fuzzy expectation | Euclidean distance between fuzzy numbers | Stock selection problem | Simplified the calculation on Z-numbers | Loss of information |
| [59] | CFPR-TOPSIS | Conversion using intuitive multiple centroid | Euclidean distance from vertical and horizontal centroids | Staff recruitment selection | Improved the method of determining the vertical and horizontal centroids | The reduction of Z-numbers into regular fuzzy numbers does not keep the initial information |
| [60] | PCA-TOPSIS-MILP | Conversion using fuzzy expectation | Distance between fuzzy numbers | Supplier selection in the pharmaceutical supply chain | The integration of PCA reduced the number of criteria | The conversion of Z-numbers leads to a loss of information |
| [61] | COPRAS | Conversion using centroid of triangular fuzzy number | Relative significance and utility degree | Prioritization of renewable energy resources | The combination of subjective weights from decision-makers and objective weights using Shannon entropy | The conversion of reliability parts into centroid leads to the dissipation of information |
| [63] | AHP | Direct calculation on discrete Z-numbers | Pairwise comparison and Pareto optimality principle | Selection of technical institutions | The preservation of information of Z-numbers as no conversion into regular fuzzy numbers was involved | The calculation of hidden probability is tedious |
| [19] | VIKOR | Direct computation of discrete Z-numbers | Hellinger distance of Z-numbers | Selection of regional circular economy development plan | The inclusion of reliability measure and underlying probability distribution in determining the weighted distance of Z-numbers give a more precise measure | Complicated and tedious calculation to solve simple problems |
| [64] | TODIM | Conversion using centroid of trapezoidal fuzzy number | Dominance of alternative over each alternative | Vehicle selection and clothing evaluation | The dominance of alternative over other alternatives is checked one by one | The consideration of centroid of reliability in the conversion dissipates some information |
| [33] | TOPSIS | Paired calculation on restriction and reliability components separately | Weighted paired distance of restriction and reliability components | Supplier selection in an automobile manufacturing company | The weight coefficients of decision makers are obtained via a programming model and the implementation of power aggregation operators in combining the decisions from all decision makers | The final relative closeness coefficient is in pairs of restriction and reliability components, which requires a further approach to combine them |
| [66] | CODAS | Conversion of Z-numbers using center of gravity defuzzification | Euclidean and Taxicab distances of regular fuzzy numbers | Supplier selection problem | The calculation of relative assessment scores based on Euclidean and Taxicab distances | The defuzzification of reliability parts via center of gravity leads to a loss of information |
| [68] | PROMETHEE | Possibility degree of Z-numbers is calculated by combining the restriction and reliability components using a convex compound | Priority index and outgoing and incoming flows | Travel plan selection | The possibility degree of Z-numbers and outranking relations do not involve the conversion of Z-numbers into regular fuzzy numbers | Priority index matrix can only be obtained when the possibility degrees of an alternative over each of the other alternatives are obtained; this is not practical when there are too many alternatives |
| [76] | AHP-WASPAS | Conversion of Z-numbers using center of gravity defuzzification | Utility score combining the weighted sum and product of fuzzy numbers | Prioritization of public services for digitalization | The consideration of weighted sum and product of fuzzy numbers in the utility score can determine the rank of alternatives effectively | The conversion of Z-numbers into regular fuzzy numbers dissipates some information |
| [77] | AHP-TOPSIS | Conversion using fuzzy expectation | Euclidean distance between fuzzy numbers | Conceptual design evaluation of kitchen waste containers | The simplification of the fuzzy TOPSIS method based on Z-numbers based on conversion into regular fuzzy numbers | Loss of information |
| [28] | TOPSIS | The relative entropy of Z-numbers | Relative entropy from the positive and negative ideal solutions | Supplier selection problem | The determination of the underlying probability distributions gives a more precise measure of the reliability components | The consideration of the underlying probability distributions in finding the entropy of Z-numbers made the calculation more tedious |
| [79] | ELECTRE-III | Defuzzification of reliability components into centroid of gravity | Credibility index of fuzzy outranking relation | Property concealment risk ranking | The expert-weight-determining method is introduced in this paper based on group consistency and reliability | The dissipation of information occurs when the reliability components of Z-numbers are defuzzified |
| [80] | ELECTRE-III | Bimodal uncertainty of Z-numbers without conversion into regular fuzzy numbers | Dominance, support, and opposition relations based on Z-numbers | Renewable energy selection problem | The outranking relations based on bimodal uncertainty of Z-numbers have a stronger role in ranking alternatives effectively | The tedious calculation involving the underlying probability of the reliability components despite solving simpler problems |
| [81] | VIKOR | The defuzzification of Z-numbers after obtaining the fuzzy best and worst values | The separation measures from the fuzzy best and worst values | Supplier selection in the pharmaceutical supply chain | The ranking approach based on fuzzy best value and fuzzy worst value can effectively prioritize the alternatives | The defuzzification of the separation measures of the restriction and reliability components dissipates some information before the final ratings are obtained |
| References | Type of Z-Numbers | Approach | Applications |
|---|---|---|---|
| [56] | Continuous trapezoidal | Conversion of Z-numbers using fuzzy expectation | Selection of stock company |
| [85] | Continuous triangular | Pairwise closeness coefficients of restriction and reliability components | Accident on a construction site by a worker |
| [86] | Continuous triangular | Pairwise closeness coefficients of restriction and reliability components | Selection of agreement from the MoU |
| [60] | Continuous triangular | Conversion of Z-numbers using fuzzy expectation | Supplier selection in a pharmaceutical company |
| [87] | Continuous trapezoidal | Conversion of Z-numbers using intuitive vectorial centroid | Company performance assessment |
| [33] | Continuous triangular | Pairwise closeness coefficients of restriction and reliability components | Supplier selection in the automobile manufacturing industry |
| [64] | Continuous triangular | Conversion of Z-numbers using fuzzy expectation | Vehicle selection [53] and clothing evaluation by male customers [88] |
| [20] | Continuous trapezoidal | Direct calculation on Z-numbers | Vehicle selection [53] |
| [89] | Continuous triangular | Conversion of Z-numbers using fuzzy expectation | Supplier selection in the automobile manufacturing industry |
| [90] | Continuous triangular | Pairwise closeness coefficients of restriction and reliability components | Engineer selection in a software company |
| [91] | Continuous triangular | Choquet integral-based distance | Supplier selection in an enterprise |
| Continuous triangular | Conversion of Z-numbers using fuzzy expectation | Evaluation of the conceptual design of waste containers | |
| [28] | Discrete | Underlying probability distributions and relative entropy of Z-numbers | Supplier selection |
| Reference | Method | Limitation |
|---|---|---|
| [55] | Fuzzy Pareto optimality | - |
| [92] | Spread, horizontal centroid, vertical centroid | Conversion of Z-numbers into regular fuzzy numbers |
| [93] | Mean, height, and spread | Conversion of Z-numbers into regular fuzzy numbers |
| [69] | Centroid, spread, and Minkowski degree of fuzziness | - |
| [94] | Total utility of Z-numbers | Involves double conversion from Z-numbers to fuzzy numbers and further converted into crisps |
| [95] | Hyperbolic tangent function and convex combination | Conversion of Z-numbers into regular fuzzy numbers |
| [96] | Sigmoid function and convex combination | Conversion of Z-numbers into regular fuzzy numbers |
| [97] | Value and ambiguity | The ignorance of the ambiguity index when the value index is not unique |
| [100] | Magnitude value | The magnitude could not make a difference on Z-numbers having similar central points with different spreads |
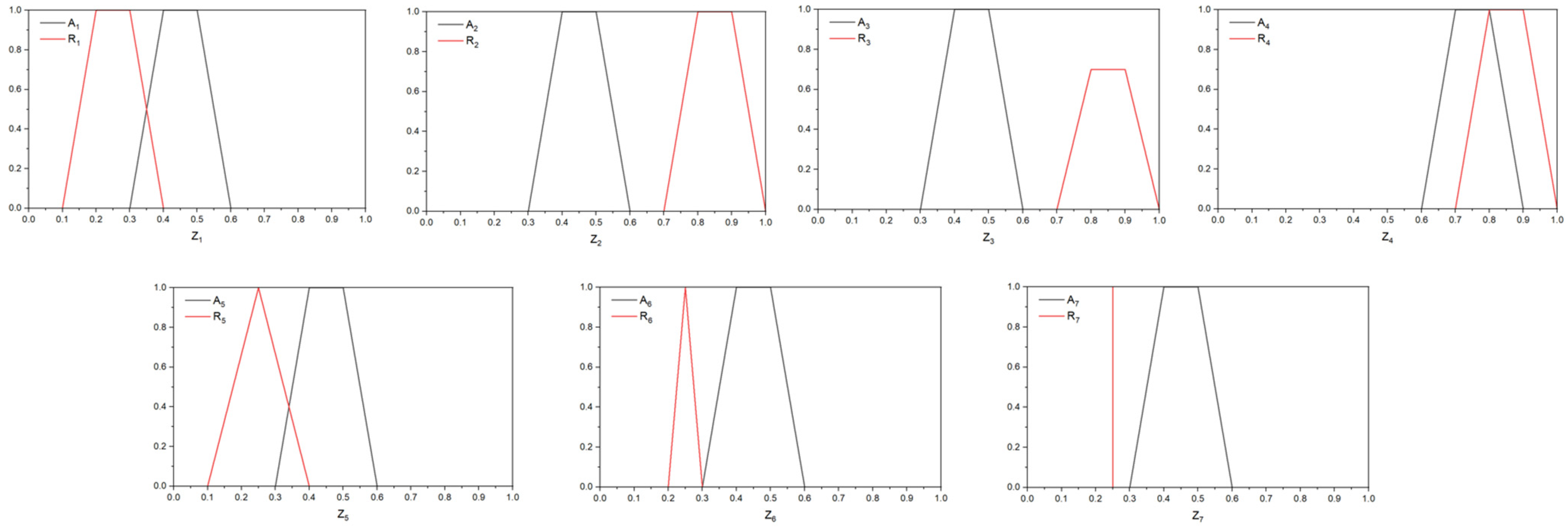
| Z-Number | Ranking Approaches | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Z | A | R | [53] | [92] | [93] | [95] | [96] | [97] | [100] | [101] |
| Z1 | (0.3,0.4,0.5,0.6;1) | (0.1,0.2,0.3,0.4;1) | 0.1125 | 0.1641 | 0.1012 | 0.2642 | 0.5672 | 0.2945 | 0.3500 | 0.1125 |
| Z2 | (0.3,0.4,0.5,0.6;1) | (0.7,0.8,0.9,1.0;1) | 0.3825 | 0.1641 | 0.3440 | 0.4935 | 0.6320 | 0.4525 | 0.6500 | 0.3825 |
| Z3 | (0.3,0.4,0.5,0.6;1) | (0.7,0.8,0.9,1.0;0.7) | 0.3825 | 0.1641 | 0.3440 | 0.4935 | 0.6320 | 0.2984 | 0.5863 | 0.3825 |
| Z4 | (0.6,0.7,0.8,0.9;1) | (0.7,0.8,0.9,1.0;1) | 0.6375 | 0.2734 | 0.4829 | 0.6616 | 0.6890 | 0.5883 | 0.8000 | 0.6375 |
| Z5 | (0.3,0.4,0.5,0.6;1) | (0.1,0.25,0.25,0.4;1) | 0.1125 | 0.1641 | 0.1012 | 0.2642 | 0.5672 | 0.2945 | 0.3500 | 0.1125 |
| Z6 | (0.3,0.4,0.5,0.6;1) | (0.2,0.25,0.25,0.3;1) | 0.1125 | 0.1641 | 0.1012 | 0.2642 | 0.5672 | 0.2945 | 0.3500 | 0.1125 |
| Z7 | (0.3,0.4,0.5,0.6;1) | (0.25,0.25,0.25,0.25;1) | 0.1125 | 0.1641 | 0.1012 | 0.2642 | 0.5672 | 0.2945 | 0.3500 | 0.1125 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alam, N.M.F.H.N.B.; Ku Khalif, K.M.N.; Jaini, N.I.; Gegov, A. The Application of Z-Numbers in Fuzzy Decision Making: The State of the Art. Information 2023, 14, 400. https://doi.org/10.3390/info14070400
Alam NMFHNB, Ku Khalif KMN, Jaini NI, Gegov A. The Application of Z-Numbers in Fuzzy Decision Making: The State of the Art. Information. 2023; 14(7):400. https://doi.org/10.3390/info14070400
Chicago/Turabian StyleAlam, Nik Muhammad Farhan Hakim Nik Badrul, Ku Muhammad Naim Ku Khalif, Nor Izzati Jaini, and Alexander Gegov. 2023. "The Application of Z-Numbers in Fuzzy Decision Making: The State of the Art" Information 14, no. 7: 400. https://doi.org/10.3390/info14070400
APA StyleAlam, N. M. F. H. N. B., Ku Khalif, K. M. N., Jaini, N. I., & Gegov, A. (2023). The Application of Z-Numbers in Fuzzy Decision Making: The State of the Art. Information, 14(7), 400. https://doi.org/10.3390/info14070400