
Intent Classification by the Use of Automatically Generated Knowledge Graphs

 , , , , , ,
, , , , , ,  and
and
Abstract
1. Introduction
2. Related Work
3. Experimental Setup
3.1. Saffron—Knowledge Extraction Framework
3.2. Knowledge Graph Embeddings
3.3. Pre-Trained Word and Sentence Embeddings
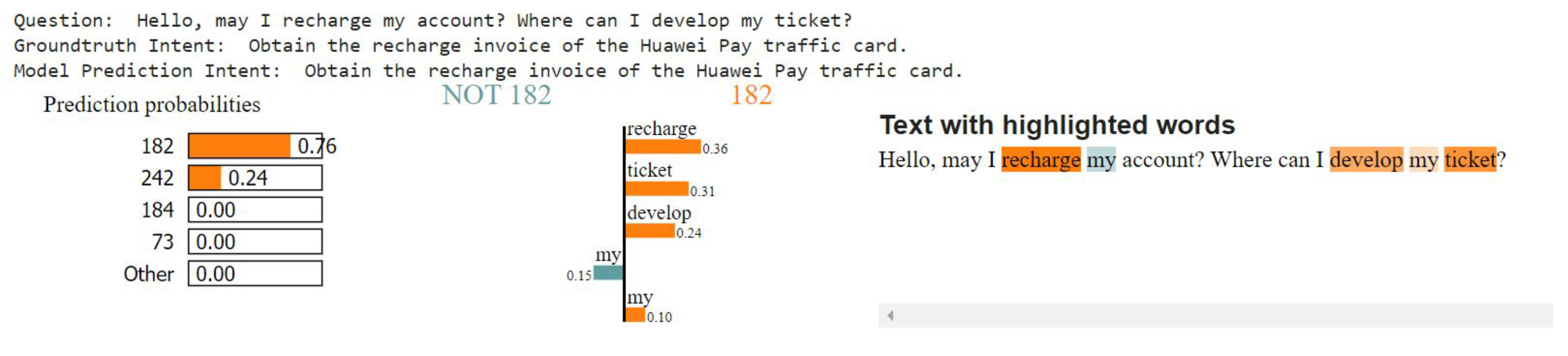
3.4. LIME
3.5. Significance Testing
3.6. Data Sets
4. Methodology
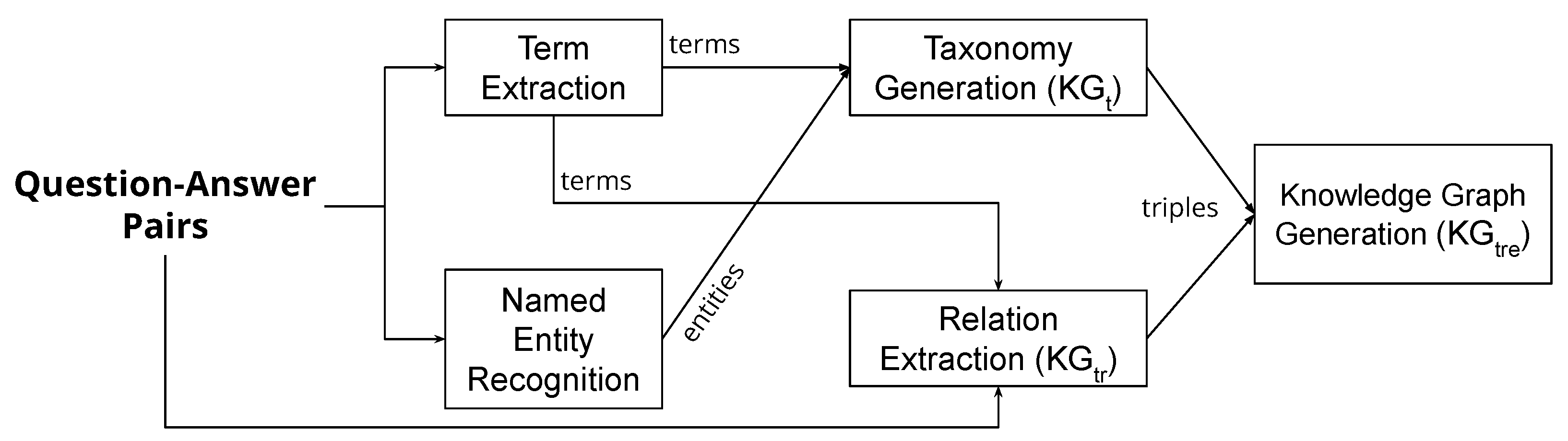
4.1. Knowledge Graph Creation Pipeline
4.1.1. Term Extraction
4.1.2. Named Entity Recognition
4.1.3. Taxonomy Generation
4.1.4. Relation Extraction
4.1.5. Knowledge Graph Generation
4.2. Intent Classification with Pre-Trained and Knowledge Graph Embeddings
4.3. Filtering Knowledge Graphs with LIME
4.4. Intent Classification on Intents Translated into English
4.5. Manual Evaluation of KGs
5. Results
5.1. Intent Classification with Recurrent Neural Networks
5.2. Siamese Network
5.3. Filtering Knowledge Graphs Using LIME
5.3.1. Filtering for Intent Classification with Recurrent Neural Networks

{kind=link}
{kind=link}
| ComQA | KG | KG | KG | KG | KG | KG | KG | KG | KG | |||||||||
| Data Set | (100) | (500) | (750) | (100) | (500) | (750) | (100) | (500) | (750) | |||||||||
| Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | |
| Embeddings | 183 | 86 | 873 | 315 | 1246 | 392 | 416 | 115 | 1272 | 347 | 1681 | 425 | 1510 | 327 | 2767 | 590 | 4133 | 628 |
| LASER+KG | 89.74 | 89.10 | 91.54 | 90.26 | 90.49 | 90.49 | 90.03 | 90.67 * | 90.26 | 90.72 | 89.33 | 90.90 | 91.48 | 91.13 | 89.74 | 89.74 | 89.22 | 89.45 |
| LASER+SBERT+KG | 94.38 | 94.84 | 95.07 | 95.25 | 95.19 | 94.67 | 95.77 | 95.65 | 94.96 | 95.36 | 94.67 | 95.25 * | 94.78 | 95.30 | 94.78 | 95.48 | 94.78 | 94.61 |
| LASER+MPNet+KG | 94.84 | 95.19 | 95.19 | 94.90 | 94.72 | 94.26 | 95.13 | 94.61 | 94.03 | 94.61 * | 93.91 | 93.91 | 94.49 | 94.38 | 92.93 | 93.39 | 93.16 | 94.20 |
| ParaLex | KG | KG | KG | KG | KG | KG | KG | KG | KG | |||||||||
| Data Set | (100) | (500) | (750) | (100) | (500) | (750) | (100) | (500) | (750) | |||||||||
| Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | |
| Embeddings | 169 | 70 | 785 | 262 | 1116 | 313 | 343 | 100 | 1156 | 313 | 1473 | 343 | 641 | 138 | 1445 | 340 | 1816 | 388 |
| LASER+KG | 54.04 | 53.57 | 54.39 | 54.22 | 54.72 | 55.14 * | 53.94 | 54.15 | 54.74 | 55.14 | 54.48 | 54.62 * | 54.39 | 54.29 | 54.34 | 55.09 | 54.08 | 55.33 |
| LASER+SBERT+KG | 54.25 | 54.08 | 54.76 | 55.11 | 54.48 | 54.27 | 54.04 | 54.11 | 54.43 | 54.41 | 55.00 | 54.48 | 53.92 | 54.46 | 54.55 | 54.69 | 55.23 | 55.14 |
| LASER+MPNet+KG | 54.48 | 54.20 | 55.40 | 54.83 | 54.81 | 54.53 | 53.89 | 53.73 | 55.07 | 55.47 | 55.16 | 55.16 | 54.41 | 54.69 | 54.95 | 54.67 | 55.21 | 55.16 |
| ProductServiceQA Data Set | KG | KG | KG | |||||||||||||||
| Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | |||||||||||||
| Embeddings | Dimension | 136 | 34 | 494 | 129 | 1280 | 286 | |||||||||||
| LASER+KG | 1324 | 63.64 | 63.51 | 63.16 | 62.42 | 63.42 | 63.16 | |||||||||||
| LASER+SBERT+KG | 2092 | 68.50 | 68.46 | 68.76 | 68.37 | 67.89 | 68.86 | |||||||||||
| LASER+MPNet+KG | 2092 | 69.60 | 68.94 | 69.03 | 69.16 | 68.77 | 68.16 | |||||||||||
5.3.2. Filtering for Intent Classification with Siamese Networks
| ComQA | KG | KG | KG | KG | KG | KG | KG | KG | KG | |||||||||
| Data Set | (100) | (500) | (750) | (100) | (500) | (750) | (100) | (500) | (750) | |||||||||
| Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | |
| Embeddings | 183 | 86 | 873 | 315 | 1246 | 392 | 416 | 115 | 1272 | 347 | 1681 | 425 | 1510 | 327 | 2767 | 590 | 4133 | 628 |
| SBERT+KG | 94.96 | 94.67 | 94.43 | 94.78 | 94.78 | 94.90 | 94.78 | 95.13 | 94.31 | 94.78 | 94.78 | 94.55 | 94.78 | 95.13 | 94.32 | 94.78 | 94.78 | 94.55 |
| SBERT+LASER+KG | 95.13 | 94.49 | 94.55 | 95.25 * | 94.60 | 94.84 | 94.78 | 94.96 | 94.55 | 94.55 | 94.95 | 94.66 | 94.14 | 94.61 | 93.80 | 94.32 | 92.93 | 92.12 |
| MPNet+KG | 95.13 | 98.63 * | 94.49 | 94.38 | 92.86 | 93.28 | 94.49 | 94.72 | 94.03 | 94.32 | 92.34 | 92.35 | 94.49 | 94.72 | 94.03 | 94.32 | 92.35 | 92.35 |
| MPNet+LASER+KG | 95.02 | 89.62 | 94.43 | 94.49 | 92.92 | 93.28 | 94.14 | 94.61 | 93.79 | 94.32 | 92.92 | 92.12 | 94.14 | 94.61 | 93.80 | 94.32 | 92.93 | 92.12 |
| ParaLex | KG | KG | KG | KG | KG | KG | KG | KG | KG | |||||||||
| Data Set | (100) | (500) | (750) | (100) | (500) | (750) | (100) | (500) | (750) | |||||||||
| Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | |
| Embeddings | 169 | 70 | 785 | 262 | 1116 | 313 | 343 | 100 | 1156 | 313 | 1473 | 343 | 641 | 138 | 1445 | 340 | 1816 | 388 |
| SBERT+KG | 49.26 | 48.59 | 48.82 | 48.43 | 49.49 | 49.53 | 48.93 | 49.13 | 49.43 | 50.23 | 49.31 | 50.42 | 49.30 | 50.14 * | 50.59 | 50.54 | 49.91 | 49.91 |
| SBERT+LASER+KG | 49.17 | 48.94 | 49.52 | 48.59 | 49.17 | 49.86 | 48.65 | 48.83 | 49.28 | 50.40 | 49.35 | 50.28 | 52.72 | 52.04 | 53.66 | 53.10 | 52.77 | 52.44 |
| MPNet+KG | 52.29 | 50.35 | 51.21 | 52.11 | 51.54 | 52.28 | 50.18 | 52.16 | 50.55 | 52.79 | 51.86 | 54.48 * | 52.89 | 52.63 | 53.14 | 53.07 | 52.79 | 52.60 |
| MPNet+LASER+KG | 51.49 | 50.54 | 50.97 | 52.42 | 50.57 | 52.46 | 50.86 | 53.26 | 51.04 | 52.58 | 51.75 | 53.87 | 52.72 | 52.04 | 53.66 | 53.10 | 52.77 | 52.44 |
| ProductServiceQA | KG | KG | KG | |||||||||||||||
| Orig. | Filt. | Orig. | Filt. | Orig. | Filt. | |||||||||||||
| Embeddings | Dimension | 136 | 34 | 494 | 129 | 1280 | 286 | |||||||||||
| SBERT+KG | 1068 | 73.51 | 73.23 | 73.77 | 73.67 | 73.73 | 73.67 | |||||||||||
| SBERT+LASER+KG | 2092 | 73.16 | 73.06 | 74.08 | 74.06 | 73.07 | 73.36 | |||||||||||
| MPNet+KG | 1068 | 73.64 | 73.80 | 74.37 | 74.50 | 73.59 | 73.45 | |||||||||||
| MPNet+LASER+KG | 2092 | 73.81 | 73.49 | 73.77 | 73.14 | 73.29 | 73.49 | |||||||||||
5.4. Multilingual Setting
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
| SOTA Embeddings | Dim. | Prec. | Best Embeddings with KG | Dim. | Prec. | |||||||
| SBERT | 768 | 98.36 | LASER+SBERT+KG (500) | 2092 | 99.45 | |||||||
| LASER | 1024 | 96.75 | LASER+MPNet+KG (750) | 2092 | 99.45 | |||||||
| MPNet | 768 | 98.63 | LASER+SBERT+KG (750)/GloVe | 2092 | 99.45 | |||||||
| LASER+SBERT | 1792 | 98.28 | ||||||||||
| LASER+SBERT+GloVe | 2092 | 98.63 | ||||||||||
| KG | KG | KG | KG | KG | KG | KG | KG | KG | ||||
| Embeddings with KG | Dim. | (100) | (500) | (750) | (100) | (500) | (750) | (100) | (500) | (750) | DBpedia | |
| KG | 300 | 40.71 | 75.41 | 86.89 | 45.08 | 75.13 | 83.61 | 79.96 | 84.70 | 93.34 | 14.92 | |
| Concat. | LASER+KG | 1324 | 95.35 | 95.62 | 95.08 | 95.63 | 95.08 | 95.08 | 95.90 | 95.90 | 95.63 | 96.17 |
| LASER+SBERT+KG | 2092 | 98.90 | 99.18 | 99.45 | 98.91 | 98.63 | 98.63 | 98.36 | 98.63 | 98.91 | 98.91 | |
| LASER+MPNet+KG | 2092 | 99.18 | 99.45 | 98.09 | 98.91 | 98.36 | 98.63 | 98.09 | 98.63 | 98.36 | 98.36 | |
| Substit. | LASER+KG/GloVe | 1324 | 94.81 | 94.54 | 95.36 | 94.81 | 93.72 | 94.26 | 95.36 | 96.72 | 95.36 | 96.72 |
| LASER+SBERT+KG/GloVe | 2092 | 98.36 | 98.63 | 98.91 | 98.09 | 98.91 | 99.45 | 98.91 | 98.91 | 98.36 | 98.09 | |
| LASER+MPNet+KG/GloVe | 2092 | 97.54 | 98.09 | 98.36 | 97.54 | 98.36 | 98.09 | 98.36 | 98.91 | 97.81 | 98.36 | |
| SOTA Embeddings | Dim. | Precision | Best Embeddings with KG | Dim. | Precision | |||||||
| SBERT | 768 | 54.06 | LASER+MPNet+KG/GloVe | 2092 | 55.42 | |||||||
| LASER | 1024 | 52.92 | ||||||||||
| MPNet | 768 | 53.80 | ||||||||||
| LASER+SBERT | 1792 | 54.07 | ||||||||||
| LASER+SBERT+GloVe | 2092 | 54.41 | ||||||||||
| KG | KG | KG | KG | KG | KG | KG | KG | KG | ||||
| Embeddings with KG | Dim. | (100) | (500) | (750) | (100) | (500) | (750) | (100) | (500) | (750) | DBpedia | |
| KG | 22.38 | 46.67 | 49.39 | 25.86 | 47.82 | 47.65 | 30.34 | 48.69 | 50.45 | 20.15 | ||
| Concat. | LASER+KG | 1324 | 54.04 | 54.39 | 54.72 | 53.94 | 54.74 | 54.48 | 54.43 | 54.95 | 54.46 | 53.24 |
| LASER+SBERT+KG | 2092 | 54.25 | 54.76 | 54.48 | 54.04 | 54.43 | 55.00 | 54.11 | 54.67 | 54.29 | 53.66 | |
| LASER+MPNet+KG | 2092 | 54.48 | 55.40 | 54.81 | 53.89 | 55.07 | 55.16 | 54.46 | 55.28 | 55.14 | 53.66 | |
| Substit. | LASER+KG/GloVe | 1324 | 51.41 | 54.27 | 53.47 | 52.91 | 54.20 | 54.27 | 54.25 | 54.46 | 54.29 | 51.55 |
| LASER+SBERT+KG/GloVe | 2092 | 52.37 | 54.39 | 53.26 | 52.11 | 52.49 | 53.54 | 54.58 | 54.90 | 55.16 | 53.43 | |
| LASER+MPNet+KG/GloVe | 2092 | 51.69 | 54.65 | 53.10 | 53.45 | 53.40 | 54.79 | 54.62 | 55.35 | 55.42 | 51.64 | |
| SOTA Embeddings | Dim. | Precision | Best Embeddings with KG | Dim. | Precision | |||||
| SBERT | 768 | 68.02 | LASER+MPNet+DBpedia | 2092 | 70.00 | |||||
| LASER | 1024 | 62.68 | ||||||||
| MPNet | 768 | 69.25 | ||||||||
| LASER+SBERT | 1792 | 68.60 | ||||||||
| LASER+SBERT+GloVe | 2092 | 68.40 | ||||||||
| Embeddings with KG | Dim. | Bench. KG | Bench. KG | Bench. KG | KG | KG | KG | KG | DBpedia | |
| KG | 300 | 26.19 | 34.91 | 38.10 | 25.62 | 31.80 | 45.15 | 39.33 | 23.61 | |
| Concat. | LASER+KG | 1324 | 63.20 | 62.06 | 62.46 | 63.64 | 63.16 | 63.42 | 63.03 | 62.77 |
| LASER+SBERT+KG | 2092 | 68.68 | 68.37 | 67.14 | 68.50 | 68.76 | 67.89 | 68.11 | 67.37 | |
| LASER+MPNet+KG | 2092 | 68.77 | 68.94 | 68.24 | 69.51 | 68.16 | 68.77 | 69.21 | 70.00 | |
| Substit. | LASER+KG/GloVe | 1324 | 59.75 | 61.76 | 60.93 | 59.75 | 60.18 | 62.33 | 62.07 | 60.27 |
| LASER+SBERT+KG/GloVe | 2092 | 67.15 | 67.85 | 68.33 | 67.76 | 68.55 | 68.46 | 68.07 | 67.76 | |
| LASER+MPNet+KG/GloVe | 2092 | 67.59 | 67.02 | 66.14 | 67.85 | 68.51 | 67.15 | 68.37 | 68.64 | |
| SOTA Embeddings | Dim. | Precision | Best Embeddings with KG | Dim. | Precision | |||
| SBERT | 768 | 98.67 | LASER+KG | 1324 | 99.25 | |||
| LASER | 1024 | 98.87 | LASER+MPNet+KG | 2092 | 99.25 | |||
| MPNet | 768 | 98.43 | LASER+SBERT+KG/GloVe | 2092 | 99.25 | |||
| LASER+SBERT | 1792 | 98.50 | LASER+MPNet+KG/GloVe | 2092 | 99.25 | |||
| LASER+SBERT+GloVe | 2092 | 98.62 | ||||||
| Embeddings with KG | Dim. | KG | KG | KG | ||||
| KG | 300 | 91.37 | 91.37 | 93.87 | ||||
| Concat. | KG | 300 | 91.37 | 91.37 | 93.87 | |||
| KG+Glove | 600 | 98.25 | 98.62 | 98.00 | ||||
| LASER+KG | 1324 | 99.25 | 98.62 | 98.25 | ||||
| LASER+SBERT+KG | 2092 | 98.25 | 99.25 | 98.50 | ||||
| LASER+MPNet+KG | 2092 | 99.25 | 99.25 | 98.50 | ||||
| Substit. | LASER+KG/GloVe | 1324 | 98.87 | 98.62 | 97.87 | |||
| LASER+SBERT+KG/GloVe | 2092 | 99.00 | 98.37 | 99.25 | ||||
| LASER+MPNET+KG/GloVe | 2092 | 99.12 | 99.12 | 99.25 | ||||
| SOTA Embeddings | Dim. | Precision | Best Embeddings with KG | Dim. | Precision | |||||
| SBERT | 768 | 95.18 | SBERT+LASER+KG | 2092 | 95.18 | |||||
| SBERT+LASER | 1792 | 94.66 | ||||||||
| MPNET | 768 | 94.37 | ||||||||
| MPNET+LASER | 1792 | 94.14 | ||||||||
| KG | KG | KG | KG | KG | KG | KG | KG | KG | ||
| Embeddings with KG | Dim. | (100) | (500) | (750) | (100) | (500) | (750) | (100) | (500) | (750) |
| SBERT+KG | 1068 | 94.96 | 94.43 | 94.78 | 94.78 | 94.31 | 94.78 | 94.55 | 94.61 | 94.78 |
| SBERT+LASER+KG | 2092 | 95.13 | 94.55 | 94.60 | 94.78 | 94.55 | 94.95 | 95.18 | 94.55 | 94.43 |
| MPNet+KG | 1068 | 95.13 | 94.49 | 92.86 | 94.49 | 94.03 | 92.34 | 93.43 | 92.87 | 92.23 |
| MPNet+LASER+KG | 2092 | 95.02 | 94.43 | 92.92 | 94.14 | 93.79 | 92.92 | 93.91 | 93.27 | 91.65 |
| SOTA Embeddings | Dim. | Precision | Best Embeddings with KG | Dim. | Precision | |||||
| SBERT | 768 | 83.31 | SBERT+LASER+KG | 2092 | 84.87 | |||||
| SBERT+LASER | 1792 | 84.12 | ||||||||
| MPNET | 768 | 83.25 | ||||||||
| MPNET+LASER | 1792 | 84.23 | ||||||||
| KG | KG | KG | KG | KG | KG | KG | KG | KG | ||
| Embeddings with KG | Dim. | (100) | (500) | (750) | (100) | (500) | (750) | (100) | (500) | (750) |
| SBERT+KG | 1068 | 83.78 | 83.48 | 84.24 | 84.07 | 84.65 | 83.95 | 84.01 | 83.31 | 83.60 |
| SBERT+LASER+KG | 2092 | 84.87 | 84.42 | 83.54 | 83.31 | 83.89 | 84.01 | 84.18 | 83.14 | 83.78 |
| MPNet+KG | 1068 | 84.29 | 84.07 | 84.12 | 84.30 | 83.37 | 83.89 | 83.95 | 83.89 | 83.95 |
| MPNet+LASER+KG | 2092 | 83.02 | 83.89 | 83.49 | 83.89 | 83.31 | 83.89 | 83.54 | 84.36 | 83.78 |
| SOTA Embeddings | Dim. | Precision | Best Embeddings with KG | Dim. | Precision | |||||
| SBERT | 768 | 48.81 | MPNet+KG | 1068 | 52.29 | |||||
| SBERT+LASER | 1792 | 49.75 | ||||||||
| MPNET | 768 | 50.33 | ||||||||
| MPNET+LASER | 1792 | 50.47 | ||||||||
| KG | KG | KG | KG | KG | KG | KG | KG | KG | ||
| Embeddings with KG | Dim. | (100) | (500) | (750) | (100) | (500) | (750) | (100) | (500) | (750) |
| SBERT+KG | 1068 | 49.26 | 48.82 | 49.49 | 48.93 | 49.43 | 49.31 | 49.28 | 49.73 | 49.12 |
| SBERT+LASER+KG | 2092 | 49.17 | 49.52 | 49.17 | 48.65 | 49.28 | 49.35 | 48.89 | 48.93 | 49.49 |
| MPNet+KG | 1068 | 52.29 * | 51.21 | 51.54 | 50.18 | 50.55 | 51.86 | 51.18 | 51.68 | 50.62 |
| MPNet+LASER+KG | 2092 | 51.49 | 50.97 | 50.57 | 50.86 | 51.04 | 51.75 | 51.28 | 50.69 | 51.20 |
| SOTA Embeddings | Dim. | Precision | Best Embeddings with KG | Dim. | Precision | ||
| SBERT | 768 | 73.94 | MPNet+LASER+KG | 2092 | 74.69 | ||
| SBERT+LASER | 1792 | 73.77 | |||||
| MPNET | 768 | 73.55 | |||||
| MPNET+LASER | 1792 | 73.51 | |||||
| Embeddings with KG | Dim. | Bench. KG | Bench. KG | Bench. KG | KG | KG | KG |
| SBERT+KG | 1068 | 74.03 | 73.73 | 74.56 | 73.51 | 73.77 | 73.73 |
| SBERT+LASER+KG | 2092 | 73.68 | 73.77 | 73.51 | 73.16 | 74.08 | 73.07 |
| MPNet+KG | 1068 | 74.08 | 73.64 | 73.68 | 73.64 | 74.37 | 73.59 |
| MPNet+LASER+KG | 2092 | 74.64 | 74.69 | 74.16 | 73.81 | 73.77 | 73.29 |
| SOTA Embeddings | Dim. | Precision | Best Embeddings with KG | Dim. | Precision | ||
| SBERT | 768 | 99.37 | MPNet+KG | 1068 | 99.50 | ||
| SBERT+LASER | 1792 | 99.00 | |||||
| MPNET | 768 | 98.62 | |||||
| MPNET+LASER | 1792 | 98.62 | |||||
| Embeddings with KG | Dim. | KG | KG | KG | |||
| SBERT+KG | 1068 | 99.25 | 99.50 | 99.37 | |||
| SBERT+LASER+KG | 2092 | 99.00 | 99.37 | 99.25 | |||
| MPNet+KG | 1068 | 99.12 | 99.12 | 99.50 | |||
| MPNet+LASER+KG | 2092 | 98.75 | 98.50 | 99.37 | |||
| SOTA Embeddings | Dim. | Precision | Best Embeddings with KG | Dim. | Precision | ||
| SBERT | 768 | 62.24 | MPNet+LASER+KG | 65.57 | |||
| MPNET | 768 | 64.34 | |||||
| SBERT+LASER | 1792 | 61.62 | |||||
| MPNET+LASER | 1792 | 65.00 | |||||
| Embeddings with KG | Dim. | Bench. KG | Bench. KG | Bench. KG | KG | KG | KG |
| SBERT+KG | 1068 | 62.89 | 61.58 | 61.76 | 62.33 | 62.41 | 62.54 |
| SBERT+LASER+KG | 2092 | 62.33 | 61.97 | 62.94 | 61.32 | 62.46 | 60.92 |
| MPNet+KG | 1068 | 63.95 | 60.00 | 61.06 | 64.34 | 63.90 | 60.31 |
| MPNet+LASER+KG | 2092 | 65.57 | 59.13 | 62.41 | 64.91 | 63.29 | 59.83 |
| SOTA Embeddings | Dim. | Precision | Best Embeddings with KG | Dim. | Precision | ||
| SBERT | 768 | 58.12 | MPNet+KG | 60.66 | |||
| MPNET | 768 | 59.30 | |||||
| SBERT+LASER | 1792 | 59.01 | |||||
| MPNET+LASER | 1792 | 59.70 | |||||
| Embeddings with KG | Dim. | Bench. KG | Bench. KG | Bench. KG | KG | KG | KG |
| SBERT+KG | 1068 | 58.47 | 58.25 | 58.56 | 58.08 | 59.70 | 58.12 |
| SBERT+LASER+KG | 2092 | 57.32 | 57.42 | 58.51 | 58.30 | 57.42 | 58.34 |
| MPNet+KG | 1068 | 60.57 | 55.71 | 56.15 | 60.66 | 59.48 | 55.54 |
| MPNet+LASER+KG | 2092 | 60.18 | 55.23 | 57.59 | 60.40 | 58.82 | 55.45 |
References
- Temerak, M.S.; El-Manstrly, D. The influence of goal attainment and switching costs on customers’ staying intentions. J. Retail. Consum. Serv. 2019, 51, 51–61. [Google Scholar] [CrossRef]
- Abujabal, A.; Roy, R.S.; Yahya, M.; Weikum, G. ComQA: A Community-sourced Dataset for Complex Factoid Question Answering with Paraphrase Clusters. arXiv 2018, arXiv:1809.09528. [Google Scholar]
- Fader, A.; Zettlemoyer, L.; Etzioni, O. Paraphrase-Driven Learning for Open Question Answering. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4–9 August 2013. [Google Scholar]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; van Kleef, P.; Auer, S.; et al. DBpedia—A Large-scale, Multilingual Knowledge Base Extracted from Wikipedia. Semant. Web J. 2015, 6, 167–195. [Google Scholar] [CrossRef]
- Cavalin, P.; Alves Ribeiro, V.H.; Appel, A.; Pinhanez, C. Improving Out-of-Scope Detection in Intent Classification by Using Embeddings of the Word Graph Space of the Classes. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 3952–3961. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, Y.; Zhan, L.M.; Chen, J.; Shi, G.; Wu, X.M.; Lam, A.Y. Effectiveness of Pre-training for Few-shot Intent Classification. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Punta Cana, Dominican Republic, 16–20 November 2021; pp. 1114–1120. [Google Scholar]
- Zhang, J.; Ye, Y.; Zhang, Y.; Qiu, L.; Fu, B.; Li, Y.; Yang, Z.; Sun, J. Multi-Point Semantic Representation for Intent Classification. Proc. AAAI Conf. Artif. Intell. 2020, 34, 9531–9538. [Google Scholar] [CrossRef]
- Purohit, H.; Dong, G.; Shalin, V.; Thirunarayan, K.; Sheth, A. Intent Classification of Short-Text on Social Media. In Proceedings of the 2015 IEEE International Conference on Smart City/SocialCom/SustainCom (SmartCity), Chengdu, China, 19–21 December 2015; pp. 222–228. [Google Scholar] [CrossRef]
- Ahmad, Z.; Ekbal, A.; Sengupta, S.; Maitra, A.; Ramnani, R.; Bhattacharyya, P. Unsupervised Approach for Knowledge-Graph Creation from Conversation: The Use of Intent Supervision for Slot Filling. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Yu, C.; Wang, W.; Liu, X.; Bai, J.; Song, Y.; Li, Z.; Gao, Y.; Cao, T.; Yin, B. FolkScope: Intention Knowledge Graph Construction for Discovering E-commerce Commonsense. arXiv 2022, arXiv:2211.08316. [Google Scholar]
- Pinhanez, C.S.; Candello, H.; Cavalin, P.; Pichiliani, M.C.; Appel, A.P.; Alves Ribeiro, V.H.; Nogima, J.; de Bayser, M.; Guerra, M.; Ferreira, H.; et al. Integrating Machine Learning Data with Symbolic Knowledge from Collaboration Practices of Curators to Improve Conversational Systems. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; Association for Computing Machinery: New York, NY, USA, 2021. [Google Scholar]
- He, Y.; Jia, Q.; Yuan, L.; Li, R.; Ou, Y.; Zhang, N. A Concept Knowledge Graph for User Next Intent Prediction at Alipay. arXiv 2023, arXiv:2301.00503. [Google Scholar] [CrossRef]
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced Language Representation with Informative Entities. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1441–1451. [Google Scholar] [CrossRef]
- He, T.; Xu, X.; Wu, Y.; Wang, H.; Chen, J. Multitask Learning with Knowledge Base for Joint Intent Detection and Slot Filling. Appl. Sci. 2021, 11, 4887. [Google Scholar] [CrossRef]
- Siddique, A.B.; Jamour, F.T.; Xu, L.; Hristidis, V. Generalized Zero-shot Intent Detection via Commonsense Knowledge. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, 11–15 July 2021. [Google Scholar]
- Shabbir, J.; Arshad, M.U.; Shahzad, W. NUBOT: Embedded Knowledge Graph With RASA Framework for Generating Semantic Intents Responses in Roman Urdu. arXiv 2021, arXiv:2102.10410. [Google Scholar]
- Sant’Anna, D.T.; Caus, R.O.; dos Santos Ramos, L.; Hochgreb, V.; dos Reis, J.C. Generating Knowledge Graphs from Unstructured Texts: Experiences in the E-commerce Field for Question Answering. In Proceedings of the Joint Proceedings of Workshops AI4LEGAL2020, NLIWOD, PROFILES 2020, QuWeDa 2020 and SEMIFORM2020 Colocated with the 19th International Semantic Web Conference (ISWC 2020), CEUR Workshop Proceedings, Virtual Conference, 1–6 November 2020; Koubarakis, M., Alani, H., Antoniou, G., Bontcheva, K., Breslin, J.G., Collarana, D., Demidova, E., Dietze, S., Gottschalk, S., Governatori, G., et al., Eds.; 2020; Volume 2722, pp. 56–71. [Google Scholar]
- Hu, J.; Wang, G.; Lochovsky, F.; Sun, J.t.; Chen, Z. Understanding User’s Query Intent with Wikipedia. In Proceedings of the 18th International Conference on World Wide Web, WWW ’09, Madrid, Spain, 20–24 April 2009; pp. 471–480. [Google Scholar] [CrossRef]
- Balažević, I.; Allen, C.; Hospedales, T.M. TuckER: Tensor Factorization for Knowledge Graph Completion. In Proceedings of the Empirical Methods in Natural Language Processing, Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Artetxe, M.; Schwenk, H. Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond. Trans. Assoc. Comput. Linguist. 2019, 7, 597–610. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Song, K.; Tan, X.; Qin, T.; Lu, J.; Liu, T.Y. MPNet: Masked and Permuted Pre-training for Language Understanding. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 16857–16867. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Mcnemar, Q. Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika 1947, 12, 153–157. [Google Scholar] [CrossRef] [PubMed]
- Bordea, G.; Buitelaar, P.; Polajnar, T. Domain-independent term extraction through domain modelling. In Proceedings of the 10th International Conference on Terminology and Artificial Intelligence (TIA 2013), Paris, France, 28–30 October 2013. [Google Scholar]
- Manjunath, S.H.; McCrae, J.P. Encoder-Attention-Based Automatic Term Recognition (EA-ATR). In Proceedings of the 3rd Conference on Language, Data and Knowledge (LDK 2021), Zaragoza, Spain, 1–3 September 2021; Schloss Dagstuhl-Leibniz-Zentrum für Informatik: Dagstuhl, Germany, 2021. [Google Scholar]
- Akbik, A.; Blythe, D.; Vollgraf, R. Contextual String Embeddings for Sequence Labeling. In Proceedings of the COLING 2018, 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 1638–1649. [Google Scholar]
- Pereira, B.; Robin, C.; Daudert, T.; McCrae, J.P.; Mohanty, P.; Buitelaar, P. Taxonomy Extraction for Customer Service Knowledge Base Construction. In Semantic Systems. The Power of AI and Knowledge Graphs; Acosta, M., Cudré-Mauroux, P., Maleshkova, M., Pellegrini, T., Sack, H., Sure-Vetter, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 175–190. [Google Scholar]
- Chen, D.; Manning, C. A Fast and Accurate Dependency Parser using Neural Networks. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 740–750. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the International Conference on Machine Learning (ICML), Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]


| ProductServiceQA | ComQA | ParaLex | ATIS | |
|---|---|---|---|---|
| # Total samples | 7611 | 1829 | 21,306 | 5632 |
| # Samples (train) | 5328 | 1463 | 17,045 | 4833 |
| # Samples (test) | 2283 | 366 | 4261 | 799 |
| # Classes | 338 | 272 | 275 | 8 |
| Benchmark KG | Benchmark KG | Benchmark KG | KG | KG | KG | |
|---|---|---|---|---|---|---|
| Taxonomy | Y | Y | Y | Y | Y | Y |
| Semantic Relations | N | Y | Y | N | Y | Y |
| Named Entities | N | N | Y | N | N | Y |
| Unique Concepts | 84 | 84 | 97 | 100 | 100 | 908 |
| Unique Relations | 1 | 221 | 221 | 1 | 230 | 259 |
| Vocabulary | 60 | 190 | 392 | 36 | 166 | 468 |
| Embedding | Precision | Recall | F |
|---|---|---|---|
| Flair (Forward+Backward) | 0.94 | 0.92 | 0.93 |
| Flair (forward+backward)+GloVe | 0.95 | 0.92 | 0.93 |
| Flair (Forward)+GloVe | 0.94 | 0.92 | 0.93 |
| GloVe | 0.92 | 0.91 | 0.91 |
| BERT | 0.93 | 0.91 | 0.93 |
| ELMo | 0.94 | 0.91 | 0.93 |
| ComQA Data Set | ParaLex Data Set | ||||
|---|---|---|---|---|---|
| SOTA Embeddings | Dimension | Precision | SOTA Embeddings | Dimension | Precision |
| SBERT | 768 | 98.36 | SBERT | 768 | 54.06 |
| LASER | 1024 | 96.75 | LASER | 1024 | 52.92 |
| MPNet | 768 | 98.63 | MPNet | 768 | 53.80 |
| LASER+SBERT | 1792 | 98.28 | LASER+SBERT | 1792 | 54.07 |
| LASER+SBERT+GloVe | 2092 | 98.63 | LASER+SBERT+GloVe | 2092 | 54.41 |
| Best Embeddings with KG | Dimension | Precision | Best Embeddings with KG | Dimension | Precision |
| LASER+SBERT+KG (750) | 2092 | 99.45 | LASER+MPNet+KG (750)/GloVe | 2092 | 55.42 |
| LASER+MPNet+KG (500) | 2092 | 99.45 | |||
| LASER+SBERT+KG (750)/GloVe | 2092 | 99.45 | |||
| ProductServiceQA Data Set | ATIS Data Set | ||||
| SOTA Embeddings | Dimension | Precision | SOTA Embeddings | Dimension | Precision |
| SBERT | 768 | 68.02 | SBERT | 768 | 98.67 |
| LASER | 1024 | 62.68 | LASER | 1024 | 98.87 |
| MPNet | 768 | 69.25 | MPNet | 768 | 98.43 |
| LASER+SBERT | 1792 | 68.60 | LASER+SBERT | 1792 | 98.50 |
| LASER+SBERT+GloVe | 2092 | 68.40 | LASER+SBERT+GloVe | 2092 | 98.62 |
| Best Embeddings with KG | Dimension | Precision | Best Embeddings with KG | Dimension | Precision |
| LASER+MPNet+KG (DBpedia) | 2092 | 70.00 | LASER+KG (100) | 1324 | 99.25 |
| LASER+SBERT+KG (100) | 2092 | 99.25 | |||
| LASER+MPNet+KG (100) | 2092 | 99.25 | |||
| LASER+MPNet+KG (100) | 2092 | 99.25 | |||
| LASER+SBERT+KG (100)/GloVe | 2092 | 99.25 | |||
| LASER+MPNet+KG (100)/GloVe | 2092 | 99.25 | |||
| Terms | 100 | 200 | 300 | 500 | 1000 |
| Unique Concepts | 908 | 1008 | 1108 | 1308 | 1808 |
| Unique Relations | 259 | 279 | 299 | 305 | 324 |
| Vocabulary | 468 | 494 | 529 | 553 | 653 |
| SOTA Embeddings | Dimension | Precision | Best Embeddings with KG | Dimension | Precision | ||
| SBERT | 768 | 68.02 | LASER+MPNet+KG (100) | 2092 | 69.99 | ||
| LASER | 1024 | 62.68 | |||||
| MPNet | 768 | 69.25 | |||||
| LASER+SBERT | 1792 | 68.60 | |||||
| LASER+SBERT+GloVe | 2092 | 68.40 | |||||
| Number of Set Terms | |||||||
| Embeddings with KG | Dimension | 100 | 200 | 300 | 500 | 1000 | |
| KG | 300 | 40.34 | 40.34 | 41.61 | 42.14 | 44.20 | |
| Concat. | LASER+KG | 1324 | 62.15 | 62.15 | 61.94 | 62.85 | 52.91 |
| LASER+SBERT+KG | 2092 | 68.24 | 68.24 | 67.89 | 67.85 | 67.85 | |
| LASER+MPNet+KG | 2092 | 69.99 | 68.37 | 68.77 | 68.29 | 68.46 | |
| Substit. | LASER+KG/GloVe | 1324 | 62.51 | 60.58 | 61.54 | 62.64 | 60.36 |
| LASER+SBERT+KG/GloVe | 2092 | 68.20 | 68.37 | 68.20 | 67.81 | 67.41 | |
| LASER+MPNet+KG/GloVe | 2092 | 67.89 | 67.90 | 67.19 | 67.76 | 67.24 | |
| ComQA Data Set | ParaLex Data Set | ||||
|---|---|---|---|---|---|
| SOTA Embeddings | Dimension | Precision | SOTA Embeddings | Dimension | Precision |
| SBERT | 768 | 95.18 | SBERT | 768 | 48.81 |
| SBERT+LASER | 1792 | 94.66 | SBERT+LASER | 1792 | 49.75 |
| MPNET | 768 | 94.37 | MPNET | 768 | 50.33 |
| MPNET+LASER | 1792 | 94.14 | MPNET+LASER | 1792 | 50.47 |
| Best Embeddings with KG | Dimension | Precision | Best Embeddings with KG | Dimension | Precision |
| SBERT+LASER+KG (100) | 2092 | 95.18 | MPNET+KG (100) | 1068 | 52.29 * |
| ProductServiceQA Data Set | ATIS Data Set | ||||
| SOTA Embeddings | Dimension | Precision | SOTA Embeddings | Dimension | Precision |
| SBERT | 768 | 73.94 | SBERT | 768 | 99.37 |
| SBERT+LASER | 1792 | 73.77 | SBERT+LASER | 1792 | 99.00 |
| MPNET | 768 | 73.55 | MPNET | 768 | 98.62 |
| MPNET+LASER | 1792 | 73.51 | MPNET+LASER | 1792 | 98.62 |
| Best Embeddings with KG | Dimension | Precision | Best Embeddings with KG | Dimension | Precision |
| MPNet+LASER+KG (100) | 2092 | 74.69 | MPNet+KG (100) | 1068 | 99.50 |
| SOTA Embeddings | Dimension | Precision |
|---|---|---|
| SBERT | 768 | 83.31 |
| SBERT+LASER | 1792 | 84.12 |
| MPNET | 768 | 83.25 |
| MPNET+LASER | 1792 | 84.23 |
| Best Embeddings with KG | Dimension | Precision |
| SBERT+LASER+KG (100) | 2092 | 84.87 |
| SOTA Embeddings | Dimension | Precision |
|---|---|---|
| SBERT | 768 | 62.24 |
| MPNET | 768 | 64.34 |
| SBERT+LASER | 1092 | 61.62 |
| MPNET+LASER | 1092 | 65.00 |
| Best Embeddings with KG | Dimension | Precision |
| MPNet+LASER+KG (100) | 1392 | 65.57 |
| SOTA Embeddings | Dimension | Precision |
|---|---|---|
| SBERT | 768 | 58.12 |
| MPNET | 768 | 59.30 |
| SBERT+LASER | 1092 | 59.01 |
| MPNET+LASER | 1092 | 59.70 |
| Best Embeddings with KG | Dimension | Precision |
| MPNet+KG (100) | 1092 | 60.66 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arcan, M.; Manjunath, S.; Robin, C.; Verma, G.; Pillai, D.; Sarkar, S.; Dutta, S.; Assem, H.; McCrae, J.P.; Buitelaar, P. Intent Classification by the Use of Automatically Generated Knowledge Graphs. Information 2023, 14, 288. https://doi.org/10.3390/info14050288
Arcan M, Manjunath S, Robin C, Verma G, Pillai D, Sarkar S, Dutta S, Assem H, McCrae JP, Buitelaar P. Intent Classification by the Use of Automatically Generated Knowledge Graphs. Information. 2023; 14(5):288. https://doi.org/10.3390/info14050288
Chicago/Turabian StyleArcan, Mihael, Sampritha Manjunath, Cécile Robin, Ghanshyam Verma, Devishree Pillai, Simon Sarkar, Sourav Dutta, Haytham Assem, John P. McCrae, and Paul Buitelaar. 2023. "Intent Classification by the Use of Automatically Generated Knowledge Graphs" Information 14, no. 5: 288. https://doi.org/10.3390/info14050288
APA StyleArcan, M., Manjunath, S., Robin, C., Verma, G., Pillai, D., Sarkar, S., Dutta, S., Assem, H., McCrae, J. P., & Buitelaar, P. (2023). Intent Classification by the Use of Automatically Generated Knowledge Graphs. Information, 14(5), 288. https://doi.org/10.3390/info14050288