


The Process of Identifying Automobile Joint Failures during the Operation Phase: Data Analytics Based on Association Rules




Abstract
1. Introduction
2. Application of Association Rules: A Literature Review
- Select quality criteria and a rule generation algorithm, determine the requirements for the input data structure and prepare statistical data on the technical defects in the vehicles, including information on the defective parts;
- Design and develop a component reliability analysis web service that allows the generation of association rules interactively and generates a list of parts to be inspected;
- Generate association rules and analyze their quality.
3. Materials and Methods
3.1. The Essence of the Association Rules Method and Selected Quality Criteria
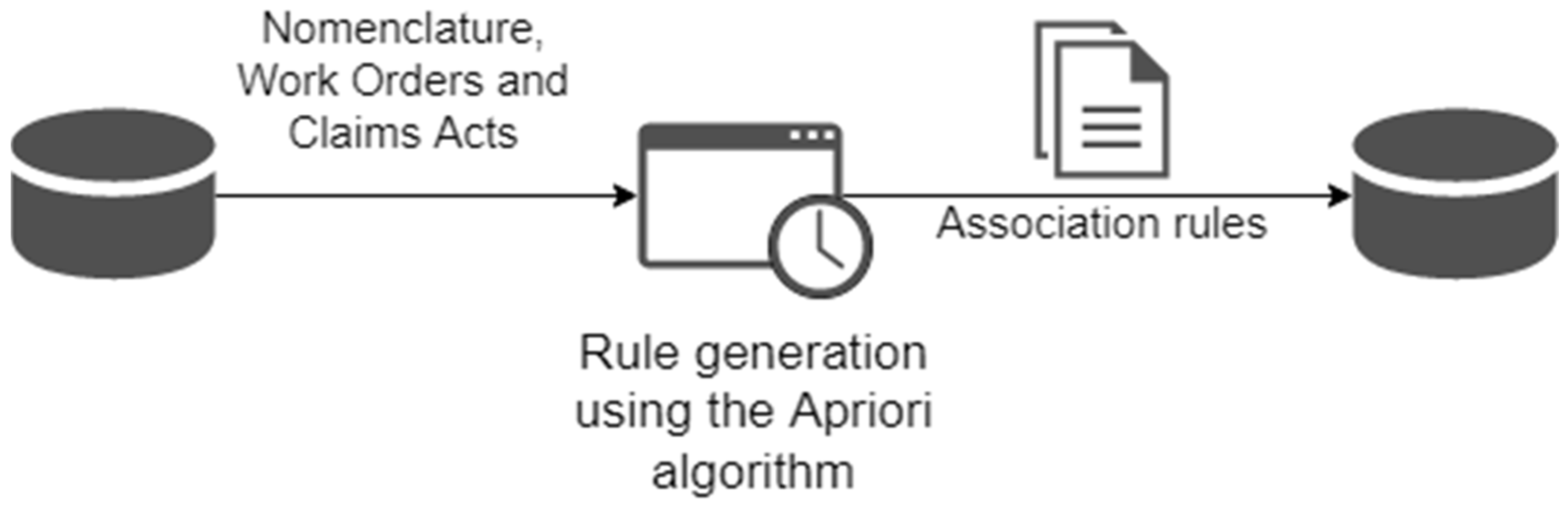
3.2. Algorithm for Generating Association Rules
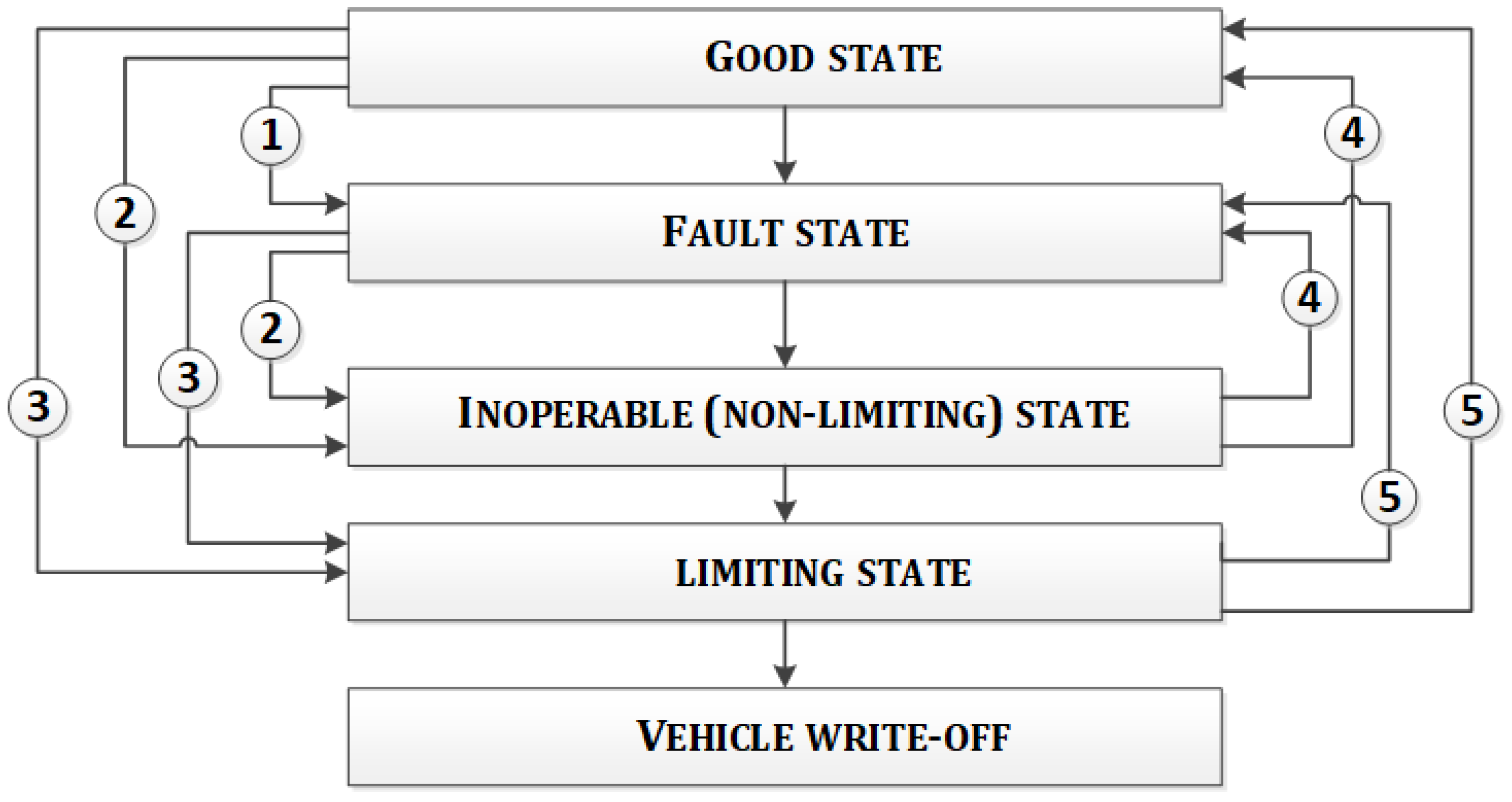
3.3. Technique for Detecting Joint Defective Parts
4. Results
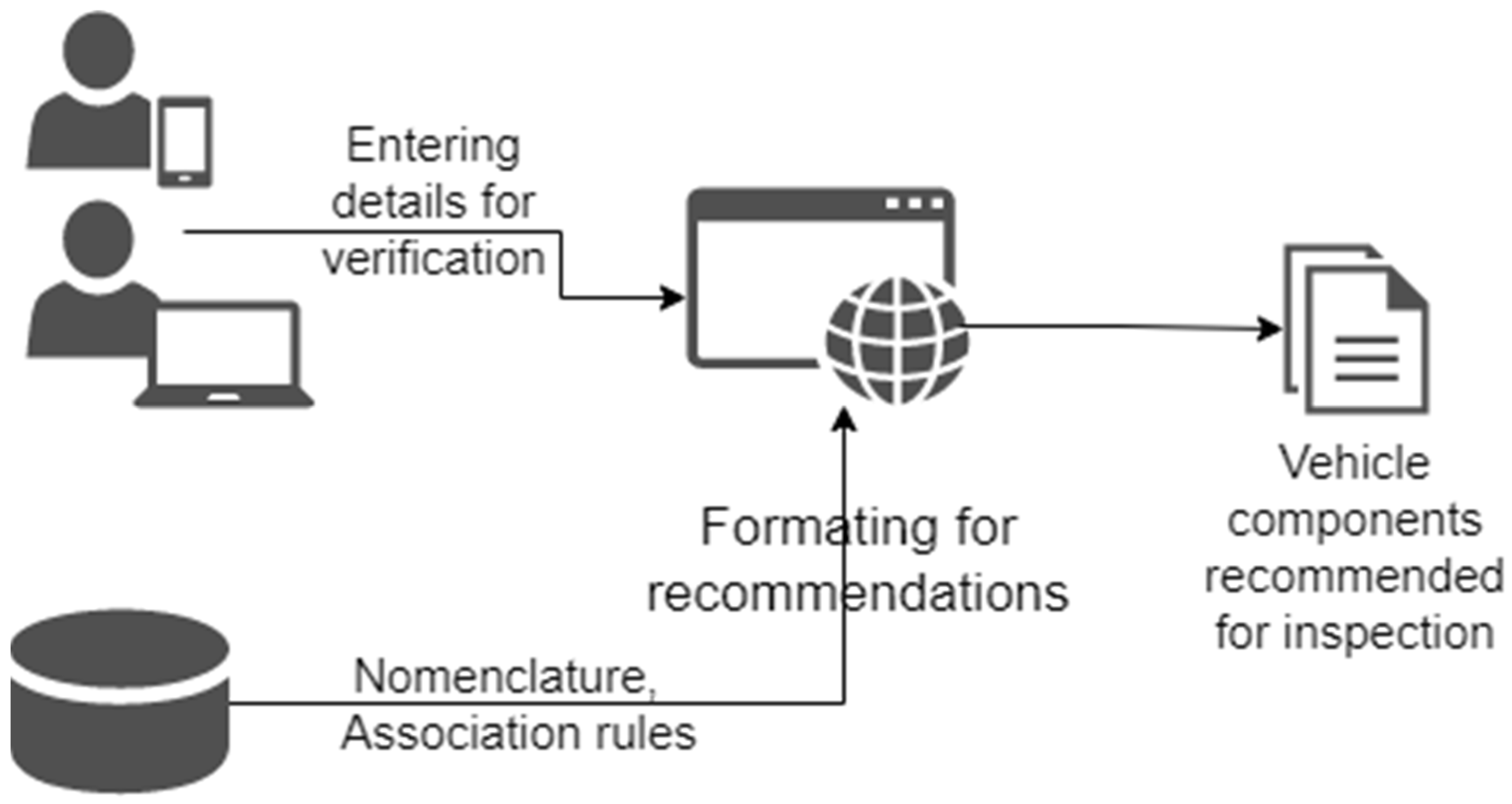
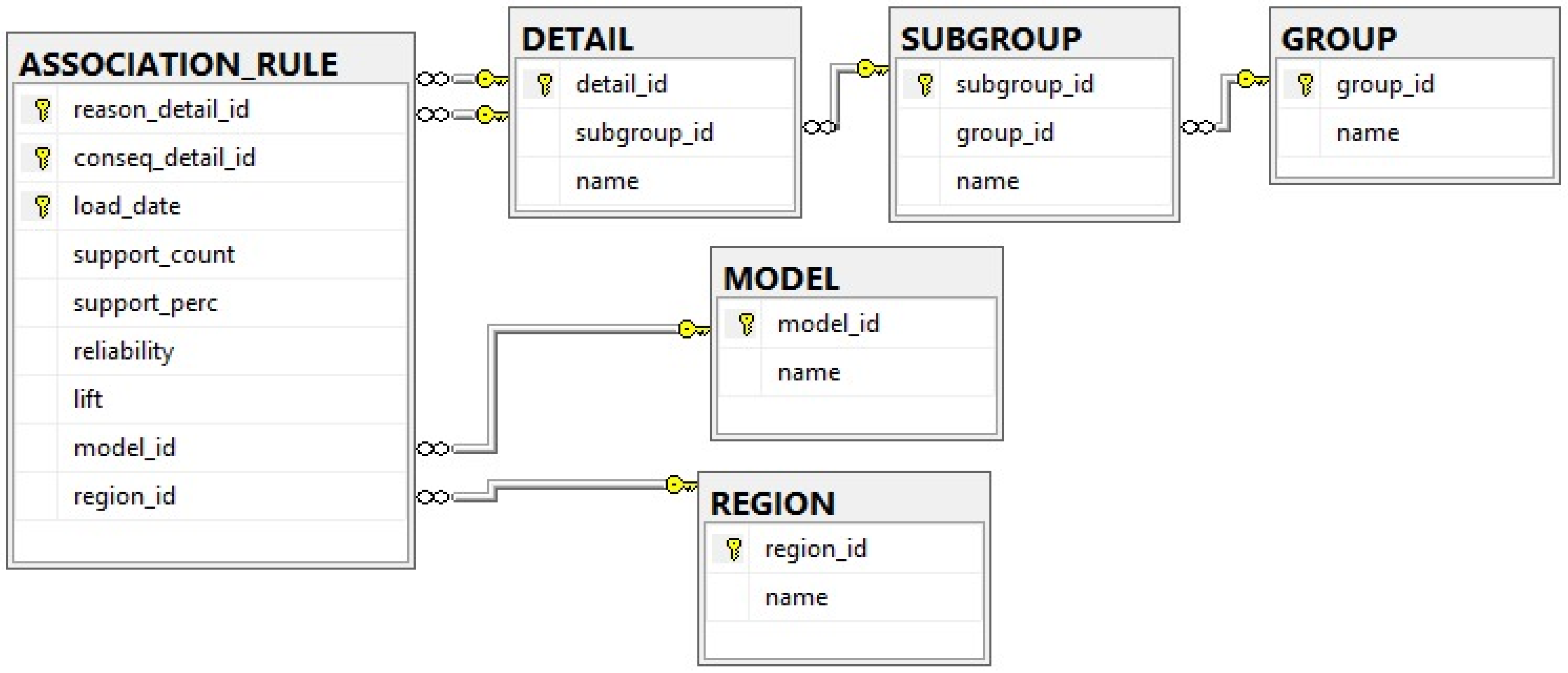
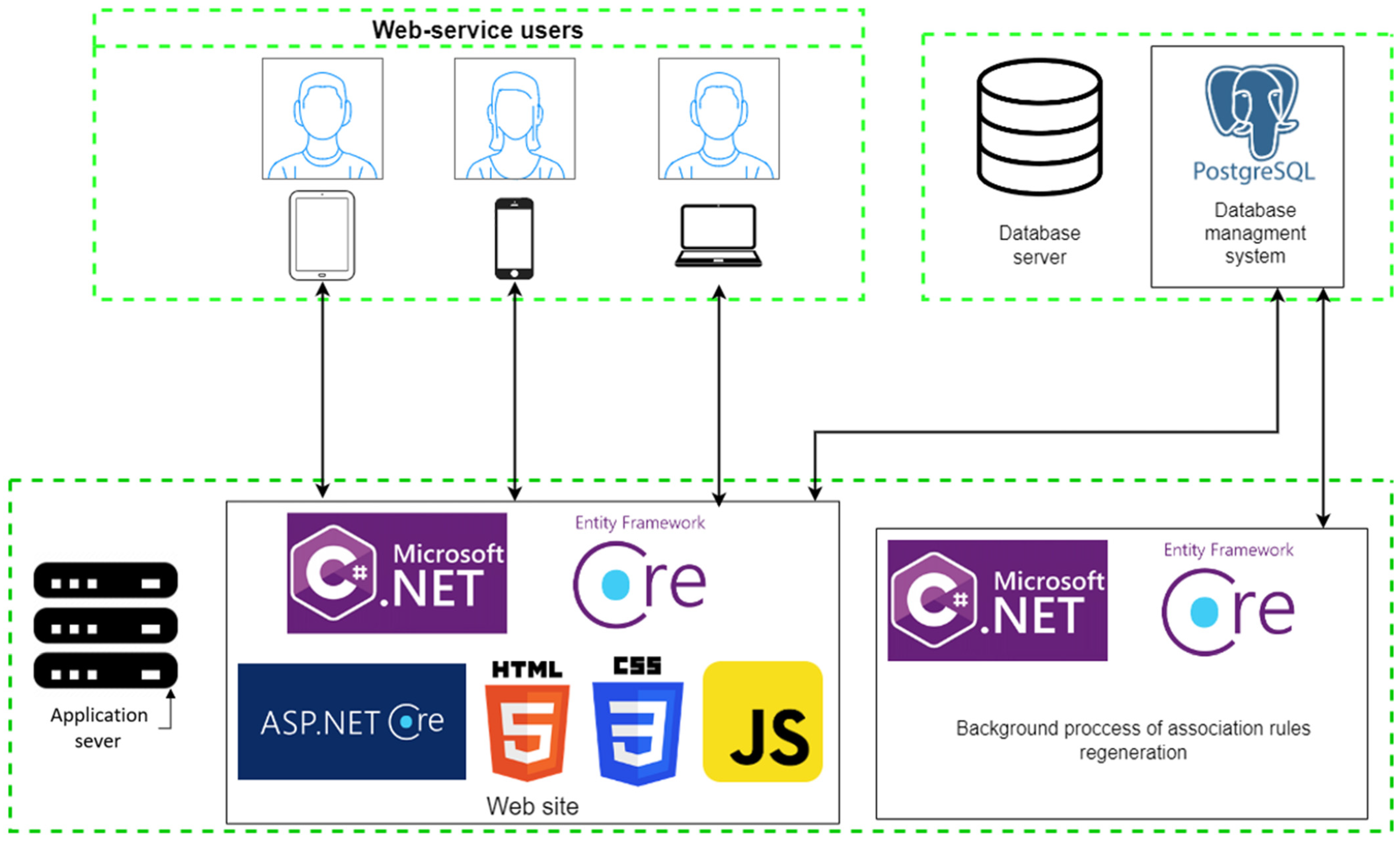
4.1. The Structure and Algorithms of the Recommendation Web Service
- A rule generation component that runs in the background on a schedule;
- A component that implements the proposed recommendation mechanism in the form of a preliminary list of faults.
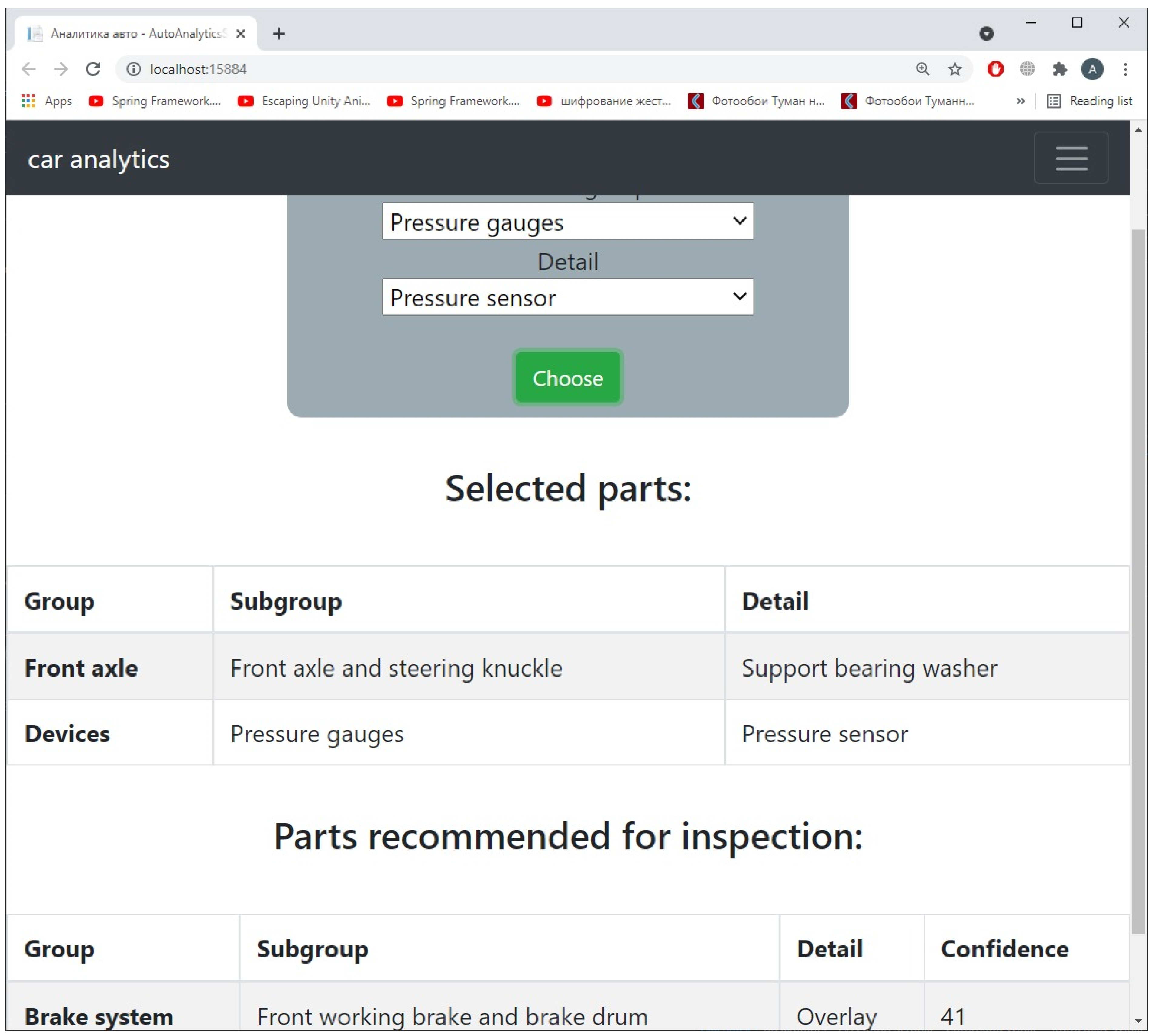
4.2. Testing a Web Recommendation Service: Derived Association Rules
- R1—improved capital cement concrete, monolithic, reinforced concrete or reinforced prefabricated, asphalt concrete, paving stones and mosaics on a concrete base;
- R2—improved lightweight from crushed stone, gravel and sand treated with binders from cold asphalt concrete;
- R3—transitional crushed stone and gravel.
- T1—flat, up to 200 m;
- T2—slightly hilly, over 200 to 300 m;
- T3—hilly, over 300 to 1000 m;
- T4—mountainous, over 1000 to 2000 m.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- James, A.T.; Gandhi, O.P.; Deshmukh, S.G. Fault diagnosis of automobile systems using fault tree based on digraph modeling. Int. J. Syst. Assur. Eng. Manag. 2018, 9, 494–508. [Google Scholar] [CrossRef]
- Ryabinin, I.A.; Strukov, A.V. Quantitative examples of safety assessment using logical-probabilistic methods. Int. J. Risk Assess. Manag. 2018, 21, 4–20. [Google Scholar] [CrossRef]
- Makarova, I.; Mukhametdinov, E.; Mavrin, V. Unified information environment role to improve the vehicle reliability at life cycle stages during the transition to industry 4.0. In Proceedings of the 2019 12th International Conference on Developments in eSystems Engineering (DeSE), Kazan, Russia, 7–10 October 2019; pp. 800–805. [Google Scholar]
- Khabibullin, R.G.; Makarova, I.V.; Belyaev, E.I.; Suleimanov, I.F.; Pernebekov, S.S.; Ussipbayev, U.A.; Junusbekov, A.S.; Balabekov, Z.A. The study and management of reliability parameters for automotive equipment using simulation modeling. Life Sci. J. 2013, 10, 828–831. [Google Scholar]
- Yadav, O.P.; Singh, N.; Goel, P.S.; Itabashi-Campbell, R. A Framework for Reliability Prediction During Product Development Process Incorporating Engineering Judgments. Qual. Eng. 2003, 15, 649–662. [Google Scholar] [CrossRef]
- Makarova, I.; Shubenkova, K.; Buyvol, P.; Shepelev, V.; Gritsenko, A. The Role of Reverse Logistics in the Transition to a Circular Economy: Case Study of Automotive Spare Parts Logistics. FME Trans. 2021, 49, 173–185. [Google Scholar] [CrossRef]
- Makarova, I.; Buyvol, P.; Mukhametdinov, E.; Pashkevich, A. Risk analysis in the appointment of the trucks’ warranty period operation. In Advances in Intelligent Systems and Computing, Proceedings of the 39th International Conference on Information Systems Architecture and Technology–ISAT 2018: Part III, Nysa, Poland, 16–18 September 2018; Springer International Publishing: Cham, Switzerland, 2019; Volume 854, pp. 293–302. [Google Scholar]
- Gritsenko, A.; Shepelev, V.; Zadorozhnaya, E.; Shubenkova, K. Test diagnostics of engine systems in passenger cars. FME Trans. 2020, 48, 46–52. [Google Scholar] [CrossRef]
- Drakaki, M.; Karnavas, Y.L.; Tzionas, P.; Chasiotis, I.D. Recent Developments Towards Industry 4.0 Oriented Predictive Maintenance in Induction Motors. Procedia Comput. Sci. 2021, 180, 943–949. [Google Scholar] [CrossRef]
- Alpaydin, E. Introduction to Machine Learning; MIT Press: Cambridge, MA, USA, 2020; 712p. [Google Scholar]
- Tian, J.; Wang, D.; Chen, L.; Zhu, Z.; Shen, C. A stable adaptive adversarial network with exponential adversarial strategy for bearing fault diagnosis. IEEE Sens. J. 2022, 22, 9754–9762. [Google Scholar] [CrossRef]
- Shi, Q.; Zhang, H. Fault Diagnosis of an Autonomous Vehicle With an Improved SVM Algorithm Subject to Unbalanced Datasets. IEEE Trans. Ind. Electron. 2021, 68, 6248–6256. [Google Scholar] [CrossRef]
- Jing, R.; Green, M.; Huang, X. Chapter 8—From traditional to deep learning: Fault diagnosis for autonomous vehicles. In Learning Control: Applications in Robotics and Complex Dynamical Systems; Elsevier: Amsterdam, The Netherlands, 2021; pp. 205–219. [Google Scholar]
- Kumar, P.; Perrollaz, M.; Lefevre, S.; Laugier, C. Learning-based approach for online lane change intention prediction. In Proceedings of the 2013 IEEE Intelligent Vehicles Symposium (IV), Gold Coast, QLD, Australia, 23–26 June 2013; pp. 797–802. [Google Scholar]
- Yi, H.; Edara, P.; Sun, C. Modeling mandatory lane changing using Bayes classifier and decision trees. IEEE Trans. Intell. Transp. Syst. 2013, 15, 647–655. [Google Scholar] [CrossRef]
- Shi, Q.; Zhang, H. An improved learning-based LSTM approach for lane change intention prediction subject to imbalanced data. Transp. Res. Part C Emerg. Technol. 2021, 133, 103414. [Google Scholar] [CrossRef]
- Ngai, E.W.T.; Xiu, L.; Chau, D.C.K. Application of data mining techniques in customer relationship management: A literature review and classification. Expert Syst. Appl. 2009, 36, 2592–2602. [Google Scholar] [CrossRef]
- Ali Alan, M.; Ince, A.R. Use of Association Rule Mining within the Framework of a Customer-Oriented Approach. Eur. Sci. J. 2016, 12, 81–99. [Google Scholar] [CrossRef]
- Lin, R.-H.; Chuang, W.W.; Chuang, C.L.; Chang, W.S. Applied Big Data Analysis to Build Customer Product Recommendation Model. Sustainability 2021, 13, 4985. [Google Scholar] [CrossRef]
- Yusupbekov, N.R.; Gulyamov, S.M.; Usmanova, N.B.; Mirzaev, D.A. Estimation of software reliability based on association rules. Math. Methods Eng. Technol. 2017, 1, 134–138. [Google Scholar]
- Yakupova, G.A.; Makarova, I.V.; Buyvol, P.A.; Mukhametdinov, E.M. Method of association rules in the analysis of road traffic accidents. Transp. Sci. Technol. Manag. 2020, 11, 40–44. (In Russian) [Google Scholar] [CrossRef]
- Introduction to the Analysis of Association Rules. Available online: https://loginom.ru/blog/associative-rules (accessed on 1 February 2023).
- Makarova, I.; Yakupova, G.; Buyvol, P.; Mukhametdinov, E.; Pashkevich, A. Association rules to identify factors affecting risk and severity of road accidents. In Proceedings of the 6th International Conference on Vehicle Technology and Intelligent Transport Systems (VEHITS), Online, 2–4 May 2020; pp. 614–621. [Google Scholar]
- Chen, Z.; Ordonez, C.; Zhao, K. Comparing Reliability of Association Rules and OLAP Statistical Tests. In Proceedings of the 2008 IEEE International Conference on Data Mining Workshops, Pisa, Italy, 15–19 December 2008; pp. 8–17. [Google Scholar]
- Jiao, M.; Tang, J.; Xu, J. Evaluation of supplier reliability based on the association rule and AHP method. In Proceedings of the 2008 Chinese Control and Decision Conference, Yantai, China, 2–4 July 2008; pp. 2266–2270. [Google Scholar]
- Tjortjis, C.; Layzell, P.J. Using data mining to assess software reliability. In Proceedings of the 12th International Symposium on Software Reliability Engineering, Hong Kong, China, 27–30 November 2001; pp. 221–223. [Google Scholar]
- Jia, X.; Zhang, D. Prediction of maritime logistics service risks applying soft set based association rule: An early warning model. Reliab. Eng. Syst. Saf. 2021, 207, 107339. [Google Scholar] [CrossRef]
- Lesage, L.; Deaconu, M.; Lejay, A. A recommendation system for car insurance. Eur. Actuar. J. 2020, 10, 377–398. [Google Scholar] [CrossRef]
- Jeong, H.; Gan, G.; Valdez, E.A. Association Rules for Understanding Policyholder Lapses. Risks 2018, 6, 69. [Google Scholar] [CrossRef]
- Katba, C. Automobile Options Association Rule Mining (Data Mining). Available online: https://katba-caroline.com/automobile-options-association-rule-mining-data-mining (accessed on 12 June 2022).
- Liu, G.; Peng, C. Research on Reliability Modeling of CNC System Based on Association Rule Mining. Procedia Manuf. 2017, 11, 1162–1169. [Google Scholar] [CrossRef]
- Zhang, R.; Jia, Y.; Sun, D. Application of Data Mining in CNC Equipment Reliability Analysis. J. Jilin Univ. 2007, 6. [Google Scholar]
- Jie, X.; Wang, H.; Fei, M.; Du, D.; Sun, Q.; Yang, T.C. Anomaly behavior detection and reliability assessment of control systems based on association rules. Int. J. Crit. Infrastruct. Prot. 2018, 22, 90–99. [Google Scholar] [CrossRef]
- Chen, B.; Qin, H.; Li, X. A Data Mining Method for Extracting Key Factors of Distribution Network Reliability. In Proceedings of the 2018 2nd IEEE Conference on Energy Internet and Energy System Integration (EI2), Beijing, China, 20–22 October 2018; pp. 1–5. [Google Scholar]
- Hui, Z.; Bi-bo, J.; Zhuo-qun, Z. Fault diagnosis of industrial boiler based on competitive agglomeration and fuzzy association rules. In Proceedings of the 2010 International Conference on Computer, Mechatronics, Control and Electronic Engineering, Changchun, China, 24–26 August 2010; pp. 64–67. [Google Scholar]
- Pan, D. Hybrid data-driven anomaly detection method to improve UAV operating reliability. In Proceedings of the 2017 Prognostics and System Health Management Conference (PHM-Harbin), Harbin, China, 9–12 July 2017; pp. 1–4. [Google Scholar]
- Rezgui, J.; Cherkaoui, S. Detecting faulty and malicious vehicles using rule-based communications data mining. In Proceedings of the 2011 IEEE 36th Conference on Local Computer Networks, Bonn, Germany, 4–7 October 2011; pp. 827–834. [Google Scholar]
- Moharana, U.C.; Sarmah, S.P.; Rathore, P.K. Application of data mining for spare parts information in maintenance schedule: A case study. J. Manuf. Technol. Manag. 2019, 30, 1055–1072. [Google Scholar] [CrossRef]
- Li, Y.; Du, X.; Yang, B. Application of Association Analysis and Visualization Methods in Car Parts Repair. In Proceedings of the Joint International Mechanical, Electronic and Information Technology Conference; Atlantis Press: Amsterdam, The Netherlands, 2015; pp. 1136–1141. [Google Scholar]
- Cao, M.; Guo, C. Research on the Improvement of Association Rule Algorithm for Power Monitoring Data Mining. In Proceedings of the 2017 10th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 9–10 December 2017; pp. 112–115. [Google Scholar]
- Jeon, J.; Sohn, S.Y. Product failure pattern analysis from warranty data using association rule and Weibull regression analysis: A case study. Reliab. Eng. Syst. Saf. 2015, 133, 176–183. [Google Scholar] [CrossRef]
- Buddhakulsomsiri, J.; Siradeghyan, Y.; Zakarian, A.; Li, X. Association rule-generation algorithm for mining automotive warranty data. Int. J. Prod. Res. 2006, 44, 2749–2770. [Google Scholar] [CrossRef]
- Mokhtari, K.; Ren, J.; Roberts, C.; Wang, J. Application of a generic bow-tie based risk analysis framework on risk management of sea ports and offshore terminals. J. Hazard. Mater. 2011, 192, 465–475. [Google Scholar] [CrossRef]
- Singh, K.; Shroff, G.; Agarwal, P. Predictive reliability mining for early warnings in populations of connected machines. In Proceedings of the 2015 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Paris, France, 19–21 October 2015; pp. 1–10. [Google Scholar]
- Chougule, R.; Rajpathak, D.; Bandyopadhyay, P. An integrated framework for effective service and repair in the automotive domain: An application of association mining and case-based-reasoning. Comput. Ind. 2011, 62, 742–754. [Google Scholar] [CrossRef]
- Rajpathak, D.G. An ontology based text mining system for knowledge discovery from the diagnosis data in the automotive domain. Comput. Ind. 2013, 64, 565–580. [Google Scholar] [CrossRef]
- Lei, Z.; Zi-dong, Z.; Xiao-dong, W.; Bin, S. The Applied Research of Association Rules Mining in Automobile Industry. In Proceedings of the 2009 WRI World Congress on Computer Science and Information Engineering, Los Angeles, CA, USA, 31 March–2 April 2009; pp. 241–245. [Google Scholar]
- Agrawal, R.; Imieli´nski, T.; Swami, A. Mining association rules between sets of items in large databases. In Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data, Washington, DC, USA, 25–28 May 1993; Volume 22, pp. 207–216. [Google Scholar]
- Han, J.; Pei, J.; Yin, Y.; Mao, R. Mining Frequent Patterns without Candidate Generation: A Frequent-Pattern Tree Approach. Data Min. Knowl. Discov. 2004, 8, 53–87. [Google Scholar] [CrossRef]
- Zaki, M.J.; Parthasarathy, S.; Ogihara, M.; Li, W. Parallel Algorithms for Discovery of Association Rules. Data Min. Knowl. Discov. 1997, 1, 343–373. [Google Scholar] [CrossRef]
- Nasr, M.; Hamdy, M.; Hegazy, D.; Bahnasy, K. An efficient algorithm for unique class association rule mining. Expert Syst. Appl. 2021, 164, 113978. [Google Scholar] [CrossRef]
- Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques, 3rd ed.; A volume in The Morgan Kaufmann Series in Data Management System; Morgan Kaufmann Publishers: Burlington, MA, USA, 2012; 740p. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | DEFECTED_DETAIL |
|---|---|
| CLAIM _1 | DEFECTED_DETAIL_1 |
| CLAIM _1 | DEFECTED_DETAIL_2 |
| CLAIM _1 | DEFECTED_DETAIL_3 |
| … | … |
| CLAIM _J | DEFECTED_DETAIL_1 |
| CLAIM _J | DEFECTED_DETAIL_2 |
| CLAIM _J | … |
| CLAIM _J | DEFECTED_DETAIL_I |
| ANTECEDENT | CONSEQUENT | SUPPORT, pcs. | SUPPORT*, % | CONFIDENCE, % | LIFT |
|---|---|---|---|---|---|
| DEFECTED_DETAIL_1 | DEFECTED_DETAIL_2 | S1 | S*1 | C1 | L1 |
| DEFECTED_DETAIL_2 | DEFECTED_DETAIL_4 | S2 | S*2 | C2 | L2 |
| DEFECTED_DETAIL_3 | DEFECTED_DETAIL_1 | S3 | S*3 | C3 | L3 |
| … | … | … | … | … | … |
| Rule Number | Antecedent, Group | Antecedent, Subgroup | Antecedent, Detail | Support, % | Confidence | Lift |
|---|---|---|---|---|---|---|
| Consequent, Group | Consequent, Subgroup | Consequent, Detail | ||||
| 1 | Brake system | Front working brake and brake drum | Cover | 0.61 | 76.9 | 52.5 |
| Front axle | Front axle and steering knuckle | Support bearing disc | ||||
| 2 | Front axle | Front axle and steering knuckle | Support bearing disc | 0.61 | 41.7 | 52.5 |
| Brake system | Front working brake and brake drum | Cover | ||||
| 3 | Brake system | Bypass brake valve | Dual-magister valve | 0.26 | 26 | 9.8 |
| Devices | Oil pressure gauge | Gauge | ||||
| 4 | Devices | Tyre pressure gauge | Pressure gauge | 0.14 | 21.2 | 8 |
| Devices | Pressure gauge | Gauge | ||||
| 5 | Electrical equipment | Generator | Relay regulator | 0.10 | 41.7 | 28.8 |
| Devices | VK403B | Reversing light switch | ||||
| 6 | Cooling system | Fan and its drive | Electromagnetic clutch engagement sensor | 0.08 | 26.6 | 17.2 |
| Cooling system | Thermostat | Thermostat |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Buyvol, P.; Makarova, I.; Voroshilov, A.; Krivonogova, A. The Process of Identifying Automobile Joint Failures during the Operation Phase: Data Analytics Based on Association Rules. Information 2023, 14, 257. https://doi.org/10.3390/info14050257
Buyvol P, Makarova I, Voroshilov A, Krivonogova A. The Process of Identifying Automobile Joint Failures during the Operation Phase: Data Analytics Based on Association Rules. Information. 2023; 14(5):257. https://doi.org/10.3390/info14050257
Chicago/Turabian StyleBuyvol, Polina, Irina Makarova, Aleksandr Voroshilov, and Alla Krivonogova. 2023. "The Process of Identifying Automobile Joint Failures during the Operation Phase: Data Analytics Based on Association Rules" Information 14, no. 5: 257. https://doi.org/10.3390/info14050257
APA StyleBuyvol, P., Makarova, I., Voroshilov, A., & Krivonogova, A. (2023). The Process of Identifying Automobile Joint Failures during the Operation Phase: Data Analytics Based on Association Rules. Information, 14(5), 257. https://doi.org/10.3390/info14050257