1. Introduction
Vast amounts of valuable information are being shared online through textual data that are posted at an extremely high rate. However, much of these data are unstructured, rendering the manual processing of such large amounts of unstructured text data challenging and tedious. Processing such large amounts of unstructured data needs intelligent domain-based techniques.
Natural language processing (NLP), a branch of artificial intelligence, processes unstructured textual data [
1] on the basis of user demand. NLP allows for computer systems to understand, interpret, and manipulate human language, and it has been implemented for many tasks, such as sentiment analysis, information extraction, and topic searching and modeling. Information mining (IE) is a technique for extracting related data from unstructured text [
2] that has been extended to several subtasks, of which one is entity recognition (NER). A named entity is a proper noun that appears in a sentence. NER recognizes the text of interest and maps it to predefined categories such as people, geographic locations, and organizations. NER can be viewed as a sequence tagging problem determining the output tags of input words presented in sentences [
3].
As the number of published biomedical texts has increased, IE has also become an essential activity in the biomedical field. Biomedical named entity recognition (BioNER) recognizes and associates biomedical facts to predefined categories such as genes, chemicals, and diseases [
4]. BioNER tasks are more difficult to implement than usual NER tasks because the biomedical literature differs in many ways from standard text data. Although there are certain conventions observed by researchers to describe biomedical concepts, there are still no hard and fast rules governing the biomedical field. It is becoming increasingly difficult to follow the same naming conventions in the open and growing biomedical literature. Another issue concerns entity classification. Different human annotators, even from the same background, may associate the same words with different medical concepts, e.g.,
“p53" corresponds to a protein in the GENIA corpus. In contrast, the HUGA nomenclature annotates it as a gene:
“TP53”.
The use of different spellings for the same entity is also very common in biomedical texts. For example, IL12, IL 12, and IL-12 refer to the same entity, but use different spelling conventions [
5]. Another challenge for BioNER is learning synonyms that appear in the text. For example,
PTEN and
MMAC1 represent the same genetic entity, but have different synonyms.
Moreover, long compound word entities complicate the training process of the BioNER model because these entities are represented by character types. For instance, “10-ethyl-5-methyl-5,10-dideazaaminopterin” and “12-o-tetradecanoylphorbol 13-acetate” contain alphanumerical and special characters. Different tokenizers treat these special characters differently. Therefore, applying different tokenizers may result in different outputs for the same entity. Descriptive entities such as “pigment-epithelium-derived factor” and “medullary thymic epithelial cells” hinder entity boundary identification. Biomedical entities may also comprise nested entities; e.g., “CIITA mRNA” symbolizes a reference to RNA, but “CIIT” refers to DNA [
6].
Furthermore, a common practice in writing biomedical texts is to use entity acronyms that may refer to different entities. For instance, “TCF” can refer to “tissue culture fluid” or “T-cell factor” [
7]. Similarly, “EGFR” can stand for “estimated glomerular filtration rate” or “epidermal growth factor receptor”. Determining acronyms for a particular entity is associated with the context of the sentence. Distinguishing such entities from each other is another challenging aspect for BioNER systems.
Due to the aforementioned limitations, BioNER tasks are more difficult than common NER tasks. Although early BioNER systems are effective, their overall performance continues to be restricted by the open and expanding biomedical literature. Traditional machine-learning algorithms show improved results compared to early dictionary-based and rule-based methods. However, machine-learning algorithms require a manual feature-engineering step that directly affects the performance of the model. Distinctive features could improve performance, while redundant and irrelevant features worsen performance.
More advanced methods rely on deep-learning techniques, eliminating the need for manual feature engineering while still providing the required outcome. A deep-learning (DL) architecture consists of several layers that help in exploring the properties and complex structure of data layer by data layer. The latent ability of DL models to learn complex features was successfully demonstrated in various domains, e.g., speech recognition [
8], drug discovery [
9,
10], the clinical setting [
11], and computer vision [
12].
Even though deep-learning models produced state-of-the-art results in many fields, the structure of these models is very complex and requires extensive computational power for training. Sutskever et al. [
13] proposed a model that comprised 4 layers of LSTMs that each had 1000 hidden units. Similarly, the model presented by Zhou et al. [
14] had multilevel LSTMs, and each layer comprised 512 hidden units. With millions of parameters, these models are computationally expensive to train. These cumbersome models also require more storage space, rendering them unsuitable for deployment with real-time data. One example is to use them on a cellphone, where limited storage and computational power are available. As a result, it is necessary to compress these complex models while preserving the generalization that they have learned—-in other words, without jeopardizing the performance of these deep-learning models. In this case, the knowledge distillation approach is utilized to compress a cumbersome model into a simple model, allowing for implementing it in end-user devices with less computational power [
15]. This work proposes the distillation knowledge approach to leverage the performance of deep-learning models. Instead of compressing the model, this research aims to maximize the efficiency and performance of the models.
Our previous work [
16] used a multitask learning (MTL) approach to leverage the performance of BioNER. The performance of the multitask model (MTM) is usually restricted or improved due to loss optimization via the joint training of different tasks. Data distribution from different tasks renders the MTM overfitted for some tasks and underfitted for other tasks. The knowledge distillation approach can overcome such limitations through, for example, the student model learning not only from the available inputs, but also through the output of the teacher model. Consequently, this article presents different knowledge distillation approaches to boost the performance of deep neural network models.
4. Experimental Settings
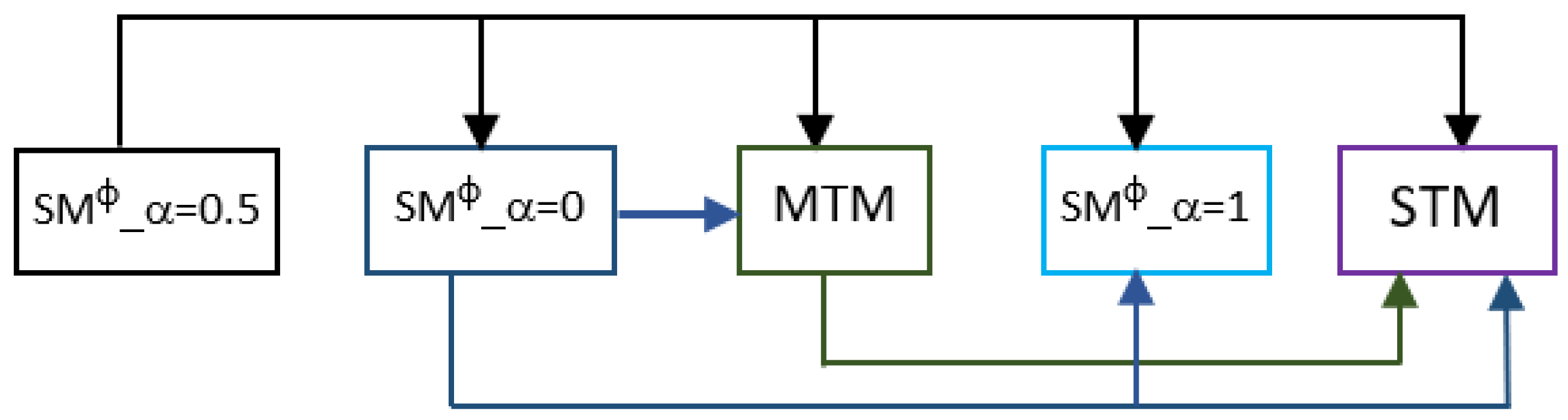
The MTM shown on the right-hand side of
Figure 1 was trained separately with an MTL approach using all the datasets presented in this paper and was then utilized for knowledge transformation into the student model (SM) [
24]. When the knowledge distillation was performed using the logits of the hidden layer, Equation (
2) was used to compute the loss of the SM. The knowledge distillation loss was the MSE of the teacher and the student logits. Here,
x represents the input,
W represents SM parameters,
is the cross-entropy loss,
y corresponds to the true labels, and
is the softmax function applied to the teacher logits,
, and student logits,
.
and
are hyperparameters to quantify each loss.
The experiments were conducted to consider different values, i.e., whereas . Hyperparameter tuning for and was not performed, and the values were naively chosen. If , the SM learnt with only distillation loss, while choosing equally used both student loss and distillation loss. Lastly, enabled the SM to utilize student loss. transformed the SM into a single-task model (STM). The SM, however, still utilized the logits of the teacher model during its training phase. This helps the SM in learning and modifying the weights of layers during the backpropagation phase.
When knowledge distillation is carried out at the task-specific BiLSTM layer along with the logits of the hidden layer, the loss is computed using Equation (
3). The new parameter,
, weighs the matching loss at the task-specific BiLSTM layer. The hyperparameters are tuned to select the best value for
. When the knowledge of the shared BiLSTM was incorporated with the above layer’s knowledge, the loss was calculated using Equation (
4). The MSE error of the task-specific BiLSTM was controlled using the new parameter,
. For Equation (
4), hyperparameter tuning was performed for
to select the best value from
for each parameter, while
was kept constant at 1. When knowledge distillation was carried out using soft labels, Equation (
5) was used to calculate the loss. Parameters
and
were retained at 0.5, while
was finetuned for each dataset. All our results were over the course of five runs, and each run was executed with different seed values. The reported F1 scores are, therefore, based on five runs.
Our experiments considered 15 datasets [
25] that had also been used by Wang et al. [
26], and Crichton et al. [
27]. The biological entities in these datasets are diseases, species, cellular components, cells, genes, proteins, and chemicals. Each dataset contains a training set, a validation set, and a test set. We followed a similar experimental setup to that of Wang et al. (
https://github.com/yuzhimanhua/Multi-BioNER, accessed on 10 February 2023), where the model was trained using both the training set and validation set.
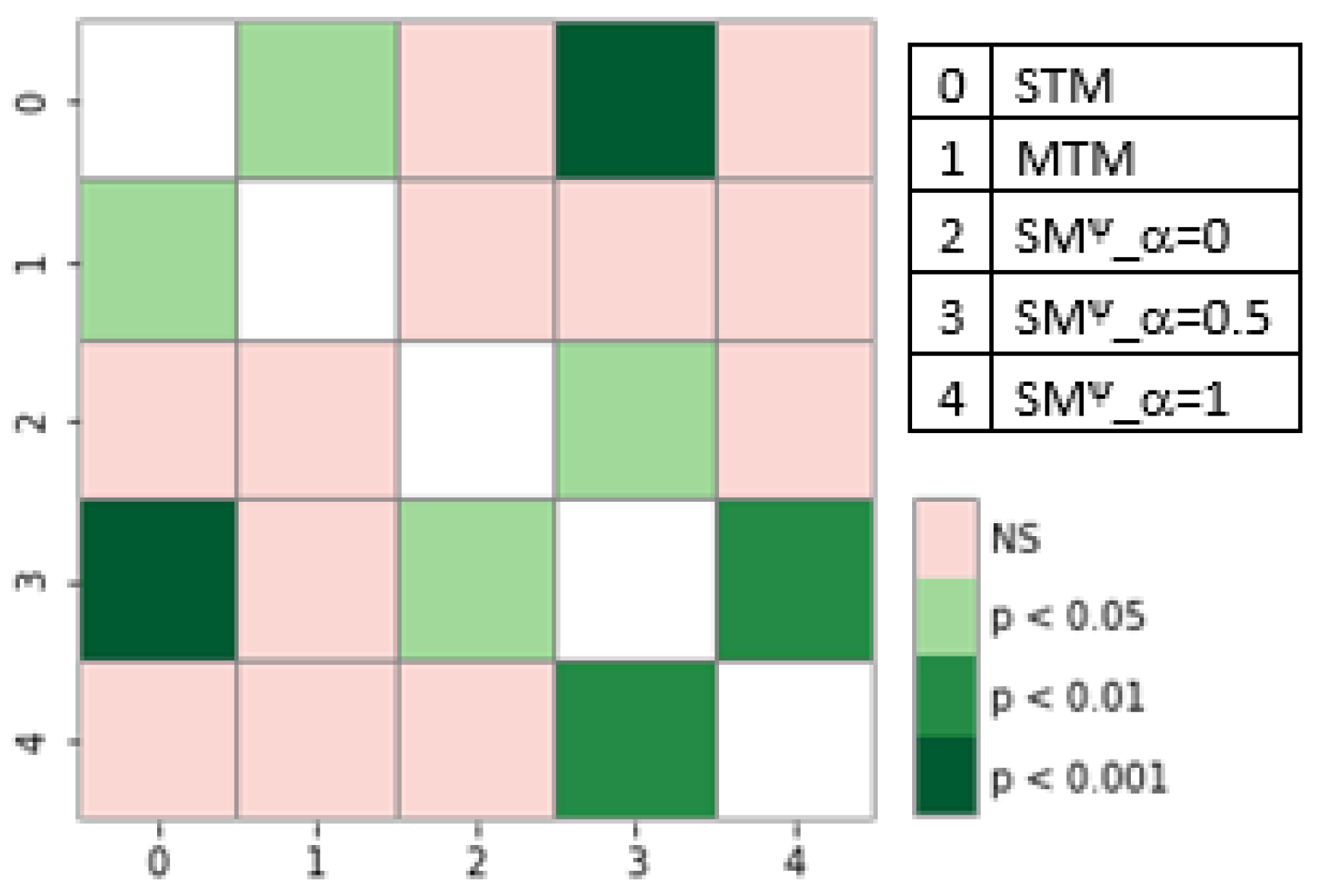
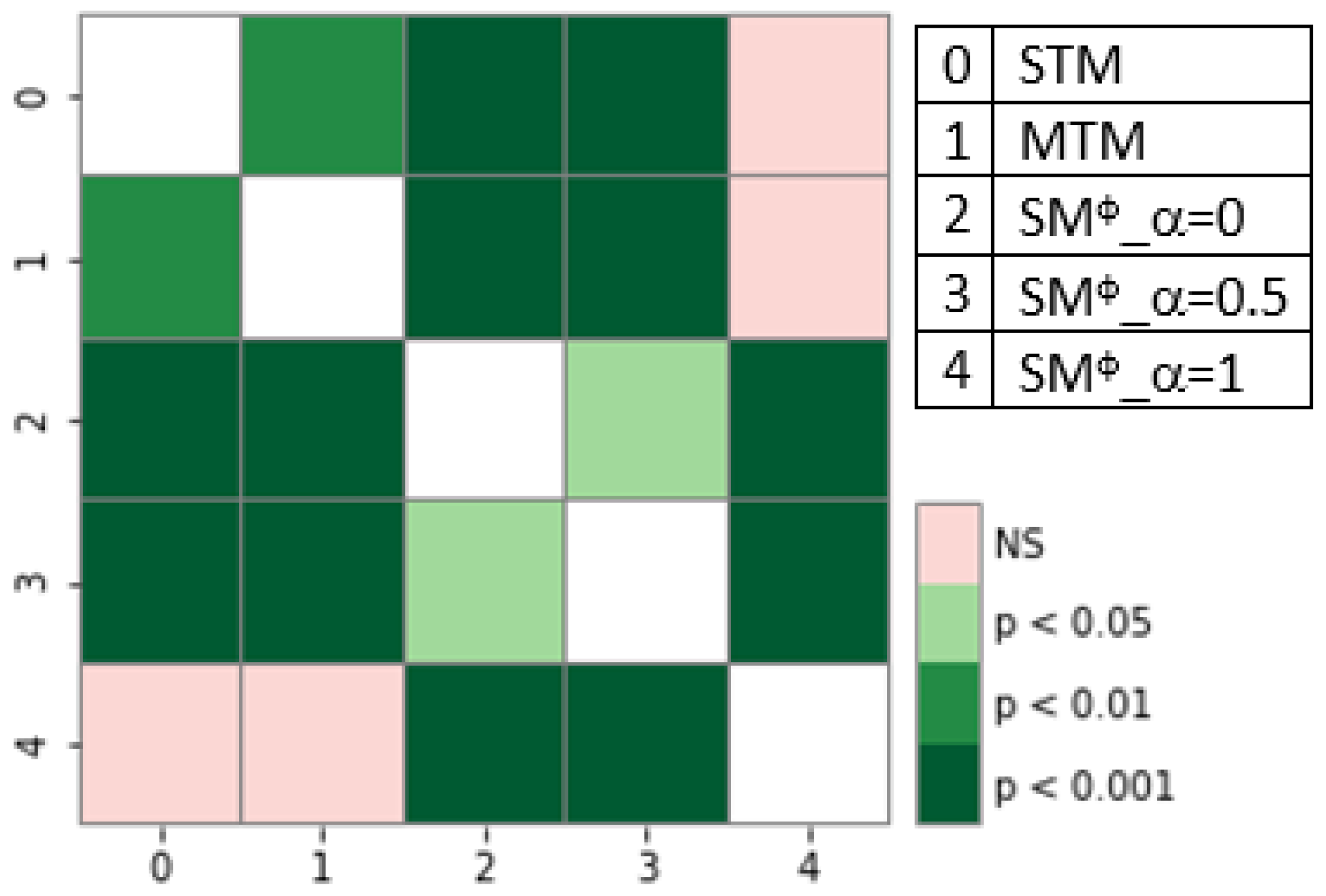
We also performed detailed statistical analysis, and used graphs to find statistical significance between the different results so that they could be better represented. Statistical analysis was performed using the Friedman test [
28] to determine the statistical significance of the differences in the results of the different models.
Author Contributions
Conceptualization and supervision, T.M., I.S., A.E.G. and A.L.; methodology, T.M. and I.S.; software and investigation, T.M.; validation, T.M. and M.O.; formal analysis, A.L.; writing—original draft preparation, T.M., I.S. and A.L.; writing—review and editing, T.M., I.S., M.O., A.L. and A.E.G.; funding acquisition, I.S. and A.E.G. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the MIUR “Fondo Departments of Excellence 2018–2022” of the DII Department at the University of Brescia, Italy. The IBM Power Systems Academic Initiative substantially contributed to the experimental analysis.
Data Availability Statement
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gerevini, A.E.; Lavelli, A.; Maffi, A.; Maroldi, R.; Minard, A.; Serina, I.; Squassina, G. Automatic classification of radiological reports for clinical care. Artif. Intell. Med. 2018, 91, 72–81. [Google Scholar] [CrossRef] [PubMed]
- Mehmood, T.; Gerevini, A.E.; Lavelli, A.; Serina, I. Combining Multi-task Learning with Transfer Learning for Biomedical Named Entity Recognition. In Proceedings of the Knowledge-Based and Intelligent Information & Engineering Systems: 24th International Conference KES-2020, Virtual Event, 16–18 September 2020; Volume 176, pp. 848–857. [Google Scholar] [CrossRef]
- Xu, M.; Jiang, H.; Watcharawittayakul, S. A Local Detection Approach for Named Entity Recognition and Mention Detection. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 1237–1247. [Google Scholar] [CrossRef]
- Mehmood, T.; Gerevini, A.; Lavelli, A.; Serina, I. Leveraging Multi-task Learning for Biomedical Named Entity Recognition. In Proceedings of the AI*IA 2019 - Advances in Artificial Intelligence—XVIIIth International Conference of the Italian Association for Artificial Intelligence, Rende, Italy, 19–22 November 2019; Volume 11946, pp. 431–444. [Google Scholar] [CrossRef]
- Settles, B. Biomedical named entity recognition using conditional random fields and rich feature sets. In Proceedings of the International Joint Workshop on Natural Language Processing in Biomedicine and its Applications (NLPBA/BioNLP), Geneva, Switzerland, 28–29 August 2004; pp. 107–110. [Google Scholar]
- Alex, B.; Haddow, B.; Grover, C. Recognising nested named entities in biomedical text. In Proceedings of the Biological, Translational, and Clinical Language Processing, Prague, Czech Republic, 29 June 2007; pp. 65–72. [Google Scholar]
- Song, H.J.; Jo, B.C.; Park, C.Y.; Kim, J.D.; Kim, Y.S. Comparison of named entity recognition methodologies in biomedical documents. Biomed. Eng. Online 2018, 17, 158. [Google Scholar] [CrossRef] [PubMed]
- Deng, L.; Hinton, G.E.; Kingsbury, B. New types of deep neural network learning for speech recognition and related applications: An overview. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2013, Vancouver, BC, Canada, 26–31 May 2013; pp. 8599–8603. [Google Scholar] [CrossRef]
- Ramsundar, B.; Kearnes, S.M.; Riley, P.; Webster, D.; Konerding, D.E.; Pande, V.S. Massively Multitask Networks for Drug Discovery. arXiv 2015, arXiv:1502.02072. Available online: https://arxiv.org/abs/1502.02072 (accessed on 10 February 2023).
- Putelli, L.; Gerevini, A.; Lavelli, A.; Serina, I. Applying Self-interaction Attention for Extracting Drug-Drug Interactions. In Proceedings of the AI*IA 2019—Advances in Artificial Intelligence—XVIIIth International Conference of the Italian Association for Artificial Intelligence, Rende, Italy, 19–22 November 2019; Volume 11946, pp. 445–460. [Google Scholar]
- Putelli, L.; Gerevini, A.E.; Lavelli, A.; Olivato, M.; Serina, I. Deep Learning for Classification of Radiology Reports with a Hierarchical Schema. In Proceedings of the Knowledge-Based and Intelligent Information & Engineering Systems: Proceedings of the 24th International Conference KES-2020, Virtual Event, 16–18 September 2020; Volume 176, pp. 349–359. [Google Scholar]
- Ciresan, D.C.; Meier, U.; Gambardella, L.M.; Schmidhuber, J. Convolutional Neural Network Committees for Handwritten Character Classification. In Proceedings of the 2011 International Conference on Document Analysis and Recognition, ICDAR 2011, Beijing, China, 18–21 September 2011; pp. 1135–1139. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. arXiv 2014, arXiv:1409.3215. [Google Scholar]
- Zhou, J.; Cao, Y.; Wang, X.; Li, P.; Xu, W. Deep recurrent models with fast-forward connections for neural machine translation. Trans. Assoc. Comput. Linguist. 2016, 4, 371–383. [Google Scholar] [CrossRef]
- Kim, Y.; Rush, A.M. Sequence-Level Knowledge Distillation. arXiv 2016, arXiv:1606.07947. [Google Scholar]
- Mehmood, T.; Serina, I.; Lavelli, A.; Putelli, L.; Gerevini, A. On the Use of Knowledge Transfer Techniques for Biomedical Named Entity Recognition. Future Internet 2023, 15, 79. [Google Scholar] [CrossRef]
- Hinton, G.E.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. Available online: http://arxiv.org/abs/1503.02531 (accessed on 10 February 2023).
- Wang, L.; Yoon, K. Knowledge Distillation and Student-Teacher Learning for Visual Intelligence: A Review and New Outlooks. arXiv 2020, arXiv:2004.05937. Available online: https://arxiv.org/abs/2004.05937 (accessed on 10 February 2023). [CrossRef] [PubMed]
- Mishra, A.K.; Marr, D. Apprentice: Using Knowledge Distillation Techniques To Improve Low-Precision Network Accuracy. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Mehmood, T.; Serina, I.; Lavelli, A.; Gerevini, A. Knowledge Distillation Techniques for Biomedical Named Entity Recognition. In Proceedings of the 4th Workshop on Natural Language for Artificial Intelligence (NL4AI 2020) co-located with the 19th International Conference of the Italian Association for Artificial Intelligence (AI*IA 2020), Online, 25–27 November 2020; Volume 2735, pp. 141–156. [Google Scholar]
- Bansal, T.; Belanger, D.; McCallum, A. Ask the gru: Multi-task learning for deep text recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, ACM, Boston, MA, USA, 15–19 September 2016; pp. 107–114. [Google Scholar]
- Wang, X.; Jiang, Y.; Bach, N.; Wang, T.; Huang, F.; Tu, K. Structure-Level Knowledge Distillation For Multilingual Sequence Labeling. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, 5–10 July 2020; pp. 3317–3330. [Google Scholar]
- Tang, R.; Lu, Y.; Liu, L.; Mou, L.; Vechtomova, O.; Lin, J. Distilling Task-Specific Knowledge from BERT into Simple Neural Networks. arXiv 2019, arXiv:1903.12136. Available online: https://arxiv.org/abs/1903.12136 (accessed on 10 February 2023).
- Mehmood, T.; Lavelli, A.; Serina, I.; Gerevini, A. Knowledge Distillation with Teacher Multi-task Model for Biomedical Named Entity Recognition. In Innovation in Medicine and Healthcare; Springer: Singapore, 2021; pp. 29–40. [Google Scholar]
- Mehmood, T.; Gerevini, A.; Lavelli, A.; Serina, I. Multi-task Learning Applied to Biomedical Named Entity Recognition Task. In Proceedings of the Sixth Italian Conference on Computational Linguistics, Bari, Italy, 13–15 November 2019; Volume 2481. [Google Scholar]
- Wang, X.; Zhang, Y.; Ren, X.; Zhang, Y.; Zitnik, M.; Shang, J.; Langlotz, C.; Han, J. Cross-type biomedical named entity recognition with deep multi-task learning. Bioinformatics 2019, 35, 1745–1752. [Google Scholar] [CrossRef] [PubMed]
- Crichton, G.; Pyysalo, S.; Chiu, B.; Korhonen, A. A neural network multi-task learning approach to biomedical named entity recognition. BMC Bioinform. 2017, 18, 368. [Google Scholar] [CrossRef] [PubMed]
- Sheldon, M.R.; Fillyaw, M.J.; Thompson, W.D. The use and interpretation of the Friedman test in the analysis of ordinal-scale data in repeated measures designs. Physiother. Res. Int. 1996, 1, 221–228. [Google Scholar] [CrossRef] [PubMed]
- Chou, H.H.; Chiu, C.T.; Liao, Y.P. Cross-layer knowledge distillation with KL divergence and offline ensemble for compressing deep neural network. APSIPA Trans. Signal Inf. Process. 2021, 10, e18. [Google Scholar] [CrossRef]
- Ranaldi, L.; Pucci, G. Knowing Knowledge: Epistemological Study of Knowledge in Transformers. Appl. Sci. 2023, 13, 677. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}