
Real-Time Cost Optimization Approach Based on Deep Reinforcement Learning in Software-Defined Security Middle Platform


Abstract
1. Introduction
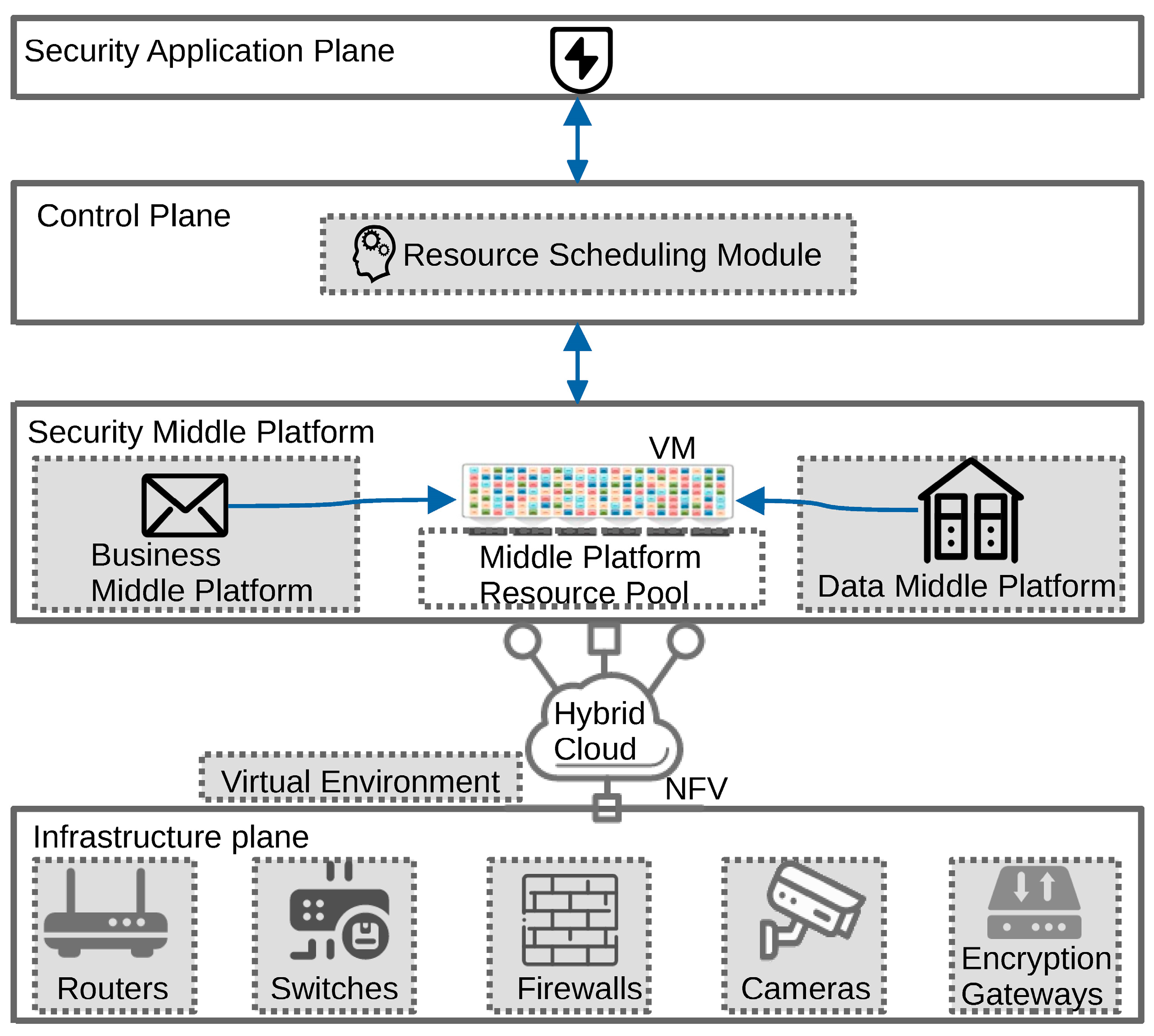
- Architecturally, it reduces deployment costs by optimizing the architecture and increasing the reuse of security infrastructure resources. Specifically, SDSmp proposes an automated control architecture for fragmented security requirements and security scenarios, realizes real-time scheduling and automatic control of Smp resources, and makes the security infrastructure physically and geographically independent through NFV and cloud computing technologies. Multi-party computation (MPC) ensures that the security application layer is data agnostic and protects user privacy from leakage, enabling the security infrastructure to achieve resource reuse by building Smp.
- In terms of modeling, an SDSmp cost optimization model is established based on DRL algorithms so that the intelligent scheduler in the control plane can learn how to rationally select Smp resources based on real-time experience. This reduces operational costs and achieves high quality-of-service satisfaction, a low response time, and load balancing.
- An experimental SDSmp environment is built for implementation. The proposed DRL-based algorithm for real-time cost optimization of MPC-SDSmp is compared with existing real-time job-scheduling algorithms under different workload patterns. The experimental results show that the proposed method outperforms existing real-time methods regarding cost, average response time, QoS satisfaction, and load balancing.
2. Related Work
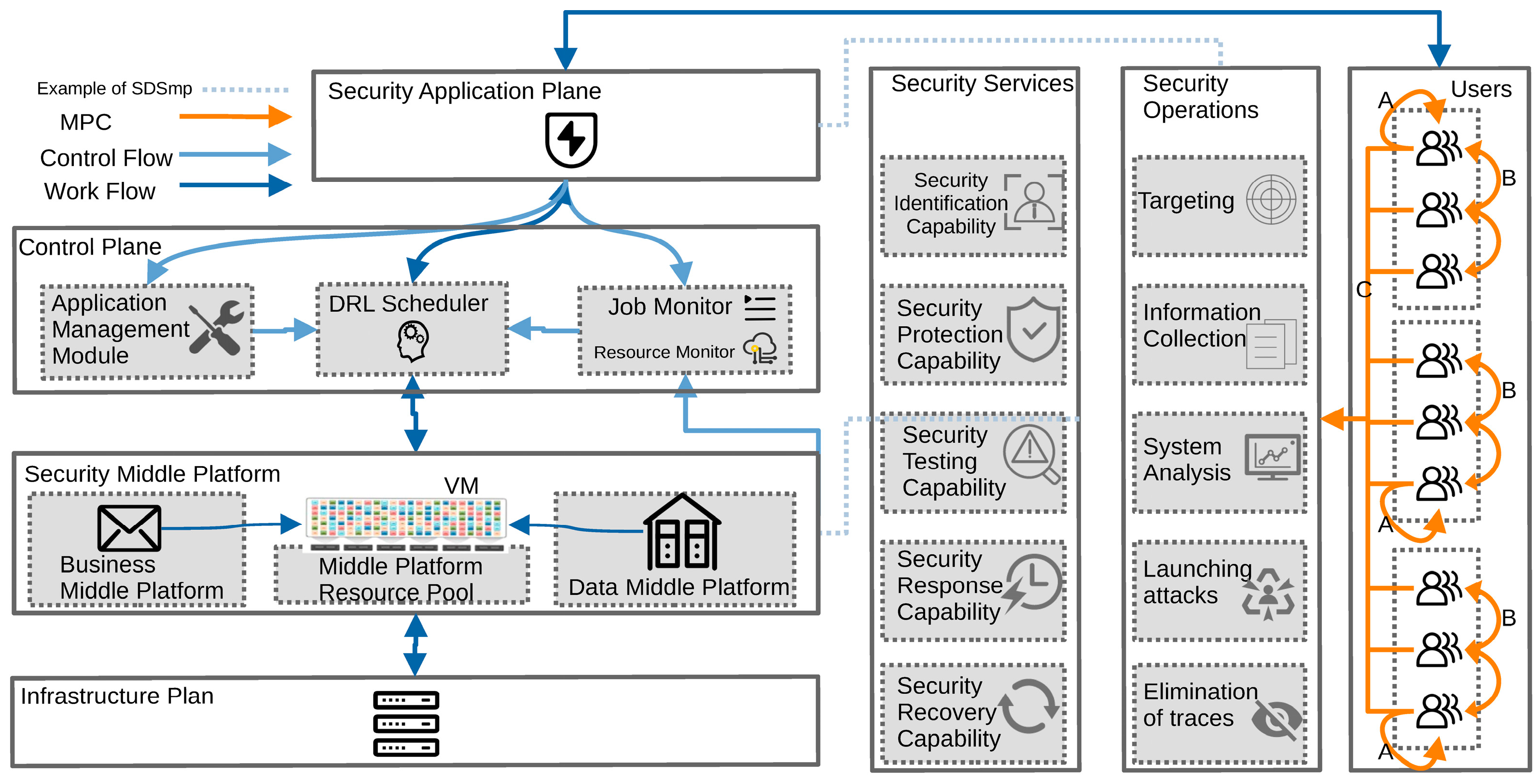
3. Our Scheduling Model
3.1. Foreground Job Characteristics
3.2. Security Middle Platform Resources
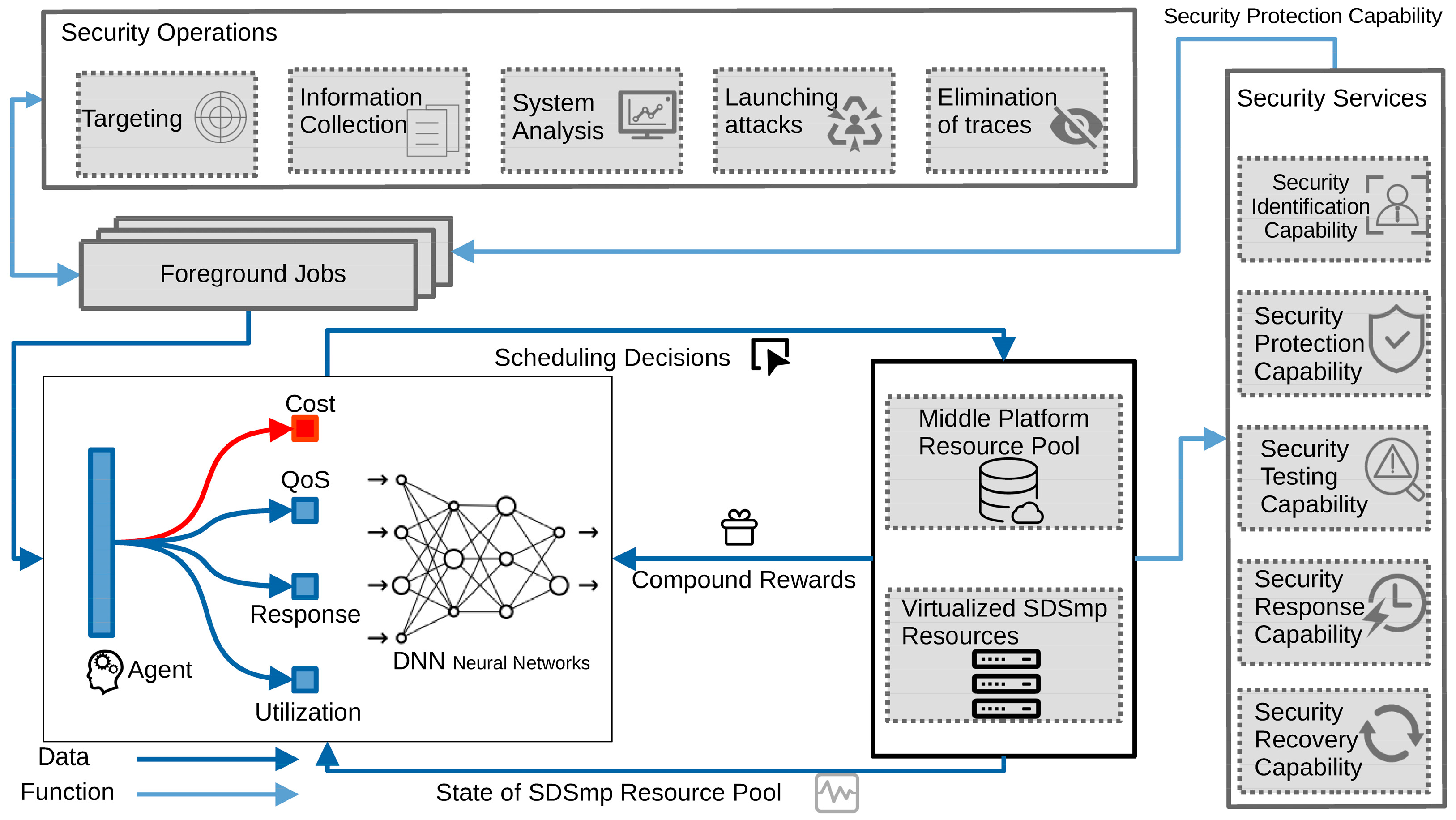
3.3. Job-Scheduling Mechanism
4. Methodology
4.1. Basics of DRL
4.2. Our DRL-Based Scheduling
4.2.1. Action Space
4.2.2. State Space
4.2.3. Action Selection and State Transition
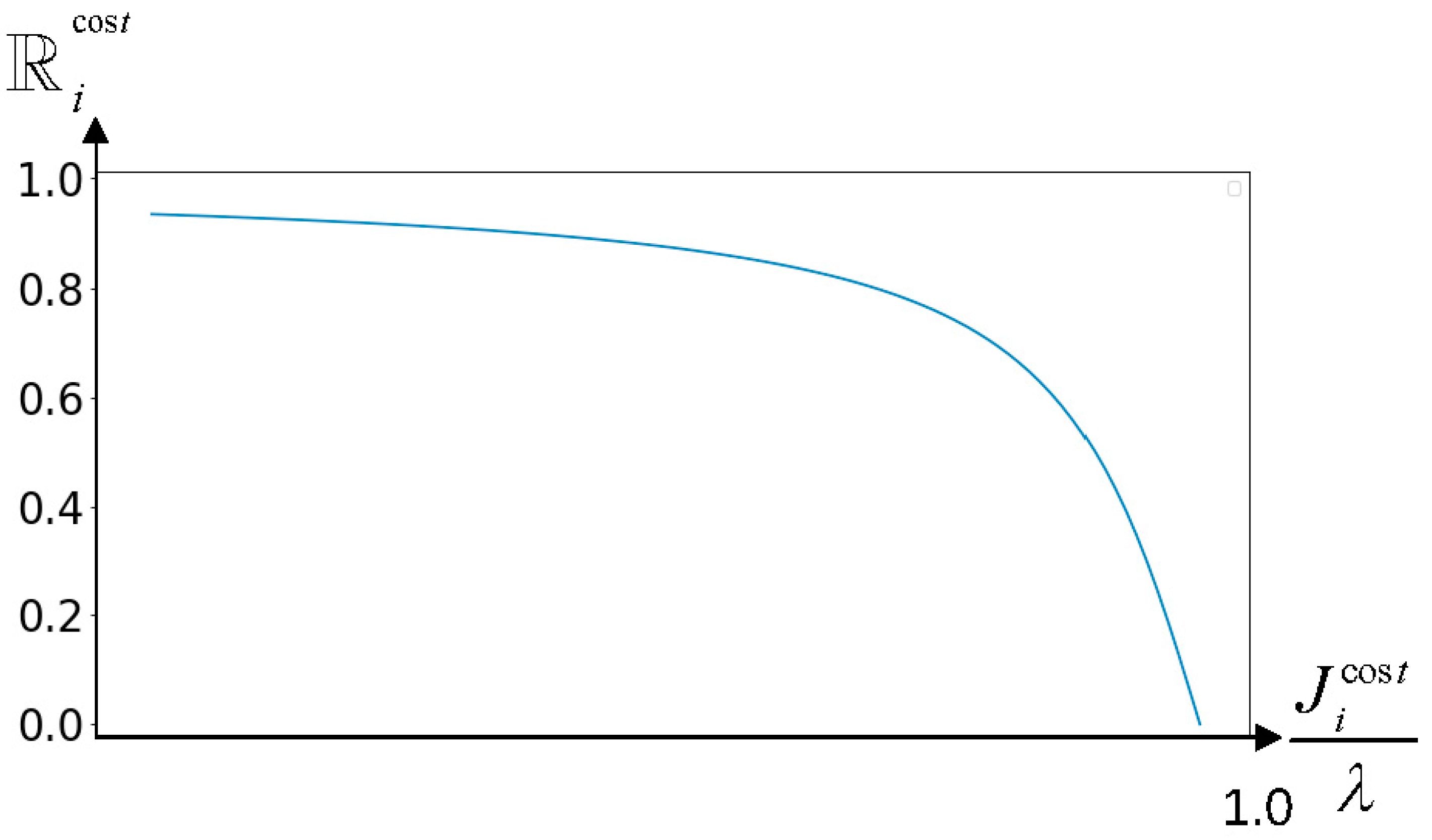
4.2.4. Reward Function
4.3. Training Phase
| Algorithm 1: The DRL-based algorithm for real-time cost optimization of the MPC-SDSmp |
|
5. Evaluation
5.1. Experimental Framework
5.2. Baseline Solutions
5.3. Experiment Results and Analysis
5.3.1. Random Workload Mode
5.3.2. Low-Frequency Workload Mode
5.3.3. High-Frequency Workload Mode
5.3.4. Experimental Analysis
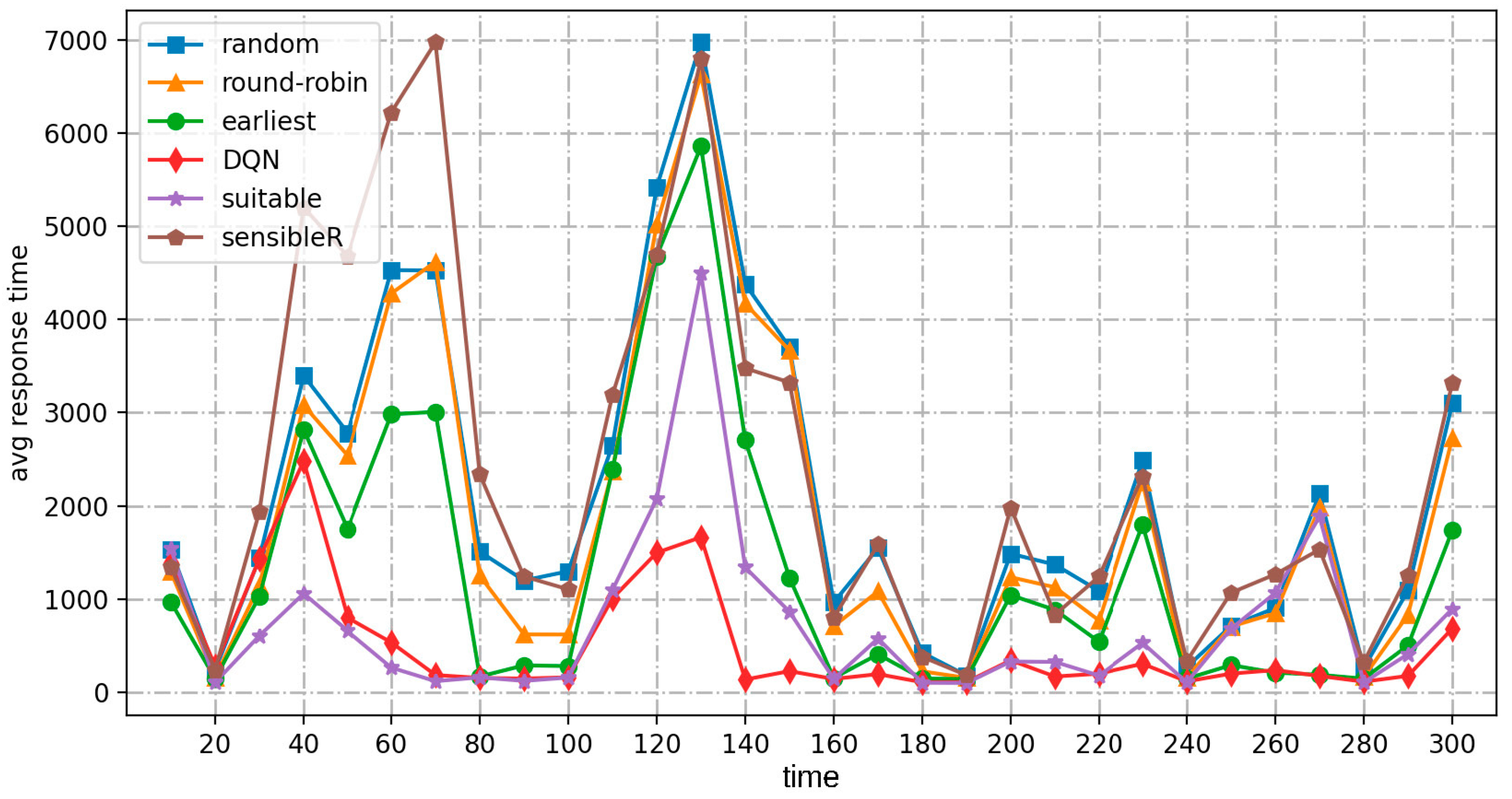
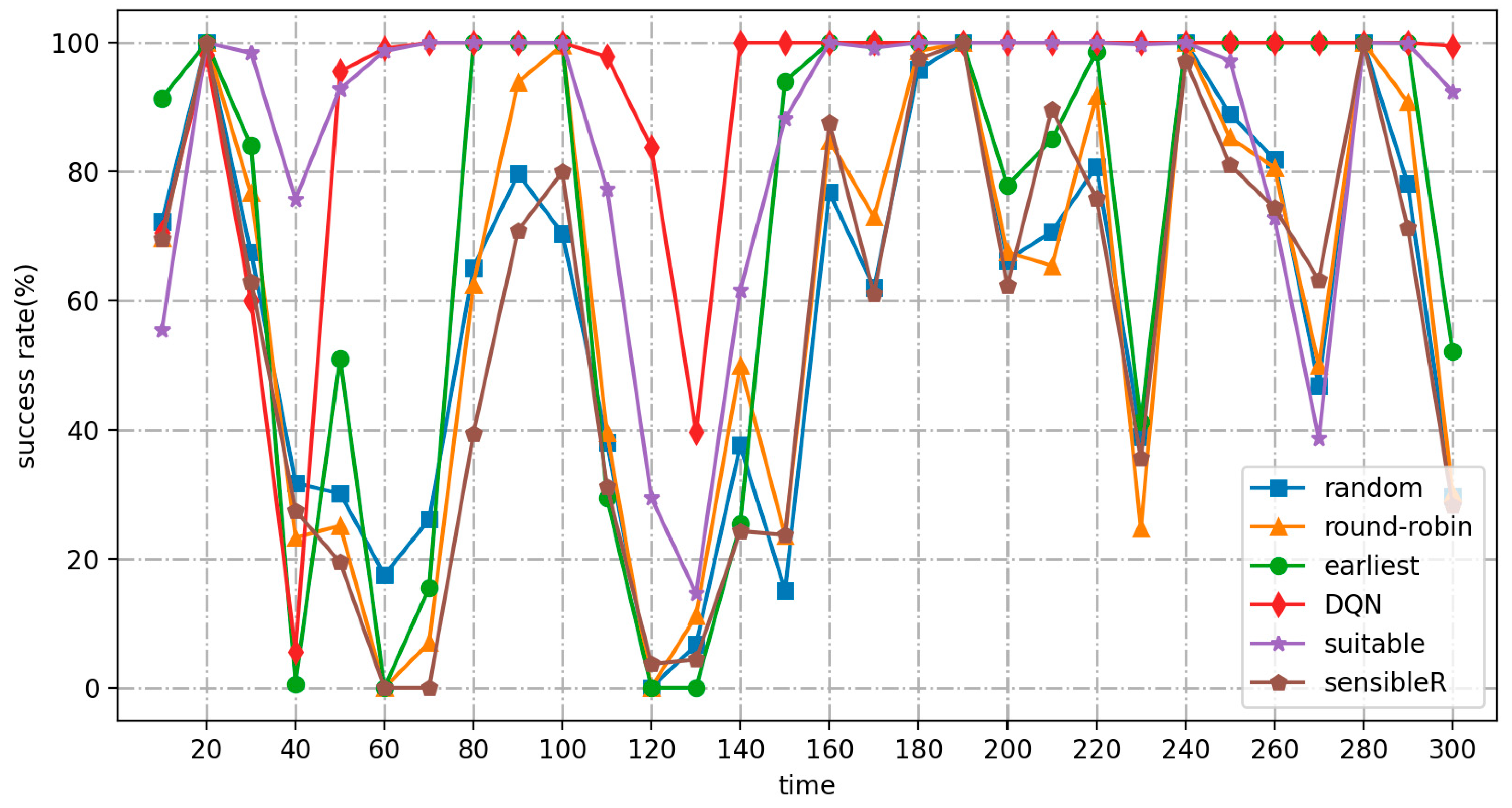
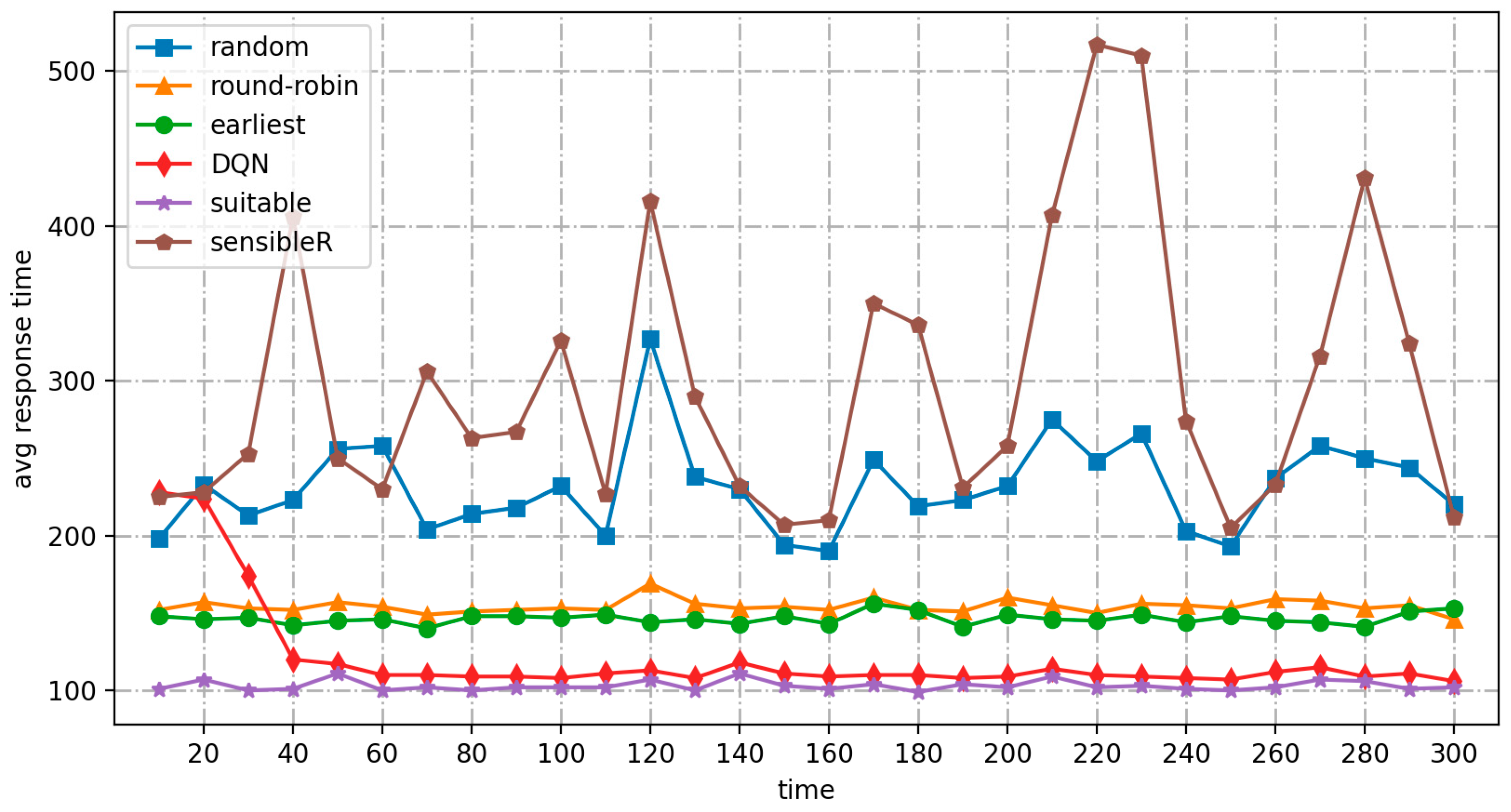
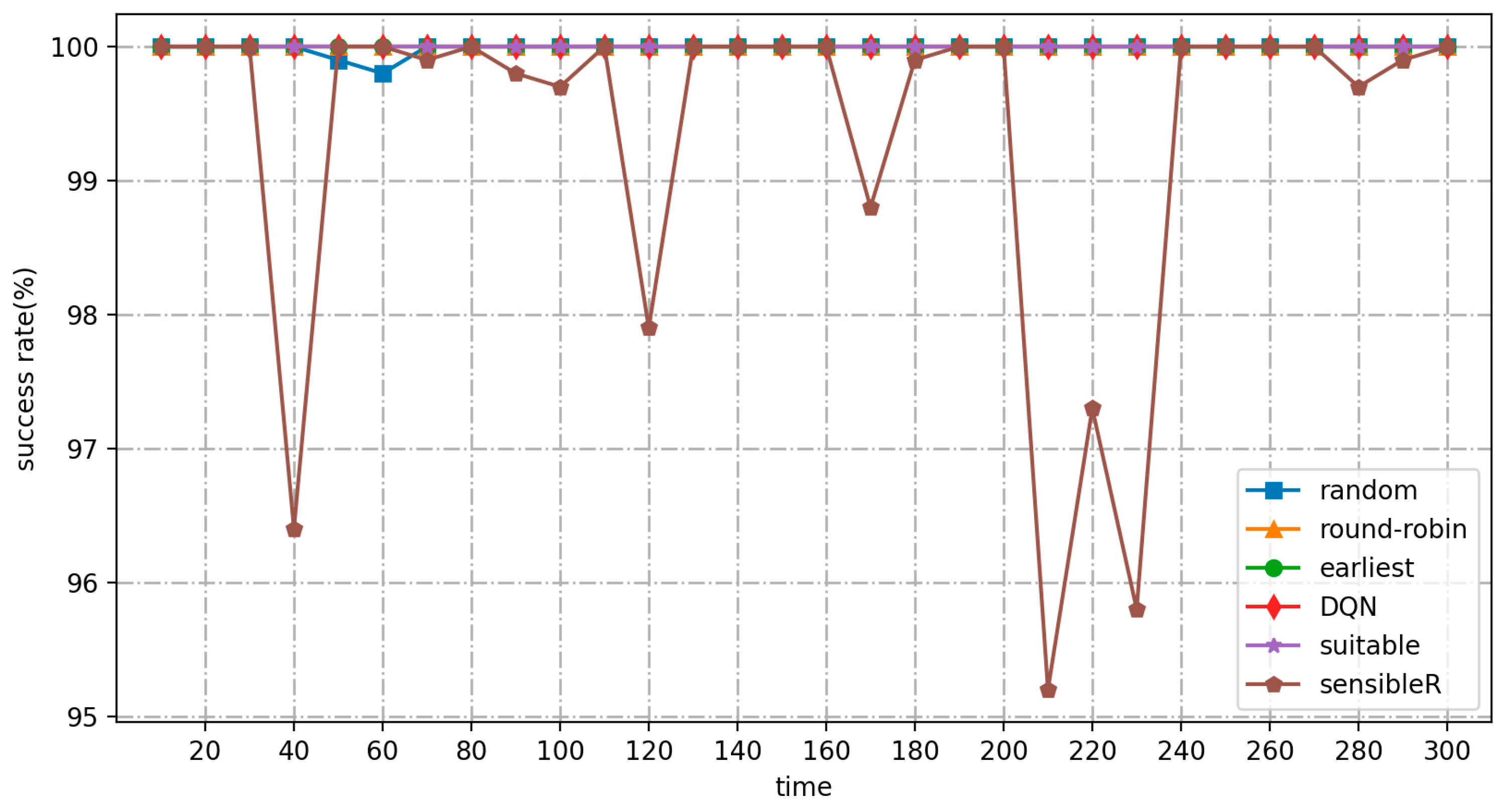
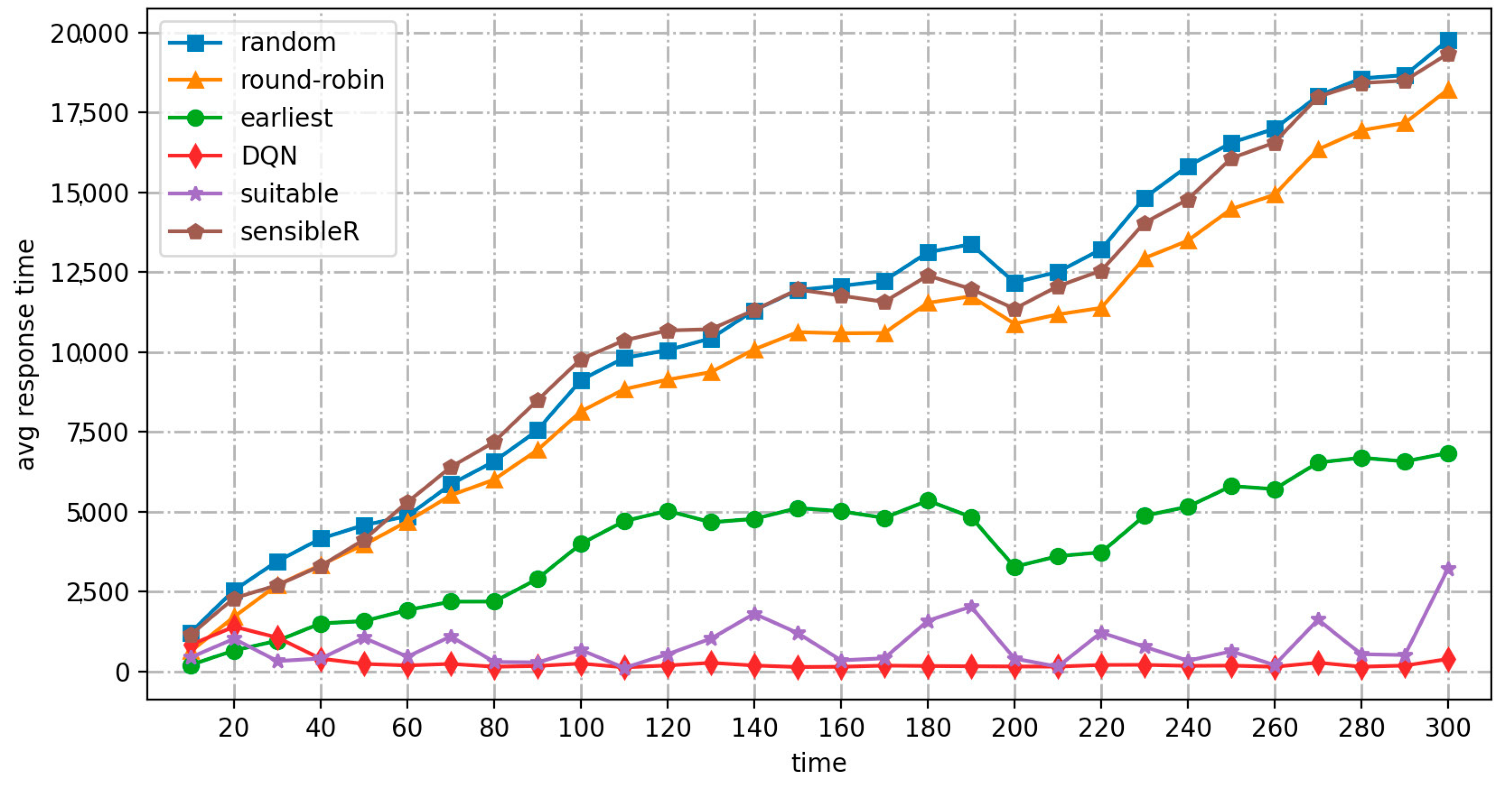
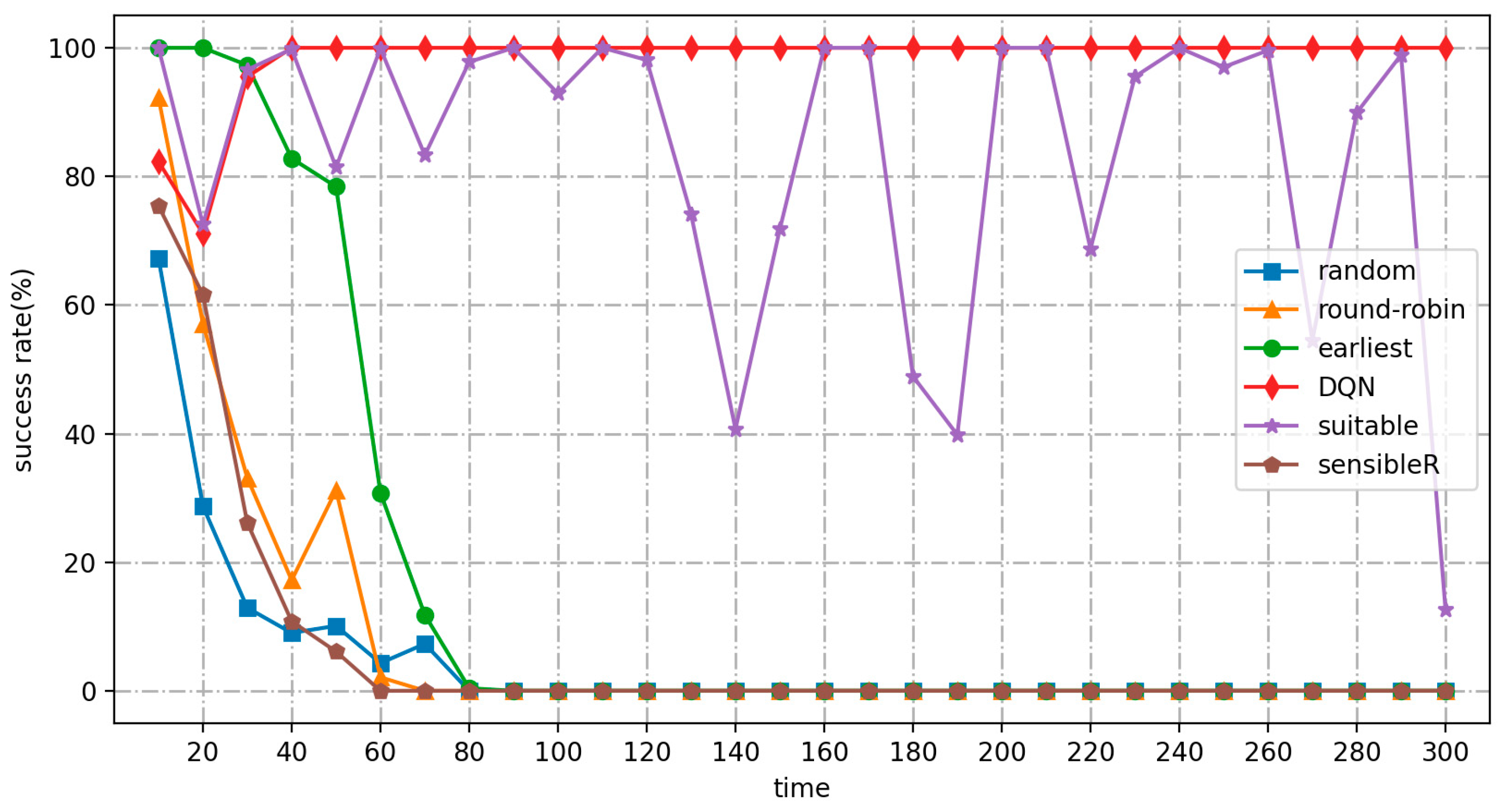
- As the number or frequency of input jobs increases, the average response time of the DRL-based algorithm for real-time cost optimization of the MPC-SDSmp increases. Comparing the low-frequency and high-frequency workload modes, the proposed algorithm shows a more significant advantage in the high-frequency workload mode, especially when it is already obvious that the other methods do not work correctly. Suitable and the proposed algorithm still meet the availability. The proposed method is the only one among the six methods that maintains a high performance and stability, has a low average response time, the lowest load balancing rate, the lowest cost, and the highest QoS satisfaction.
- Compared to the random high-frequency workload model, the proposed algorithm is based on training experience. It has good robustness after training, making it easier to handle an unknown number of job types and more suitable for real-time environments. By encapsulating the structure, the software definition also removes the Smp from the application and infrastructure layers, improving security.
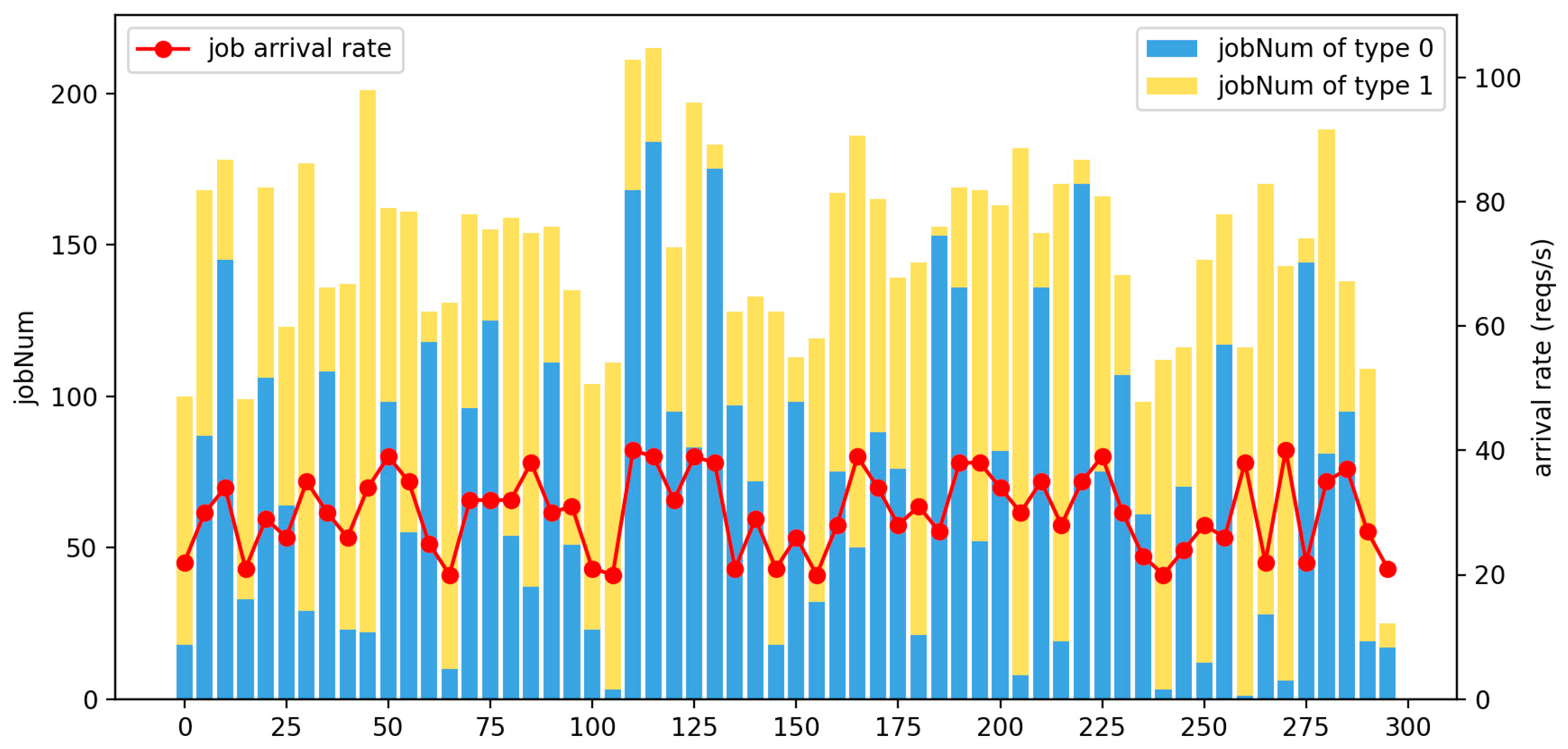
- The complete training phase from 0 s to 40 s and the subsequent execution phase during the experiment are shown in Figure 5, Figure 6, Figure 7, Figure 8, Figure 9, Figure 10, Figure 11, Figure 12 and Figure 13 instead of showing the real-time scheduling separately from the offline pretraining. It is important to emphasize that the focus is on real-time scheduling, cost, and QoS optimization of Smp resources, not offline training. Because the offline training is done locally and does not occupy the cloud Smp resources, the consumption of Smp resources is almost 0. After the training is completed, the scheduling can be done directly. In addition to the training being completed offline, as shown in Figure 8 in low-frequency time (late at night), the Smp business and service switching process provides optional smooth online senseless deployment. The advantage of online deployment is that redeployment of the new Smp service does not interrupt the original service. There is no need to shut down the system to retrain. Only the new service needs to be online after offline training. The training copy can be senselessly switched during the regular operation of the original service, which has better scalability and fault tolerance with minimal cost difference. Therefore, the method shows good stability and robustness in the variable SDSmp environment and itself has a specific resistance to attacks and disaster recovery capabilities, making it more applicable.
- The load balancing rate metric visualizes the degree of resource utilization and overhead during the actual operation of the different schemes. As shown in Table 5, both this and the suitable method achieve advantages over existing real-time methods in terms of long-term operational performance under the three workload modes. The low-frequency simulation of the quiescent environment is performed smoothly by all methods, and the load balancing rates are similar. In the high-frequency and random load modes, because both the present method and suitable have the characteristic of learning, in the continuous operation process the other methods fall far behind. In the high-frequency load mode, the other methods enter the performance bottleneck and cannot operate normally. However, the current and suitable methods still work, proving they are still available in large-scale, high-load operation scenarios. The advantages of this method in terms of cost and load balancing are apparent.
6. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Atzori, L.; Iera, A.; Morabito, G. The internet of things: A survey. Comput. Netw. 2010, 54, 2787–2805. [Google Scholar] [CrossRef]
- Xu, Y.; Xiong, C. Research on big data technology and application in internet era. In Proceedings of the 2020 International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Fuzhou, China, 12–14 June 2020; pp. 122–124. [Google Scholar]
- Harika, J.; Baleeshwar, P.; Navya, K.; Shanmugasundaram, H. A review on artificial intelligence with deep human reasoning. In Proceedings of the 2022 International Conference on Applied Artificial Intelligence and Computing (ICAAIC), Salem, India, 9–11 May 2022; pp. 81–84. [Google Scholar]
- Farhan, L.; Hameed, R.S.; Ahmed, A.S.; Fadel, A.H.; Gheth, W.; Alzubaidi, L.; Fadhel, M.A.; Al-Amidie, M. Energy efficiency for green internet of things (IoT) networks: A survey. Network 2021, 1, 279–314. [Google Scholar] [CrossRef]
- Almusaylim, Z.A.; Zaman, N. A review on smart home present state and challenges: Linked to context-awareness internet of things (IoT). Wirel. Netw. 2019, 25, 3193–3204. [Google Scholar] [CrossRef]
- Amin, F.; Abbasi, R.; Mateen, A.; Ali Abid, M.; Khan, S. A step toward next-generation advancements in the internet of things technologies. Sensors 2022, 22, 8072. [Google Scholar] [CrossRef]
- Barnett, G.A.; Ruiz, J.B.; Xu, W.W.; Park, J.Y.; Park, H.W. The world is not flat: Evaluating the inequality in global information gatekeeping through website co-mentions. Technol. Forecast. Soc. Chang. 2017, 117, 38–45. [Google Scholar] [CrossRef]
- Alhaj, A.N.; Dutta, N. Analysis of security attacks in SDN network: A comprehensive survey. In Contemporary Issues in Communication, Cloud and Big Data Analytics: Proceedings of CCB 2020; Springer: Singapore, 2022; pp. 27–37. [Google Scholar]
- Qiu, R.; Qin, Y.; Li, Y.; Zhou, X.; Fu, J.; Li, W.; Shi, J. A software-defined security middle platform architecture. In Proceedings of the 5th International Conference on Computer Science and Software Engineering, Guilin, China, 21–23 October 2022; pp. 647–651. [Google Scholar]
- Al-Ayyoub, M.; Jararweh, Y.; Benkhelifa, E.; Vouk, M.; Rindos, A. Sdsecurity: A software defined security experimental framework. In Proceedings of the 2015 IEEE International Conference on Communication Workshop (ICCW), London, UK, 8–12 June 2015; pp. 1871–1876. [Google Scholar]
- Chowdhury, S.R.; Bari, M.F.; Ahmed, R.; Boutaba, R. Payless: A low cost network monitoring framework for software defined networks. In Proceedings of the 2014 IEEE Network Operations and Management Symposium (NOMS), Krakow, Poland, 5–9 May 2014; pp. 1–9. [Google Scholar]
- Su, Z.; Wang, T.; Xia, Y.; Hamdi, M. CeMon: A cost-effective flow monitoring system in software defined networks. Comput. Netw. 2015, 92, 101–115. [Google Scholar] [CrossRef]
- Iqbal, W.; Abbas, H.; Daneshmand, M.; Rauf, B.; Bangash, Y.A. An in-depth analysis of IoT security requirements, challenges, and their countermeasures via software-defined security. IEEE Internet Things J. 2020, 7, 10250–10276. [Google Scholar] [CrossRef]
- Hawilo, H.; Shami, A.; Mirahmadi, M.; Asal, R. NFV: State of the art, challenges, and implementation in next generation mobile networks (vEPC). IEEE Netw. 2014, 28, 18–26. [Google Scholar] [CrossRef]
- Li, X.; Zheng, Z.; Dai, H.N. When services computing meets blockchain: Challenges and opportunities. J. Parallel Distrib. Comput. 2021, 150, 1–14. [Google Scholar] [CrossRef]
- Kim, Y.; Nam, J.; Park, T.; Scott-Hayward, S.; Shin, S. SODA: A software-defined security framework for IoT environments. Comput. Netw. 2019, 163, 106889. [Google Scholar] [CrossRef]
- Amin, F.; Ahmad, A.; Sang Choi, G.S. Towards trust and friendliness approaches in the social internet of things. Appl. Sci. 2019, 9, 166. [Google Scholar] [CrossRef]
- Ranjan, R.; Rana, O.; Nepal, S.; Yousif, M.; James, P.; Wen, Z.; Barr, S.; Watson, P.; Jayaraman, P.P.; Georgakopoulos, D.; et al. The next grand challenges: Integrating the internet of things and data science. IEEE Cloud Comput. 2018, 5, 12–26. [Google Scholar] [CrossRef]
- Knott, B.; Venkataraman, S.; Hannun, A.; Sengupta, S.; Ibrahim, M.; van der Maaten, L. Crypten: Secure multi-party computation meets machine learning. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2021; Volume 34, pp. 4961–4973. [Google Scholar]
- Liu, M.; Cheng, L.; Gu, Y.; Wang, Y.; Liu, Q.; O′Connor, N.E. MPC-CSAS: Multi-party computation for real-time privacy-preserving speed advisory systems. IEEE Trans. Intell. Transp. Syst. 2021, 23, 5887–5893. [Google Scholar] [CrossRef]
- Arzo, S.T.; Naiga, C.; Granelli, F.; Bassoli, R.; Devetsikiotis, M.; Fitzek, F.H.P. A theoretical discussion and survey of network automation for IoT: Challenges and opportunity. IEEE Internet Things J. 2021, 8, 12021–12045. [Google Scholar] [CrossRef]
- Ali, A.; Mateen, A.; Hanan, A.; Amin, F. Advanced security framework for internet of things (IoT). Technologies 2022, 10, 60. [Google Scholar] [CrossRef]
- Almaiah, M.A.; Al-Zahrani, A.; Almomani, O.; Alhwaitat, A.K. Classification of cyber security threats on mobile devices and applications. In Artificial Intelligence and Blockchain for Future Cybersecurity Applications; Springer International Publishing: Cham, Switzerland, 2021; pp. 107–123. [Google Scholar]
- Shehab, A.H.; Al-Janabi, S.T.F. Microsoft Azure IoT-based edge computing for smart homes. In Proceedings of the 2020 International Conference on Decision Aid Sciences and Application (DASA), Sakheer, Bahrain, 8–9 November 2020; pp. 315–319. [Google Scholar]
- Wei, Y.; Pan, L.; Liu, S.; Wu, L.; Meng, X. DRL-scheduling: An intelligent QoS-aware job scheduling framework for applications in clouds. IEEE Access 2018, 6, 55112–55125. [Google Scholar] [CrossRef]
- Wang, X.; Chen, M.; Xing, C. SDSNM: A software-defined security networking mechanism to defend against DDoS attacks. In Proceedings of the 2015 ninth international conference on frontier of computer science and technology, Dalian, China, 26–28 August 2015; pp. 115–121. [Google Scholar]
- Yanbing, L.; Xingyu, L.; Yi, J.; Yunpeng, X. SDSA: A framework of a software-defined security architecture. China Commun. 2016, 13, 178–188. [Google Scholar] [CrossRef]
- El Moussaid, N.; Toumanari, A.; El Azhari, M. Security analysis as software-defined security for SDN environment. In Proceedings of the 2017 Fourth International Conference on Software Defined Systems (SDS), Valencia, Spain, 8–11 May 2017; pp. 87–92. [Google Scholar]
- Liang, X.; Qiu, X. A software defined security architecture for SDN-based 5G network. In Proceedings of the 2016 IEEE International Conference on Network Infrastructure and Digital Content (IC-NIDC), Beijing, China, 23–25 September 2016; pp. 17–21. [Google Scholar]
- Liyanage, M.; Ahmed, I.; Ylianttila, M.; Santos, J.L.; Kantola, R.; Perez, O.L.; Jimenez, C. Security for future software defined mobile networks. In Proceedings of the 2015 9th International Conference on Next Generation Mobile Applications, Services and Technologies, Cambridge, UK, 9–11 September 2015; pp. 256–264. [Google Scholar]
- Luo, S.; Salem, M.B. Orchestration of software-defined security services. In Proceedings of the 2016 IEEE International Conference on Communications Workshops (ICC), Kuala Lumpur, Malaysia, 23–27 May 2016; pp. 436–441. [Google Scholar]
- Farahmandian, S.; Hoang, D.B. SDS 2: A novel software-defined security service for protecting cloud computing infrastructure. In Proceedings of the 2017 IEEE 16th International Symposium on Network Computing and Applications (NCA), Cambridge, MA, USA, 30 October–1 November 2017; pp. 1–8. [Google Scholar]
- Kaur, S.; Kumar, K.; Singh, J.; Ghumman, N.S. Round-robin based load balancing in Software Defined Networking. In Proceedings of the 2015 2nd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 11–13 March 2015; pp. 2136–2139. [Google Scholar]
- Compastié, M.; Badonnel, R.; Festor, O.; He, R.; Kassi-Lahlou, M. Unikernel-based approach for software-defined security in cloud infrastructures. In Proceedings of the NOMS 2018-2018 IEEE/IFIP Network Operations and Management Symposium, Taipei, Taiwan, 23–27 April 2018; pp. 1–7. [Google Scholar]
- Wang, S.; Wu, J.; Zhang, S.; Wang, K. SSDS: A smart software-defined security mechanism for vehicle-to-grid using transfer learning. IEEE Access 2018, 6, 63967–63975. [Google Scholar] [CrossRef]
- Yang, J.; Zhou, C.; Tian, Y.C.; Yang, S.H. A software-defined security approach for securing field zones in industrial control systems. IEEE Access 2019, 7, 87002–87016. [Google Scholar] [CrossRef]
- Compastié, M.; Badonnel, R.; Festor, O.; He, R. A tosca-oriented software-defined security approach for unikernel-based protected clouds. In Proceedings of the 2019 IEEE Conference on Network Softwarization (NetSoft), Paris, France, 24–28 June 2019; pp. 151–159. [Google Scholar]
- Meng, X.; Zhao, Z.; Li, R.; Zhang, H. An intelligent honeynet architecture based on software defined security. In Proceedings of the 2017 9th International Conference on Wireless Communications and Signal Processing (WCSP), Nanjing, China, 11–13 October 2017; pp. 1–6. [Google Scholar]
- Akbar Neghabi, A.; Jafari Navimipour, N.; Hosseinzadeh, M.; Rezaee, A. Nature-inspired meta-heuristic algorithms for solving the load balancing problem in the software-defined network. Int. J. Commun. Syst. 2019, 32, e3875. [Google Scholar] [CrossRef]
- Mohanty, S.; Priyadarshini, P.; Sahoo, S.; Sahoo, B.; Sethi, S. Metaheuristic techniques for controller placement in Software-Defined networks. In Proceedings of the TENCON 2019-2019 IEEE Region 10 Conference (TENCON), Kochi, India, 17–20 October 2019; pp. 897–902. [Google Scholar]
- Masood, M.; Fouad, M.M.; Seyedzadeh, S.; Glesk, I. Energy efficient software defined networking algorithm for wireless sensor networks. Transp. Res. Procedia 2019, 40, 1481–1488. [Google Scholar] [CrossRef]
- Nejad, M.M.; Mashayekhy, L.; Grosu, D. Truthful greedy mechanisms for dynamic virtual machine provisioning and allocation in clouds. IEEE Trans. Parallel Distrib. Syst. 2014, 26, 594–603. [Google Scholar] [CrossRef]
- Liu, Y.; Zhou, J.; Lim, A.; Hu, Q. A tree search heuristic for the resource constrained project scheduling problem with transfer times. Eur. J. Oper. Res. 2023, 304, 939–951. [Google Scholar] [CrossRef]
- Wang, L.; Gelenbe, E. Adaptive dispatching of tasks in the cloud. IEEE Trans. Cloud Comput. 2015, 6, 33–45. [Google Scholar] [CrossRef]
- Sahoo, K.S.; Sahoo, B.; Dash, R.; Jena, N. Optimal controller selection in software defined network using a greedy-SA algorithm. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 2342–2346. [Google Scholar]
- Badotra, S.; Panda, S.N.; Datta, P. Detection and Prevention from DDoS Attack Using Software-Defined Security. In Progress in Advanced Computing and Intelligent Engineering: Proceedings of ICACIE 2019; Springer: Singapore, 2021; Volume 1, pp. 207–217. [Google Scholar]
- Liyanage, M.; Ahmad, I.; Okwuibe, J.; de Oca, E.M.; Mai, H.L.; Perez, O.L.; Itzazelaia, M.U. Software defined security monitoring in 5G networks. In A Comprehensive Guide to 5G Security; John and Wiley and Sons: Hoboken, NJ, USA, 2018; pp. 231–243. [Google Scholar]
- Blanc, G.; Kheir, N.; Ayed, D.; Lefebvre, V.; de Oca, E.M.; Bisson, P. Towards a 5G security architecture: Articulating software-defined security and security as a service. In Proceedings of the 13th International Conference on Availability, Reliability and Security, Vienna, Austria, 23–26 August 2018; pp. 1–8. [Google Scholar]
- Kalinin, M.; Zegzhda, P.; Zegzhda, D.; Vasiliev, Y.; Belenko, V. Software defined security for vehicular ad hoc networks. In Proceedings of the 2016 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Republic of Korea, 19–21 October 2016; pp. 533–537. [Google Scholar]
- Xu, X.; Hu, L. A software defined security scheme based on SDN environment. In Proceedings of the 2017 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC), Nanjing, China, 12–14 October 2017; pp. 504–512. [Google Scholar]
- Yungaicela-Naula, N.M.; Vargas-Rosales, C.; Pérez-Díaz, J.A.; Zareei, M. Towards security automation in software defined networks. Comput. Commun. 2022, 183, 64–82. [Google Scholar] [CrossRef]
- Onyema, E.M.; Kumar, M.A.; Balasubaramanian, S.; Bharany, S.; Rehman, A.U.; Eldin, E.T.; Shafiq, M. A security policy protocol for detection and prevention of internet control message protocol attacks in software defined networks. Sustainability 2022, 14, 11950. [Google Scholar] [CrossRef]
- François-Lavet, V.; Henderson, P.; Islam, R.; Bellemare, M.G.; Pineau, J. An introduction to deep reinforcement learning. In Foundations and Trends® in Machine Learning; Now Publisher: Norwell, MA, USA, 2018; Volume 11, pp. 219–354. [Google Scholar]
- Henderson, P.; Islam, R.; Bachman, P.; Pineau, J.; Precup, D.; Meger, D. Deep reinforcement learning that matters. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. No. 1. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Hassabis, D. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Abundo, M.; Di Valerio, V.; Cardellini, V.; Presti, F.L. QoS-aware bidding strategies for VM spot instances: A reinforcement learning approach applied to periodic long running jobs. In Proceedings of the 2015 IFIP/IEEE International Symposium on Integrated Network Management (IM), Ottawa, ON, Canada, 11–15 May 2015; pp. 53–61. [Google Scholar]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Casas-Velasco, D.M.; Rendon, O.M.C.; da Fonseca, N.L. Intelligent routing based on reinforcement learning for software-defined networking. IEEE Trans. Netw. Serv. Manag. 2020, 18, 870–881. [Google Scholar] [CrossRef]
- Liu, W.X.; Cai, J.; Chen, Q.C.; Wang, Y. DRL-R: Deep reinforcement learning approach for intelligent routing in software-defined data-center networks. J. Netw. Comput. Appl. 2021, 177, 102865. [Google Scholar] [CrossRef]
- Rischke, J.; Sossalla, P.; Salah, H.; Fitzek, F.H.; Reisslein, M. QR-SDN: Towards reinforcement learning states, actions, and rewards for direct flow routing in software-defined networks. IEEE Access 2020, 8, 174773–174791. [Google Scholar] [CrossRef]
- Alzahrani, A.O.; Alenazi, M.J. Designing a network intrusion detection system based on machine learning for software defined networks. Future Internet 2021, 13, 111. [Google Scholar] [CrossRef]
- Assis, M.V.; Carvalho, L.F.; Lloret, J.; Proença, M.L., Jr. A GRU deep learning system against attacks in software defined networks. J. Netw. Comput. Appl. 2021, 177, 102942. [Google Scholar] [CrossRef]
- Chen, J.; Wang, Y.; Ou, J.; Fan, C.; Lu, X.; Liao, C.; Zhang, H. Albrl: Automatic load-balancing architecture based on reinforcement learning in software-defined networking. Wirel. Commun. Mob. Comput. 2022, 2022, 1–17. [Google Scholar] [CrossRef]
- Haque, I.T.; Abu-Ghazaleh, N. Wireless software defined networking: A survey and taxonomy. IEEE Commun. Surv. Tutor. 2016, 18, 2713–2737. [Google Scholar] [CrossRef]
- Barakabitze, A.A.; Ahmad, A.; Mijumbi, R.; Hines, A. 5G network slicing using SDN and NFV: A survey of taxonomy, architectures and future challenges. Comput. Netw. 2020, 167, 106984. [Google Scholar] [CrossRef]
- Malawski, M.; Figiela, K.; Nabrzyski, J. Cost minimization for computational applications on hybrid cloud infrastructures. Future Gener. Comput. Syst. 2013, 29, 1786–1794. [Google Scholar] [CrossRef]
- Chang, T.; Kong, D.; Hao, N.; Xu, K.; Yang, G. Solving the dynamic weapon target assignment problem by an improved artificial bee colony algorithm with heuristic factor initialization. Appl. Soft Comput. 2018, 70, 845–863. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Meaning |
|---|---|
| The ID of the foreground job | |
| The arrival time of the foreground job | |
| The type of the foreground job | |
| The length of the foreground job | |
| The QoS requirement of the foreground job | |
| The response time of the foreground job | |
| The runtime of the foreground job | |
| The waiting time of the foreground job | |
| The cost of the foreground job | |
| The ID of Smp resource (VM) | |
| The type of Smp resource (VM) | |
| The computing processing speed of Smp resource (VM) | |
| The IO processing speed of Smp resource (e.g., instructions per second) | |
| The available time of Smp resource (VM) | |
| The execution cost of Smp resource (VM) per time unit | |
| The start-up cost of Smp resource (VM) | |
| The reward function reflecting QoS satisfaction | |
| The reward function reflecting user satisfaction with costs | |
| The reward function of DRL | |
| Whether security operations are successfully dispatched and security protections take effect |
| Notation | Meaning |
|---|---|
| The reward function reflecting QoS satisfaction | |
| The runtime of the foreground job | |
| The response time of the foreground job | |
| The QoS requirement of the foreground job | |
| The reward function reflecting user satisfaction with costs | |
| The hyperparameter is used to indicate the maximum cost of the job | |
| The cost of the foreground job | |
| The reward function of DRL | |
| The return function of DRL | |
| The discount factor of DRL | |
| The Q-value function of DRL | |
| Action space | |
| State space | |
| The current time | |
| The random parameters of Q | |
| The training minibatch | |
| Fixed parameters when calculating the MSE loss | |
| The exploration rate | |
| The learning frequency | |
| The minibatch | |
| The replay period | |
| The replay memory |
| Computing-Intensive Job | IO-Intensive Job | |
|---|---|---|
| High-CPU Smp resource | AVG 1000 MIPS STD 100 MIPS | AVG 500 MIPS STD 50 MIPS |
| High-IO Smp resource | AVG 500 MIPS STD 50 MIPS | AVG 1000 MIPS STD 100 MIPS |
| Workload Modes | Arrival Rate | AVG (%) | STD (%) |
|---|---|---|---|
| Random | [0, 100] | 53.53 | 29.51 |
| Low-frequency | [20, 40] | 30.07 | 6.36 |
| High-frequency | [60, 80] | 70.32 | 5.57 |
| Workload Modes | Metric | DQN | Random | RR | Earliest | Suitable | SensibleR |
|---|---|---|---|---|---|---|---|
| Literature | Proposed | [28,30] | [29,33] | [10,16,31,32] | [42,45] | [44] | |
| Random | Cost | 312.82 | 363.32 | 365.46 | 364.77 | 346.01 | 369.39 |
| QoS satisfaction | 96.2% | 51.3% | 75.3% | 74.4% | 81.2% | 47.8% | |
| Balancing rate | 62.8% | 73.1% | 72.6% | 75.7% | 68.1% | 78.2% | |
| Response time | 0.203 | 0.712 | 0.426 | 0.421 | 0.275 | 1.116 | |
| Low-frequency | Cost | 109.30 | 123.32 | 122.32 | 128.57 | 118.56 | 121.74 |
| QoS satisfaction | 99.9% | 99.5% | 99.9% | 99.9% | 99.9% | 98.4% | |
| Balancing rate | 26.8% | 29.8% | 27.7% | 29.4% | 28.6% | 33.7% | |
| Response time | 0.115 | 0.237 | 0.163 | 0.158 | 0.057 | 0.254 | |
| High-frequency | Cost | 556.52 | 893.13 | 895.25 | 871.77 | 817.08 | 893.14 |
| QoS satisfaction | 93.7% | 11.4% | 12.6% | 13.8% | 70.3% | 12.2% | |
| Balancing rate | 73.2% | 98.4% | 91.7% | 97.4% | 76.8% | 98.1% | |
| Response time | 0.357 | 11.637 | 10.362 | 3.527 | 0.658 | 11.246 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Qin, Y. Real-Time Cost Optimization Approach Based on Deep Reinforcement Learning in Software-Defined Security Middle Platform. Information 2023, 14, 209. https://doi.org/10.3390/info14040209
Li Y, Qin Y. Real-Time Cost Optimization Approach Based on Deep Reinforcement Learning in Software-Defined Security Middle Platform. Information. 2023; 14(4):209. https://doi.org/10.3390/info14040209
Chicago/Turabian StyleLi, Yuancheng, and Yongtai Qin. 2023. "Real-Time Cost Optimization Approach Based on Deep Reinforcement Learning in Software-Defined Security Middle Platform" Information 14, no. 4: 209. https://doi.org/10.3390/info14040209
APA StyleLi, Y., & Qin, Y. (2023). Real-Time Cost Optimization Approach Based on Deep Reinforcement Learning in Software-Defined Security Middle Platform. Information, 14(4), 209. https://doi.org/10.3390/info14040209