
adaptMLLM: Fine-Tuning Multilingual Language Models on Low-Resource Languages with Integrated LLM Playgrounds

Abstract
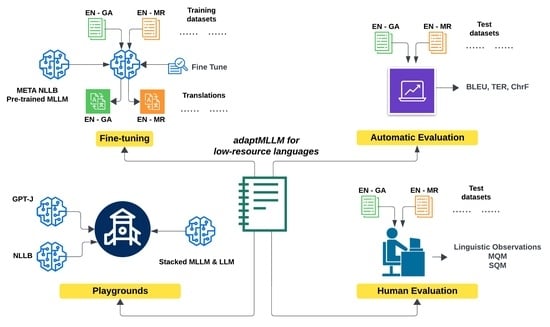
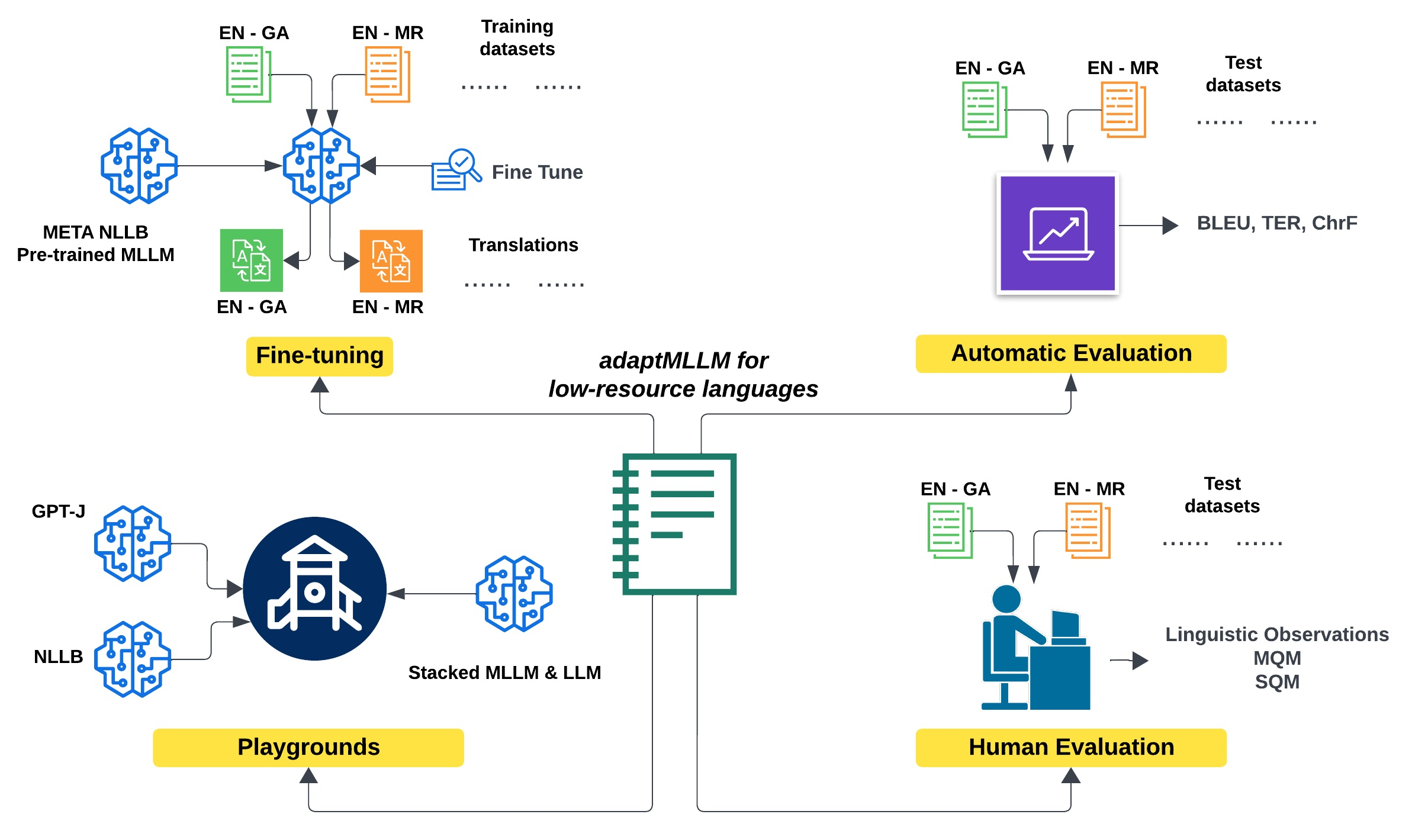
:
1. Introduction
2. Related Work
2.1. Transformer Architecture
2.2. Multilingual Language Models—NLLB
2.3. Large Language Models
2.3.1. GPT-J
2.3.2. GPT-4
2.3.3. BARD
2.4. DeepSpeed
2.5. HuggingFace
2.6. Human Evaluation
3. Datasets
3.1. Language Pairs
3.2. Shared Task Datasets
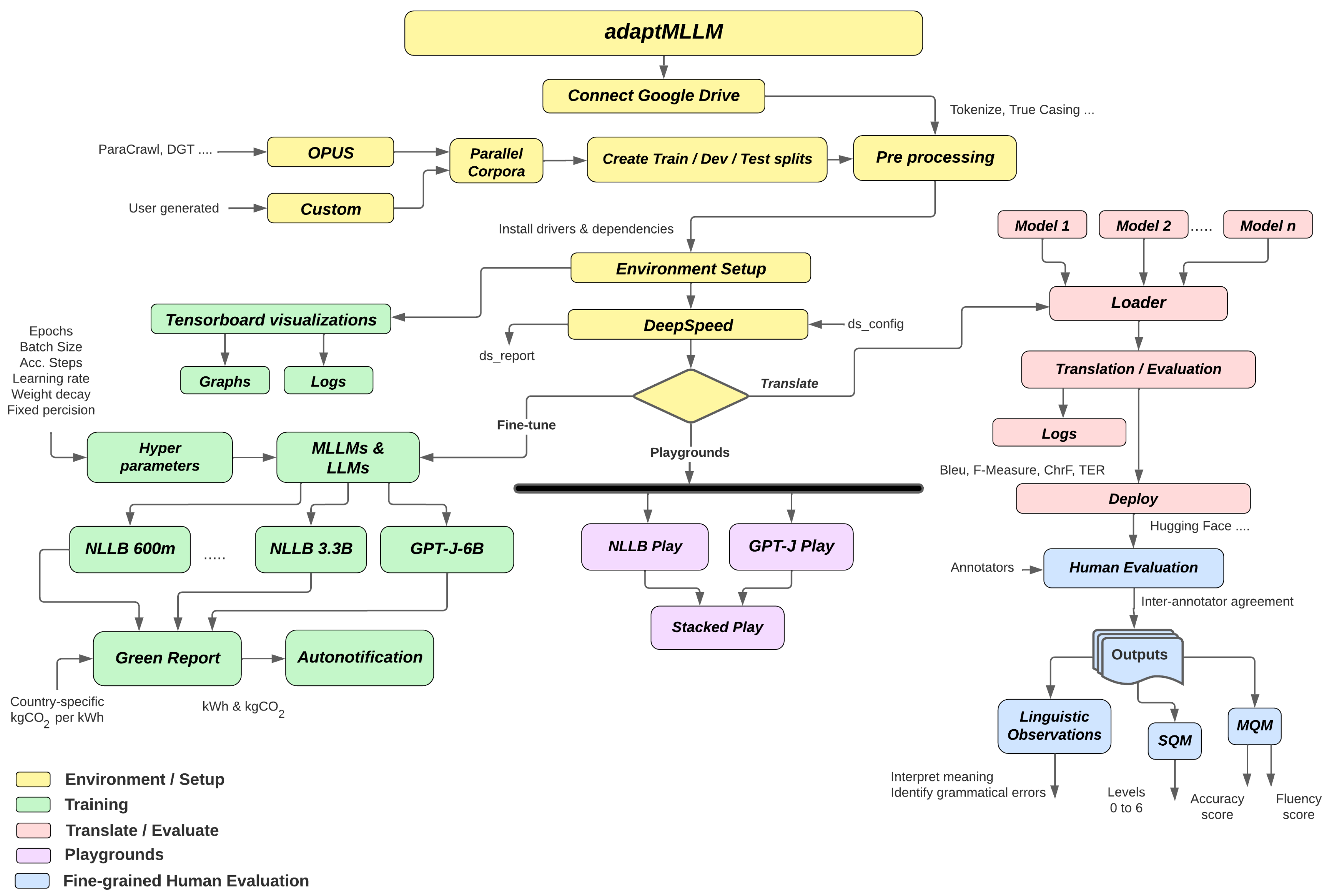
4. Approach
4.1. Initialisation and Pre-Processing
4.2. Modes of Operation
4.3. Fine-Tuning and Visualisation
4.4. Deployment
4.5. Green Report
4.6. MLLMs: Translation and Evaluation
4.7. LLMs: Playgrounds
5. Empirical Evaluation
5.1. Infrastructure and Hyperparameters
5.2. Results: Automatic Evaluation
5.2.1. Translation in the ENGA Directions
5.2.2. Translation in the ENMR Directions
5.3. Human Evaluation Results
5.3.1. Scalar Quality Metrics
5.3.2. Multidimensional Quality Metrics
5.3.3. Annotation Setup
5.3.4. Inter-Annotator Agreement
- : Relative observed agreement among raters
- : Hypothetical probability of chance agreement.
5.3.5. Inter-Annotator Reliability
5.4. Environmental Impact
6. Discussion
6.1. Performance of adaptMLLM Models Relative to Google Translate
6.2. Linguistic Observations
6.2.1. Interpreting Meaning
6.2.2. Core Grammatical Errors
7. Conclusions and Future Work
8. Limitations of the Study
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Costa-jussà, M.; Cross, J.; Çelebi, O.; Elbayad, M.; Heafield, K.; Heffernan, K.; Kalbassi, E.; Lam, J.; Licht, D.; Maillard, J.; et al. No language left behind: Scaling human-centered machine translation. arXiv 2022, arXiv:2207.04672. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, BC, Canada, 6–12 December 2020; Volume 33, pp. 1877–1901. Available online: https://dl.acm.org/doi/pdf/10.5555/3495724.3495883 (accessed on 22 November 2023).
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and Policy Considerations for Deep Learning in NLP. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 3645–3650. Available online: https://aclanthology.org/P19-1355/ (accessed on 22 November 2023).
- Henderson, P.; Hu, J.; Romoff, J.; Brunskill, E.; Jurafsky, D.; Pineau, J. Towards the systematic reporting of the energy and carbon footprints of machine learning. J. Mach. Learn. Res. 2020, 21, 10039–10081. Available online: https://dl.acm.org/doi/pdf/10.5555/3455716.3455964 (accessed on 22 November 2023).
- Lankford, S.; Afli, H.; Way, A. adaptNMT: An open-source, language-agnostic development environment for Neural Machine Translation. Lang. Resour. Eval. 2023, 57, 1671–1696. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. Available online: https://dl.acm.org/doi/pdf/10.5555/3295222.3295349 (accessed on 22 November 2023).
- Lankford, S.; Alfi, H.; Way, A. Transformers for Low-Resource Languages: Is Féidir Linn! In Proceedings of the Machine Translation Summit XVIII: Research Track, Virtual, 16–20 August 2021; pp. 48–60. Available online: https://aclanthology.org/2021.mtsummit-research.5 (accessed on 22 November 2023).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Winata, G.; Madotto, A.; Lin, Z.; Liu, R.; Yosinski, J.; Fung, P. Language Models are Few-shot Multilingual Learners. In Proceedings of the 1st Workshop on Multilingual Representation Learning, Punta Cana, Dominican Republic, 7–11 November 2011; pp. 1–15. Available online: https://aclanthology.org/2021.mrl-1.1 (accessed on 22 November 2023).
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-lingual Representation Learning at Scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 8440–8451. Available online: https://aclanthology.org/2020.acl-main.747 (accessed on 22 November 2023).
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. Available online: https://aclanthology.org/N19-1423 (accessed on 22 November 2023).
- Lepikhin, D.; Lee, H.; Xu, Y.; Chen, D.; Firat, O.; Huang, Y.; Krikun, M.; Shazeer, N.; Chen, Z. Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv 2020, arXiv:2006.16668. [Google Scholar]
- Kasneci, E.; Sessler, K.; Küchemann, S.; Bannert, M.; Dementieva, D.; Fischer, F.; Gasser, U.; Groh, G.; Günnemann, S.; Hüllermeier, E.; et al. ChatGPT for good? on opportunities and challenges of large language models for education. Learn. Individ. Differ. 2023, 103, 102274. Available online: https://www.sciencedirect.com/science/article/pii/S1041608023000195 (accessed on 22 November 2023). [CrossRef]
- Iftikhar, L.; Iftikhar, M.F.; Hanif, M.I. DocGPT: Impact of ChatGPT-3 on Health Services as a Virtual Doctor. EC Paediatr. 2023, 12, 45–55. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training; Technical Report; OpenAI: San Francisco, CA, USA, 2018. [Google Scholar]
- OpenAI. OpenAI GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Thoppilan, R.; De Freitas, D.; Hall, J.; Shazeer, N.; Kulshreshtha, A.; Cheng, H.; Jin, A.; Bos, T.; Baker, L.; Du, Y.; et al. Lamda: Language models for dialog applications. arXiv 2022, arXiv:2201.08239. [Google Scholar]
- Rasley, J.; Rajbhandari, S.; Ruwase, O.; He, Y. DeepSpeed: System Optimizations Enable Training Deep Learning Models with Over 100 Billion Parameters. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 6–10 July 2020; pp. 3505–3506. [Google Scholar] [CrossRef]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods In Natural Language Processing: System Demonstrations, Online, 16–20 October 2020; pp. 38–45. Available online: https://aclanthology.org/2020.emnlp-demos.6 (accessed on 22 November 2023).
- Belz, A.; Agarwal, S.; Graham, Y.; Reiter, E.; Shimorina, A. Proceedings of the Workshop on Human Evaluation of NLP Systems (HumEval), Online, April 2021. Available online: https://aclanthology.org/2021.humeval-1.0 (accessed on 22 November 2023).
- Bayón, M.; Sánchez-Gijón, P. Evaluating machine translation in a low-resource language combination: Spanish-Galician. In Proceedings of the Machine Translation Summit XVII: Translator, Project and User Tracks, Dublin, Ireland, 19–23 August 2019; pp. 30–35. Available online: https://aclanthology.org/W19-6705 (accessed on 22 November 2023).
- Imankulova, A.; Dabre, R.; Fujita, A.; Imamura, K. Exploiting out-of-domain parallel data through multilingual transfer learning for low-resource neural machine translation. In Proceedings of the Machine Translation Summit XVIII: Research Track, Virtual, 16–20 August 2021; Available online: https://aclanthology.org/W19-6613 (accessed on 22 November 2023).
- Läubli, S.; Castilho, S.; Neubig, G.; Sennrich, R.; Shen, Q.; Toral, A. A set of recommendations for assessing human–machine parity in language translation. J. Artif. Intell. Res. 2020, 67, 653–672. [Google Scholar] [CrossRef]
- Freitag, M.; Foster, G.; Grangier, D.; Ratnakar, V.; Tan, Q.; Macherey, W. Experts, errors, and context: A large-scale study of human evaluation for machine translation. Trans. Assoc. Comput. Linguist. 2021, 9, 1460–1474. Available online: https://aclanthology.org/2021.tacl-1.87 (accessed on 22 November 2023). [CrossRef]
- Lommel, A.; Uszkoreit, H.; Burchardt, A. Multidimensional quality metrics (MQM): A framework for declaring and describing translation quality metrics. Tradumàtica 2014, 455–463. [Google Scholar] [CrossRef]
- Ojha, A.; Liu, C.; Kann, K.; Ortega, J.; Shatam, S.; Fransen, T. Findings of the LoResMT 2021 Shared Task on COVID and Sign Language for Low-resource Languages. In Proceedings of the 4th Workshop on Technologies for MT of Low Resource Languages (LoResMT2021), Virtual, 16–20 August 2021; pp. 114–123. Available online: https://aclanthology.org/2021.mtsummit-loresmt.11 (accessed on 22 November 2023).
- Kudo, T.; Richardson, J. SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. In Proceedings of the 2018 Conference on Empirical Methods In Natural Language Processing: System Demonstrations, Brussels, Belgium, 31 October–4 November 2018; pp. 66–71. Available online: https://aclanthology.org/D18-2012 (accessed on 22 November 2023).
- Lacoste, A.; Luccioni, A.; Schmidt, V.; Dandres, T. Quantifying the carbon emissions of machine learning. arXiv 2019, arXiv:1910.09700. [Google Scholar]
- Abid, A.; Abdalla, A.; Abid, A.; Khan, D.; Alfozan, A.; Zou, J. Gradio: Hassle-free sharing and testing of ml models in the wild. arXiv 2019, arXiv:1906.02569. [Google Scholar]
- Bannour, N.; Ghannay, S.; Névéol, A.; Ligozat, A. Evaluating the carbon footprint of NLP methods: A survey and analysis of existing tools. In Proceedings of the Second Workshop on Simple and Efficient Natural Language Processing, Virtual, 7–11 November 2021; pp. 11–21. Available online: https://aclanthology.org/2021.sustainlp-1.2 (accessed on 22 November 2023).
- Post, M. A Call for Clarity in Reporting BLEU Scores. In Proceedings of the Third Conference on Machine Translation: Research Papers, Brussels, Belgium, 31 October–1 November 2018; pp. 186–191. Available online: https://aclanthology.org/W18-6319 (accessed on 22 November 2023).
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. Available online: https://aclanthology.org/P02-1040 (accessed on 22 November 2023).
- Snover, M.; Dorr, B.; Schwartz, R.; Micciulla, L.; Makhoul, J. A Study of Translation Edit Rate with Targeted Human Annotation. In Proceedings of the 7th Conference of the Association for Machine Translation In the Americas: Technical Papers, Cambridge, MA, USA, 8–12 August 2006; pp. 223–231. Available online: https://aclanthology.org/2006.amta-papers.25 (accessed on 22 November 2023).
- Popović, M. chrF: Character n-gram F-score for automatic MT evaluation. In Proceedings of the Tenth Workshop on Statistical Machine Translation, Lisbon, Portugal, 17–18 September 2015; pp. 392–395. Available online: https://aclanthology.org/W15-3049 (accessed on 22 November 2023).
- Denkowski, M.; Lavie, A. Meteor Universal: Language Specific Translation Evaluation for Any Target Language. In Proceedings of the Ninth Workshop on Statistical Machine Translation, Baltimore, ML, USA, 26–27 June 2016; pp. 376–380. Available online: https://aclanthology.org/W14-3348 (accessed on 22 November 2023).
- Melamed, I.; Green, R.; Turian, J. Precision and Recall of Machine Translation. In Companion Volume of the Proceedings of HLT-NAACL 2003—Short Papers; 2003; pp. 61–63. Available online: https://aclanthology.org/N03-2021 (accessed on 22 November 2023).
- Bisong, E. Building Machine Learning and Deep Learning Models on Google Cloud Platform: A Comprehensive Guide for Beginners; Apress: Berkeley, CA, USA, 2019. [Google Scholar]
- Lankford, S.; Afli, H.; Way, A. Machine Translation in the Covid domain: An English-Irish case study for LoResMT 2021. In Proceedings of the 4th Workshop on Technologies for MT of Low Resource Languages (LoResMT2021), Virtual, 16–20 August 2021; pp. 144–150. Available online: https://aclanthology.org/2021.mtsummit-loresmt.15 (accessed on 22 November 2023).
- Lankford, S.; Afli, H.; NíLoinsigh, Ó.; Way, A. gaHealth: An English–Irish Bilingual Corpus of Health Data. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, Marseille, France, 21–23 June 2022; pp. 6753–6758. Available online: https://aclanthology.org/2022.lrec-1.727 (accessed on 22 November 2023).
- Lankford, S.; Afli, H.; Way, A. Human Evaluation of English–Irish Transformer-Based NMT. Information 2022, 13, 309. [Google Scholar] [CrossRef]
- Klubička, F.; Toral, A.; Sánchez-Cartagena, V. Quantitative fine-grained human evaluation of machine translation systems: A case study on English to Croatian. Mach. Transl. 2018, 32, 195–215. [Google Scholar] [CrossRef]
- Ma, Q.; Graham, Y.; Wang, S.; Liu, Q. Blend: A Novel Combined MT Metric Based on Direct Assessment—CASICT-DCU submission to WMT17 Metrics Task. In Proceedings of the Second Conference on Machine Translation, Copenhagen, Denmark, 7–8 September 2017; pp. 598–603. Available online: https://aclanthology.org/W17-4768 (accessed on 22 November 2023).
- Lommel, A. Metrics for Translation Quality Assessment: A Case for Standardising Error Typologies. In Translation Quality Assessment: From Principles to Practice; Springer: Cham, Switzerland, 2018; pp. 109–127. [Google Scholar]
- Artstein, R. Inter-annotator agreement. In Handbook of Linguistic Annotation; Springer: Dordrecht, The Netherlands, 2017; pp. 297–313. [Google Scholar] [CrossRef]
- Lommel, A.; Burchardt, A.; Popović, M.; Harris, K.; Avramidis, E.; Uszkoreit, H. Using a new analytic measure for the annotation and analysis of MT errors on real data. In Proceedings of the 17th Annual Conference of the European Association for Machine Translation, Dubrovnik, Croatia, 16–18 June 2014; pp. 165–172. Available online: https://aclanthology.org/2014.eamt-1.38 (accessed on 22 November 2023).
- Callison-Burch, C.; Fordyce, C.; Koehn, P.; Monz, C.; Schroeder, J. (Meta-) Evaluation of Machine Translation. In Proceedings of the Second Workshop on Statistical Machine Translation, Prague, Czech Republic, 23 June 2014; pp. 136–158. Available online: https://aclanthology.org/W07-0718 (accessed on 22 November 2023).
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Bender, E.; Gebru, T.; McMillan-Major, A.; Shmitchell, S. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, Virtual, 3–10 March 2021; pp. 610–623. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. Available online: http://jmlr.org/papers/v13/bergstra12a.html (accessed on 22 November 2023).


{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Values |
|---|---|
| Epochs | 1, 3, 5 |
| Batch size | 8, 12, 16 |
| Gradient accumulation steps | 2, 4, 8 |
| Learning rate | 1 , 3 , 9 |
| Weight decay | 0.01, 0.1, 1, 2 |
| Mixed precision | False, True |
| Team | System | BLEU ↑ | TER ↓ | ChrF3 ↑ |
|---|---|---|---|---|
| adaptMLLM | en2ga-tuned | 41.2 | 0.51 | 0.48 |
| adapt | covid_extended | 36.0 | 0.531 | 0.60 |
| adapt | combined | 32.8 | 0.590 | 0.57 |
| adaptMLLM | en2ga-baseline | 29.7 | 0.595 | 0.559 |
| IIITT | en2ga-b | 25.8 | 0.629 | 0.53 |
| UCF | en2ga-b | 13.5 | 0.756 | 0.37 |
| Team | System | BLEU ↑ | TER ↓ | ChrF3 ↑ |
|---|---|---|---|---|
| adaptMLLM | ga2en-tuned | 75.1 | 0.385 | 0.71 |
| adaptMLLM | ga2en-baseline | 47.8 | 0.442 | 0.692 |
| IIITT | ga2en-b | 34.6 | 0.586 | 0.61 |
| UCF | ga2en-b | 21.3 | 0.711 | 0.45 |
| Team | System | BLEU ↑ | TER ↓ | ChrF3 ↑ |
|---|---|---|---|---|
| adaptMLLM | en2mr-tuned | 26.4 | 0.56 | 0.608 |
| IIITT | en2mr-IndicTrans-b | 24.2 | 0.59 | 0.597 |
| oneNLP-IIITH | en2mr-Method2-c | 22.2 | 0.56 | 0.746 |
| oneNLP-IIITH | en2mr-Method3-c | 22.0 | 0.56 | 0.753 |
| oneNLP-IIITH | en2mr-Method1-c | 21.5 | 0.56 | 0.746 |
| adaptMLLM | en2mr-baseline | 19.8 | 0.656 | 0.57 |
| adaptNMT | en2mr | 13.7 | 0.778 | 0.393 |
| Team | System | BLEU ↑ | TER ↓ | ChrF3 ↑ |
|---|---|---|---|---|
| adaptMLLM | mr2en-tuned | 52.6 | 0.409 | 0.704 |
| adaptMLLM | mr2en-baseline | 42.7 | 0.506 | 0.639 |
| oneNLP-IIITH | mr2en-Method3-c | 31.3 | 0.58 | 0.646 |
| oneNLP-IIITH | mr2en-Method2-c | 30.6 | 0.57 | 0.659 |
| oneNLP-IIITH | mr2en-Method1-c | 20.7 | 0.48 | 0.735 |
| adaptNMT | mr2en | 19.9 | 0.758 | 0.429 |
| UCF | mr2en-UnigramSegmentation-b | 7.7 | 0.24 | 0.833 |
| IIITT | mr2en-IndicTrans-b | 5.1 | 0.22 | 1.002 |
| SQM Level | Details of Quality |
|---|---|
| 6 | Perfect Meaning and Grammar: The meaning of the translation is completely consistent with the source and the surrounding context (if applicable). The grammar is also correct. |
| 4 | Most Meaning Preserved and Few Grammar Mistakes: The translation retains most of the meaning of the source. This may contain some grammar mistakes or minor contextual inconsistencies. |
| 2 | Some Meaning Preserved: The translation preserves some of the meaning of the source but misses significant parts. The narrative is hard to follow due to fundamental errors. Grammar may be poor. |
| 0 | Nonsense/No meaning preserved: Nearly all information is lost between the translation and source. Grammar is irrelevant. |
| System | BLEU ↑ | TER ↓ | ChrF3 ↑ | SQM ↑ |
|---|---|---|---|---|
| adaptMLLM en2ga | 41.2 | 0.51 | 0.48 | 4.38 |
| adaptMLLM ga2en | 75.1 | 0.385 | 0.71 | 5.63 |
| Category | Sub-Category | Description |
|---|---|---|
| Non-translation | Impossible to reliably characterise the 5 most severe errors. | |
| Accuracy | Addition | Translation includes information not present in the source. |
| Omission | Translation is missing content from the source. | |
| Mistranslation | Translation does not accurately represent the source. | |
| Untranslated text | Source text has been left untranslated. | |
| Fluency | Punctuation | Incorrect punctuation |
| Spelling | Incorrect spelling or capitalisation. | |
| Grammar | Problems with grammar, other than orthography. | |
| Register | Wrong grammatical register (e.g., inappropriately informal pronouns). | |
| Inconsistency | Internal inconsistency (not related to terminology). | |
| Character encoding | Characters are garbled due to incorrect encoding. |
| Num Errors | ENGA | GAEN |
|---|---|---|
| Annotator 1 | 53 | 7 |
| Annotator 2 | 82 | 11 |
| Error Type | ENGA Errors | GAEN Errors |
|---|---|---|
| Non-translation | 0 | 0 |
| Accuracy | ||
| Addition | 12 | 5 |
| Omission | 14 | 3 |
| Mistranslation | 41 | 6 |
| Untranslated text | 9 | 2 |
| Fluency | ||
| Punctuation | 10 | 0 |
| Spelling | 6 | 0 |
| Grammar | 27 | 0 |
| Register | 19 | 2 |
| Inconsistency | 6 | 0 |
| Character Encoding | 0 | 0 |
| Total errors | 135 | 18 |
| Error Type | ENGA | GAEN |
|---|---|---|
| Non-translation | = 1 | = 1 |
| Accuracy | ||
| Addition | 0.24 | 0 |
| Omission | 0.31 | 0 |
| Mistranslation | 0.32 | −0.11 |
| Untranslated text | 0.07 | 0 |
| Fluency | ||
| Punctuation | 1 | = 1 |
| Spelling | 0.24 | = 1 |
| Grammar | 0.59 | = 1 |
| Register | −0.07 | 0 |
| Inconsistency | 0.34 | = 1 |
| Character Encoding | = 1 | 1.0 |
| System | BLEU ↑ | TER ↓ | ChrF3 ↑ | Lines | Runtime (Hours) | kWh |
|---|---|---|---|---|---|---|
| adaptMLLM en2ga | 41.2 | 0.51 | 0.48 | 13 k | 3.51 | 1.1 |
| adaptMLLM ga2en | 75.1 | 0.385 | 0.71 | 13 k | 3.41 | 1.1 |
| adaptMLLM en2mr | 26.4 | 0.56 | 0.608 | 21 k | 5.49 | 1.8 |
| adaptMLLM mr2en | 52.6 | 0.409 | 0.74 | 21 k | 5.43 | 1.7 |
| Source Language (English) | Human Translation (Irish) |
|---|---|
| Temporary COVID-19 Wage Subsidy Scheme | Scéim Fóirdheontais Shealadaigh Pá COVID-19 |
| how COVID-19 spreads and its symptoms | conas a scaipeann COVID-19 agus na siomptóim a bhaineann leis |
| Fine-Tuned LLM | BLEU ↑ | Google Translate | BLEU ↑ |
|---|---|---|---|
| Scéim Fóirdheontais Pá Sealadach COVID-19 | 25.4 | Scéim Fóirdheontais Pá Shealadach COVID-19 | 25.4 |
| Conas a scaipeann COVID-19 agus na comharthaí a bhaineann leis | 100 | conas a scaipeann COVID-19 agus na hairíonna a bhaineann leis | 65.8 |
| Source Language (English) | Human Translation (Marathi) |
|---|---|
| Like big cities like Mumbai, Pune, Nashik, all other districts are suffering from this. | मुंबई, पुणे, नाशिकसारख्या मोठ्या शहरांप्रमाणे इतर सर्व जिल्ह्यांना याचा त्रास भोगावा लागत आहे. |
| It will be a lockdown for the next 15 days from 8 p.m. on 14 April. | 14 एप्रिल रात्री 8 वाजल्यापासून पुढील 15 दिवस हे लॉकडाऊन असणार आहे. |
| Fine-Tuned MLLM | BLEU ↑ | Google Translate | BLEU ↑ |
|---|---|---|---|
| मुंबई, पुणे, नाशिकसारख्या मोठ्या शहरांप्रमाणेच इतर सर्व जिल्हे यातच कोंबले आहेत. | 35.1 | मुंबई, पुणे, नाशिक या मोठ्या शहरांप्रमाणेच इतर सर्व जिल्ह्यांना याचा त्रास होत आहे. | 2.5 |
| Like big cities like Mumbai, Pune, Nashik, all other districts are covered in it. | Like Mumbai, Pune, Nashik and other big cities, all other districts are suffering from this. | ||
| 14 एप्रिल रोजी रात्री 8 वाजल्यापासून पुढील 15 दिवस हा लॉकडाऊन असेल. | 45.3 | 14 एप्रिल रोजी रात्री 8 वाजल्यापासून पुढील 15 दिवस लॉकडाऊन असेल. | 45.6 |
| the lockdown will be for the next 15 days from 8 p.m. on 14 April. | There will be a lockdown for the next 15 days from 8 p.m. on 14 April. |
| Type | Sentence |
|---|---|
| EN-1 | COVID-19 information and advice for taxpayers and agents |
| GA-1 | Eolas agus comhairle COVID-19 díocóirí cánach agus dionadaithe |
| EN-2 | We understand the unprecedented situation facing taxpayers as a result of the COVID-19 pandemic. |
| GA-2 | Tuigeann muid an cás gan fasach atá roimh cháiníocóirí mar thoradh ar an bpaindéim COVID-19. |
| EN-3 | Further information on Employment Wage Subsidy Scheme (EWSS) is available from the Employing people section on this website. |
| GA-3 | Tá tuilleadh faisnéise ar Scéim Fóirdheontais Pá Fostaíochta (EWSS) ar fáil ón gcuid Fostaithe ar an láithreán gréasáin seo. |
| EN-4 | Information for employers on the Temporary COVID-19 Wage Subsidy Scheme is available from the Employing people section on this website. |
| GA-4 | Tá faisnéis dfhostóirí ar an Scéim Fóirdheontais Pá Sealadach COVID-19 ar fáil ón gcuid Fostaithe ar an láithreán gréasáin seo. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lankford, S.; Afli, H.; Way, A. adaptMLLM: Fine-Tuning Multilingual Language Models on Low-Resource Languages with Integrated LLM Playgrounds. Information 2023, 14, 638. https://doi.org/10.3390/info14120638
Lankford S, Afli H, Way A. adaptMLLM: Fine-Tuning Multilingual Language Models on Low-Resource Languages with Integrated LLM Playgrounds. Information. 2023; 14(12):638. https://doi.org/10.3390/info14120638
Chicago/Turabian StyleLankford, Séamus, Haithem Afli, and Andy Way. 2023. "adaptMLLM: Fine-Tuning Multilingual Language Models on Low-Resource Languages with Integrated LLM Playgrounds" Information 14, no. 12: 638. https://doi.org/10.3390/info14120638