
Four Million Segments and Counting: Building an English-Croatian Parallel Corpus through Crowdsourcing Using a Novel Gamification-Based Platform


Abstract
1. Introduction
- (i)
- To analyze the importance of parallel corpora, specifically for machine translation purposes.
- (ii)
- To present the integration of crowdsourcing and gamification methods into a new web-based platform for creating and organizing parallel corpora.
- (iii)
- To demonstrate the functionalities of the created system.
- (iv)
- To analyze the resulting English-Croatian parallel corpus that contains more than four million segments, i.e., more precisely, translation units.
2. Related Work
2.1. Building Parallel Corpora for Machine Translation Systems and for Low-Resourced Languages
2.2. Crowdsourcing and Corpora Acquisition
2.3. The Role of Gamification and Its Potential in NLP
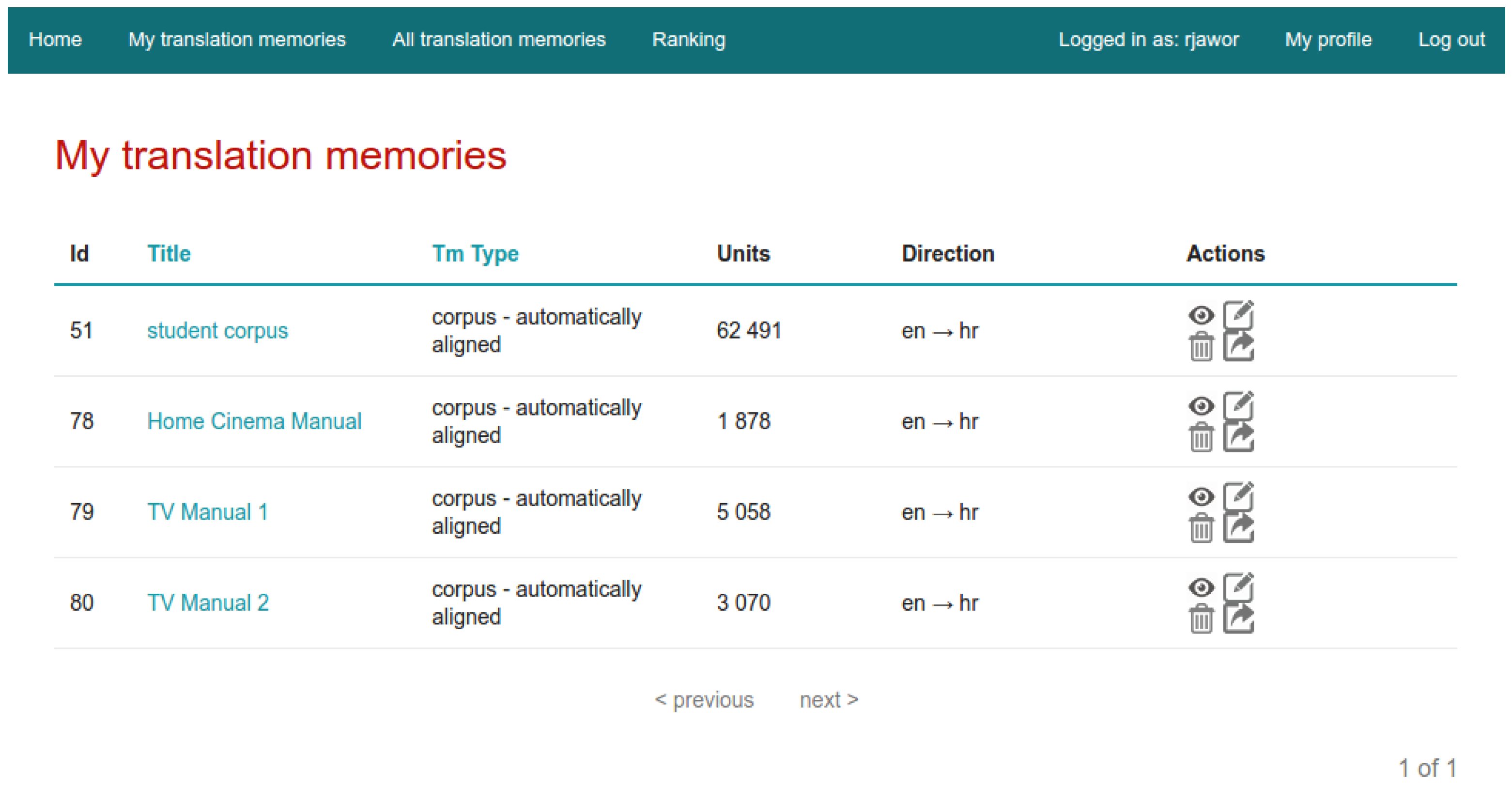
3. Novel Crowdsourcing and Gamification-Based Corpus Management Platform
- manual translation,
- manual translation—automatically aligned,
- corpus,
- corpus—automatically aligned.
- TXT,
- TMX,
- Moses parallel files (a format widely used in machine translation system training).
- source and target languages (the platform is ready to accept not only English-Croatian corpora, but the languages can be customized),
- type of corpus (manual translation, corpus, automatically aligned, etc.),
- domain (news, manuals, tourism, song lyrics, etc.).
4. Experimental Scenario
- nationality—all participating students and researchers came from Poland and Croatia;
- level of language understanding—all students and researchers had at least intermediate English understanding skills, but only Croats could read and fully understand Croatian (even though the Polish and Croatian languages exhibit some similarities, they are not mutually intelligible);
- experience—from students in the early stages of their studies and graduate students in their twenties to experienced natural language processing researchers;
- gender—the distribution of women and men among the participants was nearly even;
- occupation—participants were either studying or researching the fields of information and communication sciences, computer science, linguistics, or data science with a special focus on natural language processing.
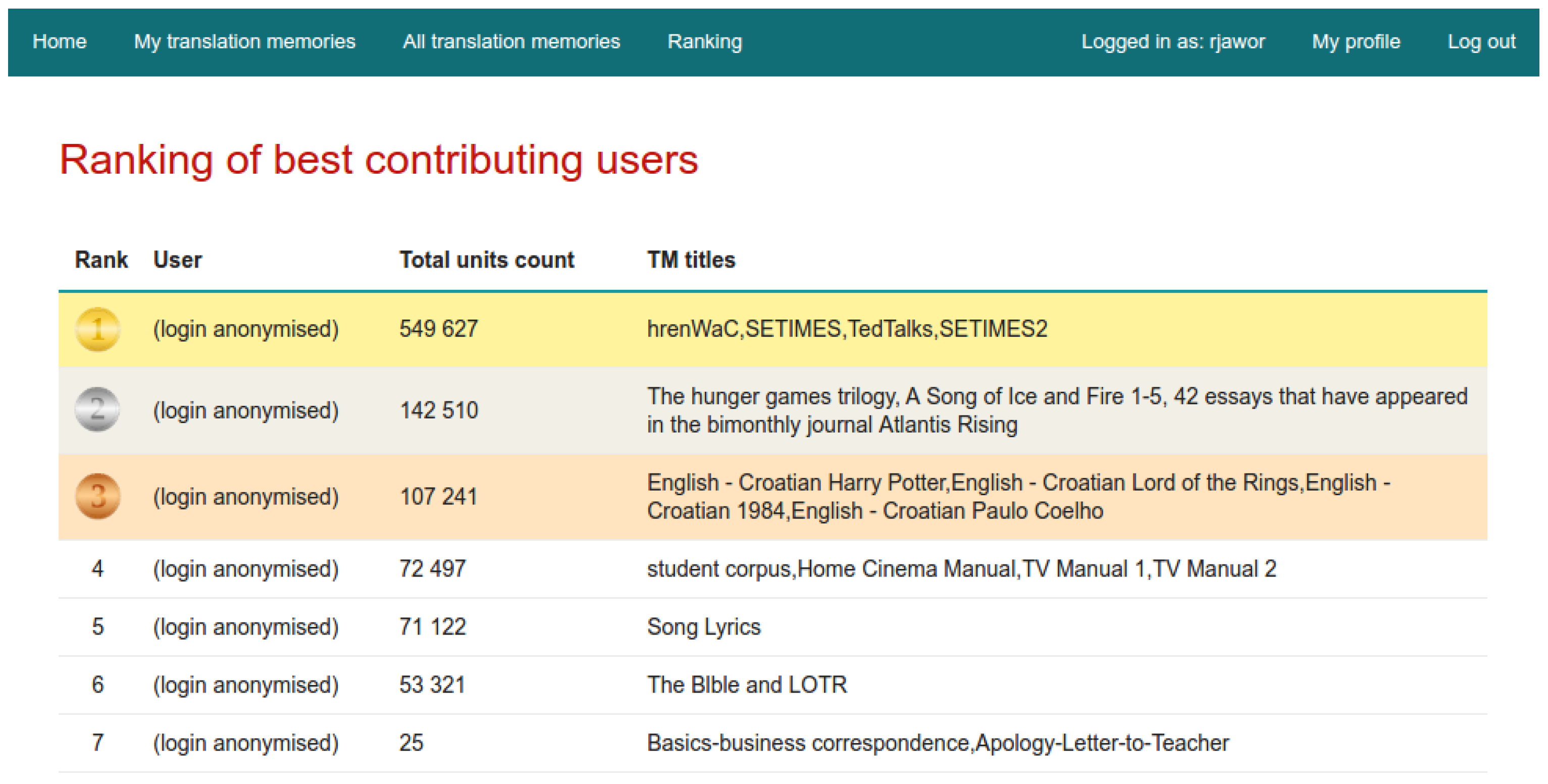
5. Collected Corpus
- Croatian-English and English-Croatian parallel corpora, such as SETIMES or TED Talks,
- technical documentation for various products,
- tourism websites,
- manuals,
- song lyrics,
- legal documents.
6. Conclusions and Future Research
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Joshi, P.; Santy, S.; Budhiraja, A.; Bali, K.; Choudhury, M. The State and Fate of Linguistic Diversity and Inclusion in the NLP World. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL 2020), Online, 5–10 July 2020; pp. 6282–6293. [Google Scholar] [CrossRef]
- Haddow, B.; Bawden, R.; Barone, A.V.M.; Helcl, J.; Birch, A. Survey of Low-Resource Machine Translation. Comput. Linguist. 2022, 48, 673–732. [Google Scholar] [CrossRef]
- Hedderich, M.A.; Lange, L.; Adel, H.; Strötgen, J.; Klakow, D. A Survey on Recent Approaches for Natural Language Processing in Low-Resource Scenarios. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), Mexico City, Mexico, 6–11 June 2021; pp. 2545–2568. [Google Scholar] [CrossRef]
- Volk, M. Parallel Corpora, Terminology Extraction and Machine Translation. In Proceedings of the 16. DTT-Symposion. Terminologie und Text(e), Mannheim, Germany, 22–24 March 2018; pp. 3–14. [Google Scholar] [CrossRef]
- Jaworski, R.; Seljan, S.; Dunđer, I. Usability Analysis of the Concordia Tool Applying Novel Concordance Searching. In Proceedings of the International Conference on Information Technology & Systems (ICITS 2021), Libertad, Ecuador, 4–6 February 2021; pp. 128–138. [Google Scholar] [CrossRef]
- Macken, L.; Prou, D.; Tezcan, A. Quantifying the Effect of Machine Translation in a High-Quality Human Translation Production Process. Informatics 2020, 7, 12. [Google Scholar] [CrossRef]
- Seljan, S.; Erdelja, N.Š.; Kučiš, V.; Dunđer, I.; Bach, M.P. Quality Assurance in Computer-Assisted Translation in Business Environments. In Natural Language Processing for Global and Local Business; Pinarbasi, F., Nurdan Taskiran, M., Eds.; IGI Global Hershey: Hershey, PA, USA, 2021; pp. 242–270. [Google Scholar] [CrossRef]
- Eo, S.; Park, C.; Moon, H.; Seo, J.; Lim, H. Comparative Analysis of Current Approaches to Quality Estimation for Neural Machine Translation. Appl. Sci. 2021, 11, 6584. [Google Scholar] [CrossRef]
- Elmakias, I.; Vilenchik, D. An Oblivious Approach to Machine Translation Quality Estimation. Mathematics 2021, 9, 2090. [Google Scholar] [CrossRef]
- Wang, Y.; Li, X.; Yang, Y.; Anwar, A.; Dong, R. Hybrid System Combination Framework for Uyghur–Chinese Machine Translation. Information 2021, 12, 98. [Google Scholar] [CrossRef]
- Seljan, S.; Dunđer, I. Automatic quality evaluation of machine-translated output in sociological-philosophical-spiritual domain. In Proceedings of the Iberian Conference on Information Systems and Technologies (CISTI 2015), Aveiro, Portugal, 17–20 June 2015; pp. 1–4. [Google Scholar] [CrossRef]
- Jaworski, R.; Seljan, S.; Dunđer, I. Towards educating and motivating the crowd—A crowdsourcing platform for harvesting the fruits of NLP students’ labour. In Proceedings of the 8th Language & Technology Conference: Human Language Technologies as a Challenge for Computer Science and Linguistics (LTC 2017), Poznań, Poland, 17–19 November 2017; pp. 332–336. [Google Scholar]
- Kučiš, V.; Seljan, S. The role of online translation tools in language education. Babel 2014, 60, 303–324. [Google Scholar] [CrossRef]
- Gašpar, A.; Seljan, S.; Kučiš, V. Measuring Terminology Consistency in Translated Corpora: Implementation of the Herfindahl-Hirshman Index. Information 2022, 13, 43. [Google Scholar] [CrossRef]
- Béchara, H.; Orăsan, C.; Parra Escartín, C.; Zampieri, M.; Lowe, W. The Role of Machine Translation Quality Estimation in the Post-Editing Workflow. Informatics 2021, 8, 61. [Google Scholar] [CrossRef]
- Han, B. Translation, from Pen-and-Paper to Computer-Assisted Tools (CAT Tools) and Machine Translation (MT). Proceedings 2020, 63, 56. [Google Scholar] [CrossRef]
- Wang, R.; Tan, X.; Luo, R.; Qin, T.; Liu, T.-Y. A Survey on Low-Resource Neural Machine Translation. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence (IJCAI-21), Online, 19–26 August 2021; pp. 4636–4643. [Google Scholar] [CrossRef]
- Ngo, T.V.; Nguyen, P.-T.; Ha, T.-L.; Dinh, K.-Q.; Nguyen, L.-M. Improving Multilingual Neural Machine Translation For Low-Resource Languages: French, English—Vietnamese. In Proceedings of the 3rd Workshop on Technologies for MT of Low Resource Languages, Suzhou, China, 4 December 2020; pp. 55–61. [Google Scholar] [CrossRef]
- Ranathunga, S.; Lee, E.-S.A.; Prifti Skenduli, M.; Shekhar, R.; Alam, M.; Kaur, R. Neural Machine Translation for Low-Resource Languages: A Survey. ACM Comput. Surv. 2023, 55, 1–37. [Google Scholar] [CrossRef]
- Koehn, P.; Och, F.J.; Marcu, D. Statistical phrase-based translation. In Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology (NAACL ’03), Edmonton, AB, Canada, 27 May–1 June 2003; Volume 1, pp. 127–133. [Google Scholar] [CrossRef]
- Kamath, U.; Liu, J.; Whitaker, J. Deep Learning for NLP and Speech Recognition; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar] [CrossRef]
- Koehn, P. Statistical Machine Translation; Cambridge University Press: New York, NY, USA, 2010. [Google Scholar] [CrossRef]
- Dong, D.; Wu, H.; He, W.; Yu, D.; Wang, H. Multi-Task Learning for Multiple Language Translation. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (ACL-IJCNLP), Beijing, China, 27–31 July 2015; Volume 1, pp. 1723–1732. [Google Scholar] [CrossRef]
- Gehring, J.; Auli, M.; Grangier, D.; Dauphin, Y. A Convolutional Encoder Model for Neural Machine Translation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 123–135. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar] [CrossRef]
- Singh, T.D. Building Parallel Corpora for SMT System: A Case Study of English-Manipuri. Int. J. Comput. Appl. 2012, 52, 47–51. [Google Scholar] [CrossRef]
- Dunđer, I. Statistical Machine Translation System and Computational Domain Adaptation (Sustav za Statističko Strojno Prevođenje i Računalna Adaptacija Domene). Ph.D. Thesis, University of Zagreb, Zagreb, Croatia, 2015. [Google Scholar]
- Parida, S.; Bojar, O.; Dash, S.R. OdiEnCorp: Odia–English and Odia-Only Corpus for Machine Translation. In Proceedings of the Third International Conference on Smart Computing and Informatics (SCI 2018-19), Bhubaneswar, India, 21–22 December 2018; Volume 1, pp. 495–504. [Google Scholar] [CrossRef]
- Ambati, V.; Vogel, S. Can Crowds Build Parallel Corpora for Machine Translation Systems? In Proceedings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with Amazon’s Mechanical Turk (CSLDAMT ‘10), Los Angeles, NY, USA, 6 June 2010; pp. 62–65. [Google Scholar]
- Abdurakhmonova, N. Linguistic Issues of Creating Parallel Corpora for Uzbek Multilingual Machine Translation System. BuxDU Ilmiy Axborotnomasi 2020, 6, 60–68. [Google Scholar]
- Doğru, G.; Martín-Mor, A.; Aguilar-Amat, A. Parallel Corpora Preparation for Machine Translation of Low-Resource Languages: Turkish to English Cardiology Corpora. In Proceedings of the LREC 2018 Workshop ‘MultilingualBIO: Multilingual Biomedical Text Processing’, Miyazaki, Japan, 7–12 May 2018; pp. 12–15. [Google Scholar]
- Shearing, S.; Kirov, C.; Khayrallah, H.; Yarowsky, D. Improving Low Resource Machine Translation using Morphological Glosses. In Proceedings of the 13th Conference of the Association for Machine Translation in the Americas, Boston, MA, USA, 17–21 March 2018; Volume 1, pp. 132–139. [Google Scholar]
- Forcada, M.L. Free/Open-Source Machine Translation for the Low-Resource Languages of Spain. In Proceedings of the 3rd Conference on Language, Data and Knowledge (LDK 2021), Zaragoza, Spain, 1–4 September 2021. [Google Scholar] [CrossRef]
- Chu, C.; Wang, R. A Survey of Domain Adaptation for Neural Machine Translation. In Proceedings of the 27th International Conference on Computational Linguistics (COLING 2018), Santa Fe, NM, USA, 20–26 August 2018; pp. 1304–1319. [Google Scholar] [CrossRef]
- Dabre, R.; Chu, C.; Kunchukuttan, A. A survey of multilingual neural machine translation. ACM Comput. Surv. 2020, 53, 99. [Google Scholar] [CrossRef]
- Maruf, S.; Saleh, F.; Haffari, G. A Survey on Document-level Neural Machine Translation: Methods and Evaluation. ACM Comput. Surv. 2021, 54, 45. [Google Scholar] [CrossRef]
- Kuwanto, G.; Akyürek, A.F.; Tourni, I.C.; Li, S.; Jones, A.G.; Wijaya, D. Low-Resource Machine Translation Training Curriculum Fit for Low-Resource Languages. arXiv 2021, arXiv:2103.13272. [cs.CL], Computation and Language. [Google Scholar] [CrossRef]
- Sen, S.; Hasanuzzaman, M.; Ekbal, A.; Bhattacharyya, P.; Way, A. Neural machine translation of low-resource languages using SMT phrase pair injection. Nat. Lang. Eng. 2020, 27, 271–292. [Google Scholar] [CrossRef]
- Beloucif, M.; Gonzalez, A.V.; Bollmann, M.; Søgaard, A. Naive Regularizers for Low-Resource Neural Machine Translation. In Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2019), Varna, Bulgaria, 2–4 September 2019; pp. 102–111. [Google Scholar] [CrossRef]
- Koehn, P.; Knowles, R. Six Challenges for Neural Machine Translation. In Proceedings of the First Workshop on Neural Machine Translation, Vancouver, BC, Canada, 3–4 July 2017; pp. 28–39. [Google Scholar] [CrossRef]
- Seljan, S.; Dunđer, I.; Pavlovski, M. Human Quality Evaluation of Machine-Translated Poetry. In Proceedings of the International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 28 September–2 October 2020; pp. 1040–1045. [Google Scholar] [CrossRef]
- Lambebo, A.; Woldeyohannis, M.; Yigezu, M. A Parallel Corpora for bi-directional Neural Machine Translation for Low Resourced Ethiopian Languages. In Proceedings of the 2021 International Conference on Information and Communication Technology for Development for Africa (ICT4DA), Bahir Dar, Ethiopia, 22–24 November 2021; pp. 71–76. [Google Scholar] [CrossRef]
- Zhang, J.; Tian, Y.; Mao, J.; Han, M.; Wen, F.; Guo, C.; Gao, Z.; Matsumoto, T. WCC-JC 2.0: A Web-Crawled and Manually Aligned Parallel Corpus for Japanese-Chinese Neural Machine Translation. Electronics 2023, 12, 1140. [Google Scholar] [CrossRef]
- Ha, T.-L.; Niehues, J.; Waibel, A. Toward Multilingual Neural Machine Translation with Universal Encoder and Decoder. In Proceedings of the 13th International Conference on Spoken Language Translation (IWSLT 2016), Seattle, DC, USA, 8–9 December 2016. [Google Scholar] [CrossRef]
- Lakew, S.M.; Cettolo, M.; Federico, M. A Comparison of Transformer and Recurrent Neural Networks on Multilingual Neural Machine Translation. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 641–652. [Google Scholar] [CrossRef]
- Tan, X.; Ren, Y.; He, D.; Qin, T.; Zhao, Z.; Liu, T.-Y. Multilingual Neural Machine Translation with Knowledge Distillation. In Proceedings of the 7th International Conference on Learning Representations (ICLR 2019), New Orleans, LA, USA, 6–9 May 2019; pp. 1–15. [Google Scholar] [CrossRef]
- Aji, A.F.; Bogoychev, N.; Heafield, K.; Sennrich, R. In Neural Machine Translation, What Does Transfer Learning Transfer? In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL 2020), Online, 5–10 July 2020; pp. 7701–7710. [Google Scholar] [CrossRef]
- Kim, Y.; Gao, Y.; Ney, H. Effective Cross-lingual Transfer of Neural Machine Translation Models without Shared Vocabularies. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL 2019), Florence, Italy, 28 July–2 August 2019; pp. 1246–1257. [Google Scholar] [CrossRef]
- Dabre, R.; Nakagawa, T.; Kazawa, H. An Empirical Study of Language Relatedness for Transfer Learning in Neural Machine Translation. In Proceedings of the 31st Pacific Asia Conference on Language, Information and Computation (PACLIC 2017), Manila, Philippines, 16–18 November 2017; pp. 282–286. [Google Scholar]
- Zoph, B.; Yuret, D.; May, J.; Knight, K. Transfer Learning for Low-Resource Neural Machine Translation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP 2016), Austin, TX, USA, 1–5 November 2016; pp. 1568–1575. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, Z.; Du, Y.; Chen, B.; Xie, J.; Luo, W. Rethinking Zero-shot Neural Machine Translation: From a Perspective of Latent Variables. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 4321–4327. [Google Scholar] [CrossRef]
- Currey, A.; Heafield, K. Zero-Resource Neural Machine Translation with Monolingual Pivot Data. In Proceedings of the 3rd Workshop on Neural Generation and Translation (NGT 2019), Hong Kong, China, 3–7 November 2019; pp. 99–107. [Google Scholar] [CrossRef]
- O’Brien, S. Collaborative translation. In Handbook of Translation Studies; Gambier, Y., van Doorslaer, L., Eds.; John Benjamins Publishing Company: Amsterdam, The Netherlands, 2011; Volume 2, pp. 17–20. [Google Scholar] [CrossRef]
- Howe, J. The Rise of Crowdsourcing. Wired Mag. 2006, 14. Available online: http://www.wired.com/wired/archive/14.06/crowds.html (accessed on 11 February 2023).
- Howe, J. Crowdsourcing: Why the Power of the Crowd Is Driving the Future of Business, 1st ed.; Crown Publishing Group: New York, NY, USA, 2008. [Google Scholar]
- Quinn, A.J.; Bederson, B.B. Human Computation: A Survey and Taxonomy of a Growing Field. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’11), New York, NY, USA, 7–12 May 2011; pp. 1403–1412. [Google Scholar] [CrossRef]
- Sabou, M.; Bontcheva, K.; Derczynski, L.; Scharl, A. Corpus Annotation through Crowdsourcing: Towards Best Practice Guidelines. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), Reykjavik, Iceland, 26–31 May 2014; pp. 859–866. [Google Scholar]
- Li, H.; Shen, H.; Xu, S.; Zhang, C. Visualizing NLP annotations for Crowdsourcing. arXiv 2015, arXiv:1508.06044. [cs.CL], Computation and Language. [Google Scholar] [CrossRef]
- Munro, R.; Gunasekara, L.; Nevins, S.; Polepeddi, L.; Rosen, E. Tracking Epidemics with Natural Language Processing and Crowdsourcing. In Proceedings of the AAAI Spring Symposium—Wisdom of the Crowd (AAAI 2012), Palo Alto, CA, USA, 26–28 March 2012. [Google Scholar]
- Sabou, M.; Bontcheva, K.; Scharl, A. Crowdsourcing Research Opportunities: Lessons from Natural Language Processing. In Proceedings of the 12th International Conference on Knowledge Management and Knowledge Technologies (i-KNOW ’12), Graz, Austria, 5–7 September 2012; pp. 1–8. [Google Scholar] [CrossRef]
- Vamshi, A.; Vogel, S.; Carbonell, J. Collaborative Workflow for Crowdsourcing Translation. In Proceedings of the ACM 2012 Conference on Computer Supported Cooperative Work (CSCW ’12), Seattle, DC, USA, 11–15 February 2012; pp. 1191–1194. [Google Scholar]
- Zaidan, O.F.; Callison-Burch, C. Crowdsourcing Translation: Professional Quality from Non-professionals. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (HLT ’11), Portland, OR, USA, 19–24 June 2011; Volume 1, pp. 1220–1229. [Google Scholar]
- Muntés-Mulero, V.; Paladini, P.; Solé, M.; Manzoor, J. Multiplying the Potential of Crowdsourcing with Machine Translation. In Proceedings of the 10th Conference of the Association for Machine Translation in the Americas: Commercial MT User Program (AMTA 2012), San Diego, CA, USA, 28 October–1 November 2012. [Google Scholar]
- Muegge, U. Teaching computer-assisted translation in the 21st century. In TransÜD. Arbeiten zur Theorie und Praxis des Übersetzens und Dolmetschens (Alles Hängt Mit Allem Zusammen: Translatologische Interdependenzen. Festschrift für Peter A. Schmitt); Ende, A.-K., Herold, S., Weilandt, A., Eds.; Frank & Timme: Berlin, Germany, 2013; Volume 59. [Google Scholar]
- Canovas, M.; Samson, R. Open source software in translator training. Rev. Tradumàtica 2011, 9, 6–56. [Google Scholar] [CrossRef]
- Robson, K.; Plangger, K.; Kietzmann, J.H.; McCarthy, I.; Pitt, L. Game on: Engaging customers and employees through gamification. Bus. Horiz. 2016, 59, 29–36. [Google Scholar] [CrossRef]
- Morschheuser, B.; Werder, K.; Hamari, J.; Abe, J. How to gamify? Development of a method for gamification. In Proceedings of the 50th Annual Hawaii International Conference on System Sciences (HICSS), Hawaii, HI, USA, 4–7 January 2017; Volume 50, pp. 1298–1307. [Google Scholar] [CrossRef]
- Abdelali, A.; Durrani, N.; Guzmán, F. iAppraise: A Manual Machine Translation Evaluation Environment Supporting Eye-tracking. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations (NAACL 2016), San Diego, CA, USA, 13–15 June 2016; pp. 17–21. [Google Scholar] [CrossRef]
- Graliński, F.; Jaworski, R.; Borchmann, Ł.; Wierzchon, P. Gonito.net—Open platform for research competition, cooperation and reproducibility. In Proceedings of the 4REAL Workshop: Workshop on Research Results Reproducibility and Resources Citation in Science and Technology of Language, Portorož, Slovenia, 28 May 2016; pp. 13–20. [Google Scholar]



{kind=link}
{kind=link}
| Key concept: | Parallel data acquisition and corpus compilation | |
| Author(s) | Outcomes and ideas for this and future research | |
| Parida et al. (2018) [29] | Scraping of websites or applying Optical Character Recognition (OCR) for low-resource languages. | |
| Abdurakhmonova (2020) [31] | Compiling multilingual parallel corpora for Uzbek, Russian, and English using a CAT tool. | |
| Shearing et al. (2018) [33] | Applying data augmentation strategies in order to create parallel resources. | |
| Kuwanto et al. (2021) [38] | Creating corpora for low-resource languages by adding comparable data and a bilingual dictionary. | |
| Sen et al. (2020) [39] | Applying augmentation of data with parallel phrases extracted from the original training data for low-resource language pairs. | |
| Beloucif et al. (2019) [40] | Penalizing translations that are very different from the input sentences, which has shown to consistently enhance translation quality across multiple low-resource languages with varying training data sizes. | |
| Lambebo et al. (2021) [43] | Analyzing challenges in collecting parallel corpora for a low-resource language pair in the domain of religion and discussing the importance of the availability and number of parallel datasets. | |
| Ranathunga et al. (2023) [19] | Augmenting data by using bilingual dictionaries, back-translation, monolingual data selection, or parallel corpus mining from comparable corpora with sentence ranking. | |
| Ngo et al. (2020) [18] | Discussing how parallel data for a low-resource language pair was obtained from TED Talks and how it was prepared for machine translation. | |
| Singh (2012) [27] | Gathering data for a low-resource language pair in order to acquire parallel segments that were needed for building an SMT system. | |
| Zhang et al. (2023) [44] | Constructing a large-scale collection of bilingual sentences for a low-resource language pair from subtitles that were manually aligned, evaluated, and tested in different translation experiments. | |
| Key concept: | Resources for building machine translation systems and their characteristics | |
| Author(s) | Outcomes and ideas for this and future research | |
| Bahdanau et al. (2015) [22] | Discussing how NMT is used as the dominant approach for building machine translation systems that rely on large amounts of corpora. | |
| Koehn et al. (2003) [20] | Presenting a machine translation model that consists of different submodels that are trained separately with bilingual and monolingual data. | |
| Koehn (2010) [23] | Discussing how the translation model in SMT is trained on large amounts of parallel data and then tuned with additional data, whereas the language model is built with monolingual data. | |
| Wang, W. et al. (2021) [52] | Discussing the zero-shot approach in NMT when no parallel data is available. | |
| Currey and Heafield (2019) [53] | Emphasizing that NMT depends on large amounts of parallel data. However, when no parallel data is available, pivot languages can be applied. | |
| Kamath et al. (2019) [21] | Explaining the architecture and the use of artificial neural networks for predicting word sequences based on corpora in the NMT model. | |
| Dong et al. (2015) [24] | Investigating the problem of how to translate one source language into several different target languages within a unified translation model that is based on the encoder-decoder architecture. | |
| Gehring et al. (2017) [25] | Discussing a fast and simple architecture based on a succession of convolutional layers, in contrast to bi-directional LSTMs that are otherwise regularly being used in order to encode the source sentence. | |
| Vaswani et al. (2017) [26] | Proposing a new simple network architecture—the transformer—that is based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. | |
| Wang, R. et al. (2021) [17] | Providing an extensive survey for low-resource NMT and analyzing related works with regard to various auxiliary data sources. | |
| Doğru et al. (2018) [32] | Discussing parallel corpora preparation for machine translation for a low-resource language pair in the domain of medicine. | |
| Dunđer (2015) [28] | Implementing domain adaptation techniques and analyzing the impact of general-domain and industry-related parallel corpora on the effectiveness of SMT. | |
| Parida et al. (2018) [29] | Scraping of websites or applying Optical Character Recognition (OCR) for low-resource languages. The corpus was collected for the purpose of building a machine translation system. | |
| Forcada (2021) [34] | Discussing the use of parallel corpora and the rule-based machine translation approach for low-resource languages and dialects of Spain. | |
| Maruf et al. (2021) [37] | Discussing document-level NMT and assessing domain-related problems with corpora. | |
| Chu and Wang (2018) [35] | Analyzing corpus size and domain adaptation in the machine translation system. | |
| Koehn and Knowles (2017) [41] | Presenting challenges in building NMT systems in terms of parallel corpora, such as domain mismatches, amount of training data, rare words, the long sizes of sentences, word alignments, etc. | |
| Seljan et al. (2020) [42] | Discussing human quality evaluation results and different criteria with regard to in-domain parallel data used in machine translation. | |
| Dabre et al. (2020) [36] | Presenting the use of NMT when machine translation needs to be performed among more than one language pair. | |
| Ha et al. (2016) [45] | Discussing the encoder-decoder architecture in a multilingual NMT model. | |
| Lakew et al. (2018) [46] | Comparing the transformer and recurrent neural networks in a multilingual NMT environment. | |
| Tan et al. (2019) [47] | Using NMT with knowledge distillation in order to boost the accuracy of multilingual machine translation. | |
| Fikri Aji et al. (2020) [48] | Studying transfer learning in NMT, as it has been shown that it improves quality for low-resource machine translation. | |
| Kim et al. (2019) [49] | Exploring effective cross-lingual transfer of NMT models without using shared vocabularies. | |
| Dabre et al. (2017) [50] | Presenting an empirical study of language relatedness for transfer learning in NMT. | |
| Zoph et al. (2016) [51] | Highlighting the importance of transfer learning for low-resource NMT. | |
| Key concept: | Crowdsourcing in data acquisition and NLP tasks | |
| Author(s) | Outcomes and ideas for this and future research | |
| O’Brien (2011) [54] | Analyzing the benefits of using crowdsourcing in order to complete certain tasks that would otherwise be assigned to stakeholders, in-house employees, etc. | |
| Howe (2006) [55] | Stating that crowdsourcing costs significantly less than paying traditional in-house employees. | |
| Howe (2008) [56] | Using crowdsourcing to carry out distinct tasks that were once only solvable by a small, highly specialized group of individuals. | |
| Quinn and Bederson (2011) [57] | Presenting various aspects of crowdsourcing, such as motivation, quality, aggregation, human skills, participation time, and cognitive load. | |
| Sabou et al. (2014) [58] | Using crowdsourcing in project-based tasks, such as the acquisition of annotated corpora and for NLP. | |
| Li et al. (2015) [59] | Presenting a visualization toolkit to allow crowd-sourced workers to annotate general categories of NLP problems, such as clustering and parsing. | |
| Munro et al., 2012 [60] | Using crowdsourcing, NLP, and big data analysis for tracking medical events on a global scale. | |
| Vamshi et al. (2012) [62] | Using a collaborative workflow for crowdsourcing translation tasks. | |
| Zaidan and Callison-Burch (2011) [63] | Discussing how crowdsourcing can play a significant role in building necessary language resources. | |
| Ambati and Vogel (2010) [30] | Analyzing challenges when preparing crowdsourcing translation tasks with Amazon Mechanical Turk, especially when working with non-professional translators. | |
| Muntés-Mulero et al. (2012) [64] | Discussing why crowdsourcing translations will be the next big breakthrough in the translation industry. | |
| Muegge (2013) [65] | Emphasizing why translation technology should include collaborative translation, machine translation, translation management systems, and crowdsourcing. | |
| Canovas and Samson (2011) [66] | Analyzing why distance and blended learning are important features of the training and teaching environment for NLP-related tasks and what is perceived as the most suitable for specific training objectives. | |
| Key concept: | Gamification and its potential in NLP | |
| Author(s) | Outcomes and ideas for this and future research | |
| Robson et al. (2016) [67] | Discussing the application of game design principles in order to change behavior in a non-gaming context, increase engagement of participants, and increase the positive motivation of users towards specific activities. | |
| Morschheuser et al. (2017) [68] | Emphasizing why gamification tends to increase the positive motivation of users and why it increases the quantity and quality of the output or outcome of given activities. | |
| Abdelali et al. (2016) [69] | Stating that gamification has been successfully applied for the purpose of machine translation evaluation, by motivating participants with feedback in the form of stars. | |
| Graliński et al. (2016) [70] | Presenting an efficient approach to applying gamification to NLP tasks using a platform that uses a system of rewards, feedback, and reproducibility; and highlighting the differences when compared to gamification-oriented elements in Kaggle. | |
| Domain | Segments (TUs) | Words |
|---|---|---|
| General | 1,091,756 | 31,595,050 |
| Technical | 668,991 | 10,693,764 |
| Tourism | 636,896 | 22,388,296 |
| Manuals | 524,186 | 7,002,834 |
| Books | 491,425 | 15,557,436 |
| News | 364,278 | 15,103,005 |
| Web | 139,488 | 5,345,973 |
| Song lyrics | 75,465 | 720,750 |
| Legal—law | 62,133 | 1,038,258 |
| Film subtitles | 36,539 | 389,094 |
| Literature—creative | 70 | 1976 |
| Total | 4,091,227 | 109,836,436 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jaworski, R.; Seljan, S.; Dunđer, I. Four Million Segments and Counting: Building an English-Croatian Parallel Corpus through Crowdsourcing Using a Novel Gamification-Based Platform. Information 2023, 14, 226. https://doi.org/10.3390/info14040226
Jaworski R, Seljan S, Dunđer I. Four Million Segments and Counting: Building an English-Croatian Parallel Corpus through Crowdsourcing Using a Novel Gamification-Based Platform. Information. 2023; 14(4):226. https://doi.org/10.3390/info14040226
Chicago/Turabian StyleJaworski, Rafał, Sanja Seljan, and Ivan Dunđer. 2023. "Four Million Segments and Counting: Building an English-Croatian Parallel Corpus through Crowdsourcing Using a Novel Gamification-Based Platform" Information 14, no. 4: 226. https://doi.org/10.3390/info14040226
APA StyleJaworski, R., Seljan, S., & Dunđer, I. (2023). Four Million Segments and Counting: Building an English-Croatian Parallel Corpus through Crowdsourcing Using a Novel Gamification-Based Platform. Information, 14(4), 226. https://doi.org/10.3390/info14040226