


Exploring Key Issues in Cybersecurity Data Breaches: Analyzing Data Breach Litigation with ML-Based Text Analytics


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Background
2.1. Data Breaches—Industry Reports and Empirical Studies
2.2. Data Breaches—Theoretical, Conceptual, and Policy-Focused Studies
2.3. Data Breach Litigation
2.4. Text Analytics and Machine Learning
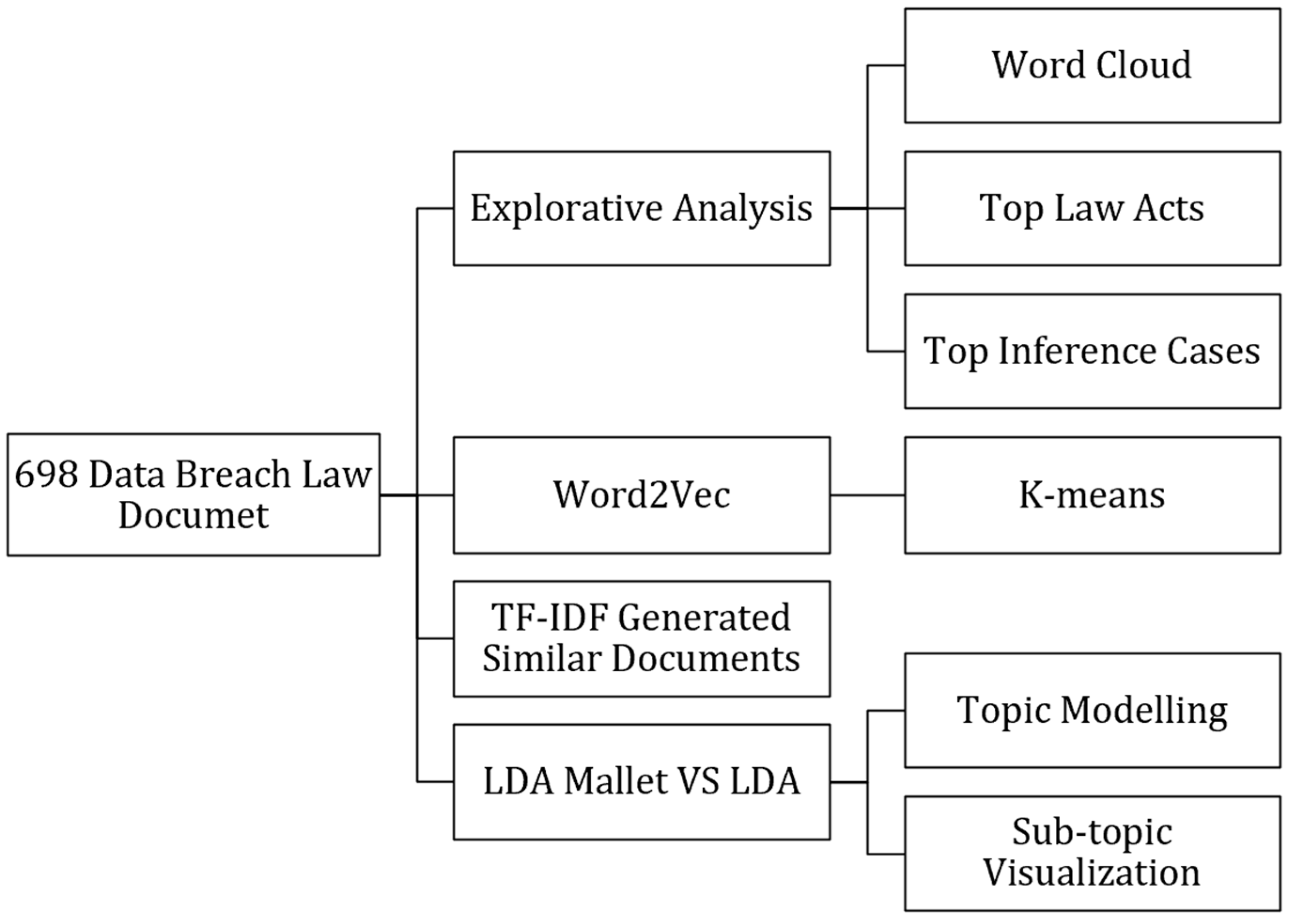
3. Methods
Text Analytics
4. Results and Analysis
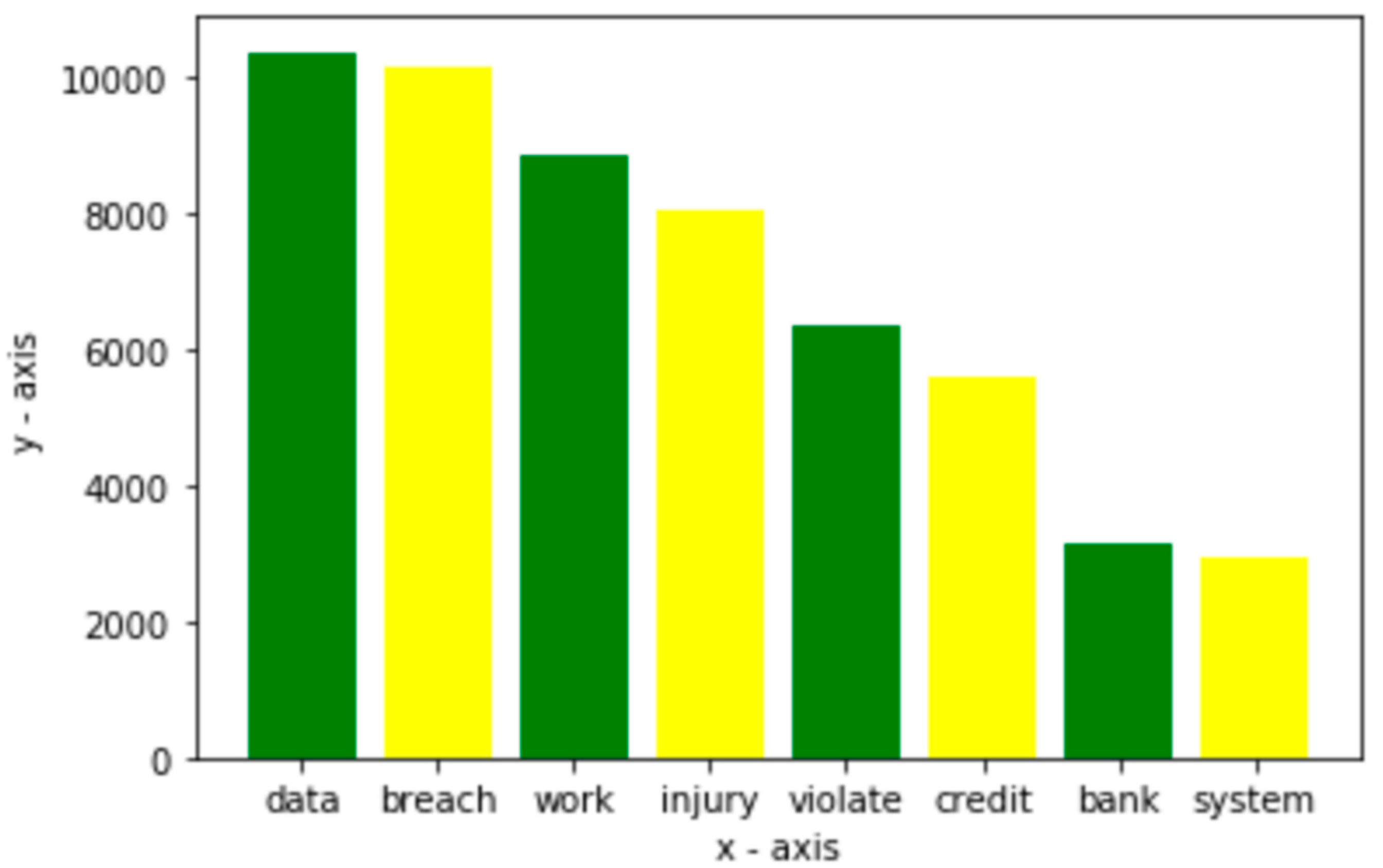
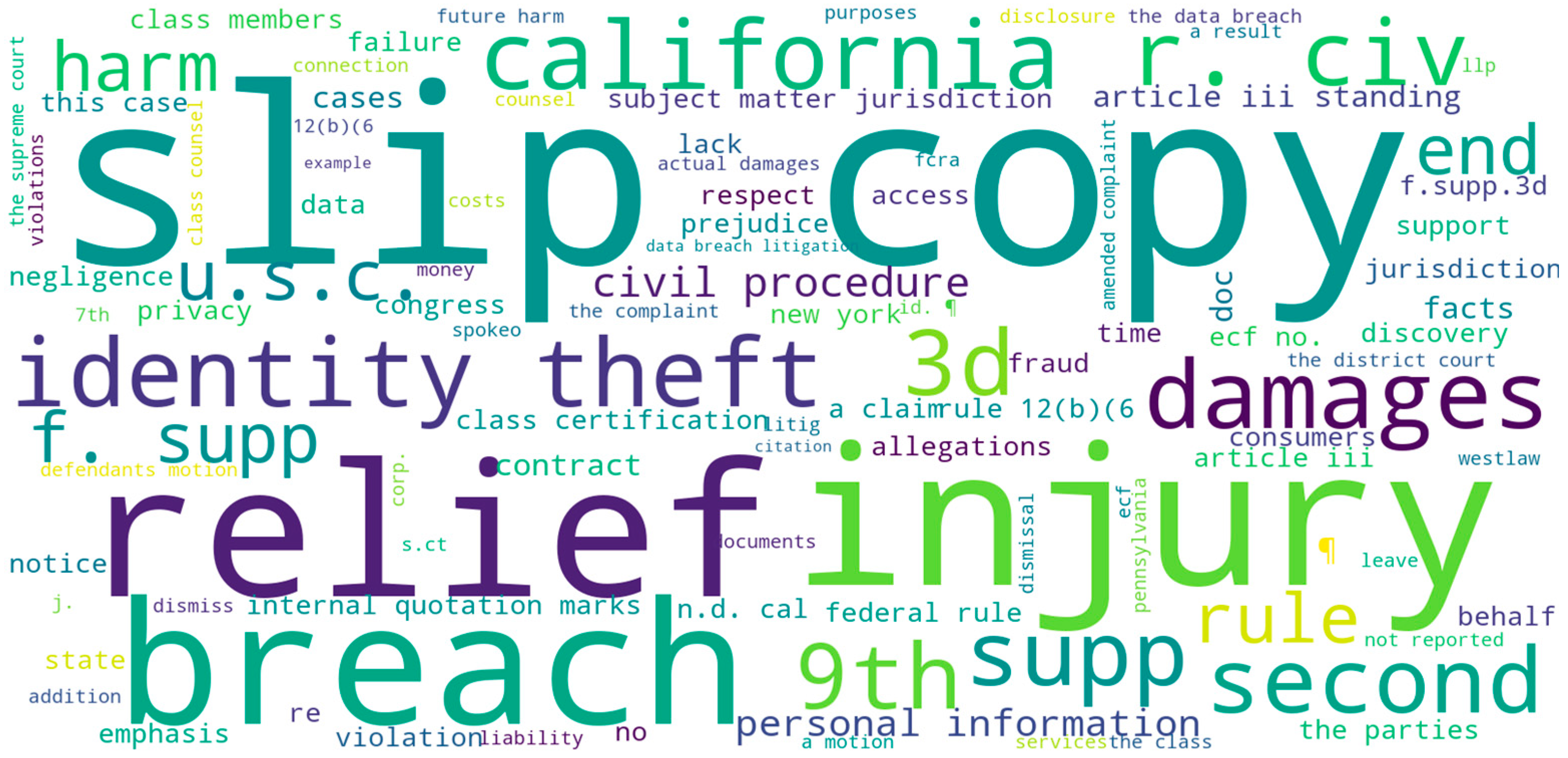
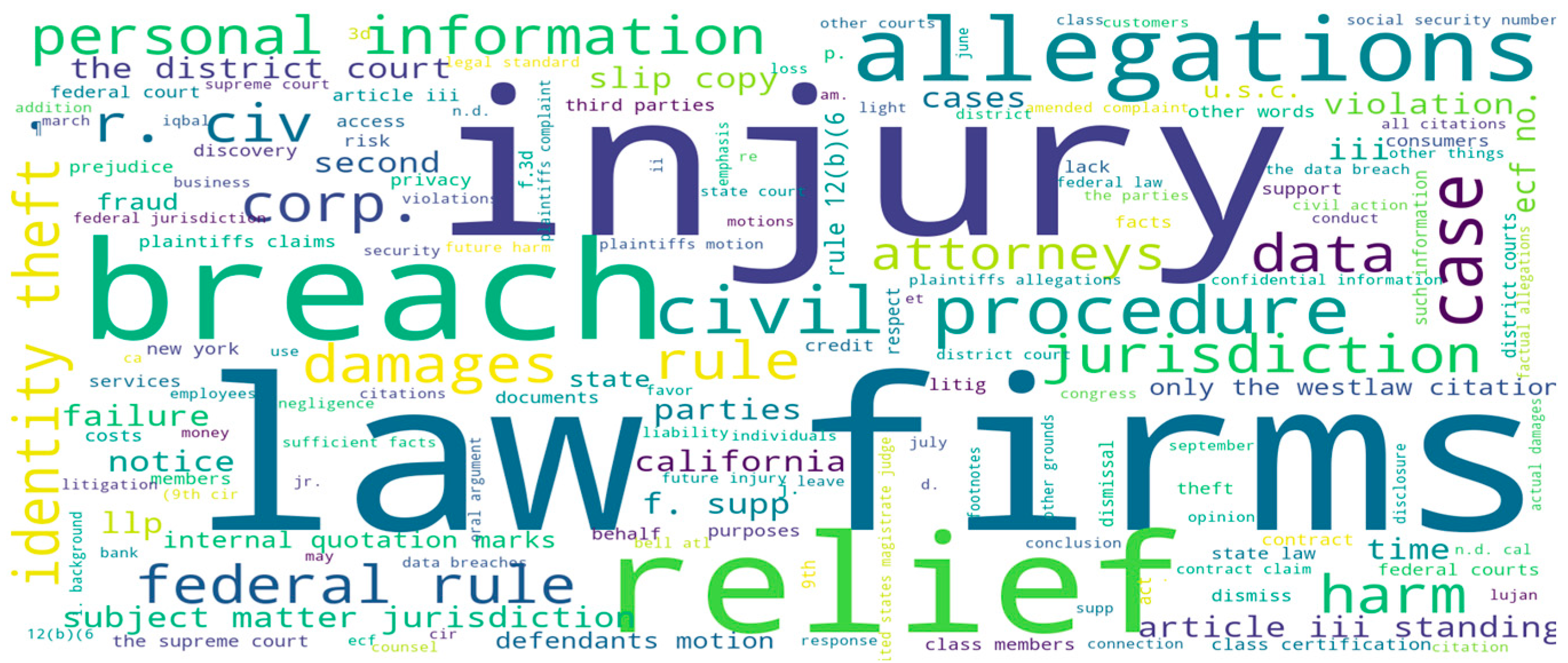
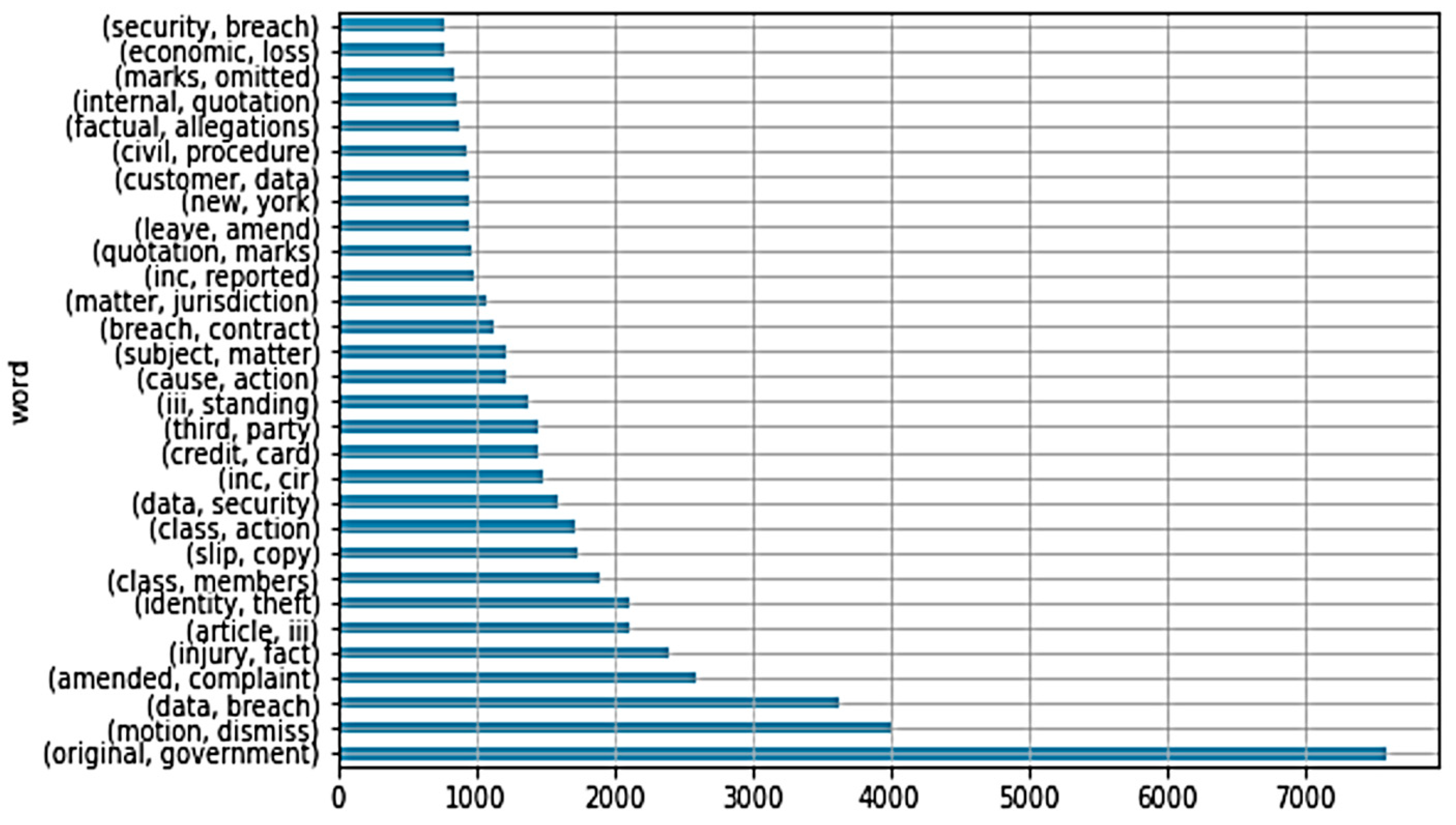
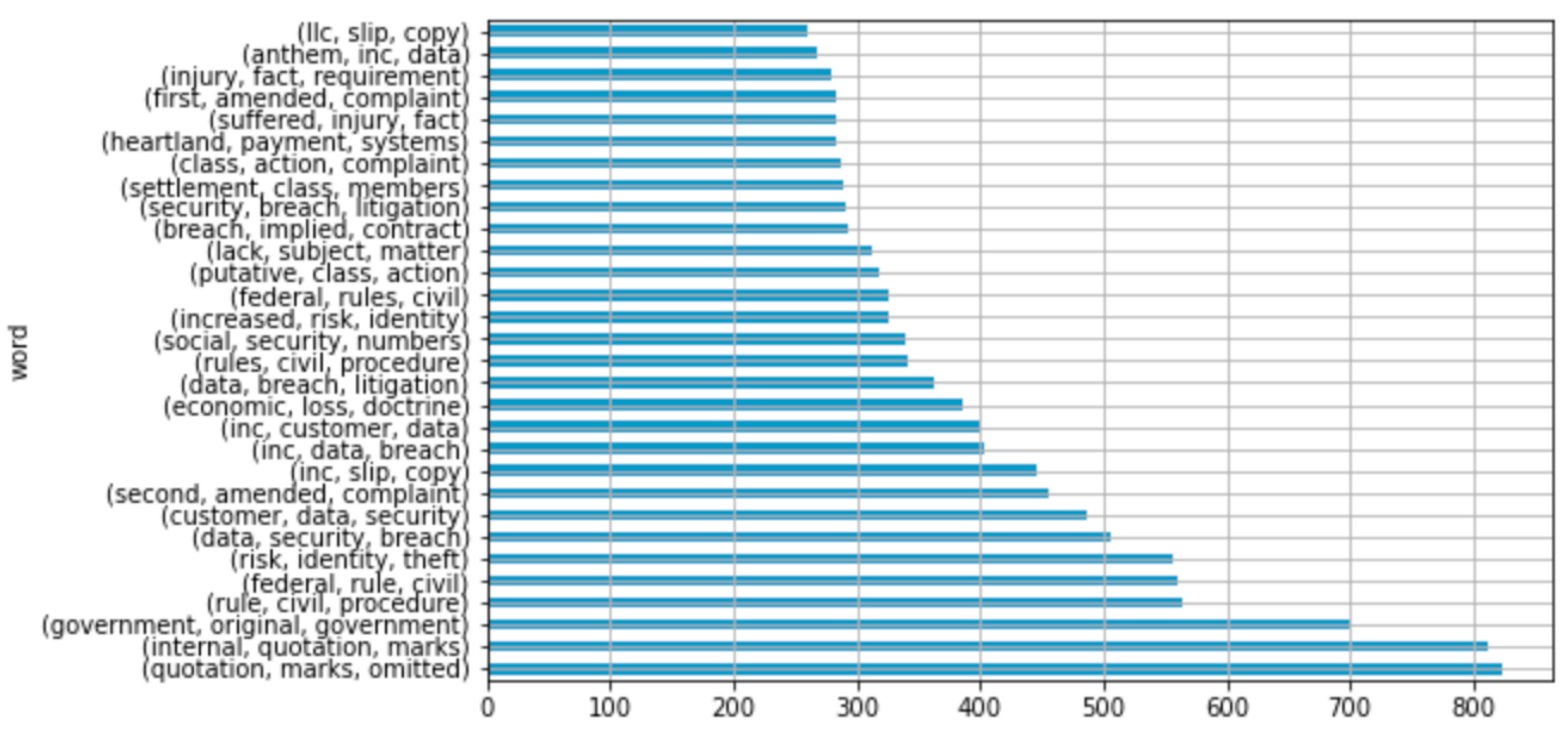
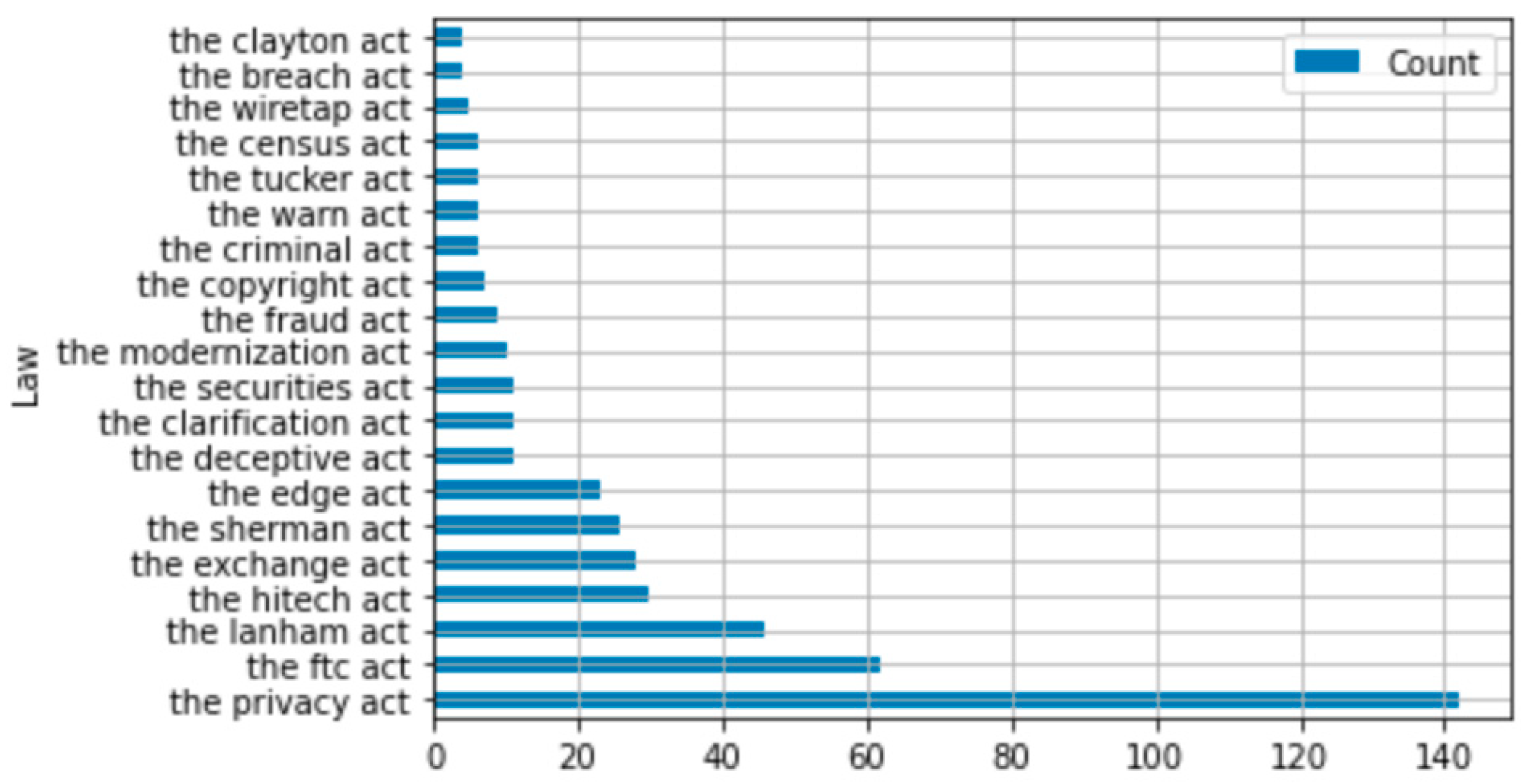
4.1. Word Cloud
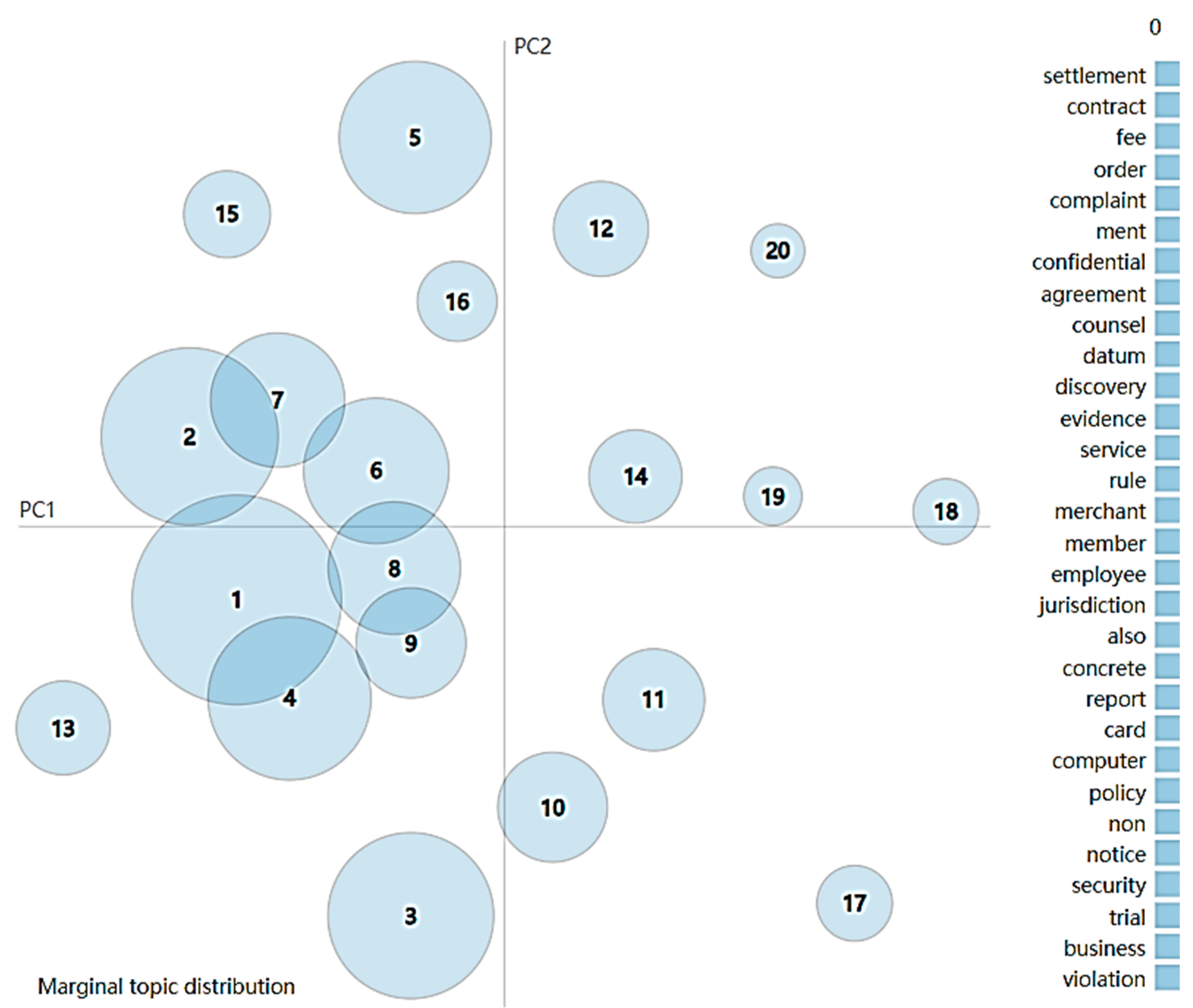
4.2. Topic Modeling
4.3. K-Means and Document Similarity
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cheng, L.; Liu, F.; Yao, D. Enterprise data breach: Causes, challenges, prevention, and future directions. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2017, 7, e1211. [Google Scholar] [CrossRef]
- Liu, Q.; Li, P.; Zhao, W.; Cai, W.; Yu, S.; Leung, V.C. A survey on security threats and defensive techniques of machine learning: A data driven view. IEEE Access 2018, 6, 12103–12117. [Google Scholar] [CrossRef]
- Schlackl, F.; Link, N.; Hoehle, H. Antecedents and consequences of data breaches: A systematic review. Inf. Manag. 2022, 59, 103638. [Google Scholar] [CrossRef]
- IBM. Cost of a Data Breach Report. 2023. Available online: https://www.ibm.com/downloads/cas/E3G5JMBP (accessed on 28 September 2023).
- PwC. PwC’s 23rd Annual Global CEO Survey. 2023. Available online: https://www.pwc.com/gx/en/issues/c-suite-insights/ceo-survey-2023.html (accessed on 28 September 2023).
- Dhillon, G.; Smith, K.; Dissanayaka, I. Information systems security research agenda: Exploring the gap between research and practice. J. Strateg. Inf. Syst. 2021, 30, 101693. [Google Scholar] [CrossRef]
- Layton, R.; Watters, P.A. A methodology for estimating the tangible cost of data breaches. J. Inf. Secur. Appl. 2014, 19, 321–330. [Google Scholar] [CrossRef]
- Sherstobitoff, R. Anatomy of a data breach. Inf. Secur. J. A Glob. Perspect. 2008, 17, 247–252. [Google Scholar] [CrossRef]
- Watters, P.A. Cyber Security: Concepts and Cases; CreateSpace Independent Publishing Platform: North Charleston, SC, USA, 2012. [Google Scholar]
- Irwin, L. The 6 Most Common Ways Data Breaches Occur. 2020. Available online: https://www.itgovernance.eu/blog/en/the-6-most-common-ways-data-breaches-occur (accessed on 28 September 2023).
- Wang, P.; Johnson, C. Cybersecurity incident handling: A case study of the Equifax data breach. Issues Inf. Syst. 2018, 19, 3. [Google Scholar]
- Wang, P.; Park, S.-A. Communication in Cybersecurity: A Public Communication Model for Business Data Breach Incident Handling. Issues Inf. Syst. 2017, 18, 2. [Google Scholar]
- Romanosky, S.; Hoffman, D.; Acquisti, A. Empirical analysis of data breach litigation. J. Empir. Leg. Stud. 2014, 11, 74–104. [Google Scholar] [CrossRef]
- Sanzgiri, A.; Dasgupta, D. Classification of insider threat detection techniques. In Proceedings of the 11th Annual Cyber and Information Security Research Conference, Oak Ridge, TN, USA, 5–7 April 2016; pp. 1–4. [Google Scholar]
- Congressional Research Service. 2015. Available online: https://crsreports.congress.gov/ (accessed on 1 November 2023).
- CNN. Yahoo Says 500 Million Accounts Stolen. 2016. Available online: https://money.cnn.com/2016/09/22/technology/yahoo-data-breach/ (accessed on 1 November 2023).
- McAfee. Grand Theft Data. 2017. Available online: https://www.mcafee.com (accessed on 1 November 2023).
- Greenberg, A. More than Half of Corporate Breaches Go Unreported, according to Study. 2013. Available online: https://www.scmagazine.com/news/more-than-half-of-corporate-breaches-go-unreported-according-to-study (accessed on 1 November 2023).
- Huq, N. Follow the data: Dissecting data breaches and debunking myths. TrendMicro Res. Pap. 2015. [Google Scholar]
- McGee Kolbasuk, M. Why Data Breaches go Unreported. 2014. Available online: https://www.bankinfosecurity.com/health-data-breaches-go-unreported-a-6804 (accessed on 1 November 2023).
- Privacy Rights Clearinghouse. Data Breaches Chronology. 2023. Available online: https://privacyrights.org/data-breaches (accessed on 28 September 2023).
- Anderson, R.; Barton, C.; Böhme, R.; Clayton, R.; Van Eeten, M.J.; Levi, M.; Moore, T.; Savage, S. Measuring the cost of cybercrime. In Proceedings of the 11th Workshop on the Economics of Information Security (WEIS), Washington, DC, USA, 11–12 June 2013; pp. 265–300. [Google Scholar]
- U.S. News. Equifax Breach Could Have ‘Decades of Impact’. 2017. Available online: https://www.usnews.com/news/articles/2017-09-08/equifax-breach-could-have-decades-of-impact-on-consumers (accessed on 1 November 2023).
- Saleem, H.; Naveed, M. SoK: Anatomy of data breaches. Proc. Priv. Enhancing Technol. 2020, 2020, 153–174. [Google Scholar] [CrossRef]
- Bielinski, C. 2018 Trustwave Global Security Report. 2018. Available online: https://www.trustwave.com/en-us/resources/library/documents/2018-trustwave-global-security-report/ (accessed on 1 November 2023).
- Manworren, N.; Letwat, J.; Daily, O. Why you should care about the Target data breach. Bus. Horiz. 2016, 59, 257–266. [Google Scholar] [CrossRef]
- Rashid, A.; Ramdhany, R.; Edwards, M.; Kibirige Mukisa, S.; Ali Babar, M.; Hutchison, D.; Chitchyan, R. Detecting and Preventing Data Exfiltration; Lancaster University: Lancaster, UK, 2014. [Google Scholar]
- Collins, J.D.; Sainato, V.A.; Khey, D.N. Organizational data breaches 2005-2010: Applying SCP to the healthcare and education sectors. Int. J. Cyber Criminol. 2011, 5, 794. [Google Scholar]
- Posey Garrison, C.; Ncube, M. A longitudinal analysis of data breaches. Inf. Manag. Comput. Secur. 2011, 19, 216–230. [Google Scholar] [CrossRef]
- Ayyagari, R. An exploratory analysis of data breaches from 2005-2011: Trends and insights. J. Inf. Priv. Secur. 2012, 8, 33–56. [Google Scholar] [CrossRef]
- Khey, D.N.; Sainato, V.A. Examining the correlates and spatial distribution of organizational data breaches in the United States. Secur. J. 2013, 26, 367–382. [Google Scholar] [CrossRef]
- Zadeh, A. Characterizing Data Breach Severity: A Data Analytics Approach. AMCIS. 2022. Available online: https://aisel.aisnet.org/treos_amcis2022/19 (accessed on 1 November 2023).
- Hammouchi, H.; Cherqi, O.; Mezzour, G.; Ghogho, M.; El Koutbi, M. Digging deeper into data breaches: An exploratory data analysis of hacking breaches over time. Procedia Comput. Sci. 2019, 151, 1004–1009. [Google Scholar] [CrossRef]
- Shu, X.; Tian, K.; Ciambrone, A.; Yao, D. Breaking the target: An analysis of target data breach and lessons learned. arXiv 2017, arXiv:1701.04940. [Google Scholar]
- Smith, T.T. Examining Data Privacy Breaches in Healthcare. Ph.D. Thesis, Walden University, Minneapolis, MN, USA, 2016. [Google Scholar]
- Holtfreter, R.E.; Harrington, A. Data breach trends in the United States. J. Financ. Crime 2015, 22, 242–260. [Google Scholar] [CrossRef]
- Neto, N.N.; Madnick, S.; Paula, A.M.G.D.; Borges, N.M. Developing a global data breach database and the challenges encountered. J. Data Inf. Qual. (JDIQ) 2021, 13, 1–33. [Google Scholar] [CrossRef]
- McLeod, A.; Dolezel, D. Cyber-analytics: Modeling factors associated with healthcare data breaches. Decis. Support Syst. 2018, 108, 57–68. [Google Scholar] [CrossRef]
- Algarni, A.M.; Malaiya, Y.K. A consolidated approach for estimation of data security breach costs. In Proceedings of the 2016 2nd International Conference on Information Management (ICIM), London, UK, 7–8 May 2016; pp. 26–39. [Google Scholar]
- Kafali, Ö.; Jones, J.; Petruso, M.; Williams, L.; Singh, M.P. How good is a security policy against real breaches? A HIPAA case study. In Proceedings of the 2017 IEEE/ACM 39th International Conference on Software Engineering (ICSE), Buenos Aires, Argentina, 20–28 May 2017; pp. 530–540. [Google Scholar]
- Sen, R.; Borle, S. Estimating the contextual risk of data breach: An empirical approach. J. Manag. Inf. Syst. 2015, 32, 314–341. [Google Scholar] [CrossRef]
- Hall, A.A.; Wright, C.S. Data security: A review of major security breaches between 2014 and 2018. Fed. Bus. Discip. J. 2018, 6, 50–63. [Google Scholar]
- Romanosky, S. Examining the costs and causes of cyber incidents. J. Cybersecur. 2016, 2, 121–135. [Google Scholar] [CrossRef]
- Goode, S.; Hoehle, H.; Venkatesh, V.; Brown, S.A. User compensation as a data breach recovery action. MIS Q. 2017, 41, 703–728. [Google Scholar] [CrossRef]
- As Data Breach Class Actions Arise. New York Law Journal. 2023. Available online: https://www.law.com/newyorklawjournal/?slreturn=20231005012616 (accessed on 1 November 2023).
- 2021 Year in Review: Data Breach and Cybersecurity Litigations. The National Law Review. 2021. Available online: https://www.privacyworld.blog/2021/12/2021-year-in-review-data-breach-and-cybersecurity-litigations/ (accessed on 1 November 2023).
- Black, M. HCA Data Breach Class Action Lawsuit May Include 11 Million; Mission Patients Notified. Asheville Citizen Times. 2023. Available online: https://www.citizen-times.com/story/news/local/2023/08/29/hca-data-breach-class-action-lawsuit-may-represent-11-million-patients/70699685007/ (accessed on 1 November 2023).
- Yenouskas, J.; Swank, L. Emerging Legal Issues in Data Breach Class Actions. 2018. Available online: https://www.americanbar.org/groups/business_law/resources/business-law-today/2018-july/emerging-legal-issues-in-data-breach-class-actions/ (accessed on 1 November 2023).
- Hill, M.; Swinhoe, D. The 15 Biggest Data Breaches of the 21st Century. 2021. Available online: https://www.csoonline.com/article/534628/the-biggest-data-breaches-of-the-21st-century.html (accessed on 1 November 2023).
- Bellamy, F.D. Data Breach Class Action Litigation and Changing Legal Landscape. 2022. Available online: https://www.reuters.com/legal/legalindustry/data-breach-class-action-litigation-changing-legal-landscape-2022-06-27/ (accessed on 1 November 2023).
- Khan, A.; Baharudin, B.; Lee, L.H.; Khan, K. A review of machine learning algorithms for text-documents classification. J. Adv. Inf. Technol. 2010, 1, 4–20. [Google Scholar]
- Landmann, J.; Zuell, C. Identifying events using computer-assisted text analysis. Soc. Sci. Comput. Rev. 2008, 26, 483–497. [Google Scholar] [CrossRef]
- Ford, J.M. Content analysis: An introduction to its methodology. Pers. Psychol. 2004, 57, 1110. [Google Scholar]
- Raghupathi, V.; Ren, J.; Raghupathi, W. Studying public perception about vaccination: A sentiment analysis of tweets. Int. J. Environ. Res. Public Health 2020, 17, 3464. [Google Scholar] [CrossRef]
- Raghupathi, V.; Zhou, Y.; Raghupathi, W. Legal decision support: Exploring big data analytics approach to modeling pharma patent validity cases. IEEE Access 2018, 6, 41518–41528. [Google Scholar] [CrossRef]
- Raghupathi, V.; Zhou, Y.; Raghupathi, W. Exploring big data analytic approaches to cancer blog text analysis. Int. J. Healthc. Inf. Syst. Inform. (IJHISI) 2019, 14, 1–20. [Google Scholar] [CrossRef]
- Ren, J.; Raghupathi, V.; Raghupathi, W. Understanding the dimensions of medical crowdfunding: A visual analytics approach. J. Med. Internet Res. 2020, 22, e18813. [Google Scholar] [CrossRef]
- Székely, N.; Vom Brocke, J. What can we learn from corporate sustainability reporting? Deriving propositions for research and practice from over 9,500 corporate sustainability reports published between 1999 and 2015 using topic modelling technique. PLoS ONE 2017, 12, e0174807. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, X.; Yuen, K.F. Sustainability disclosure for container shipping: A text-mining approach. Transp. Policy 2021, 110, 465–477. [Google Scholar] [CrossRef]
- Blei, D.M. Probabilistic topic models. Commun. ACM 2012, 55, 77–84. [Google Scholar] [CrossRef]
- Graham, S.; Weingart, S.; Milligan, I. Getting Started with Topic Modeling and MALLET. The Editorial Board of the Programming Historian. 2012. Available online: https://uwspace.uwaterloo.ca/handle/10012/11751 (accessed on 1 November 2023).
- Jelodar, H.; Wang, Y.; Yuan, C.; Feng, X.; Jiang, X.; Li, Y.; Zhao, L. Latent Dirichlet allocation (LDA) and topic modeling: Models, applications, a survey. Multimed. Tools Appl. 2019, 78, 15169–15211. [Google Scholar] [CrossRef]
- Liu, L.; Tang, L.; Dong, W.; Yao, S.; Zhou, W. An overview of topic modeling and its current applications in bioinformatics. SpringerPlus 2016, 5, 1–22. [Google Scholar] [CrossRef]
- Crain, S.P.; Zhou, K.; Yang, S.-H.; Zha, H. Dimensionality reduction and topic modeling: From latent semantic indexing to latent dirichlet allocation and beyond. Min. Text Data 2012, 129–161. [Google Scholar]
- Krestel, R.; Fankhauser, P. Tag recommendation using probabilistic topic models. ECML PKDD Discov. Chall. 2009, 2009, 131. [Google Scholar]
- Debortoli, S.; Müller, O.; Junglas, I.; Vom Brocke, J. Text mining for information systems researchers: An annotated topic modeling tutorial. Commun. Assoc. Inf. Syst. (CAIS) 2016, 39, 7. [Google Scholar] [CrossRef]
- Syed, S.; Spruit, M. Full-text or abstract? Examining topic coherence scores using latent dirichlet allocation. In Proceedings of the 2017 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Tokyo, Japan, 18 January 2018; pp. 165–174. [Google Scholar]
- Yi, Y.; Liu, L.; Li, C.H.; Song, W.; Liu, S. Machine learning algorithms with co-occurrence based term association for text mining. In Proceedings of the 2012 Fourth International Conference on Computational Intelligence and Communication Networks, Mathura, India, 3–5 November 2012; pp. 958–962. [Google Scholar]











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Molitor, D.; Raghupathi, W.; Saharia, A.; Raghupathi, V. Exploring Key Issues in Cybersecurity Data Breaches: Analyzing Data Breach Litigation with ML-Based Text Analytics. Information 2023, 14, 600. https://doi.org/10.3390/info14110600
Molitor D, Raghupathi W, Saharia A, Raghupathi V. Exploring Key Issues in Cybersecurity Data Breaches: Analyzing Data Breach Litigation with ML-Based Text Analytics. Information. 2023; 14(11):600. https://doi.org/10.3390/info14110600
Chicago/Turabian StyleMolitor, Dominik, Wullianallur Raghupathi, Aditya Saharia, and Viju Raghupathi. 2023. "Exploring Key Issues in Cybersecurity Data Breaches: Analyzing Data Breach Litigation with ML-Based Text Analytics" Information 14, no. 11: 600. https://doi.org/10.3390/info14110600
APA StyleMolitor, D., Raghupathi, W., Saharia, A., & Raghupathi, V. (2023). Exploring Key Issues in Cybersecurity Data Breaches: Analyzing Data Breach Litigation with ML-Based Text Analytics. Information, 14(11), 600. https://doi.org/10.3390/info14110600