Multi-Agent Reinforcement Learning for Online Food Delivery with Location Privacy Preservation

 and
and
Abstract
:1. Introduction
- (i)
- We propose a method that aims to improve the efficiency of online food delivery applications by guiding the courier to areas with high demand in order to increase income in the long term.
- (ii)
- We consider weekdays and weekends as a factor in the agent’s learning process to gain better results as the number of orders can vary on weekdays vs. weekends.
- (iii)
- To show more results and comparisons, this research employs two multi-agent reinforcement learning methods, QMIX and IQL, which aim to increase the number of received orders by couriers and raise long-term income.
- (iv)
- We use two datasets with different city sizes and different geographic areas to present more results.
- (v)
- We invent a privacy method called the ’Protect User Location Method’ (PULM). This method uses the city area size and customer frequency of online food delivery orders to determine the privacy parameter.
- (vi)
- We employ differential privacy (DP) by injecting Laplace noise to preserve the customer’s location along with the courier’s trajectory.
2. Literature Review
2.1. Online Food Delivery Service
2.2. Privacy Preservation
2.3. Discussion of Related Work
3. Preliminary
3.1. Dueling Network Architecture
3.2. Multi-Agent Reinforcement Learning
3.2.1. QMIX Algorithm
3.2.2. Independent Q-Learning
3.3. Trajectory Protection
3.4. Differential Privacy
4. Methods
4.1. Model Overview and Problem Statement
4.2. Multi-Agent Reinforcement Learning Formulation
4.2.1. Agent
4.2.2. State
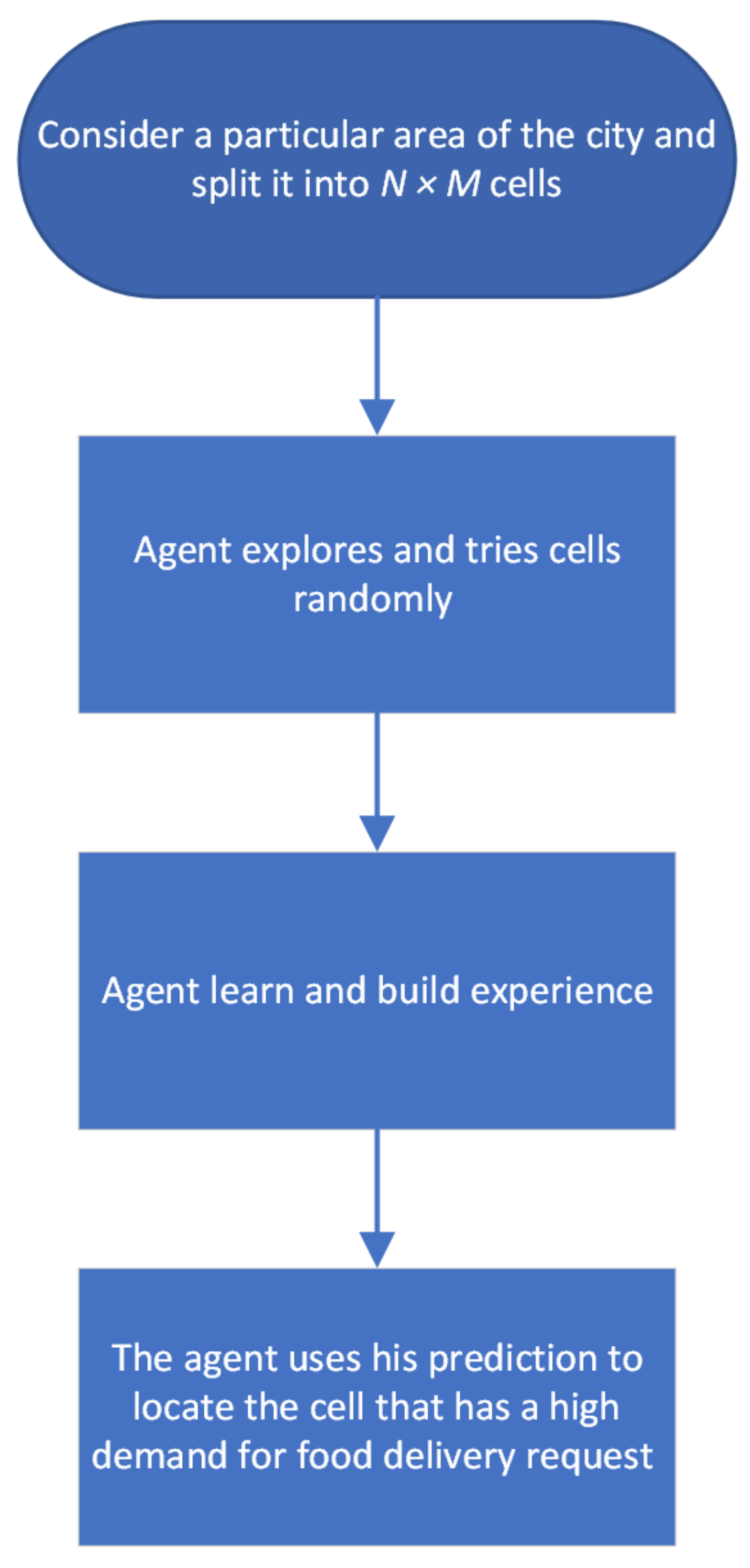
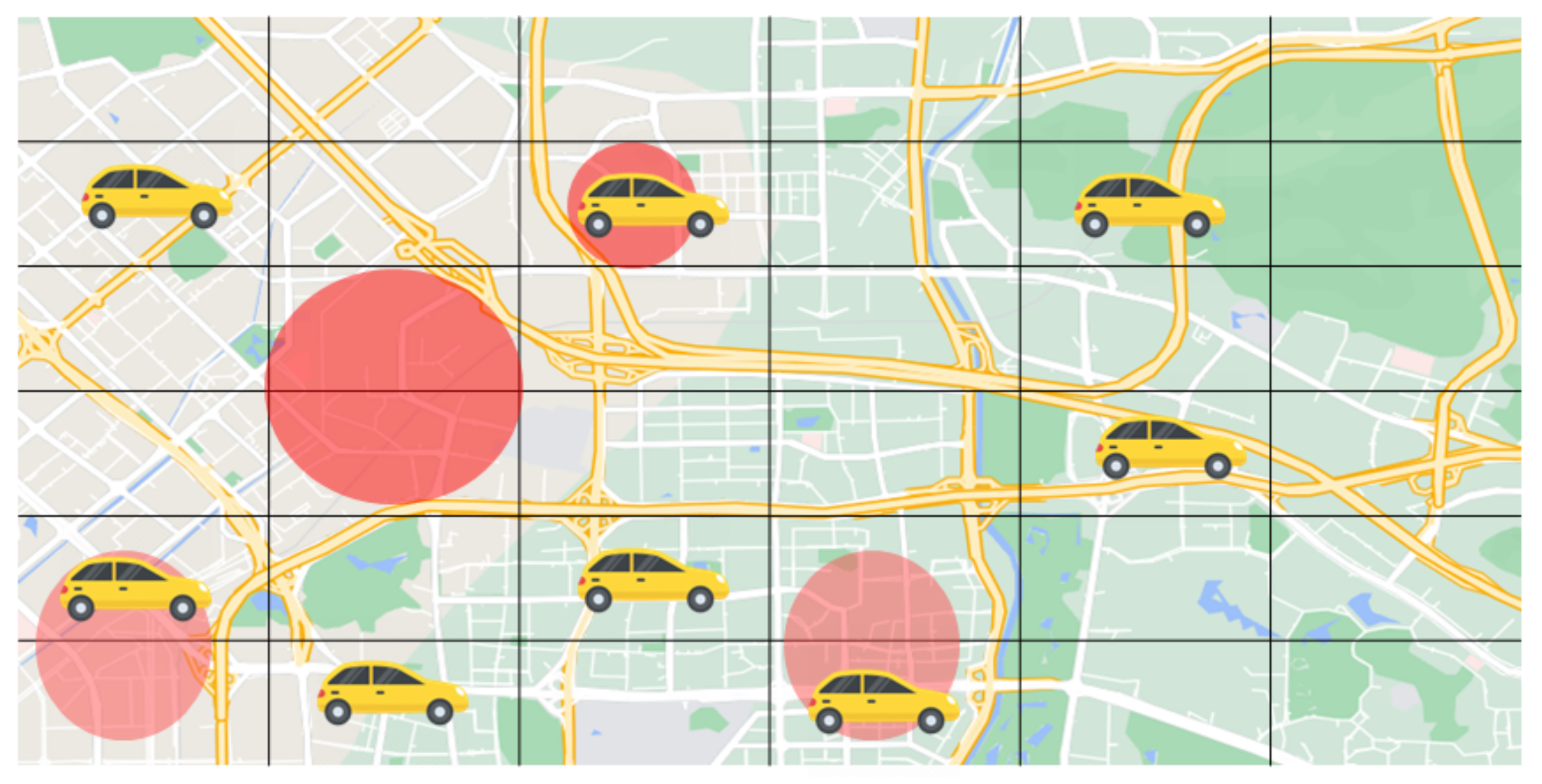
- The grid location: A certain area of the city map is considered and is divided into cells. Every divided cell illustrates a small area in the city. The agent interacts with the environment and updates his/her status. The agent then analyses and computes the available information about the environment and tries to pick a cell with high food delivery demand.
- Weekdays and weekends: On the one hand, during weekdays and weekends, different situations need to be noted and considered by the model. Therefore, in this model, we consider weekdays and weekends during the learning process for better performance.
4.2.3. Action
4.2.4. Reward Function
4.2.5. State Transition
4.2.6. Multi-Agent Reinforcement Learning for Online Food Delivery
| Algorithm 1 QMIX algorithm for online food delivery environment. |
|
4.3. Protect User Location Method
4.3.1. Overview of PULM Algorithm
| Algorithm 2 Protect User Location Method (PULM) |
|
4.3.2. City Area Size
4.3.3. Customer Frequency of Online Food Delivery Orders
5. Experiment Design
5.1. Multi-Agent Reinforcement Learning for Online Food Delivery Services
5.1.1. Applying Different Algorithms for Deep Reinforcement Learning
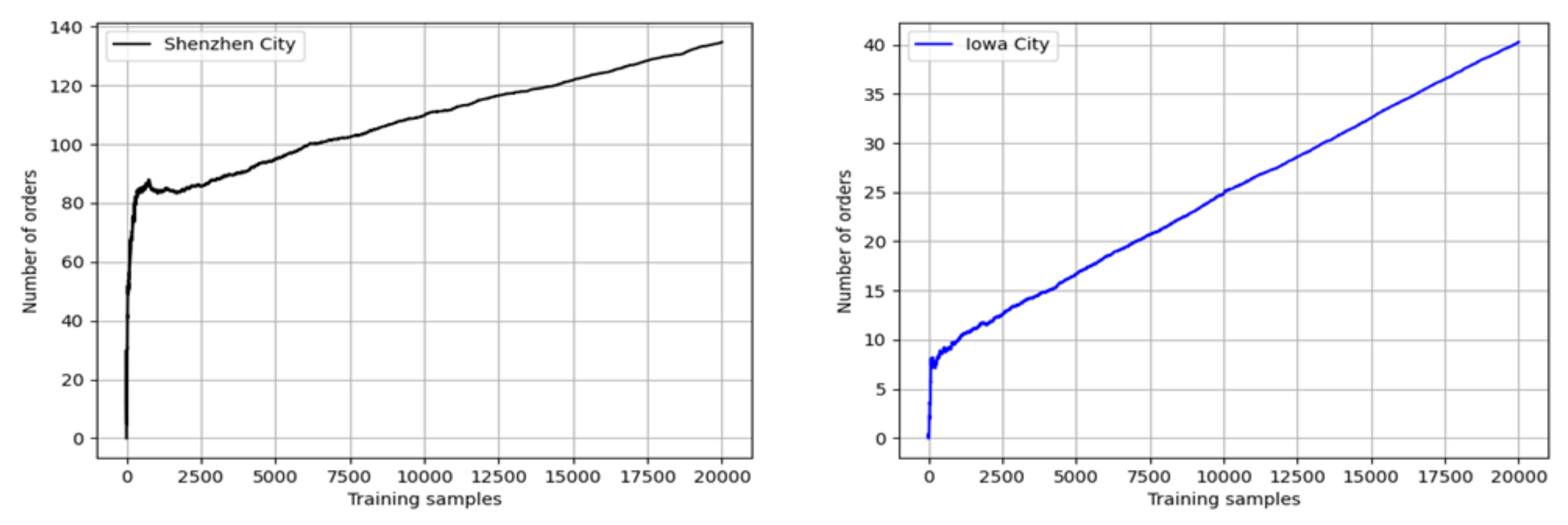
5.1.2. Number of Food Delivery Orders
5.2. Trajectory Protection Method
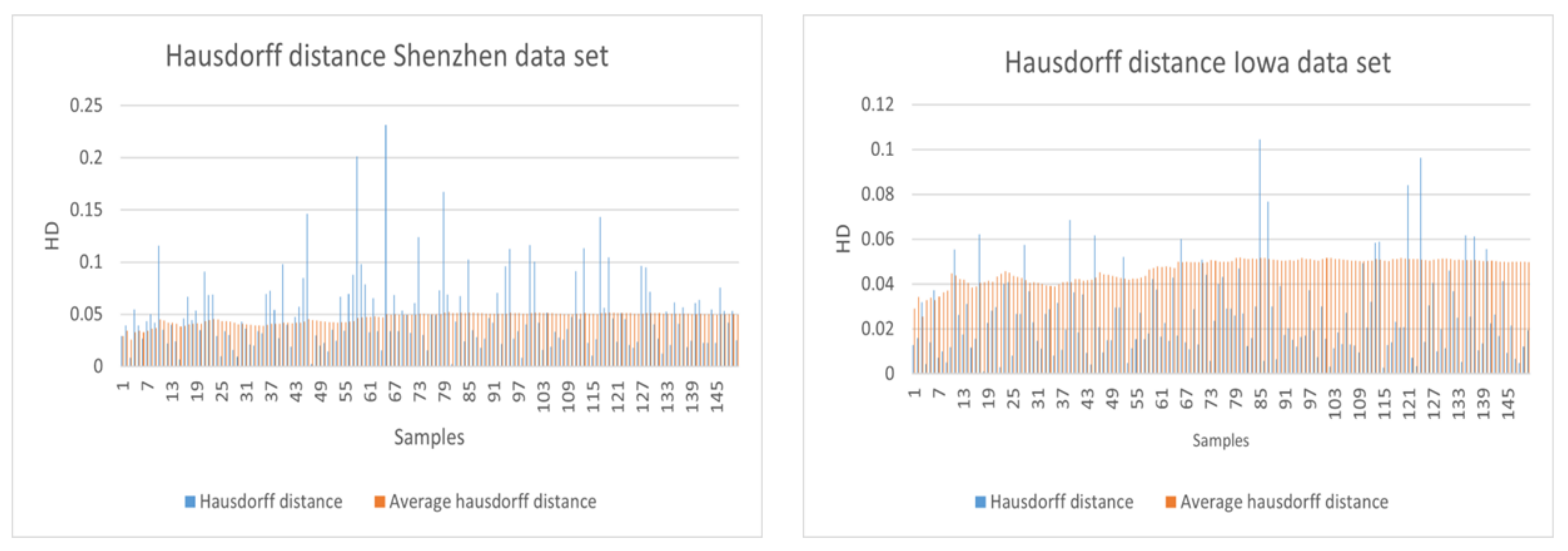
5.2.1. Trajectory Data Utility
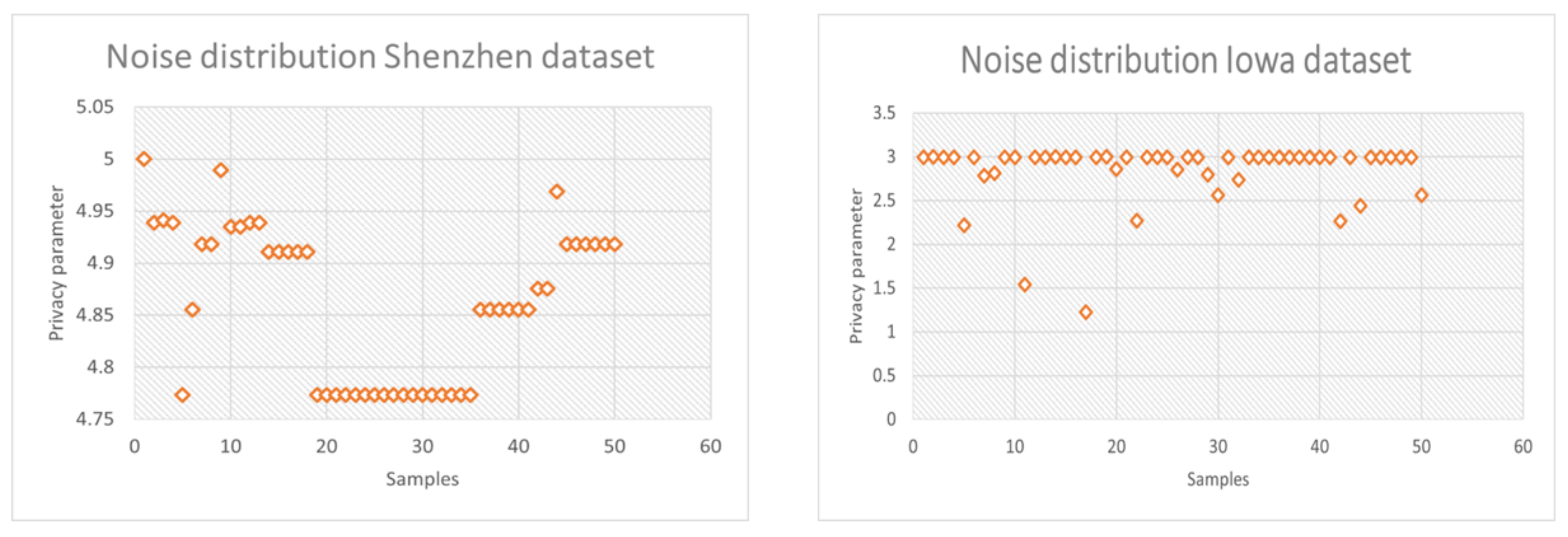
5.2.2. Analysing Privacy Parameter Intensity
5.3. Dataset Description
6. Results
6.1. Multi-Agent Reinforcement Learning for Online Food Delivery Service
6.2. Trajectory Protection Mechanism
7. Conclusions
8. Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| MARL | Multi-agent reinforcement learning |
| DRL | Deep reinforcement learning |
| DQN | Deep Q-network |
| IQL | Independent Q-learning |
| PULM | Protect User Location Method |
| DP | Differential privacy |
References
- Statista. Online Food Delivery—Worldwide. Available online: https://www.statista.com/outlook/dmo/online-food-delivery/worldwide?currency=usd (accessed on 30 August 2023).
- Chen, X.; Ulmer, M.W.; Thomas, B.W. Deep Q-learning for same-day delivery with vehicles and drones. Eur. J. Oper. Res. 2022, 298, 939–952. [Google Scholar] [CrossRef]
- Liu, S.; Jiang, H.; Chen, S.; Ye, J.; He, R.; Sun, Z. Integrating Dijkstra’s algorithm into deep inverse reinforcement learning for food delivery route planning. Transp. Res. Part Logist. Transp. Rev. 2020, 142, 102070. [Google Scholar] [CrossRef]
- Xing, E.; Cai, B. Delivery route optimization based on deep reinforcement learning. In Proceedings of the 2020 2nd International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Taiyuan, China, 23–25 October 2020; pp. 334–338. [Google Scholar]
- Ding, Y.; Guo, B.; Zheng, L.; Lu, M.; Zhang, D.; Wang, S.; Son, S.H.; He, T. A City-Wide Crowdsourcing Delivery System with Reinforcement Learning. In Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, Virtual, 24–28 October 2021; Volume 5, pp. 1–22. [Google Scholar]
- Bozanta, A.; Cevik, M.; Kavaklioglu, C.; Kavuk, E.M.; Tosun, A.; Sonuc, S.B.; Duranel, A.; Basar, A. Courier routing and assignment for food delivery service using reinforcement learning. Comput. Ind. Eng. 2022, 164, 107871. [Google Scholar] [CrossRef]
- Jahanshahi, H.; Bozanta, A.; Cevik, M.; Kavuk, E.M.; Tosun, A.; Sonuc, S.B.; Kosucu, B.; Başar, A. A deep reinforcement learning approach for the meal delivery problem. Knowl.-Based Syst. 2022, 243, 108489. [Google Scholar] [CrossRef]
- Zou, G.; Tang, J.; Yilmaz, L.; Kong, X. Online food ordering delivery strategies based on deep reinforcement learning. Appl. Intell. 2022, 52, 6853–6865. [Google Scholar] [CrossRef]
- Hu, S.; Guo, B.; Wang, S.; Zhou, X. Effective cross-region courier-displacement for instant delivery via reinforcement learning. In Proceedings of the International Conference on Wireless Algorithms, Systems, and Applications, Nanjing, China, 25–27 June 2021; pp. 288–300. [Google Scholar]
- Zhao, X.; Pi, D.; Chen, J. Novel trajectory privacy-preserving method based on clustering using differential privacy. Expert Syst. Appl. 2020, 149, 113241. [Google Scholar] [CrossRef]
- Zhang, L.; Jin, C.; Huang, H.P.; Fu, X.; Wang, R.C. A trajectory privacy preserving scheme in the CANNQ service for IoT. Sensors 2019, 19, 2190. [Google Scholar] [CrossRef]
- Tu, Z.; Zhao, K.; Xu, F.; Li, Y.; Su, L.; Jin, D. Protecting Trajectory From Semantic Attack Considering k -Anonymity, l -Diversity, and t -Closeness. IEEE Trans. Netw. Serv. Manag. 2018, 16, 264–278. [Google Scholar] [CrossRef]
- Chiba, T.; Sei, Y.; Tahara, Y.; Ohsuga, A. Trajectory anonymization: Balancing usefulness about position information and timestamp. In Proceedings of the 2019 10th IFIP International Conference on New Technologies, Mobility and Security (NTMS), Canary Islands, Spain, 24–26 June 2019; pp. 1–6. [Google Scholar]
- Zhou, K.; Wang, J. Trajectory protection scheme based on fog computing and K-anonymity in IoT. In Proceedings of the 2019 20th Asia-Pacific Network Operations and Management Symposium (APNOMS), Matsue, Japan, 18–20 September 2019; pp. 1–6. [Google Scholar]
- Zhou, S.; Liu, C.; Ye, D.; Zhu, T.; Zhou, W.; Yu, P.S. Adversarial attacks and defenses in deep learning: From a perspective of cybersecurity. Acm Comput. Surv. 2022, 55, 1–39. [Google Scholar] [CrossRef]
- Andrés, M.E.; Bordenabe, N.E.; Chatzikokolakis, K.; Palamidessi, C. Geo-indistinguishability: Differential privacy for location-based systems. In Proceedings of the Proceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security, Berlin, Germany, 4–8 November 2013; pp. 901–914. [Google Scholar]
- Deldar, F.; Abadi, M. PLDP-TD: Personalized-location differentially private data analysis on trajectory databases. Pervasive Mob. Comput. 2018, 49, 1–22. [Google Scholar] [CrossRef]
- Yang, M.; Zhu, T.; Xiang, Y.; Zhou, W. Density-based location preservation for mobile crowdsensing with differential privacy. IEEE Access 2018, 6, 14779–14789. [Google Scholar] [CrossRef]
- Yang, Y.; Ban, X.; Huang, X.; Shan, C. A Dueling-Double-Deep Q-Network Controller for Magnetic Levitation Ball System. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; pp. 1885–1890. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.; Lanctot, M.; Freitas, N. Dueling network architectures for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1995–2003. [Google Scholar]
- Lapan, M. Deep Reinforcement Learning Hands-On, 2nd ed.; Packt Publishing Ltd.: Birmingham, UK, 2020. [Google Scholar]
- Sewak, M. Deep Reinforcement Learning; Springer: Singapore, 2019. [Google Scholar]
- Cheng, Z.; Ye, D.; Zhu, T.; Zhou, W.; Yu, P.S.; Zhu, C. Multi-agent reinforcement learning via knowledge transfer with differentially private noise. Int. J. Intell. Syst. 2022, 37, 799–828. [Google Scholar] [CrossRef]
- Vamvoudakis, K.G.; Wan, Y.; Lewis, F.L.; Cansever, D. Handbook of Reinforcement Learning and Control; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Ye, D.; Zhang, M.; Sutanto, D. Cloning, resource exchange, and relationadaptation: An integrative self-organisation mechanism in a distributed agent network. IEEE Trans. Parallel Distrib. Syst. 2013, 25, 887–897. [Google Scholar]
- Ye, D.; Zhu, T.; Cheng, Z.; Zhou, W.; Yu, P.S. Differential advising in multiagent reinforcement learning. IEEE Trans. Cybern. 2020, 52, 5508–5521. [Google Scholar] [CrossRef] [PubMed]
- Rashid, T.; Samvelyan, M.; Schroeder de Witt, C.; Farquhar, G.; Foerster, J.N.; Whiteson, S. Monotonic value function factorisation for deep multi-agent reinforcement learning. J. Mach. Learn. Res. 2020, 21, 7234–7284. [Google Scholar]
- Zhang, X.; Zhao, C.; Liao, F.; Li, X.; Du, Y. Online parking assignment in an environment of partially connected vehicles: A multi-agent deep reinforcement learning approach. Transp. Res. Part Emerg. Technol. 2022, 138, 103624. [Google Scholar] [CrossRef]
- Yun, W.J.; Jung, S.; Kim, J.; Kim, J.H. Distributed deep reinforcement learning for autonomous aerial eVTOL mobility in drone taxi applications. ICT Express 2021, 7, 1–4. [Google Scholar] [CrossRef]
- Tampuu, A.; Matiisen, T.; Kodelja, D.; Kuzovkin, I.; Korjus, K.; Aru, J.; Aru, J.; Vicente, R. Multiagent cooperation and competition with deep reinforcement learning. PloS ONE 2017, 12, e0172395. [Google Scholar] [CrossRef]
- Rehman, H.M.R.U.; On, B.W.; Ningombam, D.D.; Yi, S.; Choi, G.S. QSOD: Hybrid policy gradient for deep multi-agent reinforcement learning. IEEE Access 2021, 9, 129728–129741. [Google Scholar] [CrossRef]
- Du, Y.; Han, L.; Fang, M.; Liu, J.; Dai, T.; Tao, D. Liir: Learning individual intrinsic reward in multi-agent reinforcement learning. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Chen, R.; Fung, B.; Desai, B.C. Differentially private trajectory data publication. arXiv 2011, arXiv:1112.2020. [Google Scholar]
- Ma, P.; Wang, Z.; Zhang, L.; Wang, R.; Zou, X.; Yang, T. Differentially Private Reinforcement Learning. In Proceedings of the International Conference on Information and Communications Security, London, UK, 11–15 November 2019; pp. 668–683. [Google Scholar]
- Dwork, C.; Kenthapadi, K.; McSherry, F.; Mironov, I.; Naor, M. Our data, ourselves: Privacy via distributed noise generation. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, St. Petersburg, Russia, 28 May–1 June 2006; pp. 486–503. [Google Scholar]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Proceedings of the Theory of Cryptography Conference, New York, NY, USA, 4–7 March 2006; pp. 265–284. [Google Scholar]
- Zhu, T.; Li, G.; Zhou, W.; Philip, S.Y. Differentially private data publishing and analysis: A survey. IEEE Trans. Knowl. Data Eng. 2017, 29, 1619–1638. [Google Scholar] [CrossRef]
- Zhu, T.; Philip, S.Y. Applying differential privacy mechanism in artificial intelligence. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 1601–1609. [Google Scholar]
- Zhu, T.; Ye, D.; Wang, W.; Zhou, W.; Philip, S.Y. More than privacy: Applying differential privacy in key areas of artificial intelligence. IEEE Trans. Knowl. Data Eng. 2020, 34, 2824–2843. [Google Scholar] [CrossRef]
- Assam, R.; Hassani, M.; Seidl, T. Differential private trajectory protection of moving objects. In Proceedings of the 3rd ACM SIGSPATIAL International Workshop on GeoStreaming, Redondo Beach, CA, USA, 6 November 2012; pp. 68–77. [Google Scholar]
- Tokyo’s History, Geography and Population. Available online: https://www.metro.tokyo.lg.jp/ENGLISH/ABOUT/HISTORY/history03.htm (accessed on 30 August 2023).
- U.S. Census Bureau Quickfacts: United States. Available online: https://www.census.gov/quickfacts/fact/table/US/PST045221 (accessed on 30 August 2023).
- Baker, C. City & Town Classification of Constituencies & Local Authorities. Brief. Pap. 2018, 8322. [Google Scholar]
- Liu, D.; Chen, N. Satellite monitoring of urban land change in the middle Yangtze River Basin urban agglomeration, China between 2000 and 2016. Remote Sens. 2017, 9, 1086. [Google Scholar] [CrossRef]
- Li, M.; Zhu, L.; Zhang, Z.; Xu, R. Achieving differential privacy of trajectory data publishing in participatory sensing. Inf. Sci. 2017, 400, 1–13. [Google Scholar] [CrossRef]
- Ulmer, M.W.; Thomas, B.W.; Campbell, A.M.; Woyak, N. The restaurant meal delivery problem: Dynamic pickup and delivery with deadlines and random ready times. Transp. Sci. 2021, 55, 75–100. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Method | Domain | Methodology | Objective |
|---|---|---|---|---|
| Hu et al. [9] | CDRL | Delivery services | Multi-agent actor–critic | Consider the dispatch problem of courier and balance the demand (picking up orders) and supply (couriers’ capacity) and improve the efficiency of order delivery by reducing idle displacing time. |
| Zou et al. [8] | Delivery services | Double deep Q-network | Propose a dispatch framework that gradually learns and tests the dispatch order policy by assigning the order to the selected courier, and if the order is finished within the time limit, a positive reward is given for the action. Otherwise, a negative reward is assigned for the action. | |
| Jahanshahi et al. [7] | Delivery services | Deep reinforcement learning | Consider a meal delivery service and increase the total income and quality of the service by giving the orders to the most suitable couriers in order to reduce the expected delays or by postponing or rejecting orders. | |
| Bozanta et al. [6] | Delivery services | Q-learning and double deep reinforcement learning | Consider food delivery service and increase the income derived from served orders for a limited number of couriers over a time period by utilising the order destination, order origin, and courier location. | |
| Ding et al. [5] | Delivery services | Reinforcement learning | Consider the delivery service problem and develop a crowdsourcing delivery system that uses public transport. This system incorporates some factors that impact the system, such as multi-hop delivery, profits, and time constraints. |
| Author | Method | Domain | Methodology | Objective |
|---|---|---|---|---|
| Andrés et al. [16] | geoind | Location privacy | Differential private | Consider the location privacy problem and protect actual location information. Propose a formal privacy notion of geoind for location-based systems that protects the user’s exact location and permits the release of approximate information that is usually required for certain services. |
| Deldar and Abadi [17] | PLDP | Location privacy | Differential private | Consider location privacy and guarantee that the privacy of each sensitive location or moving object is protected. |
| Zhao et al. [10] | Location privacy | Differential private | Consider protecting the location and trajectory information privacy from being disclosed by attackers. Based on clustering using differential privacy, proposed a trajectory-privacy-preservation method in order to protect trajectory information. | |
| Yang et al. [18] | Location privacy | Differential private | Consider location privacy and the privacy of the workers’ location information. Proposed data release mechanism crowdsensing techniques that aim to protect the privacy of the worker location information. |
| Rec # | Path |
|---|---|
| 1 | L4 → L5 → L6 |
| 2 | L2 → L3 |
| 3 | L2 → L4 → L5 |
| 4 | L3 → L5 → L6 |
| 5 | L4 → L5 |
| 6 | L1 → L3 |
| 7 | L3 → L2 |
| 8 | L1 → L3 → L5 → L2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abahussein, S.; Ye, D.; Zhu, C.; Cheng, Z.; Siddique, U.; Shen, S. Multi-Agent Reinforcement Learning for Online Food Delivery with Location Privacy Preservation. Information 2023, 14, 597. https://doi.org/10.3390/info14110597
Abahussein S, Ye D, Zhu C, Cheng Z, Siddique U, Shen S. Multi-Agent Reinforcement Learning for Online Food Delivery with Location Privacy Preservation. Information. 2023; 14(11):597. https://doi.org/10.3390/info14110597
Chicago/Turabian StyleAbahussein, Suleiman, Dayong Ye, Congcong Zhu, Zishuo Cheng, Umer Siddique, and Sheng Shen. 2023. "Multi-Agent Reinforcement Learning for Online Food Delivery with Location Privacy Preservation" Information 14, no. 11: 597. https://doi.org/10.3390/info14110597
APA StyleAbahussein, S., Ye, D., Zhu, C., Cheng, Z., Siddique, U., & Shen, S. (2023). Multi-Agent Reinforcement Learning for Online Food Delivery with Location Privacy Preservation. Information, 14(11), 597. https://doi.org/10.3390/info14110597