1. Introduction
Community detection [
1,
2,
3] is a crucial technique for many different areas of interest, including biology, social network analysis, and criminal justice. Any time it is useful to find groups of individuals from a seemingly arbitrarily connected network, community detection algorithms are employed. Research on community detection has been ongoing for several decades, with new methods being explored to increase the accuracy, speed, and robustness of community detection algorithms. We study the problem of detecting overlapping communities given a seed set, and a stream of edges.
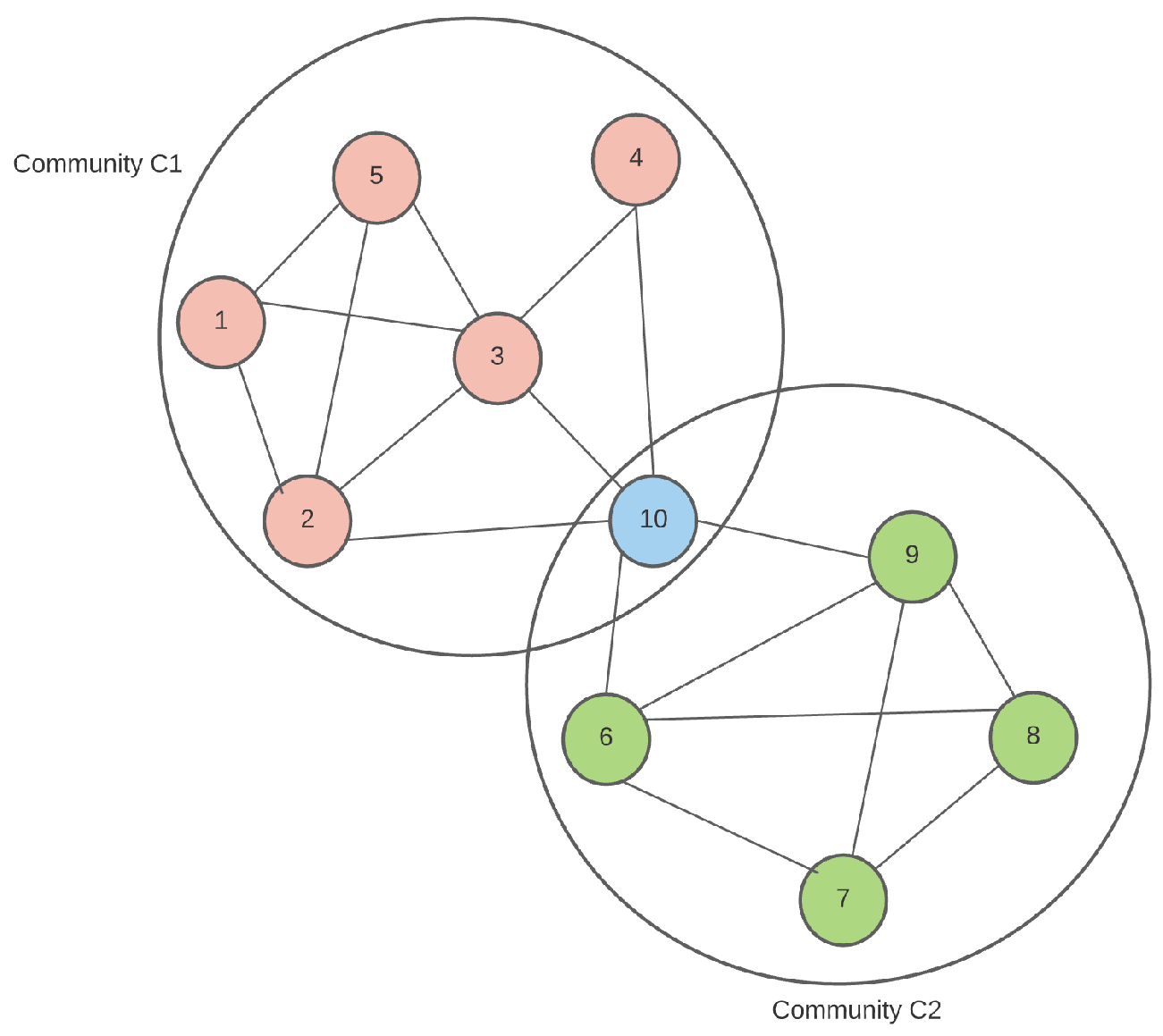
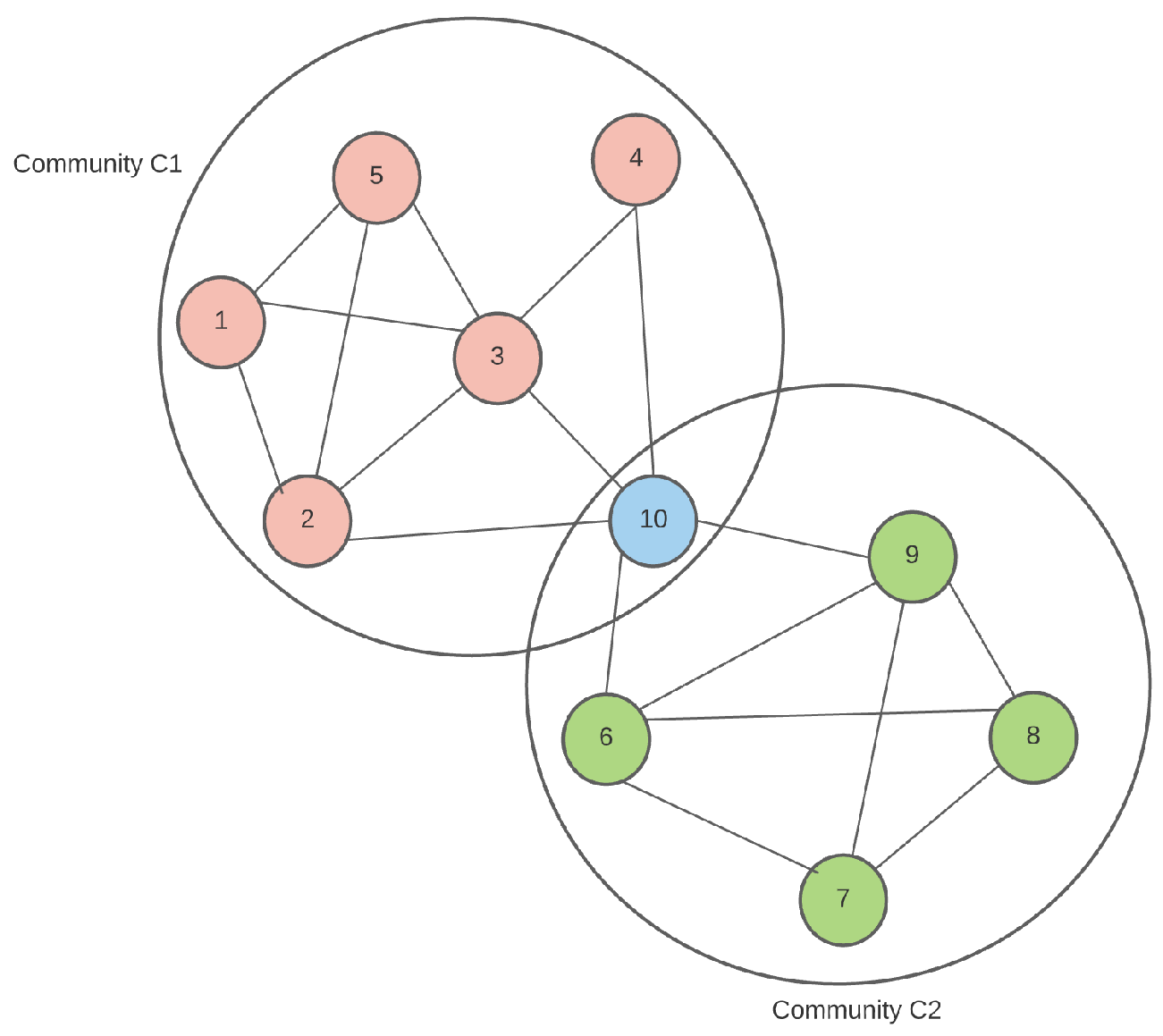
Figure 1 shows an example of two overlapping communities
and
sharing the same node 10. For this problem, we can assume that nodes 5 and 7 form the seed set, and that we are receiving the edges one at a time.
Unfortunately, as the internet has expanded, and our ability to collect data has improved, the size and complexity of the networks we wish to analyze have become prohibitively large. Social networking sites like Facebook or Twitter have millions of daily users who ‘friend’ each other or mention each other in tweets and posts several million times a day, creating massive, complex networks that are great for social network analysis, with applications in advertising and marketing. Amazon offers several hundred million products, and understanding which customers tend to buy similar items is crucial for effectively marketing those groups. Because of the big data availability, it has become difficult to process these networks in a realistic time frame; moreover, storing and accessing them in a timely manner has become a challenge.
Therefore, much of the recent research on community detection has not focused on increasing the accuracy of community detection algorithms, but on increasing the speed and amount of data that can be processed. Along the same lines, community detection algorithms that take advantage of new multi-threaded central processing units (CPUs) and distributed computing are increasingly becoming the subjects of numerous research papers [
4,
5,
6].
Liakos et al. [
7] focused on community detection via seed set expansion (CoEuS), a novel approach to the overlapping community detection problem, in the sense that it does not attempt to partition the entire graph into communities, but instead looks at only a selected number of communities of interest. This works by providing a small set of known nodes from a community of interest and then attempting to build the rest of the community from that seed set of nodes. This allows us to look at the graph edge-by-edge instead of attempting to load the entire graph at once, meaning that much larger networks can be processed. In addition to this, they expanded their approach by proposing distributed streaming community detection (DiCeS) [
8] using Apache Storm
https://storm.apache.org/, accessed on 27 October 2023, and Redis
https://redis.io/, accessed on 27 October 2023, to accelerate the algorithm proposed in [
7] by means of distributed computing.
While DiCeS [
8] is great for quickly analyzing large networks, it is not without issues. The authors of [
8] distribute the work by having each worker node process edges in parallel and write those edges to a shared list of communities, which is stored in a Redis cluster so that all worker nodes have access to all the communities that are considered. Because of this, there is added overhead to the worker nodes in accessing community data from the Redis cluster. Concurrently, protective measures increase the overhead associated with reading and writing data to the cluster.
To resolve these issues, we propose a new parallel method called the community detection with seed sets (CoDiS) algorithm. While DiCeS splits the edges among all the worker nodes, which then look at all the communities to determine if the nodes in that edge belong to any of those communities, our proposed method instead splits the communities among the worker nodes, so that each worker node only looks at a subset of all the communities considered. By doing so, although we decrease the edge processing throughput, we also decrease the amount of time each worker node spends on each edge. Crucially, we also remove the need for every worker node to have access to every community in consideration, meaning we can remove Redis from the equation, regaining the time that was lost for concurrency protection and data distribution.
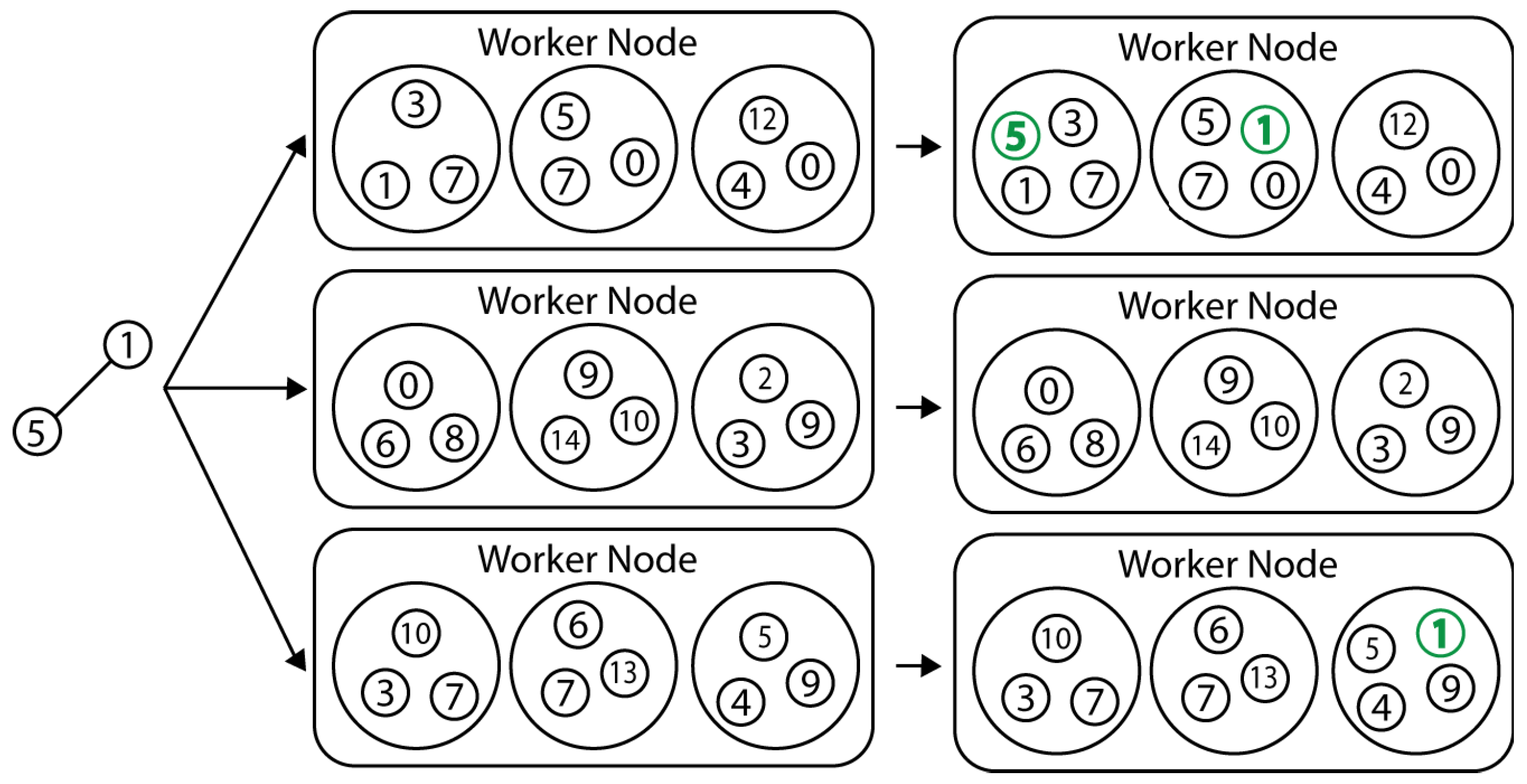
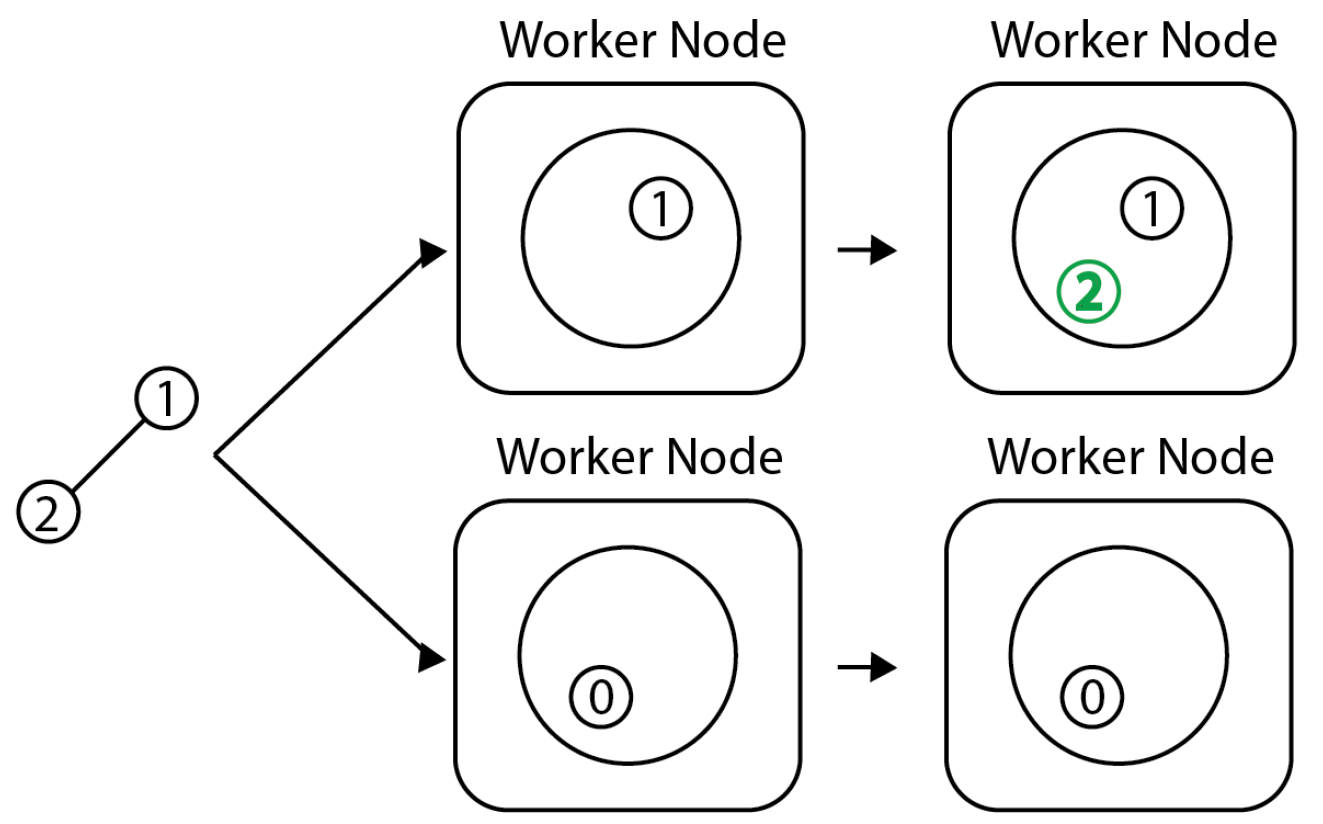
Let us consider the toy example in
Figure 2. The initial seed set nodes are 0 and 1, belonging to two different communities. Initially, each community has only one member, respectively, nodes 0 and 1; they are assigned to different worker nodes. As we process the new edge
, we expand the community structure and add node 2 to the community of node 1 of the first worker node.
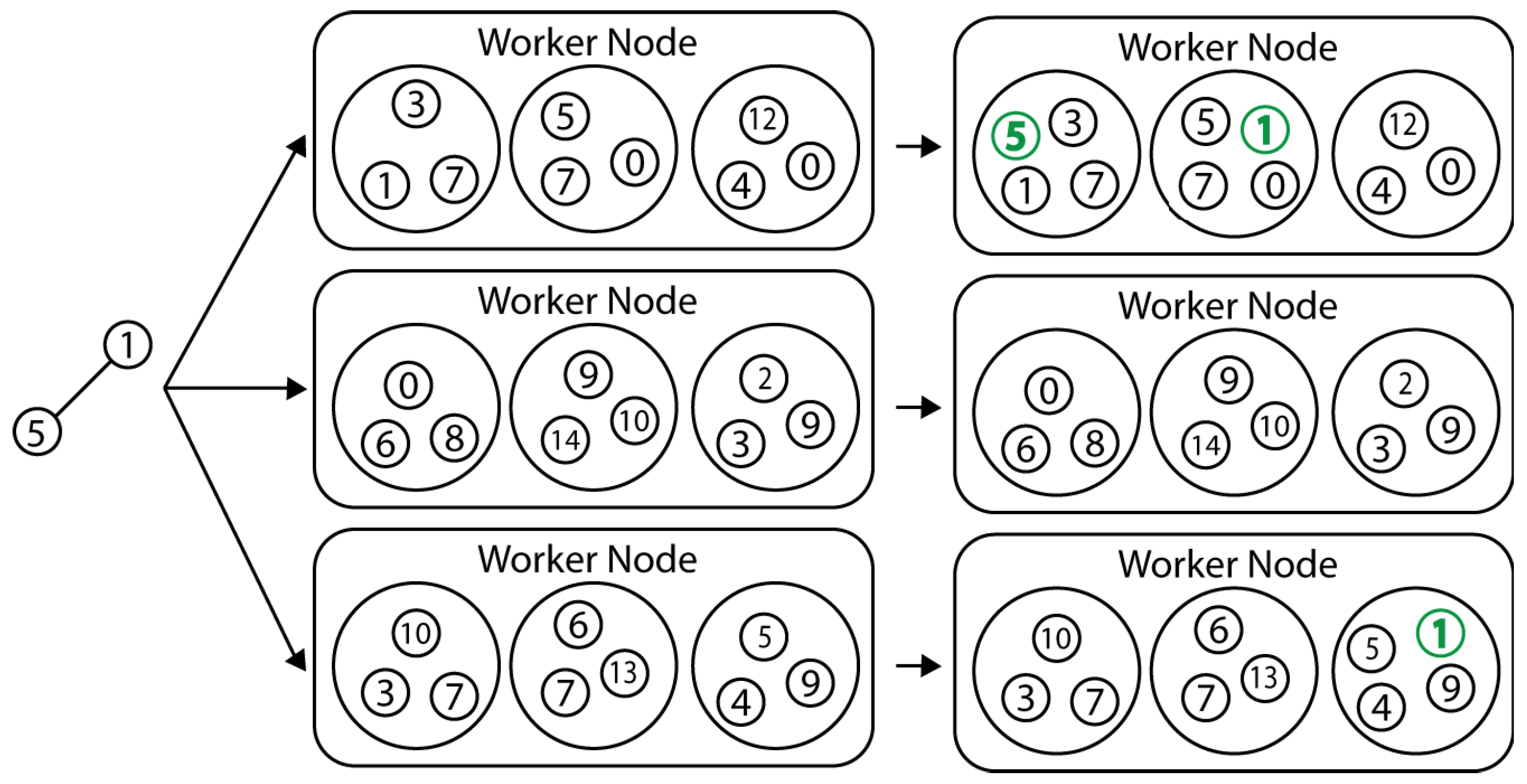
Figure 3 shows a more complicated example of each worker node (a total of three worker nodes) containing three communities, before and after seeing a new edge
and incorporating that edge into the communities.
The rest of this paper is structured as follows: Following the introduction,
Section 2 lists all terms that are useful to know when reading this paper.
Section 3 explores several current community detection approaches, from well-known and often-cited approaches to recent papers focusing on parallel community detection approaches.
Section 4 and
Section 5 delve into the changes we propose and the results of the experiments related to those changes. Finally,
Section 6 concludes the discussion and highlights some improvements that we would like to consider in future work.
2. Terminology
In this section, we present the basic definitions and notations. A graph is a set of nodes and edges,
, where
V is the set of all nodes in the graph and
E is the set of all edges. Graphs are very versatile and can be used to represent any number of complex ideas in an easy-to-parse data structure, from geographical layouts to complex interactions in social media networks. A subgraph is a graph made of a subset of the nodes and edges of another graph. Given a graph
and a subgraph
of
G, then both
and
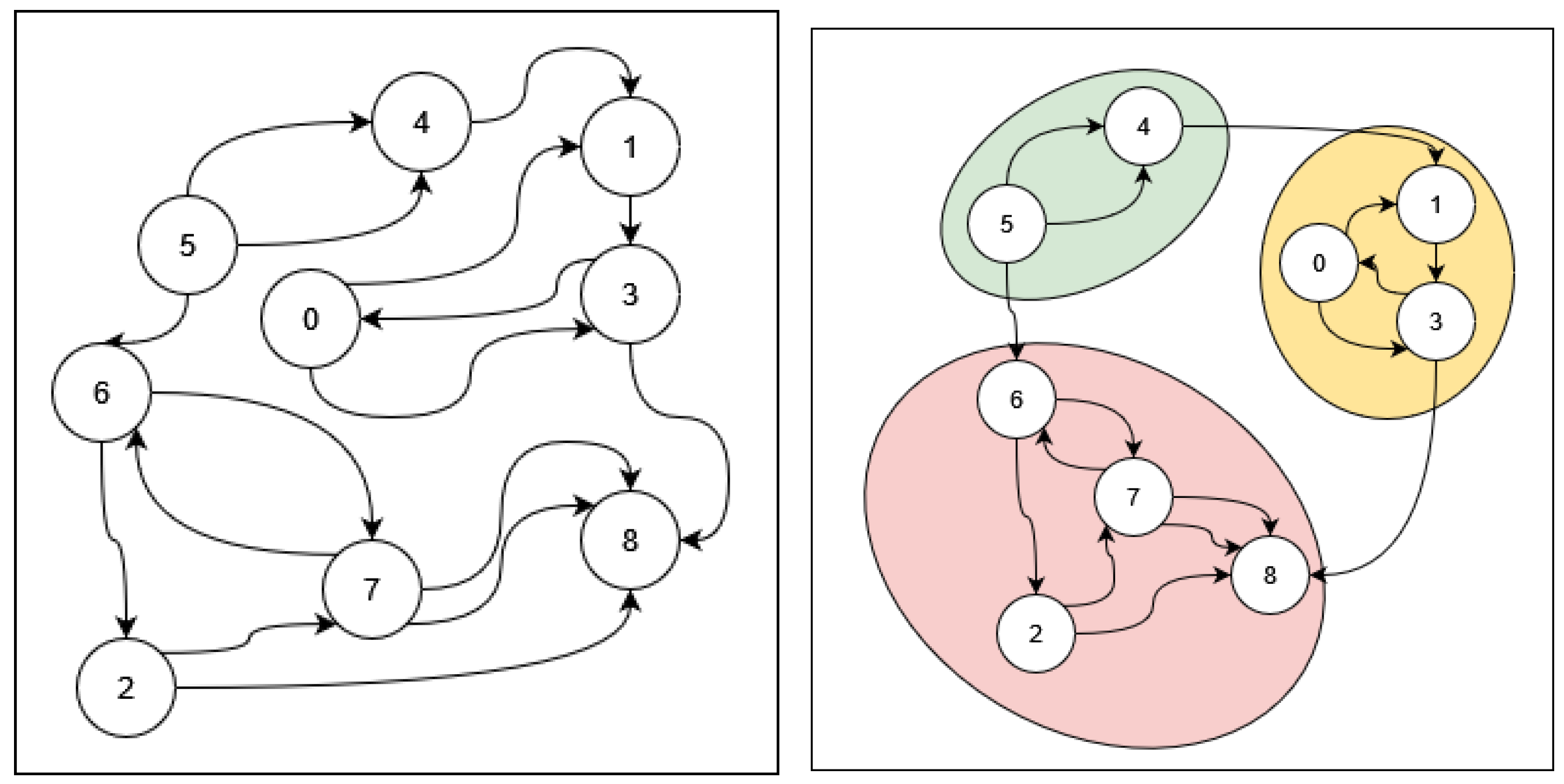
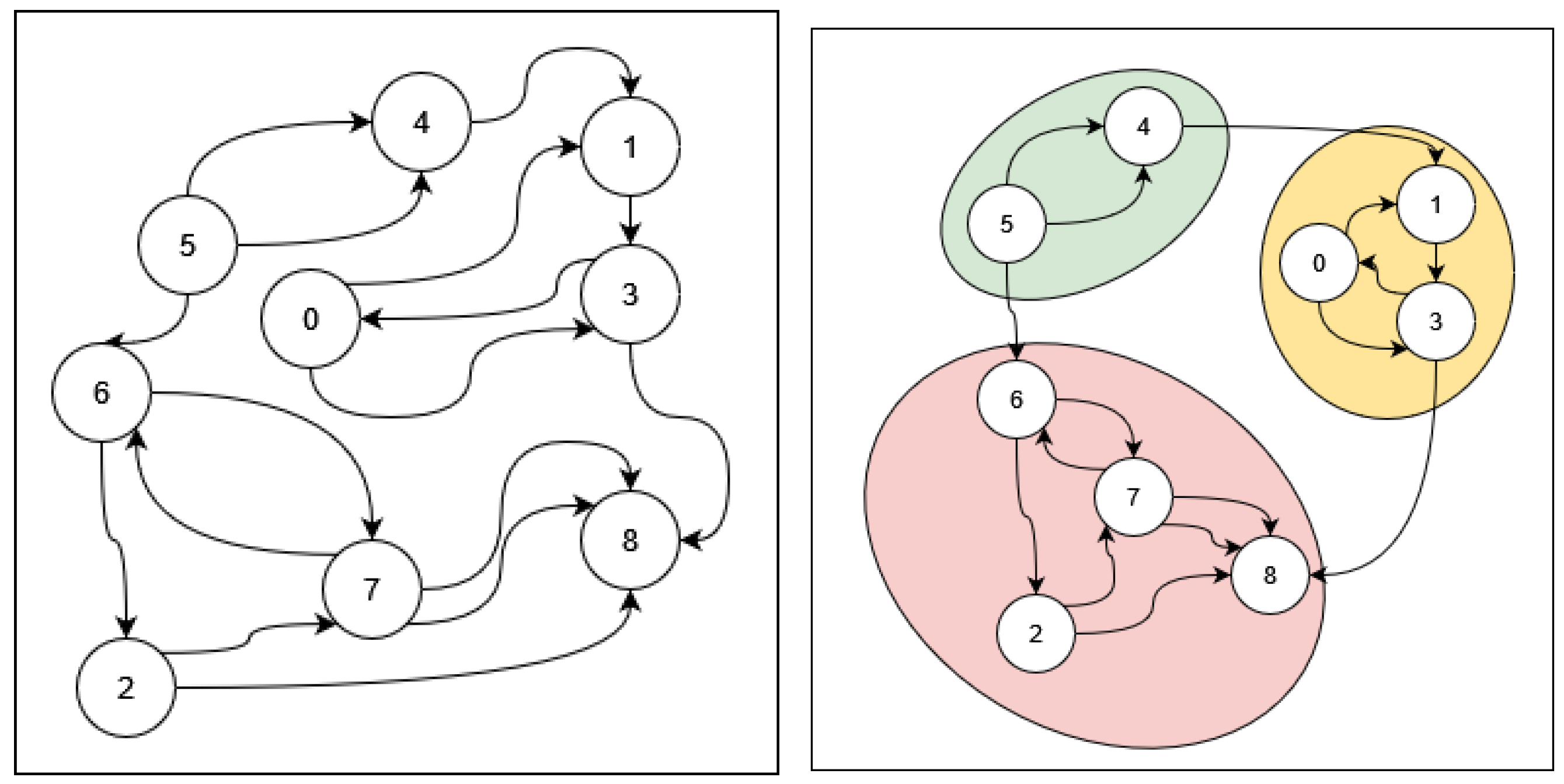
are true. A community is a subset of nodes from a graph that are densely connected to each other and weakly connected to the rest of the graph. Community detection is the process of attempting to group nodes of a graph into communities; see
Figure 4 for an example. Initially, no communities are found, as shown on the left side of
Figure 4. The right side of
Figure 4 captures the situation after discovering the three communities, which are grouped together in ovals with different colors, and are
,
, and
.
Edge betweenness measures the frequency with which an edge is traversed when determining the shortest path from every vertex in a graph to every other vertex. The edge betweenness of an edge
e is calculated by the ratio of the number of shortest paths that include the edge
e over the total number of shortest paths. A metric of the quality of the discovered communities is the modularity score when no ground truth is given. The higher the modularity score, the closer the graph is to being separated perfectly into communities, and vice versa. The community participation score [
7] measures how strongly connected a node is to the nodes of a community. The community participation of node
u in the community
C is denoted by
where
denotes the degree of node
v in
G, and
is the community degree of node
v by considering only the intra-edges (the edges between community members) of the community
C.
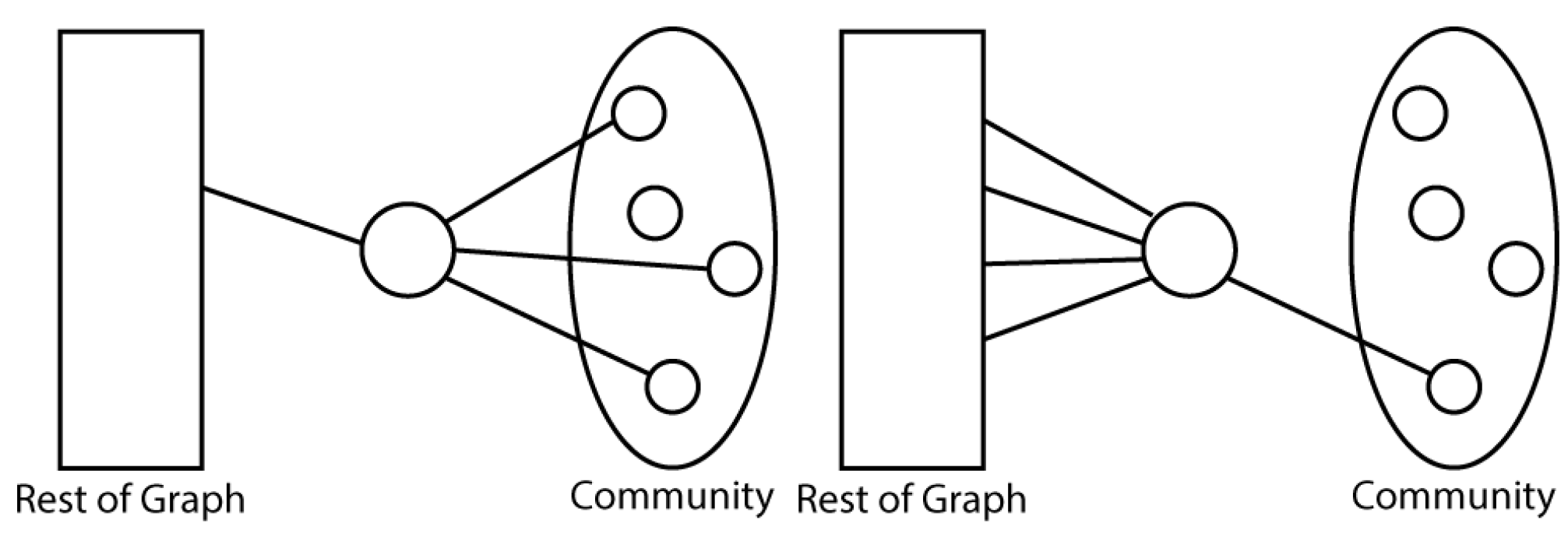
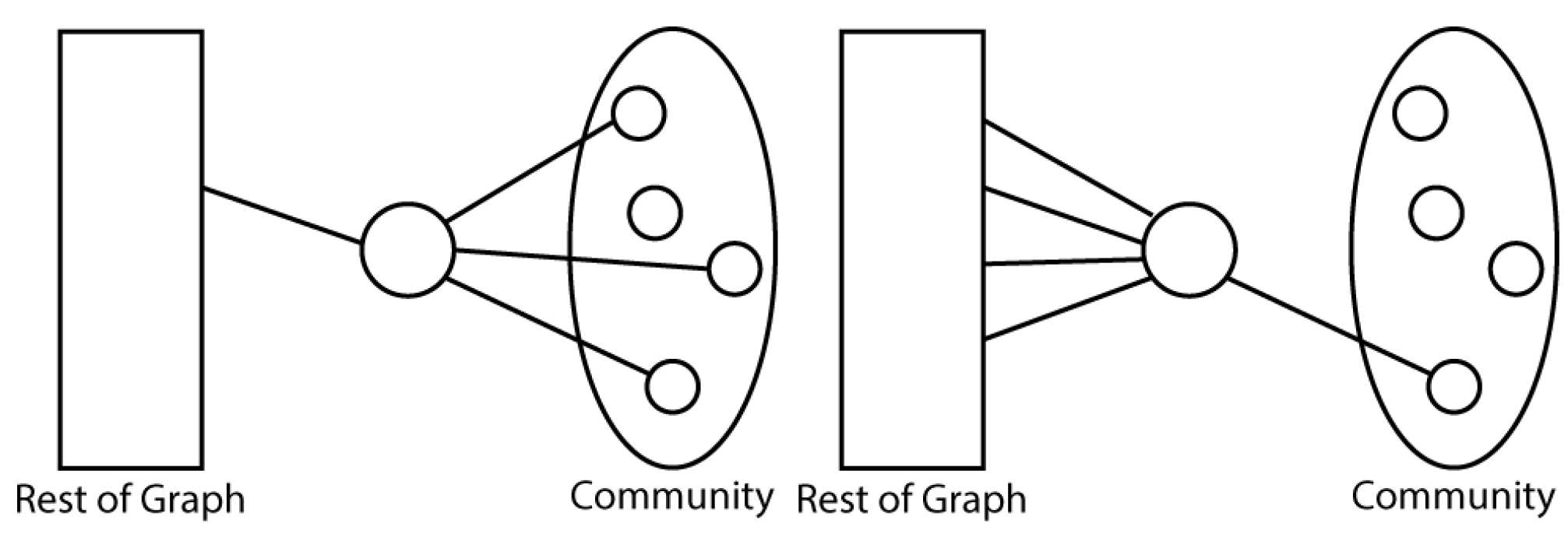
Nodes with higher values of community participation are well connected to the community while nodes with lower values are less connected to the community.
Figure 5 shows a node with a high/low participation score in the given community.
Distributing communities in worker nodes in our community detection with seed sets (CoDiS) algorithm can be defined as follows:
C: is the set of communities to be detected.
T: is the set of worker nodes available for parallel processing.
: is the set of communities assigned to the i-th worker node.
k: is the maximum number of communities in the worker nodes, e.g., .
To distribute the communities in a balanced manner among worker nodes, one can formulate the number of communities each worker node is assigned to with the following relation:
where the
term represents the average number of communities per worker node, ensuring an approximate load-balancing split. We can consider the
acting as an adjustment term that allows for slight variations for balancing the load. This term may depend on various factors, such as the computational power of each worker node (case of heterogeneous worker nodes). For our approach, we assume that all worker nodes are homogeneous, i.e., have the same computational power and hardware; thus, the term
is set to zero for all workers
. In this case, the maximum number of communities processed by each worker is at most
.
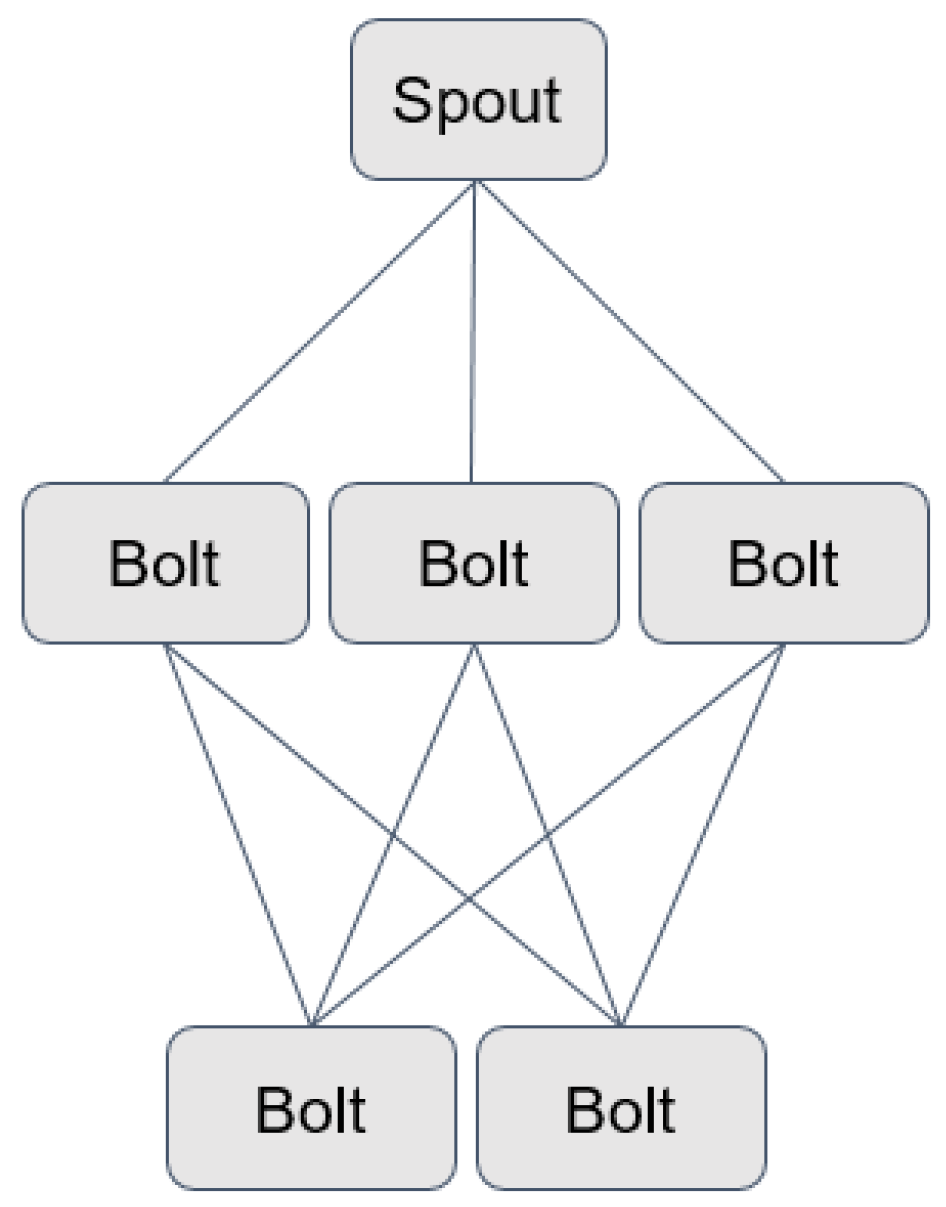
We use the Apache Storm Java framework for distributed processing using streams maintained by Twitter and the Apache Foundation. Storm abstracts the distribution and passing of messages between compute nodes. The basic data type of the Storm distribution is a Tuple, and there are two types of processing nodes: Spouts and Bolts. A Tuple contains any number of supported data types. Tuples natively support all primitive data types, as well as Strings and byte arrays. Tuples can also support custom data types if those data types implement a serializer and register that serializer with Storm. A Topology is a construct that contains all the information about the particular setup for a given Storm program. The Topology is what is submitted to an Apache Storm cluster and contains the code that computation nodes execute, as well as how the messages are distributed between nodes and which nodes listen to each other. A Topology will run indefinitely until the user stops it or submits a new Topology to the Storm cluster. One of the two main components of an Apache Storm Topology is a Spout. A Spout is responsible for creating a stream of Tuples that are then emitted to the rest of the Topology. The Topology itself takes care of how those Tuples are distributed. Spouts cannot receive Tuples from any other processing nodes, only create and emit them. The other main component of an Apache Storm Topology is a Bolt. Bolts are typically the nodes that conduct the actual processing of the Topology. Bolts receive the Tuples emitted from Spouts or even other Bolts, and conduct some kind of processing on them. Bolts can emit their own Tuples for consumption by other Bolts. Apache Storm’s Local Mode simulates distributed computing using multi-threading, allowing an Apache Storm cluster to run without the need for multiple systems. An example of an Apache Storm Topology (in which there is one spout, three bolts that listen to the output of that spout, and two additional bolts that listen to the output of the three previous bolts) is shown in
Figure 6.
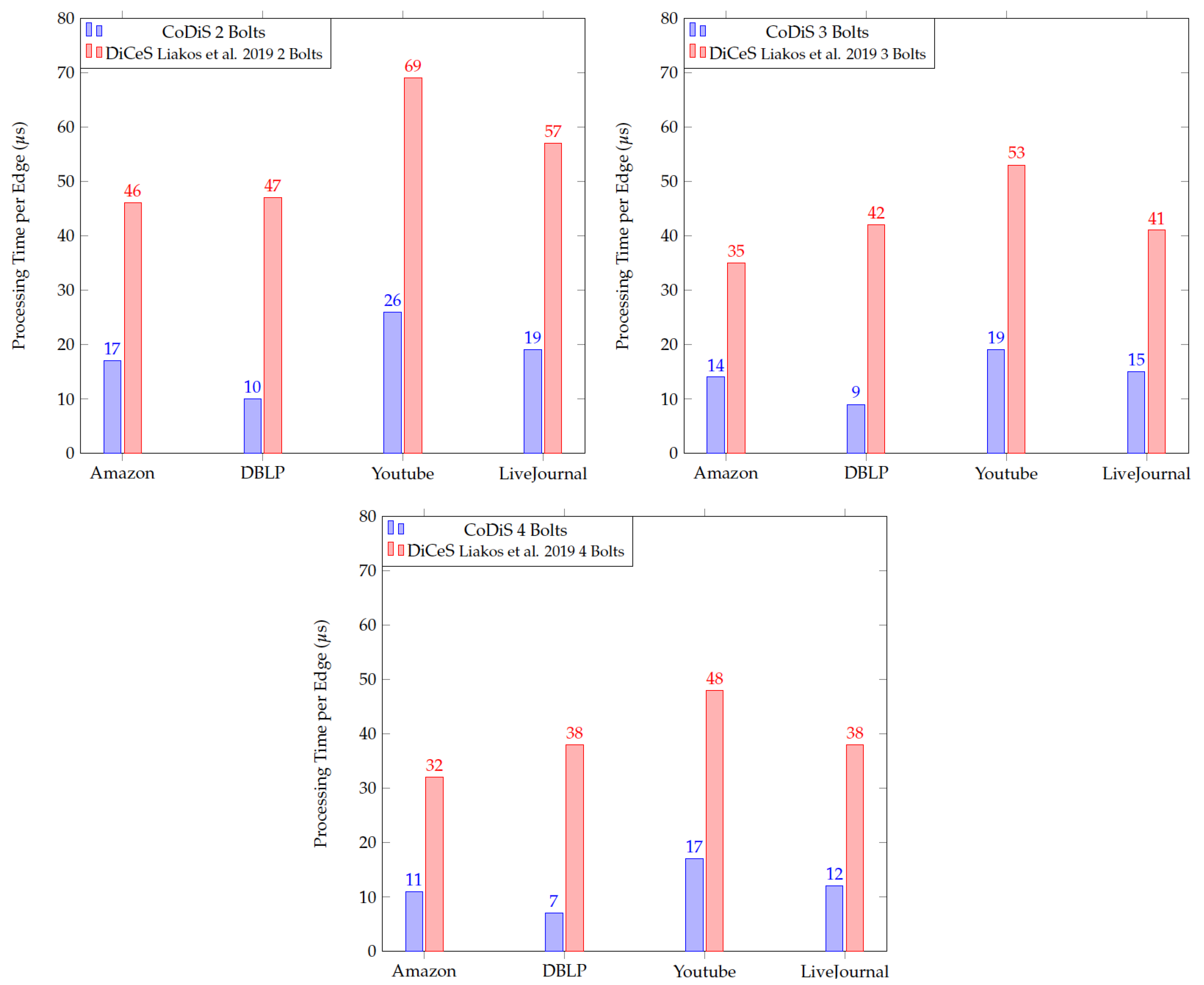
4. CoDiS Method
Here, we describe CoDiS (originally donated as SubDiCeS). Our code,
https://github.com/dude1144/SubDiCeS, accessed on 27 October 2023, is a new method that functions similarly to DiCeS [
8]; it runs the CoEuS [
7] algorithm in a distributed manner to achieve parallelism but modifies it so that each individual worker node only operates on a subset of the communities of interest. The implementation of this method is conducted in Java using Apache Storm to manage the distributed processing. Overlapping community detection methods require a seed set of nodes for each community of interest, and community detection then expands this set based on a participation score used as the metric.
4.3. Edge Processing and Community Pruning
Algorithm 3 is where the bulk of the community detection process is done. This algorithm is run in parallel by all the worker nodes. Each worker node maintains a queue of inputs received by the edge distribution node (Algorithm 2), and runs a loop of popping the next input from the queue and running Algorithm 3 with the input from the queue as the input to the algorithm.
The first thing Algorithm 3 does is check the data type of the input that is received. If the input is a
String, then we know that the
indicator has been reached, and we can calculate the average F1 score of all the communities and pass that on to the collection node; see Algorithm 5. Before calculating the F1 score, we prune the community to its final size using Algorithm 4, which can be conducted either by pruning it to the size of the ground truth community it is based on or by using the drop tail technique of [
7].
If the input is a CoDiScommunity, then that community is appended to the list of communities that the worker node has under inspection. If the input is a Tuple, then it is an edge that we need to process.
We begin by obtaining
and
from the Tuple and incrementing the total degrees for both nodes, as well as the counter that keeps track of how many edges have been processed in total by this worker node. Next, we find all the communities of this worker node that either node belongs to and start iterating over all those communities. If the community contains
, then we update the estimated community degrees of
using the community participation score of
to incorporate the edge quality and Equation (
1), and then we add
to the list of nodes that are part of this community. The same is then done for
, updating and adding
to the community, if applicable. The time complexity of Algorithm 3 is
, where
is the time complexity of Algorithm 4,
is the number of edges, and
k is the maximum number of communities each worker node processes (a total of
workers in parallel working in their assigned communities).
| Algorithm 3: Edge processing |
![Information 14 00594 i003]() |
Once the processing of the edge is done, we check if the number of processed edges is a multiple of the chosen pruning window, set to 10,000 edges, as per [
8]. If it is a multiple, we use Algorithm 4 to prune the community to a given size. This starts by obtaining a list of key–value pairs of the nodes the community contains and sorting that list in descending order by the value of the community participation score. We then obtain a subset of this list with only the top
nodes and transform the sub-list back into a map, replacing the old community node map. Before we call Algorithm 4, each community has a size that is upper-bounded by
. The most expensive step of Algorithm 4 is sorting
values. By using mergeSort, the run time is
for each community, and since each worker processes
k communities, the total running time is
for each worker. We can use maximum heaps and spend
time, assuming
.
| Algorithm 4: Prune (Community Pruning) |
![Information 14 00594 i004]() |













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}