

An AI-Based Framework for Translating American Sign Language to English and Vice Versa

 ,
,  ,
, 
Abstract
:1. Introduction
- We used the ResNet50 model and transfer learning concept to train our model to recognize and classify these words. We made use of rolling average prediction to recognize the temporal changes present in the video and recognize the word without any jitters in prediction.
- The proposed framework translates both ASL to English and English to ASL.
- To showcase the framework, we developed a web application, which makes use of the trained CNN model to translate ASL to English and vice versa.
- We generated a dataset consisting of images showing the hand gestures and facial expressions used by people to convey 2000 different words.
2. Literature Review
3. Methodology
- Dataset collection
- Data pre-processing
- Model training
- Model evaluation
- Application development

3.1. Dataset Collection
3.2. Data Pre-Processing
3.3. Model Architecture and Training
- AveragePooling2D layer with pool size (7, 7);
- Flatten layer;
- Dense layer with 512 units which has a Rectified Linear Unit (ReLU) activation function;
- Dropout layer;
- Dense layer with 2000 units which has a softmax activation function.
Model Training
3.4. Application Development
4. ASL to English and English to ASL Conversion Application
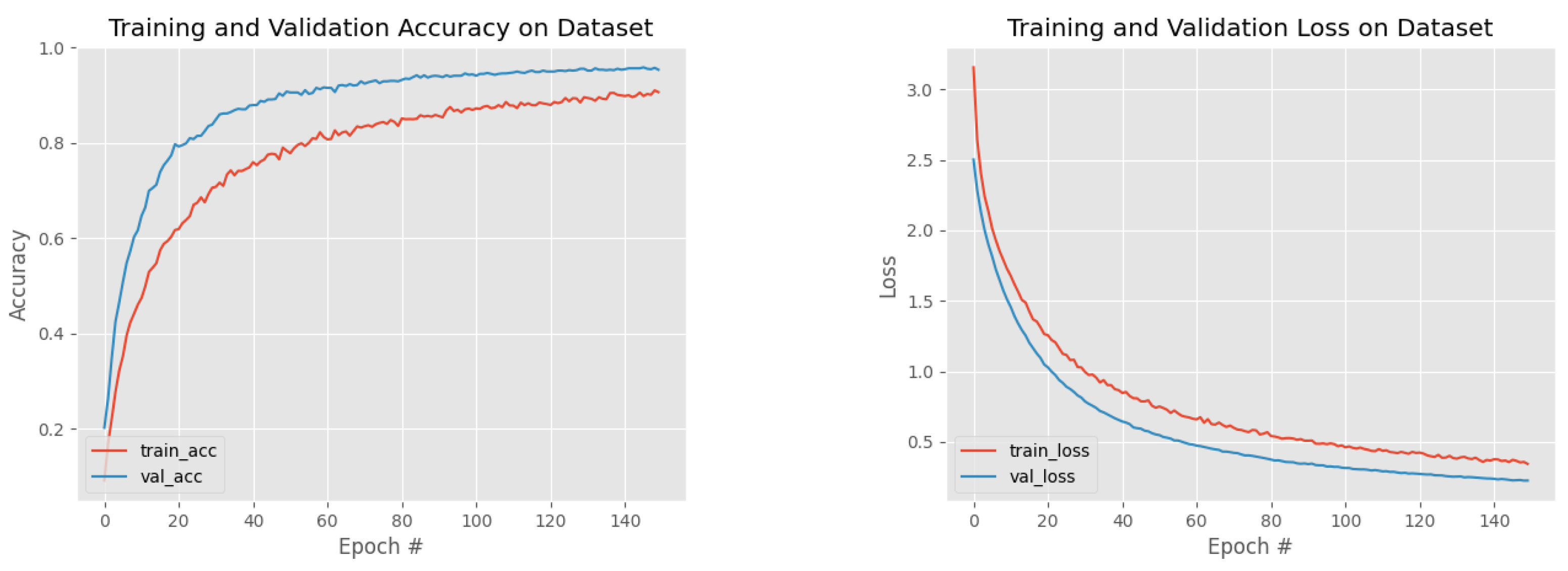
5. Results and Evaluation
6. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kuhn, J.; Aristodemo, V. Pluractionality, iconicity, and scope in French Sign Language. Semant. Pragmat. 2017, 10, 1–49. [Google Scholar] [CrossRef]
- Liddell, S.K. American Sign Language Syntax; Walter de Gruyter GmbH & Co KG: Berlin, Germany, 2021; Volume 52. [Google Scholar]
- Vicars, W.G. ASL—American Sign Language. Available online: https://www.lifeprint.com/asl101/pages-layout/lesson1.htm (accessed on 1 March 2023).
- Kudrinko, K.; Flavin, E.; Zhu, X.; Li, Q. Wearable sensor-based sign language recognition: A comprehensive review. IEEE Rev. Biomed. Eng. 2020, 14, 82–97. [Google Scholar] [CrossRef]
- Lee, B.; Lee, S.M. Smart wearable hand device for sign language interpretation system with sensors fusion. IEEE Sens. J. 2017, 18, 1224–1232. [Google Scholar] [CrossRef]
- Starner, T.; Weaver, J.; Pentl, A. Real-time american sign language recognition using desk and wearable computer based video. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1371–1375. [Google Scholar] [CrossRef]
- Munib, Q.; Habeeb, M.; Takruri, B.; Al-Malik, H.A. American sign language (ASL) recognition based on Hough transform and neural networks. Expert Syst. Appl. 2007, 32, 24–37. [Google Scholar] [CrossRef]
- Garcia, B.; Viesca, S.A. Real-time American sign language recognition with convolutional neural networks. Convolutional Neural Netw. Vis. Recognit. 2016, 2, 8. [Google Scholar]
- Kurian, E.; Kizhakethottam, J.J.; Mathew, J. Deep learning based surgical workflow recognition from laparoscopic videos. In Proceedings of the 2020 5th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 10–12 June 2020; pp. 928–931. [Google Scholar]
- Dabre, K.; Dholay, S. Machine learning model for sign language interpretation using webcam images. In Proceedings of the 2014 International Conference on Circuits, Systems, Communication and Information Technology Applications (CSCITA), Mumbai, India, 4–5 April 2014; pp. 317–321. [Google Scholar]
- Gaus, Y.F.A.; Wong, F. Hidden Markov Model-Based gesture recognition with overlapping hand-head/hand-hand estimated using Kalman Filter. In Proceedings of the 2012 Third International Conference on Intelligent Systems Modelling and Simulation, Kota Kinabalu, Malaysia, 8–10 February 2012; pp. 262–267. [Google Scholar]
- Rahman, M.M.; Islam, M.S.; Rahman, M.H.; Sassi, R.; Rivolta, M.W.; Aktaruzzaman, M. A new benchmark on american sign language recognition using convolutional neural network. In Proceedings of the 2019 International Conference on Sustainable Technologies for Industry 4.0 (STI), Dhaka, Bangladesh, 24–25 December 2019; pp. 1–6. [Google Scholar]
- Huang, J.; Zhou, W.; Li, H.; Li, W. Sign language recognition using 3d convolutional neural networks. In Proceedings of the 2015 IEEE international conference on multimedia and expo (ICME), Turin, Italy, 29 June–3 July 2015; pp. 1–6. [Google Scholar]
- Thakar, S.; Shah, S.; Shah, B.; Nimkar, A.V. Sign Language to Text Conversion in Real Time using Transfer Learning. In Proceedings of the 2022 IEEE 3rd Global Conference for Advancement in Technology (GCAT), Bangalore, India, 7–9 October 2022; pp. 1–5. [Google Scholar]
- Chung, H.X.; Hameed, N.; Clos, J.; Hasan, M.M. A Framework of Ensemble CNN Models for Real-Time Sign Language Translation. In Proceedings of the 2022 14th International Conference on Software, Knowledge, Information Management and Applications (SKIMA), Phnom Penh, Cambodia, 2–4 December 2022; pp. 27–32. [Google Scholar]
- Kasapbaşi, A.; Elbushra, A.E.A.; Omar, A.H.; Yilmaz, A. DeepASLR: A CNN based human computer interface for American Sign Language recognition for hearing-impaired individuals. Comput. Methods Progr. Biomed. Update 2022, 2, 100048. [Google Scholar] [CrossRef]
- Enrique, M.B., III; Mendoza, J.R.M.; Seroy, D.G.T.; Ong, D.; de Guzman, J.A. Integrated Visual-Based ASL Captioning in Videoconferencing Using CNN. In Proceedings of the TENCON 2022-2022 IEEE Region 10 Conference (TENCON), Hong Kong, 1–4 November 2022; pp. 1–6. [Google Scholar]
- Ye, Y.; Tian, Y.; Huenerfauth, M.; Liu, J. Recognizing american sign language gestures from within continuous videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2064–2073. [Google Scholar]
- Lichtenauer, J.F.; Hendriks, E.A.; Reinders, M.J. Sign language recognition by combining statistical DTW and independent classification. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 2040–2046. [Google Scholar] [CrossRef]
- Mahesh, M.; Jayaprakash, A.; Geetha, M. Sign language translator for mobile platforms. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Udupi, India, 13–16 September 2017; pp. 1176–1181. [Google Scholar]
- Li, D.; Rodriguez, C.; Yu, X.; Li, H. Word-level deep sign language recognition from video: A new large-scale dataset and methods comparison. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1459–1469. [Google Scholar]
- Patil, P.; Prajapat, J. Implementation of a real time communication system for deaf people using Internet of Things. In Proceedings of the 2017 International Conference on Trends in Electronics and Informatics (ICEI), Tirunelveli, India, 11–12 May 2017; pp. 313–316. [Google Scholar]
- Santon, A.L.; Margono, F.C.; Kurniawan, R.; Lucky, H.; Chow, A. Model for Detect Hand Sign Language Using Deep Convolutional Neural Network for the Speech/Hearing Impaired. In Proceedings of the 2022 International Conference on Informatics, Multimedia, Cyber and Information System (ICIMCIS), Jakarta, Indonesia, 16–17 November 2022; pp. 118–123. [Google Scholar]
- Trujillo-Romero, F.; García-Bautista, G. Mexican Sign Language Corpus: Towards an automatic translator. ACM Trans. Asian-Low-Resour. Lang. Inf. Process. 2023, 22, 1–24. [Google Scholar] [CrossRef]
- Kaggle. Available online: https://www.kaggle.com/ (accessed on 13 June 2023).
- Hashemi, M. Web page classification: A survey of perspectives, gaps, and future directions. Multimed. Tools Appl. 2020, 79, 11921–11945. [Google Scholar] [CrossRef]
- Lee, C.S.; Baughman, D.M.; Lee, A.Y. Deep learning is effective for classifying normal versus age-related macular degeneration OCT images. Ophthalmol. Retin. 2017, 1, 322–327. [Google Scholar] [CrossRef] [PubMed]
- Du, L. How much deep learning does neural style transfer really need? An ablation study. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 3150–3159. [Google Scholar]
- Mehta, T.I.; Heiberger, C.; Kazi, S.; Brown, M.; Weissman, S.; Hong, K.; Mehta, M.; Yim, D. Effectiveness of radiofrequency ablation in the treatment of painful osseous metastases: A correlation meta-analysis with machine learning cluster identification. J. Vasc. Interv. Radiol. 2020, 31, 1753–1762. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Avina, V.D.; Amiruzzaman, M.; Amiruzzaman, S.; Ngo, L.B.; Dewan, M.A.A. An AI-Based Framework for Translating American Sign Language to English and Vice Versa. Information 2023, 14, 569. https://doi.org/10.3390/info14100569
Avina VD, Amiruzzaman M, Amiruzzaman S, Ngo LB, Dewan MAA. An AI-Based Framework for Translating American Sign Language to English and Vice Versa. Information. 2023; 14(10):569. https://doi.org/10.3390/info14100569
Chicago/Turabian StyleAvina, Vijayendra D., Md Amiruzzaman, Stefanie Amiruzzaman, Linh B. Ngo, and M. Ali Akber Dewan. 2023. "An AI-Based Framework for Translating American Sign Language to English and Vice Versa" Information 14, no. 10: 569. https://doi.org/10.3390/info14100569
APA StyleAvina, V. D., Amiruzzaman, M., Amiruzzaman, S., Ngo, L. B., & Dewan, M. A. A. (2023). An AI-Based Framework for Translating American Sign Language to English and Vice Versa. Information, 14(10), 569. https://doi.org/10.3390/info14100569