
Transfer Learning-Based YOLOv3 Model for Road Dense Object Detection


Abstract
:1. Introduction
- (1)
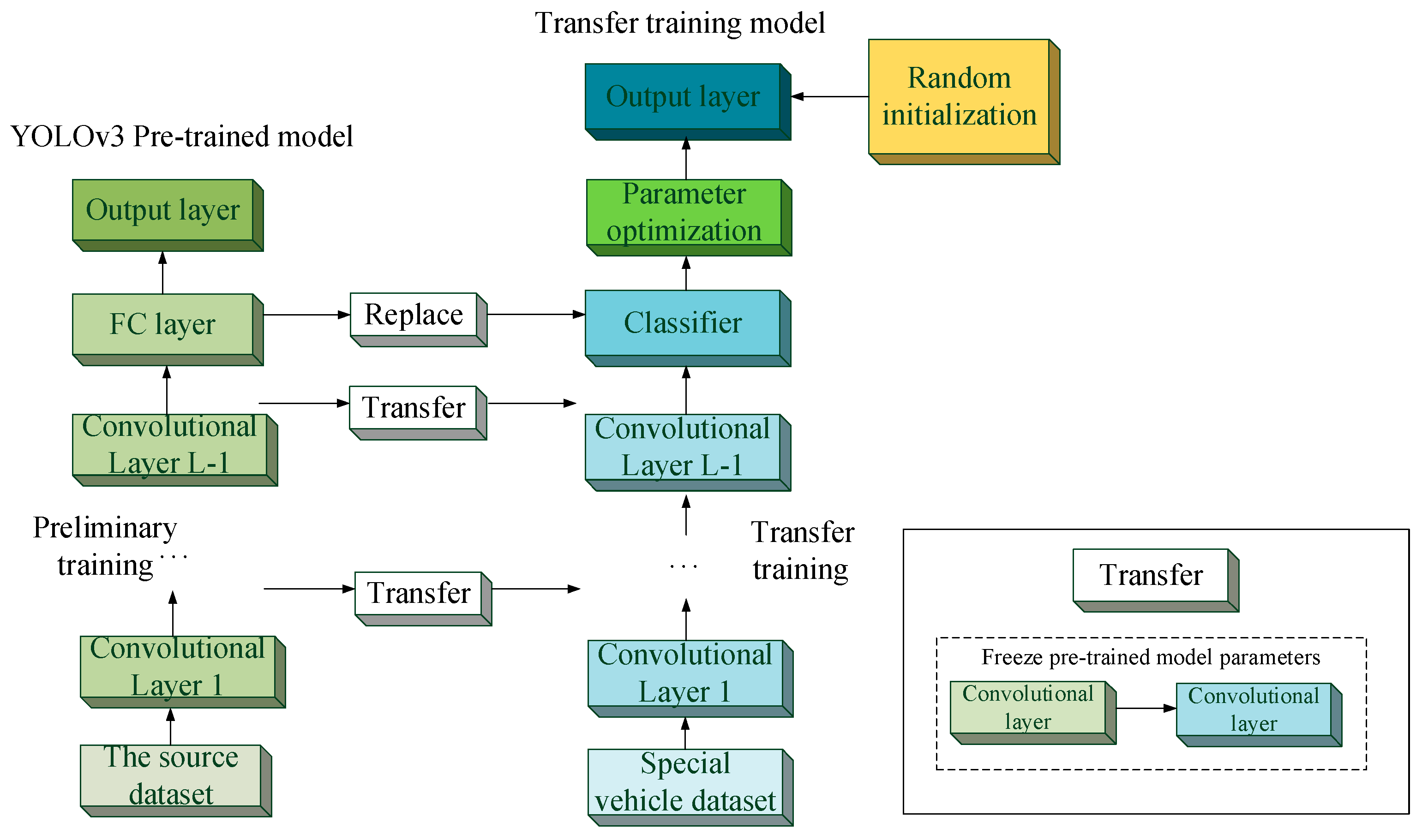
- Based on the pre-trained YOLOv3 model, the transfer training is introduced as the output layer for the special dataset containing detecting objects; moreover, one random function is adapted to initialize and optimize the weights of the transfer training model, which is separately designed from the pre-trained YOLOv3.
- (2)
- In the proposed YOLOv3, the object detection classifier replaces the full convolutional layer of the traditional YOLOv3, aiming to relieve the conflict distinguishing the edge target features and other background features caused by the excessive receptive field of the full connection layer; additionally, the introduced classifier can avoid the excessive computation from the fully connected layer in the traditional YOLOv3.
2. Related Works
2.1. Infrared Detection
2.2. Ultrasonic Detection
2.3. Radar Detection
2.4. Object Detection
2.5. Characteristics of Vehicle Detection Sensors
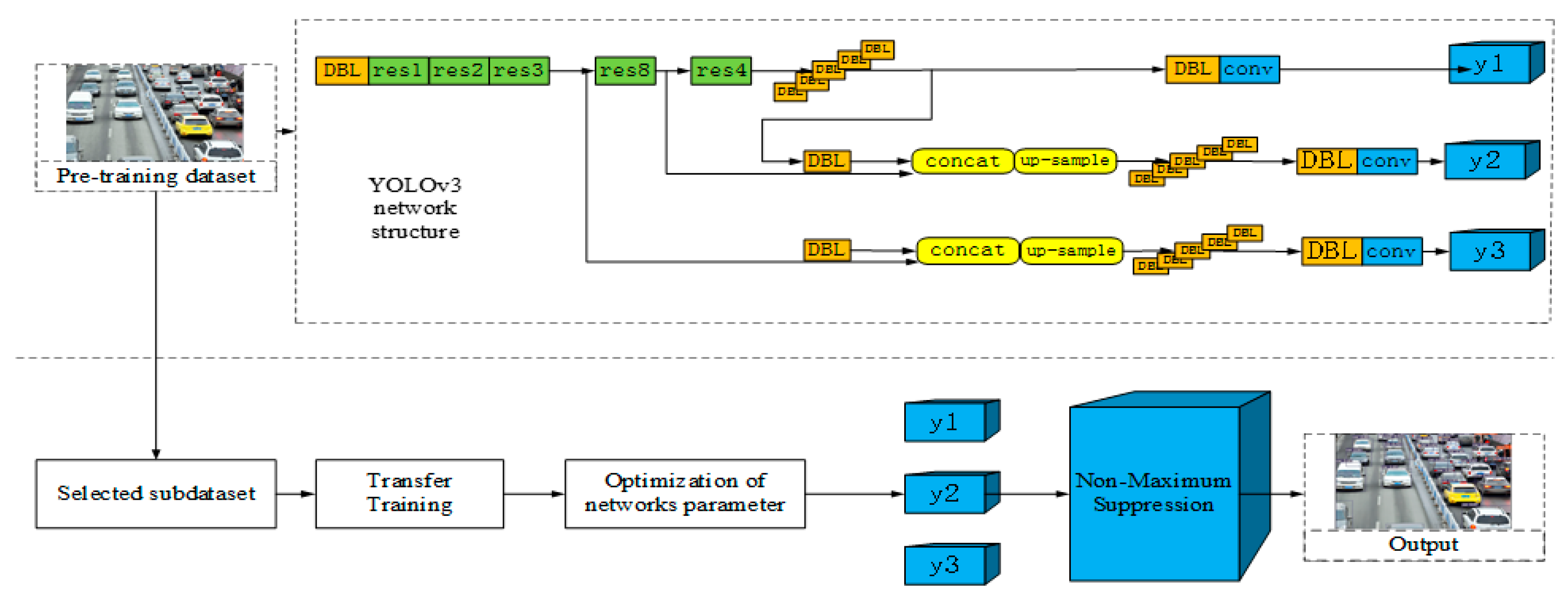
3. Algorithm Principle
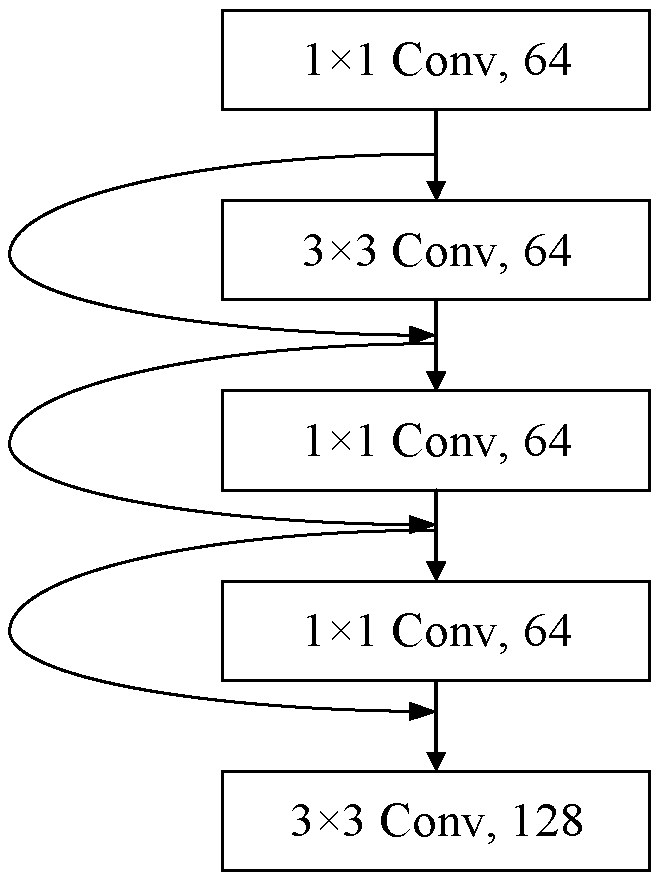
3.1. Feature Extraction Network
3.2. Training Strategy Design
- (1)
- The Batch function is set to 8. It can make the network complete an epoch in a few iterations and reach a local optimal state while finding the best gradient descent direction [30]. Increasing this value will prolong the training time but will better find the gradient descent direction; decreasing this value may cause the training to fall into a local optimum, or not converge.
- (2)
- The LEARN-RATE function is set from 10−4 to 10−6. During the training procedure [31], the total number of training cycles generally determines a learning rate that continually adapts to new input. Ten rounds of training are set. Experiments indicate that the learning rate is initially set at 0.0001 at the beginning of training and then gradually slows down after a certain number of rounds have been completed. As the training nears its conclusion, the learning rate is lowered until it hits 0.000001. The setting of the learning rate, which is based on ten training rounds, solves the problems of easy loss value explosion and easy oscillation caused by a learning rate that is too large at the beginning of training; if it is too small, it is easy to over-fit, resulting in slow network convergence.
- (3)
- The IOU function is allocated the value 0.65. In computer detection tasks, the IOU value is equal to one and the intersection is the same as the union if the actual bounding box and the predicted bounding box entirely overlap [32]. Generally, a value of 0.5 is utilized as the threshold to determine whether or not the predicted bounding box is correct. It is possible to increase the detection accuracy of tiny items and edge objects while dealing with the detection of dense road objects by setting IOU to 0.65. This will enable the gathering of higher-quality samples and enhance the identification of dense road objects.
3.3. Loss Function Selection
4. Experimental Testing and Evaluation
4.1. Required Environment
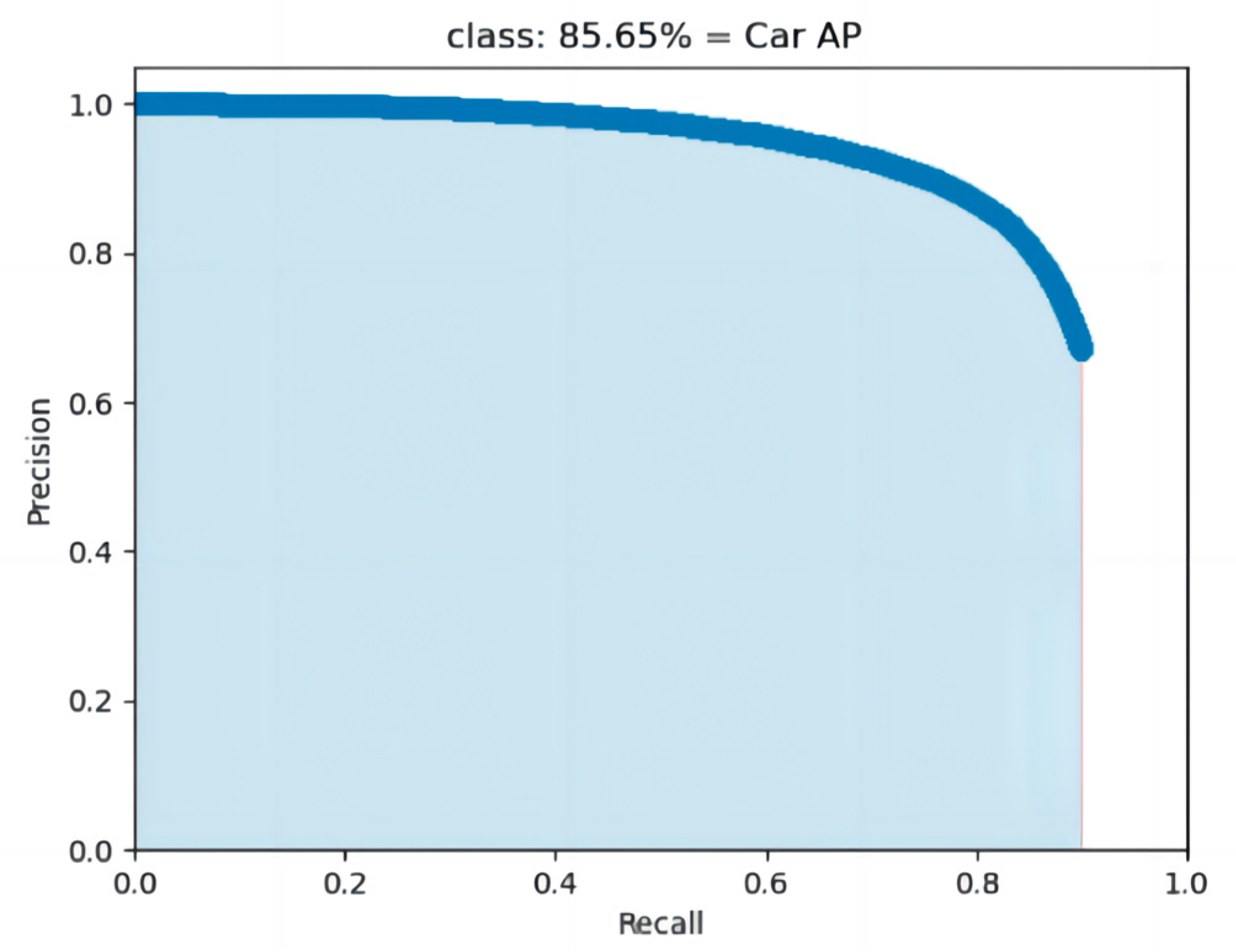
4.2. Detection Performance Evaluation
4.3. Comparative Analysis of Different Algorithms
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature List
| Abbreviation | Explanation |
| lbox | The error generated by the position in the prediction box |
| lobj | The error generated by confidence |
| lcls | The error generated by the class |
| i, j | Indicates the location of the predicted frame |
| x, y, w, h | Indicates the location of the prediction box |
References
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Oliveira, G.; Frazão, X.; Pimentel, A.; Ribeiro, B. Automatic graphic logo detection via Fast Region-based Convolutional Networks. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 985–991. [Google Scholar]
- Chen, Y.; Li, W.; Sakaridis, C.; Dai, D.; Van Gool, L. Domain Adaptive Faster R-CNN for Object Detection in the Wild. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3339–3348. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part I 14. pp. 21–37. [Google Scholar]
- Bell, S.; Zitnick, C.L.; Bala, K.; Girshick, R. Inside-Outside Net: Detecting Objects in Context with Skip Pooling and Recurrent Neural Networks. Clin. Orthop. Relat. Res. (CoRR) 2016, 2874–2883. [Google Scholar]
- Peng, Y.H.; Zheng, W.H.; Zhang, J.F. Deep learning-based on-road obstacle detection method. J. Comput. Appl. 2020, 40, 2428–2433. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Shao, L.; Zhu, F.; Li, X. Transfer learning for visual categorization: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2014, 26, 1019–1034. [Google Scholar] [CrossRef] [PubMed]
- Ai, H. Application of infrared measurement in traffic flow monitoring. Infrared Technol. 2008, 30, 201–204. [Google Scholar]
- Zhao, Y.N. Design of a vehicle detector based on ultrasound wave. Comput. Meas. Control. 2011, 19, 2542–2544. [Google Scholar]
- Jin, L. Vehicle detection based on visual and millimeter-wave radar. Infrared Millim. Wave J. 2014, 33, 465–471. [Google Scholar]
- Wang, T.T. Application of the YOLOv4-based algorithm in vehicle detection. J. Jilin Univ. (Inf. Sci. Ed.) 2023, 41, 281–291. [Google Scholar]
- Xiong, L.Y. Vehicle detection method based on the MobileVit lightweight network. Appl. Res. Comput. 2022, 39, 2545–2549. [Google Scholar]
- Yuan, L. Improve the YOLOv5 road target detection method for complex environment. J. Comput. Eng. Appl. 2023, 59, 212–222. [Google Scholar]
- Alshehri, A.; Owais, M.; Gyani, J.; Aljarbou, M.H.; Alsulamy, S. Residual Neural Networks for Origin–Destination Trip Matrix Estimation from Traffic Sensor Information. Sustainability 2023, 15, 9881. [Google Scholar] [CrossRef]
- Xue, Q.W. Vehicle detection of driverless system based on multimodal feature fusion. J. Guangxi Norm. Univ.-Nat. Sci. Ed. 2022, 40, 6198. [Google Scholar]
- Wang, W.H. Application research of obstacle detection technology in subway vehicles. Comput. Meas. Control 2022, 30, 110–116. [Google Scholar]
- Huang, K.Y.; Chang, W.L. A neural network method for prediction of 2006 World Cup Football Game. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–8. [Google Scholar]
- Oyedotun, O.K.; El Rahman Shabayek, A.; Aouada, D.; Ottersten, B. Training very deep networks via residual learning with stochastic input shortcut connections. In Proceedings of the International Conference on Neural Information Processing, Guangzhou, China, 14–18 November 2017; Springer: Cham, Switzerland, 2017; pp. 23–33. [Google Scholar]
- Zhu, B.; Huang, M.F.; Tan, D.K. Pedestrian Detection Method Based on Neural Network and Data Fusion. Automot. Eng. 2020, 42, 37–44. [Google Scholar]
- Thomee, B.; Shamma, D.A.; Friedland, G.; Elizalde, B.; Ni, K.; Poland, D.; Borth, D.; Li, L.-J. The new data and new challenges in multimedia research. Commun. ACM 2015, 59, 64–73. [Google Scholar] [CrossRef]
- Wang, S.; Huang, M.; Deng, Z. Densely connected CNN with multi-scale feature attention for text classification. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; pp. 4468–4474. [Google Scholar]
- Pan, S.J.; Kwok, J.T.; Yang, Q. Transfer learning via dimensionality reduction. In Proceedings of the AAAI, Chicago, IL, USA, 13–17 July 2008; Volume 8, pp. 677–682. [Google Scholar]
- Rezende, E.; Ruppert, G.; Carvalho, T.; Ramos, F.; De Geus, P. Malicious software classification using transfer learning of resnet-50 deep neural network. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 1011–1014. [Google Scholar]
- Huang, K.; Chang, W. An Ground Cloud Image Recognition Method Using Alexnet Convolution Neural Network. Chin. J. Electron Devices 2010, 43, 1257–1261. [Google Scholar]
- Cetinic, E.; Lipic, T.; Grgic, S. Fine-tuning convolutional neural networks for fine art classification. Expert Syst. Appl. 2018, 114, 107–118. [Google Scholar] [CrossRef]
- Majee, A.; Agrawal, K.; Subramanian, A. Few-shot learning for road object detection. In Proceedings of the AAAI Workshop on Meta-Learning and MetaDL Challenge, PMLR, Virtual, 9 February 2021; pp. 115–126. [Google Scholar]
- Xu, R.; Xiang, H.; Xia, X.; Han, X.; Li, J.; Ma, J. Opv2v: An open benchmark dataset and fusion pipeline for perception with vehicle-to-vehicle communication. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), IEEE, Philadelphia, PA, USA, 23–27 May 2022; pp. 2583–2589. [Google Scholar]
- Dogo, E.M.; Afolabi, O.J.; Nwulu, N.I.; Twala, B.; Aigbavboa, C.O. A comparative analysis of gradient descent-based optimization algorithms on convolutional neural networks. In Proceedings of the 2018 international conference on computational techniques, electronics and mechanical systems (CTEMS), IEEE, Belgaum, India, 21–22 December 2018; pp. 92–99. [Google Scholar]
- Zhang, K.; Xu, G.; Chen, L.; Tian, P.; Han, C.; Zhang, S.; Duan, N. Instance transfer subject-dependent strategy for motor imagery signal classification using deep convolutional neural networks. Comput. Math. Methods Med. 2020, 2020, 1683013. [Google Scholar] [CrossRef] [PubMed]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Wang, H.; Yu, Y.; Cai, Y.; Chen, X.; Chen, L.; Liu, Q. A comparative study of state-of-the-art deep learning algorithms for vehicle detection. IEEE Intell. Transp. Syst. Mag. 2019, 11, 82–95. [Google Scholar] [CrossRef]
- Mao, H.; Yang, X.; Dally, W.J. A delay metric for video object detection: What average precision fails to tell. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 573–582. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | Data Set | Key Aspects | Advantage | mAP | FPS | Platform |
|---|---|---|---|---|---|---|
| RC-YOLOv4 | self-made vehicle detection data set | Combine the channel and spatial attention mechanism | Pay more attention to the key information and small target information | 87.33% | 43 | Ubuntu 18.04 |
| MobileVit | KITTI | Introduce MobileVit network as the backbone feature extraction network | Fully extract the feature information and make the model lightweight | 95.36% | 58 | Window 10 |
| CTC-YOLO | KITTI | Add the context transformer and convolutional block attention module | Increase the detection accuracy of small targets by improving the network detection head and adding | 89.6% | 69 | Window 10 |
| The proposed YOLOv3 | KITTI | Adapt the transfer learning and replace the detection head of the original network | While ensuring the detection accuracy, the training and detection time is reduced | 88.24% | 78 | Window 10 |
| Methods | Advantage | Malpractice |
|---|---|---|
| Infrared detection | Solve the day–night conversion problem, and provide a lot of traffic management information | An excellent infrared focal plane detector may be required, which requires increased power and reduced reliability to achieve high sensitivity |
| Ultrasonic detection | Small size, easy to install; Long service life; Movable; Multi-lane detection is possible | The performance decreases with the influence of ambient humidity and air flow |
| Radar detection | Work in all weather, keep excellent performance harsh weather; Detect static vehicles; Detect multiple lanes in lateral mode | The higher detector installation requirements because detection accuracy decline when the road has an iron strip |
| Object detection | Provide visual images for incident management; Provide a lot of traffic management information; A single camera and processer can detect multiple lanes | Smaller vehicles cannot be detected when obscured by large vehicles |
| Classes | AP | TP | FP | mAP |
|---|---|---|---|---|
| car | 81.25% | 79.65% | 20.34% | 83.85% |
| person | 76.43% | 60% | 40% | |
| bicycle | 74.12% | 82.81% | 17.18% | |
| motorcycle | 73.08% | 74.14% | 25.85% | |
| bus | 79.14% | 81.06% | 19.02% | |
| dog | 72.44% | 77.07 | 22.92% | |
| cat | 73.34% | 65.41% | 34.58% |
| Class Name | Car | Person | Bicycle | Motorcycle | Bus | Dog | Cat |
|---|---|---|---|---|---|---|---|
| Total number | 1434 | 1360 | 860 | 430 | 300 | 220 | 180 |
| Batch | Learn-Rate | IOU | Training Time/h | mAP (%) |
|---|---|---|---|---|
| 3.52 | 83.85 | |||
| √ | 3.12 | 82.73 | ||
| √ | 3.37 | 83.14 | ||
| √ | √ | 2.93 | 82.93 | |
| √ | √ | √ | 2.96 | 87.64 |
| lbox | lobj | lcls | F1 | mAP (%) |
|---|---|---|---|---|
| 57.31% | 65.37 | |||
| √ | 63.27% | 73.64 | ||
| √ | 62.45% | 72.82 | ||
| √ | 64.87% | 75.68 | ||
| √ | √ | 69.39% | 78.94 | |
| √ | √ | 68.76% | 77.68 | |
| √ | √ | 70.32% | 79.56 | |
| √ | √ | √ | 71.47% | 83.85 |
| Operating System | CPU | Memory | GPU | CUDA | CUDNN |
|---|---|---|---|---|---|
| Windows 10(22H2) | Intel i5 | 8GB | NVIDIA GEFORCE RTX 745 | CUDA 10.04 | CUDNN 7.04 |
| Index | Param/M | FPS/Frames per Second | FLOPS/Floating-Point Operations per Second | Weight Size/M | mAP | |
|---|---|---|---|---|---|---|
| Algorithm | ||||||
| YOLOv3 | 61.53 | 54.6 | 132.69 Bn | 120.5 | 83.85% | |
| YOLOv5 | 52.5 | 55.3 | 116.54 Bn | 100.6 | 87.26% | |
| YOLOv7 | 36.49 | 87.1 | 102.37 Bn | 74.8 | 89.32% | |
| The proposed YOLOv3 | 29.84 | 91.2 | 97.62 Bn | 68.2 | 87.85% | |
| Algorithm mAP mAP | Car | Bus | Van | Others | Average mAP |
|---|---|---|---|---|---|
| YOLOv3 | 79.61% | 80.29% | 76.21% | 70.32% | 75.1% |
| YOLOv5 | 83.32% | 82.26% | 79.64% | 72.11% | 77.87% |
| The proposed YOLOv3 | 82.73% | 81.37% | 80.36% | 74.53% | 79.23% |
| Algorithm | 320 × 320 Detection Time/ms | 416 × 416 Detection Time/ms | 608 × 608 Detection Time/ms | FPS/Frames per Second |
|---|---|---|---|---|
| YOLOv3 | 22.8 | 29.4 | 51.9 | 43.6 |
| YOLOv5 | 20.3 | 26.1 | 43.1 | 56.9 |
| YOLOv7 | 19.8 | 26.7 | 41.2 | 59.7 |
| The proposed YOLOv3 | 19.2 | 24.4 | 39.7 | 61.2 |
| Algorithm | Detection Time/s | FPS/Frames per Second | FLOPS/Floating Point Operations per Second |
|---|---|---|---|
| YOLOv3 | 66.9 | 78 | 84.37 Bn |
| YOLOv5 | 64.7 | 85 | 86.38 Bn |
| YOLOv7 | 62.4 | 83 | 91.68 Bn |
| The proposed YOLOv3 | 19.2 | 84.4 | 98.7 Bn |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, C.; Liang, J.; Zhou, F. Transfer Learning-Based YOLOv3 Model for Road Dense Object Detection. Information 2023, 14, 560. https://doi.org/10.3390/info14100560
Zhu C, Liang J, Zhou F. Transfer Learning-Based YOLOv3 Model for Road Dense Object Detection. Information. 2023; 14(10):560. https://doi.org/10.3390/info14100560
Chicago/Turabian StyleZhu, Chunhua, Jiarui Liang, and Fei Zhou. 2023. "Transfer Learning-Based YOLOv3 Model for Road Dense Object Detection" Information 14, no. 10: 560. https://doi.org/10.3390/info14100560
APA StyleZhu, C., Liang, J., & Zhou, F. (2023). Transfer Learning-Based YOLOv3 Model for Road Dense Object Detection. Information, 14(10), 560. https://doi.org/10.3390/info14100560