1. Introduction
Sound event detection (SED) of domestic activities is of particular interest for various applications, including assisting the autonomous living of the elderly. According to [
1], monitoring of domestic activities by any method is important to assess the ability of the elderly to live independently and may contribute to the early detection of future critical events. To this end, there is research that traces back at least to 2010 [
2] that deals with the monitoring of domestic activities with a set of microphones and research [
3] that deals with fall detection by processing sound. While sound event detection of domestic activities is one of the technologies that can be applied for monitoring elderly living, it has important advantages. It is far more comfortable for the elderly since no wearable device is used. Everything is fully automated, and the monitored person does not have to configure or interact with the monitoring system. In addition, it is far less privacy-intrusive for the elderly, at least compared to visual cameras. The automatic processing of sound implies that only the activity is monitored, and no speech content is processed. Finally, it is cost-efficient, since the required equipment falls within the common budget of a household.
There are two important datasets concerning domestic sound event detection: (a) AudioSet [
4], which corresponds to a wide variety of activities and sound events (domestic activities are only a subset of the complete dataset) and (b) DESED [
5], which corresponds to 10 classes of domestic events (alarm/bell/ringing, blender, cat, dog, dishes, electric shaver/toothbrush, frying, running water, speech, vacuum cleaner). Although some classes in DESED are different from what is of interest in assisting autonomous living, it is highly probable that an efficient system of detecting DESED events will be efficient for detecting additional events. The DESED dataset is proposed by the DCASE community (IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events) for its yearly challenge. Most of the research in domestic SED employs the DESED dataset for training and the DESED development test dataset (and the evaluation dataset, if available) for evaluation and testing. This creates an objective comparison and this article presents an efficient method to obtain accurate results in the DESED development test dataset, which has not changed in the past few years.
Hitherto, DESED training and validation sets have been considerably enhanced. They now include strongly labeled, weakly labeled, and unlabeled clips of 10 s, in which an event of a certain class may occur for a specific duration. Events of different classes may also overlap. Various deep learning models of different complexity have been proposed in recent years and achieved high performance in terms of different metrics. These models, in most cases, transform each one-dimensional raw signal (10 s clip) into a two-dimensional frequency and time representation [
5,
6,
7,
8,
9,
10,
11,
12,
13]. The most popular representation is the log-mel-spectrogram, and even the parameters of the mel-spectrogram transform are usually the same. Modern research focuses on developing a classification/detection method and mainly the underlying deep learning model, which best exploits the information of these standard log-mel-spectrograms [
5,
6,
7,
8,
9,
10,
11,
13]. After the mel-spectrogram extraction, standard data augmentation techniques are applied in order to reduce overfitting up to a limit. In addition, there was a recent important contribution to this pre-processing step with FilterAugment [
6], where augmentation is performed by mimicking acoustic filters and imposing different weights over frequency.
Some main deep learning architectures are abstractly divided into four main components: the feature extraction component, e.g., a convolutional neural network (CNN); the sequence modeling, which is usually a convolutional recurrent neural network (CRNN); or a transformer architecture, a module that employs self-supervised learning to leverage the high amount of unlabeled data and aggregation of pre-trained embeddings with CNN features, which combines the advantages of transfer-learning and optimal encoding of sound. Finally, post-processing methods, including class-wise median filtering of results are also applied, but with limited research interest and effect on results.
In terms of feature extraction, most efficient recent methods employed a seven-layer CNN [
5,
6,
8,
10,
11,
13]. However, the 2D convolutional layers in this CNN do not take into account that the audio spectrogram is not shift-invariant in the frequency axis. A feature in the higher frequencies is different from the same feature in the lower frequencies, which does not hold in natural images. The authors of [
7] proposed a frequency-dynamic convolutional network to capture the nature of audio spectrograms more efficiently. The frequency-dynamic convolutional network (FDY-CNN) had almost the same properties as the seven-layer CNN used in other methods with the replacement of the standard 2D convolution with a frequency-dynamic convolution. To extend the capability of (FDY-CNN), a multi-dimensional frequency-dynamic convolution is proposed in [
8].
Embeddings extracted from external pre-trained models are usually aggregated with the outcome of feature extraction. The embeddings may occur by training in more audio events (AudioSet dataset) or images or video. Various embeddings have been proposed to enhance the performance of SED models, including YOLO [
14] and BYOLA [
15]. Lately, BEATs (audio pre-training with acoustic tokenizers) embeddings achieved significantly better performance in various tasks, e.g., audio classification [
16], and thus are adopted in this study.
Sequence modeling is commonly tackled using bi-directional GRU [
17] or transformers. Due to the high efficiency of transformers [
18] in image processing and natural language processing, a number of studies applied transformers in the sequence modeling part of domestic SED. Nonetheless, due to the comparatively small amount of data for domestic SED and the short-temporal features of sound events, no significant improvement in performance was observed, to the best of our knowledge, when using transformers compared to BiGRU [
12,
13]. Transformers were best exploited as a pre-trained embedding extraction method [
9] with BEATs, which also features a transformer as the final embedding extractor, achieving greater performance improvement at the time of its publication.
Concerning self-supervised learning, the mean teacher–student method is proven efficient in leveraging unlabeled data in the context of domestic SED [
19]. In this method, a “student” model is trained with an extra consistency loss, which is calculated by comparing the student’s results with a teacher model’s results. The two models are identical, however, the teacher is not training but updates its weights with an exponential moving average of the student’s weights. Other self-supervised learning techniques that are used are the confident mean teacher (CMT) [
8], which post-processes the teacher’s prediction before consistency loss calculation, and the mutual mean teacher (MMT), where the student and the teacher are trained iteratively and exchange weights [
20].
Research on domestic SED adopts and/or develops models that can be applied also to other SED tasks. However, efficient methods in other tasks may not be so efficient in domestic SED, or they have not been tested yet. Moreover, the fact that the DCASE dataset may change yearly results to a smaller number of publications that deal with the latest version of the dataset. It is also important to note that even the proposed metrics by the sound event detection community, the Polyphonic Sound Event Detection Score-Scenario-1 (PSDS1) and the Polyphonic Sound Event Detection Score-Scenario-2 (PSDS2) have evolved to be operating-point independent. PSDS scores approximate AUROC with two different calculations of true positives and true negatives. This calculation depends on specific parameters: the detection tolerance criterion, the ground-truth intersection criterion, the cost of instability across classes, the cross-trigger tolerance criterion, the cost of CTs on user experience, and the maximum false-positive rate. In the PSDS scenario, the parameter values are selected so that the SED system is evaluated more positively for its quick response at the start of a sound event. Therefore, a system maximizing the PSDS1 score is more suitable as an alarm. In the PSDS scenario, the parameters’ values are also selected so that the system is evaluated more positively on its ability to avoid misclassifications.
Due to the above reasons, the related methods for domestic SED that are presented next are the ones that provided results in terms of PSDS scores and/or used the latest editions of DESED for their analysis. Shao et al. investigated various methods of leveraging unlabeled data with a complex self-supervised system (SSL) [
10]. More specifically, during each training step, different data augmentations were applied, and each augmentation contributed to a specific loss, with losses measuring the consistency between the teacher and the student but also between the original and data-augmented sounds. The random consistency training (RCT) method used a standard RCNN and achieved a PSDS1 score of 44%, a PSDS2 score of 67.1%, and an event-based macro-averaged score of 44.5%. Koh et al. [
11] used another type of consistency SSL, named interpolation consistency learning, but also proposed a feature pyramid, where features from different layers of a CNN are aggregated before the classification layer. However, they reported only a PSDS2 score of 66.9% and an event-based macro-averaged score of 44.5% in the DCASE2020 dataset. Kim et al. also proposed a model that combines features from the last convolutional layers, and the features of these last layers pass through transformer encoders before being aggregated [
12]. Their system achieved an F1-score of 46.78 on the DCASE2019 development test dataset. This dataset is also the predecessor to the latest (DCASE2023) with minimal or no changes. They do not report PSDS scores, which are considered the most indicative, according to the DCASE organizers. Chen et al. [
21] also applied a sequence of transformers but directly to mel-spectrograms in a hierarchical manner, where each deeper swin transformer encoder was smaller than its previous one. They achieved a 50.7% event-based macro-averaged F1 score. In addition, Miyazaki et al. [
13] efficiently applied a conformer architecture [
22], a model in which each convolutional layer is followed by a transformer encoder. However, its performance was surpassed by models that do not use transformers. Kim et al. [
9], who featured the best PSDS scores in DCASE2023, employed a different module of attention, named large-kernel attention [
23], combined with frequency-dynamic convolution [
7]. Their system achieved a PSDS1 score of 56.67% and a PSDS2 score of 81.54% with a model ensemble, and 54.59% and 80.75% without an ensemble in the development test set. Meanwhile, an almost equally efficient submission by Xiao et al. achieved a PSDS1 score of 55.2% and a PSDS2 score of 79.4% by applying a multidimensional frequency-dynamic CNN [
8] with no extra attention modules, except for one in the last classification layer for weak labels. Finally, The last submissions in DCASE2023 both used BEATs embeddings in combination with features derived from their models. An assumption that can be made is that BEATs embeddings boosted the performance of domestic SED more than other techniques. It is important to note also that PSDS scores are now calculated more accurately and usually produce higher values than those calculated with older versions.
Domestic SED is a complex and challenging problem due to the small amount of labeled data, the subjectivity of annotators, the loose boundaries of events, the imbalanced dataset, and the nature of the sound events. More specifically, there are sound events with small duration, such as dog barking, and some with usually big duration, such as running water. Also, there are events that share frequency characteristics, i.e., frying, running water, blender, and vacuum cleaner. These challenges suggest that the best practices from each component of a method may not contribute as expected in the overall system. Training parameters, such as the choice of optimizer and loss function, may also have a significant effect. However, in this study, we attempt to combine best practices that intuitively should work better without constructing a very complex model. A comparatively lightweight model is proposed here, with the main target to create a model with clearer interpretation and better generalization capability.
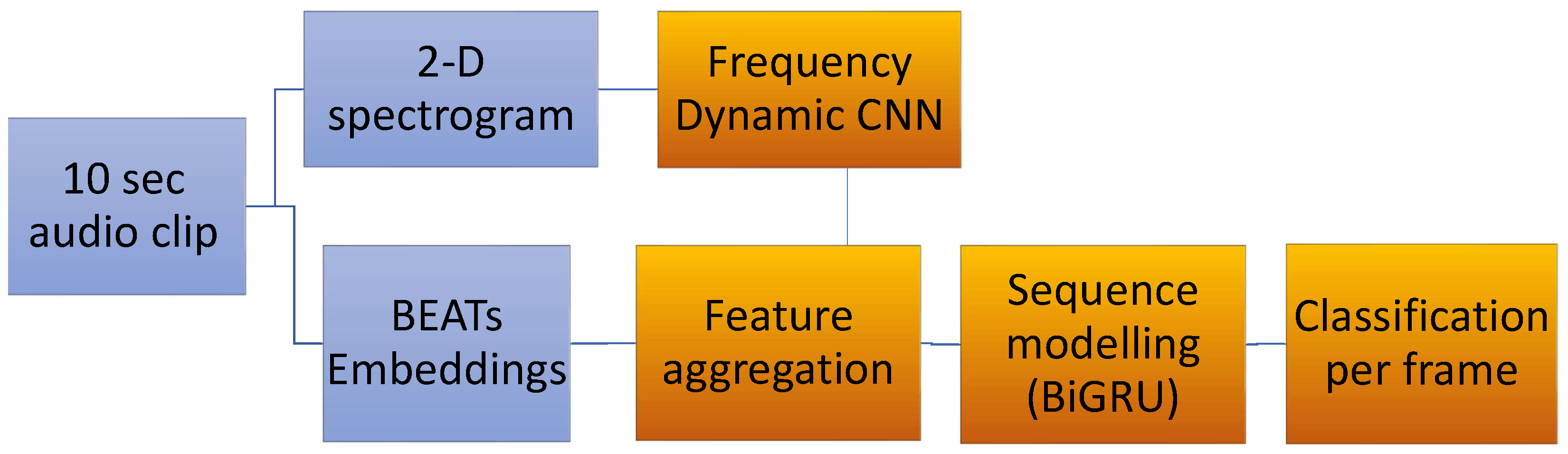
The proposed model adopts and modifies the baseline of the DCASE2023 competition by employing specific versions of the aforementioned modules. More specifically, it combines BEATs embeddings with the output of a frequency-dynamic convolution network, where an extra local attention module is added sequentially after each dynamic convolution. The combined embeddings pass through a BiGRU (bi-directional recurrent unit) unit and, finally, a classification module. The model that consists of the above modules (student) has an identical teacher model that is updated with the exponential average of the weights of students. The combination of these techniques for the SED problem is novel to the best of our knowledge and succeeds in offering a lightweight architecture with sufficient performance.
5. Discussion
A lightweight and efficient for domestic sound event detection is presented in this work. Various data augmentation techniques, feature extraction models, and self-supervised techniques were tested to optimize the outcome.
Concerning data augmentation, soft mixup, hard mixup, and filtAugment, which were tested in this study, were already proposed, and they are optimized for SED as independent units. Moreover, Gong et al. [
25] proposed model-agnostic data manipulation for SED, which included data augmentation. However, filtAugment is a new technique and evolved with a second edition, and different combinations of these data augmentation techniques with the proposed model, had to be tested to adopt the most efficient augmentation. In addition, in the presented experiments, it can be observed that while soft mixup enhances PSDS1 and hard mixup enhances PSDS2, there are other combinations that can be more efficient.
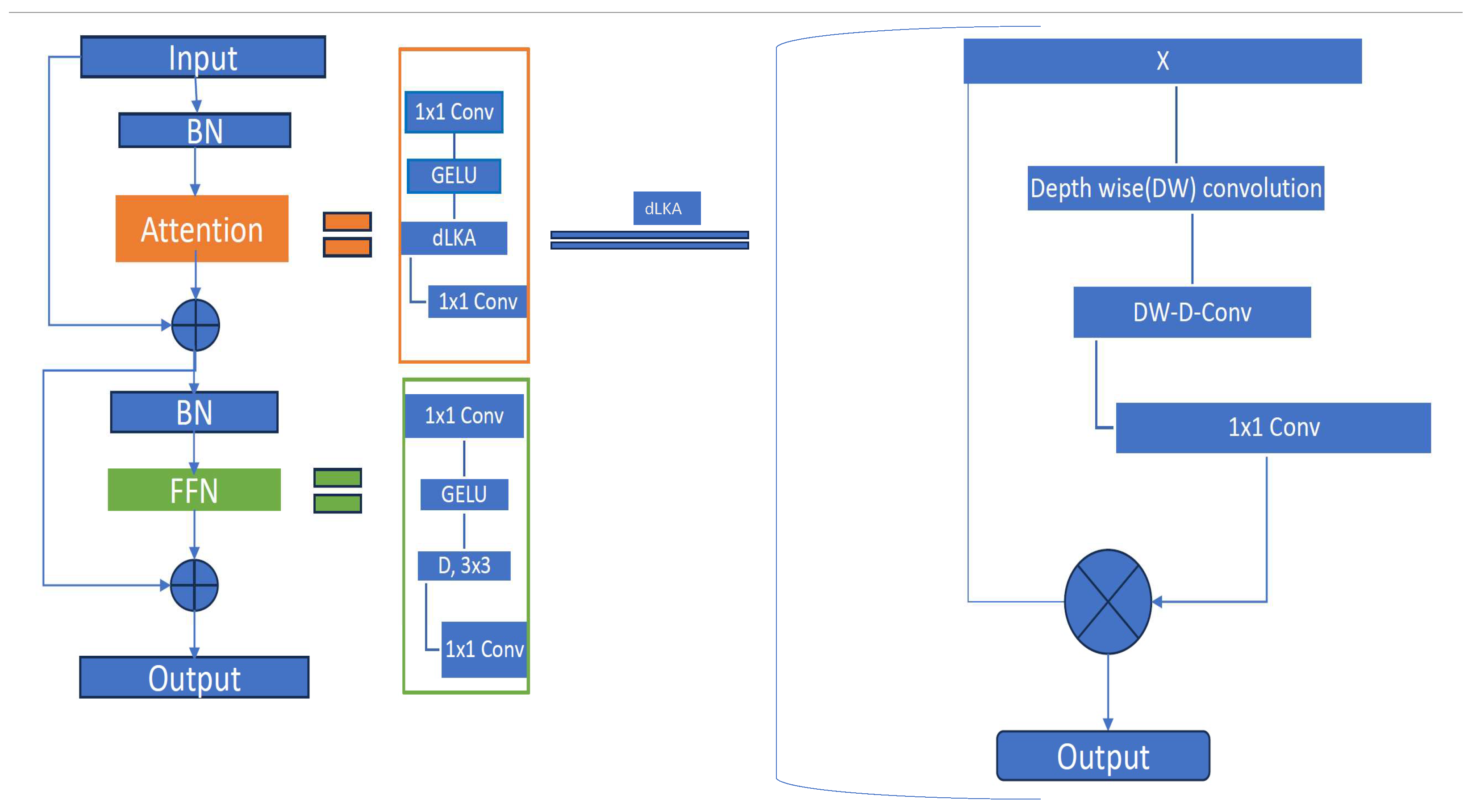
Feature extraction is the core of this method, and it was the main subject of research in domestic SED. Recent methods of frequency-dynamic convolution and multi-dimensional frequency-dynamic convolution achieved the main enhancement in results, while the rest of the SED systems had little modifications. Frequency-dynamic convolution cancels the shift-invariant nature of the convolution, while it can be considered an attention module. Attention is a hot concept in deep learning and a desired aspect of detection systems. Due to the short duration of sound events and the relatively small dataset, a global application of attention, such as the one provided by transformers, does not seem to be as efficient as local attention. In this rationale, the LKA module can be considered as a local attention module, especially when downsized to small kernel sizes. However, the enhancement in results is not so impressive, when adding LKA to frequency-dynamic convolution. Although two local attention modules in sequence may seem to have enough capacity to capture local interactions, more research can be conducted in local attention modules to be added to the effective spectrogram-specific frequency-dynamic convolution.
Another field of significant interest in domestic SED is the use of pre-trained embeddings due to the great number of AudioSet sound clips and the relatively small DESED dataset. Embeddings up to lately have relied on reconstruction loss and not discrete-level predictions. Discrete-level prediction self-supervised learning was easier to implement in music and in speech, but not in the sound events of very varying duration and frequency characteristics. BEATs embeddings achieved self-supervised with discrete-level prediction by starting the training with random discrete labels and iteratively adapting them to the encoding system, which was a transformer. The pre-trained BEATs embeddings significantly boosted the performance of various domestic SED systems when aggregated to the features extracted by CNNs and are adopted in this study. The key idea of self-supervised learning is training on discrete labels in the iterative scheme, proposed in [
16] and thus extracting higher-level features semantically richer. It is probable that research in altering the ViT transformer with another encoder in BEATs training scheme may produce embeddings with more capacity for a specific task like domestic SED.
As stated before, global attention did not improve results in domestic SED. Specifically, several research efforts have proposed various transformers in place of BiGRU or other RCNN. However, BiGRU, which demands fewer computations and memory, is to the best of our knowledge, more efficient to this date. Recently, a technique called glance-and-focus [
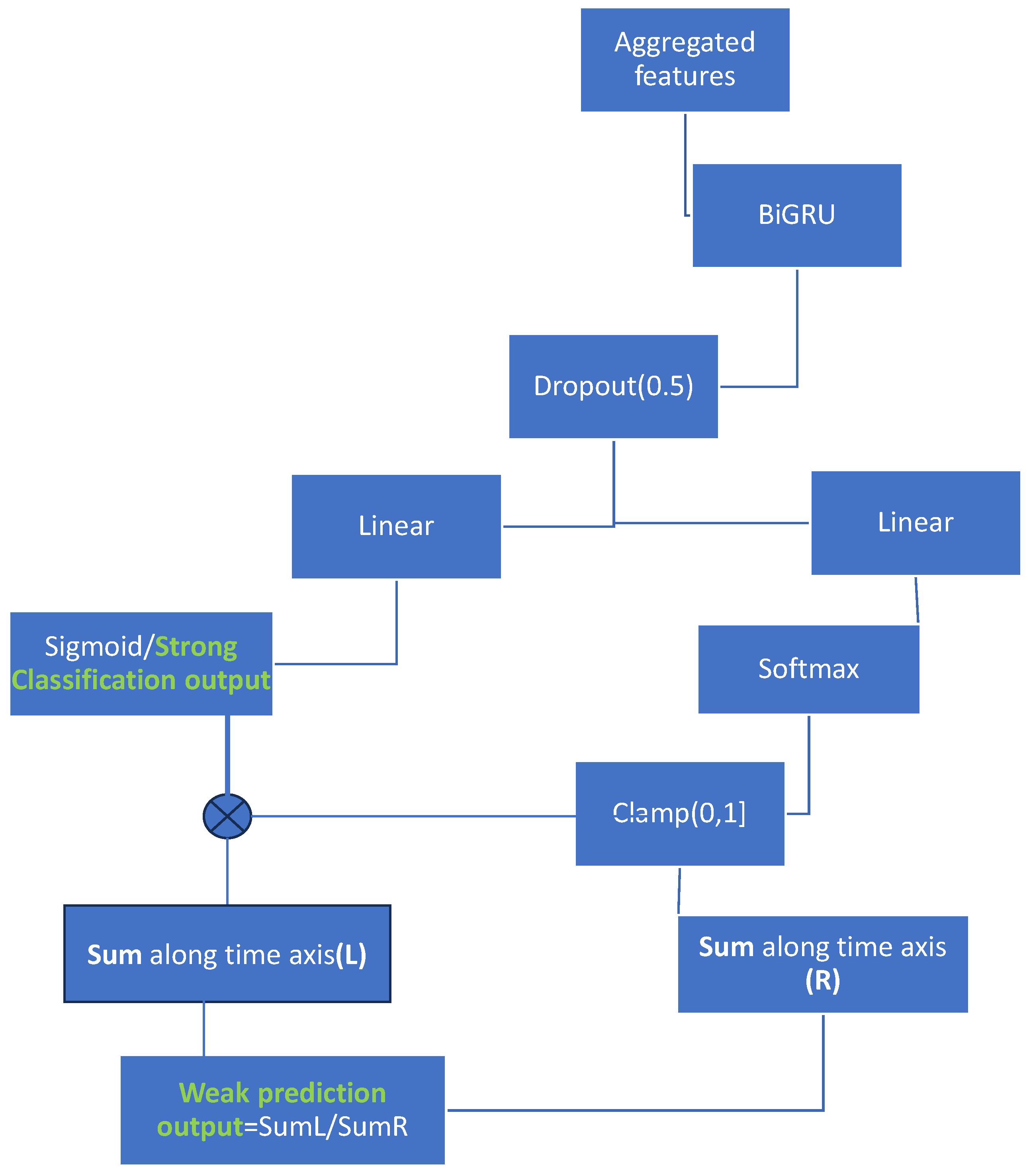
31] was published, which also uses the attention and transformer architectures. The aim is to locate an anomaly event in a long video sequence. In this approach, global attention is applied first and then local attention. This sequentially applied attention could also be applied in DESED. However, in DESED, there are 10 classes that may have any duration, and there is no notion of normality. The classification layer in the proposed method of this paper uses global attention to extract weak labels (
Figure 3). In a sense, the proposed method first uses local attention with dLKA and then global attention in a reverse manner to [
31].
Ensemble models have also proved efficient in various works. However, they demand many computational resources and many hours or days of training. This study focuses on finding an efficient single model, and this could be the basis of ensemble models that can be less than 50 models, as it is common in the winning systems of DCASE. Moreover, there is also concern about the environmental consequences of training large and complex systems.
The novelty of this method is the combination of state-of-the-art modules, which are adapted in a suitable way to perform the SED task. This combination is not encountered in the literature to the best of our knowledge. Several ablation tests were presented in the text that demonstrate that the proposed combination yields optimal performance.







{kind=link}
{kind=link}
{kind=link}