
Tool Support for Improving Software Quality in Machine Learning Programs




Abstract
:1. Introduction
- A novel maintenance technique that helps ML application developers or end users detect and correct anomalies in the application’s reasoning that aims for predictions that failed to achieve the functional requirements.
- A prototype, open-source, plug-in implementation in the Eclipse IDE that blends data maintenance features (i.e., model personalization, data version diff, and data visualization) with the IDE platform to hinder the separation of code, data, and model maintenance activities.
- A thorough case study that validates our approach by applying a text corpus in the bioengineering domain, demonstrating MLVal’s effectiveness in the model training and tuning processes.
2. Related Work
3. Design Principles
4. Design and Implementation
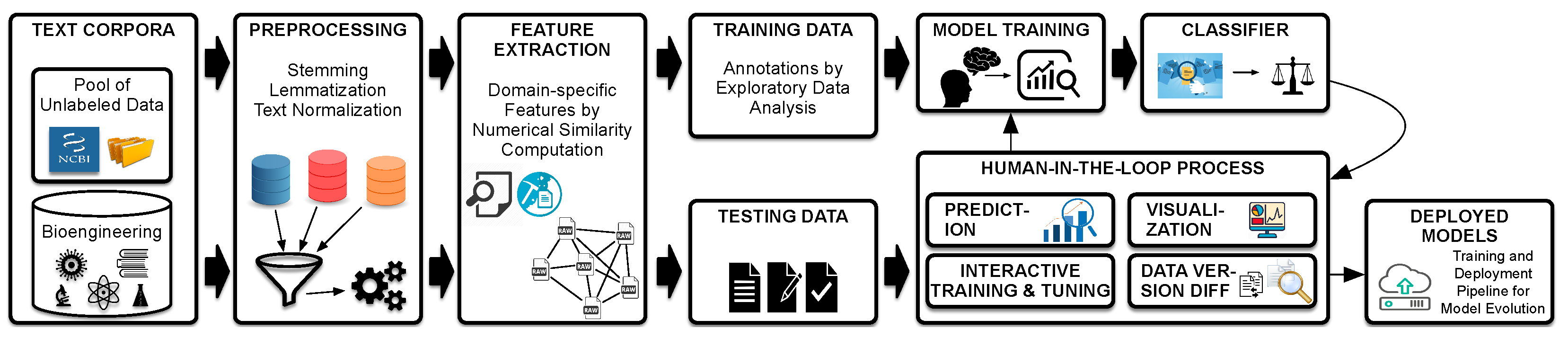
5. Approach
5.1. Preprocessing
5.2. Feature Extraction
6. Evaluation: A Case Study
- RQ1. Can MLVal help a user optimize an ML model?
- RQ2. Can MLVal help a user detect bugs in an ML model?
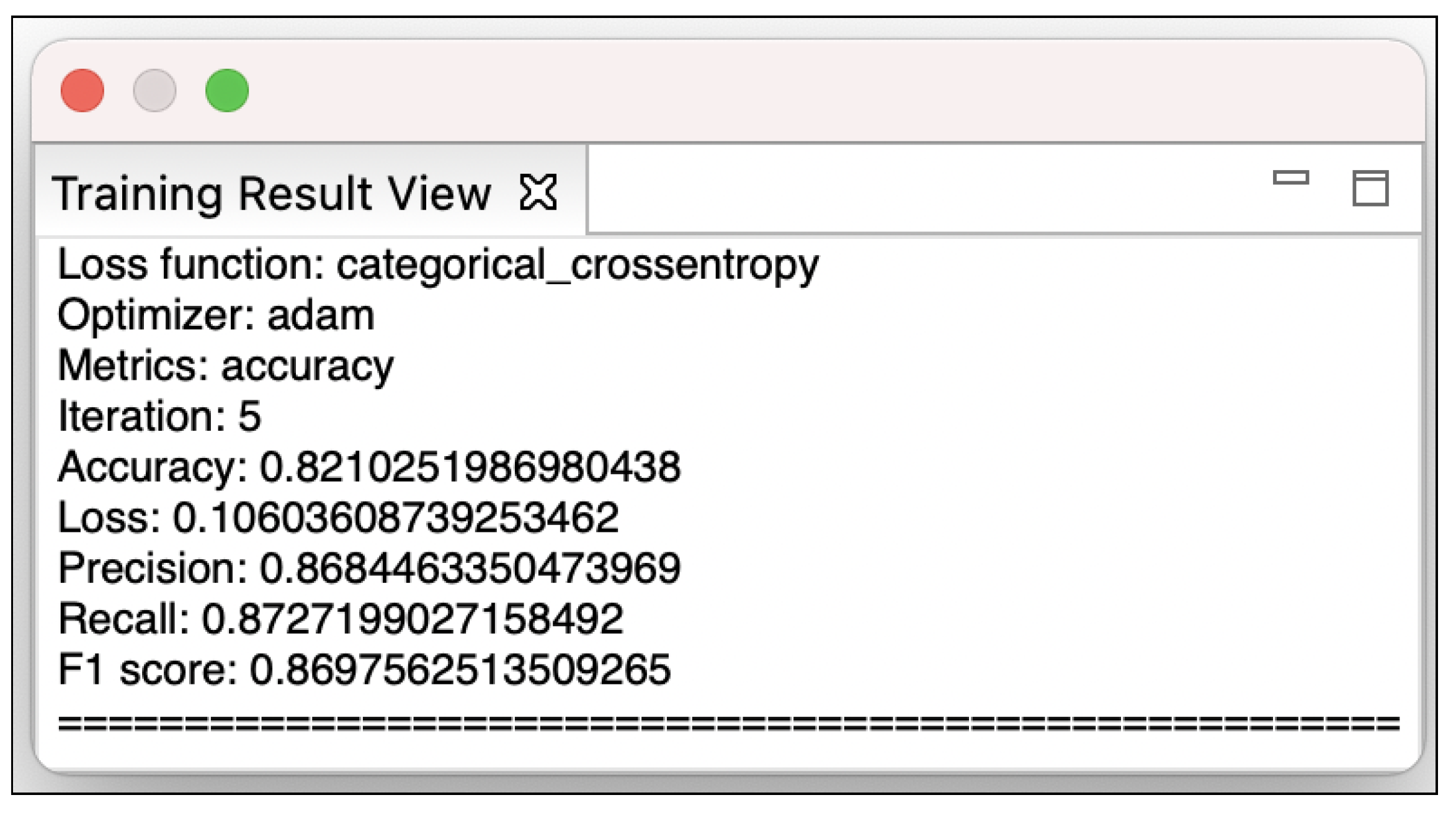
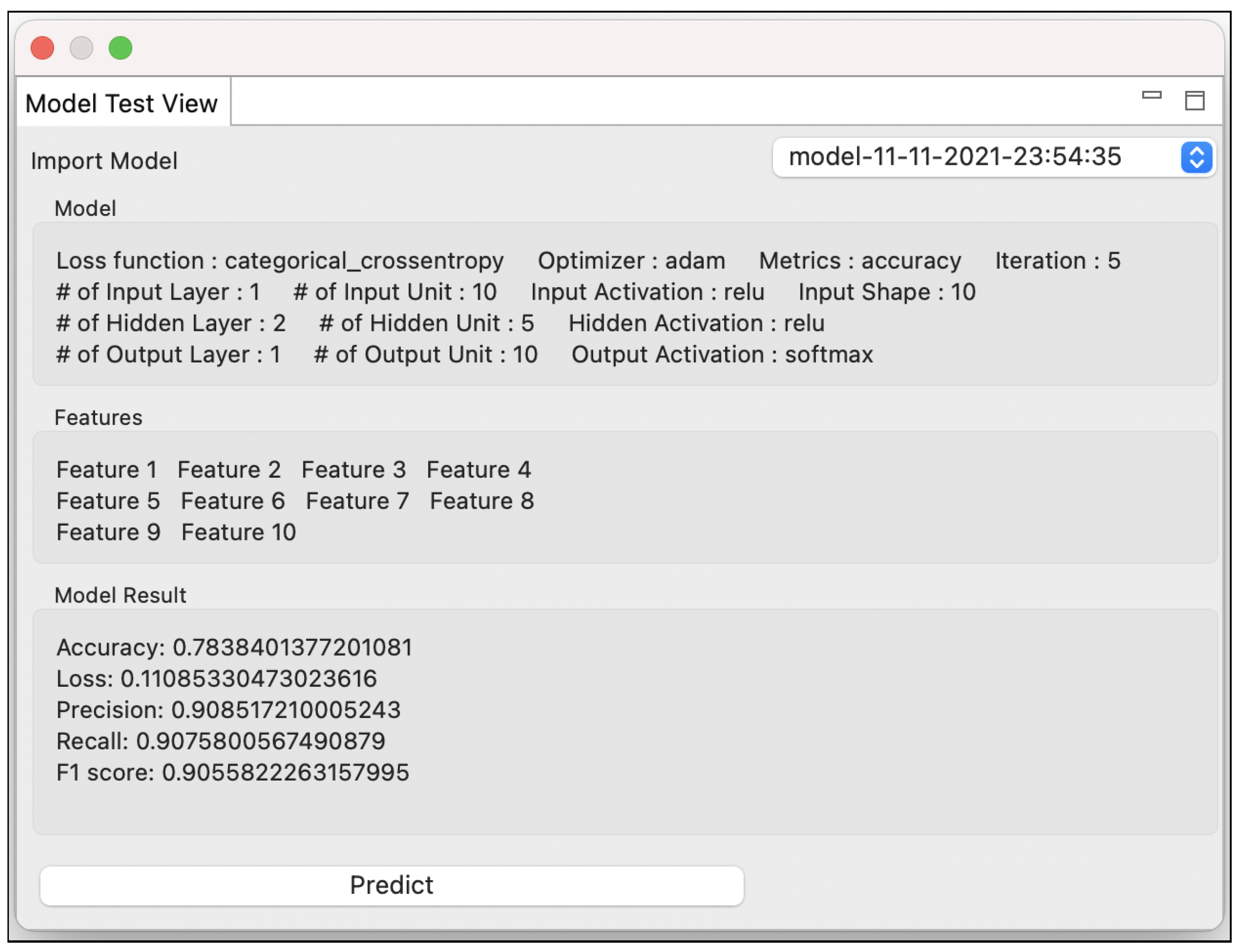
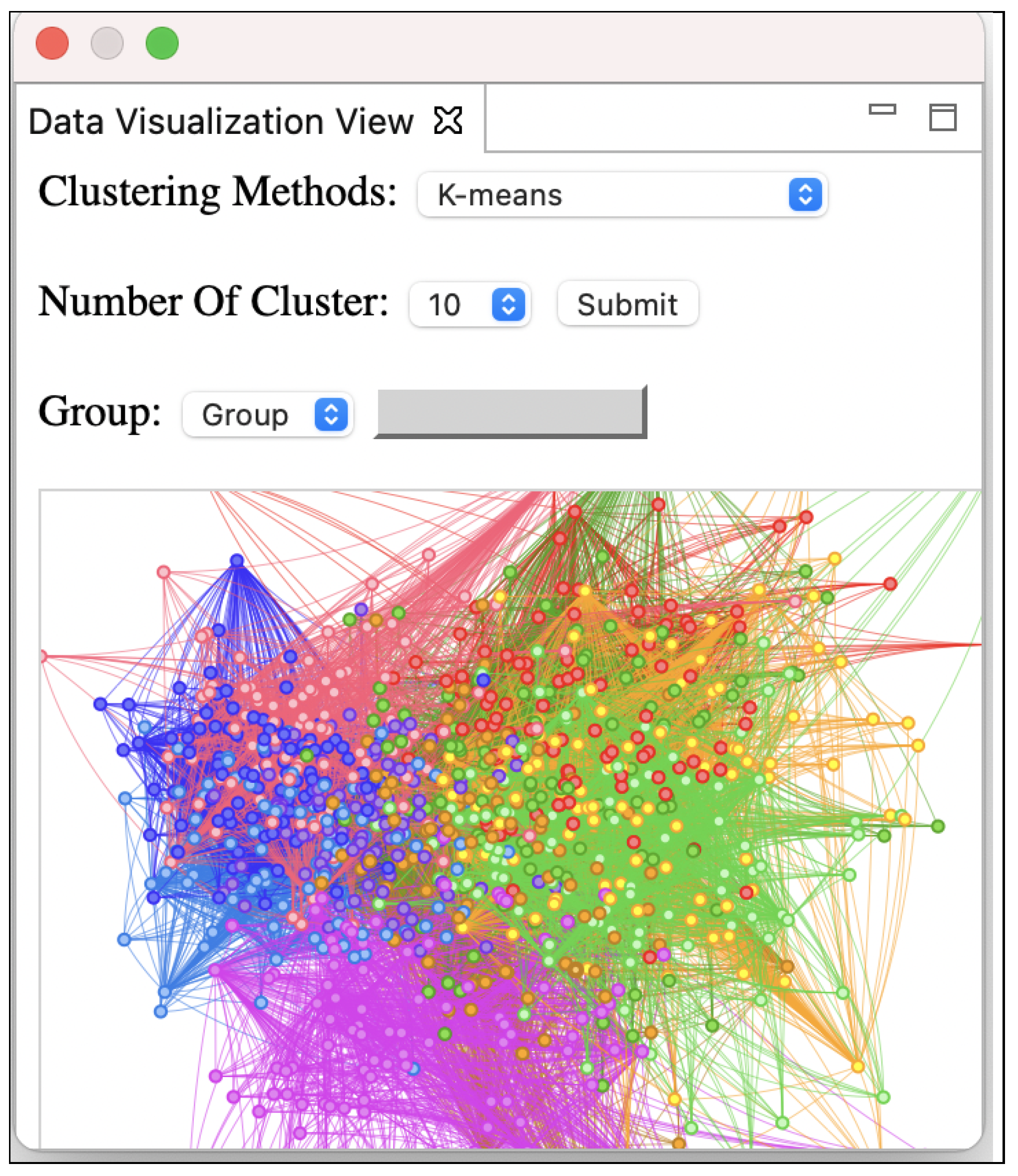
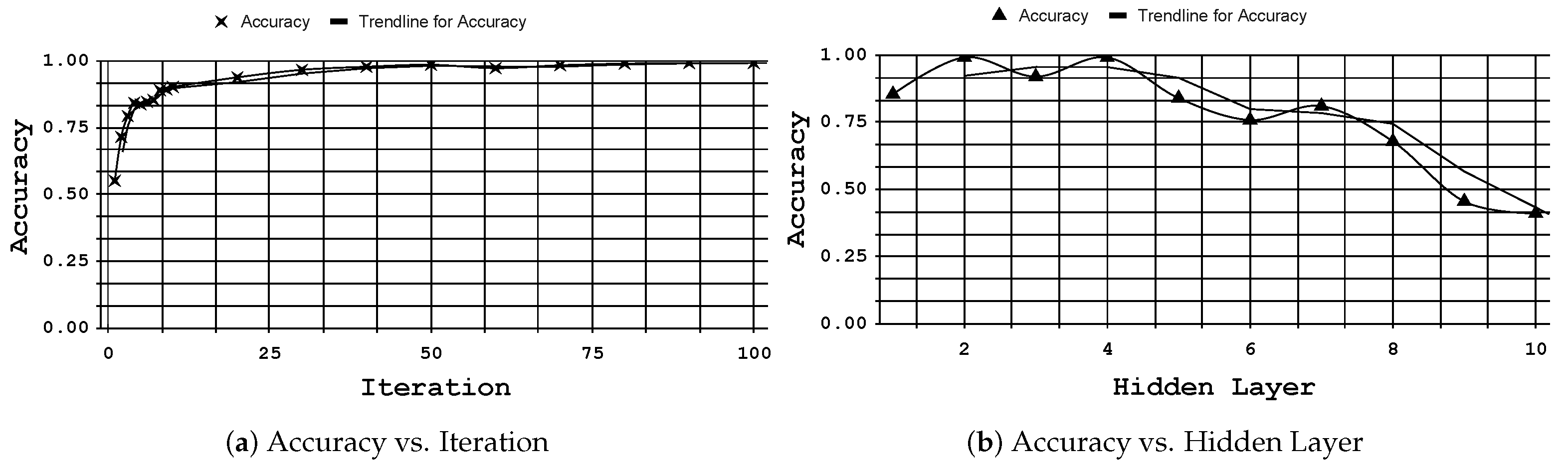
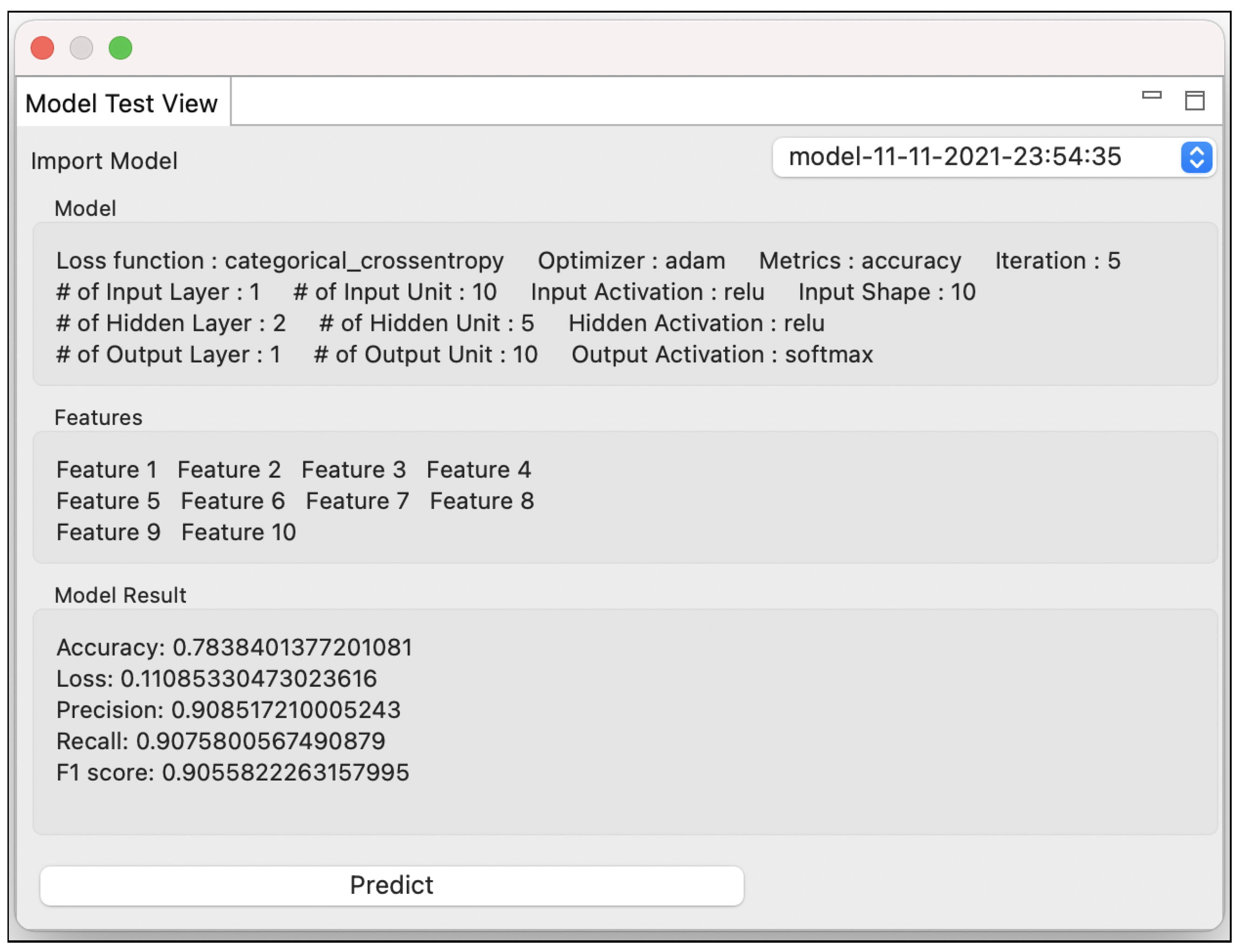
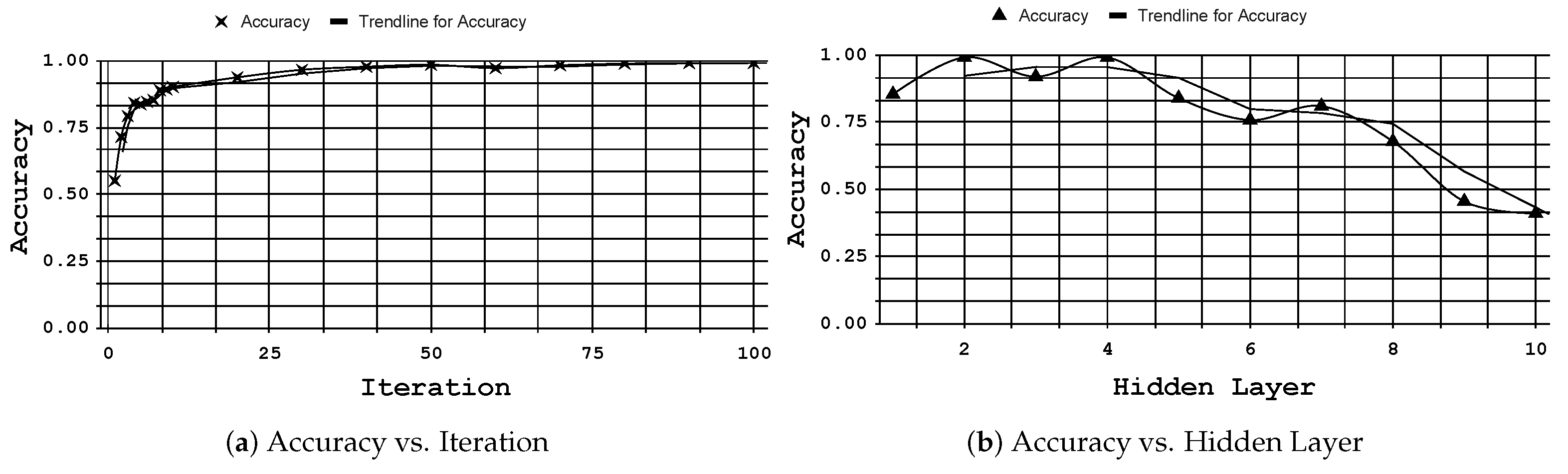
6.1. RQ1: Tool Support for Model Optimization
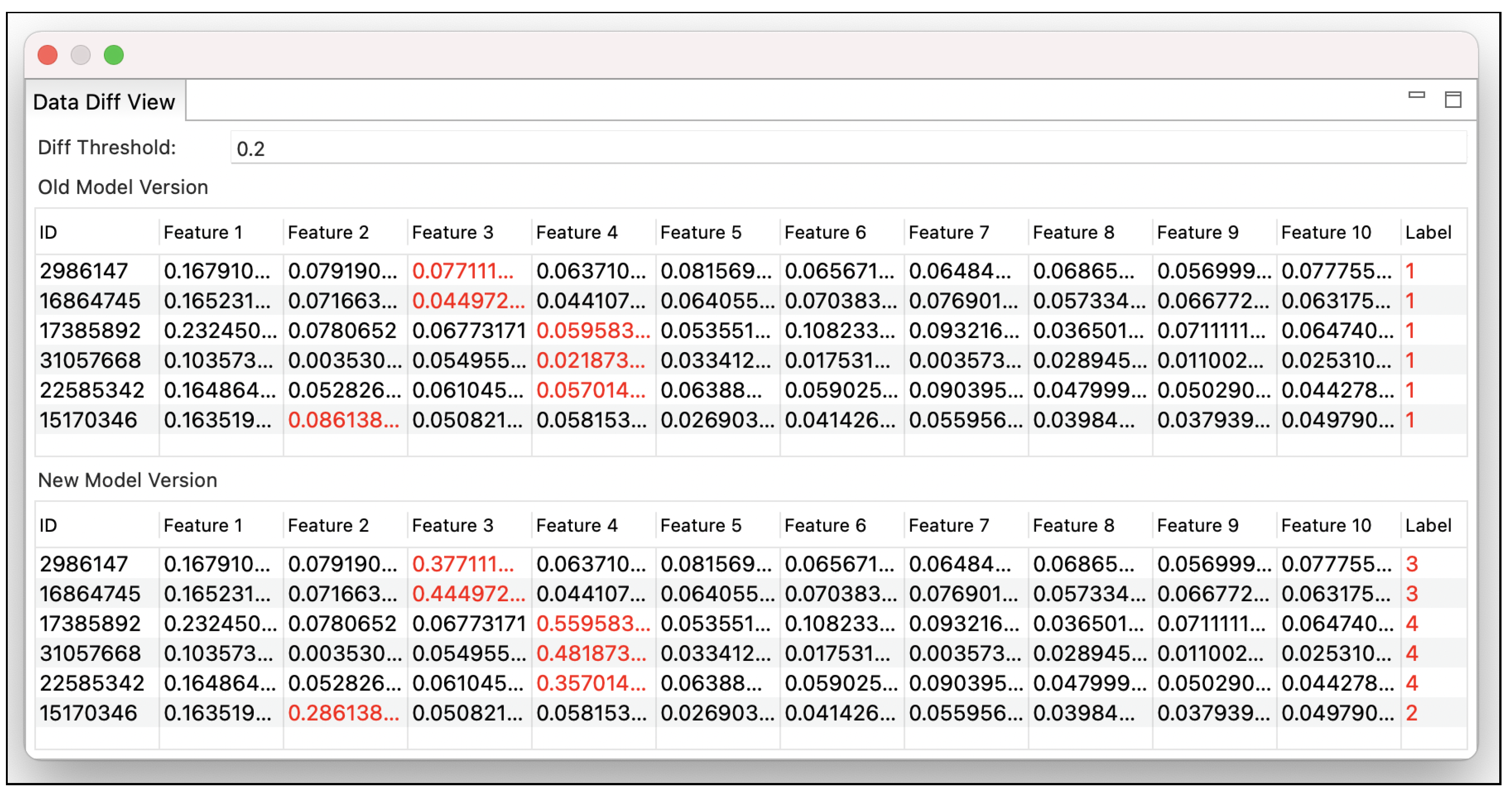
6.2. RQ2: Tool Support for Bug Detection
7. Threats to Validity
8. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cai, C.J.; Reif, E.; Hegde, N.; Hipp, J.; Kim, B.; Smilkov, D.; Wattenberg, M.; Viegas, F.; Corrado, G.S.; Stumpe, M.C.; et al. Human-centered tools for coping with imperfect algorithms during medical decision-making. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–14. [Google Scholar]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar]
- Miner, A.S.; Milstein, A.; Schueller, S.; Hegde, R.; Mangurian, C.; Linos, E. Smartphone-based conversational agents and responses to questions about mental health, interpersonal violence, and physical health. JAMA Intern. Med. 2016, 176, 619–625. [Google Scholar]
- Urmson, C.; Whittaker, W.R. Self-driving cars and the urban challenge. IEEE Intell. Syst. 2008, 23, 66–68. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Muller, M.; Lange, I.; Wang, D.; Piorkowski, D.; Tsay, J.; Liao, Q.V.; Dugan, C.; Erickson, T. How data science workers work with data: Discovery, capture, curation, design, creation. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, Scotland, UK, 4–9 May 2019; pp. 1–15. [Google Scholar]
- Andrienko, N.; Andrienko, G.; Fuchs, G.; Slingsby, A.; Turkay, C.; Wrobel, S. Visual Analytics for Data Scientists; Springer International Publishing: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Fowler, M. Refactoring: Improving the Design of Existing Code; Addison-Wesley Professional: Boston, MA, USA, 2000. [Google Scholar]
- Sculley, D.; Holt, G.; Golovin, D.; Davydov, E.; Phillips, T.; Ebner, D.; Chaudhary, V.; Young, M.; Crespo, J.F.; Dennison, D. Hidden technical debt in machine learning systems. Adv. Neural Inf. Process. Syst. 2015, 28, 2503–2511. [Google Scholar]
- Ousterhout, J.K. A Philosophy of Software Design; Yaknyam Press: Palo Alto, CA, USA, 2018; Volume 98. [Google Scholar]
- Cheng, K.S.; Ahn, T.H.; Song, M. Debugging Support for Machine Learning Applications in Bioengineering Text Corpora. In Proceedings of the 2022 IEEE 46th Annual Computers, Software, and Applications Conference (COMPSAC), Los Alamitos, CA, USA, 27 June–1 July 2022; pp. 1062–1069. [Google Scholar]
- Amershi, S.; Begel, A.; Bird, C.; DeLine, R.; Gall, H.; Kamar, E.; Nagappan, N.; Nushi, B.; Zimmermann, T. Software engineering for machine learning: A case study. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), Montreal, QC, Canada, 25–31 May 2019; pp. 291–300. [Google Scholar]
- Yang, Q.; Suh, J.; Chen, N.C.; Ramos, G. Grounding interactive machine learning tool design in how non-experts actually build models. In Proceedings of the 2018 Designing Interactive Systems Conference, Hong Kong, China, 9–13 June 2018; pp. 573–584. [Google Scholar]
- Cai, C.J.; Guo, P.J. Software developers learning machine learning: Motivations, hurdles, and desires. In Proceedings of the 2019 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC), Memphis, TN, USA, 14–18 October 2019; pp. 25–34. [Google Scholar]
- Cai, C.J.; Winter, S.; Steiner, D.; Wilcox, L.; Terry, M. “Hello AI”: Uncovering the onboarding needs of medical practitioners for human-AI collaborative decision-making. Proc. ACM Hum.-Comput. Interact. 2019, 3, 1–24. [Google Scholar]
- Amershi, S.; Weld, D.; Vorvoreanu, M.; Fourney, A.; Nushi, B.; Collisson, P.; Suh, J.; Iqbal, S.; Bennett, P.N.; Inkpen, K.; et al. Guidelines for human-AI interaction. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, Scotland, UK, 4–9 May 2019; pp. 1–13. [Google Scholar]
- Amberkar, A.; Awasarmol, P.; Deshmukh, G.; Dave, P. Speech recognition using recurrent neural networks. In Proceedings of the 2018 International Conference on Current Trends towards Converging Technologies (ICCTCT), Coimbatore, India, 1–3 March 2018; pp. 1–4. [Google Scholar]
- Dlamini, Z.; Francies, F.Z.; Hull, R.; Marima, R. Artificial intelligence (AI) and big data in cancer and precision oncology. Comput. Struct. Biotechnol. J. 2020, 18, 2300–2311. [Google Scholar]
- Vaishya, R.; Javaid, M.; Khan, I.H.; Haleem, A. Artificial Intelligence (AI) applications for COVID-19 pandemic. Diabetes Metab. Syndr. Clin. Res. Rev. 2020, 14, 337–339. [Google Scholar]
- Ye, D.; Chen, G.; Zhang, W.; Chen, S.; Yuan, B.; Liu, B.; Chen, J.; Liu, Z.; Qiu, F.; Yu, H.; et al. Towards playing full moba games with deep reinforcement learning. Adv. Neural Inf. Process. Syst. 2020, 33, 621–632. [Google Scholar]
- Nikzad-Khasmakhi, N.; Balafar, M.; Feizi-Derakhshi, M.R. The state-of-the-art in expert recommendation systems. Eng. Appl. Artif. Intell. 2019, 82, 126–147. [Google Scholar]
- Xu, W. Toward human-centered AI: A perspective from human-computer interaction. Interactions 2019, 26, 42–46. [Google Scholar]
- Zanzotto, F.M. Human-in-the-loop artificial intelligence. J. Artif. Intell. Res. 2019, 64, 243–252. [Google Scholar]
- Shneiderman, B. Human-centered artificial intelligence: Reliable, safe & trustworthy. Int. J. Hum.-Comput. Interact. 2020, 36, 495–504. [Google Scholar]
- Shneiderman, B. Human-centered artificial intelligence: Three fresh ideas. AIS Trans. Hum.-Comput. Interact. 2020, 12, 109–124. [Google Scholar]
- Müller-Schloer, C.; Tomforde, S. Organic Computing-Technical Systems for Survival in the Real World; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Artificial Intelligence Safety and Security; Chapman and Hall/CRC: London, UK, 2018; pp. 99–112. [Google Scholar]
- Lee, C.J.; Teevan, J.; de la Chica, S. Characterizing multi-click search behavior and the risks and opportunities of changing results during use. In Proceedings of the 37th International ACM SIGIR Conference on Research & Development in Information Retrieval, Gold Coast, QLD, Australia, 1–6 July 2014; pp. 515–524. [Google Scholar]
- De Graaf, M.; Allouch, S.B.; Van Diik, J. Why do they refuse to use my robot?: Reasons for non-use derived from a long-term home study. In Proceedings of the 2017 12th ACM/IEEE International Conference on Human-Robot Interaction, Vienna, Austria, 6–9 March 2017; pp. 224–233. [Google Scholar]
- Jaech, A.; Ostendorf, M. Personalized language model for query auto-completion. arXiv 2018, arXiv:1804.09661. [Google Scholar]
- Norman, D.A. How might people interact with agents. Commun. ACM 1994, 37, 68–71. [Google Scholar]
- Horvitz, E. Principles of mixed-initiative user interfaces. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Pittsburgh, PA, USA, 15–20 May 1999; pp. 159–166. [Google Scholar]
- Höök, K. Steps to take before intelligent user interfaces become real. Interact. Comput. 2000, 12, 409–426. [Google Scholar]
- Choudhury, M.D.; Lee, M.K.; Zhu, H.; Shamma, D.A. Introduction to this special issue on unifying human computer interaction and artificial intelligence. Hum.-Comput. Interact. 2020, 35, 355–361. [Google Scholar]
- Luger, E.; Sellen, A. “Like Having a Really Bad PA” The Gulf between User Expectation and Experience of Conversational Agents. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 5286–5297. [Google Scholar]
- Purington, A.; Taft, J.G.; Sannon, S.; Bazarova, N.N.; Taylor, S.H. “Alexa is my new BFF” Social Roles, User Satisfaction, and Personification of the Amazon Echo. In Proceedings of the 2017 CHI Conference Extended Abstracts on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; pp. 2853–2859. [Google Scholar]
- Defy Medi Damn You Auto Correct! Available online: http://www.damnyouautocorrect.com/ (accessed on 12 January 2023).
- Clark, L.; Pantidi, N.; Cooney, O.; Doyle, P.; Garaialde, D.; Edwards, J.; Spillane, B.; Gilmartin, E.; Murad, C.; Munteanu, C.; et al. What makes a good conversation? Challenges in designing truly conversational agents. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, Scotland, UK, 4–9 May 2019; pp. 1–12. [Google Scholar]
- Yang, Q.; Steinfeld, A.; Rosé, C.; Zimmerman, J. Re-examining whether, why, and how human-AI interaction is uniquely difficult to design. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–13. [Google Scholar]
- Nielsen, J. Ten Usability Heuristics; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2005. [Google Scholar]
- Kumar, B.A.; Goundar, M.S. Usability heuristics for mobile learning applications. Educ. Inf. Technol. 2019, 24, 1819–1833. [Google Scholar]
- Boukhelifa, N.; Bezerianos, A.; Chang, R.; Collins, C.; Drucker, S.; Endert, A.; Hullman, J.; North, C.; Sedlmair, M. Challenges in Evaluating Interactive Visual Machine Learning Systems. IEEE Comput. Graph. Appl. 2020, 40, 88–96. [Google Scholar]
- Hohman, F.; Wongsuphasawat, K.; Kery, M.B.; Patel, K. Understanding and visualizing data iteration in machine learning. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–13. [Google Scholar]
- Hohman, F.; Kahng, M.; Pienta, R.; Chau, D.H. Visual analytics in deep learning: An interrogative survey for the next frontiers. IEEE Trans. Vis. Comput. Graph. 2018, 25, 2674–2693. [Google Scholar]
- Xu, R.; Wunsch, D. Survey of clustering algorithms. IEEE Trans. Neural Netw. 2005, 16, 645–678. [Google Scholar]
- Uysal, A.K.; Gunal, S. The impact of preprocessing on text classification. Inf. Process. Manag. 2014, 50, 104–112. [Google Scholar]
- Ayedh, A.; Tan, G.; Alwesabi, K.; Rajeh, H. The effect of preprocessing on arabic document categorization. Algorithms 2016, 9, 27. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.R.; Bethard, S.; McClosky, D. The Stanford CoreNLP Natural Language Processing Toolkit. In Proceedings of the ACL (System Demonstrations), Baltimore, MD, USA, 22–27 June 2014. [Google Scholar]
- Rehurek, R.; Sojka, P. Software framework for topic modelling with large corpora. In Proceedings of the LREC Citeseer, Valletta, Malta, 17–23 May 2010. [Google Scholar]
- Hansen, P.; Jaumard, B. Cluster analysis and mathematical programming. Math. Program. 1997, 79, 191–215. [Google Scholar]
- Singhal, A.; Google, Inc. Modern information retrieval: A brief overview. IEEE Data Eng. Bull. 2001, 24, 35–43. [Google Scholar]
- Robertson, S.; Zaragoza, H.; Taylor, M. Simple BM25 extension to multiple weighted fields. In Proceedings of the IIKM, Washington, DC, USA, 8–13 November 2004. [Google Scholar]
- Manning, C.D.; Raghavan, P.; Schü tze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Fleiss, J.L. Measuring nominal scale agreement among many raters. Psychol. Bull. 1971, 76, 378. [Google Scholar]
- Apache PDFBox—A Java PDF Library. Available online: https://pdfbox.apache.org/ (accessed on 12 January 2023).
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar]
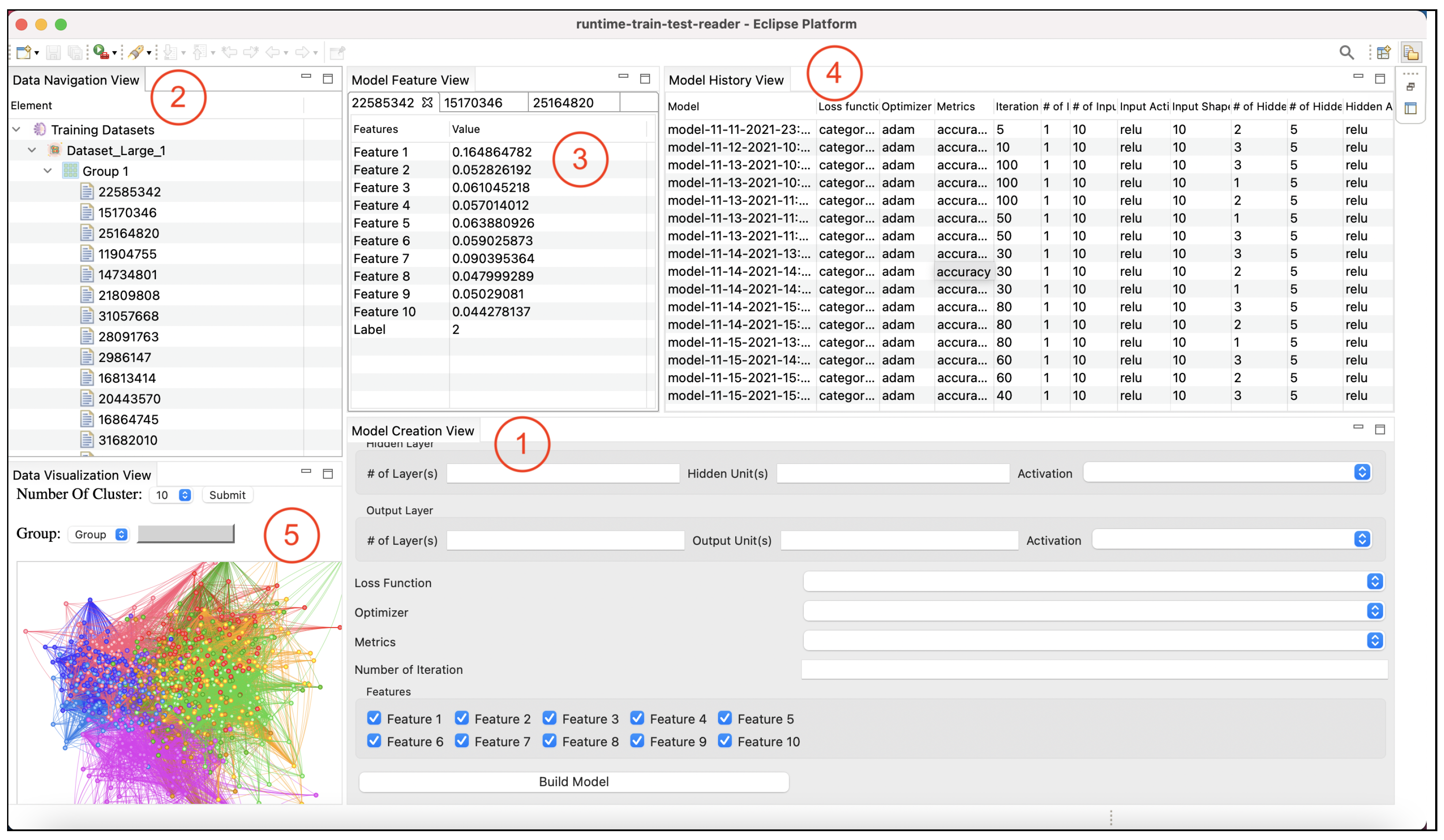
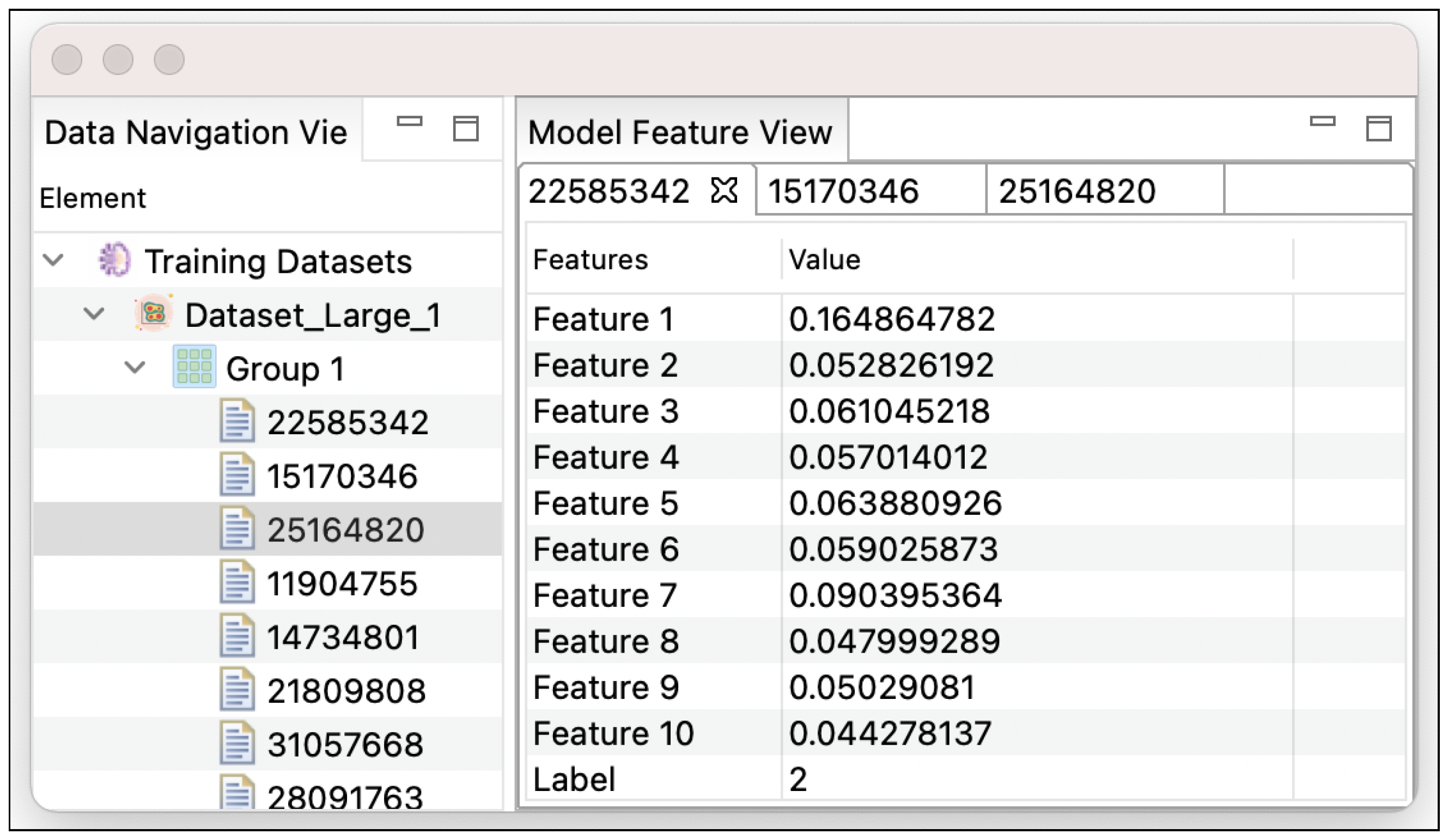

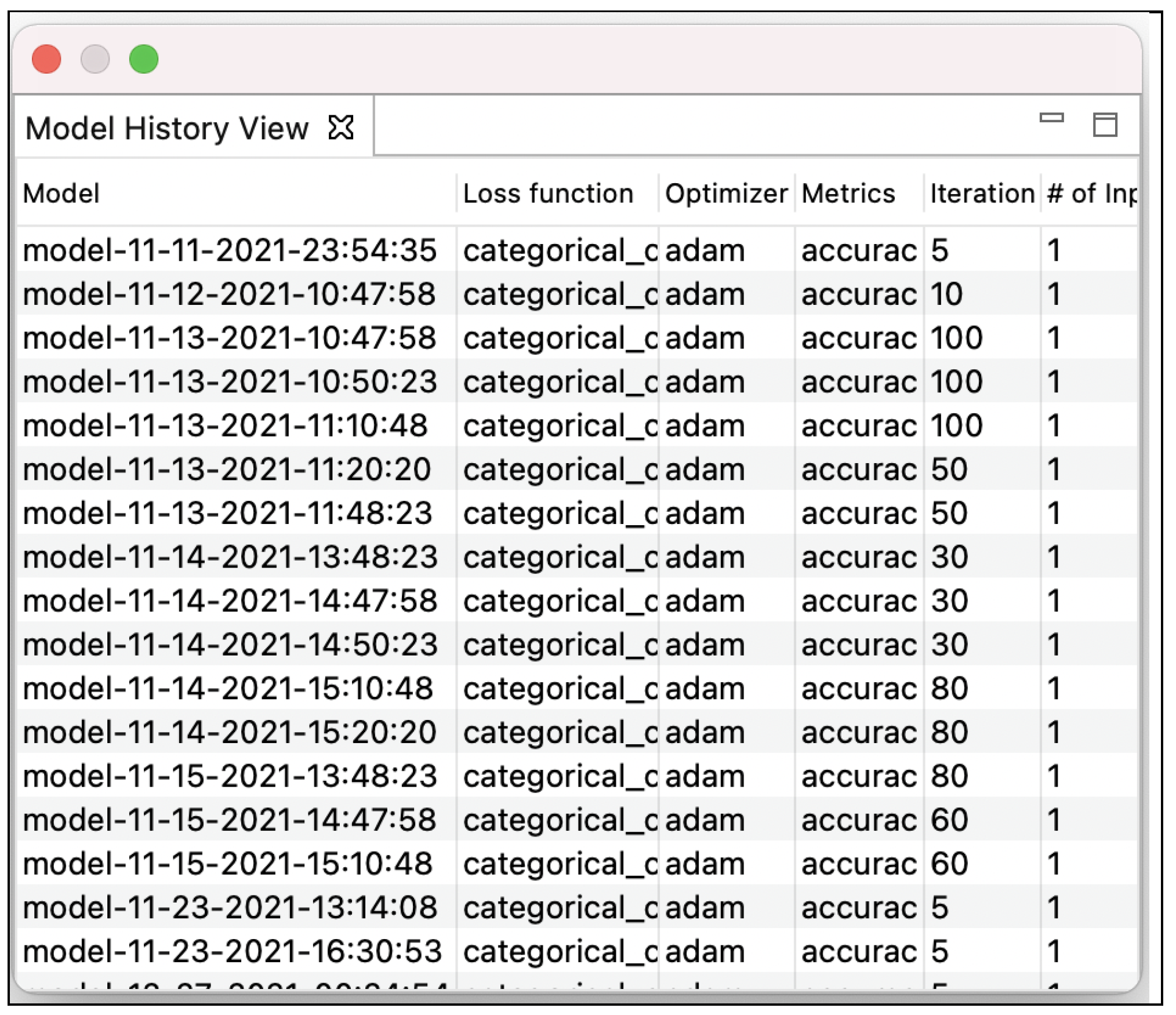
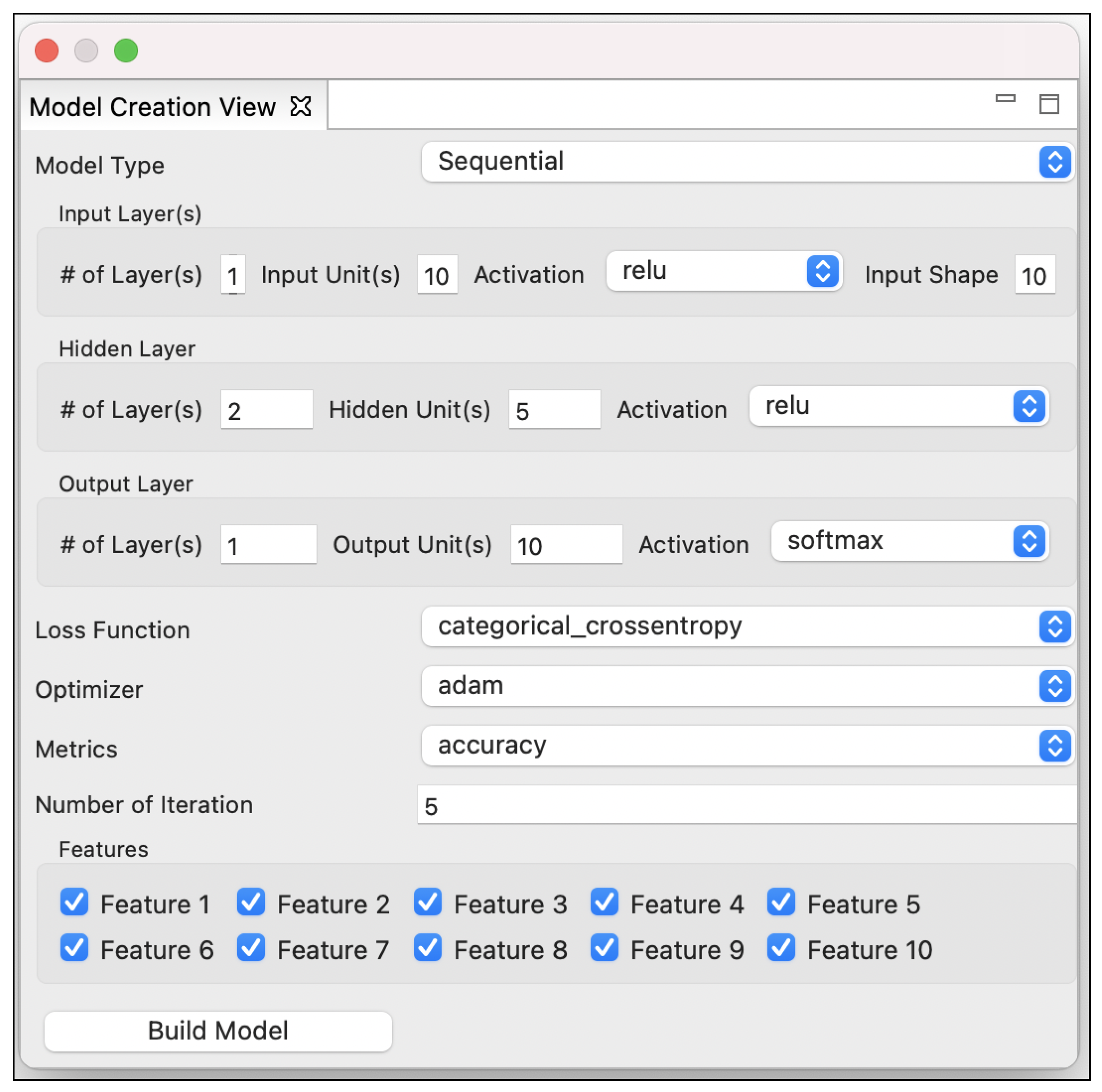


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Our Tool | Chameleon [43] | |
|---|---|---|
| User | ML model developers and builders, model users, non-experts (e.g., bioengineering researchers), educators | |
| ML Model Visualization | Explore and contrast the old and new version and highlight feature differences by controlling a diff threshold. | Visualize a primary and a secondary version and show version summaries. |
| Interactive Support | Allow users to observe how the input data and hyperparameters affect the prediction results. | |
| Eclipse IDE plug-in application incorporating code editing, program running, and model behavior validation. | Visual analysis tool support focusing on data iteration with hyperparameter updates. | |
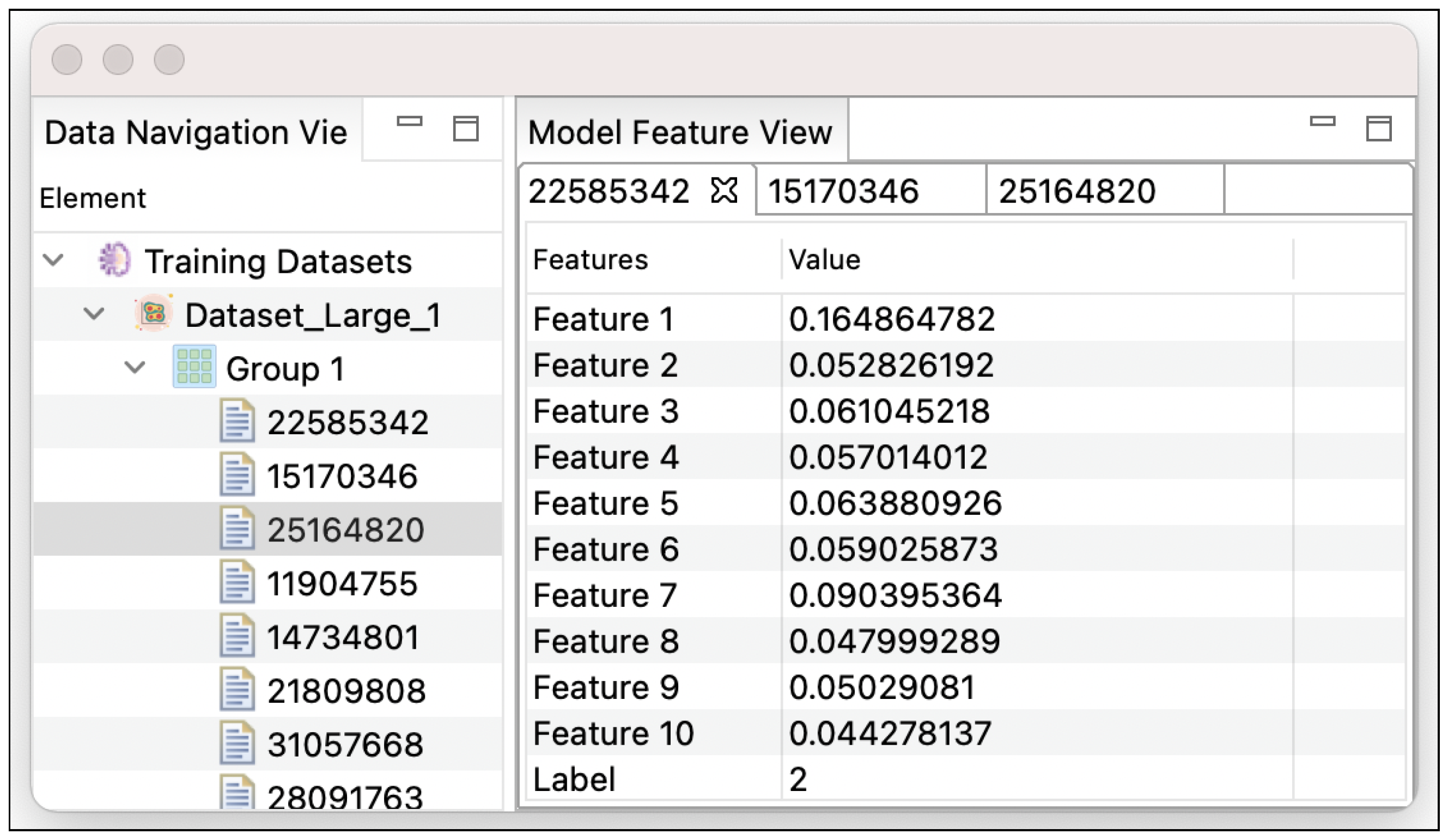
| Model/Feature View | Visualizing learned features to understand, explore, and validate models for the best performance model. | |
| Tabular style in a tab widget. | Histogram style in multiple boxes. | |
| Experimental Datasets | Datasets concerned with the process of model development and evolution. | |
| 23,500 main documents and 458,085 related documents in the bioengineering research domain. | Sensor data for activity recognition in 64,502 mobile phones. | |
| Topics | Top Term Probability |
|---|---|
| Topic 1 | (“metal”, 0.025), (“activation”, 0.022), (“form”, 0.016),.. |
| Topic 2 | (“microscopy”, 0.004), (“pathology”, 0.003), (“paper”, 0.003),.. |
| Topic 3 | (“deposition”, 0.013), (“synthesize”, 0.013), (“mechanism”, 0.013),.. |
| Topic 4 | (“conjugate”, 0.001), (“assemble”, 0.001), (“protection”, 0.001),.. |
| Topic 5 | (“affinity”, 0.005), (“supercapacitor”, 0.005), (“progenitor”, 0.005),.. |
| Topic 6 | (“transient”, 0.004), (“validation”, 0.004), (“detect”, 0.004),.. |
| Topic 7 | (“biofilm”, 0.024), (“expression”, 0.024), (“sae”, 0.024),.. |
| Topic 8 | (“duodenal”, 0.001), (“dictyostelium”, 0.001), (“evade”, 0.001),.. |
| Topic 9 | (“osteogenic”, 0.004), (“light”, 0.004), (“explore”, 0.004),.. |
| Topic 10 | (“material”, 0.013), (“thermal”, 0.013), (“direction”, 0.007),.. |
| Cosine Similarity between Topic Words and Document Attributes | Document Attribute—Titles and Abstracts in Target Paper | ||
| Document Attribute—Introduction in Target Paper | |||
| Document Attribute—Titles in Cited Paper | |||
| Document Attributes—Abstracts in Cited Paper | |||
| Document Attributes—Titles in Reference Paper | |||
| Document Attributes—Abstracts in Reference Paper | |||
| BM25 Similarity between Topic Words and Document Attributes | Document Attributes—Titles, Abstracts, and Introduction in | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, K.S.; Huang, P.-C.; Ahn, T.-H.; Song, M. Tool Support for Improving Software Quality in Machine Learning Programs. Information 2023, 14, 53. https://doi.org/10.3390/info14010053
Cheng KS, Huang P-C, Ahn T-H, Song M. Tool Support for Improving Software Quality in Machine Learning Programs. Information. 2023; 14(1):53. https://doi.org/10.3390/info14010053
Chicago/Turabian StyleCheng, Kwok Sun, Pei-Chi Huang, Tae-Hyuk Ahn, and Myoungkyu Song. 2023. "Tool Support for Improving Software Quality in Machine Learning Programs" Information 14, no. 1: 53. https://doi.org/10.3390/info14010053
APA StyleCheng, K. S., Huang, P.-C., Ahn, T.-H., & Song, M. (2023). Tool Support for Improving Software Quality in Machine Learning Programs. Information, 14(1), 53. https://doi.org/10.3390/info14010053