Abstract
With the popularity of the mobile internet, people all over the world can easily create and publish diverse media content such as multilingual and multi-dialectal audio and video. Therefore, language or dialect identification (LID) is increasingly important for practical applications such as multilingual and cross lingual processing as the front-end part of the subsequent tasks such as speech recognition and voice identification. This paper proposes a neural network framework based on a multiscale residual network (MSRN) and multi-headed self-attention (MHSA). Experimental results show that this method can effectively improve the accuracy and robustness compared to other methods. This model uses the MSRN to extract the language spectrogram feature and uses MHSA to filter useful features and suppress irrelevant features. Training and test sets are constructed from both the “Common Voice” and “Oriental Language Recognition” (AP17-OLR) datasets. The experimental results show that this model can effectively improve the accuracy and robustness of LID.
1. Introduction
Language identification (LID) applications play an increasingly important role in speech processing tasks as the front-end processing technology of speech recognition and understanding processes. LID models automatically identify the language and dialect of a speech segment [1] and embed acoustic, phonetic, and linguistic properties. Identifying the current language category with high accuracy can bring more convenience to subsequent speech processing. The speed of accurate identification is also important for tasks such as intelligent voice interaction, criminal investigation, smart homes, intelligent tourism, assisted robotics, and banking.
2. Related Work
The information on the internet is often multilingual and multi-dialectal speech or text. Furthermore, deep learning models are applied to process multilingual media with their efficient and intuitive design approaches. Language identification techniques can be traced back to the 1970s. However, there was a lack of adequate and robust datasets at that time, so development and diffusion were not very well established because of the limited resources and inefficient models. It was not until the development of neural machine learning techniques that multilingual processing and language identification research opened up new opportunities. Language identification technologies can be roughly divided into phoneme feature-based language identification, feature-based language identification, and deep learning-based language identification.
Phoneme-based identification uses the features of speech phonemes, a method of converting speech into factor sequences and then performing statistical analysis. However, the factor feature LID model has a complex structure and is unsuitable for systems with high requirements for real-time performance.
Language identification methods based on underlying acoustic features usually use the MFCC (Mel frequency cepstrum coefficients) [2], LPCC (Linear Prediction Cepstral Coefficients) [3], PLP (Perceptual Linear Predictive Coefficients) [4], and SDC (Shift Differential Cepstrum) [5] features as the underlying acoustic features for model construction. These features are extracted in the frequency domain by performing FFT (fast Fourier transform) on the original signal sequence. Furthermore, the main model approaches for LDI based on underlying acoustic features include the Gaussian mixture model, the general background model [6,7], the SVM model [8], and i-vector, x-vector, etc.
Deep neural network-based LID methods originated in 2009 when Montavon [9] et al. used neural networks to extract features. In 2014, Lei [10] et al. proposed CNN networks. DNN [11] was also applied to short-time speech, and the application of long short term memory networks [12] (LSTM) on language identification led to breakthroughs in identification performance. In 2016, Geng et al. [13] introduced the attention mechanism model to a language identification system. In 2017, Bartz et al. [14] used a convolutional network combined with a recurrent neural network approach (CRNN) for language identification. In 2018, Suwon Shon et al. [15] extracted three acoustic features, MFCC, Frank, and spectrogram, using a twin neural network. In 2019, Kexin Xie and Shengyou Qian [16] proposed a method based on the combination of the Gate Recurrent Unit (GRU) and Hidden Markov Model (HMM). They studied the extraction of speech feature parameters to recognize the Hunan dialects category. In 2020, Aitor Arronte Alvarez et al. [17] proposed an end-to-end network Res-BLSTM combining residual block and bidirectional long short term memory (BLSTM) for Arabic dialect identification.
Our contributions:
- (1)
- Introducing the idea of residuals into the baseline model [18]. This makes a smooth context connection.
- (2)
- Introducing Coordinate Attention [19] into the baseline model to highlight the valuable features and suppressed irrelevant features. Because this method embeds the location information into the channel, it reduces the computational overload.
- (3)
- Designing a multi-scale residual network. The relevant feature information in the model image is encoded and decoded from a global perspective.
- (4)
- The multi-headed self-attention [20], which helps the network capture relevant rich features.
- (5)
- Conducting experiments on two datasets. The experimental results show that the proposed model has good robustness.
3. Proposed Method
3.1. Overall Architecture
In this paper, to improve the baseline model performance, CNN-BiGRU-Attention, a multi-scale residual network model is incorporated. The overall structure of the model in this paper is shown in Figure 1. Firstly, the speech spectrogram, used as input for the multi-scale residual module (MSRN) to extract features, not only detects the image features adaptively but also performs feature fusion at different scales. Secondly, the Coordinate Attention module can further emphasize critical information and suppress irrelevant information. The Bi-directional Gated Recurrent Unit (BiGRU) connects the upper and lowers temporal contents. The multi-headed self-attentiveness helps the network to capture richer features.
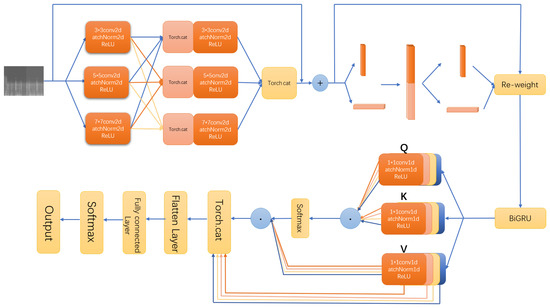
Figure 1.
Diagram of the overall structure of the network. (The MSRN module is on the top left, the coordination attention module is on the top right, and the MHSA module is on the bottom right).
3.2. Multi-Scale Residual Network
We also propose an MSRN module, with the structure shown in Figure 2. The input speech spectrum size is a 224 × 224 map, which is convoluted into two layers. The first layer is convoluted with 3 × 3, 5 × 5, and 7 × 7 convolution kernels, respectively, where the step size is 1 for these three kernels, and the padding is 1, 2, and 3, respectively. There are three input channels of the three different scales and twelve output channels. The sum of these three different scales of convolutions in the first layer is the input of the second layer, with a channel of 36, batch size of 32, and size of 224 × 224. The second layer continues to use 3 × 3, 5 × 5, and 7 × 7 convolution kernels, where the step size is 1 and the padding is 1. Finally, the second layer of convolution results is summed to produce a 224 × 224 speech map with a batch size of 32 and a channel size of 36. We added the initial speech spectrogram with the results of two-layer multi-scale convolutions. The convolution at different scales can help us extract more information in the speech spectrogram, and the jump connection can better link the information between frames before and after.
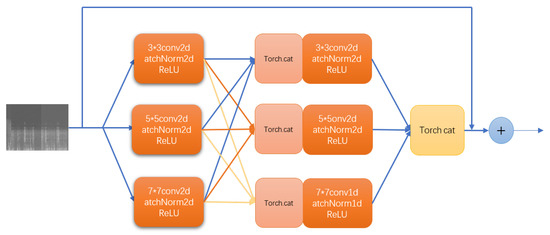
Figure 2.
Multi-scale residuals module.
3.3. Coordination Attention
The core logic of the attention mechanism is to focus attention on the context information, from focusing on the local to focusing on the critical information, thus saving resources and obtaining the most relevant information. In 2018, Jie Hu et al. [21] proposed that the channel attention mechanism, SENet, reduces the error rate of the model to a great extent and reduces the parameters and computation while reducing the model complexity with lower model complexity. However, only the channel attention is considered, and the spatial location is not considered in this model. Therefore, Sanghyun Woo et al. [22] combined channel location and spatial location to propose a more specific and more effective CBAM module with fewer parameters, but the inability of long-term dependence is still a problem. 2021 Qibin Hou et al. [19] proposed the Coordinate Attention module, which not only considered channel and space in parallel but also solved the long-term dependence problem very well. The structure of Coordinate Attention is shown in Figure 3.
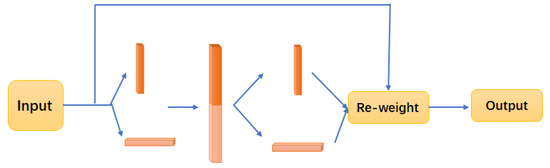
Figure 3.
Coordinated attention module.
The input feature maps are first pooled twice in 1D in both W and H directions to obtain two embedded feature maps and , where C is the channel, h is the height, and w is the width, with i denoting each width and j denoting each height, as shown in Equations (1) and (2).
Next, and are stitched in the spatial dimension, and a 1 × 1 convolution is performed for dimensionality reduction, and thus activation, as shown in Equation (3). After activation, the feature map is split along the spatial dimension to obtain two separate feature maps, as shown in Equation (4). Then, the two feature maps are transformed and sigmoid to obtain the attention vectors and , as shown in Equation (5). Finally, the original feature map is corrected using the feature vectors to obtain the corrected feature map , as shown in Equation (6):
3.4. Multi-Head Self-Attention Module
We chose to add multi-headed attention after BiGRU [20], with the structure shown in Figure 4. The number of heads is chosen to be 4. Multi-head attention is used to further emphasize helpful information and ignore irrelevant information. It captures long-term dependencies in speech, preventing the model from over-focusing on its position when encoding information at the current location. The multi-headed self-attention mechanism allows us to obtain global sequence information from multiple subspaces and mine the intrinsic features of the speech. Multi-headed self-attention is the multiple stacking of attention mechanisms. This approach extends the ability of the model to focus on different locations and gives attention the variety of sub-expression modes. Each group is randomly initialized. After training, the input vectors can be mapped to different sub-expression spaces.
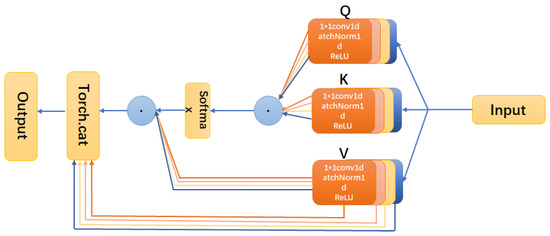
Figure 4.
Coordinated attention module.
Multi-head self-attention requires learning multiple Q, K, and V matrices individually. The self-attention was calculated for each attention head separately, and the corresponding output was obtained. We chose four heads, corresponding to , spliced all into one whole and multiplied the output matrix , as shown in Equations (7) and (8):
where , , , . denotes the sequence encoding length.
4. Experiments
4.1. Datasets
In this paper, we conducted experiments on two datasets, including dataset 1 from Common Voice, which is a large and publicly available speech dataset. Five national languages, German (de), English (en), Spanish (es), French (fr), and Russian (ru), were selected from Common Voice, and the gender, age, and accent of different speakers in the dataset vary. The number sof training, validation, and test sets for each language type are 1260, 360, and 180, respectively. Table 1 describes the details of this dataset.

Table 1.
Common Voice data set structure.
Dataset 2 came from the dataset provided by the AP17-OLR competition [22,23,24] for Eastern languages. A total of 10 oriental languages were included, mainly including Cantonese (ct-cn), Mandarin Chinese (zh-cn), Vietnamese (vi-vn), Indonesian (id-id), Japanese (ja-jp), Korean (ko-kr), Russian (ru-ru), Kazakh (Kazakh), Uyghur (Uyghur), and Tibetan (Tibetan). A total of 1800 speech data points were extracted for each language and divided according to the ratio of 7:2:1 (training set: validation set: test set), That is, the number of the training set, validation set, and test set for each language type are 1260, 360, and 180, respectively. The structure of dataset 2 is listed in Table 2.
Table 2.
Oriental language data set structure.
4.2. Loss Function
The loss function uses the cross-entropy loss function, which is very common in neural networks. It is shown in Equation (9).
x represents the specific value of the output on each distribution of the model, and class indicates the actual label. It can be roughly divided into two steps: first, calculate the probability of the value corresponding to the actual label, and second, calculate −log to get the output.
4.3. Evaluation Indicators
The evaluation metrics areaccuracy (Acc), precision (Precision), recall (Recall), and F1 value. When a voice is predicted, four statistical results are obtained. They are the target language correctly predicted (TP), the target language mispredicted (FN), the non-target language predicted as the target language (FP), and the non-target language predicted as the non-target language (TN), as shown in Table 3.
Table 3.
Identification result statistics.
According to Table 3, the formulas for accuracy, precision, recall, and F1 value can be derived, as shown in Equations (10)–(13).
4.4. Implementation Details
The experiments in this paper were conducted in a Linux environment, using python 3.6.8 as the programming language, PyTorch 1.10 as the framework for deep learning, CUDA version 11.4, and NVIDIA RTX5000 as the GPU graphics card. The model’s input is a 224 × 224 grayscale voice spectral map, the initial learning rate is 0.001, the training set batch size is 32, the validation set batch size is 4, the test set batch size is 4, and the optimizer uses Adam [25]. The size is 32, the validation set batch size is 4, the test set batch size is 4, a total of 30 epochs are set, and the optimizer uses Adam [25].
4.5. Ablation Experiments
To verify the effectiveness of each proposed module, we conducted ablation experiments on dataset 1 (Common Voice), and dataset 2 (Oriental Language dataset). The experimental subjects are Residuals (ResNet), Coordination Attention, Multi-Scale Residuals module (MSRN), and Multi-Head Self Attention module (MSRN). The experimental results on the two datasets are shown in Table 4 and Table 5.
Table 4.
Experimental results of the Common Voice dataset.
Table 5.
Experimental results of the Oriental language identification dataset.
5. Analysis
We analyzed the confusion matrix of the final model MSRN-CA-BiGRU-MHSA on both datasets, as shown in Table 6 and Table 7.
Table 6.
Confusion matrix for common voice dataset.
Table 7.
Confusion matrix of the OLR dataset for the Oriental language identification.
We can conclude from Table 6 that French can be recognized correctly, because French has strong spelling rules and can be better learned by neural networks. Two Russian words were mistaken for French, and one was mistaken for German because, although Russian borrowed many words from Old English after learning a lot from Europe, which may have caused some mistakes. There are some mistakes in English, German, and Spanish languages, mostly because they have certain shared vocabulary.
From Table 7, we can conclude that Tibetan (Tibet), Indonesian (id-id), Korean (ko-kr), and Vietnamese (vi-vn) can all be accurately recognized. Mandarin (zh cn) is mistaken for Indonesian because their pronunciation rules are very similar. We can also see some mistakes on the smaller languages such as Uyghur and Kazak.
We compared the experimental results of each module on two datasets, and the results are shown in Figure 5. The test results show that the accuracy rate ACC of each module on both datasets is higher than 96.5%, and the overall effect on the Oriental language datasets is better than that on the Common Voice datasets, up to 99.16%. Compared with the baseline model, the accuracy of the common voice dataset and the OLR dataset increased by 0.99% and 4.22%, respectively, after adding the CA attention mechanism. After the CNN was replaced with our ResNet module, the accuracy increased by 1.33% and 3.56%, respectively. The accuracy increased by 3.66% and 5.03%, respectively, after the two were combined. After Attention was replaced with MHSA, the accuracy rate increased by 0.56% and 0.3%, respectively, and after ResNet was replaced with the MSRN designed by us, the accuracy rate increased by 0.89% and 1.25%, respectively. Combined with the former, the accuracy rate increased by 1.78% and 1.69%, respectively, and the accuracy, recall, and F1 were also better than those of the baseline model.
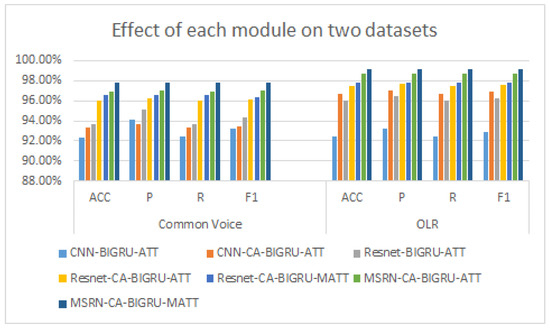
Figure 5.
Effect of each module on the two datasets.
As shown in Figure 5, a comparison of the experimental effects of each module on the two datasets was carried out. The accuracy (ACC) of each module on both datasets is higher than 96.5%, and the overall effect on the Oriental language dataset is more substantial than that on the Common Voice dataset, which can be as high as 99.16%.
Future Prospect:
- Because the datasets in this paper are all pure speech without noise and the sources of speech data in real life are complex, subsequent attempts can be made on noisy speech datasets.
- This paper only experiments on languages with richer resources, and subsequent attempts can be made on scarce resources.
- The algorithm model proposed in this paper does not use the pre-training model, and subsequent attempts can be made to adopt the pre-training method for language recognition.
6. Conclusions
In this paper, a combined MSRN-CA-BiGRU-MHSA model was constructed to identify the language types of various speech signals. Two datasets, the Oriental language dataset and Common Voice, were applied for evaluation. Four commonly used metrics, mainly accuracy, were used as the metric evaluation. The experimental results show improvements in both datasets, with accuracy levels of 96.5% and 99.16%. Furthermore, from the confusion matrix, we can see that the robustness of the language recognition algorithm is effectively improved. Compared to the baseline model, the accuracy of our final model is 5.44% higher on the common voice dataset and 6.72% higher on the OLR dataset. The other indicators also performed well on both datasets.
The datasets in this paper are pure speech without noise, but the speech data in real life are noisy and complicated and contain overlapping signals. Actual scenarios of multi-speakers and switching of languages and dialects in continuous speech signals are necessary research areas for the future. The pre-training methods can also be useful for model optimization and for languages with low resources.
Author Contributions
Conceptualization, A.Z. and M.A.; methodology, A.Z.; software, A.Z.; validation, A.Z.; formal analysis, M.A.; investigation, A.Z. and M.A.; resources, A.Z., M.A., and A.H.; data curation, A.Z.; writing—original draft preparation, A.Z.; writing—review and editing, M.A. and A.H.; visualization, A.Z., M.A., and A.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Strengthening Plan of the National Defense Science and Technology Foundation of China (2021-JCJQ-JJ-0059) and the Natural Science Foundation of China (U2003207).
Data Availability Statement
In this paper, dataset 1 is from the Common Voice (https://commonvoice.mozilla.org/zh-CN accessed on 19 November 2022). Common Voice is a large and publicly available speech dataset. Dataset 2 is from the Oriental language dataset provided by the AP17-OLR Oriental Language Recognition Contest.
Acknowledgments
The authors are very thankful to the editor and the reviewers for their valuable comments and suggestions for improving the paper.
Conflicts of Interest
The authors declare no conflictss of interest.
References
- Cao, H.B.; Zhao, J.M.; Qin, J. A Comparative Study of Multiple Methods for Oriental Language Identification. Available online: https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CPFD&dbname=CPFDLAST2018&filename=SEER201710001023&uniplatform=NZKPT&v=5Z10lhs1awqErVfB9k7dSEo5jDOKYebegcP8YjqKucFnRKP0s8c_7BHI6YaNf8tgq5EyMTbaW_w%3d (accessed on 19 November 2022).
- Dave, N. Feature extraction methods LPC, PLP and MFCC in speech recognition. Int. J. Adv. Res. Eng. Technol. 2013, 1, 1–4. [Google Scholar]
- Srivastava, S.; Nandi, P.; Sahoo, G.; Chandra, M. Formant based linear prediction coefficients for speaker identification. In Proceedings of the 2014 International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 20–21 February 2014; pp. 685–688. [Google Scholar]
- Revathi, A.; Jeyalakshmi, C. Robust speech recognition in noisy environment using perceptual features and adaptive filters. In Proceedings of the 2017 2nd International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 19–20 October 2017; pp. 692–696. [Google Scholar]
- Sangeetha, J.; Jothilakshmi, S. Automatic continuous speech recogniser for Dravidian languages using the auto associative neural network. Int. J. Comput. Vis. Robot. 2016, 6, 113–126. [Google Scholar] [CrossRef]
- Kohler, M.A.; Kennedy, M. Language identification using shifted delta cepstra. In Proceedings of the 2002 45th Midwest Symposium on Circuits and Systems, 2002. MWSCAS-2002, Tulsa, OK, USA, 4–7 August 2002; Volume 3, p. III–69. [Google Scholar]
- Torres-Carrasquillo, P.A.; Singer, E.; Kohler, M.A.; Greene, R.J.; Reynolds, D.A.; Deller, J.R., Jr. Approaches to language identification using Gaussian mixture models and shifted delta cepstral features. In Proceedings of the Interspeech, Denver, CO, USA, 16–20 September 2002. [Google Scholar]
- Campbell, W.M.; Singer, E.; Torres-Carrasquillo, P.A.; Reynolds, D.A. Language recognition with support vector machines. In Proceedings of the ODYSSEY04-The Speaker and Language Recognition Workshop, Toledo, Spain, 31 May–3 June 2004. [Google Scholar]
- Montavon, G. Deep Learning for Spoken Language Identification. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=1b17f0926b373ef49245a28fdddd3c9e90006e60 (accessed on 19 December 2022).
- Lei, Y.; Ferrer, L.; Lawson, A.; McLaren, M.; Scheffer, N. Application of Convolutional Neural Networks to Language Identification in Noisy Conditions. In Proceedings of the Odyssey, Joensuu, Finland, 16–19 June 2014. [Google Scholar]
- Lopez-Moreno, I.; Gonzalez-Dominguez, J.; Plchot, O.; Martinez, D.; Gonzalez-Rodriguez, J.; Moreno, P. Automatic language identification using deep neural networks. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 5337–5341. [Google Scholar]
- Gelly, G.; Gauvain, J.L. Spoken Language Identification Using LSTM-Based Angular Proximity. In Proceedings of the Interspeech, Stocholm, Sweden, 20–24 August 2017; pp. 2566–2570. [Google Scholar]
- Geng, W.; Wang, W.; Zhao, Y.; Cai, X.; Xu, B. End-to-End Language Identification Using Attention-Based Recurrent Neural Networks. In Proceedings of the Interspeech, San Francisco, CA, USA, 8–12 September 2016; pp. 2944–2948. [Google Scholar]
- Bartz, C.; Herold, T.; Yang, H.; Meinel, C. Language identification using deep convolutional recurrent neural networks. In Proceedings of the International Conference on Neural Information Processing, Long Beach, CA, USA, 4–9 December 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 880–889. [Google Scholar]
- Shon, S.; Ali, A.; Glass, J. Convolutional neural networks and language embeddings for end-to-end dialect recognition. arXiv 2018, arXiv:1803.04567. [Google Scholar]
- Kexin, X.; Hu, D.; Xiao, Z.; Chen, T.; Shengyou, Q. Hunan dialect recognition based on GRU-HMM acoustic model. Comput. Digit. Eng. 2019, 47, 493–496. [Google Scholar]
- Alvarez, A.A.; Issa, E.S.A. Learning intonation pattern embeddings for arabic dialect identification. arXiv 2020, arXiv:2008.00667. [Google Scholar]
- XL, M.; Ablimit, M.; Hamdulla, A. Multiclass Language Identification Using CNN-Bigru-Attention Model on Spectrogram of Audio Signals. In Proceedings of the 2021 IEEE 2nd International Conference on Pattern Recognition and Machine Learning (PRML), Chengdu, China, 16–18 July 2021; pp. 214–218. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, D.; Li, L.; Tang, D.; Chen, Q. AP16-OL7: A multilingual database for oriental languages and a language recognition baseline. In Proceedings of the 2016 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Jeju, Republic of Korea, 13–16 December 2016; pp. 1–5. [Google Scholar]
- Tang, Z.; Wang, D.; Chen, Y.; Chen, Q. AP17-OLR challenge: Data, plan, and baseline. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 749–753. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).