
A Flexible Data Evaluation System for Improving the Quality and Efficiency of Laboratory Analysis and Testing


Abstract
:1. Introduction
- This paper combs and analyses the data evaluation work in the analysis and detection business of traditional chemical analysis laboratories and points out the common problems and risks in the traditional data evaluation business.
- Taking the inorganic analytical device for the interval flow analyser as an example, a data evaluation system is developed, which realizes automatic data screening, quality evaluation, data management and distribution, integrates with the existing LIMS, provides the maximum automation effect, and improves the quality and efficiency of the analysis and testing business.
- The idea of modular design makes it easy for a data evaluation system to be partially or wholly extended to different analysis systems produced by different analysis device manufacturers. This provides a reference method for data evaluation work in a chemical analysis laboratory, as well as a reference for improving the quality and efficiency of analysis and testing.
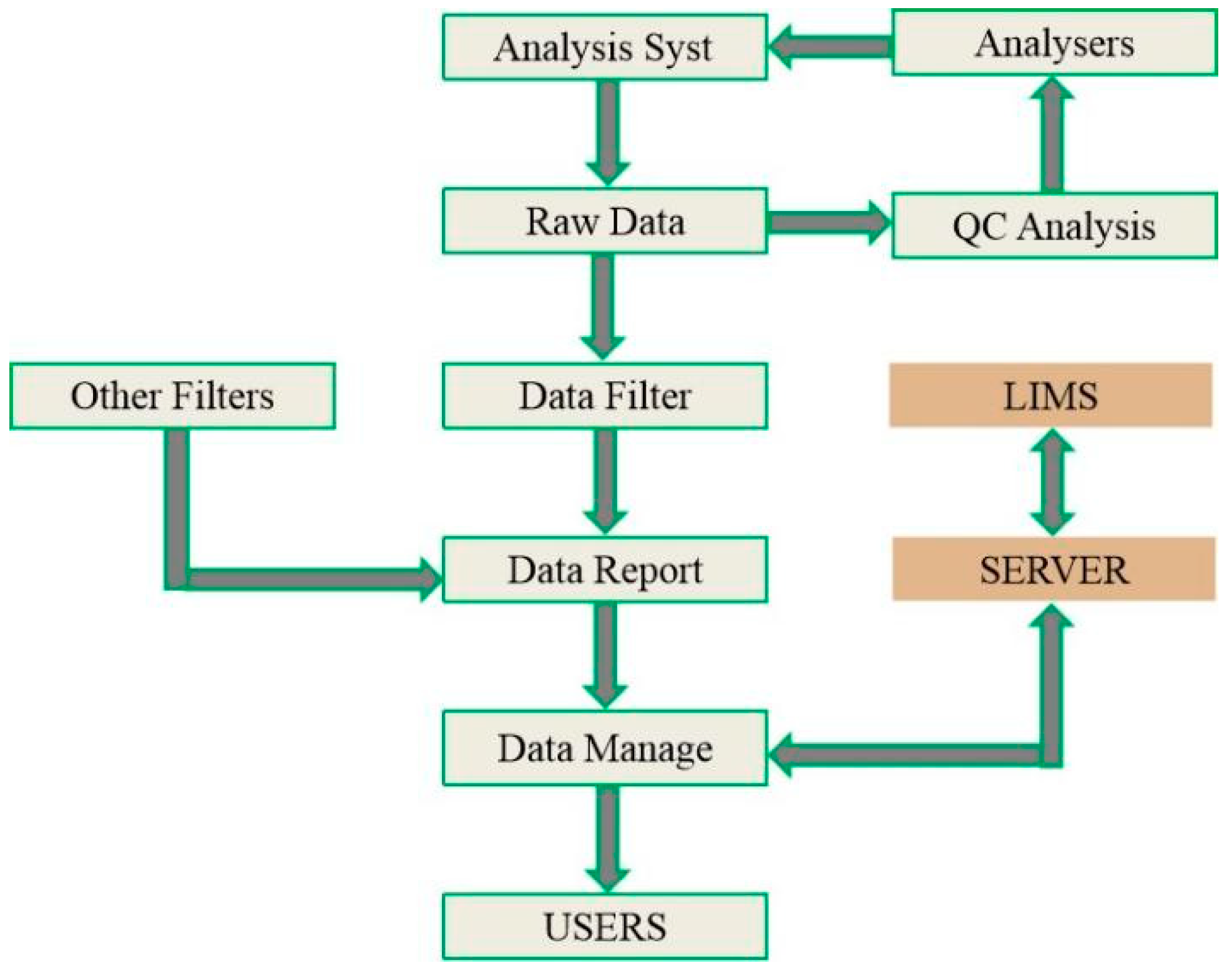
2. Overall Structure of the System
3. Modular Software Development
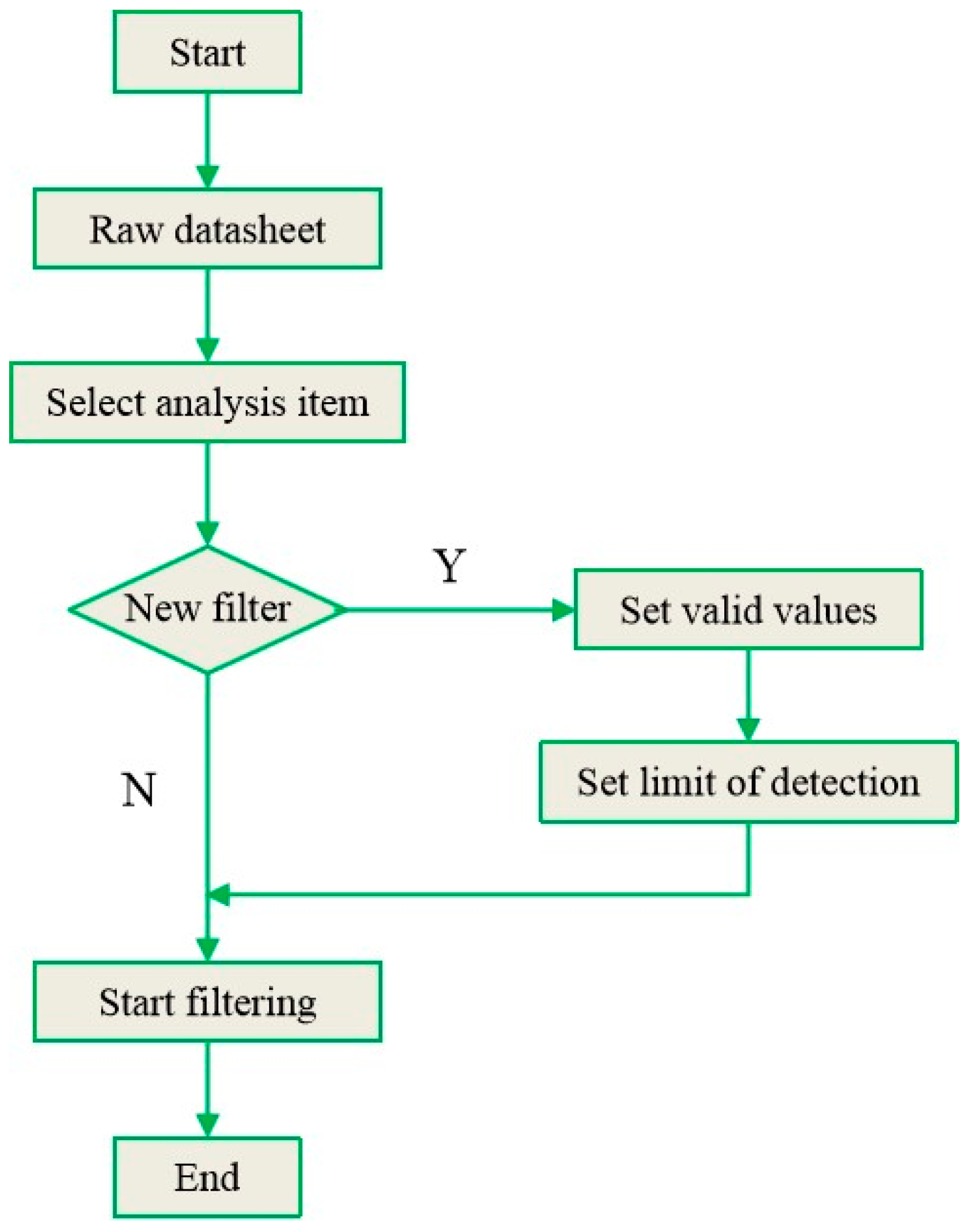
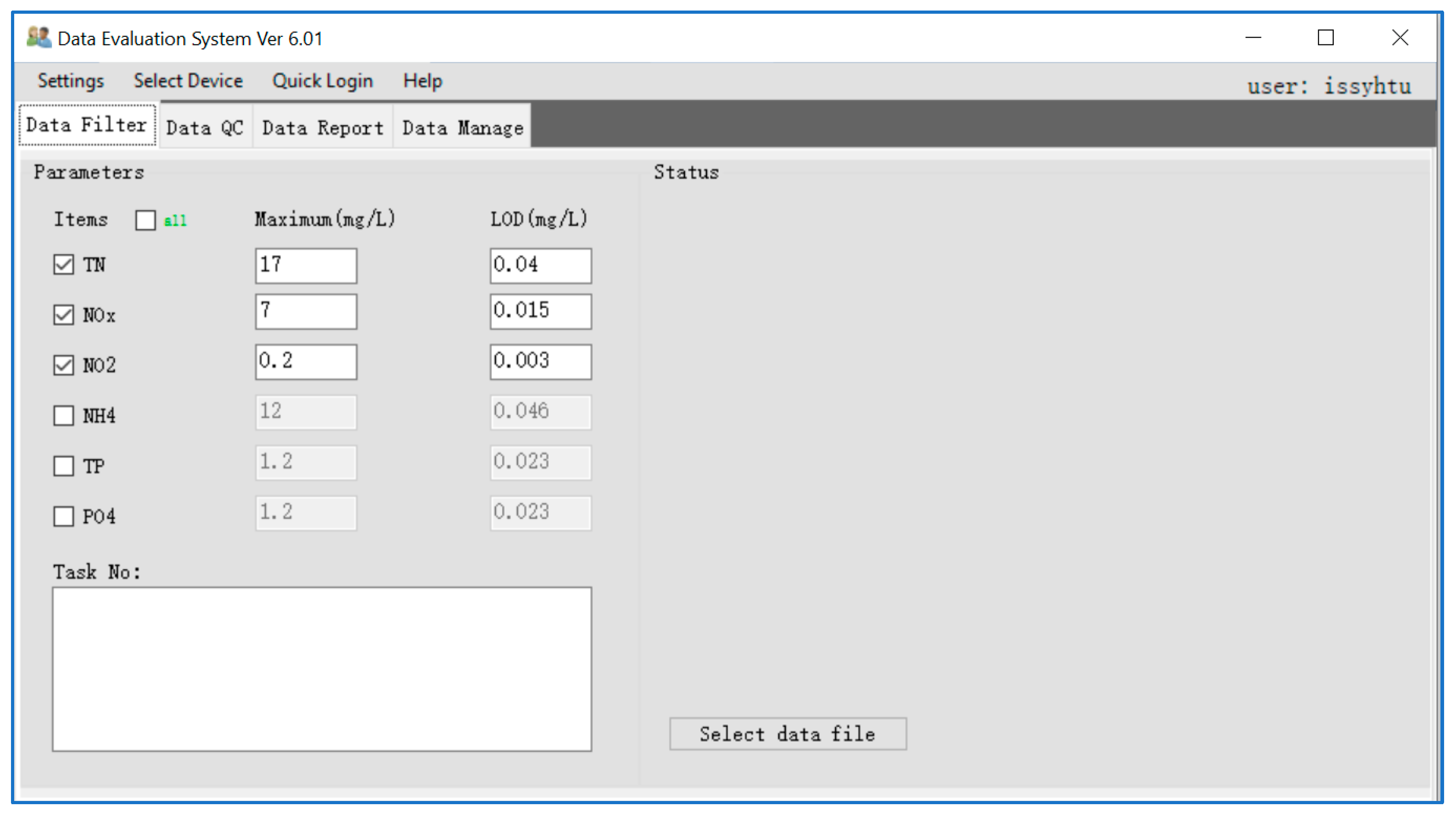
3.1. Data Filter
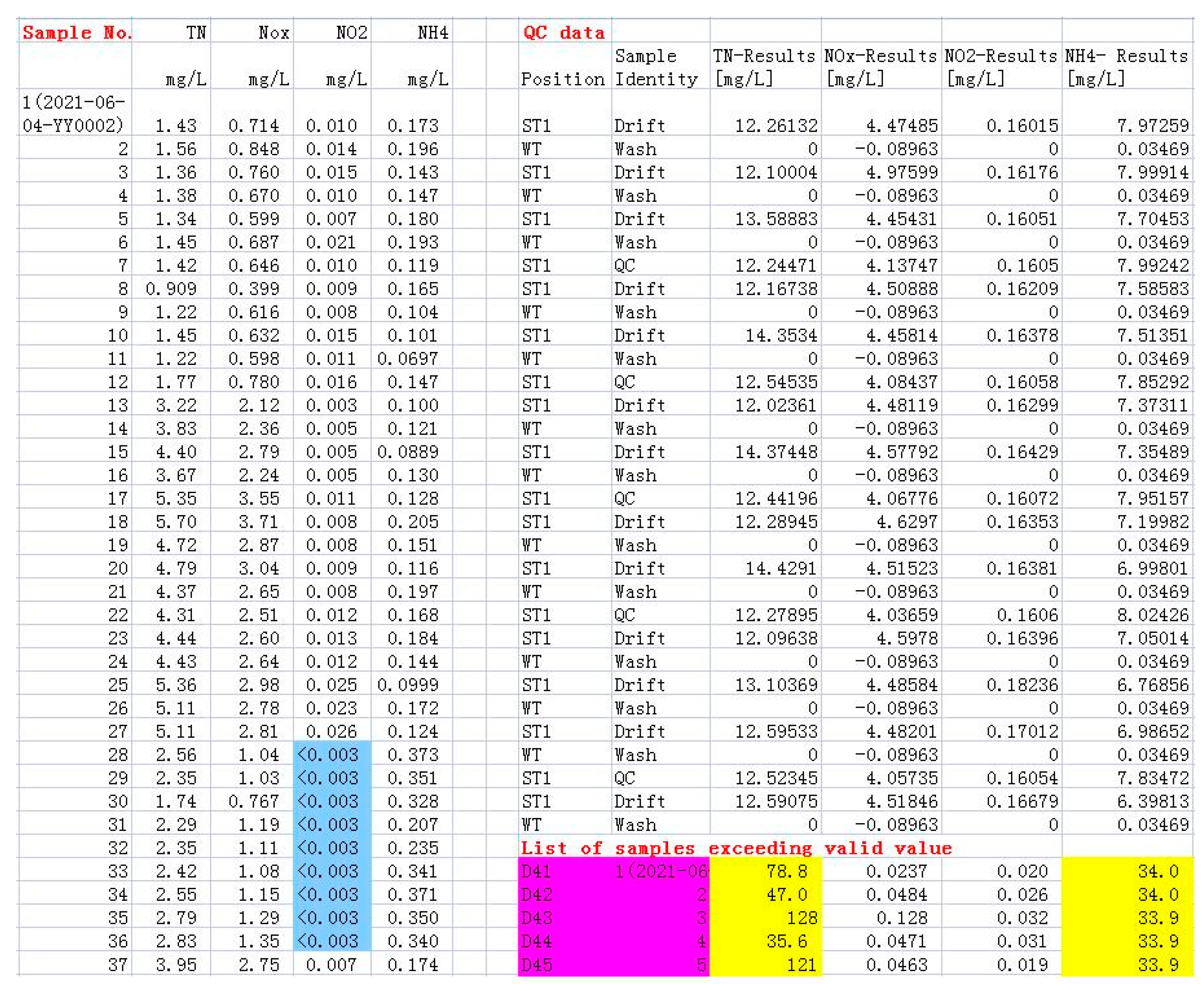
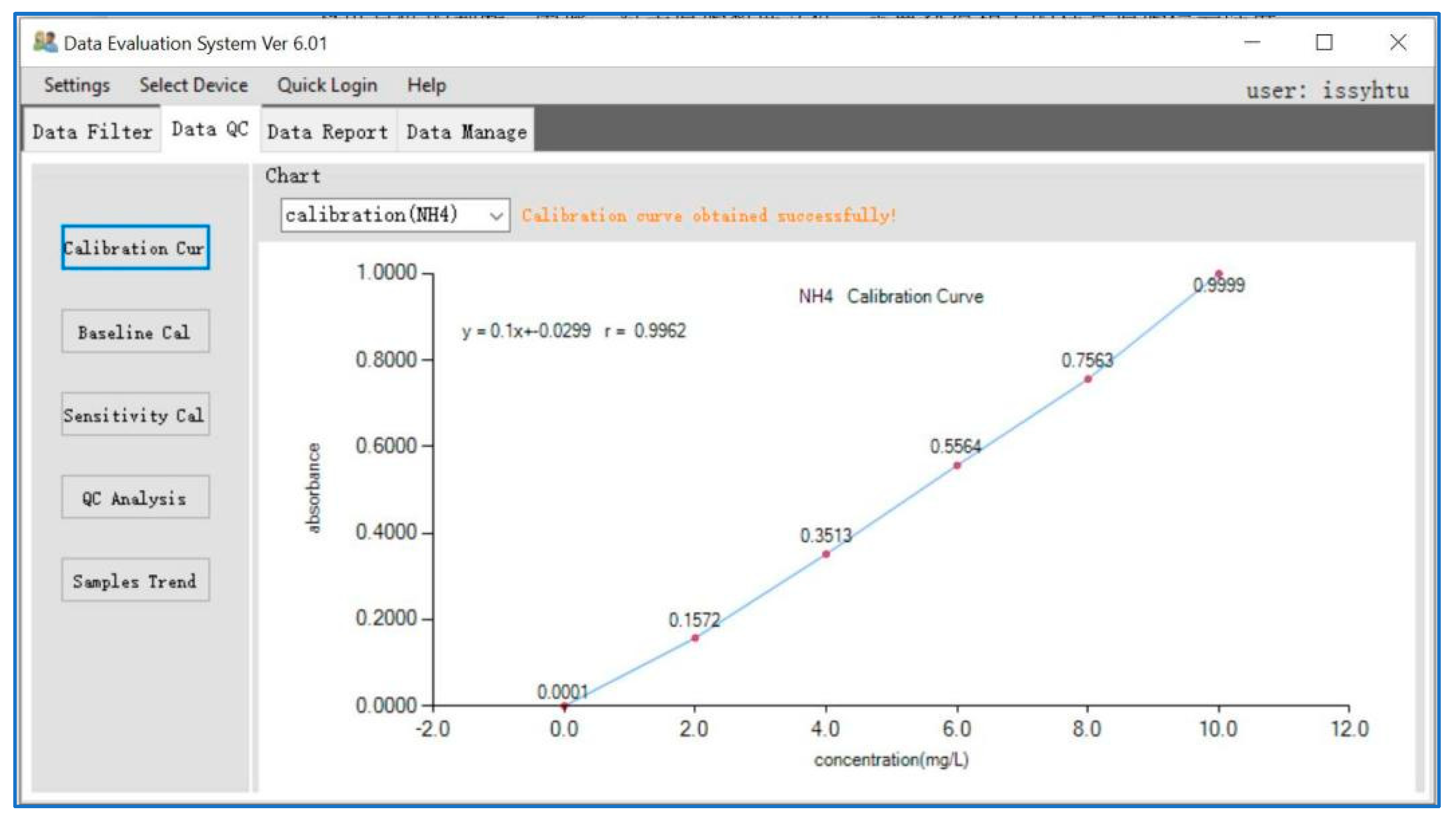
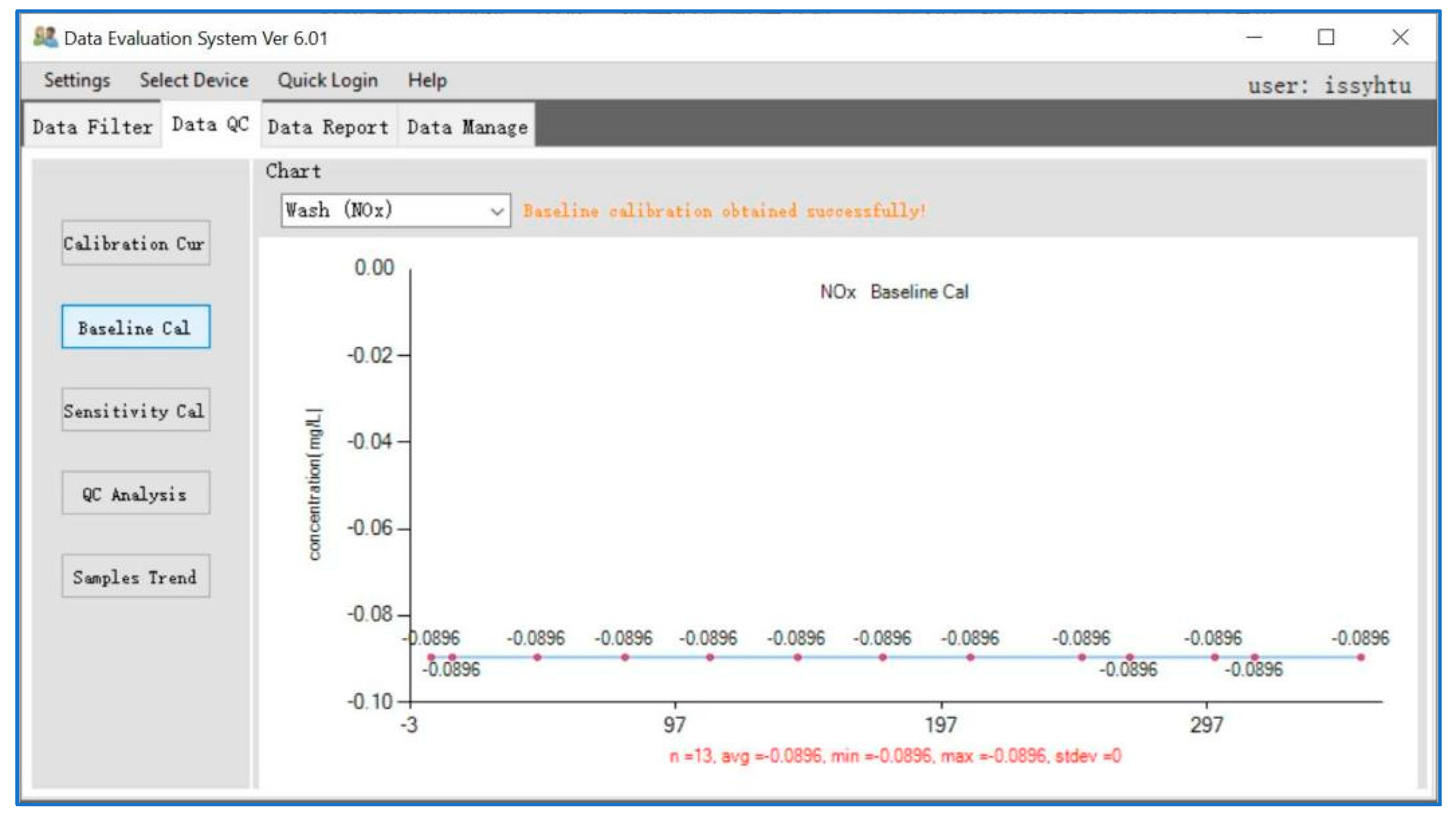
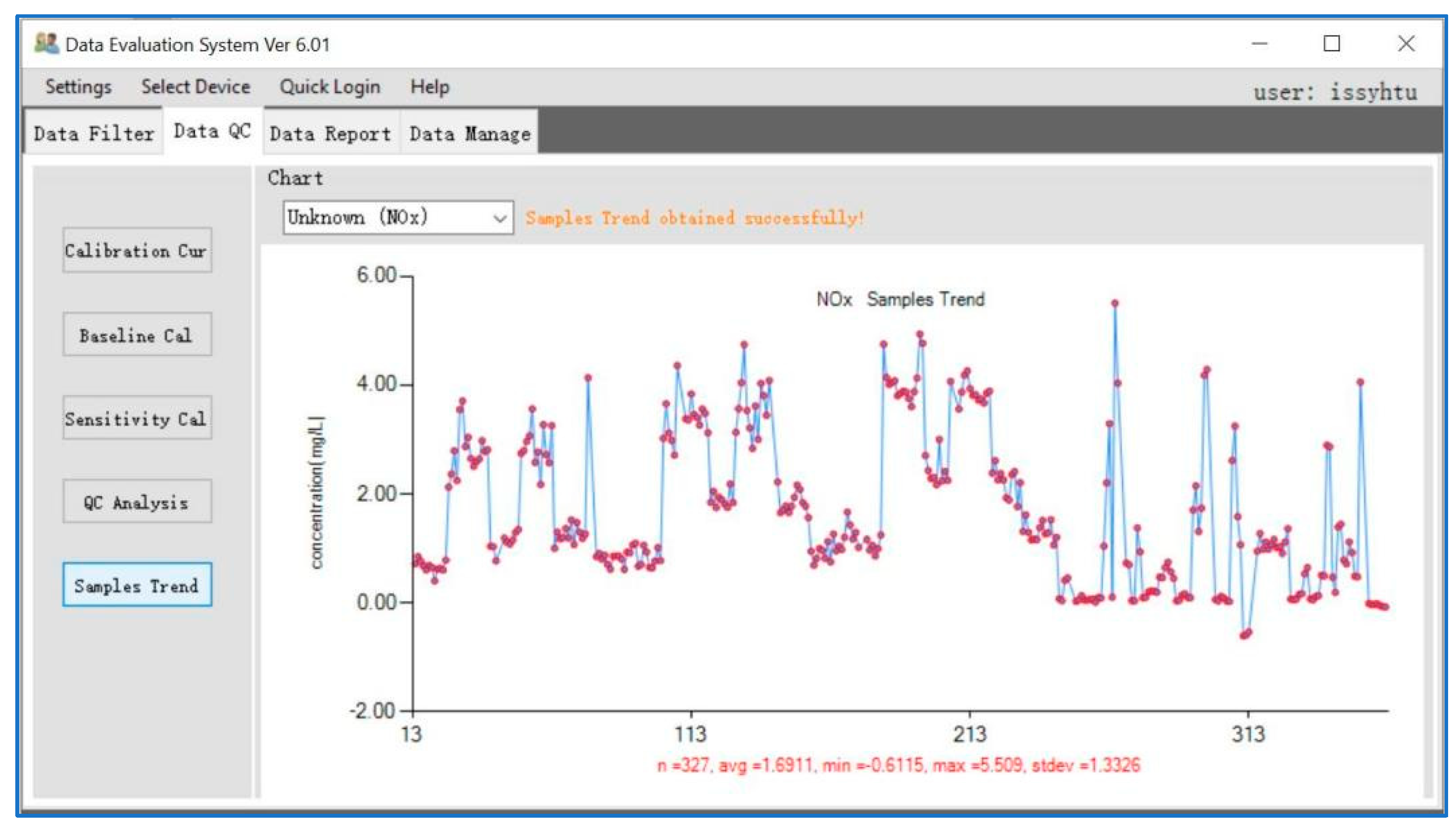
3.2. Data Quality Control
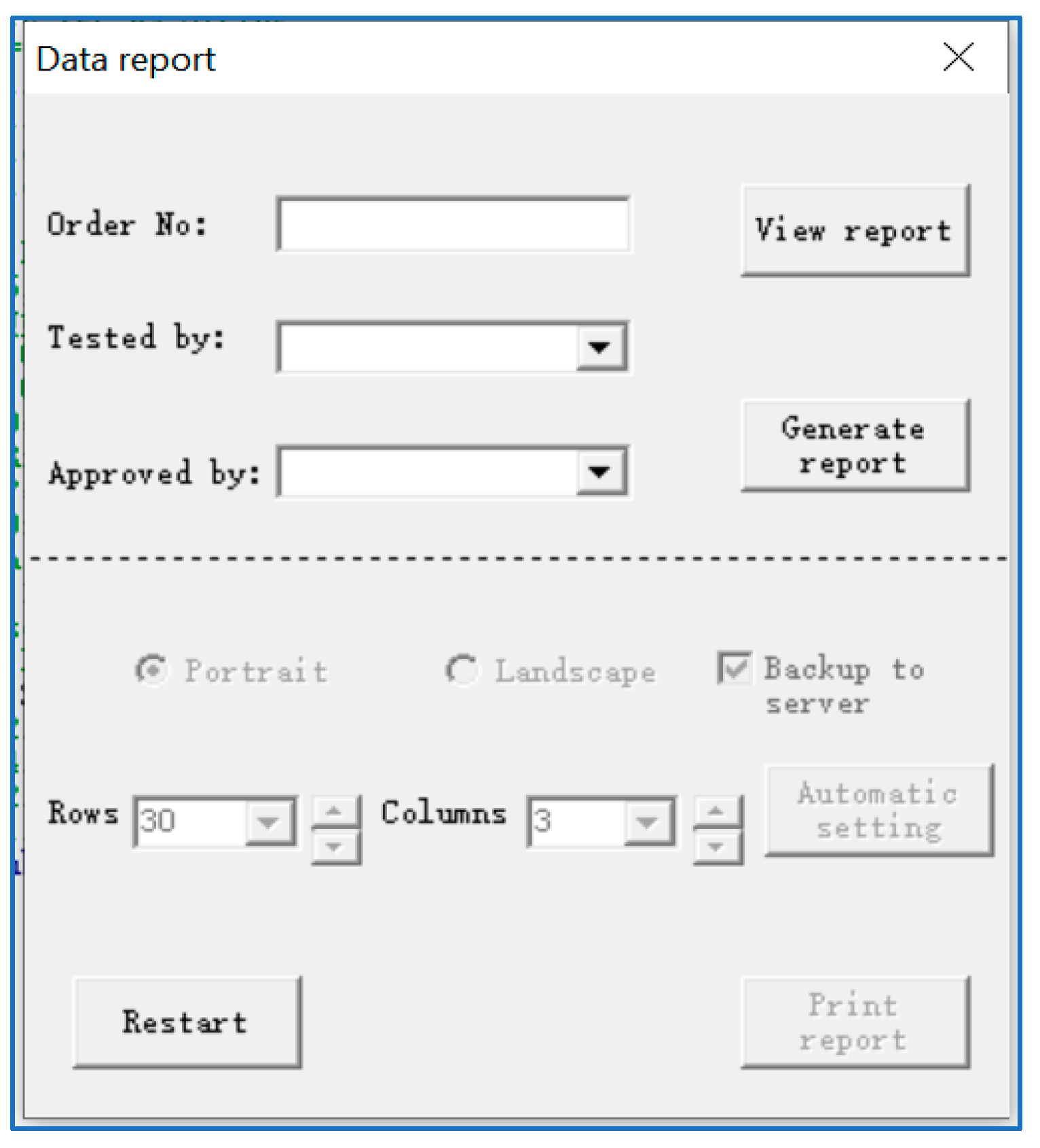
3.3. Data Report
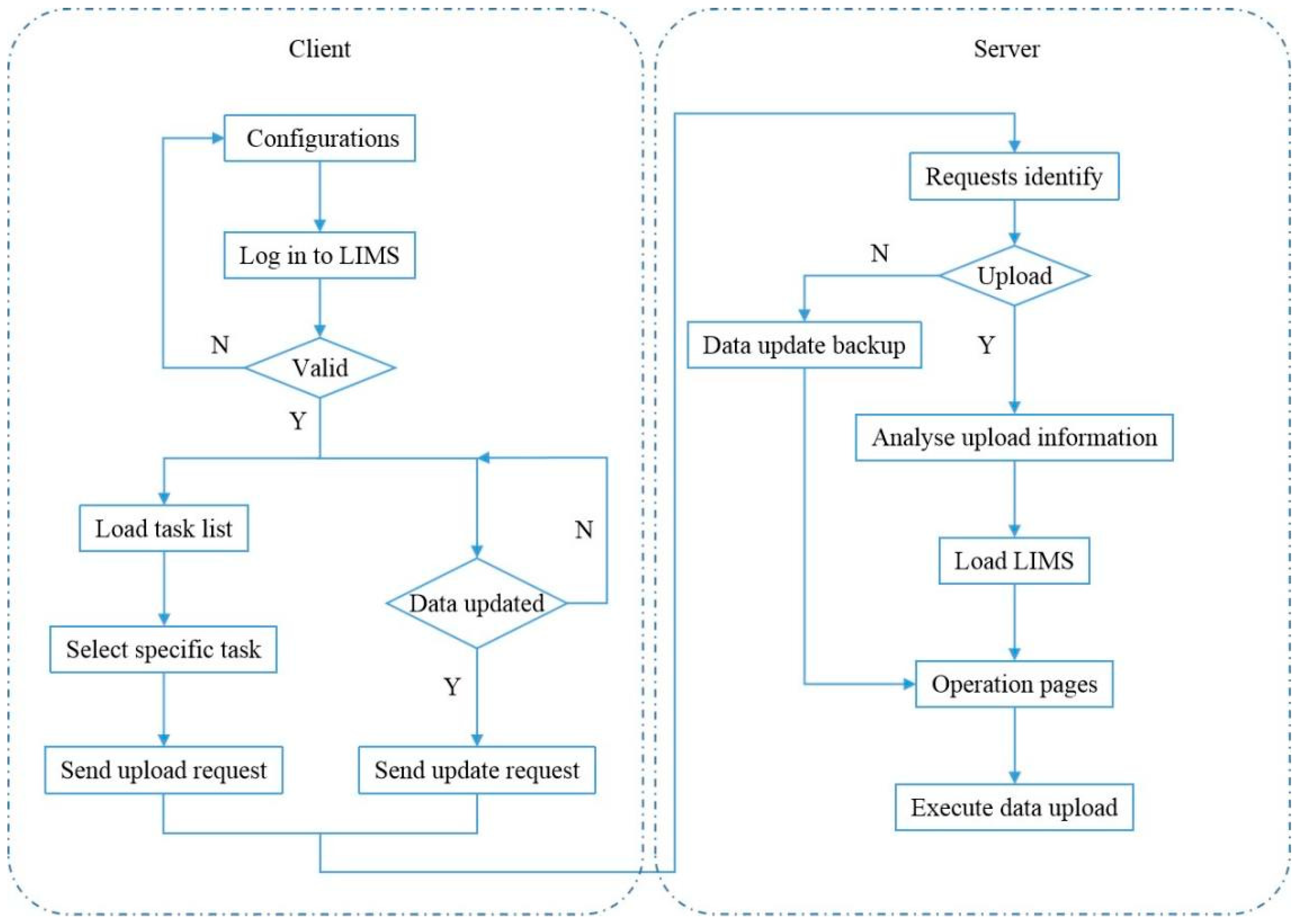
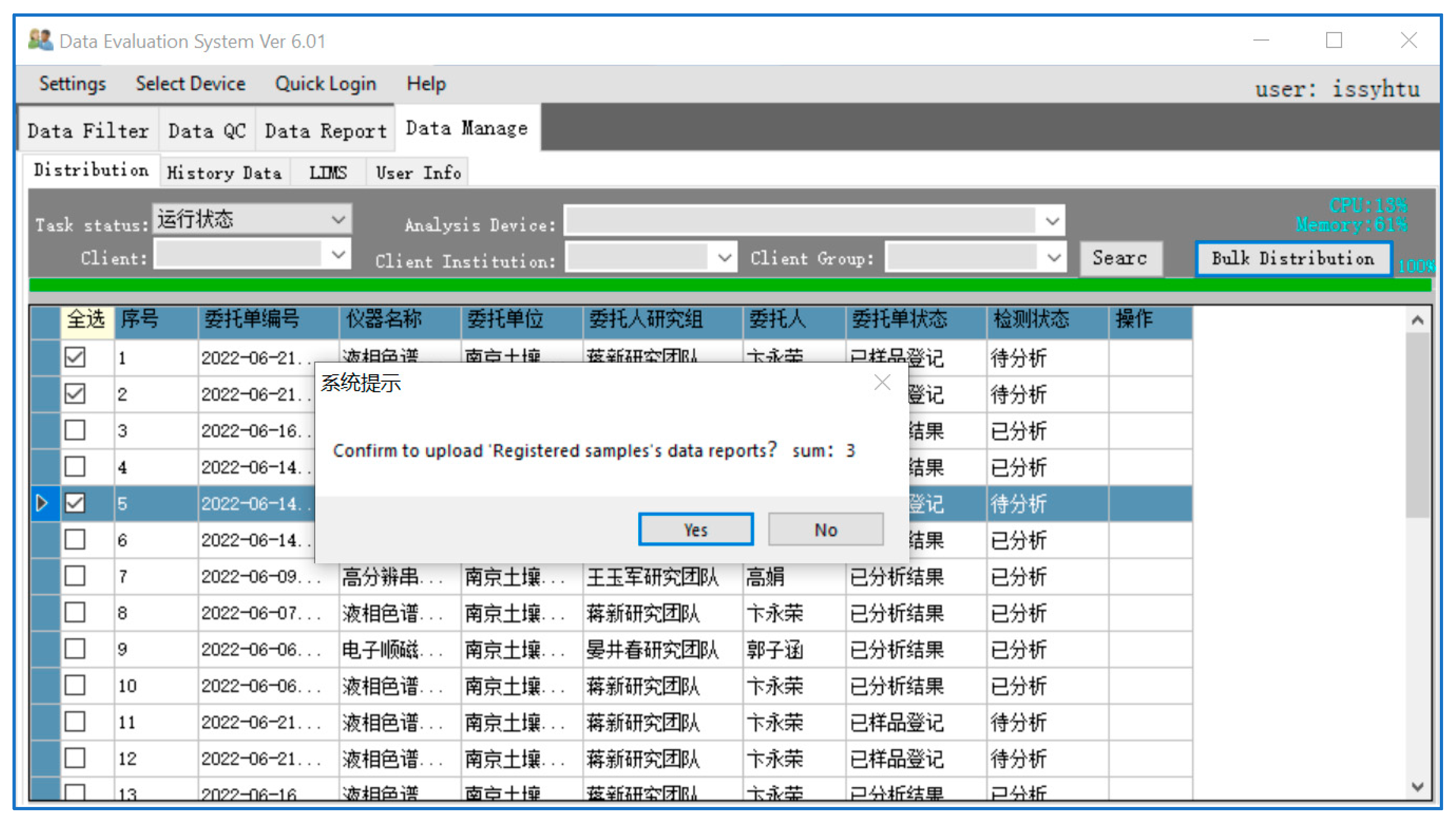
3.4. Data Manage and Distribute
4. Results and Discussion
5. Conclusions
6. Patents
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Marada, W.; Poniszewska-Marada, A.; Szymczyska, M. Data Processing in Cloud Computing Model on the Example of Salesforce Cloud. Information 2022, 13, 85. [Google Scholar] [CrossRef]
- Zhao, C.; Ding, Y.; Yang, Z. Studies on human error and its identification technique. Ind. Saf. Environ. Prot. 2002, 5, 40–43. [Google Scholar]
- Bao, Y.K.; Wang, Y.F.; Wen, Y.F. Equipment Reliability Evaluation and Maintenance Period Decision Considering the Impact of Human Factors. Power Syst. Technol. 2015, 39, 2546–2552. [Google Scholar]
- Xu, X.; Zheng, W.; Gu, Y. Analysis and Correction of Error for colormeter System based on Neural Network. Process Autom. Instrum. 2006, 2, 25–27. [Google Scholar]
- Jiang, Z.; Xu, M.; Yao, W. The Correction of Instrument System Errors based on Numerical Analysis. Geophys. Geochem. Explor. 2013, 37, 287–290. [Google Scholar]
- Thompson, M. Precision in chemical analysis: A critical survey of uses and abuses. Anal. Methods 2012, 4, 1598–1611. [Google Scholar] [CrossRef]
- Bosona, T. Urban Freight Last Mile Logistics-Challenges and Opportunities to Improve Sustainability: A Literature Review. Sustainability 2020, 12, 8769. [Google Scholar] [CrossRef]
- Fleischer, H.; Adam, M.; Thurow, K. Flexible Software Solution for Rapid Manual and Automated Data Evaluation in ICP-MS. In Proceedings of the 32nd Annual IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Pisa, Italy, 11–14 May 2015; pp. 1602–1607. [Google Scholar]
- Zhu, B.Y.; Wu, R.L.; Yu, X. Artificial Intelligence for Contemporary Chemistry Research. Acta Chim. Sin. 2020, 78, 1366–1382. [Google Scholar] [CrossRef]
- Emerson, J.; Kara, B.; Glassey, J. Multivariate data analysis in cell gene therapy manufacturing. Biotechnol. Adv. 2020, 45, 107637. [Google Scholar] [CrossRef]
- Qi, Y.L.; O’Connor, P.B. Data processing in Fourier transform ion cyclotron resonance mass spectrometry. Mass Spectrom. Rev. 2014, 33, 333–352. [Google Scholar] [CrossRef]
- Urban, J.; Vanek, J.; Stys, D. Current State of HPLC-MS Data Processing and Analysis in Proteomics and Metabolomics. Curr. Proteom. 2012, 9, 80–93. [Google Scholar] [CrossRef]
- Vervoort, Y.; Linares, A.G.; Roncoroni, M.; Liu, C.; Steensels, J.; Verstrepen, K.J. High-throughput system-wide engineering and screening for microbial biotechnology. Curr. Opin. Biotechnol. 2017, 46, 120–125. [Google Scholar] [CrossRef] [PubMed]
- Leavell, M.D.; Singh, A.H.; Kaufmann-Malaga, B.B. High-throughput screening for improved microbial cell factories, perspective and promise. Curr. Opin. Biotechnol. 2020, 62, 22–28. [Google Scholar] [CrossRef] [PubMed]
- Trapp, O. Gas chromatographic high-throughput screening techniques in catalysis. J. Chromatogr. A 2008, 1184, 160–190. [Google Scholar] [CrossRef] [PubMed]
- Shukla, S.J.; Huang, R.L.; Austin, C.P.; Xia, M.H. The future of toxicity testing: A focus on in vitro methods using a quantitative high-throughput screening platform. Drug Discov. Today 2010, 15, 997–1007. [Google Scholar] [CrossRef]
- Stephan, C.; Kohl, M.; Turewicz, M.; Podwojski, K.; Meyer, H.E.; Eisenacher, M. Using Laboratory Information Management Systems as central part of a proteomics data workflow. Proteomics 2010, 10, 1230–1249. [Google Scholar] [CrossRef]
- Cao, C. Different Analysis of Instrumental Analysis and Chemical Analysis. Chem. Eng. Des. Commun. 2016, 42, 43. [Google Scholar]
- Sinenian, N.; Zylstra, A.B.; Manuel, M.J.E.; Frenje, J.A.; Kanojia, A.D.; Stillerman, J.; Petrasso, R.D. A Multithreaded Modular Software Toolkit for Control of Complex Experiments. Comput. Sci. Eng. 2013, 15, 66–75. [Google Scholar] [CrossRef]
- Li, Z.; Cheng, L.; Yao, L.; Tong, X. Information Management of Data Resources in Product Design and Manufacture Process. In Proceedings of the International Conference on Manufacturing Engineering and Automation, Guangzhou, China, 7–9 December 2010; pp. 1674–1678. [Google Scholar]
- Poniszewska-Maranda, A.; Grzywacz, M. Storage and Processing of Data and Software Outside the Company in Cloud Computing Model. In Proceedings of the 12th International Conference on Mobile Web and Intelligent Information Systems (MobiWis), Rome, Italy, 24–26 August 2015; pp. 170–181. [Google Scholar]
- Ruzicka, J.; Hansen, E.H.; Ramsing, A.U. Flow-injection analyzer for students, teaching and research—Spectrophotometric methods. Anal. Chim. Acta 1982, 134, 55–71. [Google Scholar] [CrossRef]
- Henning, W. Semiautomatic connective-tissue and total phosphate determination using the scalar continuous-flow analyzer. Fleischwirtschaft 1990, 70, 97–101. [Google Scholar]
- Yang, J.; Zhang, Z.; Cao, G. Soil nitrate and nitrite content determined by Skalar SAN~(++). Soil Fertil. Sci. China 2014, 2, 101–105. [Google Scholar]
- Sun, X.; Qi, X.; Hou, J. The quality control method of soil or fertilizer testing laboratory. Chem. Anal. Meterage 2022, 31, 78–83. [Google Scholar]
- Wu, J.; Zuo, H.; Meng, L.; Yang, Y.; Cheng, Z.; Liu, H. IETM Data Management. In Proceedings of the Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 5158–5162. [Google Scholar]
- Tu, Y.; Tang, H.; Hu, W.; Sun, C. An Automatic Uploading Method of Customer Data in LIMS System under the User Mechanism. CN Patent CN109525642B, 15 September 2020. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Position | Type | Identity | Ext.Dil | Weight | Pre.Dil | TN mg/L | Height TN | Corr.Ht TN | Flag TN | Time TN |
|---|---|---|---|---|---|---|---|---|---|---|
| WT | IW | Initial Wash | 1 | 1 | 1 | 0 | 38,868 | 0 | IW | 805 |
| ST1 | T | Tracer | 1 | 1 | 1 | 9.09 | 41,053 | 2204 | N | 1298 |
| ST1 | D | Drift | 1 | 1 | 1 | 9.47 | 41,126 | 2296 | N | 1482 |
| Wt | W | Wash | 1 | 1 | 1 | 0 | 38,811 | 0 | N | 1646 |
| Wt | S1 | Standard 1 | 1 | 1 | 1 | −0.01 | 38,810 | −1 | A | 1846 |
| E51 | S2 | Standard 2 | 1 | 1 | 1 | 3.17 | 39,605 | 769 | N | 2065 |
| E52 | S3 | Standard 3 | 1 | 1 | 1 | 6.08 | 40,348 | 1474 | A | 2222 |
| E53 | S4 | Standard 4 | 1 | 1 | 1 | 8.98 | 41,105 | 2178 | A | 2373 |
| E54 | S5 | Standard 5 | 1 | 1 | 1 | 12.24 | 41,968 | 2967 | N | 2544 |
| ST1 | D | Drift | 1 | 1 | 1 | 10.17 | 41,279 | 2465 | N | 2719 |
| Wt | W | Wash | 1 | 1 | 1 | 0 | 38,814 | 0 | N | 2904 |
| D1 | U | 1 | 5 | 1 | 1 | 8.59 | 39,091 | 260 | A | 3077 |
| D2 | U | 2 | 5 | 1 | 1 | 8.07 | 39,071 | 244 | A | 3258 |
| D3 | U | 3 | 5 | 1 | 1 | 8.6 | 39,080 | 261 | A | 3808 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tu, Y.; Tang, H.; Gong, H.; Hu, W. A Flexible Data Evaluation System for Improving the Quality and Efficiency of Laboratory Analysis and Testing. Information 2022, 13, 424. https://doi.org/10.3390/info13090424
Tu Y, Tang H, Gong H, Hu W. A Flexible Data Evaluation System for Improving the Quality and Efficiency of Laboratory Analysis and Testing. Information. 2022; 13(9):424. https://doi.org/10.3390/info13090424
Chicago/Turabian StyleTu, Yonghui, Haoye Tang, Hua Gong, and Wenyou Hu. 2022. "A Flexible Data Evaluation System for Improving the Quality and Efficiency of Laboratory Analysis and Testing" Information 13, no. 9: 424. https://doi.org/10.3390/info13090424
APA StyleTu, Y., Tang, H., Gong, H., & Hu, W. (2022). A Flexible Data Evaluation System for Improving the Quality and Efficiency of Laboratory Analysis and Testing. Information, 13(9), 424. https://doi.org/10.3390/info13090424