
Automatic Sarcasm Detection: Systematic Literature Review



Abstract
:1. Introduction
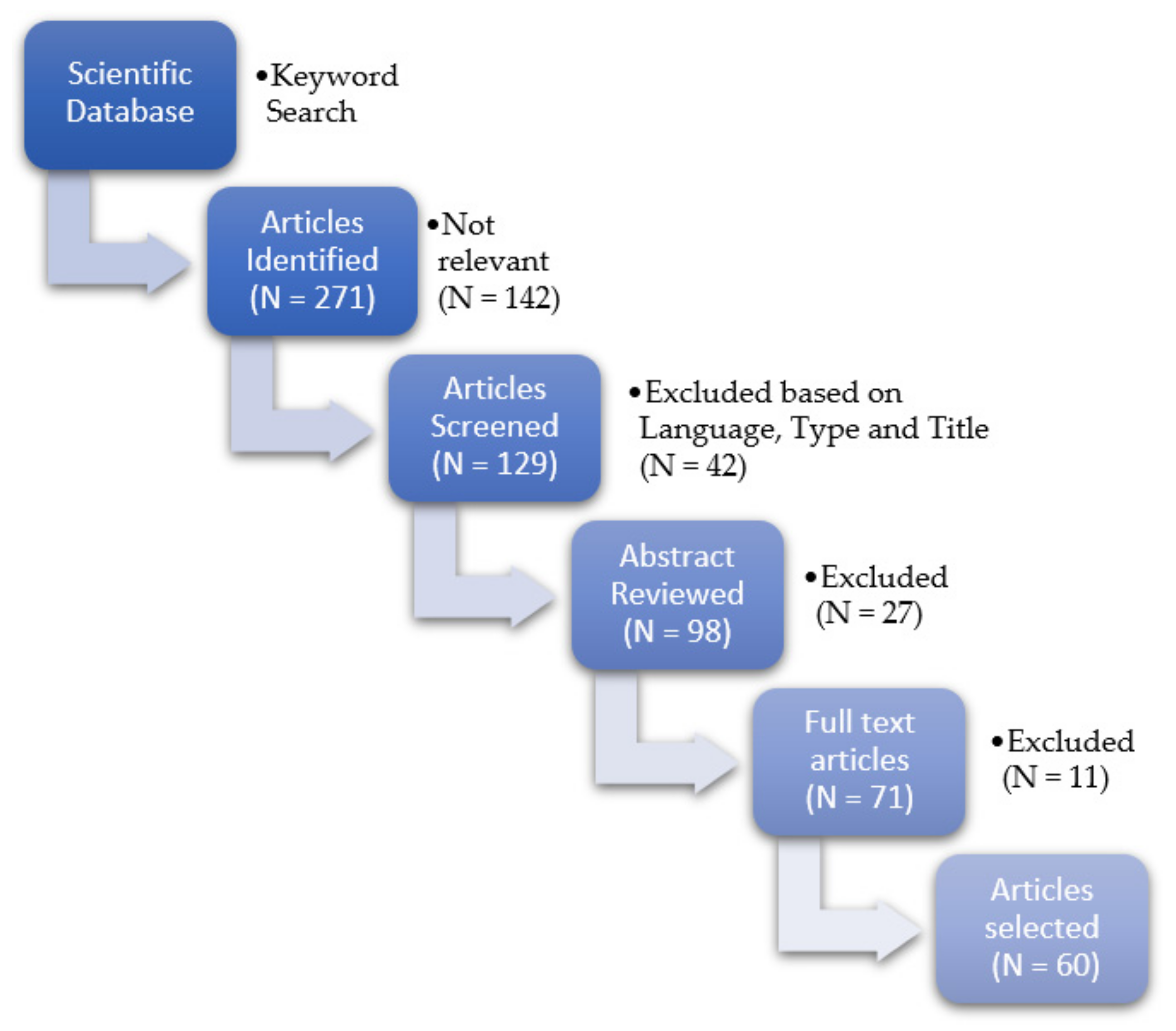
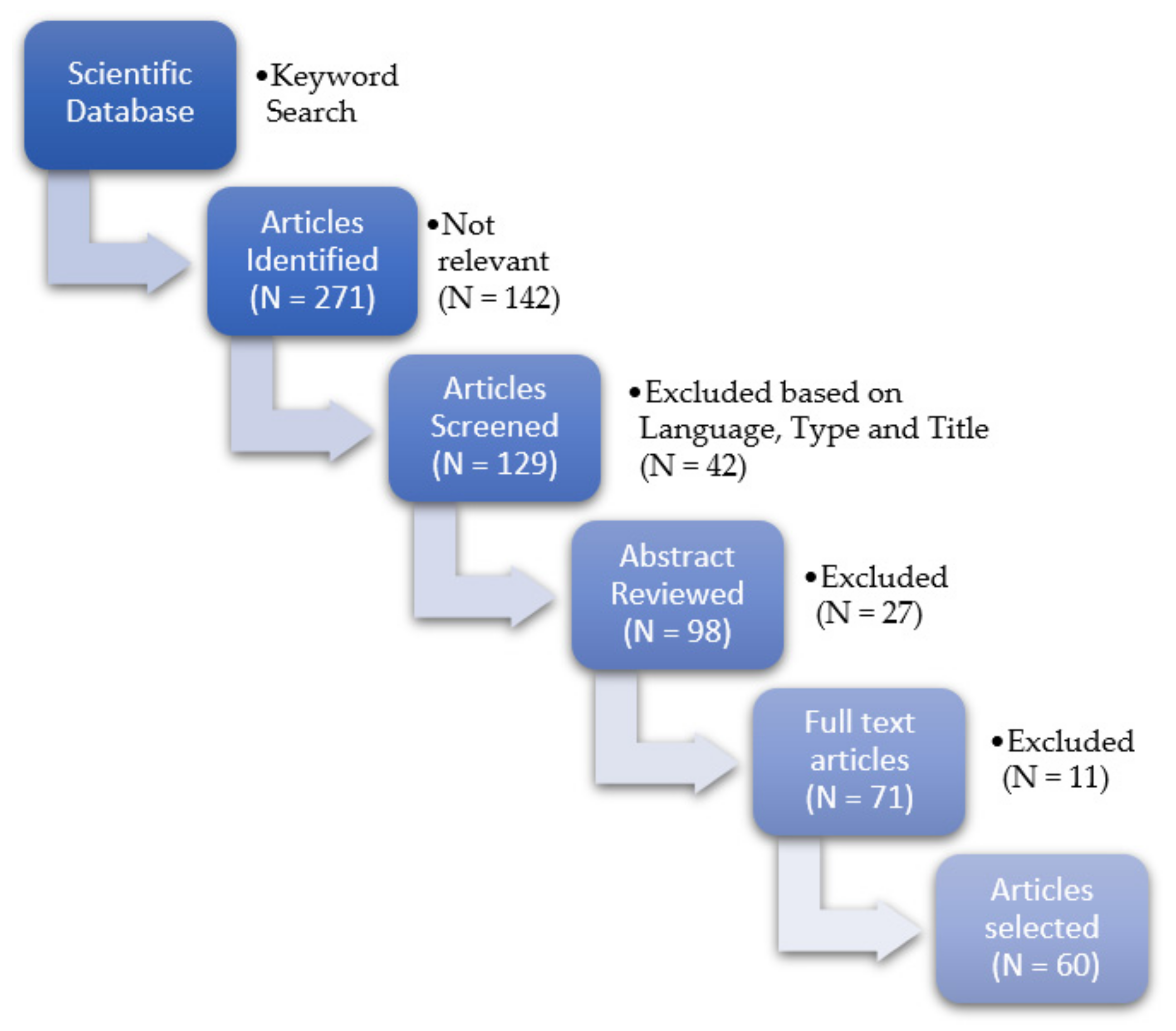
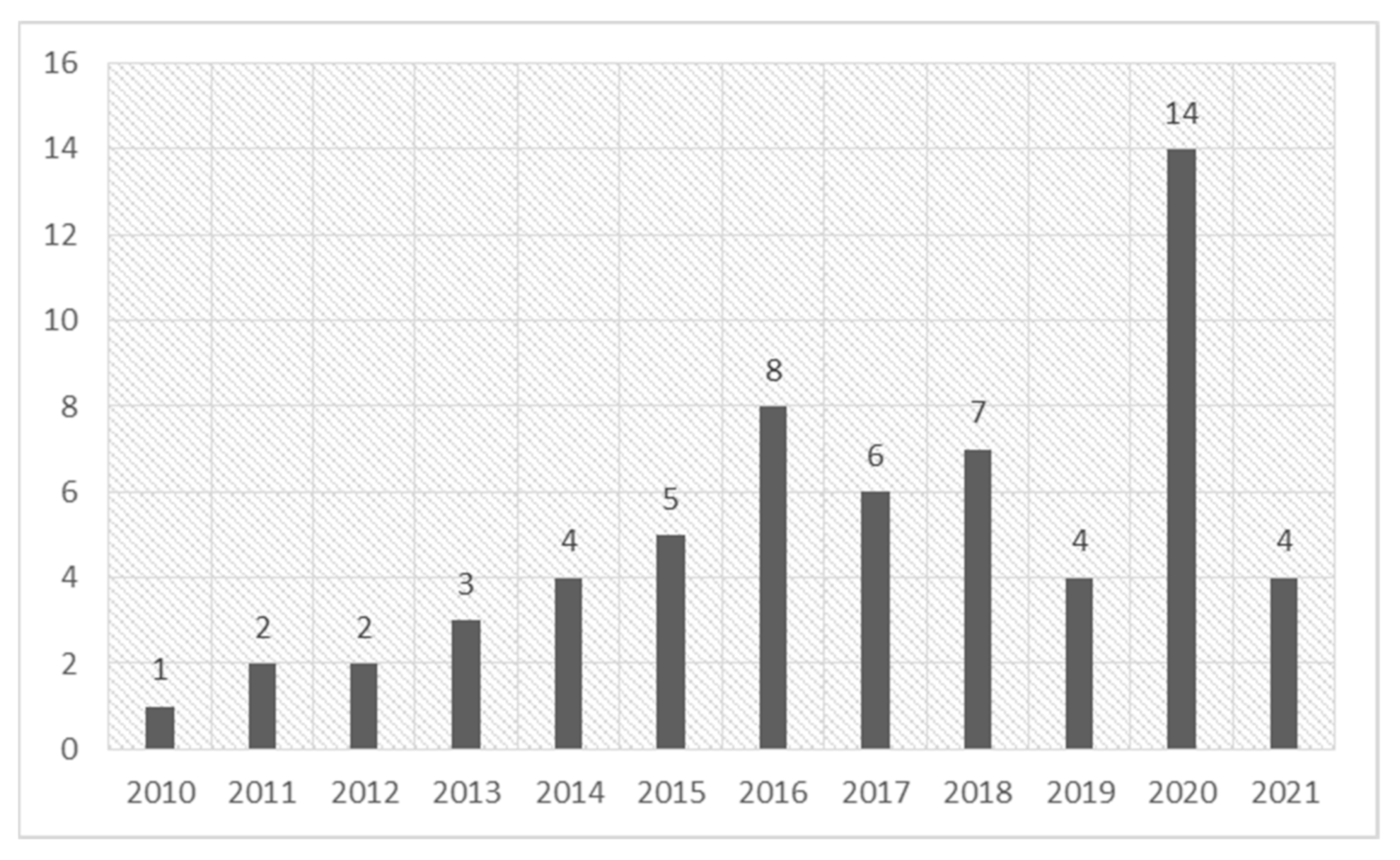
2. Materials and Methods
- What are the main areas of improvement that automatic sarcasm detection has seen since its inception?
- What are the trends that have shaped the automated sarcasm detection task in the past decade?
3. Results
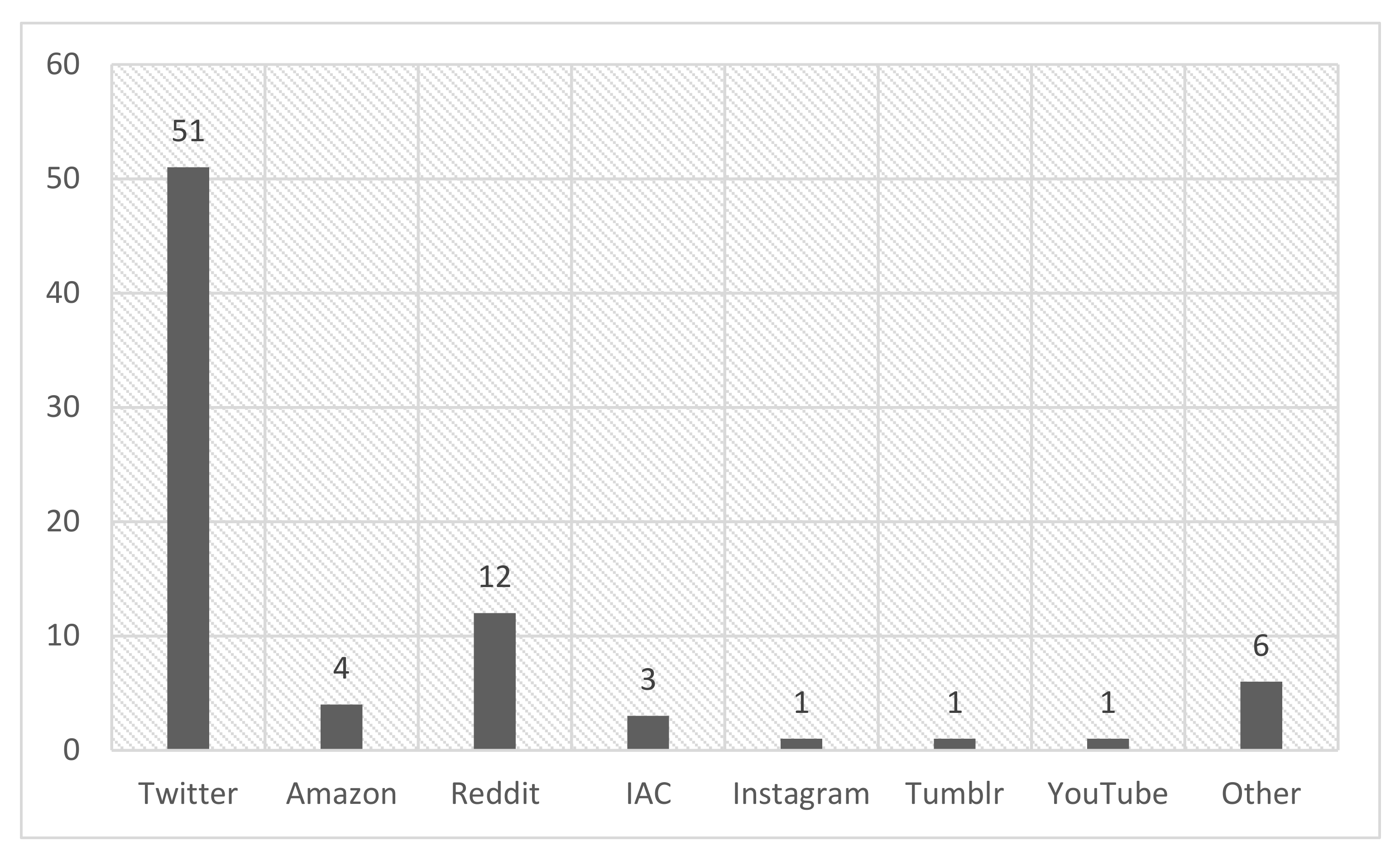
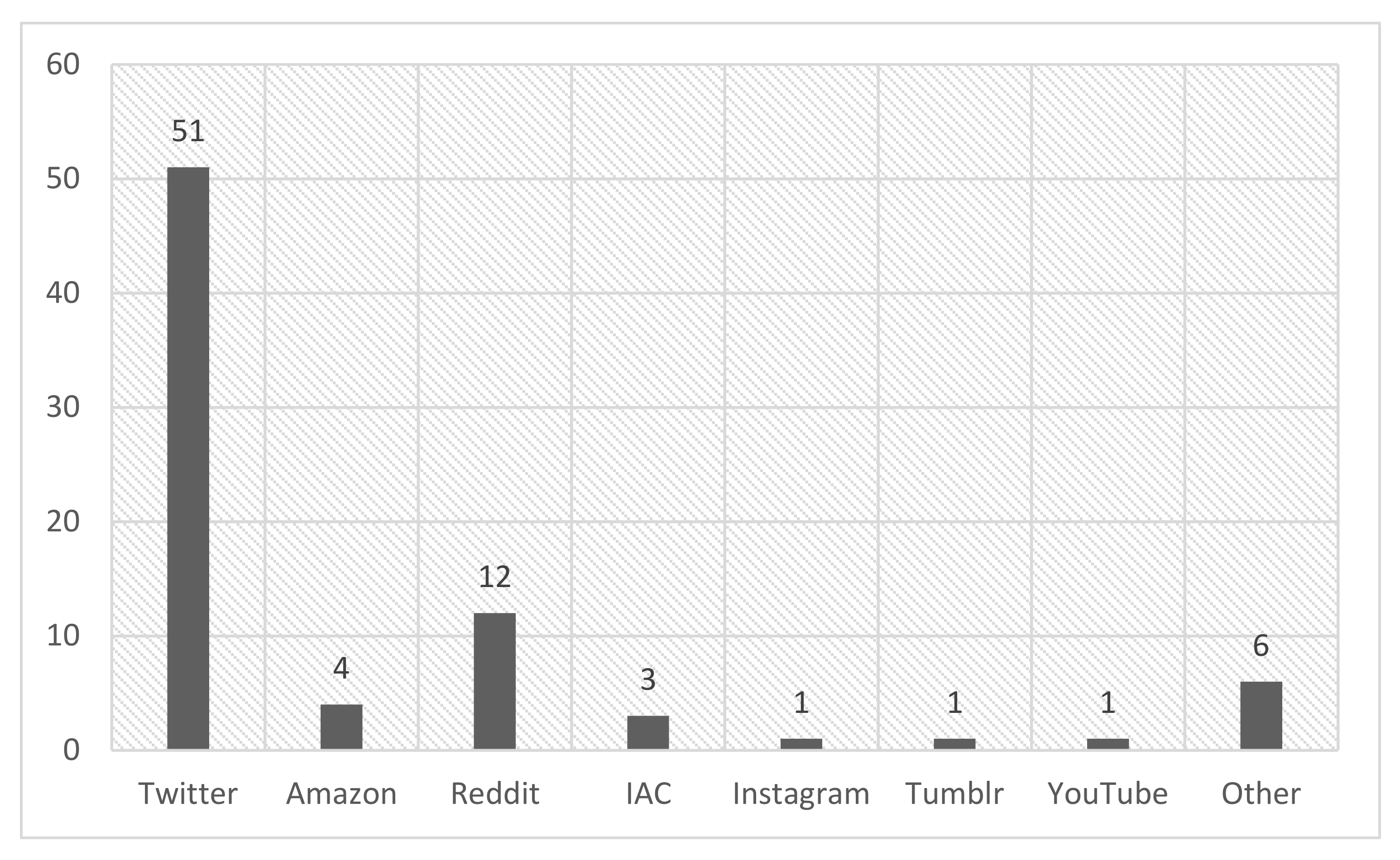
3.1. Sarcasm Detection Datasets
3.2. Automatic Sarcasm Detection
4. Discussion
5. Conclusions and Future Research
- a.
- What does automatic sarcasm detection want to achieve?
- b.
- What are the best data to train models on to replicate human level ability?
- c.
- What is the correct context in which to use sarcasm?
- d.
- How can machines generate sarcasm?
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dang, C.; Moreno-Garcia, M.; De la Prieta, F. Sentiment Analysis Based on Deep Learning: A Comparative Study. Electronics 2020, 9, 483. [Google Scholar] [CrossRef] [Green Version]
- McDonald, S.; Pearce, S. Clinical insights into pragmatic theory: Frontal lobe deficits and sarcasm. Brain Lang. 1996, 53, 81–104. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.; Katz, A. The differential role of ridicule in sarcasm and irony. Metaphor Symb. 1998, 13, 1–15. [Google Scholar] [CrossRef]
- Raharjana, I.; Siahaan, D.; Fatichah, C. User Stories and Natural Language Processing: A Systematic Literature Review. IEEE Access 2021, 9, 53811–53826. [Google Scholar] [CrossRef]
- Davidov, D.; Tsur, O.; Rappoport, A. Semi-supervised recognition of sarcastic sentences in twitter and amazon. In Proceedings of the Fourteenth Conference on Computational Natural Language Learning, Uppsala, Sweden, 15–16 July 2010. [Google Scholar]
- Carvalho, P.; Sarmento, L.; Silva, M.; de Oliveira, E. Clues for detecting irony in user-generated contents: Oh…!! it’s so easy;-). In Proceedings of the 1st International CIKM Workshop on Topic-Sentiment Analysis for Mass Opinion, Hong Kong, China, 6 November 2009. [Google Scholar]
- Tepperman, J.; Traum, D.; Narayanan, S. Yeah right: Sarcasm recognition for spoken dialogue systems. In Proceedings of the InterSpeech ICSLP, Ninth International Conference on Spoken Language Processing, Pittsburgh, PA, USA, 17–21 September 2006. [Google Scholar]
- Burfoot, C.; Baldwin, T. Automatic satire detection: Are you having a laugh? In ACLShort ’09: Proceedings of the ACL-IJCNLP 2009 Conference Short Papers, Proceedings of the Joint Conference of the 47th Annual Meeting of the Association for Computational Linguistics and the 4th International Joint Conference on Natural Language Processing Short Papers, Suntec, Singapore, 2–7 August 2009; Association for Computational Linguistics: Stroudsburg, PA, USA, 2009. [Google Scholar]
- Barbieri, F.; Saggion, H.; Ronzano, F. Modelling sarcasm in twitter, a novel approach. In Proceedings of the 5th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Baltimore, MD, USA, 27 June 2014. [Google Scholar]
- González-Ibánez, R.; Muresan, S.; Wacholder, N. Identifying sarcasm in Twitter: A closer look. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies: Short Papers, Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, Portland, OR, USA, 19–24 June 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; Volume 2. [Google Scholar]
- Reyes, A.; Rosso, P. Mining subjective knowledge from customer reviews: A specific case of irony detection. In Proceedings of the 2nd Workshop on Computational Approaches to Subjectivity and Sentiment Analysis (WASSA 2.011), Portland, OR, USA, 24 June 2011. [Google Scholar]
- Riloff, E.; Surve, P.; Qadir, A.; De Silva, L.; Gilbert, N.; Huang, R. Sarcasm as Contrast between a Positive Sentiment and Negative Situation. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; Volume 13, pp. 704–714. [Google Scholar]
- Oprea, S.; Magdy, W. iSarcasm: A Dataset of Intended Sarcasm. arXiv 2019, arXiv:1911.03123v2. [Google Scholar]
- Joshi, A.; Bhattacharyya, P.; Carman, M. Automatic Sarcasm Detection: A Survey. ACM Comput. Surv. 2018, 50, 1–22. [Google Scholar] [CrossRef]
- Filatova, E. Irony and sarcasm: Corpus generation and analysis using crowdsourcing. In Proceedings of the 12th Language Resources and Evaluation Conference, Istanbul, Turkey, 23–25 May 2012. [Google Scholar]
- Reyes, A.; Rosso, P.; Buscaldi, D. From humor recognition to irony detection: The figurative language. Data Knowl. Eng. 2012, 74, 1–12. [Google Scholar] [CrossRef]
- Lukin, S.; Walker, M. Really? Well. Apparently Bootstrapping Improves the Performance of Sarcasm and Nastiness Classifiers for Online Dialogue. In Proceedings of the Workshop on Language Analysis in Social Media, Atlanta, GA, USA, 13 June 2013. [Google Scholar]
- Liebrecht, C.; Kunneman, F.; van den Bosch, A. The perfect solution for detecting sarcasm in tweets# not. In Proceedings of the 4th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis (WASSA), Atlanta, GA, USA, 14 June 2013; Volume 2013. [Google Scholar]
- Maynard, D.; Greenwood, M. Who cares about sarcastic tweets? Investigating the impact of sarcasm on sentiment analysis. In Proceedings of the 9th International Conference on Language Resources and Evaluation, Reykjavik, Iceland, 26–31 May 2014. [Google Scholar]
- Liu, P.; Chen, W.; Ou, G.; Wang, T.; Yang, D.; Lei, K. Sarcasm Detection in Social Media Based on Imbalanced Classification. In Proceedings of the International Conference on Web-Age Information Management, Macau, China, 15–16 June 2014. [Google Scholar]
- Ptacek, T.; Habernal, I.; Hong, J. Sarcasm Detection on Czech and English Twitter. In Proceedings of the 25th International Conference on Computational Linguistics (COLING), Dublin, Ireland, 23–29 August 2014; pp. 213–223. [Google Scholar]
- Rajadesingan, A.; Zafarani, R.; Liu, H. Sarcasm detection on Twitter: A behavioral modeling approach. In Proceedings of the WSDM 2015—Proceedings of the 8th ACM International Conference on Web Search and Data Mining, Shanghai, China, 31 January 2015. [Google Scholar]
- Bamman, D.; Smith, N. Contextualized sarcasm detection on twitter. In Proceedings of the Ninth International AAAI Conference on Web and Social Media, Oxford, UK, 26–29 May 2015. [Google Scholar]
- Joshi, A.; Sharma, V.; Bhattacharyya, P. Harnessing context incongruity for sarcasm detection. In Proceedings of the International Joint Conference on Natural Language Processing (IJCNLP), Beijing, China, 26–31 July 2015; pp. 757–762. [Google Scholar]
- Ghosh, D.; Guo, W.; Muresan, S. Sarcastic or not: Word embeddings to predict the literal or sarcastic meaning of words. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015. [Google Scholar]
- Bharti, S.; Babu, K.; Jena, S. Parsing-based sarcasm sentiment recognition in Twitter data. In Proceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Paris, France, 25–28 August 2015. [Google Scholar]
- Bharti, S.; Vachha, B.; Pradhan, R.; Babu, K.; Jena, S. Sarcastic sentiment detection in tweets streamed in real time: A big data approach. Digit. Commun. Netw. 2016, 2, 108–121. [Google Scholar] [CrossRef] [Green Version]
- Abercrombie, G.; Hovy, D. Putting Sarcasm Detection into Context: The Effects of Class Imbalance and Manual Labelling on Supervised Machine Classification of Twitter Conversations. In Proceedings of the ACL 2016 Student Research Workshop, Berlin, Germany, 7–12 August 2016. [Google Scholar]
- Bouazizi, M.; Otsuki, T. A Pattern-Based Approach for Sarcasm Detection on Twitter. IEEE Access 2016, 4, 5477–5488. [Google Scholar] [CrossRef]
- Schifanella, R.; de Juan, P.; Tetreault, J.; Cao, L. Detecting Sarcasm in Multimodal Social Platforms. In Proceedings of the 2016 ACM on Multimedia Conference, Amsterdam, The Netherlands, 15–19 October 2016. [Google Scholar]
- Ravi, K.; Vadlamani, R. A novel automatic satire and irony detection using ensembled feature selection and data mining. Knowl. -Based Syst. 2016, 120, 15–33. [Google Scholar] [CrossRef]
- Zhang, M.; Zhang, Y.; Fu, G. Tweet Sarcasm Detection Using Deep Neural Network. In Proceedings of the COLING 2016, 26th International Conference on Computational Linguistics, Osaka, Japan, 11–16 December 2016. [Google Scholar]
- Sulis, E.; Farias, D.; Rosso, P.; Patti, V.; Ruffo, G. Figurative Messages and Affect in Twitter: Differences Between #irony, #sarcasm and #not. Knowl.-Based Syst. 2016, 108, 132–143. [Google Scholar]
- Ghosh, A.; Veale, T. Fracking Sarcasm Using Neural Network. In Proceedings of the 7th Workshop on Computational Approaches to Subjectivity, Sentiment & Social Media Analysis, San Diego, CA, USA, 16 June 2016. [Google Scholar]
- Saha, S.; Yadav, J.; Ranjan, P. Proposed Approach for Sarcasm Detection in Twitter. Indian J. Sci. Technol. 2017, 10, 1–8. [Google Scholar] [CrossRef]
- Ghosh, D.; Fabbri, A.; Muresan, S. The Role of Conversation Context for Sarcasm Detection in Online Interactions. In Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue (SIGDIAL 2017), Saarbrücken, Germany, 15–17 August 2017. [Google Scholar]
- Felbo, B.; Mislove, A.; Søgaard, A.; Rahwan, I.; Lehmann, S. Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017. [Google Scholar]
- Salas-Zarate, M.d.P.; Paredes-Valverde, M.; Rodriguez-Garcia, M.; Valencia-Garcia, R.; Alor-Hernandez, G. Automatic Detection of Satire in Twitter: A psycholinguistic-based approach. Knowl.-Based Syst. 2017, 128, 20–33. [Google Scholar] [CrossRef] [Green Version]
- Mishra, A.; Dey, K.; Bhattacharyya, P. Learning Cognitive Features from Gaze Data for Sentiment and Sarcasm Classification using Convolutional Neural Network. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017. [Google Scholar]
- Ghosh, A.; Veale, T. Magnets for Sarcasm: Making Sarcasm Detection Timely, Contextual and Very Personal. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017. [Google Scholar]
- Hazarika, D.; Hazarika, S.; Gorantla, S.; Cambria, E.; Zimmermann, R.; Mihalcea, R. CASCADE: Contextual Sarcasm Detection in Online Discussion Forums. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018. [Google Scholar]
- Tay, Y.; Luu, A.; Hui, S.; Su, J. Reasoning with sarcasm by reading in in-between. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Kumar, H.M.K.; Harish, B. Sarcasm classification: A novel approach by using Content Based Feature Selection Method. Procedia Comput. Sci. 2018, 143, 378–386. [Google Scholar] [CrossRef]
- Ahuja, R.; Bansal, S.; Prakash, S.; Venkataraman, K.; Banga, A. Comparative Study of Different Sarcasm Detection Algorithms Based on Behavioral Approach. Procedia Comput. Sci. 2018, 143, 411–418. [Google Scholar] [CrossRef]
- Khodak, M.; Saunshi, N.; Vodrahalli, K. A Large Self-Annotated Corpus for Sarcasm. In Proceedings of the 11th International Conference on Language Resources and Evaluation (LREC-2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Van Hee, C.; Lefever, E.; Hoste, V. SemEval-2018 task 3: Irony detection in English tweets. In Proceedings of the 12th International Workshop on Semantic Evaluation (SemEval 2018), New Orleans, LA, USA, 5–6 June 2018; pp. 39–50. [Google Scholar]
- Ren, Y.; Ji, D.; Ren, H. Context-augmented convolutional neural networks for twitter sarcasm detection. Neurocomputing 2018, 308, 1–7. [Google Scholar] [CrossRef]
- Oprea, S.; Magdy, W. Exploring Author Context for Detecting Intended vs Perceived Sarcasm. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Castro, S.; Hazarika, D.; Perez-Rosas, V.; Zimmermann, R.; Mihalcea, R.; Poria, S. Towards Multimodal Sarcasm Detection (An Obviously Perfect Paper). In Proceedings of the 57th Annual Meeting of the Association of Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Recupero, D.; Alam, M.; Buscaldi, D.; Grezka, A.; Tavazoee, F. Frame-Based Detection of Figurative Language in Tweets. IEEE Comput. Intell. 2019, 14, 77–88. [Google Scholar] [CrossRef]
- Cai, Y.; Cai, H.; Wan, X. Multi-Modal Sarcasm Detection in Twitter with Hierarchical Fusion Model. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Pan, H.; Lin, Z.; Qi, Y.; Fu, P.; Wang, W. Modeling Intra and Inter-modality Incongruity for Multi-Modal Sarcasm Detection. In Findings of the Association for Computational Linguistics: EMNLP 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; Volume 2020. [Google Scholar]
- Potamias, R.; Siolas, G.; Stafylopatis, A. A transformer-based approach to irony and sarcasm detection. Neural Comput. Appl. 2020, 32, 17309–17320. [Google Scholar] [CrossRef]
- Ren, L.; Xu, B.; Lin, H.; Liu, X.; Yang, L. Sarcasm Detection with Sentiment Semantics Enhanced Multi-level Memory Network. Neurocomputing 2020, 401, 320–326. [Google Scholar] [CrossRef]
- Sonawane, S.; Kolhe, S. TCSD: Term Co-occurrence Based Sarcasm Detection from Twitter Trends. Procedia Comput. Sci. 2020, 167, 830–839. [Google Scholar] [CrossRef]
- Jain, D.; Kumar, A.; Garg, G. Sarcasm detection in mash-up language using soft-attention based bi-directional LSTM and feature-rich CNN. Appl. Soft Comput. J. 2020, 91, 106198. [Google Scholar] [CrossRef]
- Baruah, A.; Das, K.; Barbhuiya, F.; Dey, K. Context-aware sarcasm detection using BERT. In Proceedings of the Second Workshop on Figurative Language Processing, Seattle, WA, USA, 9 July 2020. [Google Scholar]
- Kumar, A.; Anand, V. Transformers on sarcasm detection with context. In Proceedings of the Second Workshop on Figurative Language Processing, Seattle, WA, USA, 9 July 2020. [Google Scholar]
- Avvaru, A.; Vobilisetty, S.; Mamidi, R. Detecting sarcasm in conversation context using Transformer based model. In Proceedings of the Second Workshop on Figurative Language Processing, Seattle, WA, USA, 9 July 2020. [Google Scholar]
- Lemmens, J.; Burtenshaw, B.; Lotfi, E.; Markov, I.; Daelemans, W. Sarcasm detection using an ensemble approach. In Proceedings of the Second Workshop on Figurative Language Processsing, Seattle, WA, USA, 9 July 2020. [Google Scholar]
- Lee, H.; Yu, Y.; Kim, G. Augmenting data for sarcasm detection with unlabeled conversation context. In Proceedings of the Second Workshop on Figurative Language Processing, Seattle, WA, USA, 9 July 2020. [Google Scholar]
- Jaiswal, N. Neural sarcasm detection using conversation context. In Proceedings of the Second Workshop on Figurative Language Processing, Seattle, WA, USA, 9 July 2020. [Google Scholar]
- Srivastava, H.; Varshney, V.; Kumari, S.; Srivastava, S. A novel hierarchical BERT architecture for sarcasm detection. In Proceedings of the Second Workshop on Figurative Language Processing, Seattle, WA, USA, 9 July 2020. [Google Scholar]
- Dadu, T.; Pant, K. Sarcasm detection using context separators in online discourse. In Proceedings of the Second Workshop on Figurative Language Processing, Seattle, WA, USA, 9 July 2020. [Google Scholar]
- Pandey, R.; Kumar, A.; Singh, J.; Tripathi, S. Hybrid attention-based Long Short-Term Memory network for sarcasm identification. Appl. Soft Comput. J. 2021, 106, 107348. [Google Scholar] [CrossRef]
- Chia, Z.; Ptaszynski, M.; Masui, F.; Leliwa, G.; Wroczynski, M. Machine Learning and feature engineering-based study into sarcasm and irony classification with application to cyberbullying detection. Inf. Process. Manag. 2021, 58, 102600. [Google Scholar] [CrossRef]
- Parameswaran, P.; Trotman, A.; Liesaputra, V.; Eyers, D. Detecting the target of sarcasm is hard: Really? Inf. Process. Manag. 2021, 58, 102599. [Google Scholar] [CrossRef]
- Shrivastava, M.; Kumar, S. A pragmatic and intelligent model for sarcasm detection in social media text. Technol. Soc. 2021, 64, 101489. [Google Scholar] [CrossRef]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Quinlan, J. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Hochreitter, S.; Schimdhuber, J. Long-short term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Liu, Y.; Zhou, Y.; Dong, F.; Wang, C.; Wang, Z. Wasserstein GAN-based small-sample augmentation for new-generation artificial intelligence: A case study of cancer-staging data in biology. Engineering 2019, 5, 156–163. [Google Scholar] [CrossRef]
- Kim, J. How Korean EFL learners understand sarcasm in L2 English. J. Pragmat. 2014, 60, 193–206. [Google Scholar] [CrossRef]
- Ackerman, B.P. Contextual integration and utterance interpretation: The ability of children and adults to interpret sarcastic utterances. Child Dev. 1982, 53, 1075–1083. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Annotation | Context | Dataset | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Ref. | Data Source | Manual | Distant | Author | Conversation | Short | Long | Other | Size |
| [5] | x | x | 5.9 million | ||||||
| [5] | Amazon | x | x | 66,000 | |||||
| [10] | x | x | 900 | ||||||
| [11] | Amazon | x | x | 8861 | |||||
| [15] | Amazon | x | x | 1254 | |||||
| [16] | x | x | |||||||
| [17] | Internet Argument Corpus | x | x | x | 9889 | ||||
| [12] | x | x | 3000 | ||||||
| [18] | x | x | 3.3 million | ||||||
| [19] | x | x | 134 | ||||||
| [20] | x | x | 5.9 million | ||||||
| [20] | Amazon | x | x | 8661 | |||||
| [20] | News | x | x | 4233 | |||||
| [21] | x | x | 100,000 | ||||||
| [21] | x | x | 4000 | ||||||
| [9] | x | x | 60,000 | ||||||
| [22] | x | x | |||||||
| [23] | x | x | x | x | 19,534 | ||||
| [24] | x | x | 5208 | ||||||
| [24] | x | x | 2278 | ||||||
| [24] | IAC | x | x | x | 1502 | ||||
| [25] | x | x | 2.5 million | ||||||
| [26] | x | x | |||||||
| [27] | x | x | x | Up to 1 million | |||||
| [28] | x | x | x | 22,402 tweet conversations | |||||
| [29] | x | x | 6000 | ||||||
| [30] | Twitter, Instagram and Tumblr | x | x | x | 44,010 | ||||
| [31] | News | x | x | 4233 | |||||
| [32] | x | x | x | 9104 | |||||
| [33] | x | x | 50,000 | ||||||
| [34] | x | x | 39,000 | ||||||
| [35] | x | x | 650,000 | ||||||
| [36] | x | x | x | 25,991 | |||||
| [36] | IAC | x | x | x | 4692 | ||||
| [37] | x | x | 10,000 | ||||||
| [38] | x | x | |||||||
| [39] | x | x | x | 843 | |||||
| [40] | x | x | x | 40,000 | |||||
| [41] | x | x | x | x | Over 1 million | ||||
| [42] | x | x | 45,000 | ||||||
| [42] | x | x | x | 22,000 | |||||
| [42] | IAC | x | x | x | 5000 | ||||
| [43] | Amazon | x | x | 1254 | |||||
| [44] | x | x | 16,784 | ||||||
| [45] | x | x | x | Over 1.6 million | |||||
| [46] | x | x | 3000 | ||||||
| [47] | x | x | x | x | 8727 | ||||
| [48] | x | x | x | 701 | |||||
| [48] | x | x | x | 27,177 | |||||
| [49] | YouTube | x | x | x | x | 690 | |||
| [50] | x | x | 51,189 | ||||||
| [51] | x | x | x | 4819 | |||||
| [52] | x | x | x | 4819 | |||||
| [53] | x | x | 3000 | ||||||
| [53] | x | x | 3000 | ||||||
| [53] | x | x | x | Over 1.6 million | |||||
| [54] | x | x | 63,104 | ||||||
| [54] | IAC | x | x | x | 1935 | ||||
| [54] | IAC | x | x | x | 4692 | ||||
| [55] | x | x | |||||||
| [56] | x | x | 6000 | ||||||
| [57] | x | x | x | 5000 | |||||
| [57] | x | x | x | 4400 * | |||||
| [58] | x | x | x | 5000 * | |||||
| [58] | x | x | x | 4400 * | |||||
| [59] | x | x | x | 5000 * | |||||
| [59] | x | x | x | 4400 * | |||||
| [60] | x | x | x | 5000 * | |||||
| [60] | x | x | x | 4400 * | |||||
| [61] | x | x | x | 5000 * | |||||
| [61] | x | x | x | 4400 * | |||||
| [62] | x | x | x | 5000 * | |||||
| [63] | x | x | x | 5000 * | |||||
| [63] | x | x | x | 4400 * | |||||
| [64] | x | x | x | 5000* | |||||
| [64] | x | x | x | 4400 * | |||||
| [13] | x | x | x | x | 4484 | ||||
| [65] | x | x | 1956 | ||||||
| [65] | x | x | 54,931 | ||||||
| [65] | News | x | x | 26,709 | |||||
| [66] | x | x | 4618 | ||||||
| [67] | x | x | 224 | ||||||
| [67] | x | x | 950 | ||||||
| [67] | Books | x | x | 506 | |||||
| [68] | x | x | 3000 | ||||||
| No. | Dataset Source | Model | Year | Ref. |
|---|---|---|---|---|
| 1 | Twitter and Amazon | kNN | 2010 [5] | [5] |
| 2 | SVM with sequential minimal optimization (SMO) and Logistic Regression | 2011 [10] | [10] | |
| 3 | Amazon | NB, SVM, DT | 2011 [11] | [11] |
| 4 | Amazon | Dataset creation through manual annotation | 2012 [15] | [15] |
| 5 | Rule based | 2012 [16] | [16] | |
| 6 | IAC | Bootstrapped\High Precision and Pattern Based Classifiers | 2013 [17] | [17] |
| 7 | Bootstrapping | 2013 [12] | [12] | |
| 8 | Balanced Window | 2013 [18] | [18] | |
| 9 | GATE | 2014 [19] | [19] | |
| 10 | Amazon, Twitter and News | Maximum Entropy, Naïve Bayes and SVM | 2014 [20] | [20] |
| 11 | Maximum Entropy and SVM | 2014 [21] | [21] | |
| 12 | Decision Tree | 2014 [9] | [9] | |
| 13 | SCUBA: L1 regularized logistic regression | 2015 [22] | [22] | |
| 14 | l2 regularization binary logistic regression | 2015 [23] | [23] | |
| 15 | Feature-based statistical classifier | 2015 [24] | [24] | |
| 16 | SVM with MVMEwe kernel (Maximum valued matrix element word embeddings) | 2015 [25] | [25] | |
| 17 | Rule-based classifier | 2015 [26] | [26] | |
| 18 | Rule-based classifier | 2016 [27] | [27] | |
| 19 | Standard logistic regression with l2 regularization | 2016 [28] | [28] | |
| 20 | Random forest, SVM, kNN and Maximum Entropy | 2016 [29] | [29] | |
| 21 | Twitter, Instagram and Tumblr | SVM and ANN | 2016 [30] | [30] |
| 22 | News | Ensemble method | 2016 [31] | [31] |
| 23 | ANN | 2016 [32] | [32] | |
| 24 | Naïve-Bayes, Decision Tree, Random Forest, SVM, Logistic Regression | 2016 [33] | [33] | |
| 25 | SVM and CNN-DNN-LSTM | 2016 [34] | [34] | |
| 26 | Twitter and Forum | SVM and Naïve Bayes | 2017 [35] | [35] |
| 27 | SVM and LSTM | 2017 [36] | [36] | |
| 28 | LSTM | 2017 [37] | [37] | |
| 29 | SMO, BayesNet, J64 | 2017 [38] | [38] | |
| 30 | CNN | 2017 [39] | [39] | |
| 31 | Word Embeddings—2 CNN—Bi-LSTM—DNN | 2017 [40] | [40] | |
| 32 | CASCADE (Context and Content Features, CNN) | 2018 [41] | [41] | |
| 33 | MIARN | 2018 [42] | [42] | |
| 34 | SVM and Random Forest | 2018 [43] | [43] | |
| 35 | Naïve-Bayes, SVM, Decistion Tree, Random Forest, Adabosst, kNN, Gradient Boost | 2018 [44] | [44] | |
| 36 | Dataset creation through distant supervision | 2018 [45] | [45] | |
| 37 | Multiple models (SemEval 2018 submissions) | 2018 [46] | [46] | |
| 38 | CANN-KEY and CANN-ALL | 2018 [47] | [47] | |
| 39 | Exclusive and inclusive models with Cascade, Encoder decoder and summary embeddings | 2019 [48] | [48] | |
| 40 | YouTube | SVM (dataset creation-oriented) | 2019 | [49] |
| 41 | Naïve-Bayes | 2019 [50] | [50] | |
| 42 | Multimodal ANN | 2019 [51] | [51] | |
| 43 | Multimodal ANN | 2020 [52] | [52] | |
| 44 | Recurrent CNN RoBERTA | 2020 [53] | [53] | |
| 45 | MMNSS | 2020 [54] | [54] | |
| 46 | Feature-based statistical model | 2020 [55] | [55] | |
| 47 | BiLStM—CNN | 2020 [56] | [56] | |
| 48 | Twitter and Reddit | BiLSTM, BERT and SVM | 2020 [57] | [57] |
| 49 | Twitter and Reddit | BERT, RoBERTA, spanBERT | 2020 [58] | [58] |
| 50 | Twitter and Reddit | BERT 3,5,7, all | 2020 [59] | [59] |
| 51 | Twitter and Reddit | Ensemble method | 2020 [60] | [60] |
| 52 | Twitter and Reddit | Bert-large+BiLSTM+NextVLAD | 2020 [61] | [61] |
| 53 | Twitter and Reddit | Ensemble method | 2020 [62] | [62] |
| 54 | Twitter and Reddit | BERT-CNN-LSTM | 2020 | [63] |
| 55 | Twitter and Reddit | RoBERTA | 2020 [64] | [64] |
| 56 | Dataset creation through manual annotation | 2020 [13] | [13] | |
| 57 | Twitter and News | HA-LSTM | 2021 [65] | [65] |
| 58 | CNN | 2021 [66] | [66] | |
| 59 | Twitter, Reddit and Books | Ensemble method | 2021 [67] | [67] |
| 60 | BERT | 2021 [68] | [68] |
| Reference | Precision | Accuracy | Recall | F-Score | AUC | Data |
|---|---|---|---|---|---|---|
| [5] | 72.7 | 43.6 | 89.6 | 54.5 | ||
| [5] | 91.2 | 75.6 | 94.7 | 82.7 | Amazon | |
| [10] | 71 | |||||
| [11] | 77.1 | 75.75 | 72.5 | 74.7 | Amazon | |
| [16] | 78 | 70.1 | 56 | 65 | ||
| [17] | 62 | 52 | 57 | IAC | ||
| [12] | 62 | 44 | 51 | |||
| [18] | 79 | |||||
| [19] | 77.3 | 77.3 | 77.3 | |||
| [20] | 84 | |||||
| [20] | 85.4 | Amazon | ||||
| [20] | 83.3 | News | ||||
| [21] | 94.66 | |||||
| [21] | 58.2 | |||||
| [9] | 62 | 90 | 90 | |||
| [22] | 86.1 | 86 | ||||
| [23] | 85.1 | |||||
| [24] | 81.4 | 97.6 | 88.8 | |||
| [24] | 77 | 51 | 61 | |||
| [24] | 48.9 | 92.4 | 64 | IAC | ||
| [25] | 96.6 | 98.5 | 97.5 | |||
| [26] | 85 | 96 | 90 | |||
| [27] | 97 | 98 | 97 | |||
| [28] | 63 | |||||
| [29] | 91.1 | 83.1 | 73.4 | 81.3 | ||
| [30] | 69.7 | |||||
| [30] | 74.2 | |||||
| [30] | 70.9 | Tumblr | ||||
| [31] | 94.4 | 95.5 | 97.4 | News | ||
| [32] | 90.74 | 90.74 | ||||
| [33] | 58.6 | |||||
| [34] | 91.9 | 92.3 | 91.2 | |||
| [35] | 96.5 | 65.2 | 20.10 | 37.4 | ||
| [36] | 77.25 | 75.51 | 76.36 | |||
| [36] | 66.9 | 82.1 | 73.7 | IAC | ||
| [37] | 85.5 | 85.5 | 85.5 | 85.5 | ||
| [38] | 75 | |||||
| [39] | 87.1 | 86.9 | 86.97 | |||
| [40] | 90 | 89 | 90 | |||
| [41] | 79 | 86 | ||||
| [42] | 86.1 | 86.5 | 85.8 | 86 | ||
| [42] | 69.7 | 69.9 | 69.4 | 69.5 | ||
| [42] | 72.9 | 72.8 | 72.9 | 72.8 | IAC | |
| [43] | 80.1 | 73.6 | 75.2 | Amazon | ||
| [44] | 93 | 92 | ||||
| [46] | 63 | 73.5 | 80.1 | 70.5 | ||
| [47] | 63.3 | |||||
| [48] | 73.9 | |||||
| [48] | 93.4 | |||||
| [49] | 72.1 | 71.7 | 71.8 | YouTube | ||
| [50] | 89.8 | |||||
| [51] | 76.6 | 83.4 | 84.2 | 80.2 | ||
| [52] | 80.9 | 86.1 | 85.1 | 82.9 | ||
| [53] | 81 | 82 | 80 | 80 | 89 | |
| [53] | 90 | 91 | 90 | 90 | 94 | |
| [53] | 78 | 79 | 78 | 78 | 85 | |
| [54] | 89.2 | 87.1 | ||||
| [54] | 75 | 70.9 | 67.7 | IAC | ||
| [54] | 85.8 | 71.1 | 74.2 | IAC | ||
| [55] | 93.8 | 93.5 | ||||
| [56] | 78.8 | 85 | 81.3 | 79.5 | ||
| [57] | 74.4 | 74.8 | 74.3 | |||
| [57] | 65.8 | 65.8 | 65.8 | |||
| [58] | 77.3 | 77.4 | 77.2 | |||
| [58] | 69.3 | 69.9 | 69.1 | |||
| [59] | 75.2 | |||||
| [59] | 62.1 | |||||
| [60] | 74.1 | 74.6 | 74 | |||
| [60] | 67 | 67.7 | 66.7 | |||
| [61] | 93.2 | 93.6 | 93.1 | |||
| [61] | 83.4 | 83.8 | 83.4 | |||
| [62] | 79 | 79.2 | 79 | |||
| [63] | 74 | |||||
| [63] | 63.9 | |||||
| [64] | 77.2 | 77.2 | 77.2 | |||
| [64] | 71.6 | 71.8 | 71.6 | |||
| [65] | 99 | |||||
| [65] | 98 | |||||
| [65] | 88 | News | ||||
| [66] | 66 | |||||
| [67] | 54.9 | 21.7 | ||||
| [67] | 60.3 | 46.2 | ||||
| [67] | 50.8 | 18.5 | Books | |||
| [68] | 68.7 | 70.6 | 72.5 | 70.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Băroiu, A.-C.; Trăușan-Matu, Ș. Automatic Sarcasm Detection: Systematic Literature Review. Information 2022, 13, 399. https://doi.org/10.3390/info13080399
Băroiu A-C, Trăușan-Matu Ș. Automatic Sarcasm Detection: Systematic Literature Review. Information. 2022; 13(8):399. https://doi.org/10.3390/info13080399
Chicago/Turabian StyleBăroiu, Alexandru-Costin, and Ștefan Trăușan-Matu. 2022. "Automatic Sarcasm Detection: Systematic Literature Review" Information 13, no. 8: 399. https://doi.org/10.3390/info13080399
APA StyleBăroiu, A.-C., & Trăușan-Matu, Ș. (2022). Automatic Sarcasm Detection: Systematic Literature Review. Information, 13(8), 399. https://doi.org/10.3390/info13080399