
Saliency-Enabled Coding Unit Partitioning and Quantization Control for Versatile Video Coding


Abstract
:1. Introduction
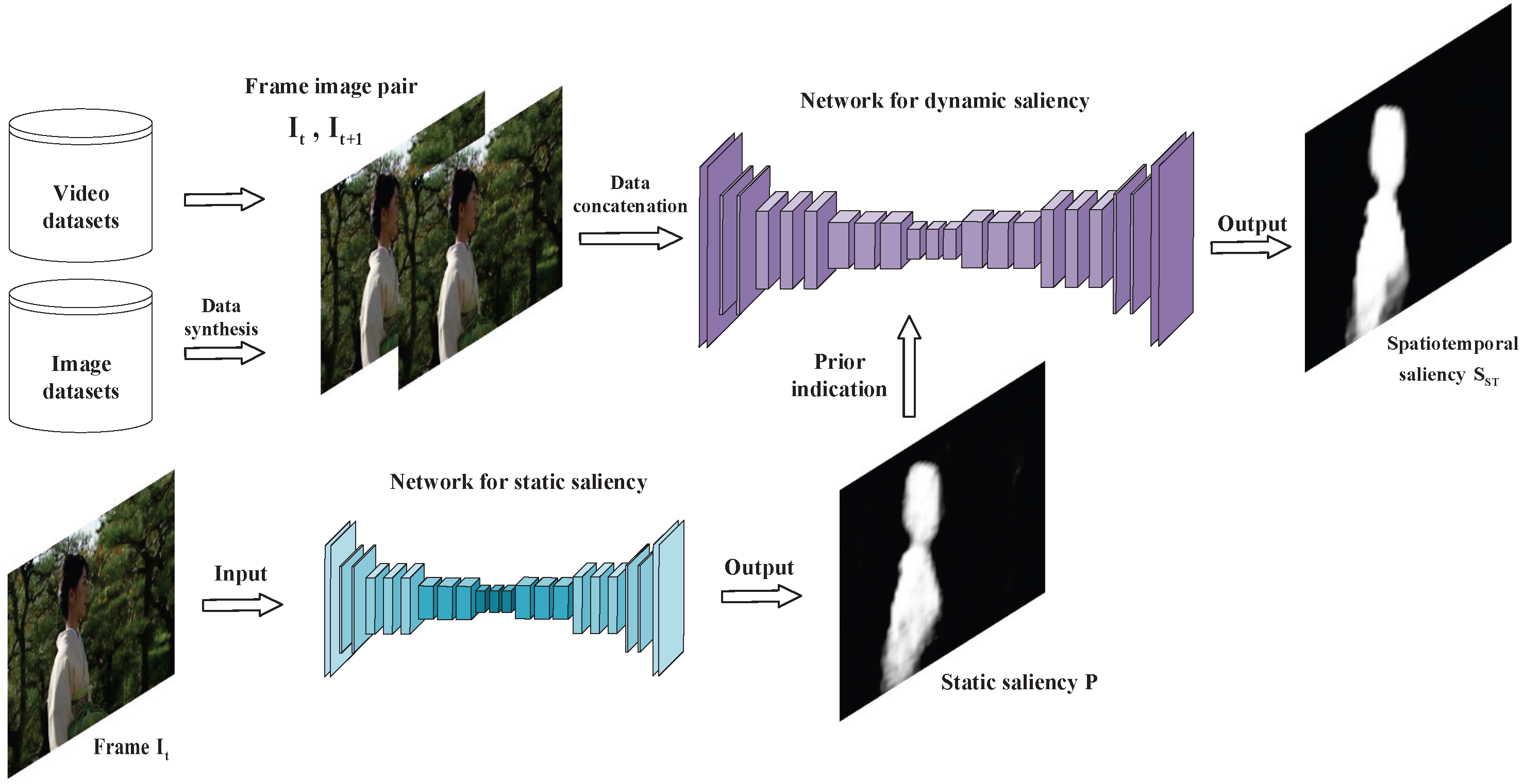
- First, we use a fully convolutional network to extract the static saliency results of video frames as a prior for another fully convolutional network consisting of frame pairs as input, and finally obtain accurate temporal saliency estimates. Unlike advanced video applications such as motion detection, video saliency requires no consideration of multi-scale oriented long-time spatiotemporal features. Short-time spatiotemporal features obtained using a combination of two full convolutional networks are sufficient without considering the complex optical flow computation and the construction of spatiotemporal fusion layers.
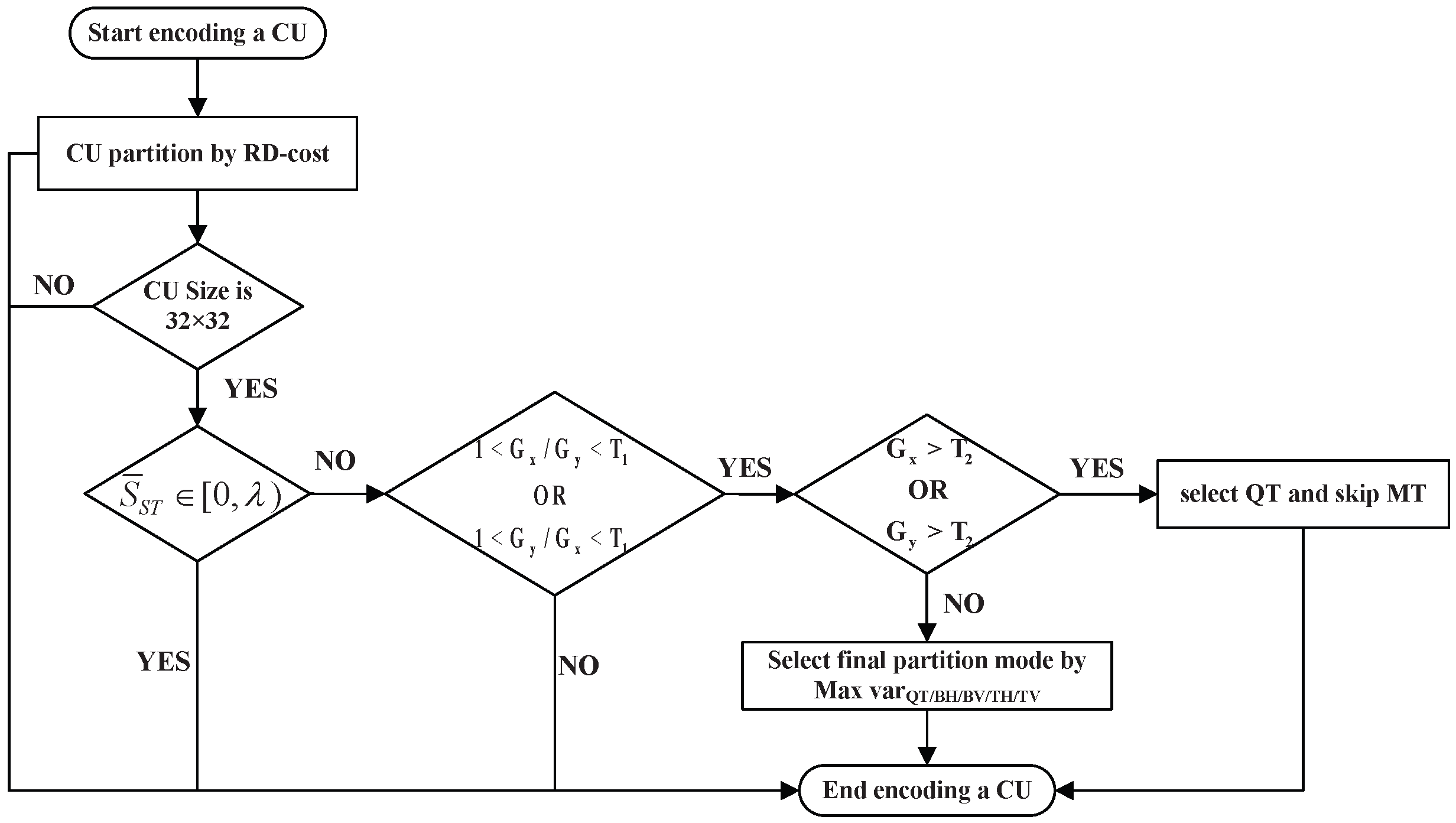
- Based on the obtained video saliency results, we propose a CU Splitting scheme, including the redetermination of QTMT Splitting depth and the execution decision of ISP. After the CU is determined to be a salient region and the CU size of 32 × 32 is satisfied, we use the Scharr operator to extract gradient features to decide whether to split this CU by QT, thus terminating the asymmetric rectangular partition. If the condition of the previous step is not satisfied, the variance of each sub-CU variance is calculated so that only one of the five QTMT partitions is selected for partitioning. If the CU is judged to be a non-salient region, the continuous division of the 32 × 32 block is directly terminated. For the ISP mode, if the CU is determined to be non-salient, decide whether to skip ISP mode in combination with the texture complexity of the block; if the block is determined to be salient, the CU is subjected to the ISP operation normally.
- After saliency detection and CU partitioning, we propose a quantization control scheme at the CU level. Firstly, the salient value of each CU is calculated based on the salient result obtained in the pre-processing stage, and then the saliency values of each CU is processed at a hierarchical level. Finally, the QP parameters of the CU are adjusted according to the set saliency levels. The three modules are progressive, thus reducing the computational complexity and bitrate without compromising the perceptual quality.
2. Related Works
2.1. Saliency Detection
2.2. CU Partitioning
2.3. Quantization Control
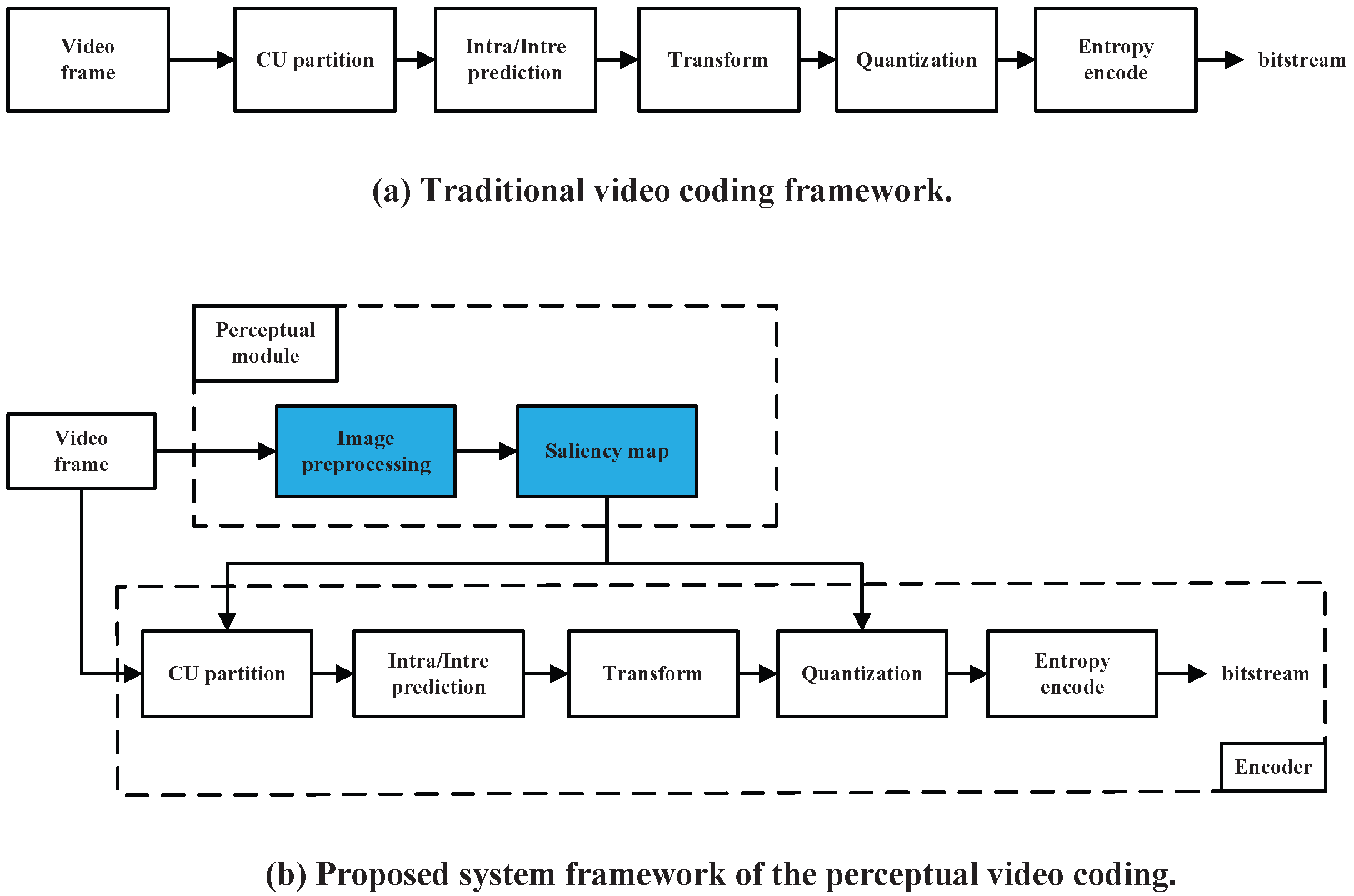
3. Proposed Perceptual Coding Scheme
3.1. System Overview
3.2. Implementation of the Visual Saliency Model
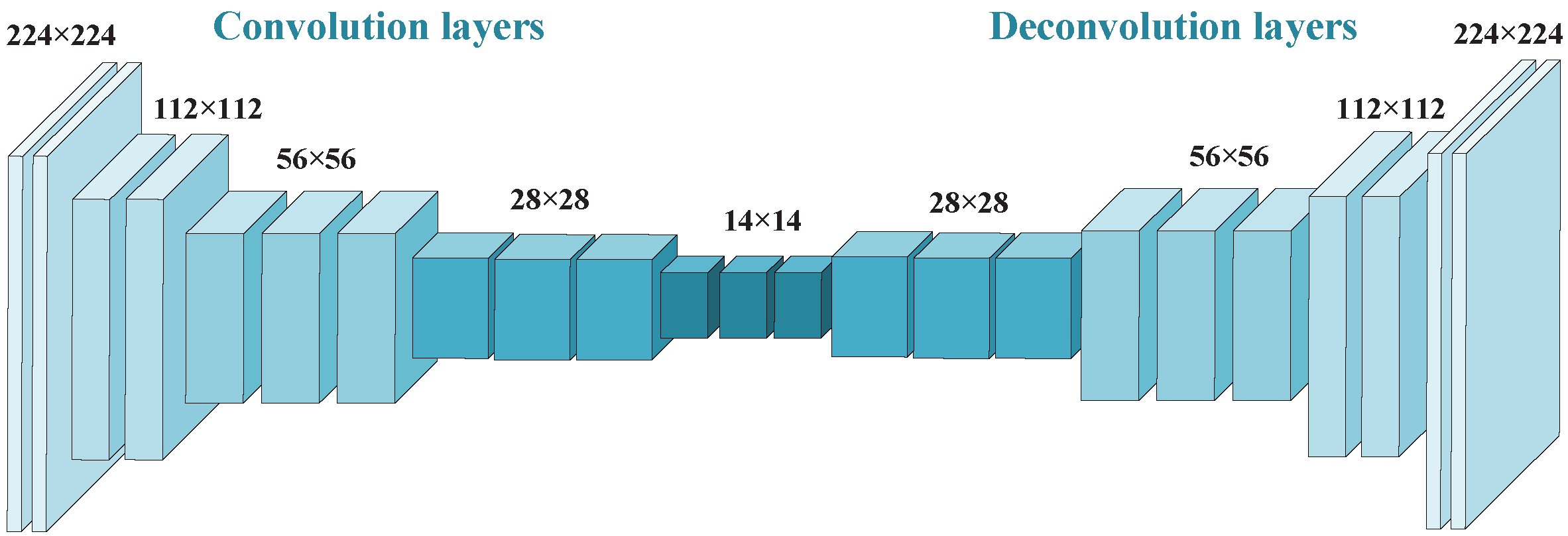
3.2.1. Deep Networks for Video Saliency Detection
3.2.2. Synthetic Video Data Generation
3.3. Perceptual Fast CU Partition
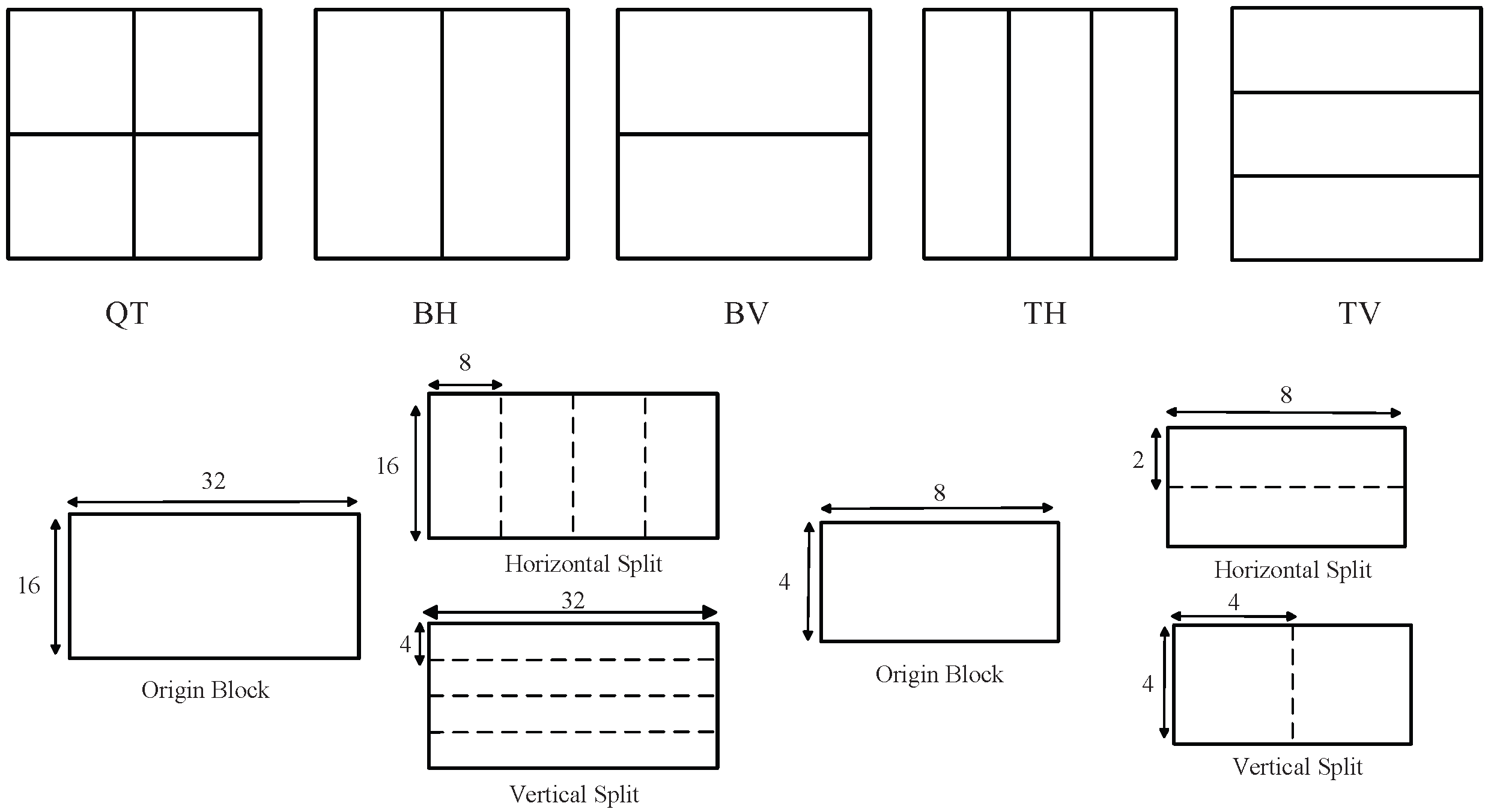
3.3.1. QTMT Partition Mode Decision
- Early Termination-Based Saliency
- B.
- Choosing QT Based on Gradient
- C.
- Choosing the Final Partition Mode Based on Variance of Variance
3.3.2. Early Termination of ISP
3.4. Saliency-Based Quantization Control Algorithm
| Algorithm 1 Saliency-based quantization control algorithm. |
|
4. Experimental Results
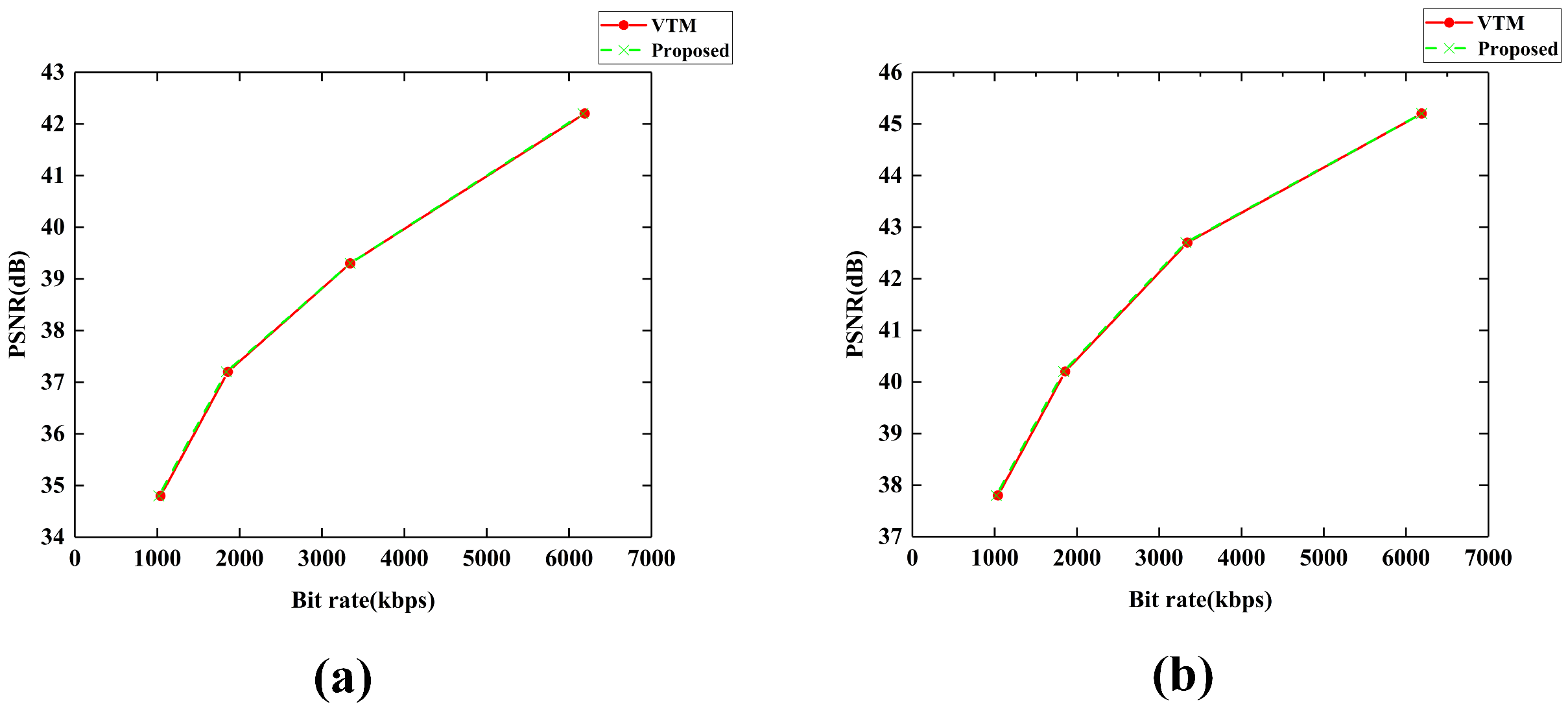
4.1. Objective Experimental Results
4.2. Subjective Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bross, B.; Chen, J.; Liu, S. Versatile Video Coding (Draft 5). Document: JVET-N1001-v10 Geneva, 19–27 March 2019. Available online: https://jvet-experts.org/ (accessed on 19 June 2022).
- Lim, S.C.; Kim, D.Y.; Kang, J. Simplification on Cross-Component Linear Model in Versatile Video Coding. Electronics 2020, 9, 1885. [Google Scholar] [CrossRef]
- Chen, J.; Ye, Y.; Kim, S. Algorithm description for Versatile Video Coding and Test Model 12 (VTM 12). Document: JVET-U2002-v1 Brussels, 6–15 January 2021. Available online: https://jvet-experts.org/ (accessed on 19 June 2022).
- Alshina, E.; Chen, J. Algorithm Description for Versatile Video Coding and Test Model 1 (VTM 1). Document JVET-Jl002-v2 San Diego, US, 10–20 April 2018. Available online: https://jvet-experts.org/ (accessed on 19 June 2022).
- Bae, S.H.; Kim, J.; Kim, M. HEVC-based perceptually adaptive video coding using a DCT-based local distortion detection probability model. IEEE Trans. Image Proc. 2016, 25, 3343–3357. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Lee, D.Y.; Jeong, S.; Cho, S. Perceptual Video Coding using Deep Neural Network Based JND Model. In Proceedings of the 2020 Data Compression Conference (DCC), Snowbird, UT, USA, 24–27 March 2020; p. 375. [Google Scholar]
- Xiang, G.; Jia, H.; Wei, K.; Yang, F.; Li, Y.; Xie, X. Rate SSIM Based Preprocessing for Video Coding. In Proceedings of the 2020 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 4–6 January 2020; pp. 1–5. [Google Scholar]
- Zheng, J.; Zhen, X. Perceptual based adaptive frequency weighting for subjective quality improvement. In Proceedings of the 2012 IEEE International Conference on Signal Processing, Communication and Computing (ICSPCC 2012), Hong Kong, China, 12–15 August 2012; pp. 349–352. [Google Scholar]
- Cheng, M.M.; Mitra, N.J.; Huang, X.; Torr, P.H.; Hu, S.M. Global contrast based salient region detection. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 569–582. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.; Zhang, L.; Lu, H.; Ruan, X.; Yang, M.H. Saliency Detection via Graph-Based Manifold Ranking. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3166–3173. [Google Scholar]
- Jiang, Z.; Davis, L.S. Submodular Salient Region Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2043–2050. [Google Scholar]
- Leborán, V.; García-Díaz, A.; Fdez-Vidal, X.R.; Pardo, X.M. Dynamic Whitening Saliency. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 893–907. [Google Scholar] [CrossRef]
- Fang, Y.; Wang, Z.; Lin, W.; Fang, Z. Video Saliency Incorporating Spatiotemporal Cues and Uncertainty Weighting. IEEE Trans. Image Process. 2014, 23, 3910–3921. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. arXiv 2014, arXiv:1406.2199v1. [Google Scholar]
- Imamoglu, N.; Oishi, Y.; Zhang, X.; Ding, G.; Fang, Y.; Kouyama, T.; Nakamura, R. Hyperspectral Image Dataset for Benchmarking on Salient Object Detection. In Proceedings of the 2018 Tenth International Conference on Quality of Multimedia Experience (QoMEX), Cagliari, Italy, 29 May–1 June 2018; pp. 1–3. [Google Scholar]
- Jiang, L.; Xu, M.; Wang, Z. Predicting video saliency with object-to-motion CNNand two-layer convolutional LSTM. arXiv 2017, arXiv:1709.06316. [Google Scholar]
- Shen, L.; Zhang, Z.; Liu, Z. Effective CU Size Decision for HEVC Intracoding. IEEE Trans. Image Process. 2014, 23, 4232–4241. [Google Scholar] [CrossRef]
- Yang, H.; Shen, L.; Dong, X.; Ding, Q.; An, P.; Jiang, G. Low-Complexity CTU Partition Structure Decision and Fast Intra Mode Decision for Versatile Video Coding. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1668–1682. [Google Scholar] [CrossRef]
- Huade, S.; Fan, L.; Huanbang, C. A fast CU size decision algorithm based on adaptive depth selection for HEVC encoder. In Proceedings of the 2014 International Conference on Audio, Language and Image Processing, Shanghai, China, 7–9 July 2014; pp. 143–146. [Google Scholar]
- Fu, T.; Zhang, H.; Mu, F.; Chen, H. Fast CU partitioning algorithm for H.266/VVC intra-frame coding. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 55–60. [Google Scholar]
- Xu, M.; Li, T.; Wang, Z.; Deng, X.; Yang, R.; Guan, Z. Reducing Complexity of HEVC: A Deep Learning Approach. IEEE Trans. Image Process. 2018, 27, 5044–5059. [Google Scholar] [CrossRef]
- Galpin, F.; Racapé, F.; Jaiswal, S.; Bordes, P.; Léannec, F.L.; François, E. CNN-Based Driving of Block Partitioning for Intra Slices Encoding. In Proceedings of the 2019 Data Compression Conference (DCC), Snowbird, UT, USA, 26–29 March 2019; pp. 162–171. [Google Scholar]
- Fischer, K.; Fleckenstein, F.; Herglotz, C.; Kaup, A. Saliency-Driven Versatile Video Coding for Neural Object Detection. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 1505–1509. [Google Scholar]
- Wang, M.; Zhang, T.; Liu, C.; Goto, S. Region-of-interest based dynamical parameter allocation for H.264/AVC encoder. In Proceedings of the Picture Coding Symposium, Chicago, IL, USA, 6–8 May 2009. [Google Scholar]
- Wang, X.; Su, L.; Huang, Q.; Liu, C. Visual perception based Lagrangian rate distortion optimization for video coding. In Proceedings of the 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 1653–1656. [Google Scholar]
- Wang, H.; Zhang, D.; Li, H. A rate-distortion optimized coding method for region of interest in scalable video coding. Adv. Multimedia 2015, 2015, 1–11. [Google Scholar] [CrossRef]
- Jiang, X.; Song, T.; Zhu, D.; Katayama, T.; Wang, L. Quality-Oriented Perceptual HEVC Based on the Spatiotemporal Saliency Detection Model. Entropy 2019, 21, 165. [Google Scholar] [CrossRef] [PubMed]
- Nami, S.; Pakdaman, F.; Hashemi, M.R. Juniper: A Jnd-Based Perceptual Video Coding Framework to Jointly Utilize Saliency and JND. In Proceedings of the 2020 IEEE International Conference on Multimedia Expo Workshops (ICMEW), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Wang, W.; Shen, J.; Shao, L. Video Salient Object Detection via Fully Convolutional Networks. IEEE Trans. Image Process. 2018, 27, 38–49. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, W.; Zisserman, A. Very deepconvolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H. ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Liu, T.; Sun, J. Learning to detect a salient object. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 353–367. [Google Scholar]
- Brox, T.; Malik, J. Object segmentation by long term analysis of point trajectories. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; pp. 282–295. [Google Scholar]
- Li, F.; Kim, T.; Humayun, A. Video segmentation by tracking many figure-ground segments. In Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV), Washington, DC, USA, 1–8 December 2013; pp. 2192–2199. [Google Scholar]
- Fan, Y.; Chen, J.; Sun, H.; Katto, J.; Jing, M. A Fast QTMT Partition Decision Strategy for VVC Intra Prediction. IEEE Access 2020, 8, 107900–107911. [Google Scholar] [CrossRef]
- Zhon, X.; Shi, G.; Zhon, W.; Duan, Z. Visual saliency-based fast intra coding algorithm for high efficiency video coding. J. Electron. Imaging 2017, 26, 013019. [Google Scholar]
- Liu, Z.; Dong, M.; Guan, X.H.; Zhang, M.; Wang, R. Fast ISP coding mode optimization algorithm based on CU texture complexity for VVC. EURASIP J. Image Video Process. 2021, 2021, 1–14. [Google Scholar] [CrossRef]
- Bossen, F.; Boyce, J.; Suehing, X.; Li, X.; Seregin, V. JVET Common Test Conditions and Software Reference Configurations for SDR Video. Document: JVET-N1010 Geneva, 19–27 March 2019. Available online: https://jvet-experts.org/ (accessed on 19 June 2022).
- Bjontegaard, G. Calculation of average PSNR difference between RD-curves. In Proceedings of the 13th VCEG-M33 Meeting, Austin, TX, USA, 2–4 April 2001. [Google Scholar]
- Zhao, T.; Huang, Y.; Feng, W.; Xu, Y. Efficient VVC Intra Prediction Based on Deep Feature Fusion and Probability Estimation. arXiv 2022, arXiv:2205.03587v1. [Google Scholar]
- Zhu, L.; Zhang, Y.; Li, N. Deep Learning-Based Intra Mode Derivation for Versatile Video Coding. arXiv 2022, arXiv:2204.04059v1. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Sequence | QPMD | ETOI | QPMD + ETOI | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BDBR (%) | BDPSNR | TS (%) | BDBR (%) | BDPSNR | TS (%) | BDBR (%) | BDPSNR | TS (%) | ||
| A1 | Tango2 | 1.33 | −0.051 | −43.98 | 0.04 | −0.032 | −7.35 | 1.52 | −0.097 | −53.53 |
| FoodMarket4 | 0.62 | −0.077 | −46.53 | 0.07 | −0.041 | −7.24 | 0.94 | −0.125 | −56.07 | |
| Campfire | 0.95 | −0.058 | −42.67 | 0.12 | −0.038 | −6.58 | 1.39 | −0.084 | −49.67 | |
| A2 | CatRobot | 1.05 | −0.045 | −49.07 | 0.05 | −0.035 | −6.11 | 1.21 | −0.109 | −56.66 |
| DaylightRoad2 | 0.43 | −0.036 | −41.19 | 0.09 | −0.029 | −8.13 | 0.77 | −0.086 | −50.73 | |
| ParkRunning3 | 0.82 | −0.109 | −49.66 | 0.12 | −0.032 | −8.45 | 1.28 | −0.069 | −57.64 | |
| B | BasketballDrive | 0.99 | −0.072 | −38.73 | 0.07 | −0.039 | −6.36 | 1.25 | −0.118 | −42.56 |
| BQTerrace | 1.72 | −0.083 | −52.11 | 0.12 | −0.027 | −4.47 | 1.68 | −0.094 | −48.19 | |
| Cactus | 2.25 | −0.114 | −42.06 | 0.14 | −0.032 | −5.39 | 2.37 | −0.127 | −48.91 | |
| Kimono | 1.44 | −0.041 | −51.47 | 0.08 | −0.019 | −6.23 | 1.83 | −0.096 | −59.46 | |
| ParkScene | 0.57 | −0.163 | −46.72 | 0.06 | −0.021 | −5.62 | 0.64 | −0.103 | −43.17 | |
| C | BasketballDrill | 1.12 | −0.027 | −47.38 | 0.24 | −0.029 | −9.41 | 1.26 | −0.085 | −52.11 |
| BQMall | 0.77 | −0.047 | −51.46 | 0.10 | −0.042 | −7.43 | 1.17 | −0.099 | −58.19 | |
| PartyScene | 1.09 | −0.052 | −37.62 | 0.08 | −0.023 | −8.21 | 1.15 | −0.087 | −41.56 | |
| RaceHorsesC | 1.34 | −0.057 | −50.52 | 0.04 | −0.020 | −5.72 | 1.22 | −0.083 | −48.39 | |
| D | BasketballPass | 1.16 | −0.093 | −44.27 | 0.09 | −0.018 | −6.07 | 0.84 | −0.108 | −52.01 |
| BlowingBubbles | 1.13 | −0.081 | −38.51 | 0.01 | −0.031 | −4.29 | 1.06 | −0.095 | −44.56 | |
| BQSquare | 0.36 | −0.059 | −32.75 | 0.18 | −0.029 | −6.08 | 0.57 | −0.091 | −39.24 | |
| RaceHorses | 0.54 | −0.032 | −36.87 | 0.15 | −0.025 | −5.39 | 0.49 | −0.074 | −41.65 | |
| E | FourPeople | 1.31 | −0.034 | −49.26 | 0.19 | −0.034 | −6.75 | 1.55 | −0.087 | −53.19 |
| Johnny | 2.07 | −0.063 | −47.39 | 0.12 | −0.029 | −6.22 | 1.97 | −0.094 | −50.24 | |
| KristenAndSara | 0.78 | −0.038 | −42.55 | 0.16 | −0.023 | −7.93 | 1.37 | −0.081 | −55.32 | |
| Average | 1.08 | −0.065 | −44.67 | 0.11 | −0.029 | −6.61 | 1.25 | −0.095 | −50.14 | |
| Class | Sequence | FQPD [35] | DFFPE [40] | Proposed QPMD | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BDBR (%) | TS (%) | TS/BDBR | BDBR (%) | TS (%) | TS/BDBR | BDBR (%) | TS (%) | TS/BDBR | ||
| A1 | Tango2 | - | - | - | 1.33 | −67.02 | −50.39 | 1.33 | −43.98 | −33.07 |
| FoodMarket4 | - | - | - | 0.97 | −53.17 | −54.81 | 0.62 | −46.53 | −75.05 | |
| Campfire | - | - | - | 1.56 | −57.32 | −36.74 | 0.95 | −42.67 | −44.92 | |
| A2 | CatRobot | - | - | - | 1.63 | −63.18 | −38.76 | 1.05 | −49.07 | −46.73 |
| DaylightRoad2 | - | - | - | 1.23 | −62.88 | −51.12 | 0.43 | −41.19 | −95.79 | |
| ParkRunning3 | - | - | - | 0.88 | −59.52 | −67.64 | 0.82 | −49.66 | −60.56 | |
| B | BasketballDrive | 3.28 | −59.35 | −18.09 | 1.53 | −60.35 | −39.44 | 0.99 | −38.73 | −39.12 |
| BQTerrace | 1.08 | −45.30 | −41.94 | 1.16 | −56.19 | −48.44 | 1.72 | −62.11 | −36.11 | |
| Cactus | 1.84 | −52.44 | −28.50 | 1.78 | −62.98 | −35.38 | 2.25 | −42.06 | −18.69 | |
| Kimono | 1.93 | −59.51 | −30.83 | 0.93 | −67.04 | −72.09 | 1.44 | −51.47 | −35.74 | |
| ParkScene | 1.26 | −51.84 | −41.14 | 1.47 | −59.66 | −40.59 | 0.57 | −46.72 | −81.96 | |
| C | BasketballDrill | 1.82 | −48.48 | −26.64 | 1.99 | −48.91 | −24.58 | 1.12 | −40.06 | −35.77 |
| BQMall | 1.87 | −52.47 | −28.06 | 2.02 | −51.22 | −25.36 | 0.77 | −51.46 | 66.83 | |
| PartyScene | 0.26 | −38.62 | −148.54 | 0.87 | −49.86 | −57.31 | 1.09 | −49.37 | −45.29 | |
| RaceHorsesC | 0.88 | −49.05 | −55.74 | 1.27 | −49.98 | −39.35 | 1.34 | −53.52 | −39.94 | |
| D | BasketballPass | 1.95 | −47.70 | −24.46 | 1.54 | −43.62 | −28.32 | 1.16 | −44.27 | −38.16 |
| BlowingBubbles | 0.47 | −40.35 | −85.85 | 0.91 | −39.74 | −43.67 | 1.13 | −38.51 | −34.08 | |
| BQSquare | 0.19 | −31.95 | −168.16 | 0.79 | −45.31 | −57.35 | 0.36 | −32.75 | −90.97 | |
| RaceHorses | 0.54 | −41.69 | −77.20 | 1.09 | −48.93 | −44.89 | 0.54 | −36.87 | −68.28 | |
| E | FourPeople | 2.70 | −57.57 | −21.32 | 1.97 | −58.45 | −29.67 | 1.31 | −49.26 | −37.60 |
| Johnny | 3.22 | −56.88 | −17.66 | 2.05 | −59.37 | −28.96 | 2.07 | −47.39 | −22.89 | |
| KristenAndSara | 2.78 | −55.11 | −19.82 | 1.90 | −58.21 | −30.64 | 0.78 | −34.55 | −44.29 | |
| Average | 1.63 | −49.27 | −30.23 | 1.40 | −55.59 | −39.71 | 1.08 | −45.10 | −41.75 | |
| Sequence | PSNR (dB) | Bitrate (kbps) | PSNR-Loss (%) | Bitrate-Reduction (%) | Time-Saving (%) | |||
|---|---|---|---|---|---|---|---|---|
| QP | VTM12.0 | Proposed | VTM12.0 | Proposed | ||||
| Tango2 (3840 × 2160) | 22 | 42.53 | 42.14 | 20,453.24 | 19,318.37 | 0.92 | 5.55 | 2.63 |
| 27 | 39.25 | 38.91 | 9862.77 | 9340.74 | 0.87 | 5.29 | 1.14 | |
| 32 | 36.86 | 36.67 | 5363.15 | 5124.33 | 0.52 | 4.45 | 0.82 | |
| 37 | 35.13 | 34.99 | 2147.82 | 2096.51 | 0.40 | 2.39 | −1.87 | |
| Average | 38.44 | 38.18 | 9456.7 | 8969.99 | 0.68 | 5.15 | 0.68 | |
| ParkScene (1920 × 1080) | 22 | 42.98 | 42.53 | 5969.62 | 5619.67 | 1.05 | 5.86 | 2.94 |
| 27 | 40.21 | 39.88 | 3123.58 | 2968.39 | 0.82 | 4.97 | 1.13 | |
| 32 | 37.59 | 37.35 | 1638.48 | 1576.05 | 0.64 | 3.81 | −1.47 | |
| 37 | 34.92 | 34.74 | 819.55 | 788.90 | 0.52 | 3.74 | −1.20 | |
| Average | 38.93 | 38.63 | 2887.81 | 2738.25 | 0.77 | 5.18 | 0.35 | |
| FourPeople (1280 × 720) | 22 | 45.54 | 45.27 | 3381.30 | 3074.26 | 0.59 | 9.08 | 0.25 |
| 27 | 43.21 | 43.03 | 2067.96 | 1982.41 | 0.42 | 4.14 | −1.82 | |
| 32 | 40.61 | 40.52 | 1278.90 | 1250.38 | 0.22 | 2.23 | −2.63 | |
| 37 | 37.71 | 37.65 | 782.88 | 766.05 | 0.16 | 2.15 | −3.19 | |
| Average | 41.77 | 41.62 | 1877.76 | 1768.28 | 0.36 | 6.33 | −1.85 | |
| BasketballDrill (832 × 480) | 22 | 43.52 | 43.29 | 2225.65 | 2101.77 | 0.53 | 5.57 | 4.21 |
| 27 | 40.38 | 40.21 | 1170.70 | 1112.98 | 0.42 | 4.93 | 0.77 | |
| 32 | 37.56 | 37.46 | 614.05 | 599.80 | 0.27 | 2.32 | −0.94 | |
| 37 | 35.13 | 35.07 | 339.40 | 331.65 | 0.17 | 2.28 | −1.36 | |
| Average | 39.15 | 39.01 | 1087.45 | 1036.55 | 0.36 | 4.68 | 0.67 | |
| RaceHorses (416 × 240) | 22 | 43.52 | 43.15 | 615.27 | 562.17 | 0.85 | 8.63 | 2.33 |
| 27 | 39.57 | 39.33 | 384.84 | 361.17 | 0.61 | 6.15 | 2.54 | |
| 32 | 35.88 | 35.72 | 223.62 | 215.26 | 0.45 | 3.74 | 1.18 | |
| 37 | 32.60 | 32.48 | 120.12 | 115.89 | 0.37 | 3.52 | 1.15 | |
| Average | 37.89 | 37.67 | 335.96 | 313.62 | 0.58 | 6.65 | 1.80 | |
| Total Average | 39.24 | 39.02 | 3129.15 | 2965.34 | 0.56 | 5.23 | 0.33 | |
| Sequence | Jiang [27] | Zhu [41] | Proposed | |||
|---|---|---|---|---|---|---|
| BS (%) | D-MOS | BS (%) | D-MOS | BS (%) | D-MOS | |
| BQTerrace | 5.9 | 0.1 | 6.8 | 0.1 | 7.2 | 0.1 |
| ParkScene | 3.3 | 0.1 | 4.1 | 0.1 | 4.5 | 0.0 |
| BasketballDrill | 1.8 | 0.3 | 0.9 | 0.2 | 3.7 | 0.1 |
| RaceHorsesC | 2.1 | 0.1 | 3.8 | 0.1 | 4.3 | 0.2 |
| Average | 3.3 | 0.2 | 3.9 | 0.1 | 4.9 | 0.1 |
| Class | Sequence | AI Configuration | LDP Configuration | RA Configuration | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BDPSNR | BS (%) | TS (%) | BDPSNR | BS (%) | TS (%) | BDPSNR | BS (%) | TS (%) | ||
| A1 | Tango2 | −0.134 | 3.23 | −46.24 | −0.142 | 3.16 | −45.36 | −0.145 | 3.07 | −45.24 |
| FoodMarket4 | −0.151 | 2.98 | −48.37 | −0.153 | 2.84 | −47.42 | −0.162 | 2.92 | −46.69 | |
| Campfire | −0.117 | 4.12 | −41.33 | −0.121 | 4.29 | −40.29 | −0.116 | 4.33 | −40.17 | |
| A2 | CatRobot | −0.145 | 3.64 | −49.26 | −0.154 | 3.13 | −48.64 | −0.147 | 3.27 | −48.92 |
| DaylightRoad2 | −0.093 | 3.71 | −46.11 | −0.095 | 3.52 | −44.88 | −0.099 | 3.36 | −44.54 | |
| ParkRunning3 | −0.082 | 3.66 | −48.87 | −0.092 | 3.91 | −49.29 | −0.103 | 3.67 | −46.76 | |
| B | BasketballDrive | −0.142 | 4.09 | −40.32 | −0.151 | 3.87 | −40.13 | −0.154 | 3.91 | −39.95 |
| BQTerrace | −0.163 | 5.18 | −45.57 | −0.172 | 4.85 | −44.61 | −0.165 | 4.64 | −45.07 | |
| Cactus | −0.158 | 4.37 | −45.24 | −0.164 | 4.16 | −44.54 | −0.154 | 3.96 | −44.27 | |
| Kimono | −0.147 | 3.92 | −56.14 | −0.151 | 3.61 | −54.32 | −0.157 | 3.95 | −54.12 | |
| ParkScene | −0.159 | 3.17 | −40.62 | −0.146 | 3.02 | −39.37 | −0.141 | 2.88 | −40.09 | |
| C | BasketballDrill | −0.098 | 2.61 | −44.03 | −0.083 | 2.48 | −45.12 | −0.086 | 2.65 | −44.83 |
| BQMall | −0.146 | 3.11 | −55.38 | −0.152 | 3.27 | −54.67 | −0.161 | 3.04 | −54.24 | |
| PartyScene | −0.062 | 3.64 | −52.74 | −0.071 | 3.38 | −54.58 | −0.073 | 3.17 | −55.21 | |
| RaceHorsesC | −0.153 | 4.23 | −54.16 | −0.144 | 3.81 | −53.36 | −0.135 | 3.92 | −52.85 | |
| D | BasketballPass | −0.135 | 2.97 | −48.39 | −0.142 | 2.64 | −47.72 | −0.145 | 2.57 | −46.39 |
| BlowingBubbles | −0.091 | 3.49 | −38.62 | −0.099 | 3.10 | −39.28 | −0.104 | 2.83 | −40.23 | |
| BQSquare | −0.124 | 4.52 | −40.27 | −0.135 | 4.24 | −39.31 | −0.127 | 4.01 | −38.56 | |
| RaceHorses | −0.113 | 3.17 | −43.25 | −0.123 | 3.06 | −42.15 | −0.131 | 3.23 | −41.37 | |
| E | FourPeople | −0.094 | 2.85 | −54.29 | −0.108 | 3.21 | −53.67 | −0.109 | 3.46 | −52.09 |
| Johnny | −0.105 | 4.21 | −48.81 | −0.112 | 3.98 | −47.39 | −0.121 | 3.74 | −46.86 | |
| KristenAndSara | −0.109 | 4.01 | −50.06 | −0.115 | 3.87 | −49.02 | −0.117 | 3.63 | −48.77 | |
| Average | −0.124 | 3.68 | −47.19 | −0.128 | 3.52 | −46.60 | −0.130 | 3.46 | −46.24 | |
| Scale | MOS |
|---|---|
| Excellent | 100 to 80 |
| Good | 80 to 60 |
| Fair | 60 to 40 |
| Poor | 40 to 20 |
| Bad | 20 to 0 |
| Class | Sequence | QP = 22 | QP = 27 | QP = 32 | QP = 37 |
|---|---|---|---|---|---|
| DMOS | DMOS | DMOS | DMOS | ||
| A1 | Tango2 | 0.06 | 0.08 | 0.16 | 0.14 |
| FoodMarket4 | 0.04 | 0.09 | 0.15 | 0.12 | |
| Campfire | 0.07 | 0.15 | 0.13 | 0.08 | |
| A2 | CatRobot | 0.09 | 0.12 | 0.08 | 0.15 |
| DaylightRoad2 | 0.07 | 0.06 | 0.09 | 0.11 | |
| ParkRunning3 | 0.06 | 0.04 | 0.11 | 0.06 | |
| B | BasketballDrive | 0.07 | 0.01 | 0.02 | 0.08 |
| BQTerrace | 0.06 | 0.08 | 0.09 | 0.02 | |
| Cactus | 0.08 | 0.17 | 0.08 | 0.12 | |
| Kimono | 0.11 | 0.13 | 0.15 | 0.17 | |
| ParkScene | 0.08 | 0.15 | 0.18 | 0.09 | |
| C | BasketballDrill | 0.07 | 0.08 | 0.08 | 0.15 |
| BQMall | 0.07 | 0.09 | 0.07 | 0.13 | |
| PartyScene | 0.07 | 0.08 | 0.09 | 0.15 | |
| RaceHorsesC | 0.08 | 0.10 | 0.12 | 0.13 | |
| D | BasketballPass | 0.09 | 0.07 | 0.03 | 0.07 |
| BlowingBubbles | 0.01 | 0.02 | 0.04 | 0.06 | |
| BQSquare | 0.03 | 0.06 | 0.07 | 0.08 | |
| RaceHorses | 0.09 | 0.08 | 0.09 | 0.11 | |
| E | FourPeople | 0.09 | 0.08 | 0.08 | 0.15 |
| Johnny | 0.08 | 0.01 | 0.03 | 0.09 | |
| KristenAndSara | 0.12 | 0.13 | 0.15 | 0.17 | |
| Average | 0.07 | 0.09 | 0.10 | 0.11 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Jiang, X.; Jin, J.; Song, T.; Yu, F.R. Saliency-Enabled Coding Unit Partitioning and Quantization Control for Versatile Video Coding. Information 2022, 13, 394. https://doi.org/10.3390/info13080394
Li W, Jiang X, Jin J, Song T, Yu FR. Saliency-Enabled Coding Unit Partitioning and Quantization Control for Versatile Video Coding. Information. 2022; 13(8):394. https://doi.org/10.3390/info13080394
Chicago/Turabian StyleLi, Wei, Xiantao Jiang, Jiayuan Jin, Tian Song, and Fei Richard Yu. 2022. "Saliency-Enabled Coding Unit Partitioning and Quantization Control for Versatile Video Coding" Information 13, no. 8: 394. https://doi.org/10.3390/info13080394
APA StyleLi, W., Jiang, X., Jin, J., Song, T., & Yu, F. R. (2022). Saliency-Enabled Coding Unit Partitioning and Quantization Control for Versatile Video Coding. Information, 13(8), 394. https://doi.org/10.3390/info13080394