
Toward Trust-Based Recommender Systems for Open Data: A Literature Review





Abstract
:1. Introduction
2. Open Data, Social Trust, and Recommender System
2.1. Open Data and Associated Concepts
2.2. Social Trust
2.3. Recommender System
3. Bibliometric Analyses of Recent Publications
3.1. Data Source and Tools for Analysis
- Listing 1. Query Codes.
| (TITLE-ABS-KEY (“open data”) AND TITLE-ABS-KEY (“recommender system”)) OR (TITLE-ABS-KEY (“open data”) AND TITLE-ABS-KEY (“trustworthy”)) OR (TITLE-ABS-KEY (“trust”) AND TITLE-ABS-KEY (“recommender system”)) AND PUBYEAR > 2006 |
3.2. Results of Bibliometric Analysis
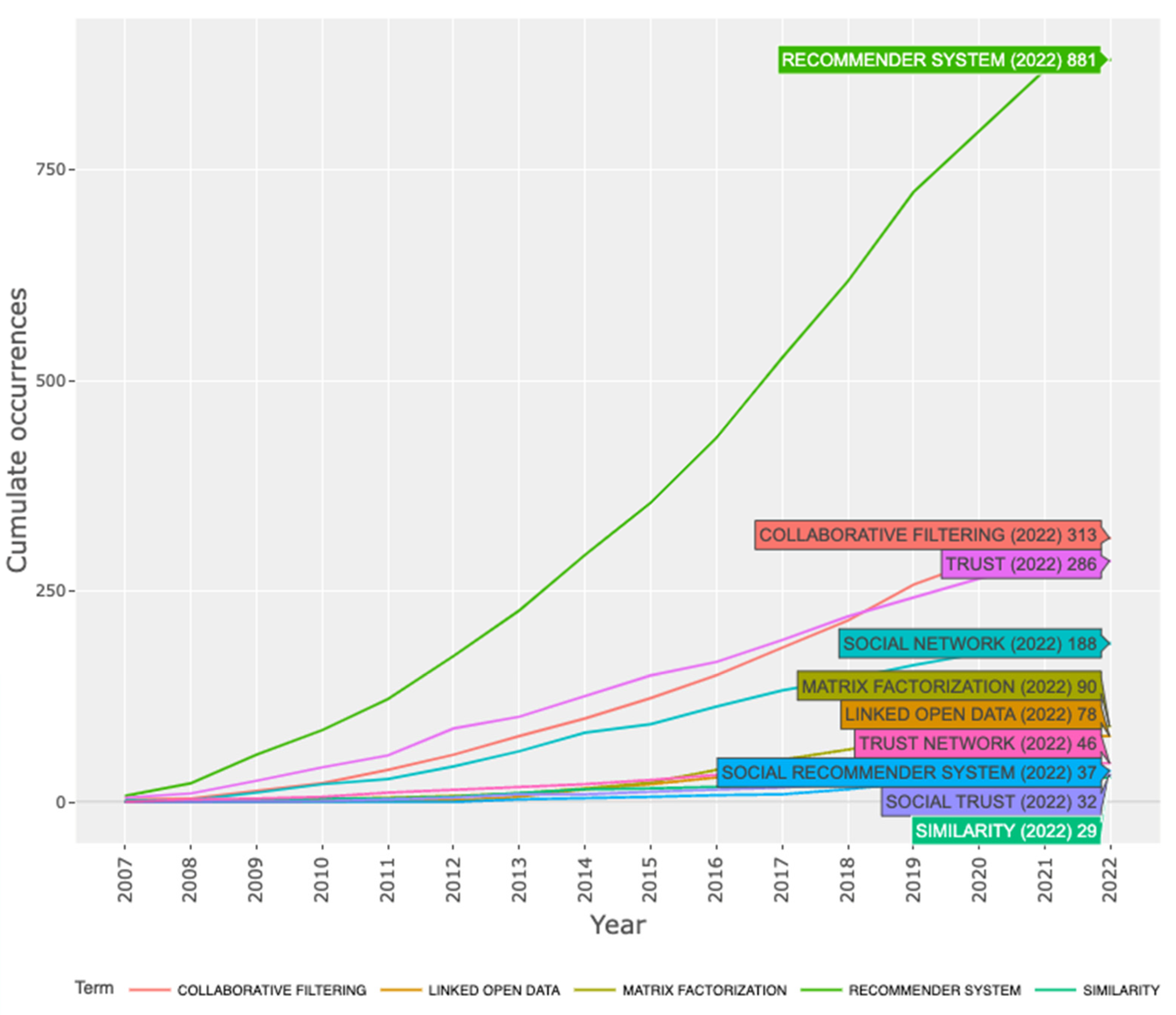
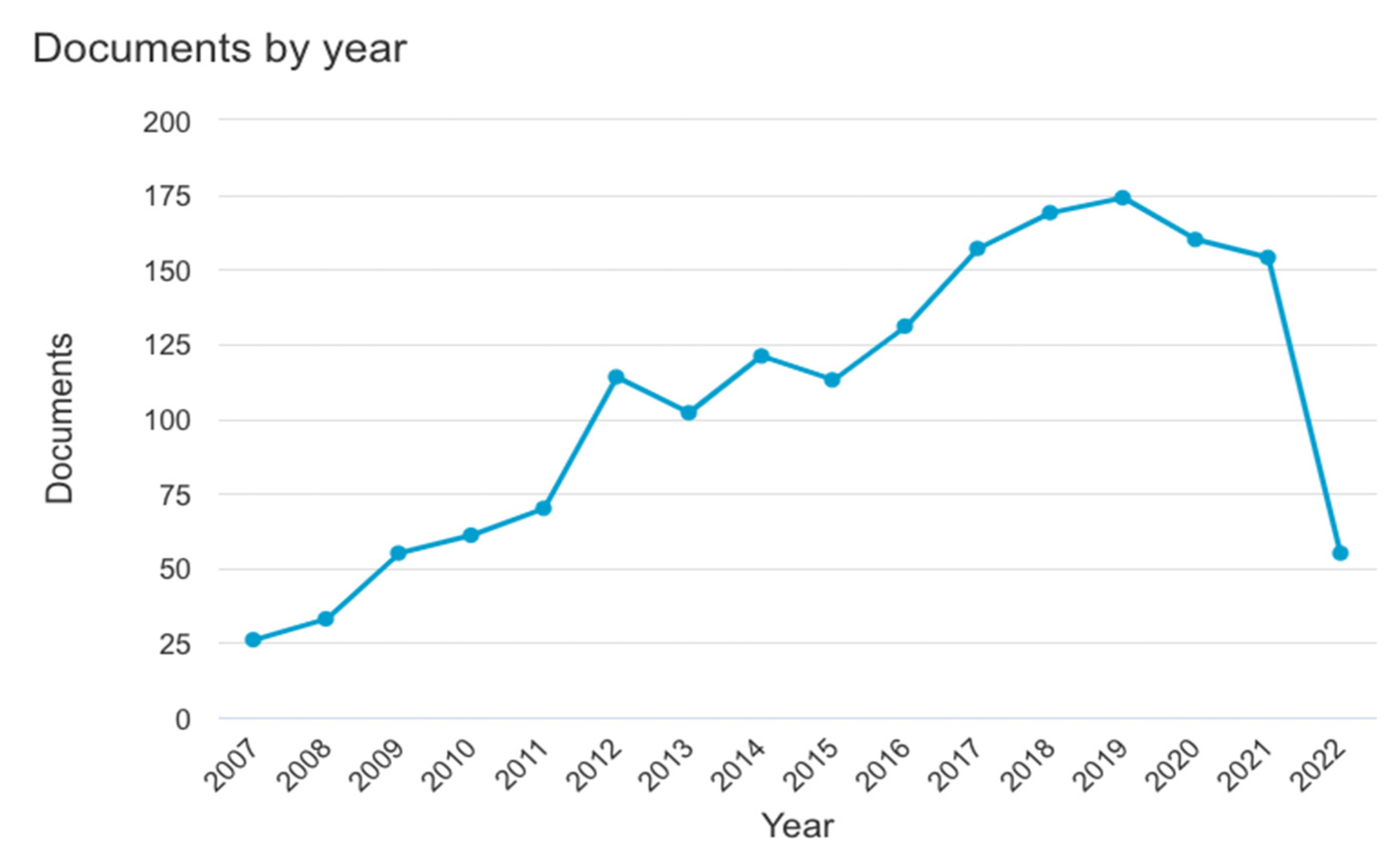
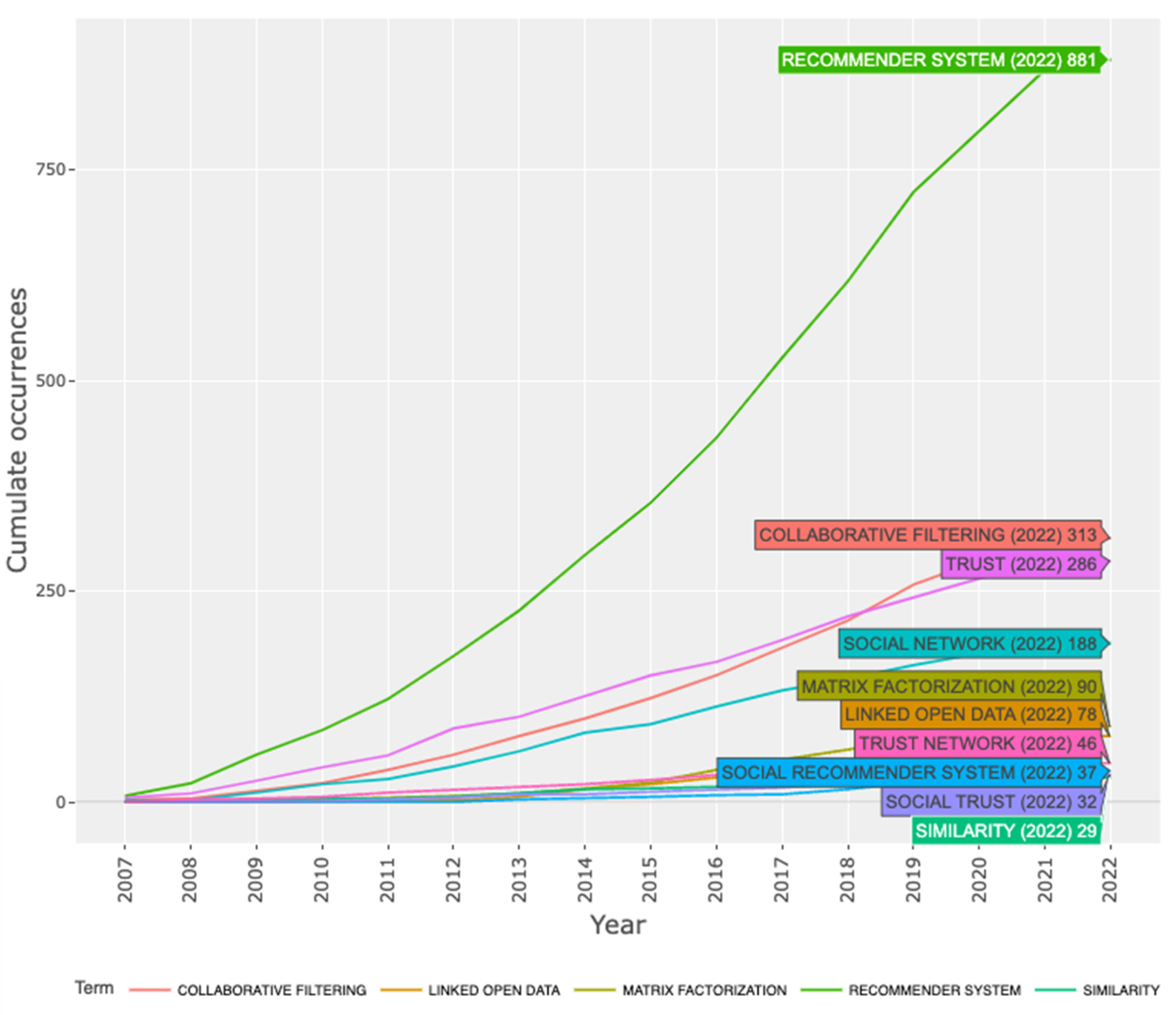
3.2.1. Timeline Analysis
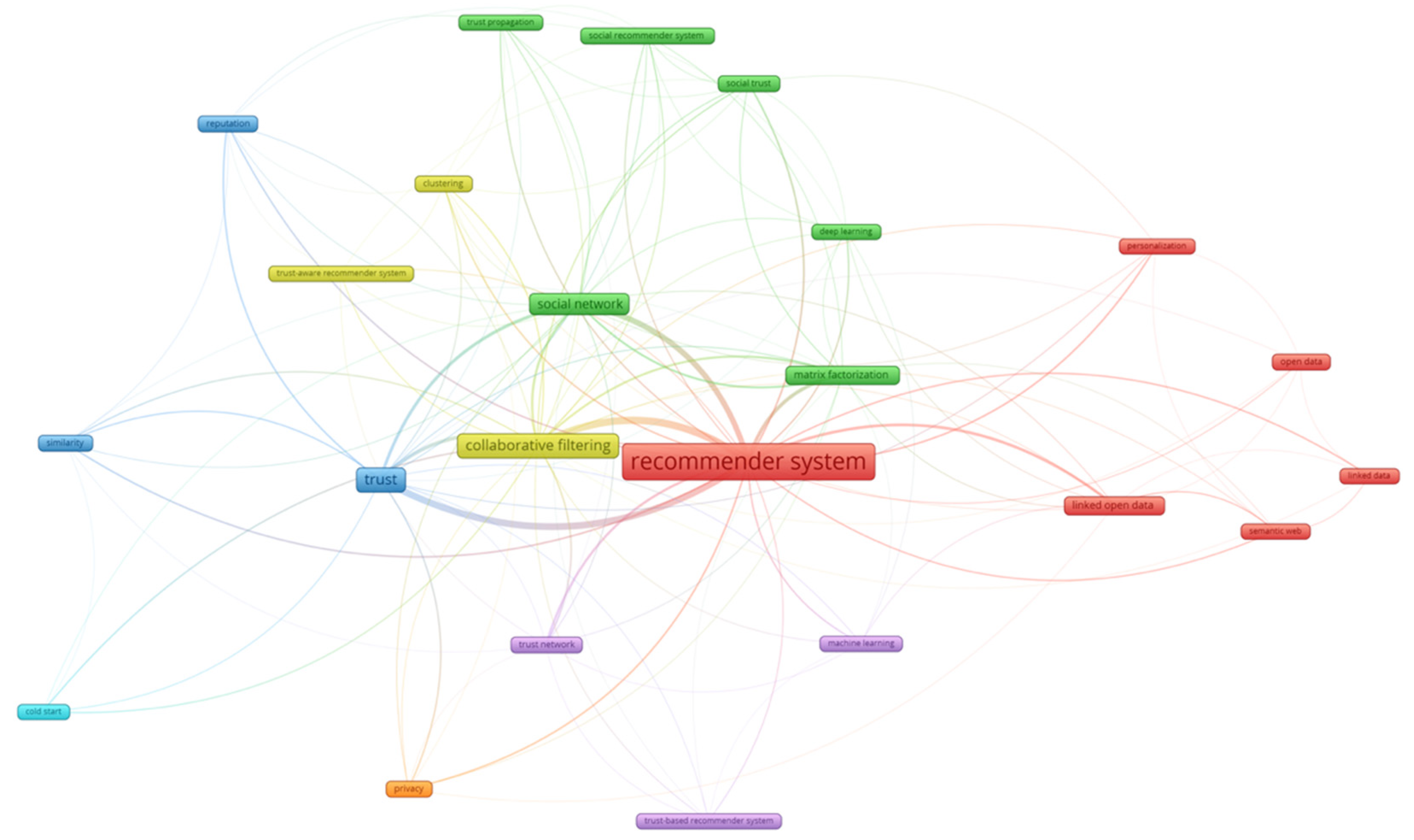
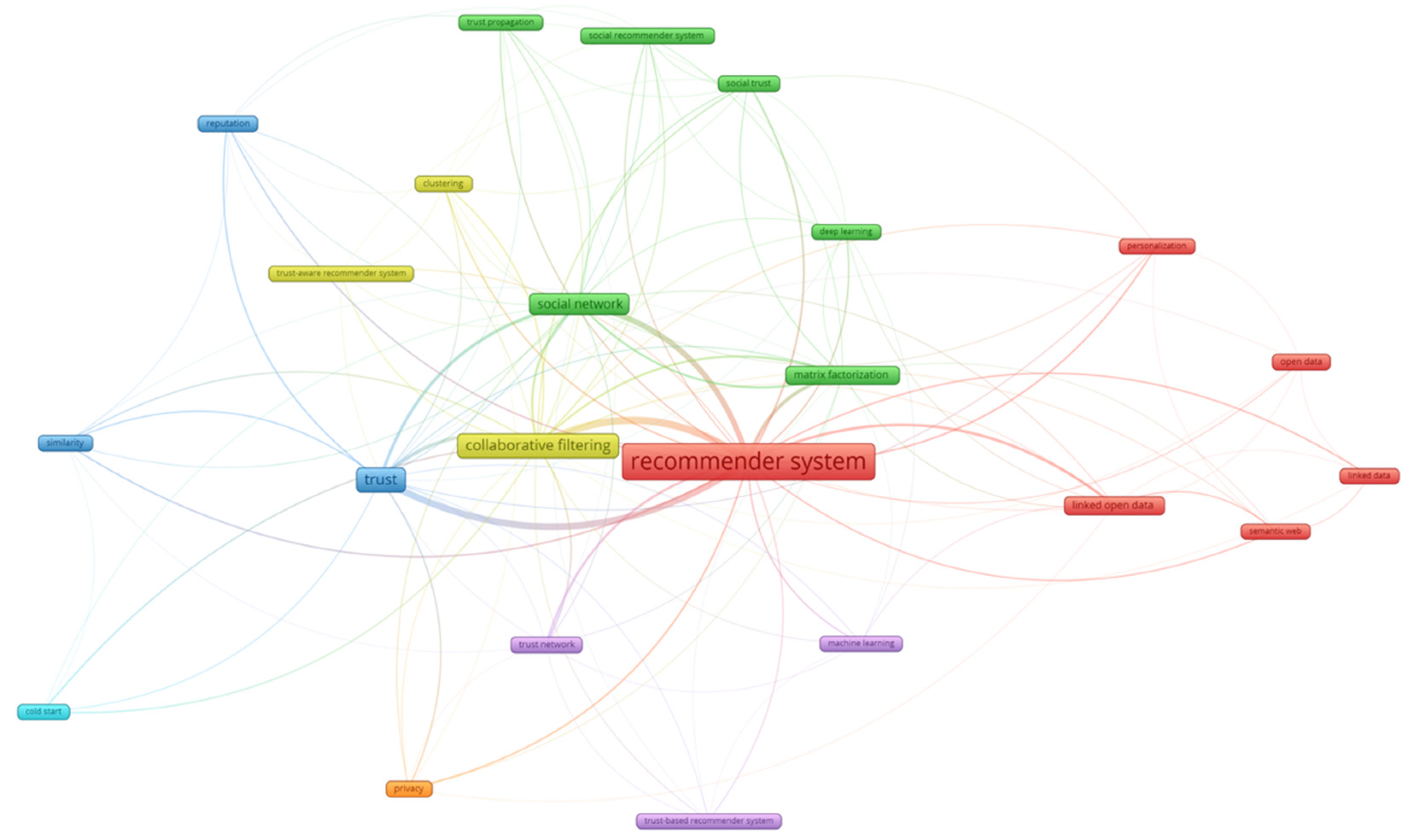
3.2.2. Keyword Co-Relationship Analysis
4. Discussion of Trends, Challenges, and Future Works
4.1. Social Trust and Recommender System
4.1.1. Trust-Based Recommender System
4.1.2. Trustworthiness of Recommender System
4.2. Open Data and Recommender System
4.3. Discussion of Potential Future Works
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jäger, B.; Bartenberger, M.; Leitner, P. A framework for semantic business process management in e-government. In Proceedings of the IADIS International Conference WWW/INTERNET 2013, Fort Worth, TX, USA, 22–25 October 2013; pp. 363–367. [Google Scholar]
- Zhu, Z.; Wulder, M.A.; Roy, D.P.; Woodcock, C.E.; Hansen, M.C.; Radeloff, V.C.; Healey, S.P.; Schaaf, C.; Hostert, P.; Strobl, P.; et al. Benefits of the free and open Landsat data policy. Remote Sens. Environ. 2019, 224, 382–385. [Google Scholar] [CrossRef]
- Science International. Open Data in a Big Data World; Science International: Paris, France, 2015. [Google Scholar]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- NASA; NOAA; USGS. Global Change Data and Information System (GCDIS): A Draft Tri-Agency Implementation Plan; National Aeronautics and Space Administration (NASA); National Oceanic and Atmospheric Administration (NOAA); U.S. Geological Survey (USGS): Washington, DC, USA, 1992. [Google Scholar]
- OECD. OECD Principles and Guidelines for Access to Research Data from Public Funding; OECD Publishing: Paris, France, 2007. [Google Scholar]
- G8. G8 Open Data Charter and Technical Annex. 2013. Available online: https://opendatacharter.net/g8-open-data-charter/ (accessed on 19 May 2022).
- European Union. Riding the Wave: How Europe Can Gain from the Rising Tide of Scientific Data. 2010. Available online: https://www.fosteropenscience.eu/content/riding-wave-how-europe-can-gain-rising-tide-scientific-data (accessed on 19 May 2022).
- Ma, X.; Asch, K.; Laxton, J.L.; Richard, S.M.; Asato, C.G.; Carranza, E.J.M.; van der Meer, F.D.; Wu, C.; Duclaux, G.; Wakita, K. Data exchange facilitated. Nat. Geosci. 2011, 4, 814. [Google Scholar] [CrossRef] [Green Version]
- International Science Council. Open Science for the 21st Century. 2020. Available online: https://council.science/publications/open-science-for-the-21st-century/ (accessed on 19 May 2022).
- Berners-Lee, T.; Hendler, J.; Lassila, O. The semantic web. Sci. Am. 2001, 284, 34–43. [Google Scholar] [CrossRef]
- Gutiérrez, C.; Sequeda, J.F. Knowledge graphs. Commun. ACM 2021, 64, 96–104. [Google Scholar] [CrossRef]
- Hitzler, P. A review of the semantic web field. Commun. ACM 2021, 64, 76–83. [Google Scholar] [CrossRef]
- Chaudhri, V.; Baru, C.; Chittar, N.; Dong, X.; Genesereth, M.; Hendler, J.; Kalyanpur, A.; Lenat, D.; Sequeda, J.; Vrandečić, D.; et al. Knowledge Graphs: Introduction, History and, Perspectives. AI Mag. 2022, 43, 17–29. [Google Scholar]
- Bizer, C.; Heath, T.; Berners-Lee, T. Linked data: The story so far. In Semantic Services, Interoperability and Web Applications: Emerging Concepts; IGI Global: Hershey, PA, USA, 2011; pp. 205–227. [Google Scholar]
- Bizer, C.; Vidal, M.E.; Skaf-Molli, H. Linked open data. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Berners-Lee, T. Linked Data Design Issues. Available online: https://www.w3.org/DesignIssues/LinkedData.html (accessed on 19 May 2022).
- Brickley, D.; Burgess, M.; Noy, N. Google Dataset Search: Building a search engine for datasets in an open Web ecosystem. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 1365–1375. [Google Scholar]
- Open Data Barometer. The Open Data Barometer: A Global Measure of How Governments are Publishing and Using Open Data for Accountability, Innovation and Social Impact. 2022. Available online: https://opendatabarometer.org (accessed on 19 May 2022).
- Loscio, B.F.; Burle, C.; Calegari, N. (Eds.) Data on the Web Best Practices. 2017. Available online: https://www.w3.org/TR/dwbp/ (accessed on 19 May 2022).
- Radford, T. Haiti 10 Years Later: Growth of a Humanitarian Mapping Community. 2020. Available online: https://www.hotosm.org/updates/haiti-10-years-later-growth-of-a-crisis-mapping-community/ (accessed on 19 May 2022).
- Ortiz-Ospina. The Rise of Social Media. 2019. Available online: https://ourworldindata.org/rise-of-social-media (accessed on 19 May 2022).
- Statista. Number of Monthly Active Facebook Users Worldwide as of 1st Quarter 2022. Available online: https://www.statista.com/statistics/264810/number-of-monthly-active-facebook-users-worldwide/ (accessed on 19 May 2022).
- Verducci, S.; Schröe, A. Social Trust. In Encyclopedia of Database Systems; Springer: New York, NY, USA, 2010. [Google Scholar] [CrossRef]
- Golbeck, J. Computing with Social Trust; Springer: London, UK, 2009. [Google Scholar]
- MacKenzie, I.; Meyer, C.; Noble, S. How Retailers Can Keep Up with Consumers. 2018. Available online: https://www.mckinsey.com/industries/retail/our-insights/how-retailers-can-keep-up-with-consumers (accessed on 19 May 2022).
- Isinkaye, F.; Folajimi, Y.; Ojokoh, B. Recommendation systems: Principles, methods and evaluation. Egypt. Inform. J. 2015, 16, 261–273. [Google Scholar] [CrossRef] [Green Version]
- Althbiti, A.; Ma, X. Collaborative Filtering. In Proceedings of the Encyclopedia of Big Data; Schintler, L.A., McNeely, C.L., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 1–4. [Google Scholar] [CrossRef] [Green Version]
- Rocca, B. Introduction to Recommender Systems. 2019. Available online: https://towardsdatascience.com/introduction-to-recommender-systems-6c66cf15ada (accessed on 19 May 2022).
- Thorat, P.B.; Goudar, R.M.; Barve, S. Survey on Collaborative Filtering, Content-based Filtering and Hybrid Recommendation System. Int. J. Comput. Appl. 2015, 110, 31–36. [Google Scholar]
- Li, C. Scopus Publication Records for a Literature Review on Recommender System, Social Trust, and Open Data. 2022. Available online: https://github.com/CHenhao-lI1995/lit-record-2022 (accessed on 2 June 2022).
- Perianes-Rodriguez, A.; Waltman, L.; Van Eck, N.J. Constructing bibliometric networks: A comparison between full and fractional counting. J. Informetr. 2016, 10, 1178–1195. [Google Scholar] [CrossRef] [Green Version]
- Aria, M.; Cuccurullo, C. bibliometrix: An R-tool for comprehensive science mapping analysis. J. Informetr. 2017, 11, 959–975. [Google Scholar] [CrossRef]
- Chen, C. Mapping Scientific Frontiers: The Quest for Knowledge Visualization; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Ozsoy, M.G.; Polat, F. Trust based recommendation systems. In Proceedings of the 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Niagara, ON, Canada, 25–28 August 2013. [Google Scholar] [CrossRef]
- Shokeen, J.; Rana, C. A trust and semantic based approach for social recommendation. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 10289–10303. [Google Scholar] [CrossRef]
- Rrmoku, K.; Selimi, B.; Ahmedi, L. An Approach of Utilizing Exponential Rank and In-Inverse Closeness Centrality on Recommender Systems. In Proceedings of the 2021 International Conference on Information Technologies (InfoTech), Varna, Bulgaria, 16–17 September 2021. [Google Scholar] [CrossRef]
- Peng, T.C.; Chou, S.-c.T. iTrustU: A blog recommender system based on multi-faceted trust and collaborative filtering. In Proceedings of the 2009 ACM Symposium on Applied Computing, Honolulu, HI, USA, 8–12 March 2009. [Google Scholar] [CrossRef]
- Dong, M.; Yao, L.; Wang, X.; Xu, X.; Zhu, L. Adversarial dual autoencoders for trust-aware recommendation. Neural Comput. Appl. 2021. [Google Scholar] [CrossRef]
- Jha, G.K.; Gaur, M.; Ranjan, P.; Thakur, H.K. A survey on trustworthy model of recommender system. Int. J. Syst. Assur. Eng. Manag. 2021. [Google Scholar] [CrossRef]
- Xue, H.; Li, F.; Seo, H.; Pluretti, R. Trust-Aware Review Spam Detection. In Proceedings of the 2015 IEEE Trustcom/BigDataSE/ISPA, Helsinki, Finland, 20–22 August 2015. [Google Scholar] [CrossRef]
- Stitini, O.; Kaloun, S.; Bencharef, O. Towards the Detection of Fake News on Social Networks Contributing to the Improvement of Trust and Transparency in Recommendation Systems: Trends and Challenges. Information 2022, 13, 128. [Google Scholar] [CrossRef]
- Torkamaan, H.; Barbu, C.M.; Ziegler, J. How can they know that? A study of factors affecting the creepiness of recommendations. In Proceedings of the 13th ACM Conference on Recommender Systems, Copenhagen, Denmark, 16–20 September 2019. [Google Scholar] [CrossRef]
- Zarzour, H.; Jararweh, Y.; Al-Sharif, Z.A. An Effective Model-Based Trust Collaborative Filtering for Explainable Recommendations. In Proceedings of the 2020 11th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 7–9 April 2020; pp. 238–242. [Google Scholar] [CrossRef]
- Parvathy, M.; Sundarakantham, K.; Shalinie, S.M.; Dhivya, C. An efficient privacy protection mechanism for recommendation using hybrid transformation technique. In Proceedings of the 2014 Sixth International Conference on Advanced Computing (ICoAC), Chennai, India, 17–19 December 2014. [Google Scholar] [CrossRef]
- Wiencierz, C.; Lünich, M. Trust in open data applications through transparency. New Media Soc. 2020. [Google Scholar] [CrossRef]
- Yochum, P.; Chang, L.; Gu, T.; Zhu, M. Linked Open Data in Location-Based Recommendation System on Tourism Domain: A Survey. IEEE Access 2020, 8, 16409–16439. [Google Scholar] [CrossRef]
- Devaraju, A.; Berkovsky, S. Do users matter?: The contribution of user-driven feature weights to open dataset recommendations. In Proceedings of the Poster Track of the 11th ACM Conference on Recommender Systems (RecSys 2017), Como, Italy, 27–31 August 2018. [Google Scholar]
- Sornkongdang, N.; Sanglerdsinlapachai, N.; Anutariya, C. DataCat: Attention-based Open Government Data (OGD) Category Recommendation Framework. In Proceedings of the 2021 16th International Joint Symposium on Artificial Intelligence and Natural Language Processing (iSAI-NLP), Ayutthaya, Thailand, 21–23 December 2021. [Google Scholar] [CrossRef]
- Peng, G.; Lacagnina, C.; Downs, R.; Ganske, A.; Ramapriyan, H.; Ivánová, I.; Wyborn, L.; Jones, D.; Bastin, L.; Shie, C.; et al. Global Community Guidelines for Documenting, Sharing, and Reusing Quality Information of Individual Digital Datasets. Data Sci. J. 2022, 21. [Google Scholar] [CrossRef]
- Lindman, J.; Kinnari, T.; Rossi, M. Business roles in the emerging open-data ecosystem. IEEE Softw. 2015, 33, 54–59. [Google Scholar] [CrossRef] [Green Version]
- Welle Donker, F.; van Loenen, B. How to assess the success of the open data ecosystem? Int. J. Digit. Earth 2017, 10, 284–306. [Google Scholar] [CrossRef] [Green Version]
- Kale, A.; Nguyen, T.; Harris, F.C.; Li, C.; Zhang, J.; Ma, X. Provenance documentation to enable explainable and trustworthy AI: 568 A literature review. Data Intell. 2022, 1–41. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| i1 | i2 | i3 | |
|---|---|---|---|
| u1 | 5 | 3 | 2 |
| u2 | 4 | 5 | 4 |
| u3 | 4 | 2 | 1 |
| Metadata Element | Utility in Trust-Based Recommender System | Utility in Content-Based Recommender System |
|---|---|---|
| description | Y | Y |
| name | N | Y |
| creator | Y | Y |
| citation | Y | Y |
| funder | Y | Y |
| hasPart | N | N |
| identifier | Y | N |
| isAccessibleForFree | N | Y |
| keywords | N | Y |
| license | Y | Y |
| measurementTechnique | Y | Y |
| sameAs | N | N |
| spatialCoverage | Y | Y |
| temporalCoverage | Y | Y |
| variableMeasured | Y | Y |
| version | Y | N |
| url | Y | N |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Zhang, J.; Kale, A.; Que, X.; Salati, S.; Ma, X. Toward Trust-Based Recommender Systems for Open Data: A Literature Review. Information 2022, 13, 334. https://doi.org/10.3390/info13070334
Li C, Zhang J, Kale A, Que X, Salati S, Ma X. Toward Trust-Based Recommender Systems for Open Data: A Literature Review. Information. 2022; 13(7):334. https://doi.org/10.3390/info13070334
Chicago/Turabian StyleLi, Chenhao, Jiyin Zhang, Amruta Kale, Xiang Que, Sanaz Salati, and Xiaogang Ma. 2022. "Toward Trust-Based Recommender Systems for Open Data: A Literature Review" Information 13, no. 7: 334. https://doi.org/10.3390/info13070334
APA StyleLi, C., Zhang, J., Kale, A., Que, X., Salati, S., & Ma, X. (2022). Toward Trust-Based Recommender Systems for Open Data: A Literature Review. Information, 13(7), 334. https://doi.org/10.3390/info13070334