
User Evaluation and Metrics Analysis of a Prototype Web-Based Federated Search Engine for Art and Cultural Heritage




Abstract
1. Introduction
- RQ1: Is it feasible to create a search engine for Arts and Cultural Heritage that uses content openly available to different entities, and what are the challenges that need to be overcome?
- RQ2: What features and technologies contribute most to the effectiveness of such a software system, both from a functionality perspective and from a user experience perspective?
- RQ3: Is the functionality provided by such a platform considered useful by the stakeholders, and can this platform cover the existing needs in the field of Arts and Culture?
2. Methodology
2.1. Research Design
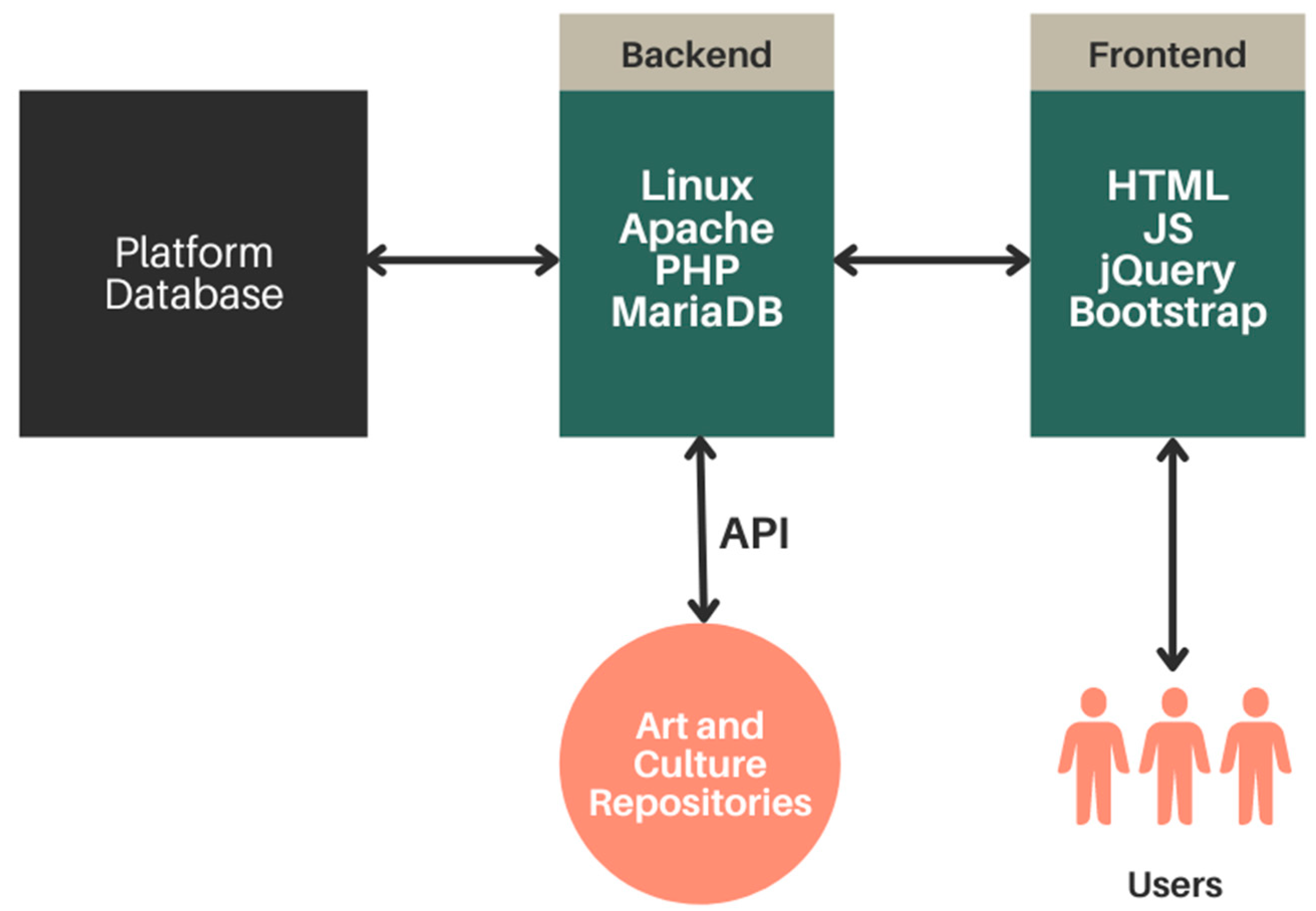
2.2. Development of the Federated Search Engine
2.2.1. Core Functionality of the FSE
- Europeana Collections
- Harvard Art Museums
- The Metropolitan Museum of Art
- The National Gallery of Denmark
- Artsy
- Crossref
- The Open Library
2.2.2. Result Aggregation and Homogenization
2.2.3. Additional Technologies
- Text to Speech functionality.
- The ability to preform a Voice Search
- The ability to preform Visual Search
- A simple User System
2.2.4. User Interface and Aesthetics
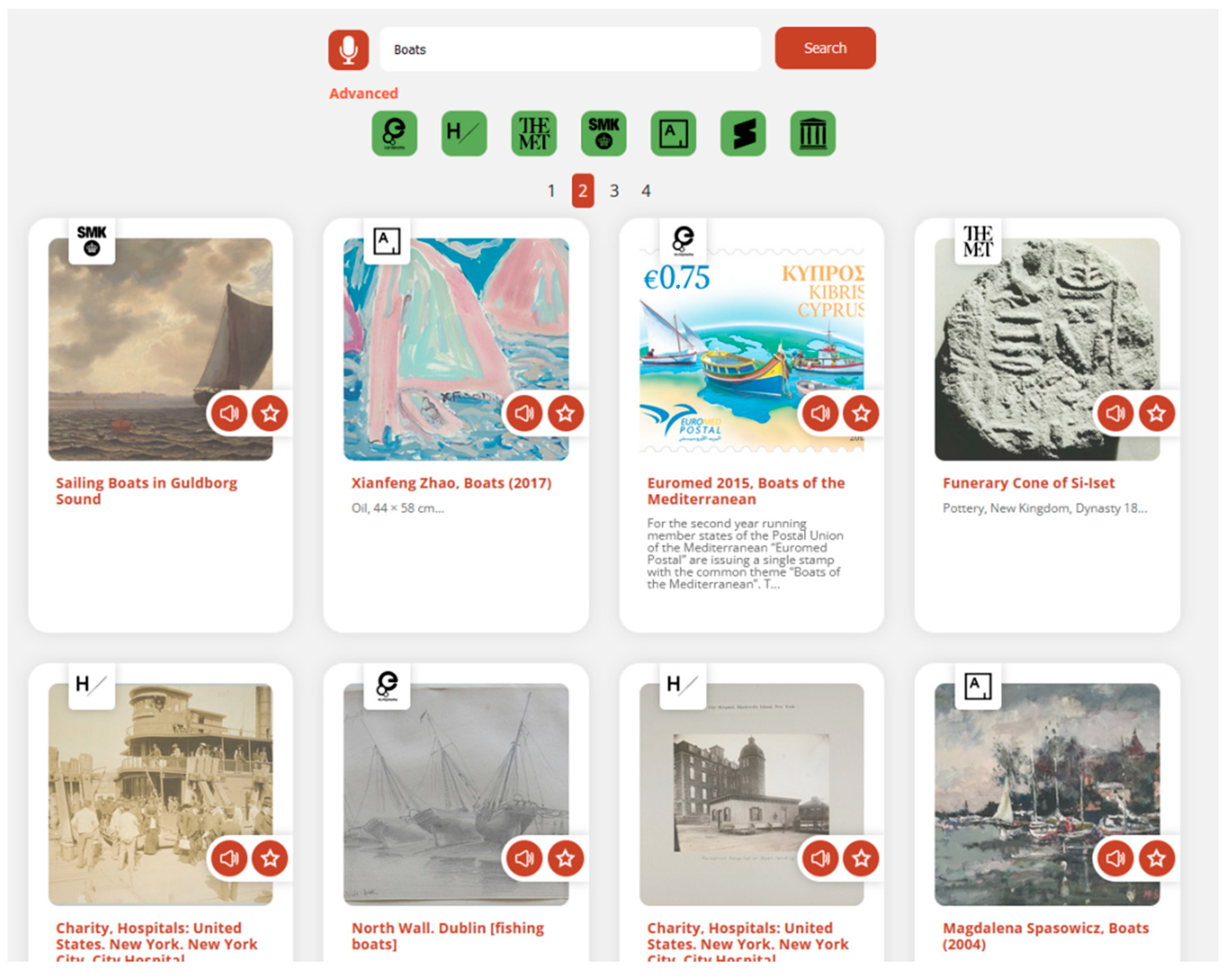
- The front page
- A page listing search results.
- A presentation page for each search result
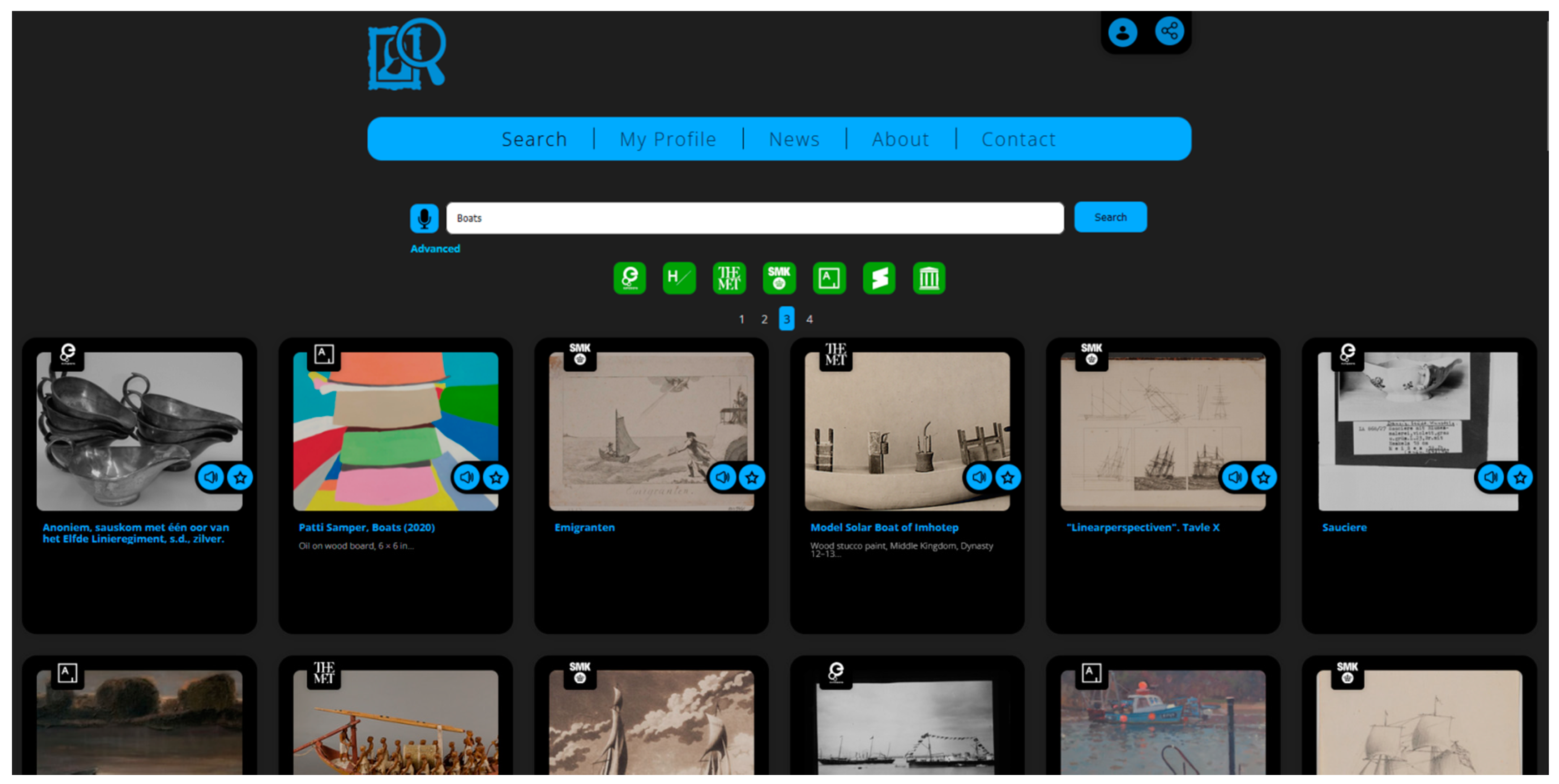
- A visual search results’ list page
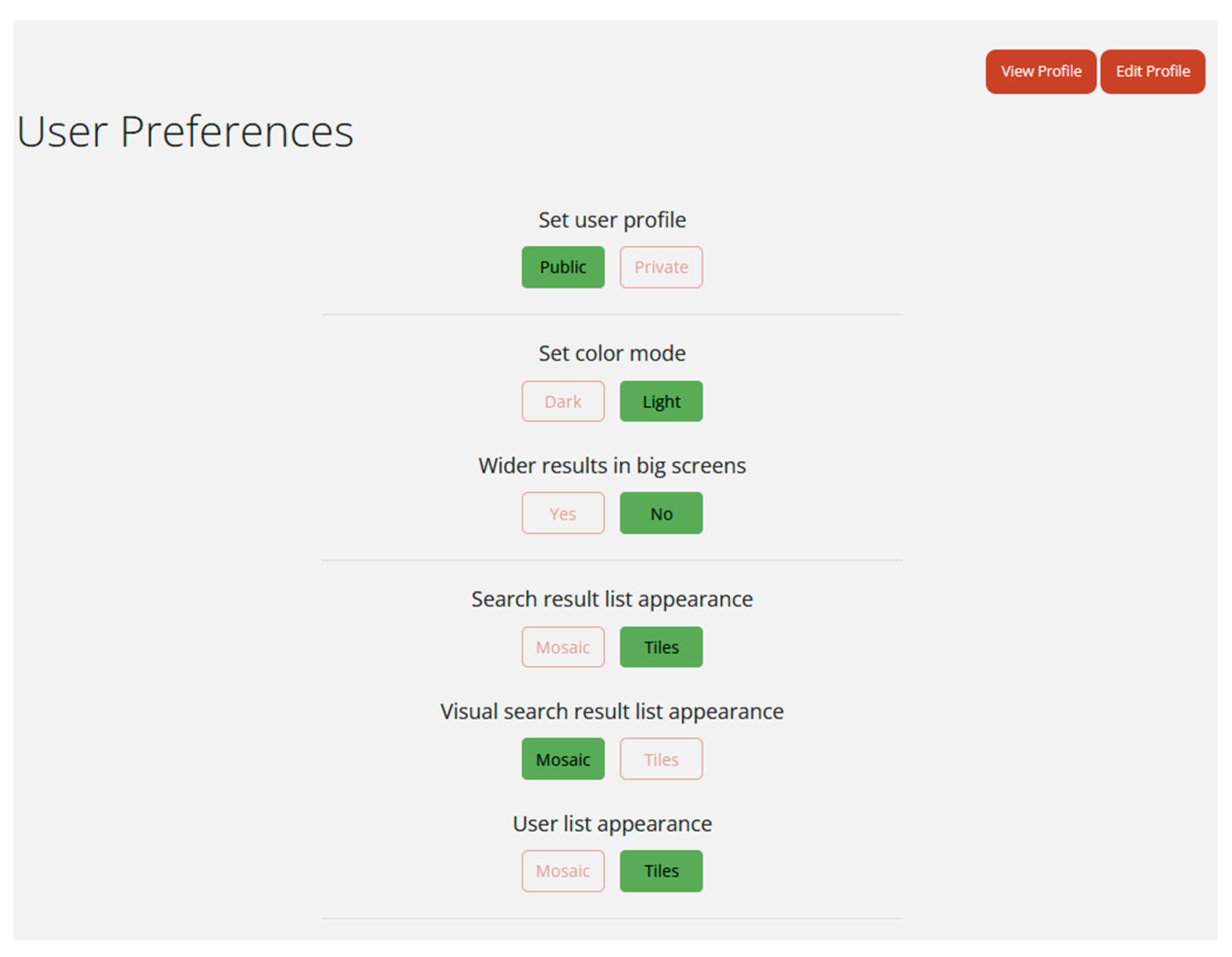
- The User profile pages
2.3. Beta Testing of the FSE
2.4. Evaluation Interviews
3. Results
3.1. Quantitative Metrics concerning the Use of the FSE Collected by the System
3.2. Qualitative Feedback concerning the Use of the FSE Provided by the Stakeholders
3.2.1. Q1: Make a First Evaluation of the Search Process—Which Are the Strong and Week Points of the Basic Search Functionality?
3.2.2. Q2: Did You Use the Voice Search and Visual Search Features? Why? Why Not?
3.2.3. Q3: Did You Use the User System and Public Profile Feature? Why? Why Not?
3.2.4. Q4: What Are the Advantages and Shortcomings of the User Interface of the Platform?
3.2.5. Q5: What Is Your Personal Opinion on the Aesthetic Look of the Platform?
3.2.6. Q6: Did You Encounter Technical Difficulties While Using the Platform? What Kind and How Did That Affect Your Experience?
3.2.7. Q7: What Additional Functionality or Interface Features Would You Like to See Added to the Platform?
3.2.8. Q8: Would You Use This Platform If It Was Made Openly Available? Why? Why Not?
3.2.9. Q9: What Other Comment Would You Like to Add That Wasn’t Covered by the Previous Points?
4. Discussion
4.1. RQ1: Is It Feasible to Create a Search Engine for Art and Cultural Heritage That Uses Content Openly Available by Different Entities and What Challenges Need to Be Overcome?
4.2. RQ2: What Features and Technologies Contribute Most to the Effectiveness of Such a Software System, Both from a Functionality and from a User Experience Perspective?
4.3. RQ3: Is the Functionality Provided by Such a Platform Considered Useful by the Stakeholders and Can This Platform Cover Existing Needs in the Field of Art and Culture?
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Respini, E. (Ed.) Art in the Age of the Internet: 1989 to Today; Yale University Press: New Haven, CT, USA, 2018. [Google Scholar]
- Manjoo, F. How the internet is saving culture, not killing it. The New York Times, 16 March 2017. [Google Scholar]
- Jones, L.S. Art Information and the Internet: How to Find It, How to Use It; Routledge: London, UK, 2013. [Google Scholar]
- Di Franco, P.D.G.; Matthews, J.L.; Matlock, T. Framing the past: How virtual experience affects bodily description of artefacts. J. Cult. Herit. 2016, 17, 179–187. [Google Scholar] [CrossRef]
- Kabassi, K. Evaluating websites of museums: State of the art. J. Cult. Herit. 2017, 24, 184–196. [Google Scholar] [CrossRef]
- Spink, A.; Jansen, B.J. (Eds.) Web Search: Public Searching of the Web; Springer: Dordrecht, The Netherlands, 2005. [Google Scholar]
- Broder, A. A Taxonomy of Web Search. ACM SIGIR Forum 2002, 36, 3–10. [Google Scholar] [CrossRef]
- Purcell, K.; Rainie, L.; Brenner, J. Search Engine Use 2012. Available online: https://www.pewresearch.org/internet/2012/03/09/search-engine-use-2012/ (accessed on 25 April 2022).
- Jansen, B.J.; Spink, A.; Koshman, S. Web searcher interaction with the Dogpile. com metasearch engine. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 744–755. [Google Scholar] [CrossRef]
- Shokouhi, M.; Si, L. Federated Search. Found. Trends Inf. Retr. 2011, 5, 1–102. [Google Scholar] [CrossRef]
- The Editors of Encyclopaedia Britannica. Encyclopaedia Britannica. Art Collection 2022. Available online: https://www.britannica.com/art/art-collection (accessed on 25 April 2022).
- Henzinger, M.R.; Motwani, R.; Silverstein, C. Challenges in web search engines. ACM SIGIR Forum 2002, 36, 11–22. [Google Scholar] [CrossRef]
- Silverstein, C.; Henzinger, M.; Marais, H.; Moricz, M. Analysis of a Very Large AltaVista Query Log; Technical Report 1998-014; Digital SRC: Palo Alto, CA, USA, 1998; pp. 383–423. [Google Scholar]
- Beus, J. Why (Almost) Everything You Knew about Google CTR is No Longer Valid—SISTRIX. SISTRIX. 2020. Available online: https://www.sistrix.com/blog/why-almost-everything-you-knew-about-google-ctr-is-no-longer-valid (accessed on 25 April 2022).
- Gudivada, V.N.; Rao, D.; Paris, J. Understanding search-engine optimization. Computer 2015, 48, 43–52. [Google Scholar] [CrossRef]
- Song, Y.; Ma, H.; Wang, H.; Wang, K. Exploring and Exploiting User Search Behavior on Mobile and Tablet Devices to Improve Search Relevance. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1201–1212. [Google Scholar]
- Chau, M.; Chen, H. A machine learning approach to web page filtering using content and structure analysis. Decis. Support Syst. 2008, 44, 482–494. [Google Scholar] [CrossRef]
- Rabiee, F. Focus-group interview and data analysis. Proc. Nutr. Soc. 2004, 63, 655–660. [Google Scholar] [CrossRef]
- Lederman, L.C. Assessing educational effectiveness: The focus group interview as a technique for data collection. Commun. Educ. 1990, 39, 117–127. [Google Scholar] [CrossRef]
- Twinn, D.S. An analysis of the effectiveness of focus groups as a method of qualitative data collection with Chinese populations in nursing research. J. Adv. Nurs. 1998, 28, 654–661. [Google Scholar] [CrossRef]
- Kontio, J.; Lehtola, L.; Bragge, J. Using the focus group method in software engineering: Obtaining practitioner and user experiences. In Proceedings of the 2004 International Symposium on Empirical Software Engineering, 2004. ISESE’04, Redondo Beach, CA, USA, 20–20 August 2004; pp. 271–280. [Google Scholar]
- Fine, M.R. Beta Testing for Better Software; John Wiley & Sons: Hoboken, NJ, USA, 2002. [Google Scholar]
- Wurangian, N.C. Testing–Alpha, Beta…. In OCLC Systems & Services: International Digital Library Perspectives; Emerald Group Publishing: Bingley, UK, 1993. [Google Scholar]
- Pergantis, M.; Lamprogeorgos, A.; Giannakoulopoulos, A. Results of a Qualitative Survey of Habits and Needs of Users Searching the Web for Art and Cultural Heritage. In Proceedings of the 3rd International Conference Digital Culture & AudioVisual Challenges Interdisciplinary Creativity in Arts and Technology, Online, 28–29 May 2021. [Google Scholar]
- Schoch, K. Case Study Research. In Research Design and Methods: An Applied Guide for the Scholar-Practitioner; SAGE Publications: New York, NY, USA, 2020; pp. 245–258. [Google Scholar]
- Winkler, D.; Mordinyi, R.; Biffl, S. Research Prototypes Versus Products: Lessons Learned from Software Development Processes in Research Projects. In Systems, Software and Services Process Improvement. EuroSPI. Communications in Computer and Information Science; McCaffery, F., O’Connor, R.V., Messnarz, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 364. [Google Scholar] [CrossRef]
- Pissinati, P.D.S.C.; Évora, Y.D.M.; Rossaneis, M.A.; Gvozd, R.; Santos, M.S.D.; Haddad, M.D.C.F.L. Development of a web software prototype to support retirement planning. Rev. Lat.-Am. De Enferm. 2019, 27. [Google Scholar] [CrossRef]
- Carvajal-Ortiz, L.; Florian-Gaviria, B.; Díaz, J.F. Models, Methods and Software Prototype to Support the Design, Evaluation, and Analysis in the Curriculum Management of Competency-Based for Higher Education. In Proceedings of the 2019 XLV Latin American Computing Conference (CLEI), Panama, Panama, 30 September–4 October 2019; pp. 1–10. [Google Scholar]
- Begic, M.; Cirimotic, M.; Farkas, I.; Skoric, I.; Car, Z.; Rasan, I.; Zilak, M. Software Prototype Based on Augmented Reality for Mastering Vocabulary. In Proceedings of the 43rd International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 28 September–2 October 2020; pp. 446–451. [Google Scholar]
- Terho, H.; Suonsyrjä, S.; Systä, K.; Mikkonen, T. Understanding the Relations between Iterative Cycles in Software Engineering. In Proceedings of the 50th Hawaii International Conference on System Sciences, Hilton Waikoloa Village, HI, USA, 4–7 January 2017. [Google Scholar]
- Suonsyrjä, S.; Systä, K.; Mikkonen, T.; Terho, H. Collecting Usage Data for Software Development: Selection Framework for Technological Approaches. 2016. Available online: https://www.ksiresearch.org/seke/seke16paper/seke16paper_186.pdf (accessed on 30 April 2022). [CrossRef]
- Litosseliti, L. Using Focus Groups in Research; Continuum, London; A&C Black: London, UK, 2003; Volume 1, p. 3. ISBN 978-0-8264-6472-9. [Google Scholar]
- Kunze, J.; Baker, T. The Dublin Core Metadata Element Set, Dublin Core Metadata Initiative, 2007. Available online: https://www.ietf.org/rfc/rfc5013.txt (accessed on 25 April 2022).
- Windhager, F.; Federico, P.; Schreder, G.; Glinka, K.; Dörk, M.; Miksch, S.; Mayr, E. Visualization of Cultural Heritage Collection Data: State of the Art and Future Challenges. IEEE Trans. Vis. Comput. Graph. 2019, 25, 2311–2330. [Google Scholar] [CrossRef] [PubMed]
- Clayphan, R.; Charles, V.; Isaac, A. Europeana Data Model—Mapping Guidelines 2.4. 2017. Available online: https://pro.europeana.eu/page/edm-documentation (accessed on 25 April 2022).
- Feigenbaum, G.; Reist, I. Provenance: An Alternate History of Art; Getty Research Institute: Los Angeles, CA, USA, 2012. [Google Scholar]
- Ng, A. The Author’s Rights in Literary and Artistic Works. In John Marshall Review of Intellectual Property Law, Forthcoming, Mississippi College School of Law Research Paper 2009. Available online: https://ssrn.com/abstract=1427989 (accessed on 25 April 2022).
- Szarkowska, A. Text-to-speech audio description: Towards wider availability of AD. J. Spec. Transl. 2011, 15, 142–162. [Google Scholar]
- Corbett, E.; Weber, A. What Can I Say? Addressing User Experience Challenges of a Mobile Voice User Interface for Accessibility. In Proceedings of the 18th International Conference on Human-Computer Interaction with Mobile Devices and Services, Florence, Italy, 6–9 September 2016; pp. 72–82. [Google Scholar]
- Sharma, H. Social Media Engagement Metrics—6 Things You Can Learn. 2011. Available online: http://www.optimizesmart.com/6-learn-postrank-social-engagement-metrics/#ixzz3OZtPcqmC (accessed on 25 April 2022).
- Gaona-Garcia, P.A.; Martin-Moncunill, D.; Montenegro-Marin, C.E. Trends and challenges of visual search interfaces in digital libraries and repositories. Electron. Libr. 2017, 35, 69–98. [Google Scholar] [CrossRef]
- Sunikka, A. Usability Evaluation of the Helsinki School of Economics Website. Master’s Thesis, Aalto University, Espoo, Finland, 2004. [Google Scholar]
- Kapsalis, E. The Impact of Open Access on Galleries, Libraries, Museums, & Archives. In Proceedings of the SXSW Conference 2016, Austin, TX, USA, 11–20 March 2016. [Google Scholar]
- Premchand, A.; Choudhry, A. Open Banking & APIs for Transformation in Banking. In Proceedings of the 2018 International Conference on Communication, Computing and Internet of Things (IC3IoT), Chennai, India, 15–17 February 2018; pp. 25–29. [Google Scholar]
- Pergantis, M.; Lamprogeorgos, A.; Giannakoulopoulos, A. Comparative Analysis of Popular APIs Providing Access to Content Related to Art and Cultural Heritage. In Proceedings of the 4th International Conference Digital Culture & AudioVisual Challenges Interdisciplinary Creativity in Arts and Technology, Corfu, Greece, 13–14 May 2022. [Google Scholar]
- Krishna, R.; Jayakrishnan, R. Impact of Cloud Services on Software Development Life Cycle. In Software Engineering Frameworks for the Cloud Computing Paradigm; Springer: London, UK, 2013; pp. 79–99. [Google Scholar]
- Li, T.; Pavlou, P.; Santos, G.D. What Drives Users’ Website Registration? A Randomized Field Experiment. In Proceedings of the 34th International Conference on Information Systems (ICIS), Milano, Italy, 15–18 December 2013. [Google Scholar]
- Gafni, R.; Nissim, D. To Social Login or not Login? Exploring Factors Affecting the Decision. Issues Inf. Sci. Inf. Technol. 2014, 11, 57–72. [Google Scholar] [CrossRef]
- Church, K.; Oliver, N. Understanding Mobile Web and Mobile Search Use in Today’s Dynamic Mobile Landscape. In Proceedings of the 13th International Conference on Human Computer Interaction with Mobile Devices and Service, Stockholm, Sweden, 30 August–2 September 2011. [Google Scholar]
- Ceccarelli, D.; Gordea, S.; Lucchese, C.; Nardini, F.M.; Perego, R.; Tolomei, G. Discovering Europeana Users’ Search Behavior. ERCIM News 2011. Available online: https://ercim-news.ercim.eu/en86/special/discovering-europeana-users-search-behavior (accessed on 25 April 2022).
- Dimoulas, C.; Veglis, A. Factors and Models Contributing to the Optimization of Search Engine Results Credibility and Application on News Content: The Cross-Credibility Engine Optimization (CCEO) Model. In Proceedings of the 23rd Pan-Hellenic Conference of Informatics, Nicosia, Cyprus, 28–30 November 2019; pp. 144–147. [Google Scholar]
- De Groote, S.L.; Appelt, K. The accuracy and thoroughness of a federated search engine in the health sciences. Internet Ref. Serv. Q. 2007, 12, 27–47. [Google Scholar] [CrossRef]
- Rehm, G.; Marheinecke, K.; Hegele, S.; Piperidis, S.; Bontcheva, K.; Hajič, J.; Choukri, K.; Vasiļjevs, A.; Backfried, G.; Prinz, C.; et al. The European Language Technology Landscape in 2020: Language-Centric and Human-Centric AI for Cross-Cultural Communication in Multilingual Europe. arXiv 2020, arXiv:2003.13833. [Google Scholar]
- Zhang, J.; Kamps, J. Search Log Analysis of User Stereotypes, Information Seeking Behavior, and Contextual Evaluation. In Proceedings of the Third Symposium on Information Interaction in Context, New Brunswick, NJ, USA, 18–21 August 2010; pp. 245–254. [Google Scholar]
- Barifah, M.; Landoni, M.; Eddakrouri, A. Evaluating the User Experience in a Digital Library. Proc. Assoc. Inf. Sci. Technol. 2020, 57, e280. [Google Scholar] [CrossRef]
- Jansen, B.J.; Spink, A.; Blakely, C.; Koshman, S. Defining a session on web search engines. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 862–871. [Google Scholar] [CrossRef]
- Jones, S.; Cunningham, S.J.; McNab, R.J.; Boddie, S.J. A transaction log analysis of a digital library. Int. J. Digit. Libr. 2000, 3, 152–169. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
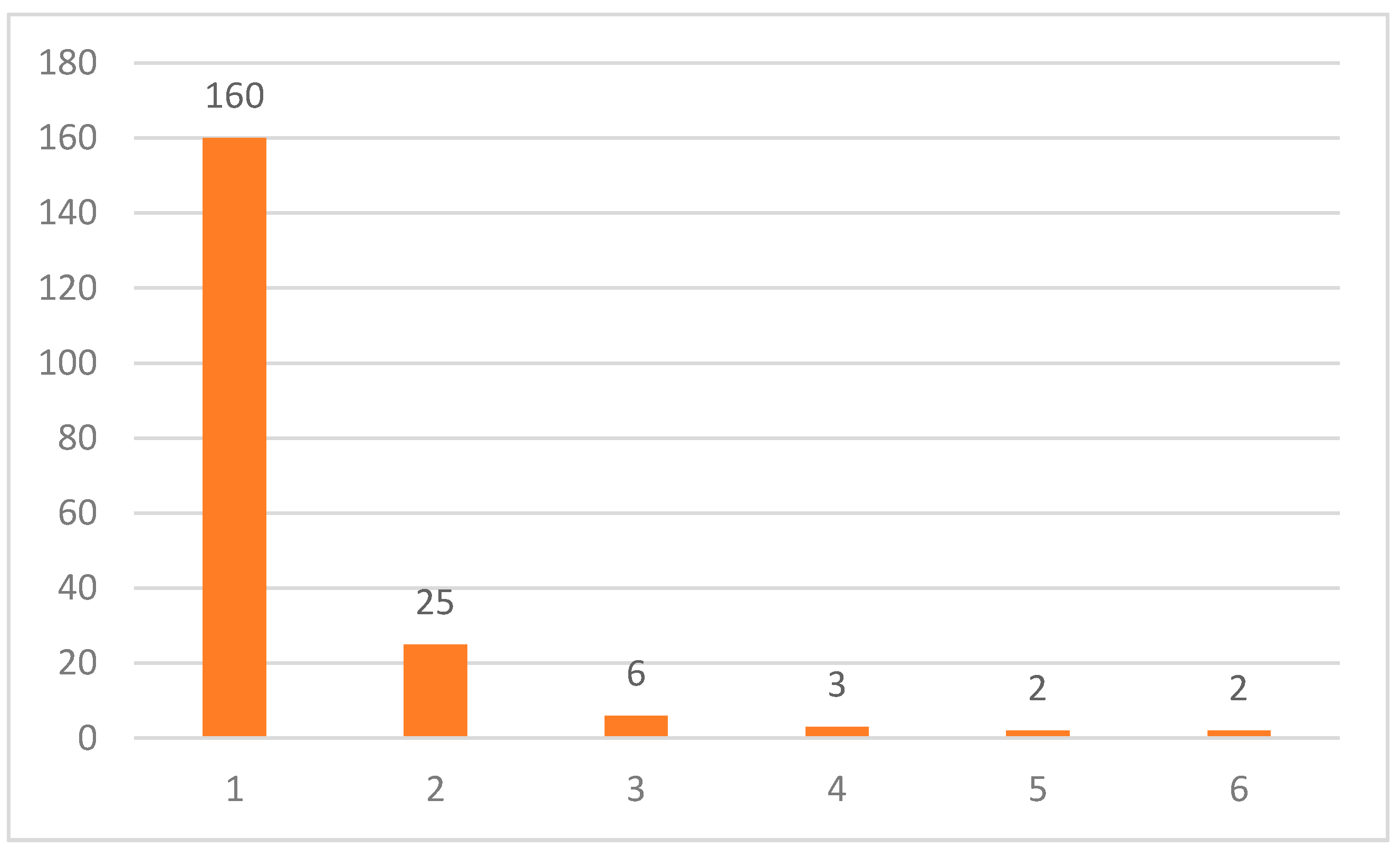{kind=link}
| Element Name | Multiplicity | Short Description |
|---|---|---|
| Title | 1 | The title of the item |
| Description | 1 | A short description of the item |
| View | 1 | The URL of the original view of the item in its original content provider. |
| Image | 1 | The URL of a representative image of the item in its original content provider |
| Thumbnail | 1 | The URL of a representative image of the item with smaller dimensions (where available) in its original content provider |
| People | 1…n | The names of people involved with the item (artists, authors, contributors etc.) |
| Time | 1…n | Temporal terms of the item (creation or publication date, time period etc.) |
| Place | 1…n | Spatial terms of the item (place of origin, place of exhibition etc.) |
| General Concepts | 1…n | General concept terms of the item (method of creation, material, technique, subject etc.) |
| Provenance | 1…n | Terms related to the ownership of the item |
| Rights | 1 | Copyright related information |
| Content Provider | 1 | Repository that provided the item |
| # | Attribute |
|---|---|
| S1 | Academic specialized in Digital Arts and Graphics |
| S2 | Middle School Teacher, PHD Candidate in the field of computer mediated realities in education |
| S3 | Academic specialized in New Media, Information and Society |
| S4 | Philologist, dilettante, professional in international relationships |
| S5 | Visual Artist, academic specialized in Digital Arts, Interior Architecture |
| S6 | Sculptor, professional engraver |
| S7 | Sculptor, academic specialized in Traditional and Digital Sculpting |
| S8 | Professional in Media and Communications, dilettante |
| S9 | Published author in Art related issues, journalist |
| S10 | Professional Art journalist, dilettante |
| S11 | Professional gallery curator |
| S12 | Postgraduate student of Fine Arts |
| # | Question |
|---|---|
| Q1 | Make a first evaluation of the search process. Which are the strong and week points of the basic search functionality? |
| Q2 | Did you use the voice search and visual search features? Why? Why not? |
| Q3 | Did you use the user system and public profile feature? Why? Why not? |
| Q4 | What are the advantages and shortcomings of the user interface of the platform? |
| Q5 | What is your personal opinion on the aesthetic look of the platform? |
| Q6 | Did you encounter technical difficulties while using the platform? What kind and how did that affect your experience? |
| Q7 | What additional functionality or interface features would you like to see added to the platform? |
| Q8 | Would you use this platform if it was made openly available? Why? Why not? |
| Q9 | What other comment would you like to add that wasn’t covered by the previous points? |
| ID | Session | User | Ip | Country | Agent | Device | Duration | Start | End |
|---|---|---|---|---|---|---|---|---|---|
| 47 | 926a09a347592a95744eec6f66dd2b2d | 0 | [redacted] | Greece | Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:99.0) Gecko/20100101 Firefox/99.0 | desktop | 58 | 2022-3-27 17:16 | 2022-3-27 17:17 |
| 48 | 3746641b4dd026602173a55511a8f9cb | 6 | [redacted] | Greece | Mozilla/5.0 (Linux; Android 11; M2004J19C) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.73 Mobile Safari/537.36 | mobile | 123 | 2022-3-27 20:03 | 2022-3-27 20:05 |
| 56 | 228f9ab2403f3b795004163a22a874fa | 0 | [redacted] | Greece | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36 Edg/99.0.1150.55 | desktop | 15 | 2022-3-28 18:33 | 2022-3-28 18:33 |
| 57 | 70a07c956c94ec6dac77109e164349e6 | 7 | [redacted] | Greece | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36 | desktop | 2159 | 2022-3-28 18:34 | 2022-3-28 19:10 |
| 59 | a450f9c69f290a1302c234889bc13772 | 0 | [redacted] | Greece | Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:99.0) Gecko/20100101 Firefox/99.0 | desktop | 71 | 2022-3-28 19:01 | 2022-3-28 19:02 |
| 64 | 1492c60316d577c5ba46217f16bc6833 | 0 | [redacted] | Greece | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36 Edg/99.0.1150.52 | desktop | 33 | 2022-3-28 19:14 | 2022-3-28 19:15 |
| 105 | fdb95802f02f5d7373cbca64e7609098 | 0 | [redacted] | Greece | Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:99.0) Gecko/20100101 Firefox/99.0 | desktop | 86 | 2022-3-28 21:04 | 2022-3-28 21:05 |
| 107 | 16e7ad7275e4e022f9e1c7ca7c474dbd | 0 | [redacted] | Greece | Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:99.0) Gecko/20100101 Firefox/99.0 | desktop | 7 | 2022-3-29 0:16 | 2022-3-29 0:16 |
| 122 | e7ef5557300065808fd66163406301ee | 0 | [redacted] | Greece | Mozilla/5.0 (Linux; Android 11; M2004J19C) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.88 Mobile Safari/537.36 | mobile | 203 | 2022-3-30 20:13 | 2022-3-30 20:16 |
| Event | Number of Occurrences | Avg # of Occurrences per Session |
|---|---|---|
| Search query submitted | 300 | 4.92 |
| Voice search used | 22 | 0.36 |
| Visual search used | 40 | 0.65 |
| Result presentation page viewed | 193 | 3.16 |
| Result presentation concept tag clicked | 18 | 0.29 |
| Result bookmarked | 23 | 0.38 |
| Result removed from bookmarks | 4 | 0.07 |
| Result original source viewed | 19 | 0.31 |
| Visual result original source viewed | 22 | 0.36 |
| Visual result bookmarked | 5 | 0.08 |
| Visual result bookmark removed | 1 | 0.02 |
| Text to Speech on result list | 6 | 0.10 |
| Text to Speech on result presentation page | 8 | 0.13 |
| Text to Speech on user profile | 9 | 0.15 |
| Text to Speech on visual result | 2 | 0.03 |
| User profile viewed | 12 | 0.2 |
| User own profile viewed | 80 | 1.31 |
| User own profile edited | 27 | 0.44 |
| User avatar updated | 8 | 0.13 |
| User preference changed | 38 | 0.62 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pergantis, M.; Varlamis, I.; Giannakoulopoulos, A. User Evaluation and Metrics Analysis of a Prototype Web-Based Federated Search Engine for Art and Cultural Heritage. Information 2022, 13, 285. https://doi.org/10.3390/info13060285
Pergantis M, Varlamis I, Giannakoulopoulos A. User Evaluation and Metrics Analysis of a Prototype Web-Based Federated Search Engine for Art and Cultural Heritage. Information. 2022; 13(6):285. https://doi.org/10.3390/info13060285
Chicago/Turabian StylePergantis, Minas, Iraklis Varlamis, and Andreas Giannakoulopoulos. 2022. "User Evaluation and Metrics Analysis of a Prototype Web-Based Federated Search Engine for Art and Cultural Heritage" Information 13, no. 6: 285. https://doi.org/10.3390/info13060285
APA StylePergantis, M., Varlamis, I., & Giannakoulopoulos, A. (2022). User Evaluation and Metrics Analysis of a Prototype Web-Based Federated Search Engine for Art and Cultural Heritage. Information, 13(6), 285. https://doi.org/10.3390/info13060285