1. Introduction
Digital media has provided a lot of benefits to our modern society, such as facilitating social interactions, boosting productivity, and improving sharing information. However, it has also led to the proliferation of fake news [
1]; that is, news articles containing false information that has been deliberately created [
2]. The effects of this kind of misinformation and disinformation spreading can be seen in different segments of our society. The Pizzagate incident [
3], as well as the mob lynchings that occurred in India [
4], are some of the most tragic examples of the consequences of fake news dissemination. Changes in health behavior intentions [
5], an increase in vaccine hesitancy [
6], and significant economic losses [
7] are also some of the negative effects that the spread of fake news may have.
Every day, a huge quantity of digital information is produced, making the detection of fake news by manual fact-checking impossible. Due to this, it becomes essential to use techniques that help us to automate the identification of fake news so that more immediate action can be taken.
During the last few years, several studies have already been carried out to perform the automatic detection of fake news [
8,
9,
10,
11,
12,
13]. Most previous works only exploit textual information for identifying fake news. These approaches can be considered unimodal methods because they only use a type of input data to deal with the task. The last few years have shown great advances in the field of machine learning by combining multiple types of data, such as audio, video, images, and text [
14], for different tasks such as text classification [
15] or image recognition [
16]. These systems are known as multimodal approaches [
14]. The use of multimodal data (combining texts and images) for detecting fake news has been explored little [
10,
11,
17]. These approaches have shown promising results, obtaining better results than the unimodal approaches. However, these studies typically address the problem of fake news detection as a binary classification task (that is, consisting of classifying news as either true or fake).
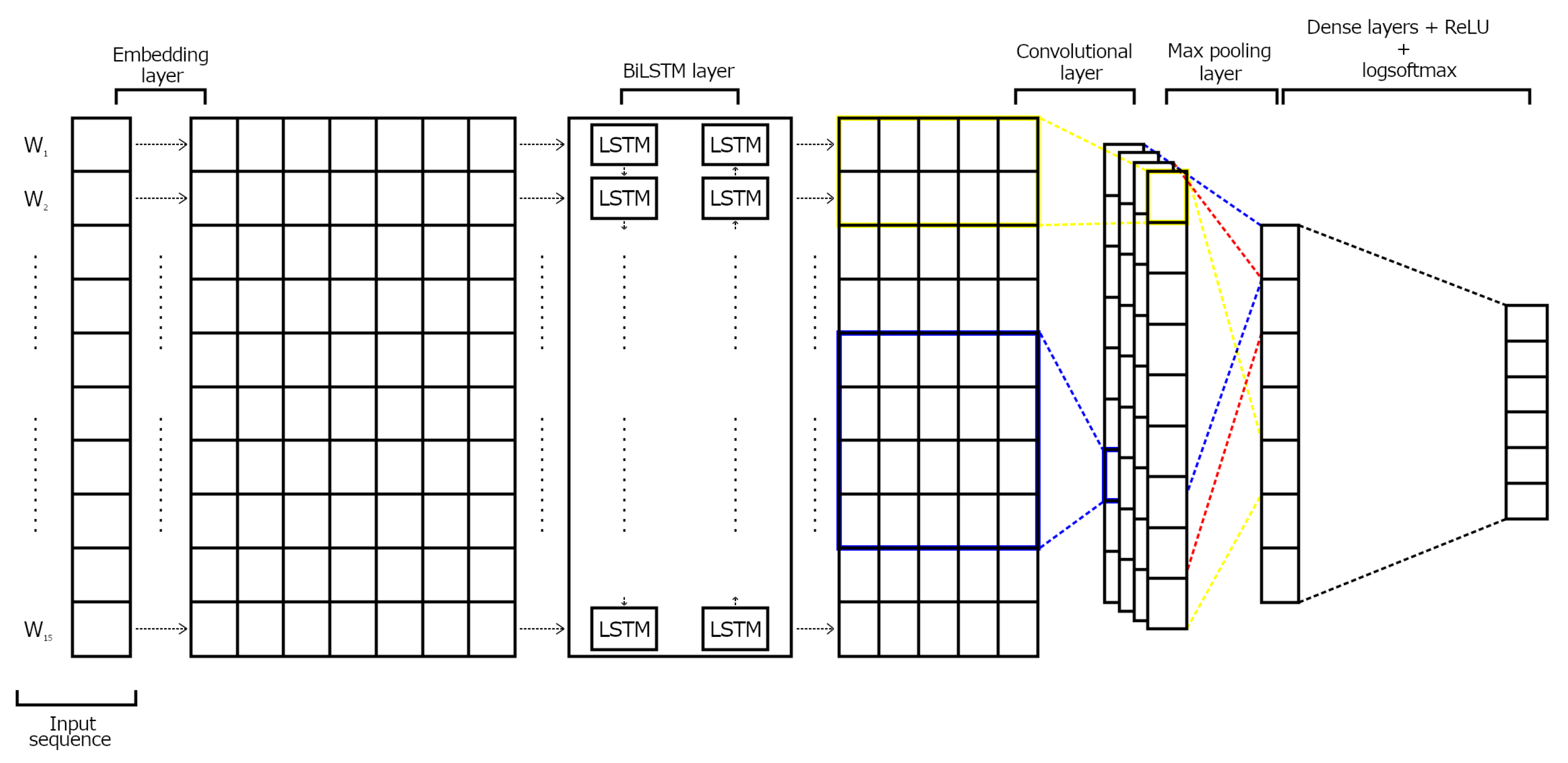
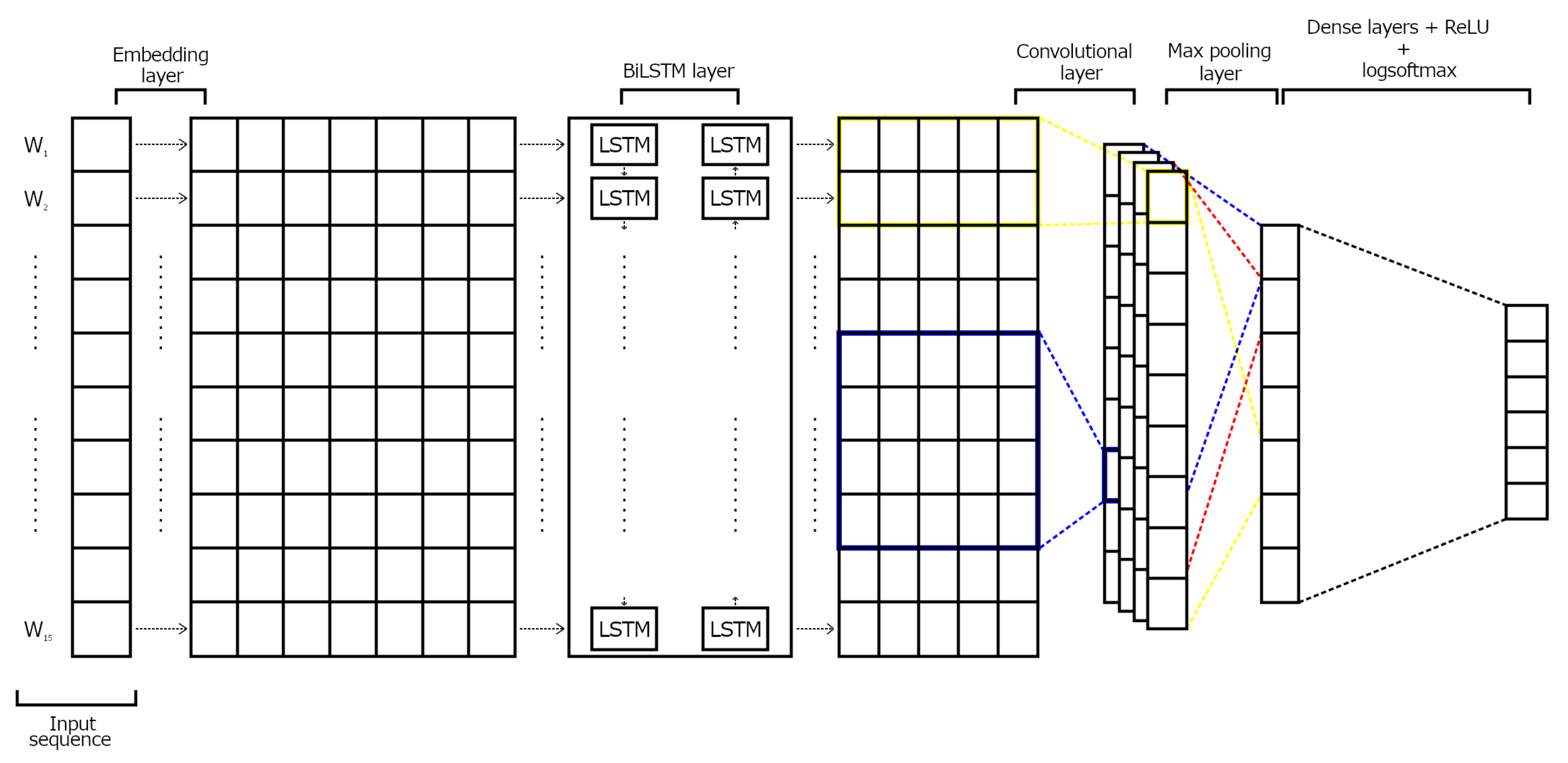
The main goal of this paper is to study both unimodal and multimodal approaches to deal with a finer-grained classification of fake news. To do this, we use the Fakeddit dataset [
18], made up of posts from Reddit. The posts are classified into the following six different classes: true, misleading content, manipulated content, false connection, imposter content, and satire. We explore several deep learning architectures for text classification, such as Convolutional Neural Network (CNN) [
19], Bidirectional Long Short-Term Memory (BiLSTM) [
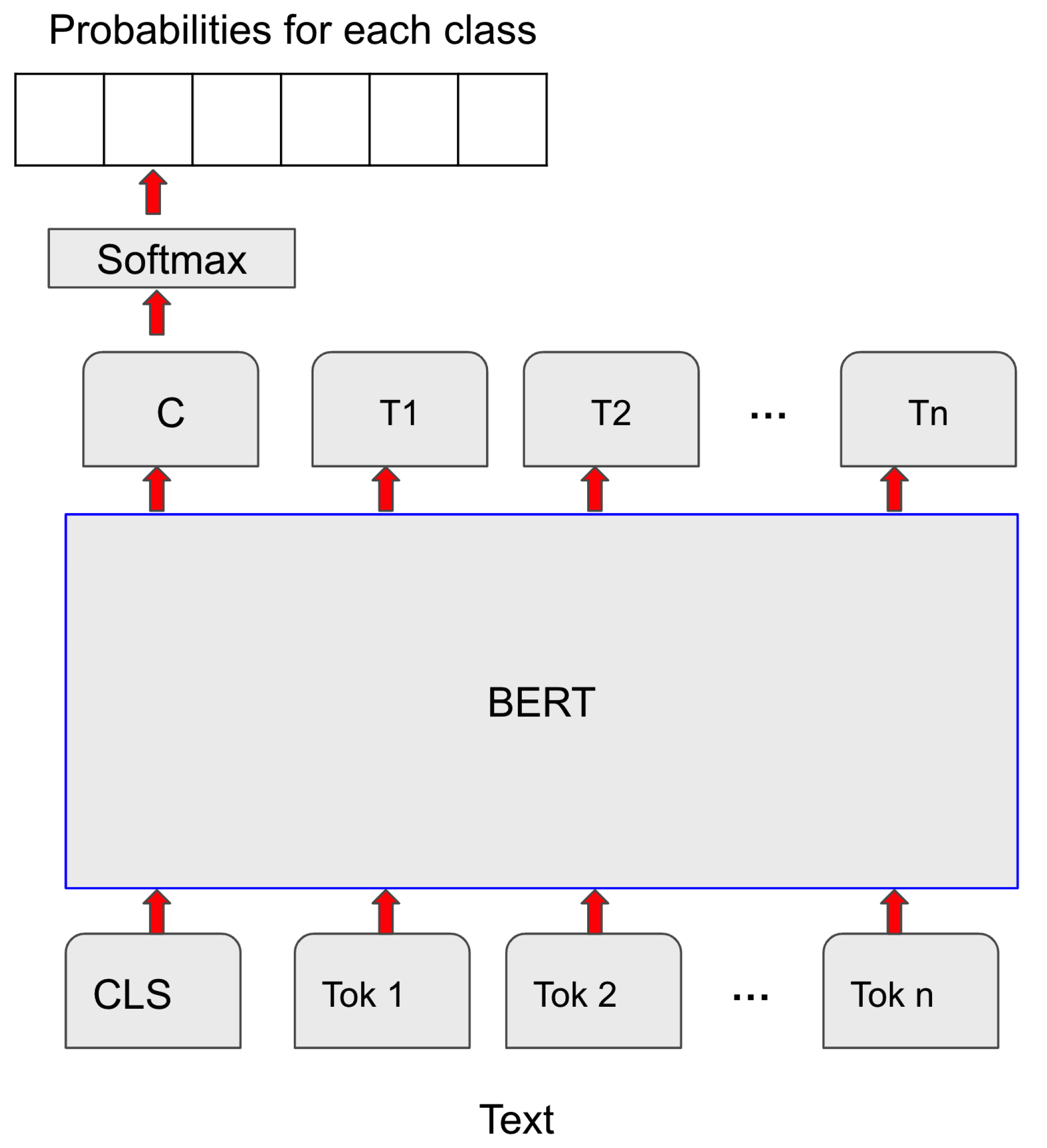
20], and Bidirectional Encoder Representations from Transformers (BERT) [
21]. As a multimodal approach, we propose a CNN architecture that combines both texts and images to classify fake news.
2. Related Work
Since the revival of neural networks in the second decade of the current century, many different applications of deep learning techniques have emerged. Many Natural Language Processing (NLP) advances are due to the incorporation of deep neural network approaches [
22,
23].
Text classification tasks such as sentiment analysis or fake news detection are also one of the tasks for which deep neural networks are being extensively used [
24]. Most of these works have been based on unimodal approaches that only exploit texts. More ambitious architectures that combine several modalities of data (such as text and image) have also been tried [
25,
26,
27,
28,
29]. The main intuition behind these multimodal approaches is that many texts are often accompanied by images, and these images may provide useful information to improve the results of the classification task [
30].
We review the most recent studies for the detection of fake news using only the textual content of the news. Wani et al. [
31] use the Constraint@AAAI COVID-19 fake news dataset [
32], which contains tweets classified as true or fake. Several methods were evaluated: CNN, LSTM, Bi-LSTM + Attention, Hierarchical Attention Network (HAN) [
33], BERT, and DistilBERT [
34], a smaller version of BERT. The best accuracy obtained was 98.41% by the DistilBERT model when it was pre-trained on a corpus of COVID-19 tweets.
Goldani et al. [
35] use a capsule network model [
36] based on CNN and pre-trained word embeddings for fake news classification of the ISOT [
37] and LIAR [
38] datasets. The ISOT dataset is made up of fake and true news articles collected from Reuters and Kaggle, while the LIAR dataset contains short statements classified into the following six classes: pants-fire, false, barely-true, half-true, mostly-true, and true. Thus, the authors perform both binary and multi-class fake news classification. The best accuracies obtained with the proposed model were 99.8% for the ISOT dataset (binary classification) and 39.5% for the LIAR dataset (multi-class classification).
Girgis et al. [
39] perform fake news classification using the above-mentioned LIAR dataset. More concretely, they use three different models: vanilla Recurrent Neural Network [
40], Gated Recurrent Unit (GRU) [
41], and LSTM. The GRU model obtains an accuracy of 21.7%, slightly outperforming the LSTM (21.66%) and the vanilla RNN (21.5%) models.
From this review on approaches using only texts, we can conclude that deep learning architectures provide very high accuracy for the binary classification of fake news; however, the performance is much lower when these methods address a fine-grained classification of fake news. Curiously enough, although BERT is reaching state-of-the-art results in many text classification tasks, it has hardly ever been used for the multiclassification of fake news.
Recently, some efforts have been devoted to the development of multimodal approaches for fake news detection. Singh et al. [
10] study the improvement in performance on the binary classification of fake news when textual and visual features are combined as opposed to using only text or image. They explored several traditional machine learning methods: logistic regression (LR) [
42], classification and regression tree (CART) [
43], linear discriminant analysis (LDA) [
44], quadratic discriminant analysis (QDA) [
44], k-nearest neighbors (KNN) [
44], naïve Bayes (NB) [
45], support vector machine (SVM) [
46], and random forest (RF) [
47]. The authors used a Kagle dataset of fake news [
48]. Random forest was the best model, with an accuracy of 95.18%.
Giachanou et al. [
11] propose a model to perform multimodal classification of news articles as either true or fake. In order to obtain textual representations, the BERT model [
21] was applied. For the visual features, the authors used the VGG (Visual Geometry Group) network [
49] with 16 layers, followed by an LSTM layer and a mean pooling layer. The dataset used by the authors was retrieved from the FakeNewsNet collection [
50]. More concretely, the authors used 2745 fake news and 2714 real news collected from the GossipCop posts of the collection. The proposed model achieved an F1 score of 79.55%.
Finally, another recent architecture proposed for multimodal fake news classification can be found in the work carried out by [
17]. The authors proposed a model that is made up of four modules: (i) ABS-BiLSTM (attention-based stacked BiLSTM) for extracting the textual features), (ii) ABM-CNN-RNN (attention based CNN-RNN) to obtain the visual representations, (iii) MFB (multimodal factorized bilinear pooling), where the feature representations obtained from the previous two modules are fused, and (iv) MLP (multi-layer perceptron), which takes the fused feature representations provided by the MFB module as input, and then generates the probabilities for each class (true of fake). In order to evaluate the model, two datasets were used: Twitter [
51] and Weibo [
52]. The Twitter dataset contains tweets along with images and contextual information. The Weibo dataset is made up of tweets, images, and social context information. The model obtains an accuracy of 88.3% on the Twitter dataset and an accuracy of 83.2% on the Weibo dataset.
Apart from the previous studies, several authors have proposed fake news classification models and have evaluated them using the Fakeddit dataset. Kaliyar et al. [
53] propose the DeepNet model for the binary classification of fake news. This model is made up of one embedding layer, three convolutional layers, one LSTM layer, seven dense layers, ReLU for activation, and, finally, the softmax function for the binary classification. The model was evaluated on the Fakeddit and BuzzFeed [
54] datasets. The BuzzFeed dataset contains news articles collected within a week before the U.S. election, and they are classified as either true or fake. The models provided an accuracy of 86.4% on the Fakeddit dataset (binary classification) and 95.2% on the BuzzFeed dataset.
Kirchknopf et al. [
55] use four different modalities of data to perform binary classification of fake news over the Fakeddit dataset. More concretely, the authors used the textual content of the news, the associated comments, the images, and the remaining metadata belonging to other modalities. The best accuracy obtained was 95.5%. Li et al. [
56] proposed the Entity-Oriented Multimodal Alignment and Fusion Network (EMAF) for binary fake news detection. The model is made up of an encapsulating module, a cross-modal alignment module, a cross-model fusion module, and a classifier. The authors evaluated the model on the Fakeddit, Weibo, and Twitter datasets, obtaining accuracies of 92.3%, 97.4%, and 80.5%, respectively.
Xie et al. [
57] propose the Stance Extraction and Reasoning Network (SERN) to obtain stance representations from a post and its associated reply. They combined these stance representations with a multimodal representation of the text and image of a post in order to perform binary fake news classification. The authors use the PHEME dataset [
58] and a reduced version of the Fakeddit dataset created by them. The PHEME dataset contains 5802 tweets, of which 3830 are real, and 1972 are false. The accuracies obtained are 96.63% (Fakeddit) and 76.53% (PHEME).
Kang et al. [
59] use a heterogeneous graph named News Detection Graph (NDG) that contains domain nodes, news nodes, source nodes, and review nodes. Moreover, they proposed a Heterogeneous Deep Convolutional Network (HDGCN) in order to obtain the embeddings of the news nodes in NDG. The authors evaluated this model using reduced versions of the Weibo and Fakeddit datasets. For the Weibo dataset, they obtained an F1 score of 96%, while for the Fakeddit dataset they obtained F1 scores of 88.5% (binary classification), 85.8% (three classes), and 83.2% (six classes).
As we can see from this review, most multimodal approaches evaluated on the Fakkeddit dataset have only addressed the binary classification of fake news. Thus far, only work [
59] has addressed the multi-classification of fake news using a reduced version of this dataset. To the best of our knowledge, our work is the first attempt to perform a fine-grained classification of fake news using the whole Fakeddit dataset. Furthermore, contrary to the work proposed in [
59], which exploits a deep convolutional network, we propose a multimodal approach that simply uses a CNN, obtaining a very similar performance.





{kind=link}
{kind=link}
{kind=link}