
Multi-Layer Contextual Passage Term Embedding for Ad-Hoc Retrieval

Abstract
:1. Introduction
- We proposed a novel multi-layer contextual document pre-processing method. Firstly, we leverage text summarization extraction to capture passage-level evidence of long document, then we concatenate the extracted sentences as local contextual information to the pre-segmented passages. In addition, we take the title of the document as the global information, these components together construct the context-aware passage-level embedding.
- We utilized the Maximal Margin Relevance (MMR) algorithm to implement passage-level summarization extraction, thus giving birth to the local contextual information, compared with leveraging original text as local evidence, the prediction performance has been improved a lot.
- We provided a practical approach for the long document to be trained in the neural networks, which addresses the previously mentioned long document constraints and can be commonly used in other neural IR models.
2. Related Works
2.1. Matching Features Methods
2.1.1. Exact Match Signals
2.1.2. Passage-Level Signals
2.2. Pre-Trained Language Model Methods
3. Materials and Methods
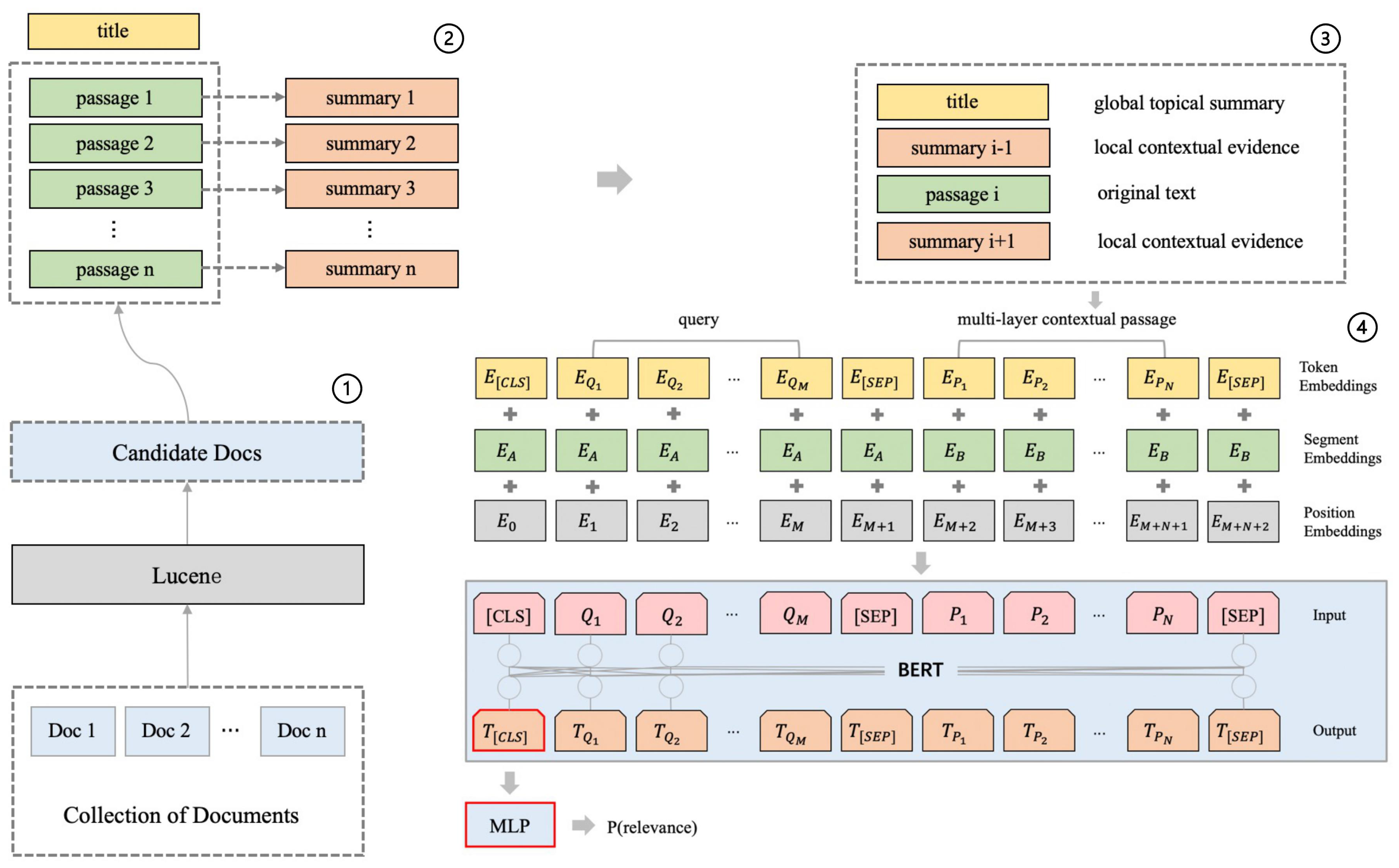
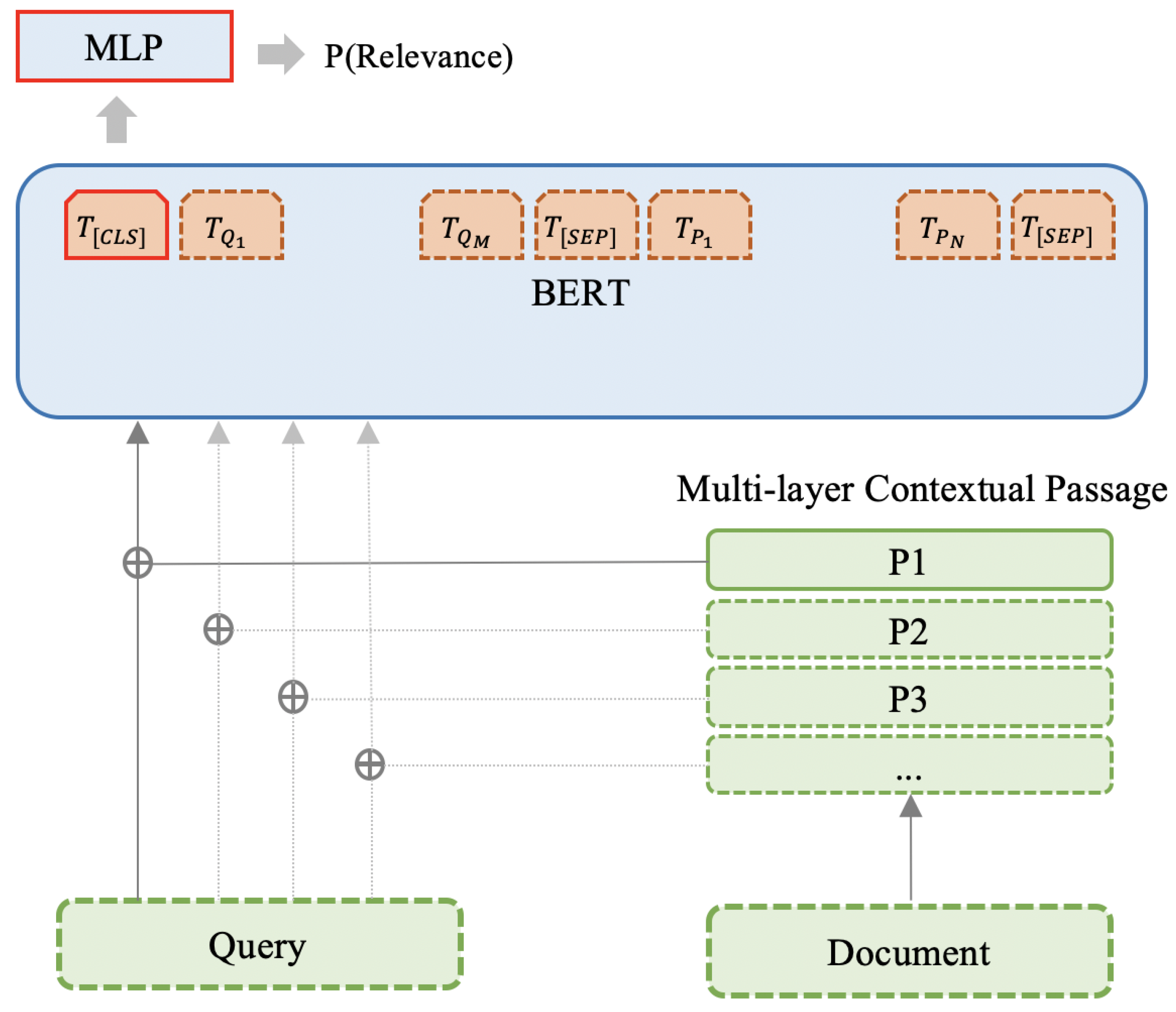
3.1. Architecture
3.2. Generation of Multi-Layer Contextual Passage
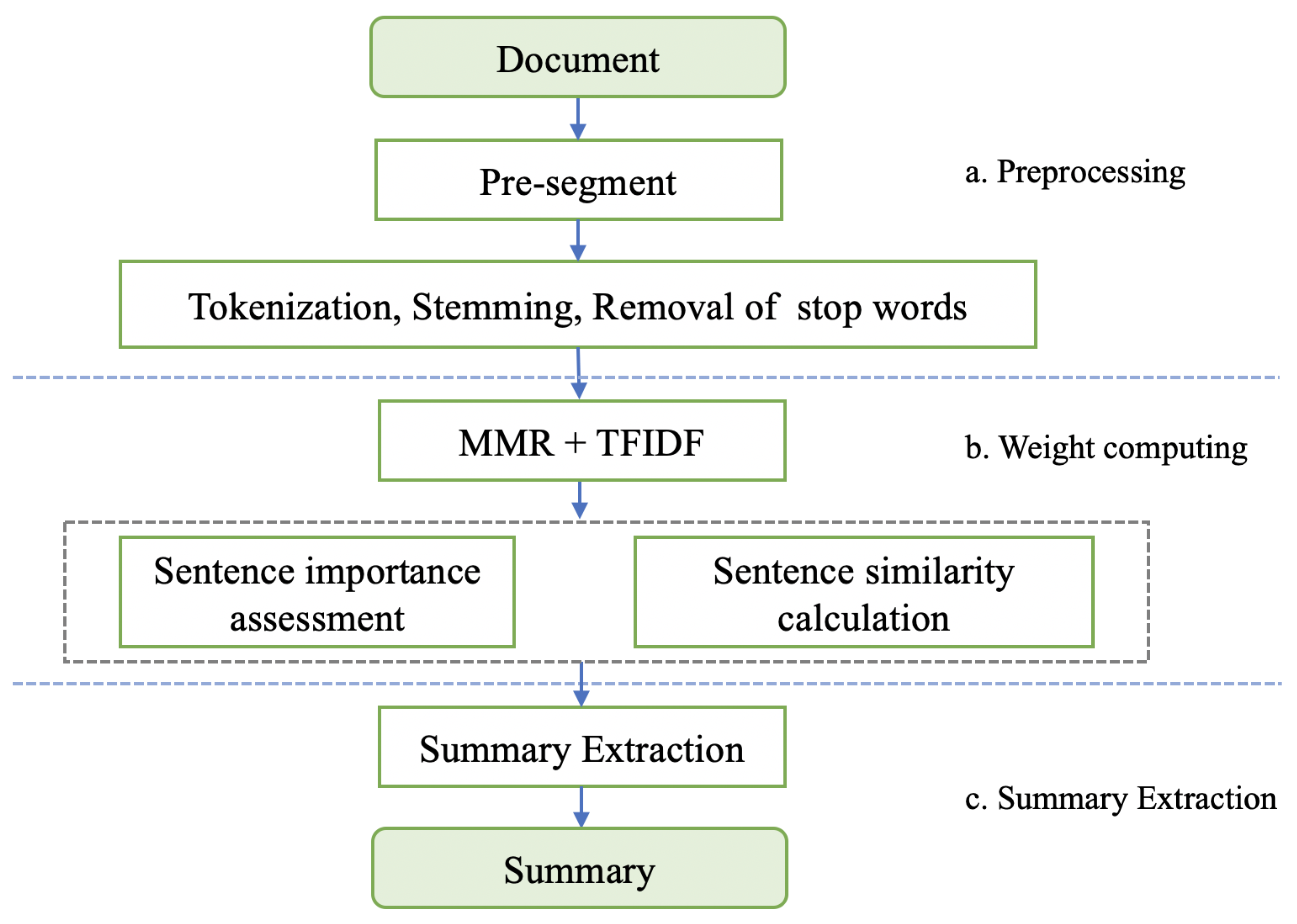
3.2.1. The Process of Summarization
- Pre-segmenting and text preprocessing. This paper first pre-segment the long document to meet the BERT’s limitation of the text sequence length of the input sequence not exceeding 512 tokens. Then the basic text preprocesses such as tokenization, word stemming and removal of stop words are performed on each passage. Stem extraction is the process of removing affixes to get roots and stop word removal is the removal of meaningless words.
- Sentence Scoring. In this paper, the Term Frequency–Inverse Document Frequency (TF-IDF) weight mechanism is used to evaluate the importance of terms in the document, the importance of sentences is evaluated according to the TF-IDF value of terms in the sentence, and the similarity between two sentence vectors is measured at the same time.
- Summary Extraction. This paper uses the Maximum Margin Relevance (MMR) algorithm to select important sentences from each passage as a passage-level summary. While ensuring that the extracted sentences and passage topics have high relevance, it eliminates the redundancy of extracted sentences and increases the diversity of results.
3.2.2. Sentence Scoring Using TF-IDF Value
- Document classification. The ordinary TF-IDF weight mechanism does not take into account that there may be unbalanced distribution of different types of articles in the document set, which may weaken the representativeness of TF-IDF values. In order to reduce this influence, we add a process. We use clustering algorithm to process the document set, the collection of documents is processed into smaller collections of documents of several categories, and the uneven distribution of different types in the document collection is reduced after processing. TF-IDF values will be calculated separately in the classified document collection.
- Term importance assessment. Term Frequency (TF) is a method to evaluate the importance of a word in a passage. The importance of a term depends on the number of times the term appears in the paragraph. After basic text preprocessing, such as removing stop words and stemming, is performed on the data, the method of calculating the TF value of the term w is as follows:where denotes the number of times a word appears in a passage and denotes a collection which contains each word in passage p, thus represents the numbers of words in passage p. While computing TF, all terms are considered equally important, thus we need to introduce the IDF to diminish the weight of frequent words. We assume the number of passages in the collection can be denoted as n, in the meanwhile denotes the number of passages which contains the word w, hence the IDF value of word w can be defined as:Hence, the IDF value of a rare word can be relatively higher than a frequent word. Finally, we can combine the calculation of term frequency and inverse document frequency to produce an aggregate weight for each term in each document. The TF-IDF weighting scheme assigns weight to word w in a certain passage p is given below:The TF-IDF value of all terms in a passage represents the importance of the term within the passage. Based on the ranking of TF-IDF value, we can take the top-n words constructs the query corresponding to the passage. The query will be applied to select the first sentence with the highest relevance score for the passage.
- Sentence Scoring. For each sentence s in the passage, we compute its TF-IDF score by summing the weights of its words:where denotes the length of the sentence s.
- Sentence Similarity Calculation. The TF-IDF mechanism makes it possible to map text sentences in the vector space. The semantic similarity between two sentences can be measured by calculating the distance between the two sentence vectors. There are many ways to measure the similarity between vectors, such as cosine similarity, Euclidean distance, or the use of neural network models for judgment. This paper uses cosine similarity to evaluate the sentence similarity of two sentence vectors and . The calculation method is as follows:
3.2.3. Summary Extraction with Maximal Marginal Relevance Algorithm
| Algorithm 1 MMR Algorithm |
Input: query Q, the collection of documents D Output: the collection of selected sentences Initialize: summary = ⌀ for each doc in D do for each passage in do for each sentence in do for each sentence in do end for end for end for end for return C |
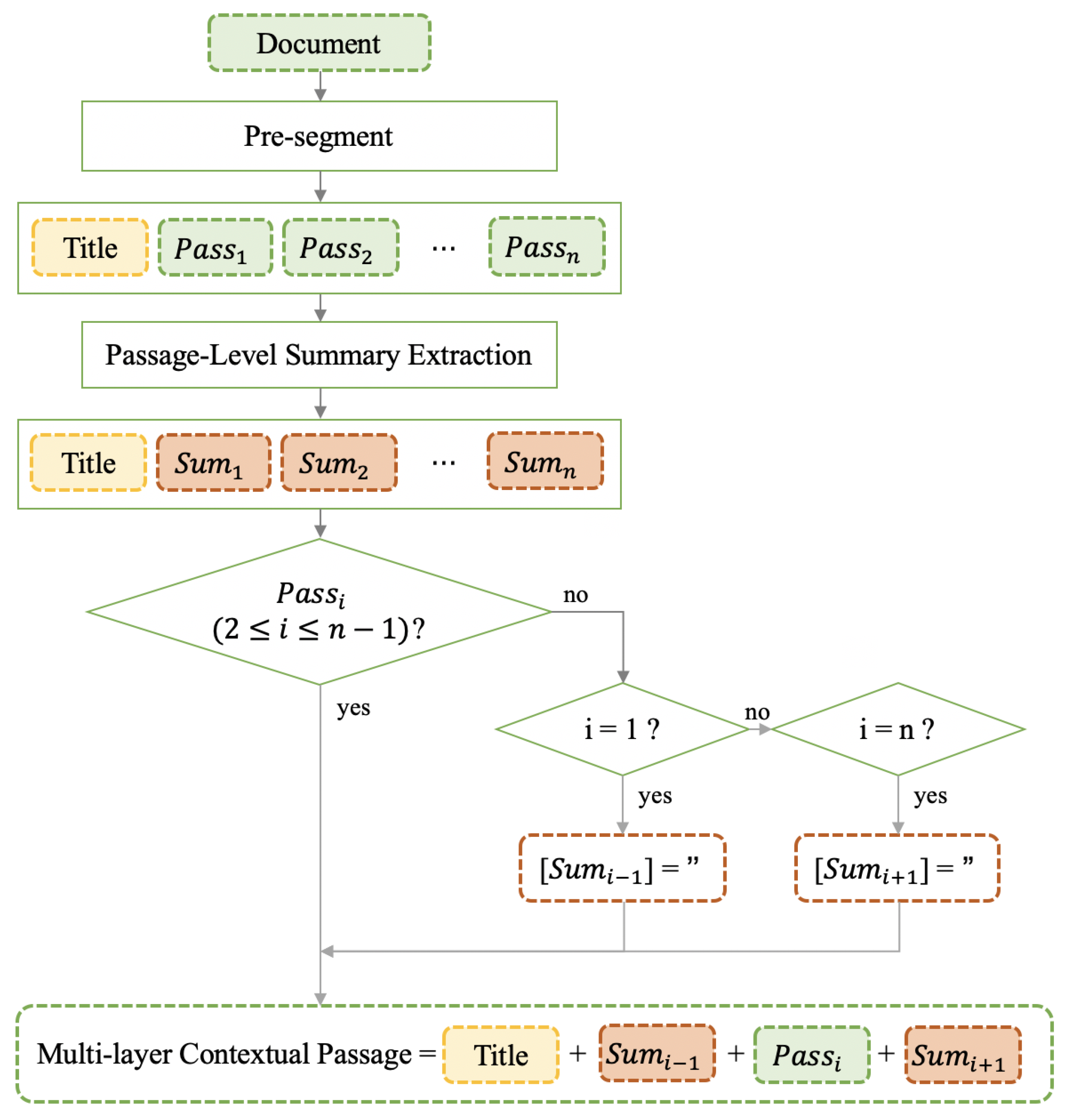
3.2.4. Generation of Multi-Layer Contextual Passage
- The document’s title. The title of a document describes briefly the central subject of a document, which can be regarded as a global information definition of a document.
- The context clue. The context clues are hints that help a reader to understand the meanings of new or unfamiliar passages. It can be regarded as a local evidence which is beneficial for achieving a better reading comprehension of a paragraph.
- The passage body. The methods mentioned above are just auxiliary strategies to help us better leverage the contextual information, eventually, we have to focus on the passage itself to dig intthe topic.
3.3. BERT-Based Query Document Relevance Retrieval with Multi-Layer Contextual Passage
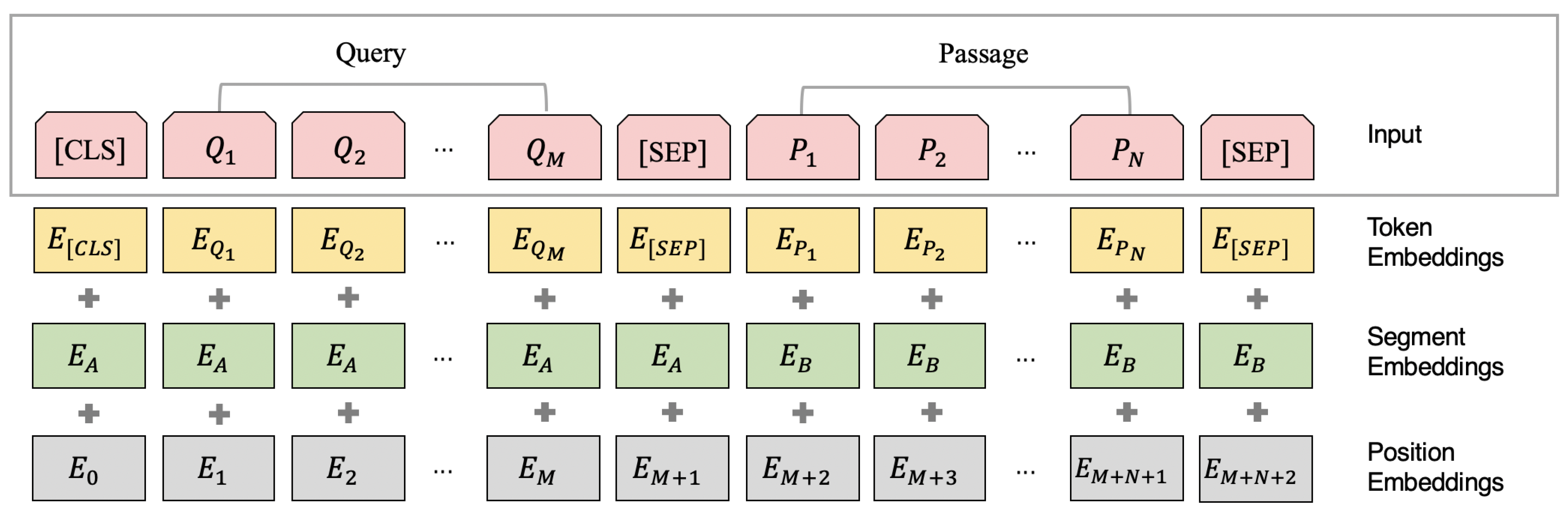
- Token embedding Let us consider a query and a passage which consists of the concatenated multi-layer contextual structure. The model takes the query Q and the passage P as the segment pairs to construct the input sequence of BERT: , the tokens of the sequence are embedded into embeddings.
- Segment embedding The query and passage pairs are separated with the [SEP] token, we add a query Q embedding to every token in the query and a passage P embedding to every token in the passage.
- Position embedding We use the positional embeddings to enable BERT to capture the word order of the input representation which contributes to the ability of learning the sequential characters.
4. Results
4.1. Datasets
4.2. Baselines
4.2.1. Traditional Retrieval Baselines
4.2.2. Early Neural Ranking Baselines
4.2.3. BERT-Based Retrieval Baselines
4.3. Experimental Setups
4.4. Performance Comparison
4.4.1. Comparison on Robust04
4.4.2. Comparison on ClueWeb09
- Title. In the Title field of the ClueWeb09 Cat B dataset, the MAP value of the model method in this paper reaches 0.189 and the value of nDCG@20 reaches 0.327, which exceeds all previous related work in this field. With the help of multi-layer contextual passage, our method brings a 12.37% improvement on nDCG@20 and a 16.67% improvement on MAP, respectively, over the best performed baseline (BERTIR-SumP). The comparison further proves the effectiveness of our method.
- Description. In the Description field of the ClueWeb09 Cat B dataset, the MAP value of the model method in this paper reaches 0.145 and the nDCG@20 value reaches 0.255, which is basically the same as the previous best model BERTIR-SumP retrieval effect and exceeds all other previous benchmark models.
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Robertson, S.; Zaragoza, H.; Taylor, M. Simple BM25 extension to multiple weighted fields. In Proceedings of the Thirteenth ACM International Conference on Information and Knowledge Management, Washington, DC, USA, 8–13 November 2004; pp. 42–49. [Google Scholar]
- Rousseau, F.; Vazirgiannis, M. Composition of TF normalizations: New insights on scoring functions for ad hoc IR. In Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 28 July–1 August 2013; pp. 917–920. [Google Scholar]
- Lv, Y.; Zhai, C.X. When documents are very long, BM25 fails! In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, Beijing, China, 24–28 July 2011; pp. 1103–1104. [Google Scholar]
- Jian, F.; Huang, J.X.; Zhao, J. A simple enhancement for ad-hoc information retrieval via topic modelling. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 733–736. [Google Scholar]
- Pan, M.; Zhang, Y.; Zhu, Q. An adaptive term proximity based rocchio’s model for clinical decision support retrieval. BMC Med. Inform. Decis. Mak. 2019, 19, 251. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mikolov, T.; Sutskever, I.; Chen, K. Distributed representations of words and phrases and their compositionality. In Proceedings of the Conference on Neural Information Processing Systems, Lake Tahoe, NV/CA, USA, 5–10 December 2013. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Yang, W.; Zhang, H.; Lin, J. Simple applications of BERT for ad hoc document retrieval. arXiv 2019, arXiv:1903.10972. [Google Scholar]
- Dai, Z.; Callan, J. Deeper text understanding for ir with contextual neural language modeling. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 985–988. [Google Scholar]
- Huang, P.S.; He, X.; Gao, J. Learning deep structured semantic models for web search using clickthrough data. In Proceedings of the 22nd ACM International Conference on Information and Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 2333–2338. [Google Scholar]
- Guo, J.; Fan, Y.; Ai, Q. A Deep Relevance Matching Model for Ad-hoc Retrieval. In Proceedings of the Conference on Information and Knowledge Management, Venice, Italy, 24–28 April 2016; pp. 55–64. [Google Scholar]
- Mcdonald, R.; Brokos, G.I.; Androutsopoulos, I. Deep Relevance Ranking Using Enhanced Document-Query Interactions. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar]
- Hui, K.; Yates, A.; Berberich, K.; Melo, G.D. PACRR: A Position-Aware Neural IR Model for Relevance Matching. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017. [Google Scholar]
- Cormack, G.; Clarke, C.; Büttcher, S. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Boston, MA, USA, 19–23 July 2009. [Google Scholar]
- Pang, L.; Lan, Y.; Guo, J.; Xu, J.; Xu, J.; Cheng, X. DeepRank: A New Deep Architecture for Relevance Ranking in Information Retrieval. In Proceedings of the CIKM, Singapore, 6–10 November 2017. [Google Scholar]
- Yilmaz, Z.A.; Yang, W.; Zhang, H.; Lin, J. Cross-Domain Modeling of Sentence-Level Evidence for Document Retrieval. In Proceedings of the EMNLP/IJCNLP, Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Zhai, C.; Lafferty, J. A study of smoothing methods for language models applied to Ad Hoc information retrieval. In Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval—SIGIR’01, New Orleans, LA, USA, 9–12 September 2001. [Google Scholar]
- Khattab, O.; Zaharia, M. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. arXiv 2020, arXiv:2004.12832. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| id | clueweb09-en0008-57-21952 |
| position | 2 |
| Title | Computer Keyboards Reviews, Buy Wireless Computer Keyboards, Best Deals of Keyboards |
| innovative approach to keyboard design, the OLED-based Optimus Maximus keyboard is best considered an expensive novelty. Its $1600 price tag keeps it out of the hands of the average consumer, and we also question the | |
| practical benefit of using 113 customizable OLED screens as an input device. There is something undoubtedly unique and appealing about the degree to which the Optimus Maximus gives you complete control over its keys appearance. However, even for gamers, designers, and others who tend to demand more from their input hardware, the Optimus Maximus offers insufficient utility to justify its high price. Read Optimus Maximus: Reviews, Deals, Specifications, Videos, and Prices Add Comments Solar Powered Computer Keyboard and Mouse Read | |
| More Weird Computer Keyboards, Wireless Keyboard Tired of changing batteries of your wireless keyboard and mouse? Probably it is the time to change. If you ask me what is the best option, I would definitely suggest this KYE Systems Slim Star |
| Title | Newspapers Electronic Media |
|---|---|
| Description | What has been the effect of the electronic media on the newspaper industry? |
| Narrative | Relevant documents must explicitly attribute effects to the electronic media: information about declining readership is irrelevant unless it attributes the cause to the electronic media. |
| Title | Starbucks |
|---|---|
| Description | Find information about the coffee company Starbucks. |
| Narrative | [“Take me to the Starbucks homepage.”, “What is the balance on my Starbucks gift card?”, “Find the menu from Starbucks, with prices.”, “Find calorie counts and other nutritional information about Starbucks products.”, “Find recipes from Starbucks, either for making or using Starbucks products.”, “I’m looking for locations of Starbucks stores worldwide.”] |
| Title | Description | |||
|---|---|---|---|---|
| Model | nDCG@20 | P@20 | nDCG@20 | P@20 |
| QL | 0.415 | 0.369 | 0.391 | 0.334 |
| BM25 | 0.418 | 0.370 | 0.399 | 0.337 |
| DSSM | 0.201 | 0.171 | 0.169 | 0.145 |
| DRMM (LCH+IDF) | 0.431 | 0.382 | 0.437 | 0.371 |
| BERTIR-MaxP | 0.469 | 0.408 | 0.529 | 0.439 |
| BERTIR-SumP | 0.467 | 0.402 | 0.524 | 0.443 |
| OurMethod-MaxP | 0.489 | 0.419 | 0.537 | 0.451 |
| Title | Description | |||
|---|---|---|---|---|
| Model | nDCG@20 | MAP | nDCG@20 | MAP |
| QL | 0.224 | 0.100 | 0.283 | 0.075 |
| BM25 | 0.225 | 0.101 | 0.196 | 0.080 |
| DSSM | 0.099 | 0.039 | 0.078 | 0.034 |
| DRMM (LCH+IDF) | 0.258 | 0.113 | 0.227 | 0.087 |
| BERTIR-MaxP | 0.287 | 0.161 | 0.261 | 0.144 |
| BERTIR-SumP | 0.291 | 0.162 | 0.266 | 0.147 |
| OurMethod | 0.327 | 0.189 | 0.260 | 0.148 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, W.; Hu, Z.; Luo, Y.; Liang, D.; Feng, Y.; Chen, J. Multi-Layer Contextual Passage Term Embedding for Ad-Hoc Retrieval. Information 2022, 13, 221. https://doi.org/10.3390/info13050221
Cai W, Hu Z, Luo Y, Liang D, Feng Y, Chen J. Multi-Layer Contextual Passage Term Embedding for Ad-Hoc Retrieval. Information. 2022; 13(5):221. https://doi.org/10.3390/info13050221
Chicago/Turabian StyleCai, Weihong, Zijun Hu, Yalan Luo, Daoyuan Liang, Yifan Feng, and Jiaxin Chen. 2022. "Multi-Layer Contextual Passage Term Embedding for Ad-Hoc Retrieval" Information 13, no. 5: 221. https://doi.org/10.3390/info13050221
APA StyleCai, W., Hu, Z., Luo, Y., Liang, D., Feng, Y., & Chen, J. (2022). Multi-Layer Contextual Passage Term Embedding for Ad-Hoc Retrieval. Information, 13(5), 221. https://doi.org/10.3390/info13050221