
Recommendation System Algorithms on Location-Based Social Networks: Comparative Study


Abstract
:1. Introduction
2. Background
2.1. Location-Based Social Networks
2.2. Content-Based POI Recommendation
2.3. Collaborative Filtering-Based POI Recommendation
2.4. Matrix Factorization
3. Description of the Investigated Algorithms
3.1. Singular Value Decomposition (SVD)
3.2. Singular Value Decomposition Plus Plus
3.3. Nonnegative Matrix Factorization
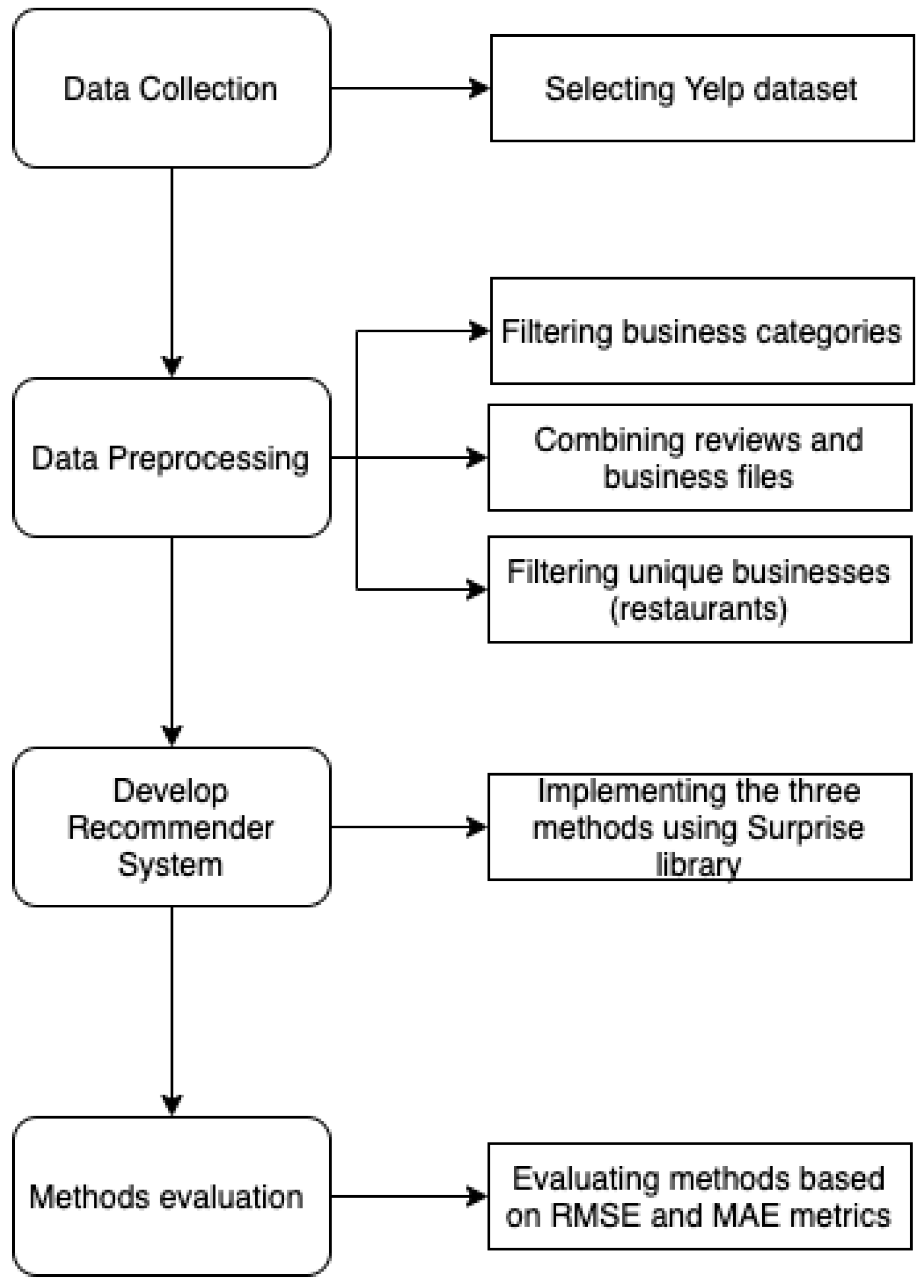
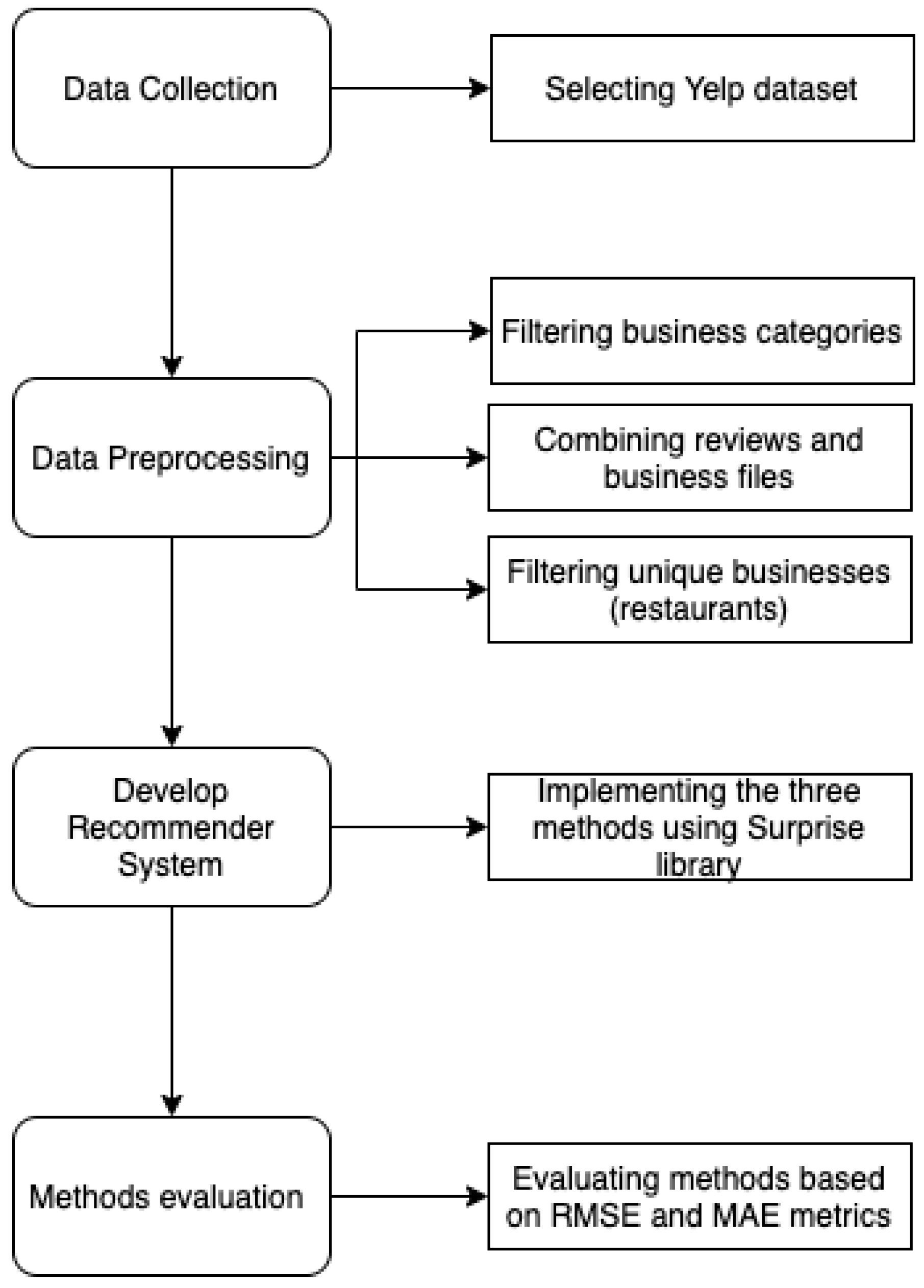
4. Experiments
4.1. Experimental Dataset
4.2. Evaluation Metrics
4.3. Experimental Setup
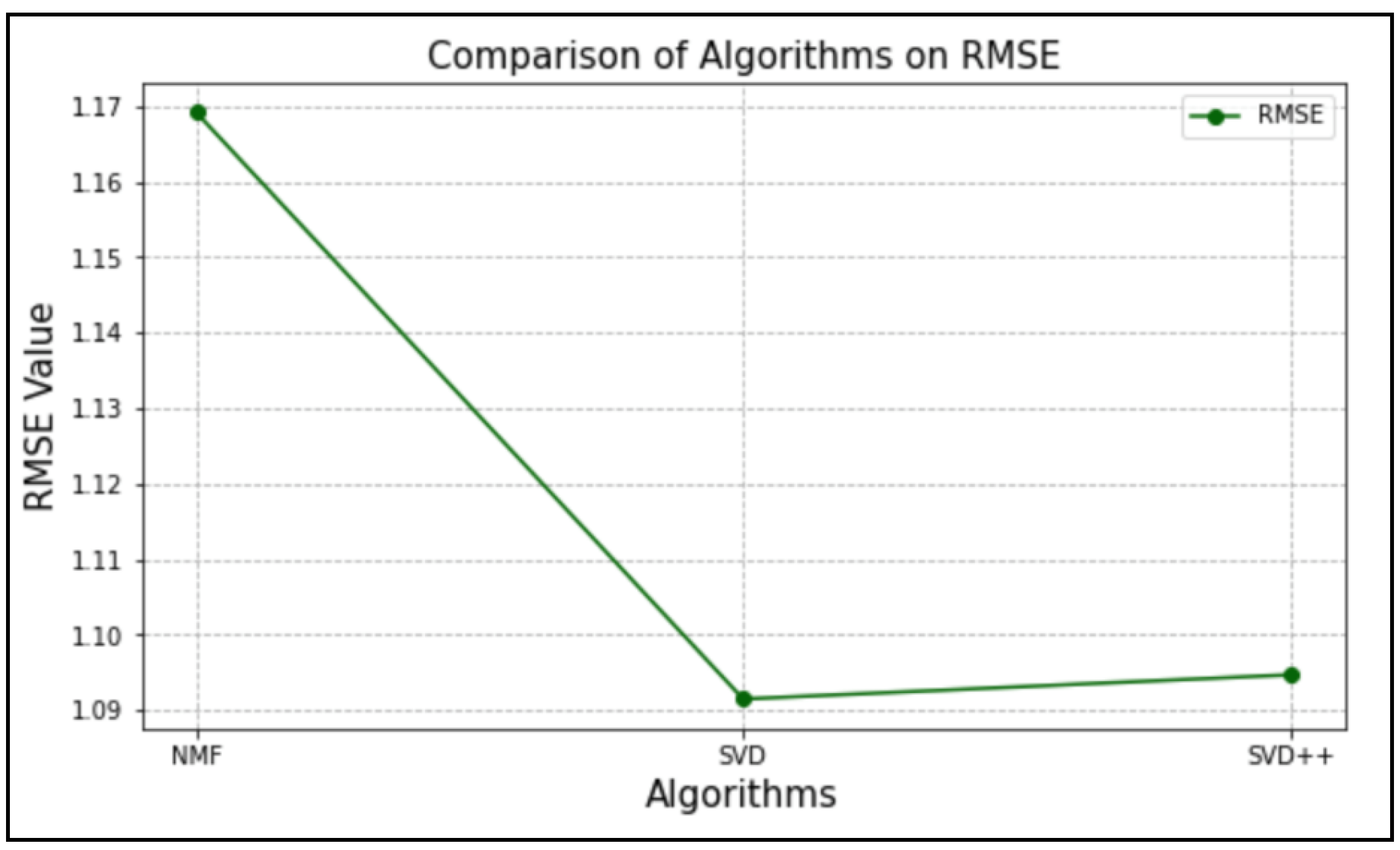
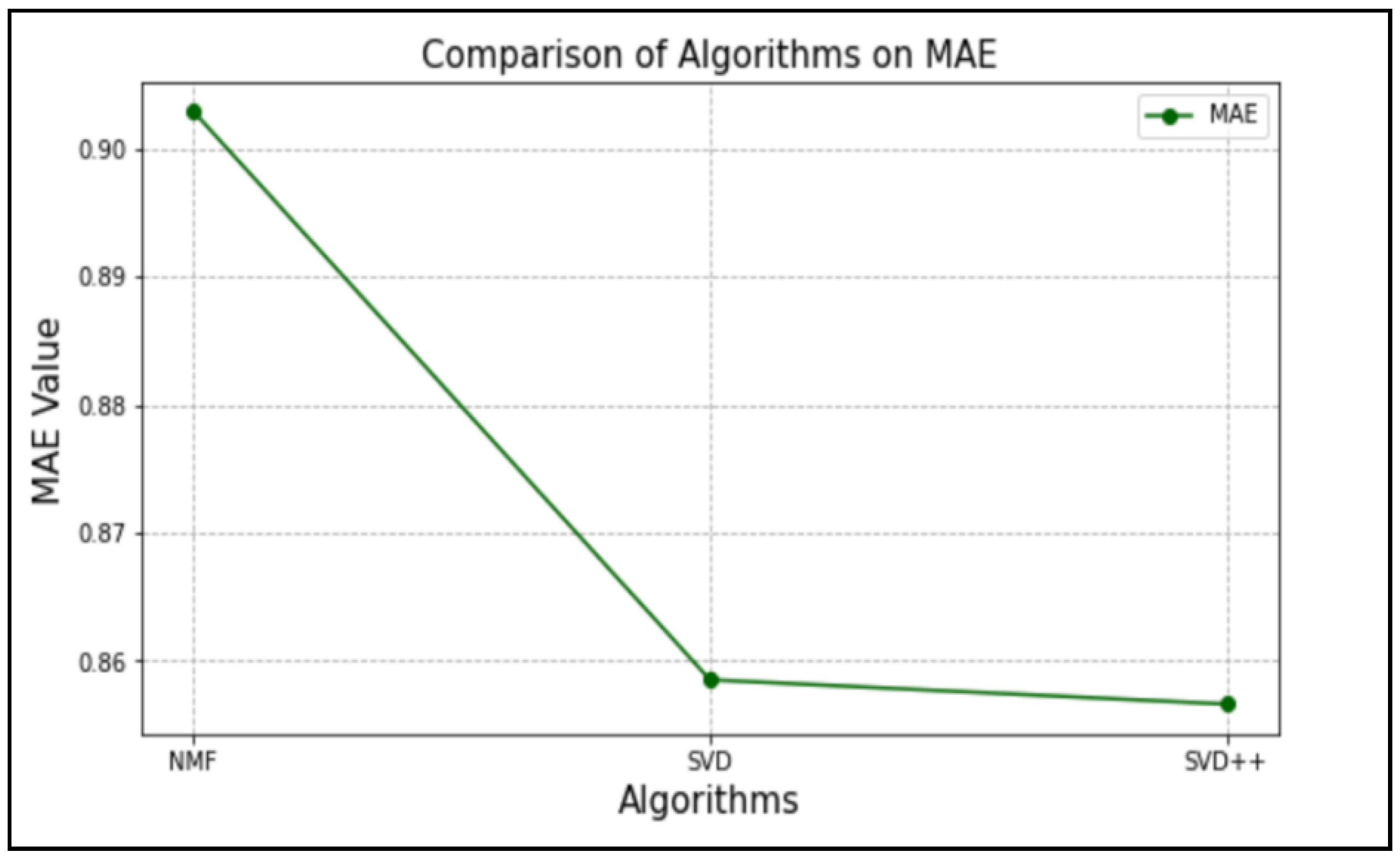
5. Performance Comparison
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, C.; Bai, L.; Zhang, C.; Yuan, Q.; Han, J. Bridging Collaborative Filtering and Semi-Supervised Learning: A Neural Approach for POI Recommendation. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1245–1254. [Google Scholar]
- Cui, Y.; Deng, L.; Zhao, Y.; Yao, B.; Zheng, V.W.; Zheng, K. Hidden POI Ranking with Spatial Crowdsourcing. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 814–824. [Google Scholar]
- Ye, M.; Yin, P.; Lee, W.-C.; Lee, D.-L. Exploiting Geographical Influence for Collaborative Point-of-Interest Recommendation. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information—SIGIR ’11, Beijing, China, 24–28 July 2011; pp. 325–334. [Google Scholar]
- Zhang, H.; Gan, M.; Sun, X. Incorporating Memory-Based Preferences and Point-of-Interest Stickiness into Recommendations in Location-Based Social Networks. ISPRS Int. J. Geo Inf 2021, 10, 36. [Google Scholar] [CrossRef]
- Ference, G.; Ye, M.; Lee, W.-C. Location Recommendation for Out-of-Town Users in Location-Based Social Networks. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management—CIKM ’13, San Francisco, CA, USA, 27 October–1 November 2013; pp. 721–726. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix Factorization Techniques for Recommender Systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Bobadilla, J.; Bojorque, R.; Esteban, A.H.; Hurtado, R. Recommender Systems Clustering Using Bayesian Non Negative Matrix Factorization. IEEE Access 2017, 6, 3549–3564. [Google Scholar] [CrossRef]
- Paatero, P.; Tapper, U. Positive Matrix Factorization: A Non-Negative Factor Model with Optimal Utilization of Error Estimates of Data Values. Environmetrics 1994, 5, 111–126. [Google Scholar] [CrossRef]
- Seung, D.; Lee, L. Algorithms for Non-Negative Matrix Factorization. Adv. Neural Inf. Process. Syst. 2001, 13, 556–562. [Google Scholar]
- Facebook. Facebook Reports Fourth Quarter and Full Year 2020 Results; Facebook Inc.: Menlo Park, CA, USA, 2020. [Google Scholar]
- Symeonidis, P.; Ntempos, D.; Manolopoulos, Y. Location-Based Social Networks. In Recommender Systems for Location-Based Social Networks; Springer: New York, NY, USA, 2014; pp. 35–48. [Google Scholar]
- Ma, X.; Zhu, J.; Zhang, S.; Zhong, Y. Multi-factor Fusion POI Recommendation Model. In Proceedings of the International Conference of Pioneering Computer Scientists, Engineers and Educators, Taiyuan, China, 18–21 September 2020; pp. 21–35. [Google Scholar]
- Wang, M.; Lu, Y.; Huang, J. SPENT: A Successive POI Recommendation Method Using Similarity-Based POI Em-Bedding and Recurrent Neural Network with Temporal Influence. In Proceedings of the IEEE International Conference on Big Data and Smart Computing (BigComp), Kyoto, Japan, 27 February–2 March 2019; pp. 1–8. [Google Scholar]
- Zhao, S.; Zhao, T.; Yang, M.R.L.; King, I. STELLAR: Spatial-Temporal Latent Ranking for Successive Point-of-Interest Recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Zhao, P. Where to Go Next: A Spatio-Temporal Gated Network for Next POI Recommendation. IEEE Trans. Knowl. Data Eng. 2020, 34, 2512–2524. [Google Scholar] [CrossRef]
- Qian, T.; Liu, B.; Nguyen, Q.V.H.; Yin, H. Spatiotemporal Representation Learning for Translation-Based POI Recommendation. ACM Trans. Inf. Syst 2019, 37, 1–24. [Google Scholar] [CrossRef]
- Cai, L.; Xu, J.; Liu, J.; Pei, T. Integrating spatial and temporal contexts into a factorization model for POI Recommendation. Int. J. Geogr. Inf. Sci 2018, 32, 524–546. [Google Scholar] [CrossRef]
- Yin, C.; Shi, L.; Sun, R.; Wang, J. Improved Collaborative Filtering Recommendation Algorithm Based on Differential Privacy Protection. J. Supercomput. 2020, 76, 5161–5174. [Google Scholar] [CrossRef]
- Jia, Z.; Yang, Y.; Gao, W.; Chen, X. User-Based Collaborative Filtering for Tourist Attraction Recommendations. In Proceedings of the 2015 IEEE International Conference on Computational Intelligence & Communication Technology, Ghaziabad, India, 13–14 February 2015; pp. 22–25. [Google Scholar]
- Xue, F.; He, X.; Wang, X.; Xu, J.; Liu, K.; Hong, R. Deep Item-Based Collaborative Filtering for Top-N Recommendation. ACM Trans. Inf. Syst. (TOIS) 2019, 37, 1–25. [Google Scholar] [CrossRef] [Green Version]
- Pujahari, A.; Sisodia, D.S. Model-Based Collaborative Filtering for Recommender Systems: An Empirical Survey. In Proceedings of the 1st International Conference on Power, Control and Computing Technologies (ICPC2T), Raipur, India, 3–5 January 2020; pp. 443–447. [Google Scholar]
- Jiang, S.; Qian, X.; Shen, J.; Fu, Y.; Mei, T. Author Topic Model Based Collaborative Filtering for Personalized POI Recommendation. IEEE Trans. Multimed. 2015, 17, 907–918. [Google Scholar] [CrossRef]
- Berry, M.W.; Dumais, S.T.; O’Brien, G.W. Using linear algebra for intelligent information retrieval. SIAM Rev. 1995, 37, 573–595. [Google Scholar] [CrossRef] [Green Version]
- Yuan, X.; Han, L.; Qian, S.; Xu, G.; Yan, H. Singular value decomposition based recommendation using imputed data. Knowl. Based Syst. 2019, 163, 485–494. [Google Scholar] [CrossRef]
- Chai, Z.; Li, Y.-L.; Han, Y.-M.; Zhu, S.-F. Recommendation System Based on Singular Value Decomposition and Multi-Objective Immune Optimization. IEEE Access 2018, 7, 6060–6071. [Google Scholar] [CrossRef]
- Bakir, C. Collaborative Filtering with Temporal Dynamics with Using Singular Value Decomposition. Teh. Vjesn. Tech. Gaz. 2018, 25, 130–135. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Arefin, M.S.; Chen, Z.; Morimoto, Y. Place Recommendation Based on Users Check-in History for Location-Based Services. Int. J. Netw. Comput. 2013, 3, 228–243. [Google Scholar] [CrossRef] [Green Version]
- Koren, Y. Factorization Meets the Neighborhood: A Multifaceted Collaborative Filtering Model. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 426–434. [Google Scholar]
- Guo, G.; Zhang, J.; Yorke-Smith, N. A Novel Recommendation Model Regularized with User Trust and Item Ratings. IEEE Trans. Knowl. Data Eng. 2016, 28, 1607–1620. [Google Scholar] [CrossRef]
- Shi, W.; Wang, L.; Qin, J. User Embedding for Rating Prediction in SVD++-Based Collaborative Filtering. Symmetry 2020, 12, 121. [Google Scholar] [CrossRef] [Green Version]
- Junior, A.F.; Medeiros, F.; Calado, I. An Evaluation of Recommendation Algorithms for Tourist Attractions. In Proceedings of the Thirty Second International Conference on Software Engineering and Knowledge Engineering (SEKE 2020), Pittsburgh, PA, USA, 9–11 July 2020. [Google Scholar]
- Hu, Z. SSL-SVD: Semi-supervised Learning–based Sparse Trust Recommendation. ACM Trans. Internet Technol. 2020, 20, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Athanasiadis, C.; Hortal, E.; Koutsoukos, D.; Lens, C.Z.; Asteriadis, S. Personalized, Affect and Perfor-Mance-Driven Computer-Based Learning. In Proceedings of the 9th International Conference on Computer Supported Education, Porto, Portugal, 21–23 April 2017; pp. 132–139. [Google Scholar]
- Massimo, D.; Ricci, F. Clustering Users’ POIs Visit Trajectories for Next-POI Recommendation. In Information and Communication Technologies in Tourism 2019, Proceedings of the International Conference in Nicosia, Cyprus, 30 January–1 February 2019; Springer: Cham, Switzerland, 2019; pp. 3–14. [Google Scholar]
- Liu, B.; Fu, Y.; Yao, Z.; Xiong, H. Learning Geographical Preferences for Point-of-Interest Recommendation. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 1043–1051. [Google Scholar]
- Yelp-Dataset. Yelp Open Dataset. Available online: https://www.yelp.com/dataset (accessed on 20 November 2021).
- Chai, T.; Draxler, R.R. Root Mean Square Error (RMSE) or Mean Absolute Error (MAE)?—Arguments against Avoiding RMSE in the Literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef] [Green Version]
- Ziad, S.; Najafi, S. Evaluating Prediction Accuracy for Collaborative Filtering Algorithms in Recommender Systems. Bachelor’s Thesis, KTH Royal Institute of Technology, Stockholm, Sweden, 2016. [Google Scholar]
- Hug, N. Surprise: A Python Library for Recommender Systems. J. Open Source Softw. 2020, 5, 2174. [Google Scholar] [CrossRef]
- Bokde, D.; Sheetal, G.; Debajyoti, M. Matrix Factorization Model in Collaborative Filtering Algorithms: A Survey. Procedia Comput. Sci. 2015, 49, 136–146. [Google Scholar] [CrossRef] [Green Version]
- Rui, C.; Qingyi, H.; Yan-Shuo, C.; Bo, W.; Lei, Z.; Xiangjie, K. A Survey of Collaborative Filtering-Based Recommender Systems: From Traditional Methods to Hybrid Methods Based on Social Networks. IEEE Access 2018, 6, 64301–64320. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Content-Based Recommendation | Ref. | Title |
|---|---|---|
| Rating prediction | [12] | Multifactor Fusion POI Recommendation Model |
| [13] | PENT: A Successive POI Recommendation Method Using Similarity-Based POI Embedding and Recurrent Neural Network with Temporal Influence. | |
| Temporal-based | [14] | STELLAR: Spatial-Temporal Latent Ranking for Successive Point-of-Interest Recommendation. |
| [15] | Where to Go Next: A Spatio-Temporal Gated Network for Next POI Recommendation. | |
| [16] | Spatiotemporal Representation Learning for Translation-Based POI Recommendation. | |
| [17] | Integrating Spatial and Temporal Contexts into a Factorization Model for POI Recommendation. |
| Collaborative Filtering | Ref. | Title |
|---|---|---|
| User-based | [3] | Exploiting geographical influence for collaborative point-of-interest recommendation. |
| [4] | Incorporating Memory-Based Preferences and Point-of-Interest Stickiness into Recommendations in Location-Based Social Networks. | |
| [19] | User-Based Collaborative Filtering for Tourist Attraction Recommendations. | |
| [1] | Bridging Collaborative Filtering and Semi-Supervised Learning: A Neural Approach for POI Recommendation. | |
| Model-based | [21] | Model-Based Collaborative Filtering for Recommender Systems: An Empirical Survey. |
| [22] | Author Topic Model-Based Collaborative Filtering for Personalized POI Recommendation. |
| Reviews | Businesses | Metropolitan Areas | Users |
|---|---|---|---|
| 8,635,403 | 160,585 | 10 | 2,189,457 |
| Root Mean Square Error (RMSE) | ||||||
| Methods | Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | Average |
| SVD | 1.09104711 | 1.09110819 | 1.09129044 | 1.09128233 | 1.09386881 | 1.0913 |
| SVD++ | 1.09515548 | 1.09543396 | 1.0948695 | 1.09637749 | 1.0939797 | 1.0952 |
| NMF | 1.17019635 | 1.16971371 | 1.16972419 | 1.17035167 | 1.17013915 | 1.1700 |
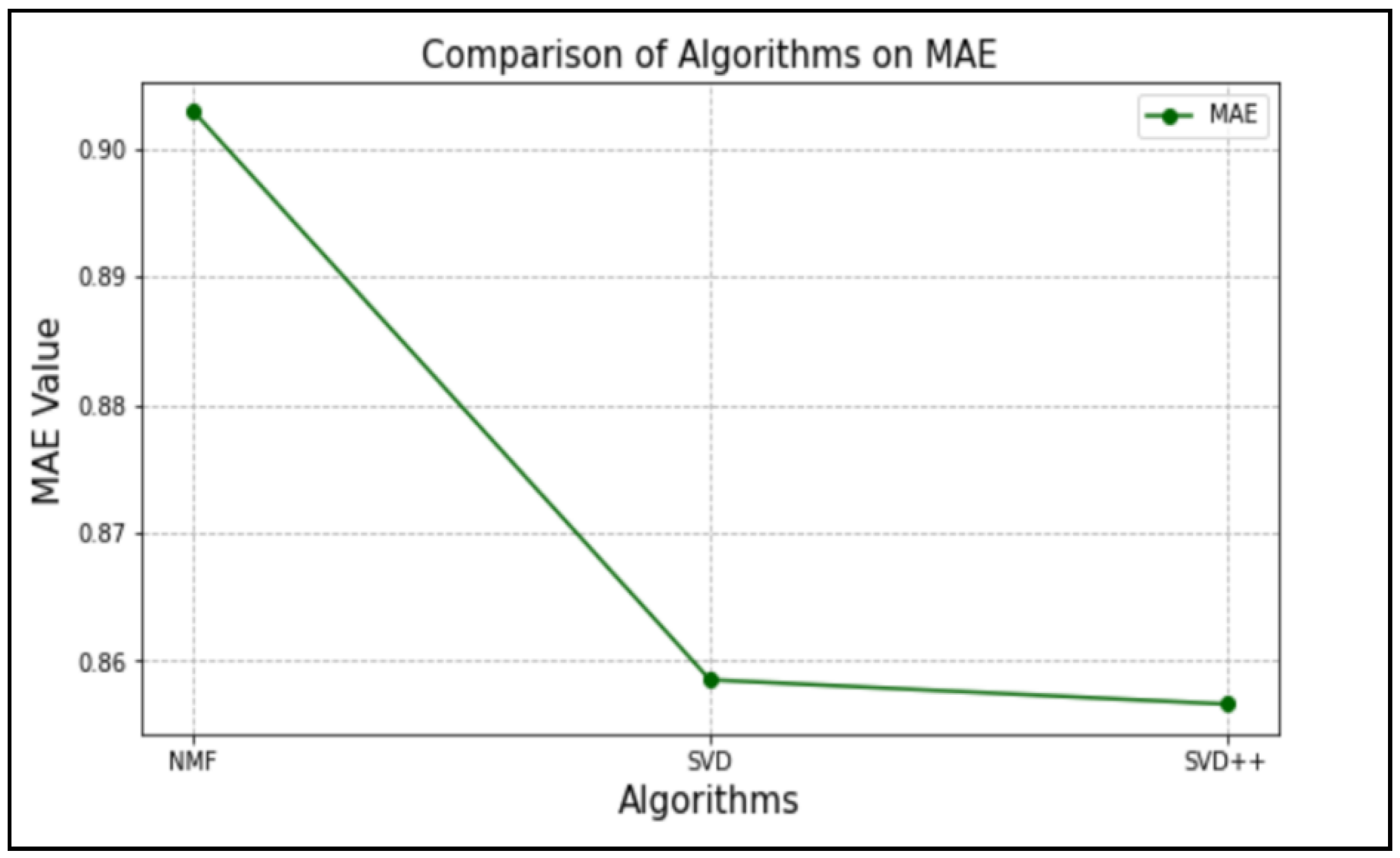
| Mean absolute error (MAE) | ||||||
| Methods | Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | Average |
| SVD | 0.85807086 | 0.8573797 | 0.85893667 | 0.85781816 | 0.86049533 | 0.8583 |
| SVD++ | 0.85673553 | 0.85692388 | 0.85634049 | 0.85816445 | 0.85572834 | 0.8568 |
| NMF | 0.90339271 | 0.90361794 | 0.9030141 | 0.90363626 | 0.90316969 | 0.9033 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Nafjan, A.; Alrashoudi, N.; Alrasheed, H. Recommendation System Algorithms on Location-Based Social Networks: Comparative Study. Information 2022, 13, 188. https://doi.org/10.3390/info13040188
Al-Nafjan A, Alrashoudi N, Alrasheed H. Recommendation System Algorithms on Location-Based Social Networks: Comparative Study. Information. 2022; 13(4):188. https://doi.org/10.3390/info13040188
Chicago/Turabian StyleAl-Nafjan, Abeer, Norah Alrashoudi, and Hend Alrasheed. 2022. "Recommendation System Algorithms on Location-Based Social Networks: Comparative Study" Information 13, no. 4: 188. https://doi.org/10.3390/info13040188
APA StyleAl-Nafjan, A., Alrashoudi, N., & Alrasheed, H. (2022). Recommendation System Algorithms on Location-Based Social Networks: Comparative Study. Information, 13(4), 188. https://doi.org/10.3390/info13040188